
Pre-Segmented Down-Sampling Accelerates Graph Neural Network-Based 3D Object Detection in Autonomous Driving


Abstract
1. Introduction
- We present a LiDAR point cloud pre-segmented down-sampling method, preserving the semantic information of the target objects while reducing the LiDAR point cloud scale to approximately 1/20 of the original.
- We present a lightweight GNN-based 3D detector for autonomous driving, which utilizes the pre-segmented down-sampled LiDAR point clouds as input. The proposed 3D detector achieves a competitive detection accuracy while delivering an impressive ~6× faster inference speed compared to the original GNN-based 3D detection model.
- We evaluate the proposed model on the KITTI 3D Object Detection Benchmark, and the results demonstrate its efficiency and effectiveness for autonomous driving 3D object detection.
2. Related Work
2.1. Projection-Based Methods
2.2. Voxelization-Based Methods
2.3. Point-Based Methods
2.4. Graph-Based Methods
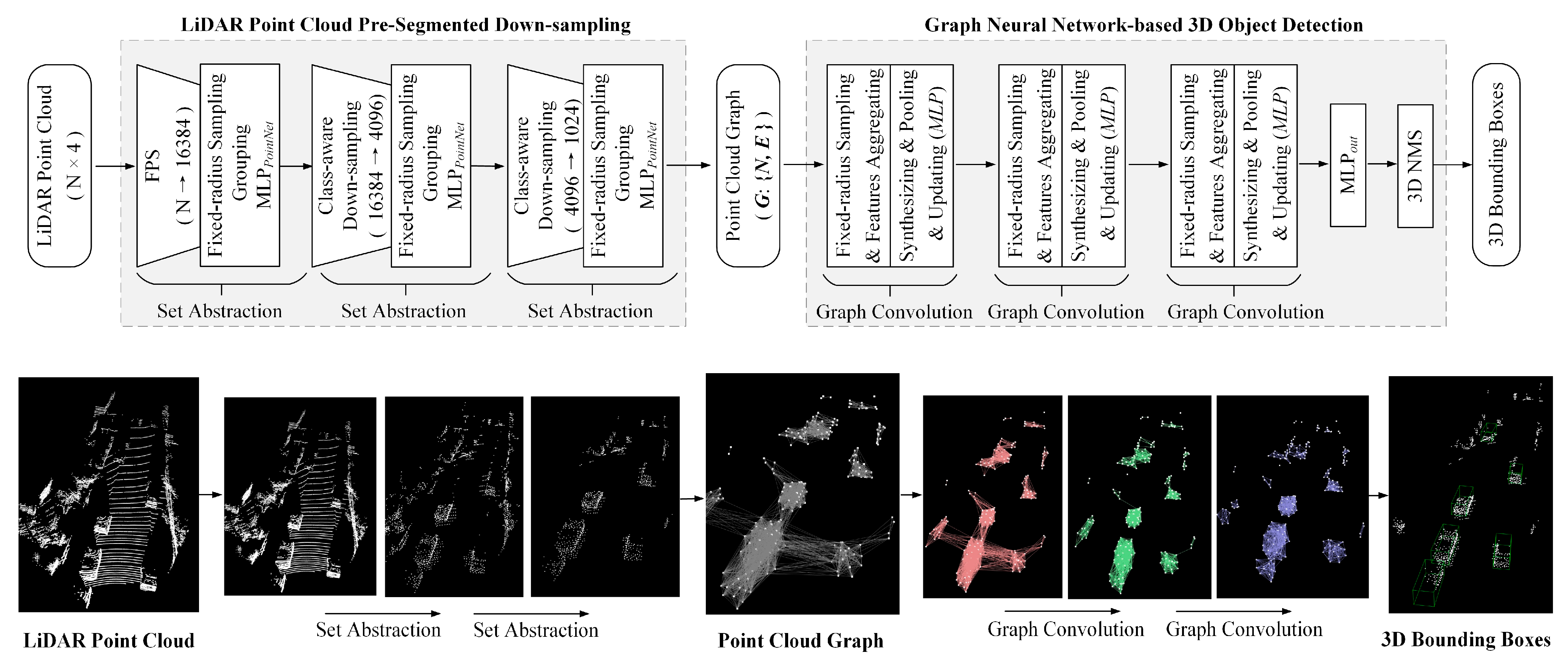
3. Method
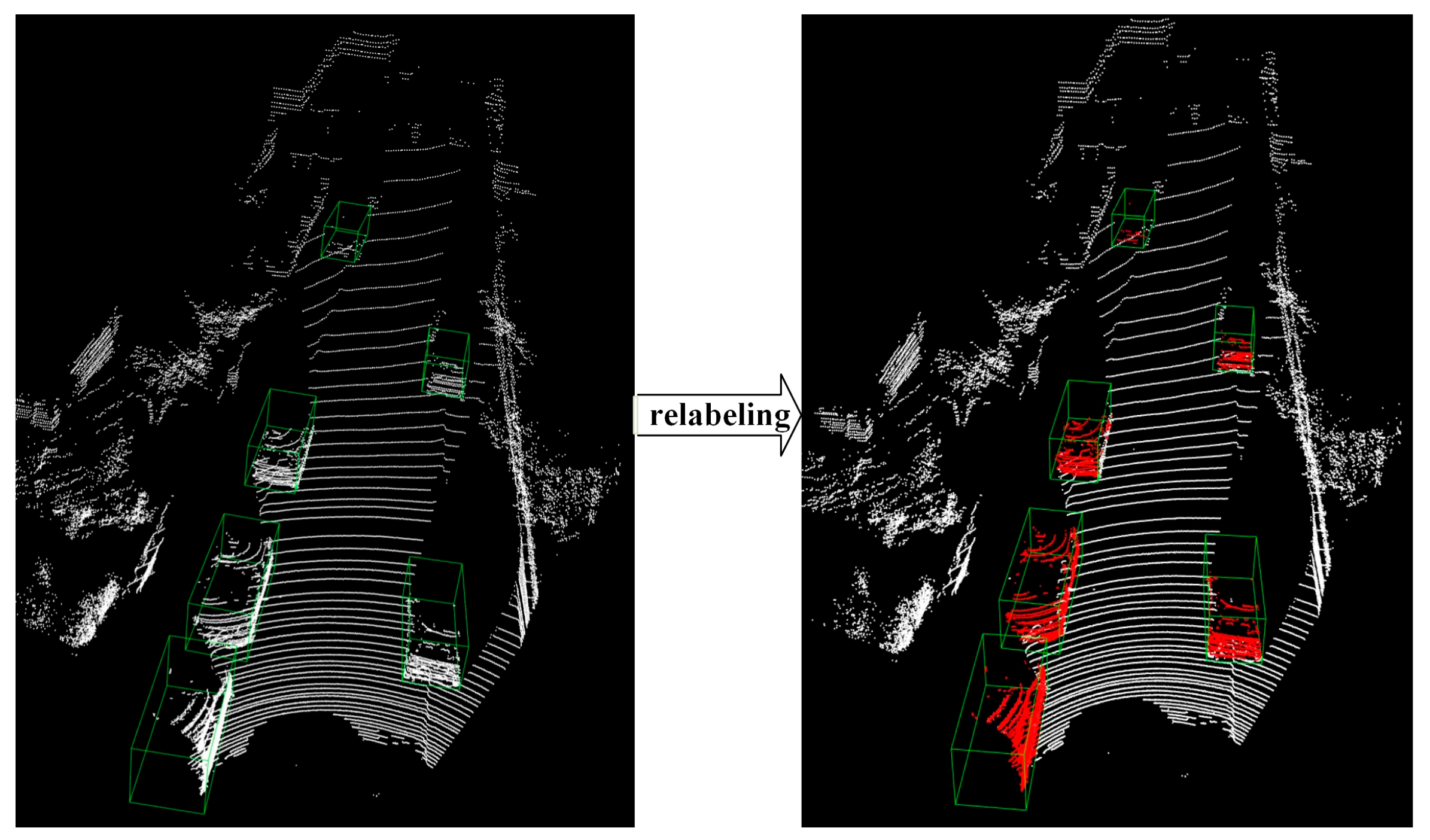
3.1. LiDAR Point Clouds Pre-Segmented Down-Sampling
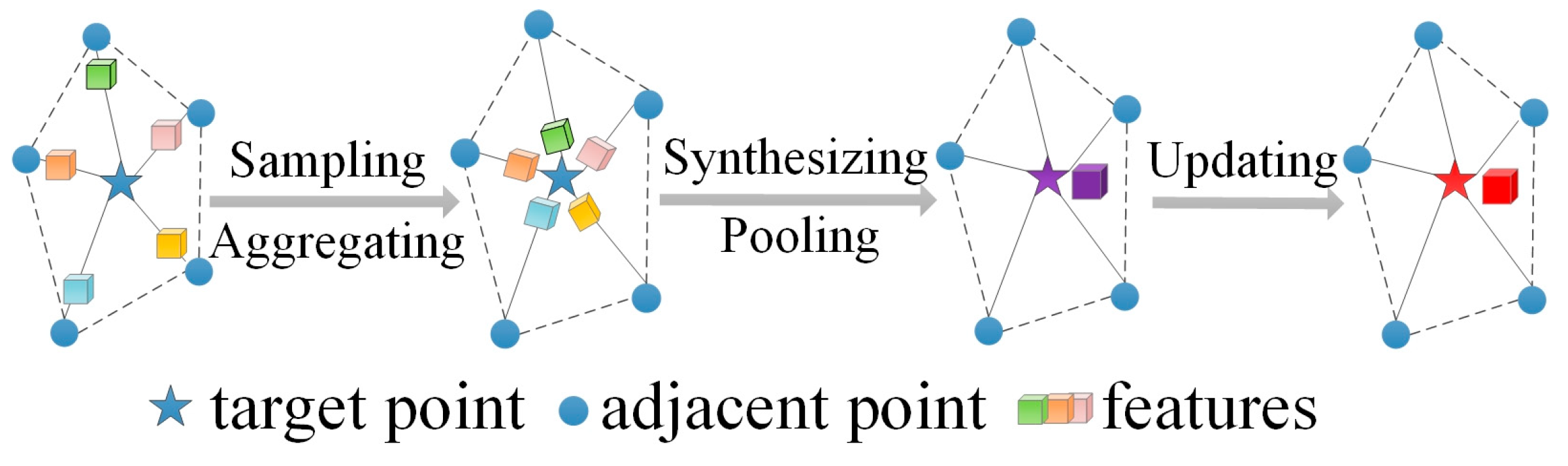
3.2. Graph Neural Network for 3D Object Detection
3.3. Loss Function
4. Experiments and Results
4.1. Dataset and Metrics
