
Efficient Keyset Design for Neural Networks Using Homomorphic Encryption †



Abstract
1. Introduction
2. Background
2.1. RNS-CKKS
2.2. Ciphertext Level and Bootstrapping
2.3. Key Switching
2.4. Rotation
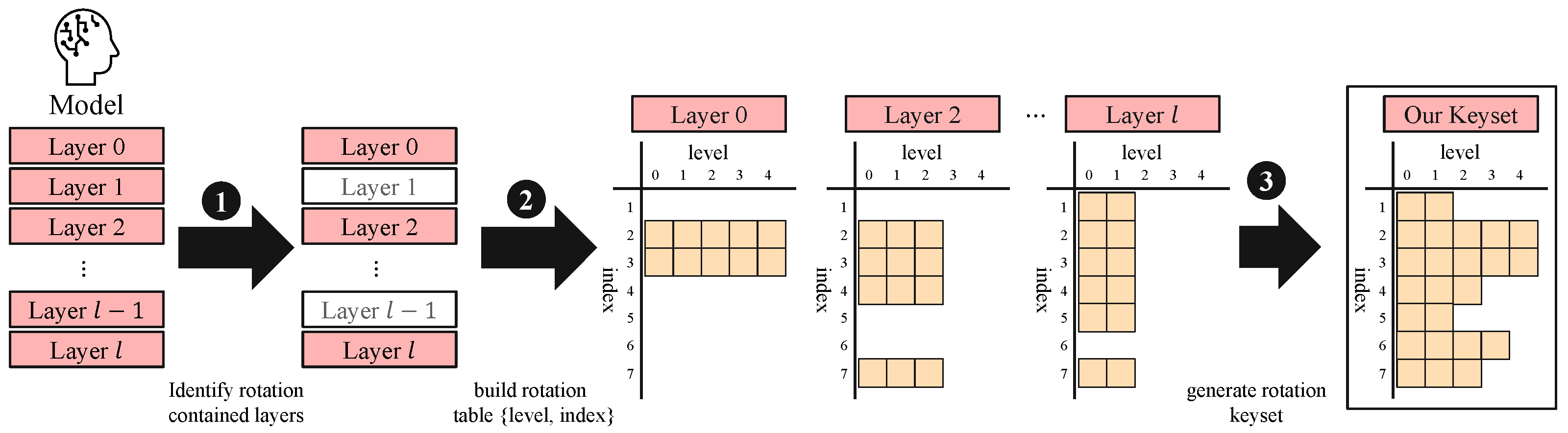
2.5. FHE Keyset Structure and Generation
3. Motivation
3.1. Difficulty in Parameter Setting for Key Switching
3.2. Memory–Latency Trade-Off of Rotations in Neural Networks
- All-Required Key Generation: This approach precomputes rotation keys for all required indices in the neural network. Although it eliminates additional rotations, it demands excessive memory storage, making it impractical for large-scale models.
- Power-of-Two Key Generation: Instead of generating keys for all indices, this approach generates rotation keys only for power-of-two indices and performs recursive rotations to achieve arbitrary shifts. Although this method reduces memory consumption, it introduces additional computational latency. For example, a rotation of index 3 requires two consecutive rotations (2 + 1) in the power-of-two approach, whereas the all-required method completes rotation in a single step.
