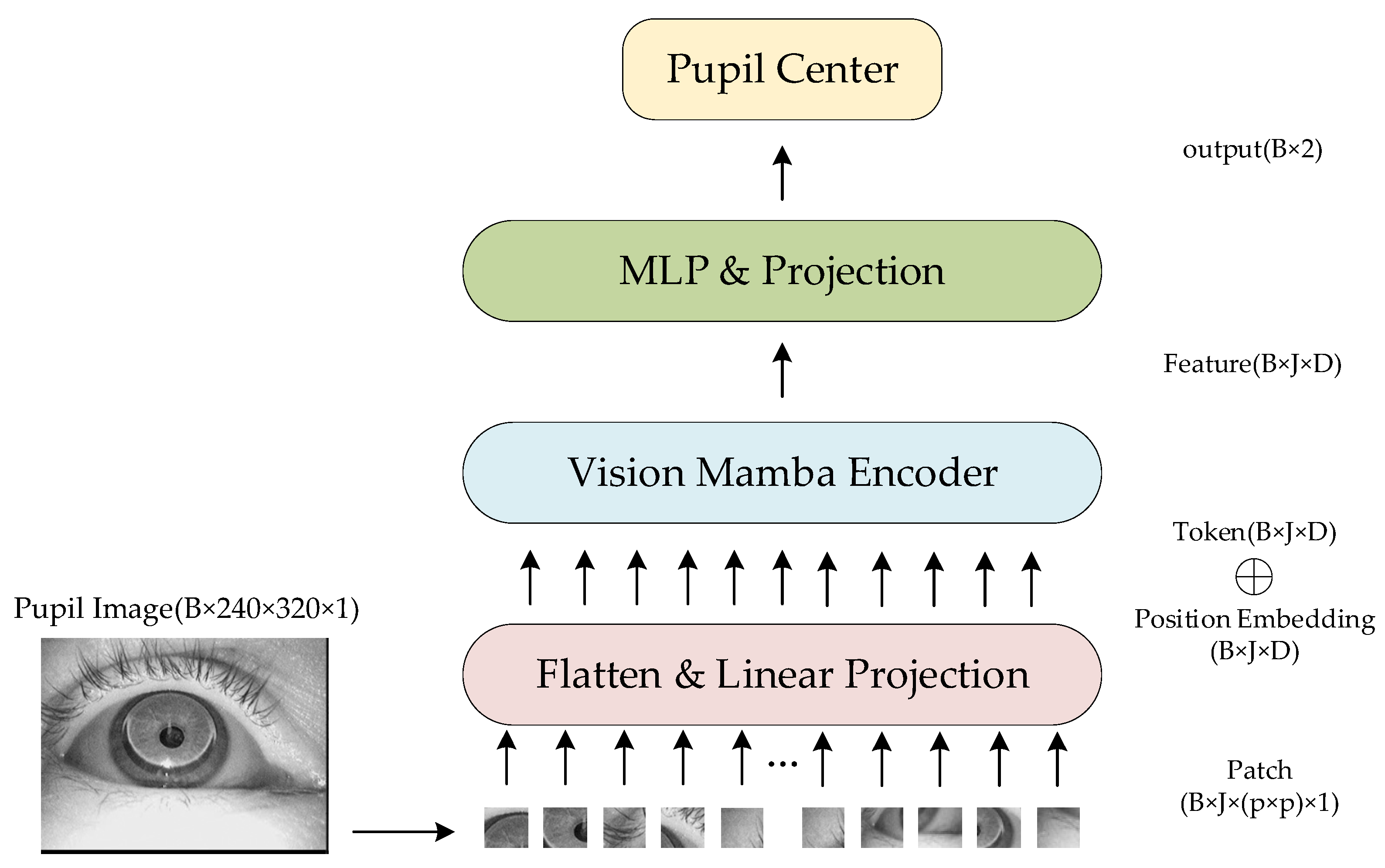
4.1. Data Acquisition
The experiment employed 30 distinct datasets comprising approximately 135,000 pupil images to evaluate the performance of the proposed ViMSA model. Among these, 29 datasets were provided by Wolfgang Fuhl’s research team and were previously cited in ExCuSe [
25], ELSe [
26], and PupilNet 2.0 [
27]. Following the naming convention established in prior researches, these 29 datasets are designated with Roman numerals as DI, DII, DIII, DIV, DV, DVI, DVII, DVIII, DIX, DX, DXI, DXII, DXIII, DXIV, DXV, DXVI, DXVII, DXVIII, DXIX, DXX, DXXI, DXXII, DXXIII, DXXIV, newDI, newDII, newDIII, newDIV, and newDV [
48].
