
Lag-Specific Transfer Entropy for Root Cause Diagnosis and Delay Estimation in Industrial Sensor Networks



Abstract
1. Introduction
2. Fundamental Concepts
2.1. Foundations of Information Theory
2.2. Transfer Entropy
3. Methodology
3.1. Principles of LSTE
3.2. Transfer Entropy Estimation
| Algorithm 1 Estimation of using KNN |
| Input: Variable X and Y, embedding dimension , embedding delay , number of neighbors ) End joint_space = [Y_future, X_embed, Y_embed] % Construct joint space [nnidx, dists] = Knn_search(joint_space, k + 1); % Find local neighborhood using KNN maxdistV = dists(end,:) % Distance to the (k + 1)-th neighbor defines the hypersphere radius [nxz, nyz, nz] = point_estimation(Y_future, X_embed, Y_embed); % Estimate local point counts = Digamma(nxz, nyz, nz) % Compute LSTE using Equation (12) |
3.3. Significance Test
| Algorithm 2 Time-shifted substitution sequences |
| Input: , time lag , causal flag c, random integer d0 = calculate_LSTE(X, Y) % Compute original LSTE LSTE_surrogates = [] % Initialize surrogate array for i = 1 to M % Generate surrogate data X_surr = shift_time_series(X, d0) % Time shift X using Equation (13) LSTE_surr = calculate_LSTE(X_surr, Y) LSTE_surrogates = LSTE_surr % Store surrogate LSTE end Compute p_value according to Equation (14) if p value < α then c = 1 end return δ, p value |
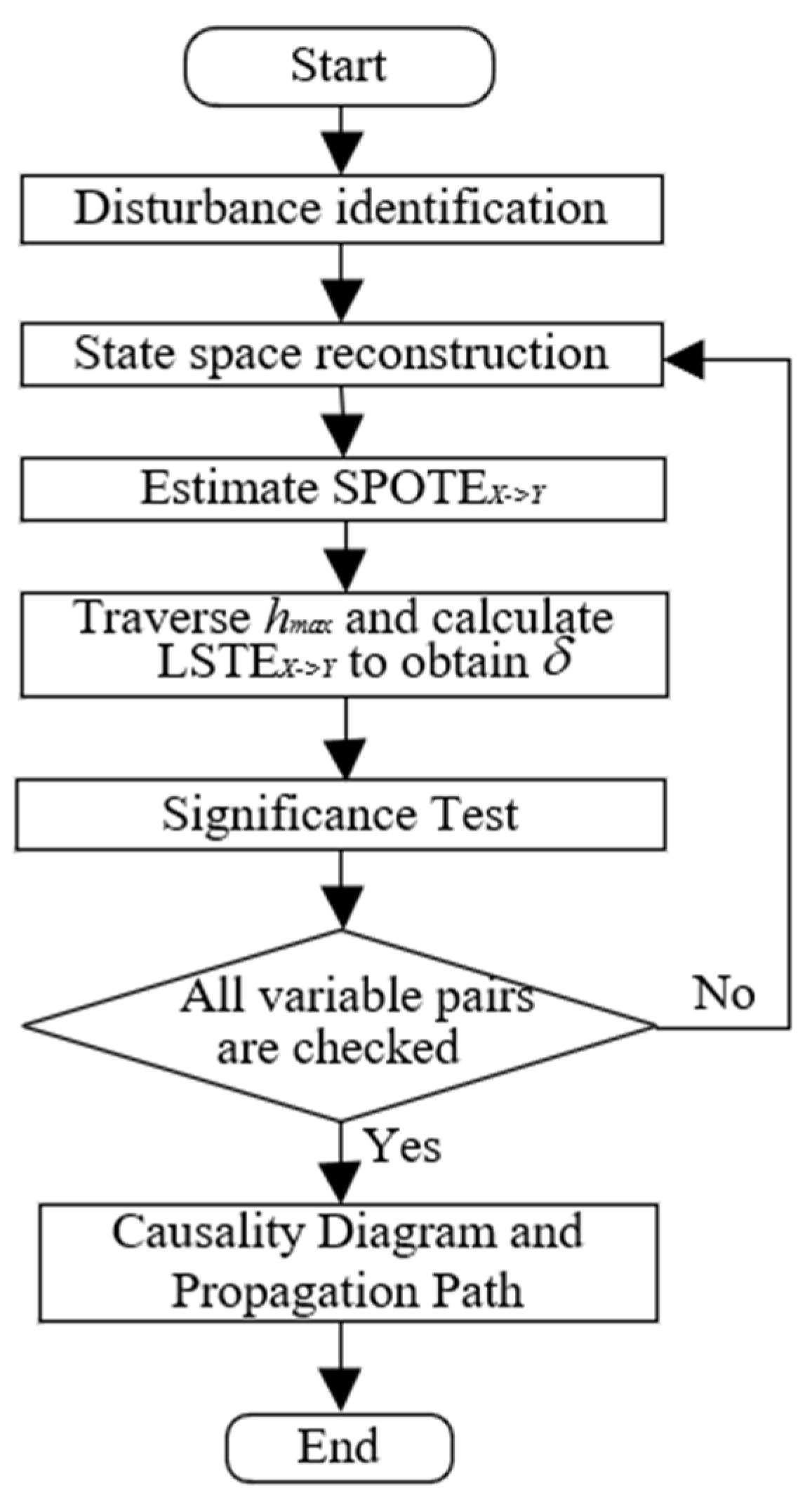
3.4. Procedure of LSTE for Disturbance RCD
4. Case Studies
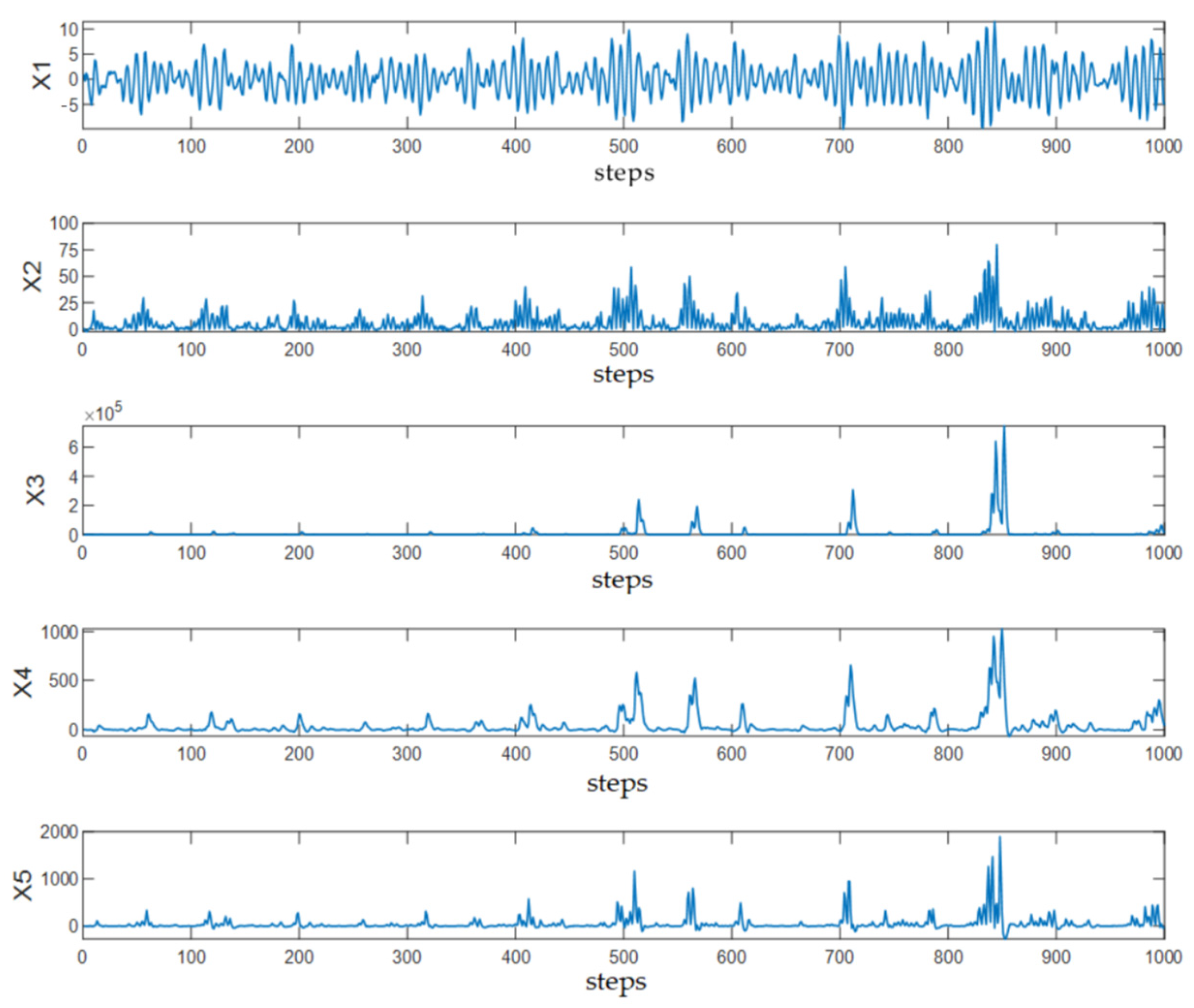
4.1. Numerical Simulation
4.2. Tennessee Eastman Process
4.2.1. Brief Introduction
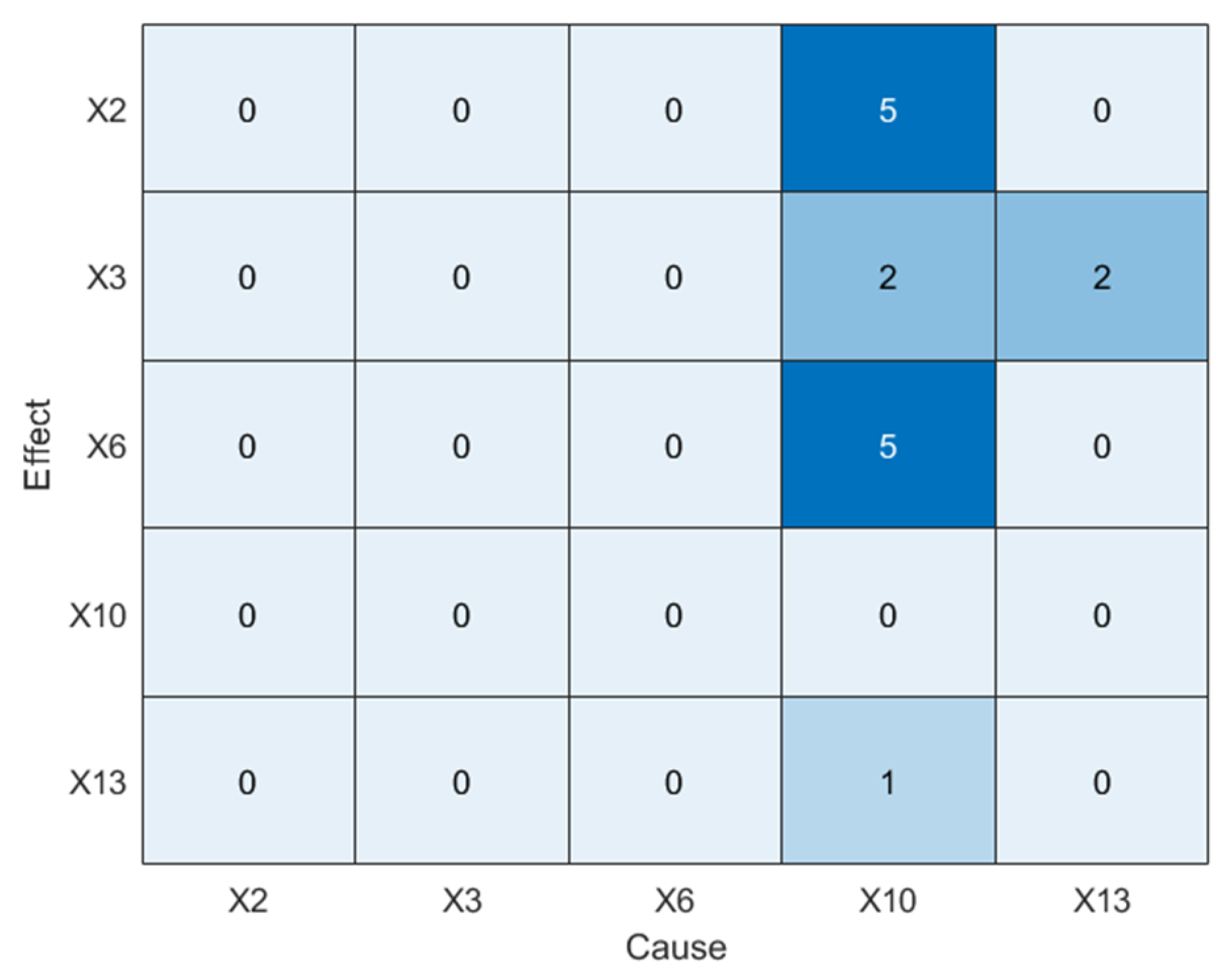
4.2.2. IDV 5
4.2.3. IDV 8
4.3. Three-Phase Flow Process
4.3.1. Brief Introduction
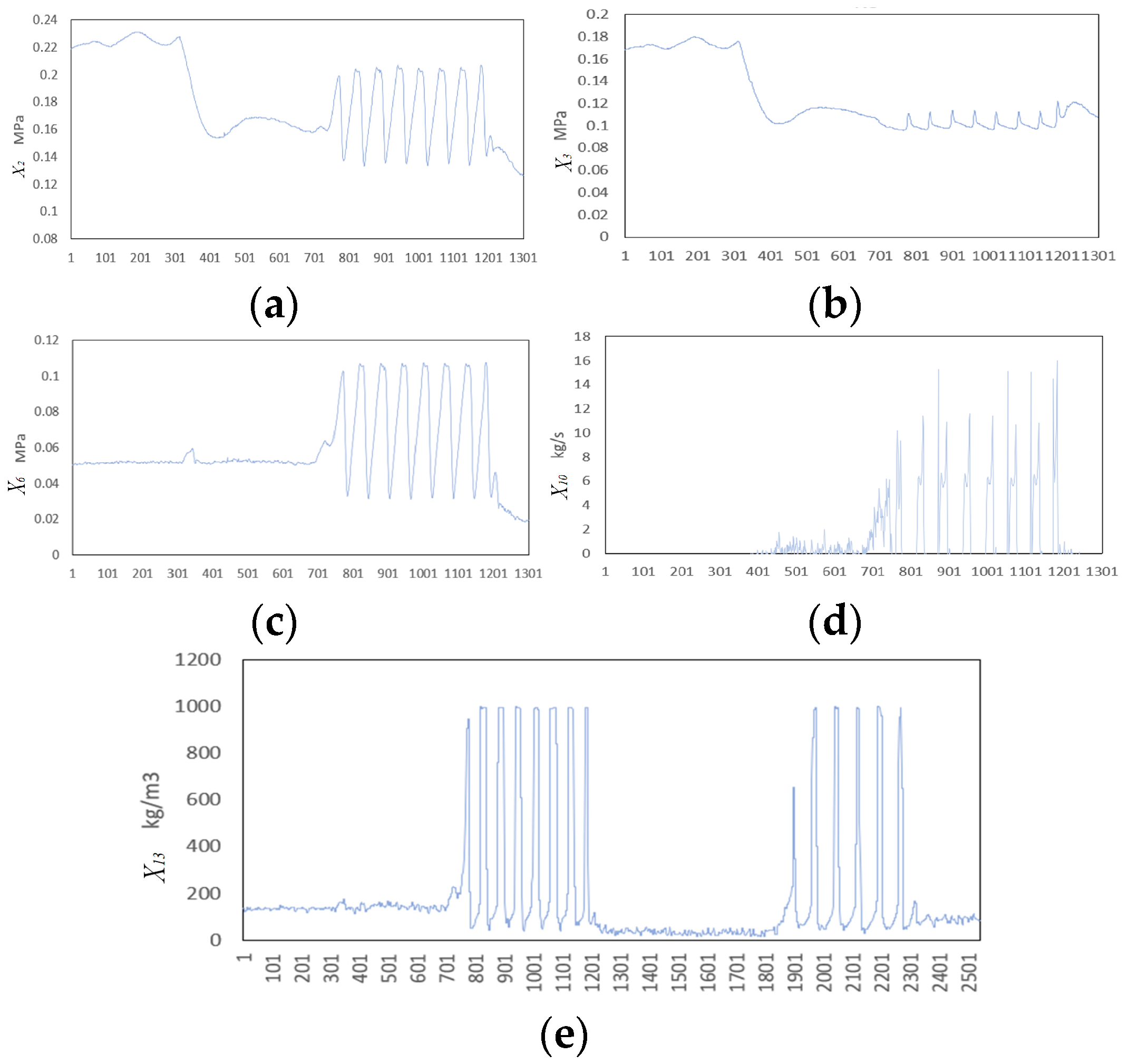
4.3.2. Disturbance 5
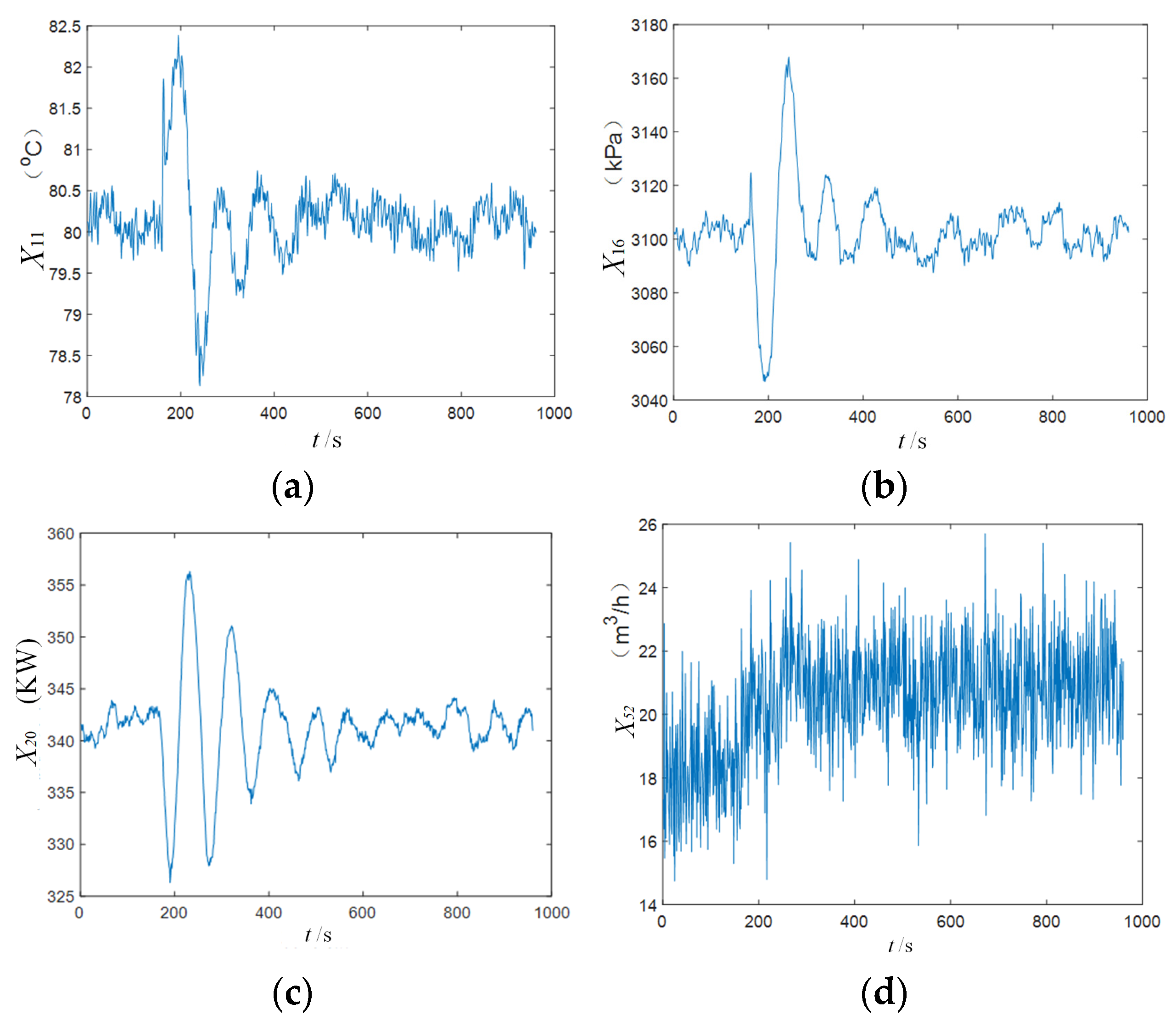
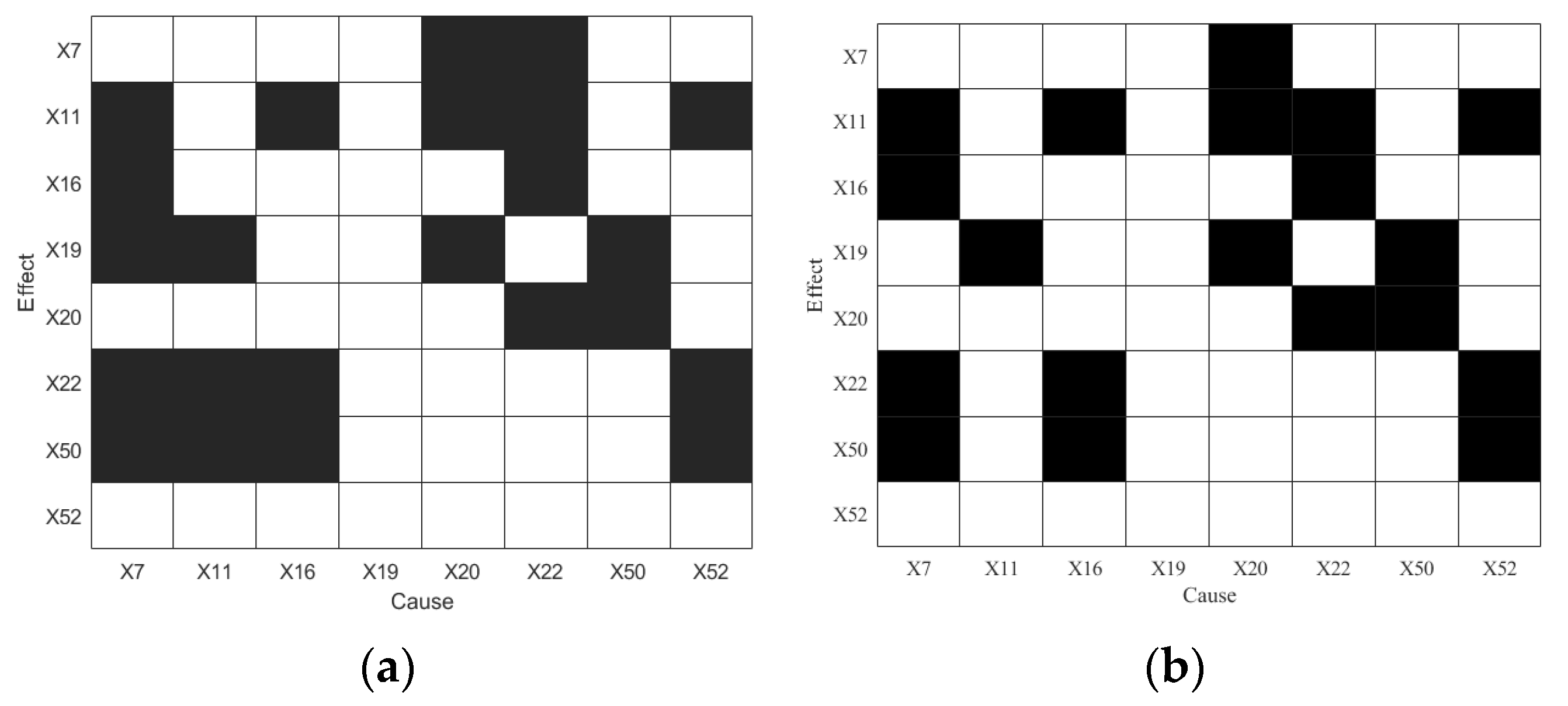
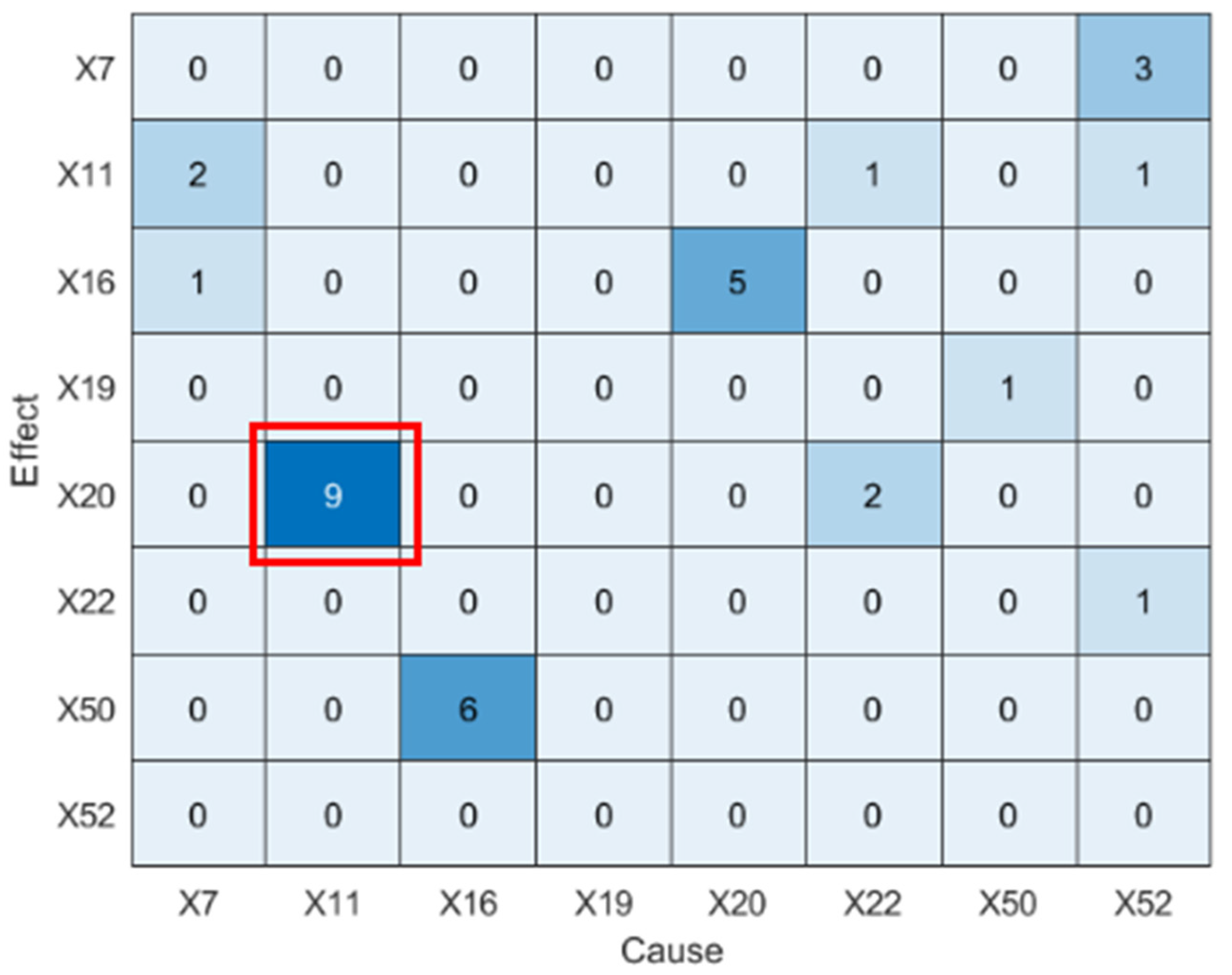
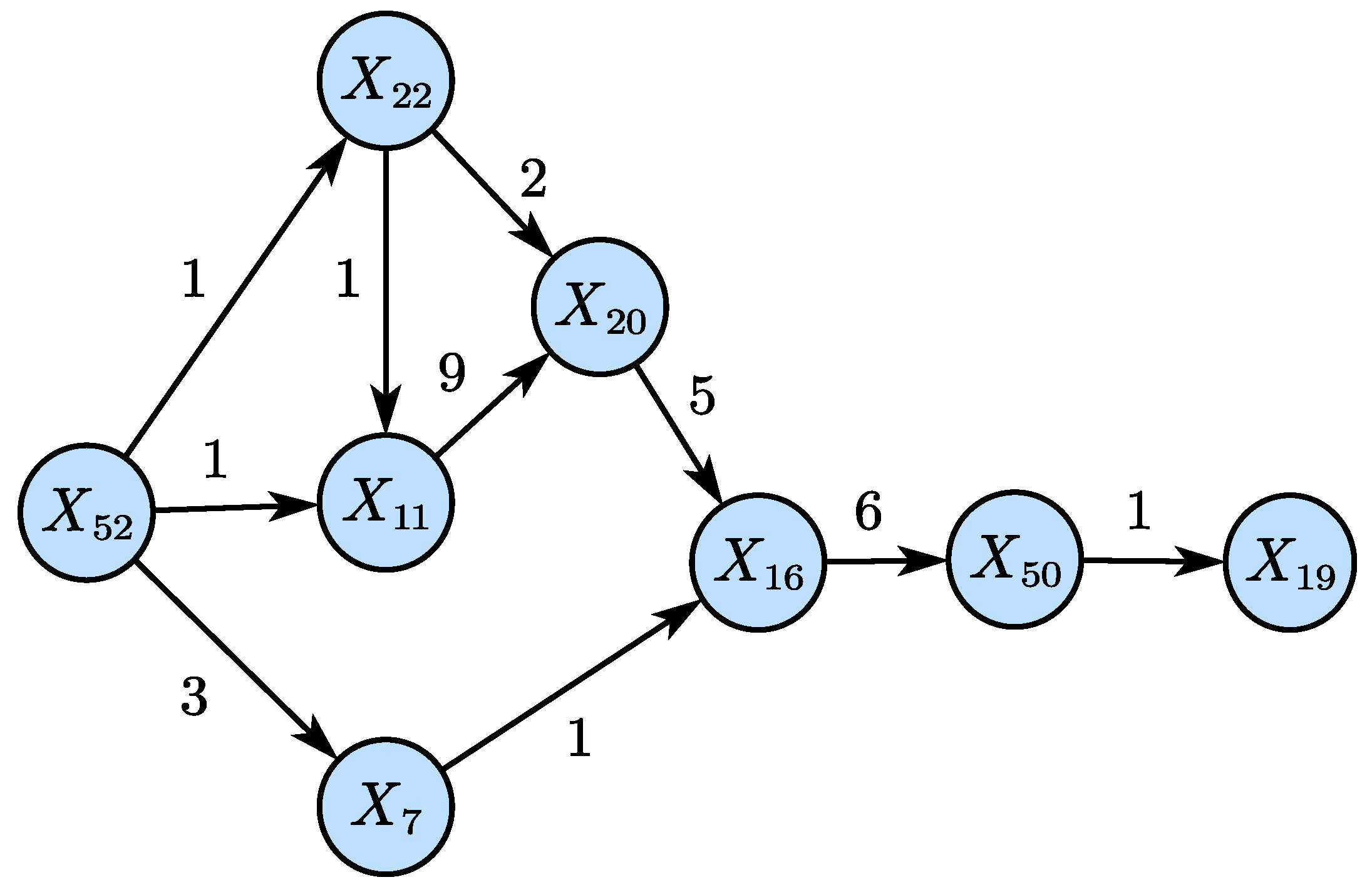
