1. Introduction
Global climate change and intensified human activities have profoundly affected the Earth’s surface. As a key component of global environmental change, land use change directly impacts ecosystem functions and regional sustainability [
1]. Therefore, accurately and promptly monitoring and analyzing the spatiotemporal dynamics of land use is essential for understanding regional environmental evolution, developing effective land management strategies, and addressing future environmental challenges. Remote sensing technology, characterized by its wide spatial coverage, rapid data acquisition, and high temporal resolution, has become a fundamental tool for land use monitoring and related research [
2].
Multi-source remote sensing data, including multispectral, hyperspectral, thermal infrared, radar satellite, and UAV data, are widely used for land use classification and monitoring [
3]. Each data source has unique strengths, and some are complementary. Consequently, extensive research efforts have been devoted to leveraging multi-source data fusion for more effective land use classification [
4]. For example, Shuang Shuai et al. classified two vegetation cover areas in Haixi Prefecture, Qinghai Province, using Gaofen and Sentinel data, demonstrating that integrating different feature sets enhanced classification accuracy [
5]. Filippi and Jensen used AVIRIS hyperspectral data and neural networks to accurately identify coastal vegetation [
6]. Nevertheless, for monitoring land use changes, the Landsat series data remain the preferred choice for many researchers due to their extensive temporal coverage, offering continuous imagery spanning several decades. This characteristic renders the data particularly valuable for long-term land use change monitoring and analysis [
7].
High-quality land use samples and optimal feature selection are crucial for accurate land use mapping [
8]. Traditional methods often rely on manual sample selection. For example, Runxiang Li et al. used field GPS to collect samples and explored the scale effect of image spatial resolution on land cover classification using multi-sensor data [
9]. Hao Yu et al. combined Sentinel-1/2 imagery, terrain data, and field samples from handheld BeiDou and drones to map wetland land use [
10]. However, manual sampling is time-consuming, labor-intensive, and prone to human bias, hindering large-scale, long-term monitoring. Recent research increasingly focuses on automated sample generation [
11]. Yanglin Cui et al. used Landsat 8 focal statistics and phenology to determine optimal focal radii for different land use types, and automatically generated training samples, achieving 92.99% accuracy with Random Forest [
12]. Yanan Wen proposed an automated methodology for collecting stable and representative maize samples from the Cropland Data Layer (CDL) product. Utilizing adaptively selected training samples, this approach enhanced maize mapping performance at large scales and in early stages, achieving an average overall accuracy of approximately 88% [
13]. Relying on a single spectral feature often inadequately captures the spectral heterogeneity inherent in complex land cover types, thus limiting classification accuracy and robustness [
4]. Consequently, the increasing incorporation of multiple features in classification studies introduces challenges such as feature interference and redundancy. Optimizing these feature sets is, therefore, a critical issue requiring resolution [
14]. Yi Zhou et al. used out-of-bag data with recursive feature elimination for optimization, achieving 93.64% overall accuracy and a 92.60% Kappa with Random Forest [
15]. Jinxi Yao et al. used the Gini index to rank feature importance and selected features based on overall accuracy and Kappa coefficient relationships [
16]. The Gini coefficient is widely used for variable importance assessment and feature optimization due to its ease of calculation, interpretability, and broad applicability [
14,
15,
16].
The classifier selection is crucial for accurate land use type identification. Classification models broadly include traditional machine learning algorithms like Support Vector Machine, Maximum Likelihood Classification, Random Forest, K-Nearest Neighbor, Recursive Boosting Tree, and Object-Oriented Classification, as well as deep learning models such as Deep Neural Networks, Recurrent Neural Networks, and Convolutional Neural Networks [
17]. Giancarlo Alciaturi et al. mapped summer and winter land use in Uruguay using Random Forest, Support Vector Machine, and Gradient Boosting Tree classifiers. Their findings confirmed the superior performance of Random Forest and Gradient Boosting Tree [
18]. Chen Zhang et al. mapped forest land using Sentinel-2 imagery and classifiers including Support Vector Machine, K-Nearest Neighbor, Random Forest, Decision Tree, and Multilayer Perceptron, achieving over 95% accuracy [
19]. Pongana et al. compared RF, Classification and Regression Trees, and Gradient Boosting Tree for rice paddy extraction in Thailand and Laos using superpixel segmentation based on a simple non-iterative clustering algorithm [
20]. Muhammad Fayaz et al. investigated transfer learning with Inception-v3 and DenseNet121 architectures to develop a reliable land area classification system for urban land use identification. Their results demonstrated the method’s effectiveness and yielded significant results [
21]. Qichi Yang et al. proposed an alpine land cover classification method based on Deep Convolutional Neural Networks and multi-source remote sensing data, achieving 86.24% overall accuracy and a Kappa coefficient of 81.56% [
22]. Fan et al. proposed a Hierarchical Convolutional Recurrent Neural Network classification model. This model combines CNN and RNN modules for pixel-level land cover classification using multispectral remote sensing data. They reported an overall accuracy of 97.62% on the Sentinel-2 dataset [
23]. While deep learning models can offer higher accuracy in certain contexts, they demand large, high-quality datasets, complex training, and significant time for large-area studies [
24]. Prior research suggests RF, SVM, and object-based classification are excellent methods for large-area land use mapping [
18,
19,
20].
