
GT-SRR: A Structured Method for Social Relation Recognition with GGNN-Based Transformer


Abstract
1. Introduction
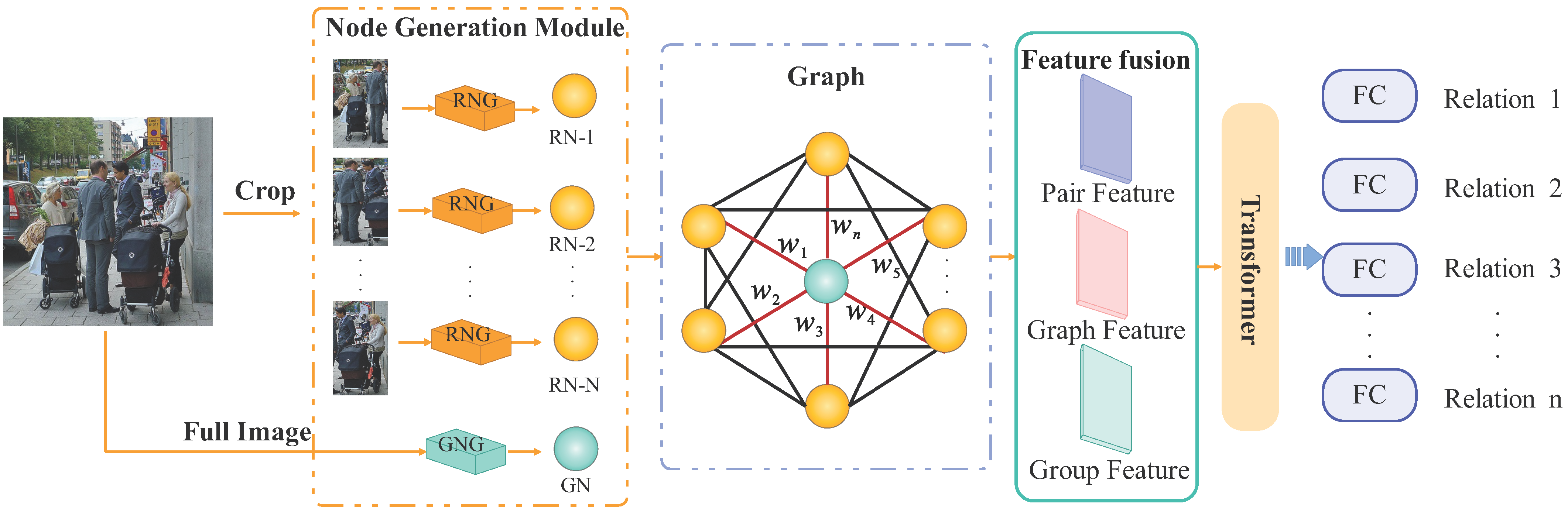
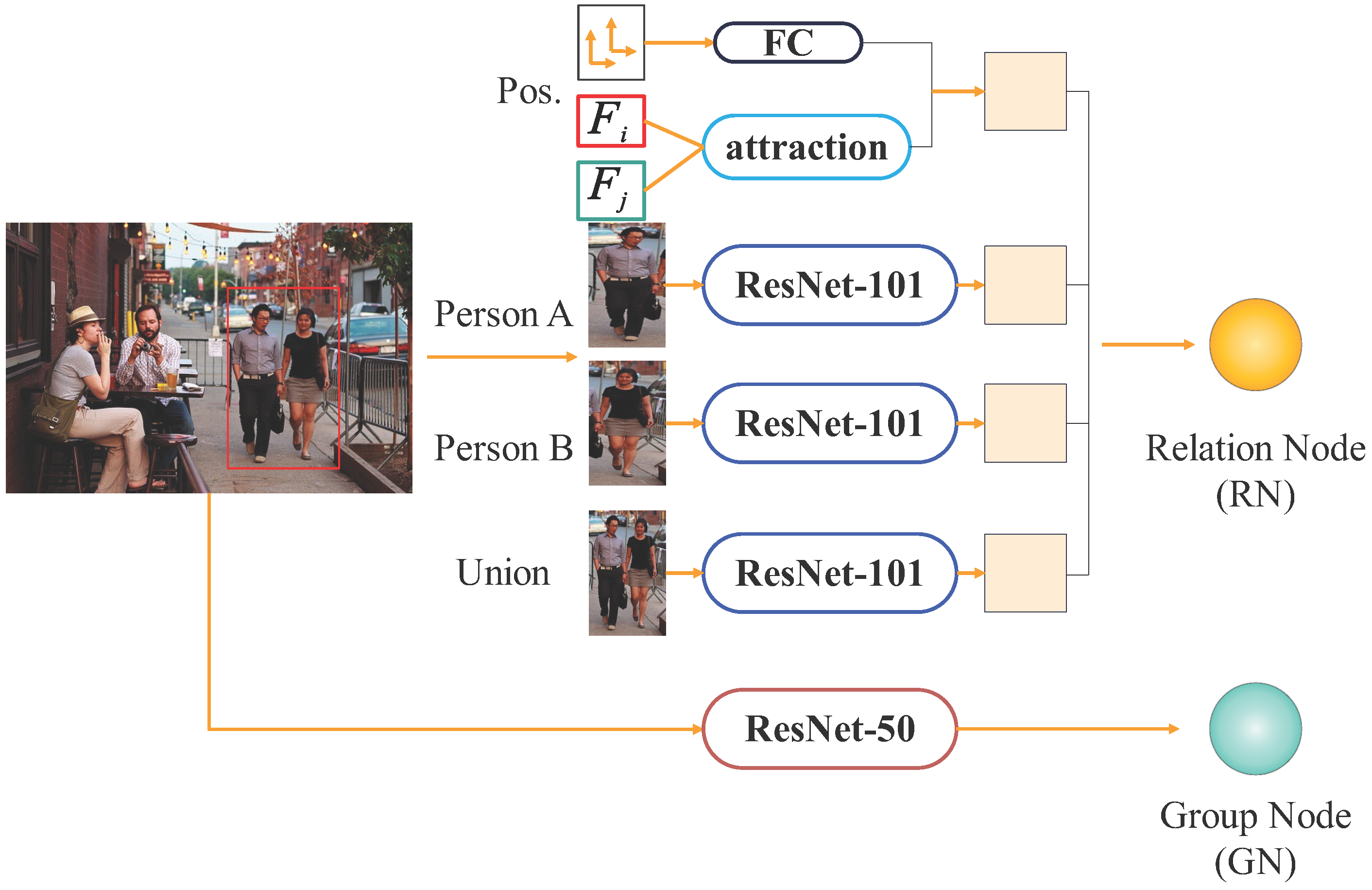
- Hybrid Feature Extraction: The model constructs relational and group nodes by leveraging multi-layer networks to extract individual features, interactional positional data, and group information. An enhanced GGNN captures the logical relationships among these nodes, while an attention mechanism dynamically weights scene features, effectively modeling complex inter-feature interactions.
