3.2. Dataset Preparation
The experiments were conducted at the Ecological Aquaculture Center in Puyue Town, Chongming District, Shanghai. During data acquisition, deliberate efforts were made to approximate real-world aquaculture conditions by adjusting camera angles, lighting intensity, and water background complexity, thereby enhancing the representativeness and diversity of the dataset. The data were captured using industrial camera equipment and saved in two formats: JPG and MP4. During the data collection process, factors such as fish overlap, occlusion, and lighting changes were taken into account. The Python program was used to extract frames from the MP4 format data and process them into multiple JPG format images, ultimately obtaining a homemade dataset of dead sea bass. Each image contains multiple states of the sea bass, for a total of 1565 data images. In order to improve the learning ability of the model and make it more applicable in practice, care was taken when collecting the dataset to ensure that the dead sea bass were in a variety of poses and that they were complete. As shown in
Figure 6, the states of the dead sea bass include dead_sideways, dead_belly_up, and dead_float.
In order to enable the model to better adapt to complex visual disturbances in real farming environments, improve the model’s generalization ability and robustness, and avoid overfitting due to the limited number of training images, this paper designs and implements a set of environmentally disturbed visual augmentation (EDVA) strategies based on the original images. This strategy combines standard augmentation techniques—such as noise injection, random rotation, image flipping, blurring, scaling, cropping, and brightness adjustment—with domain-specific operations that simulate typical visual disturbances in aquaculture. Specifically, fish overlap and occlusion were modeled through image duplication, scaling, and overlaying (
Figure 7b), while water turbidity, motion blur, and surface bubbles were simulated using a combination of Gaussian blur, motion blur, and particle overlays (
Figure 7c). A total of 8160 augmented images were generated, substantially enhancing the visual diversity and complexity of the training data and supporting the evaluation of the model’s adaptability and robustness under aquaculture-relevant visual conditions.
The three dead sea bass poses, dead_sideways, dead_belly_up, and dead_float, were set to 0, 1, and 2, respectively, using the labeling tool. The dataset was labeled to generate the YOLO data format and saved as a “.txt” file. The training set, validation set, and test set are randomly divided with a ratio distribution of 8:1:1.
3.4. Results Based on the YOLOv8n-Deadfish Dead Sea Bass Detection Model
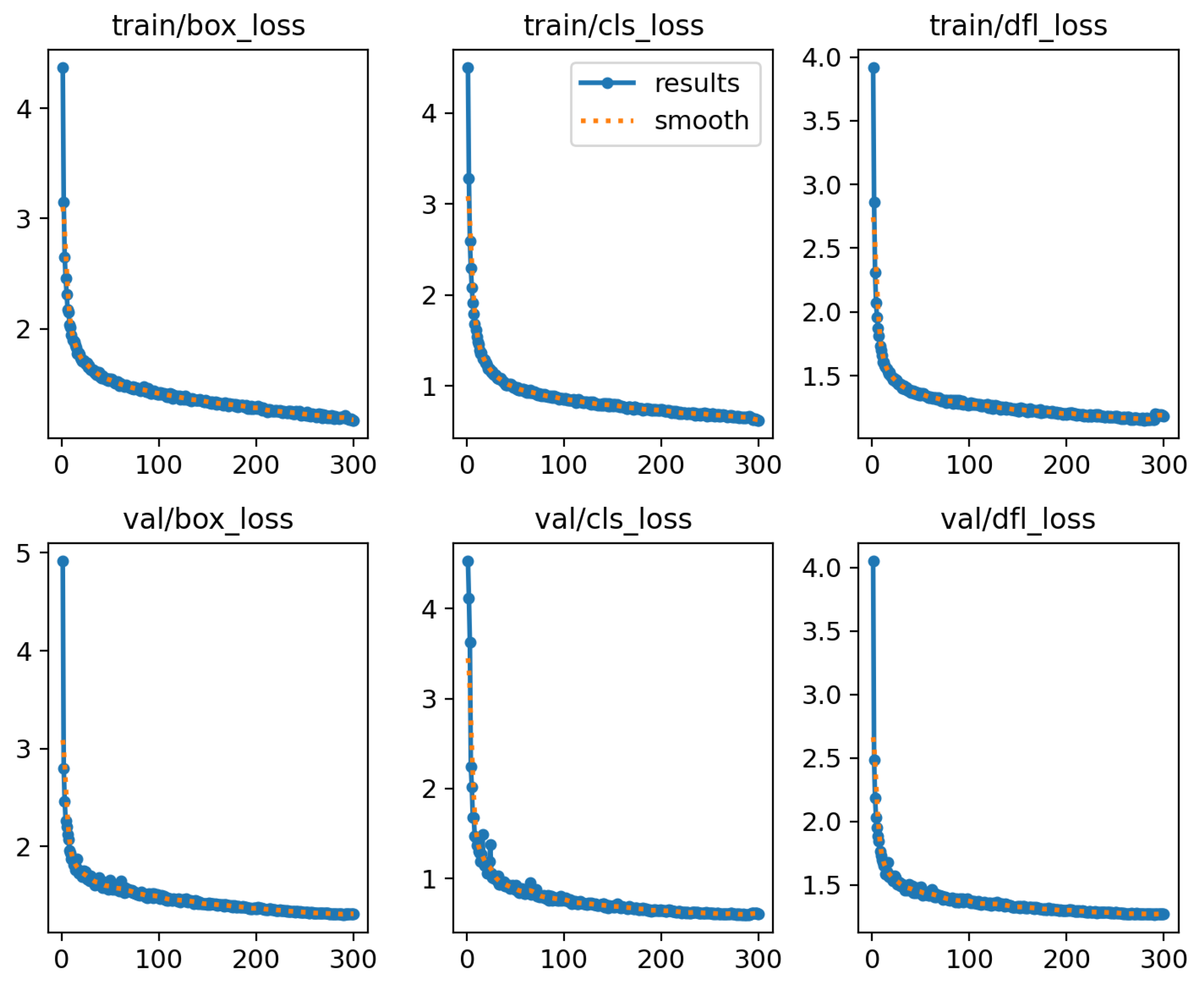
The dead sea bass posture dataset collected in this study has a high complexity, and so the overfitting problem becomes a major concern during the training process. In order to test whether overfitting occurs, loss curves were plotted during the training and validation process, and the specific results are shown in
Figure 8. In the early stage of training, the loss curves show a significant decrease within the first 30 rounds, and with the training iterations, the three training losses gradually decrease and level off after 260 epochs. This indicates that the improved model does not show the overfitting phenomenon during the training process and exhibits better convergence.
In order to more intuitively evaluate the practical effectiveness of the YOLOv8n-Deadfish dead sea bass detection model in the identification of each category, the confusion matrix between the YOLOv8n benchmark model and the proposed YOLOv8n-Deadfish model is compared, see