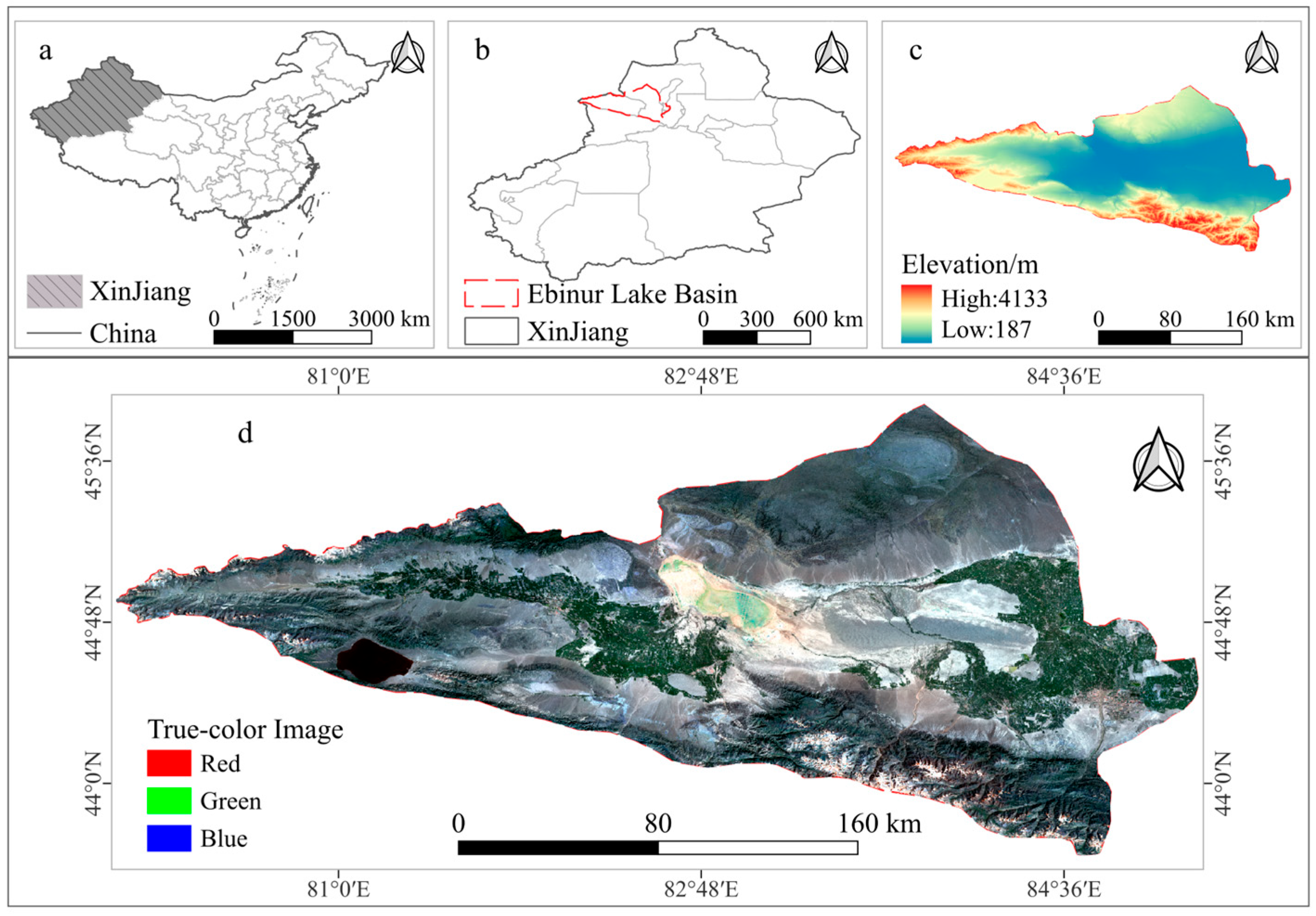
Based on the aforementioned research, this study aims to develop a highly automated technical framework that enables automated sample generation, the optimization of multidimensional feature spaces, and the construction of classification models. By utilizing multi-temporal ESA classification products and long-term Landsat imagery, multi-temporal composite data were constructed through data reorganization and reconstruction analysis. Multiple classification models were then developed to achieve accurate land use classification and spatiotemporal change analysis in the Ebinur Lake Basin.
4. Results
4.1. Composite Feature Construction and Optimization
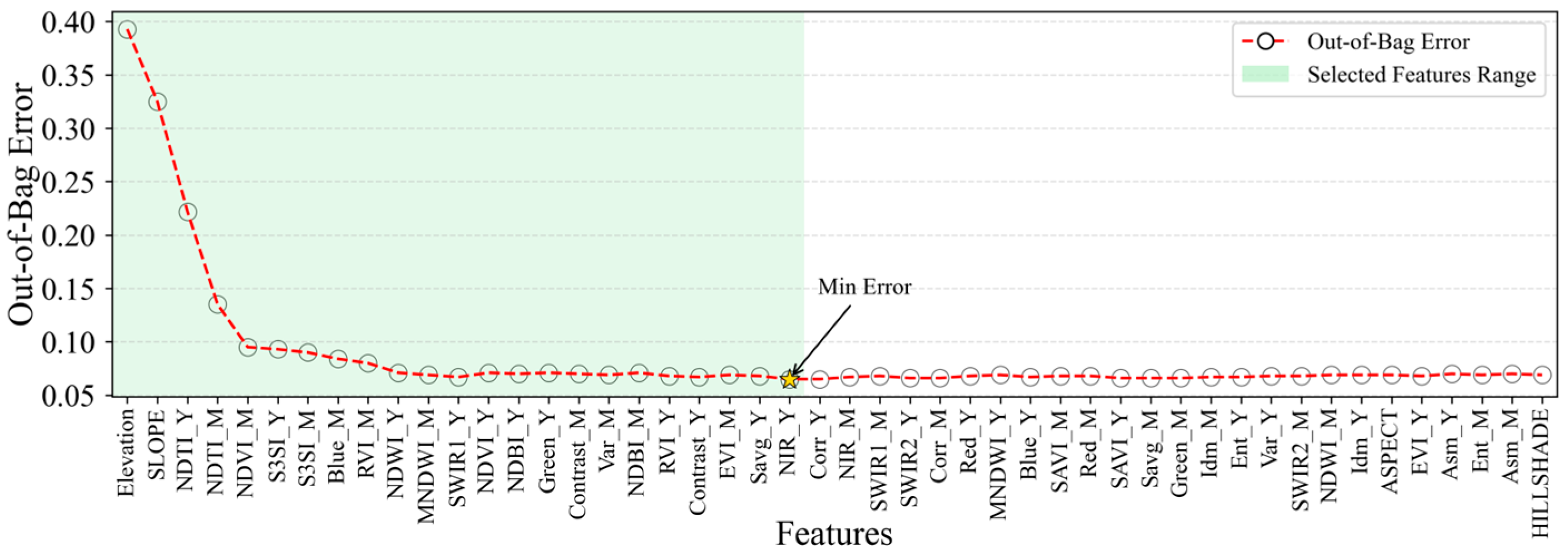
To evaluate the relative importance of various feature variables, the Gini algorithm was applied to a dataset consisting of 48 features using the GEE platform in conjunction with feature space datasets. This approach enabled the calculation and subsequent ranking of feature importance values. To allow for consistent comparison across variables, the computed importance values were normalized [
16]. Furthermore, the proportional contribution of each feature variable type to the overall variable ensemble was calculated, based on the established feature variable importance. This analysis aimed to elucidate the differential impacts of distinct feature variable types, as visually represented in
Figure 6.
