
A ROS-Based Online System for 3D Gaussian Splatting Optimization: Flexible Frontend Integration and Real-Time Refinement


Abstract
1. Introduction
- 1.
- A Tightly Coupled ORB-SLAM and 3DGS Optimization System: We first propose a ROS-based tightly coupled framework that injects real-time local bundle adjustment (Local BA) results from ORB-SLAM into the 3DGS optimization pipeline. By dynamically acquiring keyframe poses and point cloud updates, this framework enables incremental optimization of the Gaussian map, reducing the initialization time overhead by 90% compared to traditional COLMAP workflows. Leveraging ORB-SLAM’s real-time localization capabilities, the system establishes a closed-loop between localization and mapping. This integration not only accelerates the 3DGS initialization but also ensures high-quality initial inputs for Gaussian map construction through real-time feature tracking and scene understanding.
- 2.
- Local Gaussian Splatting Bundle Adjustment (LGSBA): We propose an LGSBA optimization framework based on a sliding window, which dynamically refines local viewpoint poses by integrating a rendering-quality loss function that aggregates errors from all keyframes within the window (combining L1 loss and SSIM). This algorithm adaptively adjusts the Gaussian parameters and proposes to balance pose accuracy with map rendering quality, coupling the local structure refinement of the Gaussian map with camera pose optimization to mitigate map blurring caused by projection errors in various scenes. Experiments across three datasets—TUM-RGBD, Tanks and Temples, and KITTI—demonstrate an average PSNR improvement of 1.9 dB.
- 3.
- An Open-Source Codebase: The core algorithms, including ORB-SLAM initialization, LGSBA optimization, and the tightly coupled ROS framework, are open source and available at https://github.com/wla-98/worse-pose-but-better-3DGS, accessed on 29 June 2025, enabling the reproducibility of the proposed method and facilitating further research on 3D Gaussian splatting optimization. The repository includes implementation details for real-time initialization, sliding window-based bundle adjustment, and online map refinement, providing a comprehensive resource for the research community.
2. Related Work
2.1. 3D Gaussian Splatting
2.2. Visual SLAM
3. Method
3.1. ORB-SLAM Initialization
3.2. 3DGS Fundamental Model
3.3. Local Gaussian Splatting Bundle Adjustment (LGSBA) and Mathematical Derivations
3.4. System Workflow Based on the Diagram
3.4.1. Input and Frontend Initialization (ORB-SLAM3 Leading)
- 1.
- Tracking: Monocular frames (Frame Mono) filter keyframes (Key Frame), providing basic data for subsequent optimization.
- 2.
- Local Mapping: This optimizes keyframe poses through local bundle adjustment (Local BA) and refines data with keyframe culling (Key Frame Culling).
- 3.
- Loop Closing: This triggers global bundle adjustment (Global BA) upon loop detection (Loop Detected) to correct accumulated errors, outputting optimized keyframe images, poses, and sparse point clouds (Node Image, Node Pose, Node 3D points).
3.4.2. Data Interaction and Middleware (ROS Bridging)
3.4.3. 3DGS Scene Construction and Optimization
- 1.
- Scene Creation: This generates scene information (Scene Info) by combining camera parameters (Camera Info) and Gaussian initialization (Gaussian Initial), initializing the 3DGS environment.
- 2.
- Training Strategy Selection:
- (a)
- Incremental Training (No Global Loop): When ORB-SLAM has not detected a global loop (partial keyframes processed), LGSBA optimization is employed. It uses sliding-window loss () to refine Gaussian parameters and camera poses via backpropagation and updates the map incrementally with new keyframes to maintain local consistency.
- (b)
- Random Training (Global Loop Detected): After global loop closure (all keyframes processed), the original 3DGS random optimization is selected. It uses random sampling of scene cameras for global map refinement and corrects accumulated errors to ensure global consistency.
- 3.
- Scene Update Loop: This continuously refines Gaussian map parameters during incremental training, terminates incremental training upon global loop detection, triggering random optimization, and outputs the final 3DGS map and rendered RGB images after global optimization.
3.4.4. Loop Closure and Robustness Enhancement
4. Dataset and Metrics
4.1. Datasets Description
4.1.1. TUM-RGBD Dataset (TUM)
4.1.2. Tanks and Temples Dataset (TANKS)
4.1.3. KITTI Dataset (KITTI)
- 1.
- The robustness of the SLAM frontend under dynamic disturbances;
- 2.
