
CAs-Net: A Channel-Aware Speech Network for Uyghur Speech Recognition

Abstract
1. Introduction
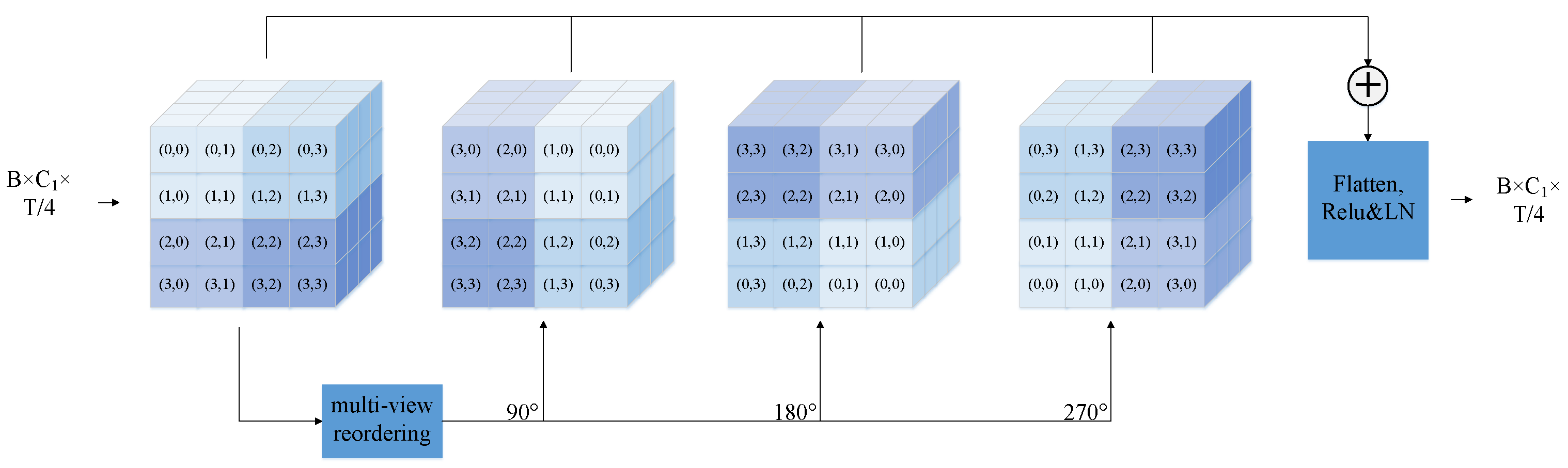
- We propose a Channel Rotation Module that reconstructs each frame’s channel vector into a spatial structure and applies a rotation operation to explicitly model the local structural relationships within the channel dimension. This addresses the structural limitations of conventional ASR encoders, which often ignore internal channel interactions, thereby enhancing the model’s contextual representation capabilities.
- We design a multi-scale convolutional structure within the Transformer framework to better accommodate the linguistic characteristics of low-resource languages such as Uyghur, which often exhibit compact articulation and complex temporal rhythms. This design improves the model’s ability to perceive and abstract multi-scale temporal information.
- Extensive experiments are conducted on multiple benchmark speech recognition datasets. Results demonstrate that the proposed method achieves significant improvements in recognition accuracy and robustness, particularly under low-resource and noisy acoustic conditions.
