
Advanced Data Processing of Pancreatic Cancer Data Integrating Ontologies and Machine Learning Techniques to Create Holistic Health Records

 , , ,
, , ,  ,
,  ,
,  ,
, 
Abstract
1. Introduction
- The introduction of an end-to-end and holistic reference architecture and data ingestion mechanism for advanced data processing and analysis in a modern HIS;
- A set of practical recommendations and implementations for the integration of techniques from the domains of data science, ML, and the Semantic Web;
- The realization of the HHR data model through the integration, standardization, and harmonization of primary and secondary data;
- Analysis and discussion of the industry-centric challenges and problems that researchers in the healthcare domain face with regard to data processing and analysis, such as data being available in divergent formats and semantic non-interoperable data.
2. Materials and Methods
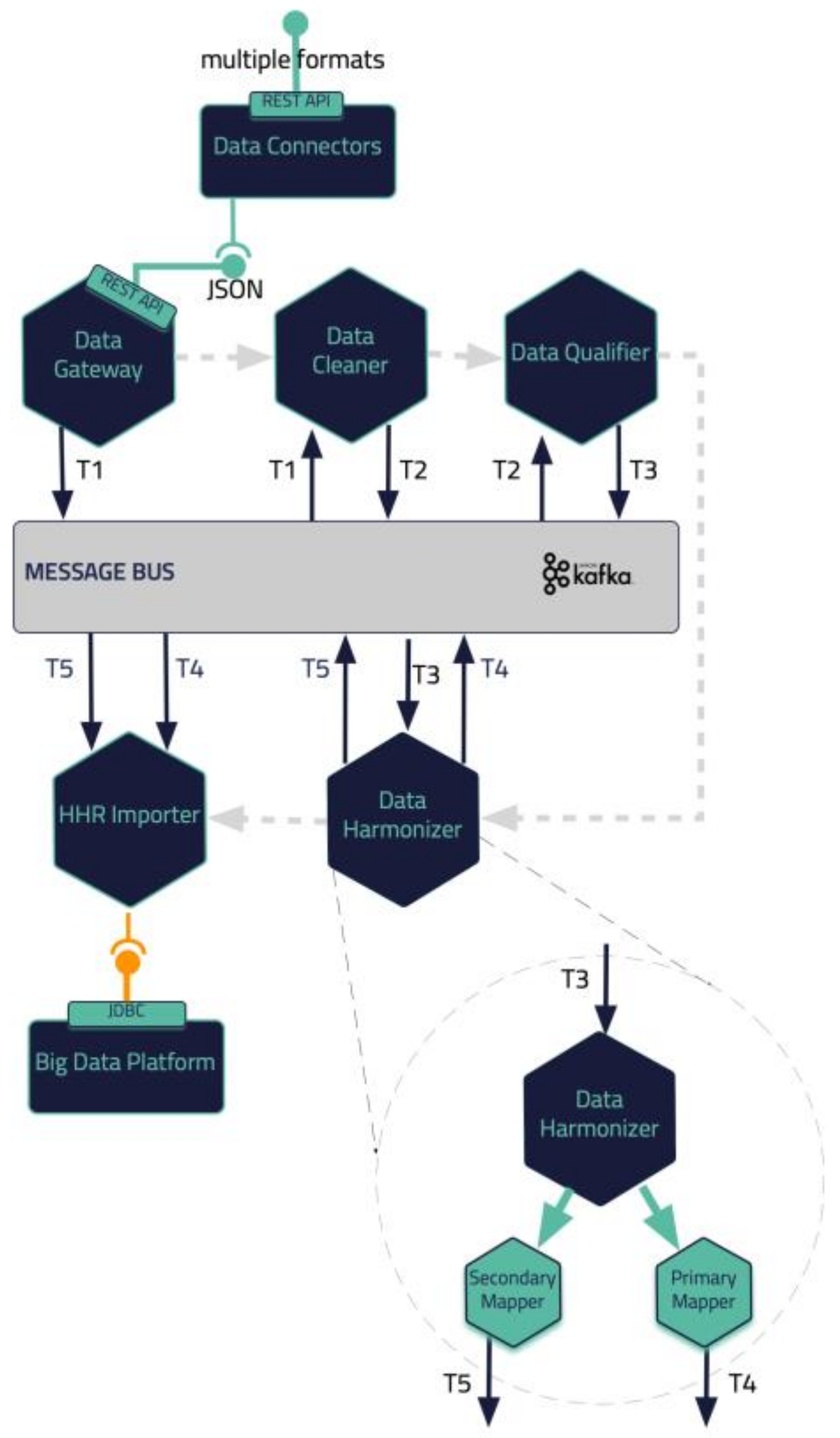
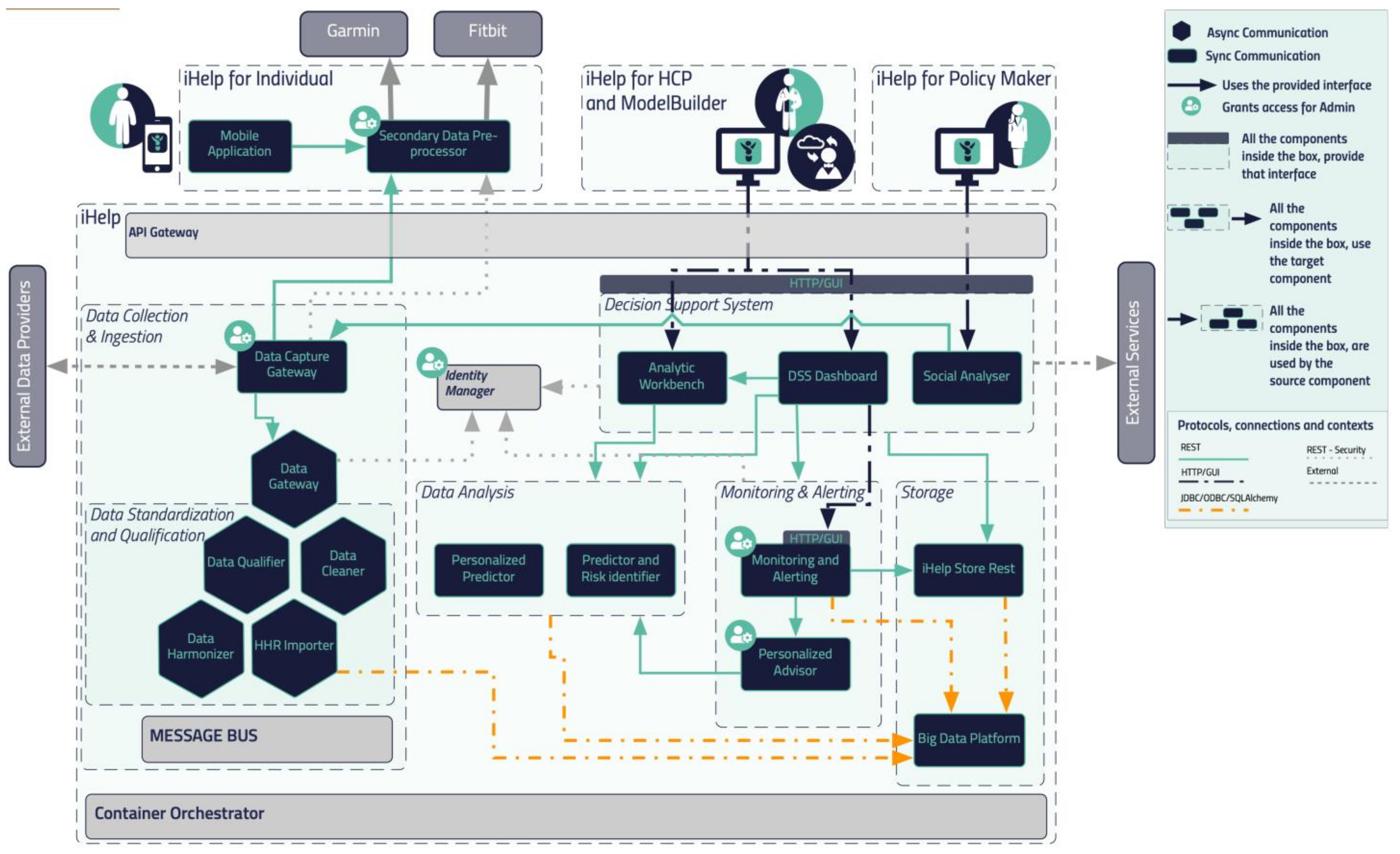
2.1. Reference Architecture
2.2. Integration Approach
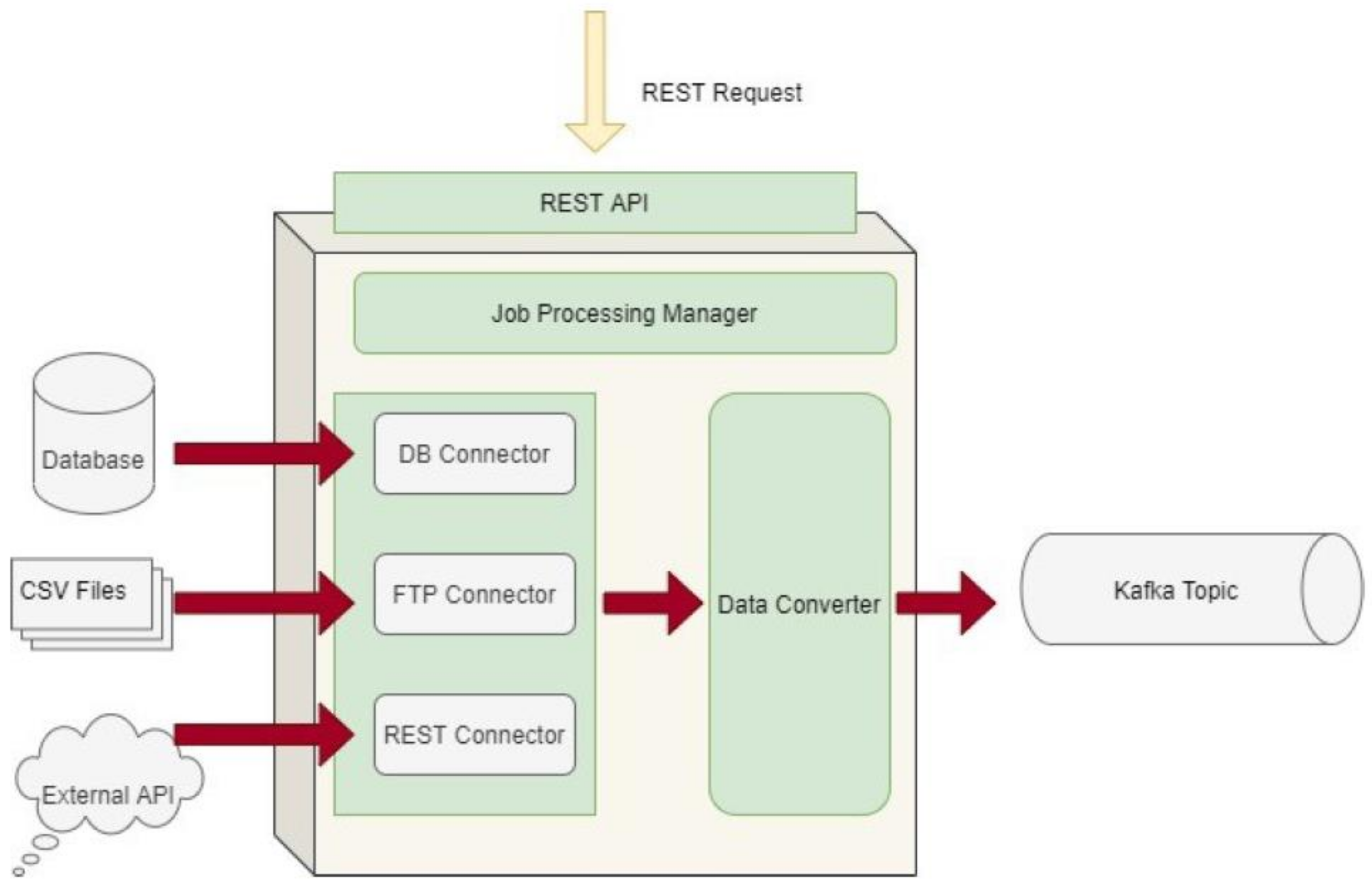
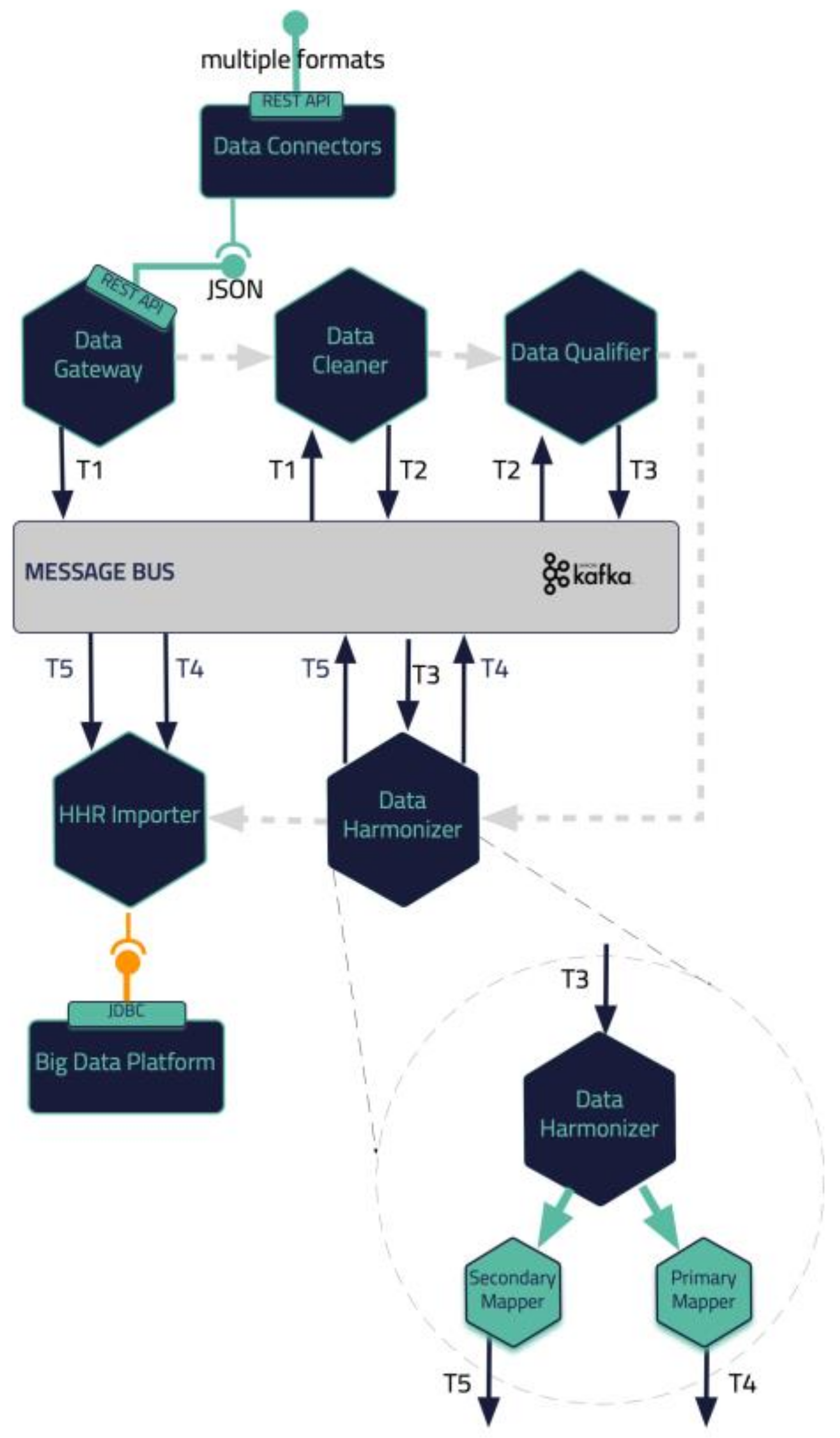
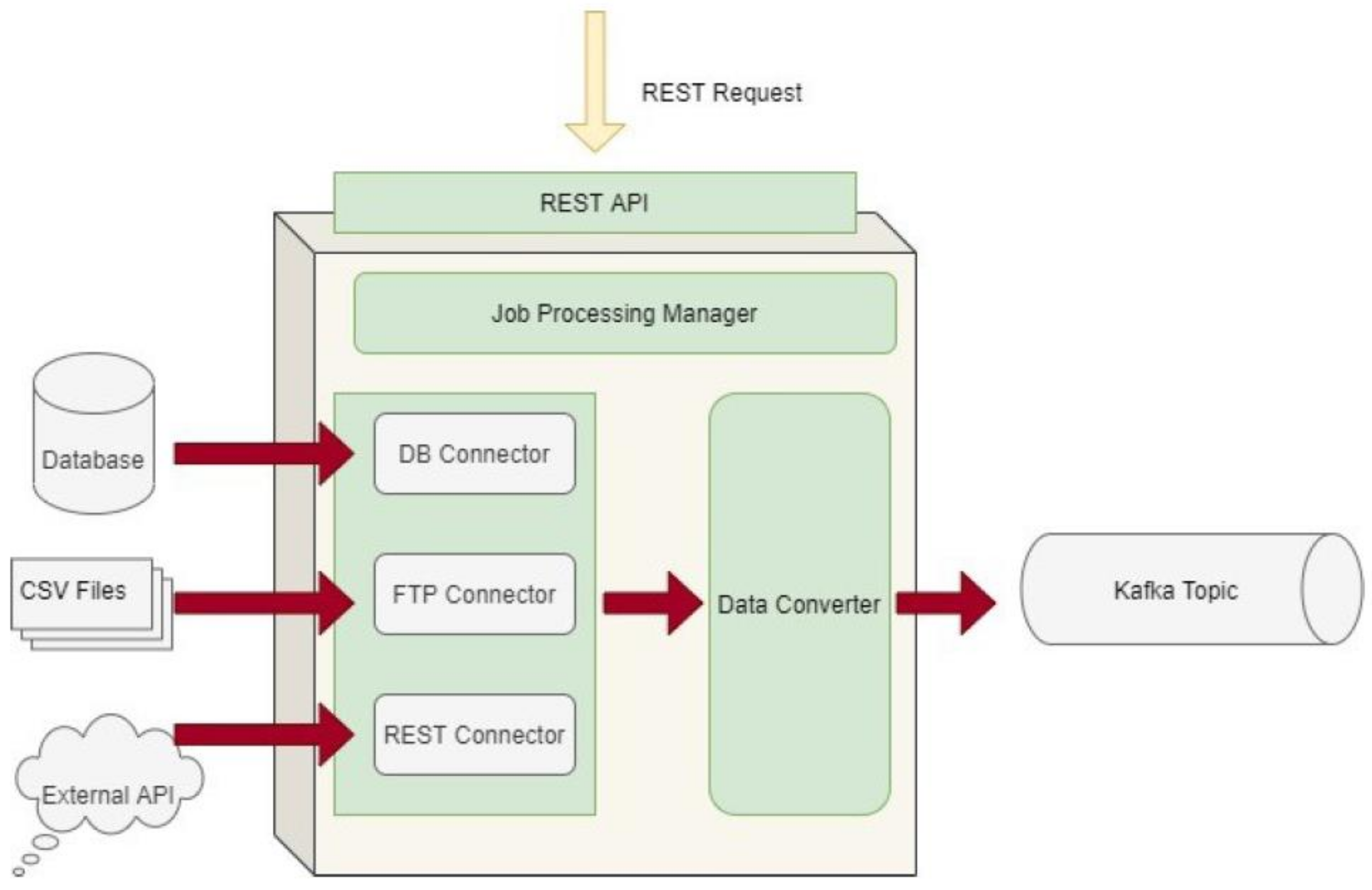
2.3. Data Collection and Ingestion Pipeline
2.4. Data Modeling and Specification of Holistic Health Records
