1. Introduction
Real-time physiological monitoring using wearable sensors is increasingly recognized as a valuable tool in psychiatric practice, offering continuous, objective data to support mental health assessment and intervention [
1,
2,
3]. Electrodermal Activity (EDA), in particular, is a measure of changes in the electrical properties of the skin influenced by the activity of sweat glands, which are regulated by the autonomic nervous system (ANS). Specifically, EDA reflects the sympathetic branch of the ANS, which is associated with physiological arousal and responses to emotional or stressful stimuli [
4]. When an individual experiences heightened emotional arousal, the sympathetic nervous system stimulates eccrine sweat glands, particularly on the palms and soles, leading to measurable fluctuations in skin conductance [
5,
6]. These fluctuations are captured as changes in electrical conductance on the skin’s surface, which is typically measured in microsiemens (µS).
EDA is widely used in psychophysiological research due to its sensitivity to emotional, cognitive, and stress-related processes [
7,
8]. It has been applied extensively in fields such as psychology, neuroscience, and human–computer interaction for applications ranging from stress and anxiety detection to emotion recognition and mental health monitoring [
9]. More recently, measuring EDA has become increasingly accessible with the advent of wearable sensors, allowing continuous and unobtrusive monitoring of physiological arousal in everyday environments. Research-grade devices such as the Feel Monitor [
10], Empatica E4 [
11], and Shimmer3 GSR+ [
12] have been widely adopted in clinical and research settings [
13,
14,
15,
16,
17,
18], while consumer-grade devices like the Fitbit and Garmin wearables are increasingly being used in mental health monitoring [
19,
20]. These platforms facilitate the detection of stress patterns and physiological correlates of emotional states, facilitating early identification of psychiatric symptoms and supporting timely, personalized interventions [
21].
EDA signals are typically divided into two primary components, phasic and tonic, each representing different aspects of ANS arousal. The phasic component reflects short-term fluctuations that are closely tied to discrete external or internal stimuli, such as sudden loud noises, visual stimuli, or cognitive tasks that elicit an arousal response. These rapid changes, also known as skin conductance responses (SCR), occur in reaction to specific events and are characterized by sharp, transient increases in skin conductance followed by a gradual return to baseline [
4]. Phasic activity provides insights into an individual’s immediate, momentary responses to stimuli, making it useful for studying arousal dynamics, event-related responses, and stimulus-triggered physiological changes [
4].
The tonic component, on the other hand, reflects overall arousal levels over longer periods. It is often referred to as the skin conductance level (SCL) and is indicative of an individual’s general physiological state or emotional baseline [
4]. The tonic component changes gradually and is influenced by factors such as stress, attention, or sustained emotional states rather than immediate stimuli. SCL provides essential context for interpreting an individual’s broader arousal state [
4].
Given the distinct physiological information each component provides, it becomes evident that decomposing EDA signals into their phasic and tonic components is critical for a comprehensive understanding of ANS functioning. This methodological distinction has direct clinical implications: accurately isolating phasic activity can help identify acute stress responses in real time, while monitoring tonic levels may reveal chronic stress or emotional dysregulation patterns. Such insights can inform timely, personalized interventions in patients with mood or anxiety disorders, making EDA decomposition not just a technical requirement but a clinically actionable step in advancing precision mental health care. By isolating these elements, researchers can better distinguish between momentary, stimulus-induced reactions and the broader, baseline arousal states that evolve over time.
However, a significant challenge in evaluating EDA decomposition techniques is the lack of a universally accepted ground truth for distinguishing phasic and tonic EDA components, which directly impacts the clinical validation and broader adoption of EDA-based monitoring tools in psychiatric care. Without clear ground truth, it becomes difficult to objectively assess the performance of different decomposition algorithms, which, in turn, complicates their integration into clinical workflows that require reliability and interpretability. This methodological gap limits the utility of EDA signals in informing treatment personalization and delays the implementation of real-time stress interventions based on these physiological markers. In lab conditions, researchers trigger ANS responses, which allow them to directly localize SCRs in the signal. Naturally, the duration of such studies is limited. This means that such experiments do not offer the opportunity to observe meaningful changes in the slow-changing SCL. Continuous monitoring, on the other hand, allows for the study of SCL but lacks explicit information about where SCRs have occurred.
Bach and Friston [
22] also discuss this lack of a definitive reference and how it hinders the objective assessment of the accuracy and reliability of different methods. They assert, however, that phasic/tonic methods are more accurate than directly analyzing the EDA signal, as was standard practice previously.
In this article, we investigate whether deep learning—specifically, a Transformer architecture in a non-autoregressive setting—can be used to address the challenge of EDA decomposition without requiring detailed supervision. This approach enables deployment in wearable devices for continuous, real-world monitoring of autonomic arousal. By facilitating real-time tracking, the method has the potential to enhance clinical decision support systems in psychiatry and bridge the gap between algorithmic innovation and clinical adoption in mental health care. In the remainder of the article, we first present the relevant background (
Section 2), including both methods specifically designed for decomposing EDA signals and data-driven methods, which identify events that stand out from the overall signal without referring to EDA-specific knowledge. We then discuss the challenge of comparing methods in the absence of ground truth and propose the comparison metrics that will be used in our experiments (
Section 3). We then present our Transformer-based architecture and how we use data collected in the wild to compare it against prior methods (
Section 4). We then present and discuss the results and the insights gained regarding relative strengths and limitations of EDA-specific methods, generic data-driven methods, and our deep-learning method (
Section 5). Finally, we conclude and present future work and potential applications (
Section 6).
