
Masked Feature Residual Coding for Neural Video Compression


Abstract
1. Introduction
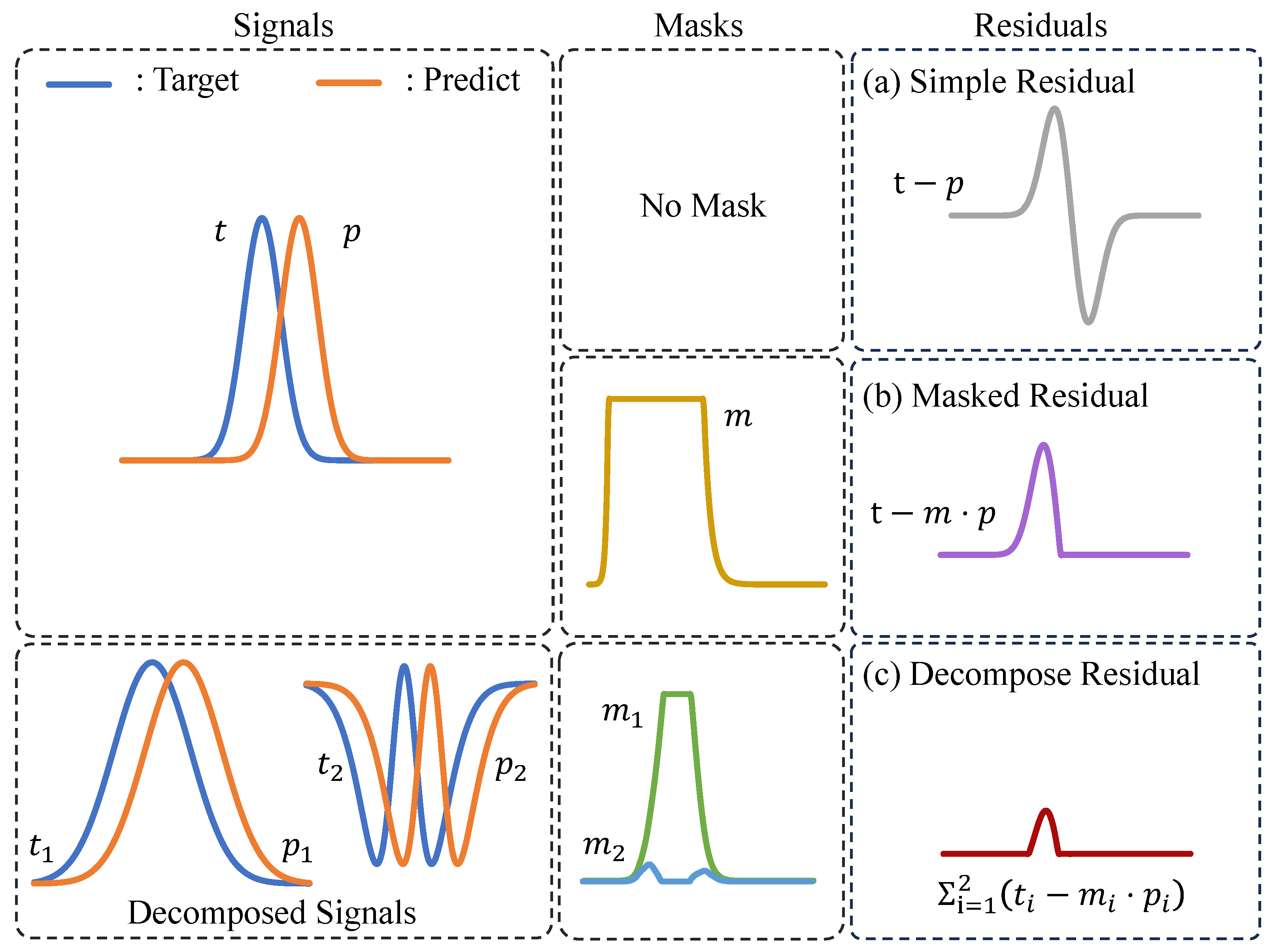
- We point out the limitations of the existing Residual-type Conditional Coding, which masks and subtracts the prediction in the pixel domain.
- To resolve this problem, we propose a CMFR Coding, which extracts the features from the image followed by masking and subtraction in the feature domain.
- We propose the SFF module to effectively subtract or add conditional information to the target or residual information in the context encoder or decoder, respectively.
- We introduce the Motion Refiner module to enhance the quality of the decompressed motion vectors.