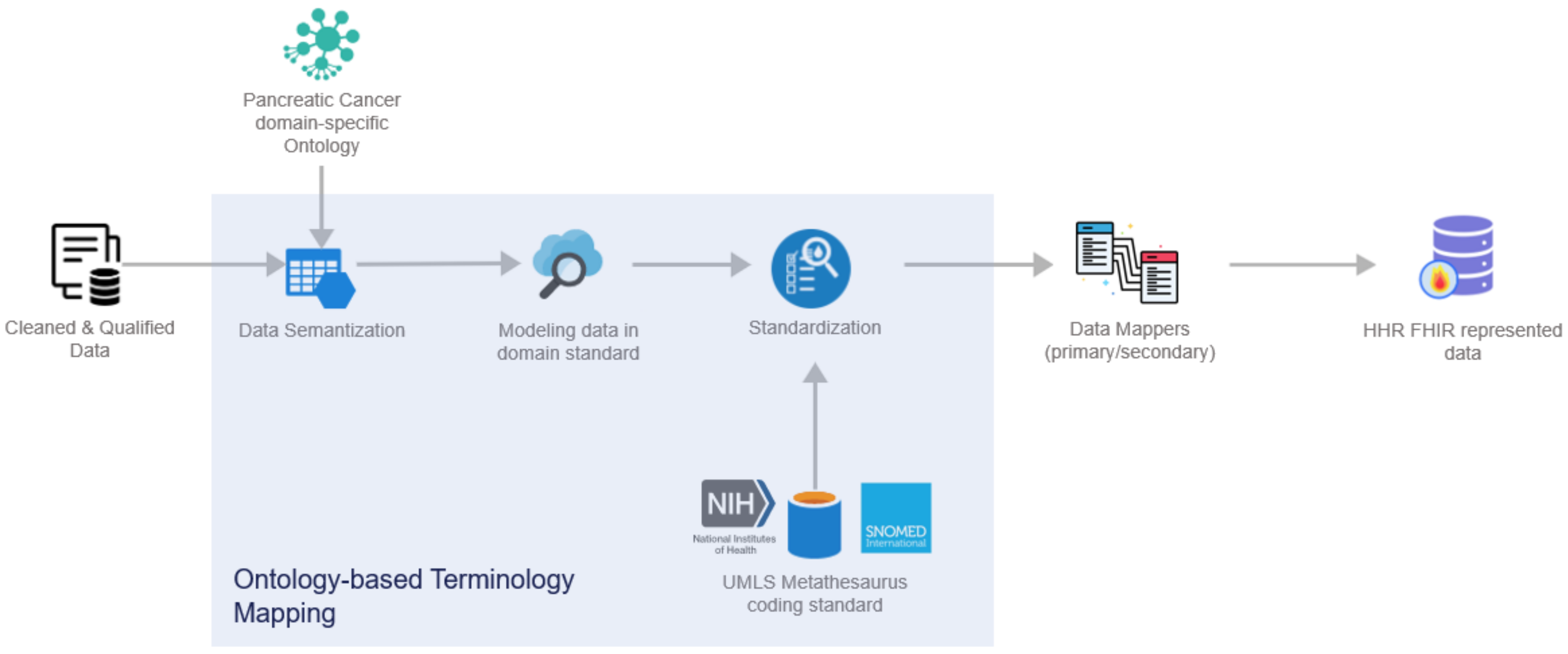
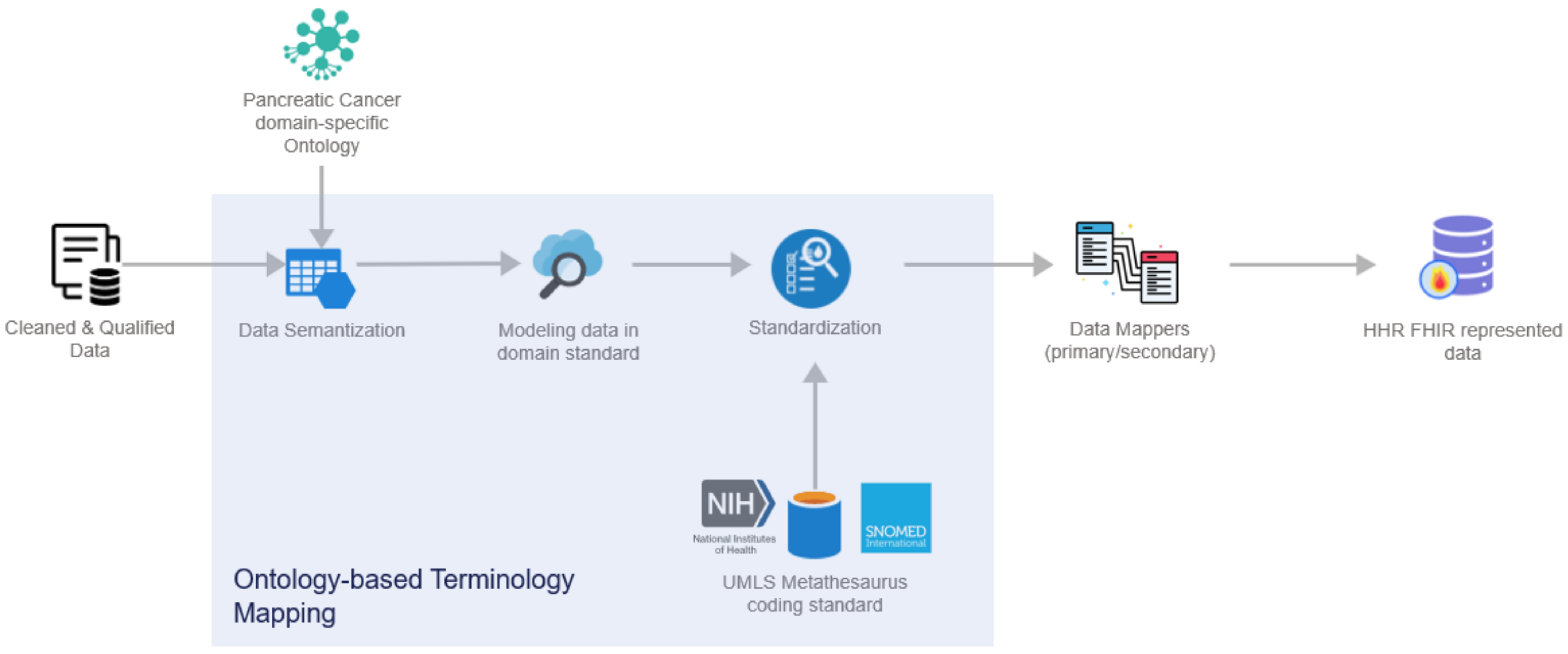
2.5. Data Standardization and Qualification Methodology
- Cleaned and qualified data are semantically analyzed and mapped to concepts and instances of a domain-specific ontology that has been provided in the context of the iHelp project [32];
- Data are standardized into the project’s common data model and domain standard;
- The PyMedTermino [42] and UMLS metathesaurus [43] are utilized, offering a wide collection of terminology services. The different terminologies, coding standards, and vocabularies that are offered through these systems are utilized to further transform the medical terms between terminologies in a controlled and supervised manner;