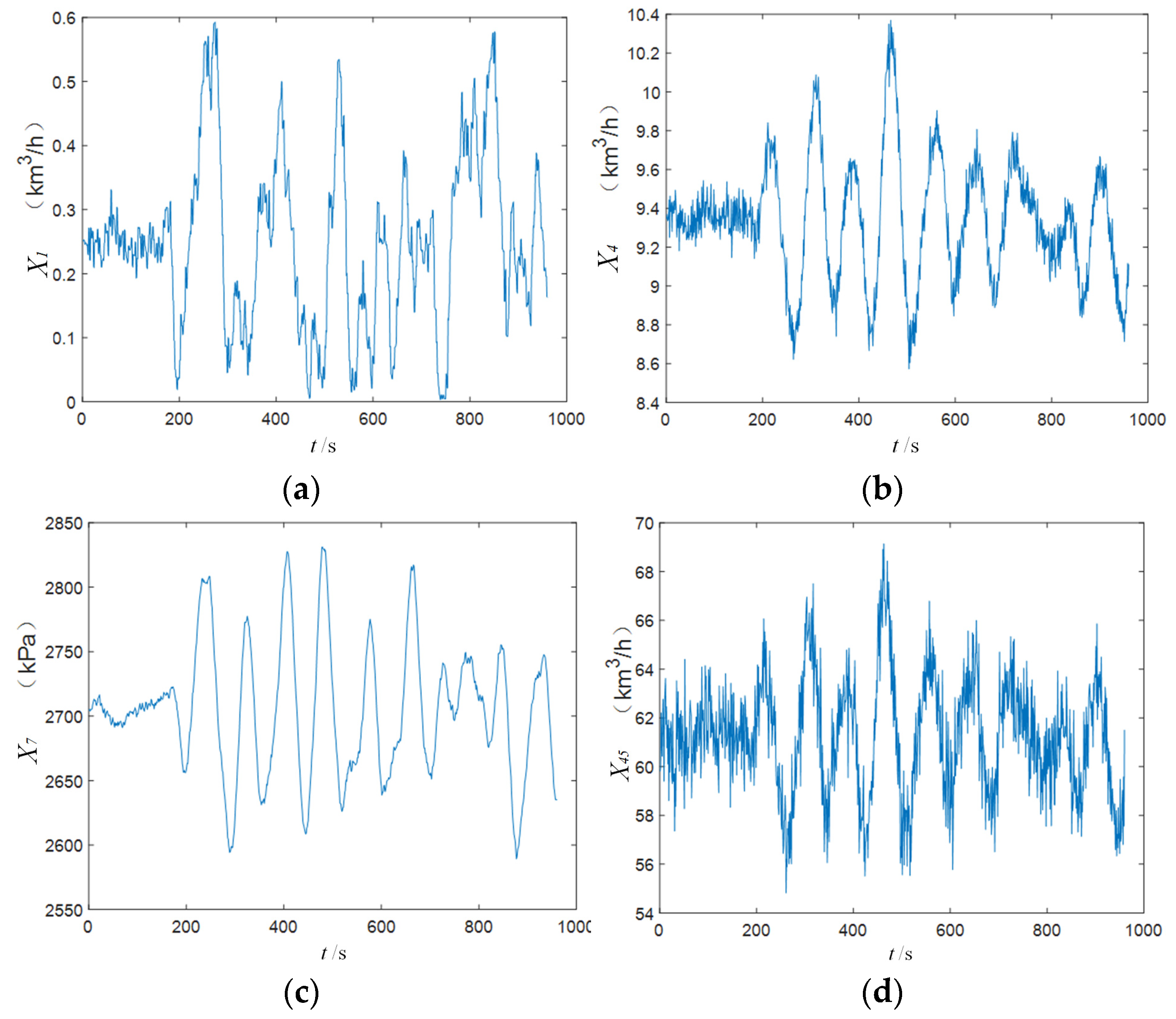
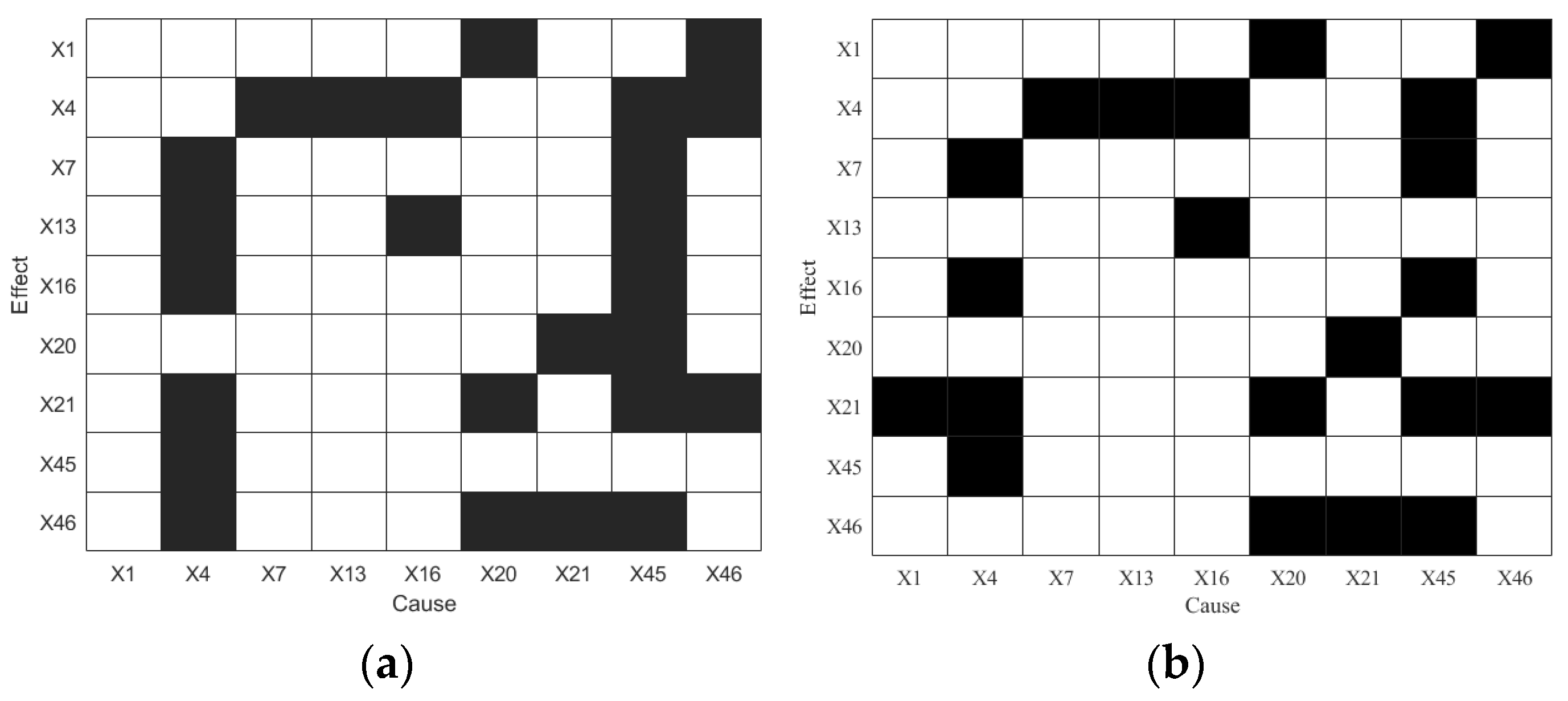
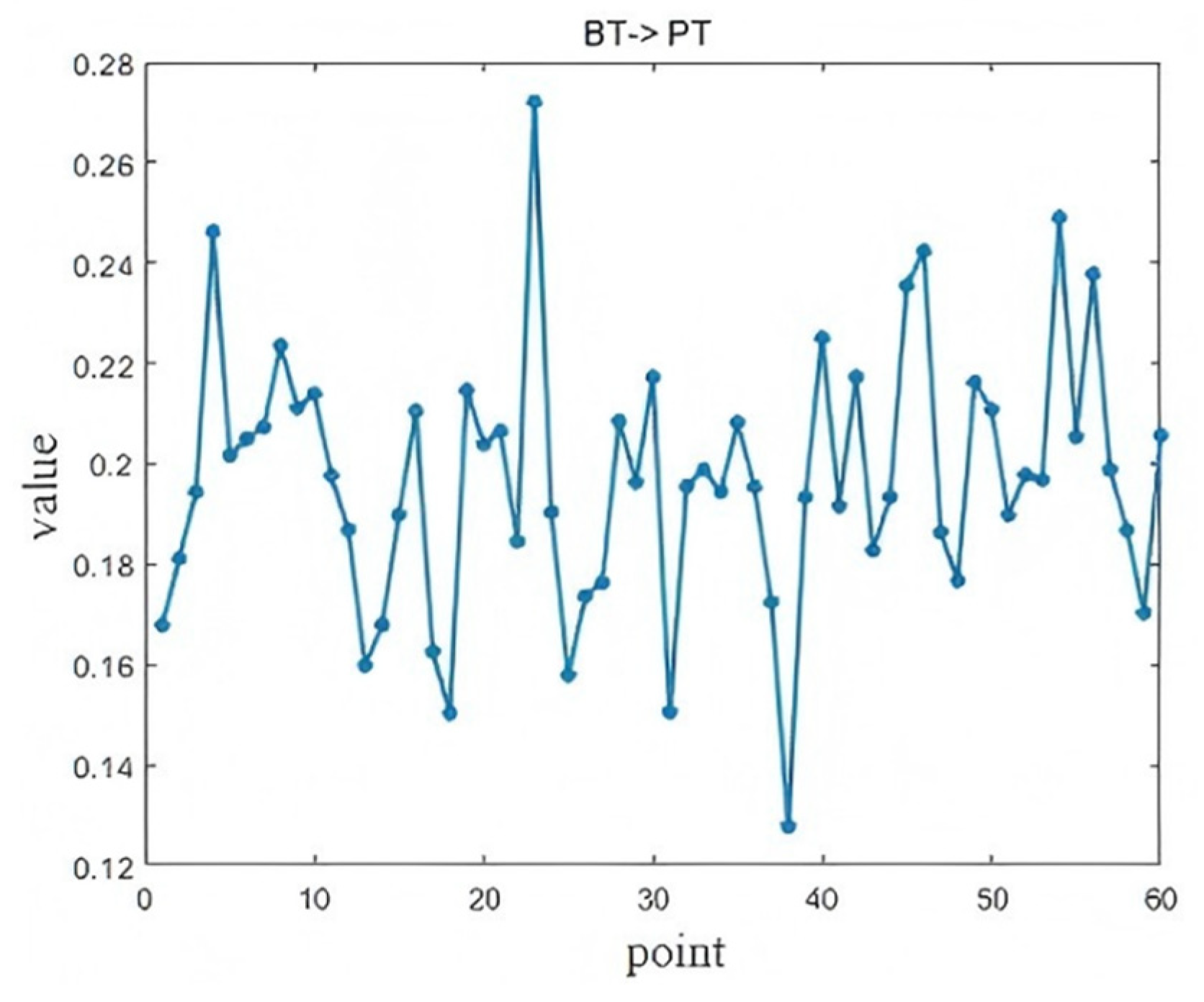
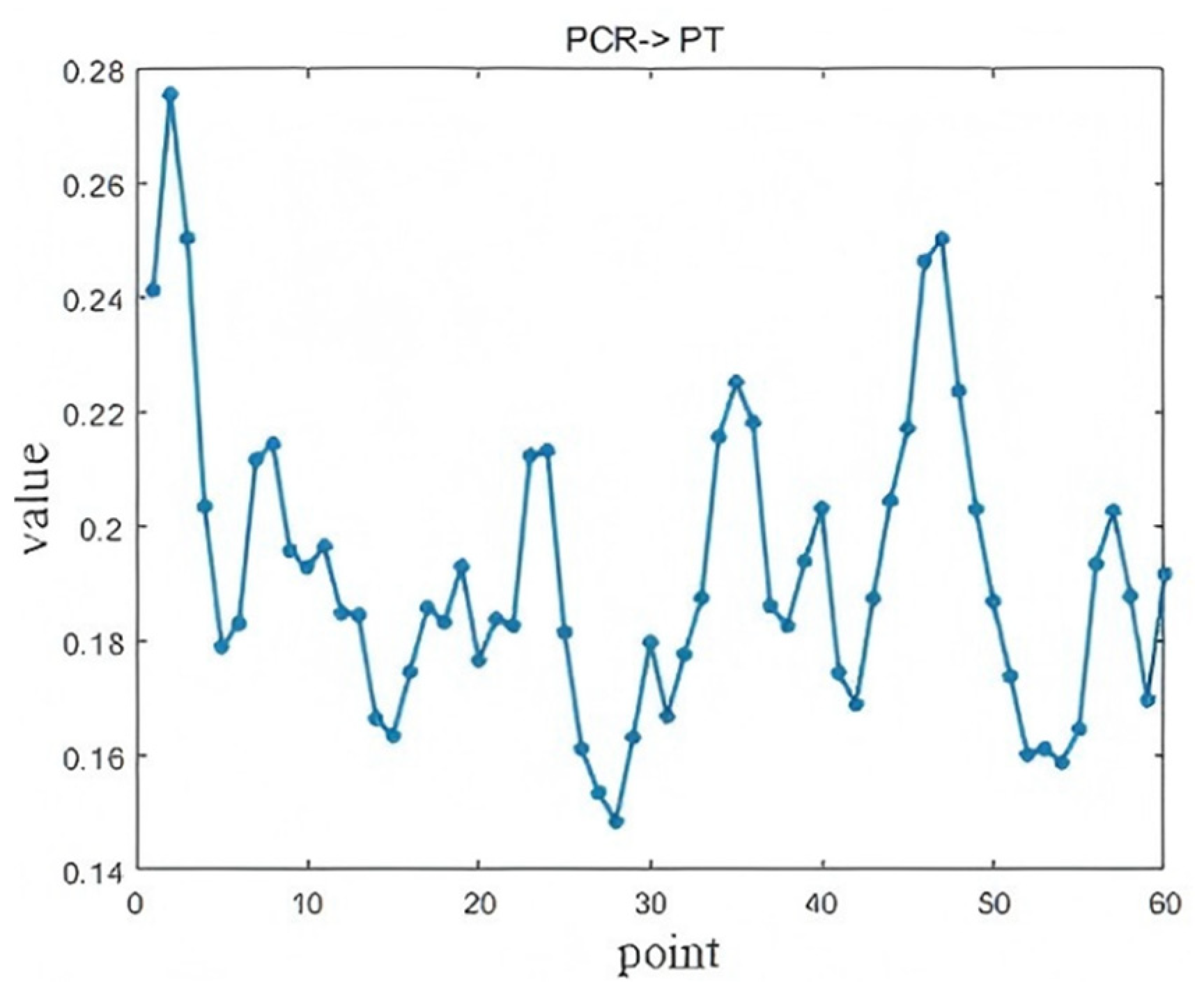
4.4. Blast Furnace Ironmaking Process
4.4.1. Brief Introduction
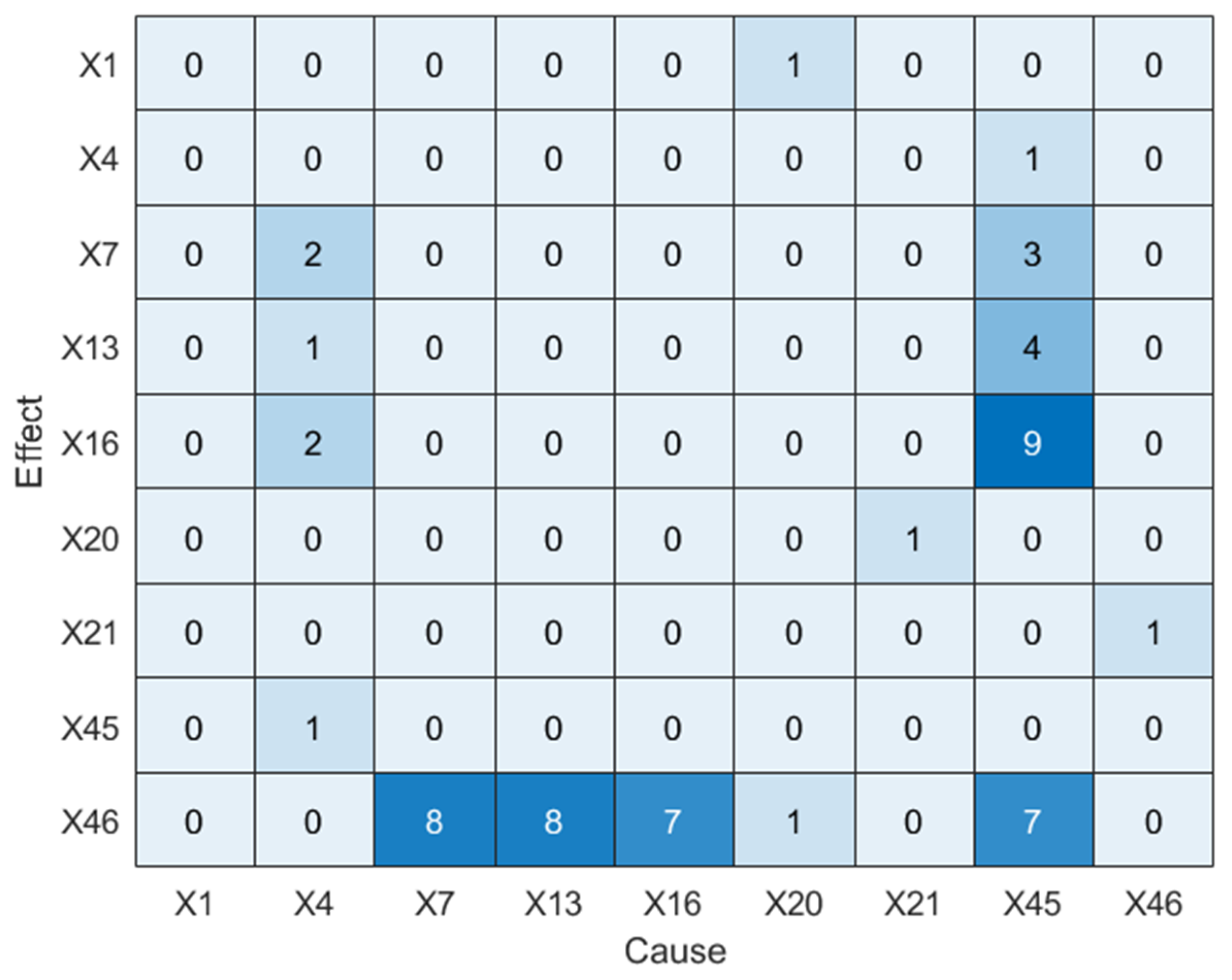
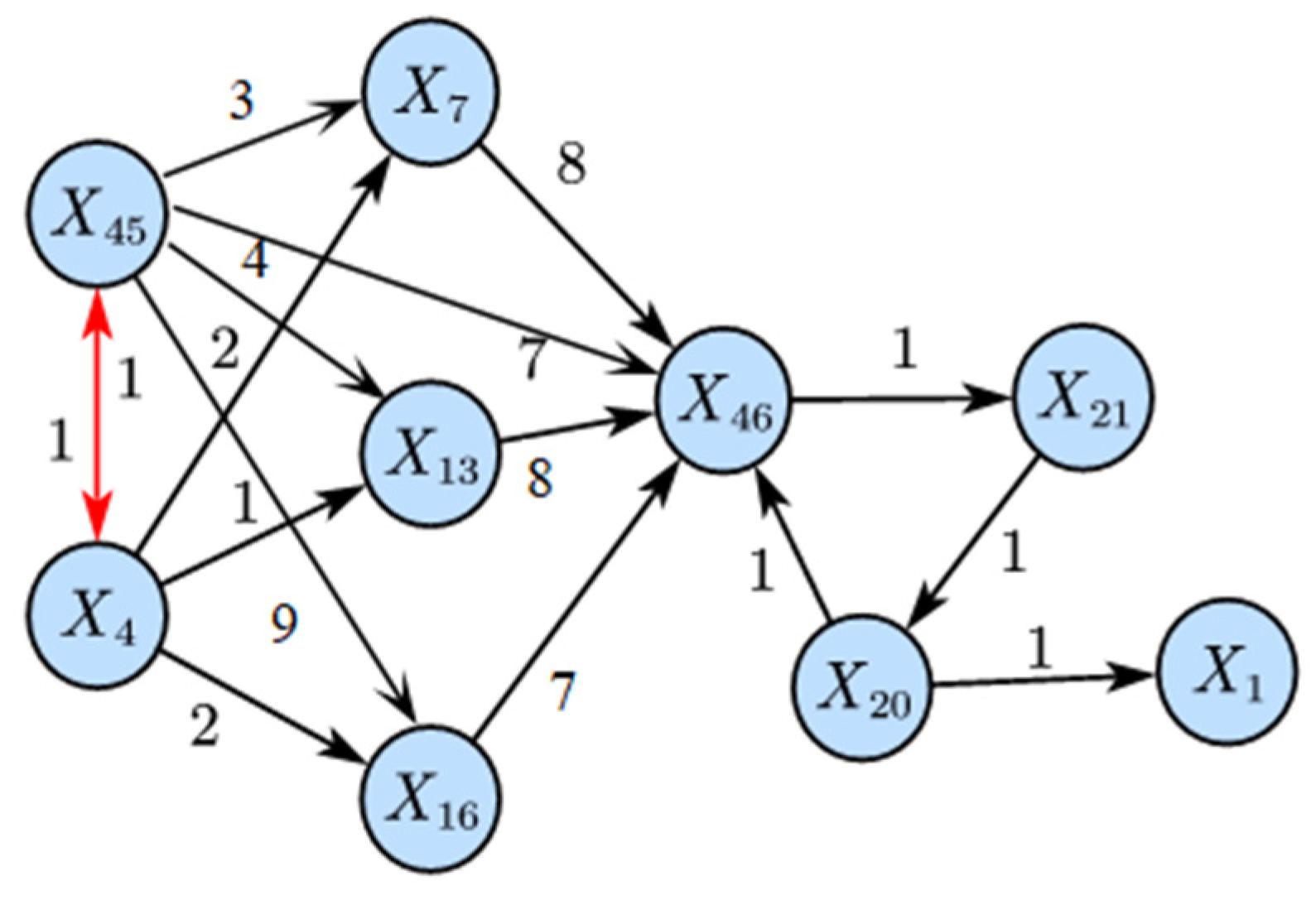
4.4.2. Results Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Tennessee Eastman Process

Appendix B. Three-Phase Flow Process

References
- Jia, M.; Hu, J.; Liu, Y. Topology-guided graph learning for process fault diagnosis. Ind. Eng. Chem. Res. 2023, 62, 3238–3248. [Google Scholar] [CrossRef]
- Aragonés, R.; Oliver, J.; Ferrer, C. Enhanced Heat-Powered Batteryless IIoT Architecture with NB-IoT for Predictive Maintenance in the Oil and Gas Industry. Sensors 2025, 25, 2590. [Google Scholar] [CrossRef]
- Giraudo, L.; Di Maggio, L.G.; Giorio, L.; Delprete, C. Dynamic Multibody Modeling of Spherical Roller Bearings with Localized Defects for Large-Scale Rotating Machinery. Sensors 2025, 25, 2419. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.G.; Chen, R.; Ye, X.Y. Data-driven root cause diagnosis of process disturbances by exploring causality change among variables. J. Process Control 2023, 129, 103062. [Google Scholar] [CrossRef]
- Smith, C.A.; Corripio, A.B. Principles and Practices of Automatic Process Control; John Wiley & Sons: Hoboken, NJ, USA, 2005. [Google Scholar]
- Lucke, M.; Chioua, M.; Thornhill, N.F. From oscillatory to non-oscillatory disturbances: A comparative review of root cause analysis methods. J. Process Control 2022, 113, 42–67. [Google Scholar] [CrossRef]
- Jiang, H.; Patwardhan, R.; Shah, S.L. Root cause diagnosis of plant-wide oscillations using the concept of adjacency matrix. J. Process Control 2009, 19, 1347–1354. [Google Scholar] [CrossRef]
- Wan, Y.; Yang, F.; Lv, N. Statistical root cause analysis of novel faults based on digraph models. Chem. Eng. Res. Des. 2013, 91, 87–99. [Google Scholar] [CrossRef]