2. Background
In this section, we first present literature specifically targeting EDA signal decomposition. These methods are characterized by the fact that they incorporate extensive domain knowledge on the morphology of SCRs and the EDA signal in general. We then proceed to present generic methods for time series detrending, Transformer neural networks, and, in general, data-driven methods that do not rely on domain-specific priors.
2.1. Knowledge-Driven Methods
Benedek and Kaernbach [
23,
24] propose the Ledalab phasic/tonic separation method, which directly reflects the physiology that generates the EDA signal. They build on earlier works that identify the Bateman biexponential function as accurately reflecting the characteristic steep onset and a slow recovery of phasic impulses; In fact, the Bateman function is both physiologically motivated and consistent with the data [
25]. In theory, one could simply fit the Bateman function to calculate the phasic component and then simply subtract that from the full EDA signal to calculate the tonic component. However, as noted by Benedek and Kaernbach [
24], this is not straightforward due to (a) the variability of the two parameters of the Bateman function both across subjects and for a given subject and (b) the fact that new responses may be superimposed on the recovery slope of previous ones.
What they do instead is to use the Bateman function as a way to detect the segment of the EDA signal that is the result of imposing the response impulse on the underlying skin conductance level assuming that the impulse peak has been detected. In other words, Ledalab does not use the Bateman function as a direct detector of SCRs, but as a way to `guess’ a Bateman-shaped area around each local maximum in the signal. To account for variation in the parameters of the Bateman function, an optimization task is performed for each maximum to estimate the parameters that maximize metrics inspired by known properties of the phasic and tonic components, which also includes elements that have been empirically found to work. This is followed by deconvolution of the EDA signal over the Bateman function. This gives a driver signal: A signal such that its convolution with the Bateman function would give the original EDA signal; or, in other words, a signal where occurrences of the shape of the Bateman function stand out more clearly. Naturally, because of the optimization step, practically all maxima fit the Bateman shape and appear in the driver signal. To separate actual impulses from noise artifacts, Ledalab applies an empirical threshold to identify `significant peaks’. Once significant peaks are detected, the region of the EDA signal that corresponds to each peak (as per the Bateman function) is zeroed out. The core idea is that phasic impulses are contained in time, so if we remove the regions with phasic activity, what remains is a purely tonic signal. The tonic component of the phasic-activity regions can then be accurately interpolated between the purely tonic regions. Once the complete tonic component is estimated, then simple subtraction gives the phasic component.
Greco et al. [
26] follow a more direct approach in their cvxEDA algorithm. Instead of Ledalab’s multi-step method, cvxEDA directly optimizes the complete formulation of EDA as the sum of a Bateman-shaped phasic component, a relatively smooth (cubic spline) tonic component, and some residual (sampling or modeling error). The optimizer finds the best parameters for all components, again guided by priors about the shape of phasic impulses.
Hernando-Gallego et al. [
27] follow a similar approach, also jointly optimizing the parameters of the phasic and the tonic model. When compared to cvxEDA, one difference is that their sparsEDA algorithm uses a dictionary of impulse models to select from, instead of allowing the optimizer to set the parameters of the Bateman function. Also, the method is more explicitly formulated to take into consideration the sampling rate and other theoretical and practical considerations regarding the sampled and discretized signal.
In a more recent variation of this optimization-based line of research, Wickramasuriya et al. [
28] use the Zdunek and Cichocki [
29] method for finding sparse overlapping signals. However, this method needs to be parameterized with the onset and recovery times, which are known to vary between subjects and even between experiments with the same subject. In order to estimate these parameters, Wickramasuriya et al. [
28] first apply cvxEDA on a short portion of the data.
Jain et al. [
30] emphasise treating a more complex tonic component than the cubic spline interpolation that is used in the works presented above. Jain et al. [
30] note that in the case of wearable devices, the baseline can have abrupt shifts due to movement, of a magnitude that cannot be captured by the usual noise models. In order to represent such discontinuities, they model EDA as being composed of a step baseline function, a tonic component, and the phasic impulses. Exploiting reasonable assumptions regarding the maximum frequency of discontinuities and the almost-sparse nature of the phasic component, they are able to formulate a solvable optimization task.
2.2. Data-Driven Methods
The methods presented above are specifically designed for decomposing the EDA signal, and thus encode prior knowledge about the shape of SCR. However, the manifestation of SCRs in actual data is not uniform and clear to the extent that we can consider recognizing them a solved problem. The amplitude of the actual responses varies, and the relative amplitude with respect to noise even more so; Furthermore, overlapping SCRs might obscure the slow-recovery pattern predicted by the Bateman function.
Given the above, it makes sense to also experiment with data-driven methods to identify responses as events that stand out from the overall signal without referring to prior observations about their shape. Framing EDA decomposition in this way, it makes sense to also consider the wide variety of statistical detrending methods that have been proposed to separate fast-moving events from any slow-moving trend in the background. Detrending typically works by fitting a linear (or, in any case, relatively simple) model for the overall trend and then subtracting that from the signal. Fitting a linear model to a time series is one of the most common tasks in non-parametric statistics, and many textbook methods (such as least squares and the Theil–Sen estimator) are part of daily practice in econometrics, physics, meteorology, and practically every natural science.