- Finally, standardized and harmonized data are fed into the Primary and Secondary Data Mappers to be transformed into the HHR FHIR-compliant format. The actual realization of the conceptual HHR model is performed with the assistance of the FHIR mappers. The implementation of them is based on the Java library of HAPI FHIR and exposes APIs that the Data Harmonizer component can consume [44].
3. Results
3.1. Use Case Description
- Individuals that are directly involved in the iHelp project for further monitoring and follow-up by the HCPs of the HDM. Out of these individuals:
- ◦
- Six are patients already diagnosed with pancreatic cancer. In the context of this pilot study, they provided their medical records and one single blood sample for the performance of epigenomic analytics;
- ◦
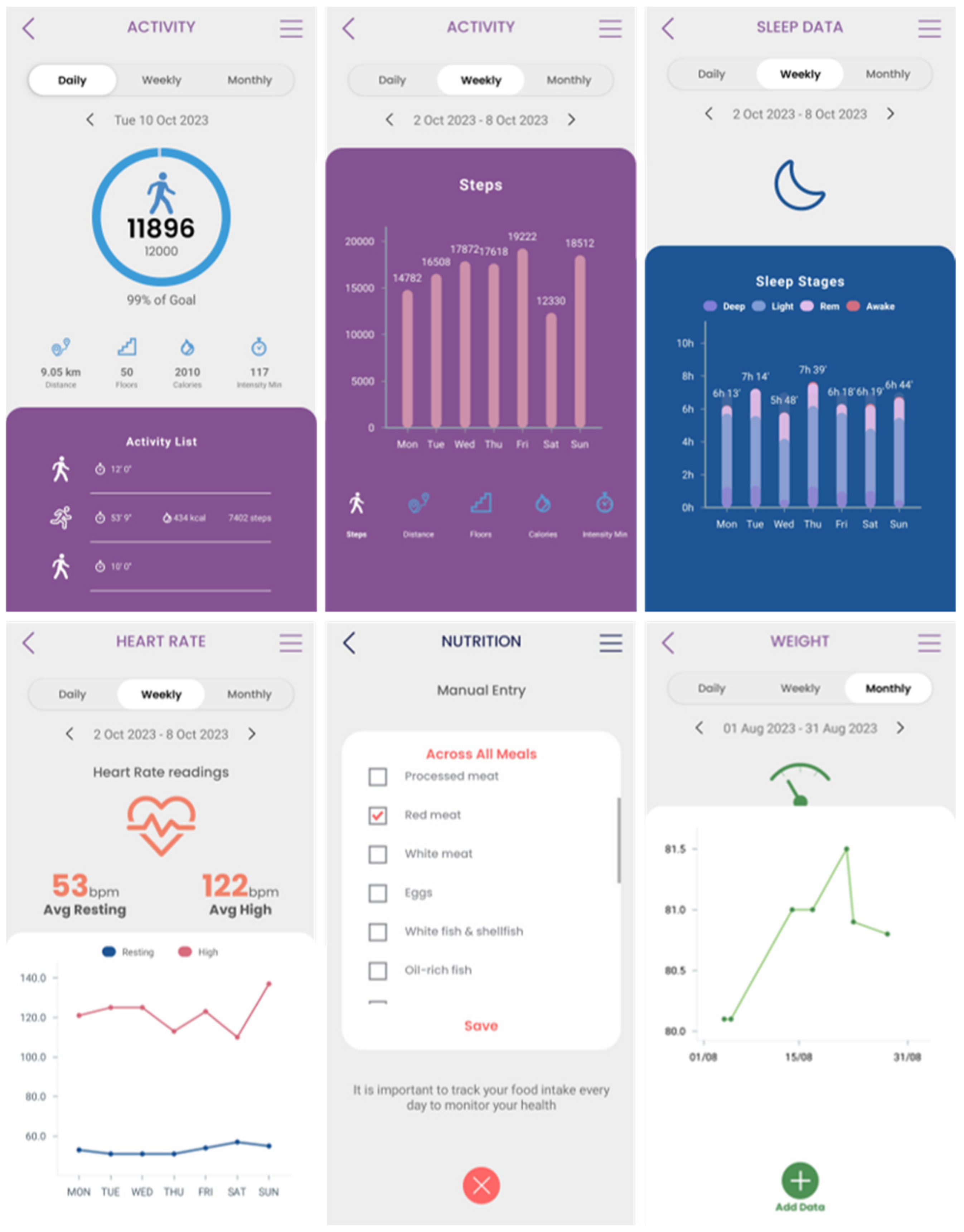
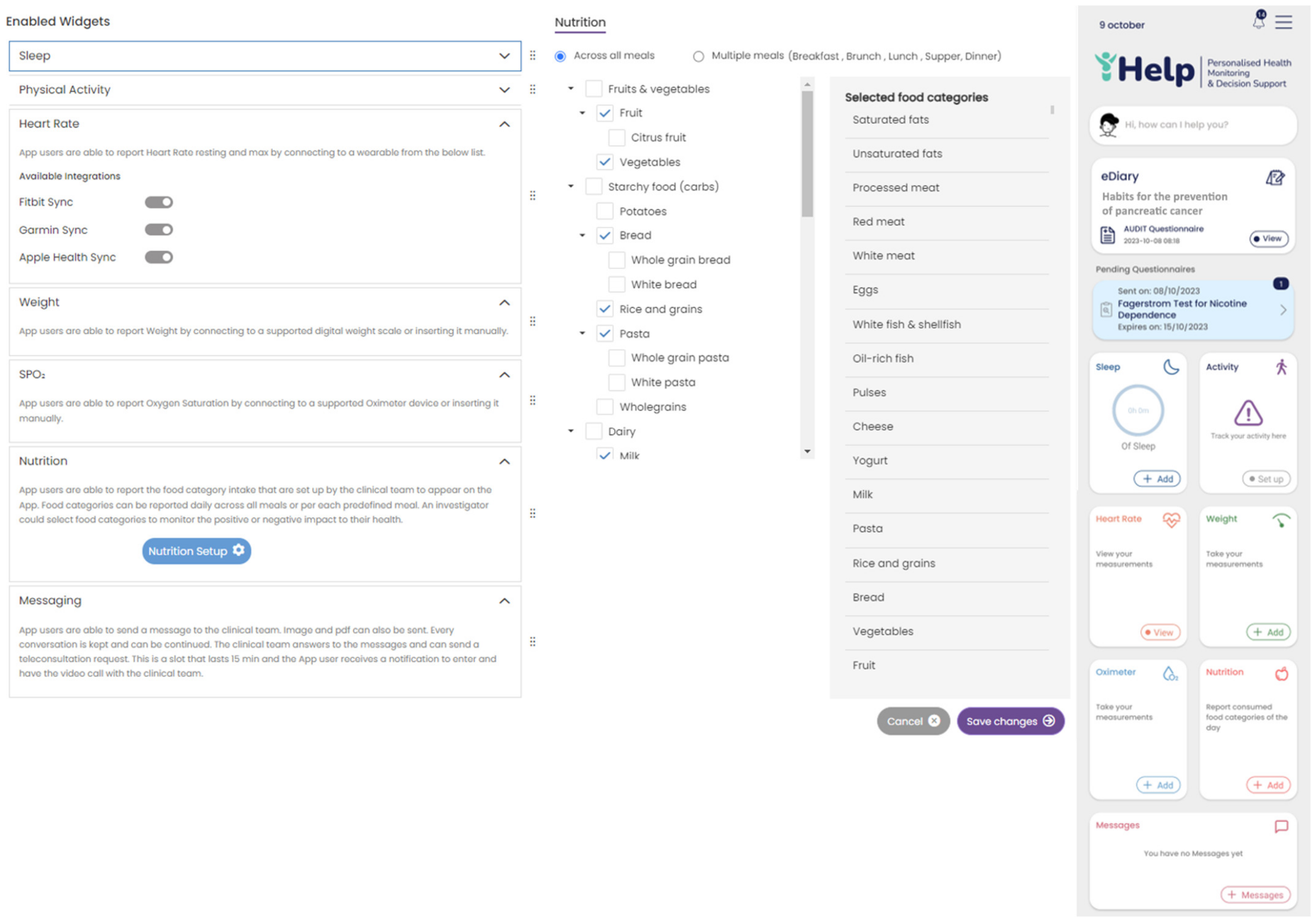
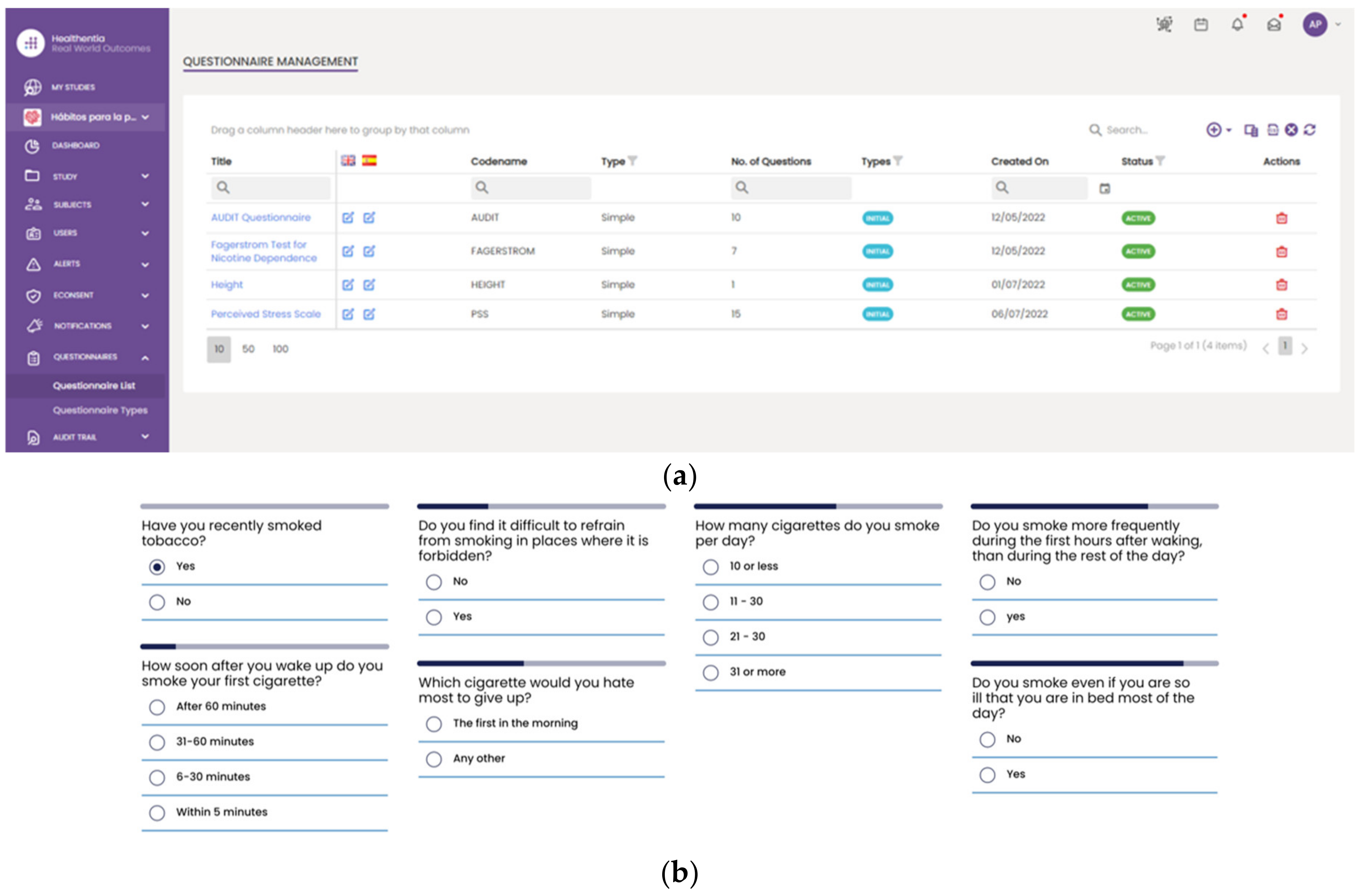
- Thirteen are patients without pancreatic cancer. In addition to their medical records, a blood sample was provided every 3 months, and lifestyle data were collected through a 9-month monitoring phase based on the wearable devices and periodic questionnaires through the Healthentia platform.
