
IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution

 ,
,
Abstract
1. Introduction
- We propose the incremental guided attention fusion model, which surpasses existing works for the task of DSR on all tested benchmark datasets for all tested benchmark resolutions.
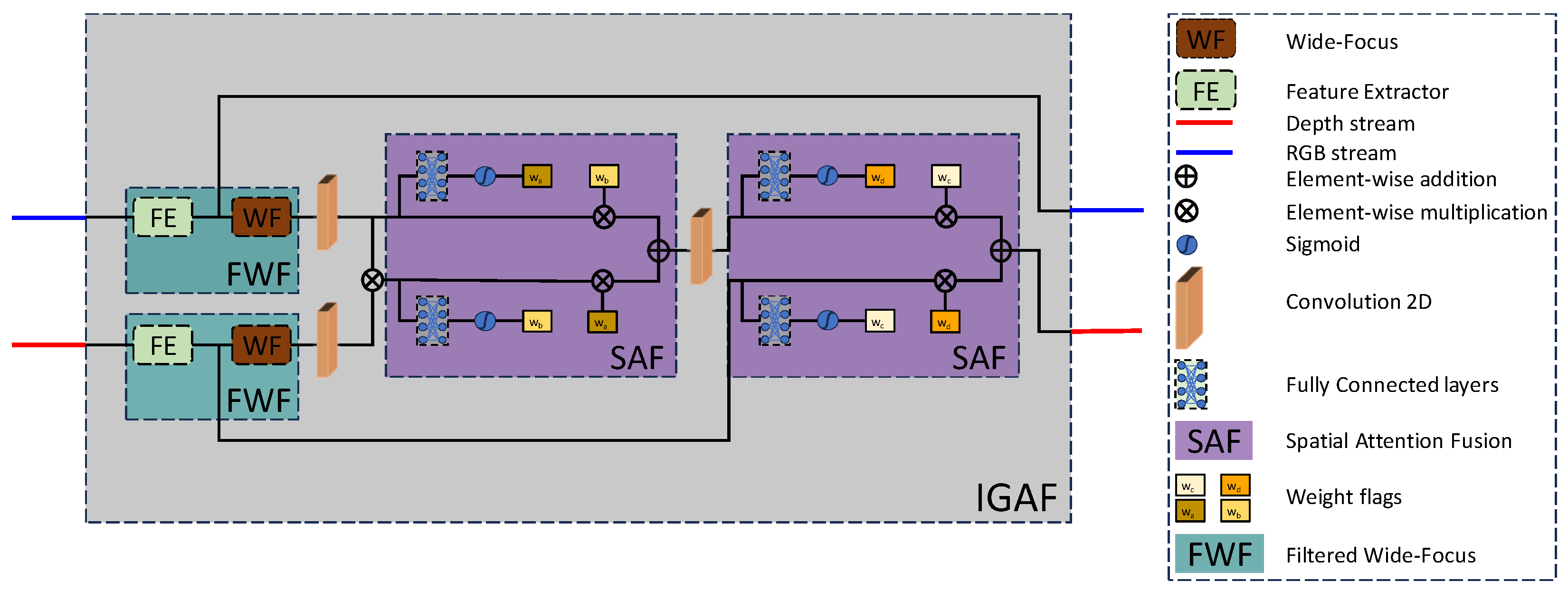
- We propose the module, which is a flexible and adaptive attention fusion strategy, with the ability to effectively fuse multi-modal features by creating weights from both modalities and then applying a two-step cross fusion.
