
A Hierarchical Dispatcher for Scheduling Multiple Deep Neural Networks (DNNs) on Edge Devices


Abstract
1. Introduction
2. A Hierarchical Dispatcher for DNNs
- High-Level Dispatcher
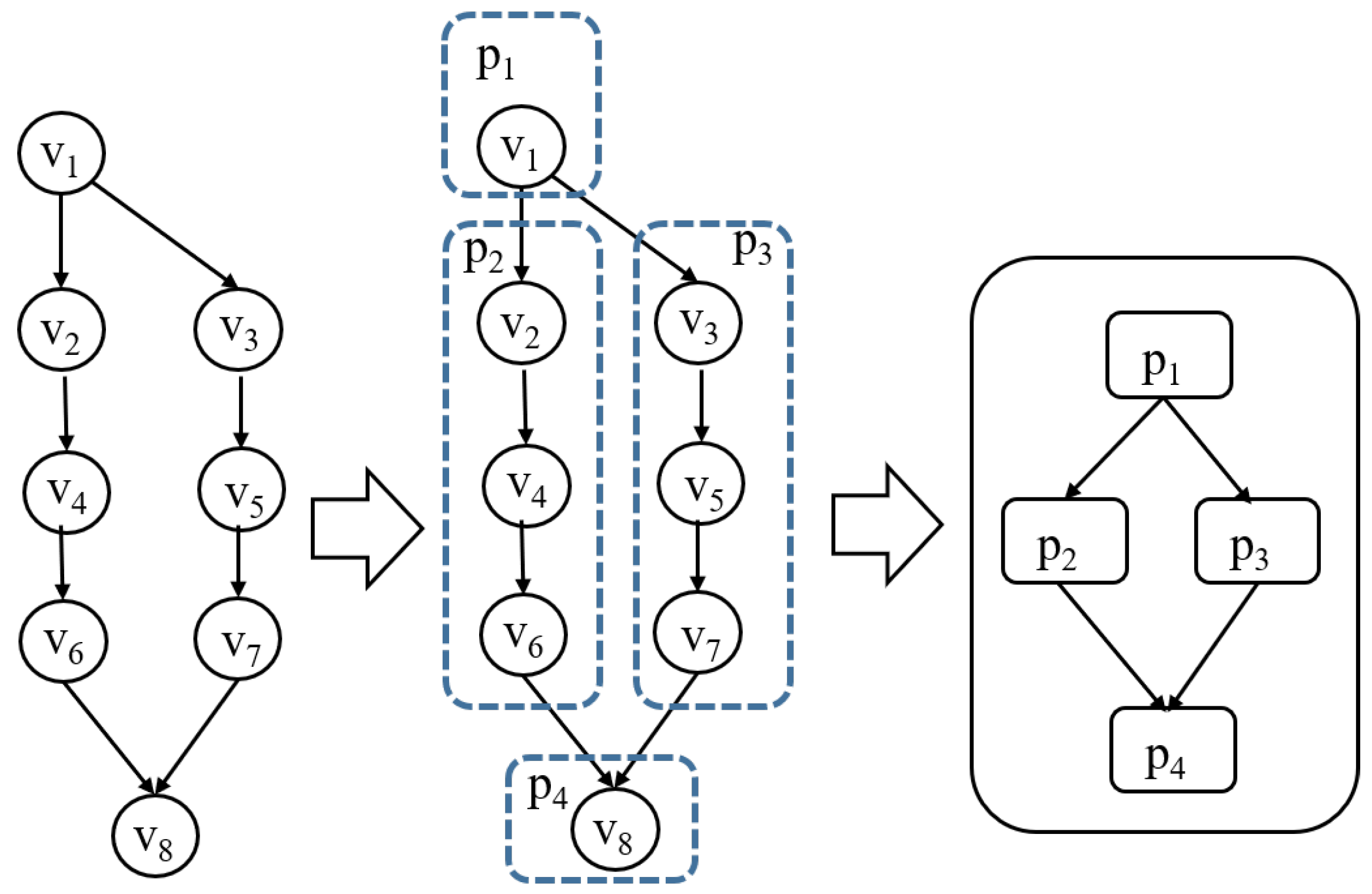
- A high-level dispatcher is responsible for constructing a graph of submodels derived from a compiled DNN model. The graph representation captures the dependencies and execution order of submodels, enabling the systematic decomposition of the DNN model into partitions, which act as scheduling units. This abstraction allows for the efficient handling of complex DNN architectures while preparing them for execution. An entering node and an exiting node of a partition are special nodes designated for receiving and sending intermediate (tensor) values, respectively. These nodes not only facilitate data transfer between partitions but also serve as synchronization points. Specifically, the entering node ensures that all required inputs are available