A Bearing Fault Diagnosis Method Based on Dual-Stream Hybrid-Domain Adaptation

Abstract
1. Introduction
- Dual-stream feature fusion: Concurrently use CNN to process raw time-domain vibration signals and MLP to process extracted frequency-domain features (such as frequency band energy, envelope spectrum peak values), then fuse the information from both to obtain more robust and comprehensive feature representations.
- Hybrid-domain adaptation: Apply MDA on the fused features for global alignment to reduce overall domain differences; apply CDA on the model output logits for conditional alignment, utilizing soft pseudo-labels to preserve class discriminability.
- GMM-based soft pseudo-labeling: Utilize GMMs trained on source domain fused features, combined with model predictions and the Mahalanobis distance, to generate more reliable soft pseudo-labels for target domain samples, providing effective unsupervised learning signals.
2. Key Theories and Technologies
2.1. Maximum Mean Discrepancy (MMD)
2.2. Covariance Alignment
2.3. Hybrid-Domain Adaptation: MDA and CDA
2.3.1. Marginal Distribution Adaptation (MDA)—Global Alignment
2.3.2. Conditional Distribution Adaptation (CDA)—Class-Conditional Alignment
2.4. Gaussian Mixture Model (GMM)
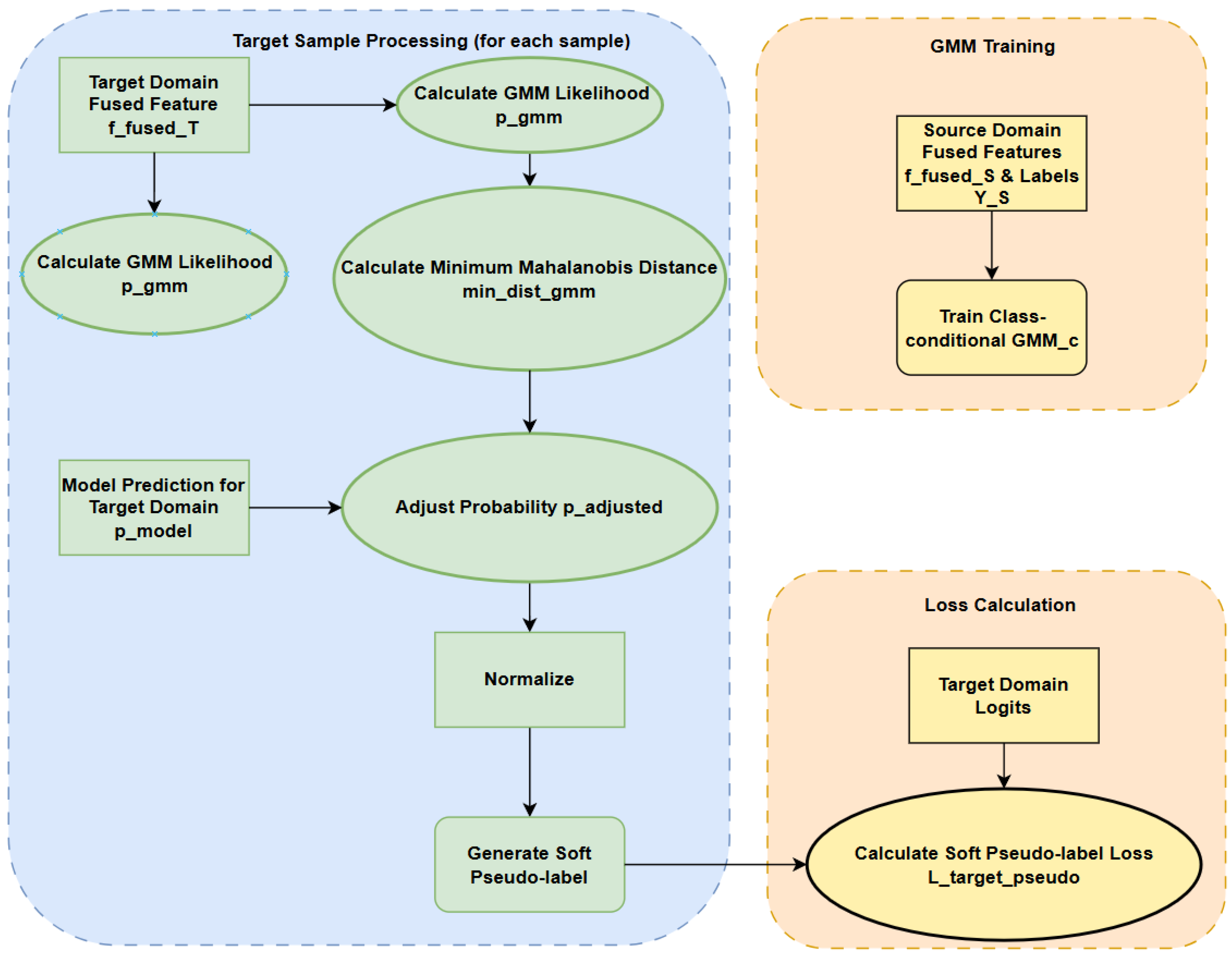
2.5. Soft Pseudo-Label Generation Based on GMM and the Mahalanobis Distance Adjustment
2.6. I-Softmax Loss Function
3. The Proposed Transfer Learning Model: DS-HDA Net
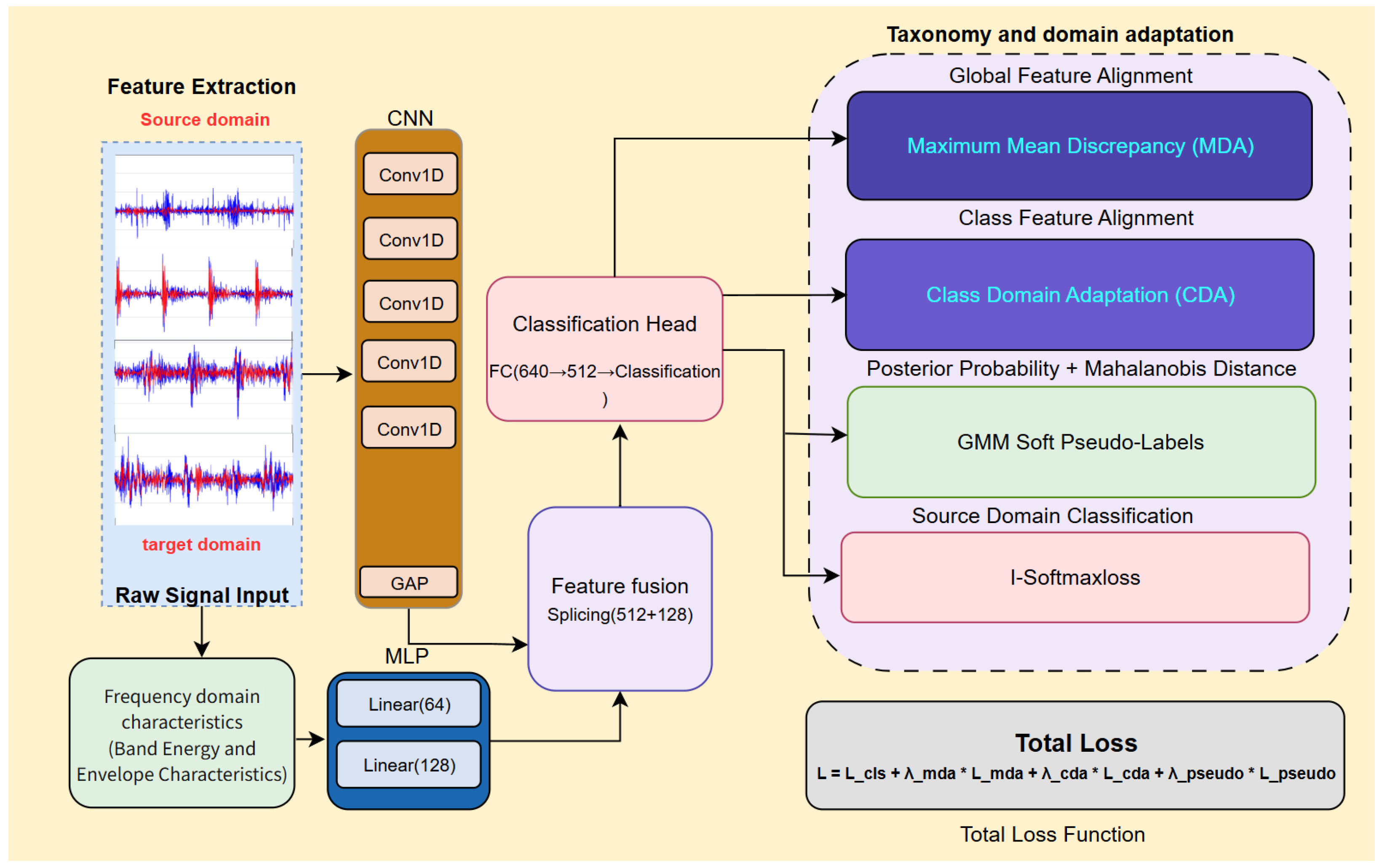
3.1. DS-HDA Net Framework
3.2. Dual-Stream Feature Extractor
3.2.1. CNN Stream for Raw Signals
3.2.2. Frequency-Domain Feature Extraction and MLP Stream
3.2.3. Feature Fusion
3.3. Hybrid-Domain Adaptation Strategy
3.3.1. Global Domain Alignment Based on Fused Features (MDA)
3.3.2. Conditional Domain Alignment Based on Logits (CDA)
3.4. Gmm-Based Soft Pseudo-Label Generation Module
3.5. Source Domain Classification Based on I-Softmax
3.6. Overall Loss Function and Optimization
4. Data Description
4.1. Paderborn University (PU) Dataset
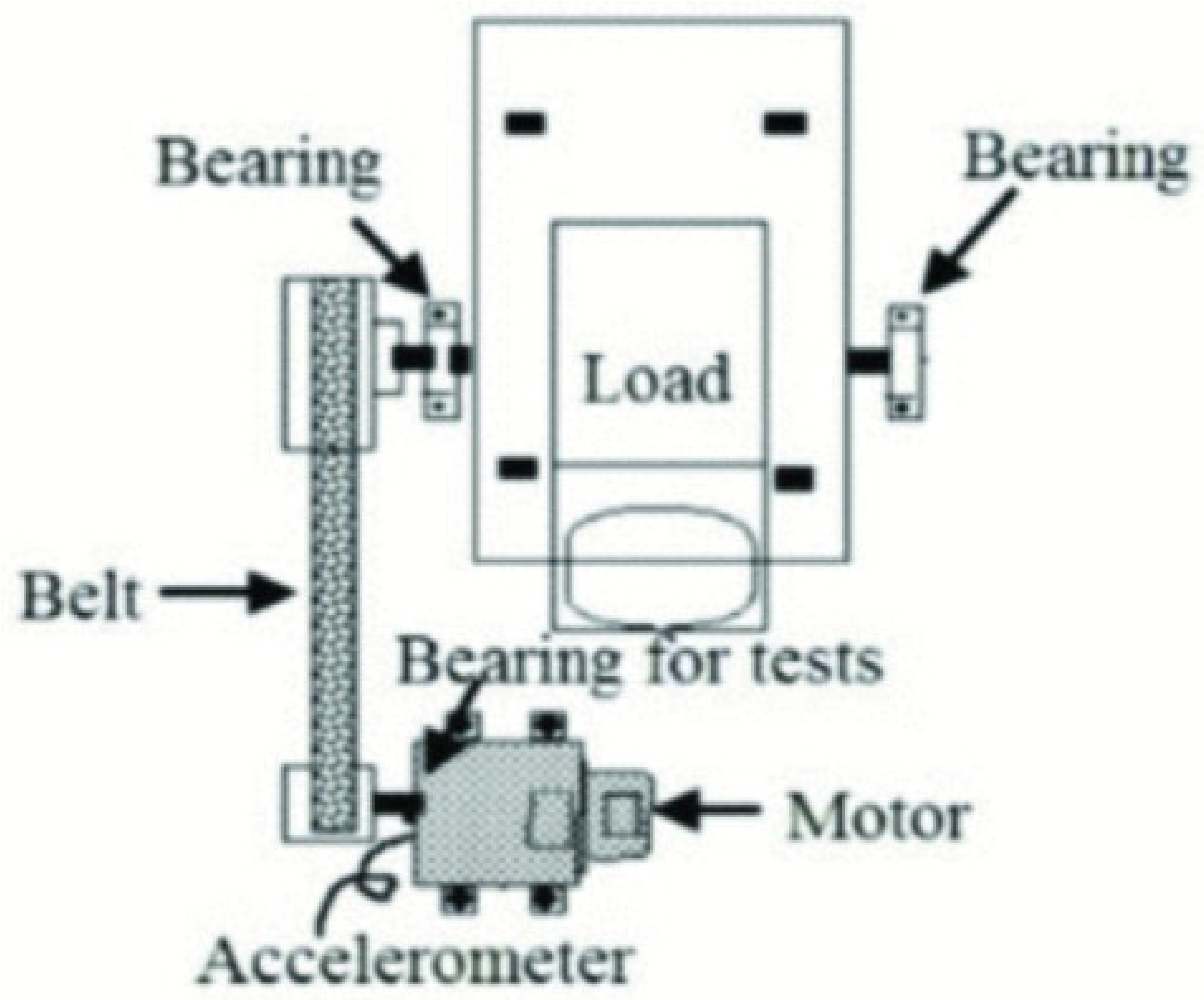
4.1.1. Data Acquisition
4.1.2. Operating Conditions and Designations
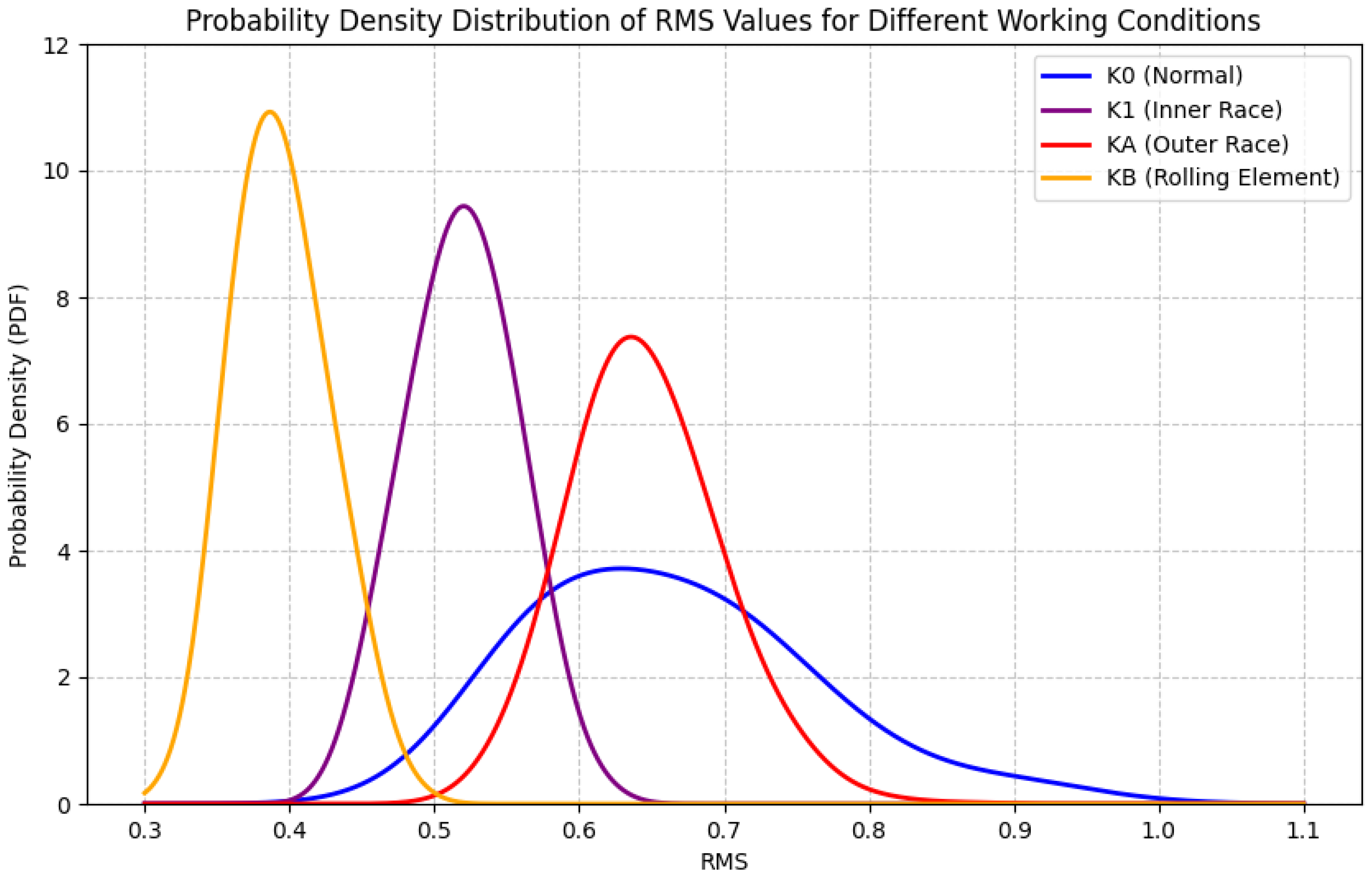
4.1.3. Fault Types
- Normal (Label 0): Healthy bearings.
