
A Lightweight Transformer Edge Intelligence Model for RUL Prediction Classification

Abstract
1. Introduction
- (1)
- Gated recurrent networks, such as LSTM and GRU, exhibit certain capabilities in processing sequential data of limited length. However, their inherent information compression mechanisms pose significant challenges when handling long sequences. As the sequence length extends, key information may be gradually lost during the iterative updating and filtering operations of the gating units, resulting in poor performance in capturing long-term dependencies. Moreover, these networks lack explicit state classification capabilities, which restricts their effectiveness in tasks that require hierarchical modeling and precise classification of complex sequential states.
- (2)
- CNN–RNN hybrid models integrate the local feature extraction advantages of convolutional neural networks with the temporal dependency modeling ability of recurrent neural networks. While they can effectively extract local features and model time series dynamics, their performance remains constrained by the information bottleneck of the RNN component. The gradient vanishing or explosion issues during the hidden state propagation in RNNs limit the model’s capacity to handle long sequences. Additionally, the intricate architecture of hybrid models, characterized by the interlacing of convolutional and recurrent layers, leads to a large number of parameters. This complexity renders lightweight design extremely challenging, as it is difficult to develop effective strategies for parameter pruning and computational optimization to meet the requirements of resource-constrained environments.
- (3)
- Attention mechanism-enhanced models, such as SA-LSTM and Res-HSA, have significantly improved prediction accuracy by enhancing the model’s ability to focus on key information. Nevertheless, when capturing long-term dependencies, these models face substantial computational burdens. The attention mechanism requires calculating the correlation between all positions in the sequence, resulting in a quadratic increase in computational complexity with the growth of sequence length. This high computational demand leads to slow inference speed and excessive memory consumption, making it difficult to deploy these models on resource-constrained edge devices, where real-time performance and low memory footprint are essential requirements.
2. Related Work
2.1. Transformer and GRU
2.2. Lightweight Methods
2.3. Contribution
- (1)
- We present TBiGNet, a lightweight Transformer-based architecture. The enhanced encoder–decoder structure significantly boosts the accuracy of the conventional Transformer by over 15%, while also achieving a reduction in more than 98% in both computational load and parameter size.
- (2)
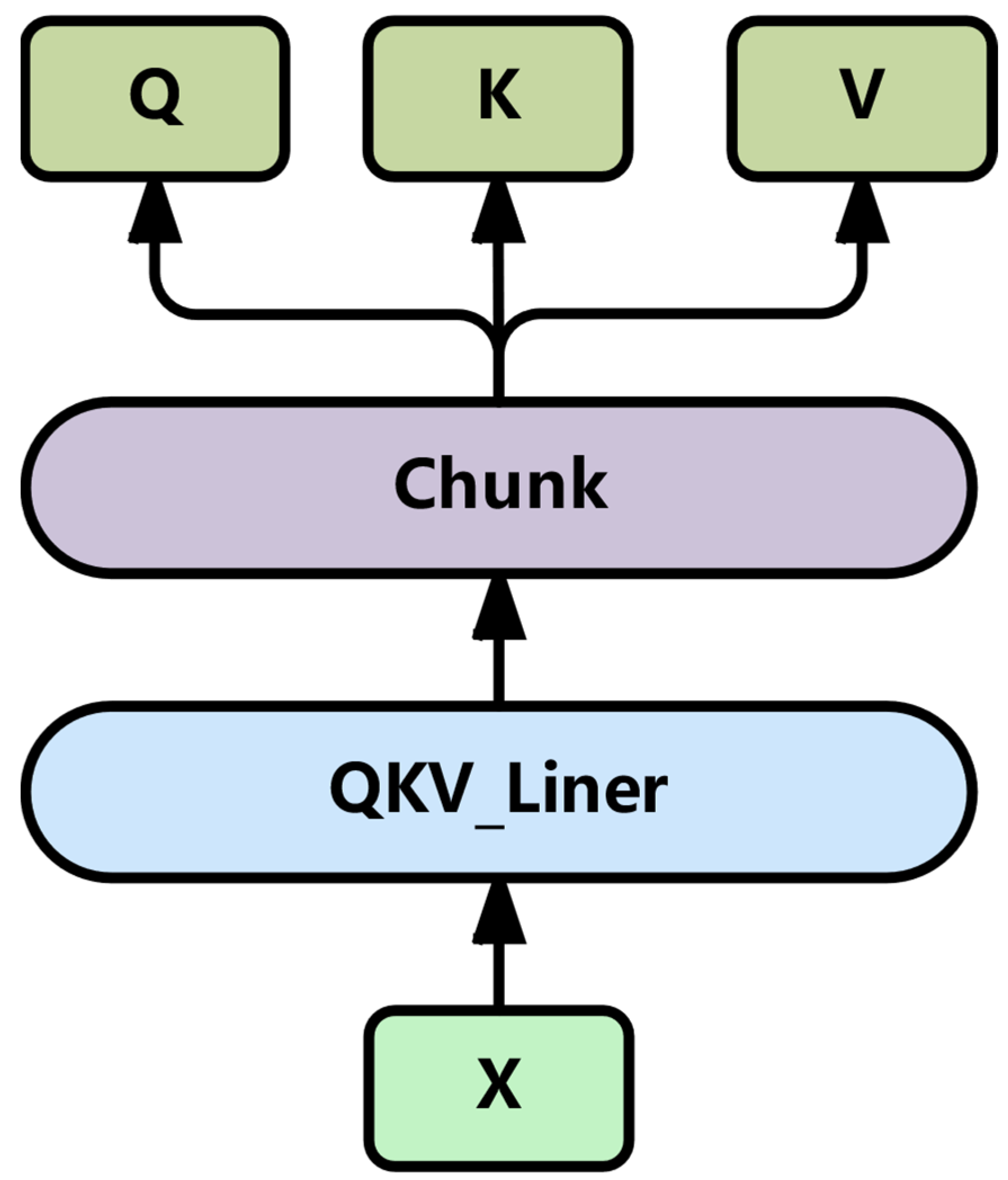
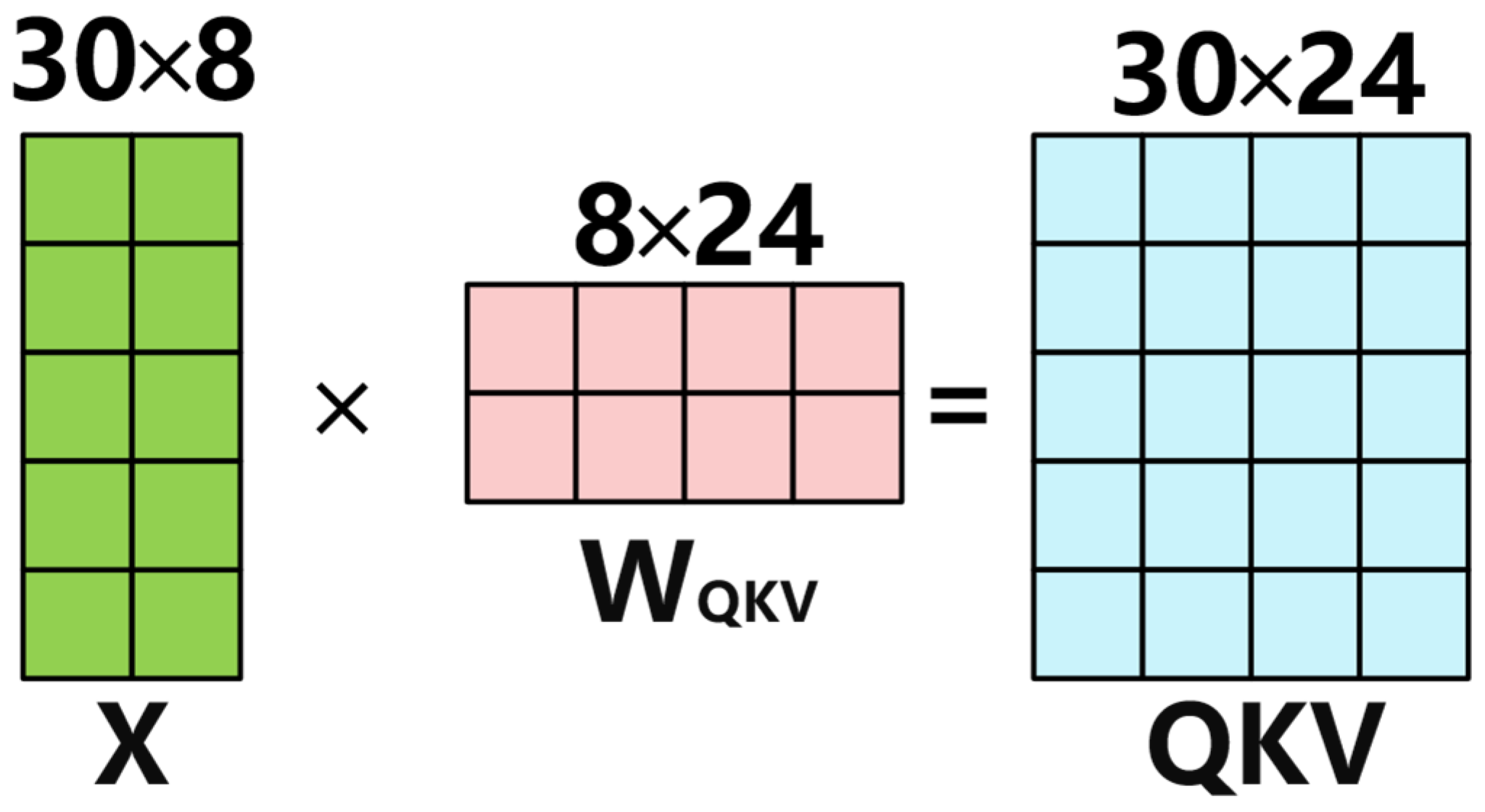
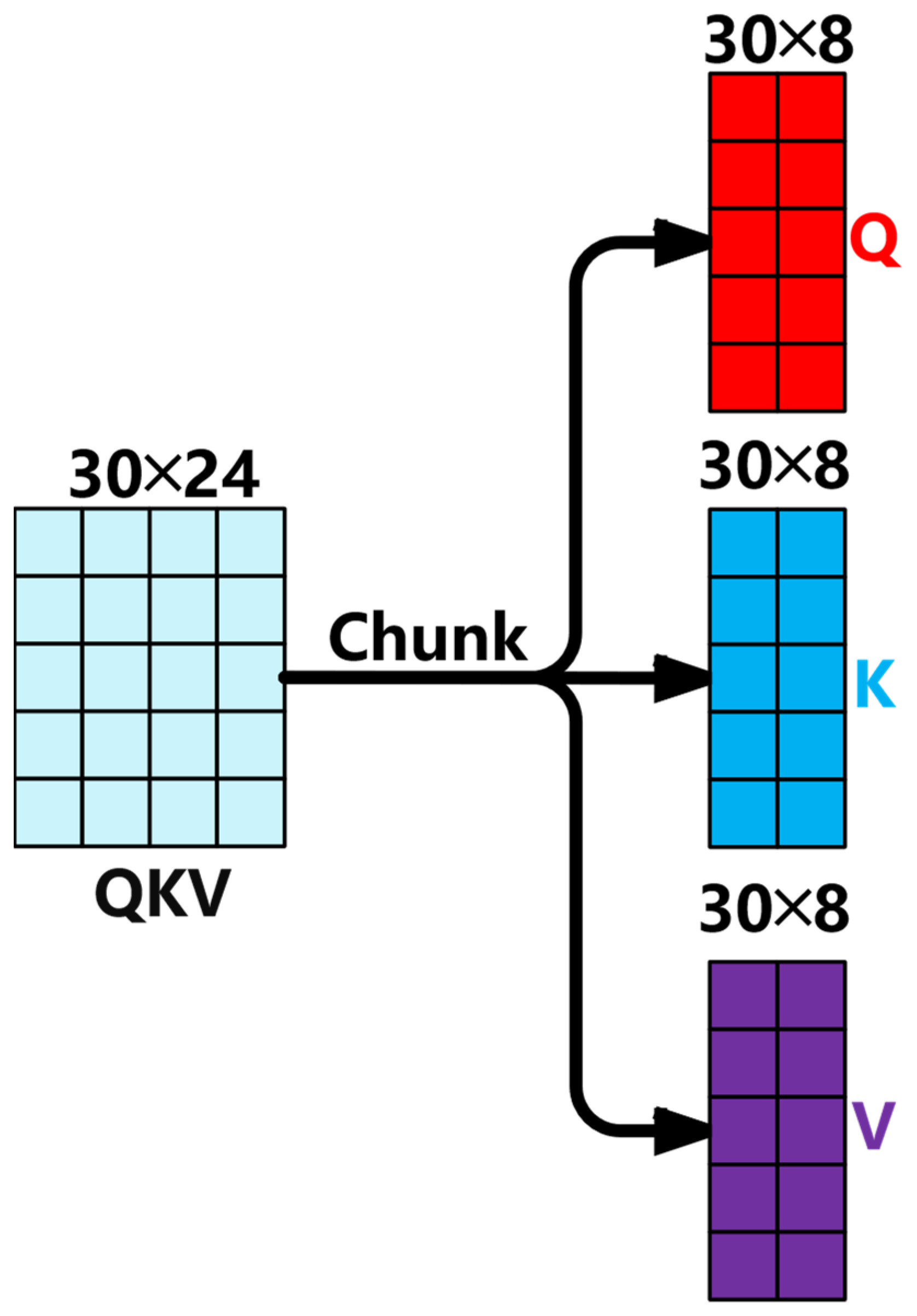
- A novel optimization of the Transformer’s multi-head attention is introduced, where the individual linear mappings of queries, keys, and values are combined into one efficient operation, achieving a 60% reduction in memory access overhead.
