
Lossless Encoding of Time-Aggregated Neuromorphic Vision Sensor Data Based on Point-Cloud Compression

Abstract
1. Introduction
1.1. Motivation
1.2. Contribution
2. Related Work
2.1. NVS Data Compression
2.2. Point Cloud Compression
3. Proposed Strategy
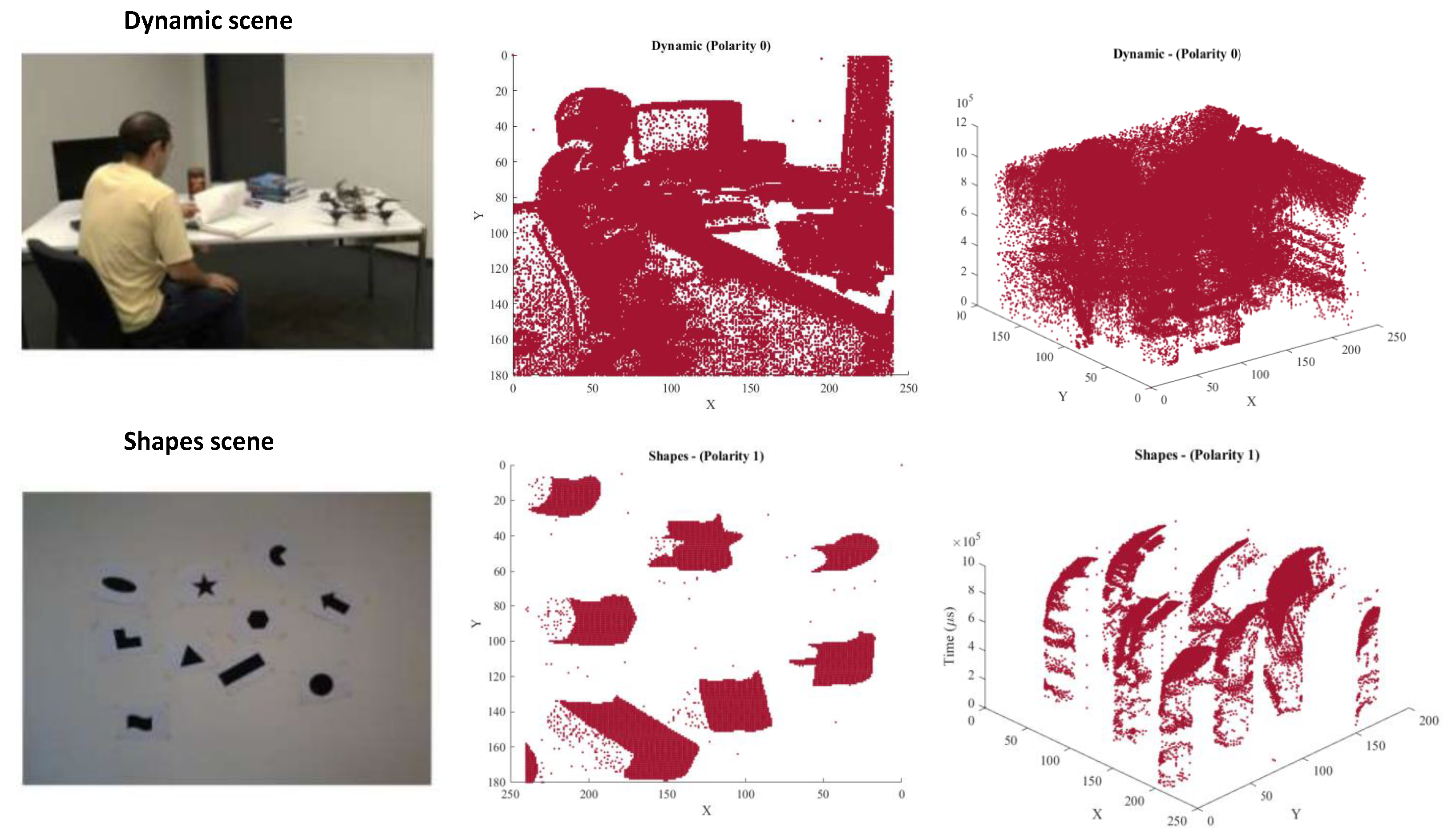
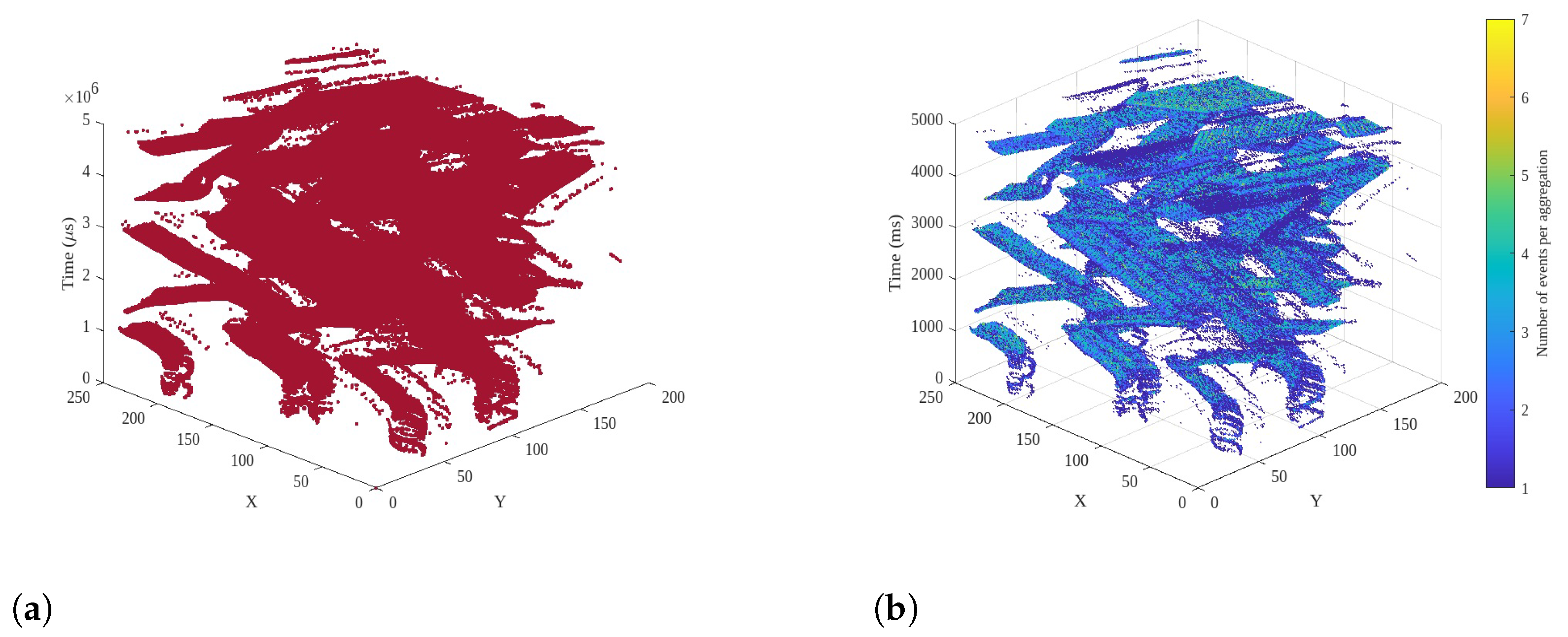
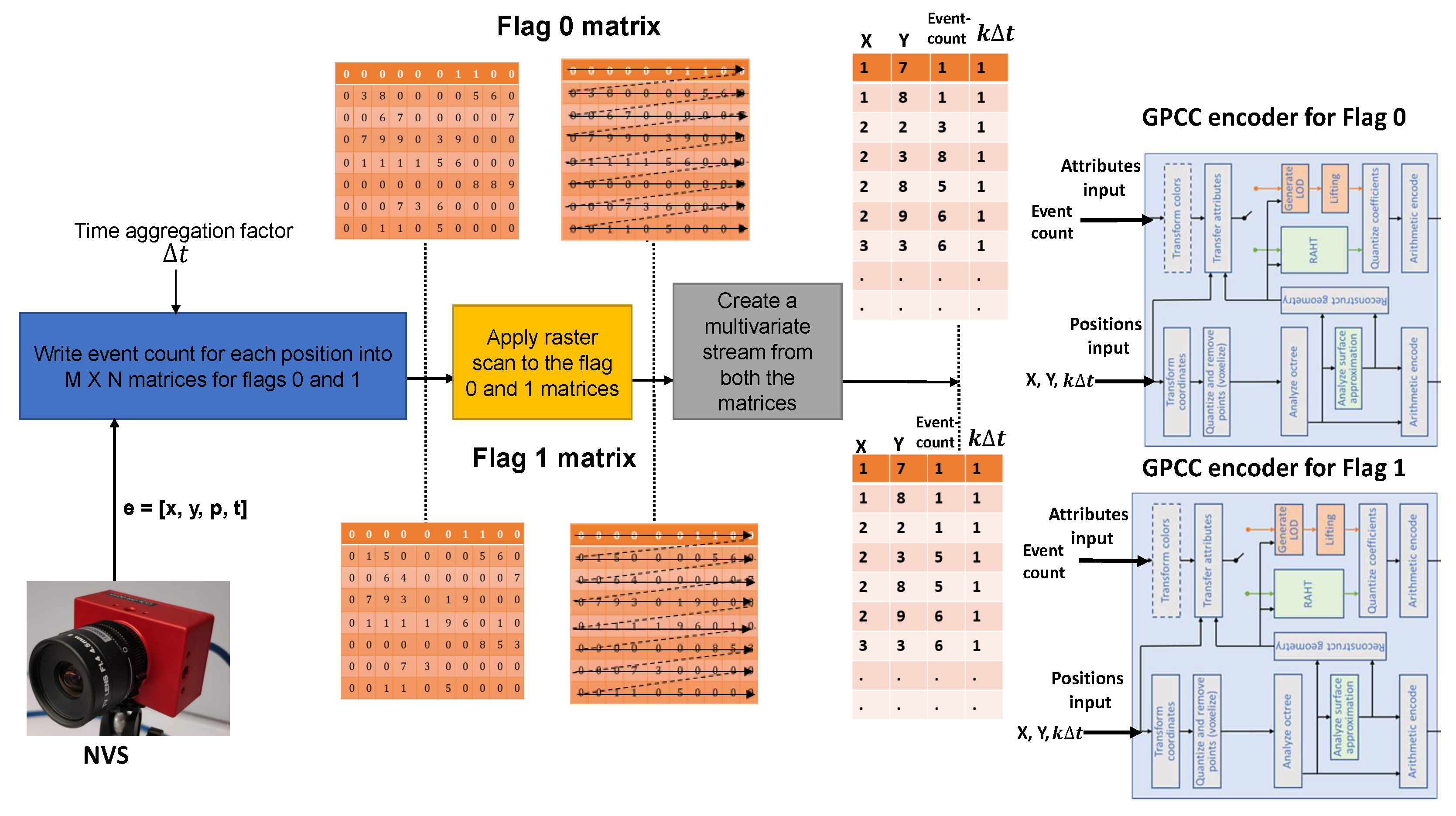
3.1. Spike Event Aggregation
3.2. Multivariate Stream
3.3. G-PCC Encoding

3.4. Implementation Details
3.5. Computation Complexity
| Algorithm 1 TALEN-PCC |
|
4. Performance Evaluation Setup
4.1. Dataset
4.2. Data Processing
4.3. Benchmark Strategies
4.4. Compression Ratio
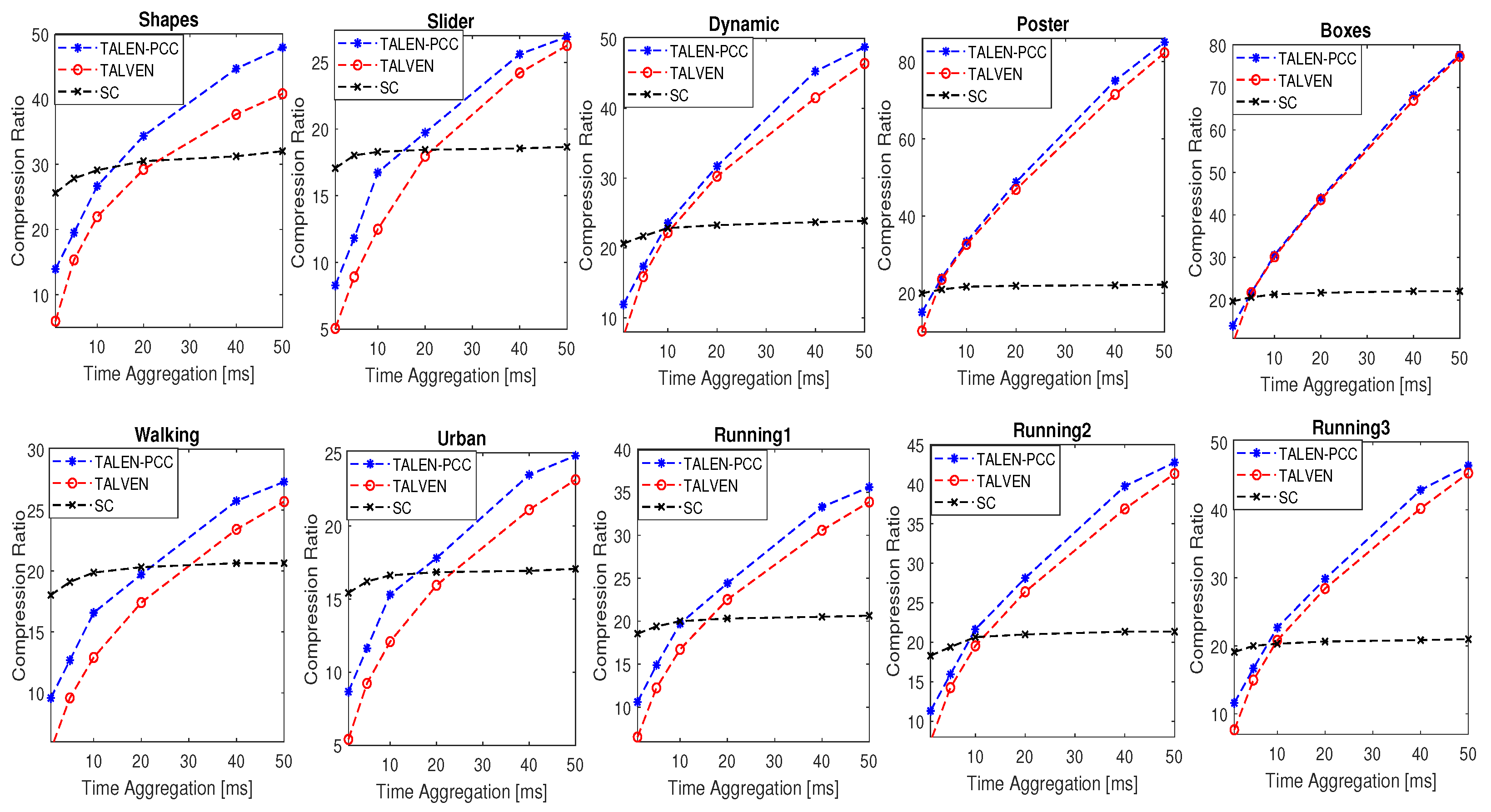
5. Results
5.1. Compression Gain Analysis at
5.2. Comparative Performance Analysis of the Proposed and Benchmark Strategies
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lichtsteiner, P.; Posch, C.; Delbruck, T. A 128 ×128 120 dB 30 mW asynchronous vision sensor that responds to relative intensity change. In Proceedings of the IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 6–9 February 2006. [Google Scholar]