- Inner race fault (Label 1): Damage to the inner race.
- Outer race fault (Label 2): Damage to the outer race.
- Compound faults (Label 3): Damage to the rolling elements.
4.1.4. Data Preprocessing
4.1.5. Transfer Task Design and Data Usage
- T1 (PUC0 → PUC2): N09_M07_F10 to N15_M07_F04 (speed and radial force changes).
- T2 (PUC0 → PUC3): N09_M07_F10 to N15_M07_F10 (speed changes).
- T3 (PUC2 → PUC3): N15_M07_F04 to N15_M07_F10 (radial force changes).
- T4 (PUC3 → PUC1): N15_M07_F10 to N15_M01_F10 (load torque changes).
4.2. Jiangnan University (JNU) Bearing Dataset
4.2.1. Data Acquisition
4.2.2. Operating Conditions and Designations
4.2.3. Fault Types
- Normal (‘n’): Healthy state.
- Outer race fault (‘o’): Damage on the outer race.
- Inner race fault (‘i’): Damage on the inner race.
- Ball/Roller fault (‘t’ or ‘b’): Damage on the rolling elements.
4.2.4. Data Preprocessing
4.2.5. Data Usage and Transfer Tasks
5. Experimental Verification
5.1. Introduction
- Performance comparison: Compare DS-HDA Net with various benchmark domain adaptation methods on two widely used bearing fault diagnosis datasets (Paderborn University PU dataset and Jiangnan University JNU dataset) [27], covering different transfer task scenarios.
- Ablation study: Systematically evaluate the contribution of key components in DS-HDA Net (such as multi-scale domain adaptation MDA, class-conditional domain adaptation CDA, GMM-based soft pseudo-label strategy, dual-stream feature fusion mechanism, I-Softmax loss function) to the overall performance by removing or replacing them.
5.2. Experimental Setup
5.2.1. Datasets and Transfer Tasks
5.2.2. Implementation Details
5.2.3. Classification Metrics and Benchmark Methods
- Maximum mean discrepancy (MMD): MMD is utilized to quantify the discrepancy between the feature distributions of the source and target domains in the learned fused feature space. A lower MMD value indicates better alignment of the global feature distributions, suggesting more effective domain adaptation.
- Silhouette coefficient: The silhouette coefficient is used to measure the quality of the learned target domain features in terms of class separability. It evaluates how similar a sample is to its own class (cohesion) compared to other classes (separation). Values range from −1 to 1, where a higher score indicates that features are more densely grouped within their respective classes and well separated from other classes, signifying better feature discriminability.
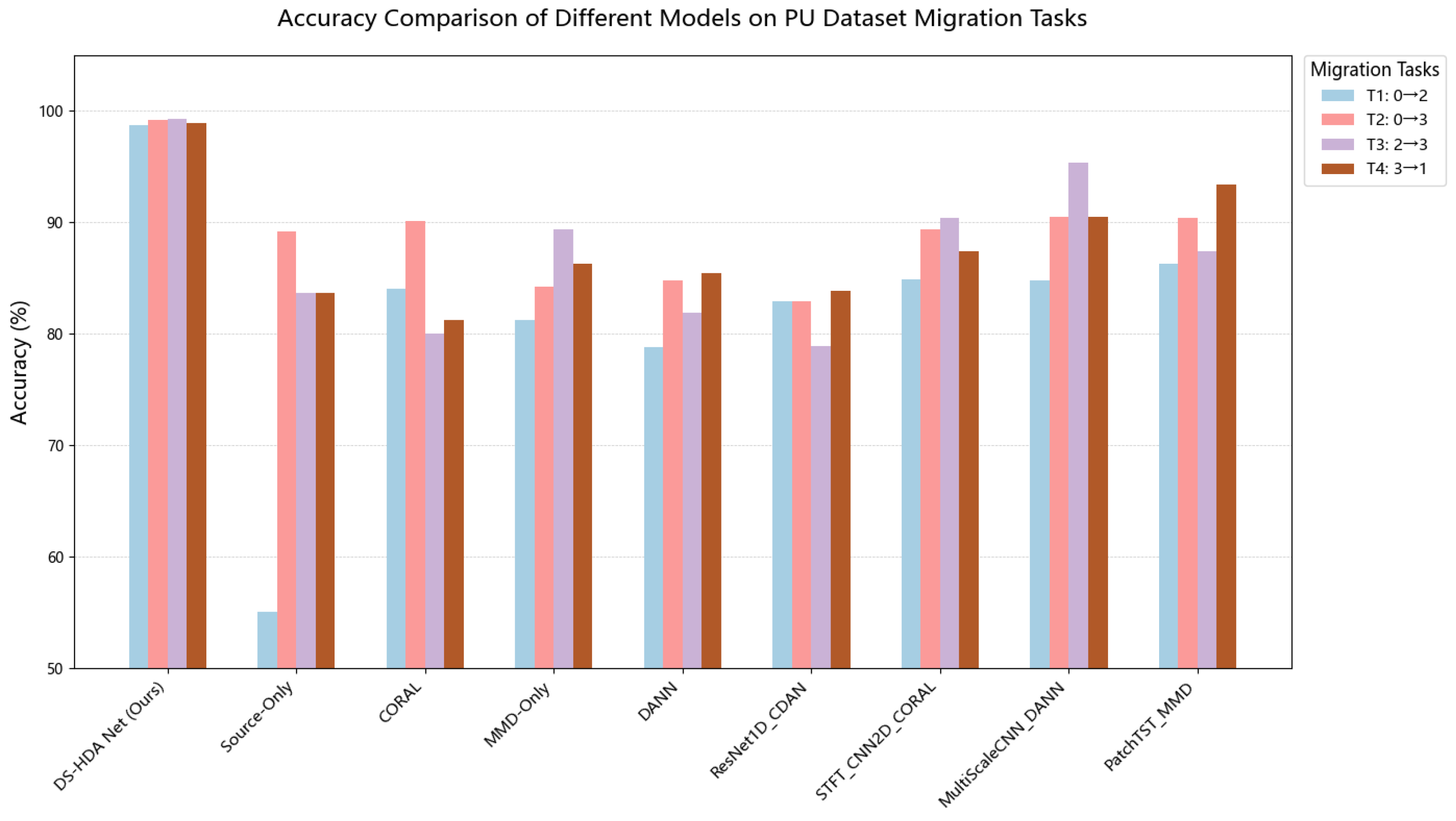
5.3. Performance Comparison on PU Dataset
5.3.1. Classification Accuracy
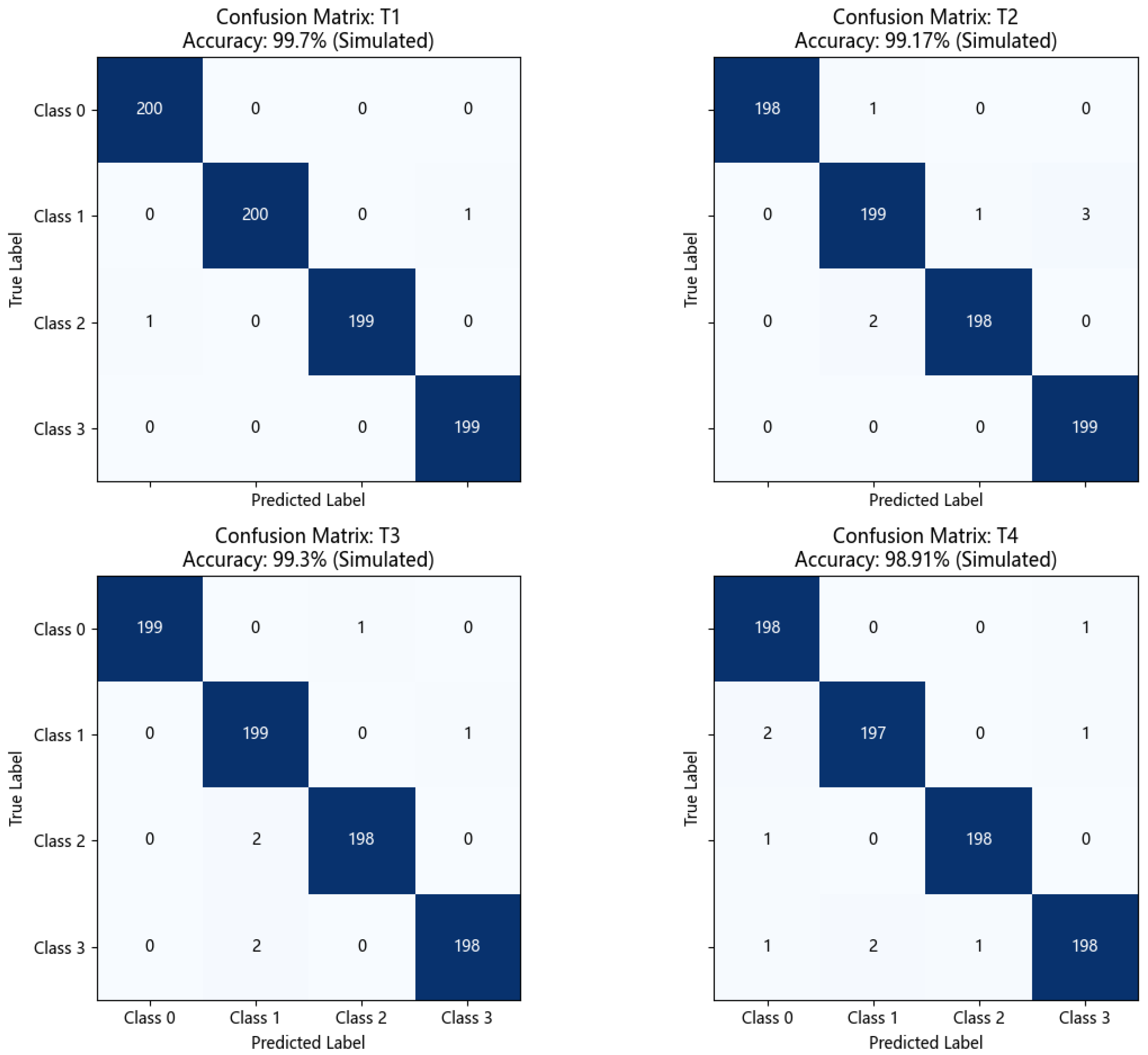
5.3.2. Confusion Matrix Analysis
- High diagonal values: The confusion matrices for all tasks show very high diagonal element values (close to or equal to 200, based on sample size per class). This indicates that DS-HDA Net can classify the normal state (Class 0) and the three fault types (Class 1: Inner Race, Class 2: Outer Race, Class 3: Rolling Element) very accurately.
- Low off-diagonal values: The values of off-diagonal elements are very small (usually 0, 1, or 2), indicating very little confusion between different classes. For example, in T1 (Accuracy: 99.90%), almost all samples were correctly classified. Even in T4 (Accuracy: 99.10%), which had the relatively lowest accuracy among the DS-HDA Net results, the number of misclassified samples was very limited.