The additional dataset used is the publicly available iris dataset CASIA-Iris-Thousand, which contains 20,000 iris images collected from 1000 participants. For convenience in subsequent experiments, this dataset will be referred to as CIT.
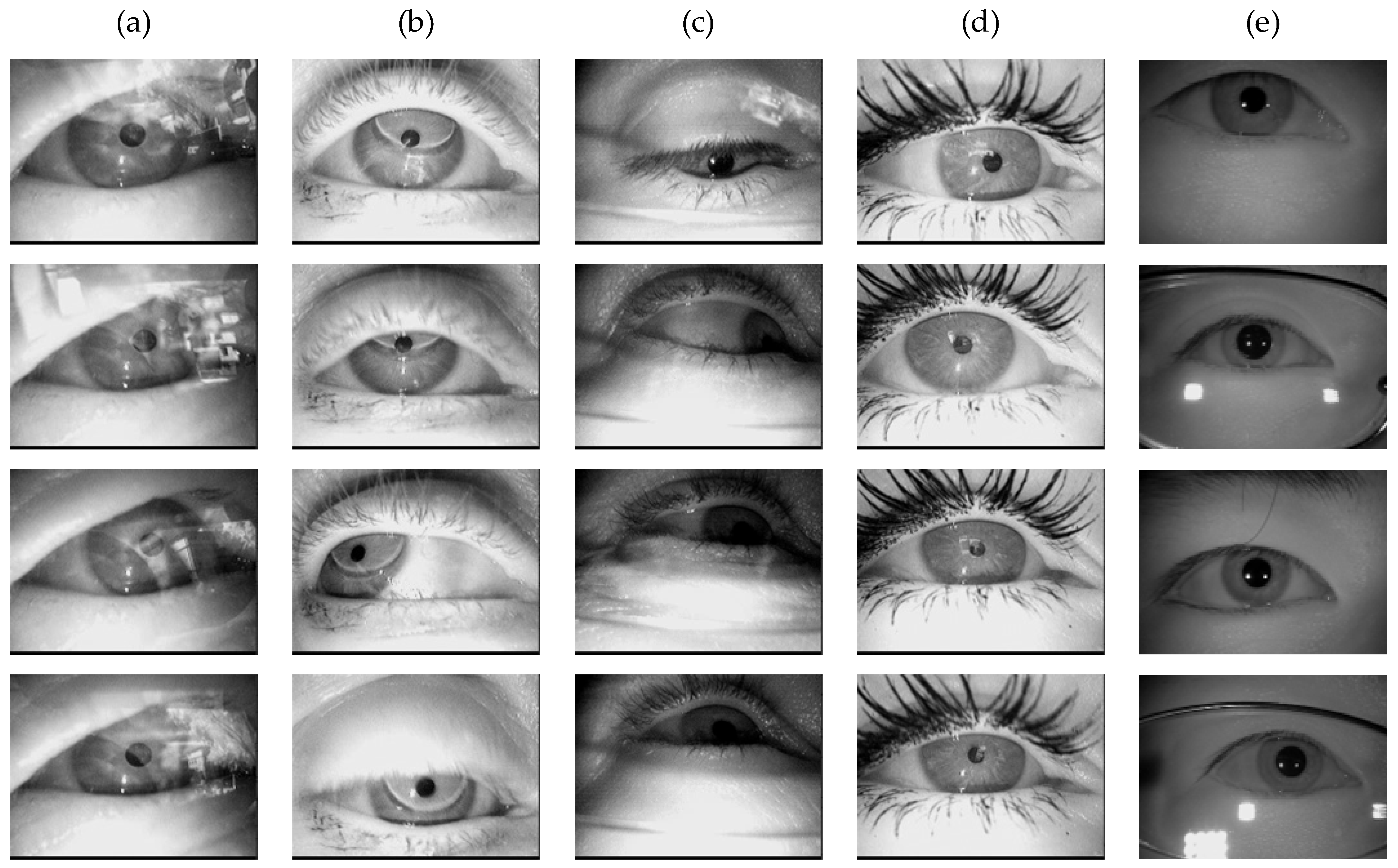
Figure 7 presents representative pupil images sampled from these datasets.
