
MEP-YOLOv5s: Small-Target Detection Model for Unmanned Aerial Vehicle-Captured Images

Abstract
1. Introduction
2. Materials and Methods
3. Improved Algorithm
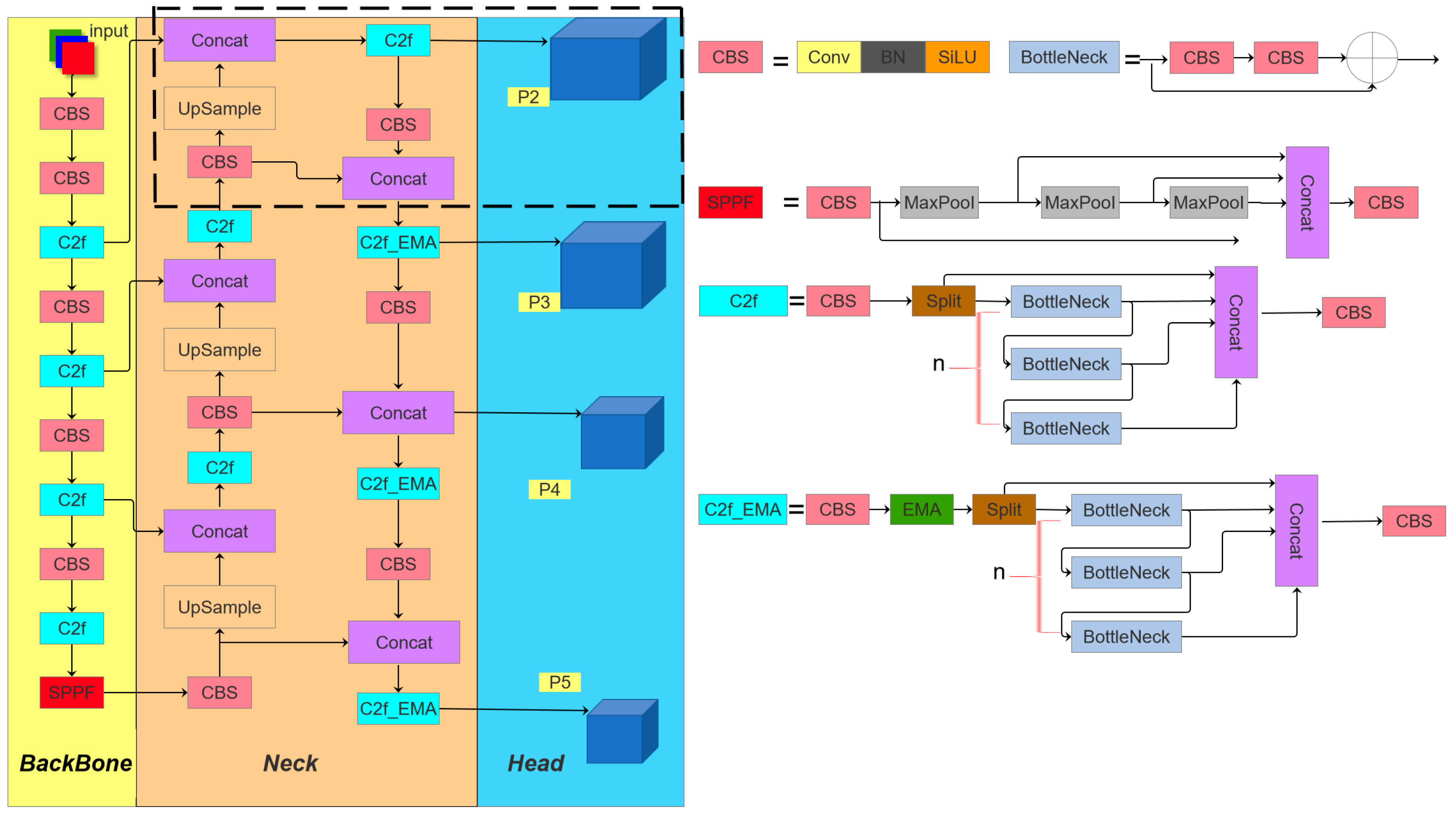
3.1. Model Structure
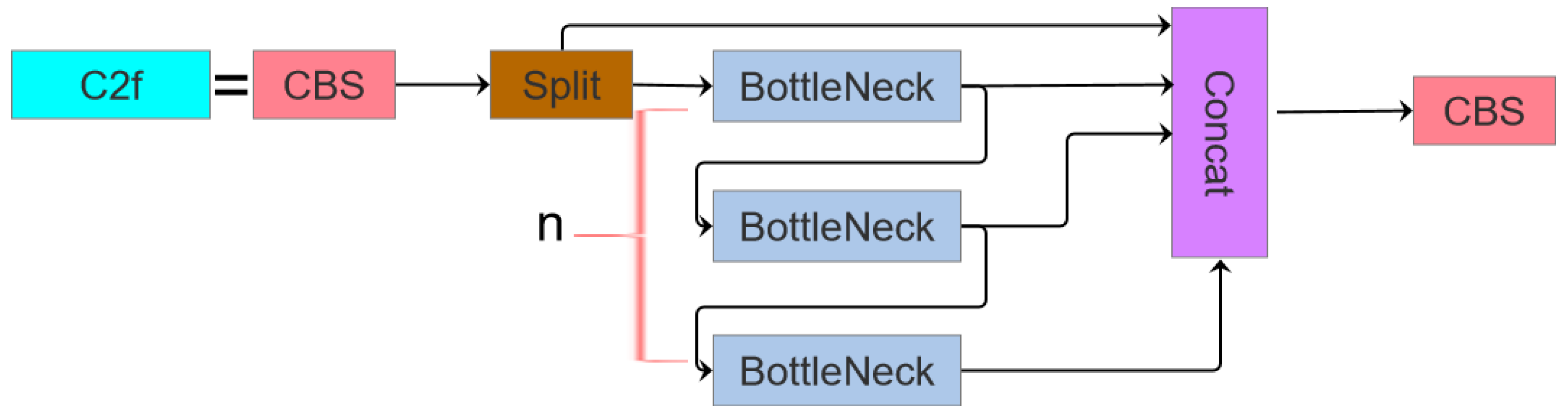
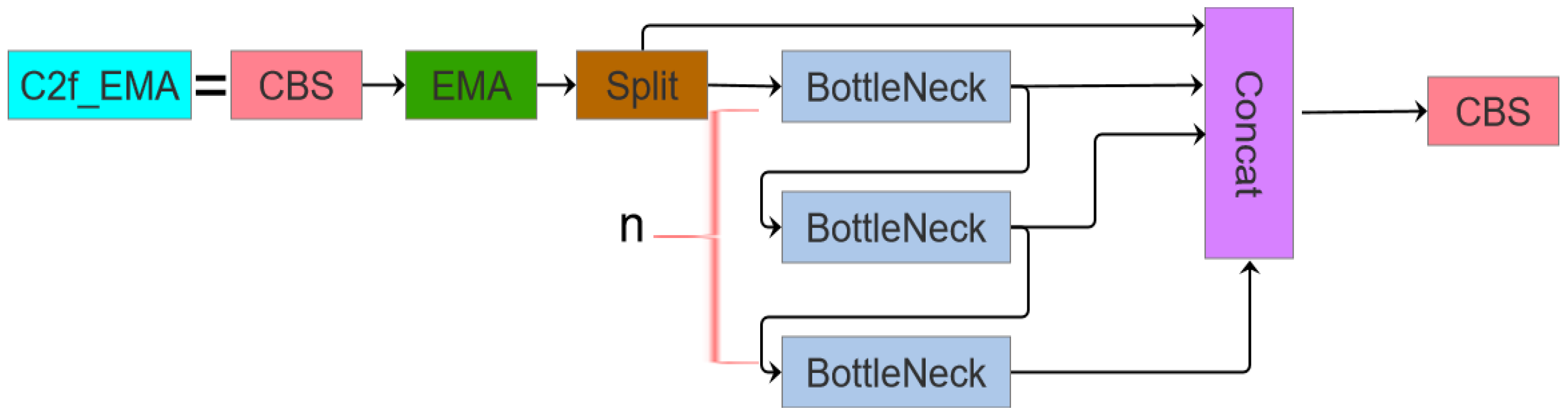
- Architectural Redesign: The original C3 module is replaced with a redesigned C2f module integrated with an Exponential Moving Average (EMA [32]) attention mechanism, forming the C2f_EMA module. This configuration optimizes the receptive field geometry to enhance the detection precision for smaller targets.
