1. Introduction
In the pursuit of attaining net zero-emission goals, renewable energy sources play a crucial role. The incorporation of Distributed Energy Resources (DERs) offers numerous benefits, such as enhanced power supply reliability, increased consumer engagement, a lowered carbon footprint, and diminished greenhouse gas emissions. Nevertheless, the integration of DERs into the grid also poses challenges in terms of protection issues in the grid and coordination between the protective devices [
1]. The integration of DERs transforms the radial distribution network configuration from a radial to a meshed structure, which results in the possibility of a bidirectional power flow [
2]. This change to the meshed structure can lead to issues such as false tripping, the blinding of protection [
3], relay over-reach, or under-reach, among other potential challenges. Furthermore, DER integration can increase fault current levels, depending on the DER type and the mode of operation with the grid [
4,
5,
6]. Hence, this potentiality gives rise to a range of technical challenges, prominently featuring fault protection as a substantial and intricate concern [
7,
8]. This highlights the imperativeness for smart protective strategies to enhance the network’s security and efficiency.
In recent times, different techniques have been defined to detect and locate faults in DSs with the help of communication systems, even when there are DERs involved. Neural Network-based methods (NN) are among these approaches [
9,
10]. They typically assure reliable fault detection and can distinguish between different types of line faults quickly in various fault scenarios. However, they demand complex calculations, require extensive training, and may require adjustments in case of grid layout changes. They also depend on the use of communication channels.
In [
11], the authors propose a two-step protection algorithm using fault-induced power changes and phase angle information for fault detection and isolation in DSs with DGs. The method effectively addresses the bi-directional power flow and ensures a rapid fault response. However, it relies on robust communication channels and has not been tested under grid reconfiguration. In [
12], the authors employ negative- and positive-sequence components of the grid voltage for fault protection. However, this method has not yet been evaluated in scenarios involving inverter-based DGs.
Contrarily, recent studies have reported the importance of THD in evaluating the power grid’s quality and performance. In this regard, a number of harmonic-based fault protection methods have emerged, utilizing the harmonic content of the grid’s voltage and current for this purpose [
13,
14,
15]. In [
13], a cost-effective protection solution is presented. It employs a novel harmonic-based relay for fault detection and isolation. This relay is activated by injecting specific harmonic signals into the grid during a fault. This method serves as a directional relay, eliminating the need for a voltage transformer. However, this approach is applicable only to three-phase faults and necessitates dependable communication links. In [
14], the THD and harmonics of each grid voltage phase were determined using the Fast Fourier Transform (FFT) for defining a protection method. However, implementing FFT, especially on each grid voltage line, can be computationally demanding. Additionally, this method cannot distinguish between different types of faults, relies on communication links, and exhibits slower trip activation compared to alternative methods.
The author’s previous work [
15,
16] offers two THD-based techniques for fault isolation in different locations of a DS grid: one using a Second-Order Generalized Integrator structure (SOGI) [
15] and another using the Multiple SOGI (MSOGI) [
16]. Both approaches exhibit the fast detection of both symmetrical and unsymmetrical faults. However, a comparison between the two THD methods is provided in [
15], in which the SOGI approach exhibits superior computational efficiency when implemented using a Digital Signal Processor (DSP) in terms of the number of processor cycles (c), requiring only 447 c compared to the MSOGI approach’s 1788 c. As a result, the SOGI approach was selected for ongoing, reliable fault detection.
Additionally, various protection methods employ distinct techniques such as wavelets [
17,
18,
19], fuzzy logic [
20], recursive least squares [
21,
22], a differential phase angle [
23], s-transform [
24], power spectral density and transform [
25], deep belief networks [
26], and Hilbert–Huang transform [
27]. Nevertheless, these methodologies necessitate sophisticated computational processes and entail relatively elevated implementation expenses.
The earlier approaches mainly focused on using communication channels to transmit trip signals between PDs. This allowed for fast and coordinated fault protection. Nevertheless, these approaches came with a drawback, as they did not offer any backup plan in case of communication failure. On the other hand, some methods can operate without communication by using local measurements from the relay. These methods, though, tend to have slower fault detection times compared to the ones that rely on communication.
