1. Introduction
Memory technology plays a pivotal role in modern computing systems. With the increasing proliferation of smart sensors and edge computing, there is a growing demand for memory solutions that support frequent write operations, low power consumption, and fast access times [
1,
2]. Conventional memory technologies, such as dynamic random-access memory (DRAM) and synchronous DRAM (SDRAM), are constrained by their volatility and relatively high energy requirements. In contrast, magnetic random-access memory (MRAM) has emerged as a promising non-volatile alternative, offering high-speed access, reduced power consumption, and superior endurance key attributes for sensor development [
3,
4].
Owing to these advantages, MRAM has been considered a candidate for unified embedded non-volatile memory (NVM) in Internet of Things (IoT) devices [
1]. Notably, its energy efficiency directly addresses the limited battery life of sensors in wireless sensor networks. Among various MRAM technologies, spin-transfer torque MRAM (STT-MRAM) is particularly noteworthy, as it combines the speed and durability of DRAM with the non-volatility of flash memory, making it highly suitable for next-generation computing applications [
1,
5,
6].
In STT-MRAM, digital data are managed via an nMOS transistor, which regulates current flow. The data themselves are stored as resistance values within a magnetic tunnel junction (MTJ). The MTJ comprises two ferromagnetic layers separated by a thin tunneling oxide barrier. These layers include a fixed “reference layer” and a “free layer”, the magnetization of which can be altered by a spin-polarized current. When the magnetization of the free layer is antiparallel to that of the reference layer, the MTJ exhibits high resistance. Conversely, when the magnetizations are aligned in parallel, the resistance is low [
7].
STT-MRAM offers several compelling advantages, positioning it as a leading contender in the non-volatile memory (NVM) market [
8]. However, similar to other established memory technologies, it faces critical technical challenges that can significantly affect its performance and reliability [
9]. One of the primary concerns is process variation, arising from inconsistencies in the geometry and resistance of the magnetic tunnel junction (MTJ) storage elements [
10]. These variations disrupt access operations, resulting in deviations in MTJ conductance and fluctuations in the switching threshold current.
Synchronization issues further impact STT-MRAM reliability. In synchronous designs, write operations are typically confined to fixed time windows, which may prevent certain memory cells from completing their state transitions within the allotted duration [
8]. Additionally, thermal fluctuations introduce further instability by injecting randomness into the switching behavior. These circuits use MTJ-based sensors and hybrid designs that include self-referencing mechanisms or poly-resistor references to stabilize read operations under changing temperature conditions [
11]. This increases the likelihood of unintended resistance changes in the MTJ, even in the absence of explicit write operations [
12,
13]. Another critical issue is read disturbance, wherein the read operation itself can inadvertently cause MTJ switching, leading to both read and write errors and thereby compromising data integrity. These reliability concerns are further exacerbated by manufacturing imperfections, which can degrade overall device performance. As technology nodes scale down, these challenges are expected to worsen, necessitating advanced design methodologies and process-level optimizations to improve STT-MRAM robustness and efficiency.
To mitigate these challenges, a variety of circuit-level and architectural solutions have been proposed. For example, the study in [
14] recommended using transistors smaller than the worst-case size to reduce write energy consumption. It further advocated a hybrid magnetic and circuit-level design approach to enhance STT-MRAM efficiency. Likewise, the authors in [
15] proposed a hybrid memory architecture that integrates static RAM (SRAM) with STT-MRAM, aiming to balance performance with energy efficiency. Another study [
16] investigated the use of write buffers to improve overall system throughput.
In the domain of signal processing, advanced channel coding plays a critical role in improving system performance and addressing the aforementioned reliability concerns. The increasing demand for high-density storage and cost-effective digital integrated circuits (ICs) has accelerated the adoption of sophisticated coding and signal processing techniques in modern memory systems [
8]. Errors occurring during read and write operations can be mitigated through the application of error-correcting codes (ECCs). For instance, the use of (71, 64) Hamming codes and (72, 64) extended Hamming codes has been proposed for STT-MRAM to correct single-bit errors efficiently [
17]. Furthermore, BCH codes with multi-bit error correction capabilities have been introduced in [
18] to enhance storage density and robustness against more severe fault conditions.
