1. Introduction
One of the main concerns for the food industry is related to the quality and cost of their products, as consumers always take into consideration these factors [
1]. Thus, food quality and safety levels have always been a central issue for discussion, as well as for taking appropriate actions to address them. The consumption of meat, which is generally considered to be an essential part of our diet, is due to the fact that it is rich in protein and contains high physiological value. This type of consumption, which includes pork, beef, and poultry, is increasing worldwide every year, and based on the 2017 report from the Organization for Economic Co-operation and Development (OECD), it was predicted that the average meat consumption per person could approach to 35.5 kg globally by 2024 [
2]. A market survey has indicated that, alongside the growth of meat consumption, meat quality is gradually becoming an essential issue in the consumers’ purchasing decisions [
3]. Despite the fact that meat is considered to be a good source of protein and other essential nutrients, it is also a suitable environment for the growth and survival of spoilage and pathogenic microorganisms. Spoilage occurs when the formation of off-flavors, off-odors, discoloration, or any other changes in physical appearance or chemical characteristics make the food unacceptable to the consumer. Changes in the muscle characteristics are due to native or microbial enzymatic activity or to other chemical reactions. However, not all bacteria are responsible for the spoilage effect; there is only an initial small group of microorganisms in meat, named as specific spoilage organisms (SSOs) [
4]. In meat products, SSOs metabolize the available substrates during storage, thus leading to changes in the meat quality and odor. The current procedure for checking the levels of meat spoilage is performed either subjectively, based on a sensory assessment, or through a microbiological analysis. Such sensory assessments usually utilize the human senses of a trained test panel to provide evidence related to color, smell, and taste, as well as the overall quality and acceptance of the meat sample. This approach, though widely utilized for the classification of meat samples, has some weaknesses, such as the high cost for training the taste panel, the reproducibility of the evaluation, and the potential low comparability between panels [
5].
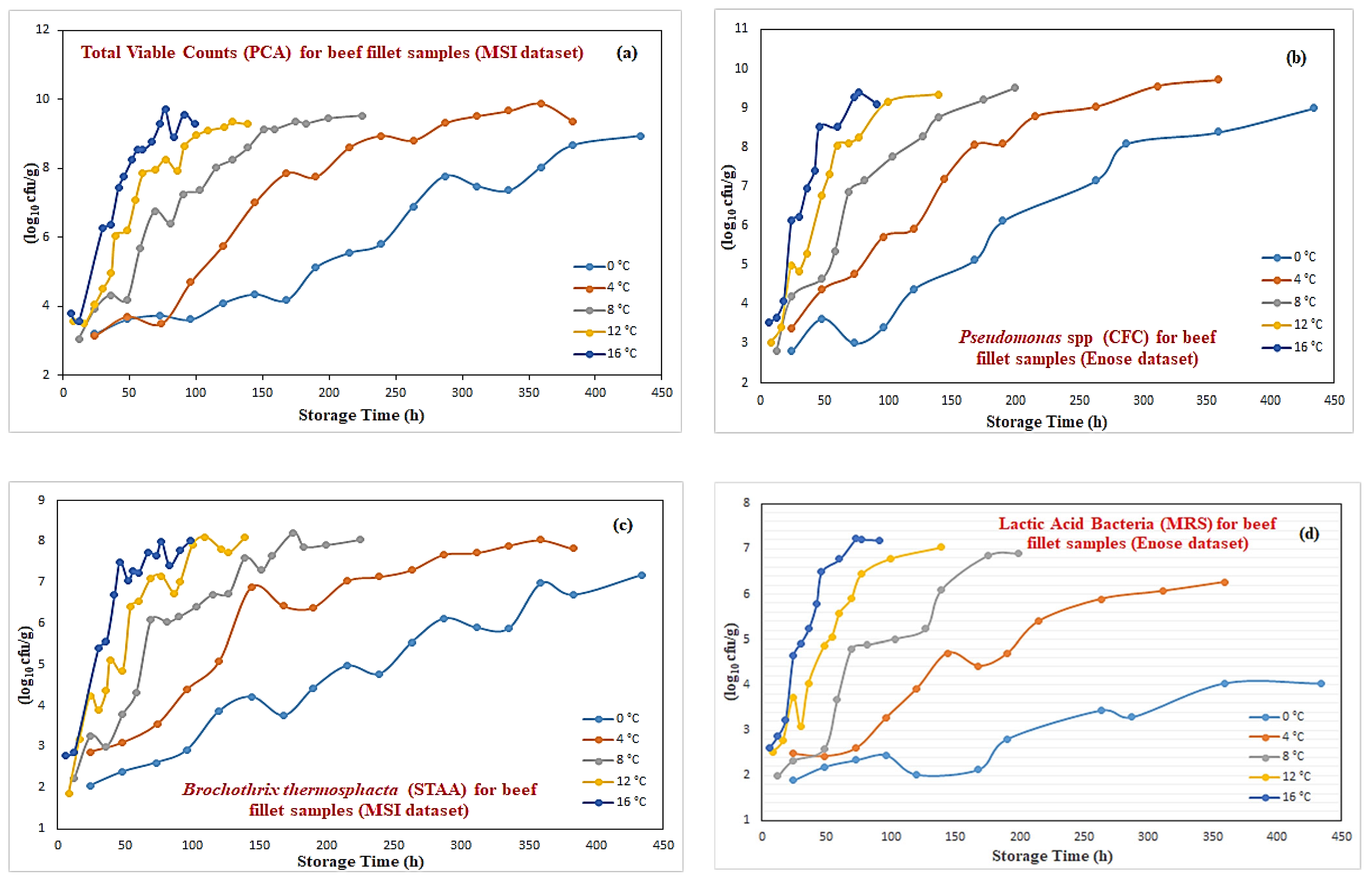
Alternatively, the conventional microbiological approach to food sampling has changed little over the previous decades and it is based on the recording of bacterial counts for a given sample as a quantitative indicator of spoilage. These bacterial counts include the total viable count (TVC),
Pseudomonas spp.,
Brochothrix thermosphacta,
Enterobacteriaceae, and lactic acid bacteria. The “standard plate count” approach was used as the main microbiological method where the sample, after the preparation and dilution stages, is mixed with a general agar media, incubated, and then the colonies are counted after 48 h. Despite its simplicity, it is a time-consuming process which employs an enormous amount of culture media, a large number of sterile test materials, as well as large incubation spaces. Biosensors represent one advanced method that was developed to provide faster microbiological information compared to the conventional microbiological approach. In the field of microorganism detection, adenosine triphosphate (ATP) bioluminescence, an effective biosensor, acts by measuring the ATP levels in bacterial cells in a culture in order to calculate the number of cells present. Although the detection time is about one to four hours, the problem with this method is that the ATP present in the meat has to be destroyed before the microbial ATP can be measured [
6]. Alternatively, a polymerase chain reaction (PCR) has successfully been used to detect microorganisms by amplification of the target DNA and detecting the target PCR products. This specific type of nucleic acid-based detection method requires the presence of intact nucleic acid sequences in the sample. Thus, the DNA from non-viable microorganisms can lead to false positive results. Another limitation is the time factor, as this can be a time-consuming method compared to ATP [
7].
While some of these methods are superior to others, and most of them provide adequate results, their main drawback, at present, is the time taken to acquire results. The optimal solution for the food industry would be a rapid, non-destructive, reagent-less, quantitative, and relatively inexpensive method for microbiological analysis. Thus, inexpensive, fast, and non-invasive methods have been explored for this purpose: to provide an alternative and reliable solution for meat spoilage detection. Such methods include various analytical lab instruments, like Fourier transform infrared spectroscopy (FTIR) [
8], hyperspectral and multispectral imaging systems [
9], Raman spectroscopy [
10], and electronic noses (e-nose) [
11]. The detection “capability” of these analytical instruments is based on the hypothesis that any produced metabolic activity from each meat sample is considered to be an individual “signature”, which practically contains important information for the level of quantitative indicators responsible for spoilage [
12]. However, the main issue with these new techniques is how to associate their produced output with the indicators responsible for spoilage, as well as with the output of a sensory assessment for the overall quality and acceptance of the meat sample. Fortunately, with the advancement of computing software, algorithmic models have been trained (offline) to associate sensorial outputs with meat quality indicators, and then the final developed models can be utilized as rapid decision models without the need of additional microbiological tests.