The relative importance of different feature variable types revealed that vegetation index features exhibited the highest influence, with an importance proportion of 39.1%. Band and texture features demonstrated moderately lower influence, accounting for 24.1% and 26.1%, respectively. Terrain features exerted the least influence, with a mere 10.7% contribution. However, when considering the importance of individual feature variables, Elevation and Slope within the terrain feature types showed relatively high proportions. Similarly, NDTI_Y, NDTI_M, NDVI_M, S3SI_Y, and S3SI_M dominated the vegetation index feature type; Blue_M, SWIR1_Y, and Green_Y were prominent within the band feature type; and Contrast_M, Var_M, and Contrast_Y exhibited high proportions within the texture feature type.
Building upon the acquired feature variable importance, an optimal feature selection was further achieved by integrating the OOBE. As depicted in
Figure 7, the OOBE reached its minimum at the 23rd feature variable. Consequently, this method effectively reduced the 48 feature variables to 23, namely, Elevation, SLOPE, NDTI_Y, NDTI_M, NDVI_M, S3SI_Y, S3SI_M, Blue_M, RVI_M, NDWI_Y, MNDWI_M, SWIR1_Y, NDVI_Y, NDBI_Y, Green, Contrast, Var_M, NDBI_M, RVI_Y, Contrast, EVI_M, Savg_Y, and NIR_Y, thereby significantly mitigating data redundancy. Within the optimized feature set, the two most critical features were elevation-related, specifically, Elevation and SLOPE, while vegetation index features also constituted a substantial portion.
4.2. Analysis of Classification Results
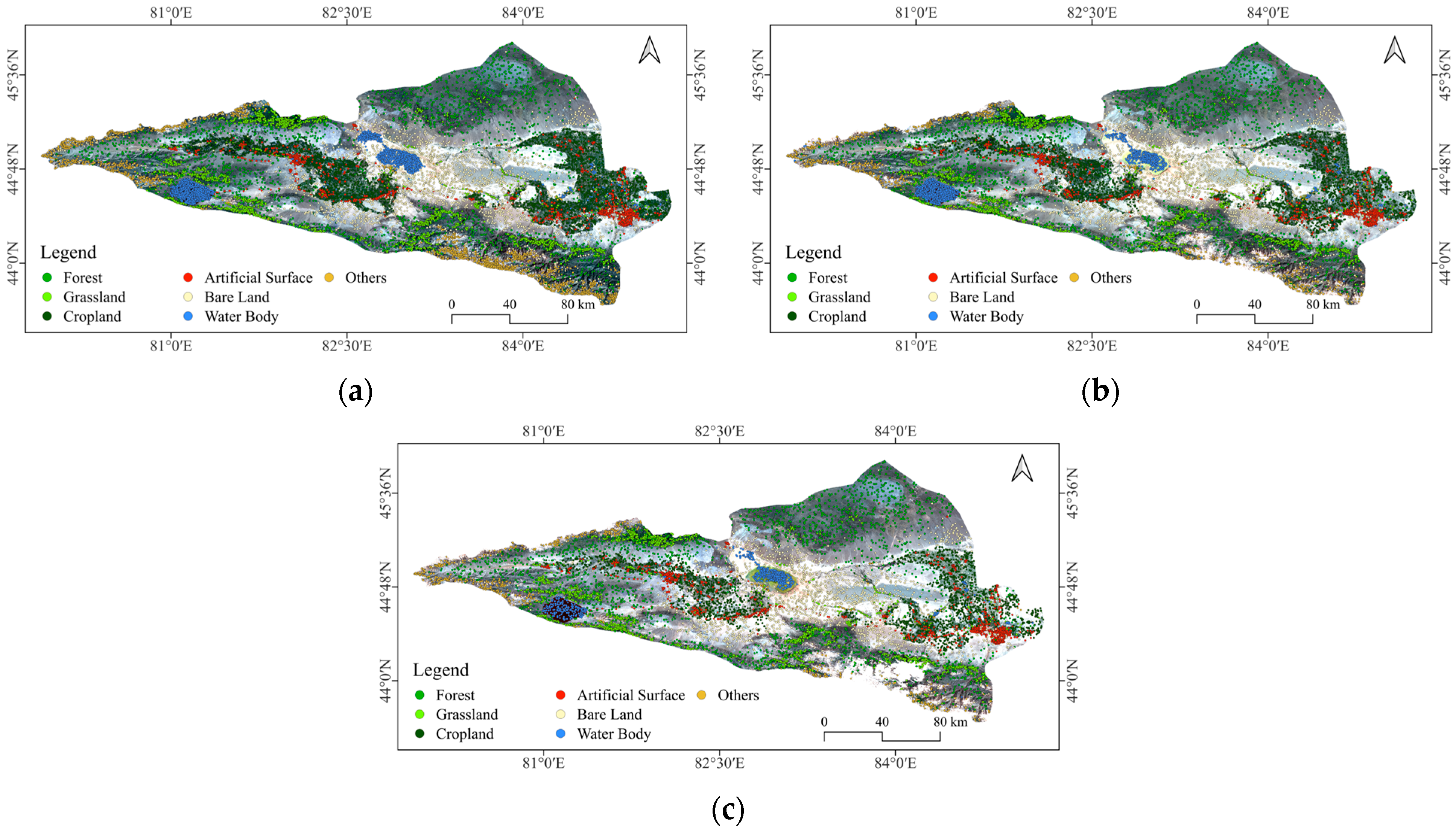
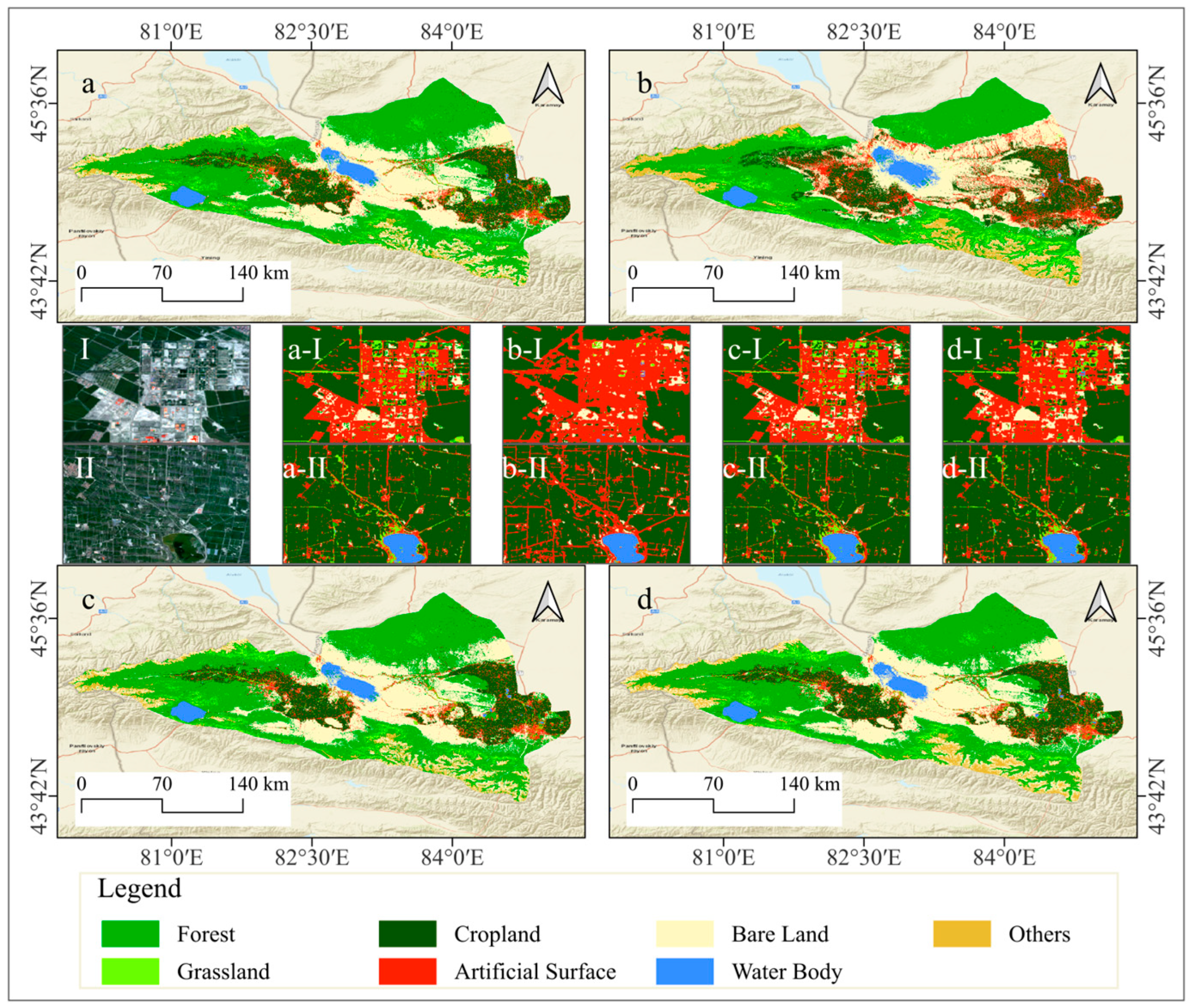
In this study, optimized feature sets derived through feature variable selection processes within GEE environment were utilized to classify land use in the Ebinur Lake Basin for the years 2001, 2011, and 2021. Four classification algorithms were employed: Random Forest, Support Vector Machine, Gradient Boosting Decision Tree, and Object-Oriented Gradient Boosting Decision Tree. The classification results are visually depicted in