- Loss Function Innovation: We replace the traditional CIoU loss function with the improved Modified Probabilistic Distance-IoU (MPDIoU [33]) loss function to enhance the convergence behavior.
- Detection Head Augmentation: A dedicated small-target detection layer is integrated into the prediction head to strengthen the network’s capability in resolving densely packed minute objects.
3.2. Feature Converged Network Architecture
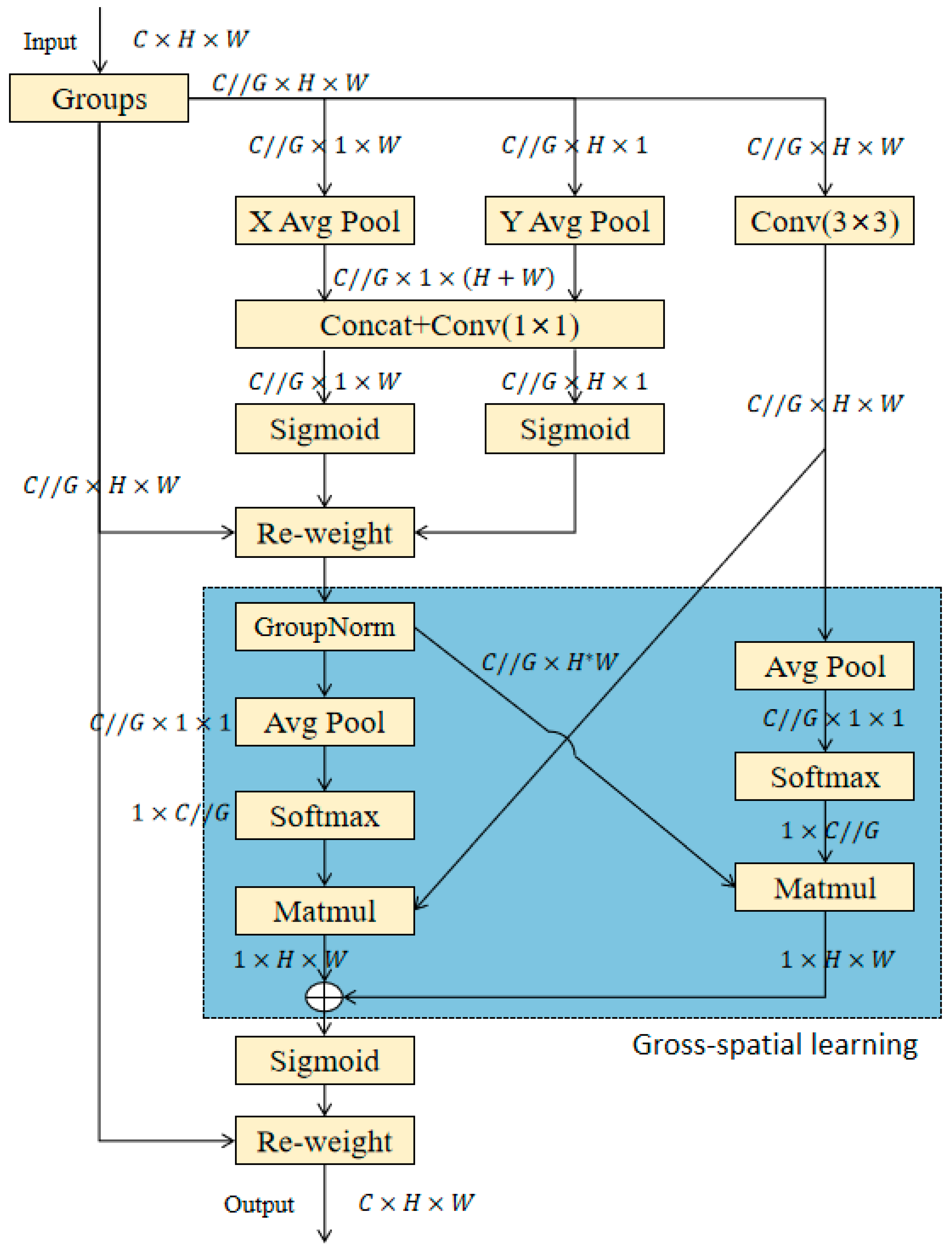
3.2.1. Attention-Based Receptive Field Feature Retrieval Module
- Feature Encoding and Dimension Preservation:
- 2.
- Attention Decomposition and Distribution:
- 3.