Due to the complexity of the chemical-based characteristics that appear in food products, the application of a single analytical instrument/sensor may not be sufficient, and multi-sensor data fusion techniques, combining the outputs of multiple instruments/sensors, could provide an alternative challenge for improving the level of the assessment of food quality [
13].
Data fusion is an emerging branch in chemometrics that analyzes the combination of information provided by different instruments, since various sources of data can potentially provide complementary information compared with the case of a single data source. Three different fusion strategies have been designed, commonly named low-level data fusion (LLF), mid-level feature fusion (MLF), and high-level decision fusion (HLF) [
14]. The LLF involves the collection of data from different sensors for the same samples, which are then directly concatenated into a single matrix (after proper pre-processing) to obtain a new, larger dataset. The limitations of LLF include the presence of a high volume of data and the possible predominance of one data source over the others. Unlike LLF, the MLF (feature level fusion) strategy integrates a feature extraction step which can incorporate adequate original information, with the extracted features combined to build quantitative or qualitative models. Previous issues encountered by the LLF are somehow resolved in the MLF, as extraction significantly reduces the data dimensionality. In this scheme, feature selection techniques and principal component analysis (PCA) are widely employed. Feature level fusion is very useful for non-commensurate type data, i.e., if sensors are looking for different physical parameters. However, the real challenge in this strategy is to find the optimal combination of extracted features and pre-processing that describes the significant variation of the original sensorial responses and provide the best final model. In the HLF (decision level fusion), models are separately developed for each individual sensor and the respective results are then integrated into a single final response. One advantage of this scheme is that each individual produced model is treated independently; as such, inferior performance from one model does not worsen the overall performance, unlike the other fusion strategies. The challenge with this scheme, however, is that special care is required to determine the most accurate individual models so that the combination of their outputs will produce a superior performance.
Several approaches of the data fusion methods have been employed for meat quality monitoring in terms of discrimination, adulteration, and prediction. Such case studies have led to an interest in exploring data fusion methodologies that could decrease the uncertainty of individual results and enable a superior performance in prediction. In one study, a decision fusion method based on hyperspectral imaging (HSI) and an electronic nose (e=nose) technique for moisture content prediction in frozen-thawed pork was explored by comparing various approaches to extract the required features, while a partial least squares (PLSR) regression model provided the prediction for moisture [
15]. In another study, the prediction of two important indicators, namely the total volatile basic nitrogen (TVB-N) and TVC, for evaluating the quality of chicken fillets was investigated through the use of two different HSI techniques, visible near-infrared (Vis-NIR) and NIR. Quantitative predictions using PLSR were calculated after the feature wavelength selection [
16]. A low-cost e-nose was fused with Fourier transform-near-infrared (FT-NIR) spectroscopy to detect the level of beef adulteration with duck. The TVB-N, protein, fat, total sugar, and ash contents were measured to investigate the differences in basic properties between the raw beef and the duck, while extreme learning based machine models were developed to identify the adulterated beef and predict the adulteration levels [
17]. Robert et al. explored the fusion of different spectroscopic techniques for meat analysis. Mid infrared (MIR), near infrared (NIR), and Raman spectroscopy were fused in an LLF scheme to estimate fatty acid composition in processed lamb using PLSR models [
18]. In a prior study, Robert et al. investigated the performance of LLF, MLF, and HLF schemes of Raman and infrared spectroscopy to predict pH and the percentage of intramuscular fat content (% IMF) for red meat quality parameters utilizing PLSR models. The HLF approach proved able to provide the best performance for the pH parameter, while the LLF showed promising results in predicting the percentage of IMF quality [
19].
The main objective of this paper is to detect beef spoilage during aerobic storage at various temperatures (0, 4, 8, 12, and 16 °C) through an advanced intelligence-based decision support system. An HLF strategy of spectral information acquired by a multispectral imaging (MSI) system and volatile fingerprints of odor profile obtained through an e-nose will be utilized as a basis for the development of the proposed decision system. The proposed analytical framework aims not only to predict the levels of meat indicators (total viable counts, Pseudomonas spp., Brochothrix thermosphacta, and lactic acid bacteria) encountered in beef samples but to categorize beef samples into three distinct classes (i.e., fresh, semi-fresh, and spoiled).
Data quantity is generally an issue of concern for machine learning applications, as small datasets usually do not lead to a robust classification/prediction performance. How to create some additional information from a small dataset is thus of considerable interest. In the proposed fusion of MSI and e-nose devices, unfortunately, the individual obtained sensorial data are not only limited but not equal in terms of the number of samples. This latter issue practically introduces an inconsistency in fusing the information acquired by different types of sensors. In this research, an efficient methodology for creating additional “virtual” sample sets, thus improving the accuracy of the proposed decision support system, was proposed. Inspired by the way the radial basis function (RBF) neural network manages to approximate levels of microorganisms [
20], a forward modeling process was used to create additional “virtual” outputs for the levels of the meat indicators that need to be predicted. In addition, an inverse RBF-based modeling process was used to create additional “virtual” sensorial outputs for both the MSI and e-nose systems. The enhanced datasets for both instruments, which include the additional “virtual” information, are then subjected to a feature selection analysis, based on the Boruta algorithm, to identify the most important features for both sensors. The selected features are then utilized as inputs to regression models built to approximate relevant meat indicators for each sensorial device. The related models’ outputs are then combined to provide the overall prediction. Finally, based in these final predictions, a simple implemented classifier predicts the class of meat samples also utilizing information from the provided sensory assessment. As the “heart” of the proposed analysis is related to the development of accurate regression models for each meat indicator, an adaptive fuzzy logic neural system (AFLS) was employed for this task. Testing performances of the AFLS models are compared against the models usually employed to related food microbiological applications, such as the PLSR and the multilayer perceptron (MLP), as well as against traditional machine learning models, such as support vector machines (SVM) and extreme gradient boosting (XGBoost), using a number of established evaluation metrics. The overall “idea” of the implemented methodology is to highlight the concept of multi-fusion analysis using advanced learning-based models in the area of food microbiology.
3. Synthetic Data Acquisition and Proposed Analytical Framework
The availability of data in terms of high quality/quantity is essential for the success of various applications across a wide range of fields. Large datasets are needed because of the basic idea that insights from such datasets may adjust decision-making and reveal previously unnoticed patterns. Unfortunately, small dataset conditions exist in many fields, such as food analysis, disease diagnosis, fault diagnosis, or deficiency detection in mechanics, among others. In many cases/applications, it is not possible to obtain a large amount of information, due to a number of reasonable causes. The main reason that small datasets cannot provide adequate information, unlike large datasets, is that gaps between the samples may exist; even the domain of the samples cannot be ensured [
26]. Thus, it is difficult with a small dataset to approximate the pattern of high order nonlinear functions through a standard machine learning model, since small sets have shown weakness in providing the necessary information for forming population patterns. Hence, for a learning system that lacks sufficient data, the knowledge learned is sometimes unacceptably rough or even unreliable. Faced with this issue, the addition of some artificial data to a learning model in order to increase its learning accuracy is one effective approach. In virtual/synthetic data generation, the existing knowledge obtained from a given small dataset helps to create virtual samples to improve performance in regression/classification tasks.
In this research, small datasets have been utilized in both sensorial experiments. In the MSI-based case, spectral information and the related microbiological analysis from 84 beef samples were acquired, while for the e-nose-based case, a subset of used data (i.e., 58 samples) were utilized to provide volatile organic compounds (VOCs) from odor samples presented in the e-nose device. This inconsistency of data quantity in these two sensorial experiments, creates a serious problem, and needs to be addressed before applying any regression/classification techniques in the proposed fusion scheme. Thus, the first objective of this section is focused on how to create additional “virtual” microbiological data from the initial 84 beef samples, and then how to generate additional “sensorial” MSI/e-nose responses. The final goal is eventually to create a larger dataset through the usage of real/virtual data for both MSI and e-nose cases, and then to proceed to the proposed data analysis.