4. Related Works
4.1. Performance Optimization on FHE and FHE-Based Neural Networks
4.2. Keyset Design Space Exploration
4.3. Keyset Design in Other Homomorphic Encryption Schemes
5. Keyset Design Space (KDS) Exploration
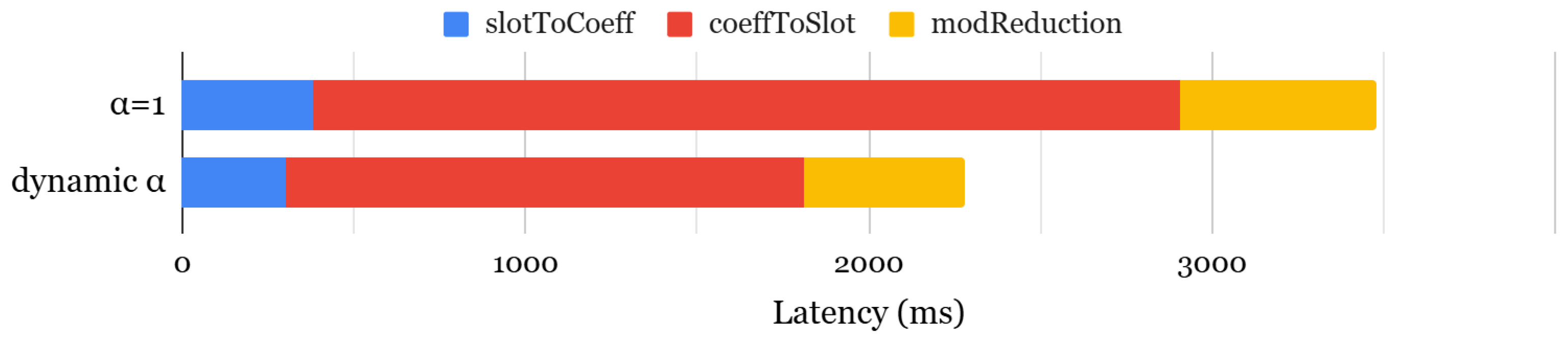
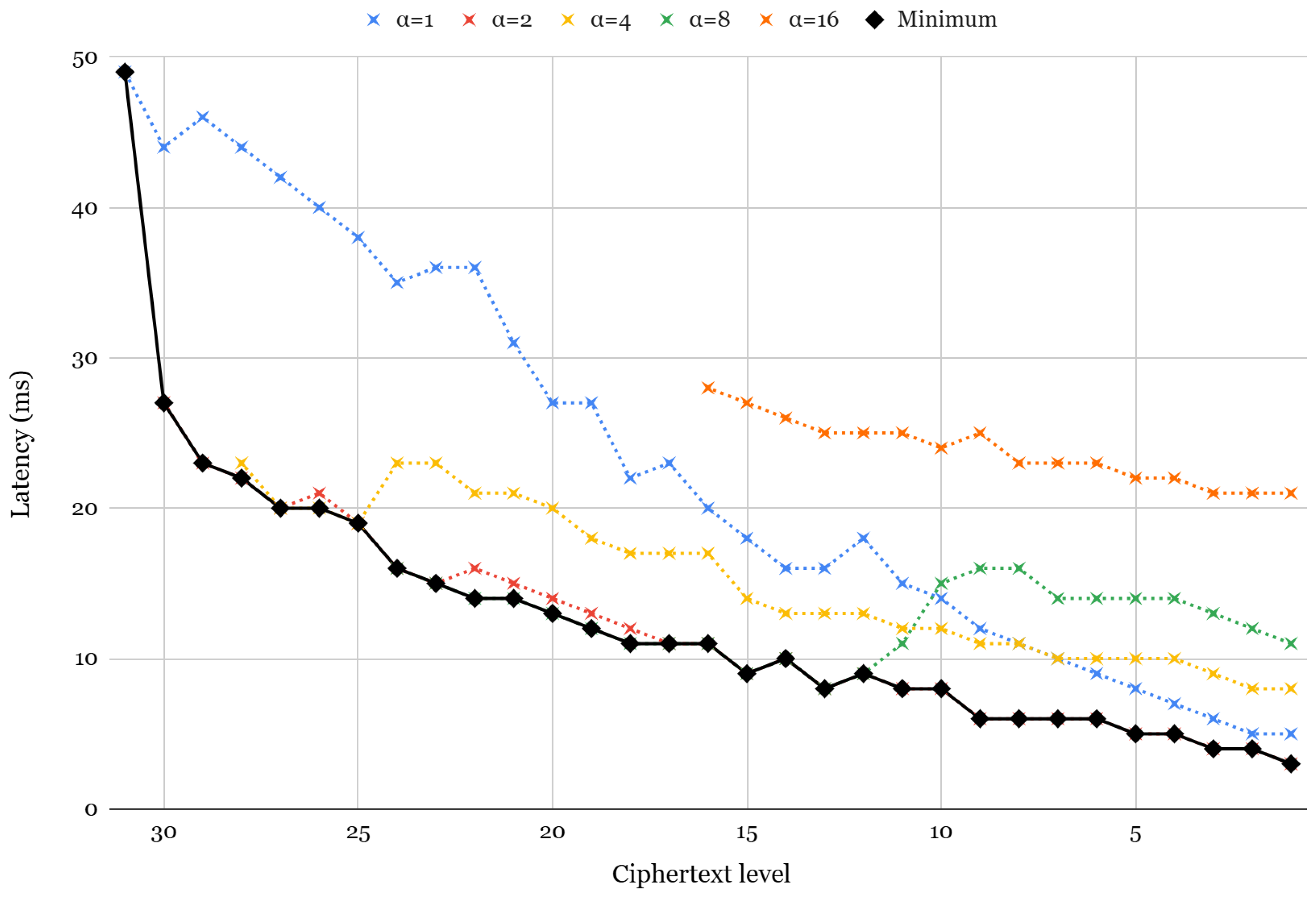
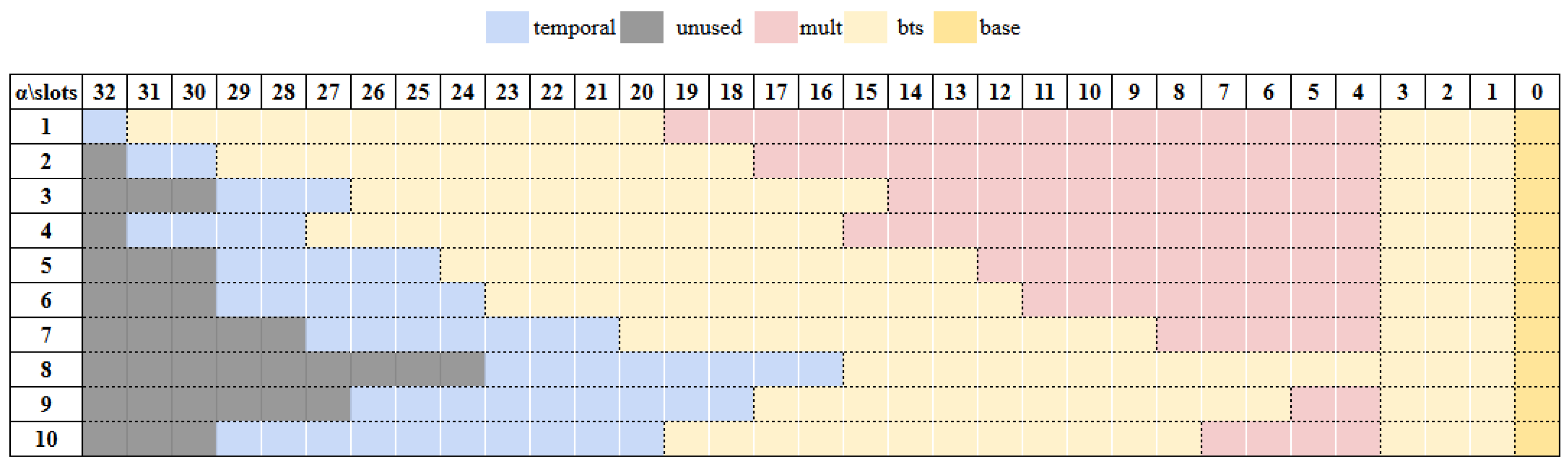
5.1. Impact of
5.2. Impact of Rotation Index Selection
5.3. Impact of the Ciphertext Level
5.4. Combining the Three Factors to Generate a Rotation Keyset for Neural Networks
6. Evaluation
6.1. Experimental Setup
6.2. Compared Baselines
- Index Selection Baselines: We considered two widely adopted index selection strategies:
- –
- Power-of-Two (Pot): Generates a default rotation keyset consisting of power-of-two indices (both positive and negative) and performs recursive rotations for arbitrary indices.