- (3)
- A new adaptive feature pruning approach is introduced into the encoder, allowing the model to selectively focus on the most critical features during processing. This strategy helps eliminate unnecessary features and boosts prediction accuracy by 6%.
- (4)
- Feature fusion for two different features is designed in the decoder. Using BiGRU to compensate for the deficiency of the attention mechanism in obtaining degraded features, compared with the traditional Transformer, the computational load and parameter number of the decoder are both reduced by more than 48%, and the model accuracy is improved by 7%.
- (5)
- Extensive experiments were conducted on the C-MAPSS dataset to validate the effectiveness of the proposed model. The results clearly show that TBiGNet surpasses existing methods in calculation accuracy, model size, and computational efficiency.
3. Methods
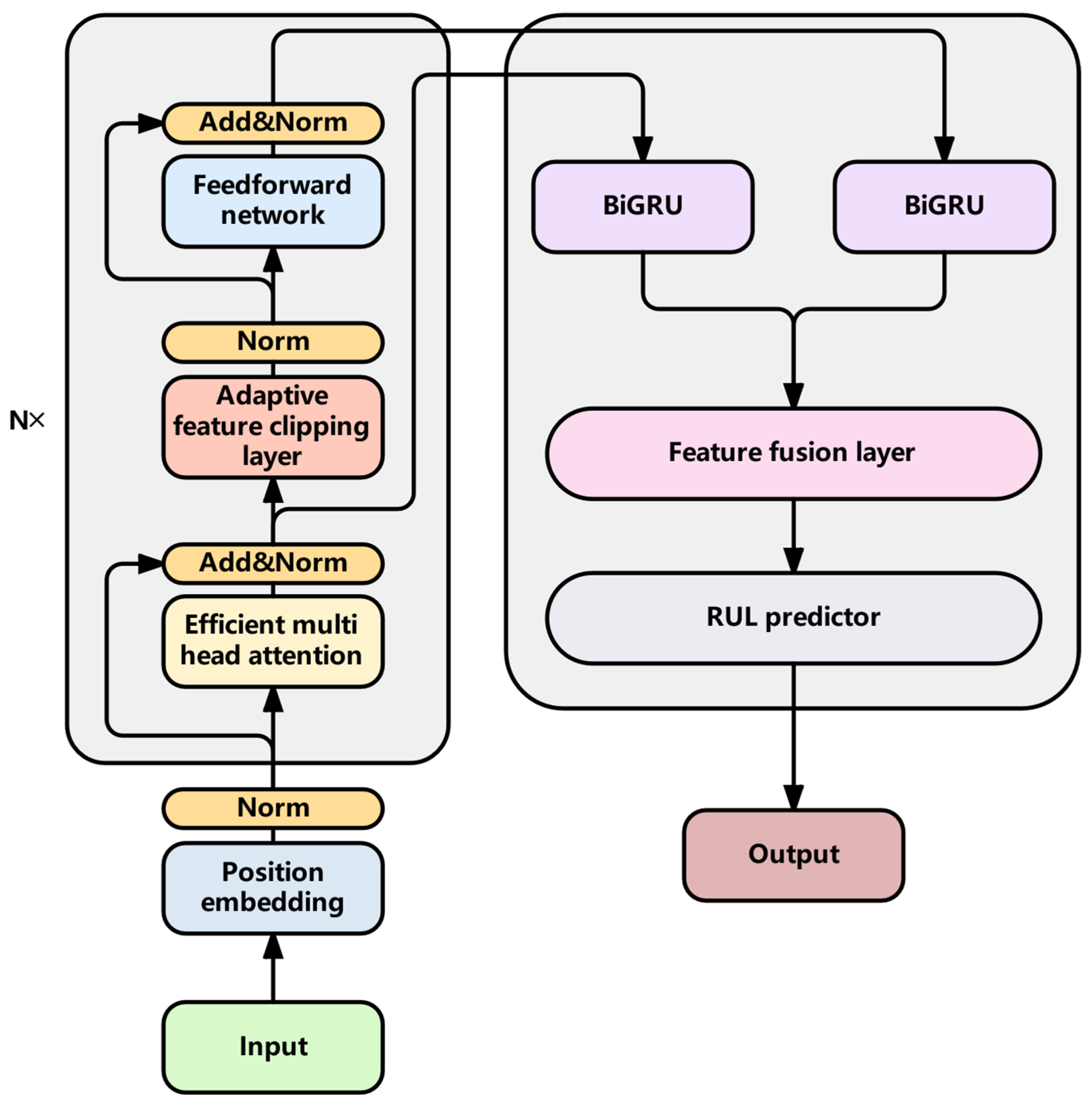
3.1. Overall Framework
3.2. Encoder Module
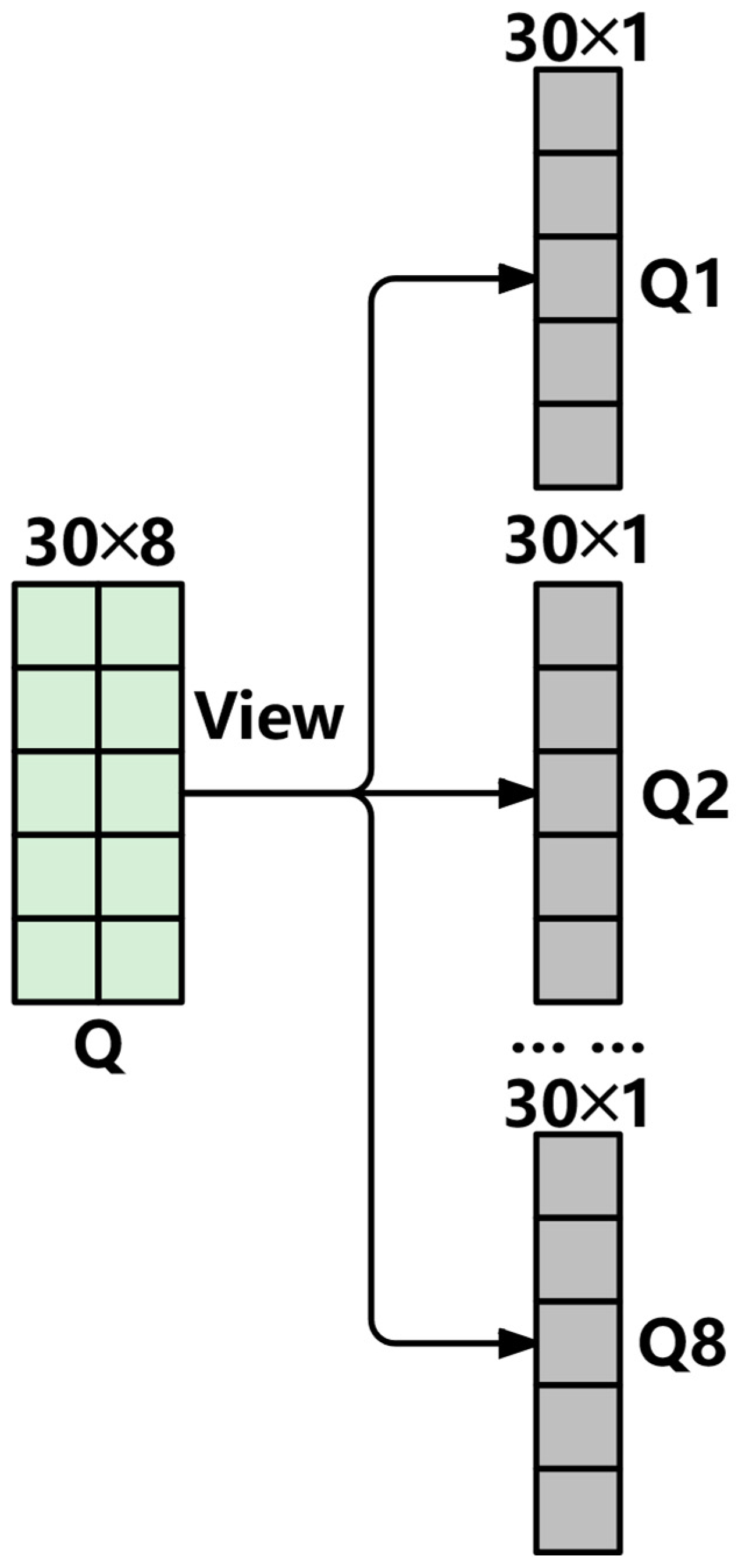
3.2.1. Efficient Multi-Head Attention Mechanism
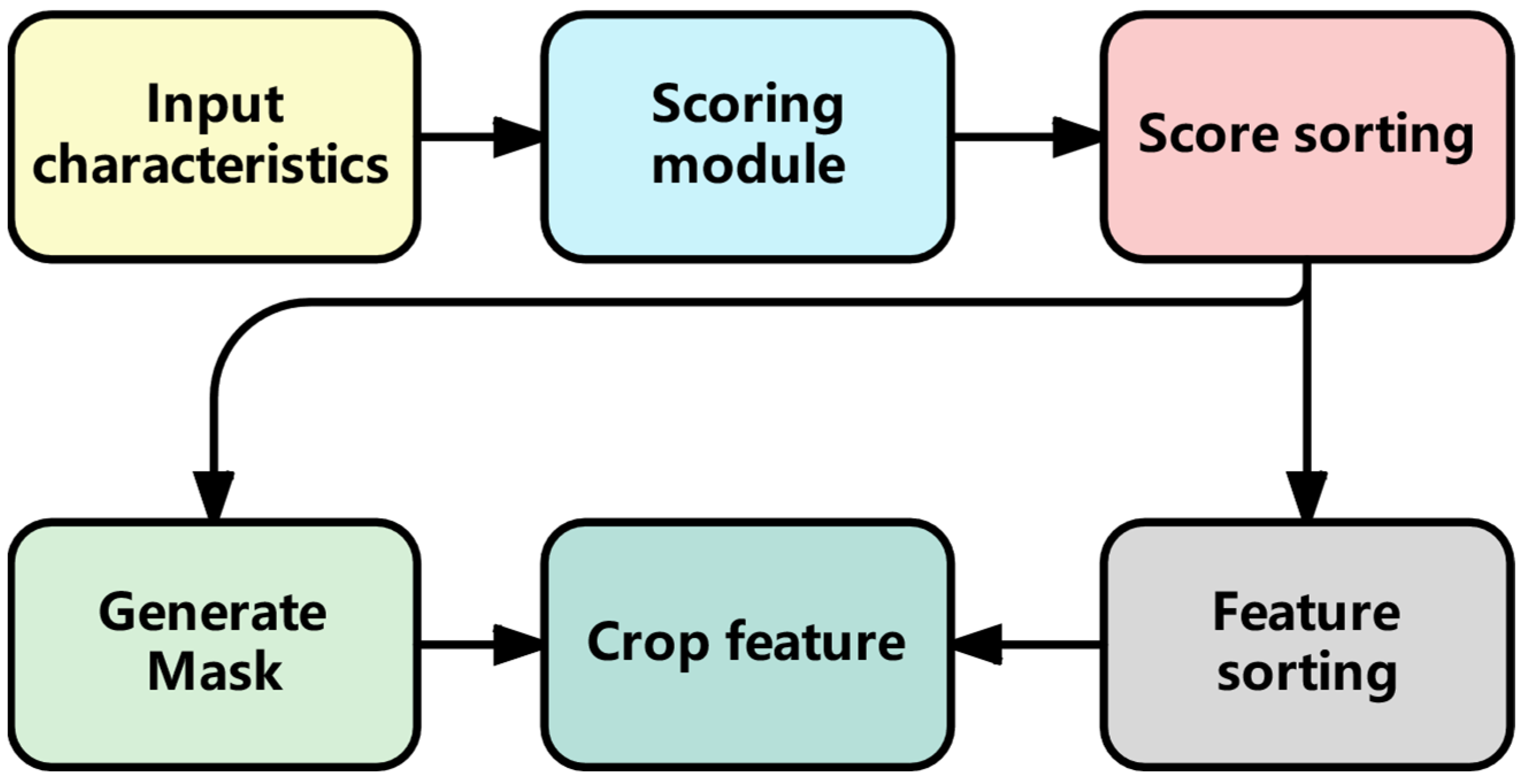
3.2.2. Adaptive Feature Cropping Layer
| Algorithm 1 Feature Clipping Step |
| Input: The extracted feature X, attenuation rate , initial reserved feature number , encoder layer number N Output: The fully cropped feature |