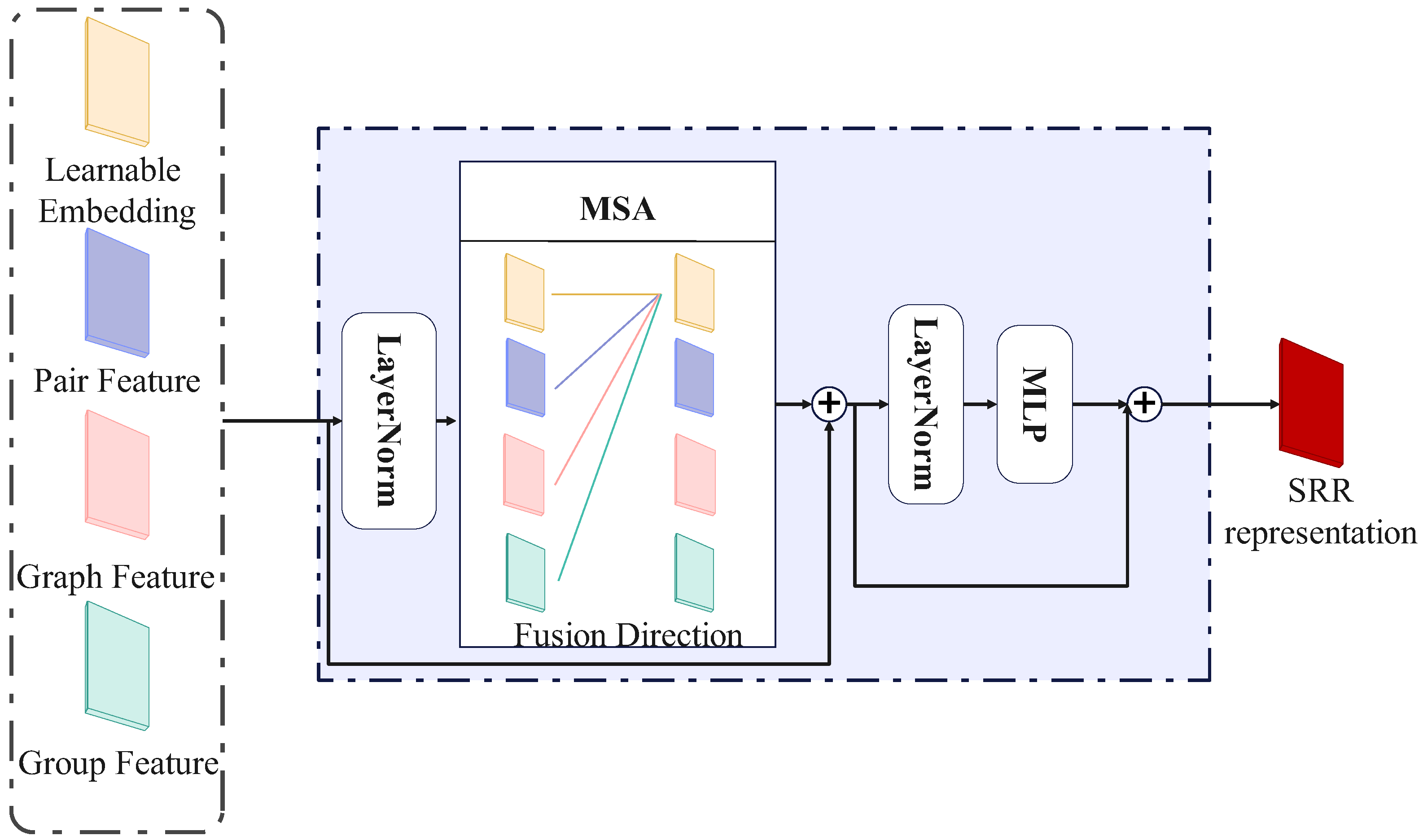
- Integrated Feature Fusion Strategy: The model integrates pairwise features, relational graph data, and group characteristics. Group features supplement pairwise recognition by offering comprehensive contextual insights. A feature weighting mechanism dynamically adjusts each feature’s impact type, enhancing the model’s expressiveness and robustness, particularly in complex relational scenarios.
