Abstract
The predictive performance of the remaining useful life (RUL) estimation model for bearings is of utmost importance, and the setting method of the bearing degradation threshold is crucial for detecting its early degradation point, as it significantly affects the performance of the RUL prediction model. To solve these problems, a bearing RUL prediction method based on early degradation detection and optimized BiLSTM is proposed: an optimized VMD combined with the Pearson correlation coefficient is used to denoise the bearing signal. Afterward, multi-domain features are extracted and evaluated using different metrics. The optimal degradation feature is then selected. Furthermore, KPCA is used to integrate the features and establish the health indicators (HIs) for early degradation detection of bearings using a sliding window method combined with the 3σ (3-sigma) criterion and the quartile method. The RUL prediction model is developed by combining the BiLSTM network with the attention mechanism and by employing the SSA to adaptively update the network parameters. The proposed RUL prediction model is tested on various datasets to evaluate its generalization ability and applicability. The obtained results demonstrate that the proposed denoising method has high performance. The dynamic 3σ-threshold setting method accurately detects the early degradation points of bearings. The proposed RUL prediction model has high performance and fitting capacity, as well as very high generalization ability and applicability, enabling the early prediction of bearing RUL.
1. Introduction
With the advent of Industry 4.0, the rotating machinery is gradually evolving toward intelligence, while its operating conditions became complex; therefore, ensuring safe and effective operation is a basic requirement of modern society [1]. Bearings are a key component that supports the rotating shaft in rotating machinery. The accurate prediction of the RUL of bearings allows a reduction in maintenance costs, improves the economic benefits, and prevents human and material losses caused by unexpected machine shutdowns [2,3]. The commonly used RUL prediction models can be divided into four types: physics-based, expert knowledge-based, hybrid method-based, and data-driven [4]. The physics-based prediction methods develop physical mechanism models of bearing failure. They adopt the Lundberg–Palmgren theory to calculate the bearing fatigue life through stress–life (S-N) curves, which is suitable for evaluating the life of different design schemes in the early stages of bearing design. They are directly based on the physical characteristics of the bearing failure, with strong theoretical explicability. However, they exhibit complex modeling and high computational load [5]. The expert knowledge-based prediction methods encode typical cases of bearing failure, expert experience, rule bases, and other knowledge into logical rules through expert systems or knowledge graphs. They also adopt real-time monitoring data to infer the life state of bearings. They have high flexibility without the need for large amounts of historical data. However, they are highly subjective, and updating their rules is slow [6]. The hybrid method-based approach to prediction leverages the advantages of physical models and data-driven methods to develop hybrid prediction models. It has high adaptability and generalization ability. However, its parameter optimization is difficult and it has a high computational load [7]. The data-driven prediction methods use machine learning or deep learning algorithms for feature extraction and modeling. They have high accuracy, real-time performance, and adaptability. A large number of studies have started to use data-driven methods for predicting the RUL of bearings [8,9,10,11]. At present, data-driven technologies mainly include CNN [12], long short-term memory (LSTM) and its variants [13], Gated Recurrent Units (GRUs) and their variants [14], RNNs and their variants [15]. The faults generated during the operation of bearings are inherently difficult to observe. Therefore, it is crucial to establish an HI in their degradation process, perform early degradation point detection, and develop RUL prediction models. Although the original vibration signals contain rich fault information, traditional single-feature extraction methods cannot comprehensively capture all fault features. This leads to incomplete information extraction, which affects the accuracy of bearing life prediction. Therefore, multi-feature fusion methods have emerged. They are able to comprehensively capture fault information in bearing vibration signals, and thus they allow for better prediction of the bearing life [16]. Zhang et al. [17] combined a TCN and an LSTM network to establish a multi-branch network based on parallel feature extraction. This method allows us to perform adaptive feature weighting and fusion, in order to accurately predict the remaining useful life (RUL) of bearings. Liu et al. [18] combined the time-domain data of bearing vibration signals and performance degradation data and used a Preprocessor–LSTM approach to predict the RUL of bearings. Li et al. [19] designed a multi-branch MBCNN prediction network, which uses raw bearing vibration signals and frequency-domain signals as dual-branch inputs. They performed RUL prediction for bearings through feature prediction and fusion. Mi et al. [20] solved the problem of insufficient feature selection and fusion for bearings by proposing a two-layer feature selection method, allowing to increase the accuracy of RUL prediction. Zhao et al. [21] used signal processing and feature fusion techniques to establish a nonlinear health indicator (HI) for bearings. They then proposed a method combining vibration signals and physical models in order to reduce the errors of RUL prediction. Zhang et al. [22] evaluated the monotonicity, robustness, and fitting errors of bearing signals to develop a fusion model for RUL prediction through weighted fusion. Tai et al. [23] used KPCA and exponential weighted average methods to build a bearing HI. This approach allowed to accurately predict the HI and RUL of bearings. Yang et al. [24] highlighted the importance of early fault detection in predicting the RUL of bearings. In normal operation, the HI remains stable. However, when faults start to occur, it changes significantly, which makes the detection of early fault points critical. Wang et al. [25] used probabilistic models for RUL prediction and early fault detection methods for determining the initial fault point of bearings. Chen et al. [26] applied the 3σ criterion to detect early fault points in bearing signals. They also combined an adaptive Wiener process with GRU for RUL prediction. Li et al. [27] proposed methods for detecting the initial degradation point (IDP) and fast degradation point (FDP) of bearing signals, enabling RUL prediction. Wang et al. [28] detected early degradation points in bearings. Cui et al. [29] used a sliding window algorithm to update the relative error of RUL predictions, allowing the identification of the first change point of faults. Wang et al. [30] proposed a hybrid model to predict the degradation trend of bearings. In addition, they used the 3σ criterion to determine early fault points in the process of signal degradation. Han et al. [31] proposed a stacked autoencoder method to fuse bearing features for RUL prediction. Balamurugan et al. [32] proposed a CNN-BiLSTM-based bearing data monitoring method allowing the detection of current and historical abnormal data. This method adopts KPCA for dimensionality reduction and CNN-BiLSTM for RUL prediction. Shen et al. [33] selected redundant features of bearings through composite evaluation metrics, established nonlinear degradation indicators (NDI), and proposed an attention-based BiLSTM network. Their results showed that this method outperforms existing ones on various datasets.
Although some studies proposed methods for processing bearing vibration signals and predicting the RUL, several limitations exist, especially the low denoising performance leading to low signal purity. The use of a single feature as HI for bearings, along with a fixed threshold for degradation detection, leads to delayed detection of early bearing degradation, which results in missed fault diagnoses. In addition, LSTM cannot process information in parallel, and BiLSTM requires waiting for the complete input sequence before making predictions. Based on the aforementioned shortcomings of RUL prediction, this paper proposes an RUL prediction method that optimizes the BiLSTM network using the SSA [34,35]. Firstly, the vibration signals of the bearings are preprocessed, multi-domain features are extracted and fused, a health indicator is constructed, and a failure threshold is set. Finally, RUL prediction is conducted to obtain more reliable RUL prediction results for the bearings. This paper is mainly divided into the following sections:
Section 1: a comprehensive review is conducted on the research background of the entire thesis.
Section 2: The NGO [36] algorithm is used to optimize the VMD [37] algorithm. Together with the Pearson correlation coefficient, it is applied to denoise the original bearing signals. Its performance is finally compared with that of other denoising methods. Multi-domain features of the bearing are extracted, and a comprehensive weighted index, which includes robustness, predictability, trendability, and monotonicity, is applied to quantify the scores of each feature.
Section 3: The optimal features are selected and fused using KPCA. A method that combines the 3σ criterion and a sliding window is used to dynamically update the degradation threshold of the bearing in real time, which allows the early detection of bearing degradation. A RUL model is established by combining BiLSTM with an attention mechanism, and the SSA is employed to automatically search for network parameters. Experimental validation is then conducted.
Section 4: the proposed method is validated through experiments, followed by an in-depth analysis of various phenomena observed during the process.
Section 5: the primary conclusions of the entire thesis are drawn.
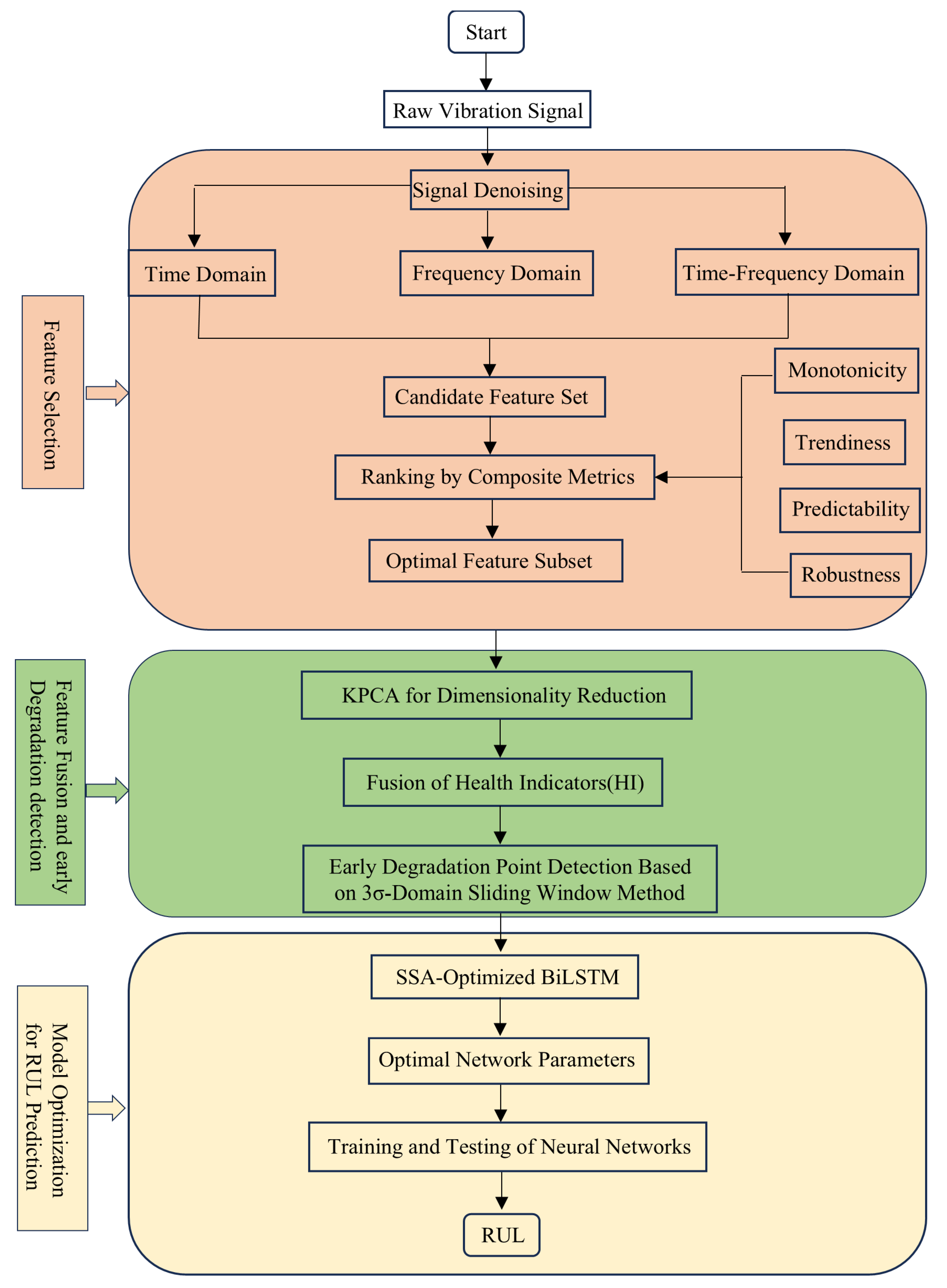
The overall RUL prediction technical roadmap is shown in Figure 1.
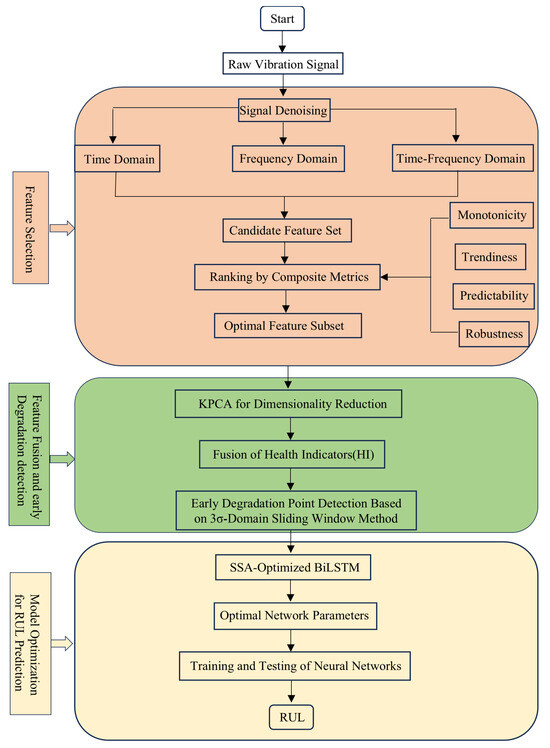
Figure 1.
Overall technical roadmap.
2. Preprocessing Methods for Bearing Vibration Signals
2.1. Signal Denoising Methods
The NGO algorithm is used to optimize the VMD algorithm. The optimized mode decomposition algorithm is referred to as NVMD. It consists of adaptively searching for the penalty factor (α) and the number of decomposed modes (k). The Pearson correlation coefficient (PCC) is used to measure the correlation between each mode and the original signal. The modes exhibiting weak (or no) correlation are considered noise (or irrelevant signals), which improves the signal purity. Afterward, each mode is reconstructed, and the results are compared with those obtained by the soft-threshold denoising method. The performance is evaluated using the Noise Mode (NM) and Signal-to-Noise Ratio (SNR) metrics.
2.1.1. Variational Mode Decomposition (VMD) Algorithm
VMD solves a constrained variational problem to decompose the input signal f into k discrete sub-modes . This can be expressed as follows [36]:
where {}: = {u1, ···, } represents the shorthand for the modes obtained after signal decomposition, {}: = {ω1, ···, } represents the corresponding central frequencies, is the Dirac delta function, and denotes the sum of all the underlying modes.
In order to more easily solve the constrained variational problem, a quadratic penalty function term and a Lagrange multiplier λ are introduced to reformulate the problem as an unconstrained optimization one [36]:
where multiplicative operators are used to iteratively update , , and until the variational model reaches an optimal solution. The modal components can be expressed as follows [36]:
By applying the Parseval/Plancherel Fourier isometry transform, Equation (4) is mapped into the frequency domain [36]:
where is the current residual of after Wiener filtering.
By continuously updating until the central frequencies are determined, we obtain the following [36]:
where represents the centroid of the power spectrum of the current modal function. Note that the real part of the inverse Fourier transform of yields .
2.1.2. Optimizing Variational Mode Decomposition (VMD) Using the Northern Goshawk Optimization (NGO) Algorithm
The optimization of VMD using the Northern Goshawk Optimization (NGO) algorithm mainly consists of two stages. The first one involves prey identification and attack (i.e., exploration phase), where the Northern Goshawk randomly selects a prey and quickly attacks it. This corresponds to a random solution in the search space, which is updated by specific strategies in order to locate the optimal solution. This phase helps identify the optimal search area (i.e., the approximate position of the global optimum).
The population is represented using the following population matrix [37]:
where Xi1(i1 = 1, 2, …, N0) represents the position of an individual.
The objective function value is given by the following [37]:
where F is the function vector, and Fi is the objective function value for individual i.
The determined optimal region is given by Pi1 = Xk1, i1 = 1, 2, ···, N0, k1 = 1, 2, ···, i1 − 1, i1 + 1···, N0 [37].
where is the prey position for the i1th Northern Goshawk, is the objective function value, is its value in the jth dimension, and is the first-phase objective function value.
The second stage consists of pursuit and escape (development stage). When the Northern Goshawk approaches its prey, the latter attempts to quickly escape, while the Northern Goshawk continues to pursue it. This corresponds to a detailed search near the optimal region to identify the most precise solution. This stage uses local search to increase optimization accuracy.