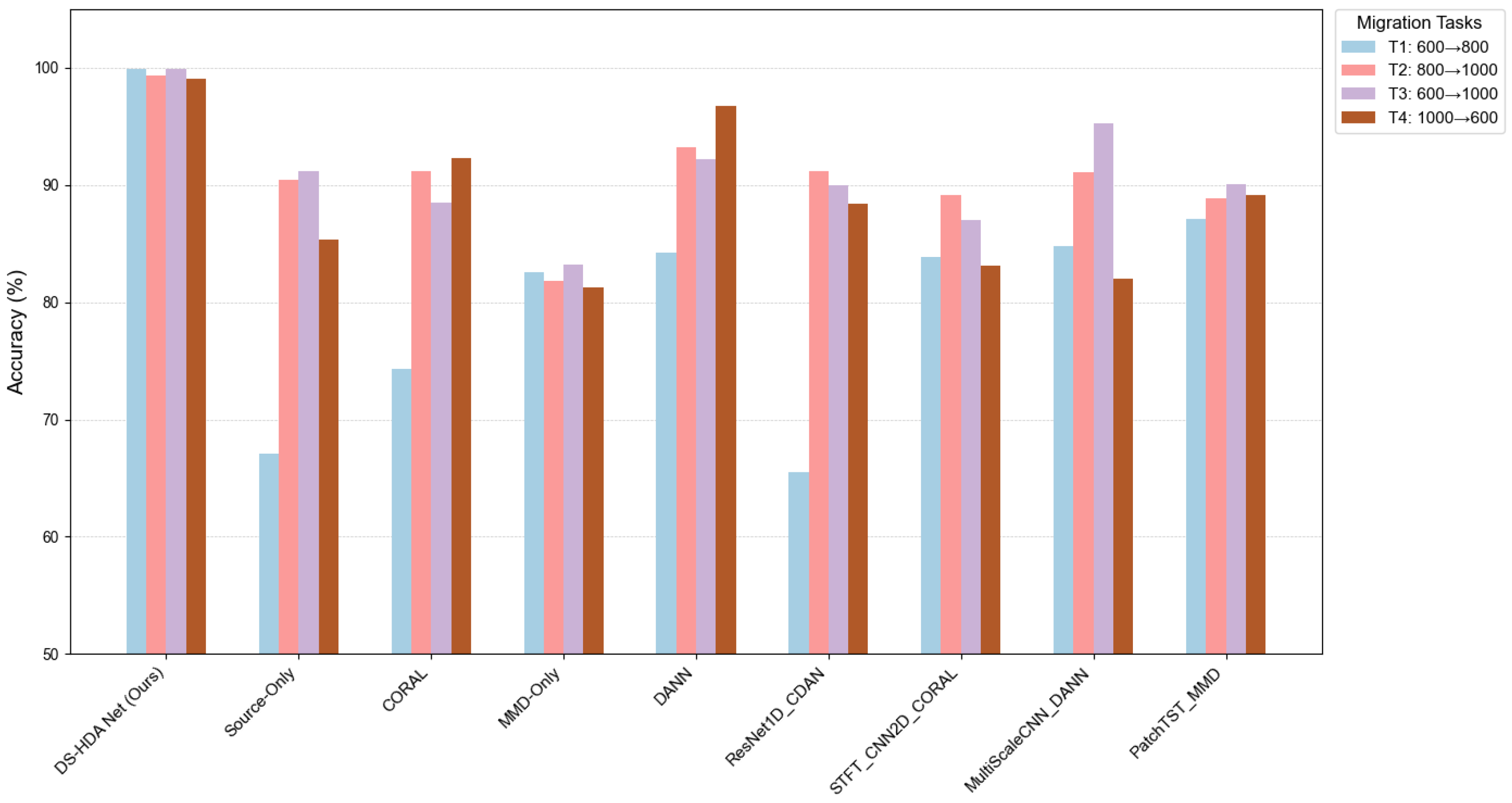
5.4. Performance Comparison on JNU Dataset
5.4.1. Classification Accuracy
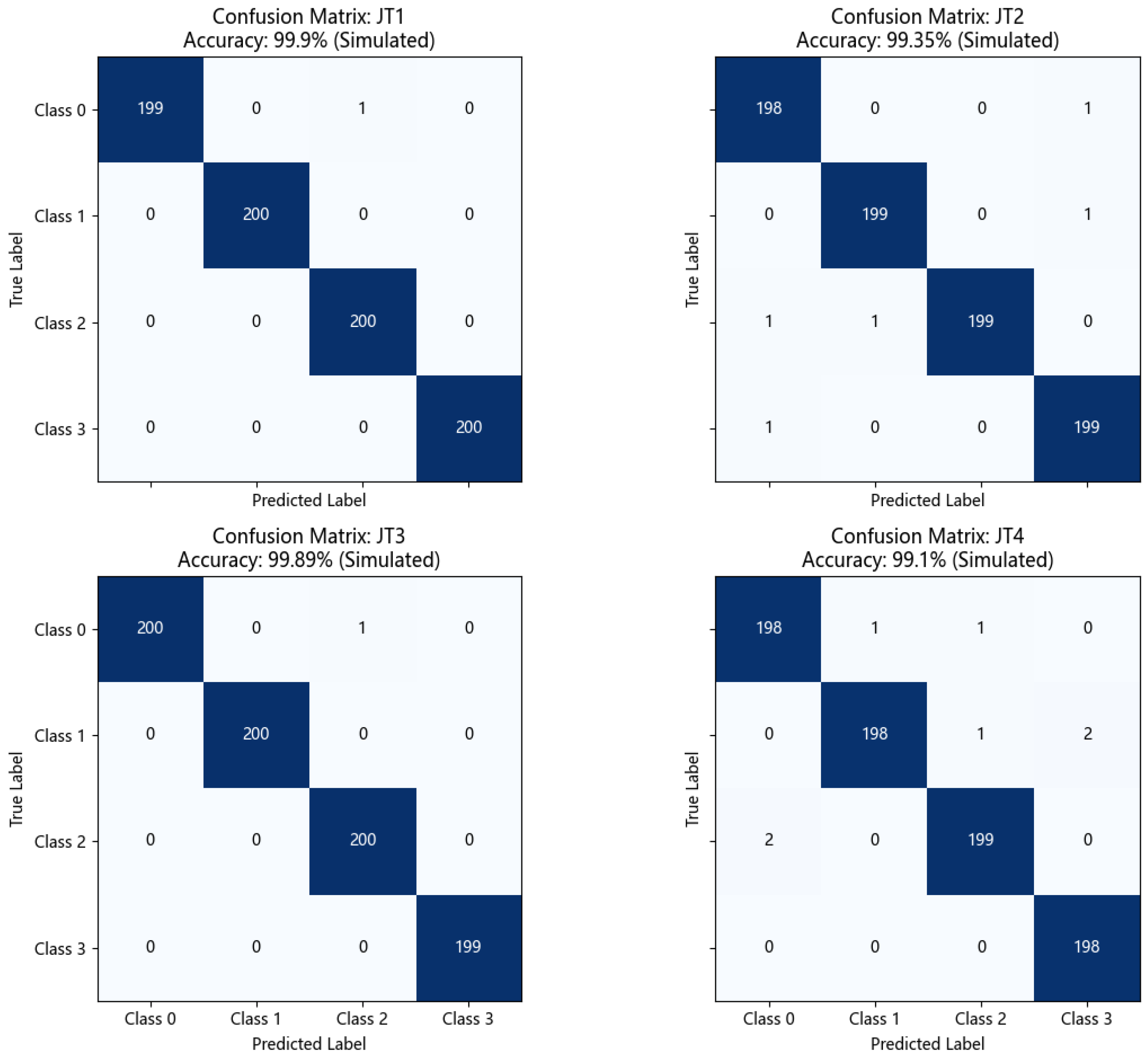
5.4.2. Confusion Matrix Analysis
5.5. Ablation Study
5.5.1. Ablation Experiment Setup
- DS-HDA Net (Full): The complete model.
- Baseline: Source Only: Only source domain training, without any domain adaptation or special components.
- DS-HDA (CNN Only): Removed the MLP branch and frequency-domain feature input, using only the CNN branch to process time-domain signals, but retaining MDA, CDA, GMM, I-Softmax, etc.
- DS-HDA w/o MDA: Removed the global domain adaptation (MDA) module, retaining other components.
- DS-HDA w/o CDA: Removed the class-conditional domain adaptation (CDA) module, retaining other components.
- DS-HDA w/o GMM (Hard PL): Used hard pseudo-labels (argmax of model’s own predictions) instead of GMM-based soft pseudo-labels for target domain supervision and CDA grouping.
- DS-HDA w/ CE: Used standard cross-entropy (CE) loss instead of I-Softmax as the source domain classification loss.
5.5.2. Ablation Results on PU Dataset
5.5.3. Ablation Results on JNU Dataset
5.6. Quantitative Analysis of Feature-Level Adaptation
5.6.1. Domain Discrepancy Analysis (MMD)
5.6.2. Target Domain Feature Separability (Silhouette Coefficient)
5.7. Hyperparameter Sensitivity Analysis
5.7.1. GMM Components Analysis
5.7.2. Mahalanobis Distance Sensitivity Parameter ()
5.7.3. Soft Label Weighting Factor ()
5.7.4. Summary of Sensitivity Analysis
6. Summary and Outlook
6.1. Summary of This Paper
6.2. Limitations and Broader Future Outlook
6.3. Real-World Deployment and Generalization Considerations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, Y.; Chen, S.; Jiang, W.; Zhang, Y.; Lu, J.; Kwok, J.T. Domain-guided conditional diffusion model for unsupervised domain adaptation. Neural Netw. 2025, 184, 107031. [Google Scholar] [CrossRef] [PubMed]
- Sobie, C.; Freitas, C.; Nicolai, M. Simulation-driven machine learning: Bearing fault classification. Mech. Syst. Signal Process. 2018, 99, 403–419. [Google Scholar] [CrossRef]
- Matania, O.; Cohen, R.; Bechhoefer, E.; Bortman, J. Zero-fault-shot learning for bearing spall type classification by hybrid approach. Mech. Syst. Signal Process. 2025, 224, 112117. [Google Scholar] [CrossRef]
- Xie, S.; Li, Y.; Tan, H.; Liu, R.; Zhang, F. Multi-scale and multi-layer perceptron hybrid method for bearings fault diagnosis. Int. J. Mech. Sci. 2022, 235, 107708. [Google Scholar] [CrossRef]
- Zuo, L.; Xu, F.; Zhang, C.; Xiahou, T.; Liu, Y. A multi-layer spiking neural network-based approach to bearing fault diagnosis. Reliab. Eng. Syst. Saf. 2022, 225, 108561. [Google Scholar] [CrossRef]
- Wang, L.; Hope, A. Fault diagnosis: Bearing fault diagnosis using multi-layer neural networks. Insight-Non Test. Cond. Monit. 2004, 46, 451–455. [Google Scholar] [CrossRef]
- Wu, Z.; Jiang, H.; Zhao, K.; Li, X. An adaptive deep transfer learning method for bearing fault diagnosis. Measurement 2020, 151, 107227. [Google Scholar] [CrossRef]