- Wang, J.G.; Chen, R.; Su, J.R. Root cause diagnosis of plant-wide oscillations based on fuzzy kernel multivariate Granger causality. J. Taiwan Inst. Chem. Eng. 2023, 149, 104928. [Google Scholar] [CrossRef]
- Mirzaei, S.; Kang, J.L.; Chu, K.Y. A comparative study on long short-term memory and gated recurrent unit neural networks in fault diagnosis for chemical processes using visualization. J. Taiwan Inst. Chem. Eng. 2022, 130, 104028. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.S.; Wu, H. Simplified Granger causality map for data-driven root cause diagnosis of process disturbances. J. Process Control 2020, 95, 45–54. [Google Scholar] [CrossRef]
- Grosicki, G.J.; Fielding, F.; Kim, J.; Chapman, C.J.; Olaru, M.; Hippel, W.V.; Holmes, K.E. Wearing WHOOP More Frequently Is Associated with Better Biometrics and Healthier Sleep and Activity Patterns. Sensors 2025, 25, 2437. [Google Scholar] [CrossRef]
- Duan, S.; Zhao, C.; Wu, M. Multiscale partial symbolic transfer entropy for time-delay root cause diagnosis in nonstationary industrial processes. IEEE Trans. Ind. Electron. 2022, 70, 2015–2025. [Google Scholar] [CrossRef]
- Zope, K.; Singhal, T.; Nistala, S.H. Transfer Entropy-Based Automated Fault Traversal and Root Cause Identification in Complex Nonlinear Industrial Processes. Ind. Eng. Chem. Res. 2023, 62, 4002–4018. [Google Scholar] [CrossRef]
- Bossomaier, T.; Barnett, L.; Harré, M. An Introduction to Transfer Entropy: Information Flow in Complex Systems. Springer Publishing Company Incorporated: New York, NY, USA, 2016. [Google Scholar]
- Papana, A.; Siggiridou, E.; Kugiumtzis, D. Detecting direct causality in multivariate time series: A comparative study. Commun. Nonlinear Sci. Numer. Simul. 2021, 99, 105797. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 3–55. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461–464. [Google Scholar] [CrossRef]
