
Few-Shot Optimization for Sensor Data Using Large Language Models: A Case Study on Fatigue Detection



Abstract
1. Introduction
- RQ1: How can the performance of few-shot prompting be improved for sensor-based classification tasks?Contribution 1: We explore the impact of optimized example selection strategies in few-shot prompting using wearable sensor data, highlighting challenges in generalization, variability, and signal ambiguity with a case study on fatigue detection.
- RQ2: How can the proposed HED-LM framework enhance example selection in few-shot prompting for sensor data?Contribution 2: We introduce HED-LM, a novel hybrid framework that integrates Euclidean distance filtering and LLM-based contextual scoring to select semantically and numerically relevant examples.
- RQ3: How does HED-LM compare to conventional example selection approaches such as random sampling and distance-based filtering in few-shot prompting?Contribution 3: We show that HED-LM improves few-shot prompting performance over conventional methods. Compared to random and distance-based selection, HED-LM achieves relative macro F1-score improvements of 16.6% and 2.3%, respectively, demonstrating the advantage of combining numerical similarity and contextual relevance in selecting examples.
2. Related Work
2.1. Few-Shot Optimization
2.2. Few-Shot Prompting on Sensor Data
2.2.1. General Challenges in Sensor Data for Few-Shot Prompting
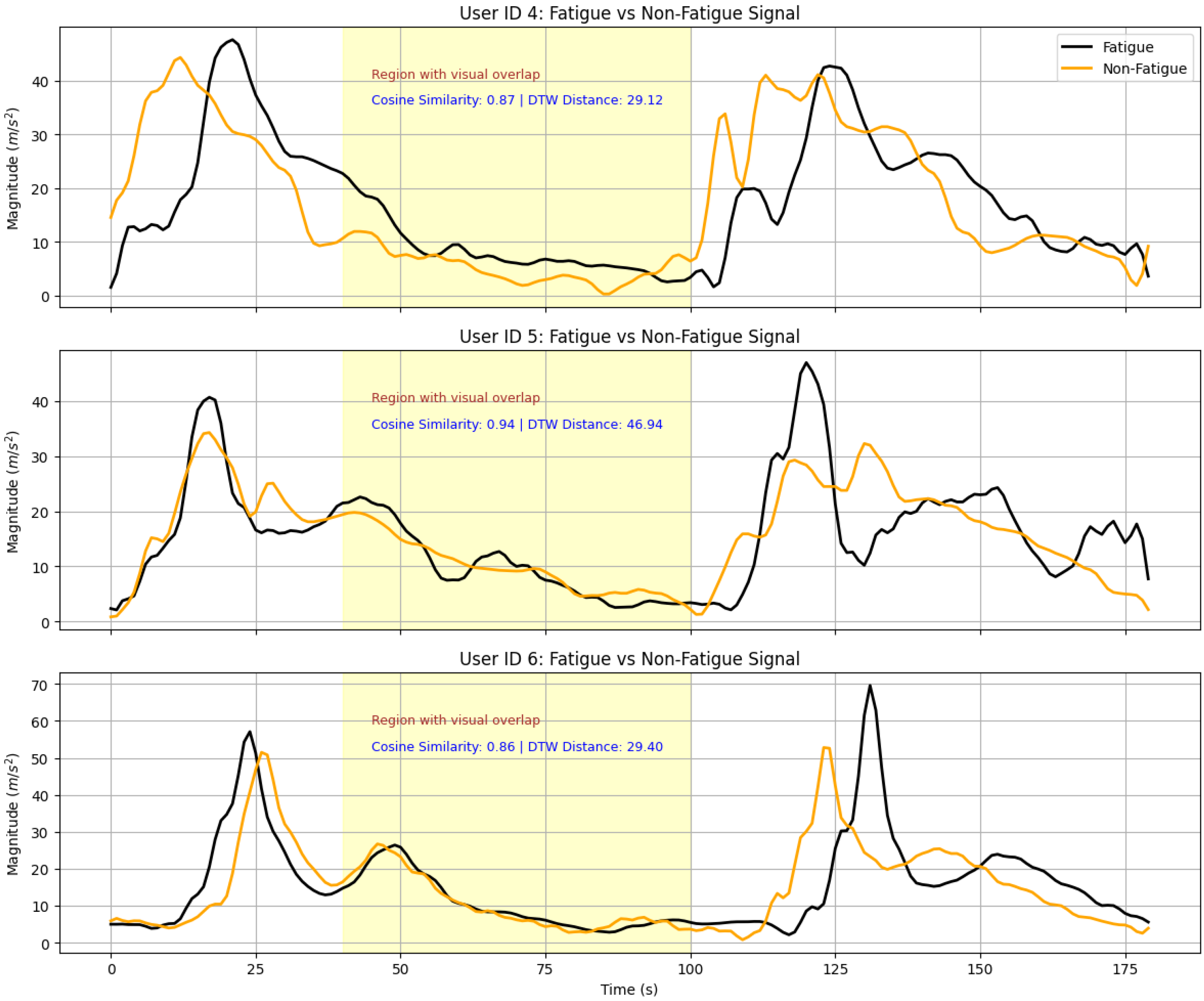
2.2.2. Fatigue Detection as a Representative Case Study
2.3. Challenges and Motivations
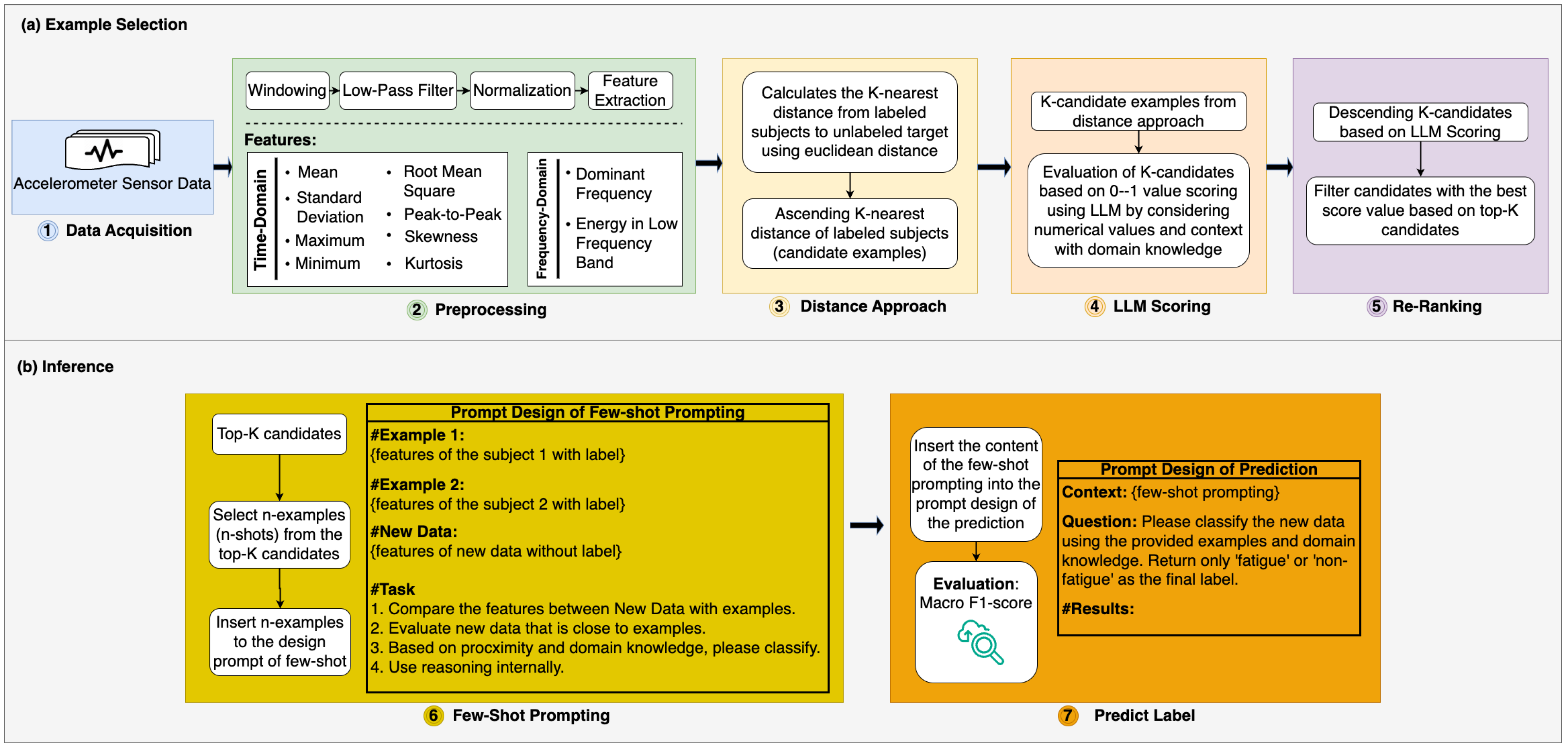
3. Proposed Method
3.1. Data Acquisition
3.2. Preprocessing
- Time-Domain Features: include mean, standard deviation, max and min values, root mean square (RMS), skewness, kurtosis, and peak-to-peak values, highlighting statistical and energetic properties.