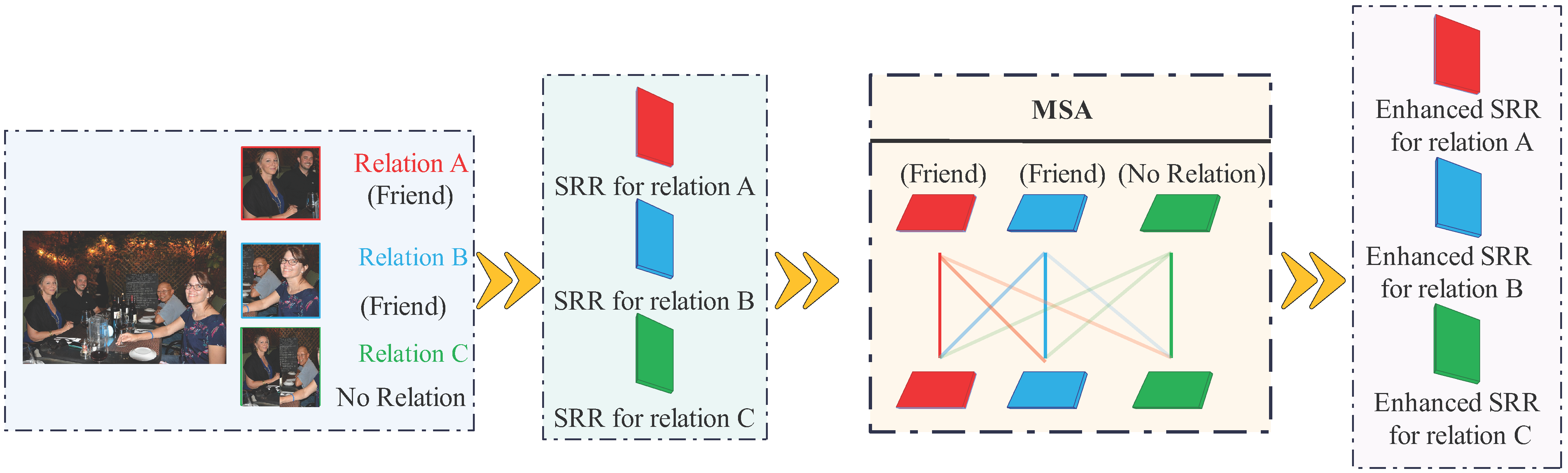
- Advanced Relationship Modeling with GGNN and Transformer: Building upon initial modeling, the combined GGNN and Transformer framework leverages the MSA feature of the Transformer to enhance global context modeling and conduct higher-order correlation analysis. While the GGNN effectively captures local feature relationships, the Transformer enables deep inter-feature interactions through global reasoning, ultimately improving the representation of social relationships and boosting classification performance.
2. Related Work
2.1. SRR
2.2. Transformer-Based Relationship Modeling
3. Methods
3.1. GT-SRR Framework Overview
3.2. Node Feature Extraction
3.3. Graph Inference Based on GGNN
3.4. Social Relationship Modeling via Transformer
3.5. Classification and Optimization
- Computing similarity between samples, including inter-class and intra-class similarity.
- Enhancing classification by aligning the predicted distribution with class-specific target distributions.
4. Experiments and Results
4.1. Dataset
4.2. Implementation Details
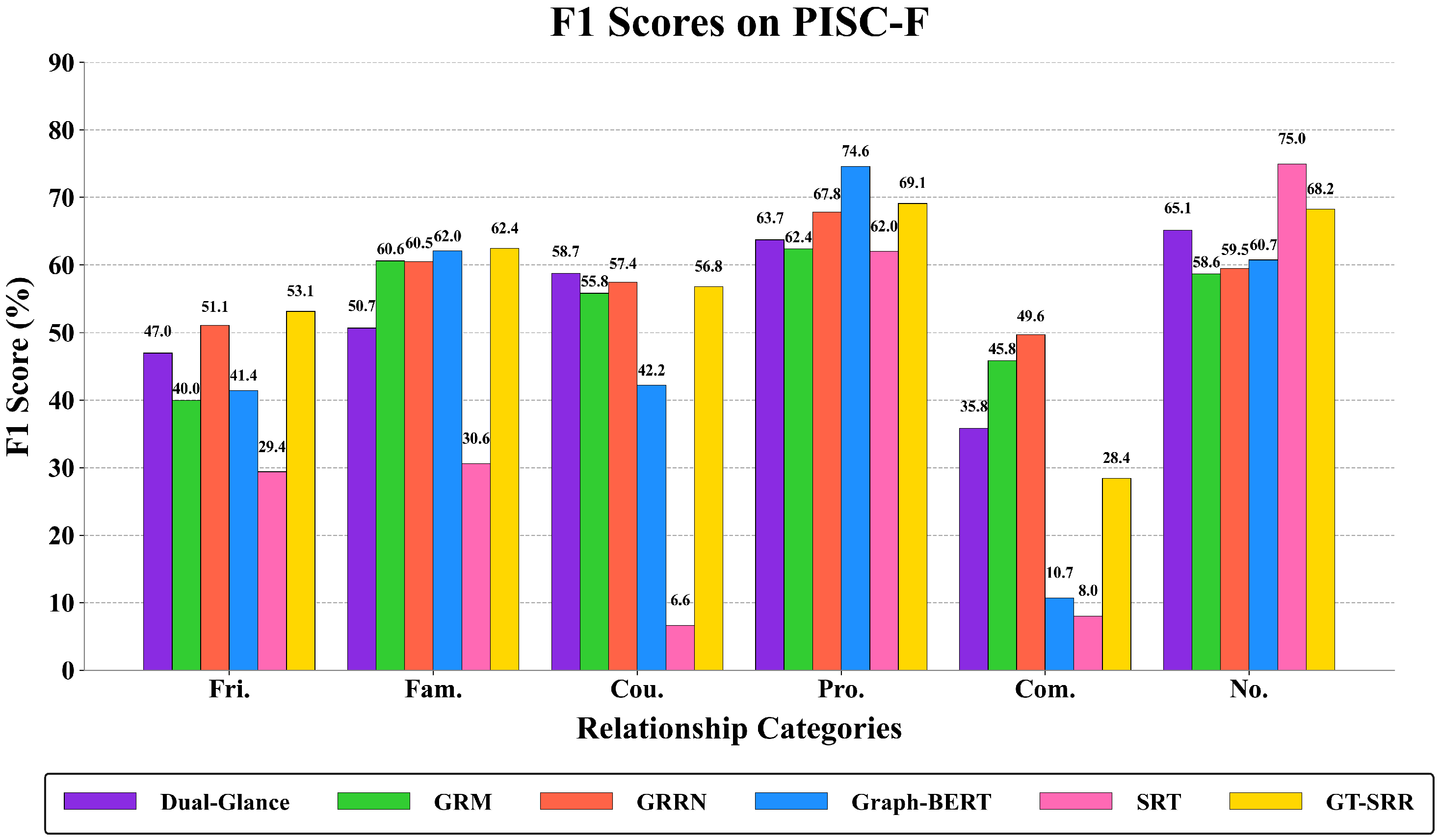
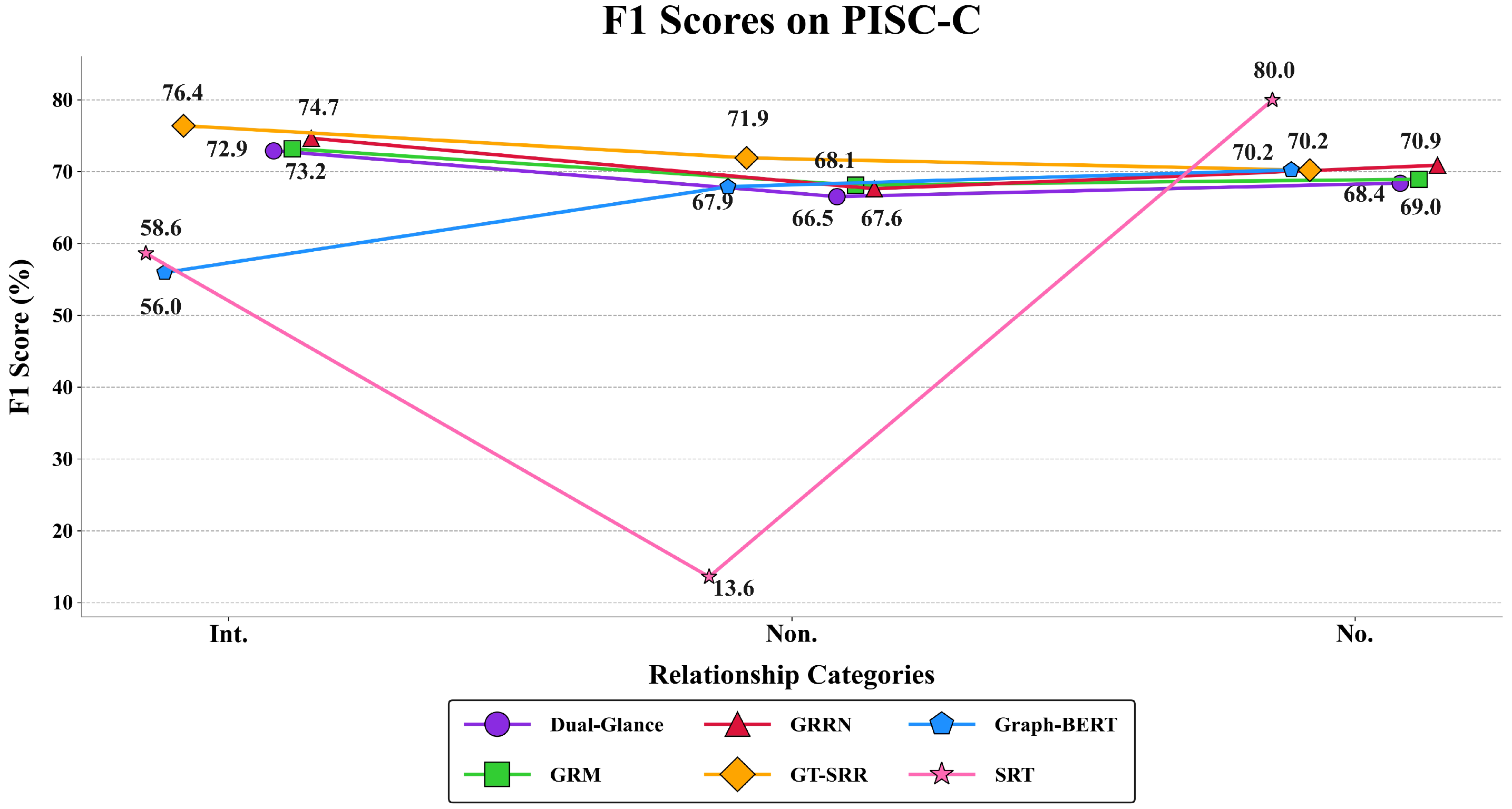
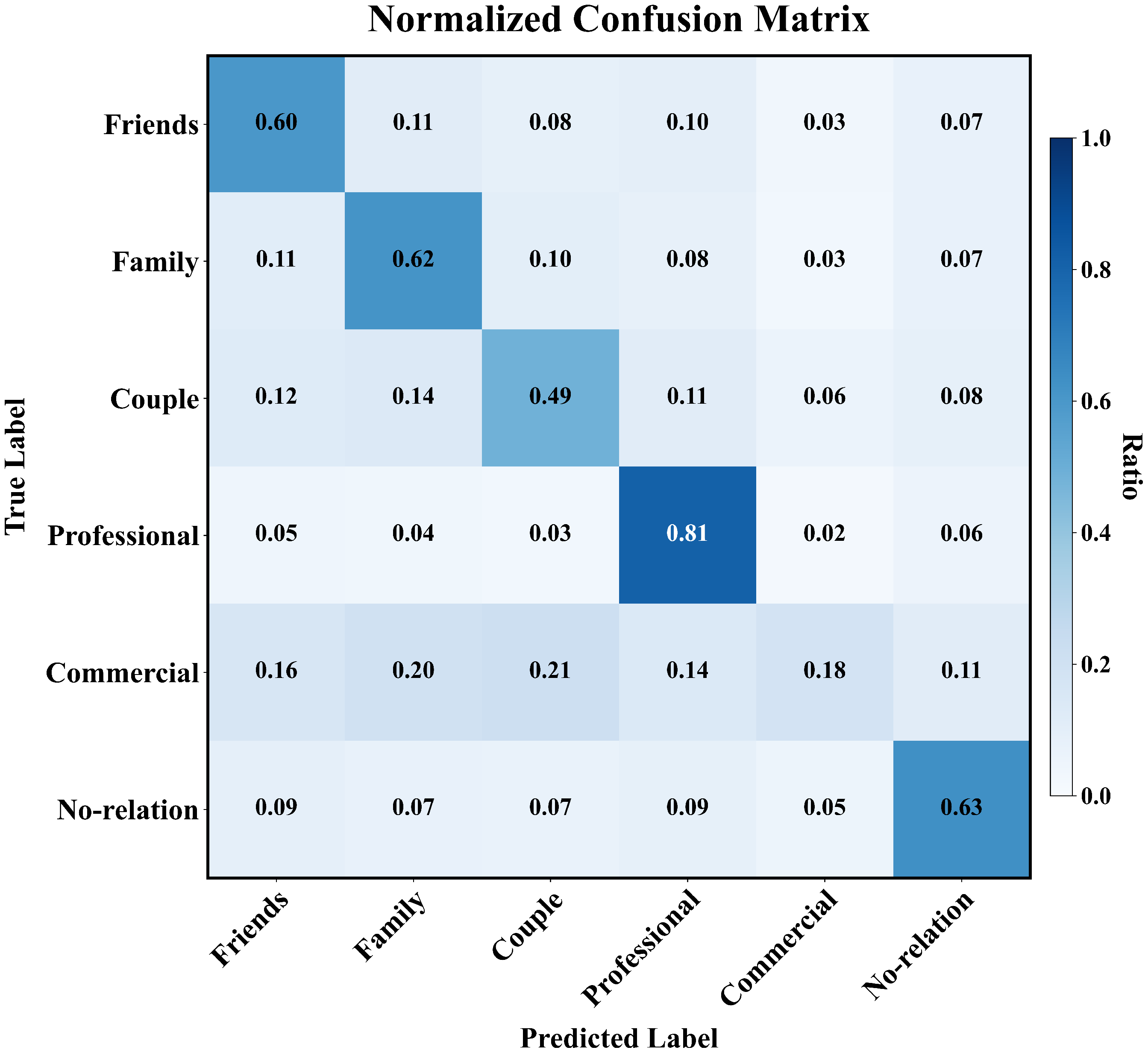
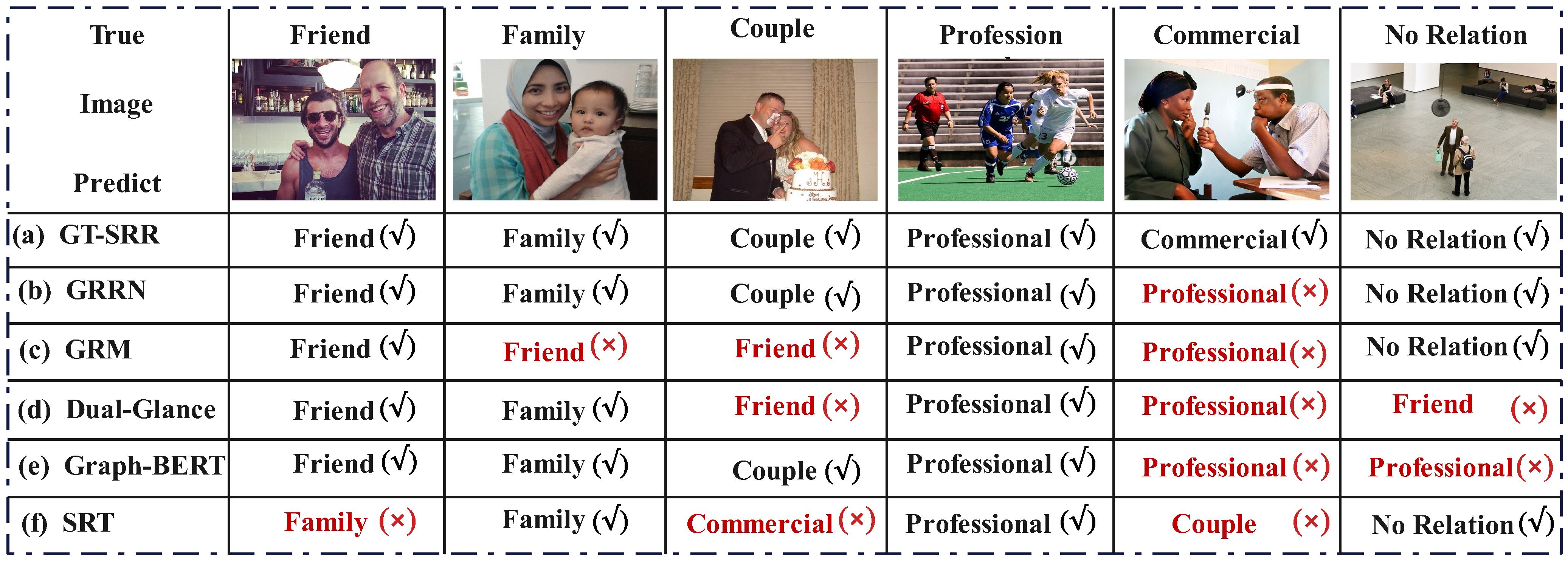
4.3. Comparative Experiments
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sou, K.; Shiokawa, H.; Yoh, K.; Doi, K. Street design for hedonistic sustainability through AI and human co-operative evaluation. Sustainability 2021, 13, 9066. [Google Scholar] [CrossRef]
- Quiroz, M.; Patiño, R.; Diaz-Amado, J.; Cardinale, Y. Group emotion detection based on social robot perception. Sensors 2022, 22, 3749. [Google Scholar] [CrossRef] [PubMed]
- Zheng, S.; Chen, S.; Jin, Q. Vrdformer: End-to-end video visual relation detection with transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18836–18846. [Google Scholar]