- Liu, S.; Rueckauer, B.; Ceolini, E.; Huber, A.; Delbruck, T. Event-Driven Sensing for Efficient Perception: Vision and audition algorithms. IEEE Signal Process. Mag. 2019, 36, 29–37. [Google Scholar] [CrossRef]
- Rigi, A.; Baghaei Naeini, F.; Makris, D.; Zweiri, Y. A novel event-based incipient slip detection using Dynamic Active-Pixel Vision Sensor (DAVIS). Sensors 2018, 18, 333. [Google Scholar] [CrossRef] [PubMed]
- Mueggler, E.; Huber, B.; Scaramuzza, D. Event-based, 6-DOF Pose Tracking for High-Speed Maneuvers. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Wang, C.; Li, C.; Han, Q.; Wu, F.; Zou, X. A Performance Analysis of a Litchi Picking Robot System for Actively Removing Obstructions, Using an Artificial Intelligence Algorithm. Agronomy 2023, 13, 2795. [Google Scholar] [CrossRef]
- Khan, N.; Martini, M.G. Bandwidth modeling of silicon retinas for next generation visual sensor networks. Sensors 2019, 19, 1751. [Google Scholar] [CrossRef] [PubMed]
- Khan, N.; Martini, M.G. Data rate estimation based on scene complexity for dynamic vision sensors on unmanned vehicles. In Proceedings of the IEEE International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Bologna, Italy, 9–12 September 2018. [Google Scholar]
