

Small Object Tracking in LiDAR Point Clouds: Learning the Target-Awareness Prototype and Fine-Grained Search Region


Abstract
1. Introduction
- We delineate the concept of small object tracking within LiDAR point cloud environments and scrutinize the unique challenges that small objects introduce to 3D single object tracking. To effectively track small objects, our model addresses the sparse distribution of foreground points and the feature degradation resulting from convolutional operations.
- We introduce two innovative modules: the target-awareness prototype mining (TAPM) module and the regional grid subdivision (RGS) module. The TAPM module adeptly enhances the density of foreground points without compromising information integrity, while the RGS module mitigates feature erosion without imposing additional computational demands.
- We devise a scaling experiment to evaluate and compare the robustness of diverse tracking methods when confronted with small objects. Our approach has yielded remarkable outcomes in standard as well as scaled experimental conditions.
2. Related Work
2.1. 3D Single Object Tracking
2.2. Small Objects Researches
3. Methodology
3.1. Problem Definition
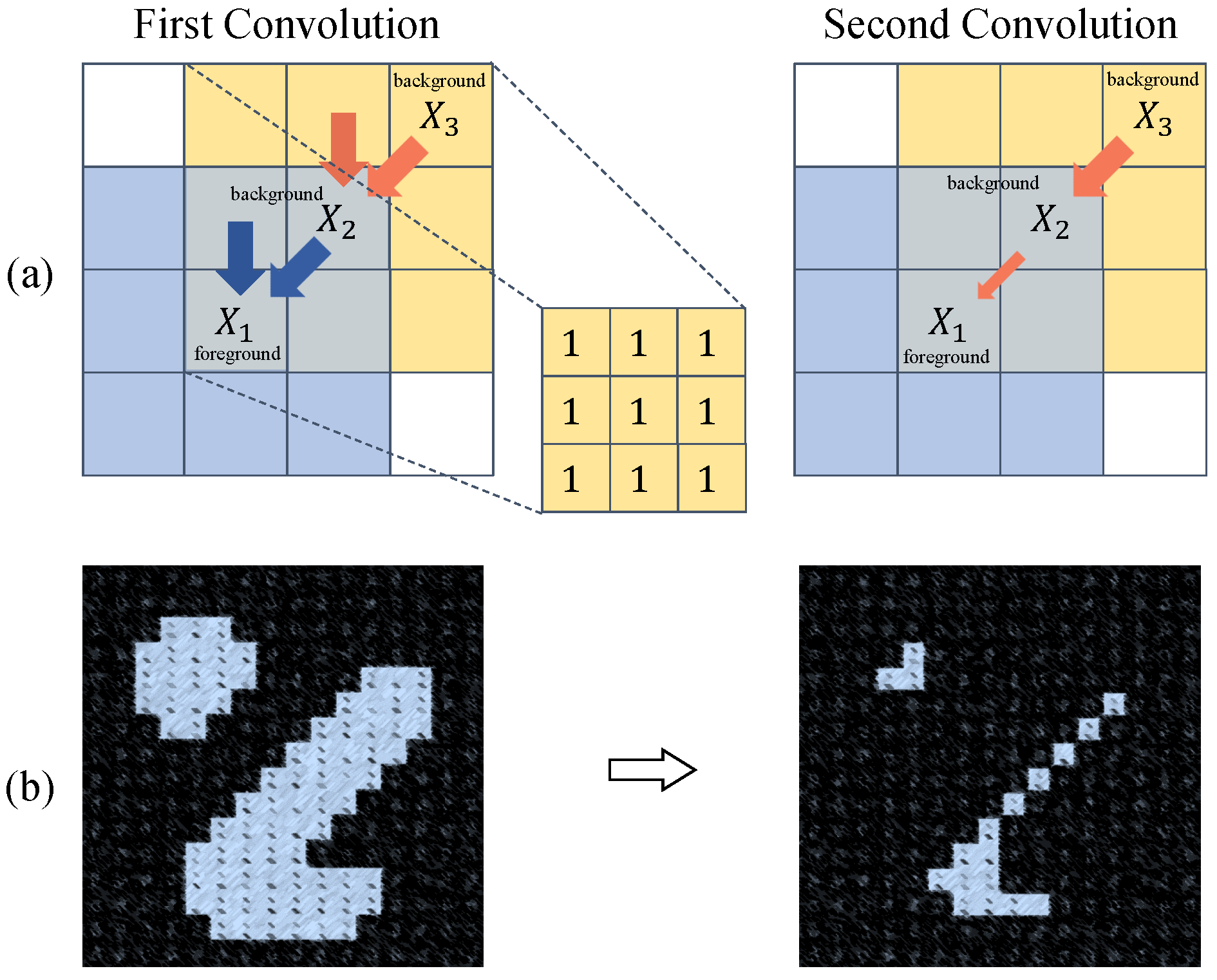
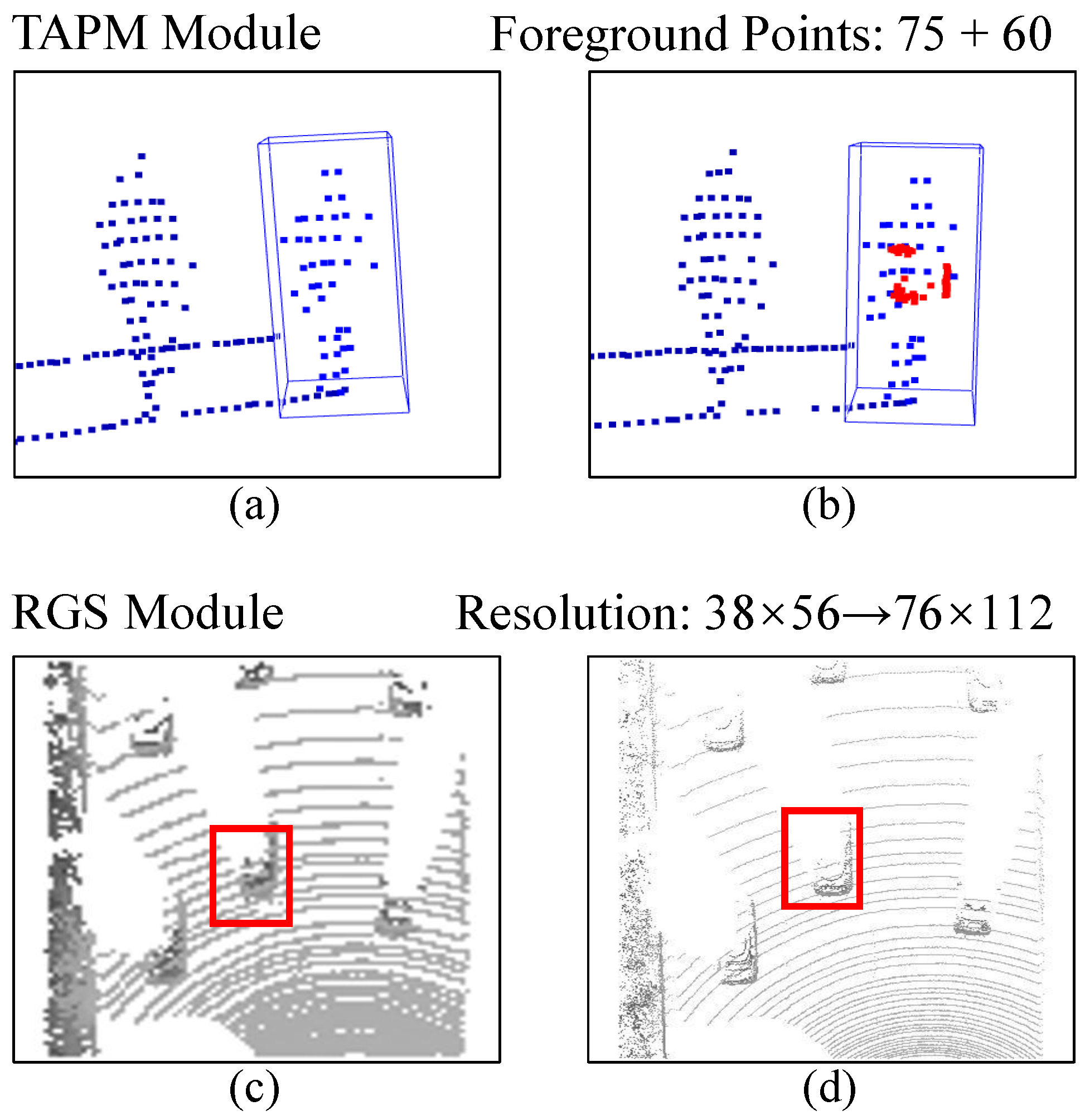
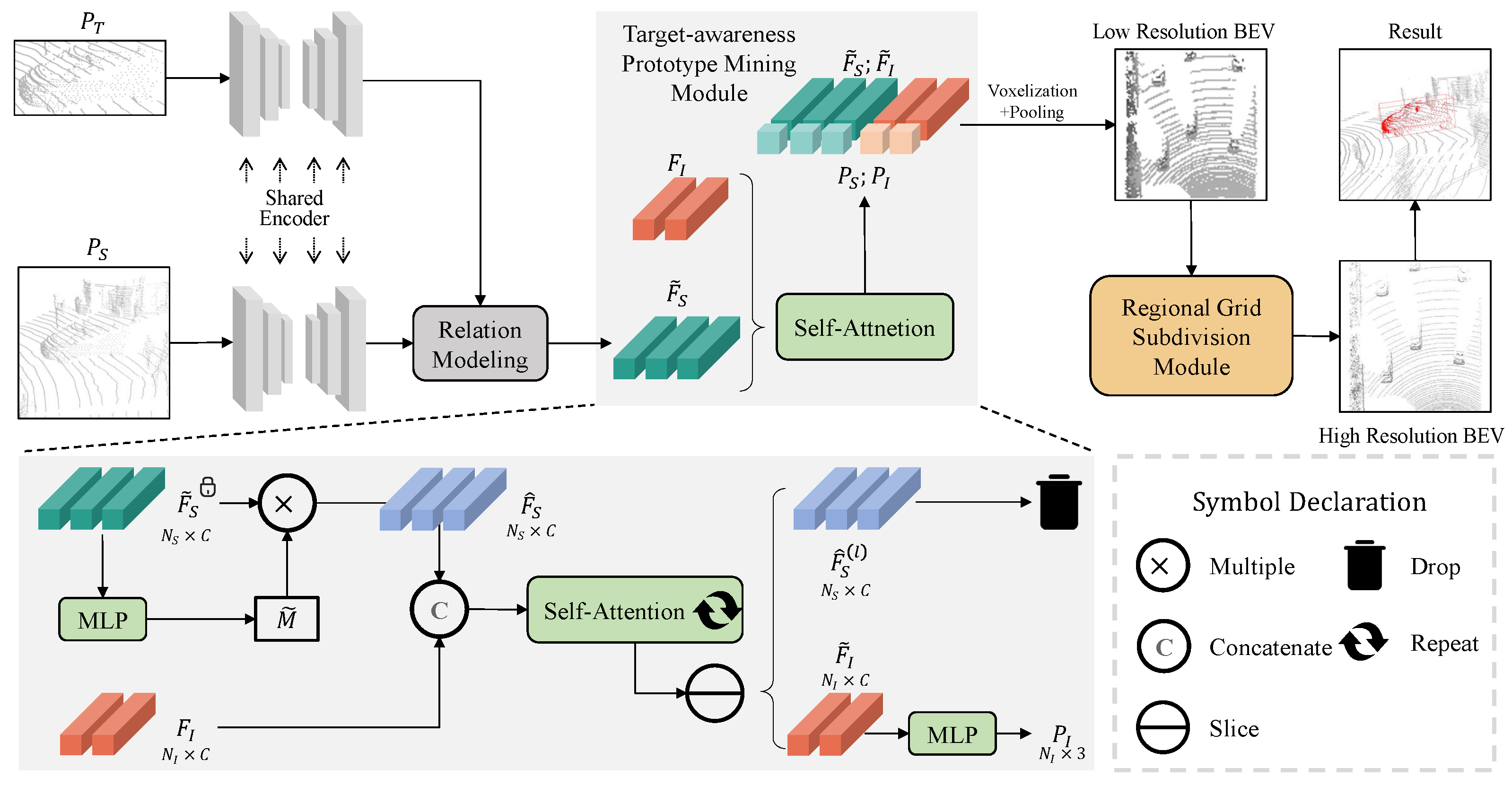
3.2. Target-Awareness Prototype Mining
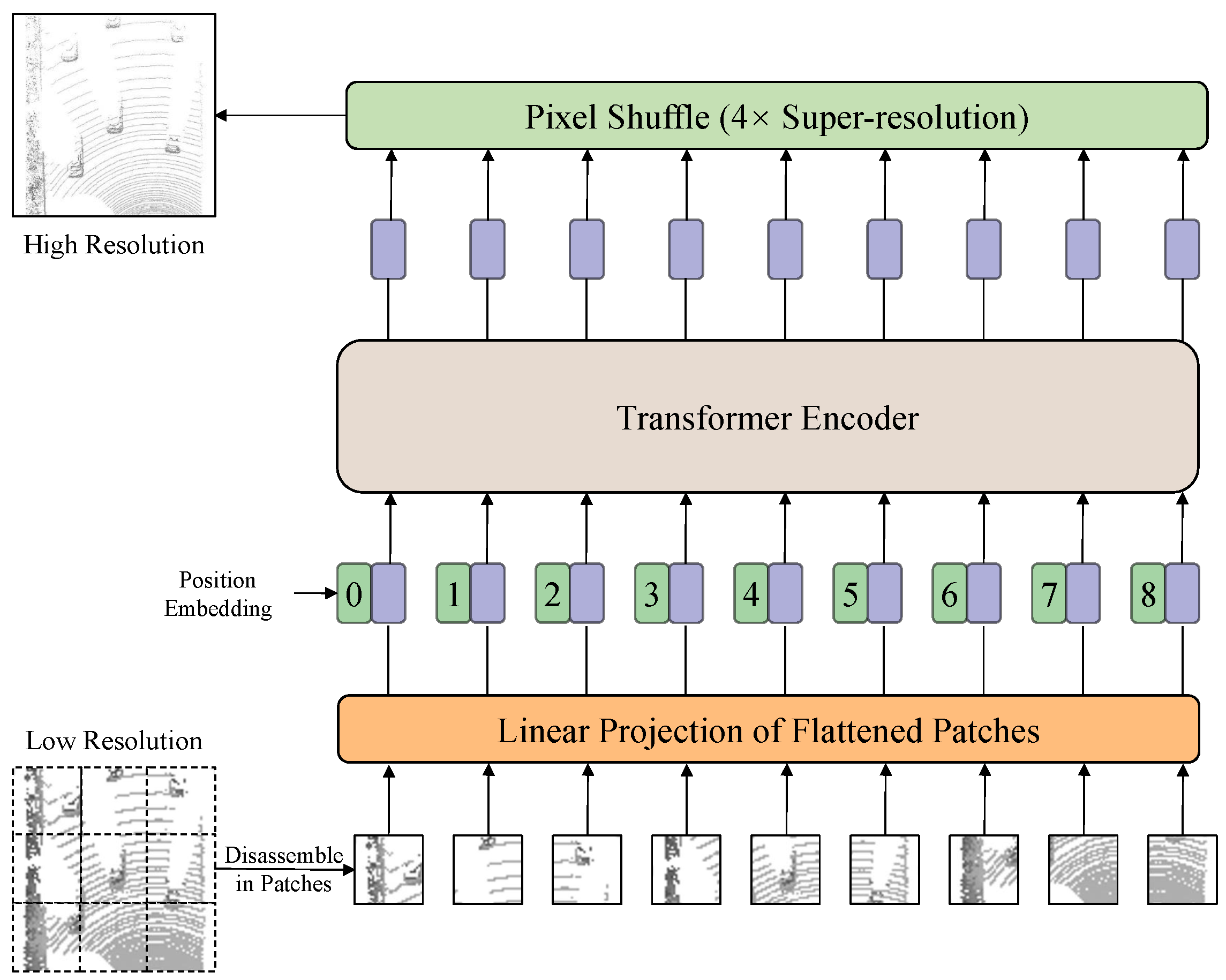
3.3. Regional Grid Subdivision
3.4. Loss Functions
4. Experiments
4.1. Experimental Settings
4.2. Results
4.3. Ablation Studies
5. Limitations
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Giancola, S.; Zarzar, J.; Ghanem, B. Leveraging Shape Completion for 3D Siamese Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1359–1368. [Google Scholar]