3.1. Synthetic Data Acquisition
In this work, an efficient data expansion technique was utilized for the obtained small dataset to create a new “virtual” sample set for the microbiological analysis. Inspired by the way the radial basis function (RBF) neural network approximates a nonlinear function through Gaussian local-basis functions, an RBF network was employed for each “microorganism case” (i.e., total viable counts,
Pseudomonas spp.,
Brochothrix thermosphacta and lactic acid bacteria), utilizing the experimental microbiological data (i.e., 84 samples) as a training set [
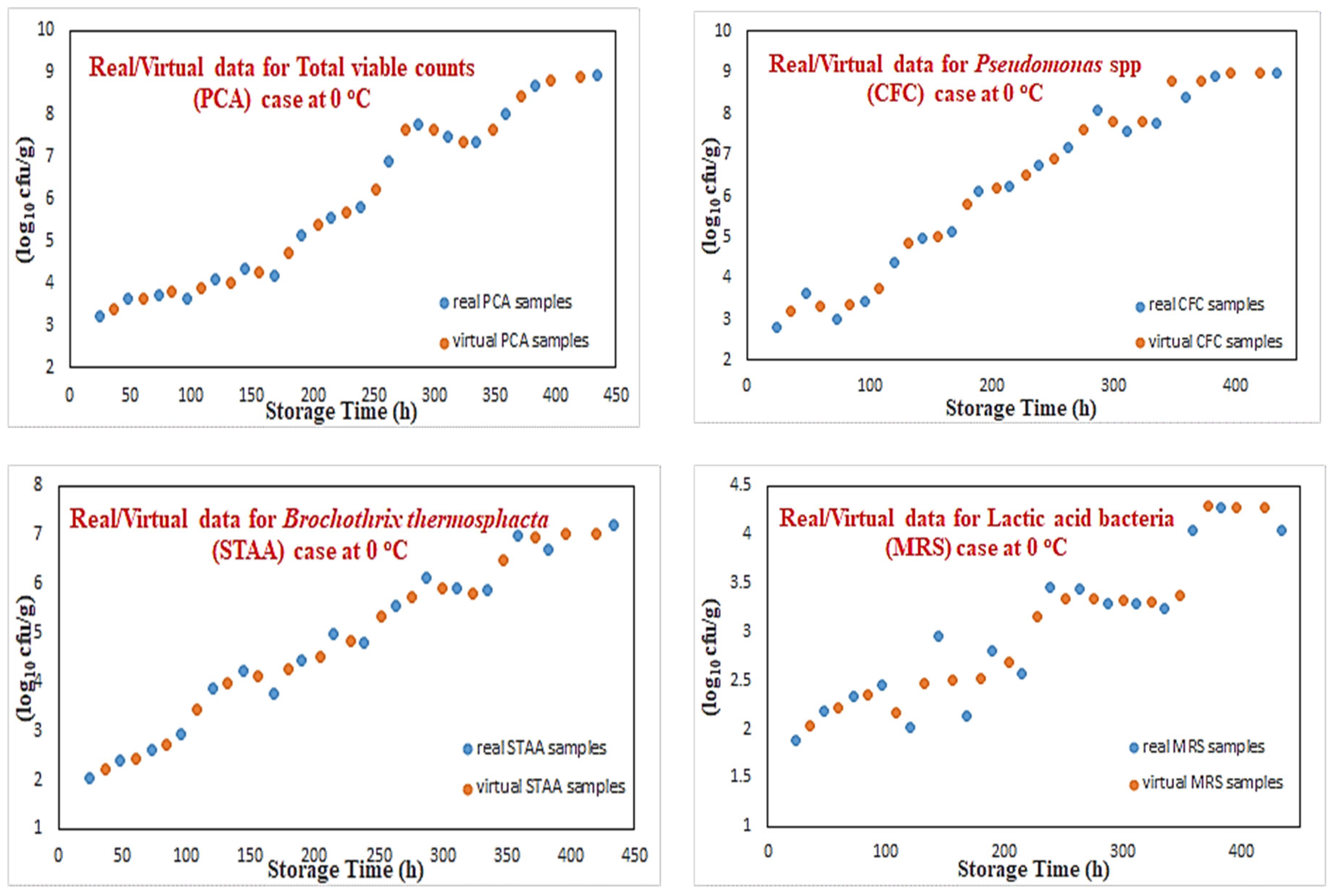
27]. Four dedicated RBF networks using the orthogonal least squares (OLS) learning algorithm have been constructed and with a smaller sampling time, through a two-inputs network, a “continuous growth curve” was obtained for each case. The RBF inputs included temperature level and sampling time-step, while the output was related to the specific microorganism predictions. Each “continuous growth curve” was verified against the real experimental data. Based on these continuous curves, 46 additional “virtual” microbiological data were obtained.
Figure 4 illustrates a sample of these growth curves for these four microorganisms at 0 °C temperature. Although in most cases there is a very close match between real and virtual data, in some other cases, some discrepancy can be noticed (such as for lactic acid bacteria). Such approximation performances can be explained by the fact that neural networks are very good models for nonlinear function approximation with good interpolating abilities. The results shown in the case of lactic acid bacteria illustrate that the generation of “virtual” data is an outcome of a learning process without the effect of data overfitting. Following this modeling procedure, a complete mixed real/virtual dataset that incorporates microbiological predictions for 130 samples has been created. This final microbiological dataset was then used to predict the class of these new “virtual” samples.
In this case, a multilayer neural network (MLP) with a two hidden layers structure was utilized. Its input vector consisted of the four “microorganisms” indicators, the temperature and time sampling, while the output node was dedicated to the class of the sample. The 84 real samples were used as the training set, while the newly acquired 46 “virtual” data as the testing set. Rather than trying to create a distinct classifier, an effort has been made to “model” the classes [
28] via a regression procedure. This is an efficient and alternative way to build a classifier without the need/complexity to define, in the model, the number of classes via multiple outputs.
Initially, values of 10, 20, and 30 have been used, respectively, to associate the three classes with a cluster center. During the identification process, the output values in the range of [5, 15] were associated to the “fresh” class with the cluster center 10, values of [15.01, 25] were associated to the “semi-fresh” class with the cluster center 20, and finally values of [25.01, 35] were associated to the “spoiled” class with the cluster center 30.
Figure 5 illustrates the classification results of these “virtual” data for the temperature of 0 °C, where a clear consistency with the real data can be observed. The creation of additional microbiological data for the “microorganisms” cases as well as the MLP-based classifier for the classes definition is considered to be a “forward modeling” process, where through some known information (i.e., time, temperature), an unknown parameter needs to be predicted (i.e., growth rates, classes).
However, the creation of “virtual” sensorial data is a more complicated task. In this paper, inspired by the inverse identification of electronic nose data [
29], a similar procedure was adopted.
The MSI and e-nose outputs consist of 18 wavelengths and eight chemical sensorial responses, respectively. All these attributes are considered to be independent, in the sense that their individual responses are not dependent on the outputs of the others. Based on this assumption, a specific RBF network was employed to model each one of these attributes. In total, 26 dedicated RBF networks were trained to approximate the behavior of the devices’ outputs.