2. Related Work
2.1. Classical and Neural Network-Based Speech Recognition Models
2.2. Sequence Modeling and Global Contextual Representation
2.3. Channel Modeling in Speech Recognition
2.4. Large-Scale Models and Low-Resource Language Limitations
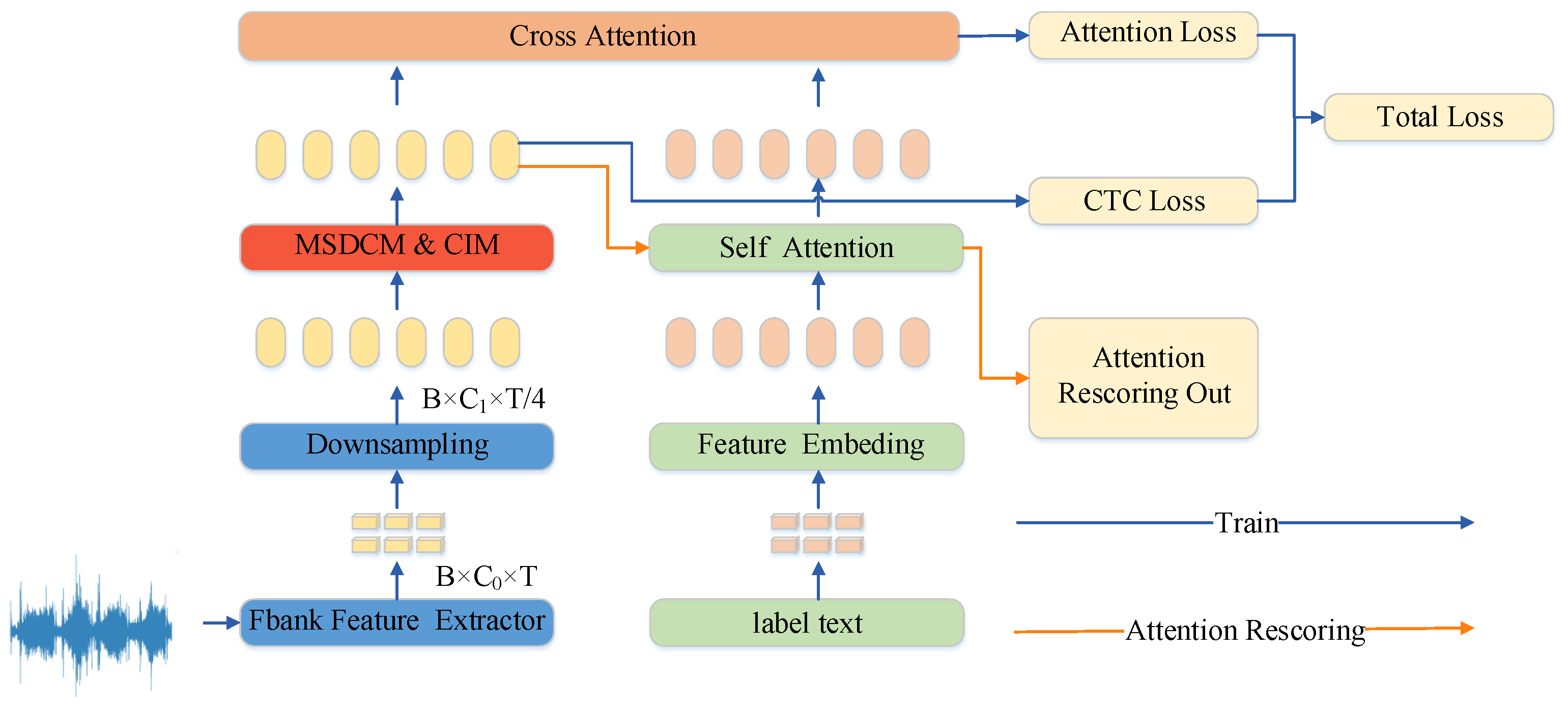
3. Methodology
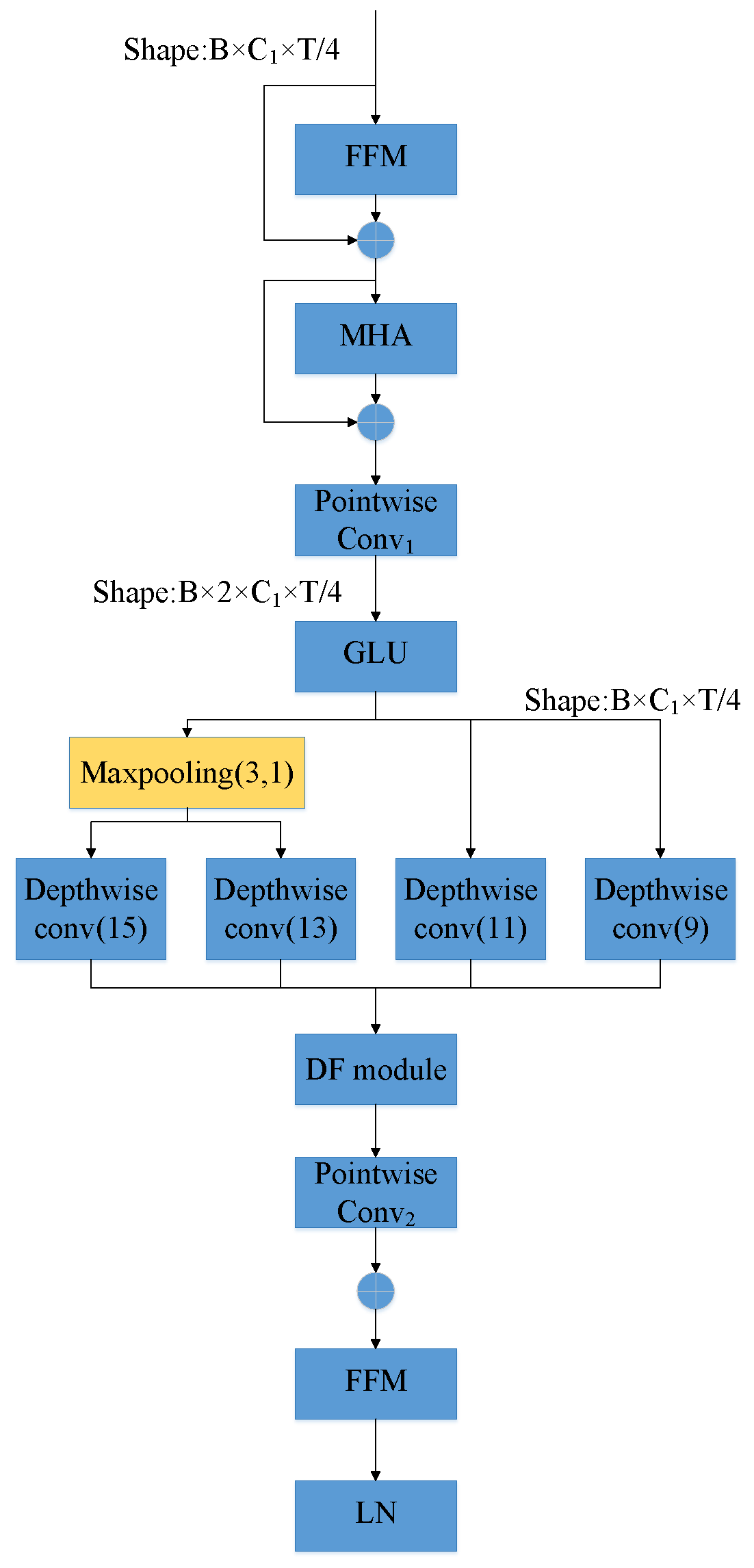
3.1. Multi-Scale Depthwise Convolution Module
3.2. Channel Interaction Module
4. Experiment and Analysis
4.1. Datasets
4.2. Experimental Setup
4.3. Comparative Experiments
4.4. Ablation Study
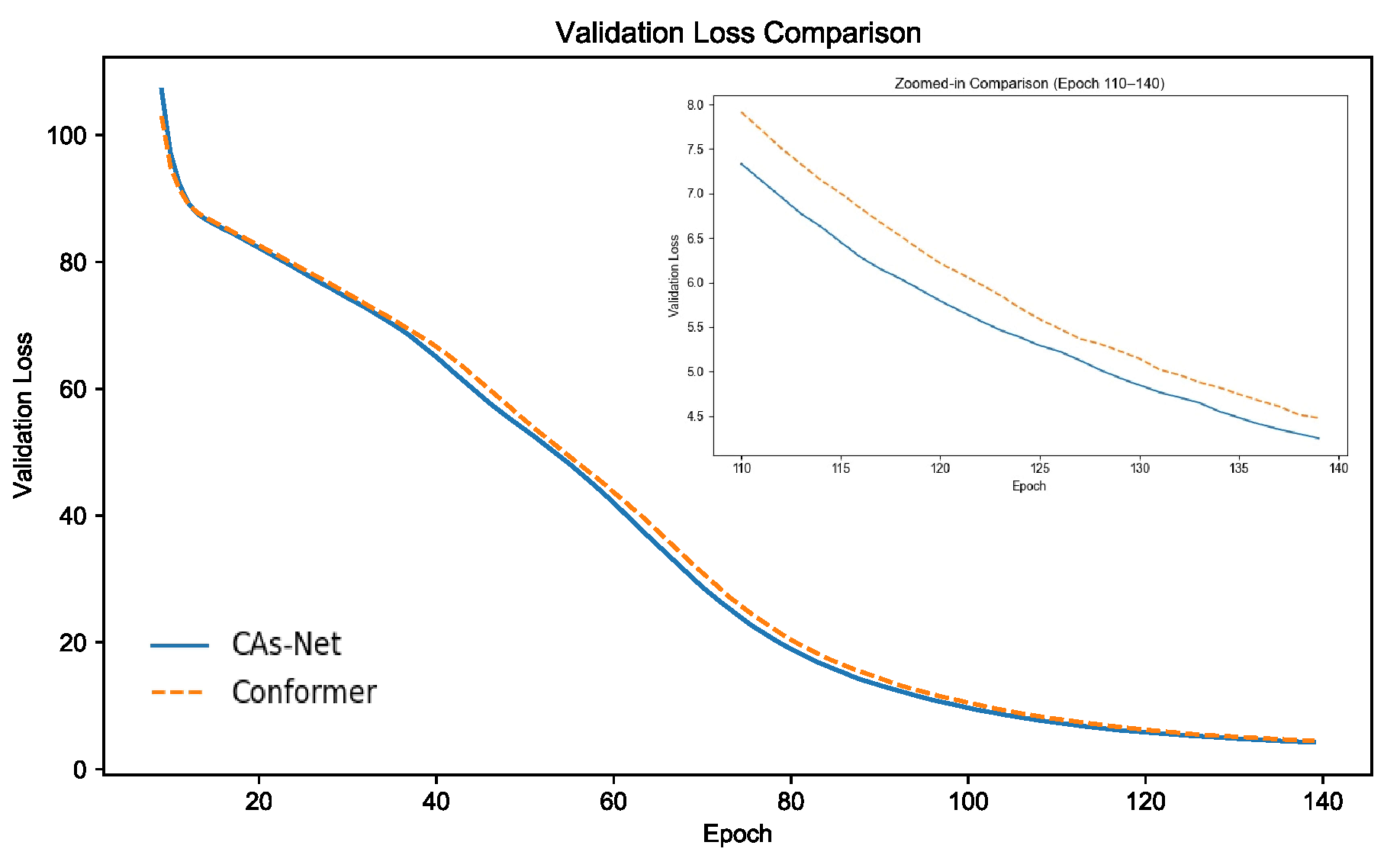
4.5. Visualization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Allauzen, C.; Variani, E.; Riley, M.; Rybach, D.; Zhang, H. A Hybrid Seq-2-Seq ASR Design for On-Device and Server Applications. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Brno, Czech Republic, 30 August–3 September 2021; Volume 2021, pp. 4044–4048. [Google Scholar]
- Zhao, R.; Xue, J.; Li, J.; Wei, W.; He, L.; Gong, Y. On Addressing Practical Challenges for RNN-Transducer. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; IEEE: New York, NY, USA, 2021; pp. 526–533. [Google Scholar]
- Lee, J.; Watanabe, S. Intermediate loss regularization for ctc-based speech recognition. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: New York, NY, USA, 2021; pp. 6224–6228. [Google Scholar]
- Dong, L.; Xu, S.; Xu, B. Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; IEEE: New York, NY, USA, 2018; pp. 5884–5888. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.r.; Jiang, H.; Penn, G. Applying Convolutional Neural Networks Concepts to Hybrid NN-HMM Model for Speech Recognition. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: New York, NY, USA, 2012; pp. 4277–4280. [Google Scholar]