Channel modeling has been extensively utilized to develop and evaluate error-correcting codes (ECCs) for STT-MRAM systems [
17,
19,
20,
21,
22]. Among these models, the cascaded channel model proposed in [
17] has proven effective in facilitating error-rate simulations and in serving as a representative communication channel model. Building upon this model, Nguyen [
8] observed that errors in STT-MRAM occur independently, with an asymmetric probability distribution between logic 0 and logic 1 bits.
To address this asymmetry, the authors in [
8] introduced a 7/9 sparse coding scheme designed to mitigate the imbalance in bit error probabilities. This method constrains the Hamming weight of each output codeword to remain below half of the total codeword length, thereby reducing the likelihood of erroneous bit flips. However, when attempting to improve the code rate by increasing the codeword length, encoding sparse codes typically relies on mapping strategies based on Euclidean distance decoding, an approach that is computationally intensive and requires substantial memory resources.
To overcome these limitations, the authors in [
23] proposed an alternative encoding method that employs a generator matrix to directly produce sparse codewords with a minimum Hamming distance (MHD) of three. Additionally, they developed a corresponding decoder based on syndrome decoding algorithms, which significantly reduced complexity and improved overall efficiency compared to the mapping-based techniques used in earlier studies. Nevertheless, the effectiveness of their syndrome decoder was limited by its assumption of an equal distribution of 0s and 1s in codewords during threshold detection. This assumption proved problematic in sparse coding contexts, ultimately restricting the decoder’s accuracy and performance.
To overcome the aforementioned limitation, we enhance the encoder and propose a novel method to improve the syndrome decoder by refining threshold detection through the dynamic and automatic estimation of bit-0 and bit-1 probabilities within the codeword. Specifically, during the encoding process, three additional bits—referred to as sparse check bits—are appended to the user data. The extended data are then processed using a generator matrix to produce the final codeword. If the generated codeword does not satisfy the sparsity constraint, it is inverted to ensure compliance with the sparse code characteristics.
On the decoding side, the received signal is processed using a syndrome decoding algorithm. The sparse check bits are utilized to detect whether the codeword was inverted during encoding, thereby enabling accurate data reconstruction. Furthermore, to support adaptive and accurate threshold detection, the initial probabilities of bit-0 and bit-1 in the codeword are computed prior to transmission. These probabilities are subsequently refined in real time during transmission using a sliding window approach, allowing the decoder to adapt to varying channel conditions and maintain high accuracy. In this study, we present simulation results that validate the effectiveness of the proposed model. The results demonstrate notable improvements in both error resilience and decoding accuracy, particularly as the density of MRAM increases.
Below is a summary of our contributions in this study:
- -
We proposed a model that uses coding with a high code rate, which helps reduce the size of STT-MRAM while maintaining performance. This leads to minimized memory footprints, making the model suitable for embedded systems in the next generation of intelligent sensors.
- -
With the proposed coding scheme based on the Hamming code, bit inversion, and a sliding window, the system can be designed simply for encoding and decoding. This helps reduce energy consumption and enables faster data transfer in sensor systems.
- -
Finally, we provided simulation results to validate the feasibility and effectiveness of the proposed system.
The remainder of this paper is organized as follows.
Section 2 provides an overview of STT-MRAM technology and introduces the associated cascaded channel model.
Section 3 presents the proposed model for generating sparse codes based on the Hamming code theory, along with the corresponding decoding method using a syndrome-based algorithm.
Section 4 offers an analysis of the simulation results and includes a comprehensive discussion of the findings. Finally,
Section 5 concludes the paper with closing remarks and future directions.