Similarly to the statistical methods discussed above, machine learning methods also have the advantage that they can exploit data to find regularities for which we lack a clear definition. Artificial Neural Networks (ANN) [
31] are known to be universal function approximators with minimal requirements for prior knowledge, but specific network architectures are best suited for different kinds of tasks. In our case, we are looking for a network that is able to capture the positional dependencies that model the steep onset and slow recovery of phasic impulses while simultaneously abstracting away the specific position of each impulse in the EDA signal. The convolutional neural network (CNN) architecture ([
31], Chapter 9) has been specifically designed to capture such local patterns and, even closer to our case, recurrent neural networks (RNN) ([
31], Chapter 10) and long short-term memory (LSTM) [
32] target capturing local events in time series.
Unlike non-parametric statistics, however, machine learning relies on a training dataset where relatively short (although not necessarily exact) spans of signal are annotated as positive and negative examples of the pattern of interest. Manually creating such a dataset at the scale required for training an ANN is a daunting task, and such methods are typically used in tasks where datasets of positive and negative examples are readily available or can be extracted at scale. In our case, it is preferable to focus on unsupervised methods that can be trained to separate the fast-moving and the slow-moving component of the EDA signal without explicit examples.
The use of CNNs, designed to reconstruct and/or forecast time series, in an autoregressive and therefore unsupervised manner, can be especially enhanced by using dilated convolutions that are able to capture long-range dependencies effectively along the temporal dimension ([
33], closing paragraph). Similar successful approaches include WaveNet, a CNN-type model with dilated convolutions for fixed-length time series [
34], and the combination of multiple CNNs, each designed to capture either closeness pattern or long and short-range dependencies in time series [
35].
Naturally, in order to be able to distinguish the two components, signal data points that are far removed from each other must be taken into account together. A transformer model with self-attention provides attention connections with a very wide receptive field where temporal correlations are less locally focused and more widely connected, allowing it to uncover long-range dependencies [
36].
A natural issue that arises with using attention on long time series is computational efficiency. In the traditional approach of scaled dot product attention, the computational complexity and memory requirements scale quadratically over the size of the input, making it difficult to handle inputs beyond 512 tokens [
37]. At the sampling rate of 8Hz, which is generally accepted as sufficient for capturing EDA features, this restricts our input to 1min. Various modified attention mechanisms have been proposed to tackle this problem, and among the most notable and successfully used are the Informer model, which uses prob-sparse self-attention (provides a probabilistic approach to sparsifying the self-attention matrix) [
38], the Reformer (LSH attention by approximating the full self-attention mechanism with a more computationally manageable variant) [
39], and the Autoformer model [
40], which uses an auto-correlation mechanism instead of traditional attention.
Our reasons for choosing the Autoformer model are mainly two. First, the model is very efficient in uncovering long-range dependencies because instead of computing pairwise attention weights between all elements in the sequence, the autocorrelation attention mechanism leverages the statistical properties of time series data to identify and focus on the most predictive parts of the sequence [
40]. Second, the Autoformer is a detrending model, as its blocks sequentially remove and refine a trend component from the time series input. Given the above, we expect the Autoformer to be an appropriate basis for developing a trend-sensitive decomposition mechanism that separates the slow-moving tonic component from the fast-moving phasic component.
3. Comparing EDA Decomposition Methods
In order to compare algorithms, we would normally go back to their purpose and define metrics that reflect how well each algorithm serves this purpose. This is less straightforward in multi-step methods, where we do not have ground truth annotations for the outputs of the intermediate steps but only for the system as a whole. Nevertheless, the core intuition behind decomposition is that once the slow-moving SCL component has been removed, SCR peaks will have similar amplitude so that peak-detection methods can be directly parameterized.
We should note here that these characteristics of the SCL and SCR components are encoded in the optimization step of Ledalab and cvxEDA; therefore, the result is expected to be optimal for a perfectly noiseless signal. However, in data collected in the wild, either algorithm can fail under different circumstances: Ledalab optimizes each peak separately, which might result in fitting peaks that are noise artifacts; cvxEDA optimizes globally, which might result in counterintuitive SCL as it tries to fit noise artifacts. We will revisit this point in
Section 5.2, but what is important is that the most informed methods in the domain often give different results without any clear, automated way to decide which is more accurate.
Without access to golden-truth decomposition, we need to establish measures of similarity between decompositions and compare the behavior of the different methods. Such a measure of similarity could be the RMS between SCL curves, or the same SCR peaks are identified under the same peak detection parameters. However, we observe that the ultimate goal is not the identification of SCR peaks per se, but statistics known to be characteristic of ANS responses: SCR frequency, mean amplitude, and the power spectral density of different frequency bands. In other words, it can happen that two alternative decompositions of the same signal might appear different when comparing whether the same SCRs have been identified, but give the same or very similar feature values.
(Kreibig [
41], Table 2) lists the EDA features proposed in the relevant literature. There seems to be a consensus on the direction of change of SCL, the frequency and amplitude of SCR, and the nonspecific skin conductance response rate. Other features that appear prominently, although not universally, include the Ohmic Perturbation Duration index (OPD) and SYDER skin potential forms. We refer the reader to Silva et al. [
42] for precise definitions. Among those, only the direction of change of SCL, the frequency of SCR, and the amplitude of SCR can be directly extracted from the decomposed signal without sophisticated further analysis. The rest of the features require identifying the onset and end timepoints of the SCR, which is either a by-product of some (but not all) of the methods under consideration or a substantial secondary analysis that can (for overlapping SCR) produce errors independently of the decomposition quality.
Based on the above, we use, in the experiments we present below, the direction of change of SCL, the frequency of SCR, and the amplitude of SCR as similarity metrics because they depend on the decomposition in a direct and straightforward way.