- Matthäus, S.; Klaus, L. Symbolic transfer entropy. Phys. Rev. Lett. 2008, 100, 158101. [Google Scholar]
- Vakorin, V.A.; Olga, A. Confounding effects of indirect connections on causality estimation. J. Neurosci. Methods 2009, 184, 152–160. [Google Scholar] [CrossRef] [PubMed]
- Papana, A.; Kyrtsou, K.; Kugiumtzis, D.; Diks, C.G.H. Partial Symbolic Transfer Entropy; Universiteit van Amsterdam, Center for Nonlinear Dynamics in Economics and Finance: Amsterdam, The Netherlands, 2013; pp. 13–16. [Google Scholar]
- Papana, A.; Kyrtsou, C.; Kugiumtzis, D. Simulation study of direct causality measures in multivariate time series. Entropy 2013, 15, 2635–2661. [Google Scholar] [CrossRef]
- Papana, A.; Kyrtsou, C.; Kugiumtzis, D. Detecting causality in non-stationary time series using partial symbolic transfer entropy: Evidence in financial data. Comput. Econ. 2016, 47, 341–365. [Google Scholar] [CrossRef]
- Jiao, J.; Zhen, W.; Zhu, W. Quality-related root cause diagnosis based on orthogonal kernel principal component regression and transfer entropy. IEEE Trans. Ind. Inform. 2020, 17, 6347–6356. [Google Scholar] [CrossRef]
- Kumari, P.; Wang, Q.; Khan, F. A Direct Transfer Entropy-Based Multiblock Bayesian Network for Root Cause Diagnosis of Process Faults. Ind. Eng. Chem. Res. 2022, 61, 16166–16178. [Google Scholar] [CrossRef]
- Zhang, X.; Hu, W.; Yang, F. Detection of cause-effect relations based on information granulation and transfer entropy. Entropy 2022, 24, 212. [Google Scholar] [CrossRef]
- Wibral, M.; Pampu, N.; Priesemann, V.; Siebenhühner, F.; Seiwert, H.; Lindner, M.; Lizier, J.T.; Vicente, R.; Hayasaka, S. Measuring information-transfer delays. PLoS ONE 2013, 8, e55809. [Google Scholar] [CrossRef] [PubMed]
- Faes, L.; Marinazzo, D.; Montalto, A. Lag-specific transfer entropy as a tool to assess cardiovascular and cardiorespiratory information transfer. IEEE Trans. Biomed. Eng. 2014, 61, 2556–2568. [Google Scholar] [CrossRef] [PubMed]
