1. Introduction
Precision air conditioning (PAC) systems are critical infrastructure for environmental control in environments where thermal stability and air quality are essential, such as data centers, biomedical laboratories, hospital facilities, and the telecommunications and electronics manufacturing industries [
1,
2]. Unlike conventional HVAC systems (heating, ventilation, and air conditioning), PACs are designed to operate continuously under demanding conditions, managing minimal thermal variations with high efficiency and reliability. This need for sustained and controlled operation introduces greater complexity in their structure, as they are composed of interdependent components such as scroll compressors, thermostatic expansion valves, condensers, and evaporators that are exposed to mechanical degradation processes, dirt accumulation, corrosion, and failures induced by refrigerant overcharge or undercharge [
3].
In this sense, the timely detection of faults in PAC systems is essential not only to ensure their correct operation, but also to avoid critical outages, increase their lifetime, and reduce energy consumption. However, traditional approaches to Fault Detection and Diagnosis (FDD)—based on manual inspections, corrective maintenance, or expert systems with fixed thresholds—have serious limitations with respect to efficiency, scalability, and adaptability, as described in [
4]. In addition, these methods are often dependent on the experience of the operator and cannot be learned or adapt to changing conditions. These limitations are exacerbated in industrial environments where systems must operate without interruption and under remote supervision.
In this context, data-driven FDD approaches have emerged as a promising alternative that allows the automation of the diagnostic process from sensor signals such as pressure, temperature, current, and voltage using Machine Learning (ML) techniques to identify anomalous patterns in real time [
5,
6]. ML-based methods have proven to be effective in HVAC systems, far outperforming physical-model-based approaches, which require detailed characterization of each system and are often inflexible in the face of structural or dynamic variability, as described in [
7,
8].
In the same sense, the authors in [
9] have shown that supervised models such as SVM, Random Forest (RF), Gradient Boosting (GB), and K-Nearest Neighbors (KNN) can achieve accuracies above 90% in the detection of faults in rooftop air conditioning units. However, the different studies have focused on specific or simulated configurations, leaving a gap in the practical implementation of embedded diagnostic systems with real-time inference and validation capabilities in real PAC units.
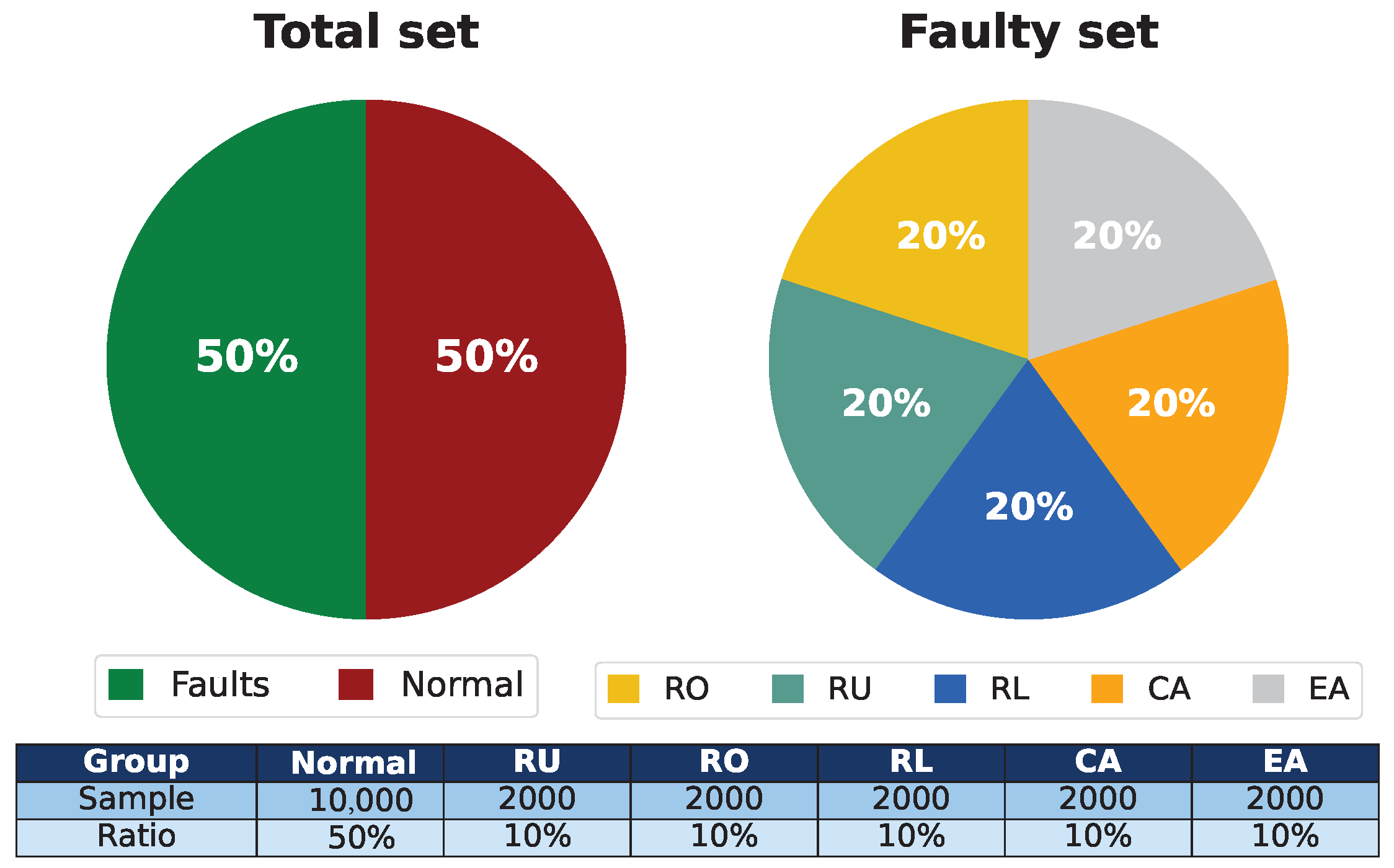
This work addresses the limitations described above by developing an automatic and embedded FDD system for PAC, leveraging a distributed acquisition and processing architecture using an Arduino and Raspberry Pi fed by real-time data from physical sensors and validated under real operating conditions. A classification methodology is proposed for five common fault types—Refrigerant Undercharge (RU), Refrigerant Overcharge (RO), Line Restriction (RL), Condenser Airflow Reduction (CA), and Evaporator Airflow Reduction (EA)—combining a robust preprocessing, including the use of RandomUnderSampler (RUS) with a comparative analysis of six classification algorithms: SVM, NB, DT, KNN, GB, and RF.
The central objective of this work is to identify the most effective ML model for accurate and efficient fault diagnosis in PAC systems, both in offline testing and online implementation, maximizing accuracy, sensitivity, and specificity while ensuring feasibility in embedded environments with limited computational resources.
This article presents the following contributions.
Develop a comprehensive database for training FDD models by capturing the behavioral patterns of five types of faults, RU, RO, RL, CA, and EA, based on critical state signals such as pressure, temperature, current, and voltage.
Evaluate and compare the performance of multiple ML classification models, including SVM, KNN, DT, GB, NB and RF, to determine the most effective algorithm for fault detection in PAC units.
Implement and validate the FDD system in real-time conditions, optimizing hyperparameters through GridSearchCV, identifying the most influential predictor variables (Tcomp, Icomp, Vcomp, Wcomp), and evaluating the viability of the system for the predictive maintenance of HVAC systems in real environments, focusing on operational efficiency, downtime reduction, and maintenance cost savings.
Compared to previous studies, this work presents three novel elements: (i) the implementation and validation of an FDD system under real-world conditions using an industrial PAC system (model SK3328.500), (ii) the use of a low-cost embedded architecture based on Arduino Nano and Raspberry Pi for real-time processing, and (iii) a comprehensive comparative approach using six ML classification models with the analysis of specific metrics such as accuracy, sensitivity, specificity, and false positive rate. This practical integration of sensing, local processing, and automated diagnosis, with validated results in real-world environments, represents a concrete contribution to the effective implementation of intelligent predictive maintenance systems in industrial HVAC systems.
