
Applying Reinforcement Learning to Protect Deep Neural Networks from Soft Errors




Abstract
1. Introduction
- Proposing a methodological framework integrating fault injection, layer-wise resiliency analysis and learning-based agent to reveal and protect DNNs against soft errors.
- Designing a layer-wise RL-based agent to identify vulnerable bits in each layer. This layer-wise learning agent efficiently and dynamically generates bit masks to protect DNNs from soft errors.
- Adopting transfer learning to improve the training efficiency and flexibility in selecting protected bits by using layer-wise resiliency as prior knowledge.
2. Related Work
2.1. Injecting Faults Within DNNs
2.2. Protecting DNNs from Soft Errors
2.3. Adopting RL to Analyze Behaviors of DNNs
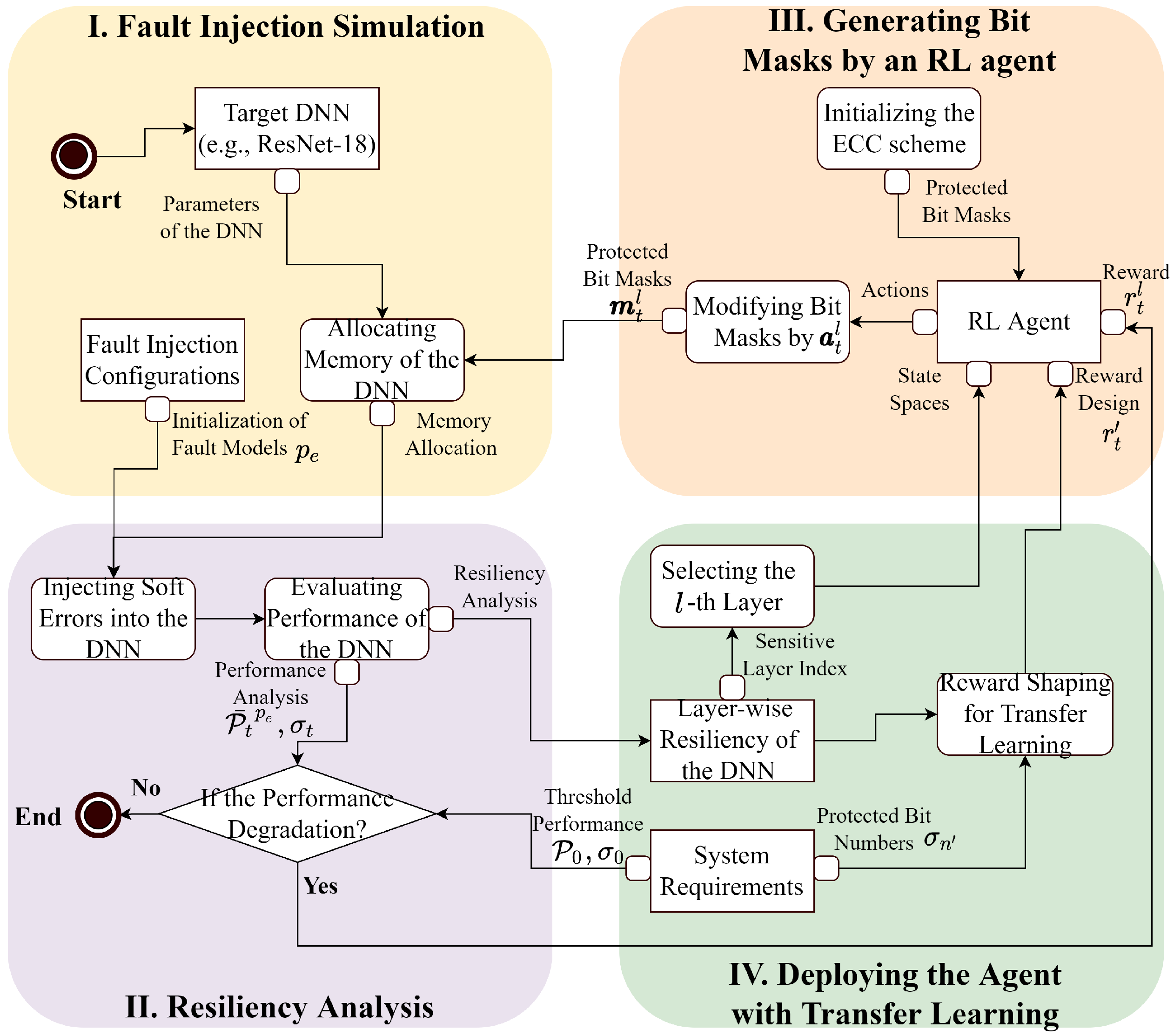
3. Methodology
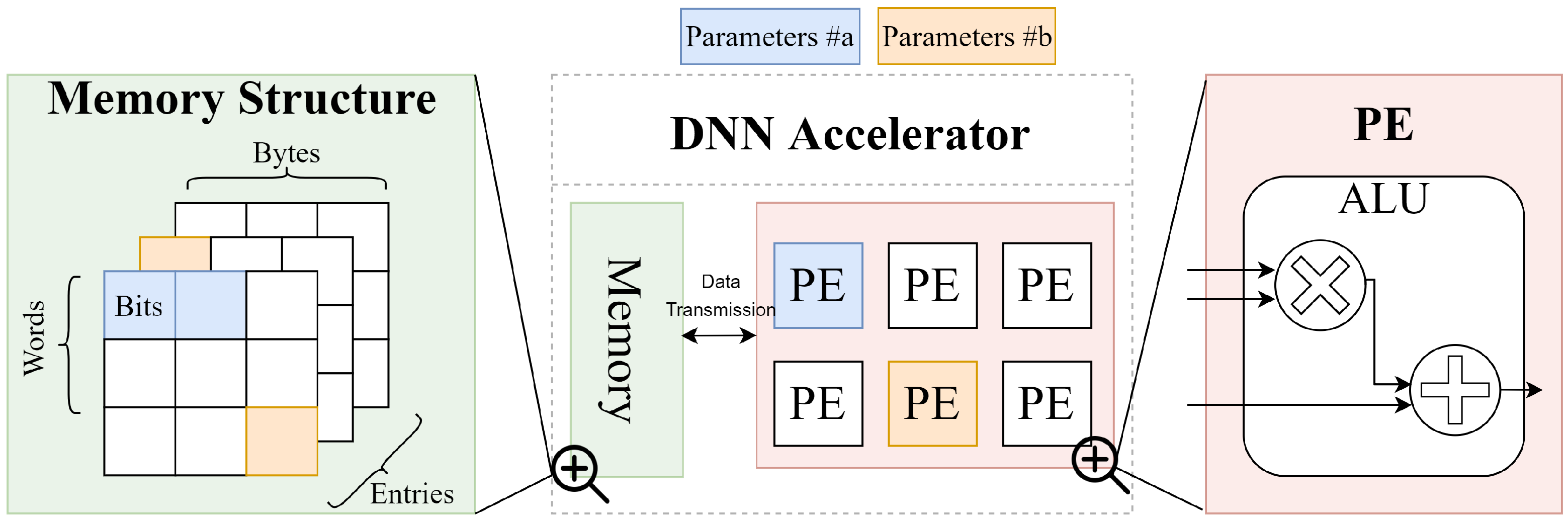
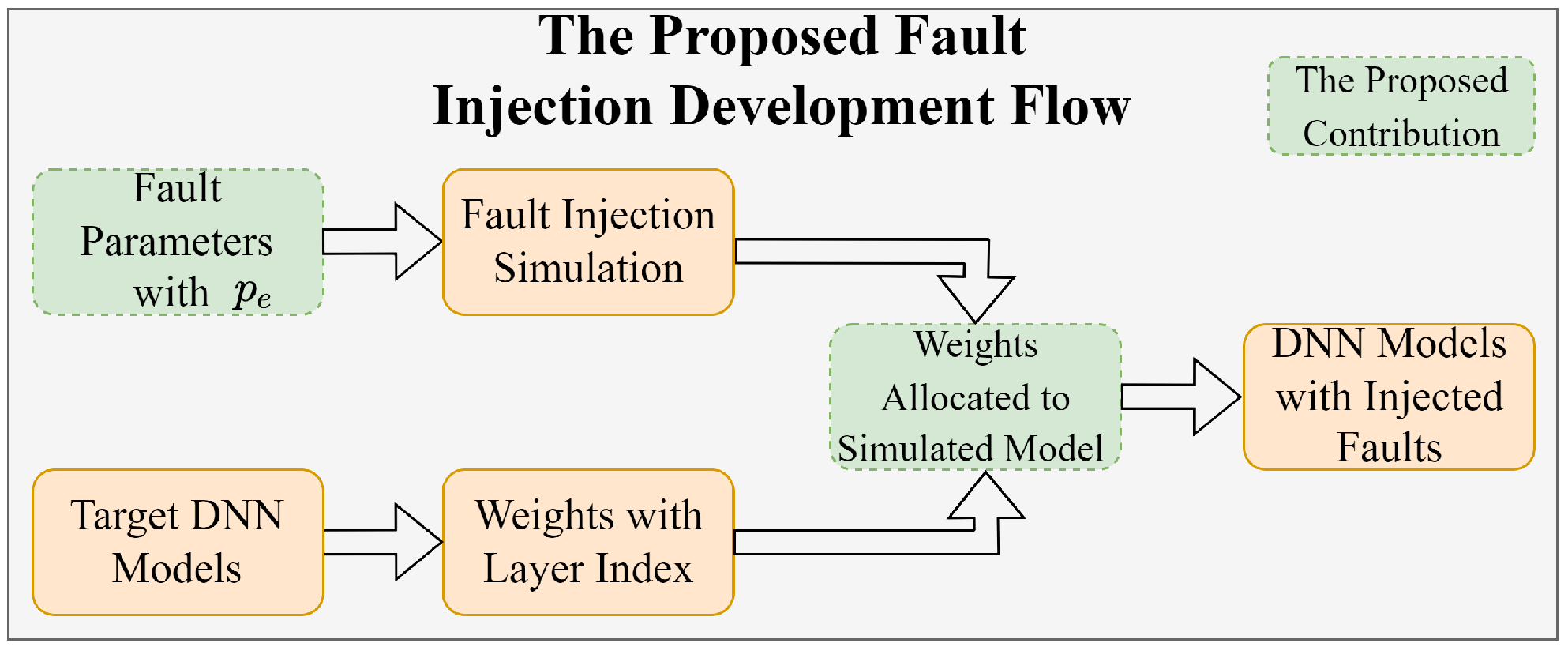
3.1. Task I: Simulating Faults Within DNNs
3.2. Task II: Analyzing Layer-Wise Resiliency of DNNs
3.3. Task III: Generating Bit Masks by a RL-Based Agent
3.4. Task IV: Deploying the Agent with Transfer Learning
4. Case Study