- –
- All-Required: Generates rotation keys for all indices required during inference, eliminating the need for recursive rotation calls.
The keyset generated by all-required depends on the benchmark, whereas power-of-two produces the same keyset across all benchmarks. - Selection Baselines: We compared our approach with two different configurations:
- –
- = 1 (P1): A standard option in several FHE libraries [60], which maximizes the available multiplicative depth.
- –
- Dynamic (Pdyn): A strategy that dynamically selects the optimal to minimize key-switching latency.
- Level-Selection Baselines: We compared our approach with a naive full-level key-generation strategy, where rotation keys are generated for all ciphertext levels. Since prior research has not explicitly considered level-aware key selection, this serves as a reference for evaluating the effectiveness of our approach.
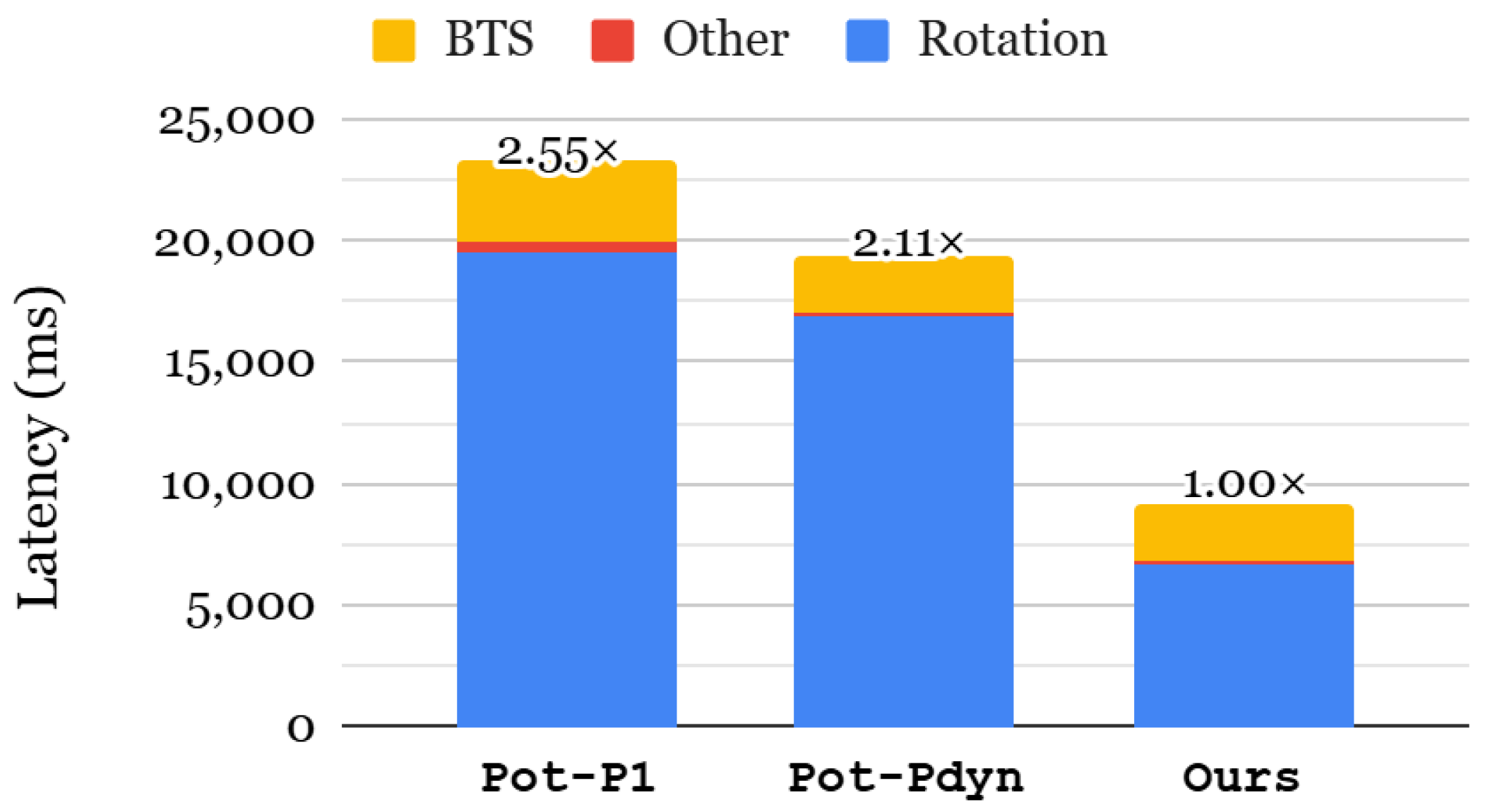
6.3. Case Study 1: Wireless Intrusion Detection System (IDS) Based on Gated Recurrent Unit (GRU)
6.3.1. End-to-End Inference Latency
6.3.2. Memory Consumption
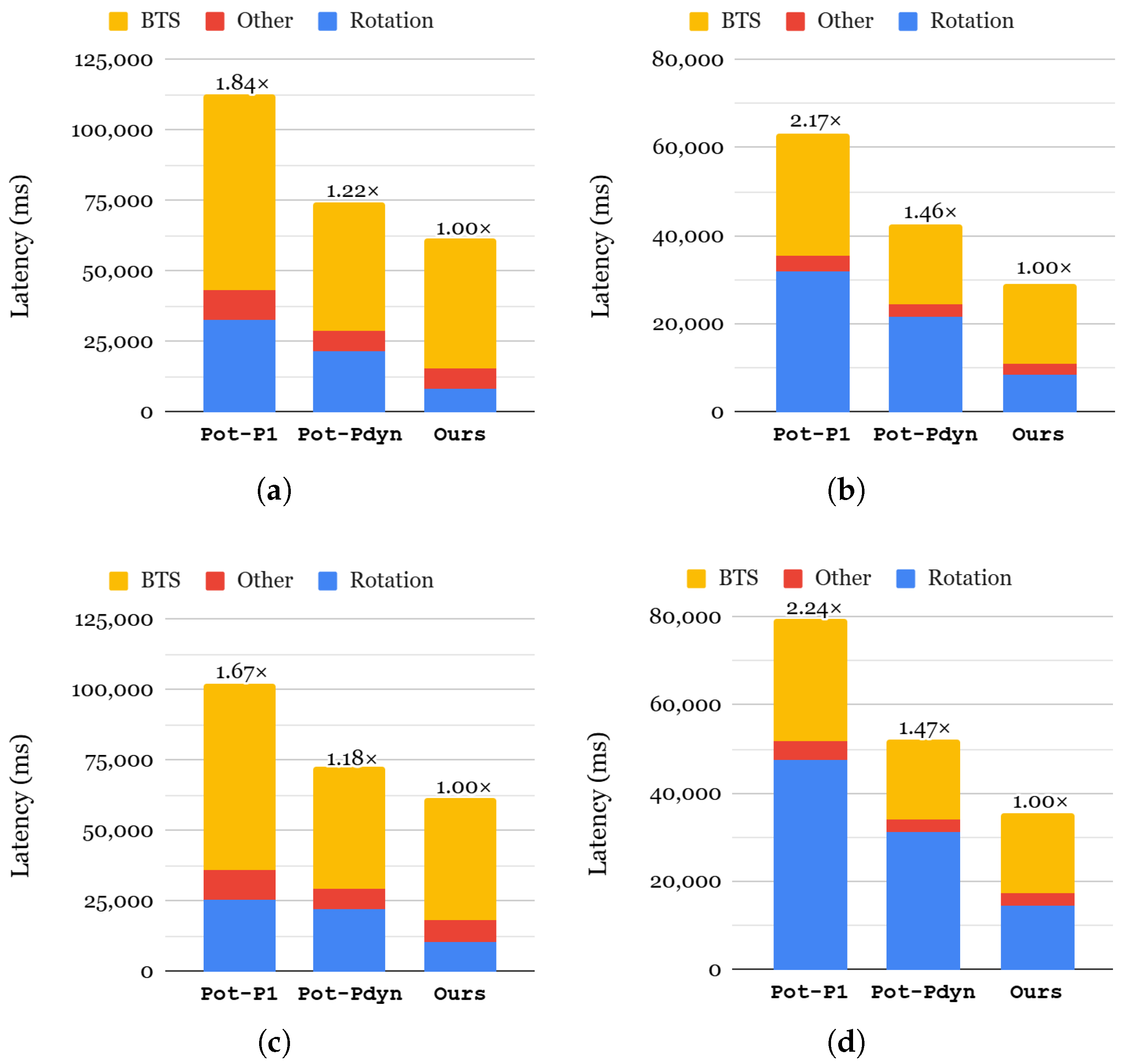
6.4. Case Study 2: Image Classification Based on Convolutional Neural Network (CNN)
6.4.1. End-to-End Inference Latency
6.4.2. Memory Consumption
7. Discussion and Future Work
7.1. Deploying Neural Networks Directly on IoT Devices
7.2. Application to Diverse Neural Networks
7.3. Future Works
- Automated FHE Keyset Configuration: The automation of FHE-applied applications has been widely studied in recent years. Several works have aimed to improve usability by automating various aspects of FHE deployment, such as FHE parameter selection [67], bootstrapping placement [53,55], and FHE-specific operation scheduling (e.g., rescaling) [89,90]. Building on these efforts, developing an automated algorithm to determine the optimal FHE keyset configuration represents a promising research direction. Given our observation that optimized keysets can lead to significant improvements in either memory efficiency or inference performance, designing keyset selection algorithms tailored to application-level requirements is a valuable next step.
- FHE Keyset Configuration via Key Extension: While our work focuses on dynamic selection, a recent study [73] proposed extending key sizes to improve performance. Specifically, they decompose keys for certain operations (including rotations), which increases memory overhead but reduces the complexity of NTT/iNTT transformations. Although this approach shows promise, several challenges remain before it can be practically implemented, including managing the trade-off between memory usage and execution speed, as well as integration with existing FHE toolchains. First, extending the key obviously induces much higher memory consumption, so performance will highly depend on