3. Proposed Model
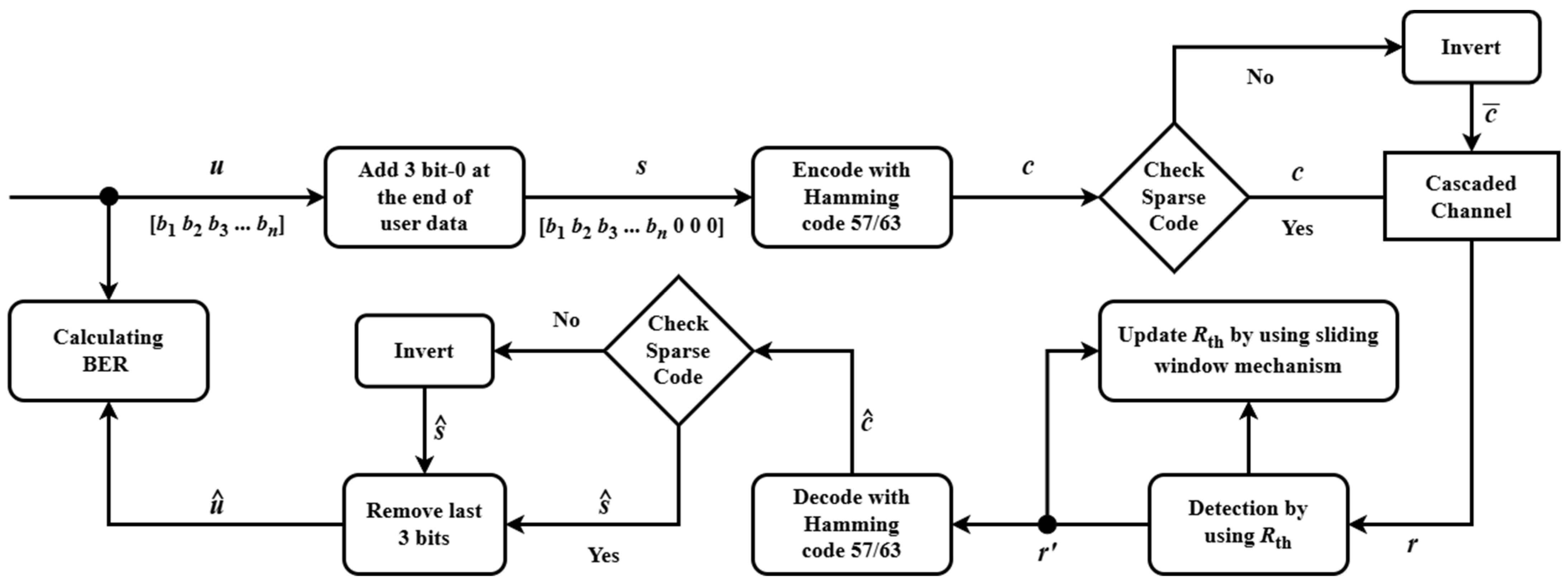
The proposed model is depicted in
Figure 6. User data
u are extended by appending three check bits designed to enforce sparse code characteristics, resulting in signal
s. This signal
s is subsequently multiplied by the generator matrix
G to generate the codeword. The sparsity of a generated codeword is evaluated by computing the total number of logical ‘1’s it contains. If the codeword does not satisfy the predefined sparsity criterion, it is inverted to ensure compliance. The resulting sparse codeword
c is then stored on the MRAM channel. Prior to transmission, the initial probabilities of bit-0 and bit-1 occurrences within the codeword are determined using the proposed method. These probabilities serve as a baseline for threshold detection, enabling more accurate and adaptive decoding in the presence of channel asymmetries and noise. The received signal
r, obtained from the resistance measurements of the magnetic tunnel junction (MTJ) in the MRAM device, is decoded using an advanced syndrome decoding algorithm. This algorithm enhances threshold detection by continuously adjusting the probabilities of bit-0 and bit-1 during transmission, employing a sliding window technique to adapt to channel variations. The decoded signal
, mirroring the structure of the sparse codeword
c, is derived from
r. The three check bits embedded in
are then examined to ascertain whether an inversion occurred during encoding, yielding the recovered signal
. This step ensures precise reconstruction of the original data. Finally, the user data
are retrieved from
by stripping away the check bits. To demonstrate the robustness of this approach across diverse channel conditions such as the offset condition and the writing error probability
, simulation results are presented and analyzed.
