1. Introduction
With the rapid development of society, people enjoy greater access to excellent material resources. However, exercise has considerably decreased, leading to various health risks. Reduced exercise has contributed to declining fitness levels and an increased risk of illness [
1,
2]. Exercise strengthens the body, prevents diseases, reduces obesity, and aids post-injury recovery. It is gradually becoming an indispensable part of daily life [
3,
4]. However, while exercise brings numerous benefits, it has some drawbacks. For example, improper exercise intensity may lead to decreased immunity, exercise addiction and damage to the body [
5,
6]. Meanwhile, during the postoperative rehabilitation process, exercise, as a crucial therapeutic approach, requires strict control over its intensity. This is because both insufficient and excessive intensity can cause secondary injuries [
7].
Currently, there are many commonly used methods for recognising exercise intensity, such as the rating of perceived exertion (RPE) scale, the talk test (TT), heart rate, motion sensors and oxygen uptake [
8,
9]. Chai G et al. studied the relationship between the RPE scale and exercise intensity and found that the percentage of heart rate reserve (%HRR) is significantly correlated with RPE. Additionally, %HRR can effectively identify exercise intensity [
10]. Porcari J P et al. used the TT method to monitor exercise intensity and found that this method is similar to the %HRR method. They pointed out that TT is a simple and low-cost method [
11]. Cowan R et al. studied the effectiveness of TT and RPE in monitoring exercise intensity and found that the measured values of RPE at low and middle exercise intensity were greater than the actual exercise intensity values. In high-intensity exercise, the measurement results were comparable to the actual exercise intensity. Researchers believe that TT is only suitable for measurements during non-strenuous exercise [
12]. However, these two methods are difficult to use for high real-time requirements.
Compared to the above-mentioned methods, using wearable devices for exercise intensity monitoring is more feasible. Ho W T et al. used wristband devices to measure the heart rate and estimate exercise intensity. They found that when exercise intensity is low, the wristband devices could accurately reflect the magnitude of exercise intensity. However, as exercise intensity increased continuously, the error rate also increased [
13]. Tylcz J B et al. collected acceleration data through a smartwatch to verify the effect of distinguishing exercise intensity and found that this method could differentiate between low, middle and high exercise intensity [
14]. Mukaino et al. used lumbar spine accelerometers and heart rate sensors to monitor the activity intensity of paraplegic persons and found a significant correlation between acceleration and heart rate data and activity intensity [
15]. In the aforementioned studies, the motion sensors contained abundant movement information, and in some studies, a strong correlation was found between heart rate and exercise intensity. This study will integrate basic information (height, weight, age, gender and resting heart rate) and motion information (triaxial acceleration, triaxial angular velocity and exercise heart rate) as features for identifying exercise intensity.
Artificial intelligence algorithms have shown great advantages in building high-dimensional exercise intensity recognition models based on basic information and motion information. Bai C et al. used machine learning algorithms based on wrist strap acceleration sensors to identify physical activity intensity. They found that machine learning algorithms could effectively recognise the levels of physical activity intensity, with the highest F1-score reaching 0.946, and could estimate the amount of physical activity of the elderly [
16]. Garcia-Garcia F et al. used accelerometer and heart rate data to construct linear discriminant analysis and k-means clustering models, and these models afforded good recognition results [
17]. Therefore, developing algorithmic models for exercise intensity recognition is considered an effective method. Owing to individual variations, it is challenging to apply models built from the data of a certain group of people to other groups. Moreover, collecting exercise data from all individuals appears to be a difficult task. In domain adaptation techniques, feature distribution alignment methods explicitly align the feature distributions between the source and target domains, effectively addressing the model generalisation issues caused by cross-domain data distribution differences. Cai Z et al. employed electroencephalography for inter-disciplinary and temporal emotion recognition, achieving an accuracy of 58.23% with their Support Vector Machine. The use of maximum classifier difference in domain adversarial neural networks increased the accuracy to 88.33% [