- Bi, M.; Qian, Y.; Yu, K. Very Deep Convolutional Neural Networks for LVCSR. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015; pp. 3259–3263. [Google Scholar]
- Cui, X.; Gong, Y. A study of variable-parameter Gaussian mixture hidden Markov modeling for noisy speech recognition. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1366–1376. [Google Scholar] [CrossRef]
- Levy, C.; Linares, G.; Bonastre, J.F. GMM-Based Acoustic Modeling for Embedded Speech Recognition. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Maas, A.L.; Qi, P.; Xie, Z.; Hannun, A.Y.; Lengerich, C.T.; Jurafsky, D.; Ng, A.Y. Building DNN Acoustic Models for Large Vocabulary Speech Recognition. Comput. Speech Lang. 2017, 41, 195–213. [Google Scholar] [CrossRef]
- Giuliani, D.; BabaAli, B. Large Vocabulary Children’s Speech Recognition with DNN-HMM and SGMM Acoustic Modeling. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Dresden, Germany, 6–10 September 2015; pp. 1635–1639. [Google Scholar]
- Hori, T.; Watanabe, S.; Zhang, Y.; Chan, W. Advances in Joint CTC-Attention Based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Stockholm, Sweden, 20–24 August 2017; pp. 949–953. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, L.; Yu, Y.; Xu, M. Nonlinear Regularization Decoding Method for Speech Recognition. Sensors 2024, 24, 3846. [Google Scholar] [CrossRef] [PubMed]
- Abulimiti, A.; Schultz, T. Automatic Speech Recognition for Uyghur through Multilingual Acoustic Modeling. In Proceedings of the Language Resources and Evaluation Conference (LREC), Marseille, France, 11–16 May 2020; pp. 6444–6449. [Google Scholar]
- Du, W.; Maimaitiyiming, Y.; Nijat, M.; Li, L.; Hamdulla, A.; Wang, D. Automatic Speech Recognition for Uyghur, Kazakh, and Kyrgyz: An Overview. Appl. Sci. 2022, 13, 326. [Google Scholar] [CrossRef]