- Bauer, M.; Cox, J.W.; Caveness, M.H. Finding the Direction of Disturbance Propagation in a Chemical Process Using Transfer Entropy. IEEE Trans. Control Syst. Technol. 2007, 15, 12–21. [Google Scholar] [CrossRef]
- Silverman, B.W. Density Estimation for Statistics and Data Analysi; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Kraskov, A.; Stögbauer, H.; Grassberger, P. Estimating mutual information. Phys. Rev. E 2004, 69, 066138. [Google Scholar] [CrossRef]
- Quiroga, R.Q.; Kraskov, A.; Kreuz, T. Performance of different synchronization measures in real data: A case study on electroencephalographic signals. Phys. Rev. E 2002, 65, 041903. [Google Scholar] [CrossRef]
- Papana, A.; Papana, D.A.; Siggiridou, E. Shortcomings of transfer entropy and partial transfer entropy: Extending them to escape the curse of dimensionality. Int. J. Bifurc. Chaos 2020, 30, 205–250. [Google Scholar] [CrossRef]
- Ragwitz, M.; Kantz, H. Markov models from data by simple nonlinear time series predictors in delay embedding spaces. Phys. Rev. E Stat. Nonlin Soft Matter Phys. 2002, 65, 056201. [Google Scholar] [CrossRef]
- Bathelt, A.; Ricker, N.L.; Jelali, M. Revision of the Tennessee Eastman Process Model. IFAC-PapersOnLine 2015, 48, 309–314. [Google Scholar] [CrossRef]
- Downs, J.J.; Vogel, F.E. A plant-wide industrial process control problem. Comput. Chem. Eng. 1993, 17, 245–255. [Google Scholar] [CrossRef]
- Kuang, T.H.; Yan, Z.; Yao, Y. Multivariate fault isolation via variable selection in discriminant analysis. J. Process Control 2015, 35, 30–40. [Google Scholar] [CrossRef]
- Koujok, M.; Ragab, A.; Ghezzaz, H. A multiagent-based methodology for known and novel faults diagnosis in industrial processes. IEEE Trans. Ind. Inform. 2020, 17, 3358–3366. [Google Scholar] [CrossRef]
- Ruiz-Cárcel, C.; Cao, Y.; Mba, D. Statistical process monitoring of a multi-phase flow facility. Control. Eng. Pract. 2015, 42, 74–88. [Google Scholar] [CrossRef]