Figure 8, and the corresponding quantitative evaluation metrics are summarized in
Table 5.
In the land cover classification of the Ebinur Lake Basin, the RF classifier achieved a high overall accuracy of 93.56% and a Kappa coefficient of 92.46%. In contrast, the SVM classifier yielded a significantly lower overall accuracy of 81.47% and a corresponding Kappa coefficient of 78.25%, indicating a notable disadvantage compared to RF. While the GBDT and OO-GBDT classifiers demonstrated improved accuracy over SVM, the GBDT classifier attained an overall accuracy of 93.85% with a Kappa coefficient of 92.82%. The OO-GBDT classifier further enhanced the overall accuracy to 93.17%, while maintaining a Kappa coefficient of 92.03%. Overall, excluding the relatively poor performance of the SVM classifier, the RF, GBDT, and OO-GBDT models exhibited high classification accuracies.
However, cropland and artificial surfaces are significantly influenced by human activities, often manifesting as regular, block-like, or linear features in remote sensing imagery. The spectral and spatial differences between these features and their surrounding land cover types are typically distinct. While maintaining classification accuracy, employing an OO-GBDT classification model effectively mitigates the presence of small, fragmented patches. Furthermore, this approach refines the separation of narrow, elongated patches and smooths the boundaries of larger patches, resulting in a land use classification map with enhanced detail and accuracy. The application of this model provides a more effective approach for the investigation of land use classification and its spatiotemporal variations in the Ebinur Lake Basin.