Figure 9. It describes the accuracy of detecting dead sea bass in the three postures in the dataset. In the confusion matrix, the rows represent the predicted labels of the model for each category, the columns represent the true labels of the labels for each category, and the values on the diagonal represent the correct detection rate. Darker colors indicate higher rates, and lighter colors indicate lower rates. This visualization facilitates the distinction between instances belonging to each category. It can be seen that the improved model has a relatively high total number of values on the diagonal and reduces false detections due to the similarity of dead_belly_up to the background features, while improving the accuracy of dead sea bass detection.
In order to evaluate the robustness of the proposed model in complex environments, two representative images of complex scenes are selected for heatmap visualization in this study. As shown in
Figure 10a, the strong reflections in the water body, the interference of the pipeline structure, and the blurred boundaries of the fish body pose challenges to the detection ability of the model; in
Figure 10b, the overall low brightness and high noise level of the image due to the low contrast between the fish body and the background similarly increase the difficulty of target recognition.
Figure 10 shows the comparison of thermogram visualization results between YOLOv8n and YOLOv8n-Deadfish models in complex aquaculture environments. In
Figure 10a, the YOLOv8n model is interfered with by the strong reflection on the water surface when recognizing the dead sea bass in the upper left, which leads to a small detection frame and unstable localization; for the fish with occlusion and overlapping at the bottom of the image, due to the blurred edges of the dead seabass, the activation area of the model shows scattered and discontinuous features, accompanied by obvious repeated detection, which makes it difficult to achieve an effective focus on the real target. In comparison, the YOLOv8n-Deadfish model is able to focus the attention area more accurately on the location of the dead sea bass body, with clear edges and accurate localization of the heatmap, and the key areas show a stronger red response, demonstrating its superior feature extraction capability and anti-interference performance.
In the low-brightness, high-noise image in
Figure 10b, although YOLOv8n generates activation responses at multiple fish locations, the activation regions have fuzzy contours and loose boundaries, and the model is not sufficiently focused on the target, making it difficult to form complete feature coverage, reflecting its limited focusing ability under complex backgrounds. On the other hand, YOLOv8n-Deadfish generates high-intensity activation regions with clear boundaries and complete structures on all four dead bass targets, and the color of the heatmap is concentrated in the red region, which shows higher focusing accuracy and feature expression power; additionally, even in the area with serious noise interference below, the model still maintains a stable response and accurately identifies the target.
In summary, the YOLOv8n-Deadfish model, by introducing improved feature extraction structure and multi-scale attention mechanism, shows stronger target focusing ability and background suppression ability when facing multiple interference factors such as strong reflections, target occlusion, complex backgrounds, or significant noise, which significantly improves the accuracy and robustness of dead sea bass detection.
