
Single Fringe Phase Retrieval for Translucent Object Measurements Using a Deep Convolutional Generative Adversarial Network



Abstract
Highlights
- An improved GAN network is proposed, capable of obtaining wrapped phase information using a single image.
- A method is introduced for obtaining high-precision phase information of translucent objects affected by scattering effects.
- The proposed method demonstrates greater robustness compared with traditional FPP algorithms and conventional deep learning-based methods.
- It retrieves more accurate phase information when the object’s surface is significantly affected by scattering effects, enabling better analysis of complex translucent objects.
Abstract
1. Introduction
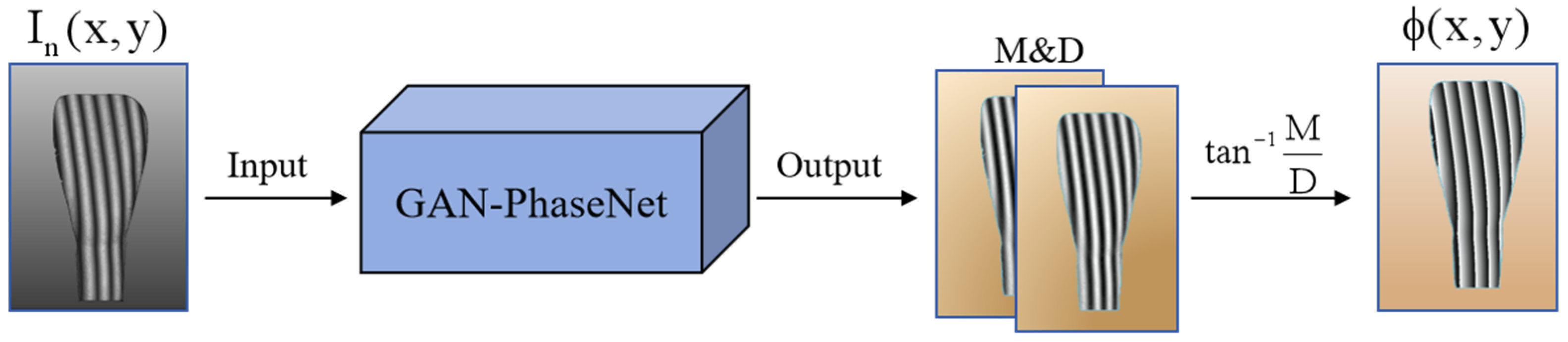
- The proposed GAN-PhaseNet enables the accurate acquisition of wrapped phase information using only a single fringe image, offering a novel approach for the surface measurement of translucent objects.
- We integrate the U-net++ architecture, Resnet101 as the backbone network for feature extraction, and a multilevel attention module for fully utilizing the source image’s high-level features, aiming to boost the generator’s feature extraction capability and generation accuracy.
- To train the GAN-PhaseNet model, we create a new dataset using our constructed FPP experimental system. This dataset focuses on translucent objects and comprises 1200 image groups, each including a fringe pattern, the numerator, and the denominator of the inverse tangent function. This dataset ensures the authenticity of the data by excluding any simulation-generated maps and providing high-quality, accurate, and reliable data to support model training.