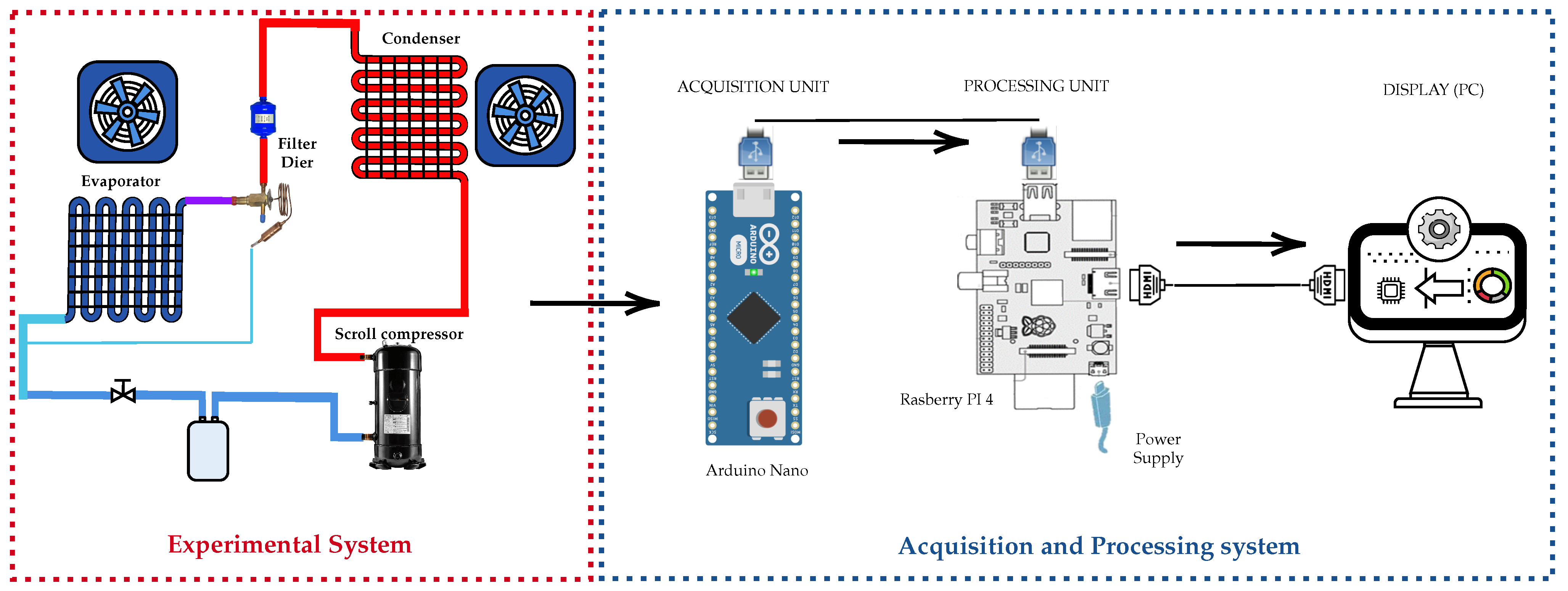
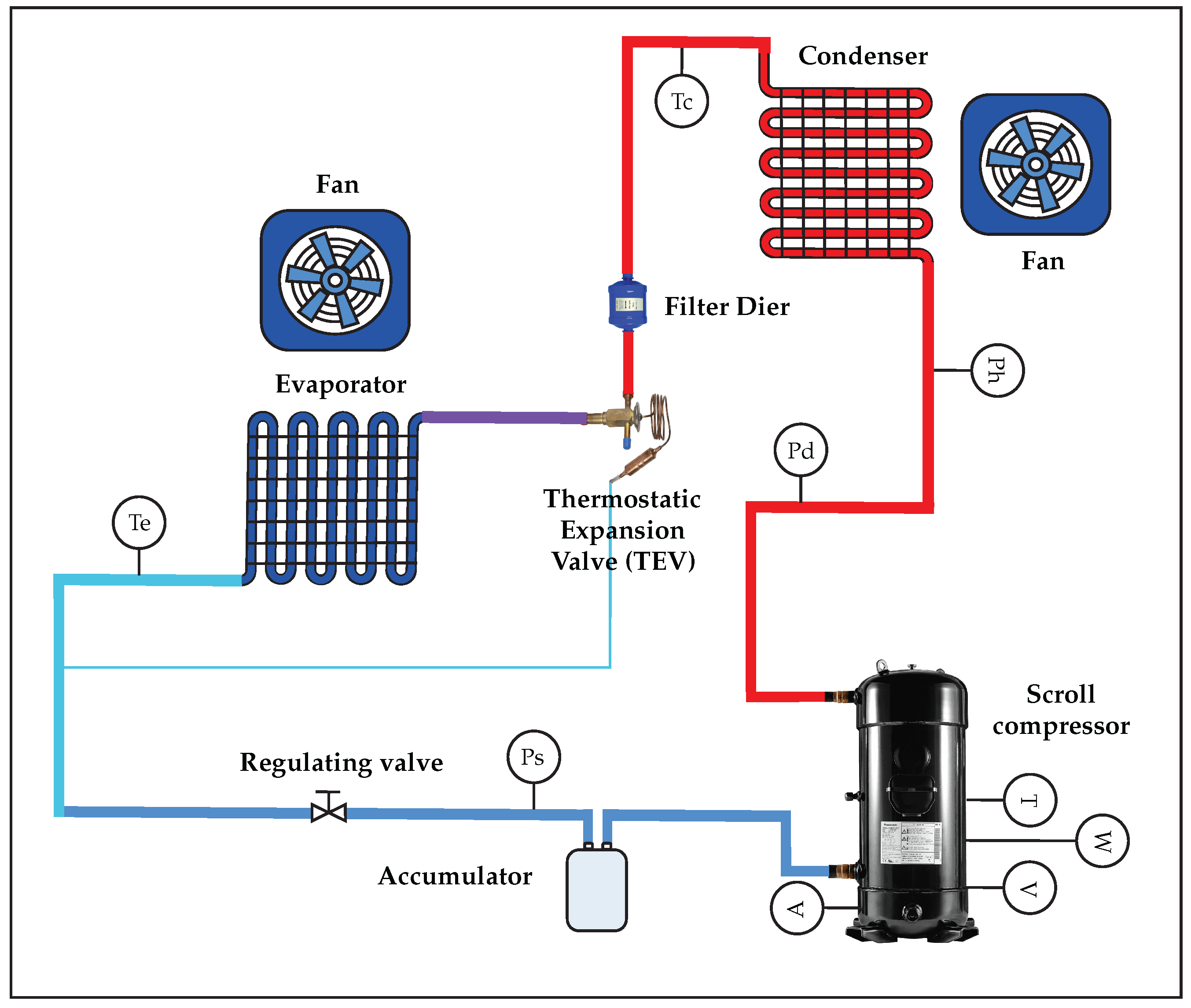
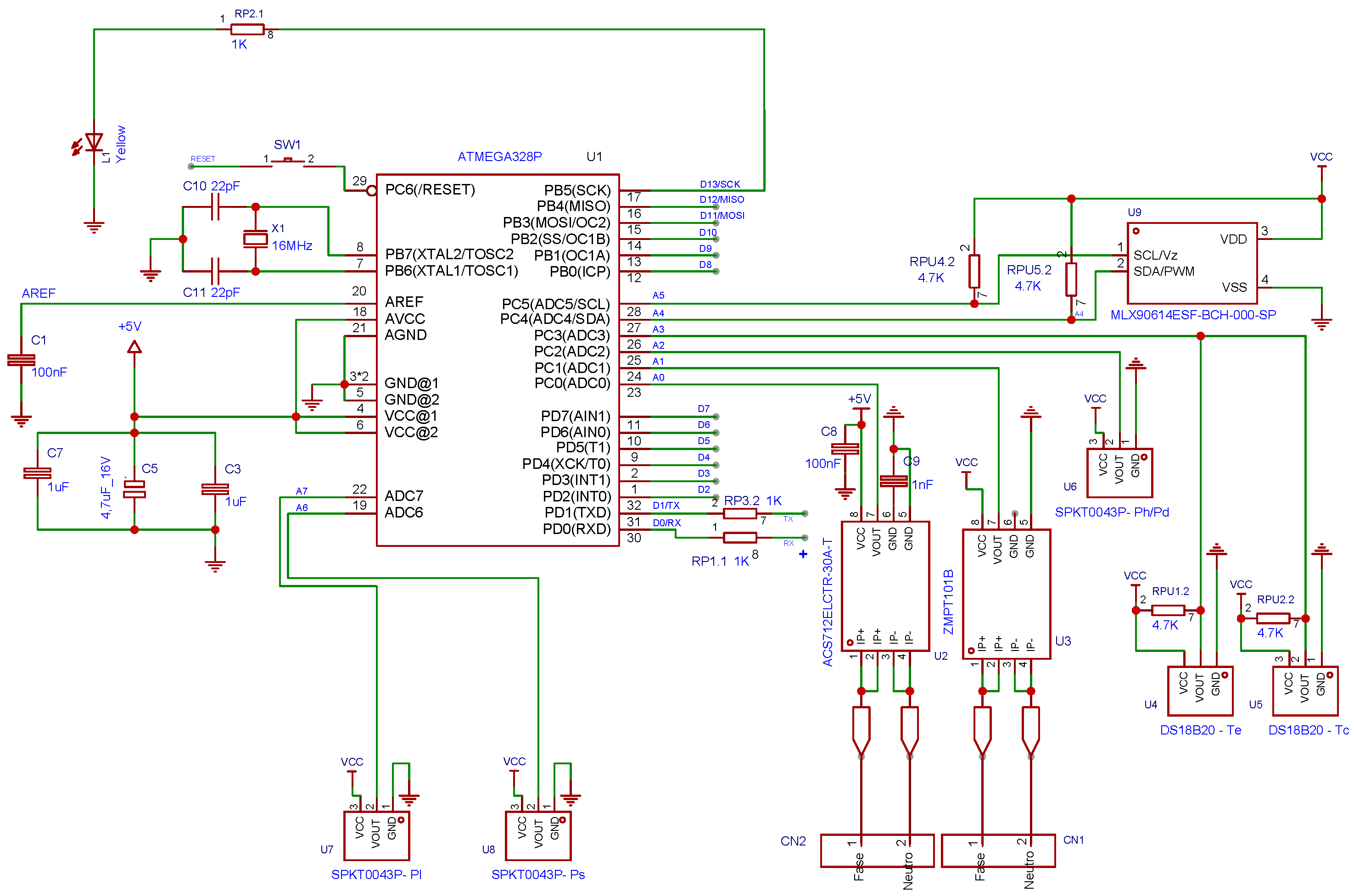
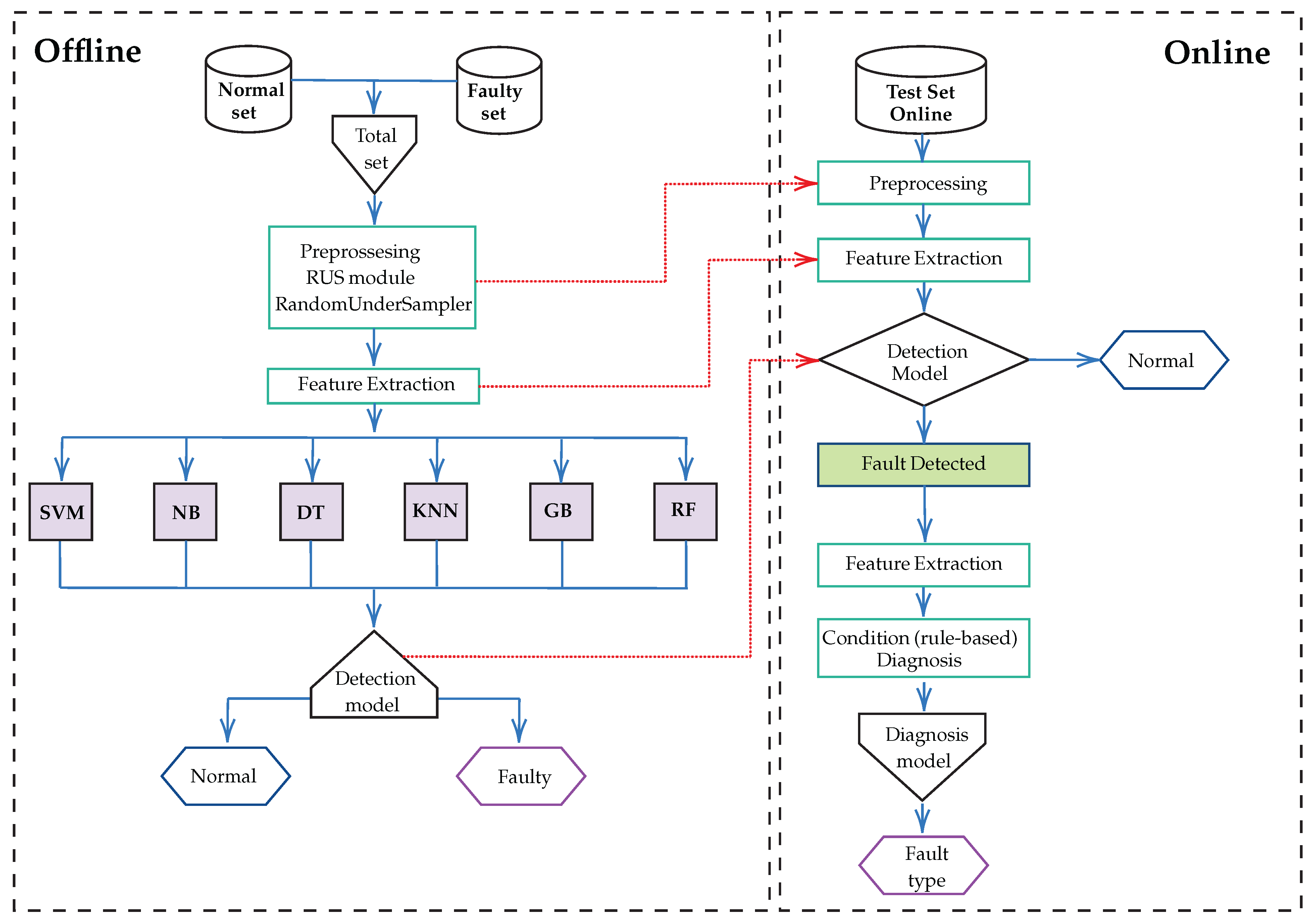
Finally, the proposed system adopts a methodology structured in five stages: (1) data acquisition using sensors installed in a real PAC unit; (2) preprocessing with cleaning and balancing techniques such as RandomUnderSampler; (3) feature extraction from pressure, temperature, current, and voltage signals; (4) the training of supervised models with libraries such as Scikit-learn; and (5) real-time validation on an embedded architecture composed of Arduino Nano and Raspberry Pi 4. The integration of specific sensors (ACS712, ZMPT101B, SPKT0043P, DS18B20, and MLX90614), together with a MySQL database and local processing, enables a robust, scalable, and reproducible solution for automated FDD in industrial HVAC systems.
Related Work
The current literature on FDD in HVAC systems revolves around four main approaches: (i) data-driven methods, (ii) classification algorithms using ML, (iii) data preprocessing and data balancing techniques, and (iv) hybrid strategies that integrate physical rules with ML in embedded implementations. In this section, we review these approaches, identifying the strengths and limitations of previous work and highlighting the gaps that the present study aims to address. In this sense, data-driven methods have proven to be an effective alternative to physical models, as they allow the analysis of large volumes of sensor data without the need to model the system’s behavior mathematically. For example, the authors in [
1] present a systematic review on the use of computational intelligence for FDD, highlighting how statistical approaches have given way to the use of big data and ML techniques. Furthermore, regarding practical applications, in [
4] the authors propose an FDD system for chillers using supervised learning, obtaining accuracies of over 95%. However, in [
4], the authors developed their method under laboratory conditions and do not consider aspects such as the unbalanced distribution of faults in real scenarios.
In the framework of the use of classification algorithms, different models, such as SVM, RF, and GB, have been compared; it has been concluded that RF achieves the best results in terms of accuracy and robustness. However, these studies usually omit alternative classifiers such as KNN or NB, as well as not including the importance analysis of predictor variables. Furthermore, the treatment of input data has been identified as a critical factor for the success of FDD. For example, the authors of [
6] employ virtual sensors to improve signal fidelity, although without comprehensively addressing the problem of class imbalance. In addition, some studies have implemented basic oversampling techniques to mitigate this effect, but without robust validation under real operating conditions [
10]. In contrast, the present study uses a controlled undersampling approach (RUS) to obtain a balanced dataset, thus ensuring a representative distribution of all types of failures.