- Jorge, J.; Giménez, A.; Iranzo-Sánchez, J.; Silvestre-Cerda, J.A.; Civera, J.; Sanchis, A.; Juan, A. LSTM-based one-pass decoder for low-latency streaming. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA, 2020; pp. 7814–7818. [Google Scholar]
- Priya, S.; Karthika Renuka, D.; Ashok Kumar, L. Robust Multi-Dialect End-to-End ASR Model Jointly with Beam Search Threshold Pruning and LLM. SN Comput. Sci. 2025, 6, 323. [Google Scholar] [CrossRef]
- Shen, L.; Sun, Y.; Yu, Z.; Ding, L.; Tian, X.; Tao, D. On Efficient Training of Large-Scale Deep Learning Models. ACM Comput. Surv. 2024, 57, 1–36. [Google Scholar] [CrossRef]
- You, Y.; Hseu, J.; Ying, C.; Demmel, J.; Keutzer, K.; Hsieh, C.J. Large-batch training for LSTM and beyond. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 16–20 June 2019; pp. 1–16. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Weng, C.; Cui, J.; Wang, G.; Wang, J.; Yu, C.; Su, D.; Yu, D. Improving Attention Based Sequence-to-Sequence Models for End-to-End English Conversational Speech Recognition. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 761–765. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-Augmented Transformer for Speech Recognition. arXiv 2020, arXiv:2005.08100. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Global context networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 45, 6881–6895. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. [Google Scholar]
- Ardila, R.; Branson, M.; Davis, K.; Kohler, M.; Meyer, J.; Henretty, M.; Morais, R.; Saunders, L.; Tyers, F.; Weber, G. Common Voice: A Massively-Multilingual Speech Corpus. In Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; Calzolari, N., Béchet, F., Blache, P., Choukri, K., Cieri, C., Declerck, T., Goggi, S., Isahara, H., Maegaard, B., Mariani, J., et al., Eds.; European Language Resources Association: Paris, France, 2020; pp. 4218–4222. [Google Scholar]