In the experiments, all pupil images were single-channel grayscale. The CIT dataset contained images sized 640 × 480, while all other datasets featured 384 × 288 images. For standardization, all images were resized to 320 × 240. Specifically: (1) CIT images were proportionally scaled down, and (2) other datasets underwent center cropping to preserve the 320 × 240 central region. The data were split into 85% for training and 15% for testing.
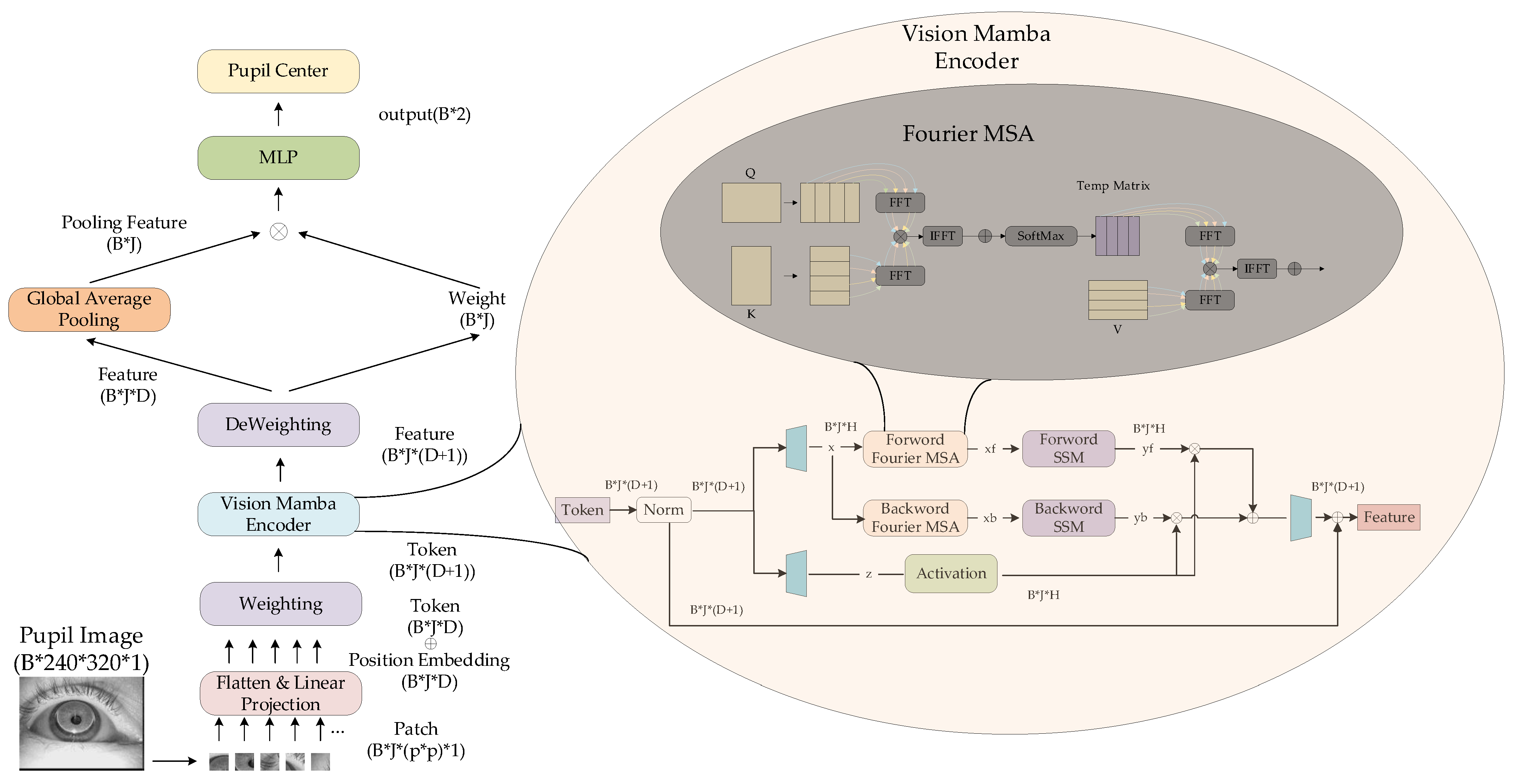
4.4. Ablation Experiment
For the experimental configuration regarding batch size, learning rate, and optimizer selection, we first fixed the learning rate at 1 × 10
−3 and chose Adam as the optimizer.
