1. Introduction
The rapid advancement of global urbanization and transportation infrastructure has led to exponentially growing demands for road maintenance worldwide. Traditional pavement distress detection through manual inspection presents well-documented limitations including labor-intensive processes and inconsistent evaluation standards. While computer vision-based approaches utilizing conventional image processing techniques have demonstrated improved efficiency in road condition assessment [
1,
2], their performance remains heavily dependent on expert-designed features and domain-specific knowledge. Such methods often fail to maintain a robust performance when applied to previously unseen distress patterns or varying environmental conditions [
3,
4].
Recent years have witnessed remarkable progress in applying deep learning to pavement distress classification [
5,
6,
7,
8]. Pioneering work by Cha et al. [
9] successfully integrated convolutional neural networks with sliding window techniques for high-resolution crack detection. Subsequent developments include Lei et al.’s [
10] grid-based deep learning approach for crack classification and Pauly et al.’s [
11] demonstration of deeper neural networks’ superior crack detection capabilities. The field further evolved with Zou et al.’s [
12] DeepCrack network implementing multi-scale feature fusion and Panella et al.’s [
13] hybrid method combining deep learning with traditional image processing for tunnel inspections. More recently, Li et al.’s [
14] GoogLeNet-based system and Tran et al.’s [
15] two-stage Mask R-CNN framework have pushed the boundaries of crack severity classification.
Despite these technological advancements, critical challenges persist in practical implementations. Current deep learning models typically require large quantities of balanced training data, which proves particularly problematic for rare distress types that are difficult to document. The models also exhibit significant performance degradation when encountering test data that deviates from the training distribution. Perhaps most crucially, conventional systems lack the capability to dynamically incorporate new distress categories after initial deployment, severely limiting their long-term utility in evolving real-world environments.
To overcome these limitations, this study introduces an innovative deep metric learning framework built upon several key technical advancements. The proposed system employs a BNInception-based [
16] feature encoder trained with SoftTriple loss [
17] to extract highly discriminative feature representations. A novel similarity-based classification strategy enables the effective few-shot recognition of rare distress patterns. Most importantly, the architecture supports dynamic category expansion without requiring complete model retraining.
Although recent transformer-based networks [
18,
19,
20,
21] have been applied to pavement defect detection, their role is essentially restricted to feature extraction. In fact, our BNInception backbone can be seamlessly replaced by any other feature extractor—including transformer-based ones—without altering the core of our approach. The main focus of this work is not the backbone architecture, but rather the design of an effective incremental classification mechanism for new distress classes.
Similarly, state-of-the-art incremental learners such as DER [
22] and FOSTER [
23] excel at mitigating catastrophic forgetting via distillation, replay, or specialized network branches, but they pay comparatively little attention to real-world challenges like high intra-class variance, ambiguous inter-class boundaries, and severe data imbalance. In contrast, our method combines SoftTriple loss with support-set based multi-centroid modeling and an adaptive weighting strategy to dynamically construct multiple class centers in feature space. This enables it to capture the complex intra-class distributions of pavement defects while enhancing inter-class separability. Moreover, since our framework does not depend on any particular backbone or heavy feature-augmentation module, it remains lightweight, broadly applicable, and well suited for deployment on resource-constrained platforms such as UAVs.
Comprehensive experimental results demonstrate the method’s superiority over conventional approaches, showing significant improvements in both detection accuracy and operational flexibility for real-world road maintenance applications.
2. Theoretical Foundations
2.1. Deep Metric Learning
Deep metric learning (DML) is a crucial subfield of machine learning that focuses on learning adaptive distance or similarity metrics in data space. Unlike traditional fixed metrics (e.g., Euclidean distance), DML learns a task-specific metric function that dynamically adjusts distance or similarity measurements based on the problem requirements. This adaptability makes DML particularly effective for handling complex data distributions and uncovering intrinsic data structures.
The primary objective of DML is to learn an embedding function that maps input samples into a metric space, where an optimized distance or similarity measure is defined. Classical metric learning methods often employ the Mahalanobis distance [
24] to quantify the similarity between two feature vectors:
where
M is a learned positive semi-definite matrix that adaptively adjusts the distance metric based on data characteristics. This learned metric better captures the underlying relationships in the data, improving performance in downstream tasks such as classification and clustering.
The core objective of deep metric learning is to learn a metric function such that the distance between features of samples from the same class is minimized in the feature space, while the distance between features of samples from different classes is maximized—or, alternatively, to maximize the similarity among same-class features and minimize it among different-class features. This metric-based approach effectively distinguishes samples of different categories, thereby improving the accuracy and robustness of tasks such as classification and clustering.
In scenarios with sparse samples, deep metric learning can enhance model performance by leveraging similarity information between samples. Unlike traditional classification methods, deep metric learning does not require explicit category definitions; instead, it distinguishes samples by measuring their pairwise similarity through the learned metric function. As a result, pavement damage image classification methods based on deep metric learning can overcome challenges in traditional deep learning approaches, such as difficulties in sample annotation and poor generalization ability.
2.2. BNInception Network
The BNInception (Batch Normalization Inception) is a deep convolutional neural network architecture and a variant of the Inception series. Its primary innovation lies in the incorporation of batch normalization (BN) technology, which accelerates network convergence and enhances model performance.