| 1: for i ← 1 to N do 2: The feature Xi extracted by the layer i encoder is scored by the Formula (7) based on the importance scoring module 3: Calculate the number of features K retained in the current layer based on Equations (13) and (14) 4: Sort the importance scores and features in descending order and calculate the threshold by Equations (8)–(10) 5: Generate the binary mask using Equation (11) 6: The input feature Xi is calculated by Formula (12) and the mask to obtain the feature trimmed by the ith layer encoder 7: end for 8: return Fully cropped feature |
3.2.3. Feedforward Network Layer
3.3. DecoderModule
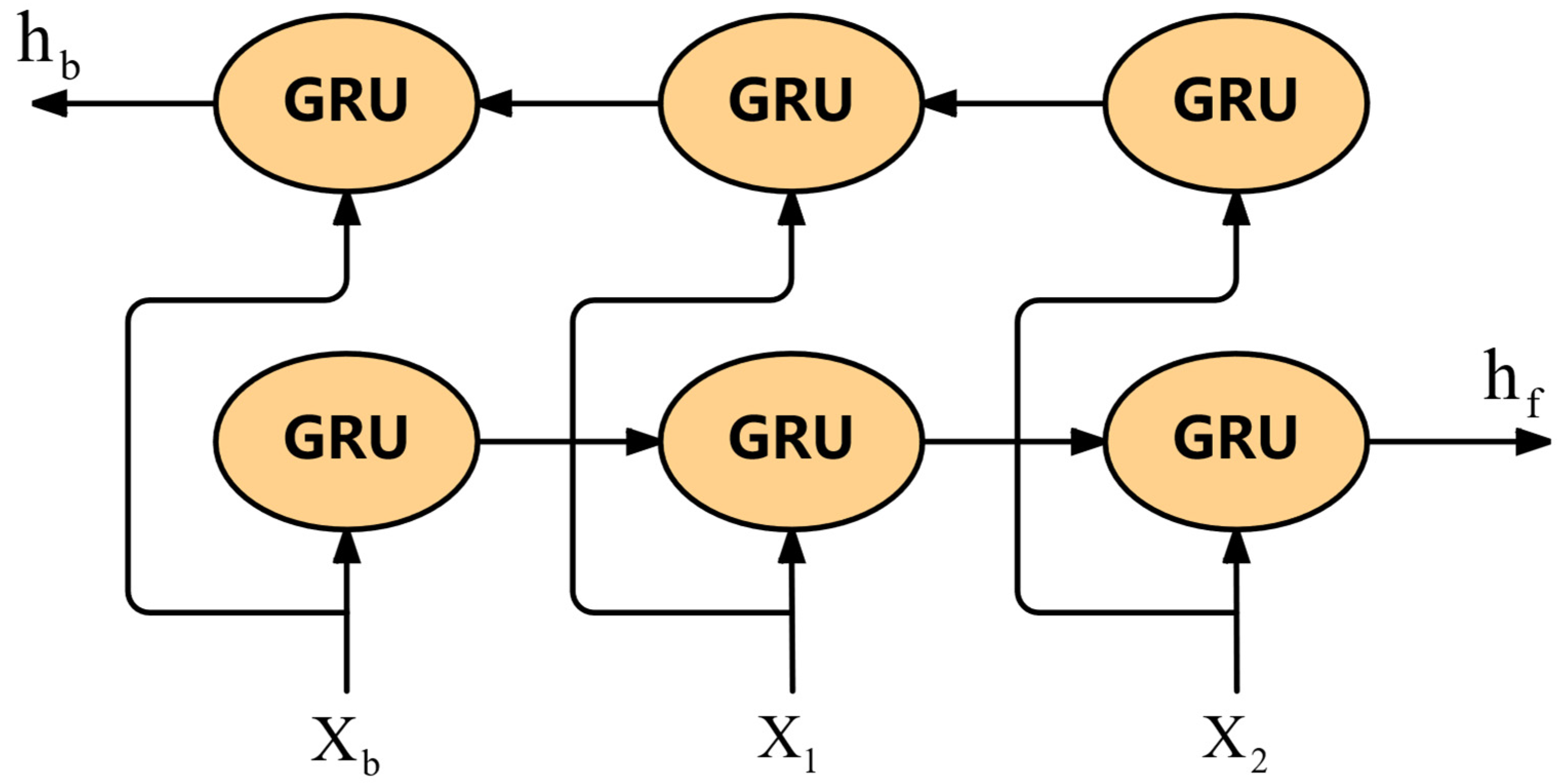
3.3.1. BiGRU
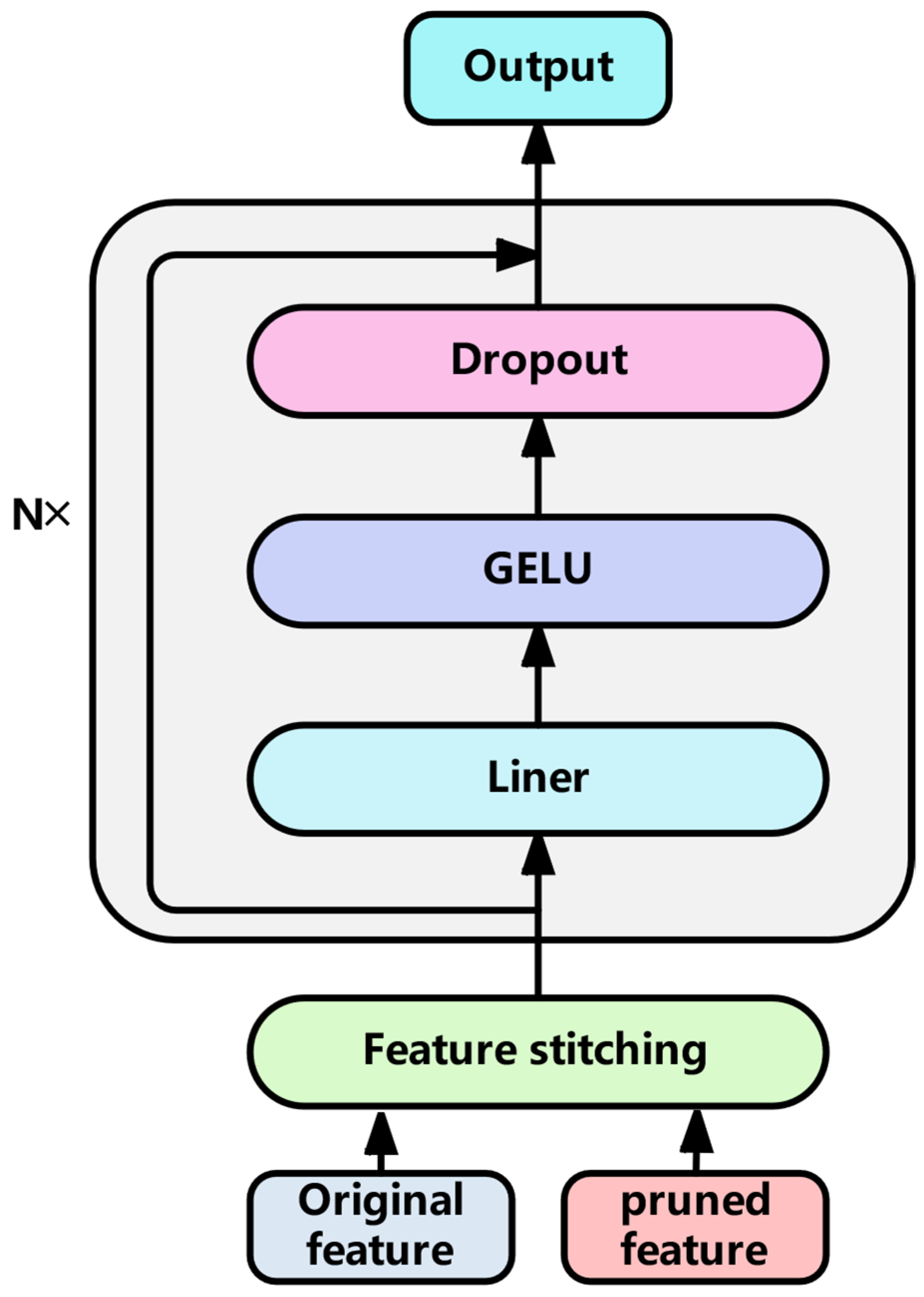
3.3.2. Feature Fusion Layer
| Algorithm 2 Multi-Scale Feature Fusion |
| Input: Original feature , fully trimmed feature , stacked feature fusion layers N Output: Characteristic of the last time step |
| 1: and use Formula (23) to splice features to obtain 2: for i ← 1 to N do 3: Input into Formula (24) to obtain the intermediate feature of the current layer 4: and are calculated through the residual link of Formula (25) to obtain 5: end for 6: return Characteristic of the last time step |
4. Experiment
4.1. Dataset Preprocessing