3.5. Ablation Experiments
In order to evaluate the effect of the improved algorithm, five ablation experiments were designed. These experiments were used to compare the effectiveness of various improvement strategies on model performance. The tests were performed using the same equipment and dataset, and other hyperparameters were kept at the same default values to ensure the comparability of the results. The results of the experiments are shown in
Table 2, and the trend curves of precision, recall, and mAP@0.5 with the training cycle are plotted in
Figure 11.
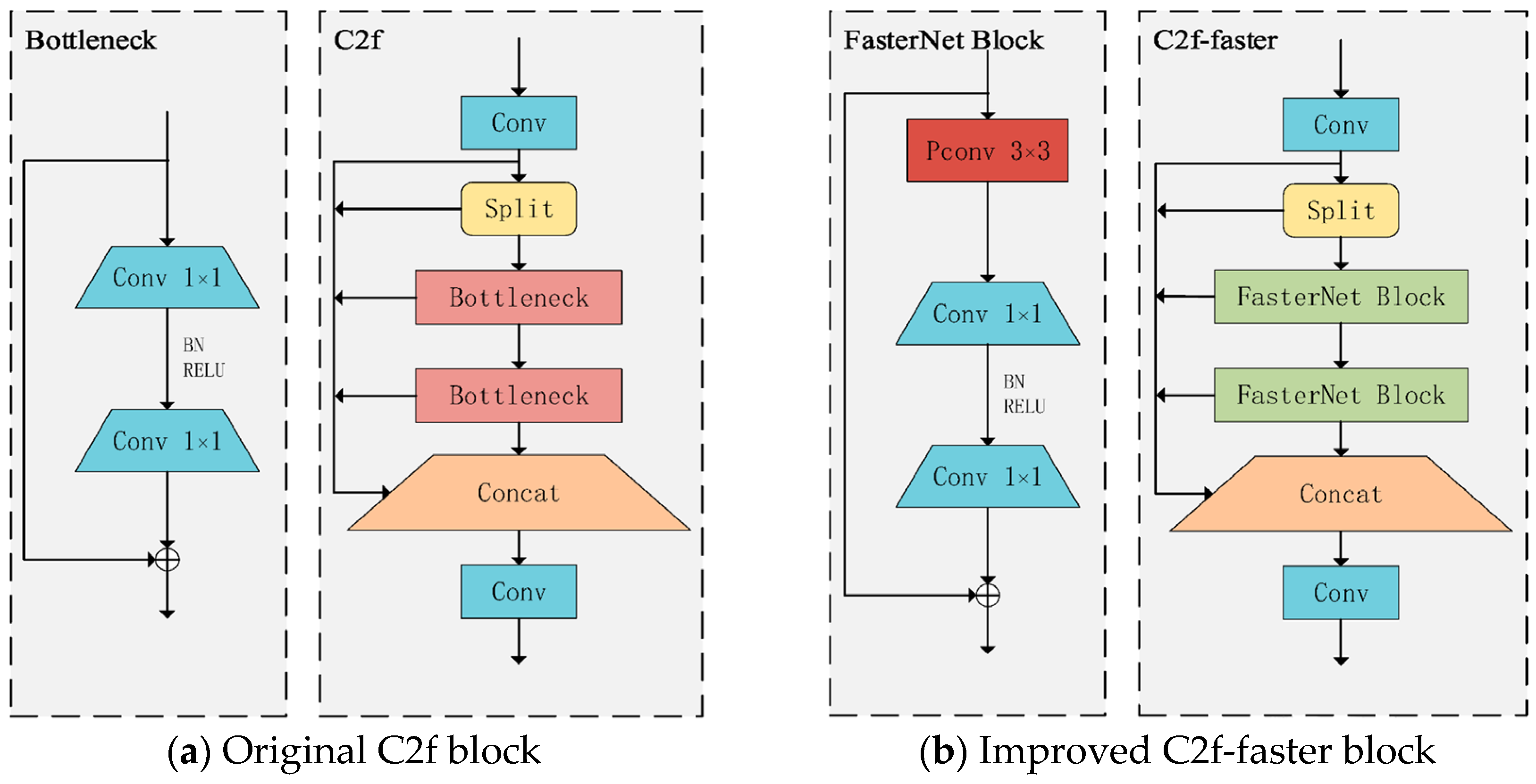
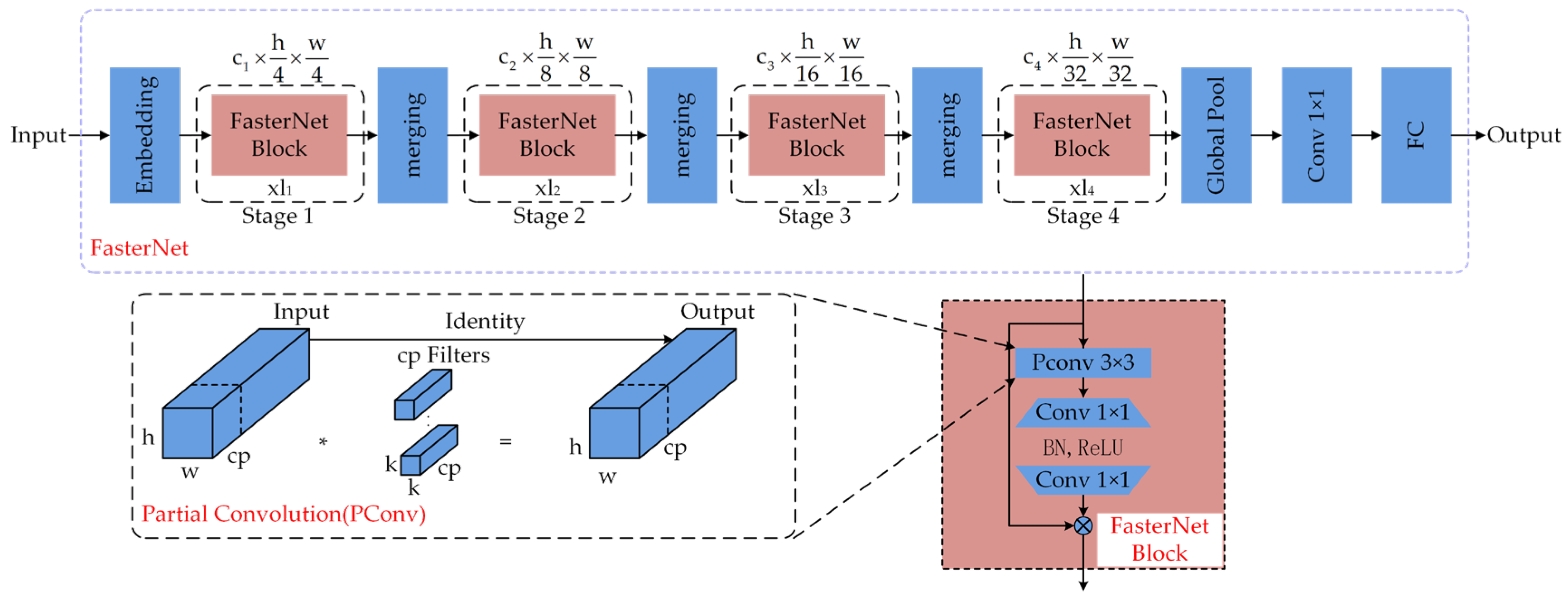
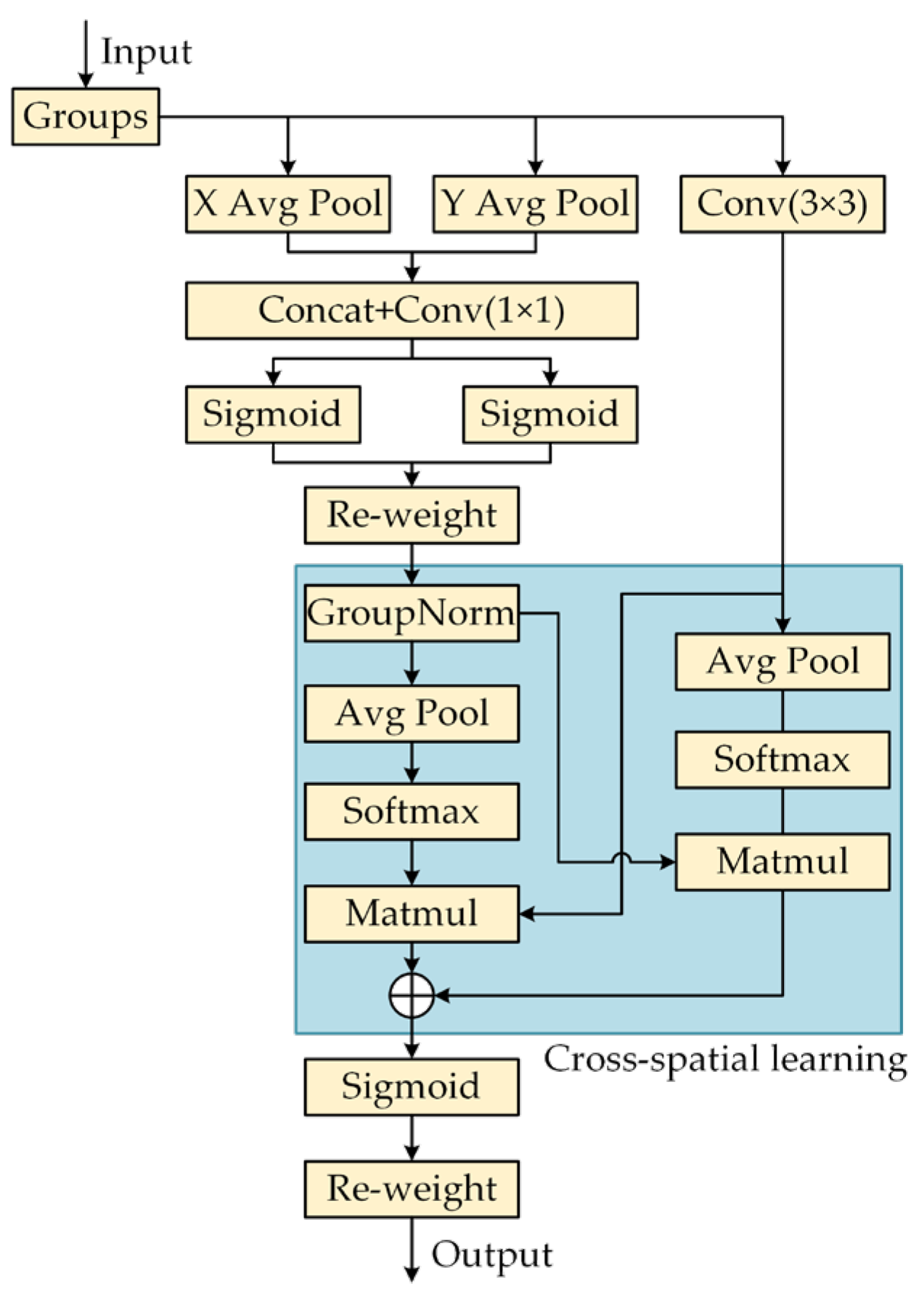
