
Airport-FOD3S: A Three-Stage Detection-Driven Framework for Realistic Foreign Object Debris Synthesis
Abstract
1. Introduction
2. Methodology
2.1. Data Augmentation
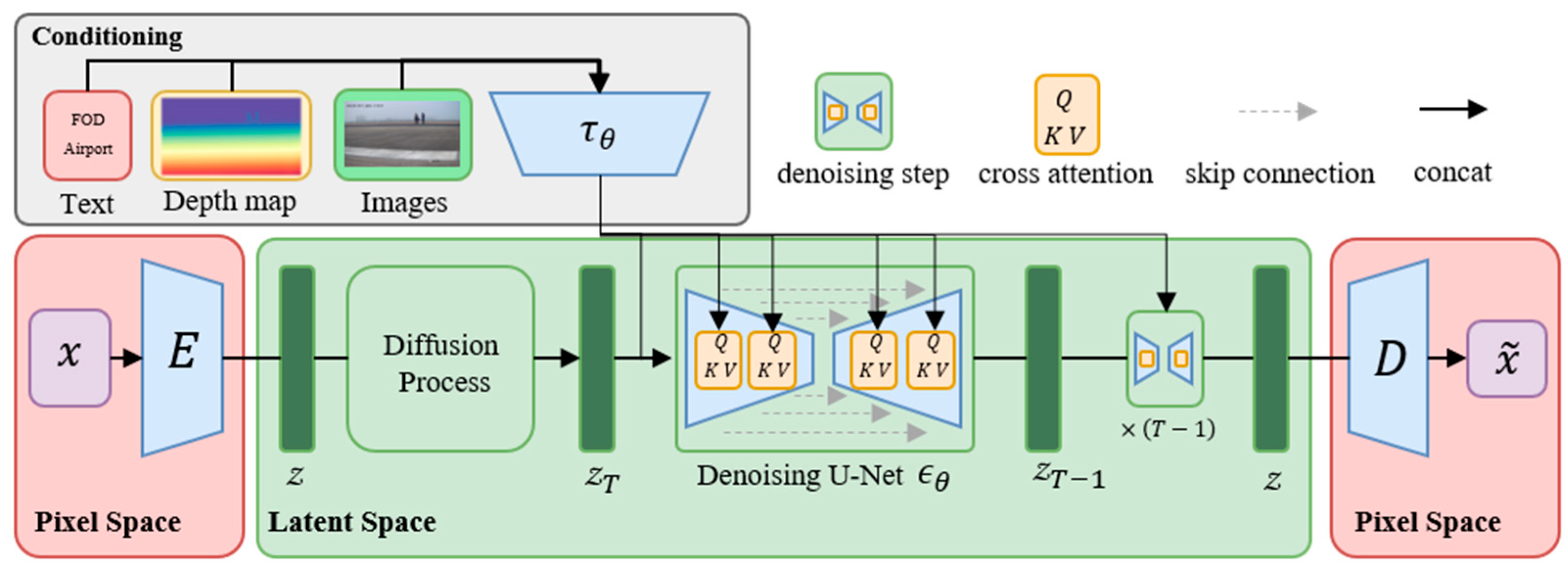
2.1.1. Airport and FOD Generation Based on Diffusion
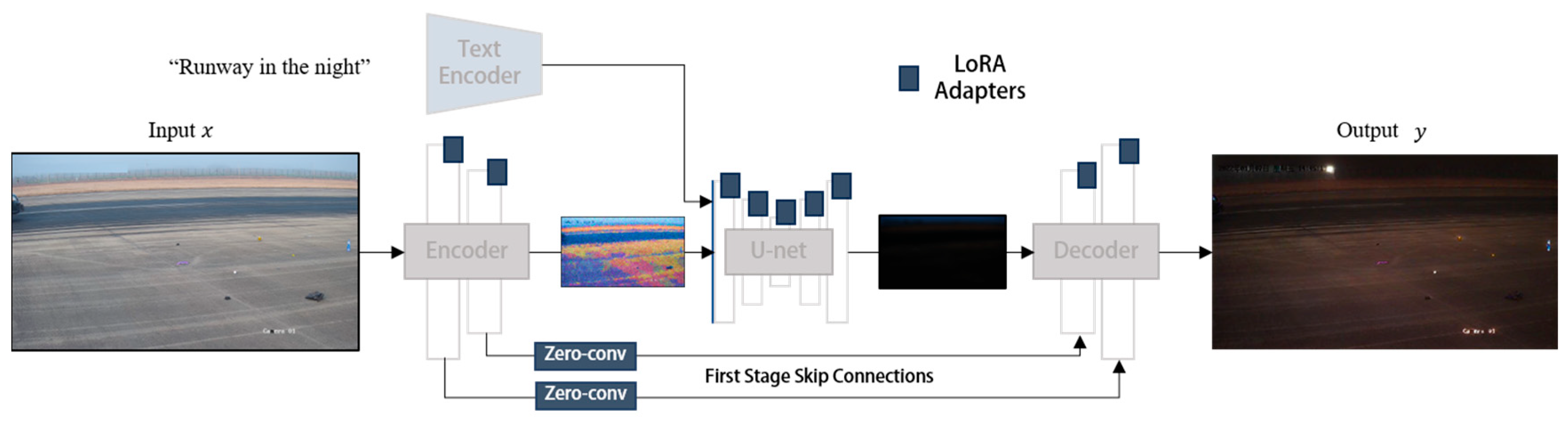
2.1.2. Airport Scene Generation in Different Condition
2.2. A Three-Stage Image Blending Approach Considering Size, Seam, and Style
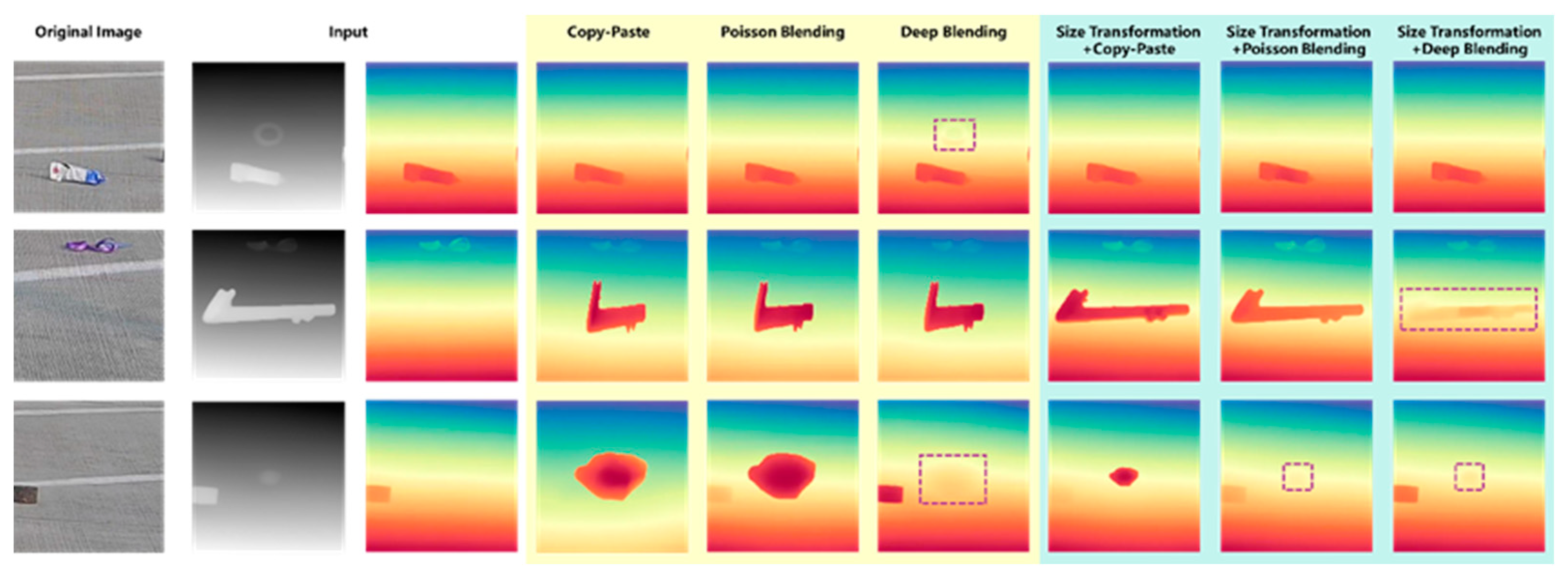
2.2.1. Size Transformation of Source Images
2.2.2. Seam Processing
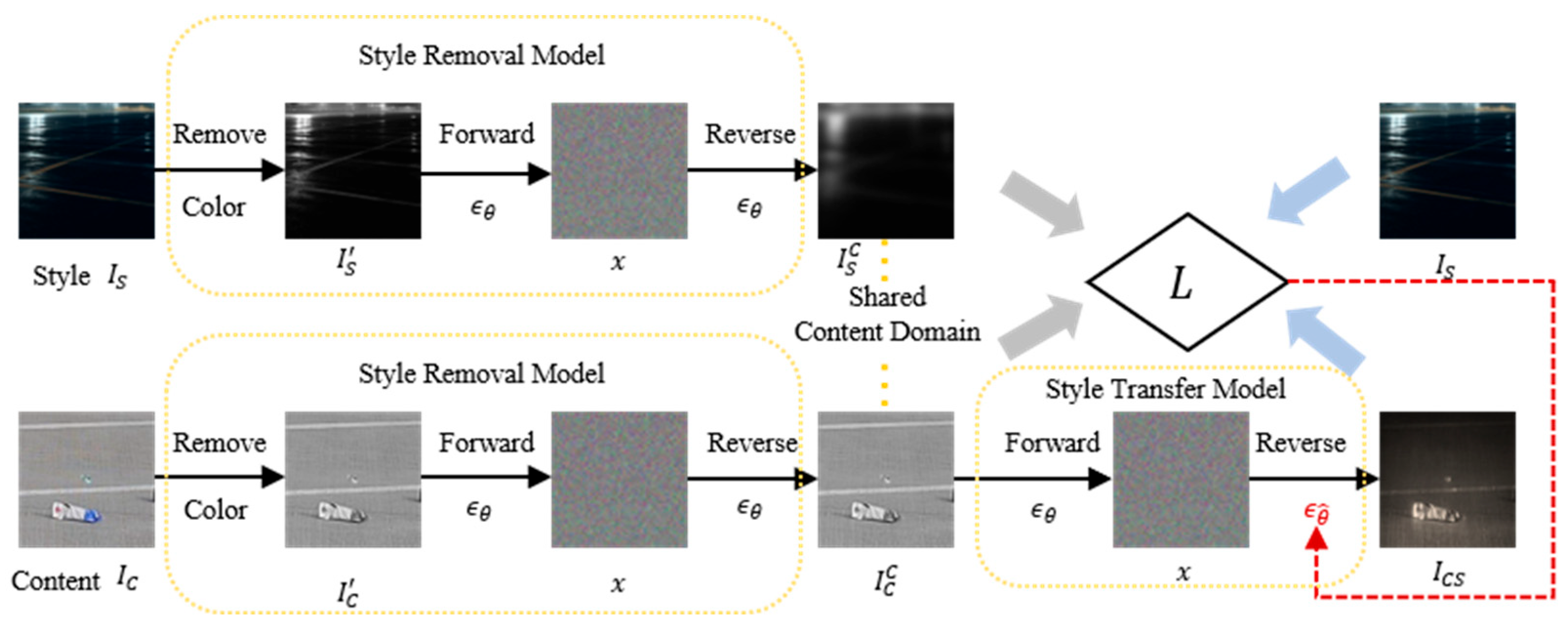
2.2.3. Style Transfer
2.2.4. Evaluation of Image Blending Performance
2.3. SimD-Based Label Assignment Strategy
3. Experiment
3.1. Data Collection
Field Data Collection
3.2. Data Augmentation
3.3. FOD Detection
4. Results and Discussion
4.1. Generation of FOD Images at Airport
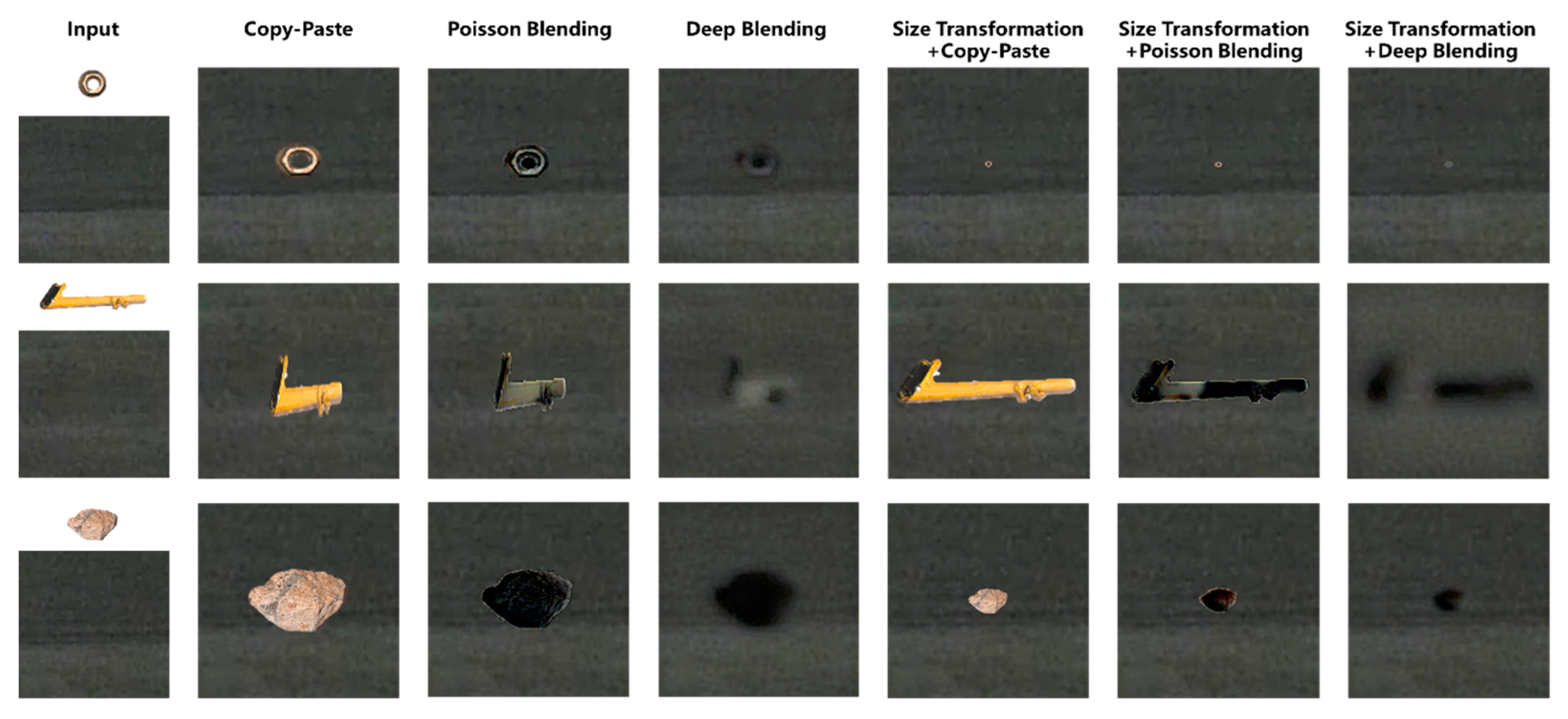
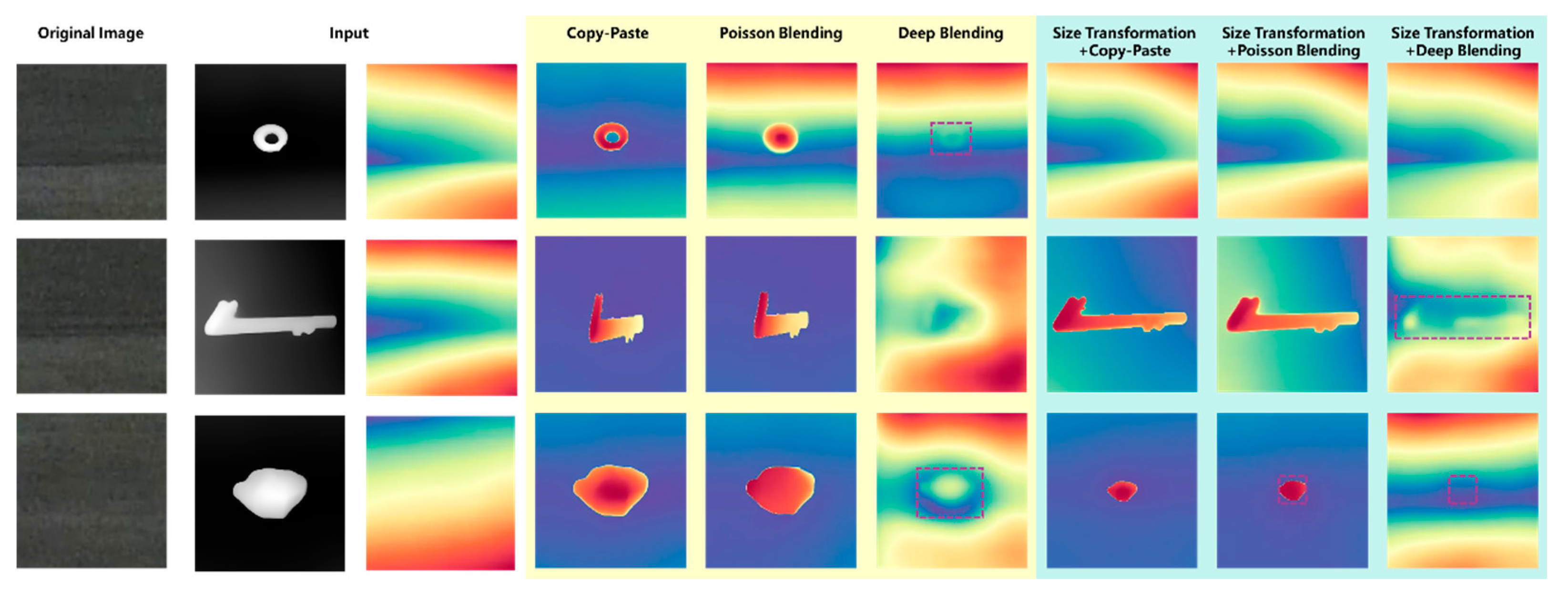
4.2. Image Blending
4.2.1. Blending Performances in Daytime
4.2.2. Blending Performances at Night-Time
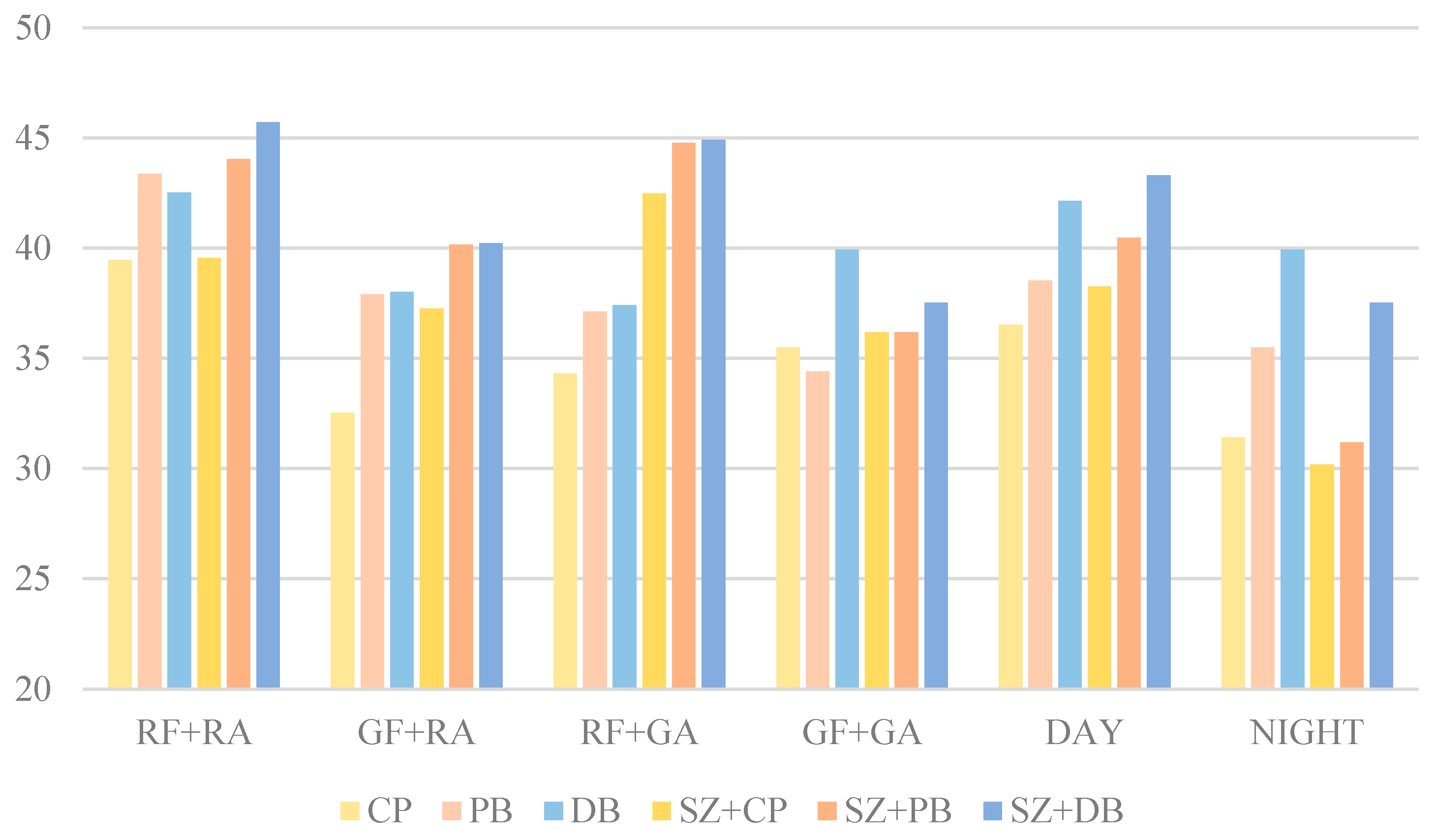
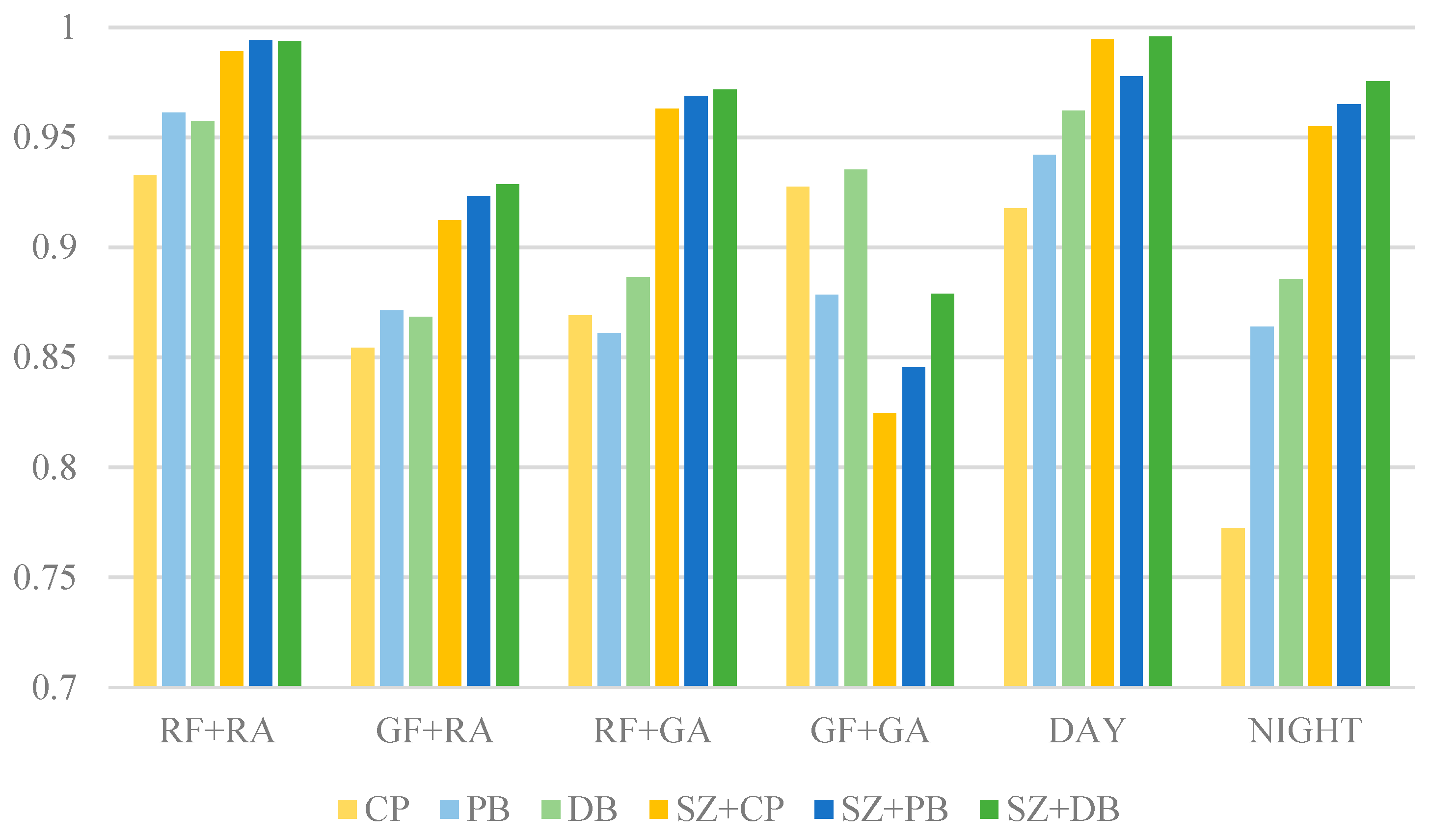
4.2.3. Quantitative Metrics
4.2.4. Expert-Based Subjective Assessment
4.3. FOD Detection Results
4.3.1. Comparison of Different Detectors with SimD
4.3.2. Computational Complexity
4.3.3. Limitations and Future Work
5. Conclusions
- A three-stage foreign-object image augmentation method was proposed. FOD was firstly transformed according to its actual sizes, was seamlessly fused with airport scene images, followed by applying style transformation, and, eventually, a comprehensive dataset for foreign-object detection was constructed;