2. Related Works
3. Method
3.1. Overall Structure
3.2. Motion Refiner
3.3. Conditional Masked Feature Residual Coding
3.4. Scaled Feature Fusion
4. Experiments
4.1. Implementation Details
4.2. Evaluation
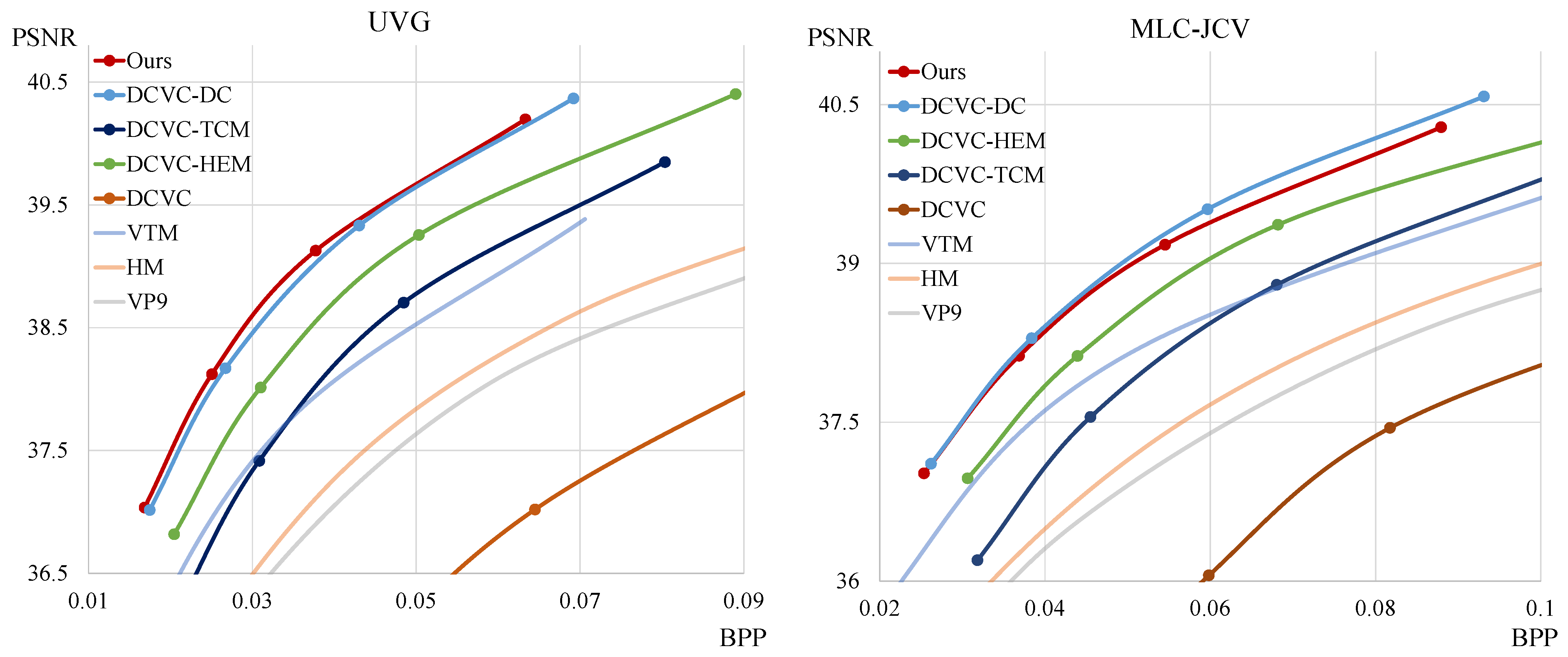
4.3. Rate-Distortion Performance
5. Discussion
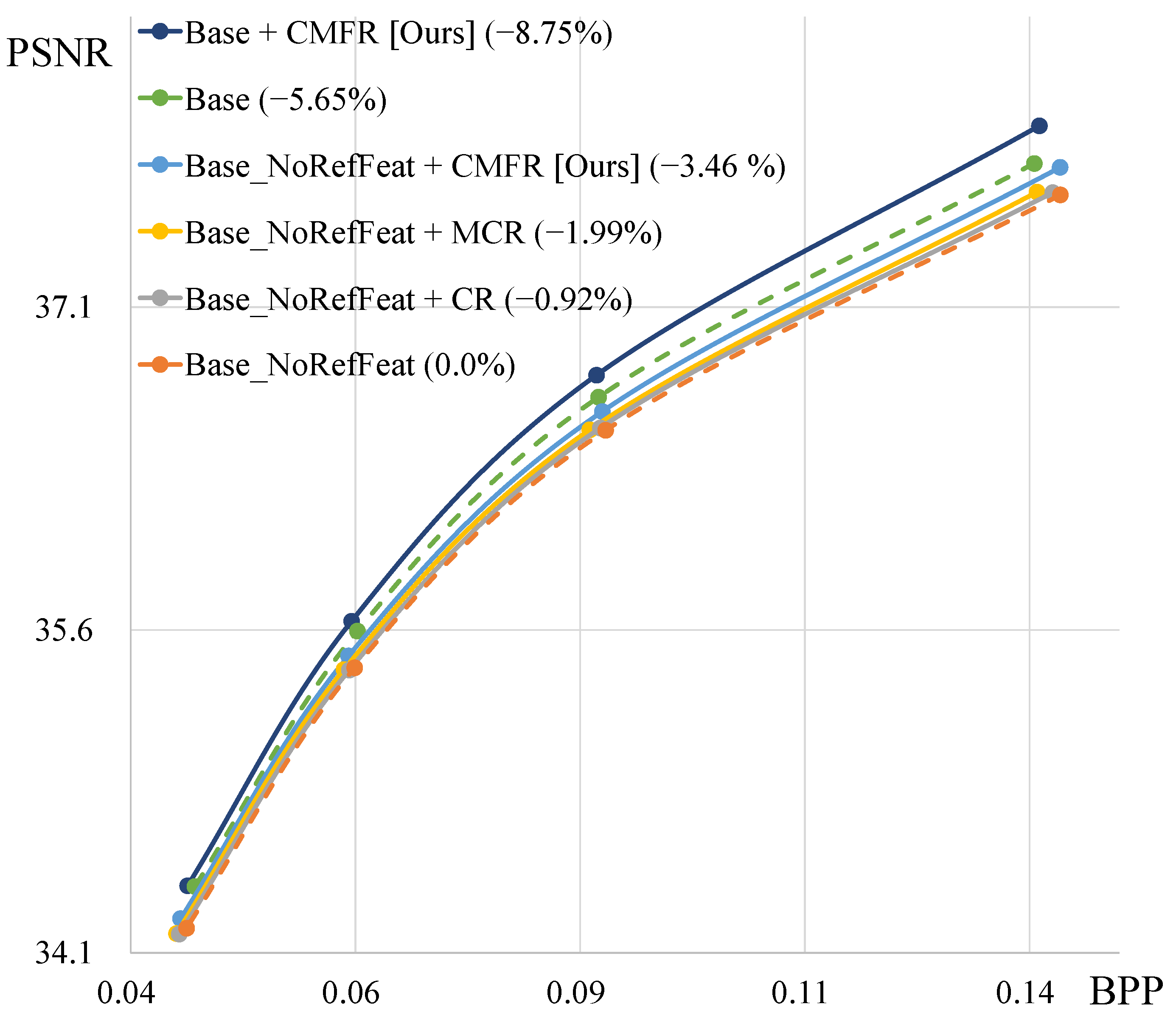
5.1. Conditional Masked Feature Residual Coding
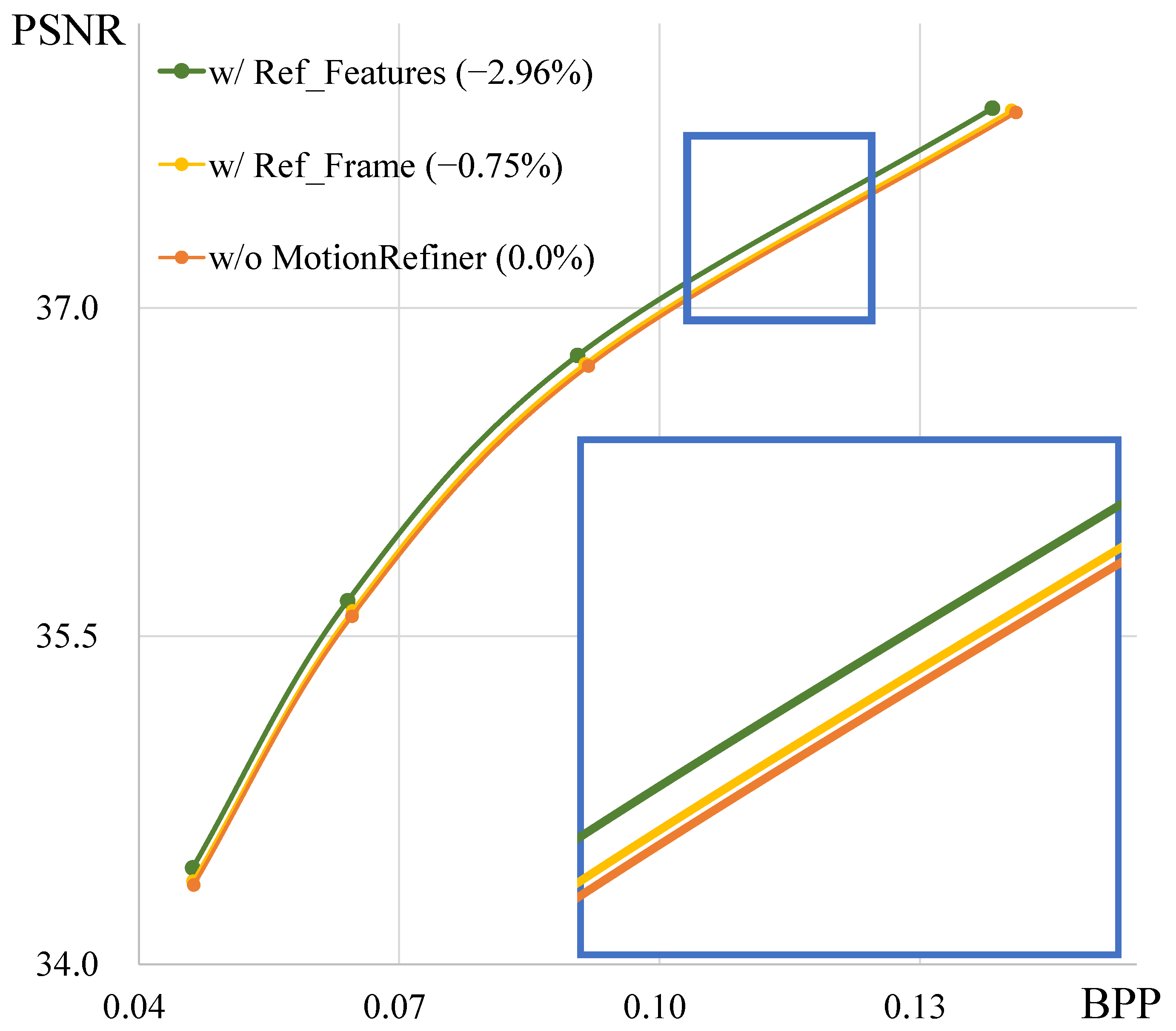
5.2. Motion Refiner
5.3. Scaled Feature Fusion
5.4. Error Propagation
5.5. Limitations and Future Works
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wiegand, T.; Sullivan, G.J.; Bjontegaard, G.; Luthra, A. Overview of the H.264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
- Sullivan, G.J.; Ohm, J.; Han, W.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Mukherjee, D.; Bankoski, J.; Grange, A.; Han, J.; Koleszar, J.; Wilkins, P.; Xu, Y.; Bultje, R. The latest open-source video codec vp9—An overview and preliminary results. In Proceedings of the 2013 Picture Coding Symposium (PCS), San Jose, CA, USA, 8–11 December 2013; pp. 390–393. [Google Scholar]
- Han, J.; Li, B.; Mukherjee, D.; Chiang, C.H.; Grange, A.; Chen, C.; Su, H.; Parker, S.; Deng, S.; Joshi, U.; et al. A Technical Overview of AV1. Proc. IEEE 2021, 109, 1435–1462. [Google Scholar] [CrossRef]
- Bross, B.; Wang, Y.K.; Ye, Y.; Liu, S.; Chen, J.; Sullivan, G.J.; Ohm, J.R. Overview of the Versatile Video Coding (VVC) Standard and its Applications. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 3736–3764. [Google Scholar] [CrossRef]
- Lim, D.; Choi, J. FDI-VSR: Video Super-Resolution Through Frequency-Domain Integration and Dynamic Offset Estimation. Sensors 2025, 25, 2402. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; Oh, T.-H. Joint Video Super-Resolution and Frame Interpolation via Permutation Invariance. Sensors 2023, 23, 2529. [Google Scholar] [CrossRef] [PubMed]