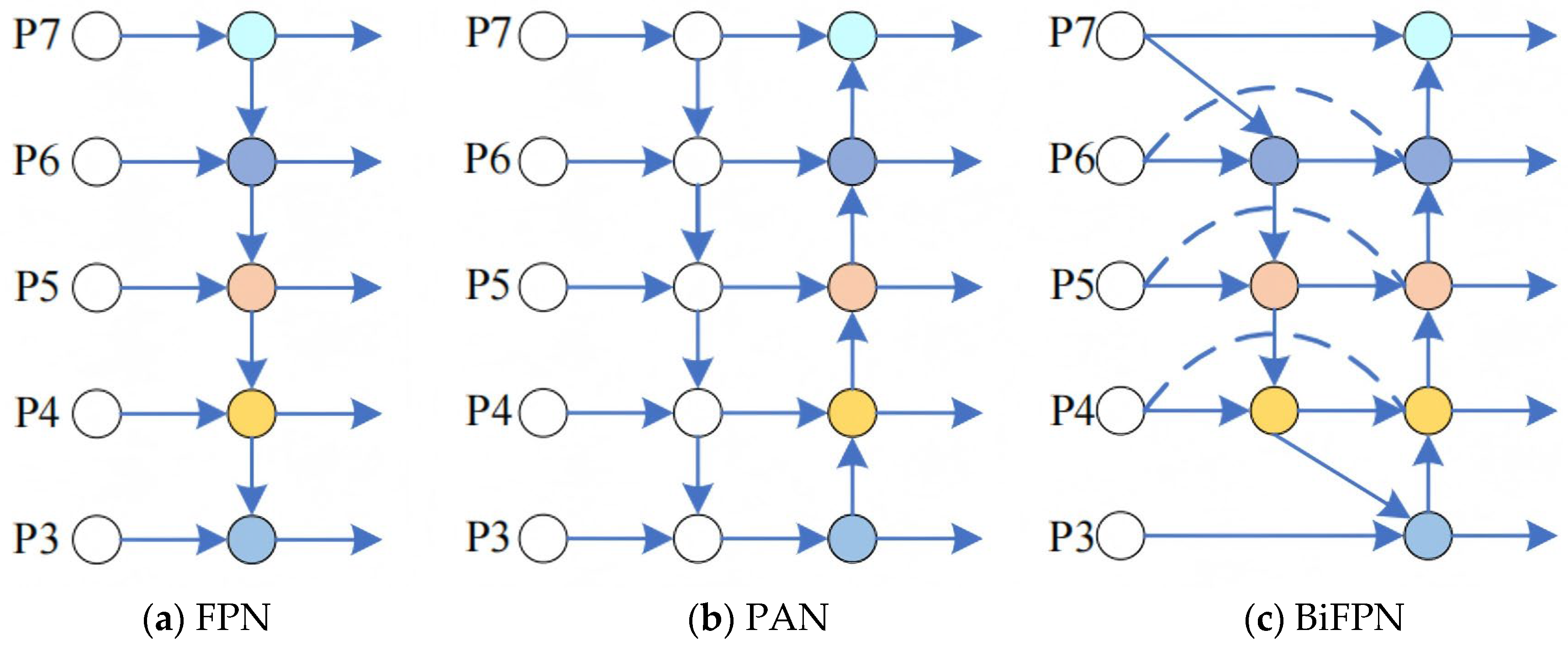
The experimental results show that after replacing the original C2f module of YOLOv8n with the C2f-faster module, the model parameters and floating-point operations are reduced by 26.7% and 22.2%, respectively, and the detection speed is significantly improved by 89.7 FPS. However, the accuracy indicators, precision, recall, and mAP@0.5 of the model, decreased by 1.6%, 2.2%, and 2.0%, respectively. The EMA attention mechanism was then introduced, which enhanced the model’s ability to capture features at different scales. Although the number of parameters and the amount of floating-point operations increased slightly, the detection accuracy rebounded to 91.1%, and the detection speed decreased slightly to 385.2 FPS. The further integration of the weighted bidirectional feature pyramid network (BiFPN) strengthened the bidirectional fusion of deep and shallow features, significantly improving the feature extraction ability, resulting in an increase of 1.9%, 0.5%, and 1.5% in precision, recall, and mAP@0.5, respectively, with only a slight decrease of 0.7 FPS in the detection speed. In addition, the Inner-CIoU loss function is used to further optimize bounding box regression, which effectively improves the convergence speed and accuracy of the model, ultimately achieving an mAP of 93.6% and an increase in detection speed to 424.6 FPS.