- The synthetic foreign object images were evaluated using DepthAnything and SSIM/PSNR metrics. The results indicated that the proposed three-stage blending method generates images with spatial distributions that were closely aligned with real-world scenarios. The SSIM and PSNR metrics outperformed other methods, reaching 0.99 and 45 dB;
- Faster R-CNN, YOLOv8, and YOLOv11 with SimD were trained on both the original and augmented datasets. The results demonstrated that both data augmentation and SimD effectively improved foreign-object detection accuracy. Among them, YOLOv11 with SimD achieved the highest AP value of 85.96, performing well in detection tasks that match the field situation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Airport Foreign Object Debris (FOD) Management; AC 150/5210-24; Federal Aviation Administration: Washington, DC, USA, 2024.
- Airport Foreign Object Debris (FOD) Detection Equipment; AC 150/5220-24; Federal Aviation Administration: Washington, DC, USA, 2009.
- Hussin, R.; Ismail, N.; Mustapa, S. A study of foreign object damage (FOD) and prevention method at the airport and aircraft maintenance area. IOP Conf. Ser. Mater. Sci. Eng. 2016, 152, 012038. [Google Scholar] [CrossRef]
- Prather, C.D. Current Airport Inspection Practices Regarding FOD (Foreign Object Debris/Damage); Transportation Research Board: Washington, DC, USA, 2011; Volume 26. [Google Scholar]
- Fizza, G.; Idrus, S.M.; Iqbal, F.; Hassan, W.H.W.; Ahmad, R.; Meerah, Z.; Kashima, K. Review on foreign object debris detection technologies and advancement for airport safety and surveillance. Turk. J. Comput. Math. Educ. 2021, 12, 1431–1436. [Google Scholar]
- Zainab, S.M.; Khan, K.; Fazil, A.; Zakwan, M. Foreign object debris (fod) classification through material recognition using deep convolutional neural network with focus on metal. IEEE Access 2023, 11, 10925–10934. [Google Scholar] [CrossRef]