- The radiance field modeling capabilities of 3DGS in scenes of varying scales;
- 3.
- The suppression of cumulative errors during long-term operations.
4.2. Evaluation Metrics
- 1.
- L1 Loss: This metric evaluates image quality by computing the pixel-wise absolute difference between the reconstructed image and the ground truth image. A lower L1 loss indicates a smaller discrepancy and, consequently, better reconstruction quality:where N is the total number of pixels.
- 2.
- PSNR: PSNR measures the signal-to-noise ratio between the reconstructed and ground truth images, expressed in decibels (dB). A higher PSNR value indicates better image quality. It is computed as:with R being the maximum possible pixel value (typically 255 for 8-bit images) and defined as:
- 3.
- SSIM: SSIM measures the structural similarity between two images by considering luminance, contrast, and texture. Its value ranges from −1 to 1, with values closer to 1 indicating higher similarity:where are the means, the variances, and the covariance of images x and y, with and being small constants.
- 4.
- LPIPS: LPIPS assesses perceptual similarity between images using deep network features. It is computed as:where represents the feature map extracted from the k-th layer of a deep convolutional network, and K is the total number of layers. A lower LPIPS indicates a smaller perceptual difference.
- 5.
- APE: APE quantifies the geometric precision of the reconstructed camera poses by computing the Euclidean distance between the translational components of the estimated and ground truth poses. For N poses, it is defined as:If rotation errors are also considered, APE can be extended as:where is the axis-angle error for rotation, and is a weighting factor (typically set to 1).
- 6.
- RMSE: RMSE measures the average error between the reconstructed and ground truth camera poses, computed as:where and denote the reconstructed and ground truth poses for frame i, respectively.
5. Experiment
5.1. Experiment 1: LGSBA Effectiveness Verification via 3DGS Training Comparison
- Leveraging ORB-SLAM’s Native BA: Initial refinement of camera poses using ORB-SLAM’s traditional bundle adjustment.
- Sliding-Window Joint Optimization: Subsequent refinement of both poses and Gaussian parameters using rendering-quality loss (), prioritizing map fidelity while maintaining acceptable pose accuracy.
5.1.1. System Workflow of 3DGS Reconstruction
- ORB-SLAM Preprocessing: Input RGB sequences are processed to select keyframes based on tracking quality and scene dynamics, leveraging ORB-SLAM’s real-time localization capabilities. This step outputs optimized camera poses and 3D point clouds , demonstrating the efficiency of ORB-SLAM initialization compared to COLMAP.
- Gaussian Map Initialization: Three-dimensional points are converted to Gaussian parameters:where is the spatial coordinate, c is the spherical harmonic coefficient for color encoding, and is the opacity. This step forms the basis for 3DGS scene representation, highlighting the innovation of using ORB-SLAM’s output for rapid initialization.
- LGSBA Sliding-Window Optimization: A seven-frame sliding window is employed for joint optimization, integrating the rendering-quality loss function:Here, balances the contributions of pixel-wise L1 loss and structural similarity (SSIM), directly reflecting the innovation of LGSBA in coupling pose optimization with rendering quality. The sliding-window strategy dynamically refines local viewpoints, mitigating map blurring caused by projection errors.
- Quantitative Evaluation: Rendered images are compared against ground truth using metrics (PSNR, SSIM, LPIPS, APE, RMSE) to quantify the improvement in 3DGS reconstruction quality. This evaluation directly measures the impact of LGSBA’s optimization on both visual fidelity and geometric accuracy, aligning with the study’s core innovation of enhancing 3DGS rendering through pose-map co-optimization.
5.1.2. Quantitative Analysis
5.1.3. Qualitative Analysis
- 1.
- Detail Preservation: LGSBA maintains sharper object contours (e.g., machinery edges in Tank-Caterpillar) and consistent surface textures (e.g., ground patterns in TUM-fg1-floor) compared to baseline methods.
- 2.
- Artifact Reduction: Noticeable reduction in rendering artifacts (blurring, floating points) in occluded regions, especially visible in Tank-Family scenes.
- 3.
- Color Consistency: More accurate color transitions and lighting reproduction, particularly evident in the Tank-horse model’s metallic surfaces.
- 4.
- Geometric Integrity: Improved depth perception and structural coherence in zoomed segments (red boxes), validating LGSBA’s effectiveness in local map refinement.