before a submodel begins execution, while the exiting node signals the completion of a computation task by transmitting outputs to subsequent partitions. By utilizing these nodes as synchronization nodes, the architecture maintains data consistency and supports asynchronous execution, effectively reducing unnecessary synchronization overhead while ensuring correctness. Figure 3 is an example of a high-level dispatcher. The criteria for partitioning are defined within the high-level scheduling policy, ensuring that partitions are created according to specific performance objectives and resource constraints.
- Low-Level Dispatcher
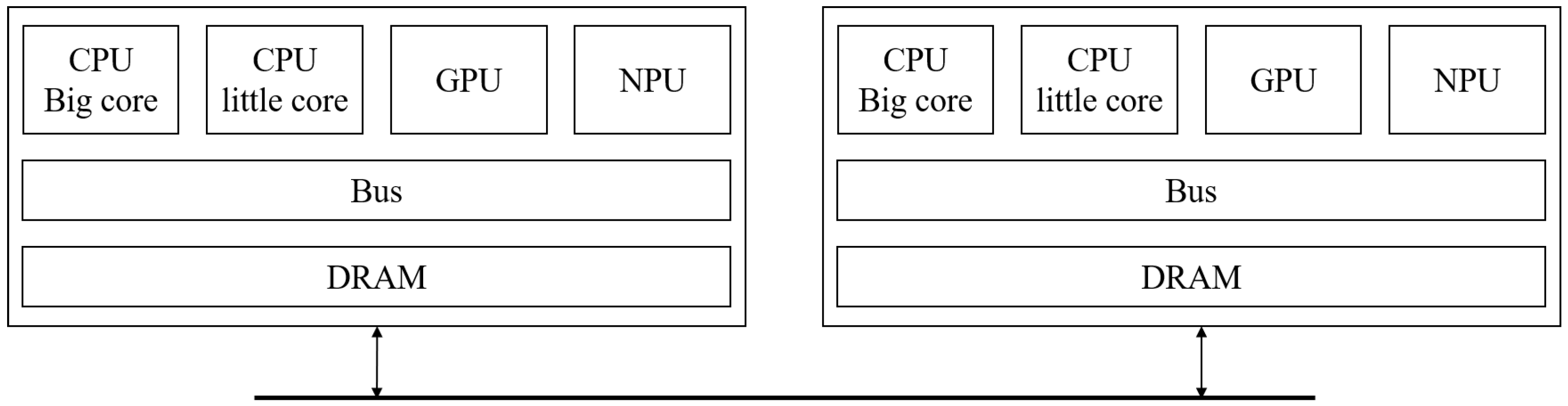
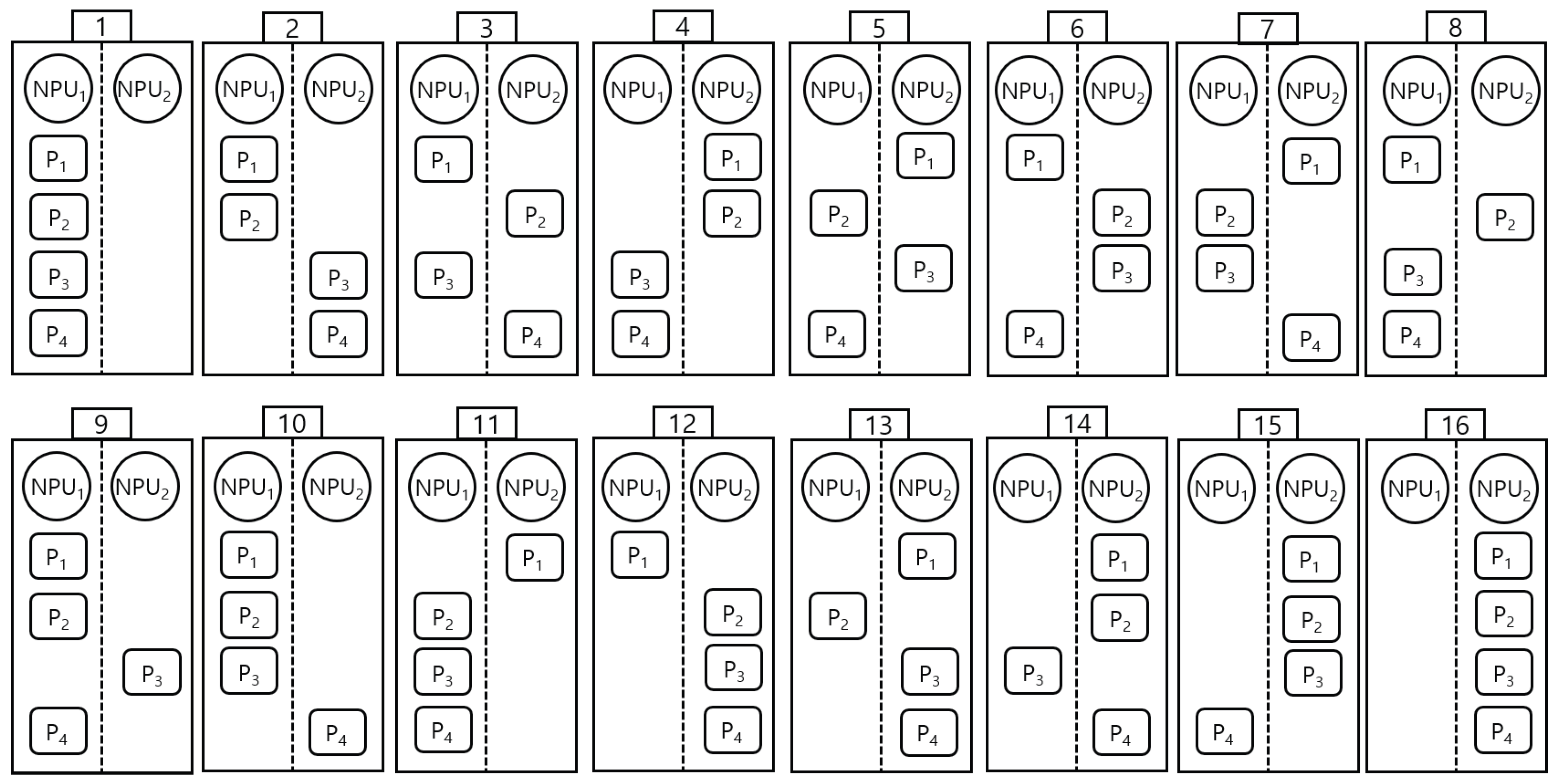
- Operating at a finer granularity, the low-level dispatcher allocates submodels to processing units (PUs), such as CPUs, GPUs, or NPUs. This allocation is performed in compliance with the selected scheduling policy, ensuring efficient resource utilization and adherence to performance objectives such as latency, throughput, and energy efficiency. Since multiple partitions can be processed simultaneously, PUs function as shared resources and must be released immediately after execution for other partitions to utilize them. Our low-level scheduling operates through the following steps: (1) verifying the maximum PU requirement upon partition input within the system, (2) allocating and executing available PUs, (3) registering the partition in a waiting queue if all PUs are occupied, and (4) releasing PUs upon execution completion and assigning them to waiting partitions. The allocation of partition on different PUs, as depicted in Figure 1, incurs a context switching time during steps (1) and (2). The context switching time includes a communication cost of data through the memory bus or networks, arising from the connection between the sender node and the receiver node. Figure 4 is an example of a low-level dispatcher.