- Lai, Y.K. Foreign object debris detection method based on fractional Fourier transform for millimeter-wave radar. J. Appl. Remote Sens. 2020, 14, 016508. [Google Scholar] [CrossRef]
- Noroozi, M.; Shah, A. Towards optimal foreign object debris detection in an airport environment. Expert Syst. Appl. 2023, 213, 118829. [Google Scholar] [CrossRef]
- Wu, S.; Xiao, C.; Wang, Y.; Yang, J.; An, W. Sparsity-Aware Global Channel Pruning for Infrared Small-target Detection Networks. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5615011. [Google Scholar] [CrossRef]
- Shan, J.; Miccinesi, L.; Beni, A.; Pagnini, L.; Cioncolini, A.; Pieraccini, M. A Review of Foreign Object Debris Detection on Airport Runways: Sensors and Algorithms. Remote Sens. 2025, 17, 225. [Google Scholar] [CrossRef]
- Elrayes, A.; Ali, M.H.; Zakaria, A.; Ismail, M.H. Smart airport foreign object debris detection rover using LiDAR technology. Internet Things 2019, 5, 1–11. [Google Scholar] [CrossRef]
- Farooq, J.; Muaz, M.; Khan Jadoon, K.; Aafaq, N.; Khan, M.K.A. An improved YOLOv8 for foreign object debris detection with optimized architecture for small objects. Multimed. Tools Appl. 2024, 83, 60921–60947. [Google Scholar] [CrossRef]
- Zhang, H.; Fu, W.; Li, D.; Wang, X.; Xu, T. Improved small foreign object debris detection network based on YOLOv5. J. Real-Time Image Process. 2024, 21, 21. [Google Scholar] [CrossRef]
- Adi, K.; Widodo, C.E.; Widodo, A.P.; Rohanudin, R.; Fadila, I. Design of foreign object debris detecting and monitoring using two sets of sensor system. Indones. J. Electr. Eng. Comput. Sci. 2023, 32, 695–703. [Google Scholar] [CrossRef]