- Individuals not directly inside the program:
- ◦
- An extraction of medical records from around 90 thousand patients is anonymized and provided to the iHelp platform.
3.2. Data Collection and Ingestion
- datasourceID: the name of the data provider;
- datasetID: the name of the dataset;
- schema: the schema of the value of the tuples, defined in Avro Schema;
- schemaKey: the schema of the key of the tuples, defined in Avro Schema;
- batchSize: the batch size;
- currentBatchStart: the index of the first element of the batch in the overall dataset;
- currentBatchEnd: the index of the last element of the batch in the overall dataset;
- confParameters: the configuration parameters required by each of the intermediate functions. It includes an array of data parameters packed in JSON format, where each JSON can be interpreted by the corresponding function. These parameters are being passed to each of the intermediate functions, and each one of those can retrieve the ones of their interest. For instance, specific cleaning rules have been set by the data provider concerning specific data attributes, as depicted in Figure 9a. These rules are consumed by the Data Cleaner to perform the necessary cleaning and validation actions on the data;
- values: a list of the exploitable data and their different values per each record.
3.3. Data Standardization and Qualification towards Holistic Health Records
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Javed, A.R.; Shahzad, F.; ur Rehman, S.; Zikria, Y.B.; Razzak, I.; Jalil, Z.; Xu, G. Future smart cities: Requirements, emerging technologies, applications, challenges, and future aspects. Cities 2022, 129, 103794. [Google Scholar] [CrossRef]
- Weaver, E.; O’Hagan, C.; Lamprou, D.A. The sustainability of emerging technologies for use in pharmaceutical manufacturing. Expert Opin. Drug Deliv. 2022, 19, 861–872. [Google Scholar] [CrossRef] [PubMed]
- Junaid, S.B.; Imam, A.A.; Balogun, A.O.; De Silva, L.C.; Surakat, Y.A.; Kumar, G.; Abdulkarim, M.; Shuaibu, A.N.; Garba, A.; Sahalu, Y.; et al. Recent advancements in emerging technologies for healthcare management systems: A survey. Healthcare 2022, 10, 1940. [Google Scholar] [CrossRef] [PubMed]
- Gartner. Emerging Technologies You Need to Know About. (n.d.). Available online: https://www.gartner.com/en/articles/4-emerging-technologies-you-need-to-know-about (accessed on 30 September 2023).
- Kasula, B.Y. Harnessing Machine Learning for Personalized Patient Care. Trans. Latest Trends Artif. Intell. 2023, 4. Available online: https://ijsdcs.com/index.php/TLAI/article/view/399 (accessed on 21 January 2024).
- Dritsas, E.; Trigka, M. Supervised machine learning models for liver disease risk prediction. Computers 2023, 12, 19. [Google Scholar] [CrossRef]
- Ramaswamy, V.D.; Keidar, M. Personalized Plasma Medicine for Cancer: Transforming Treatment Strategies with Mathematical Modeling and Machine Learning Approaches. Appl. Sci. 2023, 14, 355. [Google Scholar] [CrossRef]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Chen, Y.W.; Jain, L.C. Deep Learning in Healthcare. In Paradigms and Applications; Springer: Heidelberg, Germany, 2020. [Google Scholar]
- Yadav, S.S.; Jadhav, S.M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data 2019, 6, 113. [Google Scholar] [CrossRef]
- Omidi, A.; Mohammadshahi, A.; Gianchandani, N.; King, R.; Leijser, L.; Souza, R. Unsupervised Domain Adaptation of MRI Skull-Stripping Trained on Adult Data to Newborns. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 1–10 January 2024; pp. 7718–7727. [Google Scholar]
- Purushothaman, S.; Shanmugam, G.S.; Nagarajan, S. Achieving Seamless Semantic Interoperability and Enhancing Text Embedding in Healthcare IoT: A Deep Learning Approach with Survey. SN Comput. Sci. 2023, 5, 99. [Google Scholar] [CrossRef]
- Reddy, B.K.; Delen, D. Predicting hospital readmission for lupus patients: An RNN-LSTM-based deep-learning methodology. Comput. Biol. Med. 2018, 101, 199–209. [Google Scholar] [CrossRef]
- Kollias, D.; Tagaris, A.; Stafylopatis, A.; Kollias, S.; Tagaris, G. Deep neural architectures for prediction in healthcare. Complex Intell. Syst. 2018, 4, 119–131. [Google Scholar] [CrossRef]
- Shen, H. Enhancing Diagnosis Prediction in Healthcare with Knowledge-based Recurrent Neural Networks. IEEE Access 2023, 11, 106433–106442. [Google Scholar] [CrossRef]
- Chief Scientist and Science Division (SCI). 2023 Emerging Technologies and Scientific Innovations: A Global Public Health Perspective—Preview of Horizon Scan Results. Available online: https://www.who.int/publications/i/item/WHO-SCI-RFH-2023.05 (accessed on 21 September 2023).
- Market. Us. Wearable Technology Market Worth over USD 231 Billion by 2032, at CAGR 14.60%. GlobeNewswire News Room. 2023. Available online: https://www.globenewswire.com/en/news-release/2023/03/13/2626170/0/en/Wearable-Technology-Market-Worth-Over-USD-231-Billion-by-2032-At-CAGR-14-60.html#:~:text=It%20is%20projected%20to%20grow,CAGR%2C%20between%202023%20to%202032 (accessed on 21 September 2023).