In a region of radius R0, the target is searched for as follows [37]:
where a is the current iteration, A is the maximum number of iterations, is the value in the jth dimension, and is the second-phase objective function value. r is a random number in the range of 0–1, I is equal to 1 or 2, and r and I are parameters for generating random NGO behaviors during search and update operations, respectively.
2.1.3. Pearson Correlation Coefficient
In the modal decomposition of bearing signals, the Pearson correlation coefficient [21] is used to measure the similarity between the original data E:{e1, e2, …, ena} and the modes B:{b1, b2, …, bna}. The correlation levels between arrays are in the range of 0.8–1. Very strong, strong, moderate, weak, and very weak (or no) correlation types are, respectively, represented by the ranges of 0.6–0.8, 0.4–0.6, 0.2–0.4, and 0.0–0.2 [21].
The overall mean and overall covariance are given by the following [21]:
where na represents the number of signal data points.
2.1.4. Denoising Evaluation Metrics
Noise Mode is given by [15]
where x(t1) and are the original and denoised signals, respectively, nc represents the number of signal data points, and t1 represents the time point.
The Signal-to-Noise Ratio is calculated as [15]
2.2. Multi-Domain Feature Extraction and Domain Selection Method
Multi-domain feature extraction [36] can combine information from different domains to provide a more comprehensive description of the fault, thereby helping to improve the accuracy of the prediction model. By extracting and fusing multi-domain features, a more robust and accurate RUL prediction model can be constructed [23,24]. To extract richer information on bearing degradation, signals in the time [36], frequency [36], and time–frequency domains [36] are analyzed. The optimal features are first selected, and feature fusion is then performed.
2.2.1. Multi-Domain Feature Extraction
Table 1 presents the formulas for time-domain and frequency-domain feature calculations. Numbers 1–7 correspond to time-domain feature formulas, the unit for numbers 1, 2, and 6 is m/s2, that for numbers 3 and 5 is (m/s2)2, and numbers 4 and 7 are dimensionless. Time-domain features are characterized by changes in the signal waveform over time. Numbers 8–13 correspond to frequency-domain feature formulas. Numbers 8–11 are dimensionless, and the units of numbers 12 and 13 are m/s2 and Hz, respectively [38].

Table 1.
Feature expressions.
The db6 wavelet basis function is used for feature extraction in the time–frequency domain. A three-level wavelet packet decomposition is performed, yielding 23 = 8 sub-frequency bands [36,37,38]. The wavelet energy entropy of these eight sub-frequency bands is calculated as follows [38]:
where represents the energy characteristic of the ith sub-band, and E is the total energy of the eight sub-frequency bands [38].
The energy ratio of each sub-frequency band is calculated as [36,37,38]:
There are 8 different energy ratios, denoted by p14(3,0), p15(3,1), p16(3,2), p17(3,3), p18(3,4), p19(3,5), p20(3,6), and p21(3,7). Note that these energy ratios are dimensionless.
Based on the aforementioned analysis, 21 features should be extracted: 7 time-domain, 6 frequency-domain, and 8 time–frequency domain features [36,37,38].
2.2.2. Feature Selection Method
The monotonicity, trendability, predictability, and robustness of each bearing signal feature are comprehensively evaluated. These four metrics are then quantified, and a comprehensive score is calculated. Note that a higher score indicates a higher sensitivity, more significantly contributing to bearing life prediction [37,38].
The monotonicity metric (M) is expressed as [37,38]
where xc represents the cth feature, d denotes the number of measurements for each one, and m is the number of monitored systems [37,38].
The trendability indicator (Q) is expressed as [37,38]
where x is the rank of features, y is the rank of time, and N is the number of feature measurements. Note that, for Q = 1, the feature is strictly monotonic, while for Q = 0, it is non-monotonic [37,38].
The predictability indicator (C) is expressed as [37,38]
where (1) and (Nc) are the initial and failure values of the ic-th feature, respectively.
The robustness indicator (R) is expressed as [37,38]
where is the iR-th feature, NR represents its measurement value, and is the average trend value [37,38].
The final weighted score is obtained by summing all the metrics [37,38]:
where , , and are, respectively, the weights for the M, Q, C, and R metrics that are positive and satisfying , > 0, > 0, > 0, and > 0 [37,38]. The study presented in [38] shows that it is crucial to focus on the full life-cycle trend of the bearing and its tolerance to noise and abnormal signals. Therefore, when selecting features, greater emphasis should be placed on monotonicity and robustness. , , , and are set to 0.4, 0.2, 0.1, and 0.3, respectively. Based on the results obtained in [20], features with a J score greater than 0.5 are selected.
3. Method for Establishing RUL Prediction Model Based on Optimized BiLSTM Networks
3.1. Construction of Health Indicators and Determination of Failure Thresholds
3.1.1. Construction of Health Indicators (HIs)
These features are fused using the KPCA method [23]. This process consists of the following steps:
- (1)
- The sensitive feature subset is standardized, and the resultant feature vector matrix undergoes a nonlinear mapping using the function Φ, projecting to a higher-dimensional feature space . The samples in the input space are transformed via Φ, denoted as , and become sample points within the high-dimensional feature space , where , satisfying the centrality condition [27,38]:The covariance matrix in is given by [38]:where represents the feature sample in [38] .
- (2)
- Calculate the eigenvalues and eigenvectors of the covariance matrix [36,38]. The eigenvectors thus obtained represent the principal component directions of the original sample space in the feature space [37,38] :where represents the eigenvalue of , and v denotes the corresponding eigenvector in the feature space [37,38].
- (3)
- Given the computational challenge of directly solving , a kernel function is introduced, resulting in an symmetric positive definite matrix K, where K is the kernel matrix corresponding to , denoted as [23].
- (4)
- Centering the kernel matrix K yields the standardized kernel matrix, represented by the following formula [23]:where I is an matrix where each element is 1/n.
- (5)
- The eigenvalues and eigenvectors of , denoted as , , are calculated and arranged in descending order, represented by the following formula [23]:
- (6)
- The eigenvectors undergo Schmidt orthogonal normalization to produce the feature component matrix .
- (7)
- Extract the eigenvalue of the first principal component that accounts for more than 85% [23] of the variance, along with its corresponding eigenvector to form the projection matrix Y, where [23], and Y represents the fused feature derived from the original feature matrix X through Kernel Principal Component Analysis (KPCA) for dimensionality reduction, serving as a health indicator (HI).
3.1.2. Determination of Failure Thresholds
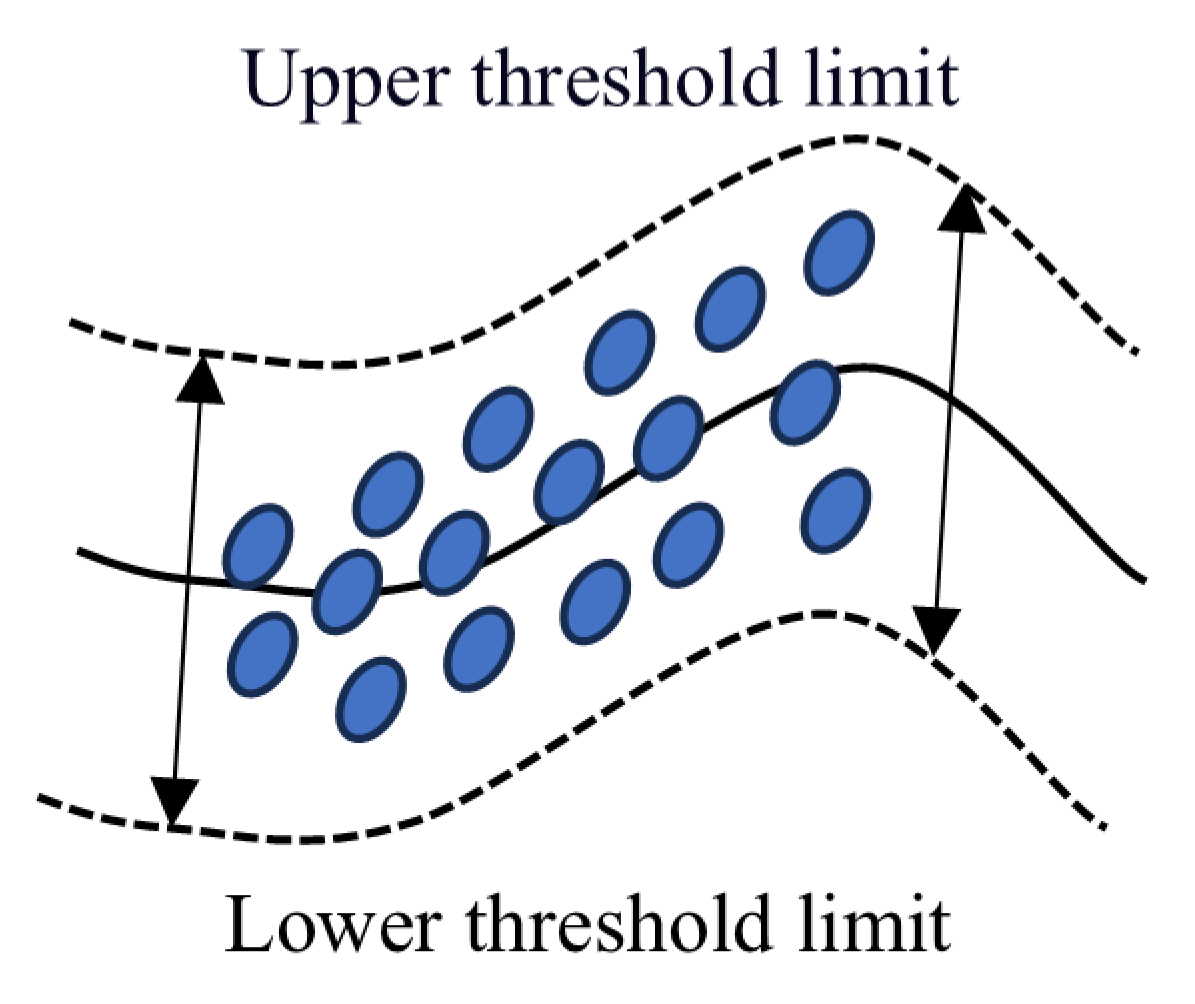
The signal is processed using a sliding window [30,31] approach. Within each window, the 3σ [26,32] method is combined with the quartile method [25] to identify significant change points indicative of fault occurrence. This combination reduces false positives and enhances detection accuracy. A schematic diagram of the dynamic threshold is shown in Figure 2.
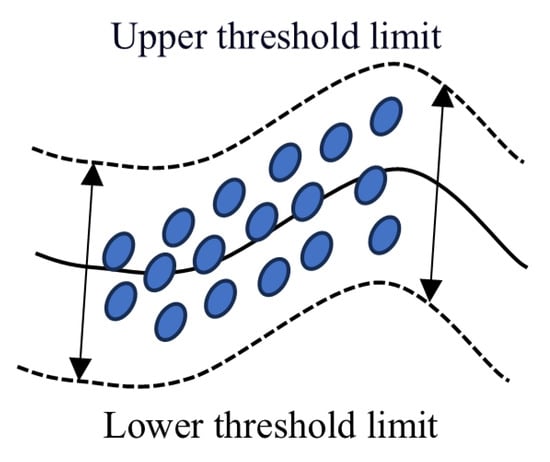
Figure 2.
Schematic diagram of dynamic thresholds.
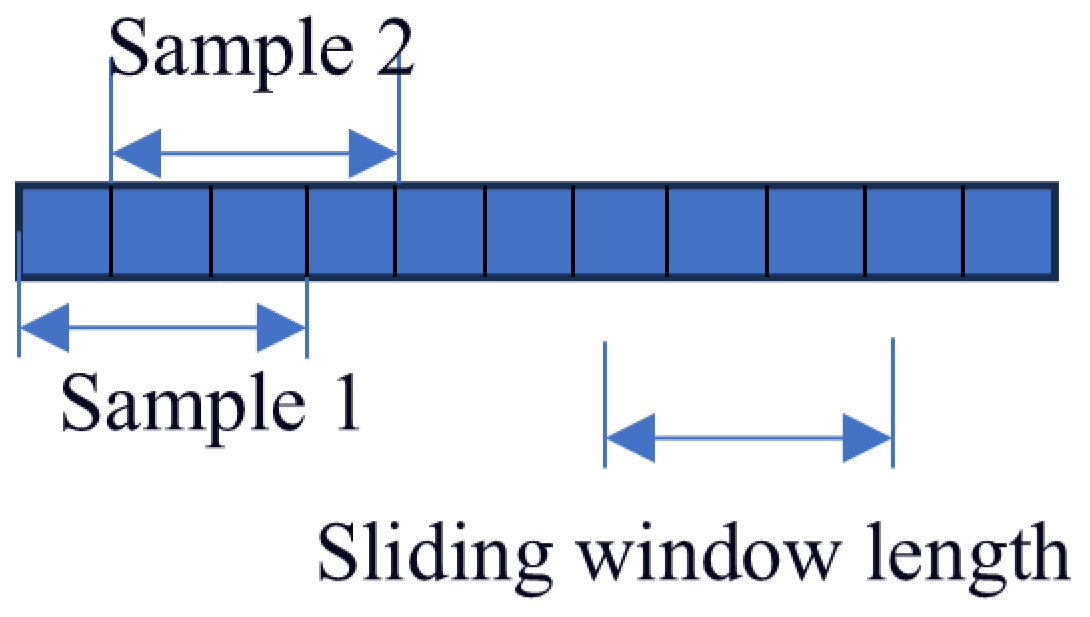
The length of the sliding window significantly affects the accuracy of the performed predictions. A too short window may reduce the complexity of network training. However, it fails to accurately capture potential correlations between multiple time steps. On the other hand, a too long sliding window can better capture the relationship between fault information and time, at the expense of increasing the network training time. Based on the results obtained in [36], the window length and sliding window step size are set to 30 and 1 samples, respectively. A detailed description of this process is shown in Figure 3.
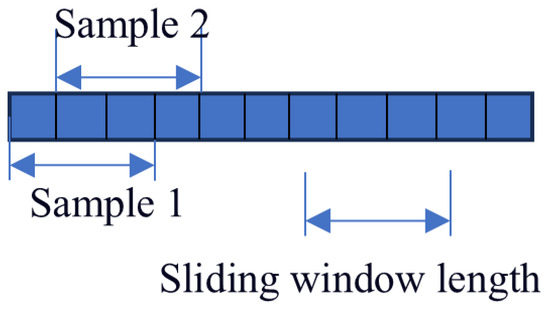
Figure 3.
Schematic diagram of sample count in sliding window.
Bearing 1-1 from the PHM2012 dataset is considered as an example. This dataset contains 2803 samples, each one consisting of 2560 data points. A sliding window is applied to form a new sample from the combination of every 30 samples. This yields 2773 new samples, since the sliding window moves by one sample at a time, and therefore the total number of samples decreases by 30 (i.e., 2803 − 30 = 2773).
The steps for determining bearing failure using the 3σ method combined with the quartile method within a sliding window are as follows:
- (1)
- Calculate the mean and standard deviation for each window [32]:where Z is the length of the sampling window, and denotes the sampled data points.
- (2)
- If a certain point satisfies condition , according to the 3σ principle, the data point is considered anomalous [32].
- (3)
- Sort the nh data points within the window in ascending order to obtain the ordered set {}. Calculate the first quartile (fQ1) and the third quartile (fQ3) [25]:In the above formula, if f is an integer, directly take the value at the corresponding position. If f is a decimal, compute the value using linear interpolation [25]:Q = x⌊f⌋ + (f − ⌊f⌋) (x⌊f⌋+1 + x⌊f⌋)Calculate the interquartile range (IQR) [25]:If the condition or the condition is satisfied, the data point is considered anomalous.
- (4)
- If data anomalies are detected in either Step (2) or Step (3), the bearing is considered to have failed.
3.2. Method for Optimizing BiLSTM Networks Using the Sparrow Search Algorithm (SSA)
In the RUL prediction stage, the SSA is used to adaptively search for the hyperparameters of the model. This aims at ensuring high prediction performance and generalization ability. The Adam algorithm has advantages in the process of updating model parameters, continuously adjusting parameters during model training to approximate local optimal solutions and thus finding a balance between global and local optimality. The Adam optimizer [36] is employed to optimize the weights and biases of the model, which enables efficient model convergence.