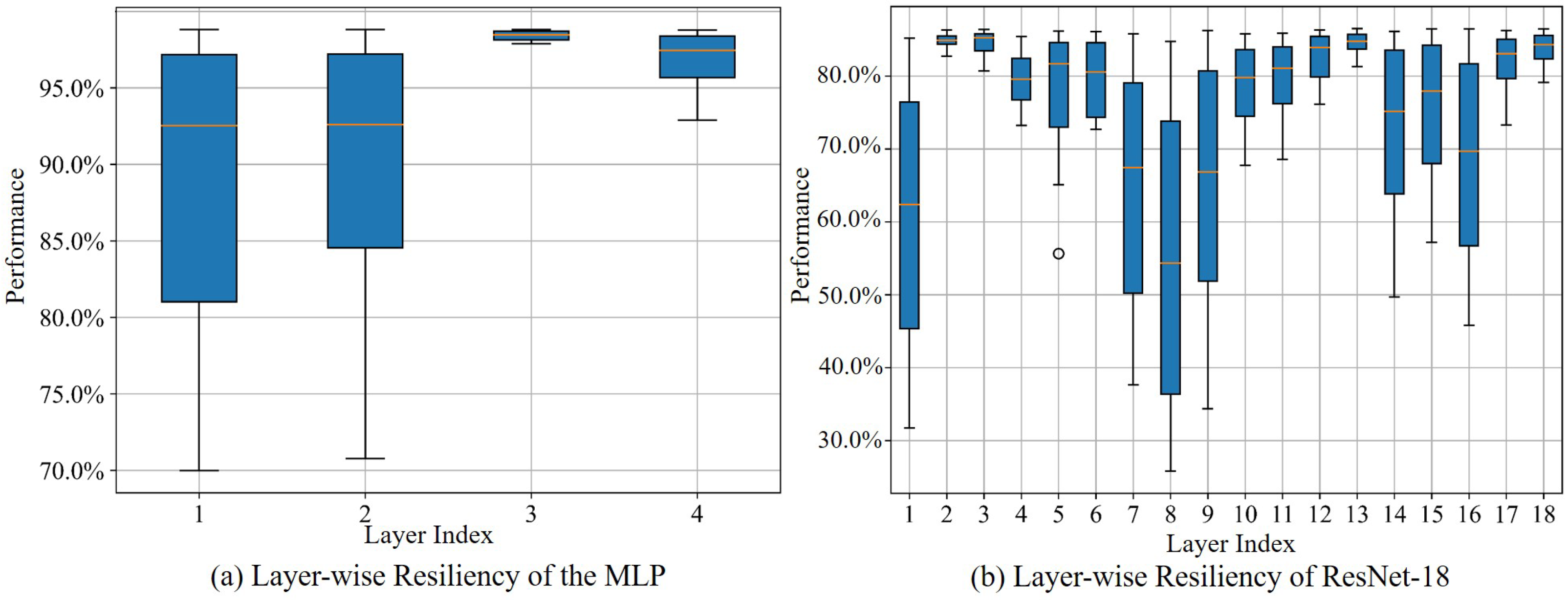
4.1. Evaluating Resiliency by Injecting Faults
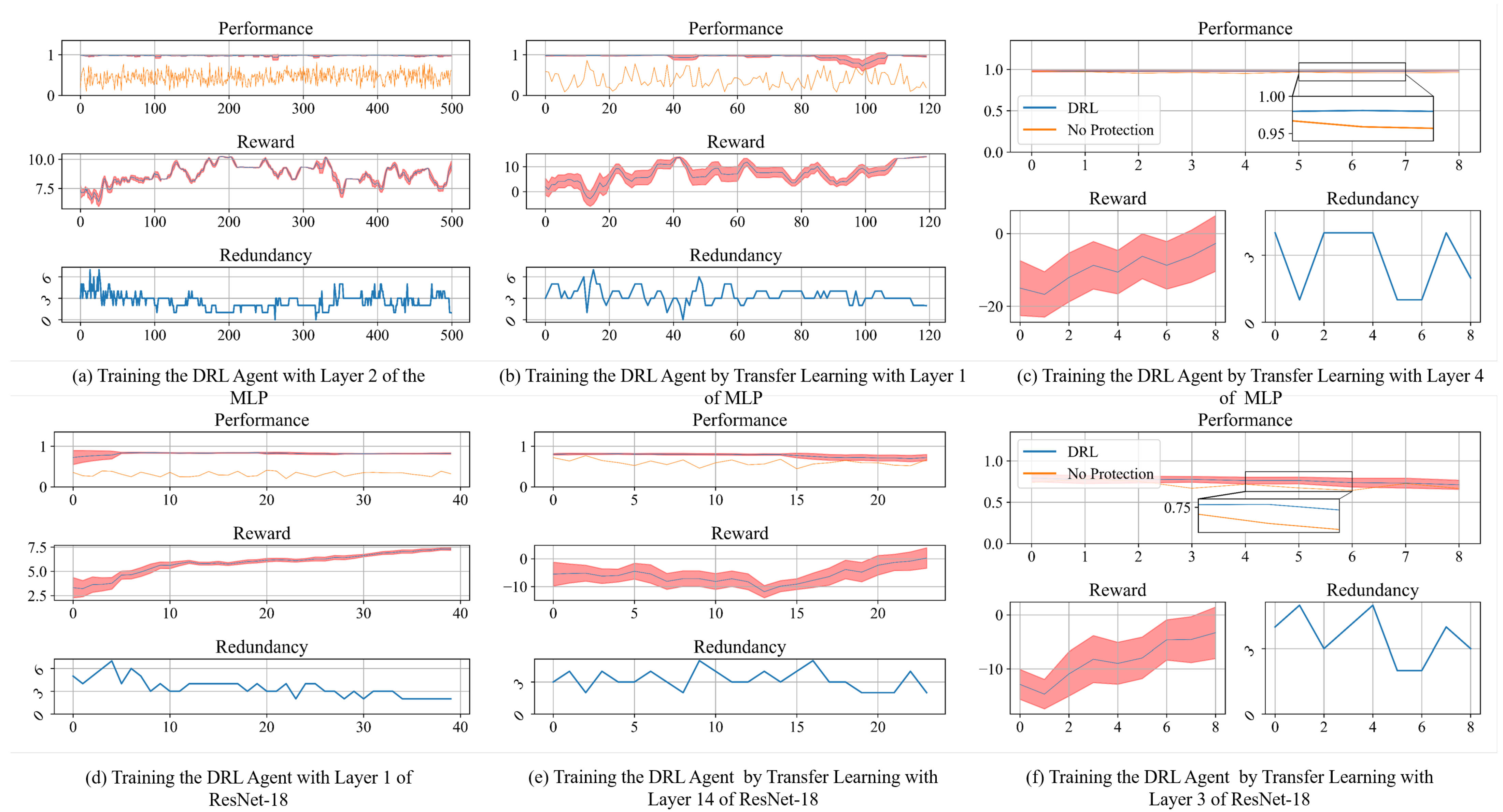
4.2. Training the DRL-Based Agent with a Specific Layer
| Algorithm 1 Training the DRL-based Agent for a Specific Layer |
|
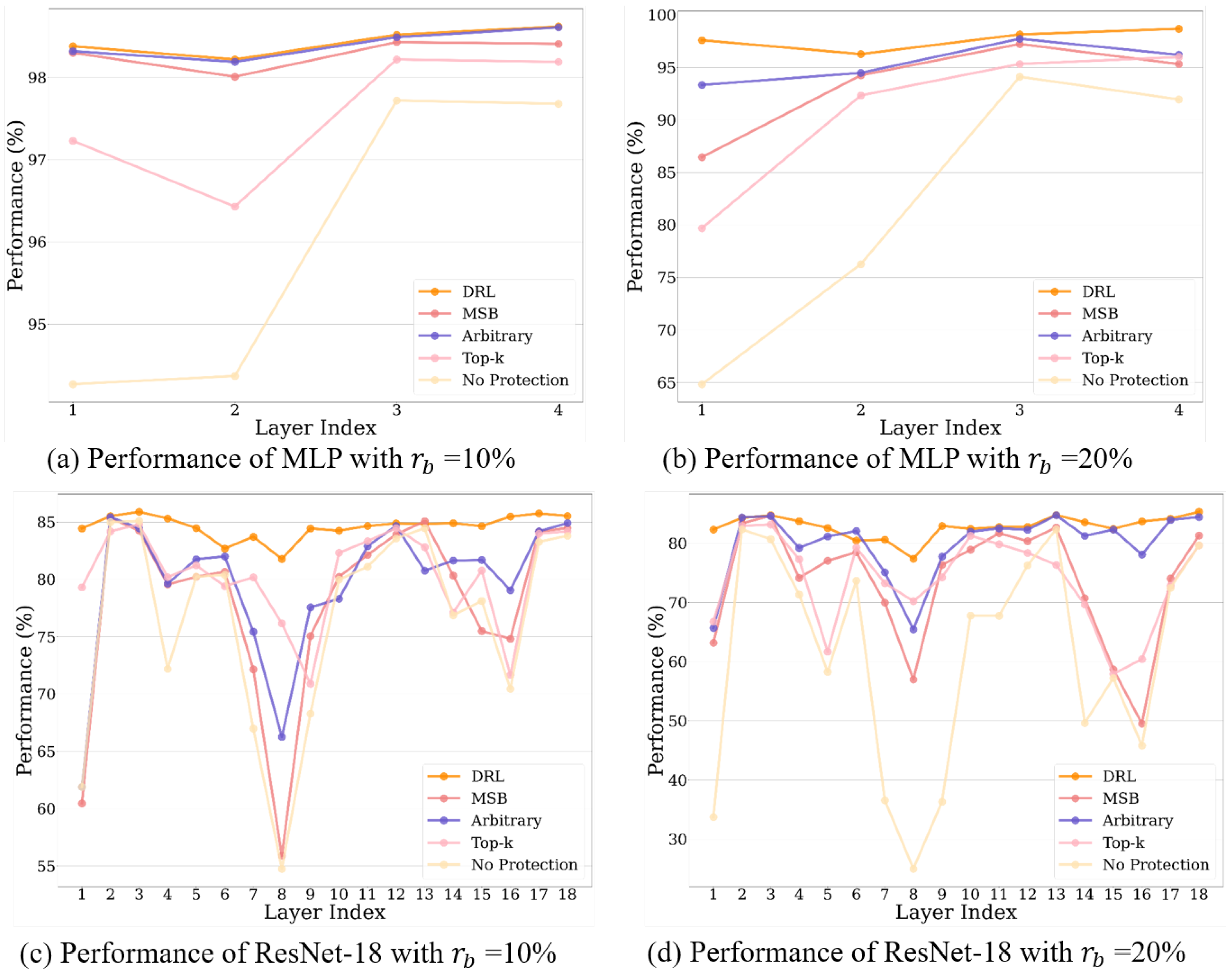
4.3. Ablation Study of Transfer Learning
4.4. Ablation Study of the Proposed Method
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cerquitelli, T.; Meo, M.; Curado, M.; Skorin-Kapov, L.; Tsiropoulou, E.E. Machine learning empowered computer networks. Comput. Netw. 2023, 230, 109807. [Google Scholar] [CrossRef]
- Su, P.; Chen, D. Using fault injection for the training of functions to detect soft errors of dnns in automotive vehicles. In Proceedings of the International Conference on Dependability and Complex Systems, Wrocław, Poland, 27 June–1 July 2022; Springer: Cham, Switzerland, 2022; pp. 308–318. [Google Scholar]
- Zhu, Z.; Su, P.; Zhong, S.; Huang, J.; Ottikkutti, S.; Tahmasebi, K.N.; Zou, Z.; Zheng, L.; Chen, D. Using a VAE-SOM architecture for anomaly detection of flexible sensors in limb prosthesis. J. Ind. Inf. Integr. 2023, 35, 100490. [Google Scholar] [CrossRef]