2.1. Formal Definitions
- The deep learning high-level dispatcher is defined aswhere
- 1.
- DNN Graph D iswhere
- -
- The set of vertices representing computational units (e.g., layers, operations, or sub-operations) in the DNN is
- -
- The set of directed edges representing dependencies between computational units is
- 2.
- The partition of the DNN graph D is defined aswhere
- -
- Each partition is a subset of V:
- -
- The union of all partitions covers the entire set of vertices is
- -
- Partitions are disjoint:
- -
- The set of directed edges between partitions is defined as
- -
- Each partition has an entering node , defined asThis represents nodes in that receive input (tensor) values from nodes in other partitions.
- -
- Each partition has an exiting node , defined asThis represents nodes in that send output (tensor) values to nodes in other partitions.
- The deep learning low-level dispatcher is defined aswhere
- -
- A set of submodels or partitions of a DNN.
- -
- A set of processing units (PUs) within a computer.
- -
- A set of computational contexts associated with each partition .
The low-level dispatcher performs the following actions.- Context Loading
- : Prepare the PU with the context for submodel , including receiving input (tensor) values from other partitions before an entering node of partition
- Partition Execution
- : Initialize and manage the PU with the context for submodel between an entering node and an exiting node.
- Context Saving
- : Save the PU with the context for submodel , including sending input (tensor) values to other partitions after an exiting node of partition .
2.2. APIs for Deep Learning Dispatcher
- load_neural_network and unload_neural_ network: These high-level dispatcher APIs manage the loading and unloading of a neural network.
- load_partition and unload_partition: These low-level dispatcher APIs handle the loading and unloading of neural network partitions on specific PUs.
- partition_create: This API is responsible for registering functions associated with the execution of the neural network partition.
- partition_input_handler and partition_output_handler: These APIs facilitate context switching such that context saving and context loading are achieved for the low-level dispatcher. partition_input_handler receives values from other partitions. It is implemented by reading values from memory or receiving values from networks. partition_output_handler sends values to other partitions. It is implemented by storing values in memory or sending values to networks.
2.3. Comparison Between Deep Learning Dispatcher and GPOS Dispatcher
3. Case Studies
3.1. Application 1: An Example of Hierarchical Scheduler: PartitionTuner
- A high-level scheduling policyA high-level scheduling policy provides the criteria for constructing a graph of submodels from the original DNN model. These criteria are generated by profiling functions in PartitionTuner along with other constraints such as resource availability, latency requirements, and task dependencies. When multiple DNN inference requests are made, the high-level dispatcher generates a graph of submodels according to the specified scheduling policy. If a specific processing unit (PU) is explicitly designated, the PU information is attached to the partition for execution by the low-level dispatcher. If no specific PU is designated, the PU information is included as a hint, allowing the low-level scheduling policy to make dynamic decisions regarding task execution. This policy ensures that DNN models are efficiently decomposed and prepared for execution in a scalable manner.
- A low-level scheduling policyA low-level scheduling policy dynamically assigns PUs within a computing system to optimize execution order and maximize resource utilization. It adjusts scheduling to allocate the required PUs during DNN partition execution, ensuring an optimal execution environment by constraining. This policy enhances PU utilization, reduces execution latency, and improves overall DNN performance. The effectiveness of both high-level and low-level scheduling techniques is demonstrated through case studies, showcasing their applicability in diverse, heterogeneous environments.