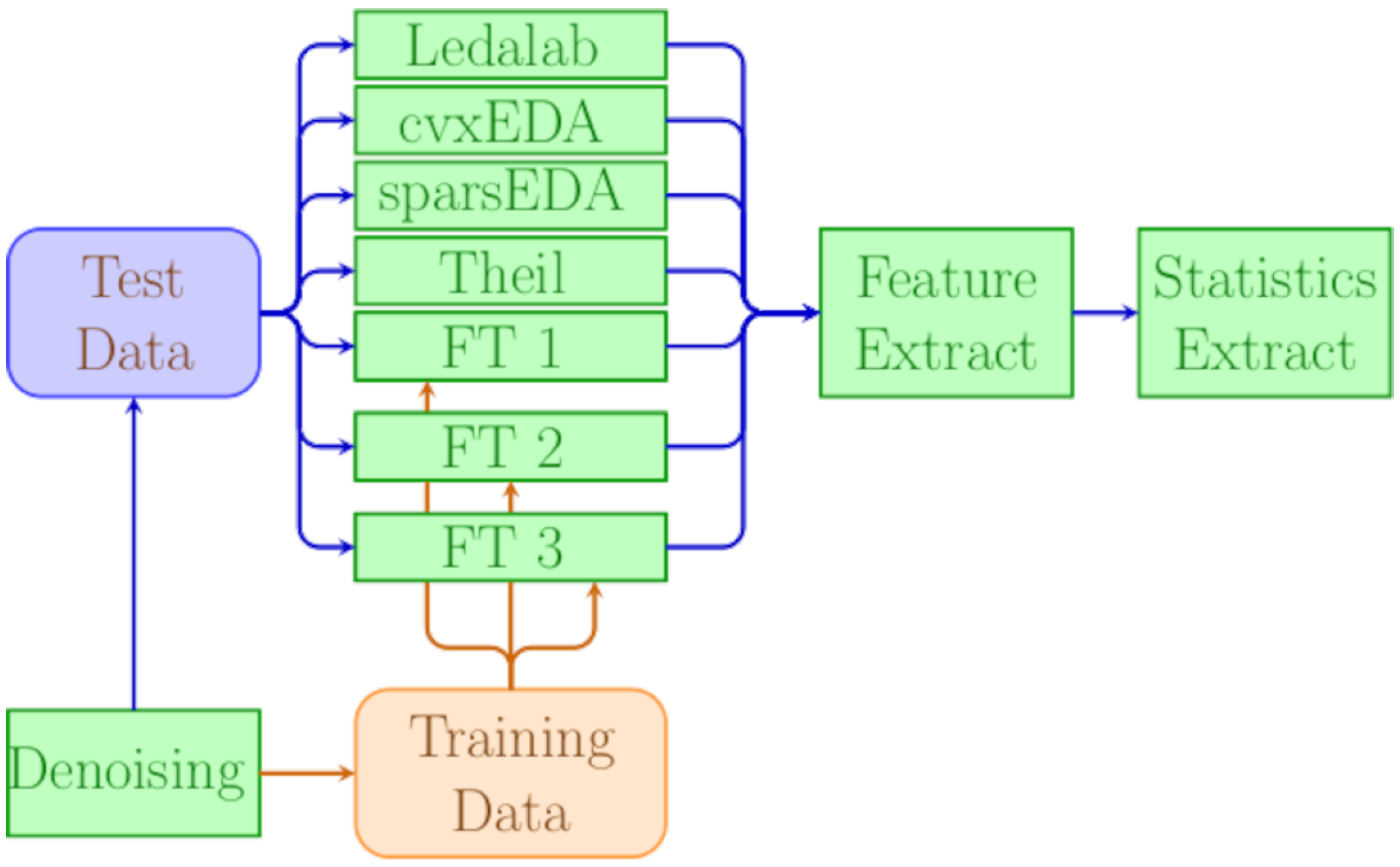
4. Experimental Setup
4.1. Datasets and Methods
Our dataset is extracted from data acquired in previous studies by Tsirmpas et al. [
18,
43], comprising longitudinal EDA data collected over a 16-week period from 40 individuals. This dataset is considerably larger-scale than most datasets previously used to study EDA, both with respect to the number of different users and with respect to the duration of the EDA signal per user. It is also acquired from wearable devices in the wild, offering a very representative sample of what EDA looks like in personalized health and well-being use cases, as opposed to controlled-environment clinical studies and research.
For our empirical comparisons, we have used the following implementations of relevant methods presented in
Section 2:
Ledalab as implemented by Pypsy 0.1.5, (Available from
https://github.com/brennon/Pypsy, accessed on 20 May 2024) with the change that the input is resampled to 24Hz instead of 25 Hz. This has no impact on the method, but makes it easier to undersample back to the 8Hz rate of our data.
cvxEDA and sparsEDA as implemented in NeuroKit2 0.2.10. (Available from
https://github.com/neuropsychology/NeuroKit, accessed on 20 May 2024) and PyPI. Note that this version or later must be used, as earlier versions do not include our sparsEDA patch.
Thiel detrending as implemented in SciPy 1.11. (Package
scipy.stats.theilslopes from
https://github.com/scipy (accessed on 20 May 2024) and PyPI.)
All methods were applied on non-overlapping 3 min frames to produce the tonic component, noting that Theil detrending produces a slope/intercept pair, which is interpreted as a straight line with those parameters. The phasic component was then calculated as the residue from the EDA signal.