- Wang, Y.; Song, Q.; Wang, J.; Yu, H. Airport runway foreign object debris detection system based on arc-scanning SAR technology. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5221416. [Google Scholar] [CrossRef]
- Zhong, J.; Zhu, J.; Ju, H.; Ma, T.; Zhang, W. Multi-scale feature fusion network for pixel-level pavement distress detection. Autom. Constr. 2022, 141, 104436. [Google Scholar] [CrossRef]
- Chauhan, T.; Goyal, C.; Kumari, D.; Thakur, A.K. A review on foreign object debris/damage (FOD) and its effects on aviation industry. Mater. Today Proc. 2020, 33, 4336–4339. [Google Scholar] [CrossRef]
- Ren, M.; Wan, W.; Yu, Z.; Zhao, Y. Bidirectional YOLO: Improved YOLO for foreign object debris detection on airport runways. J. Electron. Imaging 2022, 31, 063047. [Google Scholar] [CrossRef]
- Munyer, T.; Brinkman, D.; Zhong, X.; Huang, C.; Konstantzos, I. Foreign object debris detection for airport pavement images based on self-supervised localization and vision transformer. In Proceedings of the 2022 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1388–1394. [Google Scholar]
- Niu, Z.; Zhang, J.; Li, Z.; Zhao, X.; Yu, X.; Wang, Y. Automatic Detection and Predictive Geolocation of Foreign Object Debris on Airport Runway. IEEE Access 2024, 12, 133748–133763. [Google Scholar] [CrossRef]
- Suder, J.; Marciniak, T. Foreign Object Debris detection at aerodromes using YOLOv5. In Proceedings of the 2024 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), Poznan, Poland, 25–27 September 2024; pp. 66–71. [Google Scholar]
- Zheng, L.; Chen, X. VA-YOLO: A foreign object debris detection method on the airport runway based on vision transformer and attention. J. Electron. Imaging 2024, 33, 063006. [Google Scholar] [CrossRef]