- Jansen, F.E.; Shoham, O.; Taitel, Y. The elimination of severe slugging—Experiments and modeling. Int. J. Multi-Phase Flow. 1996, 22, 1055–1072. [Google Scholar] [CrossRef]
- Tan, R.M.; Cao, Y. Multi-layer contribution propagation analysis for fault diagnosis. Int. J. Autom. Comput. 2019, 16, 40–51. [Google Scholar] [CrossRef]
- Pan, D.; Jiang, Z.; Chen, Z.; Gui, W.; Xie, Y.; Yang, C. Temperature measurement and compensation method of blast furnace molten iron based on infrared computer vision. IEEE Trans. Instrum. Meas. 2018, 68, 3576–3588. [Google Scholar] [CrossRef]
- Zhang, S.; Jiang, D.; Wang, Z.; Wang, F.; Zhang, J.; Zong, Y.; Zeng, S. Predictive modeling of the hot metal sulfur content in a blast furnace based on machine learning. Metals 2023, 13, 288. [Google Scholar] [CrossRef]
- Yan, Z.; Yao, Y. Variable selection method for fault isolation using least absolute shrinkage and selection operator (LASSO). Chemom. Intell. Lab. Syst. 2015, 146, 136–146. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Accuracy | Sensitivity | Specificity | F1 Score | Root Cause | |
|---|---|---|---|---|---|
| TE | 0.84 | 0.64 | 1.00 | 0.78 | Yes |
| PTE | 0.88 | 0.70 | 1.00 | 0.82 | Yes |
| LSTE | 1.00 | 1.00 | 1.00 | 1.00 | Yes |
| To From | ||||||
| To | ||||||
| 0 | 0.0009 (0.213) | 0.0013 (0.154) | 0.0021 (0.173) | 0.0023 (0.324) | ||
| 0.407 (0.016) | 0 | 0.001 (0.227) | 0.007 (0.632) | 0.002 (0.542) | ||
| 0.121 (0.022) | 0.038 (0.367) | 0 | 0.067 (0.004) | 0.081(0.617) | ||
| 0.107 (0.005) | 0.152 (0.331) | 0.003 (0.514) | 0 | 0.321 (0.024) | ||
| 0.136 (0.604) | 0.226 (0.017) | 0.004 (0.324) | 0.096 (0.041) | 0 | ||
| Accuracy | Sensitivity | Specificity | F1 Score | Root Cause | |
|---|---|---|---|---|---|
| −10 dB | 0.68 | 0.4545 | 0.8571 | 0.5556 | Yes |
| −5 dB | 0.60 | 0.3636 | 0.7857 | 0.4444 | No |
| 5 dB | 0.64 | 0.4 | 0.8 | 0.4706 | No |