- Fu, J.; Yang, F.; Dang, Y.; Liu, X.; Yin, J. Learning constrained dynamic correlations in spatiotemporal graphs for motion prediction. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 14273–14287. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Jiang, F.; Han, Z.; Huang, X.; Wang, S.; Zhu, Y.; Jiang, Y.; Hu, B. Modeling Fine-Grained Relations in Dynamic Space-Time Graphs for Video-Based Facial Expression Recognition. IEEE Trans. Affect. Comput. 2025, 1–17. [Google Scholar] [CrossRef]
- Gao, K.; Chen, L.; Zhang, H.; Xiao, J.; Sun, Q. Compositional prompt tuning with motion cues for open-vocabulary video relation detection. arXiv 2023, arXiv:2302.00268. [Google Scholar]
- Wang, M.; Du, X.; Shu, X.; Wang, X.; Tang, J. Deep supervised feature selection for social relationship recognition. Pattern Recognit. Lett. 2020, 138, 410–416. [Google Scholar] [CrossRef]
- Wang, Y.; Qing, L.; Wang, Z.; Cheng, Y.; Peng, Y. Multi-level transformer-based social relation recognition. Sensors 2022, 22, 5749. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Duan, Y.; Lu, J.; Feng, J.; Zhou, J. Graph-based social relation reasoning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 18–34. [Google Scholar]
- Tang, W.; Qing, L.; Li, L.; Wang, Y.; Zhu, C. Progressive graph reasoning-based social relation recognition. IEEE Trans. Multimed. 2023, 26, 6012–6024. [Google Scholar] [CrossRef]
- Yu, X.; Yi, H.; Tang, Q.; Huang, K.; Hu, W.; Zhang, S.; Wang, X. Graph-based social relation inference with multi-level conditional attention. Neural Netw. 2024, 173, 106216. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Kalantidis, Y.; Rohrbach, M.; Paluri, M.; Elgammal, A.; Elhoseiny, M. Large-scale visual relationship understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9185–9194. [Google Scholar]