3.1. Encoder
The proposed encoding process comprises two primary steps. First, three check bits, initially set to zero, are appended to the user data vector u, forming an augmented vector s = [u 0 0 0]. Next, the corresponding codeword c is generated by multiplying s with the generator matrix G, derived from the Hamming code, i.e., c = sG. If the resulting codeword c does not satisfy the sparse code conditions, it is inverted to produce a valid sparse codeword. This ensures that the codeword meets the predefined sparsity requirement, which is critical for error resilience in asymmetric channels such as MRAM. The detailed encoding procedure is outlined as follows:
Parity matrix construction: We construct a parity matrix P, consisting of binary tuples with a weight greater than 1, where the final tuple is pk–1 = (111…111). Each binary tuple has a length of m, and the matrix P has dimensions (2m − m − 1) m, written as .
Generator matrix formation: The generator matrix
G is assembled by combining the identity matrix
I with the parity matrix
P. Mathematically,
G is represented as:
Augmented data vector: the user data vector is appended with three zero check bits to form , where .
Codeword generation: the codeword
c is computed by multiplying
s with
G, expressed as:
where
.
Sparsity check: the sparse code characteristic of the codeword
is evaluated using the formula:
If ω(c) < n/2, c is output as the final codeword. Otherwise, the process continues.
Sparse code adjustment: to ensure the codeword is sparse, the following formula is applied:
where
represents the bitwise inversion of
c.
From these steps, it is evident that the resulting sparse code achieves a code rate of . Codeword c is guaranteed to maintain sparse code characteristics.
3.2. Threshold Detection
For a cascaded channel, the threshold resistance is used to distinguish between two cell resistance states. Based on the following rule for hard decisions:
If , then .
If , then .
The bit error rate (BER) of the hard detected channel bits
can be computed as:
The BER is defined as the probability that a transmitted bit is decoded incorrectly. It accounts for the likelihood of transmitting a ‘0’ or ‘1’, as well as the conditional probability of each being erroneously decoded. Formally, the BER is computed as a weighted sum of these error probabilities, based on the respective bit occurrence probabilities in the transmitted codeword. As described in
Section 2, the GMC within the cascaded channel model represents noise as a combination of Gaussian distributions, each with distinct means and standard deviations for the transmitted bits. For hard decisions, the threshold
dictates the decoding: a received signal
exceeding
is decoded as 1, otherwise as 0. The error probabilities are then expressed using the Q-function, which quantifies the likelihood of the noisy signal crossing the threshold, transforming the BER into a form with Q-function terms that reflect the impact of Gaussian mixture noise on decision errors:
To optimize the probability
with respect to the threshold
, we set the derivative
to zero. This step identifies the critical point where
is either maximized or minimized, balancing the contributions of the two Gaussian distributions. The resulting equation ensures that the threshold
optimally separates the two distributions, weighted by their respective probabilities
and
, thereby achieving the desired performance metric for the system.
where
,
,
,
.