According to the trend curves of precision, recall, and mAP@0.5 with the training cycle in the figure, it can be seen that the proposed YOLOv8n-Deadfish performs best in the dead sea bass object detection task. In the early stages of training, the precision, recall, and mAP@0.5 metrics of the improved model all increased rapidly and were consistently higher than those of the original YOLOv8n and other improved methods. As the training cycle increased, each metric continued to show a significant advantage, with smoother curves and a tendency to stabilize, indicating that the model had stronger convergence performance and generalization ability.
Overall, the proposed network structure optimization strategy effectively takes into account the detection accuracy and speed, and is more suitable for the real-time accurate detection of dead sea bass targets.
3.6. Comparison of Different Network Models
Table 3 and
Figure 12 show the training results of the proposed YOLOv8n-Deadfish model with Faster R-CNN, SSD, RT-DETRv2-R50 [
36], and other YOLO (v5–v12) series models on the self-constructed dead sea bass dataset. The comparative analysis of the performance metrics shows that the YOLOv8n-Deadfish model outperforms the other models, displaying a superior detection capability. Specifically, the model proposed in this study attained a precision (P) of 90.0%, a recall (R) of 90.4%, and a mean average precision at IoU 0.5 (mAP@0.5) of 93.6%. These figures markedly exceed those of the classical Faster R-CNN and SSD detectors and also outperform models from the same YOLO family, including YOLOv5s (88.1%, 88.4%, and 91.0%), YOLOv7-tiny (86.2%, 87.1%, and 91.8%) [
37], YOLOv10n [
38] (87.4%, 88.0%, and 91.0%), and YOLOv12n [
39] (88.1%, 88.4%, and 91.6%); compared to the latest RT-DETRv2-R50 non-lightweight model, YOLOv8n-Deadfish is better in terms of detection precision, recall, and average precision, which are slightly higher than the RT-DETRv2-R50 model by 0.5, 1.6, and 0.9 percentage points, respectively. This indicates that the YOLOv8n-Deadfish model is able to capture the feature information of the target more effectively through the optimization of the network structure and the loss function, reducing the phenomenon of missed detection and false detection, thus achieving a higher detection precision.
While maintaining the advantage of detection accuracy, YOLOv8n-Deadfish also demonstrates significant lightweight characteristics in terms of model complexity and computational resource overhead. The model contains only 2.3 M parameters and 6.6 G of floating-point operations, which is much lower than the mainstream detectors such as Faster R-CNN (136.7 M, 401.7 G), SSD (26.3 M, 282.0 G), and RT-DETRv2-R50 (36 M, 100 G); and the number of parameters and the amount of computation are 11.5% and 1.0% lower than that of YOLOv12n and YOLOv8n, respectively. For YOLOv12n, the number of parameters and computation volume are also 11.5% and 1.5% lower than those of the latest YOLO series models, respectively. In particular, compared with RT-DETRv2-R50, YOLOv8n-Deadfish has about 94% fewer parameters and 93% less computation, which significantly reduces the model volume and computation burden with similar detection accuracy.
This lightweight advantage makes YOLOv8n-Deadfish more flexible for deployment in practical applications, especially for embedded devices, edge computing platforms, or resource-constrained systems, such as real-time video monitoring in aquaculture farms, underwater cameras, and other typical scenarios. In terms of detection speed, the model reaches 424.6 FPS, which is significantly better than all the compared models, fully demonstrating its advantages in real-time and efficiency.