the memory bandwidth of the running hardware platform. Considering that the minimal keyset already consumed tens of GB, the increase leads to higher memory transfer latency. Meanwhile, note that the results we acquired are from CPUs with DDR4 DRAM memory, where the memory bandwidth is merely 64 bits. Since memory bandwidth is already low and each key is worth MBs (thus, not many cache hits), memory transfer is already at the peak, requiring reading keys per FHE operations. As a result, the increased memory consumption from the key extension does not lead to extensive performance degradation. The contrast between the impacts suggests that we need to consider the characteristics of the running hardware platform in order to choose the appropriate keyset design because an efficient keyset for a platform does not necessarily lead to good performance on others.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| MLaaS | Machine Learning as a Service |
| PPML | Privacy-Preserving Machine Learning |
| RLWE | Ring Learning with Error |
| FHE | Fully Homomorphic Encryption |
| KDS | Keyset design space |
| RNS | Residue Number System |
| IDS | Intrusion detection system |
References
- Xie, L.; Li, Z.; Zhou, Y.; He, Y.; Zhu, J. Computational diagnostic techniques for electrocardiogram signal analysis. Sensors 2020, 20, 6318. [Google Scholar] [CrossRef] [PubMed]
- Neri, L.; Oberdier, M.T.; van Abeelen, K.C.; Menghini, L.; Tumarkin, E.; Tripathi, H.; Jaipalli, S.; Orro, A.; Paolocci, N.; Gallelli, I.; et al. Electrocardiogram monitoring wearable devices and artificial-intelligence-enabled diagnostic capabilities: A review. Sensors 2023, 23, 4805. [Google Scholar] [CrossRef] [PubMed]
- Arakawa, T. Recent research and developing trends of wearable sensors for detecting blood pressure. Sensors 2018, 18, 2772. [Google Scholar] [CrossRef] [PubMed]
- Konstantinidis, D.; Iliakis, P.; Tatakis, F.; Thomopoulos, K.; Dimitriadis, K.; Tousoulis, D.; Tsioufis, K. Wearable blood pressure measurement devices and new approaches in hypertension management: The digital era. J. Hum. Hypertens. 2022, 36, 945–951. [Google Scholar] [CrossRef]
- Lazazzera, R.; Belhaj, Y.; Carrault, G. A new wearable device for blood pressure estimation using photoplethysmogram. Sensors 2019, 19, 2557. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR: Cambridge, MA, USA, 2019; pp. 6105–6114. [Google Scholar]
- Li, X.; Li, Y.; Li, Y.; Cao, T.; Liu, Y. Flexnn: Efficient and adaptive dnn inference on memory-constrained edge devices. In Proceedings of the 30th Annual International Conference on Mobile Computing and Networking, Washington, DC, USA, 30 September–4 October 2024; pp. 709–723. [Google Scholar]
- Manage Your App’s Memory. Android Developers. 2023. Available online: https://developer.android.com/topic/performance/memory (accessed on 5 May 2025).