- Kumari, P.; Keck, S.; Sohn, E.; Kern, J.; Raedle, M. Advanced Imaging Integration: Multi-Modal Raman Light Sheet Microscopy Combined with Zero-Shot Learning for Denoising and Super-Resolution. Sensors 2024, 24, 7083. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Yuan, Q.; Shen, H.; Li, J.; Zhang, L. A Single-Frame and Multi-Frame Cascaded Image Super-Resolution Method. Sensors 2024, 24, 5566. [Google Scholar] [CrossRef] [PubMed]
- Lu, M.; Zhang, P. Real-World Video Super-Resolution with a Degradation-Adaptive Model. Sensors 2024, 24, 2211. [Google Scholar] [CrossRef] [PubMed]
- Tsai, F.J.; Peng, Y.T.; Tsai, C.C.; Lin, Y.Y.; Lin, C.W. Banet: A blur-aware attention network for dynamic scene deblurring. IEEE Trans. Image Process. 2022, 31, 6789–6799. [Google Scholar] [CrossRef] [PubMed]
- Wei, P.; Xie, Z.; Li, G.; Lin, L. Taylor neural network for real-world image super-resolution. IEEE Trans. Image Process. 2023, 32, 1942–1951. [Google Scholar] [CrossRef] [PubMed]
- Feng, G.; Han, L.; Jia, Y.; Huang, P. Single Image Defocus Deblurring Based on Structural Information Enhancement. IEEE Access 2024, 12, 153471–153480. [Google Scholar] [CrossRef]
- Lu, G.; Ouyang, W.; Xu, D.; Zhang, X.; Cai, C.; Gao, Z. DVC: An end-to-end deep video compression framework. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10998–11007. [Google Scholar]
- Li, J.; Li, B.; Lu, Y. Deep contextual video compression. In Proceedings of the 34th Conference on Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 10–16 December 2021; pp. 1–12. [Google Scholar]
- Brand, F.; Seiler, J.; Kaup, A. Conditional Residual Coding: A Remedy for Bottleneck Problems in Conditional Inter Frame Coding. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 6445–6459. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Xie, H.-S.; Chen, C.-W.; Gao, Z.-L.; Benjak, M.; Peng, W.-H.; Ostermann, J. MaskCRT: Masked Conditional Residual Transformer for Learned Video Compression. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 11980–11992. [Google Scholar] [CrossRef]