Finally, in relation to hybrid systems and real-time applications, solutions combining physical rules with ML algorithms have been proposed, as in [
11], where a hybrid architecture based on RF and SVM is used. However, most of these works do not implement complete embedded solutions and do not offer real-time explainable diagnostics. On the other hand, ref. [
5] demonstrates that electrical signals such as current and voltage can be successfully employed for basic FDD in rooftop units but cannot be extended to more structurally complex PAC systems.
Considering what has been described in the previous paragraphs, the present work differentiates itself by integrating multiple classifiers, applying a detailed analysis of critical features, and developing a real-time embedded system that allows both the detection and automated diagnosis of faults in industrial HVAC systems to seeking to close some of the technical and methodological gaps present in the described state of the art.
The remainder of this article is structured as follows.
Section 2 presents and describes the system model and its structure, divided into two parts: an experimental system and an acquisition and processing system.
Section 3 describes the research methodology, which addresses data preparation and processing, supervised models, and proposed rules-based diagnosis.
Section 4 summarizes the main research results, comparing the performance of six ML models.
Section 5 presents a discussion of our results in comparison with the results of previous studies.
Section 6 describes the overall conclusions of the study. Finally,
Section 7 suggests future research avenues that are opened up by this study.
4. Results
This section presents the main results obtained from the models described in the previous sections. It summarizes the operation of the cooling system, the feature selection process used for the classification methods, the model evaluation results, the fault detection in offline mode, and the rule-based diagnosis in online mode.
In addition, the hardware, software, and tools used to design and implement the proposed system are detailed based on [
15]. The system uses a Raspberry Pi 4 Model B (Manufacturer: Raspberry Pi Foundation; Cambridge, UK), equipped with a Broadcom BCM2711 chipset and a quad-core ARM Cortex-A72 processor (Manufacturer: Broadcom Inc.; San Jose, CA, USA). Data acquisition is performed by an Arduino Nano (Manufacturer: Arduino AG; Boston, MA, USA), which features an ATmega328P microcontroller (Manufacturer: Microchip Technology Inc.; Chandler, AZ, USA), 2 KB of RAM, 32 KB of flash memory, and a 10-bit analog-to-digital converter (ADC). The instrumentation system consists mainly of five types of sensors selected for their accuracy, compatibility, and relevance to HVAC applications. The ACS712-30A Hall-effect sensor measures compressor current, offering electrical isolation and a range of ±30 A with analog output. The ZMPT101B module measures AC voltage by electromagnetic induction, providing a stable sinusoidal analog output and high accuracy in voltage detection. Two types of temperature sensors were implemented: the MLX90614, an infrared sensor capable of non-contact surface temperature measurement, and the DS18B20, a single-wire digital sensor for internal air temperature readings with a 0.5 °C resolution. The piezoresistive sensor SPKT0043P, capable of reading up to 500 psi with high stability, was implemented for pressure measurement. The system was programmed and executed with Python 3.11.9, Scikit-learn for ML implementations, and MySQL for structured data storage. Circuit simulation and PCB design were performed with EasyEDA, and signal analysis was performed with the support of Wolfram Mathematica 12.3.
4.1. Dataset and Parameter
The analysis of the causes, characteristics, and consequences of each failure is performed to explain the dataset of the cooling system, i.e., the interaction of the parameters.
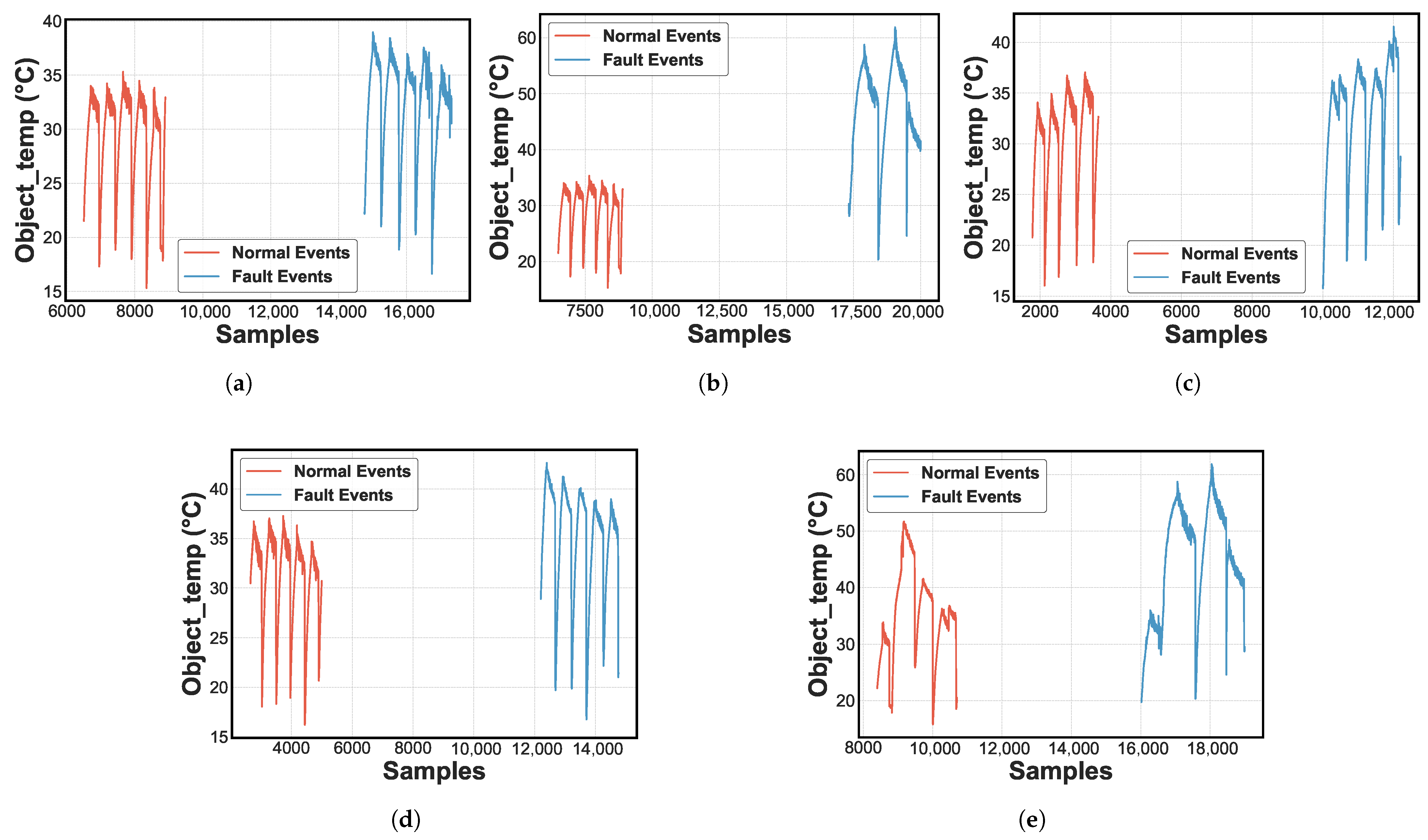
Figure 7 shows the evolution of the characteristics of the five types of faults evaluated [
3,
25]. Specifically,
Figure 7a shows an RO failure.
Figure 7b shows an RU failure.
Figure 7c shows a liquid LR failure.
Figure 7d shows a CA failure.
Figure 7e shows an EA failure [
11]. The blue line represents normal operation, and the orange represents failure events. Specifically, the compressor temperature (°C) is selected as the main variable due to its ability to differentiate between normal and fault conditions. Also, a differentiated increase in the temperature level related to each failure pattern is observed.