- Zhang, Y.; Tong, Z.; She, X.; Wang, S.; Zhang, W.; Fan, J.; Cheng, H.; Yang, H.; Cao, J. SWC-Net and multi-phase heterogeneous FDTD model for void detection underneath airport pavement slab. IEEE Trans. Intell. Transp. Syst. 2024, 25, 20698–20714. [Google Scholar] [CrossRef]
- Zhong, J.; Ma, Y.; Zhang, M.; Xiao, R.; Cheng, G.; Huang, B. A pavement crack translator for data augmentation and pixel-level detection based on weakly supervised learning. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13350–13363. [Google Scholar] [CrossRef]
- Zunair, H.; Khan, S.; Hamza, A.B. RSUD20K: A dataset for road scene understanding in autonomous driving. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 708–714. [Google Scholar]
- Zhong, J.; Ju, H.; Zhang, W.; Cheng, H.; Zhang, J.; Tong, Z.; Jiang, X.; Huang, B. A deeper generative adversarial network for grooved cement concrete pavement crack detection. Eng. Appl. Artif. Intell. 2023, 119, 105808. [Google Scholar] [CrossRef]
- Yang, H.; Ma, T.; Tong, Z.; Wang, H.; Wang, N.; Cheng, H. Deployment strategies for lightweight pavement defect detection using deep learning and inverse perspective mapping. Autom. Constr. 2024, 167, 105682. [Google Scholar] [CrossRef]
- Yang, H.; Ju, H.; Ma, T.; Tong, Z.; Han, C.; Xie, T. Novel Computer Tomography image enhancement deep neural networks for asphalt mixtures. Constr. Build. Mater. 2022, 352, 129067. [Google Scholar] [CrossRef]
- Yu, M.; Zhao, Q.; Cheng, S.; Cai, H.; Liu, L. An automatic detecting method for multi-scale foreign object debris in civil aircraft manufacturing and assembly scenario. J. Intell. Manuf. 2024, 1–23. [Google Scholar] [CrossRef]
- Fairuzi, M.R.; Zulkifli, F.Y. Performance analysis of YOLOv4 and SSD MobileNet v2 for foreign object debris (FOD) detection at airport runway using custom dataset. In Proceedings of the 2021 17th International Conference on Quality in Research (QIR): International Symposium on Electrical and Computer Engineering, Depok, Indonesia, 13–15 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 11–16. [Google Scholar]