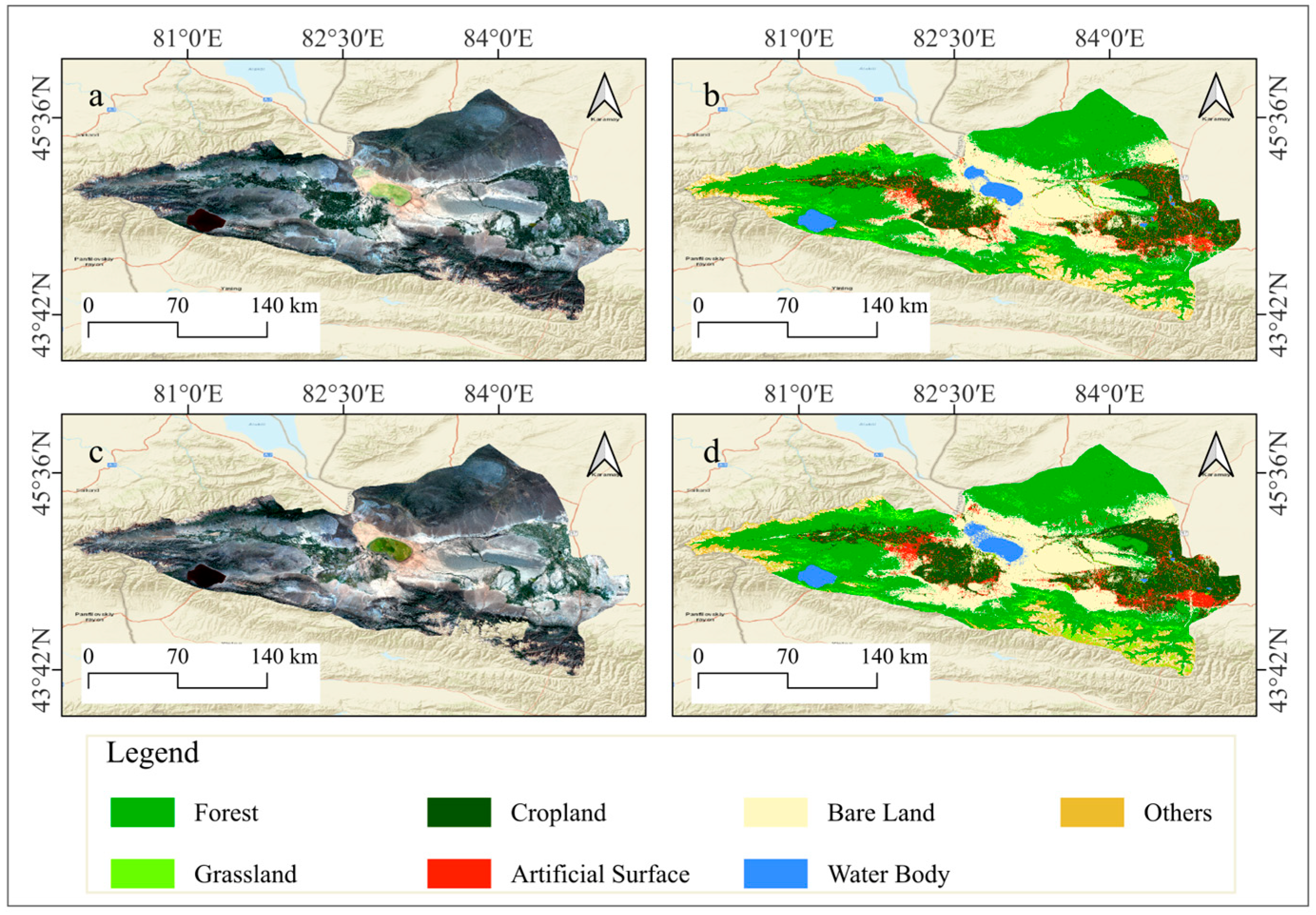
Furthermore, the OO-GBDT classifier was employed to classify land use types in the Ebinur Lake Basin for the years 2011 and 2001, yielding satisfactory classification results (
Figure 9). Specifically, the overall accuracy and Kappa coefficient for the 2011 classification were 88.93% and 86.96%, respectively, while for the 2001 classification, they were 84.76% and 81.84% (
Table 6).
4.3. Spatial and Temporal Analysis of Regional Land Use Change
Spatiotemporal changes in different land use types in the Ebinur Lake Basin were analyzed based on land use classification results from 2001, 2011, and 2021, with particular attention to mutual conversions, area changes, and spatial pattern dynamics over the study period.
Multi-temporal land use maps of the Ebinur Lake Basin were analyzed. This determined the area and percentage of each land use type across various time periods (
Table 7). Overall, Forest, Bare Land, and Cropland were the predominant land use types across the three periods. Grassland, Artificial Surface, Water Body, and Other land use types exhibited relatively limited distribution. Notably, during the period from 2001 to 2021, Woodland exhibited a gradual increase. Grassland trends shifted from a decrease to an increase. Conversely, Cultivated Land showed a reduction. These changes are primarily attributed to local policies implemented during this period, which strictly prohibited overgrazing and deforestation, as well as the influence of natural climatic variations.