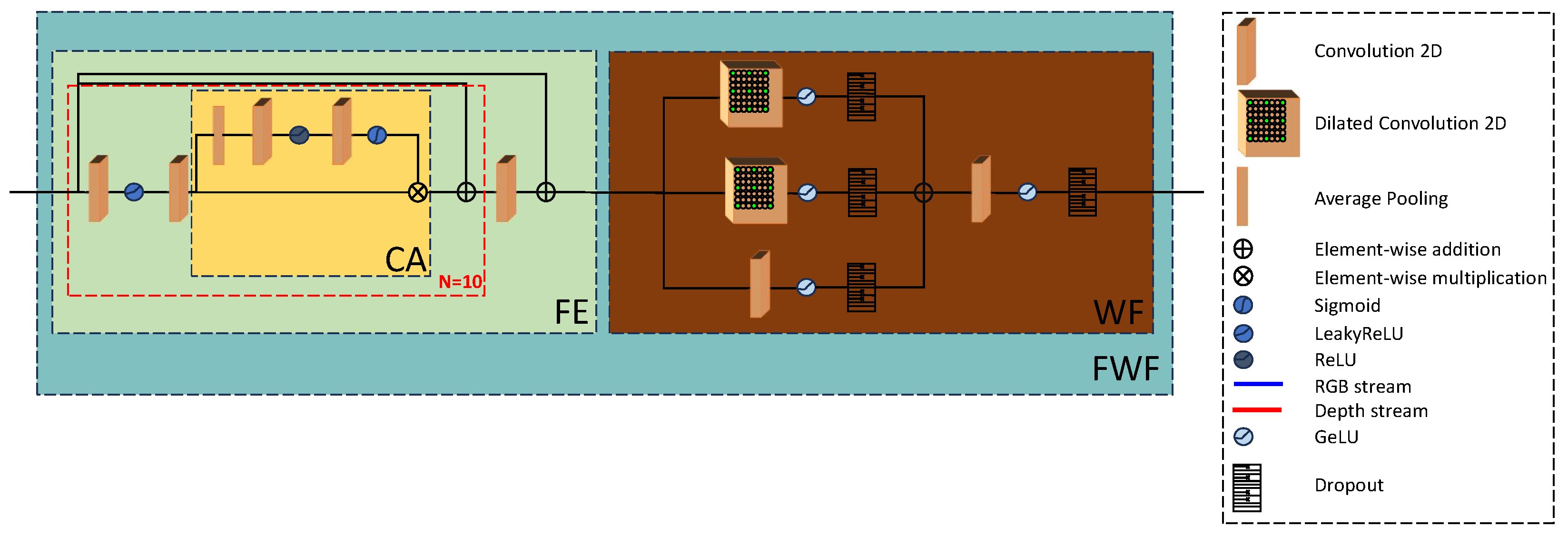
- We propose the filtered wide-focus block, a strong feature extractor composed of two modules, the feature extractor and wide-focus . The with the help of channel attention is able to highlight relevant feature channels in feature volumes, and the using varying dilation rates in the convolution layers per branch, creates multi-receptive field spatial information that allows integrating global resolution features using dynamic receptive fields to better highlight textures and edges. The combination of the two forms a general-purpose feature extractor specifically tailored towards DSR.