- Sheng, X.; Li, J.; Li, B.; Li, L.; Liu, D.; Lu, Y. Temporal Context Mining for Learned Video Compression. IEEE Trans. Multimed. 2023, 25, 7311–7322. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Lu, Y. Hybrid Spatial-Temporal Entropy Modelling for Neural Video Compression. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 1503–1511. [Google Scholar]
- Li, J.; Li, B.; Lu, Y. Neural video compression with diverse contexts. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22616–22626. [Google Scholar]
- Li, J.; Li, B.; Lu, Y. Neural video compression with feature modulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 26099–26108. [Google Scholar]
- Jin, I.; Xia, F.; Ding, F.; Zhang, X.; Liu, M.; Zhao, Y.; Lin, W.; Meng, L. Customizable ROI-Based Deep Image Compression. arXiv 2025, arXiv:2507.00373. [Google Scholar] [CrossRef]
- He, D.; Zheng, Y.; Sun, B.; Wang, Y.; Qin, H. Checkerboard context model for efficient learned image compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 14771–14780. [Google Scholar]
- Ballé, J.; Minnen, D.; Singh, S.; Hwang, S.J.; Johnston, N. Variational image compression with a scale hyperprior. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–23. [Google Scholar]
- x265 HEVC Encoder/h.265 Video Codec. Available online: https://www.x265.org/ (accessed on 1 July 2025).
- Agustsson, E.; Minnen, D.; Johnston, N.; Ballé, J.; Hwang, S.J.; Toderici, G. Scale-space flow for end-to-end optimized video compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 8500–8509. [Google Scholar]
- Hu, Z.; Lu, G.; Guo, J.; Liu, S.; Jiang, W.; Xu, D. Coarse-to-fine deep video coding with hyperprior-guided mode prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5911–5920. [Google Scholar]
- Rippel, O.; Anderson, A.G.; Tatwawadi, K.; Nair, S.; Lytle, C.; Bourdev, L. ELF-VC: Efficient learned flexible-rate video coding. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 14459–14468. [Google Scholar]