The formula for calculating the threshold includes a constant representing the probability of 0 and 1 in the codeword before going through the channel. To improve accuracy, we proposed a new algorithm to compute this probability more effectively. The detailed steps are outlined as follows:
After determining the probabilities of 1 and 0 in the codeword, these values are applied to the formula above to initialize the threshold resistance
, which serves as a reference for decoding in the proposed model. To further enable adaptive threshold detection during transmission, a sliding window technique is employed to dynamically update the probability of 0 (
), allowing the system to adapt to variations in the MRAM channel, as depicted in
Figure 7. The sliding window operates over the entire user data stream, which consists of a sequence of bits derived from the received signal measured via the magnetic tunnel junction (MTJ) resistance in the MRAM device. This window of a fixed size is segmented into three distinct regions: the “previous sub-window”, which contains bits from the prior position of the window before it advances; the “new window”, which represents the current set of bits under analysis; and the “new sub-window”, which includes the newly incorporated bits as the window slides forward. As transmission progresses, the window moves in a sliding fashion, continuously updating its contents by adding bits from the new sub-window and discarding bits from the previous sub-window, thereby maintaining a real-time view of the bit stream. This mechanism is integrated into an advanced syndrome decoding algorithm, which leverages the updated probability to adjust the detection threshold, ensuring accurate decoding of the sparse codeword under varying channel conditions. The probability
is computed as the ratio of the net number of 0s in the window to the total number of bits considered, using the formula:
where
is the number of 0s in the previous window;
is the number of 0s in the new sub-window;
is the number of 0s in the previous sub-window;
is the total number of bits in the window.
3.3. Decoder
After applying threshold detection to convert the scalar signal received from the cascaded channel into a binary signal r’, this binary signal is multiplied with to identify the error bit position in the error table. The error table enables correction of a single bit error in r’. Once the error is corrected, the resulting codeword is checked for its sparse code characteristics. Specifically, if the last three bits of are any of the following: [0 0 0], [0 0 1], [0 1 0], or [1 0 0], these last three bits are removed to retrieve the user data (recovered signal) . Otherwise, is inverted, and then, the last three bits are removed to obtain . Finally, the signals u and are utilized to evaluate the BER performance.
4. Results and Simulation
For the simulation, a total of 540,000,000 user data bits (u) are used. Following the sparse code characteristic check and necessary adjustments, the codeword (c) is generated and stored in the MRAM. During the data retrieval phase, the received signal (y) is obtained by measuring the resistance of the MTJ in the MRAM, where errors may occur. To mitigate these errors, the proposed threshold detection and syndrome-based decoder are applied to the received signal to reconstruct the estimated user data (). The BER performance is then evaluated by comparing the original data (u) with the recovered data ().
In the initial simulation, we aim to identify the optimal parameters for the sliding window by conducting a comprehensive survey. Theoretical insights suggest that a larger window size may overlook subtle data variations, whereas a smaller one might fail to capture sufficient contextual information. To balance this trade-off, we performed simulations across a range of window sizes to determine the configuration that yields the best BER performance. Specifically, we evaluated our method using window sizes corresponding to 5000, 7000, 10,000, 13,000, and 15,000 block codes, with each block consisting of 63 bits. Additionally, the is updated every 1000 block codes.
Figure 8 illustrates the BER performance of our method using various window sizes: 5000, 7000, 10,000, 13,000, and 15,000 block codes. The results indicate that a window size of 10,000 block codes achieves the best BER performance (i.e., the optimal point) at a
ratio of 8%. Furthermore, in the range of
ratios from 9.5% to 16%, the performance gap among different window sizes is negligible. We also conducted simulations for
ratios between 5% and 7%; however, the results were not significantly different from those at 8% and thus are not included in the figure. Based on these findings, we selected 10,000 block codes as the sliding window size for our proposed model.