2. Literature Review
3. Methodology
3.1. Problem Statement
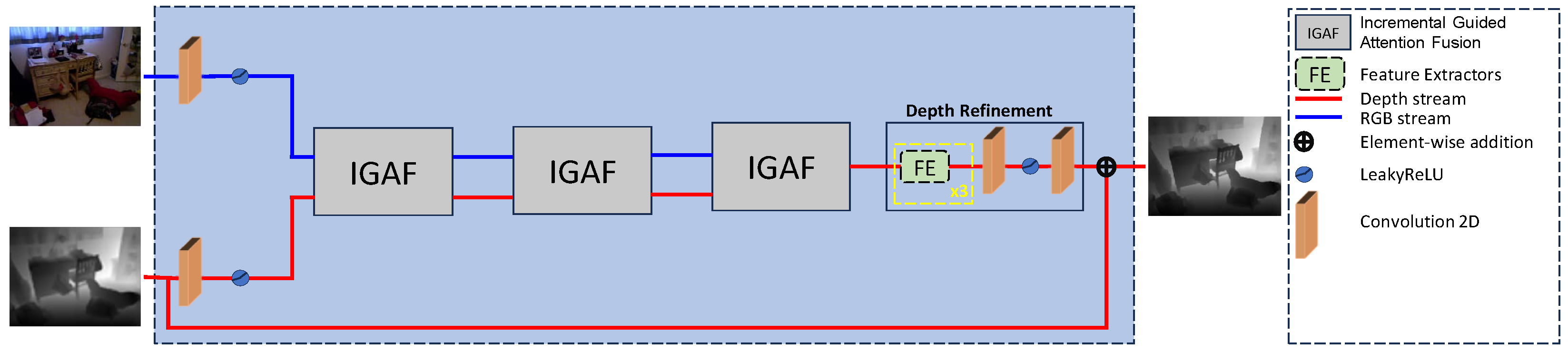
3.2. Model Architecture
3.2.1. The Module
4. Experiments
5. Results
6. Ablation Study
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual odometry and mapping for autonomous flight using an RGB-D camera. In Proceedings of the Robotics Research: The 15th International Symposium ISRR, Flagstaff, AZ, USA, 28 August–1 September 2011; Springer: Cham, Switzerland, 2017; pp. 235–252. [Google Scholar]
- Stowers, J.; Hayes, M.; Bainbridge-Smith, A. Altitude control of a quadrotor helicopter using depth map from Microsoft Kinect sensor. In Proceedings of the 2011 IEEE International Conference on Mechatronics, Istanbul, Turkey, 13–15 April 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 358–362. [Google Scholar]
- Melchiorre, M.; Scimmi, L.S.; Pastorelli, S.P.; Mauro, S. Collison avoidance using point cloud data fusion from multiple depth sensors: A practical approach. In Proceedings of the 2019 23rd International Conference on Mechatronics Technology (ICMT), Salerno, Italy, 23–26 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Gao, X.; Uchiyama, Y.; Zhou, X.; Hara, T.; Asano, T.; Fujita, H. A fast and fully automatic method for cerebrovascular segmentation on time-of-flight (TOF) MRA image. J. Digit. Imaging 2011, 24, 609–625. [Google Scholar] [CrossRef] [PubMed]
- Penne, J.; Höller, K.; Stürmer, M.; Schrauder, T.; Schneider, A.; Engelbrecht, R.; Feußner, H.; Schmauss, B.; Hornegger, J. Time-of-flight 3-D endoscopy. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Marrakesh, Morocco, 7–11 October 2009; Springer: Cham, Switzerland, 2009; pp. 467–474. [Google Scholar]
- Zhong, Z.; Liu, X.; Jiang, J.; Zhao, D.; Ji, X. Guided depth map super-resolution: A survey. ACM Comput. Surv. 2023, 55, 1–36. [Google Scholar] [CrossRef]
- Yang, Q.; Yang, R.; Davis, J.; Nistér, D. Spatial-depth super resolution for range images. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Riemens, A.; Gangwal, O.; Barenbrug, B.; Berretty, R.P. Multistep joint bilateral depth upsampling. In Proceedings of the Visual Communications and Image Processing, San Jose, CA, USA, 20–22 January 2009; SPIE: Bellingham, WA, USA, 2009; Volume 7257, pp. 192–203. [Google Scholar]
- Liu, M.Y.; Tuzel, O.; Taguchi, Y. Joint geodesic upsampling of depth images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 169–176. [Google Scholar]
- Lo, K.H.; Wang, Y.C.F.; Hua, K.L. Edge-preserving depth map upsampling by joint trilateral filter. IEEE Trans. Cybern. 2017, 48, 371–384. [Google Scholar] [CrossRef] [PubMed]
- Sun, Z.; Han, B.; Li, J.; Zhang, J.; Gao, X. Weighted guided image filtering with steering kernel. IEEE Trans. Image Process. 2019, 29, 500–508. [Google Scholar] [CrossRef] [PubMed]
- Qiao, Y.; Jiao, L.; Li, W.; Richardt, C.; Cosker, D. Fast, High-Quality Hierarchical Depth-Map Super-Resolution. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 4444–4453. [Google Scholar]
- Diebel, J.; Thrun, S. An application of markov random fields to range sensing. Adv. Neural Inf. Process. Syst. 2005, 18, 291–298. [Google Scholar]