18]. Huang D et al. constructed a cross-individual emotion recognition algorithm model through an electroencephalogram, mainly guided by the idea of a generative adversarial network, and performed feature alignment, providing a new idea for cross-individual emotion recognition. This demonstrates that domain adaptation methods hold significant potential in addressing cross-individual issues [
19].
The American College of Sports Medicine (ACSM) categorises exercise intensity into five levels based on %VO
2max. Exercise intensities below 37% are classified as low intensity, 37–45% as light intensity, 46–63% as middle intensity, 64–90% as vigorous intensity and ≥91% as very vigorous to maximal intensity [
20]. In daily life, people can achieve low exercise intensity through regular activities, but it is difficult to reach very vigorous to maximal intensity. The ‘Guidelines on Physical Activity and Sedentary Behavior’ issued by the World Health Organization and the ‘Chinese Physical Activity Guidelines (2021)’ issued by the Disease Prevention and Control Bureau of the National Health Commission of China propose that people should perform a certain duration of middle- and high-intensity exercise every week or every day [
1,
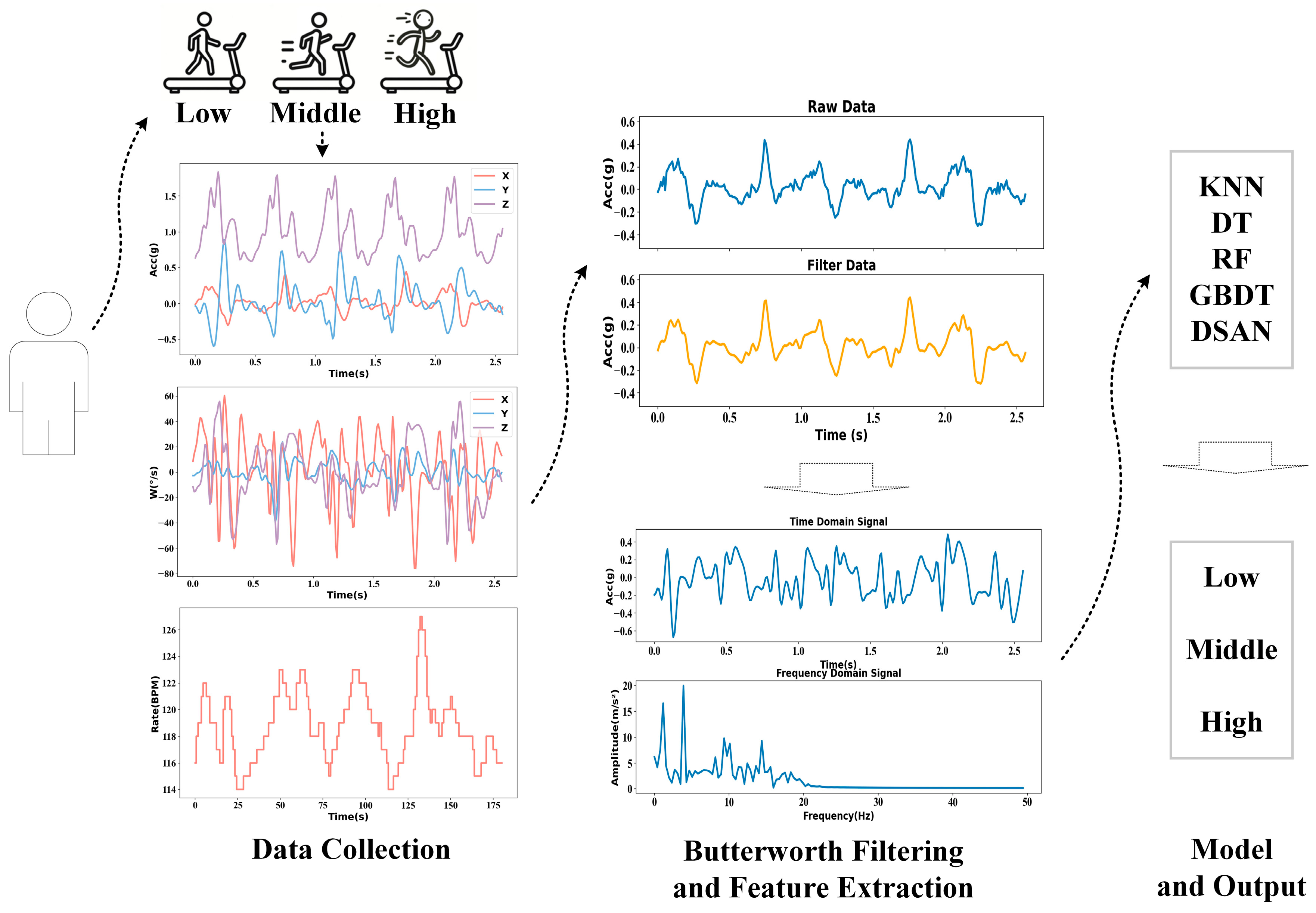
21]. Therefore, this study utilised multi-dimensional data combined with artificial intelligence algorithms to perform cross-individual recognition for low, middle and vigorous exercise intensities, subsequently re-classifying them into the low, middle and high exercise levels. The main work of this study is as follows: (1) collecting multi-dimensional motion data, (2) data cleaning and processing, (3) extracting time-domain and frequency-domain features of three-axis acceleration and three-axis angular velocity data and constructing a dataset and (4) comparing the recognition rates of the classical machine learning algorithm, ensemble learning algorithm and domain adaptation algorithm in different parts of low-, middle- and high-intensity exercises across individuals. The framework of this study is shown in
Figure 1.
2. Methodology
2.1. Participants
In this study, 24 students from the Capital University of Physical Education and Sports (China) participated in the experiment (
Table 1). The age span of the participants was small (20–30), and there were significant differences in weight and resting heart rate among women, while the corresponding differences between men were relatively small. The study protocol was approved by the Ethics Committee at the Capital University of Physical Education and Sports. Participants with healthy limbs were recruited, the participants in the experiment had no medical conditions for which exercise was not advised by doctors and they had no open or closed injuries within the past three months. Before the beginning of the experiment, the participants were provided with a detailed introduction to the overall process of the experiment and an informed consent form was signed.
2.2. Experimental Equipment
Basic information: In this study, multiple sensor devices were used to collect data, a body measuring ruler was used to measure participant height and a body composition analyser named InBody 270 Analyzer (InBody Co., Ltd., Seoul, Republic of Korea) was used to measure participant weight. OMEGwave (Beijing Yanding Huachuang Sports Development Co., Ltd., Beijing, China) was used to collect the human resting heart rate.
Motion information: The speed of the h/p/cosmos para treadmill (h/p/cosmos sports & medical GmbH, Nussdorf-Traunstein, Germany) was controlled through the serial port to control the power output of the participant. The maximal oxygen uptakes and real-time oxygen uptakes of the participant were measured by the CARDIOVIT AT-104 ErgoSpiro (Schiller International AG; Alfred Schiller (Beijing, China) Medical Technology Co., Ltd., Beijing, China). A Polar H10 heart rate band (Polar Electro Oy, Kempele, Finland; Alfred Schiller (Beijing, China) Medical Technology Co., Ltd., Beijing, China) collected the heart rates of the participants in real time and uploaded them to the APP via Bluetooth, with a collection frequency of 1 Hz. WitMotion BWT901BCL0.5 (WitMotion Shenzhen Co., Ltd., Shenzhen, China) collected triaxial acceleration, triaxial angular velocity and triaxial Euler angle information in real time in the adjustable data acquisition frequency range of 1–1000 Hz.