- Frequency-Domain Features: computed using Fast Fourier Transform (FFT), these include dominant frequency and low-frequency energy, reflecting motion’s spectral characteristics.
3.3. Distance-Based Filtering in Candidate Selection
3.4. LLM Scoring for Contextual Candidate Evaluation
- Structuring Prompts for Effective Contextual Reasoning. Structured prompts are created for each candidate–new subject pair to facilitate accurate evaluations. These prompts are designed with three essential components:
- Numeric Features: Each prompt provides statistical metrics and frequency-based characteristics extracted from the three signal segments (e.g., segment 1, segment 2, and segment 3). These features represent the signal’s critical characteristics.
- Labeled Subject (Old Subject Label): The candidate subject’s label (e.g., fatigue or non-fatigue) offers a basis for comparison with the new subject.
- LLM Guidance: Specific instructions to direct the reasoning process, such as “Please compare the numeric data segment by segment. If the differences in Mean, Std, RMS etc. are very small ⇒ high relevance. Also check whether the labeled subject labels (Fatigue/Non-Fatigue) are aligned with the numeric pattern of the new subject”.
This structured approach ensures that the LLM provides all necessary information for a detailed and comprehensive assessment, minimizing ambiguity in its evaluation process. - Assigning Relevance Scores with Justifications. The LLM assesses the relevance of each candidate–new subject pair by assigning a score ranging from 0 to 1, where higher scores reflect more substantial alignment between the candidate’s label and the new subject’s signal patterns. An explanation accompanies each score, adding transparency and interpretability to the process. The output format follows a consistent template:
- Score: A numerical value indicating relevance (e.g., SCORE: 0.90).
- Reason: A concise justification, e.g.,: “Segments 1 and 2 exhibit high similarity in RMS values; the label ‘fatigue’ is appropriate due to elevated RMS levels in these segments”.
This dual output format ensures that each decision is well supported, combining numeric analysis with contextual reasoning. By leveraging the LLM’s chain-of-thought reasoning, the scoring mechanism provides a nuanced understanding of the relationships between signal features and labels. - Contextual Label Synergy for Accurate Evaluations. A critical aspect of the scoring process is the assessment of label synergy, where the LLM evaluates how well the candidate’s label aligns with the new subject’s signal characteristics. For instance:
- If a labeled subject’s signal (e.g., “fatigue”) aligns with the numeric patterns of the new subject (e.g., high RMS values in segments 2 and 3), a high relevance score is assigned.
- Conversely, if the labeled subject’s label is “non-fatigue” but the new subject exhibits fatigue-like patterns, the relevance score is reduced, even in high numeric similarity.
This contextual evaluation is formalized in Equation (7) as follows:where is the feature vector on the labeled subject; is the feature vector on the new subject (unlabeled subject); is the labeled subject; measures numerical differences in features such as mean, RMS, etc.; evaluates the alignment of the old subject’s label with the new subject’s signal pattern; and represents the LLM’s reasoning process. The LLM scoring mechanism enhances the precision of candidate selection for few-shot prompting by combining numerical comparisons with label alignment.
3.5. Re-Ranking
- : feature vector of the new subject.
- : feature vector of a labeled candidate within the closest subjects.
- : relevance score assigned by the LLM, reflecting numeric similarity and label alignment.
- : a function that indexes candidates in descending order of their LLM scores and selects the top-K candidates.
3.6. Few-Shot Prompt
- Numeric Data Summary: a concise representation of extracted features from the three signal segments (Segment 1, Segment 2, and Segment 3).
- Relevance Score and Reason: the relevance score assigned during the LLM scoring stage and a brief explanation of why the example aligns contextually with the new subject.
- Label Conclusion: a definitive statement summarizing the example’s label, such as “Conclusion: The label is fatigue” or “Conclusion: The label is non-fatigue”.
- P is the prompt that combines two labeled examples and one unlabeled target.
- Shot-1 and Shot-2 provide the LLM with explicit references to numerical patterns and their associated labels.
- The new data serve as the input for the LLM’s final label prediction.
3.7. Predict Label
- Calling the LLM for Label Prediction. The finalized prompt, including the two most contextually relevant examples (2-shot) and the new subject’s unlabeled numeric data, is submitted to the LLM with explicit instructions. The LLM’s task is to generate a concise, single-word output, either “fatigue” or “non-fatigue”, to ensure focus and eliminate unnecessary verbosity. The process can be represented in Equation (10) as:where P is the constructed prompt containing the selected examples and the new subject’s numeric data. This approach ensures that the LLM remains focused on label prediction, using the provided examples to make an informed decision based on numerical and contextual relevance.
- Parsing the LLM’s Response. The output of the LLM is parsed to extract the final label:
- If the response is “fatigue”, the new subject is labeled “fatigue”.
- If the response is “non-fatigue”, the new subject is labeled “non-fatigue”.
In cases where the LLM produces an ambiguous response (e.g., “I believe it is non-fatigue, but maybe fatigue?”), a fallback mechanism is employed. This involves analyzing the frequency of “fatigue” and “non-fatigue” in the LLM’s output. The label with the higher frequency is selected, ensuring systematic resolution of ambiguity without compromising the consistency of the prediction process. - Mapping Numeric Data to Labels. The overall label prediction process can be formalized mathematically in Equation (11) as follows:where:
- : Feature vector of the new subject.
- prompt shots: The labeled examples are provided in the few-shot prompt.
- : Function selecting the label (“fatigue” or “non-fatigue”) with the highest confidence or frequency.
This representation captures the relationship between the new subject’s numeric data, the prompt examples, and the LLM’s output. It formalizes the label prediction process as a function of both prompt design and the LLM’s reasoning capabilities.
| Algorithm 1 HED-LM Algorithm with k-shot Examples |
| Require: File Path (), Distance (), Top-K ( Require: Domain Knowledge (DK), Few-Shot Examples ()
|
4. Experiments
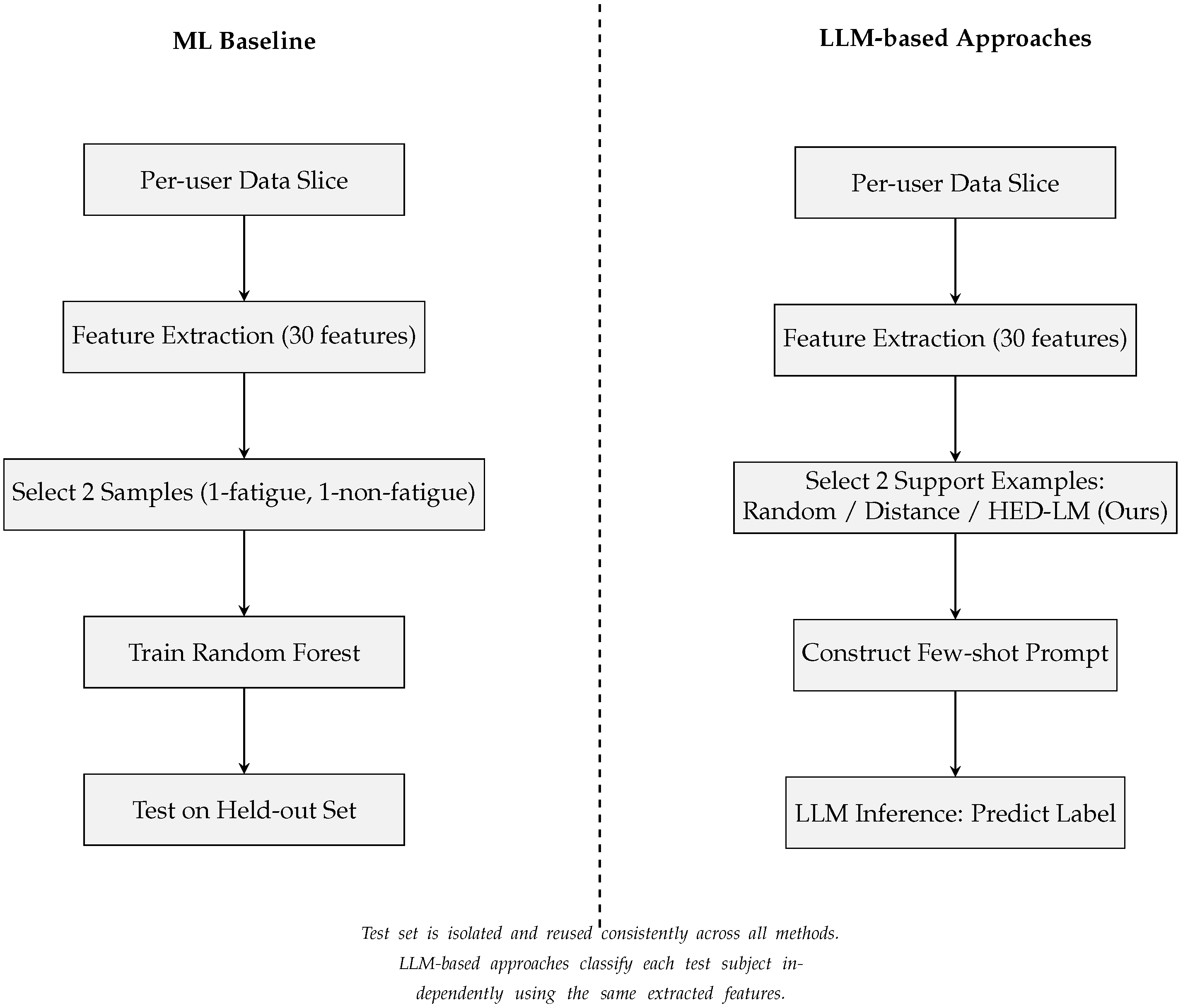
4.1. Experimental Setup
- Testing the effectiveness of our approach. We intend to examine whether the end-to-end framework of our approach can improve the classification of physical fatigue detection compared to three baselines: (a) traditional machine learning, (b) randomized approach, and (c) distance approach.