- Dual-Path Attention Aggregation:
- (1)
- 1 × 1 Branch: Intra-group channel attention is aggregated through element-wise multiplication to achieve diversified cross-channel interactions.
- (2)
- 3 × 3 Branch: Local cross-channel interaction information is captured via convolution, augmenting the feature space expressiveness. For the 3 × 3 branch, the 3 × 3 convolution operation is first performed as , followed by cross-channel interaction attention mechanism fusion, and finally the combined output is performed. The specific process is as follows:
- (1)
- Calculate the global weight of the weighted features and respectively:
- (2)
- Cross attention fusion:
- (3)
- Adjust the weight shape and act on the grouped features:
- 4.
- Spatial Attention Weighting:
3.2.2. The Improvement of the Loss Function
| Algorithm 1. Intersection over Union with Minimum Points Distance. |
| Input: Two arbitrary convex shapes: , width and height of input image: 1: For and , denote the top-left and bottom-right point coordinates of denote the top-left and bottom-right point coordinates of B. 2: |
| 3: |
3.2.3. Small Target Detection Layer
4. Experiment and Result Analysis
4.1. Experimental Setup
4.1.1. Experimental Datasets
4.1.2. Experimental Evaluation Metrics
- Precision (P) is defined as the proportion of true positive samples among those predicted as positive by the model. The calculation formula is:where TP represents True Positive, i.e., the number of samples correctly predicted as positive by the model, and FP represents False Positive, i.e., the number of samples incorrectly predicted as positive by the model.
- Recall (R) represents the proportion of true positive samples that are correctly predicted, and the calculation formula is:where FN represents False Negative, i.e., the number of samples incorrectly predicted as negative by the model.
- F1 score (also known as the F-score or F-measure) is the harmonic mean of Precision and Recall, serving as a balanced evaluation metric that combines both a model’s precision and recall capabilities, and the calculation formula is:where P and R, respectively, denote Precision and Recall.
- The Average Precision (AP) for a single class is calculated by interpolating and integrating the precision–recall curve, and the formula is:where P (R) represents the precision at recall rate R.
- The mean Average Precision (mAP) is the average of AP across all the classes, and the calculation formula is:where N represents the total number of classes, and represents the average precision of the i-th class.
4.2. Contrast Experiment
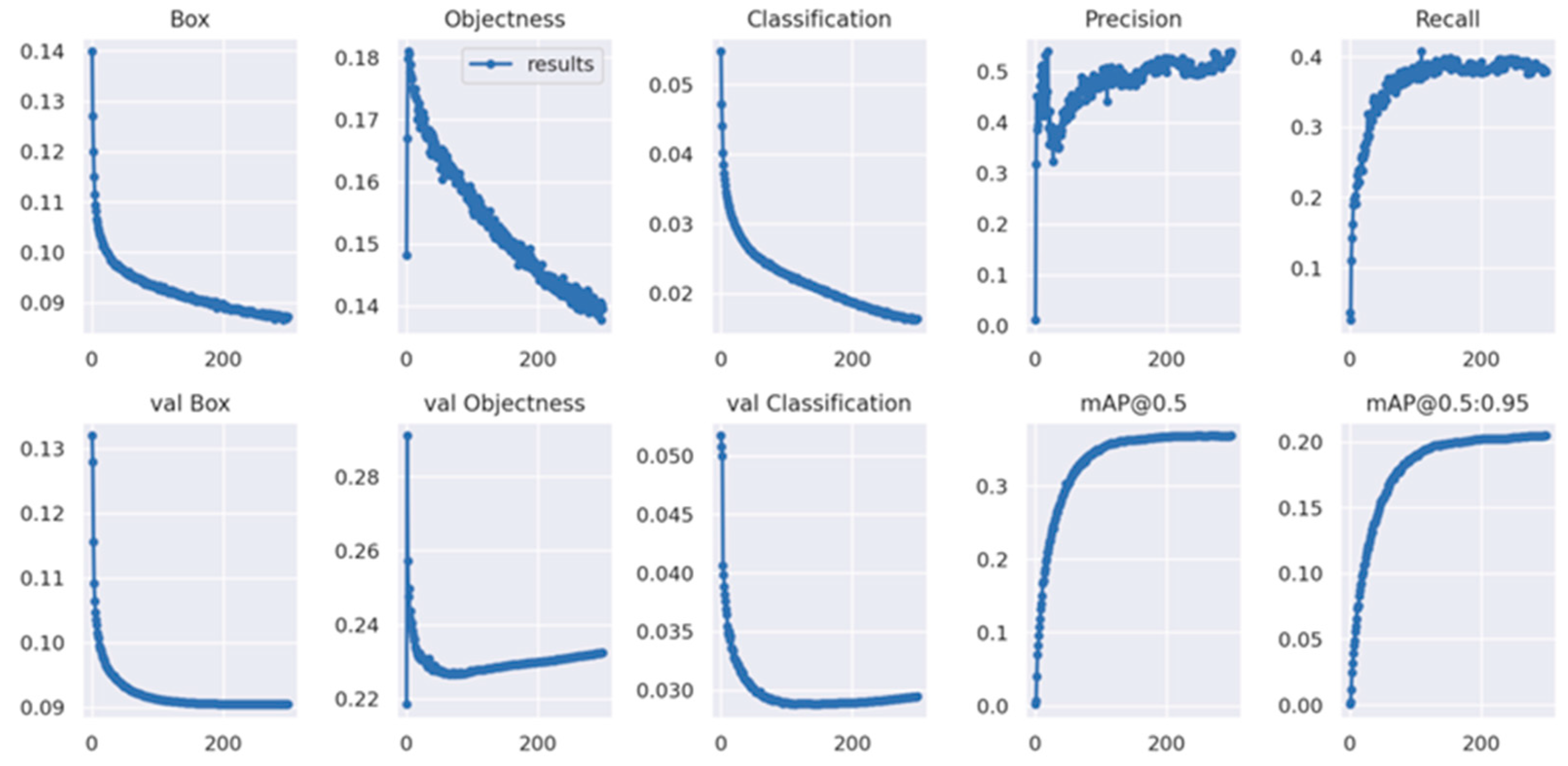
4.2.1. Results of the MEP-YOLOv5s Experiments
4.2.2. Effect Diagram
4.2.3. Ablation Experiment
4.3. Comparison with the Other Models
4.4. Comparative Experiments on the Other Datasets
5. Summary and Expectation