2.3. Experimental Design
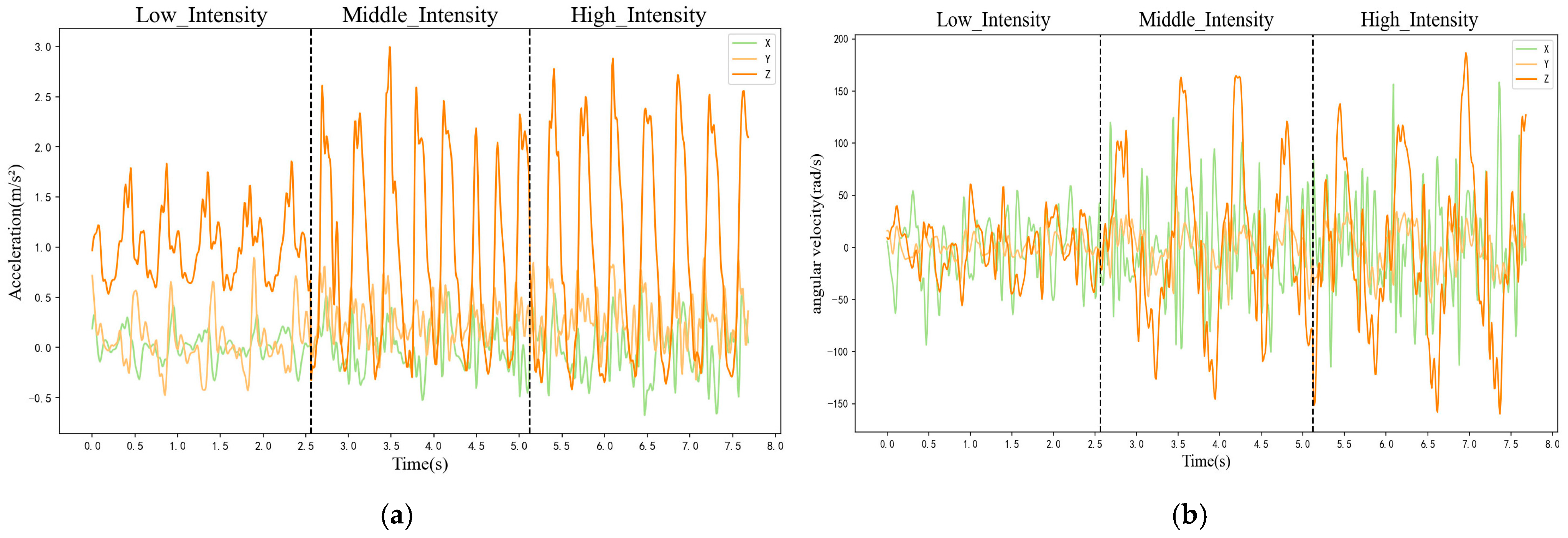
The participants did not engage in any strenuous exercise within 24 h before the experiment, and the experiment was conducted at least 1 h after meals. The indoor environment was well ventilated, quiet and tidy. The room temperature was maintained at 20–30 °C, and there were no safety hazards present. To reduce the error caused by the inconsistent orientation of the WitMotion sensor, the WitMotion switch direction was uniformly upward. Previous work showed that the frequency of acceleration and angular velocity should be set to at least 100 Hz [
22] during external load monitoring, so we set the WitMotion acquisition frequency to 100 Hz. As the acquisition frequencies of the inertial sensor and HR were 100 and 1 Hz, respectively, and heart rate changes little within a second, the HR data were upsampled to 100 Hz using the zero-order hold method. This involved duplicating each HR value collected per second 100 times to match the data sampling frequency of the inertial sensor. Motion data were collected from three stages of running: low, middle and high intensity. The detailed information is shown in
Table 2.
Before the experiment, the experiment procedure and precautions were explained to the participants. After starting the experiment, the basic information of the participants (height, weight, age and gender) was first collected, and OMEGwave was used to measure their resting heart rate. The participants were then fitted with experimental devices (energy respiratory metaboliser and Polar heart rate band) and WitMotion sensors on seven parts of the body, uniformly keeping the sign of the data transmission interface up. The experiment was divided into two, with a time interval of 24 h. The maximal oxygen uptake was measured in the first experiment, and the exercise data for low, middle and high intensity were collected in the second experiment.
First, the VO2max of each participant was measured. After the formal start of the experiment, the participants were instructed to sit still for 5 min. After the resting state was completed, they began to warm up on the h/p/cosmos para treadmill to prepare for the subsequent maximum-oxygen-uptake test. The initial speed of the participants on the treadmill was 7 km/h, and the 1 min increasing rate (1 km/h) was maintained to enter the stage of linear increasing load exercise. The experimenter gave appropriate verbal encouragement according to the physiological performance of the participants during exercise. When any three of the following criteria were met or the participants were subjectively unable to continue the exercise load, the exercise load was stopped immediately: achieving the maximum heart rate (208 − 0.7 × age according to the ACSM’s guidelines for healthy individuals), respiratory entropy (as measured by the instrument) > 1.15, self-perceived exhaustion of the participant and reaching the point of oxygen consumption plateau. Even after reaching exercise exhaustion, the participants continued to steadily jog at 7 km/h for an additional 3 min until the conclusion of the experiment. The maximal oxygen consumption metrics were recorded, and the respiratory mask was disinfected. Following the first experiment, participants were instructed to maintain their regular schedule before the second experiment, such as avoiding staying up late, drinking alcohol, or excessive exercise, to minimise any potential impact on the results.
Subsequently, data for low, middle and high exercise intensities were collected. After the experiment commenced, participants similarly engaged in a 5 min seated rest period, followed by sequential data collection corresponding to the states of low-, middle- and high-intensity exercise. Taking low-intensity data collection as an example, participants gradually increased the load on the h/p/cosmos para treadmill from the lowest speed until their oxygen uptake reached 0–45% of their maximum oxygen uptake and stabilised. They maintained this speed for 4 min and then rested until their heart rate dropped below 80 bpm. For middle-intensity (46–63%) and high-intensity (64–100%) exercises, the above-mentioned protocol was repeated. After the experiment, the exercise data of the participants were recorded, and the respiratory mask was disinfected.