- Lukezic, A.; Matas, J.; Kristan, M. A Discriminative Single-Shot Segmentation Network for Visual Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 9742–9755. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Song, Y.; Song, C.; Tian, H.; Zhang, S.; Sun, J. CVTrack: Combined Convolutional Neural Network and Vision Transformer Fusion Model for Visual Tracking. Sensors 2024, 24, 274. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Jiang, C.; Wu, G.; Wang, L. MixFormer: End-to-End Tracking with Iterative Mixed Attention. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4129–4146. [Google Scholar] [CrossRef] [PubMed]
- Lin, L.; Fan, H.; Zhang, Z.; Wang, Y.; Xu, Y.; Ling, H. Tracking Meets LoRA: Faster Training, Larger Model, Stronger Performance. In Proceedings of the Computer Vision–ECCV 2024, Milan, Italy, 29 September–4 October 2024; pp. 300–318. [Google Scholar]
- Tian, S.; Liu, X.; Liu, M.; Bian, Y.; Gao, J.; Yin, B. Learning the Incremental Warp for 3D Vehicle Tracking in LiDAR Point Clouds. Remote Sens. 2021, 13, 2770. [Google Scholar] [CrossRef]
- Qi, H.; Feng, C.; CAO, Z.; Zhao, F.; Xiao, Y. P2B: Point-to-Box Network for 3D Object Tracking in Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 6328–6337. [Google Scholar]
- Hui, L.; Wang, L.; Cheng, M.; Xie, J.; Yang, J. 3D Siamese Voxel-to-BEV Tracker for Sparse Point Clouds. In Proceedings of the Neural Information Processing Systems, Virtual, 6–14 December 2021; pp. 28714–28727. [Google Scholar]
- Hui, L.; Wang, L.; Tang, L.Y.; Lan, K.; Xie, J.; Yang, J. 3D Siamese Transformer Network for Single Object Tracking on Point Clouds. In Proceedings of the European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 25–27 October 2022; pp. 293–310. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Chen, C.; Liu, M.Y.; Tuzel, O.; Xiao, J. R-CNN for Small Object Detection. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 214–230. [Google Scholar]