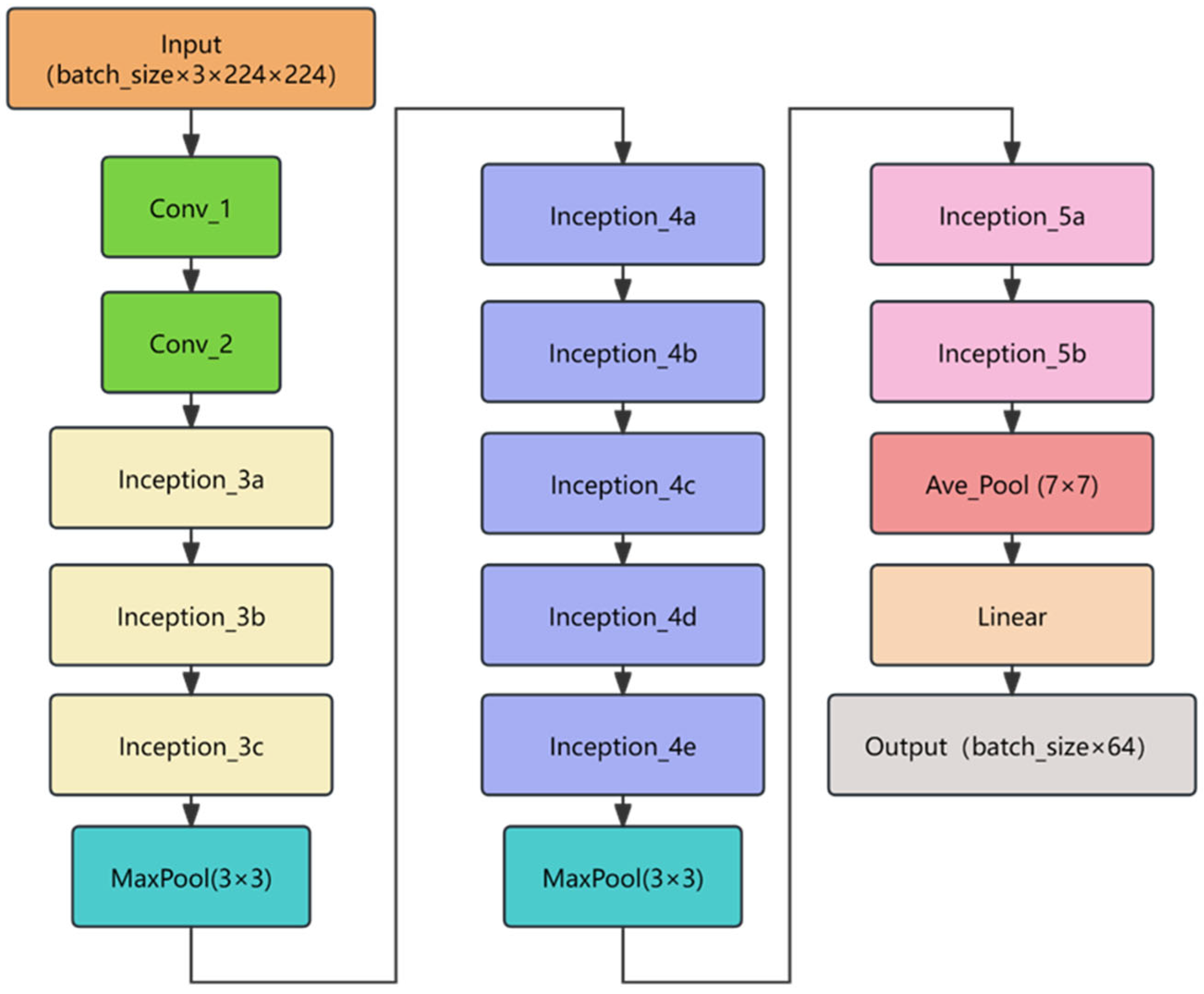
The BNInception architecture builds upon Inception v2 and Inception v3, adopting a similar design philosophy of Inception modules. Specifically, it employs multiple parallel branches to extract features at different scales and resolutions, subsequently concatenating or aggregating these features to produce richer and more diverse representations. Additionally, BNInception introduces batch normalization layers after each convolutional layer, normalizing the outputs to stabilize training. This technique mitigates issues such as vanishing or exploding gradients, thereby improving both convergence speed and generalization capability. The network architecture of BNInception is shown in
Figure 1.
BNInception exhibits three key characteristics: multi-scale feature extraction, batch normalization, and lightweight design. By utilizing convolutional kernels and pooling operations of varying sizes in parallel, the network effectively captures both local and global image features. The integration of batch normalization not only accelerates training but also enhances the model’s robustness to shifts in input data distribution. Compared to networks like Inception v3, BNInception reduces both parameter count and computational complexity, making it particularly suitable for deployment in resource-constrained environments.
In this paper, BNInception is used solely as a feature extractor to extract features of pavement distress, and this component can be replaced with any other feature extractor.
2.3. SoftTriple Loss
SoftTriple is a loss function designed for metric learning in classification tasks, addressing the challenge of learning discriminative feature space representations. Recognized for its simple yet effective design [
25,
26], SoftTriple loss consists of two key components: a classification term and a regularization term.
The core idea of SoftTriple is to define a distance metric suitable for metric learning by learning a set of class-specific centers. Unlike traditional deep metric learning methods, SoftTriple not only considers intra-class distance relationships but also incorporates inter-class relationships. Specifically, SoftTriple introduces a parameterized class center matrix and learns the distances between samples and these centers. This enables the mapping of samples onto a high-dimensional feature space where the distances between samples of the same class are minimized, and the distances between samples of different classes are maximized.
SoftTriple loss is computed as follows. Let the feature vector of an input sample be
, with the corresponding true label
. In order to better capture intra-class diversity, SoftTriple loss introduces
cluster centers for each class. Denote the
-th center of the
-th class as
and all centers are
-normalized:
The cosine similarity between the sample
and each center is defined as
For each class
, compute the weight for each of the
centers using the softmax function:
where
is the temperature parameter. Consequently, the aggregated similarity of the sample to class
is given by
To enhance inter-class separation, a margin
is subtracted from the aggregated similarity corresponding to the true class
. That is, define the adjusted similarity as
Scale each class similarity by a factor
to obtain the logits:
Then, the classification loss is computed using the cross-entropy loss:
To prevent multiple centers within the same class from being overly similar (or, in some implementations, to merge redundant sub-centers to reduce overfitting), a regularization term is introduced for the centers. After normalization, the pairwise cosine similarity between centers is
The regularization term is defined as
where
is a small constant added for numerical stability. Combining the above components, the SoftTriple loss is defined as
where
is the weight hyperparameter for the regularization term.
3. Method
3.1. Problem Definition
Assuming the use of a CNN as a feature extractor, which maps the feature maps of input images to an N-dimensional vector space. In this procedure, the objective is to depict the characteristic vectors of diverse categories within this vector space in a manner that minimizes the distances between vectors belonging to the same class while maximizing the distances between vectors from different classes. Ultimately, this model generates feature vectors with N dimensions to distinguish various road surface defects in images. In order to tackle this issue, there are two crucial inquiries that need to be addressed. Firstly, it is essential to determine the suitable loss function and training methodology for effectively training this model. This involves selecting a loss function to guide how the network effectively separates feature vectors of different classes in the vector space. The choice of training approach is crucial as it determines how network parameters are updated during training to maximize the optimization goal of the loss function.