3.2.1. Sparrow Search Algorithm (SSA)
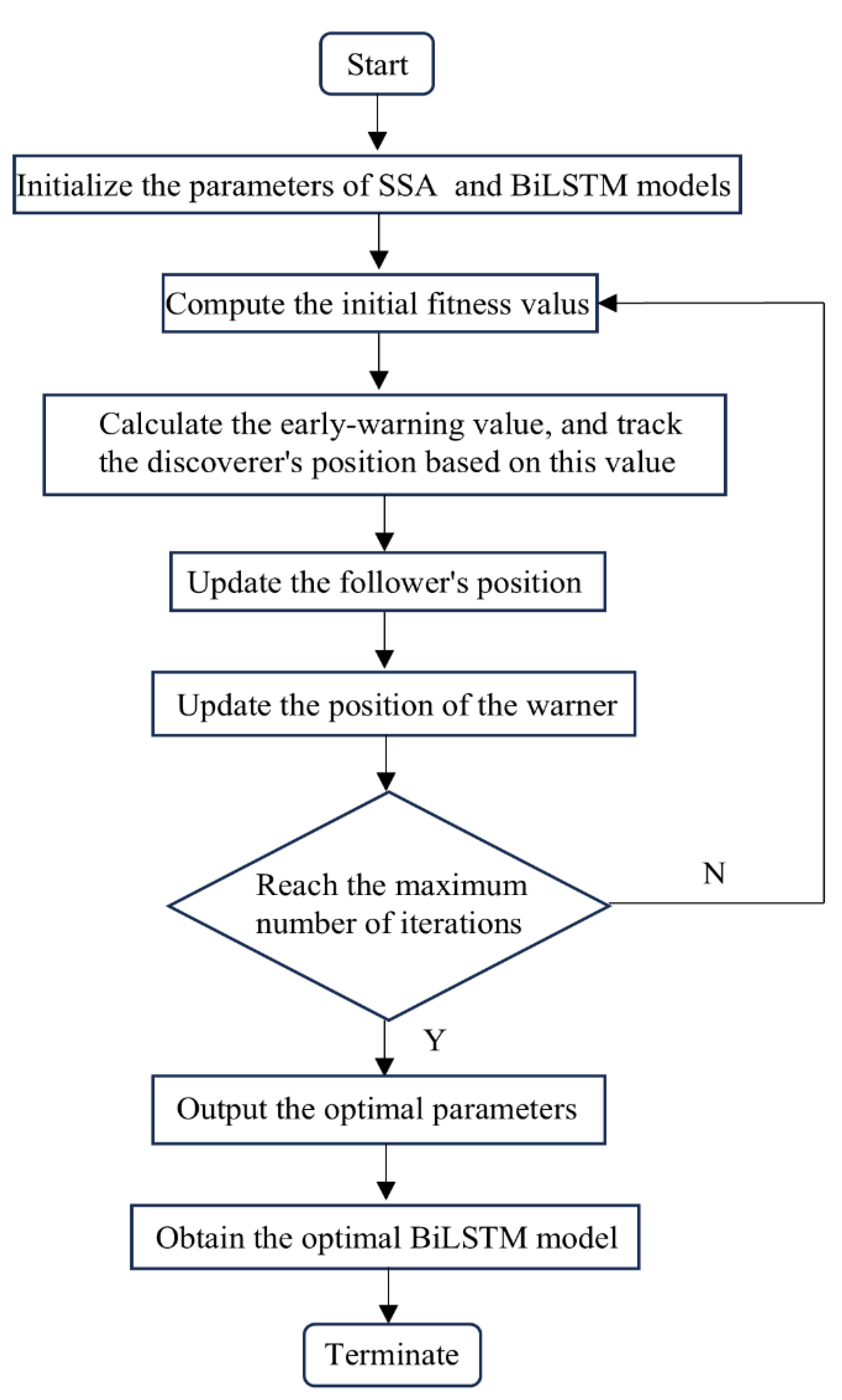
The adopted process is summarized as follows:
- (1)
- The SSA objective function is considered as the prediction error on the test set, the reciprocal of the MSE is used as the fitness value. The MSE is expressed as [36]where ny represents the number of test samples, and y represents the serial number of the data point [38].The fitness value is given by [36]
- (2)
- The position update rule for discoverers in the SSA algorithm is expressed as [36]where d represents the current iteration number, V represents the total number of iterations, represents the position information of the ath sparrow in the bth dimension at the dth iteration, represents a random number in the range of 0–1, represents the warning value in the range of 0–1, represents the safety value in the range of 0.5–1, Z0 represents a random number following normal distribution, and A0 represents a multi-dimensional row matrix of all ones.
- (3)
- The position update formula for followers is given by [36]where represents the best position occupied by discoverers, represents the global worst position, represents a matrix of all ones comprising elements randomly set to 0 or 1, and . Note that, for , half of the following sparrows cannot share the optimal position of the discoverer, and they should search on their own.
Assuming that alerters occupy 10–20% of the population and their initial positions are random, their position update can be expressed as [36]
where represents the current global optimal position, represents a random number of standard normal distribution, , , , and , respectively, represent the current alerter sparrow, current global best and worst fitness values, and represents a very small constant used to prevent a null denominator.
The optimized hyperparameters consist of a number of hidden layer neurons ([16, 512]), initial learning rate ([10−4, 1]), batch size ([16, 512]), number of iterations ([50, 3000]), dropout ratio ([0, 0.5]), and number of BiLSTM network layers ([1, 4]) [36,37,38].
Assuming the population size of the Sparrow Search Algorithm is NSSA, the number of iterations is TSSA, and the problem dimension is Dw, then the time complexity of the SSA algorithm is [36]
where is the complexity of fitness, .
The overall optimization process is illustrated in Figure 4.
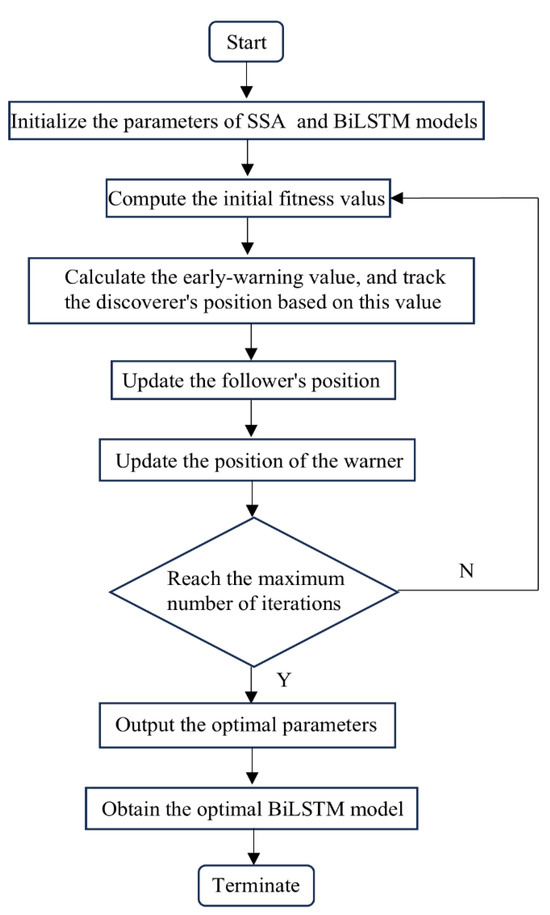
Figure 4.
The overall optimization process.
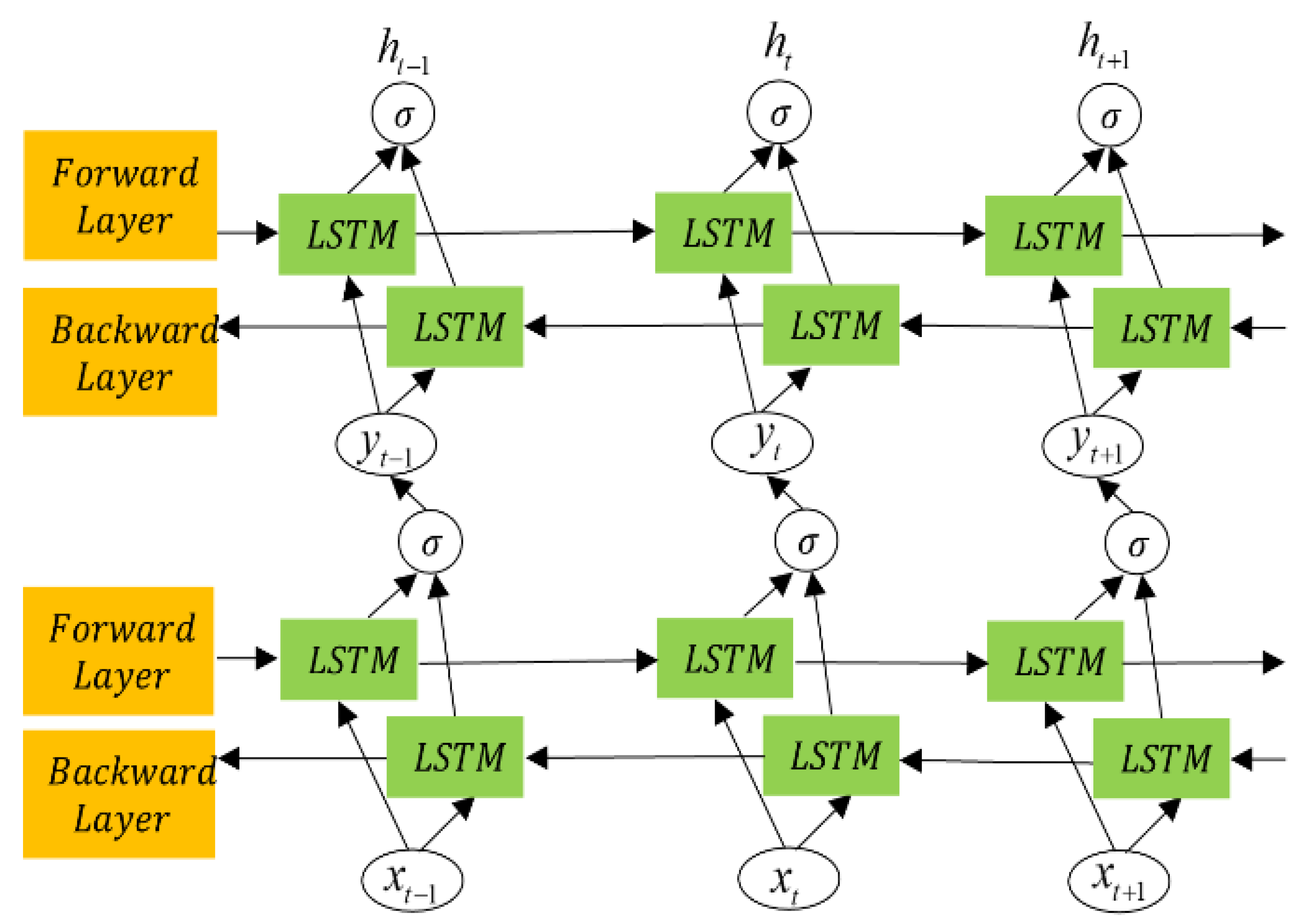
3.2.2. BiLSTM Network Algorithm
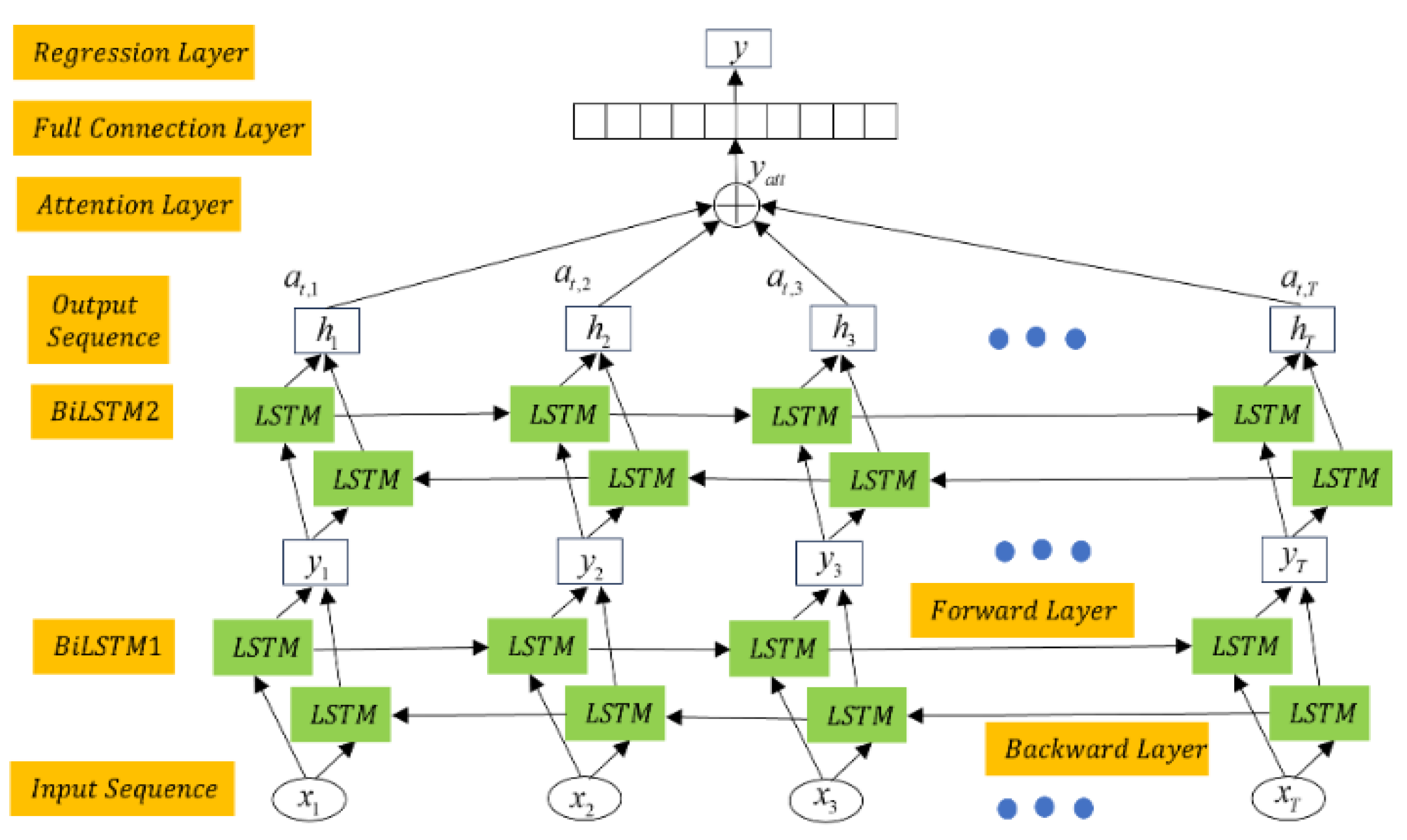
As shown in Figure 5, it is the optimized BiLSTM network, which two BiLSTM layers stacked to form a dual BiLSTM network, where the output of the first BiLSTM layer serves as the input for the second one. This structure combines BiLSTM networks with a multi-layer stacked architecture. Compared with traditional long LSTM networks and BiLSTM networks, the dual-layer BiLSTM provides unique advantages in bearing life prediction: higher feature extraction capacity, adaptability to complex data, higher prediction accuracy.
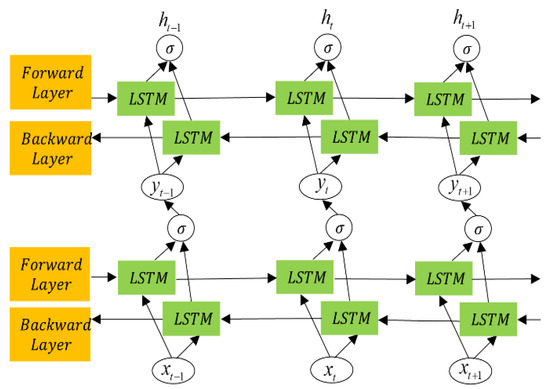
Figure 5.
Memory cell of LSTM network.