- Li, L.; Qing, L.; Wang, Y.; Su, J.; Cheng, Y.; Peng, Y. HF-SRGR: A new hybrid feature-driven social relation graph reasoning model. Vis. Comput. 2022, 38, 3979–3992. [Google Scholar] [CrossRef]
- Qing, L.; Li, L.; Wang, Y.; Cheng, Y.; Peng, Y. SRR-LGR: Local–global information-reasoned social relation recognition for human-oriented observation. Remote Sens. 2021, 13, 2038. [Google Scholar] [CrossRef]
- Ramanathan, V.; Yao, B.; Fei-Fei, L. Social role discovery in human events. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2475–2482. [Google Scholar]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Dual-glance model for deciphering social relationships. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2650–2659. [Google Scholar]
- Guo, X.; Polania, L.; Zhu, B.; Boncelet, C.; Barner, K. Graph neural networks for image understanding based on multiple cues: Group emotion recognition and event recognition as use cases. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Seattle, WA, USA, 13–19 June 2020; pp. 2921–2930. [Google Scholar]
- Zhang, M. Graph neural networks: Link prediction. In Graph Neural Networks: Foundations, Frontiers, and Applications; Springer: Singapore, 2022; pp. 195–223. [Google Scholar]
- Gao, J.; Qing, L.; Li, L.; Cheng, Y.; Peng, Y. Multi-scale features based interpersonal relation recognition using higher-order graph neural network. Neurocomputing 2021, 456, 243–252. [Google Scholar] [CrossRef]
- Fang, R.; Tang, K.D.; Snavely, N.; Chen, T. Towards computational models of kinship verification. In Proceedings of the 2010 IEEE International Conference on Image Processing, Hong Kong, China, 26–29 September 2010; pp. 1577–1580. [Google Scholar]
- Yan, H.; Lu, J.; Zhou, X. Prototype-based discriminative feature learning for kinship verification. IEEE Trans. Cybern. 2014, 45, 2535–2545. [Google Scholar] [CrossRef] [PubMed]