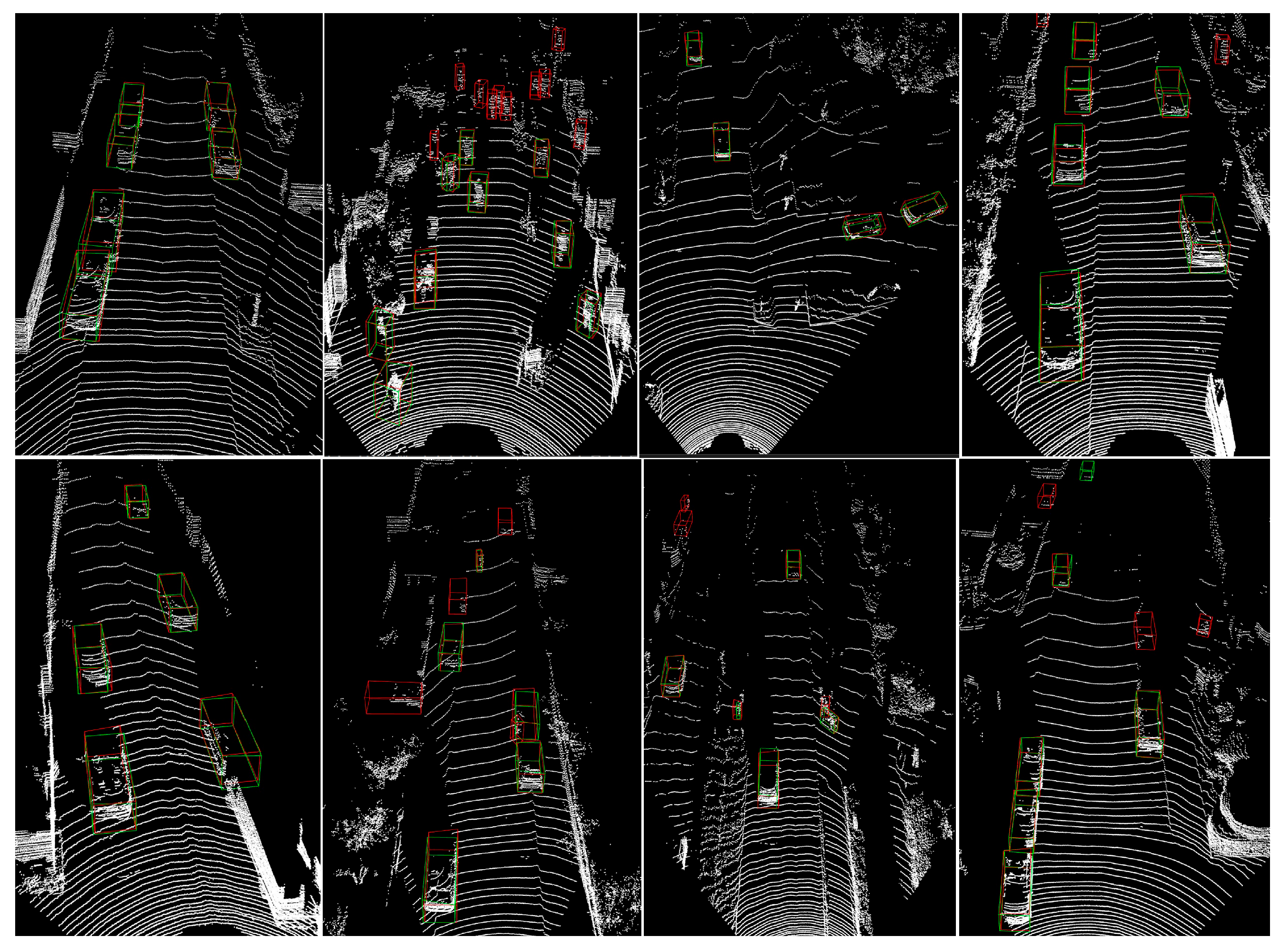
4.2. Quantitative Results and Discussion
4.3. Quantitative Results and Discussion
4.4. Ablation Study
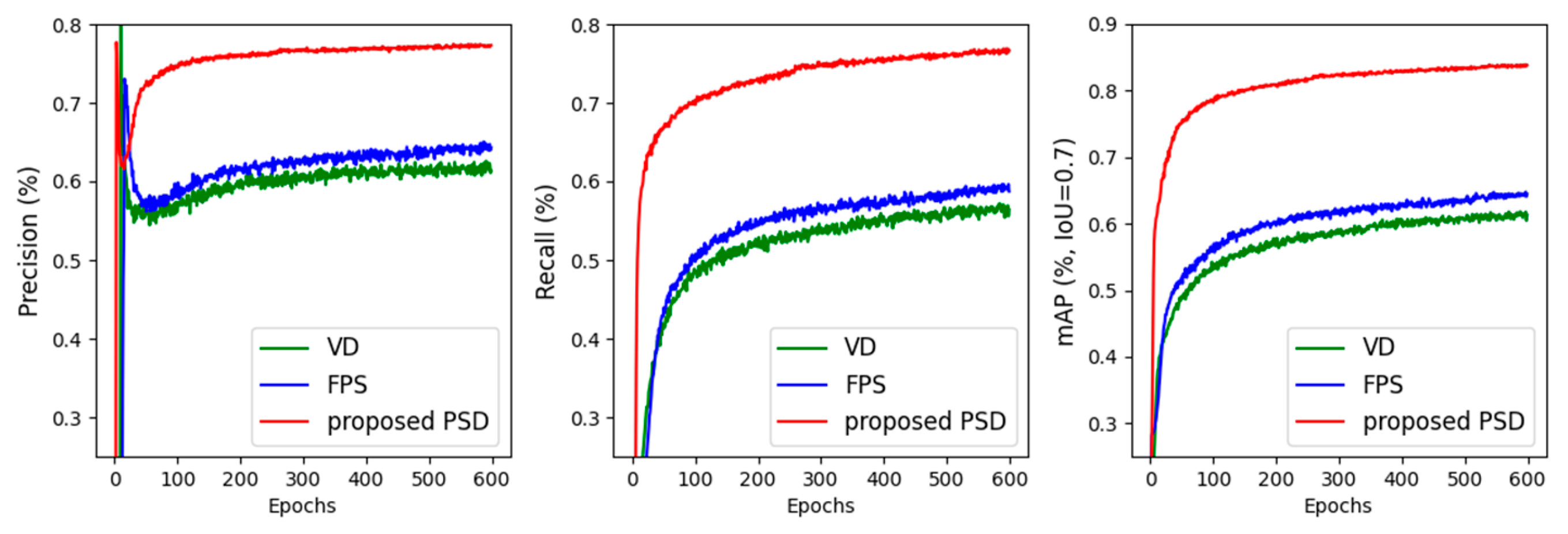
4.4.1. Analysis of Effectiveness of the Pre-Segmented Down-Sampling Method
4.4.2. Analysis of the Down-Sampling Scales in PSD Module
4.4.3. Analysis of the Number of Graph Convolutional Layers in the GNN-Based 3D Detection Module
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fethi, D.; Nemra, A.; Louadj, K.; Hamerlain, M. Simultaneous localization, mapping, and path planning for unmanned vehicle using optimal control. Adv. Mech. Eng. 2018, 10, 1687814017736653. [Google Scholar] [CrossRef]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar] [CrossRef]
- Li, B. 3d fully convolutional network for vehicle detection in point cloud. In Proceedings of the 2017 IEEE International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1513–1518. [Google Scholar] [CrossRef]
- Beltran, J.; Guindel, C.; Moreno, F.M.; Cruzado, D.; Garcia, F.; De La Escalera, A. Birdnet: A 3d object detection framework from lidar information. In Proceedings of the International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 3517–3523. [Google Scholar] [CrossRef]