- Symvoulidis, C.; Kiourtis, A.; Marinos, G.; Tom-Ata, J.D.T.; Manias, G.; Mavrogiorgou, A.; Kyriazis, D. A User Mobility-based Data Placement Strategy in a Hybrid Cloud/Edge Environment using a Causal-aware Deep Learning Network. IEEE Trans. Comput. 2023, 72, 3603–3616. [Google Scholar] [CrossRef]
- Ghaderzadeh, M.; Hosseini, A.; Asadi, F.; Abolghasemi, H.; Bashash, D.; Roshanpoor, A. Automated detection model in classification of B-lymphoblast cells from normal B-lymphoid precursors in blood smear microscopic images based on the majority voting technique. Sci. Program. 2022, 2022, 4801671. [Google Scholar] [CrossRef]
- Rajabi, M.; Golshan, H.; Hasanzadeh, R.P. Non-local adaptive hysteresis despeckling approach for medical ultrasound images. Biomed. Signal Process. Control 2023, 85, 105042. [Google Scholar] [CrossRef]
- Shumba, A.T.; Montanaro, T.; Sergi, I.; Fachechi, L.; De Vittorio, M.; Patrono, L. Leveraging IOT-aware technologies and AI techniques for real-time critical healthcare applications. Sensors 2022, 22, 7675. [Google Scholar] [CrossRef]
- Karatas, M.; Eriskin, L.; Deveci, M.; Pamucar, D.; Garg, H. Big Data for Healthcare Industry 4.0: Applications, challenges and future perspectives. Expert Syst. Appl. 2022, 200, 116912. [Google Scholar] [CrossRef]
- Mitchell, M.; Kan, L. Digital technology and the future of health systems. Health Syst. Reform 2019, 5, 113–120. [Google Scholar] [CrossRef]
- Mlakar, I.; Šafran, V.; Hari, D.; Rojc, M.; Alankuş, G.; Pérez Luna, R.; Ariöz, U. Multilingual conversational systems to drive the collection of patient-reported outcomes and integration into clinical workflows. Symmetry 2021, 13, 1187. [Google Scholar] [CrossRef]
- Dash, S.; Shakyawar, S.K.; Sharma, M.; Kaushik, S. Big data in healthcare: Management, analysis and future prospects. J. Big Data 2019, 6, 54. [Google Scholar] [CrossRef]
- Mavrogiorgou, A.; Kiourtis, A.; Manias, G.; Symvoulidis, C.; Kyriazis, D. Batch and Streaming Data Ingestion towards Creating Holistic Health Records. Emerg. Sci. J. 2023, 7, 339–353. [Google Scholar] [CrossRef]
- Rajabion, L.; Shaltooki, A.A.; Taghikhah, M.; Ghasemi, A.; Badfar, A. Healthcare big data processing mechanisms: The role of cloud computing. Int. J. Inf. Manag. 2019, 49, 271–289. [Google Scholar] [CrossRef]
- Rezayi, S.; Mohammadzadeh, N.; Bouraghi, H.; Saeedi, S.; Mohammadpour, A. Timely diagnosis of acute lymphoblastic leukemia using artificial intelligence-oriented deep learning methods. Comput. Intell. Neurosci. 2021, 2021, 5478157. [Google Scholar] [CrossRef] [PubMed]
- KE, T.M.; Lophatananon, A.; Muir, K.; Nieroda, M.; Manias, G.; Kyriazis, D.; Wajid, U.; Tomson, T. Risk Factors of Pancreatic Cancer: A Literature Review. Cancer Rep. Rev. 2022, 6. [Google Scholar] [CrossRef]
- Johnson, K.B.; Wei, W.Q.; Weeraratne, D.; Frisse, M.E.; Misulis, K.; Rhee, K.; Zhao, J.; Snowdon, J.L. Precision medicine, AI, and the future of personalized health care. Clin. Transl. Sci. 2021, 14, 86–93. [Google Scholar] [CrossRef] [PubMed]
- Qureshi, T.A.; Javed, S.; Sarmadi, T.; Pandol, S.J.; Li, D. Artificial intelligence and imaging for risk prediction of pancreatic cancer. Chin. Clin. Oncol. 2022, 11, 1. [Google Scholar] [CrossRef] [PubMed]
- Manias, G.; Den Akker, H.O.; Azqueta, A.; Burgos, D.; Capocchiano, N.D.; Crespo, B.L.; Dalianis, A.; Damiani, A.; Filipov, K.; Giotis, G.; et al. iHELP: Personalised Health Monitoring and Decision Support Based on Artificial Intelligence and Holistic Health Records. In Proceedings of the 2021 IEEE Symposium on Computers and Communications (ISCC), Athens, Greece, 5–8 September 2021. [Google Scholar]
- Thein, K.M.M. Apache kafka: Next generation distributed messaging system. Int. J. Sci. Eng. Technol. Res. 2014, 3, 9478–9483. [Google Scholar]
- Luksa, M. Kubernetes in Action; Simon and Schuster: New York, NY, USA, 2017. [Google Scholar]
- Smuck, M.; Odonkor, C.A.; Wilt, J.K.; Schmidt, N.; Swiernik, M.A. The emerging clinical role of wearables: Factors for successful implementation in healthcare. NPJ Digit. Med. 2021, 4, 45. [Google Scholar] [CrossRef]
- El Khatib, M.; Hamidi, S.; Al Ameeri, I.; Al Zaabi, H.; Al Marqab, R. Digital disruption and big data in healthcare-opportunities and challenges. Clin. Outcomes Res. 2022, 14, 563–574. [Google Scholar] [CrossRef]
- Pnevmatikakis, A.; Kanavos, S.; Matikas, G.; Kostopoulou, K.; Cesario, A.; Kyriazakos, S. Risk assessment for personalized health insurance based on real-world data. Risks 2021, 9, 46. [Google Scholar] [CrossRef]
- Bender, D.; Sartipi, K. HL7 FHIR: An Agile and RESTful approach to healthcare information exchange. In Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems, Porto, Portugal, 20–22 June 2013. [Google Scholar]
- Chang, E.; Mostafa, J. The use of SNOMED CT, 2013–2020: A literature review. J. Am. Med. Inform. Assoc. 2021, 28, 2017–2026. [Google Scholar] [CrossRef] [PubMed]
- Feldman, K.; Johnson, R.A.; Chawla, N.V. The state of data in healthcare: Path towards standardization. J. Healthc. Inform. Res. 2018, 2, 248–271. [Google Scholar] [CrossRef] [PubMed]
- Manias, G.; Azqueta-Alzúaz, A.; Damiani, A.; Dhar, E.; Kouremenou, E.; Patino-Martínez, M.; Savino, M.; Shabbir, S.A.; Kyriazis, D. An Enhanced Standardization and Qualification Mechanism for Heterogeneous Healthcare Data. In Caring is Sharing–Exploiting the Value in Data for Health and Innovation; IOS Press: Amsterdam, The Netherlands, 2023; p. 153. [Google Scholar]
- Lamy, J.B.; Venot, A.; Duclos, C. PyMedTermino: An open-source generic API for advanced terminology services. In Digital Healthcare Empowering Europeans; IOS Press: Amsterdam, The Netherlands, 2015; pp. 924–928. [Google Scholar]
- Chanda, A.K.; Bai, T.; Yang, Z.; Vucetic, S. Improving medical term embeddings using UMLS Metathesaurus. BMC Med. Inform. Decis. Mak. 2022, 22, 114. [Google Scholar] [CrossRef] [PubMed]