2. Materials and Methods
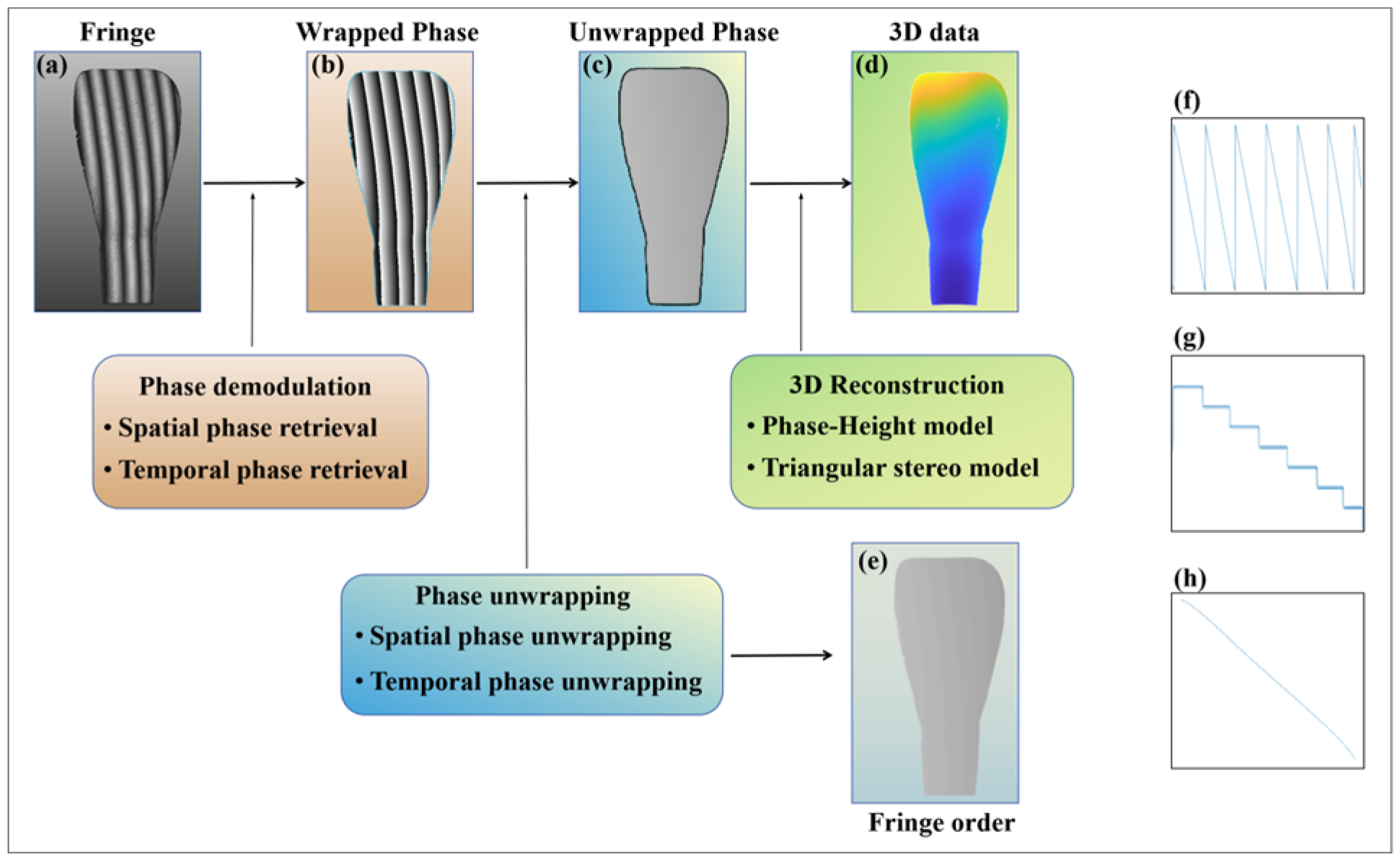
2.1. Principle of FPP
2.2. Network Architecture
- Adopting the U-net++ structure as the core architecture of the generator and adding multilevel attention fusion modules at the longest jump connections of levels 2, 3, and 4. Additionally, a pre-trained VGG-19 is used as the second branch for source image feature extraction, whose feature maps primarily serve the fusion in multilevel attention fusion modules to enhance the network’s ability to capture multi-scale features.
- Incorporation of the Resnet101 network into the backbone for feature extraction, aiding in capturing rich and hierarchical features from input images to enhance overall feature representation.
- Integration of a multilevel attention module to improve the multi-scale expression ability of the network and increase the receptive field of the network to strengthen the connection between high-level and low-level feature maps.
- An attention mechanism module was added to extract the local features of the focal region.
2.2.1. U-Net++ Architecture
2.2.2. Backbone Extraction Network
2.2.3. Multilevel Attention Fusion Module
2.2.4. Discriminator Architecture
2.3. Loss Function
3. Experimental Results and Discussion
3.1. Measurement System Setup
3.2. Training Implementation Details
3.3. Ablation Studies
3.3.1. Network Framework and Backbone Network
3.3.2. Effectiveness of Multilevel Attention Fusion Module
- Pre-trained VGG-19 Network
- 2.