For all methods, the EDA signal was first cleaned with a low-pass filter with a 3Hz cutoff frequency and a 4th order Butterworth filter. The number of peaks was calculated using the NeuroKit2 peak detection algorithm with default parameters. Since we are interested in observing differences between the peaks detected after different decomposition methods, the specific algorithm and parameters used are not expected to affect our results, as long as the same algorithm/parameters is used for all methods. For this reason, we have not used the peaks reported by decomposition methods such as Ledalab, where detecting SCR is an integral part of the algorithms.
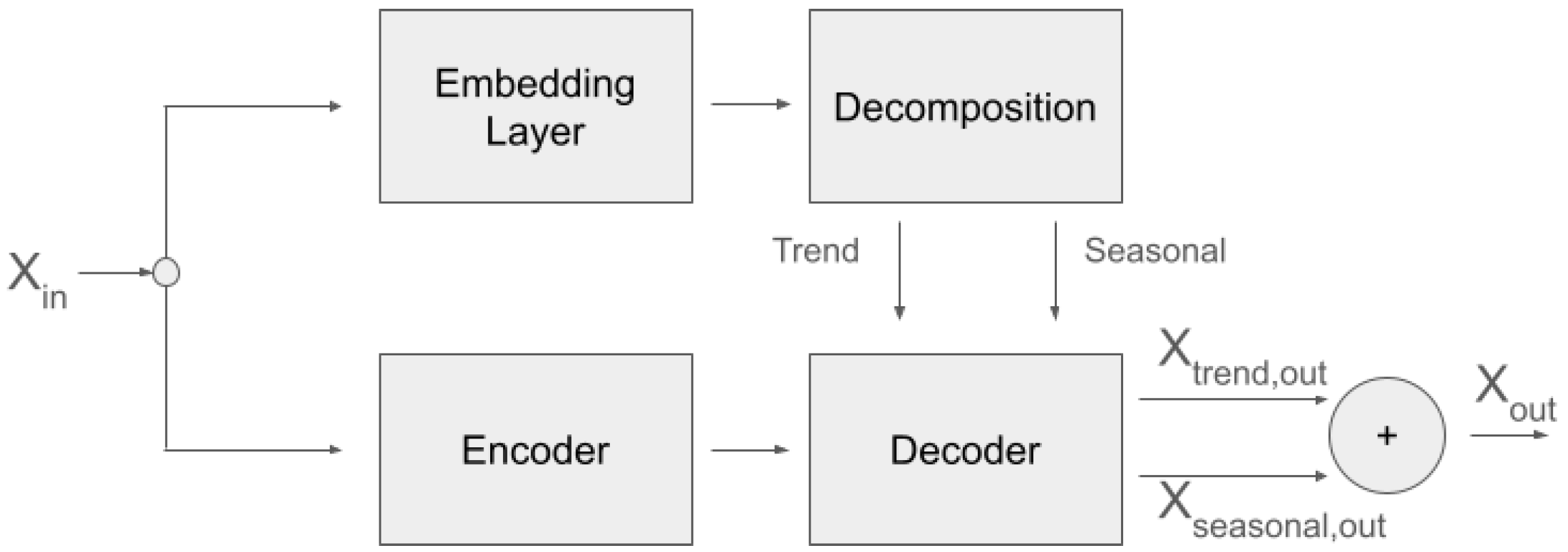
4.2. Feel Transformer
We base our Feel Transformer on the Autoformer [
40], but we effected several changes in the architecture, although we largely re-used the implementations of the individual layers from the original Autoformer implementation (Available from
https://github.com/thuml/Autoformer, accessed on 20 May 2024). We used one encoder and two decoder blocks, with the aim of adding more processing power and depth to our network. At the same time, using the input sequence again before the decoder blocks acts as a residual connection. We use the network in a non-autoregressive fashion. That is, there is no left-to-right processing as is usual with the decoder part of a transformer, but rather the sequence is processed bidirectionally in both encoder and decoder blocks. An overview of the architecture is shown in
Figure 1.
The motivation behind this modification comes from the lack of explicit supervision regarding how EDA is decomposed in its SCL and SCR components, with the simultaneous lack of supervision regarding when to expect ANS responses in our in-the-wild data acquisition. Since ANS responses follow (unknown to us) stimuli and cannot possibly be predicted from past EDA signal, our objective cannot be prediction (forecasting) as in the original Autoformer paper, but the non-autoregressive reconstruction of the input into two components. The loss function is the mean squared error between the original time series and the addition of the two components into a reconstruction of the full signal.
To bias the decomposition toward a slow-moving SCL and a fast-moving SCR component, we simplified the network that produces the SCL part of the output to a max-pooling layer, forcing the deeper part of the network to reconstruct the SCR component. The intuition behind this is that the SCR network will be challenged to converge when it is presented with data where similar morphologies appear at different amplitude levels, but it can converge by learning morphologies that are at roughly the same amplitude level since the loss is calculated after adding the SCL and the SCR components.
The network of the Feel Transformer has the following characteristics:
There is one encoder layer and two decoder layers. The dimension of the embedding is 32. The output dimension of the first convolution of the feed-forward block is 16.
There are 4 attention heads.
The SCL component is modeled by 1-D average pooling.