- Mueggler, E.; Rebecq, H.; Gallego, G.; Delbruck, T.; Scaramuzza, D. The Event-Camera Dataset and Simulator: Event-based Data for Pose Estimation, Visual Odometry, and SLAM. Int. J. Robot. Res. 2017, 36, 91–97. [Google Scholar] [CrossRef]
- Cohen, G.; Afshar, S.; Orchard, G.; Tapson, J.; Benosman, R.; van Schaik, A. Spatial and Temporal Downsampling in Event-Based Visual Classification. IEEE Trans. Neural Networks Learn. Syst. 2018, 29, 5030–5044. [Google Scholar] [CrossRef] [PubMed]
- Maqueda, A.I.; Loquercio, A.; Gallego, G.; Garcia, N.; Scaramuzza, D. Event-based Vision meets Deep Learning on Steering Prediction for Self-driving Cars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Naeini, F.B.; Alali, A.; Al-Husari, R.; Rigi, A.; AlSharman, M.K.; Makris, D.; Zweiri, Y. A Novel Dynamic-Vision-Based Approach for Tactile Sensing Applications. IEEE Trans. Instrum. Meas. 2020, 69, 1881–1893. [Google Scholar] [CrossRef]
- Cannici, M.; Ciccone, M.; Romanoni, A.; Matteucci, M. Asynchronous Convolutional Networks for Object Detection in Neuromorphic Cameras. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, M.; Delbruck, T. Adaptive Time-Slice Block-Matching Optical Flow Algorithm for Dynamic Vision Sensors. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–12. [Google Scholar]
- Rebecq, H.; Gallego, G.; Mueggler, E.; Scaramuzza, D. EMVS: Event-Based Multi-View Stereo—3D Reconstruction with an Event Camera in Real-Time. Int. J. Comput. Vis. 2019, 126, 1394–1414. [Google Scholar] [CrossRef]
- Naeini, F.B.; Kachole, S.; Muthusamy, R.; Makris, D.; Zweiri, Y. Event Augmentation for Contact Force Measurements. IEEE Access 2022, 10, 123651–123660. [Google Scholar] [CrossRef]
- Baghaei Naeini, F.; Makris, D.; Gan, D.; Zweiri, Y. Dynamic-Vision-Based Force Measurements Using Convolutional Recurrent Neural Networks. Sensors 2020, 20, 4469. [Google Scholar] [CrossRef]
- Khan, N.; Iqbal, K.; Martini, M.G. Time-Aggregation-Based Lossless Video Encoding for Neuromorphic Vision Sensor Data. IEEE Internet Things J. 2020, 8, 596–609. [Google Scholar] [CrossRef]
- Martini, M.; Adhuran, J.; Khan, N. Lossless Compression of Neuromorphic Vision Sensor Data Based on Point Cloud Representation. IEEE Access 2022, 10, 121352–121364. [Google Scholar] [CrossRef]