- Assessing the role of domain knowledge. We also investigate how the influence of domain knowledge inserted in the LLM scoring and prediction process can affect the relevance assessment of the original subject to the new subject so that the final label becomes more precise in performance.
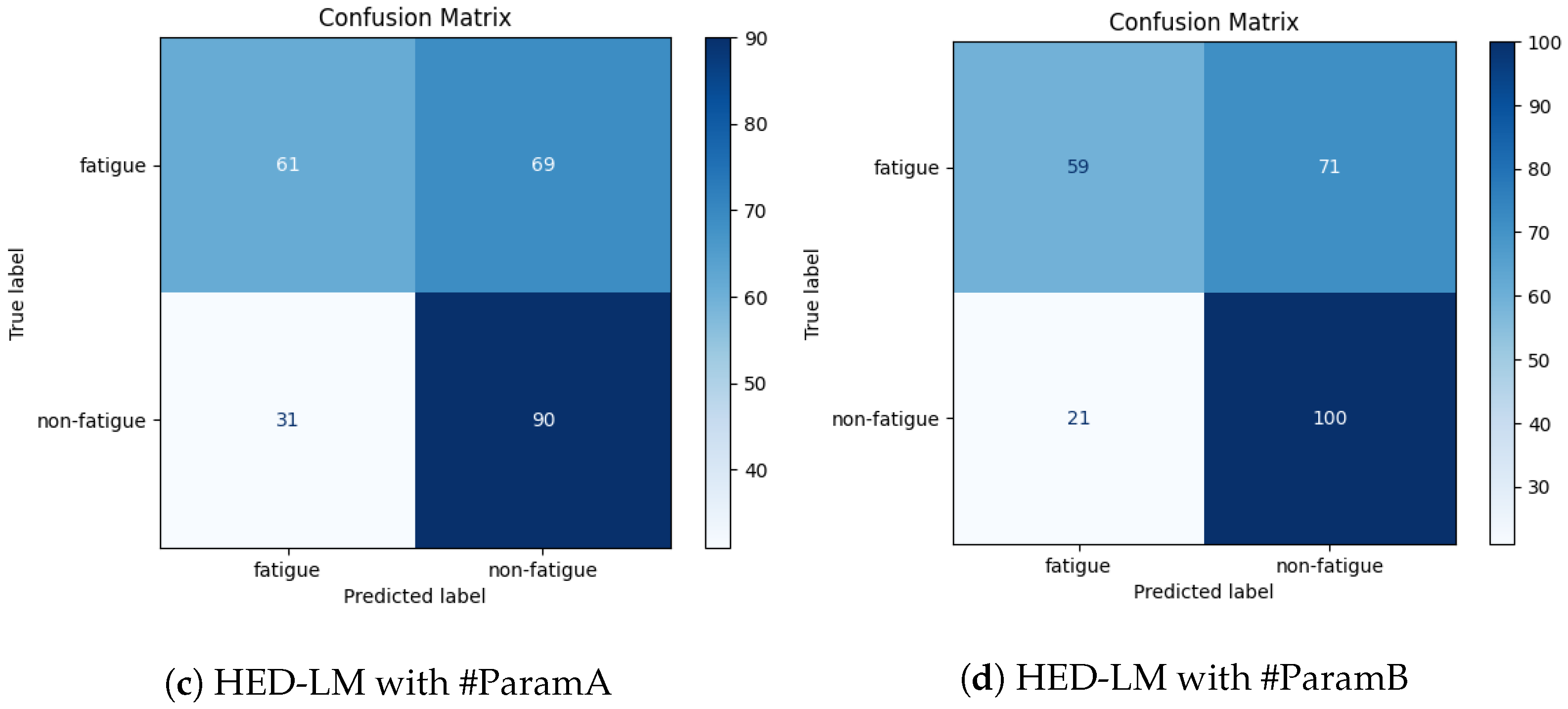
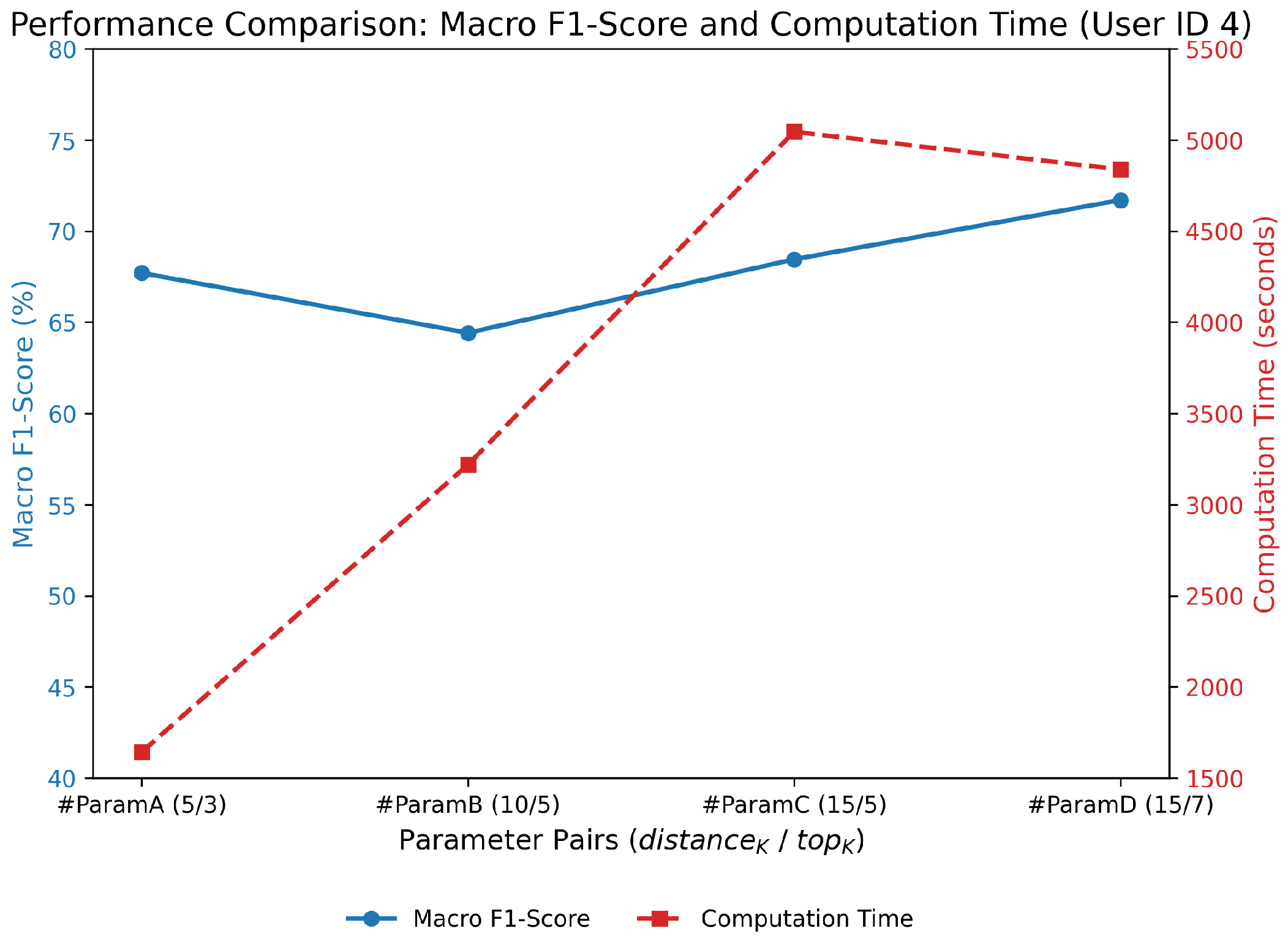
- #ParamA has a distance parameter setting and LLM scoring that uses Euclidean distance with , meaning we only take the five closest subjects as candidates and perform LLM scoring with , which only takes the three best candidates from the five candidate distance approach based on integrated relevance assessment with domain knowledge.