The input to the network Y = [Y1, Y2,.…, Yn] is transformed, through iterative mapping, into the output h = [h1, h2,.…, hn] over time steps t = [1, 2,.…, t − 1,.…, T]. The corresponding gates in the LSTM unit are expressed as [38]
where , , , and represent the weight matrices between the input layer and corresponding gates at time t; , , , and represent the weight matrices of the hidden layer between time values t and t – 1; , , , and , respectively, represent the bias values of the input, forget, control, and output gates; and , respectively, represent the hidden and cell states of the previous time value t – 1; , , , and , respectively, represent the output values of the input, forget, control, and output gates; and , respectively, represent the current cell state and hidden state at time t; and , respectively, represent the tanh and sigmoid activation functions; and represents the point-wise multiplication operator [38].
The dual-layer BiLSTM generates hidden sequences in forward and backward directions. The forward and backward hidden sequences are denoted by and , respectively. The final output is determined by concatenating the forward and backward outputs. The encoded vectors generated by the two hidden layers are expressed as [38]
where represents the output of the network expressed in the first hidden layer as yt = [y1, y2,.…, yt,.…, yn] [38].
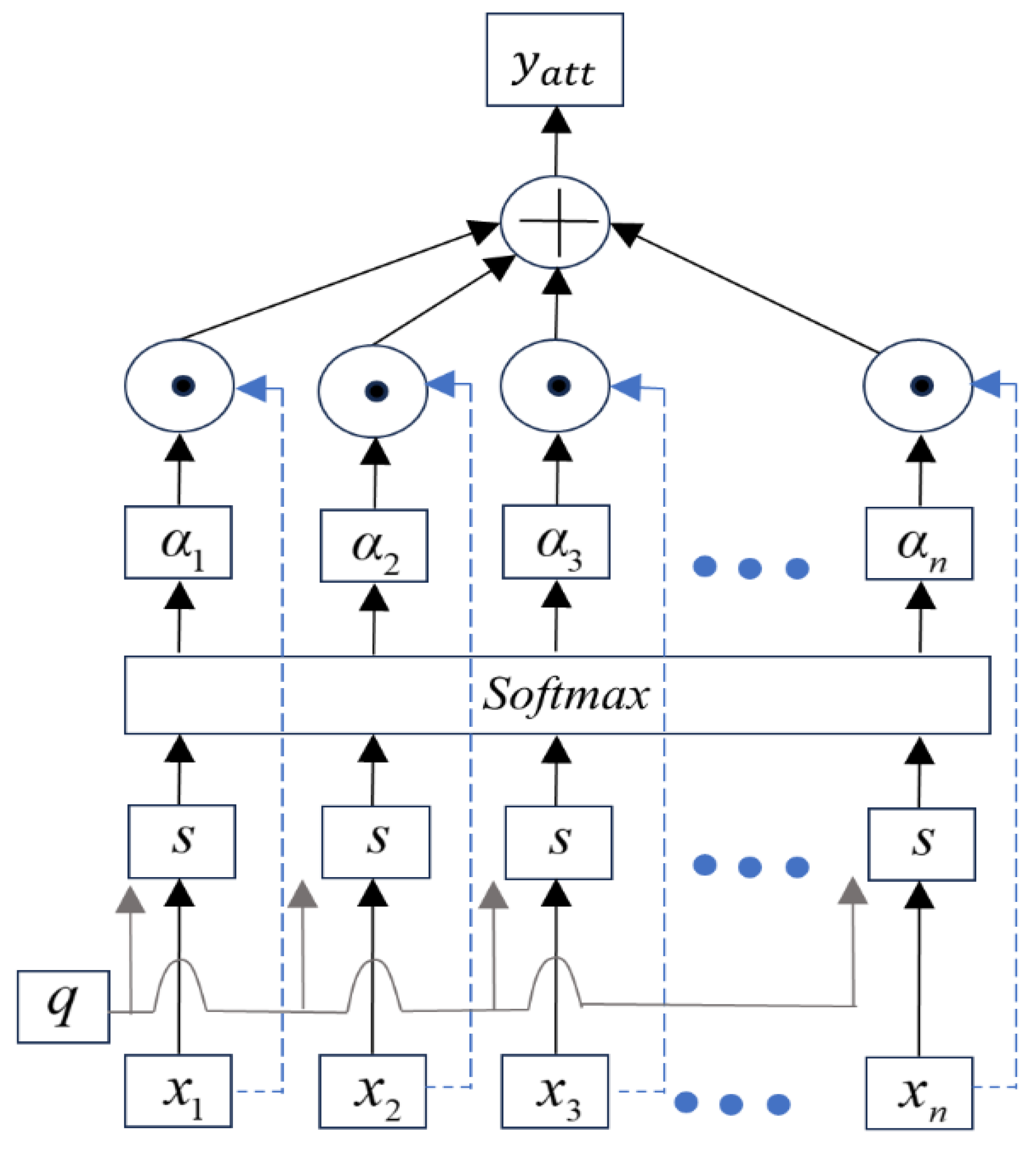
When training data using the BiLSTM model, the attention mechanism [38] can directly model the relationships between any two time steps, allowing to better capture long-range dependencies. This helps the model extract the most critical information from these complex signals for predicting the RUL of bearings [1,2,3,38]. Figure 6 illustrates the network structure, where the output of the attention layer is given by [15]
where represents the scoring function, and represents the attention coefficient [38].
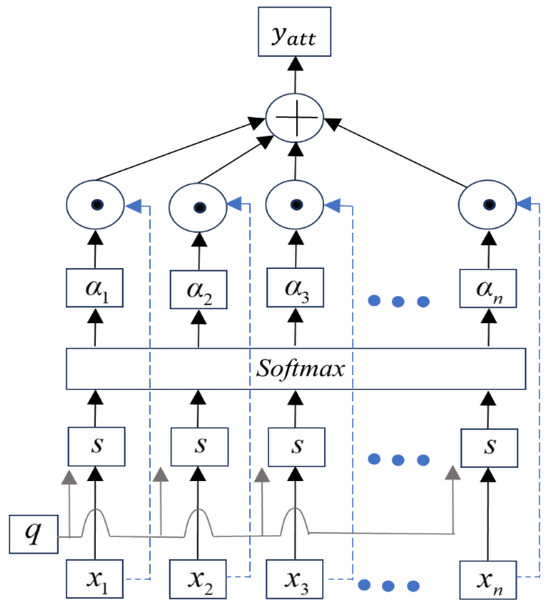
Figure 6.
Structure of the attention mechanism network.
is given by [15]
The output of the attention mechanism is given by [15]
For the output values of the BiLSTM layer, the output of the attention mechanism is given by [15]
The final output yatt represents the high-level abstract information of the input, which is used to evaluate the bearing degradation function of time [17,38].
The weights and biases of the network are optimized using the Adam optimizer. The Adam optimization is expressed as [36]
where and , respectively, represent the estimates of the first-order and second-order moments of the gradient; and are, respectively, the corrected values; represents the training sample; , wt, and are, respectively, the input, weight, and output values; g represents the gradient; a0 represents the learning rate; and , respectively, represent the gradient and squared gradient decay factors; and is a very small constant used for numerical stability (usually set to = [36]).
3.3. RUL Prediction Model
The RUL prediction of bearings mainly includes the training and testing stages. The training dataset serves as the input to the network [38], where contains N sensitive features at time t, and Yt represents the actual labels related to the degradation of the bearing at this time. By stacking two BiLSTM network layers, the degradation information of the bearing is propagated in both forward and backward directions. As shown in Figure 7, the structure combines two BiLSTM network layers with an attention mechanism. The output of BiLSTM1 is the input of BiLSTM2. The final hidden states are multiplied by the (at,1, at,2, at,3, …, at,T) attention weights and summed to generate the final output of the network, yatt [38]. The RUL prediction value is then determined through a regression layer. In the latter, the model is optimized using the mean squared error (MSE) [36]:
where Yt represents the ground truth labels of the input data, and represents the values predicted by the BiLSTM. In the testing stage, the fused features are directly input into the trained model, yielding the RUL prediction values [38].
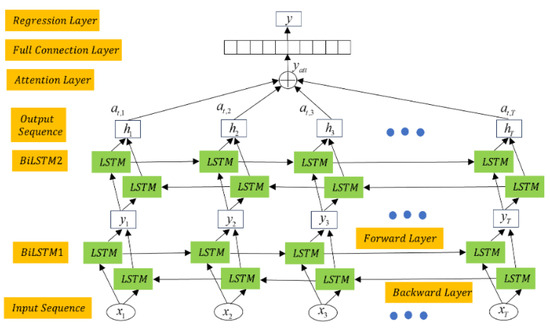
Figure 7.
The network architecture combining BiLSTM with the attention mechanism.
4. Experimental Validation and Result Analysis
4.1. Introduction to the Experimental Platform
The IEEE PHM2012 [36] and XJU-SY [36] datasets were then used. The experimental platforms are shown in Figure 8a,b, and the training and test sets are shown in Table 2. PHM2012 has a sampling frequency of 25.6 KHz [38], yielding 2560 data points every 10 s. XJU-SY has a sampling frequency of 25.6 KHZ [38], yielding 32,786 data points every 1 min, with a sampling duration of 1.28 s. The two datasets use horizontal vibration signals for experiments [12].

Figure 8.
Data acquisition platform.
Table 2.
Bearing dataset [38].
4.2. Analysis of Data Preprocessing Results
4.2.1. Analysis of Denoising Results
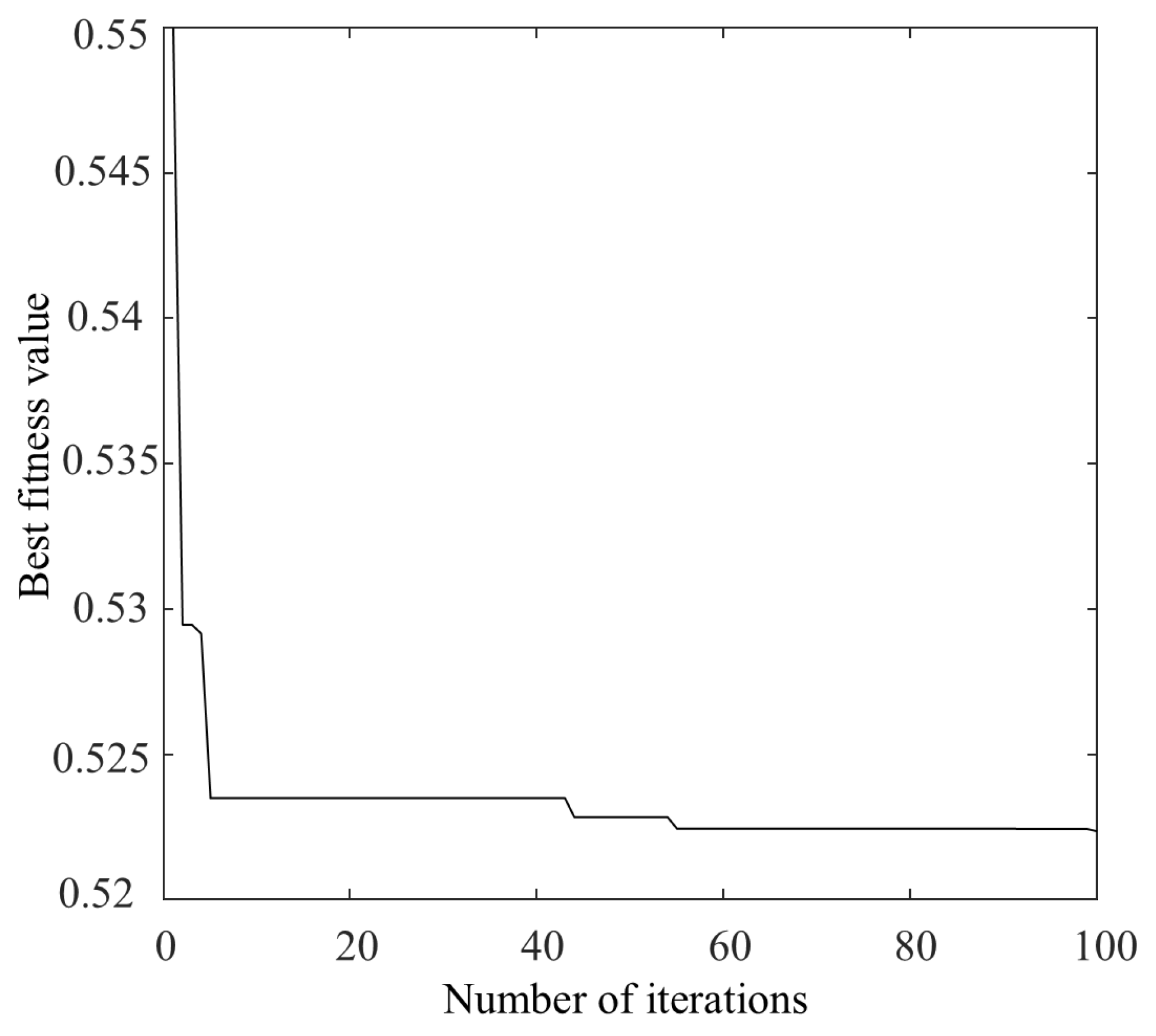
Bearing 1-3 of the PHM2012 was considered as an example, on which denoising was performed. When optimizing the parameters of VMD using the NGO algorithm, 30 different initial populations were randomly generated, with each population consisting of 20 individuals. The initial ranges for α and k were set to [1, 20] and [500, 2500], respectively. The algorithm was run for 100 iterations in each case. For each run, the mean and standard deviation of the best fitness values, as well as the mean and standard deviation of the optimal parameters [α, k], were recorded across 30 populations during independent runs. If the standard deviation is small, it indicates that the algorithm has good stability and global convergence performance. The optimal values of [α, k] were ultimately obtained as [8, 1879], and the optimal fitness curve is shown in Figure 9.
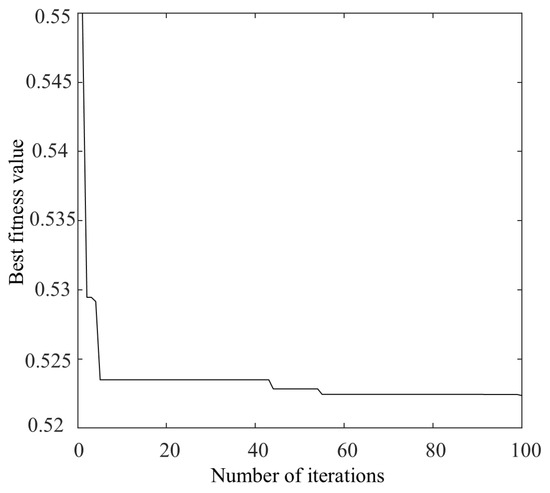
Figure 9.
Best fitness value curve.