- Ibrahim, Y.; Wang, H.; Liu, J.; Wei, J.; Chen, L.; Rech, P.; Adam, K.; Guo, G. Soft errors in DNN accelerators: A comprehensive review. Microelectron. Reliab. 2020, 115, 113969. [Google Scholar] [CrossRef]
- Li, G.; Hari, S.K.S.; Sullivan, M.; Tsai, T.; Pattabiraman, K.; Emer, J.; Keckler, S.W. Understanding error propagation in deep learning neural network (DNN) accelerators and applications. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 12–17 November 2017; pp. 1–12. [Google Scholar]
- Sullivan, M.B.; Saxena, N.; O’Connor, M.; Lee, D.; Racunas, P.; Hukerikar, S.; Tsai, T.; Hari, S.K.S.; Keckler, S.W. Characterizing and mitigating soft errors in gpu dram. In Proceedings of the MICRO-54: 54th Annual IEEE/ACM International Symposium on Microarchitecture, Online, 18–22 October 2021; pp. 641–653. [Google Scholar]
- Brown, S. Overview of IEC 61508. Design of electrical/electronic/programmable electronic safety-related systems. Comput. Control Eng. 2000, 11, 6–12. [Google Scholar] [CrossRef]
- Su, P.; Warg, F.; Chen, D. A simulation-aided approach to safety analysis of learning-enabled components in automated driving systems. In Proceedings of the 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC), Bilbao, Spain, 24–28 September 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 6152–6157. [Google Scholar]
- Su, P. Supporting Self-Management in Cyber-Physical Systems by Combining Data-Driven and Knowledge-Enabled Methods. Ph.D. Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, 2025. [Google Scholar]
- Alsboui, T.; Qin, Y.; Hill, R.; Al-Aqrabi, H. Distributed intelligence in the internet of things: Challenges and opportunities. SN Comput. Sci. 2021, 2, 277. [Google Scholar] [CrossRef]
- Li, Y.; Liu, W.; Liu, Q.; Zheng, X.; Sun, K.; Huang, C. Complying with iso 26262 and iso/sae 21434: A safety and security co-analysis method for intelligent connected vehicle. Sensors 2024, 24, 1848. [Google Scholar] [CrossRef]
- Gao, Z.; Cecati, C.; Ding, S.X. A survey of fault diagnosis and fault-tolerant techniques—Part I: Fault diagnosis with model-based and signal-based approaches. IEEE Trans. Ind. Electron. 2015, 62, 3757–3767. [Google Scholar] [CrossRef]