- Lin, J.; Liu, D.; Li, H.; Wu, F. M-LVC: Multiple Frames Prediction for Learned Video Compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 3543–3551. [Google Scholar]
- Brand, F.; Seiler, J.; Kaup, A. On benefits and challenges of conditional interframe video coding in light of information theory. In Proceedings of the 2022 Picture Coding Symposium (PCS), San Jose, CA, USA, 7–9 December 2022; pp. 289–293. [Google Scholar]
- Mentzer, F.; Toderici, G.; Minnen, D.; Hwang, S.J.; Caelles, S.; Lucic, M.; Agustsson, E. VCT: A video compression transformer. In Proceedings of the 36th Conference on Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 10–16 December 2023; pp. 13091–13103. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Lu, M.; Duan, Z.; Zhu, F.; Ma, Z. Deep hierarchical video compression. In Proceedings of the 38th Annual AAAI Conference on Artificial Intelligence (AAAI), Vancouver, BC, Canada, 20–27 February 2024; pp. 8859–8867. [Google Scholar]
- Jia, Z.; Li, B.; Li, J.; Xie, W.; Qi, L.; Li, H.; Lu, Y. Towards Practical Real-Time Neural Video Compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 10–17 June 2025; pp. 12543–12552. [Google Scholar]
- Jiang, W.; Li, J.; Zhang, K.; Zhang, L. Ecvc: Exploiting non-local correlations in multiple frames for contextual video compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 10–17 June 2025; pp. 7331–7341. [Google Scholar]
- Mercat, A.; Viitanen, M.; Vanne, J. UVG dataset: 50/120 fps 4K sequences for video codec analysis and development. In Proceedings of the 11th ACM Multimedia Systems Conference, Istanbul, Turkey, 8–11 June 2020; pp. 297–302. [Google Scholar]
- Sheng, X.; Li, L.; Liu, D.; Wang, S. Bi-directional deep contextual video compression. IEEE Trans. Multimed. 2025, 1–15. [Google Scholar] [CrossRef]
- Zhai, Y.; Tang, L.; Jiang, W.; Yang, J.; Wang, R. L-LBVC: Long-Term Motion Estimation and Prediction for Learned Bi-Directional Video Compression. In Proceedings of the IEEE Data Compression Conference (DCC), Snowbird, UT, USA, 19–21 March 2025; pp. 53–62. [Google Scholar]