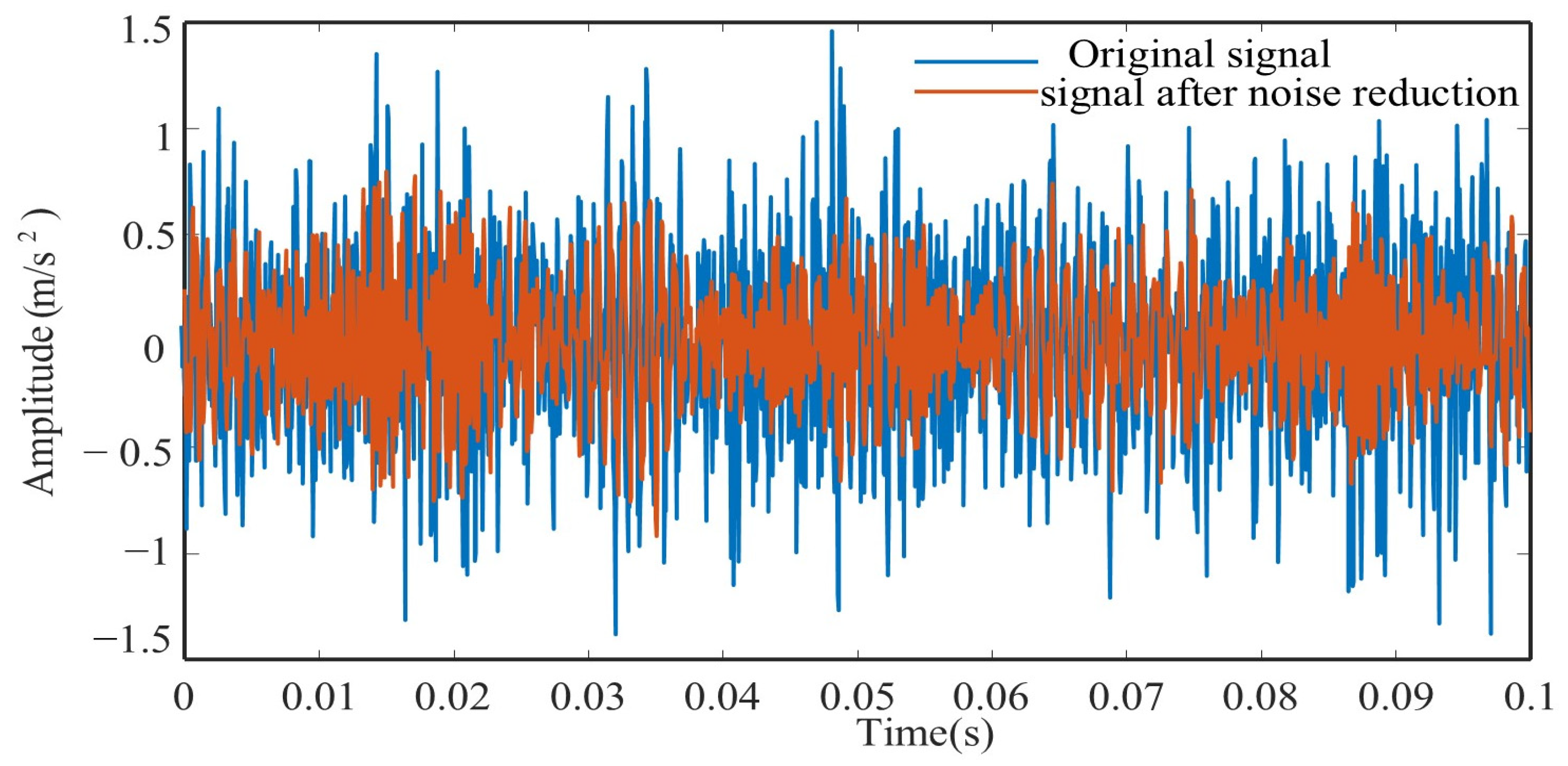
Figure 10 shows a comparison between vibration signals before and after denoising. Table 3 presents the evaluation indicators calculated on the results obtained by the proposed denoising method and soft-threshold denoising method. The proposed method exhibits higher values of NM and SNR compared to the benchmark methods, demonstrating its superior denoising capability.
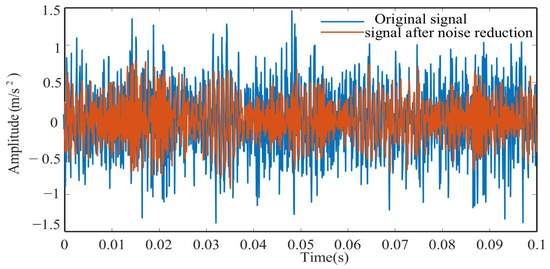
Figure 10.
Denoising result.
Table 3.
The result of signal denoising.
4.2.2. Analysis of Feature Selection Results
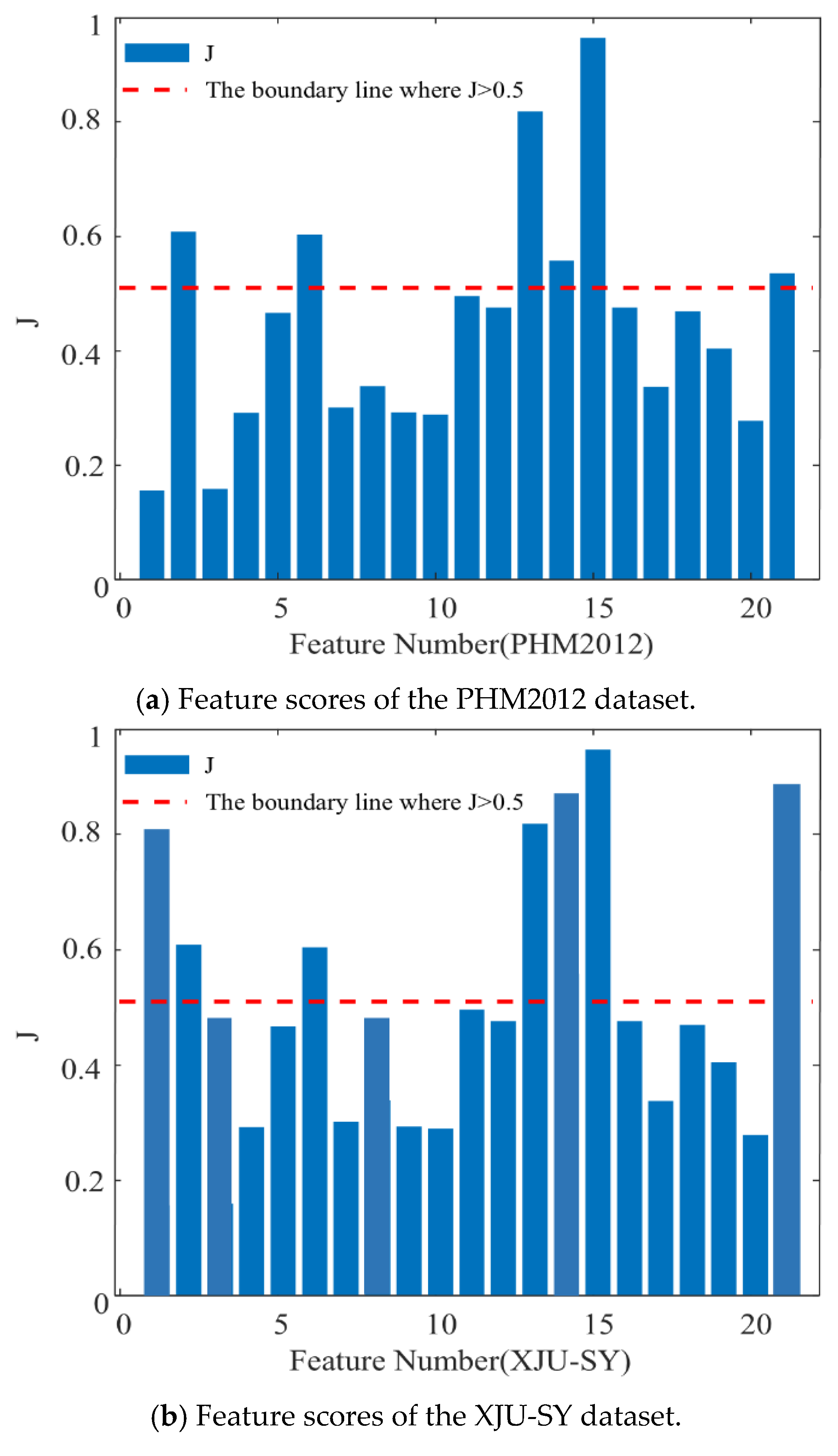
Taking bearing 1-3 from the PHM2012 dataset and bearing 1-3 from the XJU-SY dataset as examples, the score values of each feature are, respectively, illustrated in Figure 11a,b, the red curve represents the score value of 0.5. It can be seen from Figure 11a that the p2, p6, p13, p14, p15, and p21 extracted features of PHM2012 have score values greater than 0.5. Therefore, these features are considered optimal features. It can be observed from Figure 11b that the p1, p2, p6, p13, p14, p15, and p21 extracted features of XJU-SY have score values greater than 0.5, and thus they are considered optimal features. These features contain rich degradation information of bearings, allowing them to contribute effectively to the performed RUL prediction.
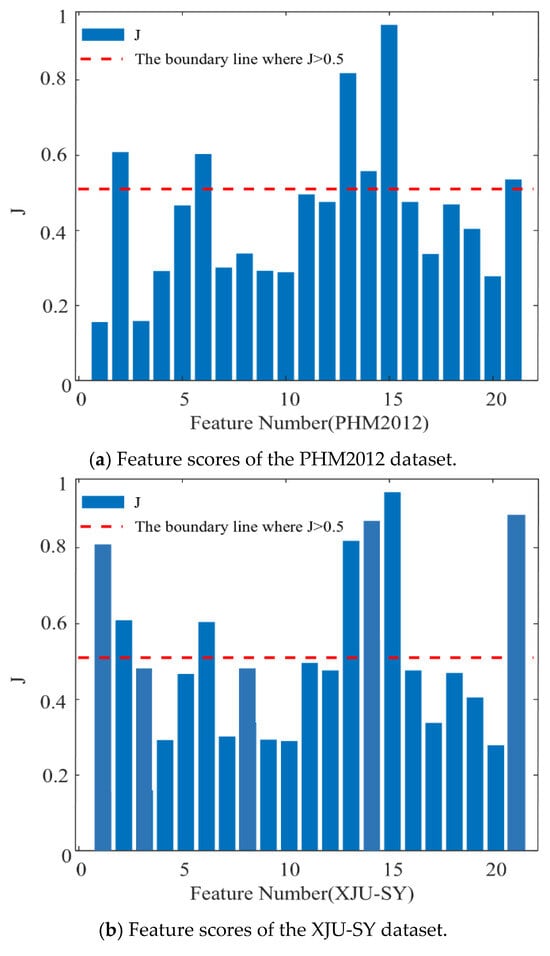
Figure 11.
Feature scores.
To verify that the selected features are the optimal ones for RUL prediction, ablation experiments were conducted using the following methods: (1) Input the selected feature (represented by p) and all features (represented by pall) into the RUL prediction model to obtain the prediction results. (2) Remove one of the selected features at a time and input the remaining features (represented by p − pio, where io stands for feature number) into the RUL prediction model to obtain the prediction results. The Root Mean Square Error (RMSE) was used as the evaluation criterion for both steps.
Due to the large amount of data in the experimental results, the ablation experiment results for Bearings 1-3 are presented for each dataset. As shown in Table 4, which presents the results after conducting the ablation experiments, when performing RUL prediction using the selected features versus all features, there is little difference in their RMSE values. This indicates that both have a similar impact on the RUL prediction results. To reduce data redundancy, it is