4.1.1. Sensor Signal Selection
4.1.2. Exponential Smoothing
4.1.3. Standardized Treatment
4.1.4. Sample Construction
4.2. Training Methods and Evaluation Indicators
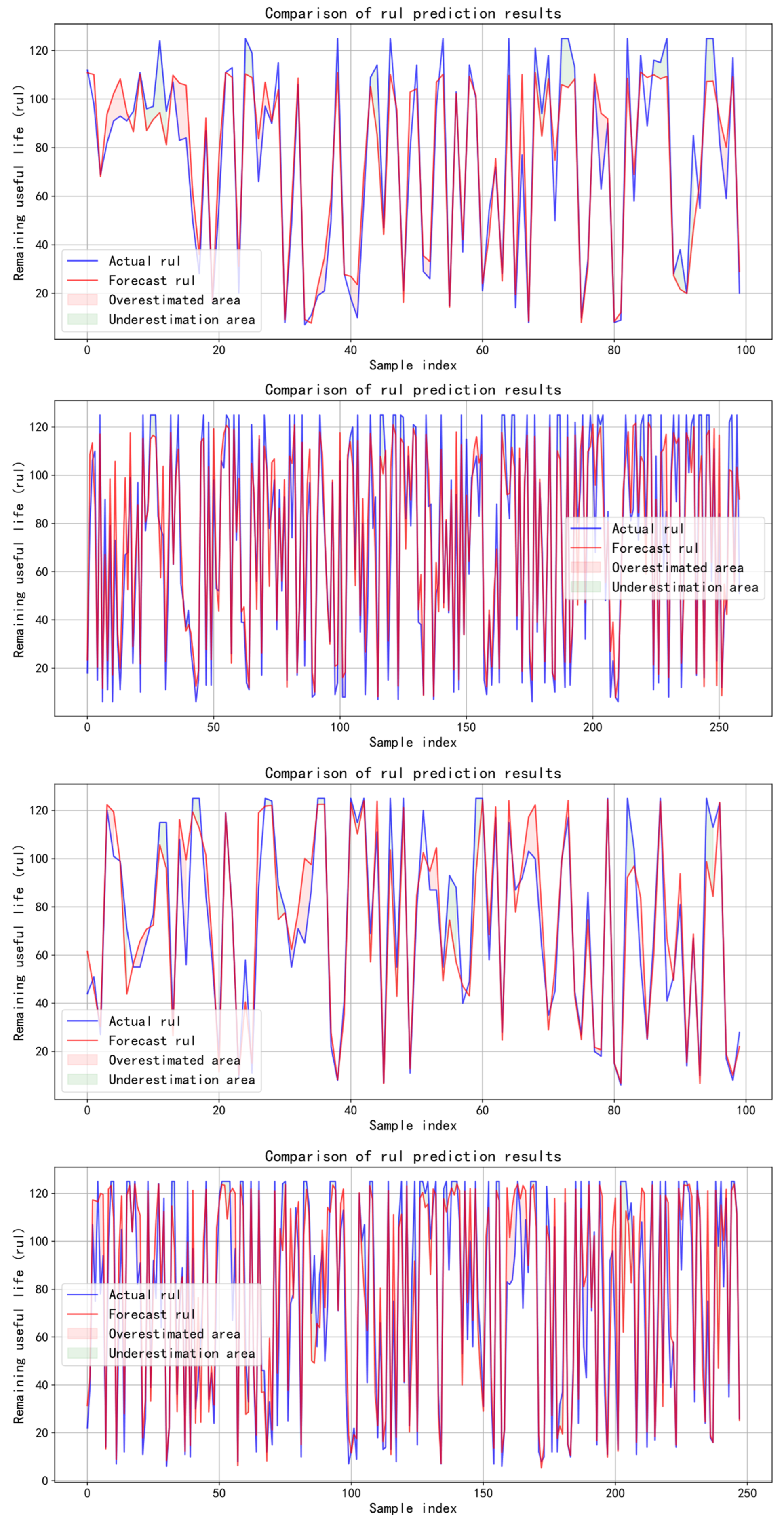
4.3. Comparative Experiment
4.4. Ablation Experiment
4.5. Complexity Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yu, W., II; Yong, K.; Chris, M. An improved similarity-based prognostic algorithm for RUL estimation using an RNN autoencoder scheme. Reliab. Eng. Syst. Saf. 2020, 199, 106926. [Google Scholar] [CrossRef]
- Yu, W., II; Yong, K.; Chris, M. Analysis of different RNN autoencoder variants for time series classification and machine prognostics. Mech. Syst. Signal Process. 2021, 149, 107322. [Google Scholar] [CrossRef]
- Xiang, S.; Li, P.; Huang, Y.; Luo, J.; Qin, Y. Single gated RNN with differential weighted information storage mechanism and its application to machine RUL prediction. Reliab. Eng. Syst. Saf. 2024, 242, 109741. [Google Scholar] [CrossRef]
- Bampoula, X.; Siaterlis, G.; Nikolakis, N.; Alexopoulos, K. A deep learning model for predictive maintenance in cyber-physical production systems using lstm autoencoders. Sensors 2021, 21, 972. [Google Scholar] [CrossRef]