- Tang, G.; Yi, C.; Liu, L.; Xing, Z.; Zhou, Q.; Lin, J. Integrating adaptive input length selection strategy and unsupervised transfer learning for bearing fault diagnosis under noisy conditions. Appl. Soft Comput. 2023, 148, 110870. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Jia, F.; Xing, S. An intelligent fault diagnosis approach based on transfer learning from laboratory bearings to locomotive bearings. Mech. Syst. Signal Process. 2019, 122, 692–706. [Google Scholar] [CrossRef]
- Misbah, I.; Lee, C.K.; Keung, K.L. Fault diagnosis in rotating machines based on transfer learning: Literature review. Knowl.-Based Syst. 2024, 283, 111158. [Google Scholar] [CrossRef]
- Zhang, H.B.; Cheng, D.J.; Zhou, K.L.; Zhang, S.W. Deep transfer learning-based hierarchical adaptive remaining useful life prediction of bearings considering the correlation of multistage degradation. Knowl.-Based Syst. 2023, 266, 110391. [Google Scholar] [CrossRef]
- Tzeng, E.; Hoffman, J.; Saenko, K.; Darrell, T. Adversarial discriminative domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7167–7176. [Google Scholar]
- Tang, G.; Yi, C.; Liu, L.; Yang, X.; Xu, D.; Zhou, Q.; Lin, J. A novel transfer learning network with adaptive input length selection and lightweight structure for bearing fault diagnosis. Eng. Appl. Artif. Intell. 2023, 123, 106395. [Google Scholar] [CrossRef]
- Cao, X.; Wang, Y.; Chen, B.; Zeng, N. Domain-adaptive intelligence for fault diagnosis based on deep transfer learning from scientific test rigs to industrial applications. Neural Comput. Appl. 2021, 33, 4483–4499. [Google Scholar] [CrossRef]
- Qian, Q.; Zhang, B.; Li, C.; Mao, Y.; Qin, Y. Federated transfer learning for machinery fault diagnosis: A comprehensive review of technique and application. Mech. Syst. Signal Process. 2025, 223, 111837. [Google Scholar] [CrossRef]
- Qin, Y.; Qian, Q.; Wang, Y.; Zhou, J. Intermediate distribution alignment and its application into mechanical fault transfer diagnosis. IEEE Trans. Ind. Inform. 2022, 18, 7305–7315. [Google Scholar] [CrossRef]
- Hou, W.; Zhang, C.; Jiang, Y.; Cai, K.; Wang, Y.; Li, N. A new bearing fault diagnosis method via simulation data driving transfer learning without target fault data. Measurement 2023, 215, 112879. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.; Li, X.; Li, N. Targeted transfer learning through distribution barycenter medium for intelligent fault diagnosis of machines with data decentralization. Expert Syst. Appl. 2024, 244, 122997. [Google Scholar] [CrossRef]
- Sinitsin, V.; Ibryaeva, O.; Sakovskaya, V.; Eremeeva, V. Intelligent bearing fault diagnosis method combining mixed input and hybrid CNN-MLP model. Mech. Syst. Signal Process. 2022, 180, 109454. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Zhuang, J.; Cao, Y.; Zhao, X.; Lee, C.G. Deep imbalanced domain adaptation for transfer learning fault diagnosis of bearings under multiple working conditions. Reliab. Eng. Syst. Saf. 2023, 230, 108890. [Google Scholar] [CrossRef]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. arXiv 2021, arXiv:2101.11605. [Google Scholar]
- Huang, M.; Yin, J.; Yan, S.; Xue, P. A fault diagnosis method of bearings based on deep transfer learning. Simul. Model. Pract. Theory 2023, 122, 102659. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M.I. Deep transfer learning with joint adaptation networks. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2208–2217. [Google Scholar]
- Tang, Z.; Bo, L.; Liu, X.; Wei, D. An autoencoder with adaptive transfer learning for intelligent fault diagnosis of rotating machinery. Meas. Sci. Technol. 2021, 32, 055110. [Google Scholar] [CrossRef]