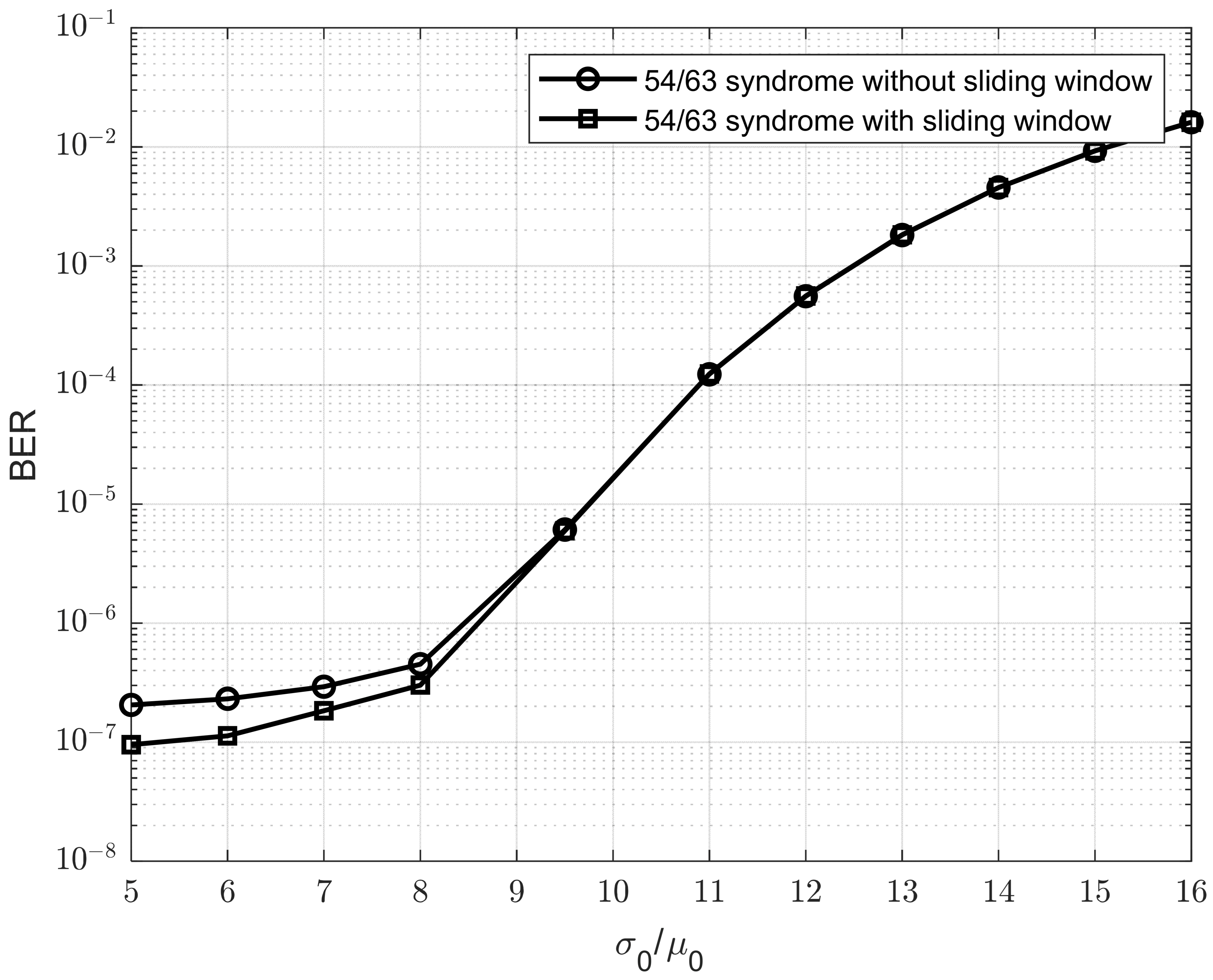
To demonstrate the impact of window sliding in our approach, we conducted simulations comparing the proposed method with and without the sliding window in
Figure 9. We can observe that the sliding window improves the BER performance of the model as the
ratio decreases. This is because a smaller
ratio indicates reduced Gaussian noise, which allows the sliding window to estimate the
Rth value more accurately and stably. As a result, the improvement becomes more significant when the
ratio is low.
In the next simulation, the proposed model is implemented using a sparse code rate of 54/63. For comparison, we also included the results of the 7/9 sparse code rate presented in [
8], the 51/63 BCH model using the decoding in [
26], and the 56/63 syndrome and low-density parity check (LDPC) described in [
23]. The device parameters for STT-MRAM are adopted from [
27]. Specifically, the write error rates are set as
= 2 × 10
−4,
= 1.02 × 10
−4, and
= 10
−6. According to [
13], the area density of an STT-MRAM cell has a direct impact on its write error rate. Therefore, we adjusted the write error rate parameters for each coding scheme based on the scaling model proposed in [
13]. To achieve the greatest impact on size, we selected the grey line representing a ‘1’ written in 10 ns as the application result in our proposed model. We assumed that no coding is used at 450 nm, as the size is expected to decrease when coding is applied. Additionally, sizes smaller than 450 nm exhibit significant variation, which further emphasizes the impact of size on the error rate.