The other is that once training is complete, we must use the output feature vectors to classify input road surface defect images. This involves designing an effective classifier based on the trained model to recognize and classify different classes of road surface defects based on feature vectors. This may include selecting suitable classification algorithms and determining how to handle and interpret classification results effectively in practical applications.
Additionally, considerations include how to train a classification model with good generalization performance using a small number of samples, and how to ensure the model can continuously learn new classes after deployment.
3.2. Overall Framework
Deep metric learning exhibits fundamental distinctions from traditional supervised learning in both training and testing paradigms. Conventional supervised learning typically employs loss functions such as cross-entropy or mean squared error to minimize discrepancies between predicted outputs and ground-truth labels, where each sample is represented by a one-hot encoded class vector. In contrast, deep metric learning focuses on learning task-specific distance or similarity metrics, utilizing pairwise or triplet-based loss functions that explicitly optimize the relative distances between samples in the embedding space. During inference, traditional supervised models directly predict class labels through forward propagation of test samples, while deep metric learning systems compute distances or similarities between test samples and reference data (e.g., class prototypes or training exemplars) to execute classification, clustering, or retrieval tasks. This divergence underscores their core philosophical differences: deep metric learning prioritizes relational structure learning between samples, whereas traditional supervised learning emphasizes precise alignment between model outputs and discrete labels. The methodology proposed in this work follows the deep metric learning paradigm, structured into three sequential phases—dataset preparation, model training, and model evaluation—each of which will be elaborated in subsequent sections.
3.3. Dataset Preparation
The UAV-PDD2023 dataset [
27] is an open-source benchmark specifically designed for unmanned aerial vehicle (UAV)-based pavement distress detection. It contains 2439 three-channel JPG images covering six predefined distress categories: longitudinal cracks (LC), transverse cracks (TC), alligator cracks (AC), oblique cracks (OC), repair marks (RP), potholes (PH). The detailed analysis of the dataset can be found in the original UAV-PDD2023 publication. To conserve space, this paper does not provide an in-depth introduction. For this study, all distress instances were extracted as square regions from the original images and saved into category-specific folders. The resulting instance counts per distress type are summarized in
Table 1. This preprocessing step ensures consistent input dimensions while preserving the critical spatial features of each distress pattern.
To train and evaluate the method based on deep metric learning proposed in this paper, five sample sets were constructed, corresponding to five separate folders. Among them, the training set, validation support set, and validation set are used during the model training phase, while the testing support set and testing set are used during the model evaluation phase, as shown in
Table 2.
To simulate real-world application scenarios, this study includes the three most common disease categories (longitudinal cracks, transverse cracks, and diagonal cracks) in all five sample sets. In contrast, the three less common and rare disease categories (alligator cracking, potholes, and patch marks) are treated as online extension classes and are only included in the testing support set and the testing set.
The reason for separating common and rare types of pavement distress during training is to simulate real-world application scenarios. In practice, when training the model, only data of common distress types may be available. In such cases, a feature extractor can be trained using only this available data. After the model is deployed, if new types of distress are encountered, images of these new types can be captured and their features extracted using the pre-trained feature extractor. These extracted features can then be added to the support set. During the subsequent classification phase, the newly added distress types can automatically participate in the classification process without the need to retrain the feature extractor. This enables the proposed method to effectively adapt to new types of pavement distress.
The number of instances in the training set is shown in
Table 3.
A total of 100 instances were sampled from each disease category in the training set to form the validation support set. The instance counts are presented in
Table 4.
The validation set also contains the same three types of diseases as the training set, but there is no overlap in data between the two sets, as shown in
Table 5.
The test support set contains six types of diseases, including all the samples used during the training phase, along with three additional types of rare (relatively less common) disease samples, as shown in
Table 6.
The test set contains the same six types of diseases as the test support set, with no data overlap with the other four sample sets, as shown in
Table 7.
3.4. Model Training
First, the BNInception model is built and combined with a feature encoding layer that maps feature maps into feature vectors, forming the final target model. Next, the SoftTriple loss function is constructed, which includes a trainable fully connected layer. After training, this layer implicitly contains the cluster centers for all classes.
The training dataset consists of three types of diseases with relatively large numbers of instances: 1892 images of longitudinal cracks, 1070 images of diagonal cracks, and 3443 images of transverse cracks.
During the model’s forward propagation, training is carried out using this dataset containing the three types of diseases. After the model reads the input images, it generates feature maps through the BNInception network, which are then passed through a feature encoding matrix to produce N-dimensional feature vectors.
The SoftTriple loss is calculated for these feature vectors as follows: the feature vector is passed through a linear layer in the SoftTriple function to compute the similarity between the feature vector of each image and all cluster centers. Since the SoftTriple loss allows each class to have multiple cluster centers, the similarities between the feature vector and all cluster centers of the same class are summed to obtain the total similarity for each class. Then, based on these similarities and the one-hot encoding of the ground truth labels, the classification loss is calculated. The objective of this loss is to maximize the similarity between the input image and the cluster centers of its true class (targeting a value of 1), while minimizing the similarity with other classes (targeting a value of 0).
After obtaining the classification loss, the regularization loss is calculated, which measures the similarity between different cluster centers. The goal of this regularization is to reduce inter-center similarity, thereby improving intra-class compactness and inter-class separability, ultimately enhancing the model’s classification performance. The total loss is the sum of the classification and regularization losses.
Finally, the model parameters are updated via backpropagation based on the computed total loss. After multiple iterations, a network model with strong feature encoding and classification performance can be obtained.
3.5. Model Testing
Since the trained model outputs only a feature vector for an input image and does not directly produce a classification result, it is necessary to design an additional category prediction method.
The goal of training a deep metric learning model is to ensure that images from the same class yield highly similar feature vectors, while images from different classes yield dissimilar ones. Therefore, after training, the model can estimate the class of an image with an unknown label by comparing the similarity between its feature vector and those of images with known labels. The image is then classified into the class whose images have the most similar features.