- Bi, Z.; Dong, S.; Tian, Y.; Huang, T. Spike coding for dynamic vision sensors. In Proceedings of the IEEE Data Compression Conference (DCC), Snowbird, UT, USA, 27–30 March 2018; pp. 117–126. [Google Scholar]
- Dong, S.; Bi, Z.; Tian, Y.; Huang, T. Spike Coding for Dynamic Vision Sensor in Intelligent Driving. IEEE Internet Things J. 2019, 6, 60–71. [Google Scholar] [CrossRef]
- Schiopu, I.; Bilcu, R.C. Lossless compression of event camera frames. IEEE Signal Process. Lett. 2022, 29, 1779–1783. [Google Scholar] [CrossRef]
- Schiopu, I.; Bilcu, R.C. Low-Complexity Lossless Coding of Asynchronous Event Sequences for Low-Power Chip Integration. Sensors 2022, 22, 10014. [Google Scholar] [CrossRef]
- Schiopu, I.; Bilcu, R.C. Memory-Efficient Fixed-Length Representation of Synchronous Event Frames for Very-Low-Power Chip Integration. Electronics 2023, 12, 2302. [Google Scholar] [CrossRef]
- Collet, Y.; Kucherawy, E.M. Zstandard-Real-Time Data Compression Algorithm. 2018. Available online: http://facebook.github.io/zstd/ (accessed on 20 November 2023).