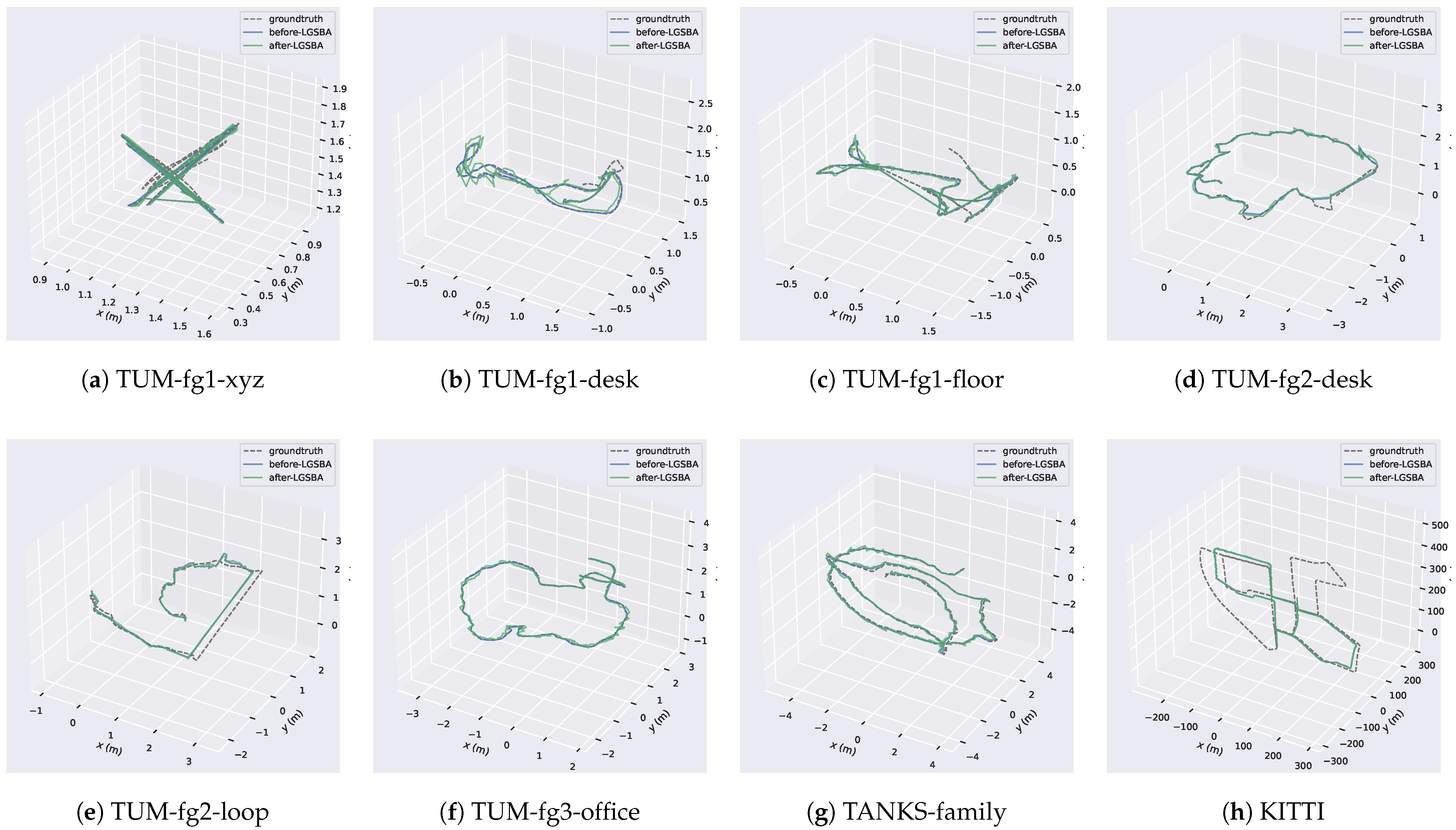
5.1.4. Camera Pose Evaluation
5.2. Online Integration of ORB-SLAM with 3DGS Map Optimization by ROS System
5.2.1. ORB-SLAM3 Frontend Processing
- 1.
- Tracking: Monocular frames are processed for feature extraction and keyframe selection based on scene dynamics and tracking quality.
- 2.
- Local Mapping: This performs local bundle adjustment (Local BA) to optimize keyframe poses and applies keyframe culling to remove redundancies.
- 3.
- Loop Closing: This detects loop closures to trigger global bundle adjustment (Global BA), correcting accumulated drift in poses and 3D points.
5.2.2. ROS Middleware Bridging
- 1.