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, Q.; Gu, J.; Huang, H. A resource-efficient online target detection system with autonomous drone-assisted IoT. IEEE Internet Things J. 2022, 9, 13755–13766. [Google Scholar] [CrossRef]
- Jha, S.S.; Nidamanuri, R.R. Dynamics of target detection using drone based hyperspectral imagery. In Proceedings of the International Conference on Unmanned Aerial System in Geomatics, Roorkee, India, 6–7 April 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 91–97. [Google Scholar]
- Rohan, A.; Rabah, M.; Kim, S.H. Convolutional neural network-based real-time object detection and tracking for parrot AR drone 2. IEEE Access 2019, 7, 69575–69584. [Google Scholar] [CrossRef]
- Liao, C.; Huang, J.; Zhou, F. Design of six-rotor drone based on target detection for intelligent agriculture. In Algorithms and Architectures for Parallel Processing: 20th International Conference, ICA3PP 2020, New York City, NY, USA, October 2–4, 2020, Proceedings, Part III; Springer International Publishing: Cham, Switzerland, 2020; pp. 270–281. [Google Scholar]
- Li, Z.; Wang, Q.; Zhang, T. UAV high-voltage power transmission line autonomous correction inspection system based on object detection. IEEE Sens. J. 2023, 23, 10215–10230. [Google Scholar] [CrossRef]
- García-Fernández, Á.F.; Xiao, J. Trajectory Poisson multi-Bernoulli mixture filter for traffic monitoring using a drone. IEEE Trans. Veh. Technol. 2023, 73, 402–413. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Zhuang, L.; Xu, Y.; Ni, B. Pedestrian Detection Using ACF Based Fast R-CNN. In Digital TV and Wireless Multimedia Communication: 14th International Forum, IFTC 2017, Shanghai, China, November 8–9, 2017, Revised Selected Papers; Springer: Singapore, 2018; Volume 815, p. 172. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn. Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6154–6162. [Google Scholar]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Chen, C.; Zheng, Z.; Xu, T. Yolo-based uav technology: A review of the research and its applications. Drones 2023, 7, 190. [Google Scholar] [CrossRef]
- YOLOv5: An Open-Source Object Detection Algorithm. Available online: https://github.com/ultralytics/yolov5 (accessed on 15 May 2024).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D. Ssd: Single shot multibox detector. In Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016, Proceedings, Part I; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Wang, Y.; Wang, C.; Zhang, H. Automatic ship detection based on RetinaNet using multi-resolution Gaofen-3 imagery. Remote Sens. 2019, 11, 531. [Google Scholar] [CrossRef]
- Shaodan, L.; Yue, Y.; Jiayi, L. Application of UAV-based imaging and deep learning in assessment of rice blast resistance. Rice Sci. 2023, 30, 652–660. [Google Scholar] [CrossRef]