- #ParamB has distance and LLM scoring parameter settings, namely using Euclidean distance with , meaning that we only take the ten closest subjects as candidates and perform LLM scoring with , which only takes the five best candidates from ten distance approach candidates based on integrated relevance assessment with domain knowledge.
- Traditional Machine Learning (ML): We used a Random Forest classifier trained on 30 features, namely eight time-domain statistical features and two frequency-domain features, which were calculated across three equally sized segments per input trace from raw accelerometer data. It does not involve any prompting or interaction with large language models. The inference is conducted locally, making it an LLM-independent, fully offline baseline.
- Random Approach: A random selection of examples is incorporated into few-shot prompting with an API GPT-4o-mini model (OpenAI, San Francisco, CA, USA; accessed in March 2025), temperature = 0.3, and added domain knowledge information generated with the GPT-4o model (OpenAI, San Francisco, CA, USA; accessed in March 2025).
- Distance Approach: Using Euclidean distance only (KNN-based), subjects with numerically close distances are input examples into few-shot prompting with GPT-4o-mini model (OpenAI, San Francisco, CA, USA; accessed in March 2025) and temperature = 0.3, adding domain knowledge information generated with the GPT-4o model (OpenAI, San Francisco, CA, USA; accessed in March 2025).
- Our proposed method, HED-LM (Hybrid Euclidean Distance with Large Language Models), filters distance-based similarity and then ranks the selected examples based on contextual relevance scored by an LLM before constructing the prompt.
4.2. Experimental Results
4.2.1. Impact of Distance-K and Top-K Parameters
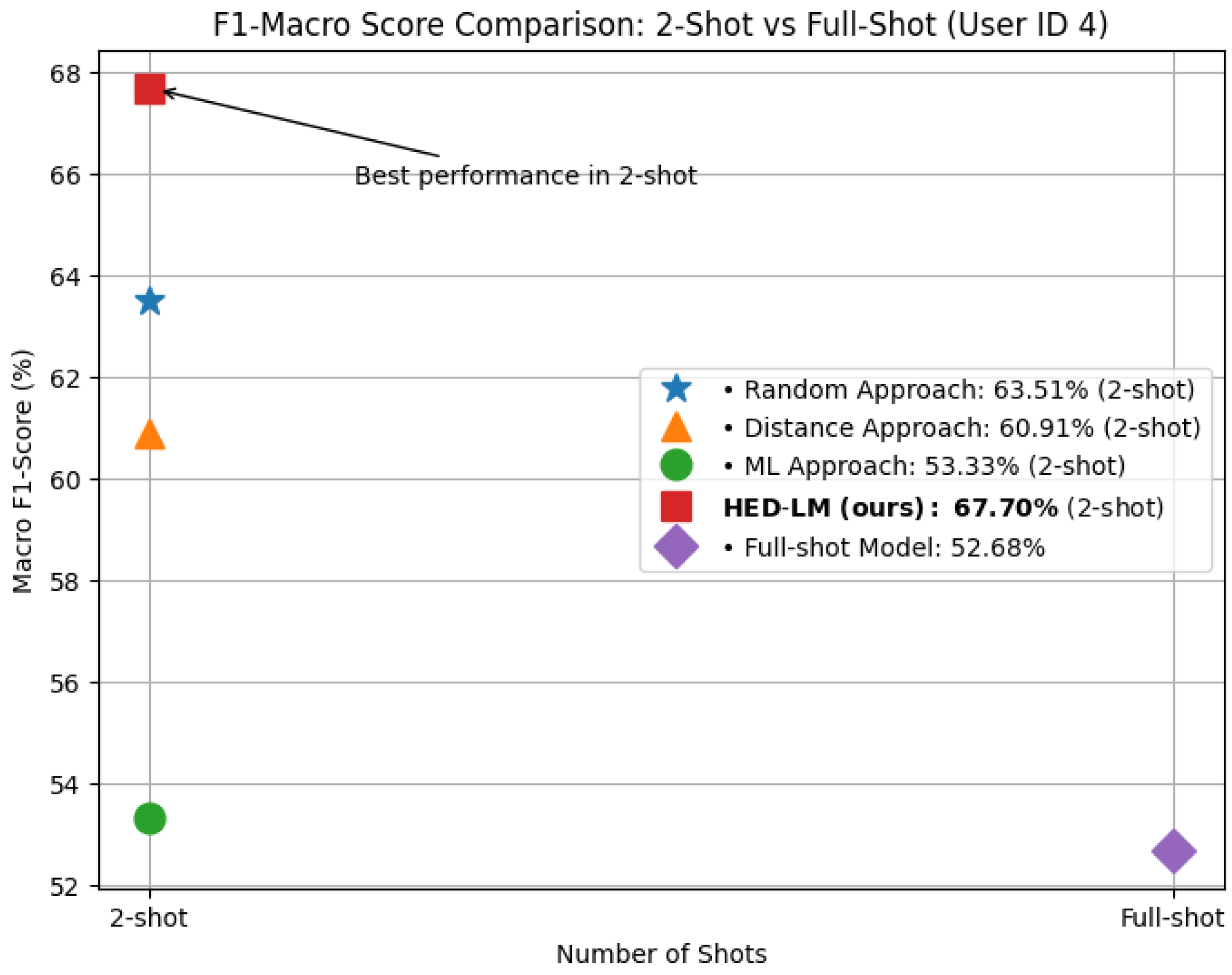
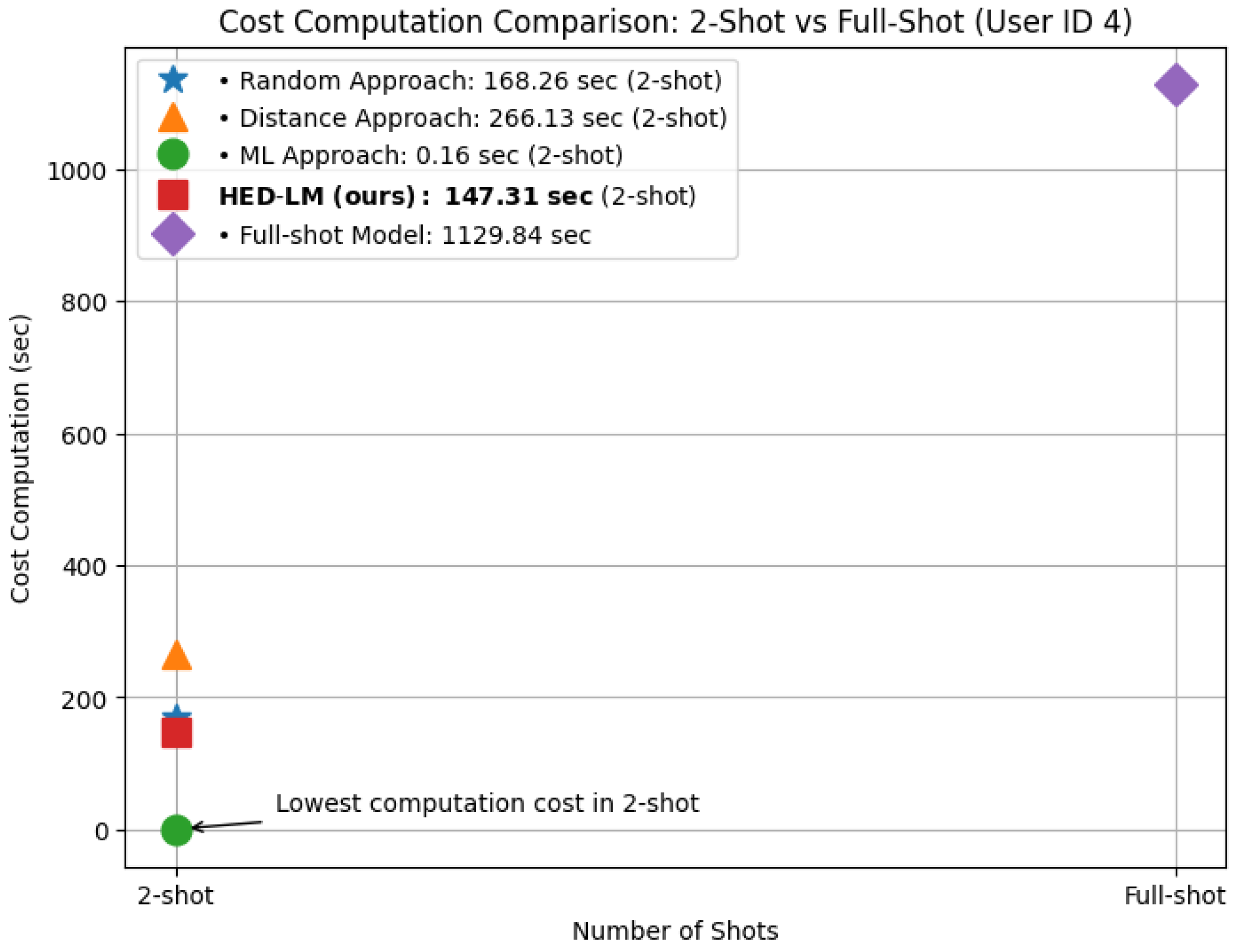
4.2.2. Effect of the Number of Shots in Few-Shot Prompting
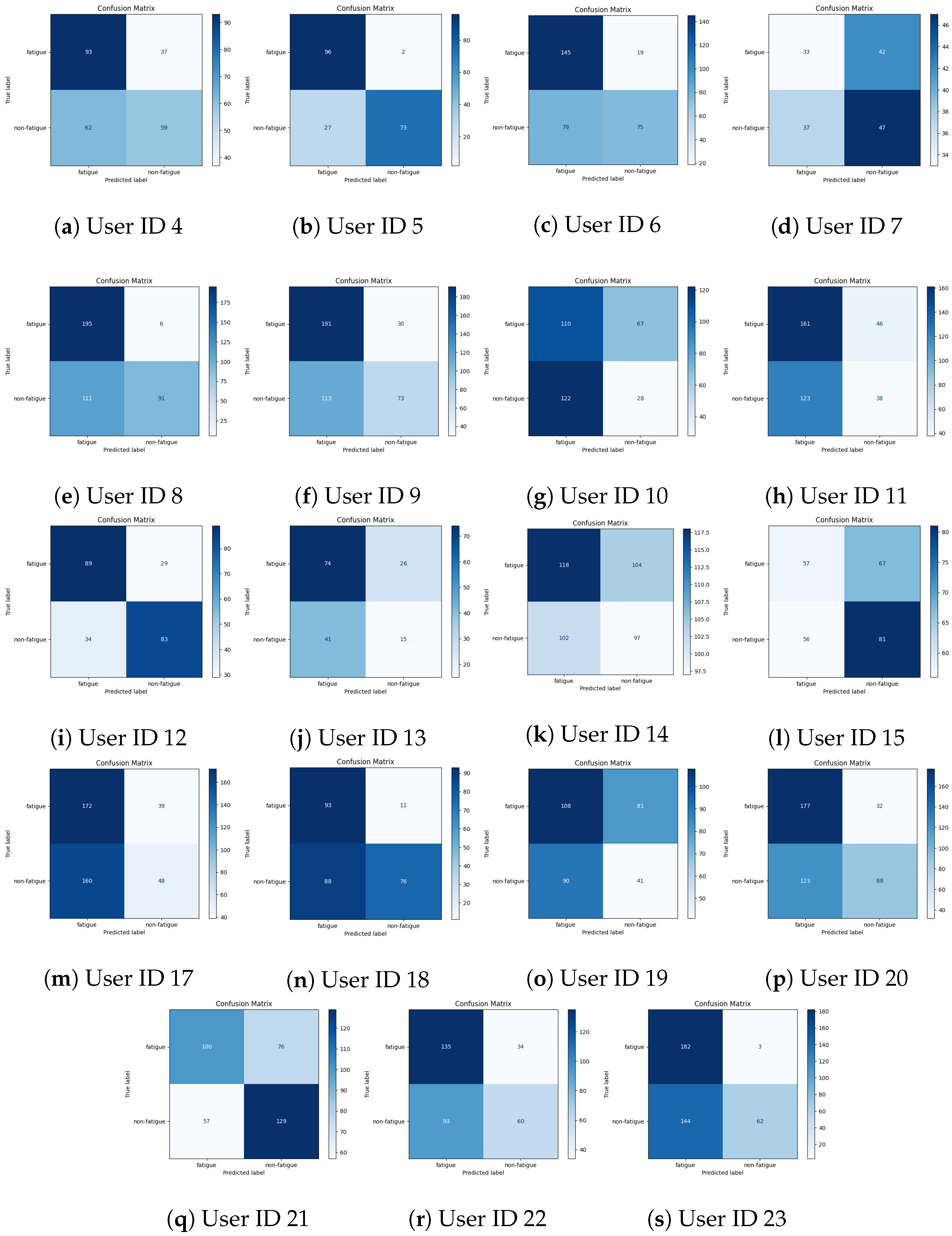
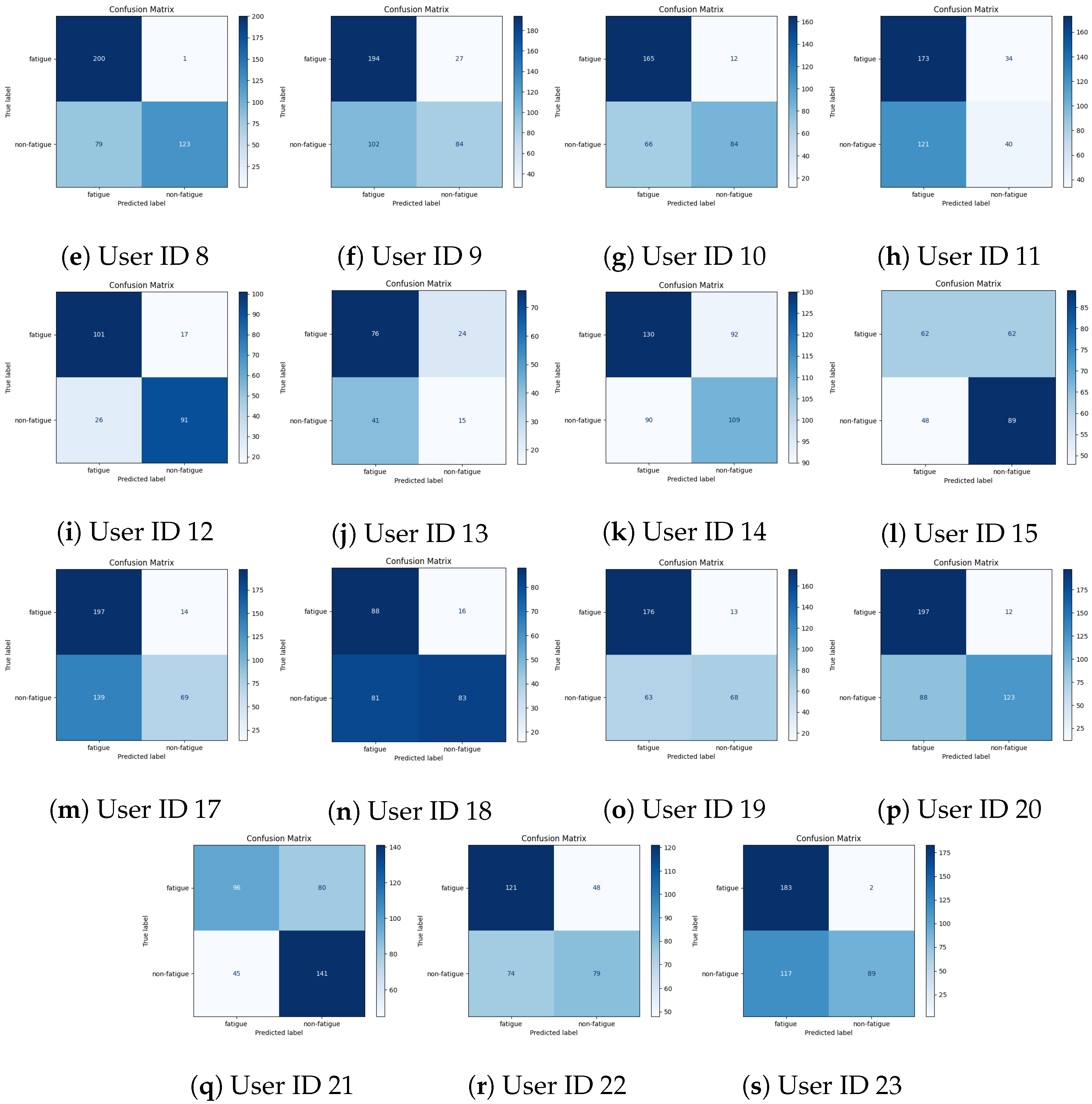
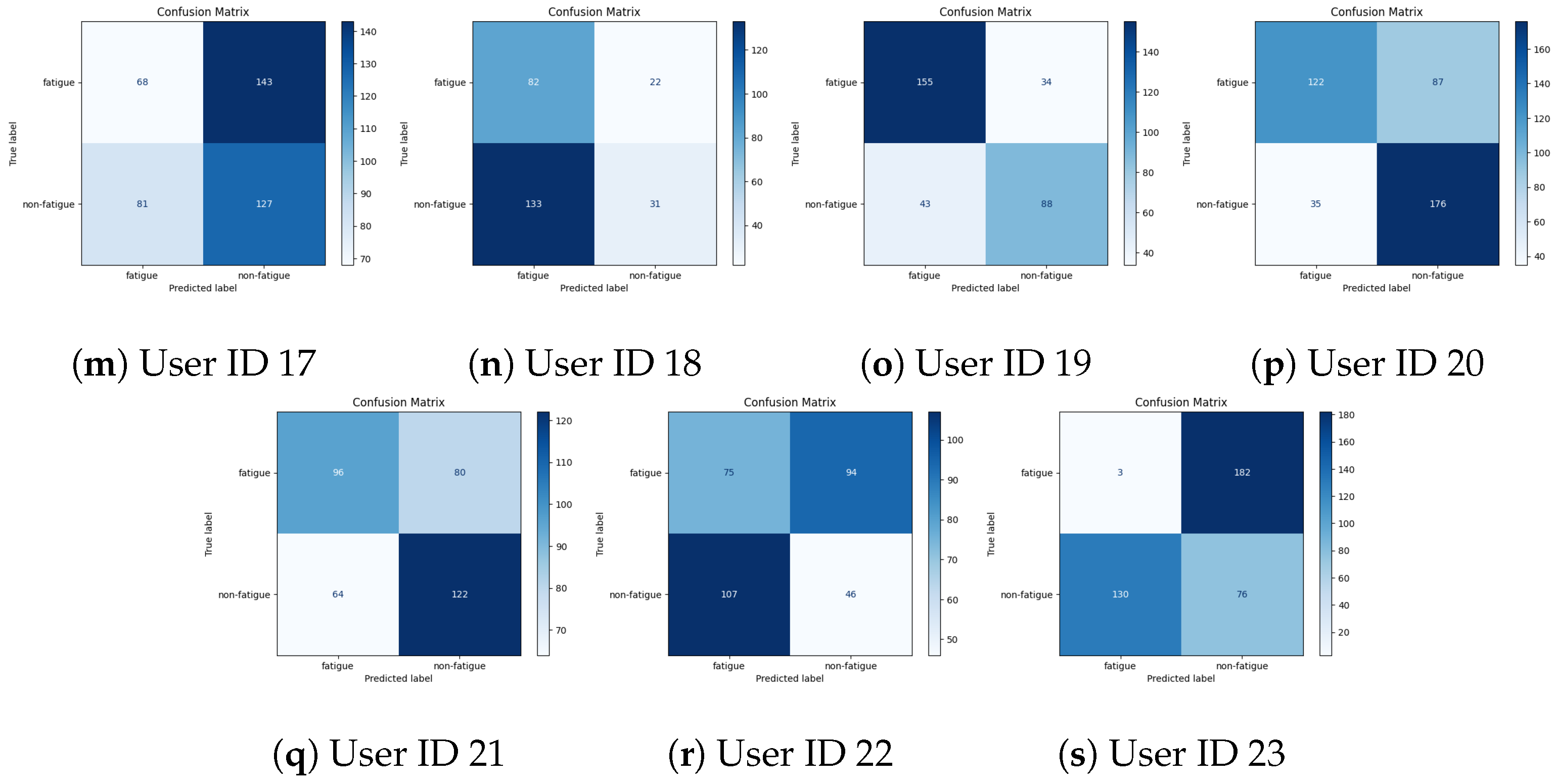
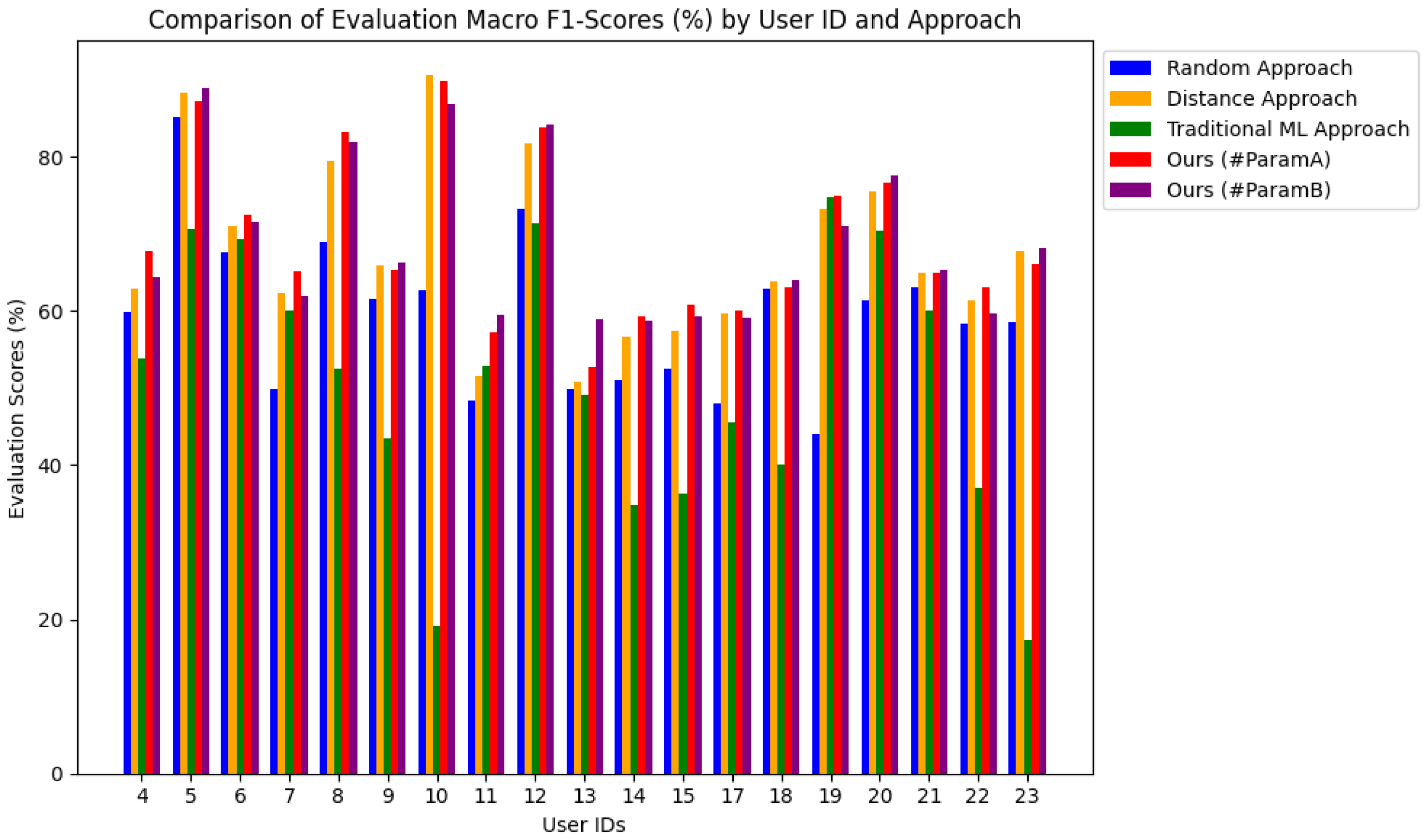
4.2.3. Per-User Performance Evaluation
4.2.4. Contribution of Domain Knowledge in Prompting
5. Discussion
5.1. Comparative Performance Overview
- Random vs. Distance (p = 0.0076) and Random vs. HED-LM (p < 0.0001) show that the Random method has a significant difference compared to Distance, HED-LM #ParamA, and HED-LM #ParamB.
- Random vs. ML (p = 0.9727) showed no significant difference, implying that both methods are relatively less accurate than the other groups.
- Distance vs. ML (p = 0.0007) was significantly different, highlighting that Distance was clearly better than ML.
- Distance vs. HED-LM #ParamA /HED-LM #ParamB (p > 0.05) was not significantly different; neither was HED-LM #ParamA vs. HED-LM #ParamB (p ≈ 1.0). This indicates that the three methods (Distance, HED-LM #ParamA, and HED-LM #ParamB) are potentially in roughly equal performance clusters.
- ML vs. HED-LM #ParamA/HED-LM #ParamB (p < 0.0001) is significantly different, indicating HED-LM #ParamA and HED-LM #ParamB are statistically superior to ML.
- Random and ML belong to lower-performing or unstable clusters; they are not significantly different from each other but clearly differentiate against other better methods.