- Alexandre, D.; Hang, H.M.; Peng, W.H. Hierarchical B-frame video coding using two-layer CANF without motion coding. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 10249–10258. [Google Scholar]
- Ranjan, A.; Black, M.J. Optical Flow Estimation Using a Spatial Pyramid Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2720–2729. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. ICML 2013, 30, 3. [Google Scholar]
- Shi, W.; Caballero, J.; Huszar, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Xue, T.; Chen, B.; Wu, J.; Wei, D.; Freeman, W.T. Video enhancement with task-oriented flow. Int. J. Comput. Vis. 2019, 127, 1106–1125. [Google Scholar] [CrossRef]
- Ma, D.; Zhang, F.; Bull, D.R. BVI-DVC: A Training Database for Deep Video Compression. IEEE Trans. Multimed. 2022, 24, 3847–3858. [Google Scholar] [CrossRef]
- Bossen, F. Common test conditions and software reference configurations. In Proceedings of the 3rd. JCT-VC Meeting, Guangzhou, China, 7–15 October 2013; Volume 12. [Google Scholar]
- Wang, H.; Gan, W.; Hu, S.; Lin, J.Y.; Jin, L.; Song, L.; Wang, P.; Katsavounidis, I.; Aaron, A.; Kuo, C.C.J. MCL-JCV: A JND-based H.264/AVC video quality assessment dataset. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1509–1513. [Google Scholar]
- Joint Video Expoloration Team (JVET) of ITU-T VCEG and ISO/IEC MPEG. HEVC Reference Software. Version 18.0. Available online: https://vcgit.hhi.fraunhofer.de/jvet/HM/-/tree/HM-18.0?ref_type=tags (accessed on 17 January 2025).
- FFmpeg. Version 7.0. Available online: https://github.com/FFmpeg/FFmpeg/tree/release/7.0 (accessed on 4 September 2024).
- Joint Video Expoloration Team (JVET) of ITU-T VCEG and ISO/IEC MPEG. VVC Reference Software. Version 23.4. Available online: https://vcgit.hhi.fraunhofer.de/jvet/VVCSoftware_VTM/-/tree/VTM-23.4?ref_type=tags (accessed on 21 October 2024).