In contrast, RT-DETRv2-R50 performs well in terms of detection accuracy but its large model size and high computational complexity limit its practical deployment in scenarios such as agriculture. Since the model usually relies on high-computing-power GPUs or servers, it is more suitable for environments with sufficient resources, such as urban traffic monitoring, industrial quality inspection, cloud image analysis, or medical diagnosis. In typical edge computing scenarios, such as agriculture and aquaculture, the detection model is often deployed on power-sensitive and arithmetic-limited end devices. Under such conditions, RT-DETRv2-R50 is not suitable for the above applications due to its high computational resource requirement, which not only significantly increases the deployment cost but also may affect the real-time quality and stability of the system due to high resource utilization.
To summarize, YOLOv8n-Deadfish, with its higher detection speed, lower model complexity, and good hardware adaptability, shows stronger practicality and promotion potential for practical deployment.
From the detection results of each mainstream target detection model on the dead sea bass dataset in
Figure 12, it can be seen that there are significant differences in the performance of different models in complex underwater environments. Faster R-CNN and SSD show obvious limitations under disturbing conditions such as insufficient illumination, turbid water, or occlusion of the fish body, and the common problems include omission of detection, misdetection, duplicate detection, and incorrect recognition of the categories. The localization of detection frames was generally inaccurate, some fish were not recognized or misclassified, the overall confidence level was low, and the stability of detection results was poor.
In contrast, the YOLO series of models (e.g., YOLOv5s, YOLOv7-tiny, YOLOv8n, YOLOv10n, and YOLOv12n) showed improved detection performance, as evidenced by higher localization accuracy and recall. However, the models still have different degrees of problems: YOLOv5s is prone to misdetection, repeated detection, and omission in water interference or fish occlusion scenarios, and the target bounding box is not precise enough; YOLOv7-tiny has decreased detection accuracy in low-light conditions, and is prone to repeat detection of the same dead sea bass and misidentify the background region as the target; YOLOv8n has improved detection performance in the case of fish occluding each other (e.g., the second column of images). YOLOv8n, in the case of fish obscuring each other (e.g., in the second column of images), the coverage of the blurred region of the boundary is not stable enough, and there is the phenomenon of missed detection, and the overall confidence level decreases; YOLOv10n, although it is able to detect most of the targets, there is still the problem of overlapping or missed detection of the individual targets due to the offset of the bounding box; and YOLOv12n’s detection confidence is on the low side. In the first column of images, the confidence levels for multiple “dead_sideways” targets are only 0.48 and 0.41, indicating that its discriminative power is insufficient in strong reflections or complex background regions; in the second column of images, the model misses the detection of a dead sea bass individual near the pipe at the bottom of the pool, indicating that its target perception ability is limited in weakly textured or partially occluded scenes. In the second column, the model misses the dead sea bass near the pipe at the bottom of the pool, indicating that it has limited target perception ability in weakly textured or partially occluded scenes; in the fourth column, the confidence level of small-sized targets in the distance is only 0.37, which reflects that it has poor recognition stability in low-contrast conditions.
In addition, although RT-DETRv2-R50, as a newer detection framework, guarantees the target localization accuracy, its confidence level for some “dead_sideways” targets in multi-target scenes is still low (e.g., 0.46 and 0.49), which reveals its discriminative power under strong background interference. This reveals the problem of its discriminative power under strong background interference. In the second column of images, the model also has a significant omission, failing to recognize a fish body near the edge of the bottom structure of the pool, which indicates that there is still a blind spot in the complex structural region.
Overall, YOLOv8n-Deadfish performs well on several evaluation dimensions. It significantly outperforms other models in terms of target classification confidence, bounding box localization accuracy, and robustness in complex scenes. This performance improvement is mainly due to the optimized design of the network structure, including the introduction of the EMA attention mechanism to enhance the multi-scale attention capability, the adoption of the BiFPN structure to strengthen the feature fusion, the use of the C2f-faster module to improve the handling of redundant information, and the Inner-CIoU loss function to improve the bounding box regression accuracy. Together, these improvements drive the accuracy and utility of the model in the dead sea bass detection task.
3.7. Experimental Analysis of Public Datasets
In order to validate the effectiveness of the YOLOv8n-Deadfish model proposed in this study for target detection in underwater images captured in real environments, the publicly available dataset Labeled Fishes in the Wild, provided by the National Marine Fisheries Service (NMFS) of the United States of America, was selected for evaluation in this paper. This dataset was constructed by Cutter et al. [
40] and consists of images taken using a remotely operated vehicle (ROV) in a rocky reef area off southern California, USA, with precise bounding box annotations of fish targets. The images cover a wide range of fish, invertebrates, and typical seafloor environments, and are suitable for assessing tasks such as automated detection, identification, and tracking of underwater organisms. The dataset contains a total of 3167 images, which are divided into training, validation, and test sets in the ratio of 8:1:1 for model training and performance evaluation in this study. In the model training process, the Yolov8n model and YOLOv8n-Deadfish model were used for comparison.