- The Local Mapping thread publishes incremental updates (keyframe poses/images/map points).
- 2.
- The Loop Closing thread triggers synchronization events upon global BA completion.
- 3.
- Custom ROS nodes ensure asynchronous communication without blocking SLAM processes.
5.2.3. 3DGS Optimization with Dynamic Strategy Switching
Incremental Training
- 1.
- Activates when no global loop is detected (partial keyframes processed);
- 2.
- Employs LGSBA with seven-frame sliding-window optimization;
- 3.
- Minimizes rendering-quality loss Equation (5) via backpropagation;
- 4.
- Jointly optimizes Gaussian parameters and poses :
Random Training
- 1.
- Activates after global loop closure (all keyframes processed);
- 2.
- Switches to original 3DGS random optimization;
- 3.
- Uses scene-wide camera sampling for global error correction;
- 4.
- Ensures consistency across large-scale environments.
5.2.4. System Advantages
- 1.
- Real-Time Capability: 10× faster initialization than COLMAP-3DGS systems.
- 2.
- Adaptive Optimization: Balances local consistency (LGSBA) and global accuracy (random training).
- 3.
- Robustness: Loop closure triggers map-wide error correction.
- 4.
- Online Performance: It achieves >25 FPS end-to-end throughput on NVIDIA RTX 3090 GPU with
- (a)
- ORB-SLAM frontend: 30+ FPS (CPU processing);
- (b)
- 3DGS optimization: 25 FPS (GPU rendering).
5.2.5. Experimental Validation of System Feasibility
Quantitative Analysis
- 1.
- At 7K Iterations: Our online method achieved a +0.27 dB PSNR gain (+1.3%), a +0.003 SSIM improvement, and a -0.030 LPIPS reduction compared to offline reconstruction, while maintaining a comparable L1 loss.
- 2.
- At 30K Iterations: Significant quality improvements emerged:
- (a)
- A +0.50 dB PSNR gain (+2.1%);
- (b)
- A +0.012 SSIM improvement;
- (c)
- A −0.042 LPIPS reduction (15.2% lower).
- 3.
- Training Efficiency: The online system reached near-optimal quality (30K-level metrics) at just 7K iterations, demonstrating accelerated convergence.
Qualitative Analysis
- 1.
- Rendering Fidelity: Figure 5 confirms
- (a)
- Photorealistic novel view synthesis;
- (b)
- Accurate lighting and material reproduction;
- (c)
- Clear structural details in close-up views.
- 2.
- Gaussian Map Quality: Figure 6 demonstrates
- (a)
- Precise geometric reconstruction of laboratory equipment;
- (b)
- Detailed surface representation (e.g., texture on cylindrical objects);
- (c)
- Minimal floating artifacts in complex areas.
- 3.
- Geometric Consistency: Figure 7 shows accurate camera pose estimation and sparse point cloud generation by ORB-SLAM, providing reliable initialization for 3DGS.
Conclusion on System Feasibility
- 1.
- Real-Time Capability: It achieved a >25 FPS throughput while maintaining reconstruction quality.
- 2.
- Quality Superiority: It outperformed offline methods in perceptual metrics (PSNR/SSIM/LPIPS).
- 3.
- Operational Robustness: Consistent performance in practical indoor environments.
6. Conclusions
- 1.
- Tightly Coupled System: A ROS-based pipeline integrating ORB-SLAM’s real-time Local Bundle Adjustment with 3DGS optimization. This reduces initialization time by 90% versus COLMAP while improving average PSNR by 1.9 dB across the TUM-RGBD, Tanks and Temples, and KITTI datasets.
- 2.
- LGSBA Algorithm: A sliding-window strategy jointly optimizes rendering-quality loss () and camera poses. This balances geometric accuracy with perceptual fidelity, mitigating blurring artifacts induced by projection errors and enhancing detail preservation in complex scenes.
- 3.
- Open-Source Implementation: The released codebase (https://github.com/wla-98/worse-pose-but-better-3DGS, accessed on 29 June 2025) supports reproducibility, providing tools for real-time initialization and online map refinement.
7. Limitations
- 1.
- Dynamic Environments: Reliance on ORB-SLAM’s feature tracking causes performance degradation with moving objects (e.g., pedestrians in TUM-RGBD). Dynamic elements introduce tracking errors, leading to inconsistent Gaussian map updates and rendering artifacts.
- 2.
- Illumination Sensitivity: ORB-SLAM’s susceptibility to lighting variations (e.g., outdoor shadows or flickering indoor lights) reduces pose estimation accuracy.