- Bertoa, T.G.; Gambardella, G.; Fraser, N.J.; Blott, M.; McAllister, J. Fault-tolerant neural network accelerators with selective TMR. IEEE Des. Test 2022, 40, 67–74. [Google Scholar] [CrossRef]
- Kim, S.; Howe, P.; Moreau, T.; Alaghi, A.; Ceze, L.; Sathe, V. MATIC: Learning around errors for efficient low-voltage neural network accelerators. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Chen, Z.; Narayanan, N.; Fang, B.; Li, G.; Pattabiraman, K.; DeBardeleben, N. Tensorfi: A flexible fault injection framework for tensorflow applications. In Proceedings of the 2020 IEEE 31st International Symposium on Software Reliability Engineering (ISSRE), Coimbra, Portugal, 12–15 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 426–435. [Google Scholar]
- Su, P.; Fan, T.; Chen, D. Scheduling Resource to Deploy Monitors in Automated Driving Systems. In Proceedings of the International Conference on Dependability and Complex Systems, Brunów, Poland, 3–7 July 2023; Springer: Cham, Switzerland, 2023; pp. 285–294. [Google Scholar]
- Moghaddasi, I.; Gorgin, S.; Lee, J.A. Dependable DNN Accelerator for Safety-critical Systems: A Review on the Aging Perspective. IEEE Access 2023, 11, 89803–89834. [Google Scholar] [CrossRef]