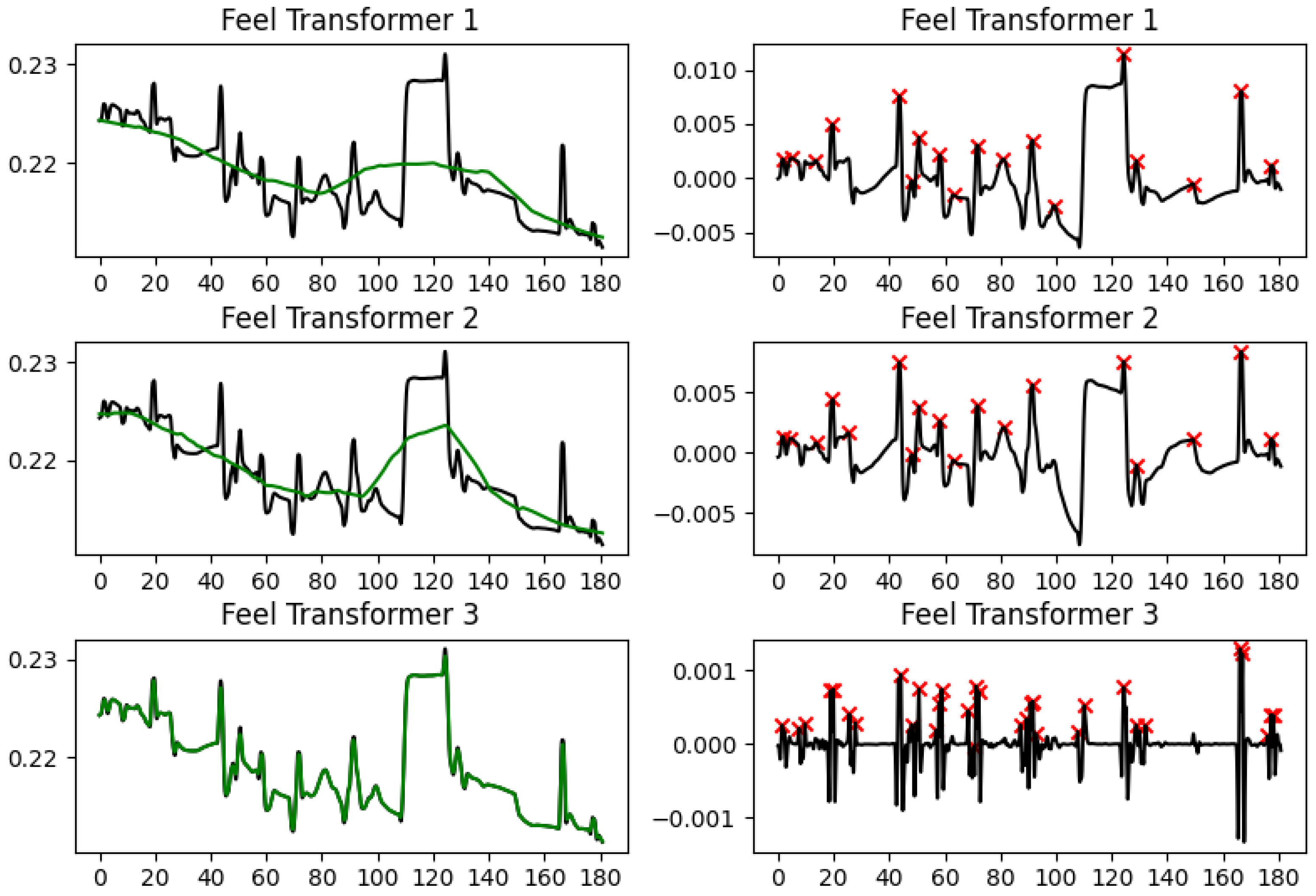
We tested three different sizes for the average pooling kernel: (a) 8 × 60 + 1 (we will refer to this as Feel Transformer 1 in the results presented below); (b) 8 × 30 + 1 (we will refer to this as Feel Transformer 2); (c) 8 × 1 + 1 (Feel Transformer 3). Since our data is at 8 Hz, this effectively means that the granularity of the SCL is 60 s, 30 s, or 1 s, respectively.
Furthermore, a ReLU activation function was used for the non-linear blocks. Regarding training, we used a learning rate of 0.001 with an Adam optimizer for the mean squared error (MSE) loss with a weight decay of 0.1. The final hyperparameter selection resulted from a search in between several hyperparameter configurations in order to optimize the MSE loss. More specifically, we formed all the possible configurations resulting from a choice of (i) 8, 16, 32, or 64 dimensions for embedding, (ii) 4, 8, or 16 dimensions for the output of the first convolution, and (iii) 2, 4, 8, or 16 attention heads. For each configuration we obtained the resulting MSE loss on a validation sub-set of the training data and observed for which configuration this loss was minimized.
Table 1 recaps all the methods included in the experiments and their key characteristics and
Figure 2 gives a graphical outline of the experiment’s workflow.
6. Conclusions and Further Work
We presented the Feel Transformer, a new method for decomposing EDA signals into a slow-moving tonic component and a sparse, fast-moving phasic component. Our method is based on the Autoformer, a variation of the Transformer NN architecture, but it departs from the standard Autoformer in that it explicitly encodes the knowledge that one of the two components must be a relatively simple and slow-moving curve that fits the general trend of the signal. In this respect, the Feel Transformer is more similar to domain-agnostic detrending, as both estimate the tonic component from the overall signal (including the SCRs), under the (reasonable) assumption that SCRs are sparse and not expected to drastically affect the estimation of the tonic component. On the other hand, the three EDA-specific methods use a three-pass approach, where they first use prior knowledge of the overall shape of SCR to identify possible SCRs, then estimate the tonic component from the remaining non-SCR signal only, and then extract the phasic component and apply peak detection to identify actual SCRs.