- Croitoru, F.A.; Hondru, V.; Ionescu, R.T.; Shah, M. Diffusion models in vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10850–10869. [Google Scholar] [CrossRef] [PubMed]
- Payne, K.; O’Bryan, C.A.; Marcy, J.A.; Crandall, P.G. Detection and prevention of foreign material in food: A review. Heliyon 2023, 9, e19574. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Wen, T.; Shi, J. Deep image blending. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 231–240. [Google Scholar]
- Noroozi, M.; Shah, A. Open-world foreign object debris detection framework empowered by generative adversarial network and computer vision models. Transp. Res. Rec. 2024, 2678, 2245–2259. [Google Scholar] [CrossRef]
- Munyer, T.; Huang, P.C.; Huang, C.; Zhong, X. Fod-a: A dataset for foreign object debris in airports. arXiv 2021, arXiv:2110.03072. [Google Scholar]
- Cheng, H.; Peng, T.; Zhang, Y.; Lin, J.; Zhang, W.; Fan, J.; Shen, X.; Li, H.; Wang, S. Automated evaluation of snow and ice conditions on airport pavement: A study based on image recognition and point cloud reconstruction. Measurement 2025, 242, 116200. [Google Scholar] [CrossRef]
- Zhong, J.; Zhang, M.; Ma, Y.; Xiao, R.; Cheng, G.; Huang, B. A multitask fusion network for region-level and pixel-level pavement distress detection. J. Transp. Eng. Part B Pavements 2024, 150, 04024002. [Google Scholar] [CrossRef]