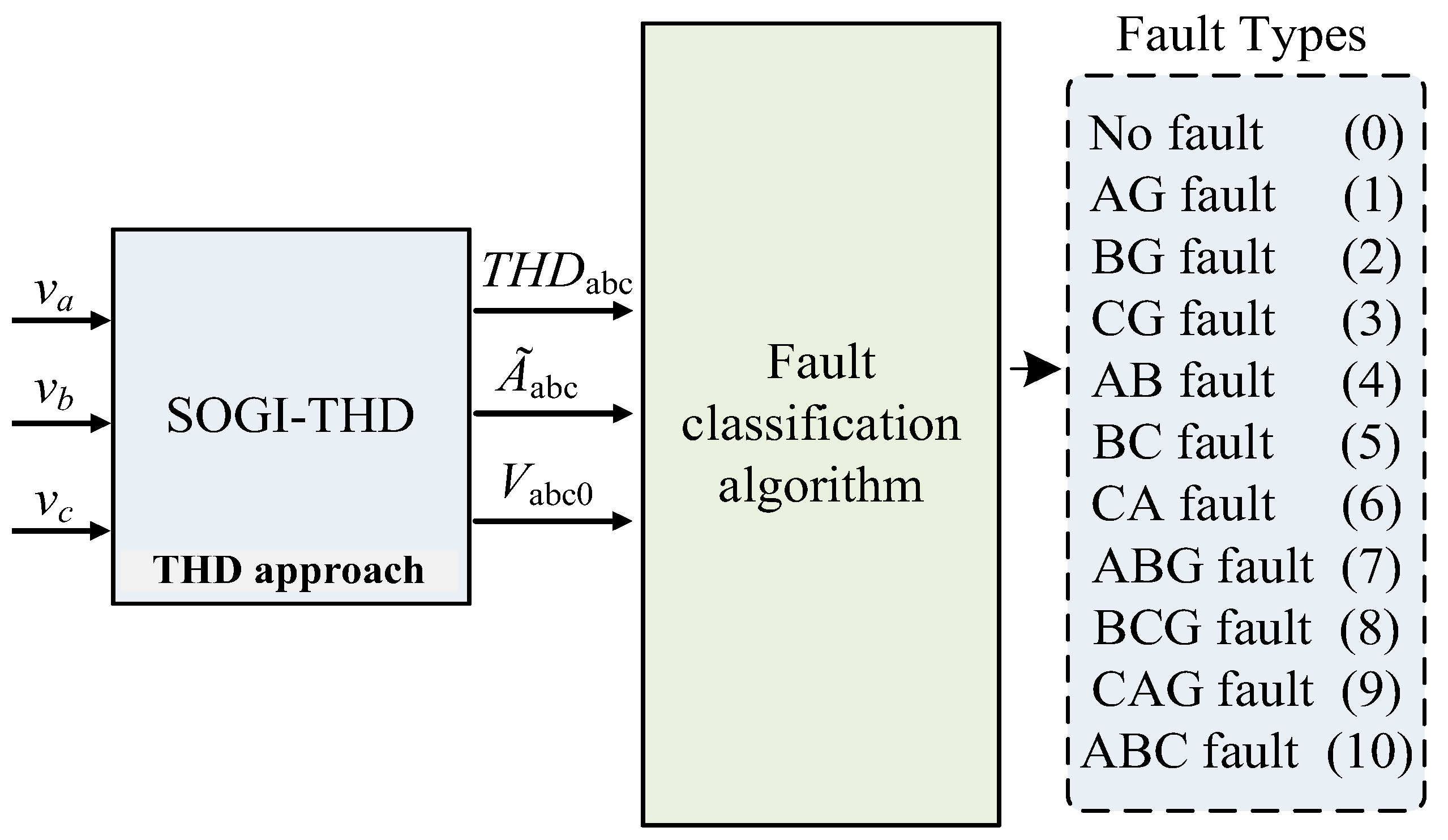
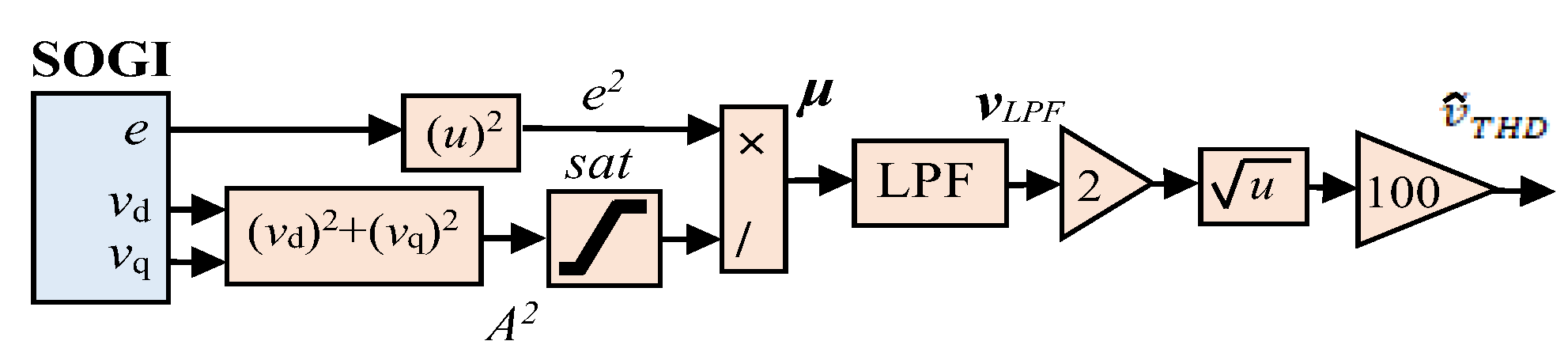