The experimental results are shown in
Table 4. Compared with the base model YOLOv8n, YOLOv8n-Deadfish improves the key metrics such as precision (P), recall (R), and mAP@0.5 by 1.1%, 1.0%, and 1.8%, respectively; at the same time, the number of parameters and the amount of floating-point operations are reduced by 23.3% and 18.5%, and the detection speed is improved from 336.1 FPS to 458.8 FPS, which shows better efficiency and lightweight advantages.
From the image detection results, as shown in
Figure 13, YOLOv8n-Deadfish also shows stronger target perception and localization capabilities.
In the first column of the image, both models successfully recognize the target categories Fragile_urchin and Human_crab, but in contrast, YOLOv8n-Deadfish’s recognition confidence for Human_crab increases from 0.88 to 0.93, indicating that it has stronger discriminative ability in fine-grained target classification. In the second column of images, the recognition confidence of YOLOv8n on Red_rockfish is only 0.75, while the confidence of YOLOv8n-Deadfish is improved to 0.78, which further reflects that it is more accurate in recognizing target boundaries and more reliable in classifying targets in low-contrast complex backgrounds. In multi-target scenarios (e.g., the third column of the image), YOLOv8n misidentifies a Yelloweye fish as multiple overlapping targets with unstable detection frames, while YOLOv8n-Deadfish accurately identifies a single target with more compact and reasonable detection frames, and the identification is more stable. In the fourth column of the image, YOLOv8n’s detection frame for Lingcod is obviously small and inaccurate, while YOLOv8n-Deadfish’s detection frame is more accurately aligned and the target coverage is more comprehensive, which indicates that it has stronger feature extraction ability under the conditions of light change and background interference.
On the whole, YOLOv8n-Deadfish outperforms the original model in terms of bounding box fitting accuracy, target confidence, and small target recognition under occlusion, which effectively verifies the practicality and robustness of the structural optimization strategies proposed in this paper (e.g., the EMA attention mechanism and the BiFPN multi-scale feature fusion) in the complex underwater detection task.
3.8. Significance Analysis of Model Performance
To validate the stability and statistical reliability of the experimental results, five independent experiments were conducted on the dead sea bass dataset and a public dataset. In each experiment, only the random seed was changed to introduce randomness into the training process. The random seed is used to initialize the pseudo-random number generator (PRNG), where different seeds generate distinct pseudo-random sequences, leading to variations in the model training process (such as weight initialization, data shuffling, and data augmentation). Conversely, the same seed generates identical sequences, ensuring the reproducibility of the experiments.
3.8.1. Statistical Significance Analysis of Model Performance Based on the Dead Sea Bass Dataset
Based on five independent experiments, this study applied statistical tests to analyze the performance differences among the models. Specifically, using YOLOv8n-Deadfish as the baseline model, we conducted a two-sample
t-test to assess the significance of the experimental results of eight other mainstream detection models in terms of precision, recall, mAP@0.5, and inference speed (FPS), as shown in
Table 5.
Among the multiple existing models compared with the YOLOv8n-Deadfish model, nearly all performance metrics (including recall, mAP@0.5, and detection speed) achieved a significance level of p = 0.000 (p < 0.01) in the t-test, indicating that the performance differences between these models and YOLOv8n-Deadfish in the aforementioned metrics are statistically significant. Although the difference in the precision metric between RT-DETRv2-R50 and YOLOv8n-Deadfish corresponds to a p-value of 0.009—which is slightly higher than that of the other comparisons—it is still less than 0.01, thus meeting the standard for statistical significance.
By integrating the results of multiple models under different random seeds and performing a t-test analysis, the YOLOv8n-Deadfish model demonstrated significant statistical advantages in accuracy, recall, detection precision, and inference speed on the dead sea bass dataset. This indicates that the performance improvements in the proposed YOLOv8n-Deadfish model in the dead sea bass detection task are not due to random fluctuations but represent substantial, stable, and statistically reliable enhancements.
3.8.2. Significance Analysis of Model Performance on the Labeled Fishes in the Wild Public Dataset
To verify whether the performance improvement in the YOLOv8n-Deadfish model on the public dataset (Labeled Fishes in the Wild) is statistically significant, an independent-samples
t-test was conducted on the results of YOLOv8n and YOLOv8n-Deadfish based on five independent experiments. The statistical results are presented in
Table 6.
As shown in the table, the calculated t-values for the four key performance metrics—precision, recall, mAP@0.5, and detection speed—are all relatively high, and the corresponding p-values are all 0.000. This indicates that the performance differences between the two models on these metrics are statistically highly significant. The results further confirm that the performance improvement in YOLOv8n-Deadfish over the original YOLOv8n model on the public dataset, Labeled Fishes in the Wild, is not due to random fluctuations but rather reflects substantial improvements that are statistically validated.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}