2.4. Data Pre-Processing and Feature Extraction
Due to the high sensitivity of the inertial sensors, some high-frequency noise may be generated during data collection, along with artifacts from clothing and similar issues. This study used Butterworth filters to filter the data and set the cut-off frequency to 25 Hz [
23]. The duration of collecting exercise data for different intensity stages was 4 min each. Therefore, to improve the accuracy of the data, the data from the first 2/3 min were deleted and then filtered using a Butterworth filter. Features of acceleration and angular velocity were extracted by summarising the relevant research literature [
24,
25,
26,
27]. In this study, the time-domain and frequency-domain features (such as mean value, standard deviation, maximum value, total energy, mean square frequency and rectification mean value) of the six-axis data (acceleration and angular velocity) were extracted using a sliding window. Sliding windows should encompass at least one complete cycle of activity [
28]. Using powers of 2 is advantageous for enhancing computational efficiency. Additionally, variations in activity cycles are considered among different subjects [
29]. Based on the above-mentioned analysis, the sliding window was set to 2.56 s and the overlapping window was 50%. Thirty-two features were extracted from each axis, and 192 features were extracted from the six-axis data. The basic information (height, weight, age, gender, resting heart rate and average heart rate in each sliding window) was integrated, and each sample comprised 198 features; the corresponding label was associated with each sample, which was trained and verified using the algorithm model.
2.5. Model Introduction
2.5.1. Classical Machine Learning Algorithms
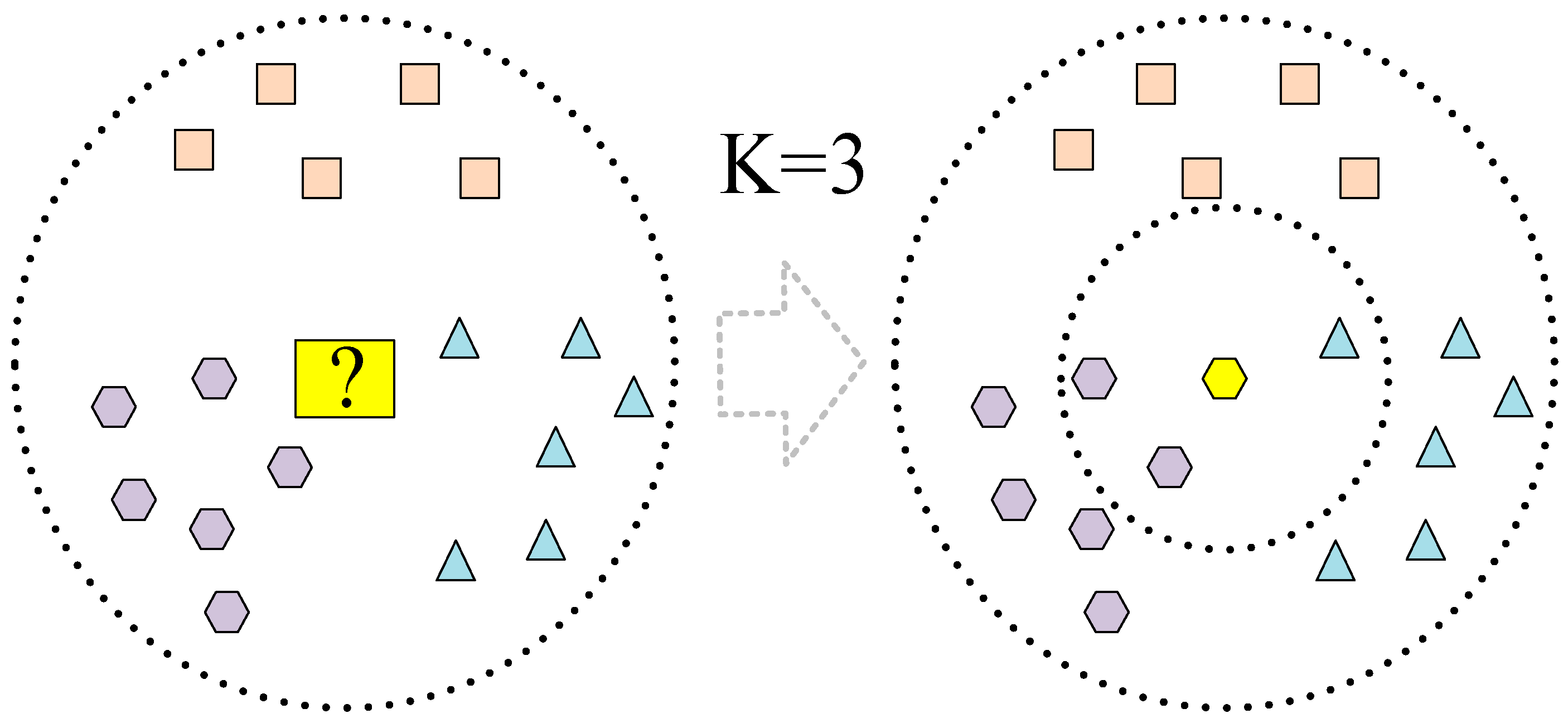
In this study, because human basic information typically comprises discrete numerical data, the range of time-domain and frequency-domain features extracted from acceleration and angular velocity data may vary significantly. The K-nearest neighbour (KNN) algorithm does not require assumptions regarding data distribution and can handle various data types effectively. Additionally, it can adapt to different types of features. The decision tree (DT) algorithm is adept at handling data with mixed feature types and can automatically perform dimensionality reduction and eliminate redundant features, which is particularly useful for dealing with high-dimensional data. Given the favourable characteristics of KNN and DT algorithms, we chose these algorithms as representative examples of classic machine learning algorithms to construct models for cross-individual exercise intensity recognition. The KNN algorithm is capable of classification and prediction tasks [
30] and is used to model data according to the similarity between various data features. The KNN algorithm projects various data features into the feature space and determines the training sample points in space by calculating the Euclidean distance, obtained using Equation (1):
where
and
represent the
k feature values of sample points
X and
Y, respectively.
Finally, the sample feature points were projected from the test set into the training space, selecting the K training set samples closest to the test sample surroundings. The KNN algorithm determines which type of training sample appears most in the K training set samples, and the sample is classified as this type. The algorithm structure is shown in
Figure 2. This study employed a grid search approach with five-fold cross-validation to determine the optimal K values for the seven designated body positions, as shown in
Table 3.