- Lu, K.; Yang, Y.; Yang, F.; Dong, R.; Ma, B.; Aihemaiti, A.; Atawulla, A.; Wang, L.; Zhou, X. Low-Resource Language Expansion and Translation Capacity Enhancement for LLM: A Study on the Uyghur. In Proceedings of the 31st International Conference on Computational Linguistics, Abu Dhabi, United Arab Emirates, 19–24 January 2025; Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2025; pp. 8360–8373. [Google Scholar]
- Thiemann, J.; Ito, N.; Vincent, E. The Diverse Environments Multi-Channel Acoustic Noise Database (DEMAND): A Database of Multichannel Environmental Noise Recordings. In Proceedings of the Meetings on Acoustics; AIP Publishing: Melville, NY, USA, 2013; Volume 19. [Google Scholar]
- Zhang, B.; Wu, D.; Peng, Z.; Song, X.; Yao, Z.; Lv, H.; Xie, L.; Yang, C.; Pan, F.; Niu, J. WeNet 2.0: More Productive End-to-End Speech Recognition Toolkit. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Incheon, Republic of Korea, 18–22 September 2022; pp. 1661–1665. [Google Scholar] [CrossRef]
- Kim, S.; Gholami, A.; Shaw, A.; Lee, N.; Mangalam, K.; Malik, J.; Mahoney, M.W.; Keutzer, K. Squeezeformer: An Efficient Transformer for Automatic Speech Recognition. Adv. Neural Inf. Process. Syst. 2022, 35, 9361–9373. [Google Scholar]
- Liao, L.; Kwofie, F.A.; Chen, Z.; Han, G.; Wang, Y.; Lin, Y.; Hu, D. A Bidirectional Context Embedding Transformer for Automatic Speech Recognition. Information 2022, 13, 69. [Google Scholar] [CrossRef]