- BenchmarksWe conducted experiments on the same environment used during the development of NEST-C, an open-source deep learning compiler [14], built upon the GLOW compiler framework [15]. The benchmark system consists of a heterogeneous computing platform featuring an ARM Cortex-A53 processor and a VTA (Versatile Tensor Accelerator) serving as the NPU [16].For evaluation, we measured the inference time of models trained on the ImageNet dataset. The evaluation was performed using seven pretrained CNN models, including ZFNet [17], AlexNet [18], GoogleNet [19], ResNet18/50 [20], ResNeXt [21], and SqueezeNet [22].Table 1 presents the inference times of these benchmark models, measured over 100 executions with different input images. The first and second columns list the model names and sizes, while the remaining columns compare inference times for execution on a CPU alone versus a CPU with an NPU. The last column shows the performance improvement ratio, calculated as CPU+NPU/CPU. On average, the application of a deep learning scheduler with an NPU improves performance by 51.6%.
3.2. Applications 2: Homogeneous Multiple NPUs
3.3. Application 3: Heterogeneous Multiple NPUs
- is the computation time for a partition node.
- is the communication time between nodes, including the context saving time and context loading time.
4. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, Q.; Wang, S. MASA: Multi-Application Scheduling Algorithm for Heterogeneous Resource Platform. Electronics 2023, 12, 4056. [Google Scholar] [CrossRef]
- Avan, A.; Azim, A.; Mahmoud, Q.H. A State-of-the-Art Review of Task Scheduling for Edge Computing: A Delay-Sensitive Application Perspective. Electronics 2023, 12, 2599. [Google Scholar] [CrossRef]
- Hajikano, K.; Kanemits, H.; Kim, M.W.; Kim, H. A Task Scheduling Method after Clustering for Data Intensive Jobs in Heterogeneous Distributed Systems. JCSE 2016, 10, 9–20. [Google Scholar]
- Liang, F.; Zhang, Z.; Lu, H.; Li, C.; Leung, V.C.M.; Guo, Y.; Hu, X. Resource Allocation and Workload Scheduling for Large-Scale Distributed Deep Learning: A Survey. arXiv 2024. [Google Scholar] [CrossRef]
- Li, S.; Zhao, Y.; Varma, R.; Salpekar, O.; Noordhuis, P.; Li, T.; Paszke, A.; Smith, J.; Vaughan, B.; Damania, P.; et al. PyTorch Distributed: Experiences on Accelerating Data Parallel Training. Proc. VLDB Endow. 2020, 13, 3005–3018. [Google Scholar]
- Gomez, A.; Key, O.; Perlin, K.; Gou, S.; Frosst, N.; Dean, J.; Gal, Y. Interlocking Backpropagation: Improving Depthwise Model-Parallelism. J. Mach. Learn. Res. 2023, 23, 1–28. [Google Scholar]
- Li, S.; Hoefler, T. Chimera: Efficiently training large-scale neural networks with bidirectional pipelines. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC’21), New York, NY, USA, 14–19 November 2021; Article 27. pp. 1–14. [Google Scholar] [CrossRef]
- Hu, J.; Liu, Y.; Wang, H.; Wang, J. AutoPipe: Automatic configuration of pipeline parallelism in shared GPU cluster. In Proceedings of the 53rd International Conference on Parallel Processing (ICPP’24), New York, NY, USA, 12–15 August 2024; pp. 443–452. [Google Scholar] [CrossRef]