- Yang, B.; Luo, W.; Urtasun, R. Pixor: Real-time 3d object detection from point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 7652–7660. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 4490–4499. [Google Scholar] [CrossRef]
- Yan, Y.; Mao, Y.; Li, B. Second: Sparsely embedded convolutional detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef] [PubMed]
- Lang, A.H.; Vora, S.; Caesar, H.; Zhou, L.; Yang, J.; Beijbom, O. Pointpillars: Fast encoders for object detection from point clouds. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12697–12705. [Google Scholar] [CrossRef]
- Shi, S.; Guo, C.; Jiang, L.; Wang, Z.; Shi, J.; Wang, X.; Li, H. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 10529–10538. [Google Scholar] [CrossRef]
- Shi, S.; Jiang, L.; Deng, J.; Wang, Z.; Guo, C.; Shi, J.; Wang, X.; Li, H. PV-RCNN++: Point-voxel feature set abstraction with local vector representation for 3D object detection. Int. J. Comput. Vis. 2023, 131, 531–551. [Google Scholar] [CrossRef]
- Noh, J.; Lee, S.; Ham, B. Hvpr: Hybrid voxel-point representation for single-stage 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Kuala Lumpur, Malaysia, 19–25 June 2021; pp. 14605–14614. [Google Scholar] [CrossRef]