- Burchi, M.; Vielzeuf, V. Efficient Conformer: Progressive Downsampling and Grouped Attention for Automatic Speech Recognition. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Cartagena, Colombia, 13–17 December 2021; IEEE: New York, NY, USA, 2021; pp. 8–15. [Google Scholar]
- Gao, Z.; Zhang, S.; Mcloughlin, I.; Yan, Z. Paraformer: Fast and Accurate Parallel Transformer for Non-Autoregressive End-to-End Speech Recognition. In Proceedings of the Conference of the International Speech Communication Association (INTERSPEECH), Incheon, Republic of Korea, 18–22 September 2022; ISCA: Singapore, 2022; pp. 2063–2067. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Parameter Value |
|---|---|
| Num_Emcoder | 12 |
| Num_Decoder | 6 |
| Dff | 2048 |
| Epoch | 140 |
| Lr | 0.0005 |
| Num_Mel | 80 |
| Frame_Length | 25 |
| Frame_Shift | 10 |
| Spec_Aug | True |
| Accum_Grad | 4 |
| Model | WER (↓) | |||
|---|---|---|---|---|
| Ug 7 | Ug 8 | Ug 9 | Ug 16 | |
| Transformer(Wenet) [31] | 20.87 | 15.02 | 14.07 | 6.28 |
| Conformer [22] | 11.83 | 8.27 | 7.53 | 5.60 |
| Conformer_bi [31] | 8.39 | 6.64 | 7.85 | 7.19 |
| Squeezeformer [32] | 11.67 | 9.67 | 15.50 | 5.89 |
| Squeezeformer_bi [33] | 11.61 | 9.23 | 10.75 | 6.76 |
| E_ConforV1 [34] | 8.56 | 12.51 | 8.98 | 5.90 |
| E_ConforV2 [34] | 9.28 | 11.64 | 7.13 | 4.68 |
| Paraformer (U2) [35] | 14.64 | - | - | 6.15 |
| CAs-Net | 5.75 | 4.05 | 1.93 | 5.24 |
| Noise | Model | Ug 7 | Ug 16 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| A | Ar | CTC | AV | A | Ar | CTC | AV | ||
| BUS (−6 dB) | Squeezeformer | 17.2 | 53.2 | 61.6 | 44.0 | 4.4 | 16.0 | 23.3 | 14.5 |
| Squeezeformer_bi | 63.3 | 58.7 | 65.1 | 62.4 | 6.2 | 15.0 | 21.4 | 14.2 | |
| Transformer | 104.2 | 97.0 | 97.4 | 99.5 | 20.7 | 52.1 | 59.7 | 44.2 | |
| EfficonformerV2 | 7.7 | 20.3 | 29.4 | 19.1 | 6.0 | 12.1 | 17.0 | 11.7 | |