- Bjøntegaard, G. Calculation of average PSNR differences between RDcurves. In Proceedings of the Thirteenth Meeting, Austin, TX, USA, 2–4 April 2001. Tech. Rep., VCEG-M33, ITU-T SG16/Q6. [Google Scholar]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the 28th Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Full Name | Explanation |
|---|---|---|
| Target frame | The current frame to be encoded. | |
| Compensated frame/Prediction | The frame predicted from previous frames with motion compensation. | |
| m | Mask | A soft mask that determines how much of the predicted pixel or features to retain. |
| Reconstructed frame | The decoded current frame. | |
| Reconstructed features | The decoded current features. This can be mapped to with a neural network. | |
| Conditional input | resolution features predicted by the reference frame or features with motion vector. | |
| Reference frame | The previously decoded frame used to encode the target frame. | |
| Reference features | The previously decoded features used to encode the target frame. |
| Model | Dataset | VP9 | HM | VTM | DCVC | DCVC-TCM | DCVC-HEM | DCVC-DC | Ours |
|---|---|---|---|---|---|---|---|---|---|
| BD-rate (%) | UVG | 54.81 | 40.82 | 0.00 | 168.37 | 0.27 | −19.74 | −35.06 | −37.90 |
| HEVC-A | 48.77 | 36.67 | 0.00 | 85.81 | −14.66 | −27.74 | −39.67 | −41.09 | |
| HEVC-B | 65.06 | 44.72 | 0.00 | 131.66 | −3.56 | −18.49 | −32.07 | −33.13 | |
| HEVC-C | 40.99 | 30.76 | 0.00 | 162.16 | 33.04 | 11.53 | −24.07 | −27.48 | |
| HEVC-D | 39.08 | 29.83 | 0.00 | 136.30 | 12.97 | −1.97 | −37.01 | −41.37 | |
| HEVC-E | 67.05 | 45.01 | 0.00 | 285.24 | 13.43 | 1.15 | −33.68 | −30.08 | |
| HEVC-avg | 46.69 | 35.65 | 0.00 | 146.61 | 10.21 | −6.38 | −34.28 | −36.28 | |
| MCL-JCV | 57.74 | 42.94 | 0.00 | 139.63 | 10.40 | −13.82 | −29.35 | −27.34 | |
| Parameters (M) | - | - | - | 7.94 | 10.71 | 17.52 | 19.78 | 19.48 | |
| GPU Enc Time (ms/frame) | - | - | - | 2438.34 | 374.15 | 318.33 | 464.75 | 482.93 | |
| GPU Dec Time (ms/frame) | - | - | - | 12,345.73 | 230.37 | 192.01 | 359.74 | 334.15 | |
| CPU Enc Time (ms/frame) | 307.89 | 8357.62 | 37,905.31 | 17,831.36 | 26,427.89 | 23,015.48 | 35,378.43 | 37,520.83 | |