To achieve this, a support set containing representative images of all target classes is required. All images in this support set are first passed through the model to obtain their corresponding feature vectors. The image to be predicted is also passed through the model to obtain its feature vector. Then, the similarity between this vector and each vector in the support set is calculated. These similarities are sorted in descending order, and the classes of the top-ranked samples are considered more likely to match the class of the image being predicted.
The specific category prediction method is as follows: After ranking the support set images by their similarity to the query image, select the top k most similar samples. Count which classes are represented among these k samples. Then, for each class, sum the similarity scores of its samples among the k selected ones, and divide this sum by the total number of samples of that class in the support set. This result is taken as the score for that class. Finally, the class with the highest score is selected as the prediction result. The overall procedure is illustrated in Algorithm 1.
| Algorithm 1. Category Prediction Method |
Input: A list of labels corresponding to support set samples, sorted in descending order of feature similarity with the query image; a list of similarity scores , aligned with ; a hyperparameter indicating the number of top similar samples to consider.
Output: Predicted label
Define a function that returns the total number of support set samples belonging to class .
Extract the top elements from and to form and .
Initialize an empty dictionary to store the cumulative score for each class, and set the initial score of each class to 0.
Obtain the key in with the maximum value as the predicted label .
|
To alleviate the problem of class imbalance in the support set and to prevent majority-class samples from dominating the similarity-based prediction, we design a weighting strategy based on both similarity and class sample count:
This strategy combines feature similarity with class density and has a reasonable theoretical foundation. From the perspective of representation learning, it incorporates a prior reflecting “sample sparsity” when weighting support samples within the same class. From a probabilistic modeling viewpoint, it resembles a soft voting mechanism within each class and implicitly treats each support sample as a potential sub-center. Moreover, this method is consistent with the multi-center concept in SoftTriple loss, enhancing the model’s ability to capture intra-class variation.
Through this design, the model can flexibly recognize all disease categories covered by the support set based on the sample information it provides. Even if some categories were not introduced during training, the model can dynamically adapt and perform classification as long as the support set contains examples of those categories—demonstrating an ability for online class-incremental learning. When a certain class is not represented in the support set, the proposed method assigns the query image to the most similar known class. To achieve accurate classification in such cases, it is necessary to include representative samples of that class in the support set.
4. Class-Incremental Comparison Experiments
4.1. Experimental Design
To test the online class-incremental ability of the proposed method for rare disease categories, this method (Control Group 1) is compared with the iCaRL class-incremental method (Control Group 2). Both the proposed method and the iCaRL method are trained using the same three common disease categories (including transverse cracks, vertical cracks, and diagonal cracks). In each training round, the validation set is used to validate the results of that round. During validation, there are slight differences between the proposed method and the iCaRL method, as the proposed method requires validation of the support set to assist in prediction, while the iCaRL method does not.
After the training phase, the iCaRL method requires incremental training for three additional rare disease categories, while the proposed method does not require any further training. Once the incremental training of the iCaRL method is complete, both methods are tested on the same test set, and the classification capabilities of both models are compared for six disease categories: transverse cracks, vertical cracks, diagonal cracks, crazing, repair marks, and potholes.
4.2. Experimental Environment and Parameter Settings
All experiments in this paper were conducted on a machine with an AMD Ryzen 7 6800U CPU, running Windows 11 as the operating system. The experimental environment includes Python 3.8.18 and PyTorch 1.8-cpu.
To meet the minimum input size requirement of the BNInception network, the input images were resized to 224 × 224 while maintaining their original aspect ratio. Any blank areas were filled with black color. The output feature vector dimension of the network’s fully connected layer was set to 64, and the feature vectors were standardized using the L2 norm [
28].
The training parameters for both methods were the same. Adam [
29] was used as the optimizer, with an initial learning rate of 0.0001 for the model. The initial learning rate for the SoftTriple cluster center fully connected layer was set to 0.01, with ε = 0.01 and weight decay set to 0.0001. The batch size during training was set to 32. The BN layer parameters were updated during training, while they were frozen during testing. The model was trained for a total of 50 epochs. The focus of this work lies in proposing an online class-incremental classification method tailored for pavement distress detection, rather than extensively exploring optimal parameter configurations for SoftTriple loss. We have adopted the commonly used parameter settings found in the literature to ensure stability and reproducibility.
4.3. Evaluation Metrics
The experiments use three commonly used image classification evaluation metrics to assess the model’s classification performance: , , and .
is one of the key metrics for measuring the performance of a classifier. It represents the ratio of the number of correctly classified samples to the total number of samples. In simple terms,
measures the proportion of correctly classified samples out of all samples. The formula for calculating
is
In the formula, represents true positive, represents true negative, represents false positive, and represents false negative.
, also known as sensitivity or the true positive rate, measures the model’s ability to correctly identify positive class samples. Specifically,
refers to the proportion of actual positive samples that are correctly predicted as positive by the model. The formula for calculating
is
In the formula, represents true positive and represents false negative.
is a metric that combines both
and
to assess the performance of a classifier. The
is the harmonic mean of these two metrics and can balance the trade-off between
and
. The formula for calculating the
is
where
represents the precision, which is calculated as
The ranges from 0 to 1, with higher values indicating a better classification performance of the model.
Since this paper addresses a multi-class classification problem, the average
for all categories is calculated as the model’s overall classification performance metric. The average
is typically calculated using either the macro-average or weighted average of the
across all classes:
In the formula, represents the number of classes, and represents the class index.
In addition to using the three metrics mentioned above to evaluate the various disease categories, additional metrics are required to assess the overall performance of the model. The macro-average and weighted average are two commonly used methods for aggregating multi-class metrics, which provide a comprehensive reflection of the model’s overall performance across all categories. These methods behave differently when addressing class imbalance issues.
The macro-average calculates the metric (such as
,
, or
) for each class individually and then takes the arithmetic average across all classes. It does not take into account the number of samples, so each class has the same weight. For example, the calculation formula for
is
where
represents the total number of categories.
The macro-average treats each class equally. If there are classes with very few samples, their performance fluctuations can significantly affect the macro-average results. Therefore, the macro-average is suitable for scenarios where the importance of each class is the same.
The weighted average calculates the metric for each class individually and then computes a weighted sum based on the proportion of samples in each class. Categories with a larger number of samples have a greater influence on the final result. The calculation formula for
is
where
is the number of samples in the class,
is the total number of samples across all classes,
represents the
for class
.