The rationale of using an RBF over an MLP neural network, is that an RBF network is a scheme that represents a function of interest by using members of a family of locally supported basis functions [
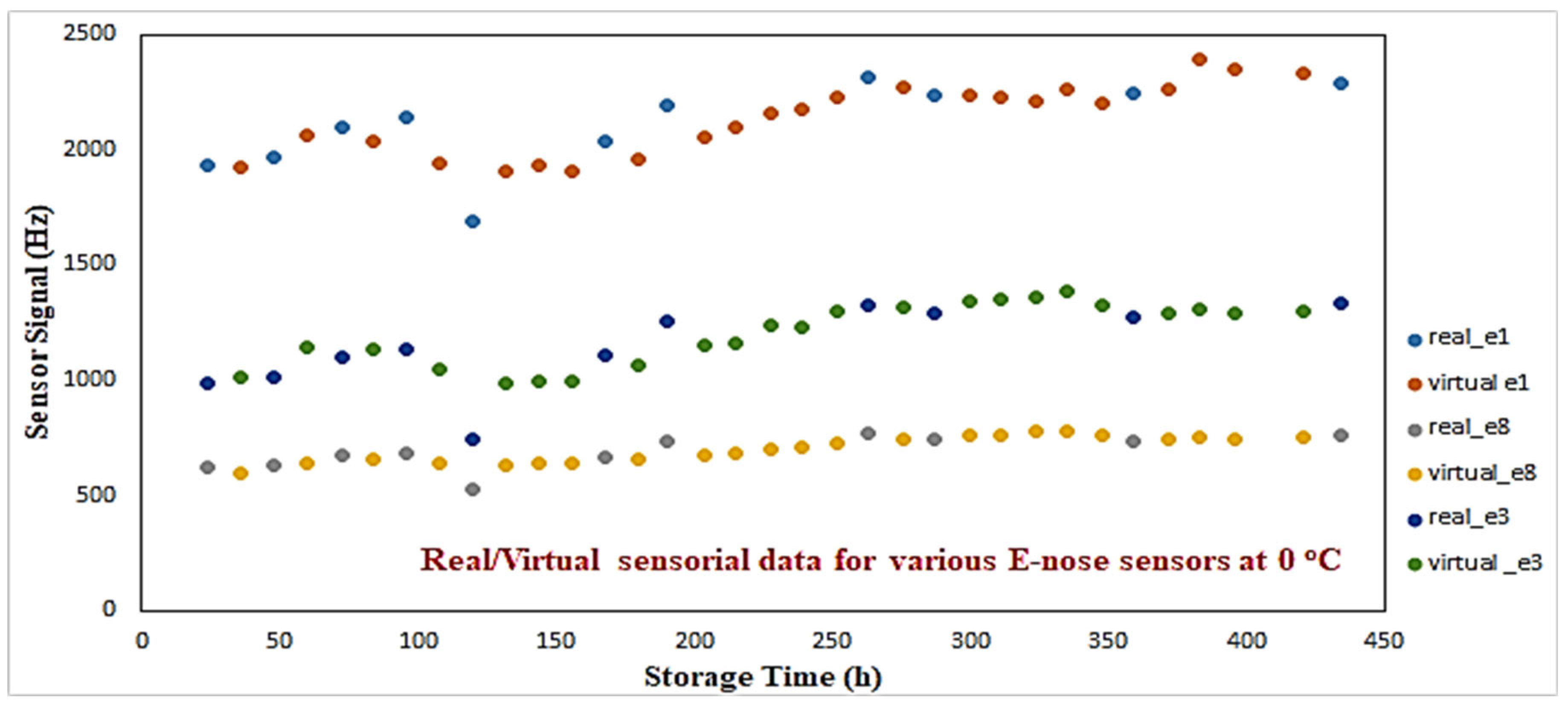
30]. The input vector for all RBF models included the four microbiological indicators, temperature, sampling time, and the class, whereas the e-nose/MSI outputs were considered to be the desired outputs. Based on this analysis, 72 additional “virtual” e-nose sensorial data (i.e., eight sensors per sample) and, similarly, 46 “virtual” MSI sensorial data (i.e., 18 wavelengths per sample) were created.
Figure 6 illustrates the virtual/real sensorial outputs from three e-nose sensors (1st, 3rd, 8th) for 0 °C. A consistency between real vs. virtual outcomes can be observed. The aim of this procedure was to produce additional sensorial outputs that satisfactorily capture the nonlinear dynamics of the real sensorial outputs. No extreme or out-of-range responses have been monitored through this process.
Similarly for the case of the MSI system,
Figure 7 illustrates a sample of various wavelengths where real and virtual data are shown. More specifically, results from four (1st, 8th, 12th, 16th) wavelengths for 0 °C are illustrated. In system identification theory, the inverse modeling process is considered more challenging from the forward one, as in some cases, the inverted model cannot approximate adequately the inverse mapping of the actual process [
31]. The use of RBF networks, which utilize local basis functions, provides an advantage over MLP neural networks, where a “global” approximation of the process is attempted compared to the “local” approximation of the RBF network.
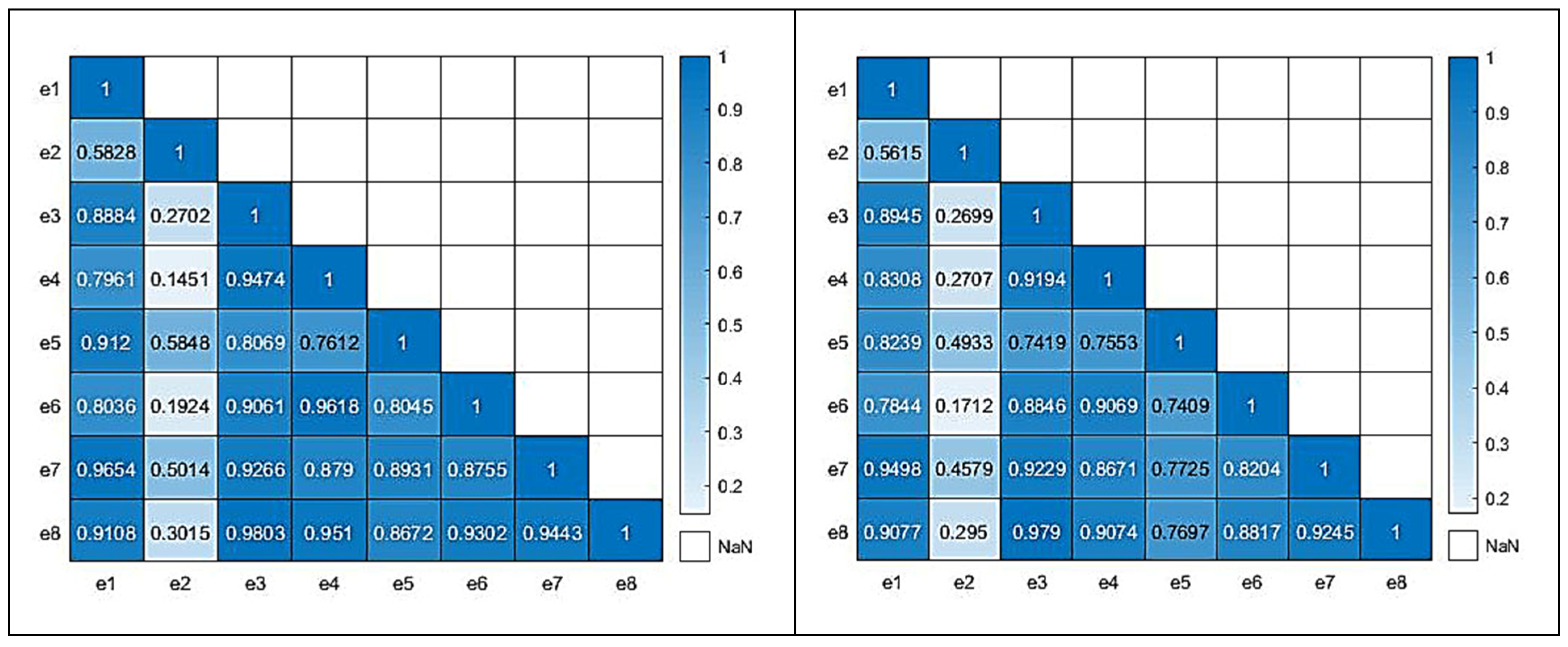
In order to evaluate the quality of the produced virtual data, two correlation matrices of the real and all data have been produced, respectively, using MATLAB (v.2021a).