- Ma, P.; Li, G.; Zhang, H.; Wang, C.; Li, X. Prediction of remaining useful life of rolling bearings based on multiscale efficient channel attention CNN and bidirectional GRU. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Sun, S.; Wang, J.; Xiao, Y.; Peng, J.; Zhou, X. Few-shot RUL prediction for engines based on CNN-GRU model. Sci. Rep. 2024, 14, 16041. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, N.; Chen, C.; Guo, Y. Adaptive self-attention LSTM for RUL prediction of lithium-ion batteries. Inf. Sci. 2023, 635, 398–413. [Google Scholar] [CrossRef]
- Zhu, J.; Jiang, Q.; Shen, Y.; Xu, F.; Zhu, Q. Res-HSA: Residual hybrid network with self-attention mechanism for RUL prediction of rotating machinery. Eng. Appl. Artif. Intell. 2023, 124, 106491. [Google Scholar] [CrossRef]
- Qin, Y.; Yang, J.; Zhou, J.; Pu, H.; Mao, Y. A new supervised multi-head self-attention autoencoder for health indicator construction and similarity-based machinery RUL prediction. Adv. Eng. Inform. 2023, 56, 101973. [Google Scholar] [CrossRef]
- Yu, Y.; Karimi, H.R.; Gelman, L.; Liu, X. A novel digital twin-enabled three-stage feature imputation framework for non-contact intelligent fault diagnosis. Adv. Eng. Inform. 2025, 66, 103434. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://arxiv.org/pdf/1706.03762 (accessed on 1 July 2025).