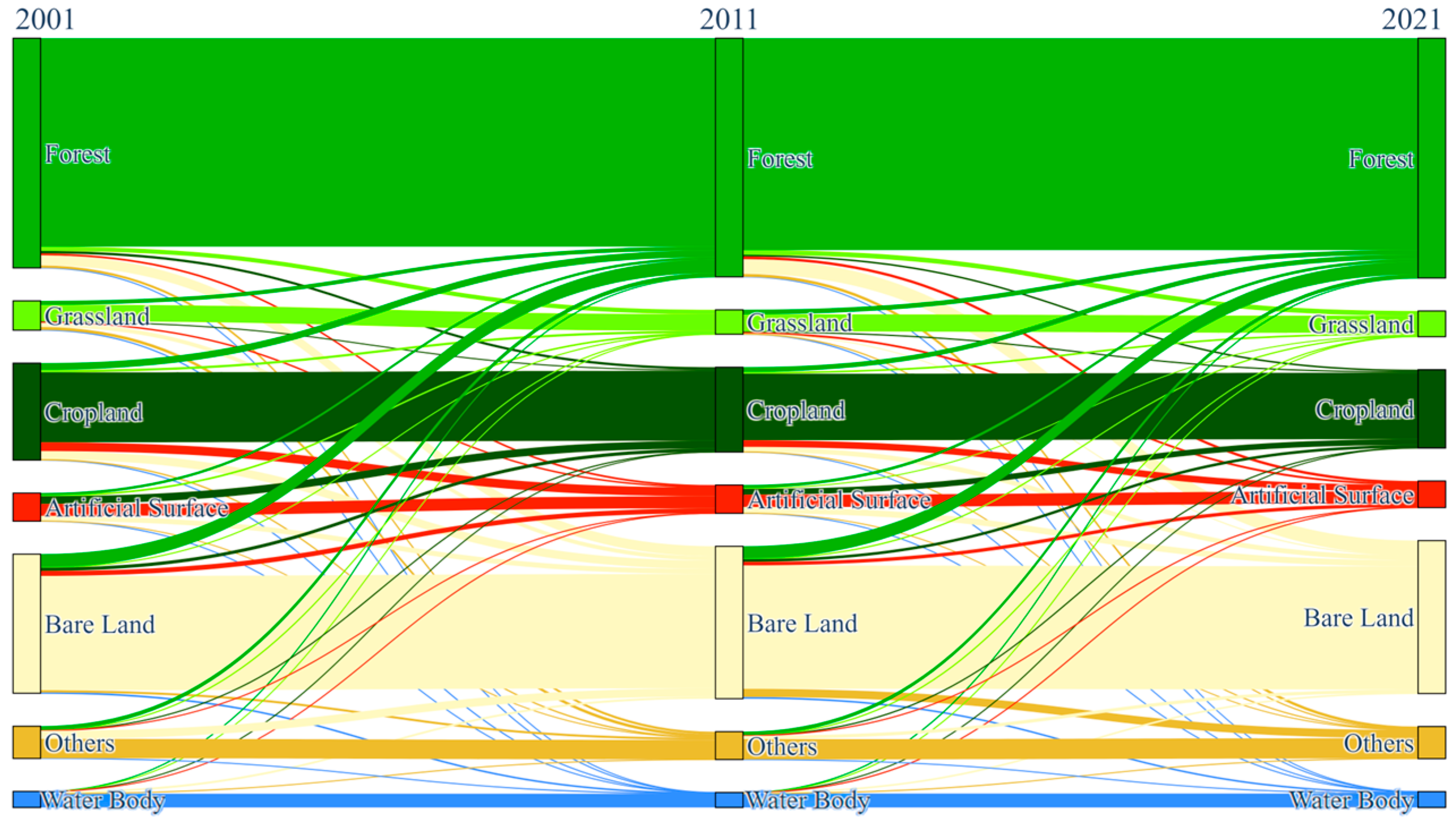
Land use changes in the Ebinur Lake Basin were examined using a transition matrix (
Figure 10) [
58]. Over the past 20 years, significant land use type changes have occurred, primarily among Forest, Cropland, Artificial Surface, and Bare Land. Analysis of land cover changes revealed a shift of 852.74 km
2 from Forest to Bare Land between 2001 and 2011. The magnitude of this transition increased in the following decade, with 1237.59 km
2 of Forest converting to Bare Land from 2011 to 2021. Cropland dynamics are influenced by both anthropogenic and natural environmental factors. Between 2001 and 2011, Cropland experienced significant land cover conversions. Specifically, 572.91 km
2 of Cropland transitioned to Forest, 743.67 km
2 to Artificial Surface, and 713.91 km
2 to Bare Land. The period from 2011 to 2021 evidenced a decline, with a corresponding 570.74 km
2 shift towards Artificial Surface. Furthermore, between 2001 and 2011, approximately 654.39 km
2 of Artificial Surface transitioned to Cropland, and 1133.7 km
2 of Bare Land changed to Forest. Between 2011 and 2021, 491.38 km
2 of Artificial Surface was converted to Cropland, and 520.91 km
2 was converted to Bare Land. During the same period, 1069.51 km
2 of Bare Land transitioned to Forest, and 696.34 km
2 transitioned to Other.
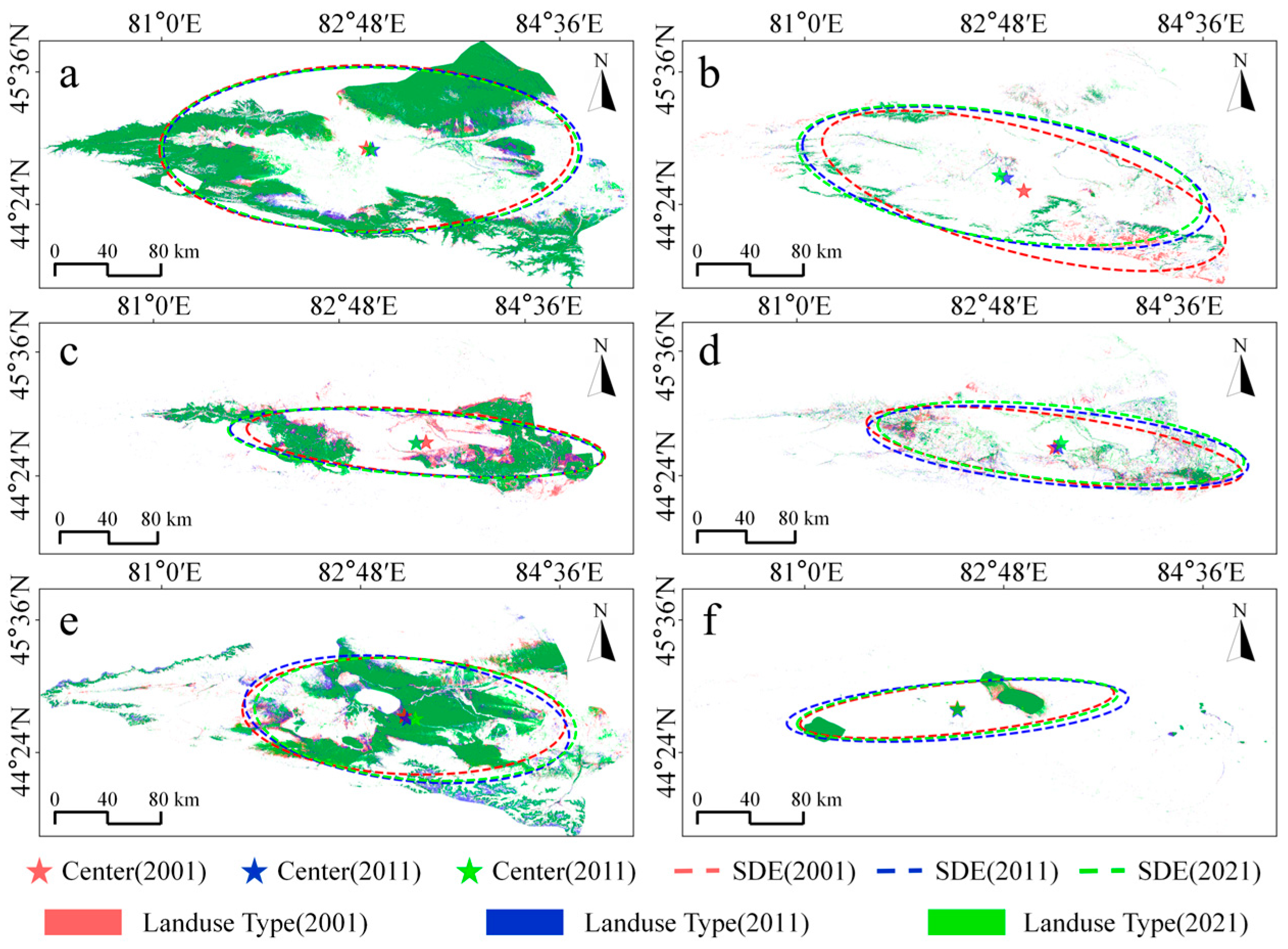
To investigate the spatial distribution and temporal change patterns and direction of each land use type within the Ebinur Lake Basin, standard deviational ellipses were generated (
Figure 11) [
59]. Within the Ebinur Lake Basin over the recent 20 years, Grassland, Cropland and Bare Land underwent notable alterations in their spatial distribution. Changes for Forest, Artificial Surface, and Water Body were comparatively less significant. Forest distribution progressively shifted eastward during the first decade. However, the mean center of Forest showed minimal change in the second decade. Over the entire 20-year period, the spatial extent of Forest gradually expanded. During 2001–2021, the Grassland distribution showed an increasing southeast-to-northwest tilt. Its