- Sanchez, Y.K.R.; Demurjian, S.A.; Baihan, M.S. A service-based RBAC & MAC approach incorporated into the FHIR standard. Digit. Commun. Netw. 2019, 5, 214–225. [Google Scholar]
- Ahmadi, N.; Peng, Y.; Wolfien, M.; Zoch, M.; Sedlmayr, M. OMOP CDM can facilitate Data-Driven studies for cancer prediction: A systematic review. Int. J. Mol. Sci. 2022, 23, 11834. [Google Scholar] [CrossRef] [PubMed]
- Sharma, R.; Atyab, M.; Sharma, R.; Atyab, M. Schema Registry. In Cloud-Native Microservices with Apache Pulsar: Build Distributed Messaging Microservices; Springer: Berlin/Heidelberg, Germany, 2022; pp. 81–101. [Google Scholar]
- Seu, K.; Kang, M.S.; Lee, H. An intelligent missing data imputation techniques: A review. JOIV Int. J. Inform. Vis. 2022, 6, 278–283. [Google Scholar]
- Haj-Hassan, A.; Habib, C.; Nassar, J. Real-time spatio-temporal based outlier detection framework for wireless body sensor networks. In Proceedings of the 2020 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), New Delhi, India, 14–17 December 2020; pp. 1–6. [Google Scholar]
- Ijaz, M.F.; Alfian, G.; Syafrudin, M.; Rhee, J. Hybrid prediction model for type 2 diabetes and hypertension using DBSCAN-based outlier detection, synthetic minority over sampling technique (SMOTE), and random forest. Appl. Sci. 2018, 8, 1325. [Google Scholar] [CrossRef]
- Vreeman, D.J.; McDonald, C.J.; Huff, S.M. LOINC®: A universal catalogue of individual clinical observations and uniform representation of enumerated collections. Int. J. Funct. Inform. Pers. Med. 2010, 3, 273–291. [Google Scholar] [CrossRef]
- Hirsch, J.A.; Nicola, G.; McGinty, G.; Liu, R.W.; Barr, R.M.; Chittle, M.D.; Manchikanti, L. ICD-10: History and context. Am. J. Neuroradiol. 2016, 37, 596–599. [Google Scholar] [CrossRef]
- Dwivedi, R.; Mehrotra, D.; Chandra, S. Potential of Internet of Medical Things (IoMT) applications in building a smart healthcare system: A systematic review. J. Oral Biol. Craniofacial Res. 2022, 12, 302–318. [Google Scholar] [CrossRef]
- Nekhlyudov, L.; Mollica, M.A.; Jacobsen, P.B.; Mayer, D.K.; Shulman, L.N.; Geiger, A.M. Developing a quality of cancer survivorship care framework: Implications for clinical care, research, and policy. JNCI J. Natl. Cancer Inst. 2019, 111, 1120–1130. [Google Scholar] [CrossRef] [PubMed]
- Ebaid, A.; Thirumuruganathan, S.; Aref, W.G.; Elmagarmid, A.; Ouzzani, M. Explainer: Entity resolution explanations. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 2000–2003. [Google Scholar]
- Bertossi, L.; Geerts, F. Data quality and explainable AI. J. Data Inf. Qual. (JDIQ) 2020, 12, 1–9. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | No. of Records | No. of Attributes | Dataset Size (in MB) | Dataset Type |
|---|---|---|---|---|
| Measurements | 3,252,920 | 17 | 564.1 | CSV |
| Observations | 339,925 | 14 | 55.4 | CSV |
| Person | 99,019 | 8 | 2.8 | CSV |
| Drug Exposure | 5,411,914 | 13 | 779.9 | CSV |
| Condition | 1,833,512 | 14 | 248.5 | CSV |
| Visit Occurrence | 5,205,819 | 13 | 727.5 | CSV |
| Procedure | 602,351 | 12 | 147.5 | CSV |
| Dataset Name | Initial Records | Erroneous Records | Corrected Records | Deleted Records | Faulty Data (%) |
|---|---|---|---|---|---|
| Measurements | 3,252,920 | 1049 | 1011 | 38 | 0.0011% |
| Observations | 339,925 | 139 | 122 | 17 | 0.005% |
| Person | 99,019 | 144 | 119 | 25 | 0.025% |
| Drug Exposure | 5,411,914 | 635 | 598 | 37 | 0.00068% |
| Condition | 1,833,512 | 336 | 325 | 11 | 0.0006% |
| Visit Occurrence | 5,205,819 | 208 | 169 | 39 | 0.0007% |
| Procedure | 602,351 | 180 | 162 | 18 | 0.0029% |
| Exercises Secondary Data | 5344 | 3 | 3 | 0 | 0.00% |
| Physiological Secondary Data | 22,136 | 9 | 6 | 3 | 0.0135% |
| Questionnaire Secondary Data | 2721 | 0 | 0 | 0 | 0.00% |
| Dataset Name | Data Source | Dataset Reliability Score | Datasource Reliability Score |
|---|---|---|---|
| Measurements | HDM Hospital | 98% | Reliable |
| Observations | HDM Hospital | 97% | Reliable |
| Person | HDM Hospital | 95% | Reliable |
| Drug Exposure | HDM Hospital | 98% | Reliable |
| Condition | HDM Hospital | 98% | Reliable |
| Visit Occurrence | HDM Hospital | 97% | Reliable |
| Procedure | HDM Hospital | 96% | Reliable |
| Secondary Data (derived from Healthentia) | Healthentia Platform | 99% | Reliable |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manias, G.; Azqueta-Alzúaz, A.; Dalianis, A.; Griffiths, J.; Kalogerini, M.; Kostopoulou, K.; Kouremenou, E.; Kranas, P.; Kyriazakos, S.; Lekka, D.; et al. Advanced Data Processing of Pancreatic Cancer Data Integrating Ontologies and Machine Learning Techniques to Create Holistic Health Records. Sensors 2024, 24, 1739. https://doi.org/10.3390/s24061739
Manias G, Azqueta-Alzúaz A, Dalianis A, Griffiths J, Kalogerini M, Kostopoulou K, Kouremenou E, Kranas P, Kyriazakos S, Lekka D, et al. Advanced Data Processing of Pancreatic Cancer Data Integrating Ontologies and Machine Learning Techniques to Create Holistic Health Records. Sensors. 2024; 24(6):1739. https://doi.org/10.3390/s24061739
Chicago/Turabian StyleManias, George, Ainhoa Azqueta-Alzúaz, Athanasios Dalianis, Jacob Griffiths, Maritini Kalogerini, Konstantina Kostopoulou, Eleftheria Kouremenou, Pavlos Kranas, Sofoklis Kyriazakos, Danae Lekka, and et al. 2024. "Advanced Data Processing of Pancreatic Cancer Data Integrating Ontologies and Machine Learning Techniques to Create Holistic Health Records" Sensors 24, no. 6: 1739. https://doi.org/10.3390/s24061739
APA StyleManias, G., Azqueta-Alzúaz, A., Dalianis, A., Griffiths, J., Kalogerini, M., Kostopoulou, K., Kouremenou, E., Kranas, P., Kyriazakos, S., Lekka, D., Melillo, F., Patiño-Martinez, M., Garcia-Perales, O., Pnevmatikakis, A., Torrens, S. G., Wajid, U., & Kyriazis, D. (2024). Advanced Data Processing of Pancreatic Cancer Data Integrating Ontologies and Machine Learning Techniques to Create Holistic Health Records. Sensors, 24(6), 1739. https://doi.org/10.3390/s24061739