- Goel, A.; Ma, K.T.; Tan, C. An end-to-end network for generating social relationship graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11186–11195. [Google Scholar]
- Wang, Z.; Chen, T.; Ren, J.; Yu, W.; Cheng, H.; Lin, L. Deep reasoning with knowledge graph for social relationship understanding. arXiv 2018, arXiv:1807.00504. [Google Scholar]
- Guo, Y.; Yin, F.; Feng, W.; Yan, X.; Xue, T.; Mei, S.; Liu, C.L. Social relation reasoning based on triangular constraints. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 737–745. [Google Scholar]
- LYU, Y.x.; HAO, S.; QIAO, G.t.; XING, Y. A Social Recommendation Algorithm Based on Graph Neural Network. J. Northeast. Univ. Nat. Sci. 2024, 45, 10. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Gao, S.; Zhou, C.; Zhang, J. Generalized Relation Modeling for Transformer Tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 18686–18695. [Google Scholar]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the blanks: Distributional similarity for relation learning. arXiv 2019, arXiv:1906.03158. [Google Scholar]
- Zhang, J.; Zhang, H.; Xia, C.; Sun, L. Graph-bert: Only attention is needed for learning graph representations. arXiv 2020, arXiv:2001.05140. [Google Scholar]
- Diao, C.; Loynd, R. Relational attention: Generalizing transformers for graph-structured tasks. arXiv 2022, arXiv:2210.05062. [Google Scholar]
- Chen, D.; O’Bray, L.; Borgwardt, K. Structure-aware transformer for graph representation learning. In Proceedings of the International Conference on Machine Learning, PMLR, Vancouver, BC, Canada, 18–22 June 2022; pp. 3469–3489. [Google Scholar]
- Zhou, C.; Han, M.; Liang, Q.; Hu, Y.F.; Kuai, S.G. A social interaction field model accurately identifies static and dynamic social groupings. Nat. Hum. Behav. 2019, 3, 847–855. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Validation | Testing | |