- Ferstl, D.; Reinbacher, C.; Ranftl, R.; Rüther, M.; Bischof, H. Image guided depth upsampling using anisotropic total generalized variation. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 993–1000. [Google Scholar]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 343–352. [Google Scholar]
- Park, J.; Kim, H.; Tai, Y.W.; Brown, M.S.; Kweon, I.S. High-quality depth map upsampling and completion for RGB-D cameras. IEEE Trans. Image Process. 2014, 23, 5559–5572. [Google Scholar] [CrossRef] [PubMed]
- Riegler, G.; Rüther, M.; Bischof, H. Atgv-net: Accurate depth super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14; Springer: Cham, Switzerland, 2016; pp. 268–284. [Google Scholar]
- Jiang, Z.; Yue, H.; Lai, Y.K.; Yang, J.; Hou, Y.; Hou, C. Deep edge map guided depth super resolution. Signal Process. Image Commun. 2021, 90, 116040. [Google Scholar] [CrossRef]
- Song, X.; Dai, Y.; Qin, X. Deep depth super-resolution: Learning depth super-resolution using deep convolutional neural network. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part IV 13. Springer: Cham, Switzerland, 2017; pp. 360–376. [Google Scholar]
- Song, X.; Dai, Y.; Zhou, D.; Liu, L.; Li, W.; Li, H.; Yang, R. Channel attention based iterative residual learning for depth map super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, DC, USA, 14–19 June 2020; pp. 5631–5640. [Google Scholar]
- Ye, X.; Sun, B.; Wang, Z.; Yang, J.; Xu, R.; Li, H.; Li, B. Depth super-resolution via deep controllable slicing network. In Proceedings of the 28th ACM International Conference on Multimedia, Virtual Event, 12–16 October 2020; pp. 1809–1818. [Google Scholar]
- Huang, L.; Zhang, J.; Zuo, Y.; Wu, Q. Pyramid-structured depth map super-resolution based on deep dense-residual network. IEEE Signal Process. Lett. 2019, 26, 1723–1727. [Google Scholar] [CrossRef]
- He, L.; Zhu, H.; Li, F.; Bai, H.; Cong, R.; Zhang, C.; Lin, C.; Liu, M.; Zhao, Y. Towards fast and accurate real-world depth super-resolution: Benchmark dataset and baseline. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 9229–9238. [Google Scholar]
- Shi, W.; Ye, M.; Du, B. Symmetric Uncertainty-Aware Feature Transmission for Depth Super-Resolution. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 3867–3876. [Google Scholar]
- Tang, J.; Chen, X.; Zeng, G. Joint implicit image function for guided depth super-resolution. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4390–4399. [Google Scholar]
- Sun, B.; Ye, X.; Li, B.; Li, H.; Wang, Z.; Xu, R. Learning scene structure guidance via cross-task knowledge transfer for single depth super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 7792–7801. [Google Scholar]
- Tang, Q.; Cong, R.; Sheng, R.; He, L.; Zhang, D.; Zhao, Y.; Kwong, S. Bridgenet: A joint learning network of depth map super-resolution and monocular depth estimation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 2148–2157. [Google Scholar]
- Zhao, Z.; Zhang, J.; Xu, S.; Lin, Z.; Pfister, H. Discrete cosine transform network for guided depth map super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5697–5707. [Google Scholar]