sufficient to use the selected features for RUL prediction. When any one feature is removed from the selected features, the RMSE fluctuates significantly, and the RMSE value calculated using the selected features is smaller. A smaller RMSE value indicates more accurate RUL prediction results. Therefore, based on the comprehensive experimental results above, it can be concluded that using the selected features for RUL prediction yields good predictive performance.
Table 4.
Evaluation results of ablation experiments.
4.3. HI and Failure Threshold Results
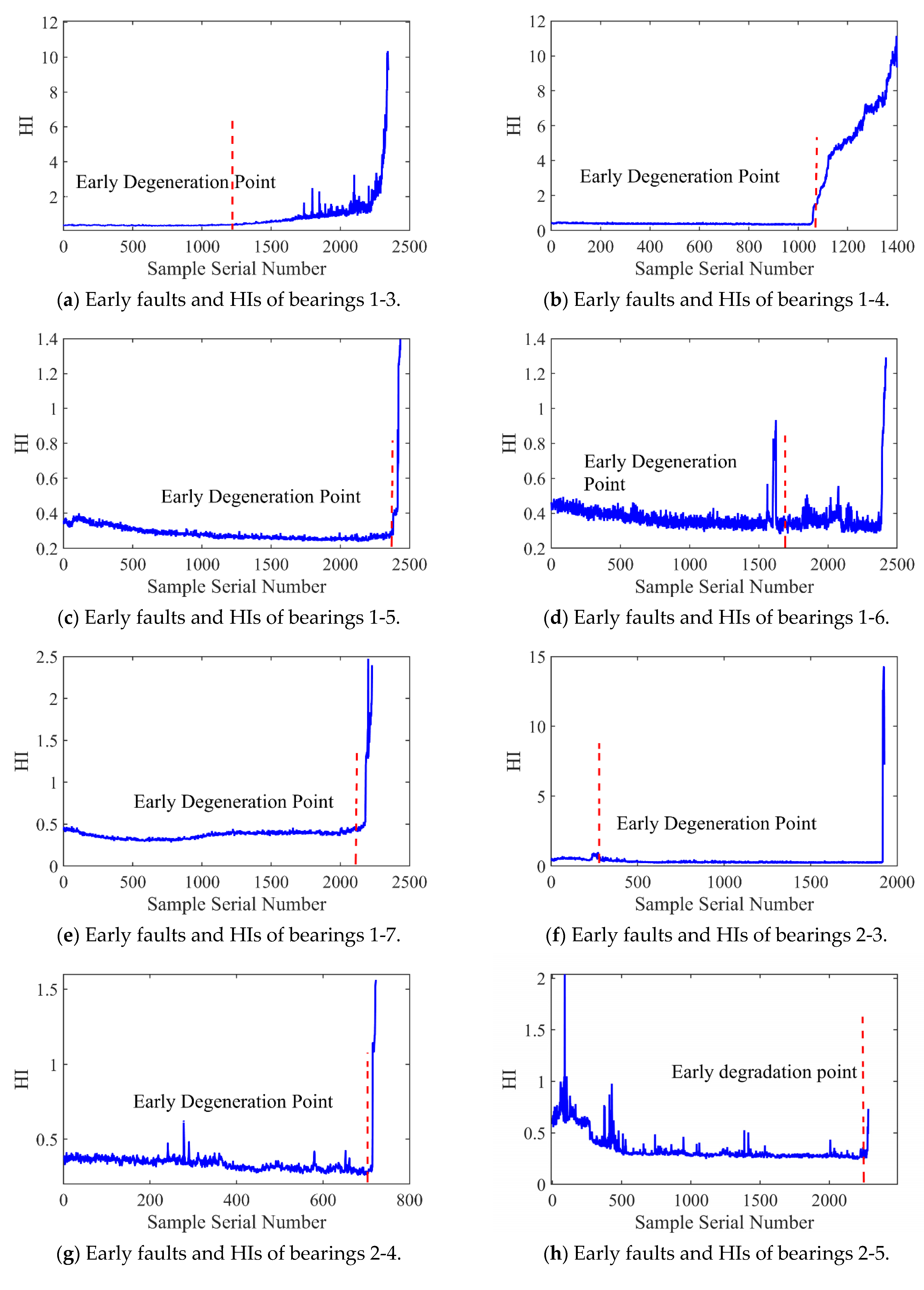
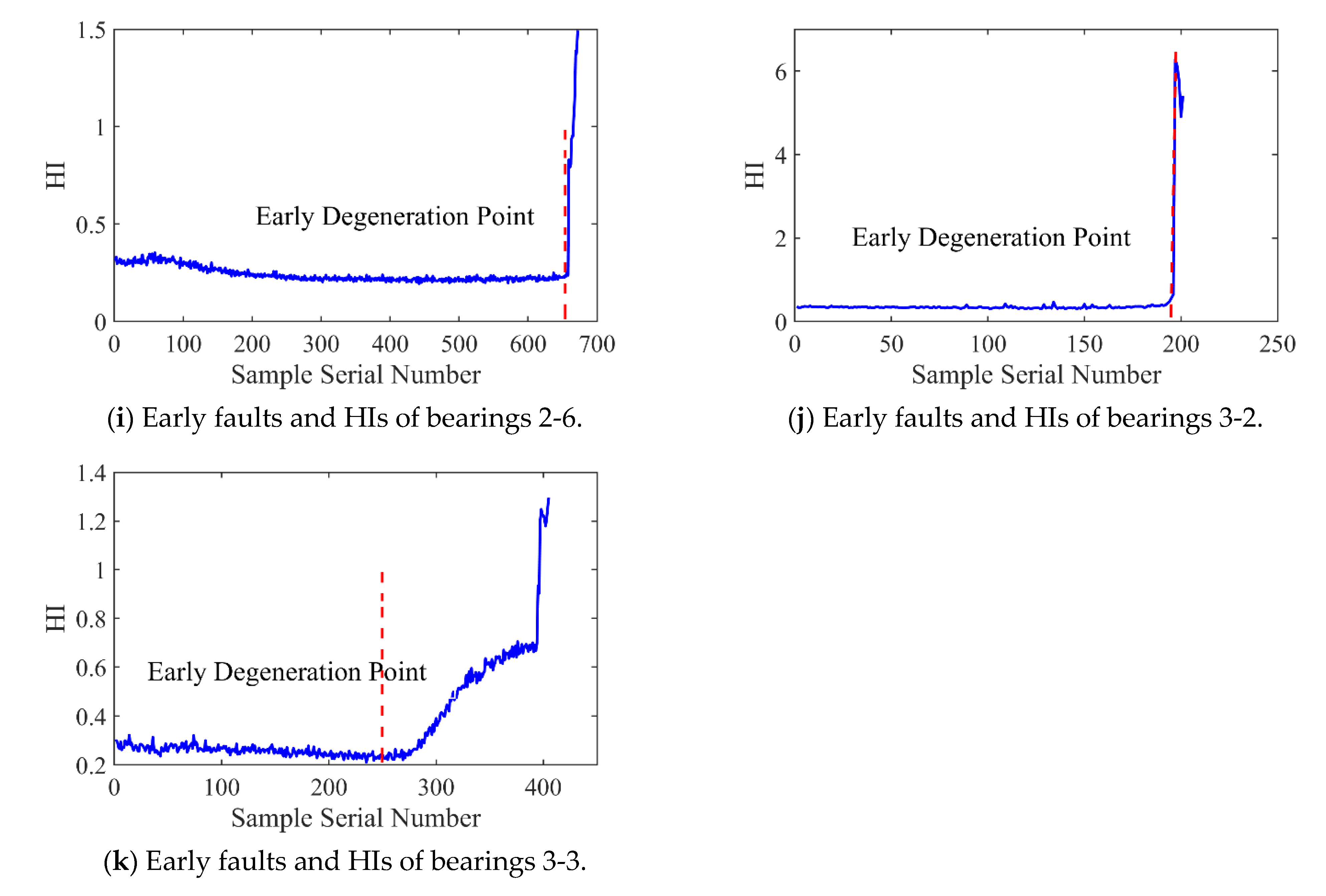
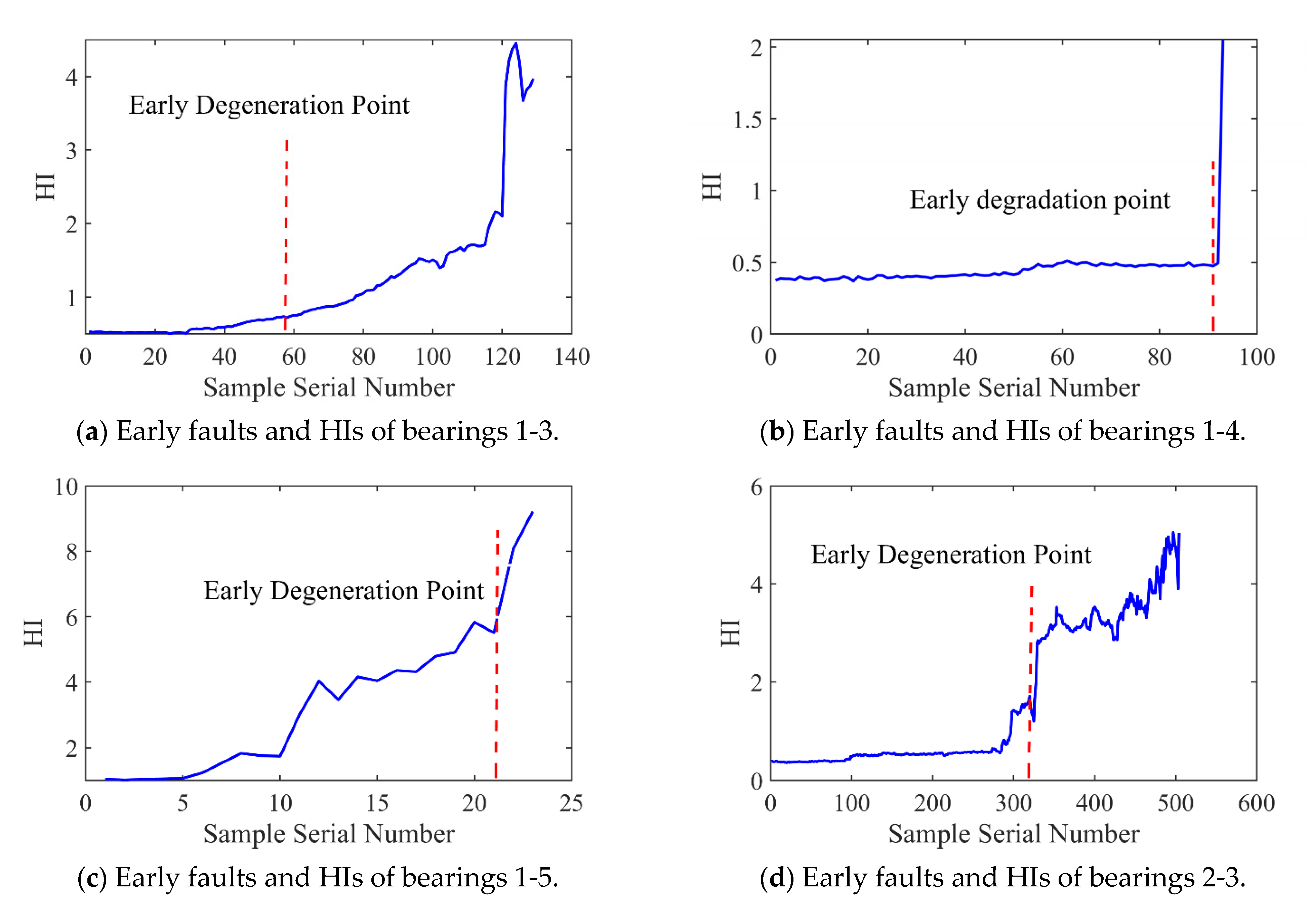
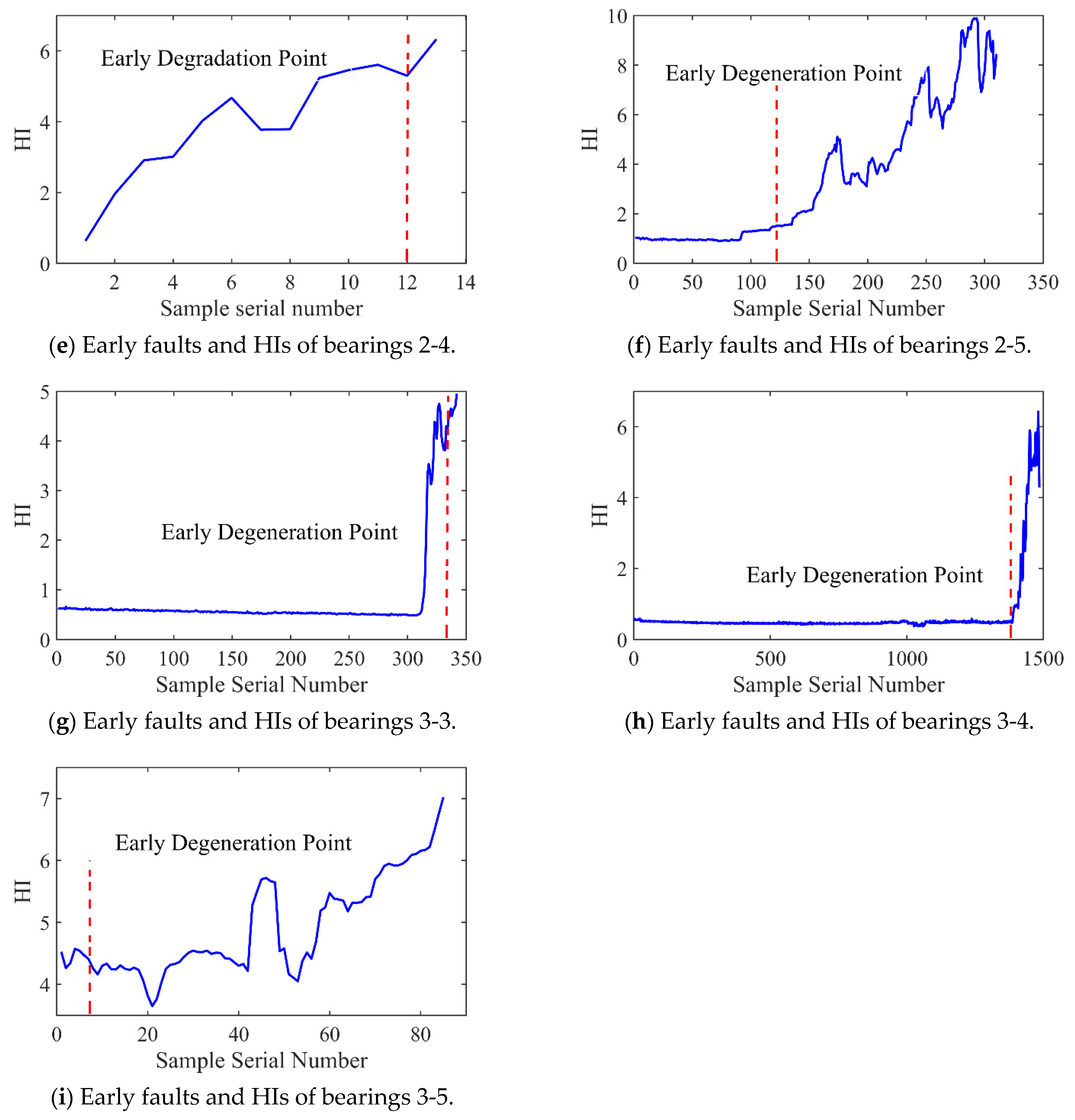
Figure 12 and Figure 13 present the HI and early degradation points of the test sets for the PHM2012 and XJU-SY datasets, respectively, the red curve represents the failure point of the bearing. Table 5 shows the bearing early degradation point detection results obtained using the dynamic threshold and fixed threshold methods.
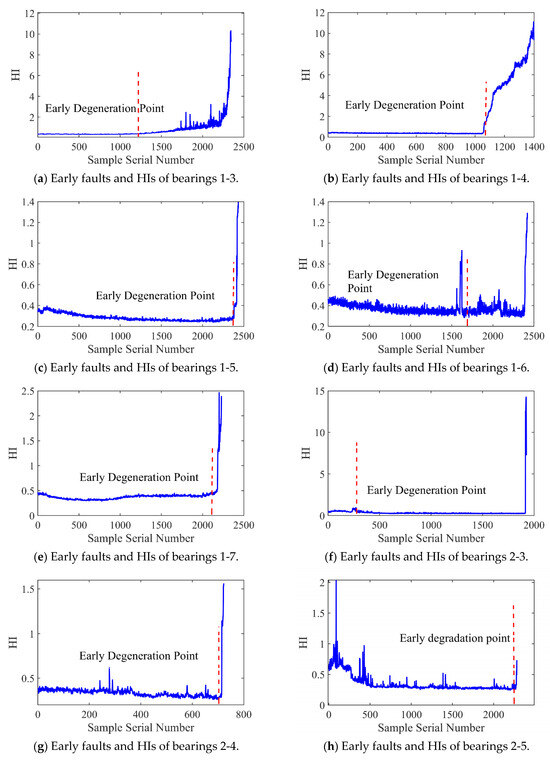
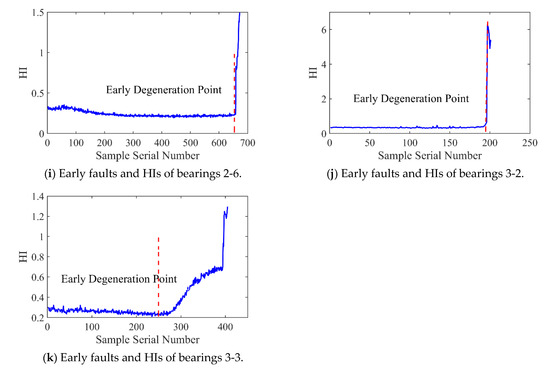
Figure 12.
Early faults and HIs for PHM2012.
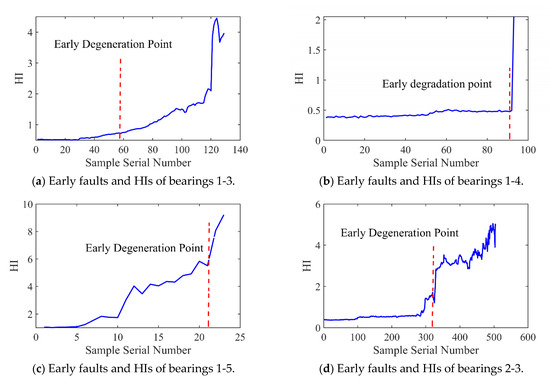
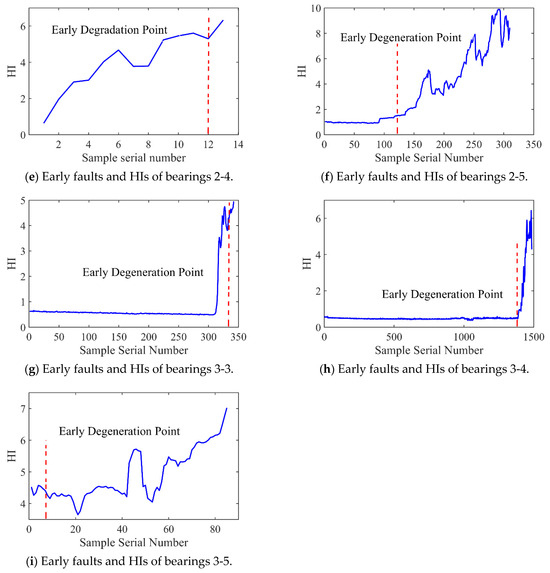
Figure 13.
Early faults and HIs for XJU-SY.
Table 5.
Comparison of different thresholding methods.
The fixed threshold method failed to detect the early degradation points of bearings 2-4 and 2-5 in the PHM dataset, as well as those of bearings 1-4 and 1-5 in the XJU-SY dataset. In contrast, the proposed method could detect early degradation points across all datasets. This is due to the fact that the dynamic threshold detection method can adaptively adjust to different working conditions and operational degradation stages of the bearing, and it can perform a real-time adjustment of the degradation threshold of the bearing to adapt to the whole process of its life, enabling early degradation detection and eliminating the risk of missed detections.
4.4. Analysis of RUL Prediction Results
Table 6 shows the detailed network parameters of the proposed RUL prediction model and those of CNN-BiLSTM and stacked BiGRU (stacking two layers of BiGRU networks) used for comparison.
Table 6.
Network architecture parameters.
Table 7 presents the time complexity of SSA-optimized BiLSTM. Both the SSA search time and inference latency are average times, measured in seconds (s).
Table 7.
Time computational complexity and inference latency.