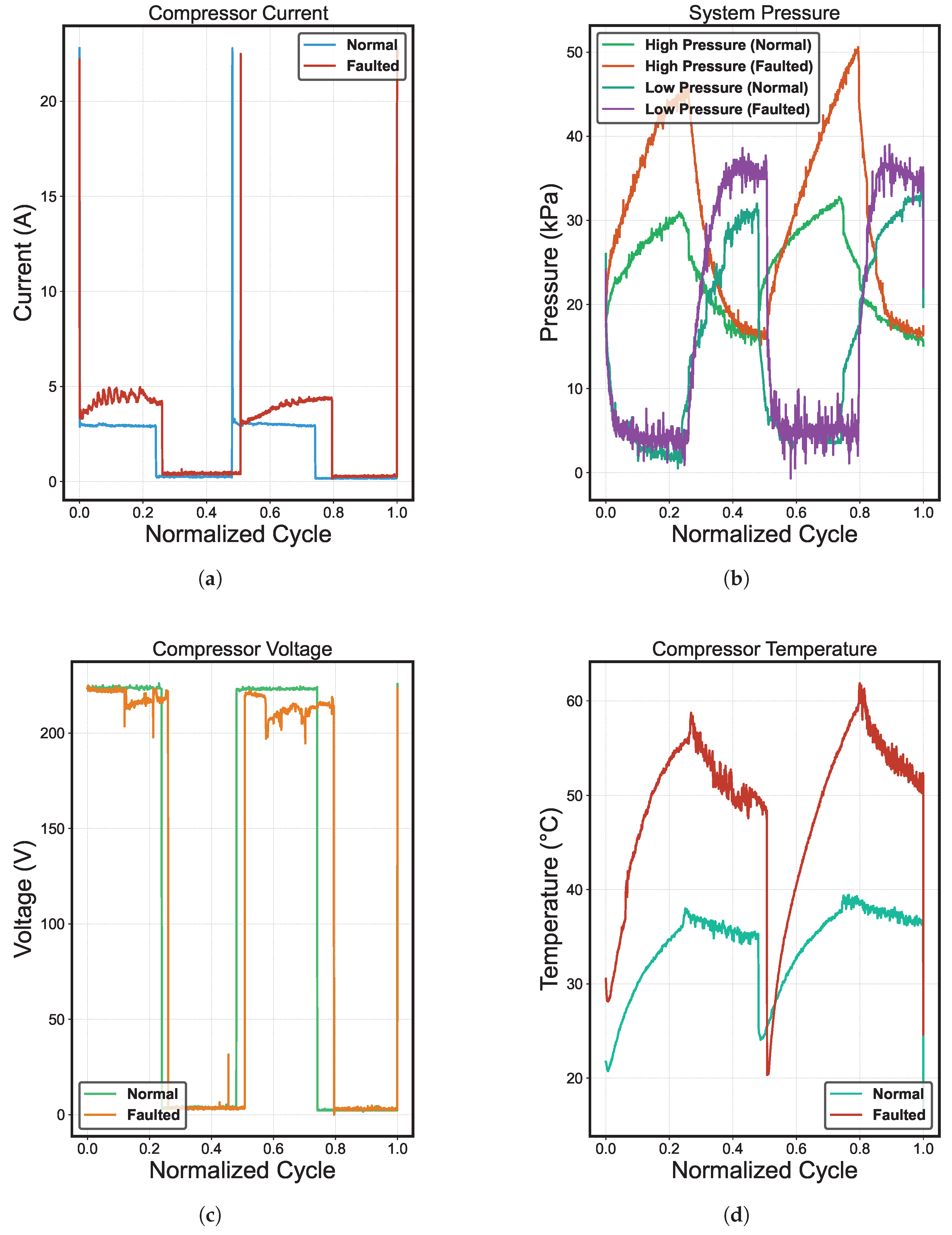
Figure 8 shows the current, voltage, temperature, and pressure behavior as a function of the normalized cycles [
25]. We can observe two complete cycles of operation of the compressor system in each result. The first was in normal conditions, and the other failed due to refrigerant undercharge. Also, the results show distinct patterns that are characteristic of critical failure. The refrigerant undercharge causes high voltage levels while the current remains unusually low, indicating that the compressor operates without adequate load. In addition, the temperature experiences a sustained rise, which is evidence of circuit overheating due to insufficient refrigerant to dissipate the generated heat. Although the pressure appears normal in terms of absolute values, its dynamic behavior deviates from the standard pattern.
4.2. Feature Selection
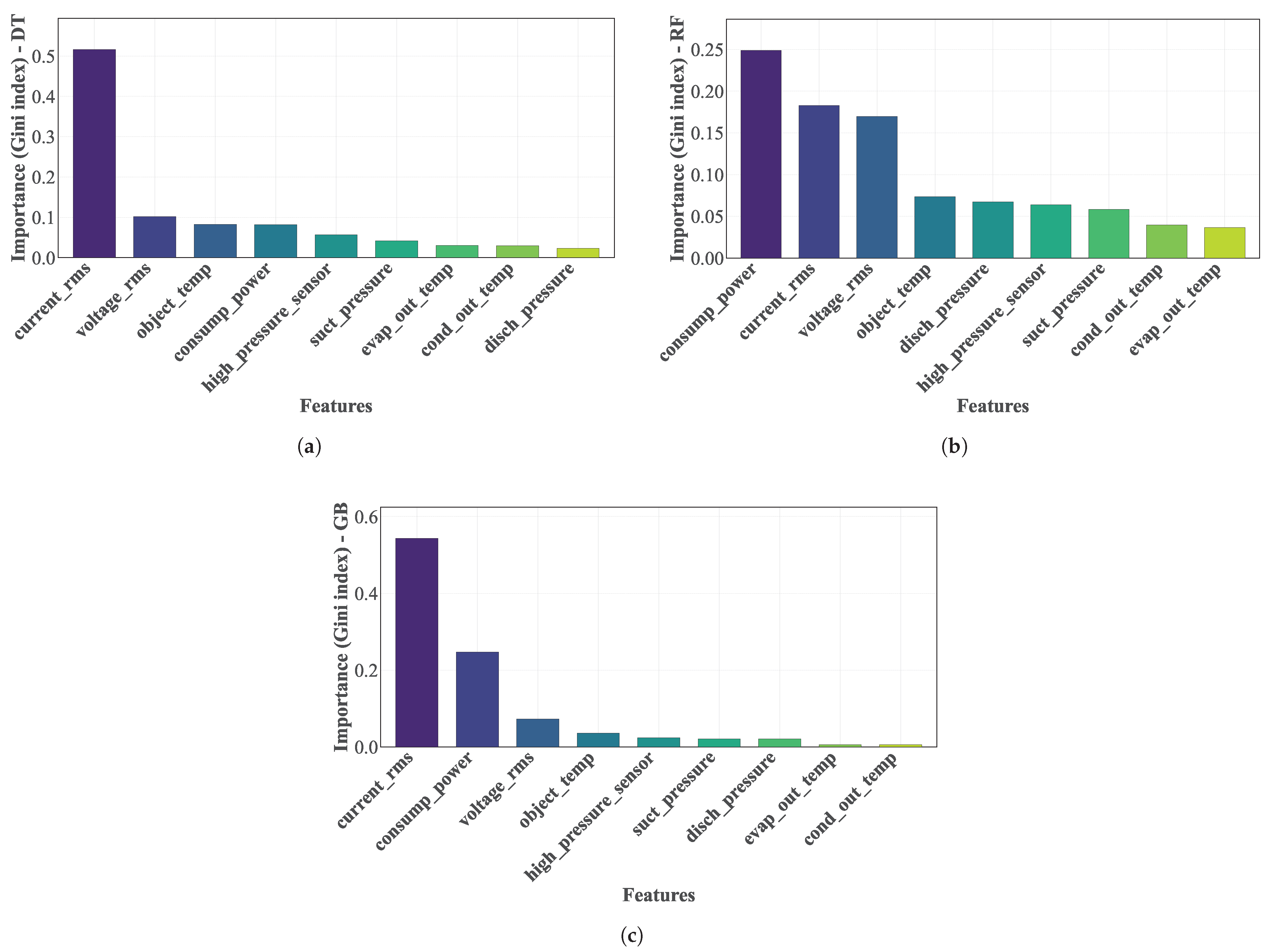
Figure 9 shows the importance of the variables in the classification task [
11].
Figure 9a shows the importance of the variables according to the DT,
Figure 9b shows the importance of variables according to the RF, and
Figure 9c shows the importance of variables according to GB. The importance (reduction in the Gini index [
23]) calculated from the split on a given predictor variable, averaged over all trees, shows that a high value in the index indicates an important predictor variable. So, for the classification methods DT, RF, and GB [
10], the variables Tcomp, Icomp, Vcomp, and Wcomp [
11,
14] are the most important predictors in the FDD process. However, there is no clear decrease in the importance of differentiating essential from non-essential predictors.
4.3. Evaluation of Models
The models were evaluated through a dataset that was systematically divided into three subsets [
25]—training (50%), validation (44%), and testing (6%)—ensuring a robust evaluation of the performance of each model. In addition, calculation of the accuracy (Equation (
22)), precision (Equation (
23)), sensitivity (Equation (
24)), and specificity (Equation (
25)) of the model results based on [
33] was necessary to complete the analysis of these models.