- Nugraha, E.S.; Apriono, C.; Zulkifli, F.Y. A systematic review of radar technologies for surveillance of foreign object debris detection on airport runway. Bull. Electr. Eng. Inform. 2024, 13, 4102–4114. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Parmar, G.; Park, T.; Narasimhan, S.; Zhu, J.Y. One-step image translation with text-to-image models. arXiv 2024, arXiv:2403.12036. [Google Scholar]
- Morel, J.M.; Petro, A.B.; Sbert, C. Fourier implementation of Poisson image editing. Pattern Recognit. Lett. 2012, 33, 342–348. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, L.; Xing, W. Stylediffusion: Controllable disentangled style transfer via diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 7677–7689. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International conference on machine learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Tanchenko, A. Visual-PSNR measure of image quality. J. Vis. Commun. Image Represent. 2014, 25, 874–878. [Google Scholar] [CrossRef]
- Yang, L.; Kang, B.; Huang, Z.; Xu, X.; Feng, J.; Zhao, H. Depth anything: Unleashing the power of large-scale unlabeled data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 10371–10381. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, Proceedings of the 29th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Curran Associates, Inc.: Red Hook, NY, USA, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Hidayatullah, P.; Syakrani, N.; Sholahuddin, M.R.; Gelar, T.; Tubagus, R. YOLOv8 to YOLO11: A Comprehensive Architecture In-depth Comparative Review. arXiv 2025, arXiv:2501.13400. [Google Scholar]
- Shi, S.; Fang, Q.; Xu, X.; Zhao, T. Similarity distance-based label assignment for tiny object detection. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 13711–13718. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Spatial Realism | Boundary Smoothness | Scene Consistency | Detectability | Average Score |
|---|---|---|---|---|---|