- Deutsch, P.; Gailly, J.L. Zlib Compressed Data Format Specification Version 3.3. Technical Report, RFC 1950, May. 1996. Available online: https://datatracker.ietf.org/doc/html/rfc1950 (accessed on 20 November 2023).
- Lempel, A.; Ziv, J. Lempel—Ziv—Markov chain algorithm, Technical Report. 1996. [Google Scholar]
- Alakuijala, J.; Szabadka, Z. Brotli Compressed Data Format. Internet Eng. Task Force RFC 7932 July 2016. Available online: https://www.rfc-editor.org/rfc/rfc7932 (accessed on 20 November 2023).
- Blalock, D.; Madden, S.; Guttag, J. Sprintz: Time series compression for the Internet of Things. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; Association for Computing Machinery: New York, NY, USA, 2018; Volume 2, p. 93. [Google Scholar]
- Lemire, D.; Boytsov, L. Decoding billions of integers per second through vectorization. Softw.-Pract. Exp. 2015, 45, 1–29. [Google Scholar] [CrossRef]
- Gunderson, S.H. Snappy: A Fast Compressor/decompressor. 2015. Available online: https://github.com/google/snappy (accessed on 20 November 2023).
- Khan, N.; Iqbal, K.; Martini, M.G. Lossless compression of data from static and mobile dynamic vision sensors—Performance and trade-offs. IEEE Access 2020, 8, 103149–103163. [Google Scholar] [CrossRef]
- Huang, B.; Ebrahimi, T. Event data stream compression based on point cloud representation. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 3120–3124. [Google Scholar]
- Dumic, E.; Bjelopera, A.; Nüchter, A. Dynamic point cloud compression based on projections, surface reconstruction and video compression. Sensors 2021, 22, 197. [Google Scholar] [CrossRef]
- Yu, J.; Wang, J.; Sun, L.; Wu, M.E.; Zhu, Q. Point Cloud Geometry Compression Based on Multi-Layer Residual Structure. Entropy 2022, 24, 1677. [Google Scholar] [CrossRef]
- Cao, C.; Preda, M.; Zaharia, T. 3D point cloud compression: A survey. In Proceedings of the The 24th International Conference on 3D Web Technology, Los Angeles, CA, USA, 26–28 July 2019; pp. 1–9. [Google Scholar]
- Schnabel, R.; Klein, R. Octree-based Point-Cloud Compression. In Proceedings of the PBG@ SIGGRAPH, Boston, MA, USA, 29–30 July 2006; pp. 111–120. [Google Scholar]
- Dricot, A.; Ascenso, J. Adaptive multi-level triangle soup for geometry-based point cloud coding. In Proceedings of the 2019 IEEE 21st International Workshop on Multimedia Signal Processing (MMSP), Kuala Lumpur, Malaysia, 27–29 September 2019; pp. 1–6. [Google Scholar]
- Tian, D.; Ochimizu, H.; Feng, C.; Cohen, R.; Vetro, A. Geometric distortion metrics for point cloud compression. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3460–3464. [Google Scholar]
- Schwarz, S.; Preda, M.; Baroncini, V.; Budagavi, M.; Cesar, P.; Chou, P.A.; Cohen, R.A.; Krivokuća, M.; Lasserre, S.; Li, Z.; et al. Emerging MPEG standards for point cloud compression. IEEE J. Emerg. Sel. Top. Circuits Syst. 2018, 9, 133–148. [Google Scholar] [CrossRef]
- Mammou, K.; Chou, P.; Flynn, D.; Krivokuća, M.; Nakagami, O.; Sugio, T. ISO/IEC JTC1/SC29/WG11 N18189; G-PCC Codec Description v2. 2019. Available online: https://mpeg.chiariglione.org/standards/mpeg-i/geometry-based-point-cloud-compression/g-pcc-codec-description-v2 (accessed on 15 November 2022).