Equations (
22)–(
25) provide the comprehensive evaluation of the performance of the classification models [
11], where TP represents true positives, TN true negatives, FP false positives, and FN false negatives. In addition, the construction of Receiver Operating Characteristic (ROC) curves [
4] is performed to better understand the classification models’ performance.
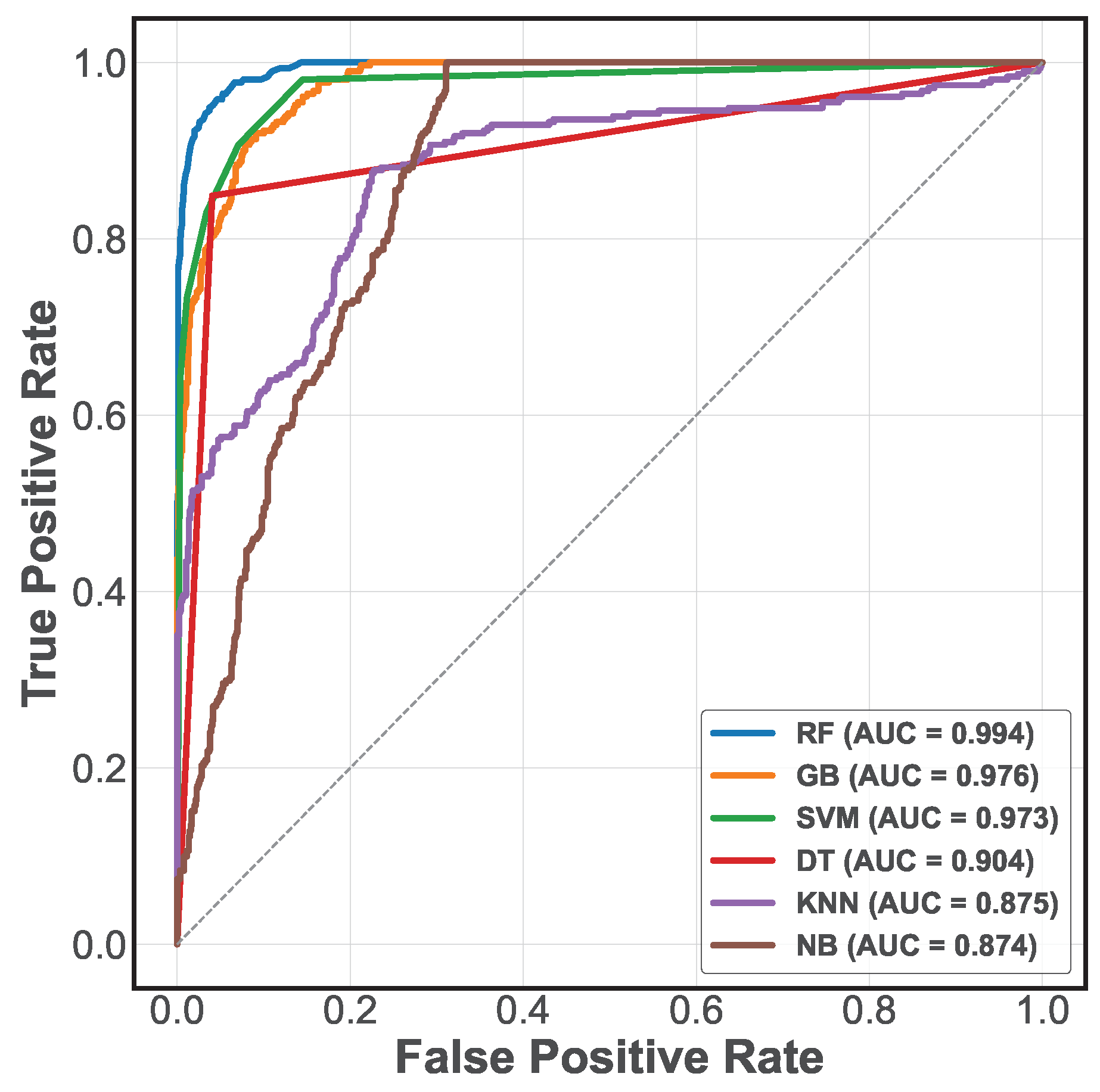
Figure 10 presents the ROC curves of the six models evaluated, showing their discriminative ability at different decision thresholds. These curves represent the trade-off between sensitivity (true positive rate) and specificity (false positive rate), giving a detailed insight into the behavior of each model under different classification conditions. In addition, the area under the ROC curve (AUC-ROC) quantifies the overall discriminative ability of the models, where a value closer to 1 indicates superior classification performance.
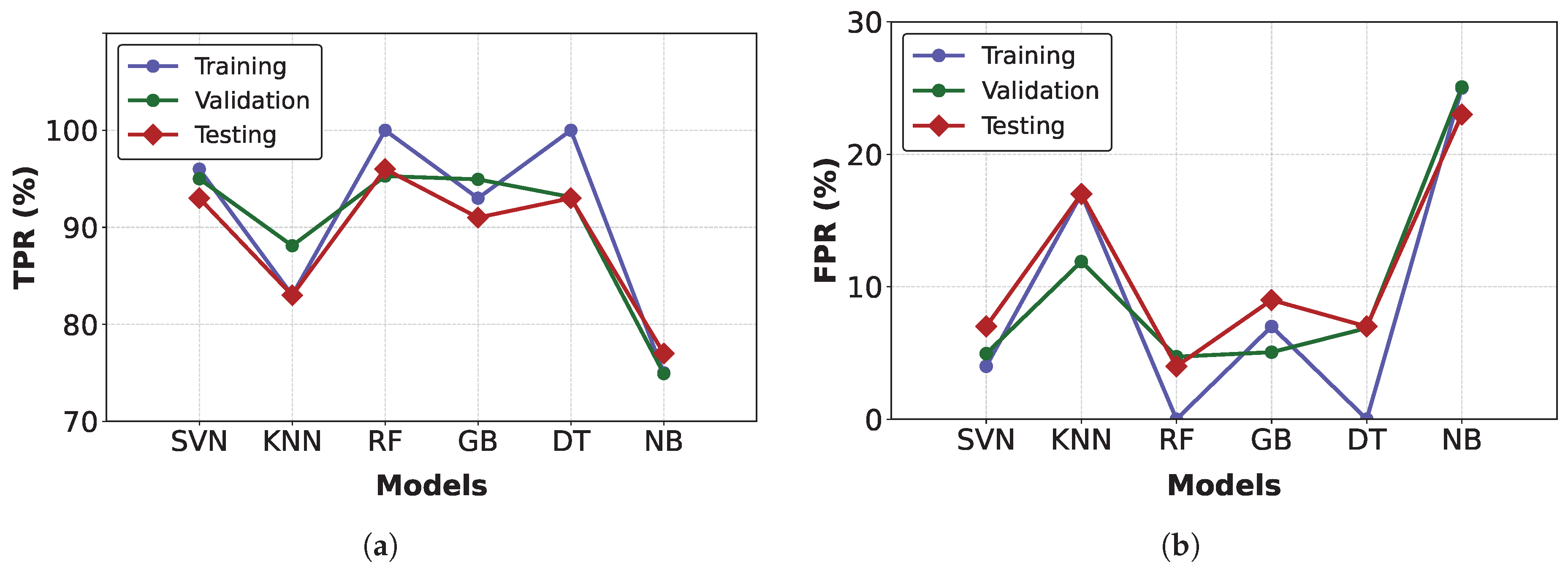
On the other hand,
Figure 11 presents the TPR and FPR values [
4] at different threshold points for the three subsets evaluated. These results demonstrate robust and reliable fault detection in PAC systems.
4.4. Fault Detection Result in Offline Mode
To validate the importance of preprocessing, the performance of the models evaluated with and without the application of the RUS module was compared.
Table 6 shows the results. An improvement in accuracy and sensitivity is observed when balancing is applied, confirming the positive impact of preprocessing.