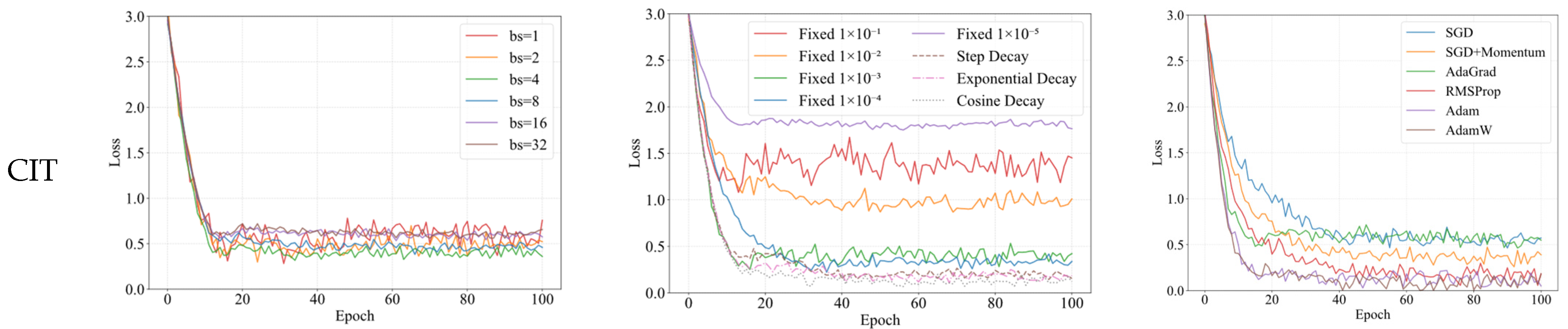
Figure 8 demonstrates the convergence behavior of the model under different batch sizes across various datasets, while
Table 2 presents the corresponding DR5 (detection rate within 5-pixel error) in % (with fixed model parameters: 8 MSA heads, 10 × 10 patch size, and Gaussian initialization for the weights in weighted fusion). In
Table 2, the first column lists the dataset names, the second column shows the corresponding data volumes, and the last column provides brief descriptions of each dataset.
Figure 8 reveals that when the batch size is relatively small (bs = 1 and bs = 2), although the model can converge to favorable values, the training process exhibits excessive fluctuations due to the gradient noise introduced by smaller batches, which helps the model escape poor local optima. Conversely, with larger batch sizes (bs = 16 and bs = 32), while the training process remains stable, the model fails to converge to better solutions, indicating it becomes trapped in inferior local optima—essentially overfitting to the training data—as the reduced inter-batch information variation diminishes necessary noise, preventing the model from escaping suboptimal solutions. Overall, when bs = 4, the model demonstrates relatively stable training while achieving superior convergence. Notably, across all batch sizes, the model converges significantly faster on the CIT dataset compared to others, likely because CIT, unlike the remaining 29 datasets, does not intentionally incorporate extreme environmental conditions (e.g., strong reflections, contact lenses, or mascara occlusion), making it inherently less challenging for detection. As shown in
Table 2, a batch size of 4 yields superior detection accuracy across most datasets. Therefore, bs = 4 is selected for subsequent experiments.
With the batch size fixed at 4 and Adam selected as the optimizer,
Figure 8 illustrates the model’s convergence behavior under different learning rate strategies, while
Table 3 presents the corresponding DR5. The evaluated learning rate configurations include: (1) fixed rates (1 × 10
−1, 1 × 10
−2, 1 × 10
−3, 1 × 10
−4, 1 × 10
−5); (2) Step Decay (1 × 10
−3 for first 40 epochs, 1 × 10
−4 for next 40 epochs, 1 × 10
−5 thereafter); (3) Exponential Decay (γ = 0.95, initial rate = 1 × 10
−3); and (4) Cosine Decay (cycle = 100, initial rate = 1 × 10
−3, minimum rate = 1 × 10
−5).
Figure 8 demonstrates that with a fixed learning rate of 1 × 10
−5, the model’s loss barely decreases due to insufficient parameter updates from excessively small gradients. Fixed rates of 1 × 10
−1 and 1 × 10
−2 initially converge rapidly but ultimately fail to train properly, as large learning rates cause overshooting and oscillate or even diverge near the loss minimum. While fixed rates of 1 × 10
−3 and 1 × 10
−4 enable stable training, they converge to suboptimal solutions, with 1 × 10
−3 showing faster early-stage convergence but 1 × 10
−4 reaching marginally better local optima later. Unlike fixed rates, adaptive learning rate strategies are more prevalent in deep learning. The Step Decay schedule in
Figure 8 exhibits distinct plateaus and abrupt drops (particularly around epoch 40), whereas Exponential Decay and Cosine Decay display smoother trajectories. Notably, Cosine Decay achieves superior convergence by maintaining: (1) smoother, continuously differentiable rate transitions than Step Decay, and (2) more gradual decay than Exponential Decay, thereby prolonging effective optimization before premature stagnation. As quantified in
Table 3, Cosine Decay performs better in most datasets, justifying its selection for subsequent experiments.