- Liu, H.; Yuan, H.; Liu, Q.; Hou, J.; Liu, J. A Comprehensive Study and Comparison of Core Technologies for MPEG 3-D Point Cloud Compression. IEEE Trans. Broadcast. 2020, 66, 701–717. [Google Scholar] [CrossRef]
- Graziosi, D.; Nakagami, O.; Kuma, S.; Zaghetto, A.; Suzuki, T.; Tabatabai, A. An overview of ongoing point cloud compression standardization activities: Video-based (V-PCC) and geometry-based (G-PCC). APSIPA Trans. Signal Inf. Process. 2020, 9, e13. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | y | p | t |
|---|---|---|---|
| 5 | 18 | 1 | 45 |
| 7 | 17 | 0 | 48 |
| 1 | 10 | 0 | 50 |
| 2 | 20 | 0 | 55 |
| 8 | 20 | 1 | 56 |
| 1 | 10 | 0 | 58 |
| 8 | 11 | 1 | 61 |
| Paper | Algorithm | Application | Task | Spike Accumulation Interval () |
|---|---|---|---|---|
| [3] | Convolutional Neural Network (CNN) | Slip detection | Object vibration and stress distribution detection | 10 ms |
| [9] | Synaptic Kernel Inverse Method (SKIM) | Visual classification | Digit classification | 20 ms |
| [10] | Deep residual network (ResNet-50) | Autonomous driving | Motion estimation | 50 ms |
| [11] | Time Delay Neural Network (TDNN) | Tactile sensing | Material classification and contact force estimation | 7 ms |
| [12] | Asynchronous Convolutional Network (YOLE) | Object detection | Detection of objects, and prediction of their direction and position | 10 ms |
| [16] | Long Short-Term Memory (LSTM) neural networks | Tactile sensing | Contact force estimation | 10 ms |
| Sequence | Event Rate (kev/s) | Extracted Sequence Duration (s) and Start/End Time (s) | Scene Complexity | Speed | |
|---|---|---|---|---|---|
| Indoor | Boxes (Rotation) | 4288.65 | 5 (45–50) | High | High |
| Poster (Rotation) | 4021.1 | 5 (45–50) | High | High | |
| Dynamic (Rotation) | 1077.73 | 20 (1–20) | Medium | Medium | |
| Slider (Depth) | 336.78 | 3 (1–3) | Medium | Low | |
| Shapes (Rotation) | 245.61 | 20 (1–20) | Low | Low | |
| Outdoor | Running3 | 1525.5 | 20 (40–60) | Medium | High |
| Running2 | 1229.4 | 20 (20–40) | Medium | Medium | |
| Running1 | 713.8 | 20 (1–20) | Medium | Medium | |
| Urban | 503.04 | 10 (1–10) | High | Low | |
| Walking | 342.2 | 20 (1–20) | Medium | Low |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Adhuran, J.; Khan, N.; Martini, M.G. Lossless Encoding of Time-Aggregated Neuromorphic Vision Sensor Data Based on Point-Cloud Compression. Sensors 2024, 24, 1382. https://doi.org/10.3390/s24051382
Adhuran J, Khan N, Martini MG. Lossless Encoding of Time-Aggregated Neuromorphic Vision Sensor Data Based on Point-Cloud Compression. Sensors. 2024; 24(5):1382. https://doi.org/10.3390/s24051382
Chicago/Turabian StyleAdhuran, Jayasingam, Nabeel Khan, and Maria G. Martini. 2024. "Lossless Encoding of Time-Aggregated Neuromorphic Vision Sensor Data Based on Point-Cloud Compression" Sensors 24, no. 5: 1382. https://doi.org/10.3390/s24051382
APA StyleAdhuran, J., Khan, N., & Martini, M. G. (2024). Lossless Encoding of Time-Aggregated Neuromorphic Vision Sensor Data Based on Point-Cloud Compression. Sensors, 24(5), 1382. https://doi.org/10.3390/s24051382