directionality became more distinct. The mean center correspondingly shifted northwest. During the first 10 years, Cropland’s spatial distribution changed significantly, observed as a gradual westward movement of its mean center. A gradual reduction in its spatial extent was noted over the 20-year period. Bare Land exhibited an increasing trend in spatial extent over the two decades, coupled with an eastward shift in its mean center. In contrast, Artificial Surface and Water Body land cover types displayed minimal changes in both spatial distribution and extent over the 20 years.
5. Discussion
Traditionally, researchers constructing land cover classification sample sets have relied on field surveys or high-resolution imagery interpretation. While this approach can ensure sample quality, it often lacks efficiency and is prone to subjectivity, resulting in inconsistencies between datasets created by different individuals [
9,
10]. Therefore, this study introduces an automated framework for sample generation. This method efficiently creates land use sample sets and enables their transfer across different years. Furthermore, the generated and transferred samples were evaluated, confirming the high quality (JM distance > 1.9) of the sample sets for all three time periods.
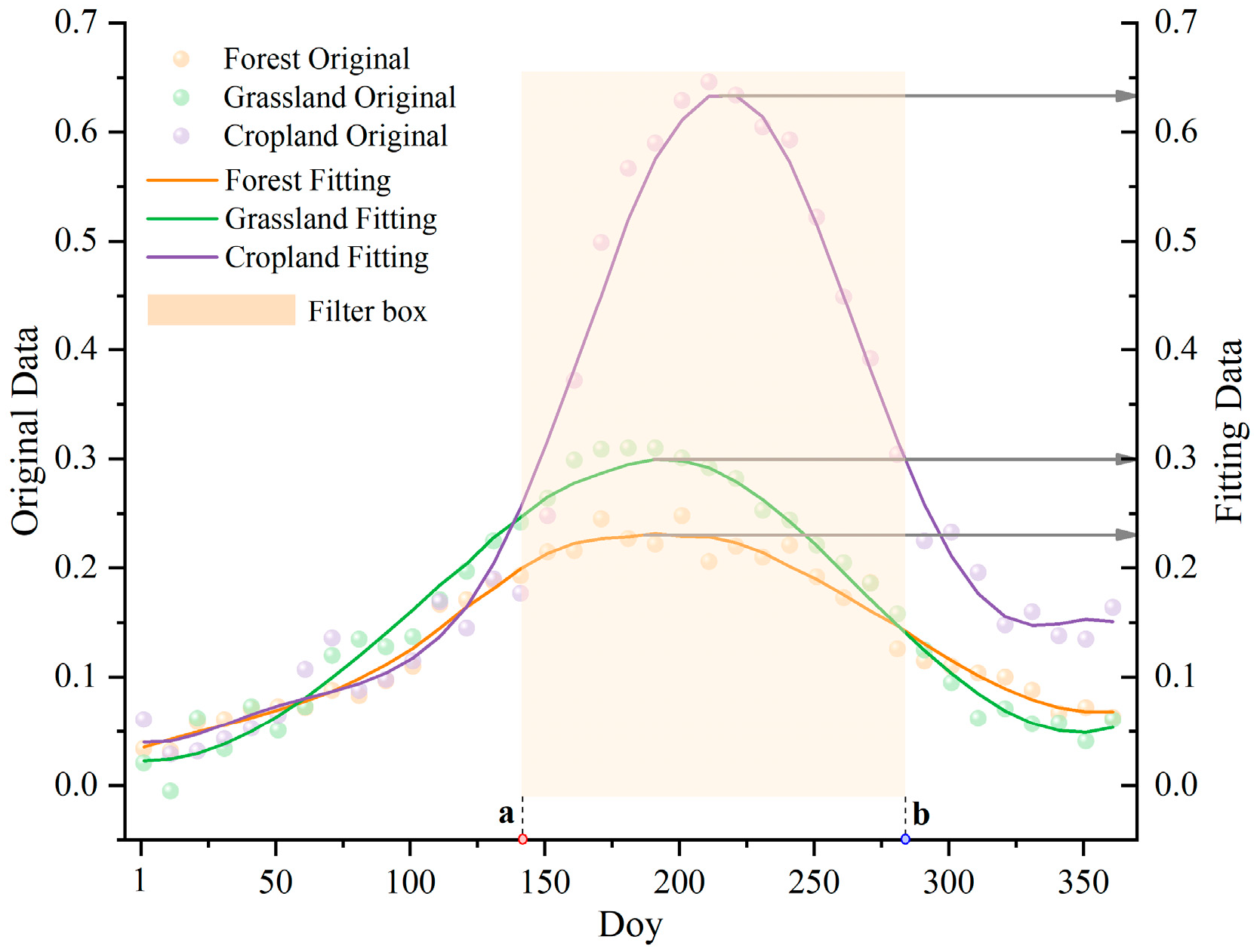
A multi-feature composite space was constructed using multi-temporal data, integrating characteristics from different land cover types. Features were derived from two sources: annual median composites and images from key phenological periods. The annual composites minimize seasonal noise and retain stable spectral properties. Images from key periods, processed using SAVI time-series analysis, effectively capture distinct phenological turning points for similar land cover types, improving dynamic feature expression and addressing the uncertainty caused by the subjective selection of data synthesis window nodes in previous studies [
16]. Feature space optimization was performed using the Gini index and OOBE. This step aimed to reduce data redundancy and lessen the impact of irrelevant features on the subsequent classification.