- Wu, H.; Wen, C.; Li, W.; Li, X.; Yang, R.; Wang, C. Transformation-equivariant 3d object detection for autonomous driving. Proc. AAAI Conf. Artif. Intell. (AAAI) 2023, 37, 2795–2802. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 652–660. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Guangzhou, China, 2017; pp. 5105–5114. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Std: Sparse-to-dense 3d object detector for point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seoul, Republic of Korea, 27–28 October 2019; pp. 1951–1960. [Google Scholar] [CrossRef]
- Shi, S.; Wang, X.; Li, H. Pointrcnn: 3d object proposal generation and detection from point cloud. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 770–779. [Google Scholar] [CrossRef]
- Yang, Z.; Sun, Y.; Liu, S.; Jia, J. 3dssd: Point-based 3d single stage object detector. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11040–11048. [Google Scholar] [CrossRef]
- Qi, C.R.; Liu, W.; Wu, C.; Su, H.; Guibas, L.J. Frustum pointnets for 3d object detection from rgb-d data. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 918–927. [Google Scholar] [CrossRef]
- Zhang, Y.; Hu, Q.; Xu, G.; Ma, Y.; Wan, J.; Guo, Y. Not all points are equal: Learning highly efficient point-based detectors for 3d lidar point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 18953–18962. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic graph CNN for learning on point clouds. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef] [PubMed]