To calculate the error rate P1 in our paper, we took a example as below.
Using the 7/9 method, 450*7/9 = 350 nm. To maintain the same area density of user bits in this method, the size of each MTJ must be reduced. This allows more MTJs to be added within the same area compared to the no-coding method. Assuming 450 nm for the no-coding method and 350 nm for the 7/9 method, the authors of [
13] indicate that this size reduction leads to a 25% increase in the error rate. We typically used
P1 = 2
10
−4. Therefore,
The updated write error rates applied in the simulation for each method are summarized in
Table 1.
Figure 10 illustrates the BER performance of the proposed method in comparison with those of previously reported techniques, incorporating updated write error rates. The results indicate that the proposed method outperforms those reported in previous studies. At a BER of 10
−4, the proposed method achieves a 2.8% improvement over the 7/9 sparse code. At a BER of 10
−6, it shows a 0.5% gain over the 56/63 sparse code. However, when the
ratio increases to 16%, the BER performance of the proposed method falls slightly behind that of the 56/63 sparse code, although it still maintains a clear advantage over the 7/9 sparse code.
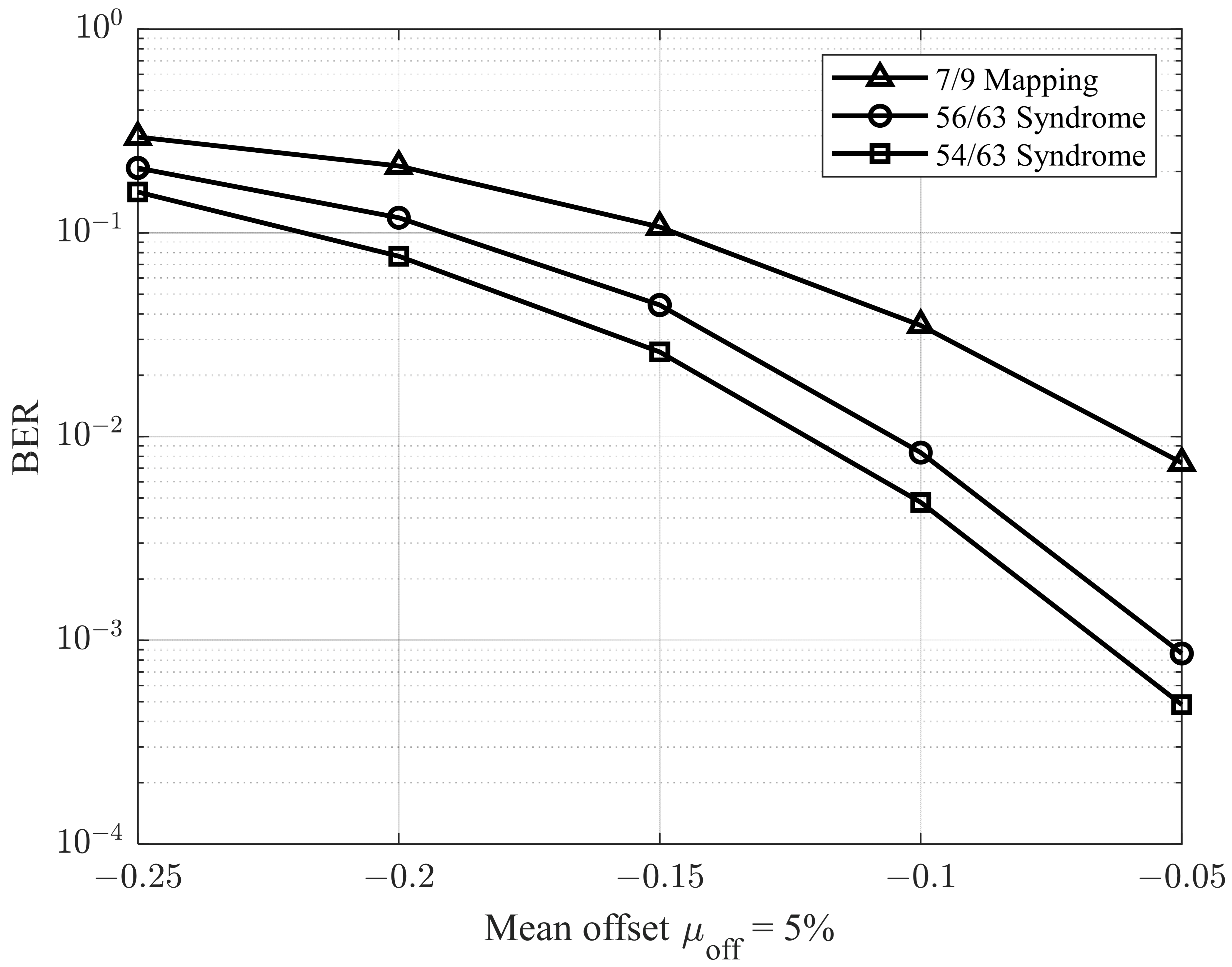
In the next simulations, we adopted the methodology described in [
28] to evaluate performance under varying offset conditions. Specifically, the environment was configured with a
ratio of 9.5%, and the mean offset
was varied from −0.25 to −0.05. The corresponding results are presented in
Figure 11 and
Figure 12, which illustrate the BER performance for
ratios of 5% and 7%, respectively. As shown in
Figure 11 and
Figure 12, the proposed model demonstrates superior performance compared to previous studies.
Finally, we set
and adjusted the writing error probability
(error rate for the 0 → 1 transition) during the writing process [
29]. The performance of the proposed model is presented in
Figure 13. As illustrated, each model exhibits a distinct threshold error probability, beyond which the BER begins to degrade from its previously stable value, indicating a loss in decoding reliability as write error rates increase. In addition, the proposed code can still improve the performance. Moreover, when