- Tang, S.; Ma, J.; Yan, Z.; Zhu, Y.; Khoo, B.C. Deep transfer learning strategy in intelligent fault diagnosis of rotating machinery. Eng. Appl. Artif. Intell. 2024, 134, 108678. [Google Scholar] [CrossRef]
- Chen, H.; Luo, H.; Huang, B.; Jiang, B.; Kaynak, O. Transfer learning-motivated intelligent fault diagnosis designs: A survey, insights, and perspectives. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 2969–2983. [Google Scholar] [CrossRef]
- Chen, X.; Yang, R.; Xue, Y.; Huang, M.; Ferrero, R.; Wang, Z. Deep transfer learning for bearing fault diagnosis: A systematic review since 2016. IEEE Trans. Instrum. Meas. 2023, 72, 3508221. [Google Scholar] [CrossRef]
- Sun, B.; Feng, J.; Saenko, K. Deep CORAL: Correlation alignment for deep domain adaptation. arXiv 2016, arXiv:1607.01719. [Google Scholar]
- Tzeng, E.; Hoffman, J.; Zhang, N.; Saenko, K.; Darrell, T. Deep domain confusion: Maximizing for domain invariance. arXiv 2014, arXiv:1412.3474. [Google Scholar]
- Long, M.; Wang, J. Learning transferable features with deep adaptation networks. arXiv 2015, arXiv:1502.02791. [Google Scholar]
- Ghifary, M.; Kleijn, W.B.; Zhang, M. Domain adaptive neural networks for object recognition. arXiv 2014, arXiv:1409.6041. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Gelly, S.; Bousquet, O. Are GANs created equal? A large scale study. arXiv 2017, arXiv:1711.10337. [Google Scholar]
- Zhang, X.; Yu, F.X.; Chang, S.F.; Wang, S. Deep transfer network: Unsupervised domain adaptation. arXiv 2015, arXiv:1503.00591. [Google Scholar]
- Jin, Y.; Hou, L.; Chen, Y. A time series transformer based method for the rotating machinery fault diagnosis. Neurocomputing 2022, 494, 379–395. [Google Scholar] [CrossRef]
- Li, T.; Zhao, Z.; Sun, C.; Yan, R.; Chen, X. Domain adversarial graph convolutional network for fault diagnosis under variable working conditions. IEEE Trans. Instrum. Meas. 2021, 70, 3515010. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stream | Layer Name/Index | Type | Kernel | Stride | Pad | In | Out | Act. | Output Shape (Example) * |
|---|---|---|---|---|---|---|---|---|---|
| CNN (Time Domain) | Input: (B, 1, 3840) (Batch, Channels, SeqLen) | ||||||||
| shared_part | |||||||||
| Conv1 | Conv1d | 64 | 16 | 24 | 1 | 32 | - | (B, 32, 240) | |
| BatchNorm1 | BatchNorm1d | num_feat.: 32 | - | - | 32 | 32 | - | (B, 32, 240) | |
| ReLU1 | ReLU | inplace = True | - | - | 32 | 32 | ReLU | (B, 32, 240) | |
| MaxPool1 | MaxPool1d | 2 | 2 | - | 32 | 32 | - | (B, 32, 120) | |
| Conv2 | Conv1d | 3 | 1 | 1 | 32 | 64 | - | (B, 64, 120) | |
| BatchNorm2 | BatchNorm1d | num_feat.: 64 | - | - | 64 | 64 | - | (B, 64, 120) | |
| ReLU2 | ReLU | inplace = True | - | - | 64 | 64 | ReLU | (B, 64, 120) | |
| MaxPool2 | MaxPool1d | 2 | 2 | - | 64 | 64 | - | (B, 64, 60) | |
| Conv3 | Conv1d | 3 | 1 | 1 | 64 | 128 | - | (B, 128, 60) | |
| BatchNorm3 | BatchNorm1d | num_feat.: 128 | - | - | 128 | 128 | - | (B, 128, 60) | |
| ReLU3 | ReLU | inplace = True | - | - | 128 | 128 | ReLU | (B, 128, 60) | |
| MaxPool3 | MaxPool1d | 2 | 2 | - | 128 | 128 | - | (B, 128, 30) | |
| classifier_part_cnn | Input: (B, 128, 30) | ||||||||
| Conv4 | Conv1d | 3 | 1 | 1 | 128 | 256 | - | (B, 256, 30) | |
| BatchNorm4 | BatchNorm1d | num_feat.: 256 | - | - | 256 | 256 | - | (B, 256, 30) | |