| EfficonformerV1 | 6.7 | 23.0 | 32.5 | 20.8 | 6.2 | 12.5 | 17.5 | 12.1 | |
| Conformer | 2.4 | 13.0 | 20.0 | 11.8 | 6.0 | 12.0 | 17.1 | 11.7 | |
| Conformer_bi | 76.5 | 72.7 | 77.2 | 75.5 | 5.9 | 10.2 | 14.6 | 10.2 | |
| CAs-Net (Ours) | 1.8 | 10.2 | 15.8 | 9.3 | 4.6 | 9.2 | 14.3 | 9.4 | |
| METRO (−6 dB) | Squeezeformer | 108.7 | 99.4 | 100.0 | 102.7 | 114.1 | 99.3 | 100.0 | 104.4 |
| Squeezeformer_bi | 95.1 | 88.7 | 89.8 | 91.2 | 15.2 | 39.6 | 48.5 | 34.4 | |
| Transformer | 120.3 | 99.3 | 99.1 | 106.2 | 86.3 | 95.8 | 96.0 | 92.7 | |
| EfficonformerV2 | 109.9 | 99.5 | 100.0 | 103.1 | 118.1 | 99.5 | 99.9 | 105.8 | |
| EfficonformerV1 | 108.2 | 99.1 | 99.3 | 102.2 | 115.3 | 99.9 | 99.9 | 105.0 | |
| Conformer | 18.7 | 50.6 | 58.1 | 42.5 | 7.1 | 26.3 | 35.1 | 22.8 | |
| Conformer_bi | 100.1 | 95.5 | 96.2 | 97.3 | 11.9 | 34.5 | 43.1 | 29.8 | |
| CAs-Net (Ours) | 11.5 | 31.4 | 38.9 | 27.3 | 12.0 | 17.4 | 25.7 | 18.4 | |
| Model | Train | Ug 7 | Ug 9 | Ug 16 | Ug 7 | Ug 9 | Ug 16 |
|---|---|---|---|---|---|---|---|
| +BUS (−6 dB) | +BUS (−6 dB) | ||||||
| Test | Real1 | Real2 | |||||
| Transformer | 116.0 | 13.4 | 23.5 | 118.5 | 46.4 | 31.0 | |
| EfficonformerV2 | 6.5 | 4.2 | 6.7 | 12.5 | 30.1 | 7.9 | |
| EfficonformerV1 | 12.7 | 7.3 | 5.9 | 18.5 | 34.3 | 12.5 | |
| Conformer | 17.6 | 6.3 | 5.9 | 26.2 | 31.8 | 7.6 | |
| Conformer_bidecoder | 89.3 | 6.0 | 5.5 | 91.2 | 35.2 | 7.2 | |
| CAs-Net (Ours) | 5.6 | 2.6 | 2.5 | 10.7 | 7.0 | 5.9 | |
| Experiment | Data | p-Value |
|---|---|---|
| Overall Comparison | Full Dataset | |
| Random Sample 1 | 100 utterances | |
| Random Sample 2 | 100 utterances | |
| Random Sample 3 | 100 utterances | |
| Random Sample 4 | 100 utterances | |
| Random Sample 5 | 100 utterances | |
| Random Sample 6 | 100 utterances | |
| Random Sample 7 | 100 utterances | |