- 3.
- Insufficient Failure Analysis: While evaluated on diverse datasets, systematic examination of edge cases (e.g., low-texture scenes or extreme lighting) is absent. Without quantitative fault diagnosis, robustness boundaries remain unquantified.
- 4.
- Computational Overhead: Despite faster initialization, optimizing high-dimensional Gaussian parameters (covariance matrices, spherical harmonics) in ultra-large scenes imposes significant GPU memory demands, constraining real-time performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3DGS | Three-Dimensional Gaussian Splatting |
| BA | Bundle Adjustment |
| LGSBA | Local Gaussian Splatting Bundle Adjustment |
| ROS | Robot Operation System |
| NeRF | Neural Radiance Fields |
| SfM | Structure-from-Motion |
| SOTA | State-of-the-Art |
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index Measure |
| LPIPS | Learned Perceptual Image Patch Similarity |
| APE | Absolute Pose Error |
| RMSE | Root Mean Square Error |
| GT | Ground Truth |
Appendix A. ORBSLAM Initialization
Appendix B. 3DGS Fundamental Model
Appendix C. Error Decomposition and Covariance Propagation Analysis
Appendix D. Nonlinear Pose-Map Interplay
- 1.
- Covariance Alignment Across Views: Pose adjustments may lead to better alignment of projected Gaussians across multiple keyframes, reducing blurring effects during multi-view fusion.
- 2.
- SSIM Reweighting: Perturbed poses can improve the structural similarity (SSIM) between projected Gaussians and ground-truth pixels, especially in high-texture regions, effectively reweighting high-contribution areas.
References
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 139–153. [Google Scholar] [CrossRef]
- Schonberger, J.L.; Frahm, J.M. Structure-From-Motion Revisited. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4104–4113. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Cheng, K.; Long, X.; Yang, K.; Yao, Y.; Yin, W.; Ma, Y.; Wang, W.; Chen, X. Gaussianpro: 3d gaussian splatting with progressive propagation. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2024. [Google Scholar]
- Zhang, J.; Zhan, F.; Xu, M.; Lu, S.; Xing, E. Fregs: 3d gaussian splatting with progressive frequency regularization. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 17–21 June 2024; pp. 21424–21433. [Google Scholar]
- Chung, J.; Oh, J.; Lee, K.M. Depth-regularized optimization for 3d gaussian splatting in few-shot images. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17–18 June 2024; pp. 811–820. [Google Scholar]
- Li, J.; Zhang, J.; Bai, X.; Zheng, J.; Ning, X.; Zhou, J.; Gu, L. Dngaussian: Optimizing sparse-view 3d gaussian radiance fields with global-local depth normalization. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 20775–20785. [Google Scholar]
- Zhu, Z.; Fan, Z.; Jiang, Y.; Wang, Z. Fsgs: Real-time few-shot view synthesis using gaussian splatting. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September 2024; Springer: Berlin/Heidelberg, Germany, 2025; pp. 145–163. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany; pp. 834–849. [Google Scholar]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 15–22. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Ragot, N.; Khemmar, R.; Pokala, A.; Rossi, R.; Ertaud, J.Y. Benchmark of visual slam algorithms: Orb-slam2 vs rtab-map. In Proceedings of the 2019 Eighth International Conference on Emerging Security Technologies (EST), Colchester, UK, 22–24 July 2019; pp. 1–6. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. Vins-mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Xu, W.; Bao, H.; Cui, Z.; Oswald, M.R.; Pollefeys, M. Nice-slam: Neural implicit scalable encoding for slam. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12786–12796. [Google Scholar]