- Distance, HED-LM #ParamA, and HED-LM #ParamB all form high-performance clusters that are not significantly different from each other. A p-value > 0.05 for each pair indicates there is no statistical evidence that one is truly superior.
- Overall, these results validate our initial findings—that both hybrid methods (HED-LM #ParamA and HED-LM #ParamB) and the Distance approach perform better than Random or ML.
- > 0 means the method to the left of “vs.” (e.g., “X vs. Y”) tends to be superior.
- < 0 means the method to the right of “vs.” is superior.
- 0.47–0.50 is often interpreted as a large effect, implying substantial differences in practice.
- Superior Cluster: Distance, HED-LM #ParamA, and HED-LM #ParamB
- Cliff’s Delta shows values close to zero when these three methods are compared against each other. For example, Distance vs. HED-LM #ParamA ( = −0.097) and Distance vs. HED-LM #ParamB ( = −0.053), which are each classified as negligible effects ( < 0.1). Similarly, HED-LM #ParamA vs. HED-LM #ParamB ( = 0.042), so there is no strong indication that one of the three stands out significantly from the others.
- In other words, within this superior cluster, the performance of Distance, HED-LM #ParamA, and HED-LM #ParamB were relatively balanced according to effect size, in line with the post hoc results, which also stated that they were not significantly different.
- Lower Cluster: Random and ML
- The inter-method comparison in this cluster also shows relatively close results (Random vs. ML: = 0.274, small–medium effect), indicating Random is slightly better but not too far behind ML.
- It is when these two methods are compared with the methods in the superior cluster that large effects are seen. For example, Random vs. HED-LM #ParamA ( = −0.524) and Random vs. HED-LM #ParamB ( = −0.485) confirm that HED-LM #ParamA and HED-LM #ParamB are far superior to Random. In addition, Distance vs. ML ( = 0.562) illustrates a significant difference with a large effect to support the superiority of Distance. A value of above 0.47 indicates a truly different performance in practical terms, not just statistically significant.
5.2. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| SD | Standard Deviation |
| GPT | Generative Pre-trained Transformer |
| HED-LM | Hybrid Edit Distance–Language Model |
| KNN | K-Nearest Neighbors |
| LLM | Large Language Model |
| LLMs | Large Language Models |
| ML | Machine Learning |
| RMS | Root Mean Square |
Appendix A
Appendix A.1


Appendix A.2




Appendix A.3



Appendix A.4





References
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Izacard, G.; Lewis, P.; Lomeli, M.; Hosseini, L.; Petroni, F.; Schick, T.; Dwivedi-Yu, J.; Joulin, A.; Riedel, S.; Grave, E. Atlas: Few-shot Learning with Retrieval Augmented Language Models. arXiv 2022, arXiv:2208.03299. [Google Scholar]
- Lin, X.V.; Mihaylov, T.; Artetxe, M.; Wang, T.; Chen, S.; Simig, D.; Ott, M.; Goyal, N.; Bhosale, S.; Du, J.; et al. Few-shot Learning with Multilingual Generative Language Models. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 9019–9052. [Google Scholar]
- Cao, K.; Brbic, M.; Leskovec, J. Concept Learners for Few-Shot Learning. arXiv 2021, arXiv:2007.07375. [Google Scholar]
- Qin, X.; Song, X.; Jiang, S. Bi-Level Meta-Learning for Few-Shot Domain Generalization. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 15900–15910. [Google Scholar] [CrossRef]
- Gao, T.; Fisch, A.; Chen, D. Making Pre-trained Language Models Better Few-shot Learners. arXiv 2021, arXiv:2012.15723. [Google Scholar]
- Sclar, M.; Choi, Y.; Tsvetkov, Y.; Suhr, A. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Adiga, R.; Subramanian, L.; Chandrasekaran, V. Designing Informative Metrics for Few-Shot Example Selection. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 10127–10135. [Google Scholar] [CrossRef]
- Shin, J.; Kang, Y.; Jung, S.; Choi, J. Active Instance Selection for Few-Shot Classification. IEEE Access 2022, 10, 133186–133195. [Google Scholar] [CrossRef]
- Feng, S.; Duarte, M.F. Few-Shot Learning-Based Human Activity Recognition. arXiv 2019, arXiv:1903.10416. [Google Scholar] [CrossRef]
- Ronando, E.; Inoue, S. Leveraging Large Language Models to Enhance Understanding of Accelerometer Data on Physical Fatigue Detection Question Answering. In Proceedings of the 112th Mobile Computing and New Social Systems, 83rd Ubiquitous Computing Systems, 41st Consumer Devices & Systems, 30th Aging Society Design Joint Research, Matsuyama, Japan, 26–27 September 2024; pp. 1–8. [Google Scholar]
- Fan, Y.; Yang, D.; He, X. CTYUN-AI at SemEval-2024 Task 7: Boosting Numerical Understanding with Limited Data Through Effective Data Alignment. In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), Mexico City, Mexico, 20–21 June 2024; Ojha, A.K., Doğruöz, A.S., Tayyar Madabushi, H., Da San Martino, G., Rosenthal, S., Rosá, A., Eds.; pp. 47–52. [Google Scholar] [CrossRef]
- Spathis, D.; Kawsar, F. The first step is the hardest: Pitfalls of Representing and Tokenizing Temporal Data for Large Language Models. J. Am. Med. Inform. Assoc. JAMIA 2023, 31, 2151–2158. [Google Scholar] [CrossRef]
- Hota, A.; Chatterjee, S.; Chakraborty, S. Evaluating Large Language Models as Virtual Annotators for Time-series Physical Sensing Data. ACM Trans. Intell. Syst. Technol. 2024, 1–25. [Google Scholar] [CrossRef]
- Li, Z.; Deldari, S.; Chen, L.; Xue, H.; Salim, F.D. SensorLLM: Aligning Large Language Models with Motion Sensors for Human Activity Recognition. arXiv 2024, arXiv:2410.10624. [Google Scholar]
- Jeworutzki, A.; Schwarzer, J.; Von Luck, K.; Stelldinger, P.; Draheim, S.; Wang, Q. Small Data, Big Challenges: Pitfalls and Strategies for Machine Learning in Fatigue Detection. In Proceedings of the 16th International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 5–7 July 2023; PETRA ’23. pp. 364–373. [Google Scholar] [CrossRef]
- Zhao, T.Z.; Wallace, E.; Feng, S.; Klein, D.; Singh, S. Calibrate Before Use: Improving Few-Shot Performance of Language Models. arXiv 2021, arXiv:2102.09690. [Google Scholar]
- Cai, W.; Louise, C. Sensorimotor distance: A grounded measure of semantic similarity for 800 million concept pairs. Behav. Res. Methods 2022, 55, 3416–3432. [Google Scholar] [CrossRef]
- Shi, Y.; Wu, X.; Lin, H. Knowledge Prompting for Few-shot Action Recognition. arXiv 2022, arXiv:2211.12030. [Google Scholar]
- Jin, W.; Cheng, Y.; Shen, Y.; Chen, W.; Ren, X. A Good Prompt Is Worth Millions of Parameters: Low-resource Prompt-based Learning for Vision-Language Models. arXiv 2022, arXiv:2110.08484. [Google Scholar]
- Min, S.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Noisy Channel Language Model Prompting for Few-Shot Text Classification. arXiv 2022, arXiv:2108.04106. [Google Scholar]
- Aguirre, C.; Sasse, K.; Cachola, I.; Dredze, M. Selecting Shots for Demographic Fairness in Few-Shot Learning with Large Language Models. arXiv 2023, arXiv:2311.08472. [Google Scholar]
- Cegin, J.; Pecher, B.; Simko, J.; Srba, I.; Bielikova, M.; Brusilovsky, P. Use Random Selection for Now: Investigation of Few-Shot Selection Strategies in LLM-based Text Augmentation for Classification. arXiv 2024, arXiv:2410.10756. [Google Scholar]
- Perez, E.; Kiela, D.; Cho, K. True Few-Shot Learning with Language Models. arXiv 2021, arXiv:2105.11447. [Google Scholar]