- Salay, R.; Queiroz, R.; Czarnecki, K. An analysis of ISO 26262: Using machine learning safely in automotive software. arXiv 2017, arXiv:1709.02435. [Google Scholar]
- Chen, D.; Johansson, R.; Lönn, H.; Blom, H.; Walker, M.; Papadopoulos, Y.; Torchiaro, S.; Tagliabo, F.; Sandberg, A. Integrated safety and architecture modeling for automotive embedded systems. Elektrotechnik Informationstechnik 2011, 128, 196. [Google Scholar] [CrossRef]
- Su, P.; Kang, S.; Tahmasebi, K.N.; Chen, D. Enhancing safety assurance for automated driving systems by supporting operation simulation and data analysis. In Proceedings of the ESREL 2023, 33nd European Safety And Reliability Conference, Southampton, UK, 3–7 September 2023. [Google Scholar]
- Koopman, P.; Wagner, M. Challenges in autonomous vehicle testing and validation. SAE Int. J. Transp. Saf. 2016, 4, 15–24. [Google Scholar] [CrossRef]
- Shuvo, A.M.; Zhang, T.; Farahmandi, F.; Tehranipoor, M. A Comprehensive Survey on Non-Invasive Fault Injection Attacks. Cryptology ePrint Archive. 2023. Available online: https://eprint.iacr.org/2023/1769 (accessed on 25 May 2025).