- Liang, H.; Lee, S.C.; Seo, S. UAV-based low altitude remote sensing for concrete bridge multi-category damage automatic detection system. Drones 2023, 7, 386. [Google Scholar] [CrossRef]
- Zhao, B.; Song, R. Enhancing two-stage object detection models via data-driven anchor box optimization in UAV-based maritime SAR. Sci. Rep. 2024, 14, 4765. [Google Scholar] [CrossRef]
- Yang, Z.; Lian, J.; Liu, J. Infrared UAV target detection based on continuous-coupled neural network. Micromachines 2023, 14, 2113. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Chen, L.; Yao, Z. Intelligent identification of pine wilt disease infected individual trees using UAV-based hyperspectral imagery. Remote Sens. 2023, 15, 3295. [Google Scholar] [CrossRef]
- Wu, D.; Qian, Z.; Wu, D. FSNet: Enhancing Forest-Fire and Smoke Detection with an Advanced UAV-Based Network. Forests 2024, 15, 787. [Google Scholar] [CrossRef]
- Guo, J.; Liu, X.; Bi, L. Un-yolov5s: A uav-based aerial photography detection algorithm. Sensors 2023, 23, 5907. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, Y.; Li, H. A Deep Learning Approach of Intrusion Detection and Tracking with UAV-Based 360° Camera and 3-Axis Gimbal. Drones 2024, 8, 68. [Google Scholar] [CrossRef]
- Dong, Y.; Ma, Y.; Li, Y. High-precision real-time UAV target recognition based on improved YOLOv4. Comput. Commun. 2023, 206, 124–132. [Google Scholar] [CrossRef]
- Su, X.; Hu, J.; Chen, L. Research on real-time dense small target detection algorithm of UAV based on YOLOv3-SPP. J. Braz. Soc. Mech. Sci. Eng. 2023, 45, 488. [Google Scholar] [CrossRef]
- Tang, H.; Xiong, W.; Dong, K. Radar-optical fusion detection of UAV based on improved YOLOv7-tiny. Meas. Sci. Technol. 2024, 35, 085110. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A self-gated activation function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Siliang, M.; Yong, X. Mpdiou: A loss for efficient and accurate bounding box regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Guo, C.; Chen, X.; Chen, Y. Multi-stage attentive network for motion deblurring via binary cross-entropy loss. Entropy 2022, 24, 1414. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Detection Branch | Anchor Frame Configuration |
|---|---|
| P2 | (4,5), (8,10), (22,18) |
| P3 | (10,13), (16,30), (33,23) |
| P4 | (30,61), (62,45), (59,119) |
| P5 | (116,90), (156,198), (373,326) |
| Parameter Name | Parameter Setting |
|---|---|
| batch size | 16 |
| learning rate | 0.01 |
| size of the image | 640 × 640 |
| number of iterations | 300 |
| network depth, network width | 0.8, 1 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | GFLOPS | CPI | ||
|---|---|---|---|---|---|---|---|---|---|
| = 0.25 | = 0.5 | = 0.75 | |||||||
| YOLOv5s | 53.9 | 37.8 | 44.43 | 36.8 | 20.5 | 93.1 | 10.00 | 18.93 | 27.86 |
| MEP-YOLOv5s | 55.3 | 45.2 | 49.74 | 44.2 | 25.7 | 112.4 | 11.71 | 22.54 | 33.37 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | GFLOPS | CPI | ||