| 10 dB | 0.64 | 0.4167 | 0.8462 | 0.5263 | No |
| From | |||||||||
| To | |||||||||
| 0 | 0.061 (0.4832) | 0.125 (0.3743) | 0.123 (0.5314) | 0.135 (0.4251) | 0.032 (0.3241) | 0.111 (0.2148) | 0.007 (0.0081) | ||
| 0.161 (0.0032) | 0 | 0.129 (0.4126) | 0.050 (0.6143) | 0.106 (0.6214) | 0.092 (0.0062) | 0.046 (0.4263) | 0.017 (0.0072) | ||
| 0.171 (0.0067) | 0.072 (0.3284) | 0 | 0.121 (0.3281) | 0.139 (0.0071) | 0.039 (0.5126) | 0.109 (0.6327) | 0.006 (0.4237) | ||
| 0.150 (0.3625) | 0.068 (0.6482) | 0.142 (0.3926) | 0 | 0.134 (0.0852) | 0.008 (0.4571) | 0.169 (0.0063) | −0.001 (0.3247) | ||
| 0.146 (0.6236) | 0.092 (0.0041) | 0.139 (0.6128) | 0.115 (0.2651) | 0 | 0.041 (0.0071) | 0.116 (0.4351) | −0.003 (0.2853) | ||
| 0.063 (0.2317) | 0.087 (0.5132) | 0.077 (0.3625) | 0.043 (0.3184) | 0.054 (0.4122) | 0 | 0.043 (0.3418) | 0.026 (0.0073) | ||
| 0.148 (0.1436) | 0.066 (0.1326) | 0.153 (0.0036) | 0.112 (0.1627) | 0.130 (0.3124) | 0.008 (0.3589) | 0 | 0.006 (0.4827) | ||
| 0.015 (0.2436) | 0.033 (0.2135) | 0.017 (0.2953) | 0.015 (0.3846) | 0.009 (0.5246) | 0.021 (0.6251) | 0.016 (0.4126) | 0 | ||
| From | ||||||||||
| To | ||||||||||
| 0 | 0.036 (0.6214) | 0.042 (0.8412) | 0.039 (7243) | 0.042 (0.4813) | 0.056 (0.0051) | 0.039 (0.3177) | 0.007 (0.3625) | 0.042 (0.5134) | ||
| 0.051 (0.1463) | 0 | 0.114 (0.3146) | 0.111 (0.4381) | 0.117 (0.2546) | 0.060 (0.3244) | 0.067 (0.3242) | 0.068 (0.0041) | 0.095 (0.4623) | ||
| 0.071 (0.2641) | 0.151 (0.0072) | 0 | 0.182 (0.6239) | 0.189 (0.3581) | 0.099 (0.3471) | 0.058 (0.5132) | 0.096 (0.6423) | 0.116 (0.6231) | ||
| 0.074 (0.5162) | 0.162 (0.0016) | 0.189 (0.2314) | 0 | 0.194 (0.2163) | 0.103 (0.2534) | 0.062 (0.4326) | 0.094 (0.0072) | 0.121 (0.7122) | ||
| 0.079 (0.4653) | 0.115 (0.0324) | 0.131 (0.3812) | 0.132 (0.6124) | 0 | 0.091 (0.3152) | 0.056 (0.3421) | 0.078 (0.0042) | 0.099 (0.3251) | ||