- Ngo, T.D.; Hua, B.S.; Nguyen, K. ISBNet: A 3D Point Cloud Instance Segmentation Network with Instance-aware Sampling and Box-aware Dynamic Convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 13550–13559. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation with Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Qi, C.; Litany, O.; He, K.; Guibas, L.J. Deep Hough Voting for 3D Object Detection in Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9276–9285. [Google Scholar]
- Wang, Z.; Xie, Q.; Lai, Y.; Wu, J.; Long, K.; Wang, J. MLVSNet: Multi-level Voting Siamese Network for 3D Visual Tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3081–3090. [Google Scholar]
- Zheng, C.; Yan, X.; Gao, J.; Zhao, W.; Zhang, W.; Li, Z.; Cui, S. Box-Aware Feature Enhancement for Single Object Tracking on Point Clouds. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 13179–13188. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Cui, Y.; Fang, Z.; Shan, J.; Gu, Z.; Zhou, S. 3D Object Tracking with Transformer. In Proceedings of the British Machine Vision Conference, Virtual, 22–25 November 2021; p. 317. [Google Scholar]
- Shan, J.; Zhou, S.; Fang, Z.; Cui, Y. PTT: Point-Track-Transformer Module for 3D Single Object Tracking in Point Clouds. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 1310–1316. [Google Scholar]
- Zhou, C.; Luo, Z.; Luo, Y.; Liu, T.; Pan, L.; Cai, Z.; Zhao, H.; Lu, S. PTTR: Relational 3D Point Cloud Object Tracking with Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8521–8530. [Google Scholar]
- Wang, K.; Fan, B.; Zhang, K.; Zhou, W. Accurate 3D Single Object Tracker in Point Clouds with Transformer. In Proceedings of the China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 6415–6420. [Google Scholar]
- Zheng, C.; Yan, X.; Zhang, H.; Wang, B.; Cheng, S.H.; Cui, S.; Li, Z. Beyond 3D Siamese Tracking: A Motion-Centric Paradigm for 3D Single Object Tracking in Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 8101–8110. [Google Scholar]