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Large-scale celebfaces attributes (celeba) dataset. Retrieved August 2018, 15, 11. [Google Scholar]
- Said, Y.; Barr, M. Human emotion recognition based on facial expressions via deep learning on high-resolution images. Multimed. Tools Appl. 2021, 80, 25241–25253. [Google Scholar] [CrossRef]
- Ning, X.; Xu, S.; Nan, F.; Zeng, Q.; Wang, C.; Cai, W.; Li, W.; Jiang, Y. Face editing based on facial recognition features. IEEE Trans. Cogn. Dev. Syst. 2022, 15, 774–783. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Kim, M.; Jain, A.K.; Liu, X. Adaface: Quality adaptive margin for face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18750–18759. [Google Scholar]
- Korshunova, I.; Shi, W.; Dambre, J.; Theis, L. Fast face-swap using convolutional neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3677–3685. [Google Scholar]
- Li, Z.; Cao, M.; Wang, X.; Qi, Z.; Cheng, M.M.; Shan, Y. Photomaker: Customizing realistic human photos via stacked id embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 8640–8650. [Google Scholar]
- Fei, B.; Lyu, Z.; Pan, L.; Zhang, J.; Yang, W.; Luo, T.; Zhang, B.; Dai, B. Generative diffusion prior for unified image restoration and enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9935–9946. [Google Scholar]
- Andriluka, M.; Pishchulin, L.; Gehler, P.; Schiele, B. 2D Human Pose Estimation: New Benchmark and State of the Art Analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3686–3693. [Google Scholar]
- Goel, S.; Pavlakos, G.; Rajasegaran, J.; Kanazawa, A.; Malik, J. Humans in 4D: Reconstructing and tracking humans with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Vancouver, BC, Canada, 17–24 June 2023; pp. 14783–14794. [Google Scholar]
- Zheng, C.; Wu, W.; Chen, C.; Yang, T.; Zhu, S.; Shen, J.; Kehtarnavaz, N.; Shah, M. Deep learning-based human pose estimation: A survey. ACM Comput. Surv. 2023, 56, 1–37. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Chudasama, V.; Kar, P.; Gudmalwar, A.; Shah, N.; Wasnik, P.; Onoe, N. M2fnet: Multi-modal fusion network for emotion recognition in conversation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4652–4661. [Google Scholar]
- Moody, G.B.; Mark, R.G. The impact of the MIT-BIH arrhythmia database. IEEE Eng. Med. Biol. Mag. 2001, 20, 45–50. [Google Scholar] [CrossRef]
- Mousavi, S.; Afghah, F. Inter-and intra-patient ecg heartbeat classification for arrhythmia detection: A sequence to sequence deep learning approach. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1308–1312. [Google Scholar]
- Tuli, S.; Casale, G.; Jennings, N.R. Tranad: Deep transformer networks for anomaly detection in multivariate time series data. arXiv 2022, arXiv:2201.07284. [Google Scholar] [CrossRef]
- Wagner, P.; Strodthoff, N.; Bousseljot, R.D.; Kreiseler, D.; Lunze, F.I.; Samek, W.; Schaeffter, T. PTB-XL, a large publicly available electrocardiography dataset. Sci. Data 2020, 7, 1–15. [Google Scholar] [CrossRef]
- Xiao, Q.; Lee, K.; Mokhtar, S.A.; Ismail, I.; Pauzi, A.L.b.M.; Zhang, Q.; Lim, P.Y. Deep learning-based ECG arrhythmia classification: A systematic review. Appl. Sci. 2023, 13, 4964. [Google Scholar] [CrossRef]
- Malakouti, S.M. Heart disease classification based on ECG using machine learning models. Biomed. Signal Process. Control 2023, 84, 104796. [Google Scholar] [CrossRef]
- Reiss, A.; Stricker, D. Introducing a new benchmarked dataset for activity monitoring. In Proceedings of the 2012 16th International Symposium on Wearable Computers, Newcastle, UK, 18–22 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 108–109. [Google Scholar]
- Zhang, S.; Li, Y.; Zhang, S.; Shahabi, F.; Xia, S.; Deng, Y.; Alshurafa, N. Deep learning in human activity recognition with wearable sensors: A review on advances. Sensors 2022, 22, 1476. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A public domain dataset for human activity recognition using smartphones. In Proceedings of the Esann, Bruges, Belgium, 24–26 April 2013; Volume 3, pp. 3–4. [Google Scholar]
- Mutegeki, R.; Han, D.S. A CNN-LSTM approach to human activity recognition. In Proceedings of the 2020 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Fukuoka, Japan, 19–21 February 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 362–366. [Google Scholar]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: https://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 5 May 2025).