4.4. Training Procedure of Class-Incremental Comparison Experiments
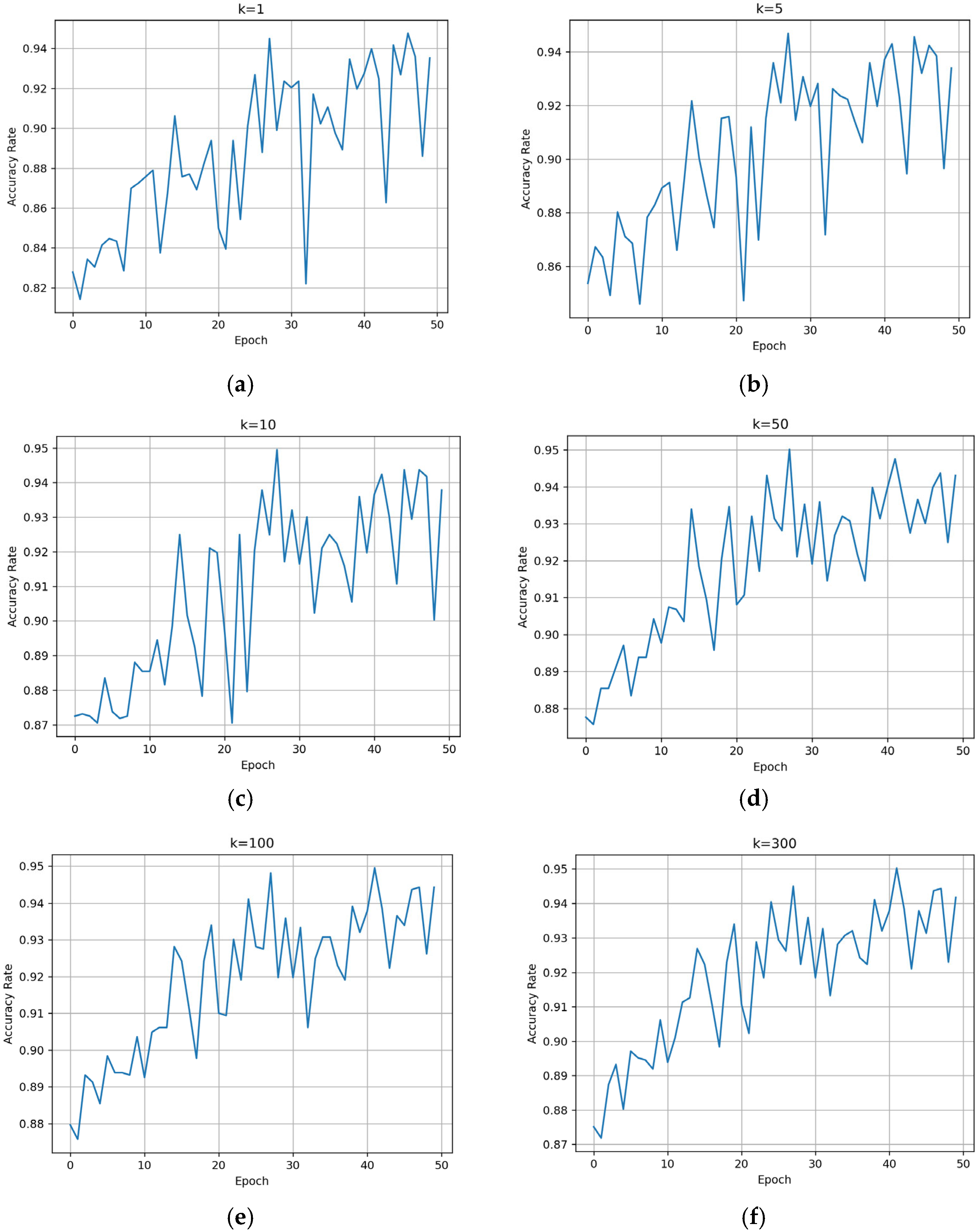
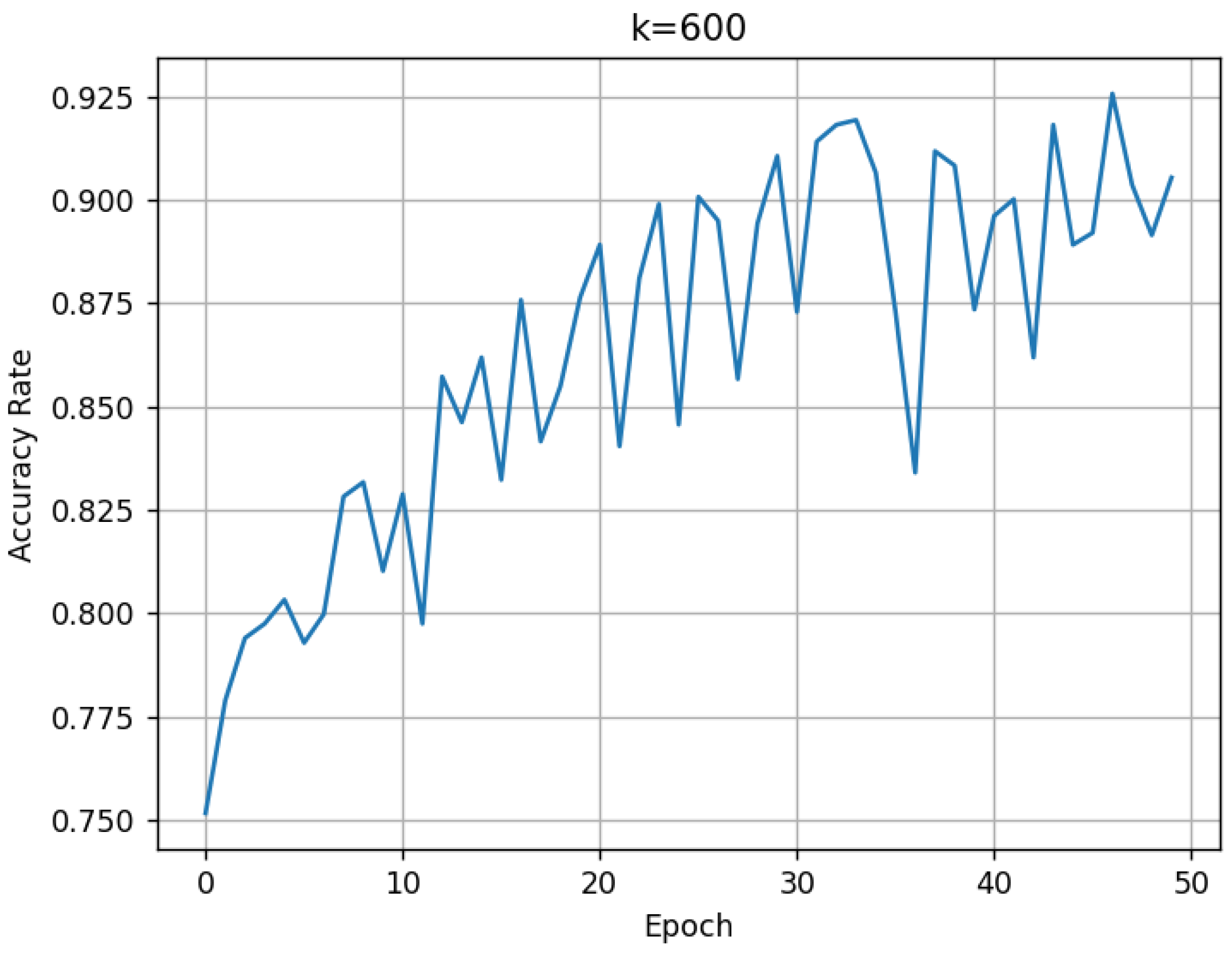
For the proposed method, the BNInception model is trained for 50 epochs using a training set consisting of three common disease categories (vertical cracks, transverse cracks, and diagonal cracks). After each training epoch, the model’s classification ability is validated using the validation support set and the validation set. During the validation process, since the validation support set contains 300 images, we traverse the hyperparameter k in Algorithm 1 from 1 to 300 to observe its impact on .