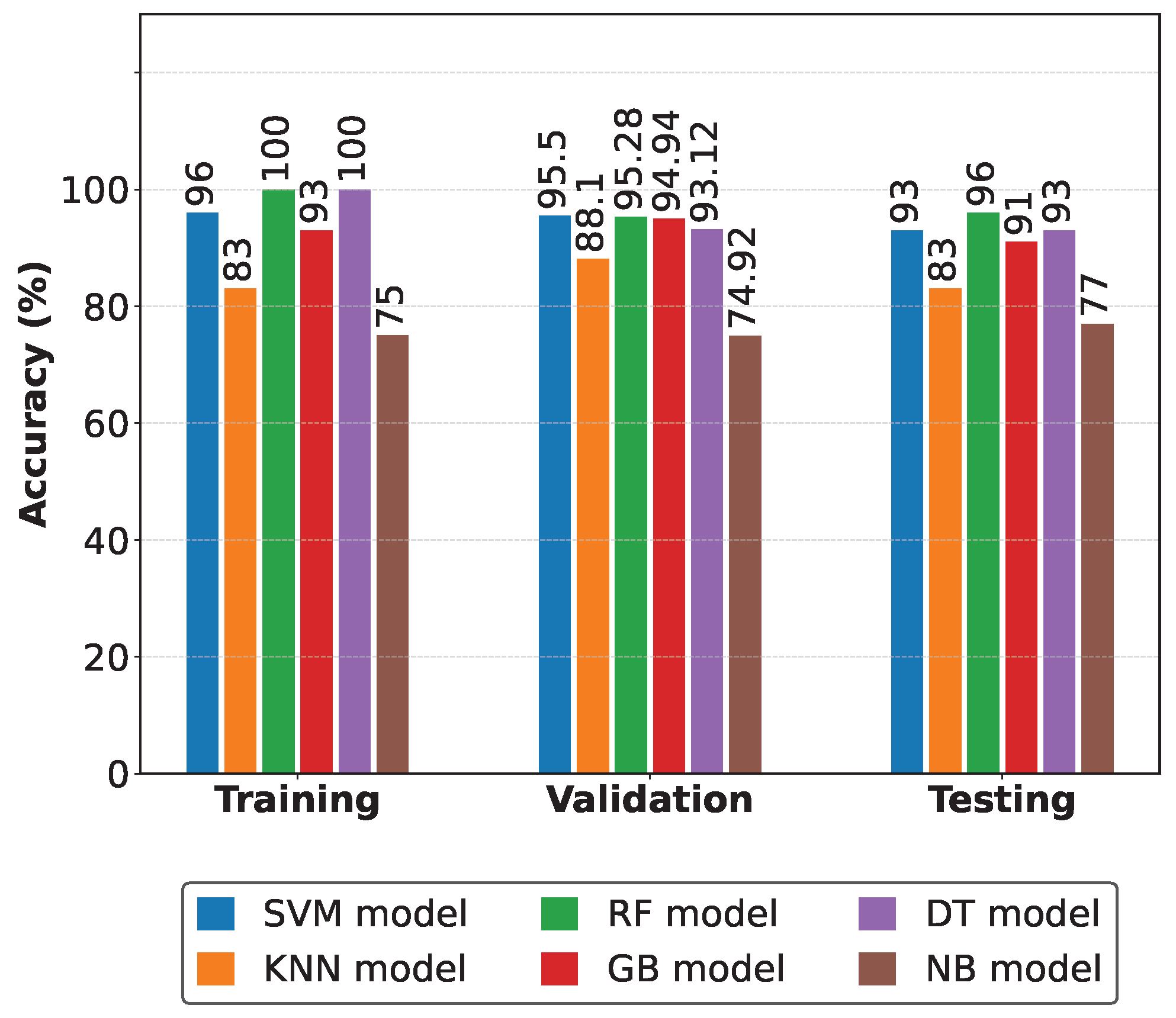
Figure 12 compares the evaluation metrics of the detection models [
33]. In this comparison, the consistent superiority of the Random Forest classifier in all evaluation phases is highlighted. Furthermore, this comparative analysis evaluates the effectiveness of the proposed FDD system. The model selection with the best conditions (metrics) for fault detection is based on tables and graphs [
3]. So, to obtain our results, we applied each classification method to our generated database. This dataset was divided into three subsets—training, validation, and testing—which allowed a thorough evaluation of the performance of each model at different stages. The main metric used for comparison was accuracy, as this directly measures the model’s ability to correctly classify both normal and faulty conditions. Furthermore, in previous studies on fault detection in cooling units, researchers have used accuracy as a key indicator due to its interpretability and relevance in classification tasks. For another data configuration (preprocessed), other levels of accuracy were observed. When the amount of data increases, the accuracy levels vary, but in the order of 0.125 or a maximum of 2 to 3%.
Table 7 summarizes the hyperparameter optimization process [
14] for each model. The optimal values of these parameters were determined using cross-validation (CV) techniques [
4]. The selected hyperparameters for each classification method were tuned to maximize model performance. This systematic optimization process was implemented using Scikit-learn’s GridSearchCV functionality, which improved the evaluation metrics, namely the accuracy during the offline validation phase. The most suitable configurations for each model were determined through iterative training and validation of the models on different subsets of the dataset. This approach not only improved the accuracy levels of the models but also prepared them for reliable implementation in the real-time fault detection system.
The variables shown in the hyperparameter column in
Table 7 are described in
Section 3.2. Specifically, Equations (
1)–(
21) describe how these variables interact.
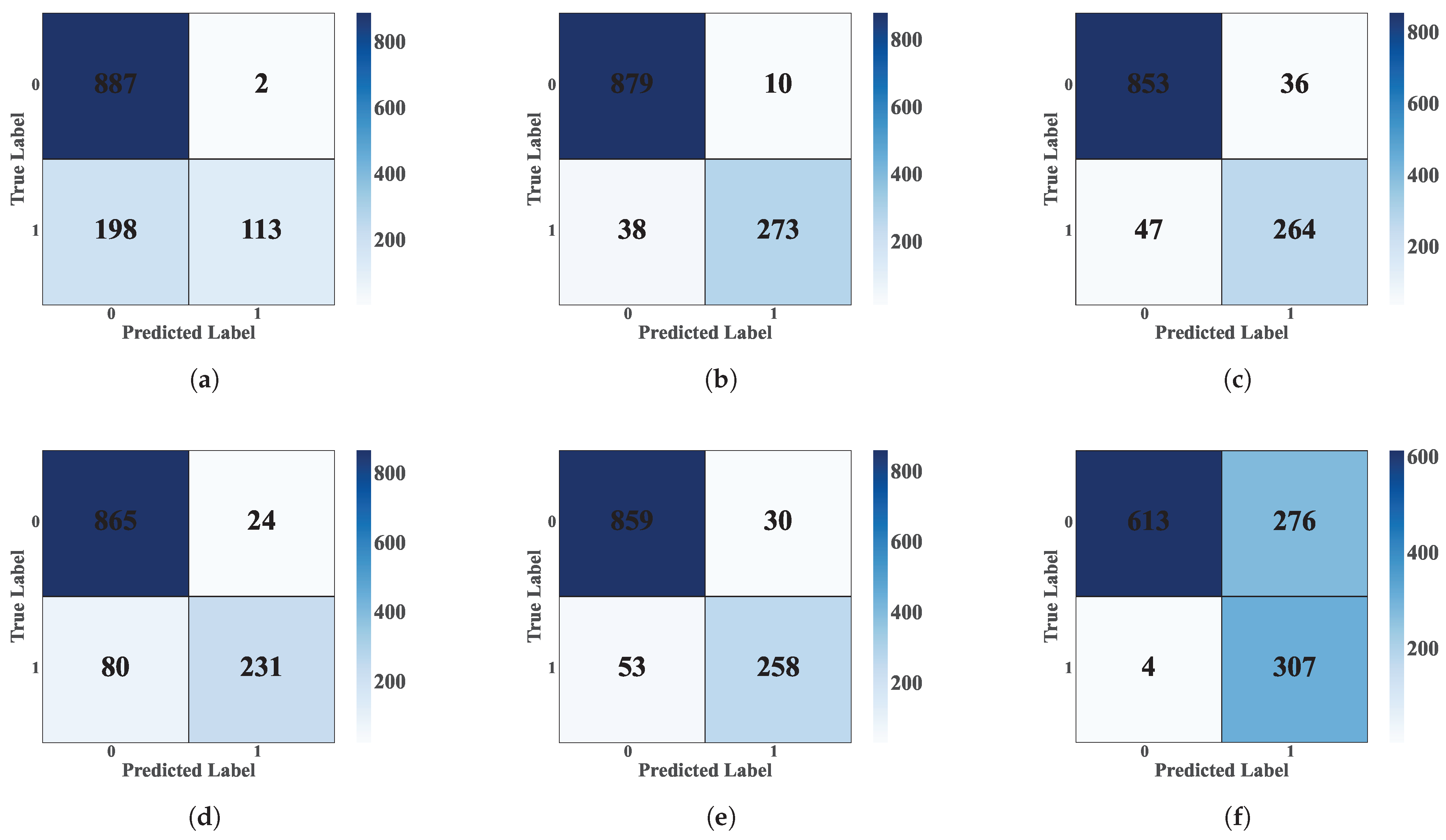
Figure 13 shows the confusion matrices for each classification model [
19]. These matrices, generated from the database’s test subset, allow the models’ performance in fault detection [
23] to be evaluated in offline mode [
10]. Each matrix cell represents the number of predictions for a given class, where the main diagonal indicates correct classifications and off-diagonal cells represent incorrect classifications [
19].