DT is a tree-structure algorithm capable of classification and prediction tasks [
31]. It is often employed as a foundational component for other intricate algorithms, such as random forest (RF) and gradient boosting decision tree (GBDT). DT is primarily constructed through a recursive approach until reaching a maximum depth or achieving a high level of purity in leaf nodes. Meanwhile, owing to the tendency of DTs to overfit, pruning is often employed to prevent overfitting. Therefore, when a test sample is input into a DT, classification can be performed by evaluating various features of the test sample. This study employed a grid search method with five-fold cross-validation to determine the optimal parameter combination for the seven designated body positions during modelling with the DT algorithm. The resulting parameter combination is presented in
Table 3. For KNN, we performed a grid search over the hyperparameter n_neighbors, testing all integer values from 1 to 49. For decision trees (DTs), the search space included four hyperparameters: the splitting strategy (best, random), the impurity measure (gini, entropy), the maximum tree depth (1 to 9) and the minimum number of samples a leaf node can contain (1, 6, 11, …, 46).
2.5.2. Ensemble Learning
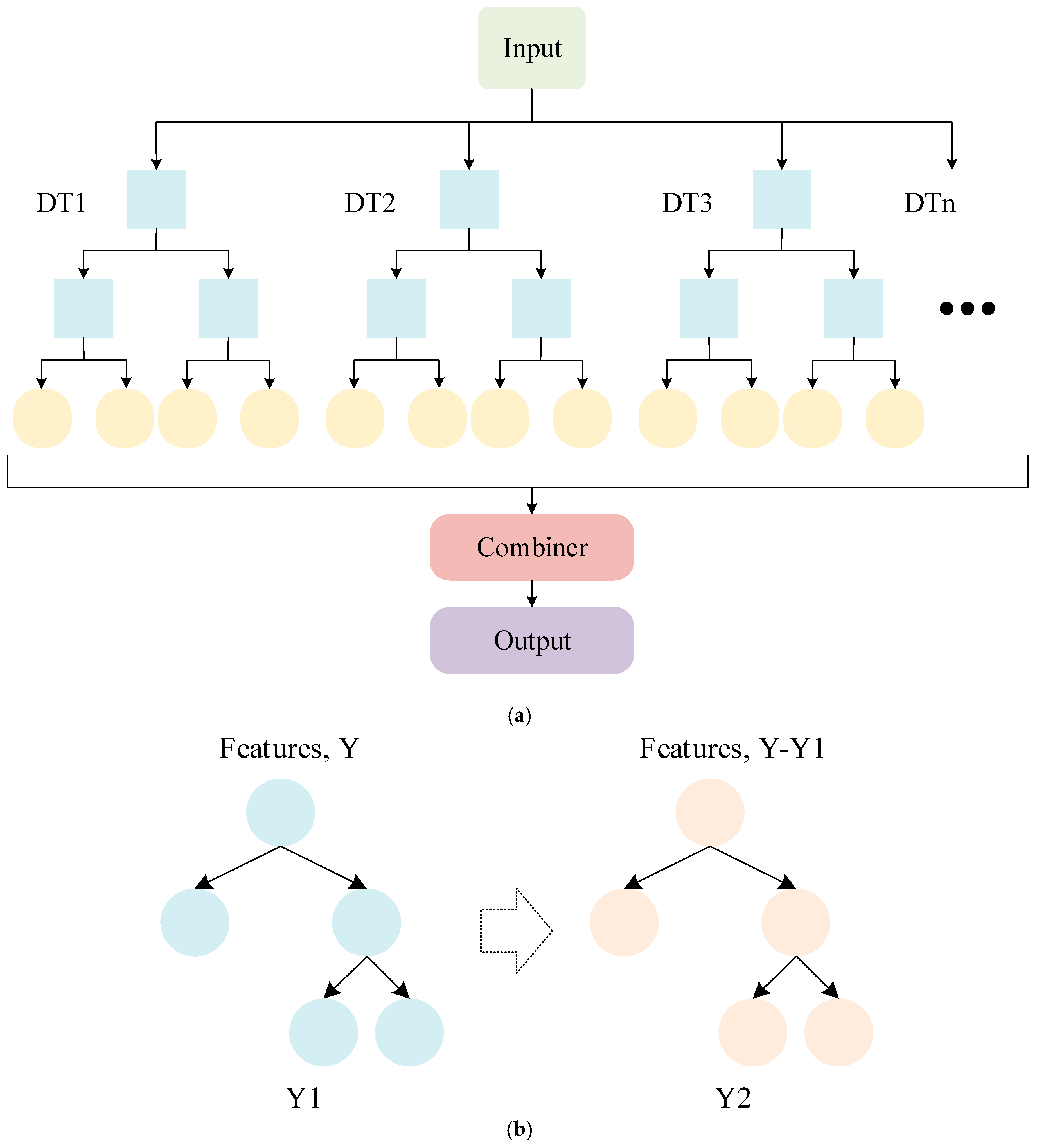
Ensemble learning combines multiple simple classifiers to form a model with stronger generalisation ability and better performance than when using individual classifiers alone, resulting in higher accuracy and robustness [
32]. RF is composed of multiple DTs, and the output result of each time is determined by multiple DTs. In classification tasks, the final classification is determined by selecting the class that the majority of DTs choose. However, RF needs to build multiple DTs, so it requires more computing resources and time overhead [
33]. GBDT is widely used in classification and prediction tasks, and it is composed of multiple DTs. During the model training process, continuous optimisation is conducted to improve the results of the previous tree, and the loss function is gradually used to fit the residuals, thereby improving the performance of the model [
34]. The ability of GBDT to optimise DTs each time enables it to achieve higher accuracy and stronger generalisation ability. It can also assess the significance of features based on the construction of DTs. However, the computational cost and parameter adjustment can be substantial. The structures of the RF and GBDT algorithms are shown in
Figure 3.