Figure 8 illustrates the correlation matrices for both the real (left) and all data (right) for the case of the e-nose system. For the correlation of the real samples, 58 sensorial outputs were utilized; while, for the all-data case, the complete set of 130 samples, which included the newly acquired virtual sensorial outputs, were utilized. A close correlation score of the matrix that also includes virtual data compared to the matrix that incorporates only real data reveals a high level of consistency and validity. There are not significant deviations from the original “real” correlation matrix, which suggests that the addition of extra “virtual” data, is able to capture the complexity and behavior of the underlying data.
Similarly to the e-nose case, relative correlation matrices for the MSI case are shown in
Figure 9 and
Figure 10, revealing a similar pattern to the previous case behavior. For the correlation of the real samples, 84 sensorial outputs were utilized; while, for the all-data case, the complete set of 130 samples, which included the newly acquired virtual wavelength outputs, were utilized. The equivalent average correlation scores for real and all data were 0.723 and 0.684, respectively. Both cases reveal that the addition of the new “virtual” data did not jeopardize the quality of the overall data.
The average correlation score for the real and complete correlation matrices were 0.7603 and 0.7323, respectively, showing similar correlation characteristics.
Another useful metric to check the quality of the produced “virtual” data, is the mutual information (MI) criterion. The MI criterion measures how much knowing the value of one variable reduces the uncertainty about the value of the other. In other words, it explores how much information about one variable is contained in the other. The MI values are always non-negative, with larger values indicating a stronger relationship. In this research, the “
mutinformation” R function from the
infotheo R package (R version 4.2.3) has been utilized to calculate the MI for real and all data matrices.
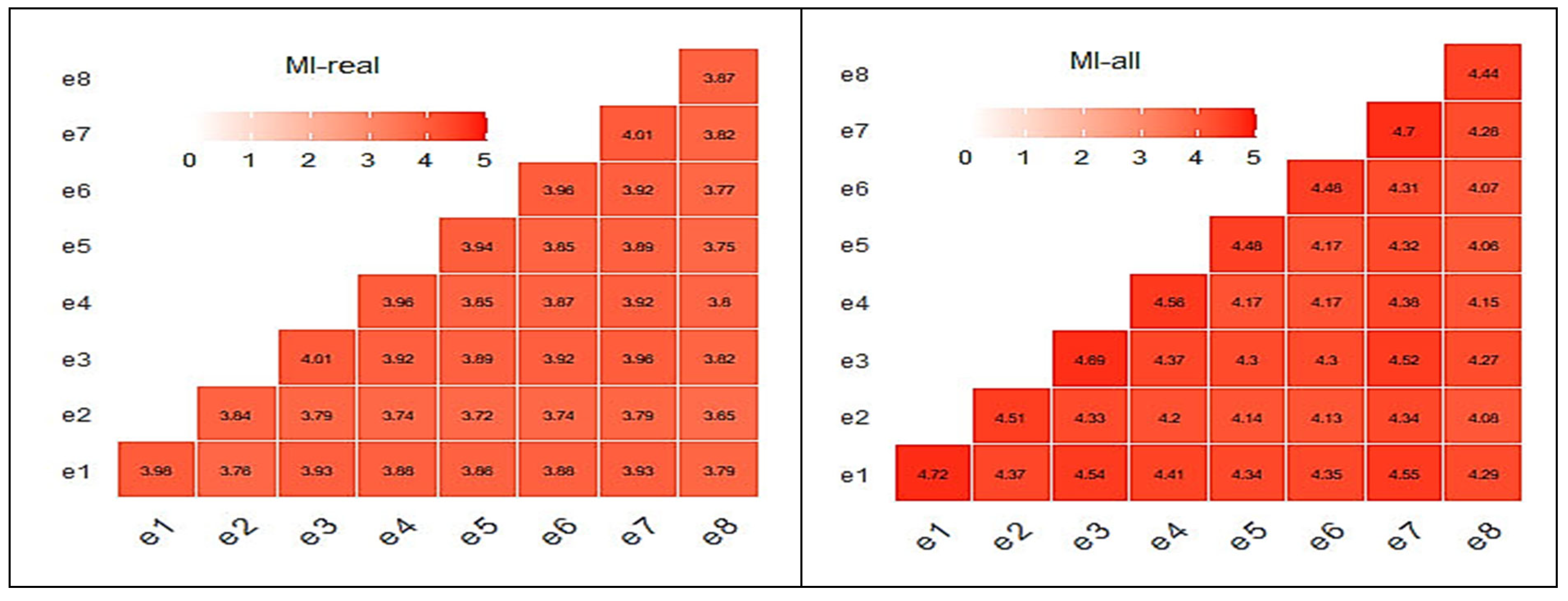
Figure 11 illustrates the MI matrices for the e-nose case. The average MI score for the real and the complete MI matrices for the case of the e-nose were 3.85 and 4.32, respectively, showing a level of resemblance. The addition of the “virtual” sensorial outputs did not have any change that could be considered to be unacceptable.
Correlation and MI matrices seem to explain the results shown in
Figure 6. Similarly to the e-nose case, relative correlation matrices for the MSI case are shown in
Figure 12 and
Figure 13 revealing a behavior similar to the previous case behavior, although with lower MI scores.
Following the graphs at
Figure 12 and
Figure 13, the related average scores for the MSI system were 1.76 and 1.46 for the real and complete data, respectively. It has to be mentioned that, for all MI cases, the “
mutinformation” R function utilized the option to compute the entropy of the empirical probability distribution. In summary, both correlation and mutual information are ways to measure the relationship between two variables. However, they capture slightly different aspects of this specific relationship. While correlation measures the degree to which the variables move together, mutual information measures the amount of information they share.
3.2. Integrated Analytical Framework
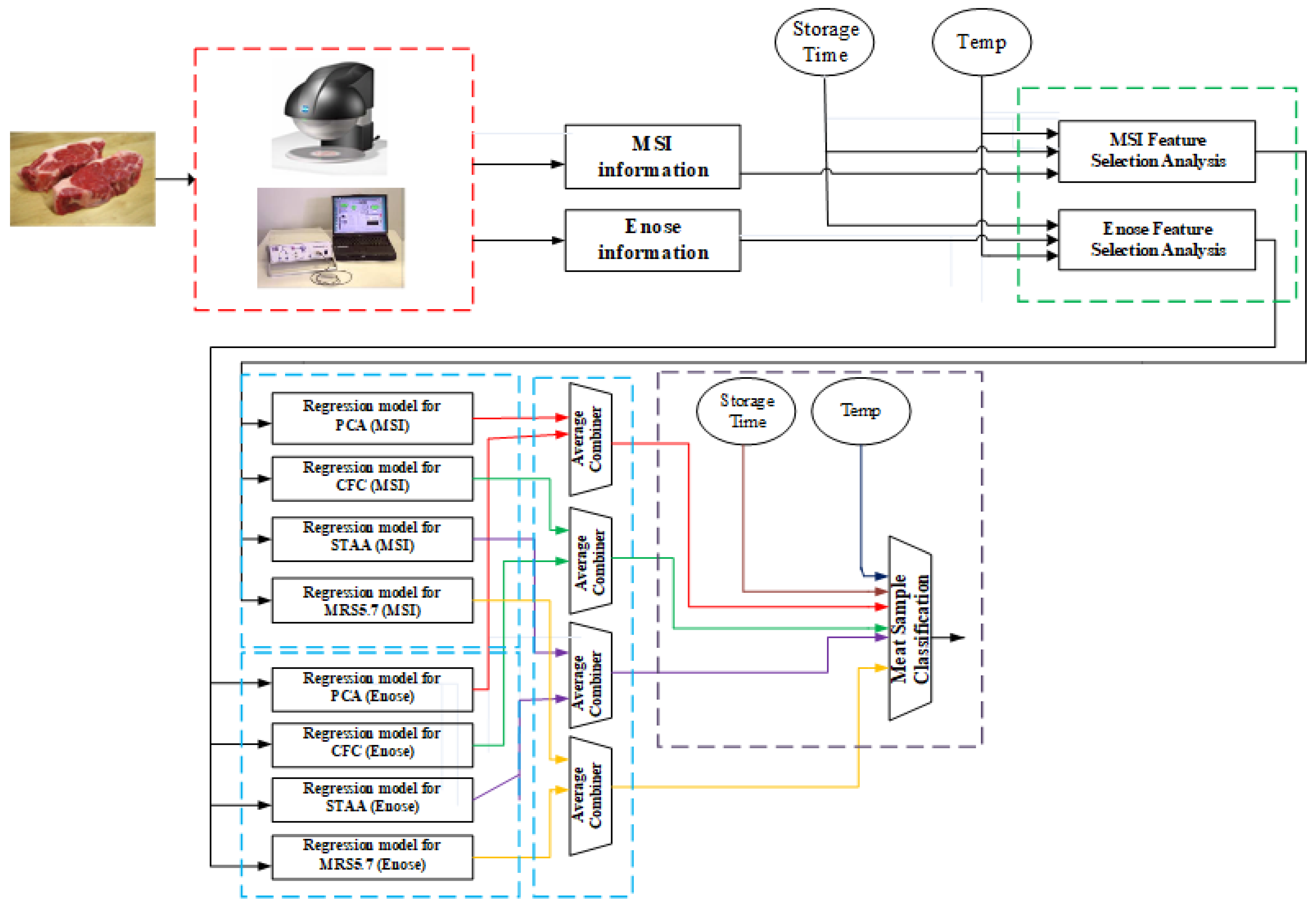
Figure 14 illustrates the proposed analytic concept, following the imaging and volatile information acquisition from the MSI and e-nose systems, respectively. Although the schematic illustrates the various steps of analysis, in reality this framework can be realized into two stages. During the first stage, the offline part, the acquisition of spectral and volatile organic compounds together with the related microbiological analysis needs to be performed. Obviously, this is a time-consuming process, but it is required for the feature selection analysis and the training of the various regression models, and eventually for the training of the classifier which will predict the class of meat sample. The main idea of this first stage is to build offline accurate models that will diminish the need of performing microbiological analysis to each testing meat samples.