- Attention Mechanism
3.3.3. Impact of Loss Function Design
3.4. Comparison Experiments
- (1)
- Non-translucent objects without scattering effects:
- (2)
- Translucent objects with slight and severe scattering effects:
3.5. Scene Presentation
3.5.1. Scene Presentation for Public Dataset (Dataset 1)
3.5.2. Scene Presentation for No Scattering Effect in the Self-Built Dataset (Dataset 2)
3.5.3. Scene Presentation for Slight Scattering Effect in the Self-Built Dataset (Dataset 2)
3.5.4. Scene Presentation for Severe Scattering Effect in the Self-Built Dataset (Dataset 2)
3.6. Performance Analysis Under the Influence of Different Noises
3.7. Performance Analysis Under the Influence of Different Fringe Frequencies
3.8. Accuracy Evaluation
4. Conclusions
- (1)
- (2)
- Data augmentation: Employ algorithm-based scattering error correction techniques to minimize dependence on AESUB coatings, streamline the data collection process, and enhance dataset diversity.
- (3)
- Multi-view input: Input multiple single-frame images captured from different angles into the network, leveraging multi-view information to strengthen the understanding of the object’s three-dimensional structure, further improving measurement accuracy and robustness.
- (4)
- Physical model integration: Explore the integration of physical models with deep learning to more effectively handle scattering effects while reducing dependence on large-scale training data.
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, S. High-speed 3D shape measurement with structured light methods: A review. Opt. Lasers Eng. 2018, 106, 119–131. [Google Scholar] [CrossRef]
- Dong, Z.; Mai, Z.; Yin, S.; Wang, J.; Yuan, J.; Fei, Y. A weld line detection robot based on structure light for automatic NDT. Int. J. Adv. Manuf. Technol. 2020, 111, 1831–1845. [Google Scholar] [CrossRef]
- Furukawa, R.; Chen, E.L.; Sagawa, R.; Oka, S.; Kawasaki, H. Calibration-free structured-light-based 3D scanning system in laparoscope for robotic surgery. Healthc. Technol. Lett. 2024, 11, 196–205. [Google Scholar] [CrossRef] [PubMed]
- Xue, J.; Zhang, Q.; Li, C.; Lang, W.; Wang, M.; Hu, Y. 3D Face Profilometry Based on Galvanometer Scanner with Infrared Fringe Projection in High Speed. Appl. Sci. 2019, 9, 1458. [Google Scholar] [CrossRef]
- Petkovic, T.; Pribanic, T.; Donlic, M.; Sturm, P. Efficient Separation Between Projected Patterns for Multiple Projector 3D People Scanning. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 815–823. [Google Scholar]
- Holroyd, M.; Lawrence, J. An analysis of using high-frequency sinusoidal illumination to measure the 3D shape of translucent objects. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 2985–2991. [Google Scholar]
- Kobayashi, T.; Higo, T.; Yamasaki, M.; Kobayashi, K.; Katayama, A. Accurate and Practical 3D Measurement for Translucent Objects by Dashed Lines and Complementary Gray Code Projection. In Proceedings of the 2015 International Conference on 3D Vision, Lyon, France, 19–22 October 2015; pp. 189–197. [Google Scholar]
- Chen, S. Intraoral 3-D Measurement by Means of Group Coding Combined with Consistent Enhancement for Fringe Projection Pattern. IEEE Trans. Instrum. Meas. 2022, 71, 5018512. [Google Scholar] [CrossRef]
- Yin, W.; Che, Y.; Li, X.; Li, M.; Hu, Y.; Feng, S.; Lam, E.Y.; Chen, Q.; Zuo, C. Physics-informed deep learning for fringe pattern analysis. Opto-Electron. Adv. 2024, 7, 230034. [Google Scholar] [CrossRef]