- Shi, W.; Rajkumar, R. Point-gnn: Graph neural network for 3d object detection in a point cloud. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 1711–1719. [Google Scholar] [CrossRef]
- He, Q.; Wang, Z.; Zeng, H.; Zeng, Y.; Liu, Y. Svga-net: Sparse voxel-graph attention network for 3d object detection from point clouds. Proc. AAAI Conf. Artif. Intell. (AAAI) 2022, 36, 870–878. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Reference | Category | Cars (IoU = 0.7) | Pedestrians (IoU = 0.5) | Cyclists (IoU = 0.5) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Easy | Mod. | Hard | Easy | Mod. | Hard | Easy | Mod. | Hard | |||
| MV3D [2] | CVPR2017 | Fusion-based | 71.09 | 62.35 | 55.12 | -- | -- | -- | -- | -- | -- |
| PIXOR [5] | CVPR2018 | Project-based | 81.70 | 77.05 | 72.95 | -- | -- | -- | -- | -- | -- |
| VoxelNet [6] | CVPR2018 | Voxel-based | 77.47 | 65.11 | 57.73 | 39.48 | 33.69 | 31.5 | 61.22 | 48.36 | 44.37 |
| SECOND [7] | SENSORS | Voxel-based | 83.13 | 73.66 | 66.20 | 51.07 | 42.56 | 37.29 | 70.51 | 53.85 | 46.90 |
| PointPillars [8] | CVPR2019 | Pillar-based | 82.58 | 74.31 | 68.99 | 51.45 | 41.92 | 38.89 | 77.10 | 58.65 | 51.92 |