Finally, this study employed a two-part strategy. First, we optimized the multi-feature composite feature space using a combined Gini coefficient and OOBE approach [
43,
44]. This method effectively reduced computational complexity and data redundancy. Compared to using a single method for feature optimization, the approach adopted in this study enhanced the robustness and stability of the feature optimization model. Second, we integrated simple non-iterative clustering with the GBDT classification model. This enhanced clustering efficiency and classification performance while ensuring accuracy. It also smoothed the land use classification boundaries and demonstrated significant noise reduction effects.
This study developed a framework for land use classification in the Ebinur Lake Basin. The framework integrates considerations of classification samples, features, and models. It effectively performs multi-temporal land use classification within the basin. This methodology can serve as a reference for applications in land use classification and target extraction. While the land use classification framework developed in this study demonstrated good applicability in the Ebinur Lake Basin, further validation across diverse study areas and scales is necessary to confirm its feasibility and utility. Additionally, certain uncertainties remain in the research process. Firstly, the generation of the target study area’s land use distribution relied on existing global land cover products, making the defined land use types dependent on the inherent classification system of these products. Secondly, although multi-year classification products and spatial filtering techniques were employed to mitigate the impact of existing product accuracy on automated sample generation, this influence could not be entirely eliminated. Finally, to analyze the long-term land use change characteristics in the Ebinur Lake Basin, this study prioritized temporal coverage over spatial resolution by using lower-resolution remote sensing data. Moreover, the selection of features inherently involved a certain level of subjectivity.
To address certain limitations inherent in the land use classification framework developed in this study, future research could consider the following: enhancing the temporal and spatial resolution of the remote sensing data; further evaluating the quality of automated classification sample generation; integrating multi-source data; incorporating vegetation phenological characteristics; and employing deep learning classification models.
6. Conclusions
In this study, we developed and implemented a land use spatiotemporal change analysis framework based on automated sample generation and multi-feature fusion, with the Ebinur Lake Basin as a demonstration area. Multi-source remote sensing data and existing classification products were integrated to generate and transfer training samples for the years 2001, 2011, and 2021. A multi-dimensional feature space comprising spectral, index-based, topographic, and textural features was constructed and subsequently optimized. By comparing and evaluating various machine learning classifiers, high-accuracy land use classification was achieved for the study area. Furthermore, based on the land use classification results from 2001, 2011, and 2021, the spatiotemporal changes of different land use types in the Ebinur Lake Basin were monitored. The main conclusions are as follows:
Based on multi-temporal existing classification products, integrating spatial convolutional filters and spectral features enables the rapid and effective generation of high-quality, representative multi-year sample datasets. Using this approach, we generated 14,000 pixels for the Ebinur Lake Basin in 2021, 12,028 in 2011, and 10,997 in 2001, and the JM distance between samples across all three years exceeded 1.9.
Based on the temporal reconstruction, a multi-dimensional feature space was constructed. To avoid data redundancy and potentially misclassified features, the Gini coefficient and OOBE algorithm were used to compress and optimize the feature space while maintaining classification accuracy, reducing the original 48 features to 23.
Land use in the Ebinur Lake Basin for 2021 was classified using Random Forest, Support Vector Machine, Gradient Boosting Tree, and Object-Based Gradient Boosting Tree. The overall accuracies and Kappa coefficients were 93.56% and 92.46%, 81.47% and 78.25%, 93.85% and 92.82%, and 93.17% and 92.03%, respectively. Object-Based Gradient Boosting Tree effectively removed small patches while maintaining accuracy, resulting in a more detailed and accurate land use classification map. For 2011, the Object-Based Gradient Boosting Tree model yielded an overall accuracy of 88.93% and a Kappa of 86.96%. The 2001 classification using the same model achieved an overall accuracy of 84.76% and a Kappa of 81.84%.
Based on multi-year land use maps of the Ebinur Lake Basin, we analyzed area changes, transfer matrices, and ellipse/centroid shifts for each land use type. Over the past two decades, Forest, Bare Land, and Cultivated Land were the dominant land use types. Significant land use transitions primarily occurred among Forest, Cultivated Land, Artificial Surfaces, And Bare Land. Notably, Grassland, Cultivated Land, And Bare Land within the Ebinur Lake Basin exhibited substantial changes in spatial distribution and patterns. Grassland distribution showed a trend tilting from southeast to northwest, with increased directionality and a corresponding average centroid shift to the northwest. Cultivated Land displayed a gradual westward shift of its average centroid. Bare Land showed an increasing spatial extent, coupled with an eastward movement of its average centroid.
In summary, this study provides a comprehensive framework for large-area land use type classification and spatiotemporal change analysis. It facilitates highly automated and accurate regional land use classification. The framework offers valuable technical references for automated sample generation, multi-feature fusion and optimization, and classification model refinement. Furthermore, it enables the effective acquisition of land use classification and spatiotemporal change information for other regions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}