These models then could be used in the second stage, the online analysis of the meat samples, where a fast response for the quality of the meat is required. In frequent time periods, with the acquisition of new samples, the offline models can be updated/retrained and then used later in the online analysis. The acquired spectral dataset consists of the mean reflectance spectrum, while the relevant e-nose dataset includes sensorial responses expressed as frequency variations (Δf). Thus, for each meat sample, a vector of 18 wavelength attributes, eight e-nose responses, and information related to storage time and temperature was considered to be its input “signature”.
One essential issue in data analysis is to determine which actual sensorial attributes could be considered important, thus reducing the initial high-dimensional feature space provided by the sensorial systems. In the proposed framework, the Boruta feature selection (FS) method has been adopted, which is a well-known FS technique, and has been implemented around the random forest (RF) algorithm.
The development of regression models that incorporate all available information, is the next step of the analysis. The main aim at this stage is to associate the sensorial information, the storage time, and the temperature with the outcomes of the microbiological analysis. As illustrated in
Figure 14, for each sensorial system and for each meat indicator, an individual regression model based on neuro-fuzzy principles has been implemented. Neuro-fuzzy models as learning systems incorporate into their “knowledge” information derived from their interpolation abilities. This is an advantage of such systems compared to traditional microbiological models which are built based on specific temperature information. Associated regression predictions are then combined through an average fusion approach in order to produce the final predictions for each meat indicator. These predictions together with information from the storage time and temperature are then utilized in a simple PLSR model to predict the class of meat samples.
5. Learning Models for Regression and Classification Tasks
The main objective in this paper is the efficient estimation of the level for each of these specific” microorganism cases” (i.e., total viable counts,
Pseudomonas spp.,
Brochothrix thermosphacta and lactic acid bacteria) through the fusion of the MSI and e-nose systems. In addition to selected sensorial outputs, information related to specific time-steps at which beef samples were analyzed during storage and temperature levels was considered to be an additional input to the various employed learning models. A follow-up objective is to predict the class of testing meat samples to their “quality” class (i.e., fresh, semi-fresh, spoiled). A simple PLSR model has been employed to predict the “class” of these samples, receiving as inputs, information from temperature, time storage, and the predicted fusion estimations for each microorganism case. One of the key elements of the proposed framework, shown in
Figure 14, are the regression models to estimate related “microorganism” cases. The AFLS scheme has been employed as a regression model, while the obtained results are compared with those obtained by the MLP neural networks, support vector machines (SVM), extreme gradient boosting (XGBoost), and PLSR models. The MLP, SVM, and XGBoost algorithms are considered very popular in the area of machine learning, while PLSR has been extensively used in food microbiological applications. In fact, PLSR’s low complexity, and its ability to provide generally satisfactory results, have attracted the interest of researchers in this specific application field.
The final dataset for each sensorial case (MSI/e-nose) consisted of 130 meat samples, which also incorporated the additional “virtual” generated samples. For each sample (real/virtual), sensorial outputs, storage time and temperature information, type of class, and the estimation of the level for each of these specific “microorganism cases” has been available. In this research study, two schemes have been considered for the training/testing stages. In the first scheme, the initial (MSI/e-nose) datasets were divided into training subsets with approx. 89% of the data and testing subsets with the remaining 11% (i.e., 15 samples). For these testing subsets, only real samples/sensorial responses were considered. These 15 testing samples were common in both the MSI and e-nose experiment and, for each temperature, three representative samples were selected. More specifically, samples at 48, 168, and 359 h time steps were chosen for 0 °C, at 24, 12, and 311 h for 4 °C, at 24, 69, and 175 h for 8 °C, at 16, 48, and 100 h for 12 °C and at 12, 36, and 77 h for 16 °C. In total, five testing samples were allocated to each meat class. For the second training/testing scheme, the leave-one-out cross-validation (LOOCV) has been employed. This is a well-known procedure applied in cases where the number of observations/samples is small, and the separation of the dataset into training and testing subsets is considered that it would result in insufficient training of the leaning model [
34].
The performance of these learning regression models has been evaluated through a number of well-established metrics. The measure of goodness-of-fit for model comparison in food microbiology is performed with the squared correlation coefficient (R
2). This metric can be explained as the ratio of the variance of the predicted responses from the objective related responses. It is considered to be a suitable evaluation criterion only under the condition that the error is normally distributed and not dependent on the mean value. In reality, for the case of bacteria growth, the distribution of the error is not clearly known, thus this metric should be used with caution, particularly in nonlinear-based regression models [
35]. Similarly to general purposes regression case studies, evaluation metrics, such as the mean absolute percentage error (MAPE), the root mean squared error (RMSE), the standard error of prediction (SEP), the absolute percentage error (APE), and the mean absolute error (MAE) metrics, have also been explored in this research. Finally, three chemometric metrics, which are used extensively in spectroscopic applications, namely residual prediction deviation (RPD), range error ratio (RER), and the ratio of performance to interquartile distance (RPIQ), were also utilized in this paper. The RPD is calculated as the ratio of the standard deviation of the desired variable to the RMSE. Any model with an RPD value above three is generally assumed to be an excellent model in terms of reliability. The ratio of performance to interquartile distance (RPIQ), which is defined as an interquartile range of the observed values divided by the RMSE, is considered to be a metric of model validity that is more objective than the RMSE. A larger RPIQ value is considered to be desirable. Finally, the range error ratio (RER) is equal to the range in the observed values (i.e., the maximum value minus the minimum value) divided by the RMSE. Any RER value above 10 is considered to be desirable [
36].
5.1. “Regression” Task
All regression models for each microorganism case have been implemented utilizing the same input vector which is illustrated in
Table 3. Initially, models were developed based on the reduced (115/15) dataset scenario. Using a trial and error method, it has been found that the chosen number of fuzzy rules was ranged between 10 and 16 for these AFLS models used to approximate the specific microorganism case for each sensorial system. The number of membership functions for each input variable is directly associated with the number of rules; hence, each input signal is “distributed” through Gaussian functions with different centers and widths to every rule node via a product operator. The values of the parameters (centers and widths) of the Gaussian membership functions have been adjusted by the gradient descent (GD) learning algorithm that was utilized as a learning scheme. Although the AFLS scheme shared with the MLP model the same learning algorithm, the training time was completed in less than 1000 epochs, much faster from the equivalent time used to train the MLP neural network.