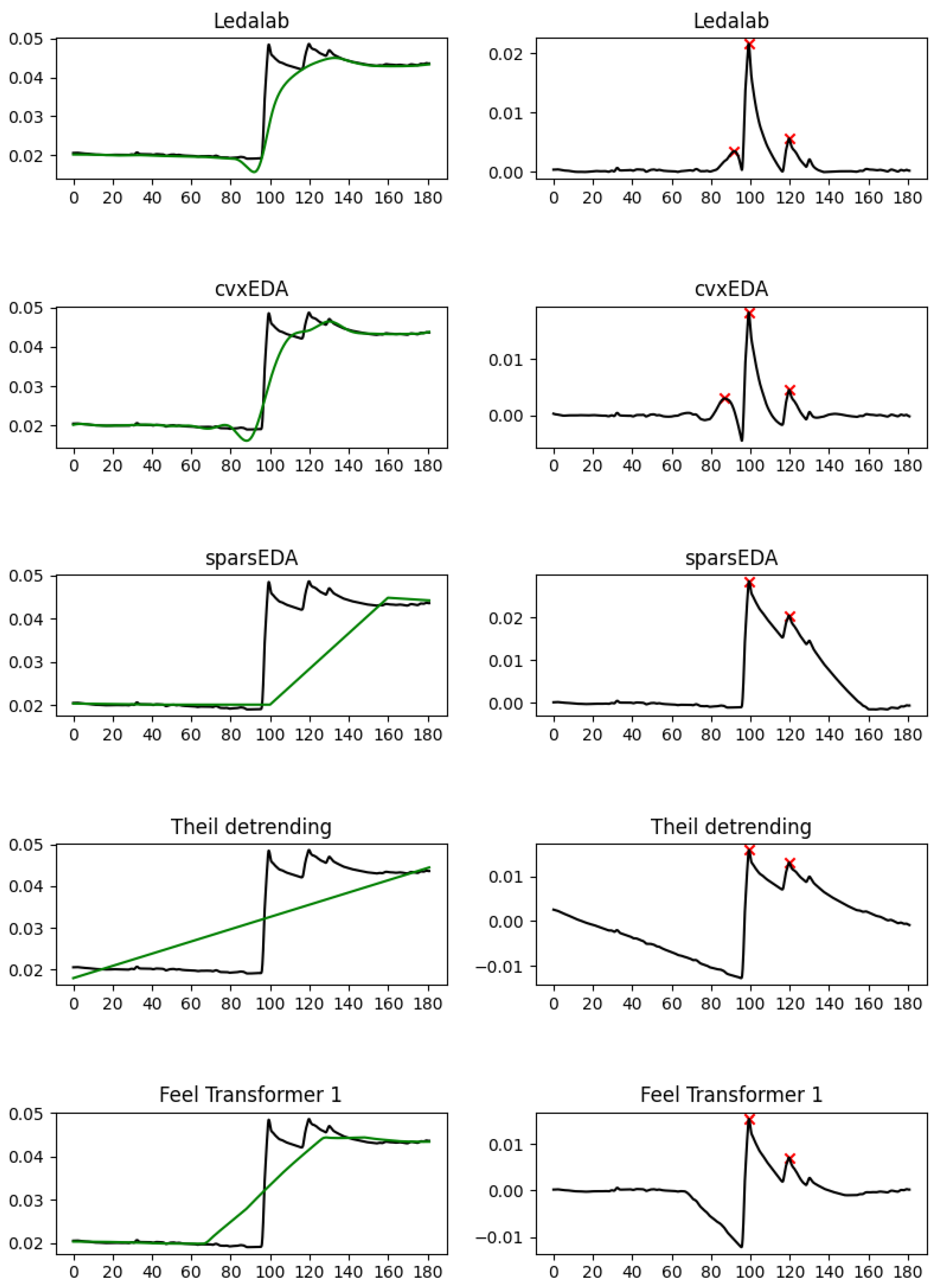
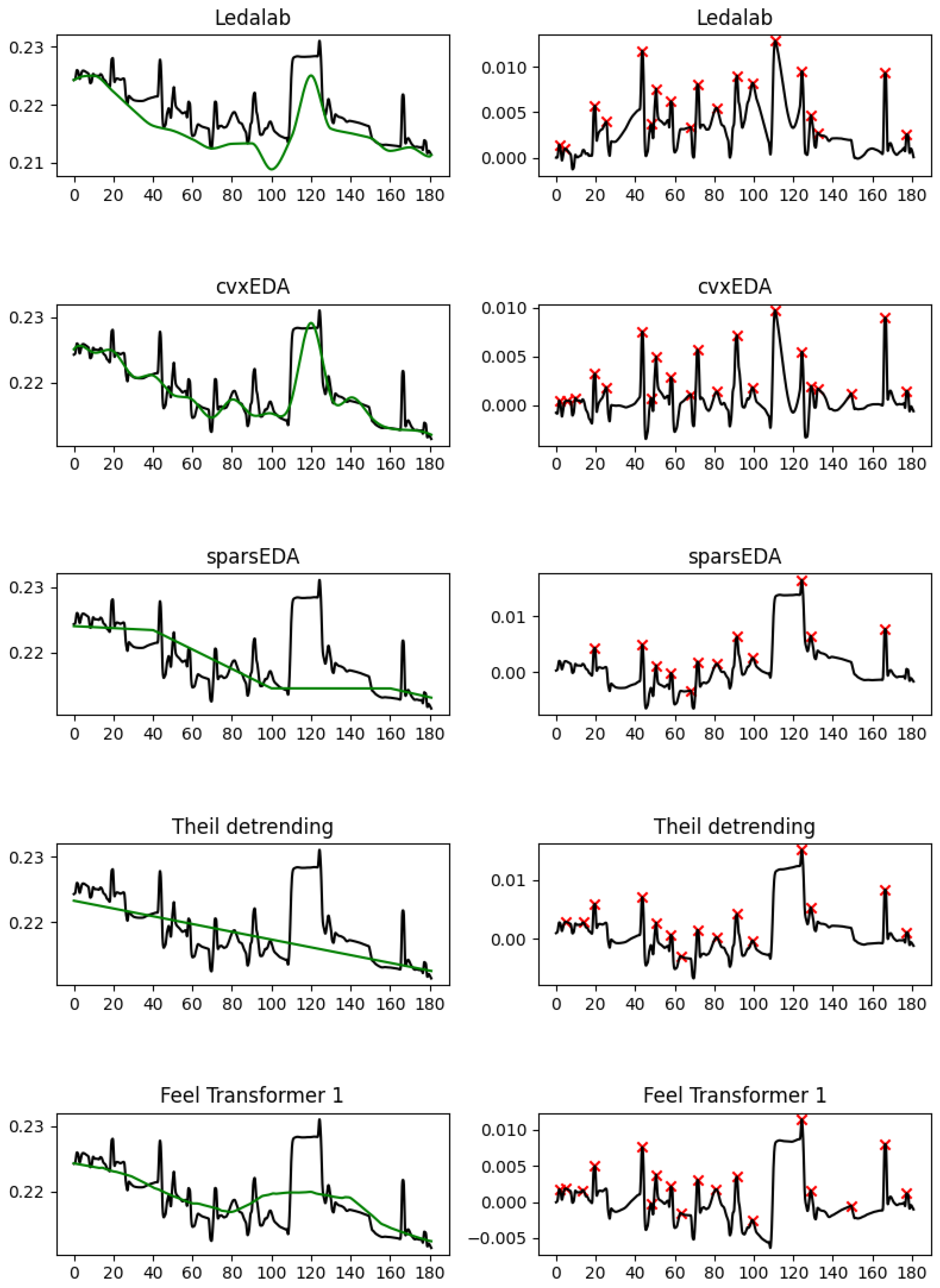
The empirical results validate this similarity: When extracting the features generally considered as most useful in EDA analysis (SCL direction, SCR density, SCR amplitude), the Feel Transformer agrees with detrending on all three features, while the Feel Transformer and detrending agree with Ledalab, cvxEDA on SCR density, and sparsEDA on SCR amplitude (
Section 5.1). The visual inspection of characteristic frames reveals that the cubic interpolation used by Ledalab and cvxLeda creates non-existent peaks when the EDA signal has abrupt changes. Such changes are rare in laboratory conditions, where datasets are usually acquired, but are a lot more common in personal healthcare and well-being applications that rely on the EDA signal acquired in the wild from wearable devices. It should also be noted that laboratory studies validate methods by observing signal segments that are known to contain ANS responses because such responses have been explicitly elicited by stimuli. However, such approaches cannot validate the tonic component since their limited duration cannot contain meaningful SCL changes. Based on the above, we observe that the agreement of the Feel Transformer with domain-specific methods on the SCR features is a positive indication for the validity of our method; the minor disagreement between the Feel Transformer and domain-specific methods on the SCL should not be taken into account since the performance of domain-specific methods on the SCL features has not been validated.
As future work, we plan to investigate the robustness of the Feel Transformer to noisy signals. Wearable biosensors used in real-world settings often introduce artifacts due to movement, sweat, and intermittent signal loss. In contrast to traditional statistical deconvolution methods, which treat all deviations symmetrically and lack contextual understanding, Transformer-based models can learn to identify and ignore non-informative segments