The fixed batch size is 4, and the learning rate adjustment strategy is Cosine Decay.
Figure 8 shows the convergence of the model under different optimizers, and
Table 4 shows the corresponding DR5.
Figure 8 demonstrates that SGD exhibits the slowest convergence due to its lack of adaptive learning rate adjustment. While AdaGrad converges relatively quickly, its training progress nearly stagnates after epoch 40 because it uses the accumulated sum of historical gradient squares as the denominator, causing the learning rate to decrease monotonically until it becomes infinitesimally small in later stages, halting parameter updates. Adam combines momentum with adaptive learning rates for faster convergence, whereas AdamW further improves upon Adam by decoupling weight decay to resolve conflicts between adaptive learning rates and L2 regularization, resulting in more stable training. As shown in
Figure 8, AdamW slightly outperforms Adam in both convergence speed and stability.
Table 4 confirms that AdamW achieves superior results on most datasets. Therefore, AdamW is selected as the optimizer for subsequent experiments.
After completing the ablation experiment of training hyperparameters, it is necessary to experimentally verify and select the hyperparameters of the model.
This paper compares two adjustable parameters in the experiment: patch size and the number of MSA modules, as well as the weight initialization scheme used in the weighted feature fusion method.
The weighted feature fusion method’s performance is significantly affected by weight initialization, as it determines the learning direction of weight vectors. This paper systematically evaluates three distinct initialization approaches: fixed initialization where weights are set to a constant value of 1, random initialization with values uniformly distributed between 1 × 10
−5 and 1, and Gaussian initialization where weights are randomly generated following a normal distribution centered on a 30 × 30-pixel region of the image with a standard deviation of 1. All experiments were performed using the default parameters of ViT and ViM models, maintaining a consistent patch size of 16 × 16 pixels and employing 8 MSA modules, with DR5 serving as the evaluation metric. The comprehensive comparison results are presented in
Table 5.
Figure 9 shows the convergence of the model under different weight initialization schemes.
As evidenced in
Figure 9, the fixed initialization scheme yields the slowest convergence and even fails to converge normally on datasets like DI (with reflections), DII (poor illumination), and DV (contact lenses). This likely occurs because: (1) complex data distributions require differentiated feature learning, but fixed initialization forces identical neuron updates during backpropagation, reducing the network to single-neuron functionality; (2) while random initialization breaks symmetry and enables diversified feature learning, improperly configured random values may cause gradient instability and neuron saturation. In contrast, Gaussian initialization achieves the fastest convergence since: (a) its zero-centered symmetric weight distribution aligns with pupil image characteristics; (b) appropriate numerical ranges prevent activation saturation (e.g., ReLU outputs) during forward propagation, avoiding vanishing gradients; (c) uniform gradient distribution during backpropagation; and (d) random gaussian noise ensures differential initial weights for accelerated specialized learning. From
Table 5, it can be seen that the Gaussian initialization scheme achieved better results on all datasets. Therefore, in the subsequent experiments, Gaussian initialization was chosen as the initialization scheme for the weights in the weighted feature fusion module.
Regarding patch size and the number of MSA modules, the original ViM model uses a 16 × 16 patch size, while the original ViT model employs 8 MSA heads. Set the patch size to 8 × 8,
Figure 9 shows the loss curves of the model on different datasets under different MSA heads, and
Table 6 shows the corresponding DR5.
Figure 9 demonstrates that when the number of MSA heads is too small (2 or 4 heads), convergence is slower and settles at suboptimal solutions due to insufficient capacity to capture the diversity and complexity in input data, limiting feature learning. Conversely, excessive heads (16 or 24) accelerate convergence but fail to escape poor local optima, as redundant heads may overfit to noise rather than meaningful patterns. Comparative analysis reveals that 12 heads strike an optimal balance, delivering moderate convergence speed and superior performance across most datasets. Thus, 12 MSA heads are selected for subsequent experiments.