- Zuo, C.; Qian, J.; Feng, S.; Yin, W.; Li, Y.; Fan, P.; Han, J.; Qian, K.; Chen, Q. Deep learning in optical metrology: A review. Light Sci. Appl. 2022, 11, 39. [Google Scholar] [CrossRef]
- Liu, H.; Yan, N.; Shao, B.; Yuan, S.; Zhang, X. Deep learning in fringe projection: A review. Neurocomputing 2024, 581, 127493. [Google Scholar] [CrossRef]
- Feng, S.J.; Chen, Q.; Gu, G.H.; Tao, T.Y.; Zhang, L.; Hu, Y.; Yin, W.; Zuo, C. Fringe pattern analysis using deep learning. Adv. Photonics 2019, 1, 025001. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Q.; Zuo, C.; Feng, S. High-speed high dynamic range 3D shape measurement based on deep learning. Opt. Lasers Eng. 2020, 134, 106245. [Google Scholar] [CrossRef]
- Li, Y.X.; Qian, J.M.; Feng, S.J.; Chen, Q.; Zuo, C. Single-shot spatial frequency multiplex fringe pattern for phase unwrapping using deep learning. In Proceedings of the Optics Frontier Online 2020: Optics Imaging and Display, Shanghai, China, 19–20 June 2020; pp. 314–319. [Google Scholar]
- Chi, W.L.; Choo, Y.H.; Goh, O.S. Review of Generative Adversarial Networks in Image Generation. J. Adv. Comput. Intell. Intell. Inform. 2022, 26, 3–7. [Google Scholar] [CrossRef]
- Rajshekhar, G.; Rastogi, P. Fringe analysis: Premise and perspectives. Opt. Lasers Eng. 2012, 50, III–X. [Google Scholar] [CrossRef]
- Su, X.Y.; Chen, W.J. Fourier transform profilometry: A review. Opt. Lasers Eng. 2001, 35, 263–284. [Google Scholar] [CrossRef]
- Kemao, Q. Two-dimensional windowed Fourier transform for fringe pattern analysis: Principles, applications and implementations. Opt. Lasers Eng. 2007, 45, 304–317. [Google Scholar] [CrossRef]
- Zhong, J.G.; Weng, J.W. Spatial carrier-fringe pattern analysis by means of wavelet transform: Wavelet transform profilometry. Appl. Opt. 2004, 43, 4993–4998. [Google Scholar] [CrossRef]
- Zuo, C.; Feng, S.; Huang, L.; Tao, T.; Yin, W.; Chen, Q. Phase shifting algorithms for fringe projection profilometry: A review. Opt. Lasers Eng. 2018, 109, 23–59. [Google Scholar] [CrossRef]
- Zhang, S. Absolute phase retrieval methods for digital fringe projection profilometry: A review. Opt. Lasers Eng. 2018, 107, 28–37. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.H.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, Hawaii, 21–26 July 2017; IEEE: Piscataway, NJ, USA; pp. 5967–5976. [Google Scholar]
- Zhou, Z.W.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J.M. UNet plus plus: Redesigning Skip Connections to Exploit Multiscale Features in Image Segmentation. IEEE Trans. Med. Imaging 2020, 39, 1856–1867. [Google Scholar] [CrossRef]
- Liu, J.; Lin, R.; Wu, G.; Liu, R.; Luo, Z.; Fan, X. CoCoNet: Coupled Contrastive Learning Network with Multi-level Feature Ensemble for Multi-modality Image Fusion. Int. J. Comput. Vis. 2023, 132, 1748–1775. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S.J.C.S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Popescu, D.; Deaconu, M.; Ichim, L.; Stamatescu, G. Retinal Blood Vessel Segmentation Using Pix2Pix GAN. In Proceedings of the 2021 29th Mediterranean Conference on Control and Automation (MED), Puglia, Italy, 22–25 June 2021; pp. 1173–1178. [Google Scholar]
- Su, Z.; Zhang, Y.; Shi, J.; Zhang, X.-P. A Survey of Single Image Rain Removal Based on Deep Learning. ACM Comput. Surv. 2023, 56, 103. [Google Scholar] [CrossRef]
- Lai, B.-Y.; Chiang, P.-J. Improved structured light system based on generative adversarial networks for highly-reflective surface measurement. Opt. Lasers Eng. 2023, 171, 107783. [Google Scholar] [CrossRef]