|---|---|---|---|
| PISC-C | 13,142/49,017 | 4000/14,536 | 4000/15,497 |
| PISC-F | 23,207/72,612 | 500/1505 | 1250/3961 |
| Rel. | Fri | Fam | Cou | Pro | Com | No |
|---|---|---|---|---|---|---|
| Samples | 12,686 | 7818 | 1552 | 20,842 | 6523 | 11,979 |
| Model | PISC-C | PISC-F | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Int. | Non. | No. | mAP | Fri. | Fam. | Cou. | Pro. | Com. | No. | mAP | |
| Dual-Glance | 78.25 | 65.04 | 63.99 | 76.40 | 56.51 | 39.44 | 63.92 | 75.06 | 25.71 | 59.75 | 57.15 |
| GRM | 76.12 | 68.28 | 68.13 | 74.84 | 38.14 | 60.41 | 61.18 | 67.72 | 46.33 | 54.97 | 56.45 |
| GRRN | 79.08 | 64.25 | 69.36 | 77.30 | 58.67 | 57.61 | 77.25 | 64.10 | 48.59 | 52.63 | 63.17 |
| Graph-BERT | 55.95 | 67.90 | 70.24 | 71.30 | 41.39 | 62.04 | 42.19 | 74.59 | 10.73 | 60.72 | 59.79 |
| SRT | 58.62 | 13.58 | 79.97 | 52.35 | 29.37 | 30.58 | 6.64 | 62.00 | 8.03 | 74.95 | 45.28 |
| GT-SRR (Ours) | 80.10 | 73.69 | 64.48 | 80.52 | 60.08 | 61.60 | 48.63 | 81.12 | 18.08 | 63.06 | 64.06 |
| Component | Dual-Glance | GRM | GRRN | Graph-BERT | SRT | GT-SRR (Ours) |
|---|---|---|---|---|---|---|
| Individual Feature Extraction | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Interaction Modeling (Position + Behavior) | ROI-based Glance Module | 3D Geometric Encoding | GRU-based Edge Modeling | Graph-Based Interaction | Simple Distance Rule | Hybrid Interaction |
| Scene Context Integration | – | ✓ | ✓ | ✓ | ✓ | ✓ |
| Group Semantics Modeling | – | – | – | – | – | ✓ |
| Feature Fusion Strategy | Concat- enation | Geometric-Spatial Fusion | Contextual Feature Fusion | MLP-based Fusion | Direct Concatenation | Cross-modal Attention Fusion |
| Graph Structure (RNs + GN) | – | – | Static Graph | BERT-Enhanced Graph | – | Hierarchical Graph |
| Relational Reasoning Method | – | – | GRU-based Local Reasoning | Graph-BERT Layers | Rule-based Prediction | GGNN + Transformer |