Table 8 summarizes the comparative analysis of the evaluation metrics [
33]. This analysis allowed the selection of the ML model with the best performance in fault event detection [
4]. The models were evaluated against key metrics such as accuracy, precision, specificity, false positive rate (FPR), and true positive rate (TPR). The RF model demonstrated the best performance, achieving an accuracy of 95.75%, the highest among all classifiers evaluated. In addition, this model exhibited an excellent balance between accuracy (95.74%) and sensitivity (98.65%), with a relatively low FPR of 12.54%. On the other hand, the SVM model performed with an accuracy of 93.08%, closely followed by the DT model with 93.83%. Although the GB model achieved an accuracy of 91.33%, its performance was lower than that of the other models. On the other hand, the KNN and NB algorithms presented limitations, with accuracies of 83.33% and 76.67%, respectively. We can note that the NB model showed the highest overall classification accuracy (99.35%) but the lowest sensitivity (68.96%), indicating its tendency to minimize false positives at the cost of omitting real detections. This comprehensive evaluation confirms that the RF model provides the best balance between the various performance metrics for fault detection in PAC systems.
4.5. FDD Result Online Mode
In
Figure 7, unique patterns of signal variation were observed for each type of fault [
3]. High voltage levels, low current, normal pressure, and elevated temperature are observed for refrigerant undercharge, indicating poor compression and circuit overheating. In RO faults, voltage levels are normal. However, current, pressure, and temperature are high and there is a risk of freezing and prolonged cycling. So, in liquid line restrictions, the variables are normal except for high temperature, which shows similar behavior. On the other hand, in failures due to reduced airflow in the condenser or evaporator, combinations of high or low voltage with irregular current and high temperatures were detected, showing overheating and altered cooling times.
Table 9 shows the classification rules derived from the analysis based on what was described in
Section 4.2. We can observe the identification of the four key variables most relevant in the FDD process: Tcomp, Icomp, Vcomp, and Wcomp [
14,
34]. The rules indicate that Tcomp plays a crucial role in differentiating between the different failure modes, with further refinement provided by Icomp, Vcomp, and Wcomp. Furthermore, the most influential variable does not always correspond to the first division in decision making, as the latter is determined by information gain rather than absolute importance. Therefore, this classification framework ensures reliable real-time fault detection based on sensor data.
The results obtained from tests in both delayed (database) and real-time conditions validated the effectiveness of early fault detection. The RF model stood out for its superior performance, achieving 96% accuracy in the delayed condition and 95.28% in the real-time test. The accuracy of 95.31% indicates that, when predicting a positive class, the model has a high probability of being correct, thus reducing false positives. Sensitivity, with a value of 81.87%, quantifies the model’s ability to detect real failures, minimizing false negatives. Specificity, which reached 98.9%, indicates correctly identifying fault-free instances and avoiding false positives, as shown in
Table 10. Finally, the analysis is observed in the real-time validation test (P-V), simulating the system’s real behavior together with a constant heat injector element (heater).
4.6. Final Prototype
The final prototype developed and implemented for the study is shown in
Figure 14.
5. Discussion
The results obtained align with previous research on data-driven FDD methodologies for cooling systems. Ebrahimifakhar et al. [
10] demonstrated the effectiveness of ML classification models for FDD in rooftop units by evaluating multiple algorithms from SVM, RF, and GB models to diagnose faults such as compressor valve leakage (VL), RU, RO, RL, CA, EA, and the presence of noncondensable (NC) gases. Their study highlighted the high classification accuracy of SVM (96.2%). In comparison, models such as Linear Discriminant Analysis performed worse (76.2%), indicating that the choice of ML model significantly influences the reliability of fault detection. Our research similarly implemented a multi-class classification approach, training six ML models, SVM, RF, GB, GB, DT, KNN, and NB, using key operational variables (pressure, temperature, current, and voltage). Consistent with previous work, the RF model outperformed the other classifier models, achieving 96% accuracy, while the NB model exhibited the worst performance (77%). These results reinforce the effectiveness of ensemble-based methods for handling non-linear relationships and complex failure patterns in refrigeration units. In addition, data preprocessing was key in improving model performance. On the other hand, in [
3], the authors have emphasized that outlier removal and transient behavior analysis are essential to improve accuracy in FDD, an approach we incorporated using RUS to balance the dataset.
Our results agree with the results obtained in [
5], which explored non-intrusive load monitoring (NILM) for fault detection in HVAC systems using electrical measurements (voltage and current). While NILM provides a complementary approach to sensor-based FDD, our results suggest that direct sensor measurements allow for higher classification accuracy due to their ability to capture real-time fluctuations in system behavior. The integration of real-time data processing and ML models offers a robust and scalable solution for fault diagnosis in PAC systems, addressing a key gap in the existing methodologies. Also,
Table 11 shows a concrete comparison between the previously mentioned research results and our results. This comparison is based on five aspects: the faults evaluated, the methods used, the variables considered in the research, the data source, and the experimental validation. We can observe that for the experimental validation in [
10], the results do not have real tests, while in [
2] the authors do not have results in a real system. Likewise, in [
5], the experimental validation of the results was via analysis methods without HVAC intervention, and in [
3], the results do not have controlled experimental validation. In comparison, our results had full experimental validation, i.e., in a real system and full experimental validation.
Finally, the superior performance of the RF model can be attributed to its ability to handle non-linear relationships, its tolerance to overfitting, and its robustness to noise in the data. Its assembly mechanism, which is achieved through bagging and random feature selection, allows it to capture complex patterns. In contrast, models such as KNN or NB are sensitive to scaling and variable redundancy, negatively affecting their performance. In environments with high-class separation, models such as SVM could provide similar or even better results. However, RF demonstrated better stability and accuracy in real-world conditions with non-linear and noisy data. Therefore, the performance of models is a function of the type and amount of data. We also sought to improve the performance through a preprocessing step.
6. Conclusions
This study developed an automatic real-time FDD system that classifies events as faulty or normal by analyzing status signals. The analyzed models are based on data and ML, where a specific strategy is proposed for five types of system faults. Firstly, a comprehensive database was developed to train FDD models under specific fault conditions, allowing the analysis of critical status signals such as pressure, temperature, current, and voltage. Secondly, a real-time FDD system that leverages ML algorithms to detect and diagnose faults with high accuracy and reliability was implemented. Through a comparative evaluation of six ML classification models (SVM, KNN, DT, GB, NB, and RF), the RF model was found to be the most effective, achieving 96% accuracy in offline evaluation. This model demonstrated superior performance in handling non-linear relationships and complex fault patterns. In addition, real-time validation of the RF model on the SK3328.500 system achieved an accuracy of 95.28%. An additional validation test under real-world conditions for the PAC system confirmed an accuracy of 93.49%, with the optimal hyperparameters set to max_depth = 25 and n_estimators = 150. We conclude that the most influential predictor variables in fault classification were Tcomp, Icomp, Vcomp, and Wcomp, with decision rules that allowed the accurate differentiation of fault types. Despite some false positives and negatives, the system effectively detected and classified key fault scenarios, including RU, RO, RL, CA, and EA.
Finally, the use of paired t-tests and Wilcoxon tests confirmed that the Random Forest model consistently outperformed all other classifiers, with p-values less than 0.05. This constitutes statistical evidence of the robustness and accuracy of the proposed failure detection system.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}