- Xu, T.; Guo, Y.; Lai, Y.; Zhang, S. CXTrack: Improving 3D Point Cloud Tracking with Contextual Information. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 1084–1093. [Google Scholar]
- Xu, T.X.; Guo, Y.C.; Lai, Y.K.; Zhang, S.H. MBPTrack: Improving 3D Point Cloud Tracking with Memory Networks and Box Priors. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023; pp. 9911–9920. [Google Scholar]
- Wu, Q.; Xia, Y.; Wan, J.; Chan, A.B. Boosting 3D Single Object Tracking with 2D Matching Distillation and 3D Pre-training. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 270–288. [Google Scholar]
- Cheng, G.; Yuan, X.; Yao, X.; Yan, K.; Zeng, Q.; Han, J. Towards Large-Scale Small Object Detection: Survey and Benchmarks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 13467–13488. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Li, C.; Liu, Y.; Wang, X.; Tang, J.; Luo, B.; Huang, Z. Tiny Object Tracking: A Large-Scale Dataset and a Baseline. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 10273–10287. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.B.; He, K.; Hariharan, B.; Belongie, S.J. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12592–12601. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6053–6062. [Google Scholar]
- Bell, S.; Zitnick, C.L.; Bala, K.; Girshick, R.B. Inside-Outside Net: Detecting Objects in Context with Skip Pooling and Recurrent Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2874–2883. [Google Scholar]
- Tang, X.; Du, D.K.; He, Z.; Liu, J. PyramidBox: A Context-assisted Single Shot Face Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 812–828. [Google Scholar]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation Networks for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3588–3597. [Google Scholar]