by capturing global signal structure. This ability is particularly critical in differentiating emotional stress from physical exertion in ambulatory monitoring scenarios, such as in cases of Post-traumatic stress disorder (PTSD) or Attention-deficit/hyperactivity disorder (ADHD). Demonstrating that the Feel Transformer can reliably extract meaningful features from such noisy, in-the-wild data would mark a major advancement over laboratory-optimized methods.
A further advantage of the Feel Transformer is that, in contrast to the other methods, it is a generative model. This offers the opportunity to non-autoregressively simulate or forecast future physiological states (features) and then use the generated signal to extract further features besides the ones used to generate the signal in the first place. This enables applications such as anticipatory interventions and anomaly detection in psychiatry, ranging from predicting stress overload and panic attack onset to forecasting depressive episode relapse.
Recent work supports the feasibility of such applications: Yang et al. [
44] demonstrated the use of Transformer-based models to forecast affective states by integrating wearable sensor data with self-reported diaries, achieving high accuracy in mood prediction across temporal windows. Also, works like the one from Halkiopoulos and Gkintoni [
45] highlighted that Transformer and reinforcement learning are used extensively over biosingals like heart rate and EDA fluctuations during virtual reality-based therapeutic stimuli, where predictive simulations enable adaptive adjustments to therapeutic content in real time, tailoring intervention intensity to the individual’s physiological profile. The above are some of the studies that highlight the potential of models like the Feel Transformer, not only to decompose biosignals but also to generate plausible physiological trajectories—an essential capability for real-world mental health applications.


 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}