This study employed a grid search method with five-fold cross-validation to optimise the parameters of the RF and GBDT algorithms and determine the best parameters for each of the seven sensor placement positions. The optimal parameter combinations for these positions are detailed in
Table 4 and
Table 5. For GBDT, we explored a broad parameter space, including the learning rate (0.01, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3), the n_estimators (50, 100, 150, 200, 250, 300), the max tree depth (3, 5, 6, 7, 8, 9, 10), the subsample (0.5, 0.6, 0.7, 0.8, 0.9, 1.0) and the max features for splitting (Auto, sqrt, log2). For RF, the grid search covered the n_estimators (50, 100, 150, 200), max depth (None, 2, 6, 10), minimum samples required to split a node (2, 5, 10), minimum samples per leaf (1, 2, 5) and the maximum features for splitting (sqrt, log2).
2.5.3. Domain Adaptation
In traditional machine learning algorithms, it is often assumed that the distribution of one domain (source domain) is similar to that of another domain (target domain), and the source domain model is applied to the target domain. In this scenario, the source domain model exhibits good performance on the target domain. However, when there are disparities in the distribution between the source and target domains, it leads to rapid deterioration in model performance. Domain adaptation effectively addresses the issue of disparate distributions between the source and the target domains. It refers to the application of a model trained in the source domain to another related but different target domain. By learning the mapping relationship between the source domain and the target domain, the model gains better generalisation capabilities in the target domain and solves the problem of performance degradation caused by domain differences. The deep subdomain adaptation network (DSAN) is a deep learning algorithm designed to address disparities between domains. Unlike other domain adaptation methods that focus on global alignment, this algorithm adopts a more granular approach. This algorithm divides source domain data into multiple sub-domains by category and aligns the source and target domains with features in the sub-domains to reduce the deviation between the source and target domains. Lastly, the classifier is equipped with the ability to distinguish the features of the target domain and the source domain through adversarial training, thereby achieving domain adaptation. The core of the DSAN algorithm is to align the feature distributions of the same class in both the source and target domains through Local Maximum Mean Discrepancy (LMMD), as shown in Equation (2):
Here, and represent the feature representations of the source and target domains, while and represent the sub-domain distributions of class c in the source and target domains. This method measures the distribution difference between data, making the distributions of relevant sub-domains in the same class more similar.
Assuming classification can be achieved through the weights