| CPU Dec Time (ms/frame) | 6.41 | 30.71 | 45.8 | 16,446.42 | 23,247.03 | 19,253.71 | 27,824.46 | 26,073.00 | |
| KMACs/pixel (Enc) | - | - | - | 1180.38 | 1750.62 | 1700.87 | 1360.05 | 1490.21 | |
| KMACs/pixel (Dec) | - | - | - | 776.26 | 933.10 | 1270.31 | 930.52 | 918.71 | |
| Model | Dataset | VP9 | HM | VTM | DCVC | DCVC-TCM | DCVC-HEM | DCVC-DC | Ours |
|---|---|---|---|---|---|---|---|---|---|
| BD-rate (%) | UVG | 32.23 | 18.68 | 0.00 | 57.97 | −12.22 | −36.08 | −40.44 | −42.07 |
| HEVC-A | 35.22 | 24.73 | 0.00 | 71.61 | −0.15 | −31.46 | −38.18 | −37.25 | |
| HEVC-B | 33.24 | 23.19 | 0.00 | 55.32 | −15.12 | −45.74 | −51.15 | −52.46 | |
| HEVC-C | 28.35 | 22.07 | 0.00 | 40.13 | −17.88 | −41.57 | −53.48 | −55.61 | |
| HEVC-D | 30.1 | 25.16 | 0.00 | 18.73 | −31.02 | −54.20 | −61.91 | −63.79 | |
| HEVC-E | 32.08 | 28.49 | 0.00 | 104.56 | −28.67 | −54.57 | −59.83 | −57.32 | |
| HEVC-avg | 32.84 | 23.41 | 0.00 | 62.48 | −25.4 | −41.29 | −53.41 | −56.41 | |
| MCL-JCV | 31.57 | 27.63 | 0.00 | 29.06 | −11.77 | −36.61 | −48.75 | −46.03 |
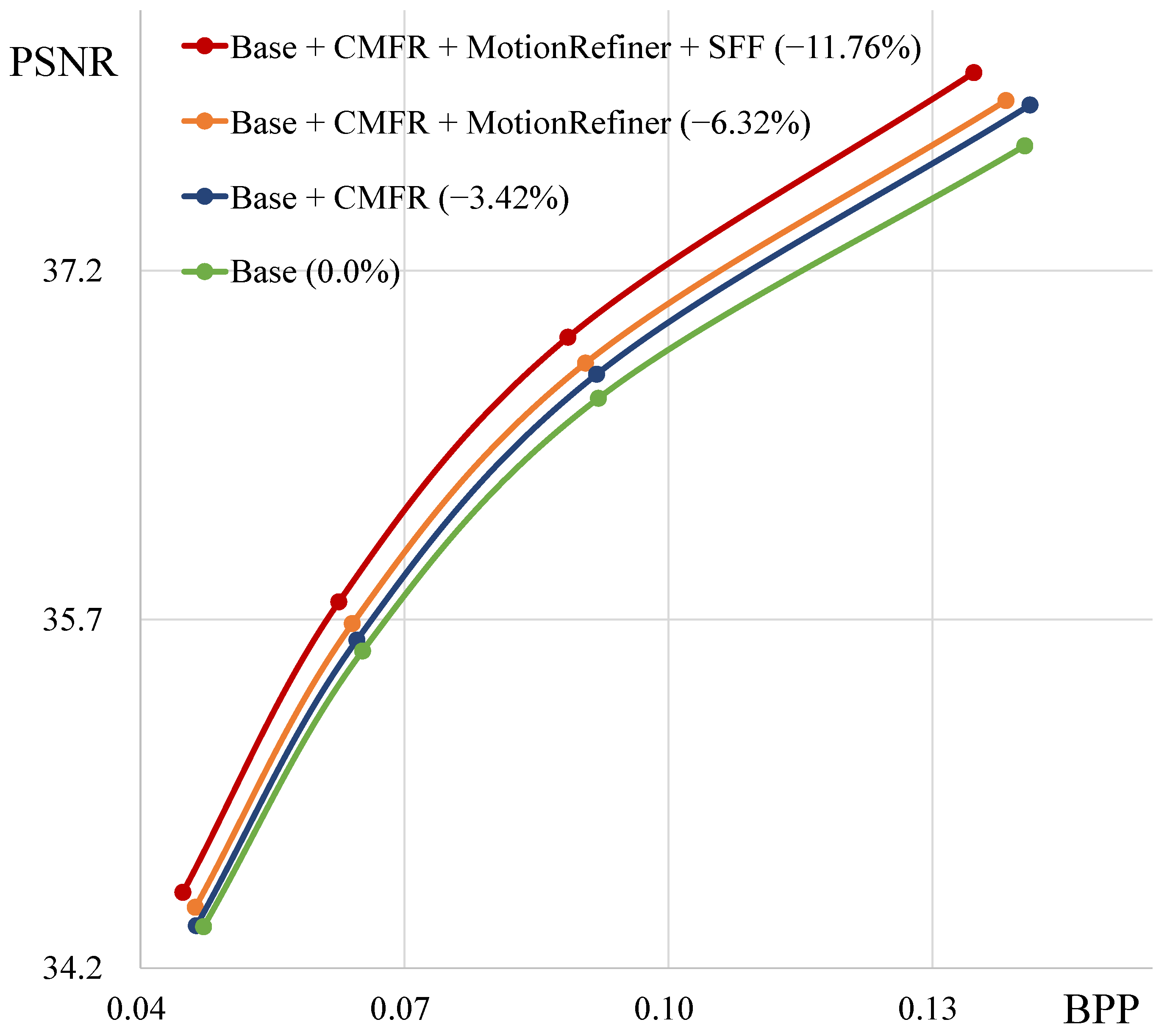
| A | B | C | D | |
|---|---|---|---|---|
| CMFR | ✓ | ✓ | ✓ | |
| MotionRefiner | ✓ | ✓ | ||
| SFF | ✓ | |||
| BD-rate (%) | 0.0 | −3.42 | −6.32 | −11.76 |
| Parameters (M) | 17.41 | 17.64 | 18.34 | 19.48 |
| GPU Enc Time (ms/frame) | 332.79 | 398.66 | 411.18 | 482.93 |
| GPU Dec Time (ms/frame) | 212.48 | 275.73 | 298.03 | 334.15 |
| Model | w/o SFF | w/SFF | w/3 D-ResBlks |
|---|---|---|---|
| BD-rate (%) | 0 | −5.87 | −1.46 |
| Parameters (M) | 18.34 | 19.48 | 20.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, C.; Kim, Y.; Choi, K.; Lee, S. Masked Feature Residual Coding for Neural Video Compression. Sensors 2025, 25, 4460. https://doi.org/10.3390/s25144460
Shin C, Kim Y, Choi K, Lee S. Masked Feature Residual Coding for Neural Video Compression. Sensors. 2025; 25(14):4460. https://doi.org/10.3390/s25144460
Chicago/Turabian StyleShin, Chajin, Yonghwan Kim, KwangPyo Choi, and Sangyoun Lee. 2025. "Masked Feature Residual Coding for Neural Video Compression" Sensors 25, no. 14: 4460. https://doi.org/10.3390/s25144460
APA StyleShin, C., Kim, Y., Choi, K., & Lee, S. (2025). Masked Feature Residual Coding for Neural Video Compression. Sensors, 25(14), 4460. https://doi.org/10.3390/s25144460