k values ranging from 1 to 300 are recorded. The resulting validation performance is shown in
Figure 2.
It can be observed that as the number of training epochs increases, the
shows an overall upward trend. The larger the value of
k, the more stable the
becomes. By the 50th training epoch, the
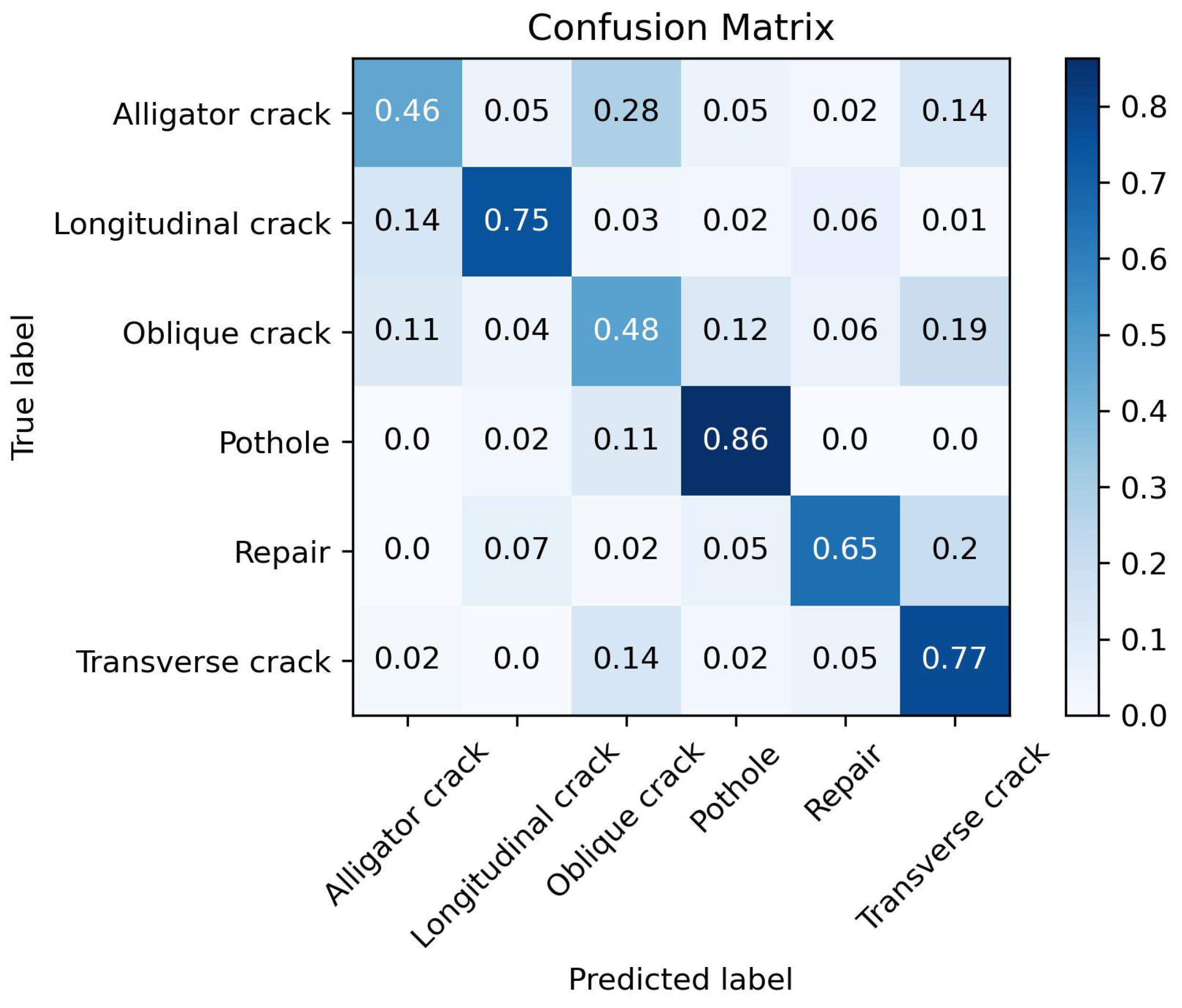
for the three disease categories reaches approximately 94%. The confusion matrix tested on the validation set is shown in
Figure 3.
From the confusion matrix in
Figure 3, it can be seen that the trained model exhibits a good classification ability for the three disease categories. At this point, the proposed method has completed its training.