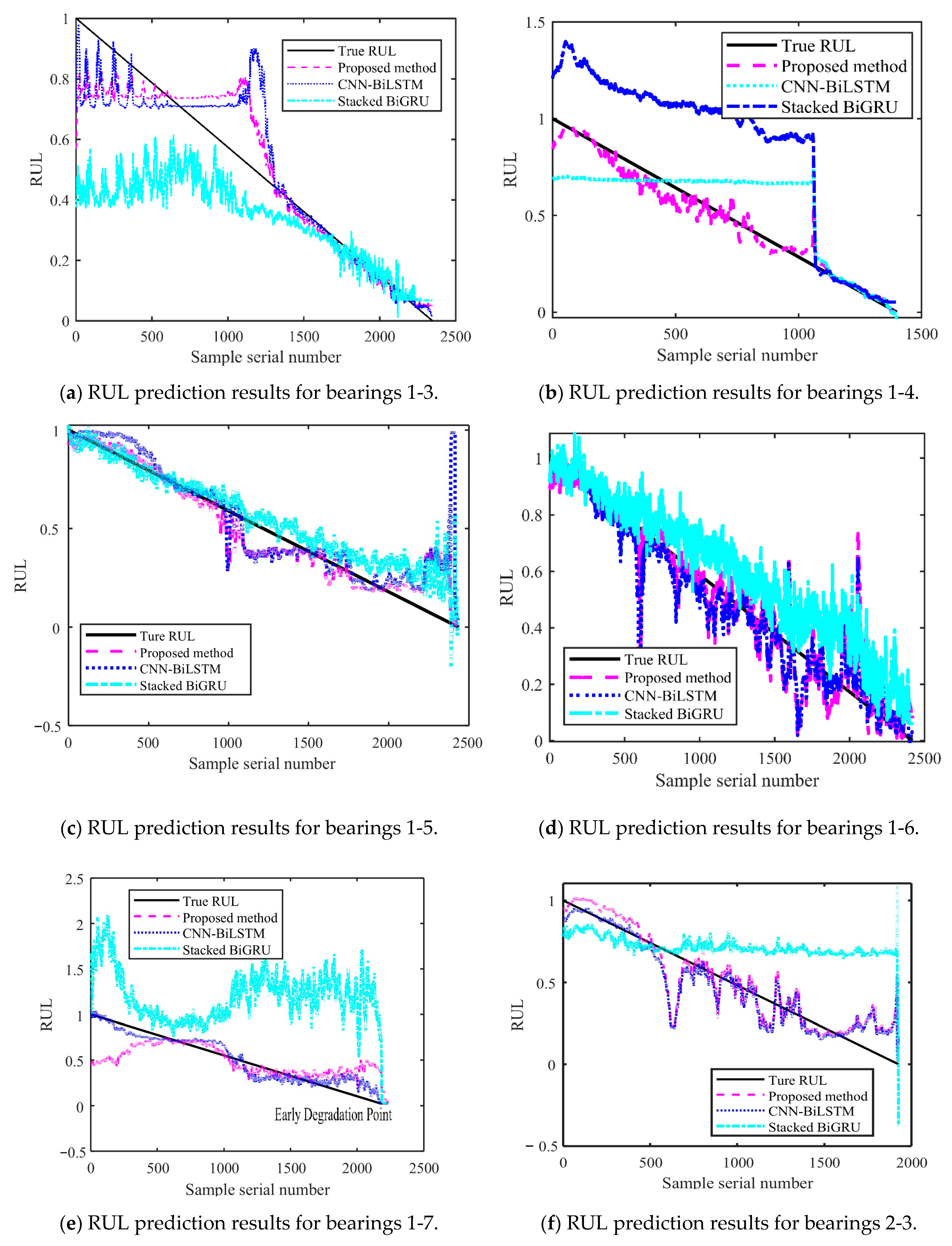
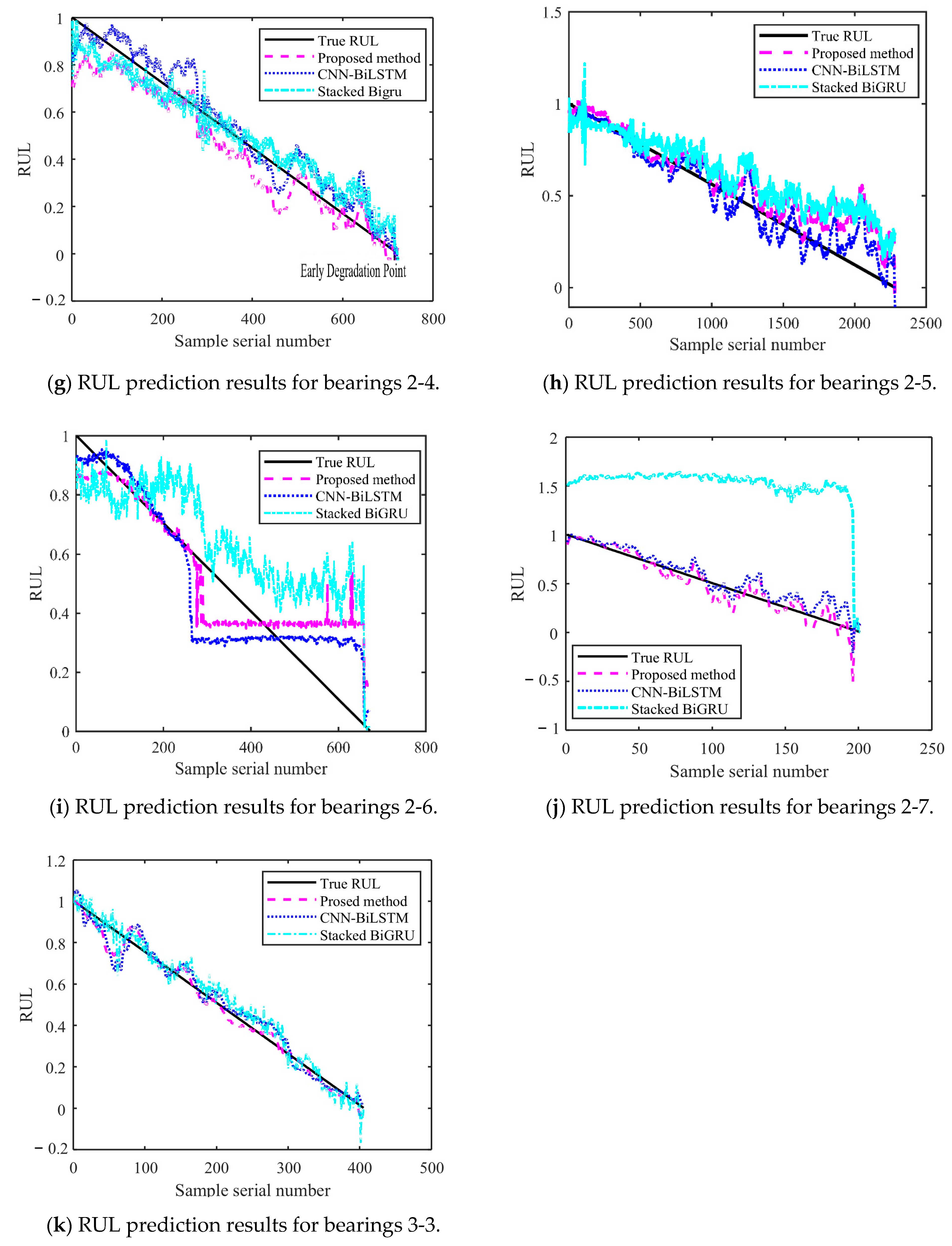
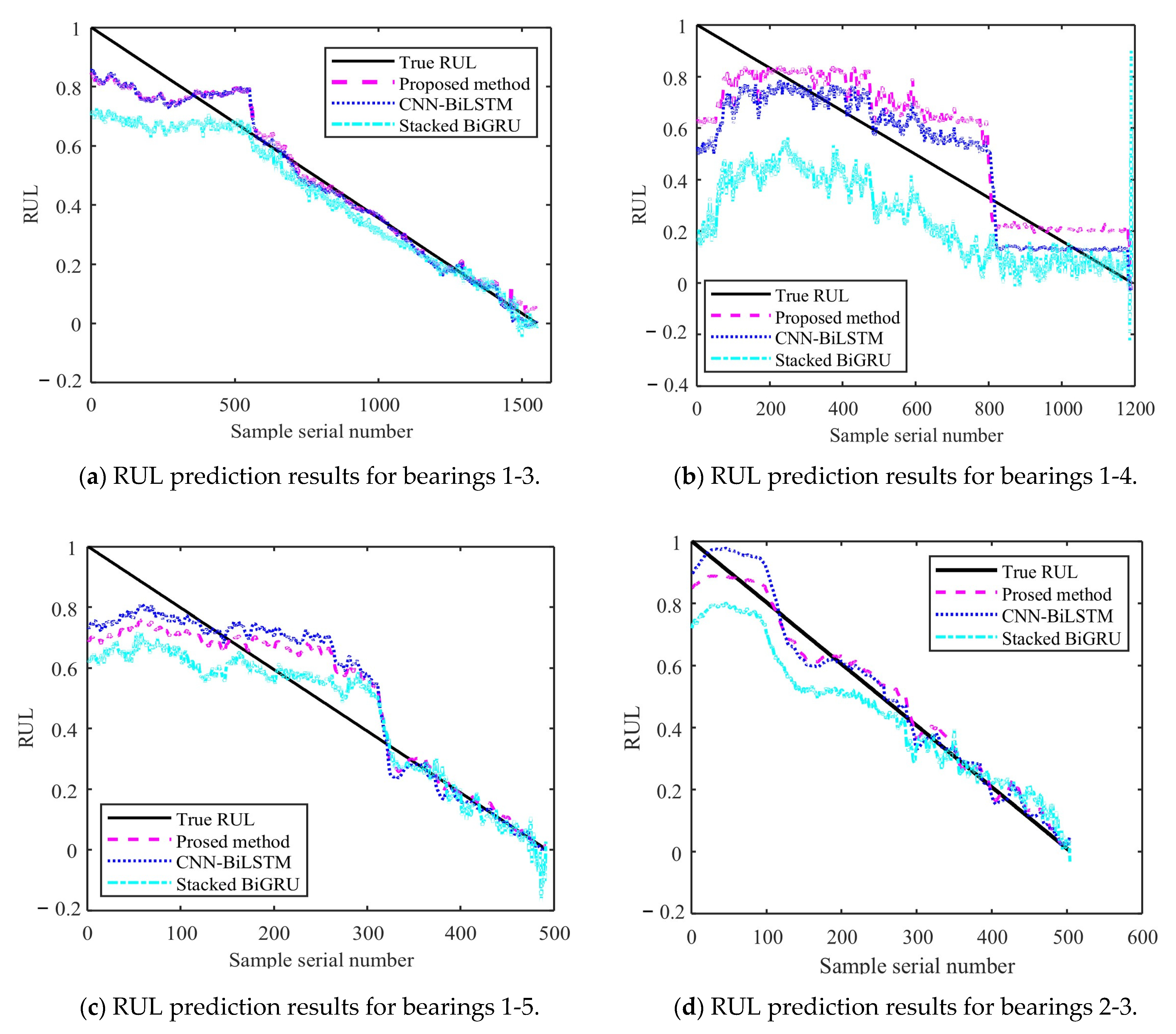
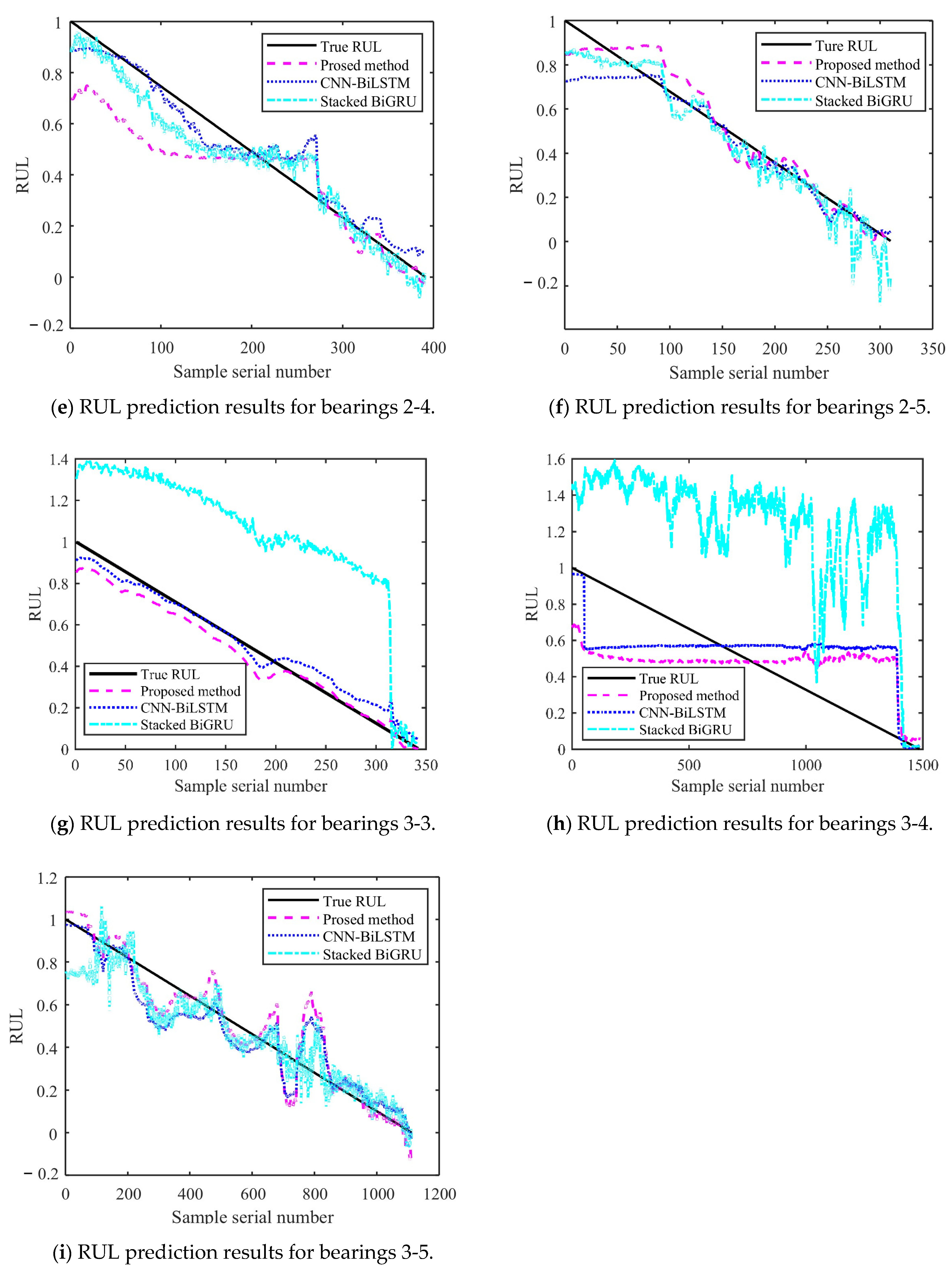
Figure 14 and Figure 15 show the results of the test set obtained by testing on PHM2012 and XJU-SY, respectively. It can be seen that the RUL prediction curves exhibit a monotonically decreasing trend. The analysis presented in Section 4.3 demonstrates that, during the operation of bearings, their performance is gradually degraded because of many factors, such as wear, fatigue, and corrosion. Over time, the degradation effects accumulate, leading to a further decrease in bearing performance. Therefore, when the bearing service time increases, its remaining life time is gradually shortened. It can also be seen from the RUL prediction curves that the three methods can predict the RUL of bearings. However, in general, the proposed method exhibits a smaller curve fluctuation range compared to those of the other methods, which demonstrates that it has higher stability.
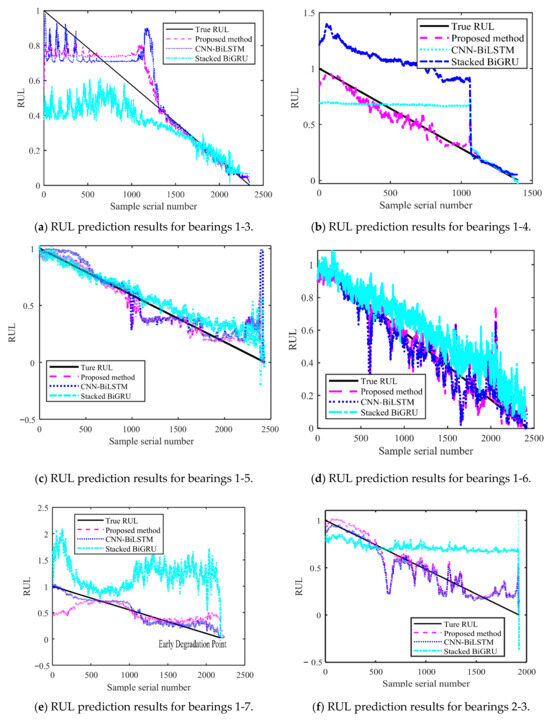
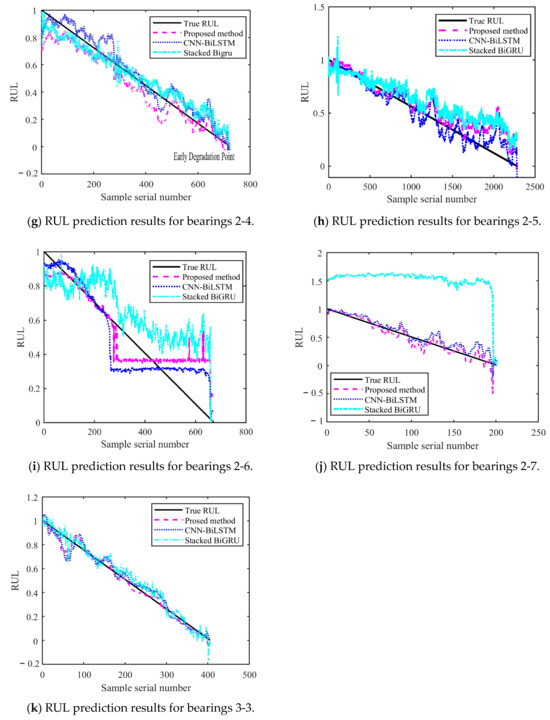
Figure 14.