| Random Sample 8 | 100 utterances | |
| Random Sample 9 | 100 utterances | |
| Random Sample 10 | 100 utterances |
| Noise | Model Variant | WER | |||
|---|---|---|---|---|---|
| Ug7 | Ug8 | Ug9 | Ug16 | ||
| BUS ( dB) | CAs-Net | 1.75 | 1.50 | 2.51 | 4.56 |
| -MSDCM | 1.96 | 2.15 | 3.05 | 4.59 | |
| -O3 | 2.04 | 1.91 | 2.89 | 4.86 | |
| -O2-O3 | 2.34 | 2.30 | 3.08 | 4.94 | |
| METRO ( dB) | CAs-Net | 11.45 | 8.01 | 9.12 | 11.98 |
| -MSDCM | 12.84 | 8.66 | 9.87 | 12.40 | |
| -O3 | 12.37 | 8.37 | 9.55 | 12.06 | |
| -O2-O3 | 14.71 | 9.11 | 10.24 | 12.77 | |
| Noise | Model Variant | WER | |||
|---|---|---|---|---|---|
| Ug7 | Ug8 | Ug9 | Ug16 | ||
| BUS ( dB) | CAs-Net | 2.19 | 1.03 | 2.16 | 4.28 |
| -MSDCM | 2.79 | 1.2 | 2.63 | 4.34 | |
| -O3 | 2.87 | 1.97 | 2.71 | 4.31 | |
| -O2-O3 | 2.94 | 2.28 | 2.98 | 4.41 | |
| METRO ( dB) | CAs-Net | 10.03 | 1.57 | 3.30 | 5.26 |
| -MSDCM | 10.26 | 1.65 | 3.71 | 5.78 | |
| -O3 | 10.27 | 1.64 | 3.9 | 5.34 | |
| -O2-O3 | 10.31 | 3.21 | 4.55 | 5.41 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Xu, M.; Xu, L.; Ma, Y. CAs-Net: A Channel-Aware Speech Network for Uyghur Speech Recognition. Sensors 2025, 25, 3783. https://doi.org/10.3390/s25123783
Zhang J, Xu M, Xu L, Ma Y. CAs-Net: A Channel-Aware Speech Network for Uyghur Speech Recognition. Sensors. 2025; 25(12):3783. https://doi.org/10.3390/s25123783
Chicago/Turabian StyleZhang, Jiang, Miaomiao Xu, Lianghui Xu, and Yajing Ma. 2025. "CAs-Net: A Channel-Aware Speech Network for Uyghur Speech Recognition" Sensors 25, no. 12: 3783. https://doi.org/10.3390/s25123783
APA StyleZhang, J., Xu, M., Xu, L., & Ma, Y. (2025). CAs-Net: A Channel-Aware Speech Network for Uyghur Speech Recognition. Sensors, 25(12), 3783. https://doi.org/10.3390/s25123783