| 0.064 (0.6438) | 0.070 (0.6312) | 0.115 (0.2147) | 0.114 (0.4231) | 0.122 (0.2731) | 0 | 0.108 (0.0126) | 0.031 (0.4631) | 0.118 (0.6211) | ||
| 0.039 (0.3512) | 0.097 (0.1843) | 0.084 (0.1762) | 0.083 (0.3621) | 0.075 (0.7211) | 0.078 (0.6427) | 0 | 0.045 (0.4352) | 0.079 (0.0041) | ||
| 0.013 (0.2315) | 0.074 (0.0037) | 0.061 (0.0832) | 0.062 (0.2573) | 0.045 (0.2372) | 0.015 (0.2144) | 0.027 (0.5231) | 0 | 0.031 (0.3214) | ||
| 0.061 (0.3415) | 0.094 (0.5236) | 0.139 (0.0483) | 0.137 (0.0037) | 0.142 (0.0041) | 0.139 (0.0034) | 0.133 (0.4326) | 0.056 (0.0034) | 0 | ||
| From | ||||||
| To | ||||||
| 0 | 0.163 (0.4326) | 0.032 (0.3251) | 0.037 (0.0023) | 0.053 (0.3214) | ||
| 0.141 (0.2341) | 0 | 0.053 (0.4312) | 0.113 (0.0041) | 0.178 (0.0057) | ||
| 0.115 (0.4232) | 0.194 (0.3743) | 0 | 0.183 (0.0062) | 0.089 (0.4951) | ||
| 0.067 (0.3411) | 0.076 (0.6245) | 0.076 (0.4823) | 0 | 0.074 (0.2637) | ||
| 0.084 (0.6234) | 0.015 (0.4621) | 0.085 (0.7231) | 0.072 (0.0214) | 0 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, R.; Liang, S.; Wang, J.-G.; Yao, Y.; Su, J.-R.; Liu, L.-L. Lag-Specific Transfer Entropy for Root Cause Diagnosis and Delay Estimation in Industrial Sensor Networks. Sensors 2025, 25, 3980. https://doi.org/10.3390/s25133980
Chen R, Liang S, Wang J-G, Yao Y, Su J-R, Liu L-L. Lag-Specific Transfer Entropy for Root Cause Diagnosis and Delay Estimation in Industrial Sensor Networks. Sensors. 2025; 25(13):3980. https://doi.org/10.3390/s25133980
Chicago/Turabian StyleChen, Rui, Shu Liang, Jian-Guo Wang, Yuan Yao, Jing-Ru Su, and Li-Lan Liu. 2025. "Lag-Specific Transfer Entropy for Root Cause Diagnosis and Delay Estimation in Industrial Sensor Networks" Sensors 25, no. 13: 3980. https://doi.org/10.3390/s25133980
APA StyleChen, R., Liang, S., Wang, J.-G., Yao, Y., Su, J.-R., & Liu, L.-L. (2025). Lag-Specific Transfer Entropy for Root Cause Diagnosis and Delay Estimation in Industrial Sensor Networks. Sensors, 25(13), 3980. https://doi.org/10.3390/s25133980