| PV-RCNN [9] | CVPR2020 | Point-Voxel | 90.25 | 81.43 | 76.82 | 52.17 | 43.29 | 40.29 | 78.60 | 63.71 | 57.65 |
| PV-RCNN++ [10] | IJCV2023 | Voxel-Point | -- | 81.88 | -- | -- | 47.19 | -- | -- | 67.33 | -- |
| HVPR [11] | CVPR2021 | Voxel-Point | 86.38 | 77.92 | 73.04 | 53.47 | 43.96 | 40.64 | -- | -- | -- |
| TED [12] | AAAI2023 | Fusion-based | 91.61 | 85.28 | 80.68 | 55.85 | 49.21 | 46.52 | 88.82 | 74.12 | 66.84 |
| STD [15] | ICCV2019 | Point-based | 87.95 | 79.71 | 75.09 | 53.29 | 42.47 | 38.35 | 78.69 | 61.59 | 55.30 |
| PointRCNN [16] | CVPR2019 | Point-based | 85.94 | 75.76 | 68.32 | 49.43 | 41.78 | 38.63 | 73.93 | 59.60 | 53.59 |
| 3DSSD [17] | CVPR2020 | Point-based | 88.36 | 79.57 | 74.55 | 54.64 | 44.27 | 40.23 | 82.48 | 64.10 | 56.90 |
| F-PointNet [18] | CVPR2018 | Fusion-based | 81.20 | 70.39 | 62.19 | 51.21 | 44.89 | 40.23 | 71.96 | 56.77 | 50.39 |
| IA-SSD [19] | CVPR2022 | Point-based | 88.34 | 80.13 | 75.04 | 46.51 | 39.03 | 35.60 | 78.35 | 61.94 | 55.70 |
| Point-GNN [22] | CVPR2020 | Graph-based | 88.33 | 79.47 | 72.29 | 51.92 | 43.77 | 40.14 | 78.60 | 63.48 | 57.08 |
| Ours | Graph-based | 88.41 | 80.18 | 74.10 | 48.09 | 41.16 | 38.71 | 78.13 | 62.45 | 56.14 | |
| Method | Precision | Recall | mAP | Time Cost |
|---|---|---|---|---|
| VD | 0.578 | 0.519 | 0.553 | 37.9 ms |