- Li, Y.X.; Qian, J.M.; Feng, S.J.; Chen, Q.; Zuo, C. Deep-learning-enabled dual-frequency composite fringe projection profilometry for single-shot absolute 3D shape measurement. Opto-Electron. Adv. 2022, 5, 210021. [Google Scholar] [CrossRef]
- Yu, H.; Chen, X.; Huang, R.; Bai, L.; Zheng, D.; Han, J. Untrained deep learning-based phase retrieval for fringe projection profilometry. Opt. Lasers Eng. 2023, 164, 107483. [Google Scholar] [CrossRef]
- Nguyen, H.; Novak, E.; Wang, Z. Accurate 3D reconstruction via fringe-to-phase network. Measurement 2022, 190, 110663. [Google Scholar] [CrossRef]
- Li, Y.X.; Qian, J.M.; Feng, S.J.; Chen, Q.; Zuo, C. Composite fringe projection deep learning profilometry for single-shot absolute 3D shape measurement. Opt. Express 2022, 30, 3424–3442. [Google Scholar] [CrossRef]
- Fu, Y.; Huang, Y.; Xiao, W.; Li, F.; Li, Y.; Zuo, P. Deep learning-based binocular composite color fringe projection profilometry for fast 3D measurements. Opt. Lasers Eng. 2024, 172, 107866. [Google Scholar] [CrossRef]
- Qian, J.; Feng, S.; Li, Y.; Tao, T.; Han, J.; Chen, Q.; Zuo, C. Single-shot absolute 3D shape measurement with deep-learning-based color fringe projection profilometry. Opt. Lett. 2020, 45, 1842–1845. [Google Scholar] [CrossRef]
- Jacob, B.; Kligys, S.; Chen, B.; Zhu, M.; Tang, M.; Howard, A.; Adam, H.; Kalenichenko, D. Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2704–2713. [Google Scholar]
- Xu, S.; Li, Y.J.; Liu, C.J.; Zhang, B.C. Learning Accurate Low-bit Quantization towards Efficient Computational Imaging. Int. J. Comput. Vis. 2024. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset’s Name (Total Number) (Source) | Classification of Datasets (Number) | Collection Objects |
|---|---|---|
| Dataset 1 (1000) (publicly available [10]) | Train (800) | Gypsum |
| Validation (50) | Gypsum | |
| Test A (150) | Gypsum | |
| Dataset 2 (1200) (self-built) | Train (1000) | Gypsum and objects with a slight scattering effect |
| Validation (97) | Gypsum and objects with a slight scattering effect | |
| Test 1 (29) | Gypsum | |
| Test 2 (50) | Objects with a slight scattering effect | |
| Test 3 (24) | Objects with severe scattering effects |
| Method | Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Test A | Test 1 | Test 2 | Test 3 | ||||||
| Frame | Backbone | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) |
| U-net | CNN | 0.1139 | 0.6557 | 0.1096 | 0.1553 | 0.1276 | 0.1202 | 0.2835 | 0.4433 |
| DenseNet | 0.0802 | 0.4987 | 0.0487 | 0.1010 | 0.0834 | 0.1000 | 0.1831 | 0.2944 | |
| ResNet-50 | 0.0939 | 0.5432 | 0.0498 | 0.0982 | 0.0951 | 0.1089 | 0.1908 | 0.3098 | |
| ResNet-101 | 0.0876 | 0.5236 | 0.0463 | 0.0938 | 0.0888 | 0.1036 | 0.1868 | 0.2956 | |
| ResNeXt-50 | 0.0936 | 0.5414 | 0.0413 | 0.0946 | 0.0906 | 0.1073 | 0.1751 | 0.3066 | |
| ResNeXt-101 | 0.0850 | 0.5137 | 0.0462 | 0.0904 | 0.0854 | 0.1032 | 0.1764 | 0.2977 | |
| U-net++ | CNN | 0.0823 | 0.5052 | 0.0487 | 0.0980 | 0.0871 | 0.0981 | 0.1848 | 0.3074 |
| DenseNet | 0.0785 | 0.4956 | 0.0479 | 0.0976 | 0.0821 | 0.0986 | 0.1826 | 0.2871 | |
| ResNet-50 | 0.0786 | 0.4942 | 0.0442 | 0.0797 | 0.0839 | 0.0925 | 0.1681 | 0.2883 | |
| ResNet-101 | 0.0768 | 0.4806 | 0.0418 | 0.0773 | 0.0803 | 0.0887 | 0.1659 | 0.2820 | |
| ResNeXt-50 | 0.0793 | 0.4886 | 0.0429 | 0.0820 | 0.0822 | 0.0917 | 0.1679 | 0.2840 | |
| ResNeXt-101 | 0.0780 | 0.4816 | 0.0435 | 0.0837 | 0.0813 | 0.0942 | 0.1693 | 0.2866 | |
| Model’s Acronym | Description of Model |
|---|---|
| u | Network without the pre-trained VGG-19, without CA |