| Int. | Non. | No. | mAP | |
|---|---|---|---|---|
| GGNN | 70.02 | 30.11 | 61.52 | 55.54 |
| Transformer | 68.93 | 24.18 | 64.16 | 54.07 |
| GGNN+Transformer (without group feature) | 83.09 | 52.41 | 62.03 | 74.84 |
| GGNN+Transformer+group feature (ours) | 80.10 | 73.69 | 64.48 | 80.52 |
| Int. | Non. | No. | mAP | |
|---|---|---|---|---|
| GCN | 66.62 | 67.90 | 70.08 | 73.52 |
| GAT | 64.75 | 70.26 | 68.70 | 74.17 |
| GGNN | 80.10 | 73.69 | 64.48 | 80.52 |
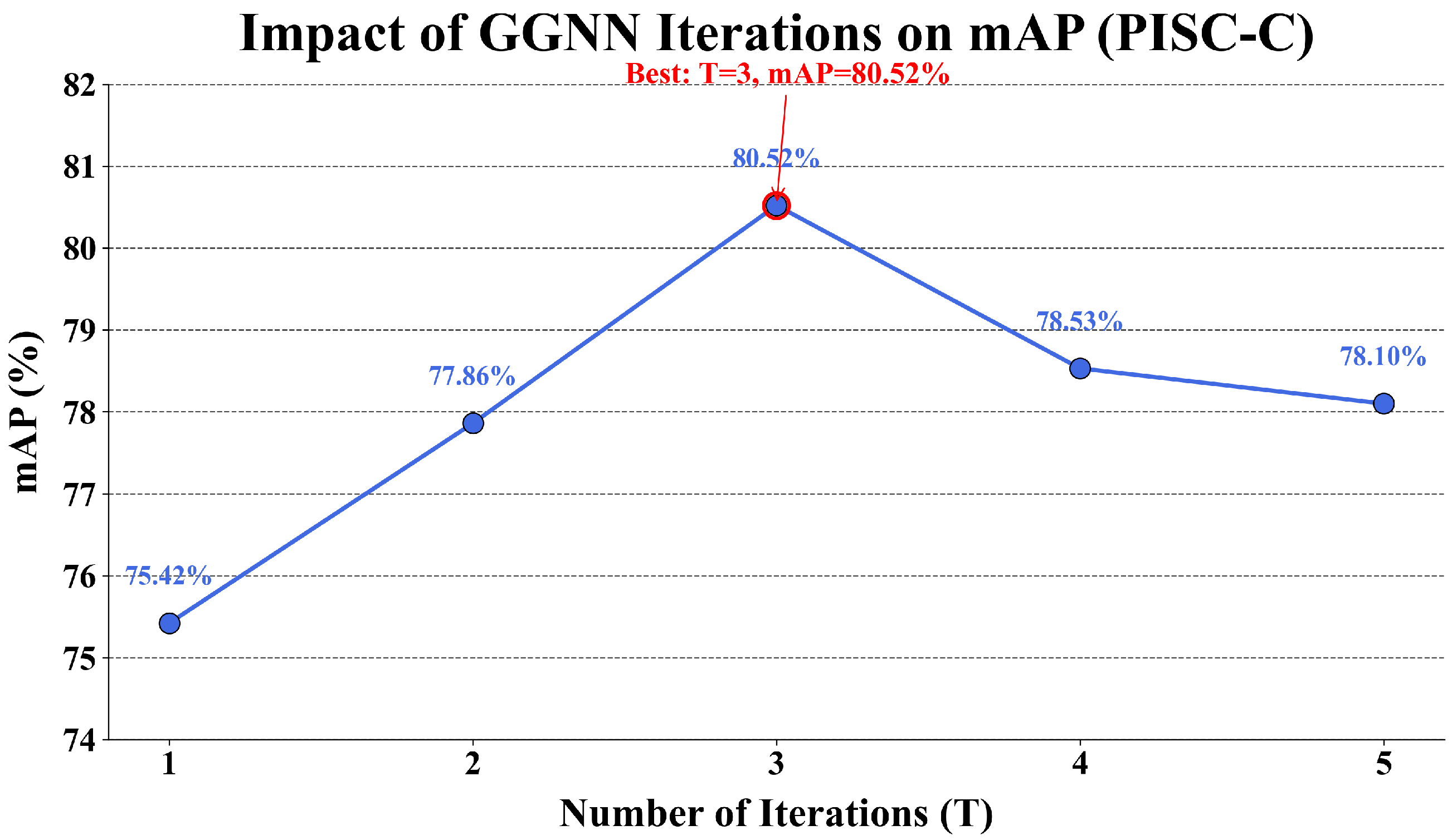
| Iterations (T) | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| mAP (%) | 75.42 | 77.86 | 80.52 | 78.53 | 78.10 |
| Fusion Method | Int. | Non. | No. | mAP |
|---|---|---|---|---|
| Simple Concatenation | 72.12 | 45.33 | 61.49 | 70.35 |
| Attention-based Fusion | 78.37 | 52.84 | 68.00 | 73.24 |
| Gated Fusion | 80.62 | 56.20 | 56.84 | 73.97 |
| MSA (ours) | 80.10 | 73.69 | 64.48 | 80.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, D.; Xia, M.; Chang, R.; Kong, X.; Guo, S. GT-SRR: A Structured Method for Social Relation Recognition with GGNN-Based Transformer. Sensors 2025, 25, 2992. https://doi.org/10.3390/s25102992
Huang D, Xia M, Chang R, Kong X, Guo S. GT-SRR: A Structured Method for Social Relation Recognition with GGNN-Based Transformer. Sensors. 2025; 25(10):2992. https://doi.org/10.3390/s25102992
Chicago/Turabian StyleHuang, Dejiao, Menglei Xia, Ruyi Chang, Xiaohan Kong, and Shuai Guo. 2025. "GT-SRR: A Structured Method for Social Relation Recognition with GGNN-Based Transformer" Sensors 25, no. 10: 2992. https://doi.org/10.3390/s25102992
APA StyleHuang, D., Xia, M., Chang, R., Kong, X., & Guo, S. (2025). GT-SRR: A Structured Method for Social Relation Recognition with GGNN-Based Transformer. Sensors, 25(10), 2992. https://doi.org/10.3390/s25102992