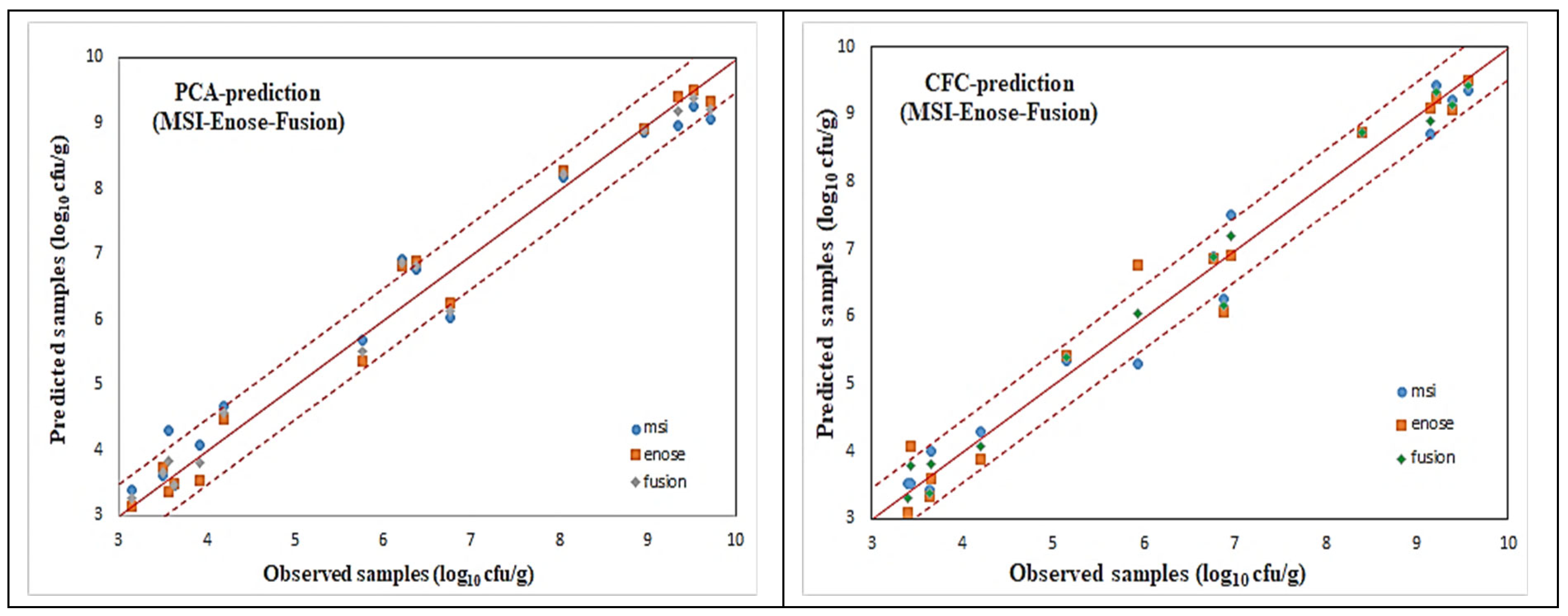
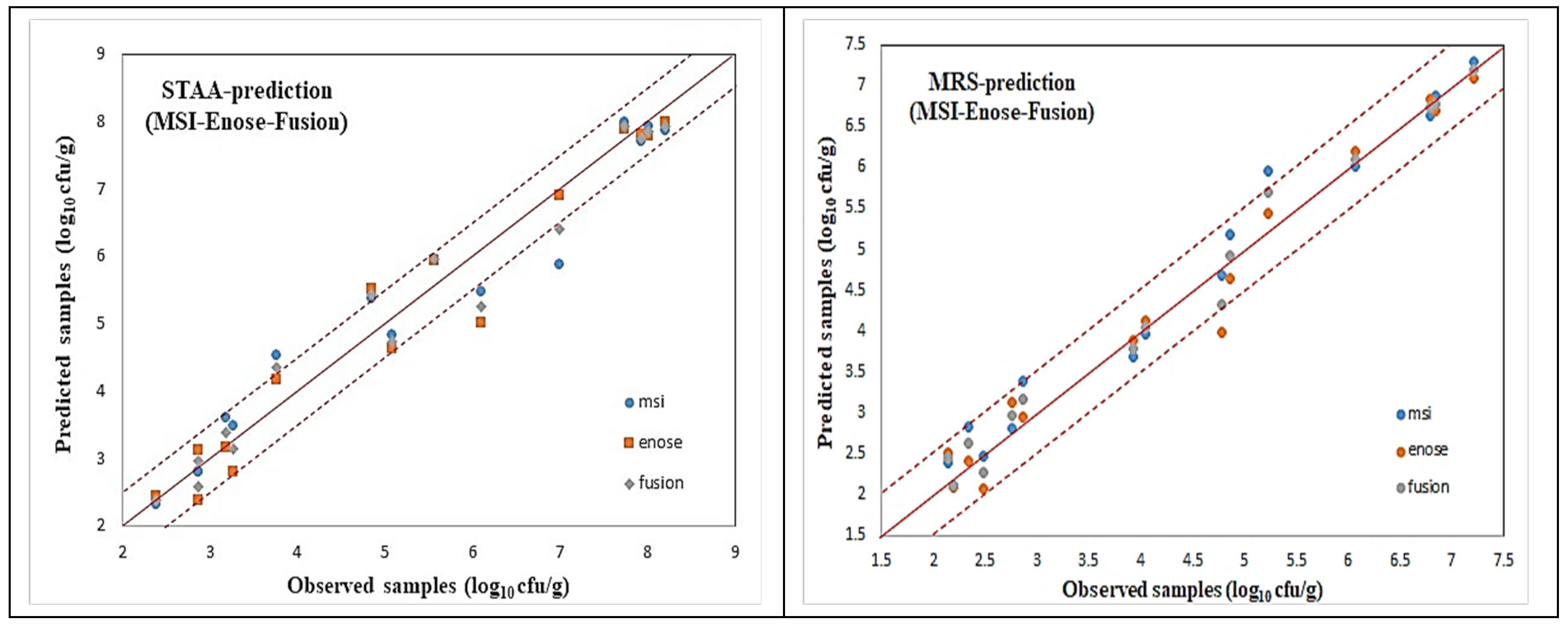
For all these microorganism cases, illustrated via the name of the agar medium used, scatter plots of the predicted (via AFLS) vs. the observed testing samples for the reduced case are illustrated in
Figure 18 and
Figure 19, which reveal a very good distribution around the line of equity (y = x), with the vast majority of the data included within the ±0.5 log area, especially for the fusion (i.e., average) scheme.
Even though the fusion scheme seems to be more accurate, it is interesting to notice the performances of the e-nose and MSI cases from these figures. It is rather difficult to confirm which sensorial device is the winner. This is due to the fact that the e-nose sensors and MSI wavelengths “capture” different characteristics of the same meat sample. Such diversity in the acquired results from the MSI and the e-nose is evidence of the validity of the sensor fusion hypothesis.
The testing performance of all the developed models to predict the above mentioned microorganism cases in the beef samples, in terms of statistical indices, are presented in
Table 4 and
Table 5. Even though fusion (via averaging) results for all the microbiological cases are superior, it is interesting to notice that the obtained individual per device results are acceptable, by checking especially the chemometric metrics for RPD, RER, and RPIQ. Such values reveal a clear robustness of the produced AFLS models.