is less than 10
−5, which is very small, the error in the writing process does not affect the performance of the codes, but the read-decision error occurs at the GMC with the resistance spread
.
To compare the complexity of our proposed decoder with that of previous studies, we quantified and grouped both addition and comparison operations as equivalent addition operations for the purpose of complexity analysis.
Table 2 presents the results of the complexity comparison.
In
Table 2, we reference the complexities of the 7/9 mapping, the 56/63 sum-product, and the 54/63 syndrome (without the sliding window), as presented in [
23]. Our proposed model is based on the 54/63 syndrome method from [
23] and, therefore, achieves a similar level of complexity. The primary distinction between our model and the 54/63 syndrome in [
23] lies in the use of sliding window operators. Compared to the 7/9 mapping, our model represents a trade-off between performance and complexity. In contrast to the 56/63 sum-product method, our model reduces complexity, as the sum-product algorithm relies on iterative computations, which significantly increase the number of required operations.
To calculate the complexity of our proposed model, we began with the decoding model of the 54/63 syndrome and added the operators introduced by the sliding window mechanism. The number of sliding window operators was estimated based on Equation (13), which was used to count the total number of addition operations across 10,000 data blocks. The value of
Rth obtained from these 10,000 blocks was then used to detect the next 1000 data blocks, using a step size of 1000 blocks (i.e., the previous sub-window size was 1000). Therefore, the total number of operators for the 10,000 blocks was divided by 1000 to determine the average number of operations per data block. Since each data block consisted of 63 bits, the number of operations per block was further divided by 63 to compute the number of operations per detected bit. This final value was then added to the number of operators used in the 54/63 syndrome decoding from [
23].











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}