between different samples, the formula can be expressed as Equation (3):
where
and
represent the weights of different classes, and
and
represent the weighted sums on class c.
The weight
is calculated using Equation (4):
where
represents the category label value of the
-th sample in the
-th sub-domain, and
represents the sum of the category label values of all samples in the dataset
in the
-th sub-domain.
To compute LMMD loss across multiple network feature layers, the source domain data is used with real labels, while the target domain data use soft labels predicted by the network. This can be expanded as shown in Equation (5):
where
and
represent the source and target domain features at layer
.
With reference to the structure of the DSAN network model [
35], this study removed the feature extraction part of the convolutional neural network and determined the optimal hyperparameter combination through the grid search method. The hyperparameters of the network are listed in
Table 6. For DSAN, we explored a broad hyperparameter space, including activation functions (ReLU, Leaky ReLU, ELU), optimisers (Adam, AdamW, RMSprop, SGD with momentum = 0.9), batch sizes (32, 64, 128, 256) and the number of neurons, among others. The Leaky ReLU is a variant of the ReLU activation function. The ReLU function outputs zero for all negative inputs, whereas the Leaky ReLU allows for a small negative slope in the negative region to prevent the neurons from becoming inactive. The Leaky ReLU improves the limitations of the traditional ReLU by introducing a small slope in the negative region, which is particularly beneficial in the backpropagation process to prevent the vanishing gradient problem. The formula for the Leaky ReLU is shown in Equation (6):
where 0 <
< 1.
The Leaky ReLU can alleviate the vanishing gradient problem and improve the generalisation ability of the model. By adjusting , the gradient size for negative inputs can be controlled.
The network structure diagram is shown in
Figure 4.
2.5.4. t-Distributed Stochastic Neighbour Embedding (t-SNE)
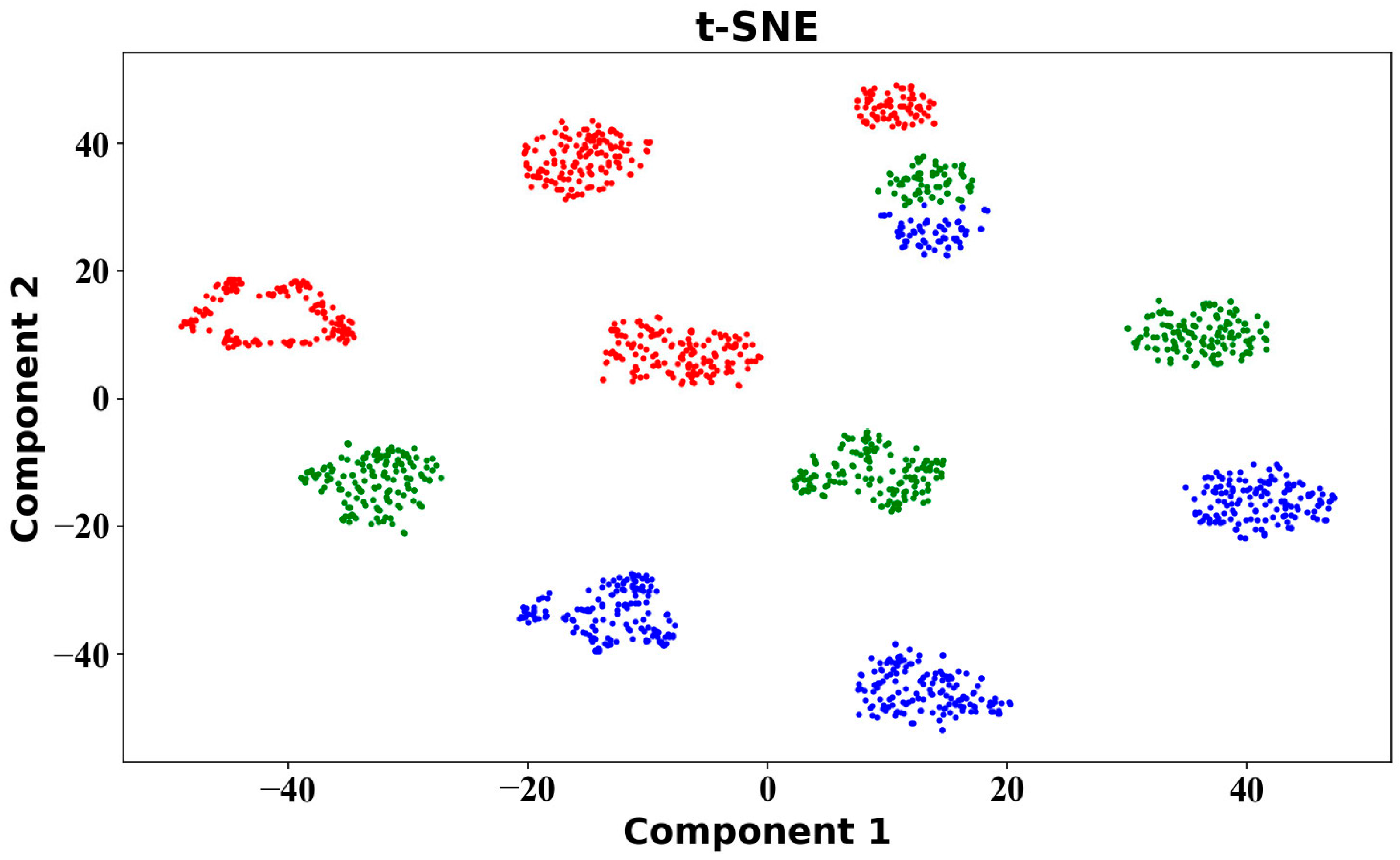
In this study, the sample set consists of high-dimensional data, and there is limited understanding of the data distribution, making it difficult to choose suitable algorithms. t-SNE can solve this problem. It enables the mapping of high-dimensional data to a lower-dimensional space through a non-linear process, maintaining similar relationships in high-dimensional spaces and thus achieving data dimensionality reduction [
36]. First, t-SNE calculates the probability
of point
in high-dimensional space under the condition of point
, with the calculation in Equation (7) as follows:
reflects the local scale parameter of point
, therefore achieving symmetry. The joint probability
is defined in Equation (8).
where
represents the number of data points.
In low-dimensional space, the similarity probability
of the data points is calculated using Equation (9).
Then, the optimal low-dimensional mapping is sought by minimising the Kullback–Leibler divergence between
and
, as shown in Equation (10):