- Chen, Y.; Zhang, P.; Li, Z.; Li, Y.; Zhang, X.; Meng, G.; Xiang, S.; Sun, J.; Jia, J. Stitcher: Feedback-driven Data Provider for Object Detection. arXiv 2020, arXiv:2004.12432. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. SOD-MTGAN: Small Object Detection via Multi-Task Generative Adversarial Network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 210–226. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual Generative Adversarial Networks for Small Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1951–1959. [Google Scholar]
- Noh, J.; Bae, W.; Lee, W.; Seo, J.; Kim, G. Better to Follow, Follow to Be Better: Towards Precise Supervision of Feature Super-Resolution for Small Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9724–9733. [Google Scholar]
- Zhang, S.; Zhu, X.; Lei, Z.; Shi, H.; Wang, X.; Li, S. S3FD: Single Shot Scale-Invariant Face Detector. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 192–201. [Google Scholar]
- Liu, G.; Han, J.; Rong, W. Feedback-driven loss function for small object detection. Image Vis. Comput. 2021, 111, 104197. [Google Scholar] [CrossRef]
- Liu, C.; Ding, W.; Yang, J.; Murino, V.; Zhang, B.; Han, J.; Guo, G. Aggregation Signature for Small Object Tracking. IEEE Trans. Image Process. 2019, 29, 1738–1747. [Google Scholar] [CrossRef] [PubMed]
- Xue, Y.; Jin, G.; Shen, T.; Tan, L.; Wang, N.; Gao, J.; Wang, L. SmallTrack: Wavelet Pooling and Graph Enhanced Classification for UAV Small Object Tracking. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5618815. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual, 3–7 May 2021. [Google Scholar]
- Kristan, M.; Matas, J.; Leonardis, A.; Vojír, T.; Pflugfelder, R.P.; Fernandez, G.J.; Nebehay, G.; Porikli, F.M.; Cehovin, L. A Novel Performance Evaluation Methodology for Single-Target Trackers. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 2137–2155. [Google Scholar] [CrossRef] [PubMed]
- Fang, Z.; Zhou, S.; Cui, Y.; Scherer, S.A. 3D-SiamRPN: An End-to-End Learning Method for Real-Time 3D Single Object Tracking Using Raw Point Cloud. IEEE Sens. J. 2021, 21, 4995–5011. [Google Scholar] [CrossRef]