- Taheri, M.; Ahmadilivani, M.H.; Jenihhin, M.; Daneshtalab, M.; Raik, J. Appraiser: Dnn fault resilience analysis employing approximation errors. In Proceedings of the 2023 26th International Symposium on Design and Diagnostics of Electronic Circuits and Systems (DDECS), Tallinn, Estonia, 3–5 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 124–127. [Google Scholar]
- Hoang, L.H.; Hanif, M.A.; Shafique, M. Ft-clipact: Resilience analysis of deep neural networks and improving their fault tolerance using clipped activation. In Proceedings of the 2020 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1241–1246. [Google Scholar]
- Ruospo, A.; Gavarini, G.; Bragaglia, I.; Traiola, M.; Bosio, A.; Sanchez, E. Selective hardening of critical neurons in deep neural networks. In Proceedings of the 2022 25th International Symposium on Design and Diagnostics of Electronic Circuits and Systems (DDECS), Prague, Czech Republic, 6–8 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 136–141. [Google Scholar]
- He, Y.; Balaprakash, P.; Li, Y. Fidelity: Efficient resilience analysis framework for deep learning accelerators. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 270–281. [Google Scholar]
- Chatzidimitriou, A.; Bodmann, P.; Papadimitriou, G.; Gizopoulos, D.; Rech, P. Demystifying soft error assessment strategies on arm cpus: Microarchitectural fault injection vs. neutron beam experiments. In Proceedings of the 2019 49th Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Portland, OR, USA, 24–27 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 26–38. [Google Scholar]
- Tsai, T.; Hari, S.K.S.; Sullivan, M.; Villa, O.; Keckler, S.W. Nvbitfi: Dynamic fault injection for gpus. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 284–291. [Google Scholar]
- Papadimitriou, G.; Gizopoulos, D. Demystifying the System Vulnerability Stack: Transient Fault Effects Across the Layers. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 902–915. [Google Scholar]
- Parasyris, K.; Tziantzoulis, G.; Antonopoulos, C.D.; Bellas, N. Gemfi: A fault injection tool for studying the behavior of applications on unreliable substrates. In Proceedings of the 2014 44th Annual IEEE/IFIP International Conference on Dependable Systems and Networks, Atlanta, GA, USA, 23–26 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 622–629. [Google Scholar]
- dos Santos, F.F.; Hari, S.K.S.; Basso, P.M.; Carro, L.; Rech, P. Demystifying GPU reliability: Comparing and combining beam experiments, fault simulation, and profiling. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Portland, OR, USA, 17–21 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 289–298. [Google Scholar]
- Moskalenko, V.; Kharchenko, V.; Moskalenko, A.; Kuzikov, B. Resilience and Resilient Systems of Artificial Intelligence: Taxonomy, Models and Methods. Algorithms 2023, 16, 165. [Google Scholar] [CrossRef]
- Torres-Huitzil, C.; Girau, B. Fault and error tolerance in neural networks: A review. IEEE Access 2017, 5, 17322–17341. [Google Scholar] [CrossRef]
- Krcma, M.; Kotasek, Z.; Lojda, J. Triple modular redundancy used in field programmable neural networks. In Proceedings of the 2017 IEEE East-West Design & Test Symposium (EWDTS), Novi Sad, Serbia, 29 September–2 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Arifeen, T.; Hassan, A.S.; Lee, J.A. Approximate triple modular redundancy: A survey. IEEE Access 2020, 8, 139851–139867. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Dutta, S.; Bai, Z.; Low, T.M.; Grover, P. CodeNet: Training large scale neural networks in presence of soft-errors. arXiv 2019, arXiv:1903.01042. [Google Scholar]
- Shi, Y.; Wang, B.; Luo, S.; Xue, Q.; Zhang, X.; Ma, S. Understanding and Mitigating the Soft Error of Contrastive Language-Image Pre-training Models. In Proceedings of the 2024 IEEE International Test Conference in Asia (ITC-Asia), Changsha, China, 18–20 August 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Liu, T.; Wen, W.; Jiang, L.; Wang, Y.; Yang, C.; Quan, G. A fault-tolerant neural network architecture. In Proceedings of the 56th Annual Design Automation Conference, Las Vegas, NV, USA, 2–6 June 2019; pp. 1–6. [Google Scholar]
- Abbaspour, A.; Mokhtari, S.; Sargolzaei, A.; Yen, K.K. A survey on active fault-tolerant control systems. Electronics 2020, 9, 1513. [Google Scholar] [CrossRef]
- Beyer, M.; Schorn, C.; Fabarisov, T.; Morozov, A.; Janschek, K. Automated hardening of deep neural network architectures. In Proceedings of the ASME International Mechanical Engineering Congress and Exposition, Online, 1–5 November 2021; American Society of Mechanical Engineers: New York, NY, USA, 2021; Volume 85697, p. V013T14A046. [Google Scholar]
- Abich, G.; Gava, J.; Garibotti, R.; Reis, R.; Ost, L. Applying lightweight soft error mitigation techniques to embedded mixed precision deep neural networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2021, 68, 4772–4782. [Google Scholar] [CrossRef]
- Xiao, H.; Cao, M.; Peng, R. Artificial neural network based software fault detection and correction prediction models considering testing effort. Appl. Soft Comput. 2020, 94, 106491. [Google Scholar] [CrossRef]
- Lu, Q.; Li, G.; Pattabiraman, K.; Gupta, M.S.; Rivers, J.A. Configurable detection of SDC-causing errors in programs. ACM Trans. Embed. Comput. Syst. (TECS) 2017, 16, 1–25. [Google Scholar] [CrossRef]