- Chang, E.; Shen, X.; Yeh, H.S.; Demberg, V. On Training Instance Selection for Few-Shot Neural Text Generation. arXiv 2021, arXiv:2107.03176. [Google Scholar]
- Margatina, K.; Schick, T.; Aletras, N.; Dwivedi-Yu, J. Active Learning Principles for In-Context Learning with Large Language Models. arXiv 2023, arXiv:2305.14264. [Google Scholar]
- Yao, B.; Chen, G.; Zou, R.; Lu, Y.; Li, J.; Zhang, S.; Sang, Y.; Liu, S.; Hendler, J.; Wang, D. More Samples or More Prompts? Exploring Effective In-Context Sampling for LLM Few-Shot Prompt Engineering. arXiv 2024, arXiv:2311.09782. [Google Scholar]
- Pecher, B.; Srba, I.; Bielikova, M.; Vanschoren, J. Automatic Combination of Sample Selection Strategies for Few-Shot Learning. arXiv 2024, arXiv:2402.03038. [Google Scholar]
- Qin, C.; Zhang, A.; Chen, C.; Dagar, A.; Ye, W. In-Context Learning with Iterative Demonstration Selection. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; Al-Onaizan, Y., Bansal, M., Chen, Y.N., Eds.; pp. 7441–7455. [Google Scholar]
- An, S.; Zhou, B.; Lin, Z.; Fu, Q.; Chen, B.; Zheng, N.; Chen, W.; Lou, J.G. Skill-Based Few-Shot Selection for In-Context Learning. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; pp. 13472–13492. [Google Scholar] [CrossRef]
- Liu, X.; McDuff, D.; Kovacs, G.; Galatzer-Levy, I.; Sunshine, J.; Zhan, J.; Poh, M.Z.; Liao, S.; Achille, P.D.; Patel, S. Large Language Models are Few-Shot Health Learners. arXiv 2023, arXiv:2305.15525. [Google Scholar]
- Siraj, F.M.; Ayon, S.T.K.; Uddin, J. A Few-Shot Learning Based Fault Diagnosis Model Using Sensors Data from Industrial Machineries. Vibration 2023, 6, 1004–1029. [Google Scholar] [CrossRef]
- Kathirgamanathan, B.; Cunningham, P. Generating Explanations to understand Fatigue in Runners Using Time Series Data from Wearable Sensors. In Proceedings of the ICML 3rd Workshop on Interpretable Machine Learning in Healthcare (IMLH), Honolulu, HI, USA, 28 July 2023; pp. 1–11. [Google Scholar]
- Zhang, X.; Jiang, S. Application of Fourier Transform and Butterworth Filter in Signal Denoising. In Proceedings of the 2021 6th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 9–11 April 2021; pp. 1277–1281. [Google Scholar] [CrossRef]
- de Souza, P.; Silva, D.; de Andrade, I.; Dias, J.; Lima, J.P.; Teichrieb, V.; Quintino, J.P.; da Silva, F.Q.B.; Santos, A.L.M. A Study on the Influence of Sensors in Frequency and Time Domains on Context Recognition. Sensors 2023, 23, 5756. [Google Scholar] [CrossRef]
- Chen, Z.; Li, H. A survey on distance and similarity measures for time-series data analysis. Inf. Sci. 2020, 546, 441–465. [Google Scholar] [CrossRef]
- Truong, C.; Oudre, L.; Vayatis, N. Selective review of offline change point detection methods. Signal Process. 2020, 167, 107299. [Google Scholar] [CrossRef]
- Min, S.; Lewis, M.; Zettlemoyer, L.; Hajishirzi, H. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 11044–11064. [Google Scholar]
- Xue, W.; Duan, L.; Hong, X.; Zheng, X. Adaptive weighting and nearest neighbor-based area control for imbalanced data classification. Appl. Soft Comput. 2025, 177, 113171. [Google Scholar] [CrossRef]
- Wang, J.; Sun, S.; Sun, Y. A Muscle Fatigue Classification Model Based on LSTM and Improved Wavelet Packet Threshold. Sensors 2021, 21, 6369. [Google Scholar] [CrossRef]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting. In Proceedings of the AAAI 2021, Online, 2–9 February 2021; pp. 11106–11115. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef]
- Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the EMNLP 2021, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.; Rocktäschel, T.; et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In Proceedings of the NeurIPS 2020, Virtual, 6–12 December 2020. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approach | Uses LLM | Example Selection | API Call | Prompt-Based |
|---|---|---|---|---|
| ML (Random Forest) | No | No (offline learning) | No | No |
| Random Approach | Yes | Random selection | Yes | Yes |
| Distance Approach | Yes | Euclidean distance | Yes | Yes |
| HED-LM (Ours) | Yes | Distance + LLM semantic scoring | Yes | Yes |
| Component | ML (Random Forest) | Random Approach | Distance Approach | HED-LM (Ours) |
|---|---|---|---|---|
| Data Source | Per-user slice | Same | Same | Same |
| Data Range | Per-user slice | Same | Same | Same |
| Training Samples (n) | 2 | 2 | 2 | 2 |
| Test Set | Held-out | Same | Same | Same |
| Selection Strategy | Random from class | Random | Euclidean distance | Distance + LLM scoring |
| Prompt Structure | N/A | 2-shot | 2-shot | 2-shot, label-balanced |
| Leakage Prevention | Yes | Yes | Yes | Yes |
| User ID | ML Approach | Random Approach | Distance Approach | HED-LM (Ours) | |
|---|---|---|---|---|---|
| (%) | (%) | (%) | (%) | ||
| #ParamA | #ParamB | ||||
| 4 | 53.92 | 59.82 | 62.89 | 67.70 | 64.42 |
| 5 | 70.51 | 85.15 | 88.30 | 87.23 | 88.83 |
| 6 | 69.22 | 67.61 | 71.04 | 72.45 | 71.57 |
| 7 | 59.97 | 49.93 | 62.26 | 65.14 | 61.93 |
| 8 | 52.57 | 68.90 | 79.40 | 83.19 | 81.87 |
| 9 | 43.52 | 61.64 | 65.81 | 65.25 | 66.19 |
| 10 | 19.10 | 62.69 | 90.51 | 89.88 | 86.83 |
| 11 | 52.85 | 48.30 | 51.55 | 57.24 | 59.49 |
| 12 | 71.45 | 73.17 | 81.67 | 83.81 | 84.25 |
| 13 | 49.11 | 49.88 | 50.81 | 52.76 | 58.89 |
| 14 | 34.79 | 50.95 | 56.66 | 59.31 | 58.64 |
| 15 | 36.39 | 52.47 | 57.40 | 60.85 | 59.37 |
| 17 | 45.46 | 47.95 | 59.73 | 59.97 | 59.18 |
| 18 | 39.99 | 62.91 | 63.79 | 63.00 | 64.08 |
| 19 | 74.83 | 44.11 | 73.20 | 74.90 | 70.93 |
| 20 | 70.46 | 61.36 | 75.43 | 76.68 | 77.57 |
| 21 | 60.01 | 63.02 | 64.93 | 64.93 | 65.28 |
| 22 | 37.07 | 58.30 | 61.46 | 63.11 | 59.63 |
| 23 | 17.32 | 58.49 | 67.70 | 66.11 | 68.09 |
| (Mean ± SD) | (50.4 ± 17.13) | (59.30 ± 10.13) | (67.61 ± 11.39) | (69.13 ± 10.71) | (68.79 ± 10.24) |
| Random | Distance | ML | HED-LM #ParamA | HED-LM #ParamB | |
|---|---|---|---|---|---|
| Random | 1.000000 | 0.007625 | 0.972672 | 0.00001085355 | 0.00002331567 |
| Distance | 0.007625 | 1.000000 | 0.0007448186 | 0.5369701 | 0.6372963 |
| ML | 0.972672 | 0.000745 | 1.000000 | 0.0000004028977 | 0.0000009506715 |
| HED-LM #ParamA | 0.000011 | 0.536970 | 0.0000004028977 | 1.000000 | 0.9998743 |
| HED-LM #ParamB | 0.000023 | 0.637296 | 0.0000009506715 | 0.9998743 | 1.000000 |
| Comparison | t-Test p-Value | Wilcoxon p-Value |
|---|---|---|
| HED-LM #ParamA vs. Random | 0.00004 | 0.00000 |
| HED-LM #ParamA vs. Distance | 0.02716 | 0.00240 |
| HED-LM #ParamA vs. ML | 0.00006 | 0.00002 |
| HHED-LM #ParamB vs. Random | 0.00005 | 0.00000 |
| HED-LM #ParamB vs. Distance | 0.09976 | 0.06021 |
| HED-LM #ParamB vs. ML | 0.00009 | 0.00004 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ronando, E.; Inoue, S. Few-Shot Optimization for Sensor Data Using Large Language Models: A Case Study on Fatigue Detection. Sensors 2025, 25, 3324. https://doi.org/10.3390/s25113324
Ronando E, Inoue S. Few-Shot Optimization for Sensor Data Using Large Language Models: A Case Study on Fatigue Detection. Sensors. 2025; 25(11):3324. https://doi.org/10.3390/s25113324
Chicago/Turabian StyleRonando, Elsen, and Sozo Inoue. 2025. "Few-Shot Optimization for Sensor Data Using Large Language Models: A Case Study on Fatigue Detection" Sensors 25, no. 11: 3324. https://doi.org/10.3390/s25113324
APA StyleRonando, E., & Inoue, S. (2025). Few-Shot Optimization for Sensor Data Using Large Language Models: A Case Study on Fatigue Detection. Sensors, 25(11), 3324. https://doi.org/10.3390/s25113324