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Cao, C.; Sun, Z.; Lv, Q.; Min, L.; Zhang, Y. VS-TransGRU: A novel transformer-GRU-based framework enhanced by visual-semantic fusion for egocentric action anticipation. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 11605–11916. [Google Scholar] [CrossRef]
- Zhang, B.; Zhou, W. Transformer-encoder-GRU (TE-GRU) for Chinese sentiment analysis on Chinese comment text. Neural Process. Lett. 2023, 55, 1847–1867. [Google Scholar] [CrossRef]
- Yan, X.; Jin, X.; Jiang, D.; Xiang, L. Remaining useful life prediction of rolling bearings based on CNN-GRU-MSA with multi-channel feature fusion. Nondestruct. Test. Eval. 2024, 1–26. [Google Scholar] [CrossRef]
- Cao, L.; Zhang, H.; Meng, Z.; Wang, X. A parallel GRU with dual-stage attention mechanism model integrating uncertainty quantification for probabilistic RUL prediction of wind turbine bearings. Reliab. Eng. Syst. Saf. 2023, 235, 109197. [Google Scholar] [CrossRef]
- Ren, L.; Wang, H.; Mo, T.; Yang, L.T. A lightweight group transformer-based time series reduction network for edge intelligence and its application in industrial RUL prediction. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 3720–3729. [Google Scholar] [CrossRef]
- Ren, L.; Wang, T.; Jia, Z.; Li, F.; Han, H. A lightweight and adaptive knowledge distillation framework for remaining useful life prediction. IEEE Trans. Ind. Inform. 2022, 19, 9060–9070. [Google Scholar] [CrossRef]
- Shi, J.; Gao, J.; Xiang, S. Adaptively Lightweight Spatiotemporal Information-Extraction-Operator-Based DL Method for Aero-Engine RUL Prediction. Sensors 2023, 23, 6163. [Google Scholar] [CrossRef]
- Deng, X.; Zhu, G.; Zhang, Q. Bearing RUL prediction and fault diagnosis system based on parallel multi-scale MIMT lightweight model. Meas. Sci. Technol. 2024, 35, 126216. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, X.; Wang, J. Lightweight bidirectional long short-term memory based on automated model pruning with application to bearing remaining useful life prediction. Eng. Appl. Artif. Intell. 2023, 118, 105662. [Google Scholar] [CrossRef]
- Lu, Z.; Li, X.; Yi, R. Small language models: Survey, measurements, and insights. arXiv 2024, arXiv:2409.15790. [Google Scholar]
- Lian, B.; Wei, Z.; Sun, X.; Li, Z.; Zhao, J. A review on rainfall measurement based on commercial microwave links in wireless cellular networks. Sensors 2022, 22, 4395. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Wu, J.; Fu, S.; Zhang, S.; Tong, C.; Zu, L. Channel attention & temporal attention based temporal convolutional network: A dual attention framework for remaining useful life prediction of the aircraft engines. Adv. Eng. Inform. 2024, 60, 102372. [Google Scholar]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective deep belief networks ensemble for remaining useful life estimation in prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2306–2318. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Ding, Q.; Sun, J.-Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, W.; Li, Q. Dual-aspect self-attention based on transformer for remaining useful life prediction. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- Khelif, R.; Chebel-Morello, B.; Malinowski, S.; Laajili, E.; Fnaiech, F.; Zerhouni, N. Direct remaining useful life estimation based on support vector regression. IEEE Trans. Ind. Electron. 2016, 64, 2276–2285. [Google Scholar] [CrossRef]
- Giduthuri, S.B.; Zhao, P.; Li, X.-L. Deep convolutional neural network based regression approach for estimation of remaining useful life. In Proceedings of the Database Systems for Advanced Applications: 21st International Conference, DASFAA 2016, Dallas, TX, USA, April 16-19, 2016; Proceedings, Part i 21. Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Zheng, S.; Ristovski, K.; Farahat, A.K.; Gupta, C. Long short-term memory network for remaining useful life estimation. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; IEEE: New York, NY, USA, 2017. [Google Scholar]
- Verstraete, D.; Droguett, E. A deep adversarial approach based on multi-sensor fusion for semi-supervised remaining useful life prognostics. Sensors 2019, 20, 176. [Google Scholar] [CrossRef]
- Hu, Q.; Zhao, Y.; Wang, Y.; Peng, P.; Ren, L. Remaining useful life estimation in prognostics using deep reinforcement learning. Ieee Access 2023, 11, 32919–32934. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, Y.; Wu, S.; Li, X.; Luo, H.; Yin, S. Prediction of remaining useful life based on bidirectional gated recurrent unit with temporal self-attention mechanism. Reliab. Eng. Syst. Saf. 2022, 221, 108297. [Google Scholar]
- Dong, Z.-C.; Fan, P.-Z.; Lei, X.-F.; Panayirci, E. Power and rate adaptation based on CSI and velocity variation for OFDM systems under doubly selective fading channels. IEEE Access 2016, 4, 6833–6845. [Google Scholar] [CrossRef]
- Liu, H.; Liu, Z.; Jia, W.; Lin, X. Remaining useful life prediction using a novel feature-attention-based end-to-end approach. IEEE Trans. Ind. Inform. 2020, 17, 1197–1207. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Q.; Li, X.; Huang, B. Remaining useful life estimation via transformer encoder enhanced by a gated convolutional unit. J. Intell. Manuf. 2021, 32, 1997–2006. [Google Scholar]
- Liu, Z.; Zheng, X.; Xue, A.; Ge, M.; Jiang, A. Multi-Head Self-Attention-Based Fully Convolutional Network for RUL Prediction of Turbofan Engines. Algorithms 2024, 17, 321. [Google Scholar]