Traditionally, in machine learning based applications, a common practice is to compare any proposed algorithm against other well-established methods in order to validate the chosen approach. In this research, four alternative regression models have also been developed. An MLP network utilizing two hidden layers, as well as a partial least squares regression (PLSR) scheme have also been implemented, due to the fact that these two schemes have been widely utilized in such applications. Additionally, support vector machine (SVM) and extreme gradient boosting (XGBoost) models, widely used in machine leaning, have been added due to the fact these specific algorithms are usually considered to be “competitors” to neural networks. The performance of all these models to predict the above mentioned microorganism cases for both the MSI and e-nose scenarios, in terms of statistical indices, are presented in
Table 6,
Table 7,
Table 8 and
Table 9.
The performance of the classic MLP neural network can be considered to be acceptable, although inferior to the related AFLS performance. Especially for the e-nose/STAA case, the MLP model, built with the backpropagation learning algorithm, achieved a rather comparable performance against the equivalent AFLS model. However, such performances were achieved with a relative high computational cost (more than 10,000 epochs). A two hidden layers structure was adopted for all models, while the number of nodes in the first and second hidden layers were ranged between 16 and 20 and 8 and 12, respectively. Overall, both the AFLS and MLP models revealed their robustness in predicting such complex dynamic characteristics as these microorganisms, regardless of the sensorial device used, proving that these learning architectures can be considered to be general purpose learning schemes.
A support vector machine (SVM) is a powerful machine learning approach based on statistical learning theory. Its advantages over the MLP models include a global optimal solution and robustness to outliers. In the context of regression, SVM aims to find a hyperplane that maximizes the margin between the predicted values and the actual values. It utilizes the so-called support vectors, which are the data points closest to the hyperplane, to define the regression line. The specific SVM used in this research involves epsilon support vector regression (
). The value of epsilon is used to measure the error between the predicted and the real values in a high-dimension space, and its value is determined based on practical experience. For this specific case study, SVR models were implemented in R using the e1071 R package. The penalty coefficient
was ranged to values >200, the gamma (
) parameter that controls the smoothness of the decision boundary in the feature space was set to values >0.01, while the epsilon tolerance value was set to values >0.03. The results shown in
Table 6,
Table 7,
Table 8 and
Table 9 reveal an inferior regression performance over the MLP network; however, these results could be considered to be acceptable as the calculated RPD was greater than three. Similarly to the MLP case, the SVM revealed a rather stable performance regardless of the sensorial device used.
The XGBoost algorithms belong to the group of ensemble learning, specifically boosting, where multiple weak learners (typically decision trees) are jointly used to create a robust and accurate predictive model [
37]. The goal is to minimize a loss function, and each weak learner is projected to correct the errors in the present ensemble. The algorithm’s strength stems from its ability to balance predictive accuracy and regularization, making it flexible and suitable for a wide range of machine learning applications. In this research, the XGBoost R package was employed to apply this algorithm for this application. The results shown at
Table 6,
Table 7,
Table 8 and
Table 9 reveal some diversity in terms of the sensorial device used and the specific microorganism case. Generally speaking, the application of XGBoost to the MSI cases was disappointed. A very low RPD value, along with the other metrics, proved the difficulty of this algorithm to handle this specific regression application. On the other hand, the e-nose application was much more improved, especially with the cases of PCA and STAA, where the algorithm really achieved a remarkable performance. Finally, a partial least squares regression (PLSR) scheme was applied to the same datasets. The PLS models were constructed using the same input vectors as the previous models, while the PLS_Toolbox (v. R9.1) software in association with MATLAB was used to perform the PLS analysis. The SIMPLS algorithm was chosen as the appropriate optimization scheme. The algorithm calculates the PLS factors directly as linear combinations of the original variables. These factors are determined so as to maximize a covariance criterion, while obeying certain orthogonality and normalization restrictions. It is well known that, in the modeling of real complex processes, linear PLSR has some difficulties, since most real problems are inherently nonlinear and dynamic. Although the method has a very low computational cost, and has wide applicability in food microbiological applications, the obtained results in all cases were rather disappointing. A close inspection at these results reveals that, for the case of the PLSR scheme, the obtained RPD values revealed that such a model cannot be considered to be acceptable/preferable.
Additionally, for each microorganism case, the proposed AFLS architecture was implemented in a LOOCV scenario for both the MSI and the e-nose components.
Table 10 and
Table 11 illustrate the related results via the same performance indices. Similar to the previous scenario, even in the LOOCV scheme, the proposed average fusion scheme outperformed the individual sensorial performances.
In summary, these regression results justified the need for advanced learning methods to regression tasks related to food analysis. The generic algorithms in machine learning, like MLP and SVM, proved their suitability, even if they have been outperformed by the hybrid neuro-fuzzy models. However, it was a surprise to see algorithms well known for their regression capabilities, like XGBoost, produce such diverse experience. One of the lessons learned by this research is that we always need to provide “tailored” solutions to specific problems. Unfortunately, in such types of applications, it is also rather restricted to accommodate an enormous amount of experimental data. Therefore, researchers need to search for methodologies that will enable them to create additional “virtual” data. In this research, through the use of RBF neural networks, additional data (microbiological as well as sensorial) were created, keeping the number of available temperatures constant. It might be interesting, in a future work, to investigate the creation of additional data in an expanded range of temperatures, and then to explore how a set of experimental data in a given temperature will perform in a regression task (through the interpolation abilities of learning based systems).
5.2. “Classification” Case Study
The final step in the proposed analytic framework is related to the identification of the class of testing meat samples. For this specific step, a simple PLSR scheme was employed in order to predict the type of class (i.e., fresh/semi-fresh/spoiled) of meat. This PLSR scheme was applied in the reduced scenario case (115 training vs. 15 testing samples respectively). The input vector consisted of the final four microorganism prediction levels (PCA, CFC, STAA and MRS) after the fusion, storage time, and temperature while the output of the regression model corresponded to the three-class cases (10, 20, and 30) which correspond to fresh/semi-fresh/spoiled classes. Details of the proposed PLSR scheme is shown in the following equation:
Table 12 shows the related PLSR results on the testing dataset. It is clear that a 100% classification rate has been achieved, thereby verifying the validity of the framework concept shown at
Figure 14.
Although, in this specific case study, only two individual sensing devices were utilized and their subsequent fusion was based on a simple average scheme, such a concept could be easily extended to include additional sensors and thus more advanced fusion strategies could be applied.
6. Conclusions
In this research, a proposed machine learning based framework for the detection of meat spoilage through the fusion of MSI and e-nose information has been investigated. The limitation of small size available datasets was addressed with the generation of additional “virtual” microbiological and sensorial data through the use of radial basis function neural networks. Feature selection analysis for each sensorial device was performed via the Boruta algorithm, while the AFLS NF regression models were employed to approximate each microorganism case through a high level fusion scheme. The performance of the AFLS models was evaluated through a number of established metrics, and compared successfully against the MLP, SVM, XGBoost, and PLSR models. Finally, a simple PLSR model was employed to predict the type of testing for the meat samples into three distinct classes, namely fresh, semi-fresh, and spoiled. Even though the performance of the implemented analytical framework was great, a number of open issues still remain. Future work will concentrate on modifying the existing analytical framework by incorporating additional sensorial information, such as FTIR, and utilizing an ensemble stacking model instead of the classic average fusion scheme. Although it achieved a robust performance, the AFLS model needs to be modified, as currently the number of fuzzy rules are chosen by the user. It would be interesting to automate this structural process by introducing a clustering component that will determine the number of input memberships/fuzzy rules. Neural networks are considered to be the most advanced techniques of automated data generation. They can handle much richer data distributions than traditional algorithms, such as decision trees. Although currently, an RBF neural network was utilized as the data generator, alternative algorithms based on neural network principles, such as variational autoencoders and generative adversarial networks, could provide an alternative solution. Obviously, the application domain can be expanded by investigating a freshness assessment for pork, poultry, and fish products. Similarly, the quality evaluation of fruits is of particular interest, through the use of multiple sensorial devices. Finally, authentication and control of adulteration are crucial for the meat and olive oil industry to ensure levels of quality for their products, as well as to safeguard the health and safety of consumers.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}