| FPS | 0.601 | 0.542 | 0.596 | 63.1 ms |
| PSD | 0.747 | 0.729 | 0.814 | 19.3 ms |
| No. Points | Precision | Recall | mAP |
|---|---|---|---|
| 2048 | 0.750 | 0.731 | 0.815 |
| 1024 | 0.747 | 0.729 | 0.814 |
| 512 | 0.722 | 0.705 | 0.783 |
| No. Layers | Precision | Recall | mAP |
|---|---|---|---|
| 1 | 0.706 | 0.652 | 0.749 |
| 2 | 0.731 | 0.704 | 0.806 |
| 3 | 0.747 | 0.729 | 0.814 |
| 4 | 0.748 | 0.731 | 0.813 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, Z.; Huang, Y.; Bai, Y. Pre-Segmented Down-Sampling Accelerates Graph Neural Network-Based 3D Object Detection in Autonomous Driving. Sensors 2024, 24, 1458. https://doi.org/10.3390/s24051458
Liang Z, Huang Y, Bai Y. Pre-Segmented Down-Sampling Accelerates Graph Neural Network-Based 3D Object Detection in Autonomous Driving. Sensors. 2024; 24(5):1458. https://doi.org/10.3390/s24051458
Chicago/Turabian StyleLiang, Zhenming, Yingping Huang, and Yanbiao Bai. 2024. "Pre-Segmented Down-Sampling Accelerates Graph Neural Network-Based 3D Object Detection in Autonomous Driving" Sensors 24, no. 5: 1458. https://doi.org/10.3390/s24051458
APA StyleLiang, Z., Huang, Y., & Bai, Y. (2024). Pre-Segmented Down-Sampling Accelerates Graph Neural Network-Based 3D Object Detection in Autonomous Driving. Sensors, 24(5), 1458. https://doi.org/10.3390/s24051458