- Rosinol, A.; Leonard, J.J.; Carlone, L. Nerf-slam: Real-time dense monocular slam with neural radiance fields. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 3437–3444. [Google Scholar]
- Zhu, Z.; Peng, S.; Larsson, V.; Cui, Z.; Oswald, M.R.; Geiger, A.; Pollefeys, M. Nicer-slam: Neural implicit scene encoding for rgb slam. In Proceedings of the 2024 International Conference on 3D Vision (3DV), Davos, Switzerland, 18–21 March 2024; pp. 42–52. [Google Scholar]
- Kong, X.; Liu, S.; Taher, M.; Davison, A.J. vmap: Vectorised object mapping for neural field slam. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 952–961. [Google Scholar]
- Sandström, E.; Li, Y.; Van Gool, L.; Oswald, M.R. Point-slam: Dense neural point cloud-based slam. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 18433–18444. [Google Scholar]
- Chung, C.M.; Tseng, Y.C.; Hsu, Y.C.; Shi, X.Q.; Hua, Y.H.; Yeh, J.F.; Chen, W.C.; Chen, Y.T.; Hsu, W.H. Orbeez-slam: A real-time monocular visual slam with orb features and nerf-realized mapping. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 9400–9406. [Google Scholar]
- Huang, H.; Li, L.; Cheng, H.; Yeung, S.K. Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular Stereo and RGB-D Cameras. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 21584–21593. [Google Scholar]
- Yugay, V.; Li, Y.; Gevers, T.; Oswald, M.R. Gaussian-slam: Photo-realistic dense slam with gaussian splatting. arXiv 2023, arXiv:2312.10070. [Google Scholar]
- Yan, C.; Qu, D.; Xu, D.; Zhao, B.; Wang, Z.; Wang, D.; Li, X. Gs-slam: Dense visual slam with 3d gaussian splatting. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 19595–19604. [Google Scholar]
- Li, M.; Liu, S.; Zhou, H.; Zhu, G.; Cheng, N.; Deng, T.; Wang, H. Sgs-slam: Semantic gaussian splatting for neural dense slam. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2019; Springer: Berlin/Heidelberg, Germany, 2025; pp. 163–179. [Google Scholar]
- Keetha, N.; Karhade, J.; Jatavallabhula, K.M.; Yang, G.; Scherer, S.; Ramanan, D.; Luiten, J. SplaTAM: Splat Track & Map 3D Gaussians for Dense RGB-D SLAM. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 21357–21366. [Google Scholar]
- Ji, Y.; Liu, Y.; Xie, G.; Ma, B.; Xie, Z. Neds-slam: A novel neural explicit dense semantic slam framework using 3d gaussian splatting. arXiv 2024, arXiv:2403.11679. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, S.; Wang, S.; Yin, Y.; Yang, Y.; Fan, Q.; Chen, B. SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos. arXiv 2024, arXiv:2412.09401. [Google Scholar]
- Smart, B.; Zheng, C.; Laina, I.; Prisacariu, V.A. Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs. arXiv 2024, arXiv:2412.09401. [Google Scholar]
- Teed, Z.; Deng, J. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras. In Proceedings of the 35th International Conference on Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Wang, S.; Leroy, V.; Cabon, Y.; Chidlovskii, B.; Revaud, J. Dust3r: Geometric 3d vision made easy. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 20697–20709. [Google Scholar]