| Copy-Paste | 2.3 | 2.0 | 2.4 | 2.7 | 2.4 |
| Poisson Blending | 3.0 | 2.9 | 3.2 | 3.3 | 3.1 |
| FOD3S (Ours) | 4.4 | 4.5 | 4.3 | 4.2 | 4.3 |
| Detector | With SimD | Original Dataset (mAP, %) | With Poisson Blending (mAP, %) | With FOD3S (Ours) (mAP, %) |
|---|---|---|---|---|
| Faster R-CNN | ✕ | 70.43 | 71.32 | 74.82 |
| ✓ | 72.65 | 73.34 | 77.12 | |
| YOLOv8 | ✕ | 74.37 | 75.45 | 80.32 |
| ✓ | 78.63 | 79.14 | 82.35 | |
| YOLOv11 | ✕ | 80.85 | 82.24 | 83.54 |
| ✓ | 82.12 | 82.96 | 85.96 |
| Detector | With SimD | Parameters (M) | FLOPs (G) | Inference Time (ms) | FPS (on Jetson Orin) |
|---|---|---|---|---|---|
| Faster R-CNN | ✕ | 138.3 | 250.7 | 115.3 | 8.7 |
| ✓ | 141.2 | 255.3 | 117.6 | 8.5 | |
| YOLOv8 | ✕ | 68.2 | 257.8 | 35.4 | 28.2 |
| ✓ | 69.5 | 263.8 | 37.1 | 26.9 | |
| YOLOv11 | ✕ | 56.9 | 194.9 | 31.0 | 32.2 |
| ✓ | 57.9 | 198.9 | 32.4 | 30.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, H.; Li, Y.; Zhang, R.; Zhang, W. Airport-FOD3S: A Three-Stage Detection-Driven Framework for Realistic Foreign Object Debris Synthesis. Sensors 2025, 25, 4565. https://doi.org/10.3390/s25154565
Cheng H, Li Y, Zhang R, Zhang W. Airport-FOD3S: A Three-Stage Detection-Driven Framework for Realistic Foreign Object Debris Synthesis. Sensors. 2025; 25(15):4565. https://doi.org/10.3390/s25154565
Chicago/Turabian StyleCheng, Hanglin, Yihao Li, Ruiheng Zhang, and Weiguang Zhang. 2025. "Airport-FOD3S: A Three-Stage Detection-Driven Framework for Realistic Foreign Object Debris Synthesis" Sensors 25, no. 15: 4565. https://doi.org/10.3390/s25154565
APA StyleCheng, H., Li, Y., Zhang, R., & Zhang, W. (2025). Airport-FOD3S: A Three-Stage Detection-Driven Framework for Realistic Foreign Object Debris Synthesis. Sensors, 25(15), 4565. https://doi.org/10.3390/s25154565