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–6. [Google Scholar]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An intrusion detection system using a deep neural network with gated recurrent units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Fu, Y.; Du, Y.; Cao, Z.; Li, Q.; Xiang, W. A deep learning model for network intrusion detection with imbalanced data. Electronics 2022, 11, 898. [Google Scholar] [CrossRef]
- Winkler, T.; Rinner, B. Privacy and security in video surveillance. In Intelligent Multimedia Surveillance: Current Trends and Research; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–66. [Google Scholar]
- Liranzo, J.; Hayajneh, T. Security and privacy issues affecting cloud-based IP camera. In Proceedings of the 2017 IEEE 8th Annual Ubiquitous Computing, Electronics and Mobile Communication Conference (UEMCON), New York City, NY, USA, 19–21 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 458–465. [Google Scholar]
- Li, J.; Zhang, Z.; Yu, S.; Yuan, J. Improved secure deep neural network inference offloading with privacy-preserving scalar product evaluation for edge computing. Appl. Sci. 2022, 12, 9010. [Google Scholar] [CrossRef]
- Zhu, W.; Sun, Y.; Liu, J.; Cheng, Y.; Ji, X.; Xu, W. Campro: Camera-based anti-facial recognition. arXiv 2023, arXiv:2401.00151. [Google Scholar]
- Bigelli, L.; Contoli, C.; Freschi, V.; Lattanzi, E. Privacy preservation in sensor-based Human Activity Recognition through autoencoders for low-power IoT devices. Internet Things 2024, 26, 101189. [Google Scholar] [CrossRef]
- Newaz, A.I.; Sikder, A.K.; Rahman, M.A.; Uluagac, A.S. A survey on security and privacy issues in modern healthcare systems: Attacks and defenses. ACM Trans. Comput. Healthc. 2021, 2, 1–44. [Google Scholar] [CrossRef]
- Celik, Z.B.; McDaniel, P.; Tan, G. Soteria: Automated {IoT} safety and security analysis. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 147–158. [Google Scholar]
- Ometov, A.; Molua, O.L.; Komarov, M.; Nurmi, J. A survey of security in cloud, edge, and fog computing. Sensors 2022, 22, 927. [Google Scholar] [CrossRef]
- Nassif, A.B.; Talib, M.A.; Nasir, Q.; Albadani, H.; Dakalbab, F.M. Machine learning for cloud security: A systematic review. IEEE Access 2021, 9, 20717–20735. [Google Scholar] [CrossRef]
- Attaullah, H.; Sanaullah, S.; Jungeblut, T. Analyzing Machine Learning Models for Activity Recognition Using Homomorphically Encrypted Real-World Smart Home Datasets: A Case Study. Appl. Sci. 2024, 14, 9047. [Google Scholar] [CrossRef]
- Kim, S.; Kim, J.; Kim, M.J.; Jung, W.; Kim, J.; Rhu, M.; Ahn, J.H. Bts: An accelerator for bootstrappable fully homomorphic encryption. In Proceedings of the 49th Annual International Symposium on Computer Architecture, New York, NY, USA, 18–22 June 2022; pp. 711–725. [Google Scholar]
- Riazi, M.S.; Laine, K.; Pelton, B.; Dai, W. HEAX: An architecture for computing on encrypted data. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 1295–1309. [Google Scholar]
- Cheon, S.; Lee, Y.; Kim, D.; Lee, J.M.; Jung, S.; Kim, T.; Lee, D.; Kim, H. {DaCapo}: Automatic Bootstrapping Management for Efficient Fully Homomorphic Encryption. In Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, USA, 14–16 August 2024; pp. 6993–7010. [Google Scholar]
- Lee, E.; Lee, J.W.; Lee, J.; Kim, Y.S.; Kim, Y.; No, J.S.; Choi, W. Low-complexity deep convolutional neural networks on fully homomorphic encryption using multiplexed parallel convolutions. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; PMLR: Cambridge, MA, USA, 2022; pp. 12403–12422. [Google Scholar]
- Ao, W.; Boddeti, V.N. {AutoFHE}: Automated Adaption of {CNNs} for Efficient Evaluation over {FHE}. In Proceedings of the 33rd USENIX Security Symposium (USENIX Security 24), Philadelphia, PA, USA, 14–16 August 2024; pp. 2173–2190. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Advances in Cryptology—ASIACRYPT 2017, Proceedings of the 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Proceedings, Part I 23; Springer: Berlin/Heidelberg, Germany, 2017; pp. 409–437. [Google Scholar]
- Cheon, J.H.; Han, K.; Kim, A.; Kim, M.; Song, Y. A full RNS variant of approximate homomorphic encryption. In Selected Areas in Cryptography—SAC 2018, Proceedings of the 25th International Conference, Calgary, AB, Canada, 15–17 August 2018; Revised Selected Papers 25; Springer: Berlin/Heidelberg, Germany, 2019; pp. 347–368. [Google Scholar]
- Han, K.; Ki, D. Better bootstrapping for approximate homomorphic encryption. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 24–28 February 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 364–390. [Google Scholar]
- CryptoLab. HEaaN Private AI Homomorphic Encryption Library. 2025. Available online: https://heaan.it/ (accessed on 5 May 2025).
- Microsoft SEAL, Version 4.1; Microsoft Research, Redmond, WA, USA. 2023. Available online: https://github.com/Microsoft/SEAL (accessed on 5 May 2025).
- Lattigo v5. EPFL-LDS, Tune Insight SA. 2023. Available online: https://github.com/tuneinsight/lattigo (accessed on 5 May 2025).