- Zhao, Z.; Zhang, J.; Gu, X.; Tan, C.; Xu, S.; Zhang, Y.; Timofte, R.; Van Gool, L. Spherical space feature decomposition for guided depth map super-resolution. arXiv 2023, arXiv:2303.08942. [Google Scholar]
- Xu, D.; Fan, X.; Gao, W. Multiscale Attention Fusion for Depth Map Super-Resolution Generative Adversarial Networks. Entropy 2023, 25, 836. [Google Scholar] [CrossRef]
- Wang, J.; Huang, Q. Depth Map Super-Resolution Reconstruction Based on Multi-Channel Progressive Attention Fusion Network. Appl. Sci. 2023, 13, 8270. [Google Scholar] [CrossRef]
- Song, X.; Zhou, D.; Li, W.; Dai, Y.; Liu, L.; Li, H.; Yang, R.; Zhang, L. WAFP-Net: Weighted Attention Fusion Based Progressive Residual Learning for Depth Map Super-Resolution. IEEE Trans. Multimed. 2021, 24, 4113–4127. [Google Scholar] [CrossRef]
- Zhong, Z.; Liu, X.; Jiang, J.; Zhao, D.; Chen, Z.; Ji, X. High-resolution depth maps imaging via attention-based hierarchical multi-modal fusion. IEEE Trans. Image Process. 2021, 31, 648–663. [Google Scholar] [CrossRef] [PubMed]
- Tragakis, A.; Kaul, C.; Murray-Smith, R.; Husmeier, D. The fully convolutional transformer for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 3660–3669. [Google Scholar]
- Silberman, N.; Hoiem, D.; Kohli, P.; Fergus, R. Indoor segmentation and support inference from rgbd images. In Proceedings of the Computer Vision–ECCV 2012: 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Proceedings, Part V 12. Springer: Cham, Switzerland, 2012; pp. 746–760. [Google Scholar]
- Hirschmuller, H.; Scharstein, D. Evaluation of cost functions for stereo matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Scharstein, D.; Pal, C. Learning conditional random fields for stereo. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Lu, S.; Ren, X.; Liu, F. Depth enhancement via low-rank matrix completion. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 3390–3397. [Google Scholar]
- Gu, S.; Zuo, W.; Guo, S.; Chen, Y.; Chen, C.; Zhang, L. Learning dynamic guidance for depth image enhancement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3769–3778. [Google Scholar]
- Pan, J.; Dong, J.; Ren, J.S.; Lin, L.; Tang, J.; Yang, M.H. Spatially variant linear representation models for joint filtering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1702–1711. [Google Scholar]
- Kim, B.; Ponce, J.; Ham, B. Deformable kernel networks for guided depth map upsampling. arXiv 2019, arXiv:1903.11286. [Google Scholar]
- Li, Y.; Huang, J.B.; Ahuja, N.; Yang, M.H. Joint image filtering with deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1909–1923. [Google Scholar] [CrossRef] [PubMed]
- Su, H.; Jampani, V.; Sun, D.; Gallo, O.; Learned-Miller, E.; Kautz, J. Pixel-adaptive convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11166–11175. [Google Scholar]
- Hui, T.W.; Loy, C.C.; Tang, X. Depth map super-resolution by deep multi-scale guidance. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Cham, Switzerland, 2016; pp. 353–369. [Google Scholar]
- Li, Y.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep joint image filtering. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part IV 14. Springer: Cham, Switzerland, 2016; pp. 154–169. [Google Scholar]