| ReLU4 | ReLU | inplace = True | - | - | 256 | 256 | ReLU | (B, 256, 30) | |
| MaxPool4 | MaxPool1d | 2 | 2 | - | 256 | 256 | - | (B, 256, 15) | |
| Conv5 | Conv1d | 3 | 1 | 1 | 256 | 512 | - | (B, 512, 15) | |
| BatchNorm5 | BatchNorm1d | num_feat.: 512 | - | - | 512 | 512 | - | (B, 512, 15) | |
| ReLU5 | ReLU | inplace = True | - | - | 512 | 512 | ReLU | (B, 512, 15) | |
| GlobalAvgPool | AdaptiveAvgPool1d | Output Size: 1 | - | - | 512 | 512 | - | (B, 512, 1) →(B, 512) | |
| MLP (Freq. Domain) | Input: (B, 11) (Batch, Features) | ||||||||
| freq_feature_mlp | |||||||||
| Linear1 | Linear | In: 11, Out: 64 | - | - | 11 | 64 | - | (B, 64) | |
| BatchNorm6 | BatchNorm1d | num_feat.: 64 | - | - | 64 | 64 | - | (B, 64) | |
| ReLU6 | ReLU | inplace = True | - | - | 64 | 64 | ReLU | (B, 64) | |
| Linear2 | Linear | In: 64, Out: 128 | - | - | 64 | 128 | - | (B, 128) | |
| BatchNorm7 | BatchNorm1d | num_feat.: 128 | - | - | 128 | 128 | - | (B, 128) | |
| ReLU7 | ReLU | inplace = True | - | - | 128 | 128 | ReLU | (B, 128) | |
| Fusion & Classifier | Input: (B,512) CNN, (B,128) MLP → (B,640) concat | ||||||||
| FeatureFusion | torch.cat | CNN (512) + MLP (128) | - | - | 512+128 | 640 | - | (B, 640) | |
| fc (Classifier) | |||||||||
| Linear3 | Linear | In: 640, Out: 512 | - | - | 640 | 512 | - | (B, 512) | |
| ReLU8 | ReLU | inplace = True | - | - | 512 | 512 | ReLU | (B, 512) | |
| Dropout | Dropout | Rate: 0.5 | - | - | 512 | 512 | - | (B, 512) | |
| Linear4 (Logits) | Linear | In: 512, Out: | - | - | 512 | - | (B, ) (e.g., 4) | ||
| Condition ID | Condition Code | Rotational Speed (rpm) | Load Torque (Nm) | Radial Force (N) |
|---|---|---|---|---|
| PUC0 | N09_M07_F10 | 900 | 0.7 | 1000 |
| PUC1 | N15_M01_F10 | 1500 | 0.1 | 1000 |
| PUC2 | N15_M07_F04 | 1500 | 0.7 | 400 |
| PUC3 | N15_M07_F10 | 1500 | 0.7 | 1000 |
| Condition ID | Description | Rotational Speed (rpm) |
|---|---|---|
| JNUC0 | Low-speed operation | 600 |
| JNUC1 | Medium-speed operation | 800 |
| JNUC2 | High-speed operation | 1000 |
| Method Name | T1 | T2 | T3 | T4 | Average |
|---|---|---|---|---|---|
| DS-HDA Net (Ours) | 99.90 | 99.70 | 99.30 | 99.90 | 99.43 |
| Source-Only | 55.00 | 89.13 | 93.62 | 83.62 | 80.34 |
| CORAL | 84.00 | 90.14 | 89.96 | 91.23 | 88.83 |
| MMD-Only | 91.25 | 84.23 | 89.31 | 96.30 | 90.27 |
| DANN | 88.75 | 94.78 | 91.88 | 95.41 | 92.70 |
| ResNet1D_CDAN | 72.87 | 92.87 | 88.87 | 93.87 | 87.12 |
| STFT_CNN2D_CORAL | 74.87 | 89.37 | 90.37 | 77.37 | 83.00 |
| MultiScaleCNN_DANN | 74.75 | 90.50 | 95.38 | 80.50 | 85.28 |
| PatchTST_MMD | 56.25 | 90.37 | 87.37 | 93.37 | 81.84 |
| Method | JT1: 600→800 | JT2: 800→1000 | JT3: 600→1000 | JT4: 1000→600 | Average |
|---|---|---|---|---|---|
| DS-HDA Net (Ours) | 99.90 | 99.35 | 99.89 | 99.10 | 99.56 |
| Source-Only | 67.11 | 90.45 | 91.18 | 85.34 | 83.52 |
| CORAL | 74.31 | 91.20 | 88.49 | 92.33 | 88.83 |
| MMD-Only | 82.56 | 81.79 | 83.17 | 81.29 | 82.20 |
| DANN | 84.25 | 93.18 | 92.22 | 96.71 | 91.59 |
| ResNet1D_CDAN | 65.54 | 91.17 | 89.95 | 88.37 | 83.76 |
| STFT_CNN2D_CORAL | 83.85 | 89.12 | 87.02 | 83.12 | 85.78 |
| MultiScaleCNN_DANN | 84.75 | 91.12 | 95.23 | 81.98 | 88.27 |
| PatchTST_MMD | 87.12 | 88.90 | 90.04 | 89.15 | 88.80 |
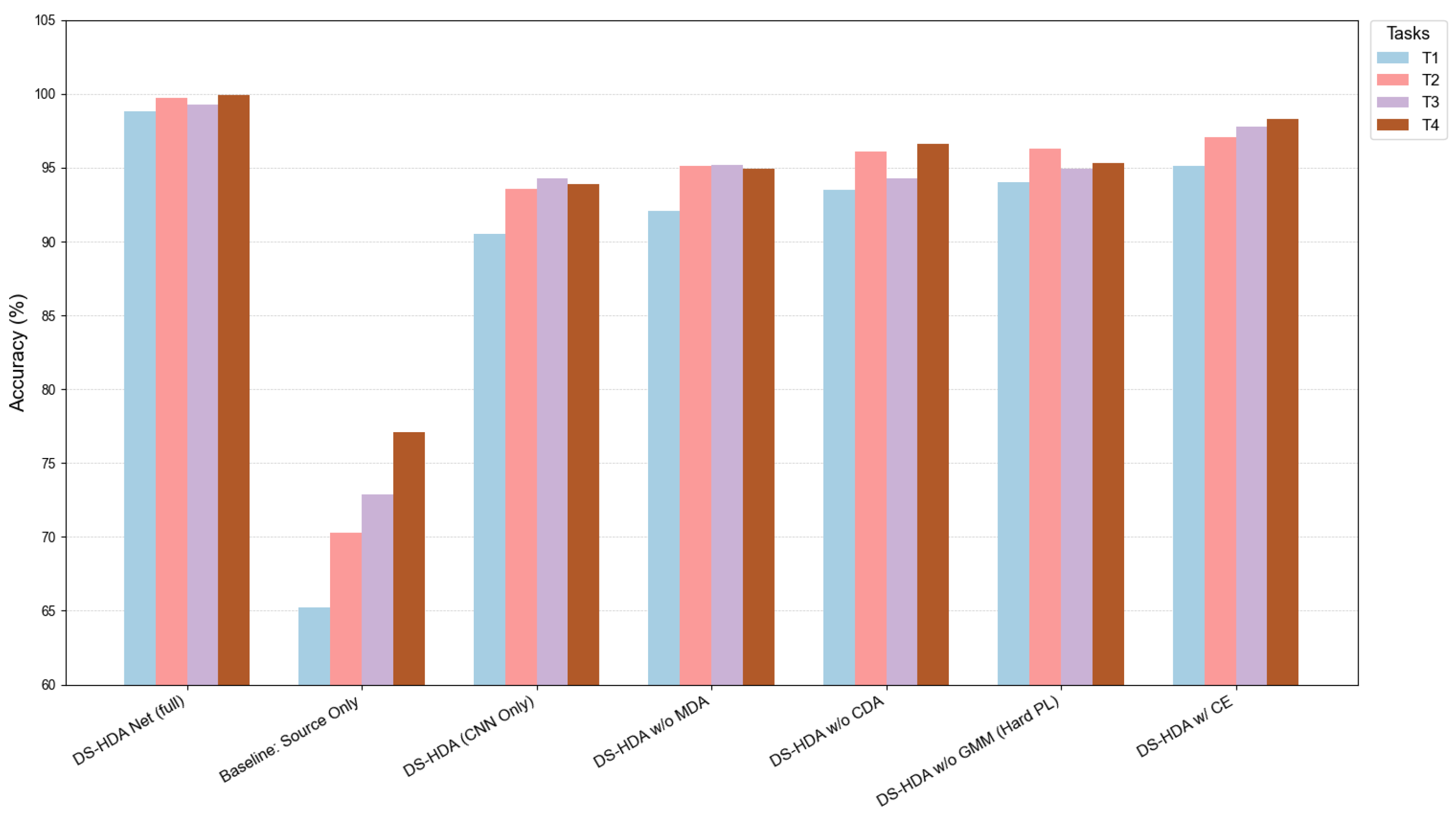