| u/v | Network with the pre-trained VGG19, without CA |
| Two branches in the MAFM include CA | |
| Backbone branch with CA, the VGG-19 branch without CA | |
| Backbone branch without CA, the VGG-19 branch with CA |
| Model Name | Method | Dataset 1 | Dataset 2 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Test A | Test 1 | Test 2 | Test 3 | ||||||
| MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | ||
| u | Without VGG19 | 0.0768 | 0.4806 | 0.0418 | 0.0773 | 0.0803 | 0.0887 | 0.1659 | 0.2820 |
| u/v | With VGG19 | 0.0751 | 0.4795 | 0.0400 | 0.0742 | 0.0775 | 0.0827 | 0.1642 | 0.2647 |
| Model Name | CA Position | Dataset 1 | Dataset 2 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Test A | Test 1 | Test 2 | Test 3 | |||||||
| u | v | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | |
| u/v | 0.0751 | 0.4795 | 0.0400 | 0.0742 | 0.0775 | 0.0827 | 0.1642 | 0.2647 | ||
| u/vCA | √ | 0.0742 | 0.4785 | 0.0383 | 0.0708 | 0.0724 | 0.0797 | 0.1637 | 0.2576 | |
| uCA/v | √ | 0.0772 | 0.4881 | 0.0545 | 0.0868 | 0.0898 | 0.0966 | 0.1889 | 0.2841 | |
| uCA/vCA | √ | √ | 0.0771 | 0.4867 | 0.04751 | 0.0858 | 0.0830 | 0.0950 | 0.1714 | 0.2796 |
| Model | Dataset 1 | Dataset 2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Test A | Test 1 | Test 2 | Test 3 | |||||
| MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | MAE (mm) | RMSE (mm) | |
| Without MSE loss | 0.0742 | 0.4785 | 0.0383 | 0.0708 | 0.0724 | 0.0797 | 0.1637 | 0.2576 |
| With MSE loss | 0.0725 | 0.4672 | 0.0342 | 0.0700 | 0.0690 | 0.0757 | 0.1314 | 0.2366 |
| Model | Dataset 1 | ||
|---|---|---|---|
| Test A | |||
| MAE (mm) | RMSE (mm) | PSNR | |
| CDLP | 0.1115 | 0.5859 | 9.1032 |
| Unet-Phase | 0.1105 | 0.5643 | 9.3049 |
| DCFPP | 0.1011 | 0.5322 | 9.6079 |
| Ours | 0.0725 | 0.4672 | 10.4177 |
| Model | Dataset 2 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Test 1 | Test 2 | Test 3 | |||||||
| MAE (mm) | RMSE (mm) | PSNR | MAE (mm) | RMSE (mm) | PSNR | MAE (mm) | RMSE (mm) | PSNR | |
| CDLP | 0.0980 | 0.2101 | 15.2484 | 0.0961 | 0.1269 | 22.8727 | 0.3192 | 0.4693 | 8.9490 |
| Unet-Phase | 0.0811 | 0.1922 | 16.1272 | 0.0864 | 0.1097 | 24.2756 | 0.2766 | 0.3927 | 10.3986 |
| DCFPP | 0.0691 | 0.1636 | 17.4531 | 0.0798 | 0.0988 | 26.7437 | 0.2827 | 0.4043 | 9.9743 |
| Ours | 0.0342 | 0.0700 | 29.2371 | 0.0690 | 0.0757 | 31.7041 | 0.1314 | 0.2366 | 13.5463 |
| Method | Time (s) |
|---|---|
| CDLP | 16.74 |
| Unet-Phase | 22.88 |
| DCFPP | 14.91 |
| Ours | 37.81 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Huang, Y.; Wu, J.; Tang, Y.; Wang, W. Single Fringe Phase Retrieval for Translucent Object Measurements Using a Deep Convolutional Generative Adversarial Network. Sensors 2025, 25, 1823. https://doi.org/10.3390/s25061823
He J, Huang Y, Wu J, Tang Y, Wang W. Single Fringe Phase Retrieval for Translucent Object Measurements Using a Deep Convolutional Generative Adversarial Network. Sensors. 2025; 25(6):1823. https://doi.org/10.3390/s25061823
Chicago/Turabian StyleHe, Jiayan, Yuanchang Huang, Juhao Wu, Yadong Tang, and Wenlong Wang. 2025. "Single Fringe Phase Retrieval for Translucent Object Measurements Using a Deep Convolutional Generative Adversarial Network" Sensors 25, no. 6: 1823. https://doi.org/10.3390/s25061823
APA StyleHe, J., Huang, Y., Wu, J., Tang, Y., & Wang, W. (2025). Single Fringe Phase Retrieval for Translucent Object Measurements Using a Deep Convolutional Generative Adversarial Network. Sensors, 25(6), 1823. https://doi.org/10.3390/s25061823