- Oh, H.; Lee, J.; Kim, H.; Seo, J. Out-of-order backprop: An effective scheduling technique for deep learning. In Proceedings of the Seventeenth European Conference on Computer Systems (EuroSys’22), New York, NY, USA, 5–8 April 2022; pp. 435–452. [Google Scholar] [CrossRef]
- Aghapour, E.; Sapra, D.; Pimentel, A.; Pathania, A. ARM-CO-UP: ARM COoperative Utilization of Processors. ACM Trans. Des. Autom. Electron. Syst. 2024, 29, 1–30. [Google Scholar] [CrossRef]
- Xu, Z.; Yang, D.; Yin, C.; Tang, J.; Wang, Y.; Xue, G. A Co-Scheduling Framework for DNN Models on Mobile and Edge Devices With Heterogeneous Hardware. IEEE Trans. Mob. Comput. 2023, 22, 1275–1288. [Google Scholar] [CrossRef]
- Zhang, J.; Ma, S.; Yan, Z.; Huang, J. Joint DNN Partitioning and Task Offloading in Mobile Edge Computing via Deep Reinforcement Learning. J. Cloud Comput. 2023, 12, 116. [Google Scholar] [CrossRef]
- Yu, M.; Kwon, Y.; Lee, J.; Park, J.; Park, J.; Kim, T. PartitionTuner: An operator scheduler for deep-learning compilers supporting multiple heterogeneous processing units. ETRI J. 2023, 45, 318–328. [Google Scholar] [CrossRef]
- Available online: http://github.com/etri/nest-compiler (accessed on 30 March 2025).
- Rotem, N.; Fix, J.; Abdulrasool, S.; Deng, S.; Dzhabarov, R.; Hegeman, J.; Levenstein, R.; Maher, B.; Satish, N.; Olesen, J.; et al. Glow: Graph Lowering Compiler Techniques for Neural Networks. arXiv 2018, arXiv:1805.00907. [Google Scholar]
- Moreau, T.; Chen, T.; Jiang, Z.; Ceze, L.; Guestrin, C.; Krishnamurthy, A. VTA: An Open Hardware-Software Stack for Deep Learning. arXiv 2018, arXiv:1807.04188. [Google Scholar]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50× Fewer Parameters and <0.5MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benchmarks | Time (s) | Performance | ||
|---|---|---|---|---|
| Name | Size (Mbytes) | Baseline (CPU) | CPU + NPU | Improvement (%) |
| ZFNet | 349 | 2435.17 | 1694.38 | 69.6 |
| AlexNet | 244 | 860.10 | 810.73 | 94.3 |
| GoogleNet | 171 | 1465.80 | 482.30 | 32.9 |
| ResNet50 | 103 | 3183.74 | 636.19 | 20.0 |
| ResNeXt50 | 100 | 6638.85 | 3959.94 | 59.6 |
| ResNet18 | 47 | 1269.18 | 249.03 | 19.6 |
| SqueezeNet | 5 | 298.64 | 195.46 | 65.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jun, H.K.; Kim, T.; Kim, S.C.; Eom, Y.I. A Hierarchical Dispatcher for Scheduling Multiple Deep Neural Networks (DNNs) on Edge Devices. Sensors 2025, 25, 2243. https://doi.org/10.3390/s25072243
Jun HK, Kim T, Kim SC, Eom YI. A Hierarchical Dispatcher for Scheduling Multiple Deep Neural Networks (DNNs) on Edge Devices. Sensors. 2025; 25(7):2243. https://doi.org/10.3390/s25072243
Chicago/Turabian StyleJun, Hyung Kook, Taeho Kim, Sang Cheol Kim, and Young Ik Eom. 2025. "A Hierarchical Dispatcher for Scheduling Multiple Deep Neural Networks (DNNs) on Edge Devices" Sensors 25, no. 7: 2243. https://doi.org/10.3390/s25072243
APA StyleJun, H. K., Kim, T., Kim, S. C., & Eom, Y. I. (2025). A Hierarchical Dispatcher for Scheduling Multiple Deep Neural Networks (DNNs) on Edge Devices. Sensors, 25(7), 2243. https://doi.org/10.3390/s25072243