- Ozen, E.; Orailoglu, A. Boosting bit-error resilience of DNN accelerators through median feature selection. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 3250–3262. [Google Scholar] [CrossRef]
- Wang, Y.; Su, H.; Zhang, B.; Hu, X. Interpret neural networks by identifying critical data routing paths. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8906–8914. [Google Scholar]
- Chen, Z.; Li, G.; Pattabiraman, K. A low-cost fault corrector for deep neural networks through range restriction. In Proceedings of the 2021 51st Annual IEEE/IFIP International Conference on Dependable Systems and Networks (DSN), Taipei, Taiwan, 21–24 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–13. [Google Scholar]
- Wang, K.; Louri, A.; Karanth, A.; Bunescu, R. High-performance, energy-efficient, fault-tolerant network-on-chip design using reinforcement learning. In Proceedings of the 2019 Design, Automation & Test in Europe Conference & Exhibition (DATE), Florence, Italy, 25–29 March 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1166–1171. [Google Scholar]
- Wang, K.; Louri, A. Cure: A high-performance, low-power, and reliable network-on-chip design using reinforcement learning. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 2125–2138. [Google Scholar] [CrossRef]
- Huang, K.; Siegel, P.H.; Jiang, A.A. Functional Error Correction for Reliable Neural Networks. In Proceedings of the 2020 IEEE International Symposium on Information Theory (ISIT), Los Angeles, CA, USA, 21–26 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2694–2699. [Google Scholar]
- Huang, K.; Siegel, P.H.; Jiang, A. Functional error correction for robust neural networks. IEEE J. Sel. Areas Inf. Theory 2020, 1, 267–276. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutorials 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Su, P.; Lu, Z.; Chen, D. Combining self-organizing map with reinforcement learning for multivariate time series anomaly detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Honolulu, HI, USA, 1–4 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1964–1969. [Google Scholar]
- He, Y.; Lin, J.; Liu, Z.; Wang, H.; Li, L.J.; Han, S. Amc: Automl for model compression and acceleration on mobile devices. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 784–800. [Google Scholar]
- Chen, J.; Chen, S.; Pan, S.J. Storage efficient and dynamic flexible runtime channel pruning via deep reinforcement learning. In Proceedings of the Annual Conference on Neural Information Processing Systems 2020: Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Online, 6–12 December 2020; pp. 14747–14758. [Google Scholar]
- Hamming, R.W. Error detecting and error correcting codes. Bell Syst. Tech. J. 1950, 29, 147–160. [Google Scholar] [CrossRef]
- Li, Y. Deep reinforcement learning: An overview. arXiv 2017, arXiv:1701.07274. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Badreddine, S.; Spranger, M. Injecting prior knowledge for transfer learning into reinforcement learning algorithms using logic tensor networks. arXiv 2019, arXiv:1906.06576. [Google Scholar]
- Tang, M.; Cai, S.; Lau, V.K. Online system identification and control for linear systems with multiagent controllers over wireless interference channels. IEEE Trans. Autom. Control. 2022, 68, 6020–6035. [Google Scholar] [CrossRef]
- Zhu, Z.; Lin, K.; Jain, A.K.; Zhou, J. Transfer learning in deep reinforcement learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 13344–13362. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Choi, J.; Chen, C.Y.; Wang, N.; Venkataramani, S.; Srinivasan, V.V.; Cui, X.; Zhang, W.; Gopalakrishnan, K. Hybrid 8-bit floating point (HFP8) training and inference for deep neural networks. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019: Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Wang, N.; Choi, J.; Brand, D.; Chen, C.Y.; Gopalakrishnan, K. Training deep neural networks with 8-bit floating point numbers. In Proceedings of the Annual Conference on Neural Information Processing Systems 2018: Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DNN Type | (%) | Average Performance Protecting in Critical Layers (%) | SDC Ratio Across the DNN | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Our
Method |
Without
Protection |
Hamming
Code | MSB | Top-k |
Our
Method |
Without
Protection |
Hamming
Code | MSB | Top-k | ||
| MLP | 10 | 98.30 | 94.32 | 98.26 | 98.16 | 96.83 | 0.47 | 2.92 | 0.50 | 0.62 | 1.40 |
| 20 | 97.67 | 70.55 | 93.91 | 90.35 | 86.61 | 1.24 | 17.30 | 3.50 | 5.64 | 8.15 | |
| ResNet-18 | 10 | 83.60 | 62.98 | 70.29 | 65.89 | 76.63 | 5.55 | 14.63 | 11.17 | 12.93 | 9.91 |
| 20 | 80.80 | 32.91 | 70.98 | 66.61 | 71.11 | 7.57 | 31.99 | 10.92 | 18.03 | 9.93 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Su, P.; Li, Y.; Lu, Z.; Chen, D. Applying Reinforcement Learning to Protect Deep Neural Networks from Soft Errors. Sensors 2025, 25, 4196. https://doi.org/10.3390/s25134196
Su P, Li Y, Lu Z, Chen D. Applying Reinforcement Learning to Protect Deep Neural Networks from Soft Errors. Sensors. 2025; 25(13):4196. https://doi.org/10.3390/s25134196
Chicago/Turabian StyleSu, Peng, Yuhang Li, Zhonghai Lu, and Dejiu Chen. 2025. "Applying Reinforcement Learning to Protect Deep Neural Networks from Soft Errors" Sensors 25, no. 13: 4196. https://doi.org/10.3390/s25134196
APA StyleSu, P., Li, Y., Lu, Z., & Chen, D. (2025). Applying Reinforcement Learning to Protect Deep Neural Networks from Soft Errors. Sensors, 25(13), 4196. https://doi.org/10.3390/s25134196