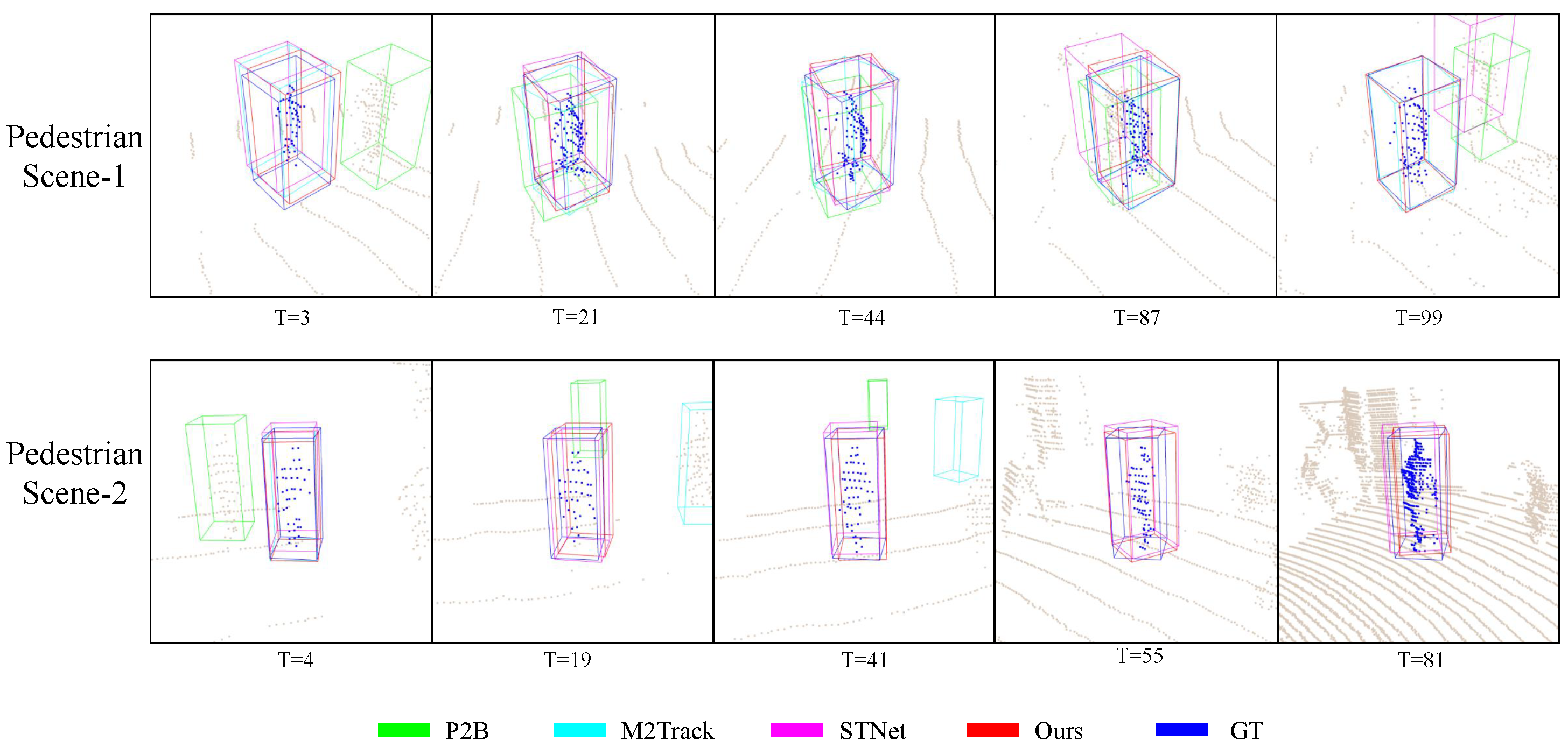
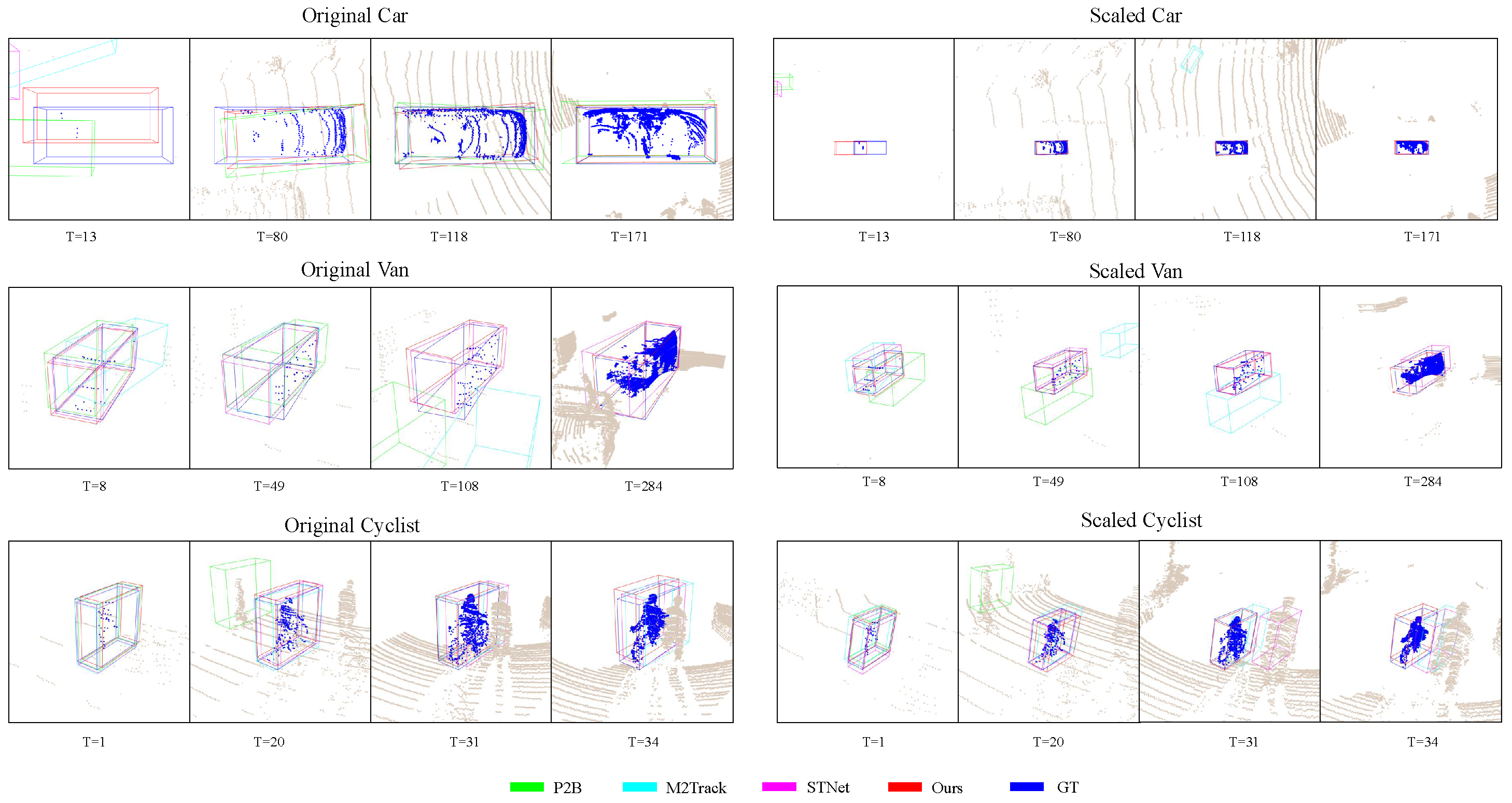

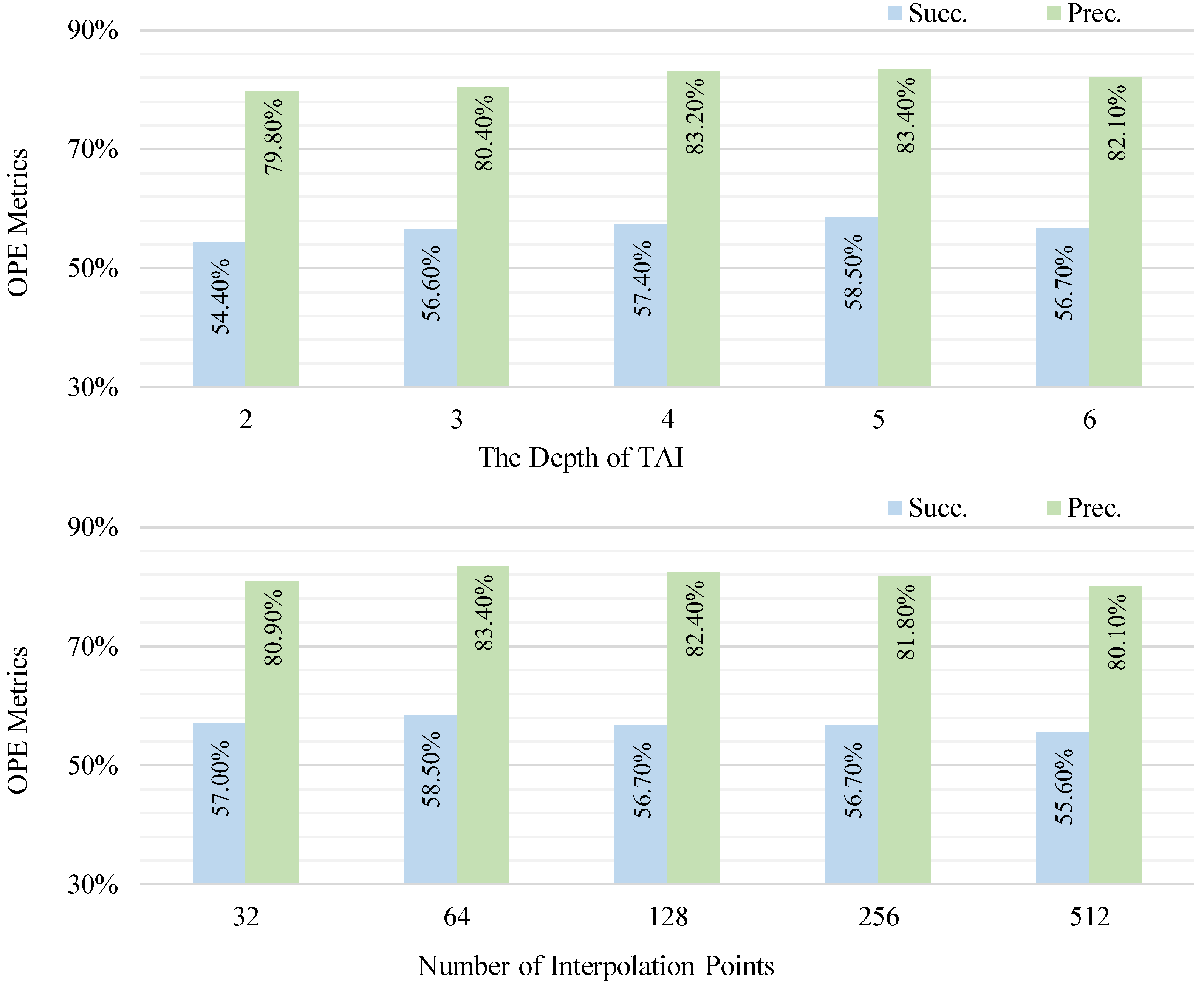

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Pedestrian | Car | Van | Cyclist | Mean | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| ORIG | ORIG | SC | ORIG | SC | ORIG | SC | ORIG | SC | GAP | |
| Success Metric | ||||||||||
| P2B | 28.7 | 56.2 | 15.4 | 40.8 | 12.2 | 32.1 | 34.9 | 42.4 | 21.3 | −21.1 |
| BAT | 42.1 | 60.5 | 16.2 | 52.4 | 10.2 | 33.7 | 17.9 | 51.2 | 26.9 | −24.3 |
| M2Track | 61.5 | 65.5 | 22.4 | 53.8 | 8.6 | 73.2 | 69.7 | 62.9 | 38.9 | −20.5 |
| STNet | 49.9 | 72.1 | 60.5 | 58.0 | 48.1 | 73.5 | 69.4 | 61.3 | 55.0 | −6.3 |
| Ours | 58.5 | 71.5 | 63.5 | 60.3 | 51.1 | 73.0 | 73.8 | 64.9 | 60.4 | −4.5 |
| Improvement | ↑8.6 | ↓0.6 | ↑3.0 | ↑2.3 | ↑3.0 | ↓0.5 | ↑4.3 | ↑3.6 | ↑5.4 | ↑1.8 |
| Precision Metric | ||||||||||
| P2B | 49.6 | 72.8 | 13.3 | 48.4 | 4.7 | 44.7 | 53.5 | 60.0 | 29.1 | −30.9 |
| BAT | 70.1 | 77.7 | 20.9 | 67.0 | 9.0 | 45.4 | 29.7 | 72.8 | 41.3 | −31.5 |
| M2Track | 88.2 | 80.8 | 28.0 | 70.7 | 5.9 | 93.5 | 87.8 | 83.4 | 53.4 | −30.7 |
| STNet | 77.2 | 84.0 | 82.2 | 70.6 | 77.8 | 93.7 | 96.5 | 80.1 | 79.9 | −0.2 |
| Ours | 83.4 | 84.0 | 84.6 | 74.9 | 83.4 | 93.9 | 97.1 | 83.0 | 84.2 | 1.2 |
| Improvement | ↑6.2 | −0.0 | ↑2.4 | ↑4.3 | ↑5.6 | ↑0.2 | ↑0.6 | ↑2.9 | ↑4.3 | ↑1.4 |
| Methods | Car (6424) | Pedestrian (6088) | Van (1248) | Cyclist (308) | Mean |
|---|---|---|---|---|---|
| Success Metric (%) | |||||
| SC3D | 41.3 | 18.2 | 40.4 | 41.5 | 31.2 |
| P2B | 56.2 | 28.7 | 40.8 | 32.1 | 42.4 |
| 3DSiamRPN | 58.2 | 35.2 | 45.7 | 36.2 | 46.7 |
| LTTR | 65.0 | 33.2 | 35.8 | 66.2 | 48.7 |
| MLVSNet | 56.0 | 34.1 | 52.0 | 34.3 | 45.7 |
| BAT | 60.5 | 42.1 | 52.4 | 33.7 | 51.2 |
| PTT | 67.8 | 44.9 | 43.6 | 37.2 | 55.1 |
| V2B | 70.5 | 48.3 | 50.1 | 40.8 | 58.4 |
| PTTR | 65.2 | 50.9 | 52.5 | 65.1 | 57.9 |