| Exp. No. | Model Variant Name | (CNN +MLP) | (MDA) | (CDA) | GMM | I-Softmax | T1 Acc. (%) | T2 Acc. (%) | T3 Acc. (%) | T4 Acc. (%) | Avg. Acc. (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | DS-HDA Net (full) | Y | Y | Y | Y | Y | 99.90 | 99.70 | 99.30 | 99.90 | 99.43 |
| 1 | Baseline: Source Only | Y | N | N | N | Y | 55.00 | 89.13 | 93.62 | 83.62 | 80.34 |
| 2 | DS-HDA (CNN Only) | N | Y | Y | Y | Y | 90.50 | 93.60 | 94.30 | 93.90 | 93.07 |
| 3 | DS-HDA w/o MDA | Y | N | Y | Y | Y | 92.10 | 95.10 | 95.20 | 94.90 | 94.32 |
| 4 | DS-HDA w/o CDA | Y | Y | N | Y | Y | 93.50 | 96.10 | 94.30 | 96.60 | 95.12 |
| 5 | DS-HDA w/o GMM (Hard PL) | Y | Y | Y | N | Y | 94.00 | 96.30 | 94.90 | 95.30 | 95.13 |
| 6 | DS-HDA w/ CE | Y | Y | Y | Y | N | 95.10 | 97.10 | 97.80 | 98.30 | 97.08 |
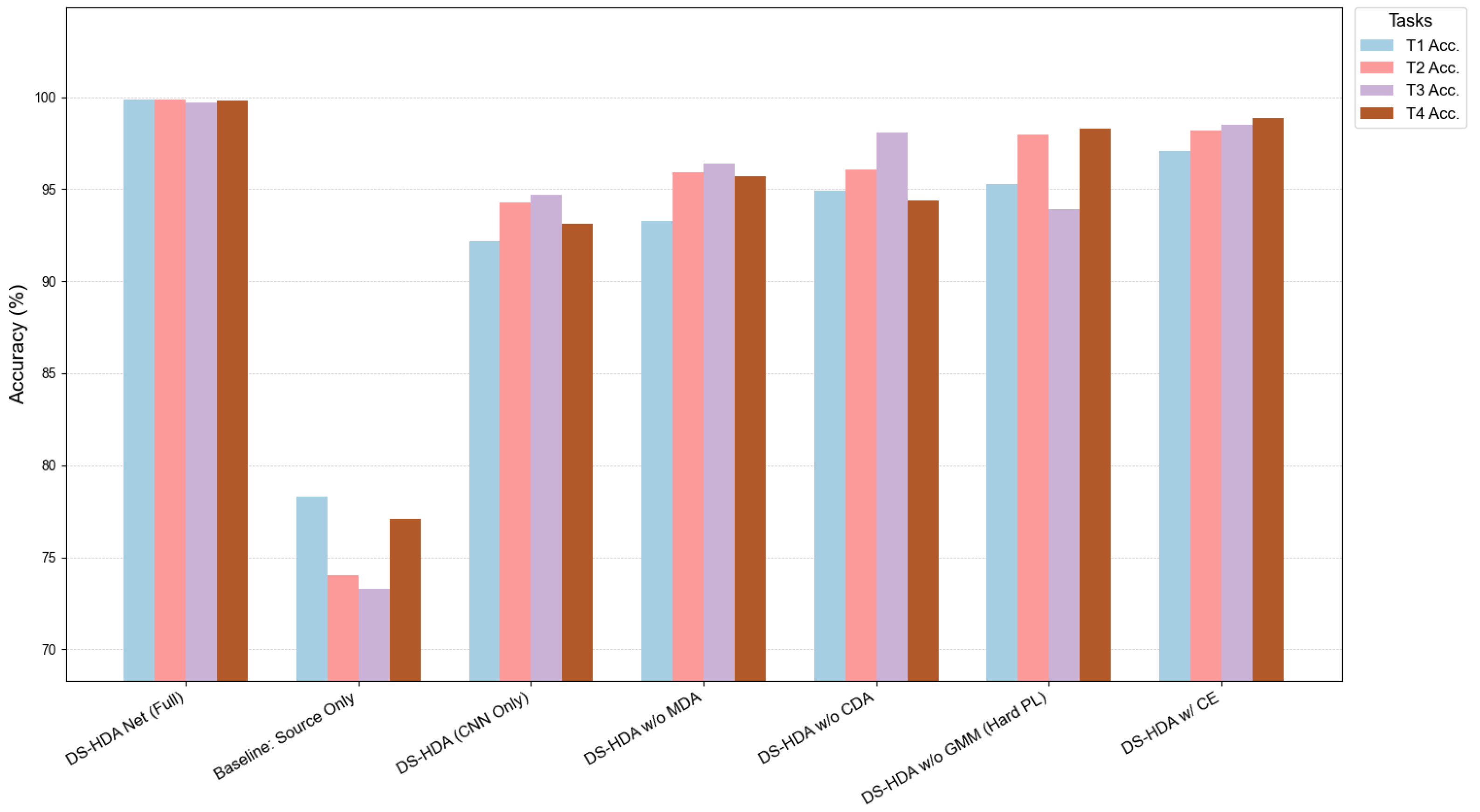
| Exp. No. | Model Variant Name | (CNN +MLP) | (MDA) | (CDA) | GMM | I-Softmax | T1 Acc. (%) | T2 Acc. (%) | T3 Acc. (%) | T4 Acc. (%) | Avg. Acc. (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | DS-HDA Net (Full) | Y | Y | Y | Y | Y | 99.90 | 99.90 | 99.70 | 99.80 | 99.83 |
| 1 | Baseline: Source Only | Y | N | N | N | Y | 78.30 | 74.00 | 73.30 | 77.10 | 75.68 |
| 2 | DS-HDA (CNN Only) | N | Y | Y | Y | Y | 92.20 | 94.30 | 94.70 | 93.10 | 93.57 |
| 3 | DS-HDA w/o MDA | Y | N | Y | Y | Y | 93.30 | 95.90 | 96.40 | 95.70 | 95.33 |
| 4 | DS-HDA w/o CDA | Y | Y | N | Y | Y | 94.90 | 96.10 | 98.10 | 94.40 | 95.88 |
| 5 | DS-HDA w/o GMM (Hard PL) | Y | Y | Y | N | Y | 95.30 | 98.00 | 93.90 | 98.30 | 96.38 |
| 6 | DS-HDA w/ CE | Y | Y | Y | Y | N | 97.10 | 98.20 | 98.50 | 98.90 | 98.18 |
| Model Configuration | MMD Value (↓) |
|---|---|
| Source-Only | 0.873 |
| DS-HDA Net w/o MDA | 0.521 |
| DS-HDA Net (Full) | 0.289 |
| Model Configuration | Silhouette Coefficient (↑) |
|---|---|
| Source-Only | 0.15 |
| DS-HDA Net w/o CDA | 0.45 |
| DS-HDA Net (Full) | 0.62 |
| K Components | T1 Acc. | T2 Acc. | T3 Acc. | T4 Acc. | Avg. Acc. |
|---|---|---|---|---|---|
| 1 | 97.20 | 97.80 | 97.10 | 97.50 | 97.40 |
| 2 (default) | 99.90 | 99.70 | 99.30 | 99.90 | 99.43 |
| 3 | 99.10 | 99.20 | 98.90 | 99.30 | 99.13 |
| 4 | 98.70 | 98.90 | 98.50 | 98.80 | 98.73 |
| Value | T1 Acc. | T2 Acc. | T3 Acc. | T4 Acc. | Avg. Acc. |
|---|---|---|---|---|---|
| 0.05 | 98.10 | 98.30 | 98.00 | 98.20 | 98.15 |
| 0.1 (default) | 99.90 | 99.70 | 99.30 | 99.90 | 99.43 |
| 0.2 | 99.20 | 99.10 | 98.80 | 99.20 | 99.08 |
| 0.5 | 97.50 | 97.80 | 97.30 | 97.70 | 97.58 |
| Value | Avg. Accuracy (%) | Std. Dev. |
|---|---|---|
| 0.3 | 98.75 | 0.42 |
| 0.5 (default) | 99.43 | 0.28 |
| 0.7 | 99.21 | 0.31 |
| 0.9 | 98.92 | 0.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, X.; Zhang, J.; Cao, J. A Bearing Fault Diagnosis Method Based on Dual-Stream Hybrid-Domain Adaptation. Sensors 2025, 25, 3686. https://doi.org/10.3390/s25123686
Jiao X, Zhang J, Cao J. A Bearing Fault Diagnosis Method Based on Dual-Stream Hybrid-Domain Adaptation. Sensors. 2025; 25(12):3686. https://doi.org/10.3390/s25123686
Chicago/Turabian StyleJiao, Xinze, Jianjie Zhang, and Jianhui Cao. 2025. "A Bearing Fault Diagnosis Method Based on Dual-Stream Hybrid-Domain Adaptation" Sensors 25, no. 12: 3686. https://doi.org/10.3390/s25123686
APA StyleJiao, X., Zhang, J., & Cao, J. (2025). A Bearing Fault Diagnosis Method Based on Dual-Stream Hybrid-Domain Adaptation. Sensors, 25(12), 3686. https://doi.org/10.3390/s25123686