- Matsuki, H.; Murai, R.; Kelly, P.H.; Davison, A.J. Gaussian splatting slam. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 18039–18048. [Google Scholar]
- Lu, T.; Yu, M.; Xu, L.; Xiangli, Y.; Wang, L.; Lin, D.; Dai, B. Scaffold-gs: Structured 3d gaussians for view-adaptive rendering. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 20654–20664. [Google Scholar]
- Zwicker, M.; Pfister, H.; Van Baar, J.; Gross, M. EWA volume splatting. In Proceedings of the Proceedings Visualization, 2001. VIS’01, San Diego, CA, USA, 21–26 October 2001; pp. 29–538. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenes | Iterations | 3DGS w. ORB-SLAM | Scaffold-GS [36] w. ORB-SLAM | LGSBA w. ORB-SLAM | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| L1 ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | L1 ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | L1 ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | ||||
| TUM-fg2 | 7000 | 0.04445 | 22.7231 | 0.7398 | 0.3392 | 0.05892 | 19.5031 | 0.6562 | 0.3605 | 0.04147 | 23.2687 | 0.7564 | 0.3190 | ||
| desk | 30,000 | 0.03106 | 25.4048 | 0.8079 | 0.2526 | 0.03963 | 24.1913 | 0.7816 | 0.2749 | 0.02675 | 26.3698 | 0.8215 | 0.2366 | ||
| TUM-fg3 | 7000 | 0.02967 | 25.9192 | 0.8702 | 0.2132 | 0.03046 | 26.1320 | 0.8495 | 0.2171 | 0.02788 | 26.6086 | 0.8754 | 0.1790 | ||
| long office | 30,000 | 0.02271 | 27.8335 | 0.8962 | 0.1739 | 0.02254 | 28.3261 | 0.8871 | 0.1710 | 0.02148 | 28.6190 | 0.9029 | 0.1448 | ||
| TUM-fg2 | 7000 | 0.06844 | 18.6592 | 0.7093 | 0.3832 | 0.04203 | 22.7576 | 0.8250 | 0.3370 | 0.06613 | 18.4161 | 0.7306 | 0.3476 | ||
| large loop | 30,000 | 0.03502 | 23.5877 | 0.8487 | 0.2321 | 0.02675 | 26.5550 | 0.8923 | 0.2297 | 0.03297 | 23.9026 | 0.8613 | 0.2121 | ||
| TUM-fg1 | 7000 | 0.04084 | 24.1946 | 0.7139 | 0.4045 | 0.11536 | 16.4651 | 0.5028 | 0.5832 | 0.03785 | 24.7616 | 0.7615 | 0.2751 | ||
| floor | 30,000 | 0.02246 | 28.6884 | 0.8123 | 0.2447 | 0.08608 | 18.8924 | 0.5747 | 0.4874 | 0.02111 | 29.2896 | 0.8756 | 0.1493 | ||
| TUM-fg1 | 7000 | 0.04271 | 21.7174 | 0.8032 | 0.3109 | 0.02675 | 26.2993 | 0.8503 | 0.2593 | 0.03837 | 22.9983 | 0.8162 | 0.2823 | ||
| desk | 30,000 | 0.02467 | 26.6830 | 0.8783 | 0.2234 | 0.01646 | 30.6417 | 0.9160 | 0.1568 | 0.02117 | 28.1143 | 0.8954 | 0.1827 | ||
| TANKS | 7000 | 0.07196 | 18.4721 | 0.6110 | 0.4194 | 0.06984 | 18.6930 | 0.5614 | 0.5110 | 0.03922 | 23.3886 | 0.7625 | 0.2996 | ||
| family | 30,000 | 0.05907 | 19.9479 | 0.6985 | 0.3254 | 0.05224 | 20.6179 | 0.6758 | 0.3822 | 0.02978 | 24.9964 | 0.8308 | 0.2174 | ||
| TANKS | 7000 | 0.09600 | 16.6443 | 0.4398 | 0.6024 | 0.07732 | 18.4520 | 0.4906 | 0.5410 | 0.04741 | 22.7639 | 0.5953 | 0.4220 | ||
| Caterpillar | 30,000 | 0.07899 | 17.8833 | 0.4994 | 0.5322 | 0.06325 | 19.8104 | 0.5540 | 0.4780 | 0.02791 | 25.5355 | 0.7991 | 0.2577 | ||
| TANKS | 7000 | 0.04580 | 21.1421 | 0.7017 | 0.4393 | 0.05177 | 20.7905 | 0.6669 | 0.4058 | 0.03578 | 22.2298 | 0.7901 | 0.3279 | ||
| M60 | 30,000 | 0.03388 | 23.1617 | 0.7808 | 0.3381 | 0.03472 | 23.8326 | 0.7897 | 0.2907 | 0.02820 | 23.7872 | 0.8426 | 0.2699 | ||
| TANKS | 7000 | 0.06553 | 19.7737 | 0.6387 | 0.4786 | 0.05711 | 20.6153 | 0.6727 | 0.4603 | 0.05074 | 21.1269 | 0.6978 | 0.3882 | ||
| Panther | 30,000 | 0.05116 | 21.5959 | 0.7051 | 0.3954 | 0.03952 | 23.4914 | 0.7759 | 0.3586 | 0.04139 | 22.7304 | 0.7591 | 0.3242 | ||