This achieves the mapping of high-dimensional data to low-dimensional space while preserving the local structure of the original data, thus fulfilling the purpose of dimensionality reduction and visualisation.
4. Conclusions
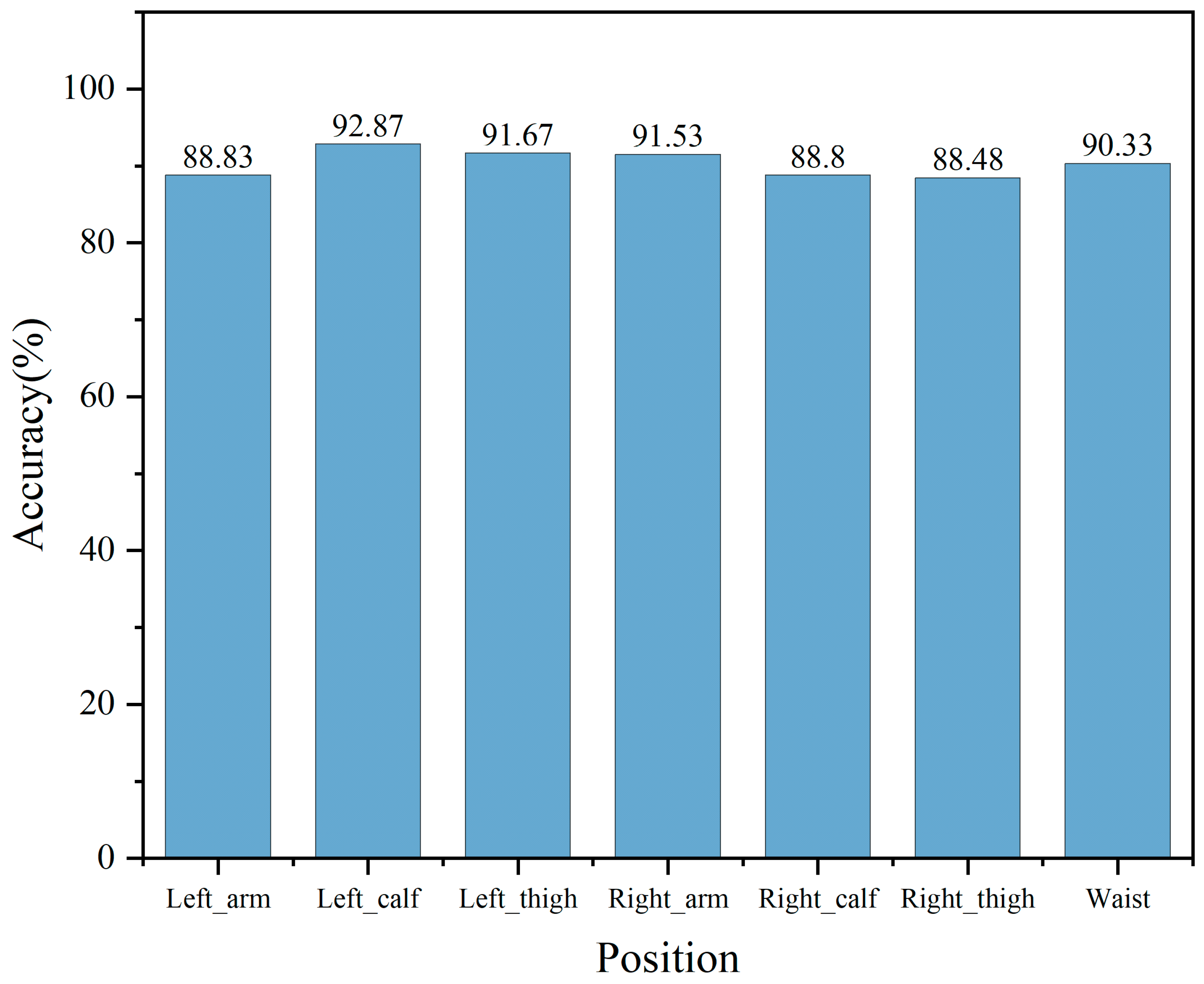
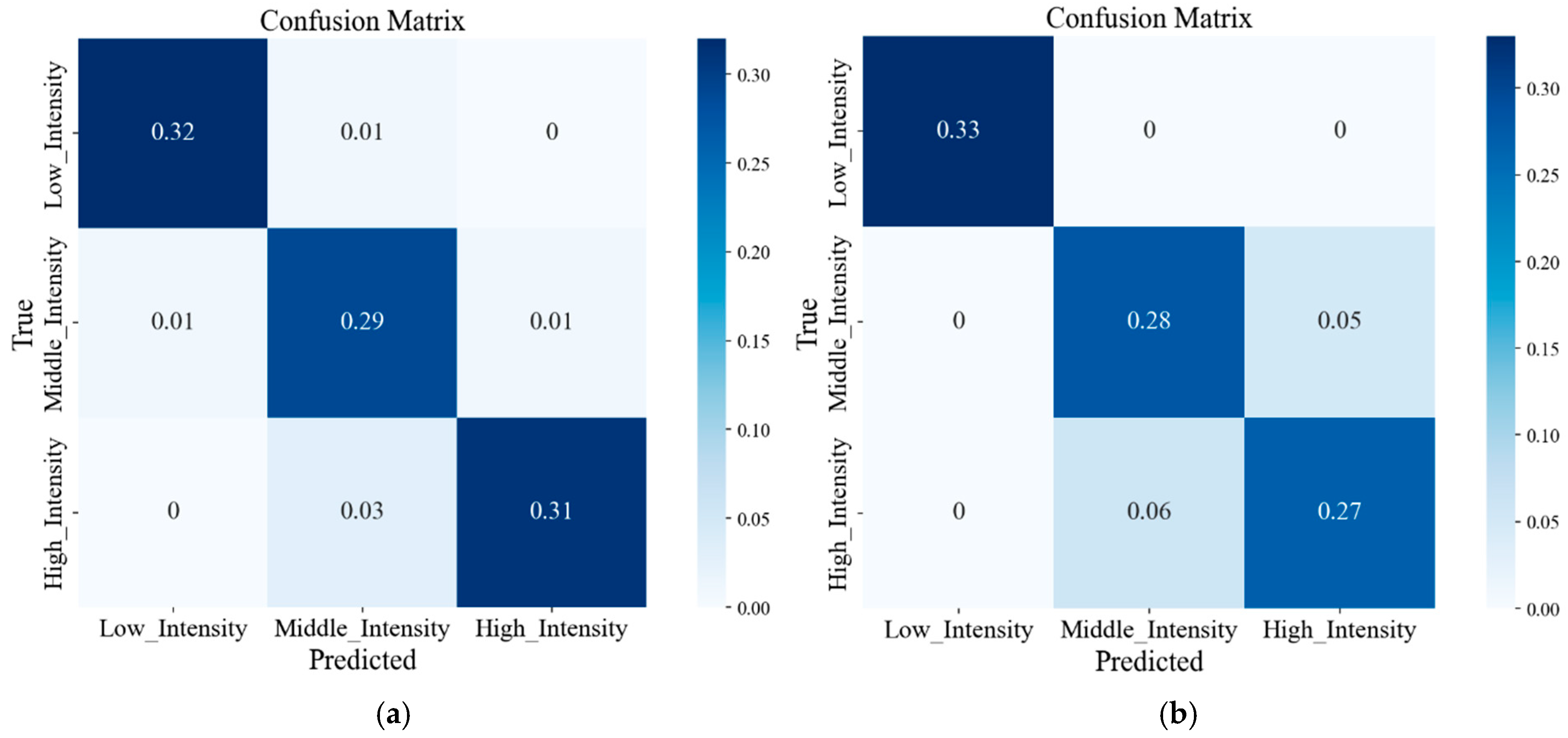
In daily life, exercise intensity is a crucial metric that people typically pay attention to during physical activities, and the accurate monitoring of low-, middle- and high-intensity exercises is of great significance to people’s health. Therefore, this study proposed to use easily collected multi-dimensional human body data to identify low-, middle- and high-intensity exercises. t-SNE visualisation results showed that the exercise data of most people do not conform to a unified distribution, indicating that individual differences have a certain impact on the data distribution. The use of classical machine learning algorithm models for cross-individual exercise intensity recognition showed poor performance. Meanwhile, the performance of ensemble learning algorithm models was slightly better than that of classical machine learning algorithm models. However, the accuracy exhibited a considerable gap compared to that when using the training set, indicating a difficulty for both ensemble learning and machine learning algorithms in handling cross-individual recognition. This is because their recognition premise is that the data follow a uniform distribution. The DSAN algorithm was capable of effectively handling data that did not conform to a uniform distribution. This algorithm represented a more fine-grained method, outperforming several other algorithm models, and the highest recognition rate reached 92.87%. Thus, DSAN excellently addressed the issue arising from individual variations. All algorithmic models consistently indicated that the recognition performance in the left body parts was superior to that in the right body parts. Simultaneously, misclassifications often occurred in middle- and high-intensity exercises, probably due to the subtle distinctions between middle- and high-intensity exercises. This study establishes a theoretical foundation and exhibits practical significance for the identification of exercise intensity through the combination of multi-dimensional sensors and domain adaptation methods.
This study has several limitations. First, the grading of exercise intensity is not sufficiently detailed. Second, the age range distribution of participants for data collection is relatively narrow. Third, the establishment of cross-individual exercise intensity recognition methods is not comprehensive enough. Therefore, in future studies, more detailed classifications of exercise intensity levels should be established, and data from more people should be collected for exercise intensity monitoring. Moreover, using additional feature extraction methods, more rich features can be extracted, and the cross-individual deep algorithm model can be optimised to achieve improved recognition effects.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}