Keeping the number of MSA heads fixed at 12,
Figure 9 shows the loss curves of the model on different datasets for different patch sizes, and
Table 7 shows the corresponding DR5.
Figure 9 demonstrates that when the patch size is too small (e.g., 4 × 4 or 8 × 8), the model converges faster but with relatively unstable training dynamics, as smaller patches preserve finer local details but are also more susceptible to local noise, resulting in larger gradient fluctuations. Conversely, excessively large patch sizes (e.g., 20 × 20 or 40 × 40) lead to more stable training but tend to converge to poorer local optima due to the loss of discriminative fine-grained features. The analysis reveals that a 16 × 16 patch size achieves an optimal balance, delivering faster convergence, moderate stability, and superior final performance. As evidenced in
Table 7, the 16 × 16 configuration outperforms other settings across most datasets. Therefore, a patch size of 16 × 16 is selected for subsequent experiments.
4.5. Horizontal Experiment
This paper conducts a comparative analysis of both classical and state-of-the-art models in pupil detection. The evaluated models include: classical approaches—ExCuSe [
25] (abbreviated as Ex), ELSe [
26] (EL), PuReST [
27] (PR), PupilNet v2.0 [
35] (Pu, which contains three sub-models: direct approach SK8P8 (SK), direct coarse positioning and fine positioning implemented with FCKxPy (FC) and FSKxPy (FS)); and recent models from literature [
15] (GC), [
16] (KX), [
17] (CS), [
18] (ZHM), [
19] (ZG), [
20] (WL), [
21] (JXM), [
22] (ZB), [
37] (GB), [
38] (GY), along with ViT, ViM, ViM+MSA (VM), and ViT+FMSA (the proposed Fourier-accelerated MSA, denoted as VF).
Table 8 and
Table 9 summarize the RMSE values of classical and emerging models across all datasets, respectively, while
Table 10 and
Table 11 present the DR5 metrics for classical and emerging models on all datasets correspondingly.
The accuracy of models Ex, EL, Pu, and GB can be reused across some shared datasets. As shown in
Table 8 and
Table 9 (RMSE) versus
Table 10 and
Table 11 (DR5), classical pupil detection algorithms (Ex, EL, Pu) fail to deliver satisfactory results under varying illumination conditions. In contrast, the proposed ViMSA model maintains robust detection rates even under extreme conditions including poor lighting, reflections, contact lens, and mascara application, outperforming both classical image-processing-based methods and recently proposed detection algorithms in DR5 and RMSE metrics across most datasets. Notably, the SK sub-model of Pu achieves 99% accuracy and 1.7px RMSE on dataset DXVII, surpassing ViMSA’s performance—likely because this dataset contains only 268 images, whereas ViMSA (like other deep learning models) requires larger training sets to achieve optimal generalization, while the simpler SK architecture may perform better on smaller datasets. This suggests that expanding the pupil image volume could further improve ViMSA’s performance on such datasets.
Table 9 and
Table 11 demonstrates identical results between VM and ViMSA, as well as between VF and ViT, since their core computational workflows remain fundamentally unchanged, with FFT primarily serving to accelerate matrix multiplication.
Figure 10 shows the loss function curves of the latest pupil detection model on different datasets.
From
Figure 10, it can be seen that the convergence stability and efficiency of ViMSA are slightly better than other latest models.
Table 12 shows the GFLOPs and running time for each model.
As evidenced in
Table 12, the proposed ViMSA model demonstrates superior computational efficiency compared to most state-of-the-art approaches, with a notably low complexity of 0.102 GFLOPs—surpassed only by the GB model and original ViM architecture. While GB achieves faster execution through its simplified dual-convolutional design (processing x/y coordinates separately), this decoupled approach fails to capture spatial correlations between coordinates, resulting in lower accuracy than ViMSA. The baseline ViM, though efficient, exhibits weaker global modeling capability versus ViT. ViMSA addresses this by integrating ViT’s MSA mechanism for enhanced global representation, achieving accuracy improvements with merely a 0.008 GFLOPs overhead. Experimental results confirm that replacing standard MSA with FFT-accelerated MSA in ViT (yielding VF) improves both speed and complexity. Ultimately, ViMSA meets real-time pupil detection requirements (>100 FPS) while maintaining robust performance across challenging conditions (poor illumination, occlusions etc.), as it combines: (1) ViM’s efficient SSM backbone, (2) MSA’s global attention, and (3) FFT optimization—collectively solving critical issues in extreme scenarios.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}