| STNet | 72.1 | 49.9 | 58.0 | 73.5 | 61.3 |
| M2Track | 65.5 | 61.5 | 53.8 | 73.2 | 62.9 |
| Trans3DT | 73.3 | 53.5 | 59.2 | 46.3 | 62.9 |
| Ours | 71.5 | 58.5 | 60.3 | 73.0 | 64.9 |
| Precision Metric (%) | |||||
| SC3D | 57.9 | 37.8 | 47.0 | 70.4 | 48.5 |
| P2B | 72.8 | 49.6 | 48.4 | 44.7 | 60.0 |
| 3DSiamRPN | 76.2 | 56.2 | 52.9 | 49.0 | 64.9 |
| LTTR | 77.1 | 56.8 | 45.6 | 89.9 | 65.8 |
| MLVSNet | 74.0 | 61.1 | 61.4 | 44.5 | 66.7 |
| BAT | 77.7 | 70.1 | 67.0 | 45.4 | 72.8 |
| PTT | 81.8 | 72.0 | 52.5 | 47.3 | 74.2 |
| V2B | 81.3 | 73.5 | 58.0 | 49.7 | 75.2 |
| PTTR | 77.4 | 81.6 | 61.8 | 90.5 | 78.1 |
| STNet | 84.0 | 77.2 | 70.6 | 93.7 | 80.1 |
| M2Track | 80.8 | 88.2 | 70.7 | 93.5 | 83.4 |
| Trans3DT | 84.7 | 79.8 | 70.5 | 56.5 | 80.7 |
| Ours | 84.0 | 83.4 | 74.9 | 93.9 | 83.0 |
| Methods | Car (15,578) | Pedestrian (8019) | Truck (3710) | Bicycle (501) | Mean |
|---|---|---|---|---|---|
| Success Metric (%) | |||||
| SC3D | 25.0 | 14.2 | 25.7 | 17.0 | 21.8 |
| P2B | 27.0 | 15.9 | 21.5 | 20.0 | 22.9 |
| BAT | 22.5 | 17.3 | 19.3 | 17.0 | 20.5 |
| V2B | 31. | 17.3 | 21.7 | 22.2 | 25.8 |
| STNet | 32.2 | 19.1 | 22.3 | 21.2 | 26.9 |
| Trans3DT | 31.8 | 17.4 | 22.7 | 18.5 | 26.2 |
| P2B * | 24.1 | 16.5 | 18.8 | 17.5 | 21.1 |
| M2Track * | 27.2 | 16.4 | 20.1 | 16.9 | 23.0 |
| STNet * | 25.5 | 14.9 | 18.9 | 17.0 | 21.4 |
| Ours | 25.6 | 15.3 | 12.7 | 17.5 | 20.8 |
| Precision Metric (%) | |||||
| SC3D | 27.1 | 17.2 | 21.9 | 18.2 | 23.1 |
| P2B | 29.2 | 22.0 | 16.2 | 26.4 | 25.3 |
| BAT | 24.1 | 24.5 | 15.8 | 18.8 | 23.0 |
| V2B | 35.1 | 23.4 | 16.7 | 19.1 | 29.0 |
| STNet | 36.1 | 27.2 | 16.8 | 29.2 | 30.8 |
| Trans3DT | 35.4 | 23.3 | 17.1 | 23.9 | 29.3 |
| P2B * | 24.6 | 20.0 | 13.1 | 18.9 | 21.6 |
| M2Track * | 28.3 | 18.9 | 16.5 | 16.6 | 23.8 |
| STNet * | 27.0 | 16.3 | 13.3 | 16.4 | 21.9 |
| Ours | 27.5 | 17.4 | 18.5 | 18.4 | 23.2 |
| Methods | Car (6424) | Pedestrian (6088) | Van (1248) | Cyclist (308) | Mean |