- Bae, Y.; Cheon, J.H.; Kim, J.; Park, J.H.; Stehlé, D. HERMES: Efficient ring packing using MLWE ciphertexts and application to transciphering. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 37–69. [Google Scholar]
- Hwang, I.; Seo, J.; Song, Y. Optimizing HE operations via Level-aware Key-switching Framework. In Proceedings of the 11th Workshop on Encrypted Computing & Applied Homomorphic Cryptography, Copenhagen, Denmark, 26 November 2023; pp. 59–67. [Google Scholar]
- Juvekar, C.; Vaikuntanathan, V.; Chandrakasan, A. {GAZELLE}: A low latency framework for secure neural network inference. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1651–1669. [Google Scholar]
- Wang, W.; Huang, X.; Emmart, N.; Weems, C. VLSI design of a large-number multiplier for fully homomorphic encryption. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 22, 1879–1887. [Google Scholar] [CrossRef]
- Turan, F.; Roy, S.S.; Verbauwhede, I. HEAWS: An Accelerator for Homomorphic Encryption on the Amazon AWS FPGA. IEEE Trans. Comput. 2020, 69, 1185–1196. [Google Scholar] [CrossRef]
- Dathathri, R.; Kostova, B.; Saarikivi, O.; Dai, W.; Laine, K.; Musuvathi, M. EVA: An Encrypted Vector Arithmetic Language and Compiler for Efficient Homomorphic Computation. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation, London, UK, 15–20 June 2020; pp. 546–561. [Google Scholar]
- Dathathri, R.; Saarikivi, O.; Chen, H.; Laine, K.; Lauter, K.; Maleki, S.; Musuvathi, M.; Mytkowicz, T. CHET: An optimizing compiler for fully-homomorphic neural-network inferencing. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, Phoenix, AZ, USA, 22–26 June 2019; pp. 142–156. [Google Scholar]
- Malik, R.; Sheth, K.; Kulkarni, M. Coyote: A Compiler for Vectorizing Encrypted Arithmetic Circuits. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; Volume 3, pp. 118–133. [Google Scholar]
- Viand, A.; Jattke, P.; Haller, M.; Hithnawi, A. HECO: Automatic code optimizations for efficient fully homomorphic encryption. arXiv 2022, arXiv:2202.01649. [Google Scholar]
- Al Badawi, A.; Jin, C.; Lin, J.; Mun, C.F.; Jie, S.J.; Tan, B.H.M.; Nan, X.; Aung, K.M.M.; Chandrasekhar, V.R. Towards the Alexnet Moment for Homomorphic Encryption: Hcnn, the First Homomorphic CNN on Encrypted Data with GPUs. IEEE Trans. Emerg. Top. Comput. 2020, 9, 1330–1343. [Google Scholar] [CrossRef]
- Park, J.; Kim, M.J.; Jung, W.; Ahn, J.H. AESPA: Accuracy preserving low-degree polynomial activation for fast private inference. arXiv 2022, arXiv:2201.06699. [Google Scholar]
- Kim, M.; Lee, D.; Seo, J.; Song, Y. Accelerating HE operations from key decomposition technique. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 20–24 August 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 70–92. [Google Scholar]
- Chan, J.L.; Lee, W.K.; Wong, D.C.K.; Yap, W.S.; Goi, B.M. ARK: Adaptive Rotation Key Management for Fully Homomorphic Encryption Targeting Memory Efficient Deep Learning Inference. Cryptol. ePrint Arch. 2024; 2024/1948. [Google Scholar]
- Joo, Y.; Ha, S.; Oh, H.; Paek, Y. Rotation Keyset Generation Strategy for Efficient Neural Networks Using Homomorphic Encryption. In Proceedings of the International Conference on Artificial Intelligence Computing and Systems (AIComps), Jeju, Republic of Korea, 16–18 December 2024; KIPS: Seoul, Republic of Korea, 2024; pp. 37–42. [Google Scholar]
- Li, J.; Li, Z.; Tyson, G.; Xie, G. Your privilege gives your privacy away: An analysis of a home security camera service. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 387–396. [Google Scholar]
- Apthorpe, N.; Huang, D.Y.; Reisman, D.; Narayanan, A.; Feamster, N. Keeping the smart home private with smart (er) iot traffic shaping. arXiv 2018, arXiv:1812.00955. [Google Scholar] [CrossRef]
- Acar, A.; Fereidooni, H.; Abera, T.; Sikder, A.K.; Miettinen, M.; Aksu, H.; Conti, M.; Sadeghi, A.R.; Uluagac, S. Peek-a-boo: I see your smart home activities, even encrypted! In Proceedings of the 13th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Linz, Austria, 8–10 July 2020; pp. 207–218. [Google Scholar]
- Copos, B.; Levitt, K.; Bishop, M.; Rowe, J. Is Anybody Home? Inferring Activity From Smart Home Network Traffic. In Proceedings of the 2016 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 245–251. [Google Scholar] [CrossRef]
- Jang, J.; Lee, Y.; Kim, A.; Na, B.; Yhee, D.; Lee, B.; Cheon, J.H.; Yoon, S. Privacy-preserving deep sequential model with matrix homomorphic encryption. In Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security, Nagasaki, Japan, 30 May–3 June 2022; pp. 377–391. [Google Scholar]
- Iandola, F.N. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Lee, E.; Lee, J.W.; No, J.S.; Kim, Y.S. Minimax approximation of sign function by composite polynomial for homomorphic comparison. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3711–3727. [Google Scholar] [CrossRef]
- Wu, H.; Judd, P.; Zhang, X.; Isaev, M.; Micikevicius, P. Integer quantization for deep learning inference: Principles and empirical evaluation. arXiv 2020, arXiv:2004.09602. [Google Scholar]