- Deng, X.; Dragotti, P.L. Deep convolutional neural network for multi-modal image restoration and fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3333–3348. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Bicubic | DG [39] | SVLRM [40] | DKN [41] | FDSR [23] | SUFT [24] | CTKT [26] | JIIF [25] | IGAF |
|---|---|---|---|---|---|---|---|---|---|
| ×4 | 8.16 | 1.56 | 1.74 | 1.62 | 1.61 | 1.14 | 1.49 | 1.37 | 1.12 |
| ×8 | 14.22 | 2.99 | 5.59 | 3.26 | 3.18 | 2.57 | 2.73 | 2.76 | 2.48 |
| ×16 | 22.32 | 5.24 | 7.23 | 6.51 | 5.86 | 5.08 | 5.11 | 5.27 | 5.00 |
| Method | Bicubic | DJFR [42] | PAC [43] | DKN [41] | FDKN [41] | FDSR [23] | JIIF [25] | SUFT [24] | IGAF |
|---|---|---|---|---|---|---|---|---|---|
| ×4 | 2.00 | 3.35 | 1.25 | 1.30 | 1.18 | 1.16 | 1.17 | 1.20 | 1.08 |
| ×8 | 3.23 | 5.57 | 1.98 | 1.96 | 1.91 | 1.82 | 1.79 | 1.77 | 1.69 |
| ×16 | 5.16 | 7.99 | 3.49 | 3.42 | 3.41 | 3.06 | 2.87 | 2.81 | 2.69 |
| Method | Bicubic | DMSG [44] | DG [39] | DJF [45] | DJFR [42] | PAC [43] | JIIF [25] | DKN [41] | IGAF |
|---|---|---|---|---|---|---|---|---|---|
| ×4 | 2.42 | 2.30 | 2.06 | 1.65 | 1.15 | 1.20 | 0.85 | 0.96 | 0.82 |
| ×8 | 4.54 | 4.17 | 4.19 | 3.96 | 3.57 | 2.33 | 1.73 | 2.16 | 1.68 |
| ×16 | 7.38 | 7.22 | 6.90 | 6.75 | 6.77 | 5.19 | 4.16 | 5.11 | 4.14 |
| Method | Bicubic | DJF [45] | DJFR [42] | FDKN [41] | DKN [41] | FDSR [23] | JIIF [25] | SUFT [24] | IGAF |
|---|---|---|---|---|---|---|---|---|---|
| “real-world manner” | 9.15 | 7.90 | 8.01 | 7.50 | 7.38 | 7.50 | 8.41 | 7.17 | 7.01 |
| Method | Bicubic | PAC [43] | DKN [41] | FDKN [41] | CUNet [46] | JIIF [25] | SUFT [24] | FDSR [23] | IGAF |
|---|---|---|---|---|---|---|---|---|---|
| ×4 | 2.28 | 1.32 | 1.23 | 1.08 | 1.10 | 1.09 | 1.20 | 1.13 | 1.01 |
| ×4 | 3.98 | 2.62 | 2.12 | 2.17 | 2.17 | 1.82 | 1.76 | 2.08 | 1.73 |
| ×16 | 6.37 | 4.58 | 4.24 | 4.50 | 4.33 | 3.31 | 3.29 | 4.39 | 3.24 |
| Fusion Method | Addition | Concatenation | IGAF |
|---|---|---|---|
| ×4 | 1.23 | 1.22 | 1.12 |
| Test | Relocated Skip Connection | Extra IGAF Module | Without Weights | One Layer MLP | Without WF | Full Model |
|---|---|---|---|---|---|---|
| ×4 | 1.14 | 1.14 | 1.17 | 1.15 | 1.14 | 1.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tragakis, A.; Kaul, C.; Mitchell, K.J.; Dai, H.; Murray-Smith, R.; Faccio, D. IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution. Sensors 2025, 25, 24. https://doi.org/10.3390/s25010024
Tragakis A, Kaul C, Mitchell KJ, Dai H, Murray-Smith R, Faccio D. IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution. Sensors. 2025; 25(1):24. https://doi.org/10.3390/s25010024
Chicago/Turabian StyleTragakis, Athanasios, Chaitanya Kaul, Kevin J. Mitchell, Hang Dai, Roderick Murray-Smith, and Daniele Faccio. 2025. "IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution" Sensors 25, no. 1: 24. https://doi.org/10.3390/s25010024
APA StyleTragakis, A., Kaul, C., Mitchell, K. J., Dai, H., Murray-Smith, R., & Faccio, D. (2025). IGAF: Incremental Guided Attention Fusion for Depth Super-Resolution. Sensors, 25(1), 24. https://doi.org/10.3390/s25010024