| TANKS | 7000 | 0.03704 | 22.3863 | 0.7689 | 0.2957 | 0.05187 | 20.8398 | 0.7611 | 0.3327 | 0.02885 | 25.0431 | 0.8344 | 0.2404 | ||
| Horse | 30,000 | 0.029178 | 24.2530 | 0.8263 | 0.2284 | 0.03315 | 24.6180 | 0.8305 | 0.2537 | 0.02376 | 26.4398 | 0.8703 | 0.1921 | ||
| TANKS | 7000 | 0.07377 | 18.7738 | 0.5714 | 0.4680 | 0.06106 | 19.5181 | 0.6711 | 0.3860 | 0.04691 | 21.4430 | 0.7350 | 0.2839 | ||
| Train | 30,000 | 0.05424 | 20.9735 | 0.6781 | 0.3498 | 0.05012 | 20.9398 | 0.7425 | 0.3110 | 0.03743 | 23.0867 | 0.8009 | 0.2146 | ||
| TANKS | 7000 | 0.04761 | 20.8189 | 0.7084 | 0.3546 | 0.03904 | 22.5495 | 0.7917 | 0.3203 | 0.03289 | 22.9611 | 0.8092 | 0.2290 | ||
| Lighthouse | 30,000 | 0.03683 | 22.7946 | 0.7728 | 0.2814 | 0.02433 | 26.3856 | 0.8633 | 0.2332 | 0.02426 | 25.0581 | 0.8507 | 0.1863 | ||
| KITTI | 7000 | 0.14224 | 13.3166 | 0.5003 | 0.5895 | 0.13359 | 14.1273 | 0.4716 | 0.6247 | 0.14586 | 13.2683 | 0.4808 | 0.6128 | ||
| 00 | 30,000 | 0.07117 | 18.0943 | 0.5973 | 0.5340 | 0.08427 | 17.3860 | 0.5659 | 0.5334 | 0.06340 | 18.5983 | 0.6029 | 0.5117 | ||
| Average | 0.05217 | 21.7478 | 0.7146 | 0.3619 | 0.05339 | 22.0166 | 0.7144 | 0.3654 | 0.03996 | 23.6464 | 0.7830 | 0.2810 | |||
| Pose Estimation | Metric | TUM-fg2 | TUM-fg1 | Others | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Desk | Long Office | Large w. loop | xyz | Floor | Desk | KITTI-00 | TANKS-Family | TANKS-Caterpillar | ||||
| Pose Estimation | APE (cm) ↓ | 0.4590 | 0.8744 | 7.0576 | 0.6736 | 9.2631 | 1.3382 | 14.3767 | 13.0878 | 0.1005 | ||
| RMSE (cm) ↓ | 0.4962 | 0.9844 | 8.5865 | 0.7624 | 10.8200 | 1.5237 | 17.4024 | 15.5307 | 0.1074 | |||
| APE (cm) ↓ | 4.1687 | 8.0663 | 7.7640 | 1.0193 | 3.4214 | 2.1502 | 14.4333 | 17.5868 | 0.1003 | |||
| RMSE (cm) ↓ | 4.9558 | 9.0545 | 8.9127 | 1.0869 | 4.1349 | 2.9608 | 17.4314 | 20.6191 | 0.1070 | |||
| Quality | PSNR ↑ | 25.4048 | 27.8335 | 23.5877 | 28.1725 | 28.6884 | 26.6830 | 18.0943 | 19.9479 | 17.8833 | ||
| PSNR ↑ | 26.3698 | 28.6190 | 23.9026 | 28.5573 | 29.2896 | 28.1143 | 18.5983 | 24.9964 | 25.5355 | |||
| Scene | Iterations | Offline Reconstruction | Online Reconstruction (Ours) | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| L1↓ | PSNR↑ | SSIM↑ | LPIPS↓ | L1↓ | PSNR↑ | SSIM↑ | LPIPS↓ | |||
| Lab | 7K | 0.0575 | 21.20 | 0.775 | 0.363 | 0.0467 | 21.47 | 0.778 | 0.333 | |
| 30K | 0.0297 | 24.15 | 0.858 | 0.276 | 0.0299 | 24.65 | 0.870 | 0.234 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Xu, J.; An, X.; Ji, Y.; Wu, Y.; Ma, Z. A ROS-Based Online System for 3D Gaussian Splatting Optimization: Flexible Frontend Integration and Real-Time Refinement. Sensors 2025, 25, 4151. https://doi.org/10.3390/s25134151
Wang L, Xu J, An X, Ji Y, Wu Y, Ma Z. A ROS-Based Online System for 3D Gaussian Splatting Optimization: Flexible Frontend Integration and Real-Time Refinement. Sensors. 2025; 25(13):4151. https://doi.org/10.3390/s25134151
Chicago/Turabian StyleWang, Li’an, Jian Xu, Xuan An, Yujie Ji, Yuxuan Wu, and Zhaoyuan Ma. 2025. "A ROS-Based Online System for 3D Gaussian Splatting Optimization: Flexible Frontend Integration and Real-Time Refinement" Sensors 25, no. 13: 4151. https://doi.org/10.3390/s25134151
APA StyleWang, L., Xu, J., An, X., Ji, Y., Wu, Y., & Ma, Z. (2025). A ROS-Based Online System for 3D Gaussian Splatting Optimization: Flexible Frontend Integration and Real-Time Refinement. Sensors, 25(13), 4151. https://doi.org/10.3390/s25134151