|---|---|---|---|---|---|---|---|---|---|
| = 0.25 | = 0.5 | = 0.75 | |||||||
| YOLOv5s | 53.2 | 38.1 | 44.40 | 36.8 | 20.5 | 93.1 | 10.00 | 18.93 | 27.86 |
| +P2 | 57 | 43.9 | 49.59 | 43.5 | 24.8 | 104.1 | 11.59 | 22.23 | 32.86 |
| +C2f_EMA | 57.3 | 44.3 | 49.96 | 43.7 | 25.3 | 112.4 | 11.59 | 22.29 | 32.99 |
| +MPDIOU | 55 | 45.9 | 50.03 | 44.5 | 25.9 | 112.4 | 11.79 | 22.69 | 33.59 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | GFLOPS | CPI | ||
|---|---|---|---|---|---|---|---|---|---|
| = 0.25 | = 0.5 | = 0.75 | |||||||
| Faster-RCNN | - | - | - | 39.4 | 23 | 251.4 | 10.14 | 19.89 | 29.64 |
| YOLOv3 | 51.8 | 39 | 44.49 | 37.8 | 20.8 | 154.7 | 9.93 | 19.22 | 28.51 |
| YOLO5s | 53.2 | 38.1 | 44.40 | 36.8 | 20.5 | 93.1 | 10.00 | 18.93 | 27.86 |
| YOLOv5m | 51.9 | 37.1 | 43.26 | 35.8 | 19.9 | 50.7 | 10.42 | 18.88 | 27.34 |
| YOLOv5L | 54.1 | 38.8 | 45.19 | 37.8 | 21.5 | 114.1 | 10.10 | 29.33 | 28.56 |
| YOLOv7 | 51.6 | 41.3 | 45.87 | 40 | 22.8 | 103.3 | 10.72 | 20.48 | 30.24 |
| YOLOv8 | 51.5 | 40.1 | 45.09 | 41 | 24.4 | 165.7 | 10.70 | 20.80 | 30.90 |
| MEP-YOLOv5s | 55 | 45.9 | 50.03 | 44.5 | 25.9 | 112.4 | 11.79 | 22.69 | 33.59 |
| Model | Precision (%) | Recall (%) | F1 (%) | mAP@0.5 (%) | mAP@0.5:0.95 (%) | GFLOPS | CPI | ||
|---|---|---|---|---|---|---|---|---|---|
| = 0.25 | = 0.5 | ||||||||
| Faster-RCNN | - | - | - | 74.6 | 47.6 | 251.4 | 18.94 | 37.49 | 56.04 |
| YOLOv3 | 94.9 | 83.5 | 88.83 | 89.7 | 60.9 | 154.7 | 22.90 | 45.17 | 67.43 |
| YOLOv5s | 95.9 | 83.5 | 89.27 | 88.3 | 59.6 | 93.1 | 22.88 | 44.68 | 66.49 |
| YOLOv5m | 93.6 | 83.4 | 88.20 | 88.2 | 59.2 | 50.7 | 23.52 | 45.08 | 66.64 |
| YOLOv5L | 93.6 | 84.4 | 88.76 | 89.2 | 60.4 | 114.7 | 22.95 | 45.03 | 67.11 |
| YOLOv7 | 94.6 | 82.3 | 88.02 | 89.6 | 56 | 103.3 | 23.12 | 45.28 | 67.44 |
| YOLOv8 | 90.4 | 82 | 85.99 | 86.7 | 57.9 | 165.7 | 22.12 | 43.65 | 65.17 |
| MEP-YOLOv5s | 93.0 | 84.2 | 88.38 | 90.0 | 59.1 | 112.4 | 23.16 | 45.44 | 67.72 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, S.; Zhang, S.; Li, C.; Liu, S.; Chen, D. MEP-YOLOv5s: Small-Target Detection Model for Unmanned Aerial Vehicle-Captured Images. Sensors 2025, 25, 3468. https://doi.org/10.3390/s25113468
Zhou S, Zhang S, Li C, Liu S, Chen D. MEP-YOLOv5s: Small-Target Detection Model for Unmanned Aerial Vehicle-Captured Images. Sensors. 2025; 25(11):3468. https://doi.org/10.3390/s25113468
Chicago/Turabian StyleZhou, Shengbang, Song Zhang, Chuanqi Li, Shutian Liu, and Dong Chen. 2025. "MEP-YOLOv5s: Small-Target Detection Model for Unmanned Aerial Vehicle-Captured Images" Sensors 25, no. 11: 3468. https://doi.org/10.3390/s25113468
APA StyleZhou, S., Zhang, S., Li, C., Liu, S., & Chen, D. (2025). MEP-YOLOv5s: Small-Target Detection Model for Unmanned Aerial Vehicle-Captured Images. Sensors, 25(11), 3468. https://doi.org/10.3390/s25113468