- Ren, L.; Li, S.; Laili, Y.; Zhang, L. BTCAN: A binary trend-aware network for industrial edge intelligence and application in aero-engine RUL prediction. IEEE Trans. Instrum. Meas. 2024, 73, 1–10. [Google Scholar]
- Zhang, X.; Sun, J.; Wang, J.; Jin, Y.; Wang, L.; Liu, Z. PAOLTransformer: Pruning-adaptive optimal lightweight Transformer model for aero-engine remaining useful life prediction. Reliab. Eng. Syst. Saf. 2023, 240, 109605. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # | Attribute | Description | Unit |
|---|---|---|---|
| 1 | ID | engine IDs | - |
| 2 | cycle | flight cycles | - |
| 3 | altitude | flight height of the aircraft | foot |
| 4 | Mach number | ratio of flight speed to speed of sound | - |
| 5 | sea-level temperature | flight temperature of the aircraft | °F |
| 6 | T2 | total temperature at fan inlet | °R |
| 7 | T24 | total temperature at LPC outlet | °R |
| 8 | T30 | total temperature at HPC outlet | °R |
| 9 | T50 | total temperature at LPT outlet | °R |
| 10 | P2 | total pressure at fan inlet | psia |
| 11 | P15 | total pressure in the bypass | psia |
| 12 | P30 | total pressure at HPC outlet | psia |
| 13 | Nf | physical speed of low-pressure shaft | rpm |
| 14 | Nc | physical speed of high-pressure shaft | rpm |
| 15 | epr | engine pressure ratio | - |
| 16 | Ps30 | static pressure at HPC outlet | psia |
| 17 | phi | ratio of fuel flow to Ps30 | pps/psi |
| 18 | NRf | corrected fan speed of low-pressure shaft | rpm |
| 19 | NRc | corrected core speed of high-pressure shaft | rpm |
| 20 | BPR | bypass ratio | - |
| 21 | farB | burner fuel-air ratio | - |
| 22 | htBleed | enthalpy of bleed | - |
| 23 | Nf_dmd | demanded fan speed | rpm |
| 24 | PCNfR_dmd | demanded corrected fan speed | rpm |
| 25 | W31 | HPT coolant bleed | lbm/s |
| 26 | W32 | LPT coolant bleed | lbm/s |
| Dataset | FD001 | FD002 | FD003 | FD004 |
|---|---|---|---|---|
| Training set | 100 | 260 | 100 | 249 |
| Test set | 100 | 259 | 100 | 248 |
| Operating conditions | 1 | 6 | 1 | 6 |
| Fault status | 1 | 1 | 2 | 2 |
| Model | FD001 | FD002 | FD003 | FD004 | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | Score | RMSE | Score | RMSE | Score | RMSE | Score | |
| SVR | 18.28 | 1004.75 | 30.50 | 17,132.17 | 21.37 | 2084.75 | 34.11 | 15,740.27 |
| CNN | 18.44 | 1286.70 | 30.29 | 13,570 | 19.81 | 1596.20 | 29.15 | 7886.40 |
| DBN | 15.21 | 417.59 | 27.12 | 9031.64 | 14.71 | 442.43 | 29.88 | 7954.51 |
| ELM | 17.27 | 523 | 37.28 | 498,149 | 18.90 | 573 | 38.43 | 121,414 |
| GB | 15.67 | 474.01 | 29.09 | 87,280.06 | 16.84 | 576.72 | 29.01 | 17,817.92 |
| RF | 17.91 | 479.75 | 29.59 | 70,456.86 | 20.27 | 711.13 | 31.12 | 46,567.63 |
| LSTM-FNN | 16.14 | 338 | 24.49 | 4450 | 16.18 | 852 | 28.17 | 5550 |
| GAN | 16.91 | N/A | N/A | N/A | N/A | N/A | 46.40 | N/A |
| IDMFFN | 12.18 | 205 | 18.19 | 10,412 | 11.89 | 206 | 21.72 | 3339 |
| BIGRU-TSAM | 12.56 | 213 | 18.94 | 2264 | 12.45 | 233 | 20.47 | 3610 |
| AM-LSTM | 14.53 | 322.44 | N/A | N/A | N/A | N/A | 27.08 | 5649.14 |
| AGCNN | 12.42 | 226 | 19.43 | 1492 | 13.39 | 227 | 21.50 | 3392 |
| GCU-Transformer | 11.27 | N/A | 22.81 | N/A | 11.42 | N/A | 24.86 | N/A |
| Cau-AttnPINN | N/A | N/A | 19.08 | 1665 | N/A | N/A | 20.70 | 3035 |
| BTCAN | 14.46 | 309 | 19.88 | 2800 | 12.79 | 298 | 22.03 | 4224 |
| PAOLTransformer | 12.49 | 257.71 | 21.63 | 1692.59 | 12.66 | 274.15 | 23.86 | 3163.41 |
| TBiGNet | 12.53 | 219.80 | 13.67 | 812.10 | 13.59 | 775.69 | 17.40 | 2347.92 |
| Model | Parameter Num | FLOPs |
|---|---|---|
| PAOLTransformer | 2.6 × 105 | 6 × 107 |
| GCU-Transformer | 1,781,937 | 6.32 × 107 |
| AM-BGRU | 18,629 | 1.58 × 106 |
| BIGRU-TSAM | 2,825,443 | 1.68 × 108 |
| AM-LSTM | 90,061 | 1.06 × 106 |
| TBiGNet | 1890 | 1.31 × 105 |
| Model | RMSE Mean | Score Mean |
|---|---|---|
| PAOLTransformer | 16.28 | 1346 |
| GCU-Transformer | 17.59 | N/A |
| AM-BGRU | 16.69 | 1334 |
| BIGRU-TSAM | 16.10 | 1580 |
| AM-LSTM | 20.81 | 2985 |
| TBiGNet | 14.20 | 1038 |
| Model | FD001 | FD002 | FD003 | FD004 | ||||
|---|---|---|---|---|---|---|---|---|
| RMSE | Score | RMSE | Score | RMSE | Score | RMSE | Score | |
| Transformer | 15.11 | 480.28 | 15.87 | 1780.14 | 15.33 | 607.16 | 20.68 | 6819.97 |
| Model 1 | 14.22 | 425.51 | 15.48 | 1116.11 | 13.36 | 389.95 | 19.79 | 4822.15 |
| Model 2 | 13.69 | 420.54 | 15.22 | 922.28 | 13.83 | 480.83 | 18.54 | 3181.45 |
| TBiGNet | 12.53 | 219.80 | 13.67 | 812.10 | 13.33 | 370.81 | 17.40 | 2347.92 |
| Model | Parameter Num | Bytes | FLOPs |
|---|---|---|---|
| Transformer | 1.39 × 105 | 4.54 × 106 | 7.89 × 106 |
| Model 1 | 7.18 × 104 | 2.61 × 106 | 4.09 × 106 |
| Model 2 | 7.03 × 104 | 2.28 × 106 | 3.98 × 106 |
| TBiGNet | 1890 | 2.72 × 105 | 1.31 × 105 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Li, Y.; Liu, H.; Liu, T. A Lightweight Transformer Edge Intelligence Model for RUL Prediction Classification. Sensors 2025, 25, 4224. https://doi.org/10.3390/s25134224
Wang L, Li Y, Liu H, Liu T. A Lightweight Transformer Edge Intelligence Model for RUL Prediction Classification. Sensors. 2025; 25(13):4224. https://doi.org/10.3390/s25134224
Chicago/Turabian StyleWang, Lilu, Yongqi Li, Haiyuan Liu, and Taihui Liu. 2025. "A Lightweight Transformer Edge Intelligence Model for RUL Prediction Classification" Sensors 25, no. 13: 4224. https://doi.org/10.3390/s25134224
APA StyleWang, L., Li, Y., Liu, H., & Liu, T. (2025). A Lightweight Transformer Edge Intelligence Model for RUL Prediction Classification. Sensors, 25(13), 4224. https://doi.org/10.3390/s25134224