- Li, Z.; Li, H.; Meng, L. Model compression for deep neural networks: A survey. Computers 2023, 12, 60. [Google Scholar] [CrossRef]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Kuzmin, A.; Nagel, M.; Van Baalen, M.; Behboodi, A.; Blankevoort, T. Pruning vs quantization: Which is better? Adv. Neural Inf. Process. Syst. 2023, 36, 62414–62427. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. Mobilebert: A compact task-agnostic bert for resource-limited devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Lee, Y.; Cheon, S.; Kim, D.; Lee, D.; Kim, H. {ELASM}: {Error-Latency-Aware} Scale Management for Fully Homomorphic Encryption. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 4697–4714. [Google Scholar]
- Lee, Y.; Cheon, S.; Kim, D.; Lee, D.; Kim, H. Performance-aware scale analysis with reserve for homomorphic encryption. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, La Jolla, CA, USA, 27 April–1 May 2024; Volume 1, pp. 302–317. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Sensor | Acquired Data | Dataset | Usagex |
|---|---|---|---|
| Camera | Face | CelebA [11] | Emotion recognition [12] Face edit [13] Image generation [14] |
| LFWA [15] | Face recognition [16] Face swapping [17] Image synthesis [18] Image restoration [19] | ||
| Human action | MPII Human pose [20] | Human tracking [21] Pose estimation [22] | |
| IEMOCAP [23] | Emotion recognition [24] | ||
| Bio-sensor | Electrocardiography (ECG) | MIT-BIH [25] | Arrhythmia detection [26,27] |
| PTB-XL [28] | Arrhythmia classification [29] Heart disease classification [30] | ||
| Accelerometer and Gyroscope | Linear acceleration & Angular velocity | PAMAP2 [31] | Human activity recognition [32,33] |
| ADL [34] | Human activity recognition [35,36] | ||
| Wireless | Packet | KDD99 [37], NSL-KDD [38] | Intrusion detection system [39,40] |
| Level (ms) | 4 | 8 | 12 | 16 | 20 | 24 | 28 |
|---|---|---|---|---|---|---|---|
| Padd | 3.865 | 6.187 | 8.39 | 10.532 | 13.054 | 15.68 | 18.876 |
| Cadd | 1.647 | 1.671 | 1.703 | 1.793 | 1.515 | 2.206 | 2.606 |
| Pmult | 4.217 | 4.219 | 4.214 | 5.038 | 2.938 | 4.477 | 4.685 |
| Cmult | 86.499 | 126.161 | 171.98 | 235.959 | 243.882 | 358.755 | 462.816 |
| Rescale | 44.681 | 54.322 | 63.343 | 68.839 | 87.189 | 106.11 | 118.971 |
| Rotation | 73.299 | 108.481 | 149.512 | 193.197 | 206.114 | 301.402 | 415.616 |
| Bootstrapping | 3335 | ||||||
| Hamming weight | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| Relative latency | 1.0 | 2.6 | 3.8 | 5.3 | 5.8 | 7.6 | 8.3 |
| Latency (ms) | ResNet-20 MPCNN | ResNet-20 AESPA | ||
|---|---|---|---|---|
| Power-of-Two | All-Required | Power-of-Two | All-Required | |
| Rotation | 25,264 | 12,919 | 47,507 | 24,637 |
| Other | 10,823 | 10,823 | 4210 | 6210 |
| BTS | 66,082 | 66,082 | 27,824 | 27,824 |
| Total | 102,169 | 89,824 | 79,541 | 58,671 |
| Multiplication Depth | Static | Dynamic | Dynamic +Level-Aware | |
|---|---|---|---|---|
| = 1 | Maximum | |||
| 16 | 40.802 GB | 48.318 GB | 61.641 GB | 25.535 GB |
| † 15 | 38.292 GB | |||
| 14 | 35.861 GB | 35.861 GB | 56.741 GB | 18.895 GB |
| † 13 | 33.510 GB | |||
| 12 | 31.239 GB | 10.239 GB | 56.063 GB | 10.305 GB |
| 11 | 29.048 GB | 12.316 GB | 10.400 GB | 10.273 GB |
| 10 | 26.936 GB | 16.562 GB | 13.986 GB | 13.413 GB |
| 9 | 24.904 GB | 6.842 GB | 5.778 GB | 5.557 GB |
| 8 | 22.951 GB | 5.474 GB | 24.864 GB | 6.250 GB |
| † 7 | 21.078 GB | |||
| 6 | 19.285 GB | 11.938 GB | 17.094 GB | 9.597 GB |
| 5 | 17.572 GB | 3.822 GB | 9.643 GB | 4.448 GB |
| 4 | 15.938 GB | 2.737 GB | 35.024 GB | 4.452 GB |
| † 3 | 14.384 GB | |||
| 2 | 12.910 GB | 2.454 GB | 29.327 GB | 4.05 GB |
| † 1 | 11.515 GB | |||
| Key Design Space (KDS) | GRU+MLP | ||
|---|---|---|---|
| Index | α | Level | |
| All-required | dynamic | All | 553.648 GB |
| All-required | α = 1 | All | 307.09 GB |
| Power-of-two | dynamic | All | 83.752 GB |
| Power-of-two | α = 1 | All | 55.835 GB |
| All-required | dynamic | Needed | 52.026 GB |
| Key Design Space (KDS) | SqueezeNet | ResNet-20 | ||||
|---|---|---|---|---|---|---|
| Index | α | Level | MPCNN | AESPA | MPCNN | AESPA |
| All-required | Dynamic | All | 490.968 GB | 534.656 GB | ||
| All-required | α = 1 | All | 253.403 GB | 275.952 GB | ||
| Power-of-two | Dynamic | All | 108.179 GB | 108.179 GB | ||
| Power-of-two | α = 1 | All | 55.835 GB | 55.835 GB | ||
| All-required | dynamic | Needed | 45.353 GB | 46.016 GB | 47.32 GB | 53.511 GB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Joo, Y.; Ha, S.; Oh, H.; Paek, Y. Efficient Keyset Design for Neural Networks Using Homomorphic Encryption. Sensors 2025, 25, 4320. https://doi.org/10.3390/s25144320
Joo Y, Ha S, Oh H, Paek Y. Efficient Keyset Design for Neural Networks Using Homomorphic Encryption. Sensors. 2025; 25(14):4320. https://doi.org/10.3390/s25144320
Chicago/Turabian StyleJoo, Youyeon, Seungjin Ha, Hyunyoung Oh, and Yunheung Paek. 2025. "Efficient Keyset Design for Neural Networks Using Homomorphic Encryption" Sensors 25, no. 14: 4320. https://doi.org/10.3390/s25144320
APA StyleJoo, Y., Ha, S., Oh, H., & Paek, Y. (2025). Efficient Keyset Design for Neural Networks Using Homomorphic Encryption. Sensors, 25(14), 4320. https://doi.org/10.3390/s25144320