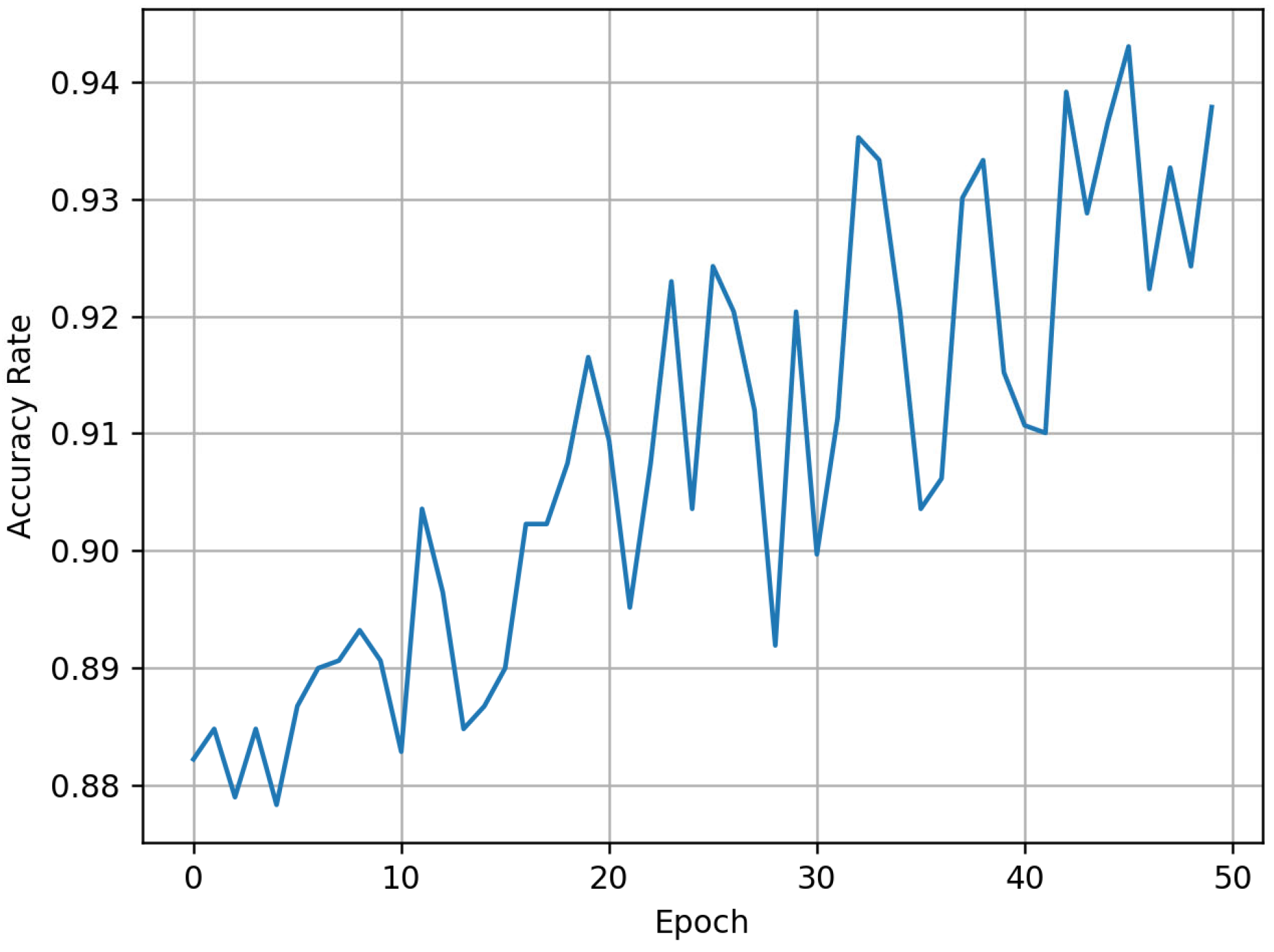
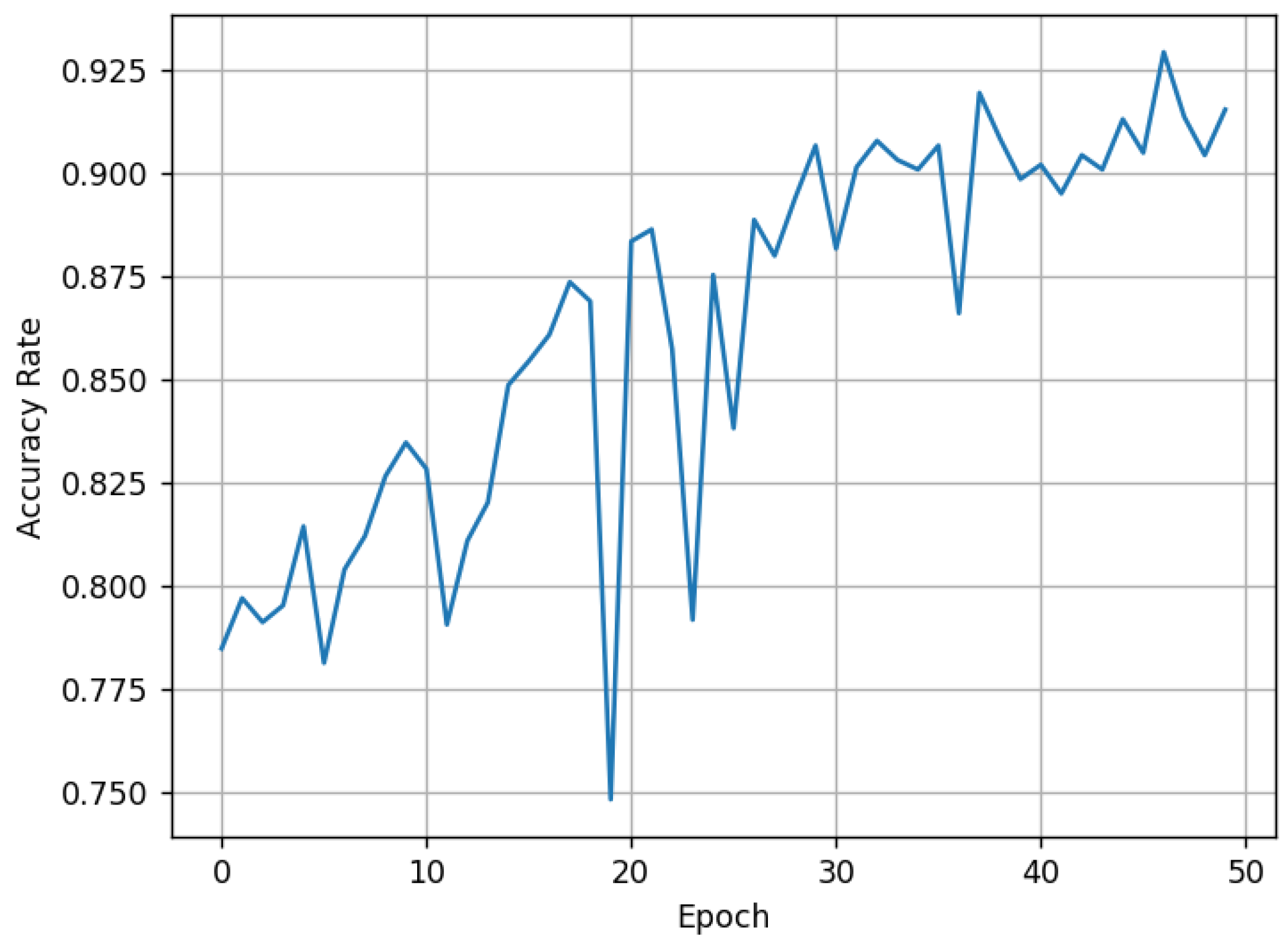
Next, the iCaRL method is used for the first phase of training. The model is initially trained using the same three common disease categories (transverse cracks, vertical cracks, and diagonal cracks) as the training set, with training parameters identical to those in control group 1. The
changes during the training process are shown in
Figure 4.