|---|---|---|---|---|---|
| Success Metric | |||||
| STNet-0.2 | 70.8 | 55.4 | 39.0 | 71.6 | 61.3 |
| STNet-0.3 | 70.5 | 51.4 | 56.5 | 72.9 | 61.0 |
| STNet-0.4 | 69.2 | 46.0 | 58.0 | 73.3 | 58.3 |
| Ours-0.2 | 71.5 | 58.5 | 60.3 | 73.0 | 64.9 |
| Ours-0.3 | 71.4 | 54.5 | 60.0 | 73.2 | 63.1 |
| Ours-0.4 | 69.0 | 50.7 | 59.7 | 74.0 | 60.3 |
| Precision Metric | |||||
| STNet-0.2 | 82.6 | 79.9 | 45.7 | 93.9 | 78.4 |
| STNet-0.3 | 82.7 | 78.8 | 67.0 | 94.0 | 79.9 |
| STNet-0.4 | 82.0 | 74.0 | 68.1 | 94.2 | 77.6 |
| Ours-0.2 | 84.0 | 83.4 | 73.9 | 93.9 | 83.0 |
| Ours-0.3 | 84.2 | 81.1 | 73.2 | 94.1 | 82.1 |
| Ours-0.4 | 81.7 | 78.1 | 72.7 | 94.5 | 79.6 |
| TAPM Module | PixelShuffle | ViT Layer | Success | Precision |
|---|---|---|---|---|
| \ | \ | \ | 51.6 | 73.6 |
| ✓ | \ | \ | 51.7 | 74.9 |
| \ | ✓ | \ | 49.8 | 70.7 |
| \ | \ | ✓ | 56.0 | 80.7 |
| ✓ | ✓ | \ | 54.2 | 75.9 |
| \ | ✓ | ✓ | 56.4 | 82.4 |
| ✓ | \ | ✓ | 56.4 | 81.5 |
| ✓ | ✓ | ✓ | 58.5 | 83.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, S.; Han, Y.; Zhao, X.; Liu, X. Small Object Tracking in LiDAR Point Clouds: Learning the Target-Awareness Prototype and Fine-Grained Search Region. Sensors 2025, 25, 3633. https://doi.org/10.3390/s25123633
Tian S, Han Y, Zhao X, Liu X. Small Object Tracking in LiDAR Point Clouds: Learning the Target-Awareness Prototype and Fine-Grained Search Region. Sensors. 2025; 25(12):3633. https://doi.org/10.3390/s25123633
Chicago/Turabian StyleTian, Shengjing, Yinan Han, Xiantong Zhao, and Xiuping Liu. 2025. "Small Object Tracking in LiDAR Point Clouds: Learning the Target-Awareness Prototype and Fine-Grained Search Region" Sensors 25, no. 12: 3633. https://doi.org/10.3390/s25123633
APA StyleTian, S., Han, Y., Zhao, X., & Liu, X. (2025). Small Object Tracking in LiDAR Point Clouds: Learning the Target-Awareness Prototype and Fine-Grained Search Region. Sensors, 25(12), 3633. https://doi.org/10.3390/s25123633