RUL prediction results for PHM2012.
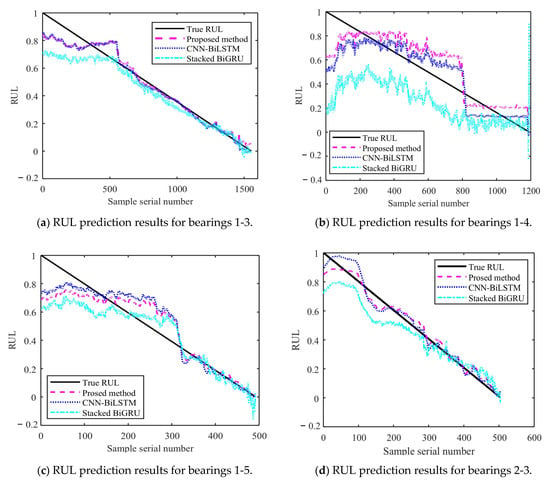
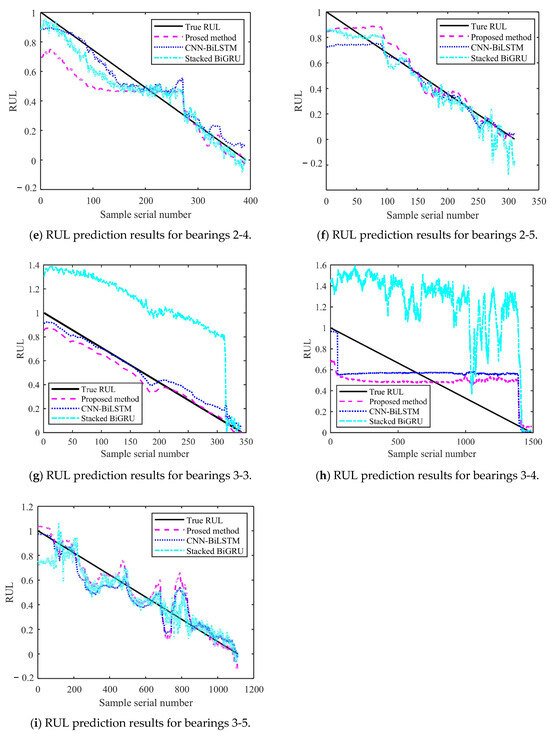
Figure 15.
RUL prediction results for XJU-SY.
The Root Mean Square Error (RMSE) emphasizes the impact of large errors and facilitates horizontal comparisons with other models. The Mean Absolute Error (MAE) provides an intuitive measure of the average prediction error and can more robustly evaluate the performance of the model. The Coefficient of Determination (R2) measures the degree of fit of the model to the data, with a value closer to 1 indicating better fit. It is suitable for scenarios where it is necessary to compare the fitting effects of different models. The formula for RMSE has already been provided in Section 4.2.2. The formulas for MAE and R2 are as follows, respectively [36]:
The obtained MAE, RMSE, and R2 values are presented in Table 8. It can be seen that the MAE and RMSE of the BiLSTM model are smaller than those of the other two methods, demonstrating higher performance. The R2 value of the BiLSTM model is greater than that of the other methods. This shows that the fitting degree of the proposed network model is higher than those of the other methods. By predicting the bearing RUL, a preventive maintenance of machines can be performed, providing time for staff to establishing repair strategies and reducing the economic losses caused by failures. When inputting two different datasets into the proposed RUL prediction model, it demonstrates high prediction ability. This shows that it has high adaptability and generalization ability, yielding prediction results that are more stable than those obtained by other methods.
Table 8.
Evaluation metric values.
5. Conclusions
The NGO method was used to optimize the VMD algorithm (NVMD). The Pearson correlation coefficient was adopted to denoise the original vibration signals of bearings. The obtained results were compared with those of the soft-threshold denoising method, and optimal features were selected based on monotonicity, trendability, predictability, and robustness indicators. The KPCA method was used to fuse features in order to determine the HI of the bearing. A dynamic threshold method was proposed to detect the early degradation point of bearings. The obtained results were compared with those of the fixed threshold method. The BiLSTM model was combined with the attention mechanism for RUL prediction. The SSA was used to adaptively find the network parameters, allowing prediction of the bearing RUL. The obtained results were compared with those of the CNN-BiLSTM and stacked BiGRU methods. The main conclusions are summarized as follows:
- (1)
- The proposed method exhibits high denoising capability. The denoising capability significantly affects the quality of the results of bearing RUL prediction. After filtering using the NVMD method, the bearing signal becomes purer, which improves its quality for the subsequent bearing signal feature extraction, early degradation detection, and life prediction.
- (2)
- Different bearing features encapsulate degradation information from various aspects. During feature selection, it is necessary to comprehensively consider multiple features. Based on the ablation experiment results across different features, the features extracted using the proposed method contain richer degradation information. By fusing only these sensitive features, accurate prediction can be performed for RUL prediction.
- (3)
- Early degradation time detection is a crucial parameter in the evaluation of the bearing performance. Since the characteristics of bearing vibration signals change in real time, the degradation threshold of the signal also varies over time. Using a dynamic threshold setting method to determine the degradation threshold of bearing vibration signals, real-time updates of the mean and standard deviation can be performed. This allows us to update the failure threshold in real time. Compared with the fixed threshold method, the dynamic threshold method can detect the bearing degradation time earlier, enabling the preventive maintenance of bearings.
- (4)
- A comparison was conducted among the RUL, CNN-BiLSTM, and stacked BiGRU prediction performances. The obtained results showed that the proposed RUL prediction method demonstrates higher performance and stronger fitting ability. This demonstrates that it has higher effectiveness in predicting RUL. The proposed model was then applied on the PHM2012 and XJU-SY datasets, demonstrating its high generalization ability and performance. The use of the proposed method for RUL prediction allows for timely detection of potential bearing faults. This provides sufficient time for performing timely bearing repair, guiding staff in formulating complete maintenance measures.
Author Contributions
Conceptualization, Y.Z. and W.S.; methodology, Y.Z.; software, Y.Z.; validation, Y.Z., T.X. and B.W.; formal analysis, Y.Z.; investigation, B.W. and T.X.; resources, W.S.; data curation, Y.Z.; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z.; visualization, Y.Z.; supervision, Y.Z.; project administration, Y.Z.; funding acquisition, W.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by Special Project for Central Government Guiding Local Science and Technology Development (grant no. ZYYD2025JD07).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Acknowledgments
We would like to thank all the contributors in the laboratory.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yang, H.; Jiang, G.; Tian, W.; Mei, X.; Nee, A.Y.C.; Ong, S.K. Microservice-based digital twin system towards smart manufacturing. Robot. Comput. Integr. Manuf. 2025, 91, 102858. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, D.; Shi, N.; Li, Y.; Liang, P.; Zhang, L.; Zheng, Z. Intelligent fault diagnosis of rolling bearing based on an active federated local subdomain adaptation method. Adv. Eng. Inform. 2024, 62, 102807. [Google Scholar] [CrossRef]
- He, D.; Zhang, Z.; Jin, Z.; Zhang, F.; Yi, C.; Liao, S. RTSMFFDE-HKRR: A fault diagnosis method for train bearing in noise environment. Measurement 2025, 239, 115417. [Google Scholar] [CrossRef]
- He, D.; Zhao, J.; Jin, Z.; Huang, C.; Zhang, F.; Wu, J. Prediction of bearing remaining useful life based on a two-stage updated digital twin. Adv. Eng. Inform. 2025, 65, 103123. [Google Scholar] [CrossRef]
- Liu, S.; Fan, L. An adaptive prediction approach for rolling bearing remaining useful life based on multistage model with three-source variability. Reliab. Eng. Syst. Saf. 2022, 218, 108182. [Google Scholar] [CrossRef]
- Zimmermann, N.; Lang, S.; Blaser, P.; Mayr, J. Adaptive input selection for thermal error compensation models. CIRP Ann. 2020, 69, 485–488. [Google Scholar] [CrossRef]
- Sheng, Y.; Liu, H.; Li, J. Bearing performance degradation assessment and remaining useful life prediction based on data-driven and physical model. Meas. Sci. Technol. 2023, 34, 055002. [Google Scholar] [CrossRef]
- Shuang, L.; Shen, X.; Zhou, J.; Miao, H.; Qiao, Y.; Lei, G. Bearings remaining useful life prediction across equipment-operating conditions based on multisource-multitarget domain adaptation. Measurement 2024, 236, 115026. [Google Scholar] [CrossRef]
- Wu, J.; He, D.; Li, J.; Miao, J.; Li, X.; Li, H.; Shan, S. Temporal multi-resolution hypergraph attention network for remaining useful life prediction of rolling bearings. Reliab. Eng. Syst. Saf. 2024, 247, 110143. [Google Scholar] [CrossRef]
- Wu, C.; He, J.; Shen, W.; Xu, W.; Lv, J.; Liu, S. Remaining useful life prediction across operating conditions based on deep subdomain adaptation network considering the weighted multi-source domain. Knowl.-Based Syst. 2024, 301, 112291. [Google Scholar] [CrossRef]
- Qiu, H.; Niu, Y.; Shang, J.; Gao, L.; Xu, D. A piecewise method for bearing remaining useful life estimation using temporal convolutional networks. J. Manuf. Syst. 2023, 68, 227–241. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, B.; Feng, B.; Liu, L.; Gao, Z. A hybrid method for cutting tool RUL prediction based on CNN and multistage Wiener process using small sample data. Measurement 2023, 213, 112739. [Google Scholar] [CrossRef]
- Yousuf, S.; Khan, S.A.; Khursheed, S. Remaining useful life (RUL) regression using long–short term memory (LSTM) networks. Microelectron. Reliab. 2022, 139, 114772. [Google Scholar] [CrossRef]
- Xiang, S.; Li, P.; Huang, Y.; Luo, J.; Qin, Y. Single gated RNN with differential weighted information storage mechanism and its application to machine RUL prediction. Reliab. Eng. Syst. Saf. 2024, 242, 109741. [Google Scholar] [CrossRef]
- Kebede, G.A.; Lo, S.-C.; Wang, F.-K.; Chou, J.-H. Transfer learning-based deep learning models for proton exchange membrane fuel remaining useful life prediction. Fuel 2024, 367, 131461. [Google Scholar] [CrossRef]
- Chen, X.; Li, K.; Wang, S.; Liu, H. A hybrid prognostic approach combined with deep Bayesian transformer and enhanced particle filter for remaining useful life prediction of bearings. Measurement 2025, 252, 117184. [Google Scholar] [CrossRef]
- Zhang, G.; Jiang, D. Research on the Remaining Life Prediction Method of Rolling Bearings Based on Multi-Feature Fusion. Appl. Sci. 2024, 14, 1294. [Google Scholar] [CrossRef]
- Liu, Y.; Song, J.; Zhao, Z.; Ye, G.; Liu, Z.; Zhou, Y. Adaptive Residual Life Prediction for Small Samples of Mechanical Products Based on Feature Matching Preprocessor-LSTM. Appl. Sci. 2022, 12, 8236. [Google Scholar] [CrossRef]
- Li, J.; Huang, F.; Qin, H.; Pan, J. Research on Remaining Useful Life Prediction of Bearings Based on MBCNN-BiLSTM. Appl. Sci. 2023, 13, 7706. [Google Scholar] [CrossRef]
- Mi, J.H.; Liu, L.L.; Zhuang, Y.H. A Synthetic Feature Processing Method for Remaining Useful Life Prediction of Rolling Bearings. IEEE Trans. Reliab. 2023, 72, 110123. [Google Scholar] [CrossRef]
- Zhao, X.; Yang, Y.; Huang, Q.; Fu, Q.; Wang, R.; Wang, L. Rolling bearing remaining useful life prediction method based on vibration signal and mechanism model. Appl. Acoust. 2025, 228, 110334. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, E.; Zhang, B.; Miao, Q. RUL prediction and uncertainty management for multisensor system using an integrated data-level fusion and UPF approach. IEEE Trans. Ind. Inform. 2021, 17, 4692–4701. [Google Scholar] [CrossRef]
- Tai, Y.F.; Yan, X.Y.; Geng, X.Y.; Mu, L.; Jiang, M.S.; Zhang, F.Y. Data-driven method for predicting remaining useful life of bearings based on multi-layer perceptron neural network and bidirectional long short-term memory network. Struct. Durab. Health Monit. 2025, 19, 365–383. [Google Scholar] [CrossRef]
- Yang, L.; Li, T.; Dong, Y.; Duan, R.; Liao, Y. A knowledge-data integration framework for rolling element bearing RUL prediction across its life cycle. ISA Trans. 2024, 152, 27. [Google Scholar] [CrossRef]
- Wang, T.; Liu, Z.; Mrad, N. A probabilistic framework for remaining useful life prediction of bearings. IEEE Trans. Instrum. Meas. 2021, 70, 3503412. [Google Scholar] [CrossRef]
- Chen, Z.; Xia, T.; Li, Y.; Pan, E. A hybrid prognostic method based on gated recurrent unit network and an adaptive Wiener process model considering measurement errors. Mech. Syst. Signal Process. 2021, 158, e107785. [Google Scholar] [CrossRef]
- Li, Y.; Wang, Z.; Li, F.; Li, Y.; Zhang, X.; Shi, H.; Dong, L.; Ren, W. An ensembled remaining useful life prediction method with data fusion and stage division. Reliab. Eng. Syst. Saf. 2024, 242, 109804. [Google Scholar] [CrossRef]
- Wang, G.; Xiang, J. Remain useful life prediction of rolling bearings based on exponential model optimized by gradient method. Measurement 2021, 176, 109161. [Google Scholar] [CrossRef]
- Cui, L.; Wang, X.; Wang, H.; Ma, J. Research on remaining useful life prediction of rolling element bearings based on time-varying Kalman filter. IEEE Trans. Instrum. Meas. 2019, 69, 2858–2867. [Google Scholar] [CrossRef]
- Wang, D.; Tsui, K.L. Two novel mixed effects models for prognostics of rolling element bearings. Mech. Syst. Sig. Process. 2018, 99, 1–13. [Google Scholar] [CrossRef]
- Han, T.; Pang, J.; Tan, A.C.C. Remaining useful life prediction of bearing based on stacked autoencoder and recurrent neural network. J. Manuf. Syst. 2021, 61, 576–591. [Google Scholar] [CrossRef]
- Balamurugan, R.; Takale, D.G.; Parvez, M.M.; Gnanamurugan, S. A novel prediction of remaining useful life time of rolling bearings using convolutional neural network with bidirectional long short term memory. J. Eng. Res. 2024. [Google Scholar] [CrossRef]
- Shen, Y.Z.; Tang, B.P.; Li, B.; Tan, Q.; Wu, Y.L. Remaining useful life prediction of rolling bearing based on multi-head attention embedded Bi-LSTM network. Measurement 2022, 202, 111803. [Google Scholar] [CrossRef]
- Zhang, T.; Chen, Y.; Liao, Z.; Chen, Y. A VMD-MRE bearing fault diagnosis method for parameter optimization of northern goshawk. Mech. Sci. Technol. Aerosp. Eng. 2025, 1–8. [Google Scholar] [CrossRef]
- Pan, L.; Gao, J.; Shao, X. Rolling bearing remaining life prediction model based on improved VMD and BiLSTM. Electron. Des. Eng. 2024, 32, 27–31. [Google Scholar]
- Meng, Q.Y. Research on the Tracking Method of Rolling Bearing Performance Degradation. Master’s Thesis, Anhui University of Engineering, Wuhu, China, 2024. [Google Scholar] [CrossRef]
- Shang, Y.; Tang, X.; Zhao, G.; Jiang, P.; Lin, T.R. A remaining life prediction of rolling element bearings based on a bidirectional gate recurrent unit and convolution neural network. Measurement 2022, 202, 111893. [Google Scholar] [CrossRef]
- Zou, Y.; Sun, W.; Wang, H.; Xu, T.; Wang, B. Research on Bearing Remaining Useful Life Prediction Method Based on Double Bidirectional Long Short-Term Memory. Appl. Sci. 2025, 15, 4441. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).