It can be observed that after the first phase of training using the iCaRL method, the model achieves an
of 94% for classifying the three common disease categories. The confusion matrix for this model is shown in
Figure 5.
Next, the second phase of incremental class training is carried out using the iCaRL method, where three additional rare disease categories (cracking, repair traces, and potholes) are introduced. A total of 50 epochs are used for this second phase of training. After training is completed, both control groups have prepared models ready for testing.
4.5. Results of Class-Incremental Comparison Experiments
The models from control group 1 and control group 2 are tested on the test set introduced in the previous section. The obtained test results are shown in
Figure 6 and
Figure 7 and
Table 8 and
Table 9.
From the experimental results, it can be seen that the macro-average and weighted average of the proposed method are 60.9% and 81.5%, respectively, which are 6.7% and 8.5% higher than those of the iCaRL method. This indicates that the proposed method demonstrates a better incremental class performance.
7. Discussion
The proposed deep metric learning framework tackles two key difficulties in pavement distress classification: the need for large-scale annotated datasets and the inflexibility in handling new distress categories incrementally.By establishing multiple intra-class centroids through SoftTriple loss, our method explicitly models the high intra-class variance commonly observed in real-world distress images (e.g., cracks with varying orientations, scales, and lighting conditions), a challenge inadequately handled by conventional single-center supervised learning. This design aligns with recent findings in material defect detection, where multi-cluster representation improves feature discrimination for irregular patterns [
30].
Our adaptive weighting strategy demonstrates superior performance over class-rebalancing techniques like Focal Loss [
31], particularly in scenarios with an extreme data imbalance (e.g., rare distress types in newly constructed roads). Unlike SMOTE-based oversampling [
32], which risks generating unrealistic synthetic samples, our approach leverages both sample similarity and class priors to dynamically adjust learning focus—proven effective by the 6.7% macro-F1 improvement over iCaRL. This echoes advancements in few-shot medical image analysis [
33], where similarity-guided adaptation outperforms explicit data augmentation.
The soft-label mechanism provides a viable solution to labeling noise, a persistent issue in pavement inspection where visual similarities between distress types (e.g., alligator cracks vs. map cracks) often lead to annotation inconsistencies. By evaluating sample-to-exemplar similarity, our method achieves “self-cleaning” of noisy labels, analogous to prototype refinement strategies in semi-supervised metal surface defect detection [
30]. However, unlike the work of [
30] that requires iterative clustering, our single-pass support-set comparison reduces computational overhead—a critical advantage for UAV-based real-time inspection.
Practical deployment considerations reveal two promising directions: First, the method’s compatibility with incremental learning makes it adaptable to region-specific distress patterns (e.g., freeze-thaw cracks in cold climates vs. thermal cracks in deserts), enabling localized model updates without full retraining. Second, the reduced annotation dependency aligns with industry needs for low-cost pavement monitoring, particularly in developing regions with limited inspection budgets.
Key limitations include the following: (1) performance degradation when novel classes exhibit visual overlaps with multiple existing clusters, a scenario requiring explicit cross-centroid relationship modeling; (2) dependence on UAV image quality—heavy shadows or occlusions may distort similarity measurements, necessitating fusion with LiDAR or infrared data in future work.
Inference speed depends on various factors, including hardware capabilities, the structure of the feature extractor, and the size of the support set. This work focuses on proposing an online class-incremental classification method tailored to pavement distress, rather than practical deployment. In real-world applications, one can select more powerful hardware, lightweight feature extractors, and an appropriately sized support set to increase the FPS.
8. Conclusions
This chapter addresses the issues of traditional convolutional neural network (CNN) learning methods in road damage image classification tasks, such as low accuracy, limited sample sizes for rare damage categories, and the need to retrain the model when new damage categories are introduced. To overcome these challenges, a deep metric learning approach is innovatively introduced for pavement damage classification research. The SoftTriple loss function is used to train the BNInception network, enabling the network’s output feature vectors to exhibit strong intra-class cohesion and inter-class separation. Then, similarity calculations are performed with the features of the exemplar images in the support set, and the final predicted category is determined using a category prediction strategy.
The experimental results show that the classification method proposed in this chapter can train a network model with good classification performance, even with limited samples for rare damage categories. Its macro-average is 3.2% higher than traditional supervised learning methods, making it suitable for application scenarios where high rates are critical for pavement damage classification. Moreover, the method has online class-incremental capabilities. A comparison with the iCaRL incremental learning method reveals that the proposed method achieves a 6.7% and 8.5% increase in the macro-average and weighted average , respectively, demonstrating a better classification performance for newly added rare damage categories. The method is both practical and scalable.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}