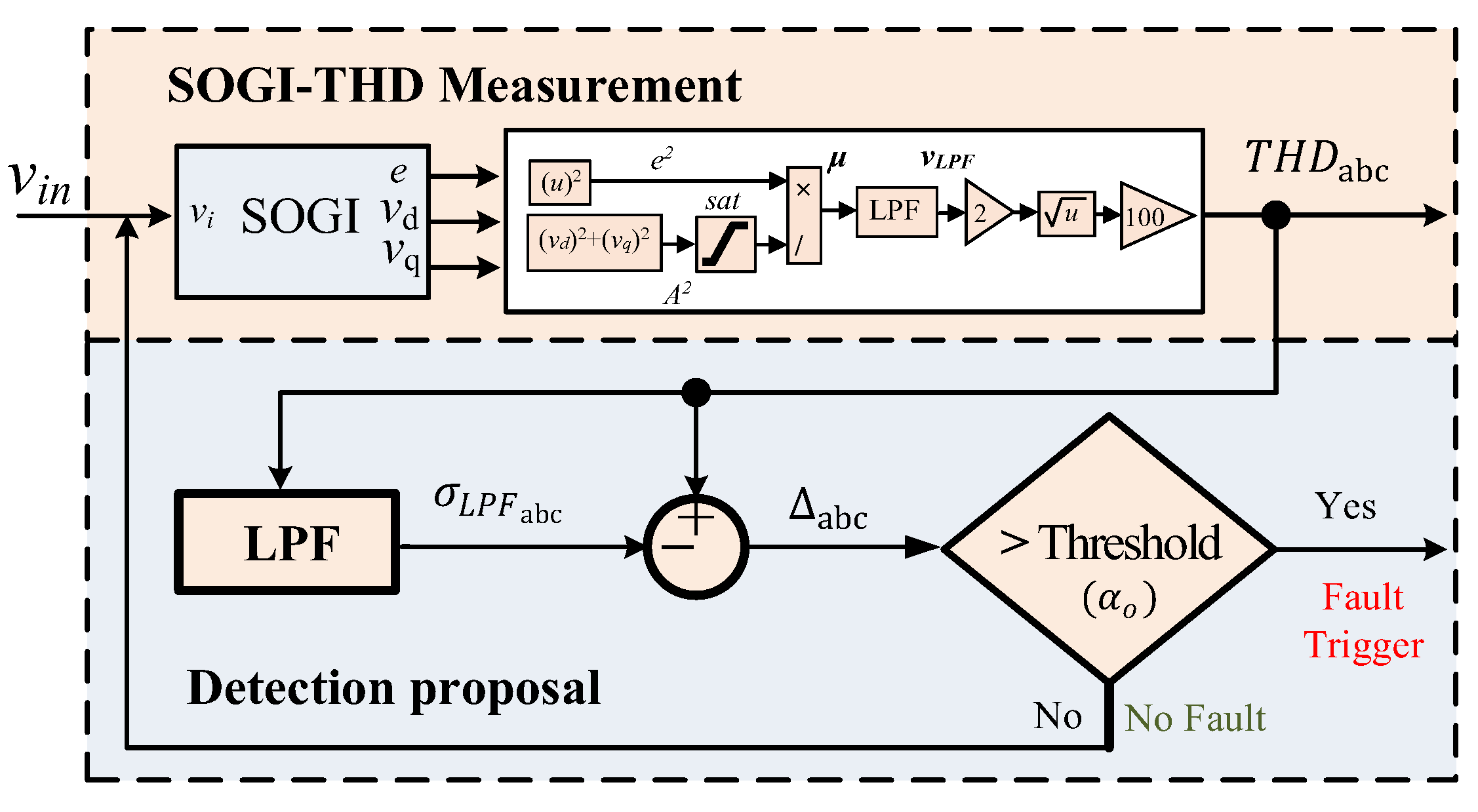
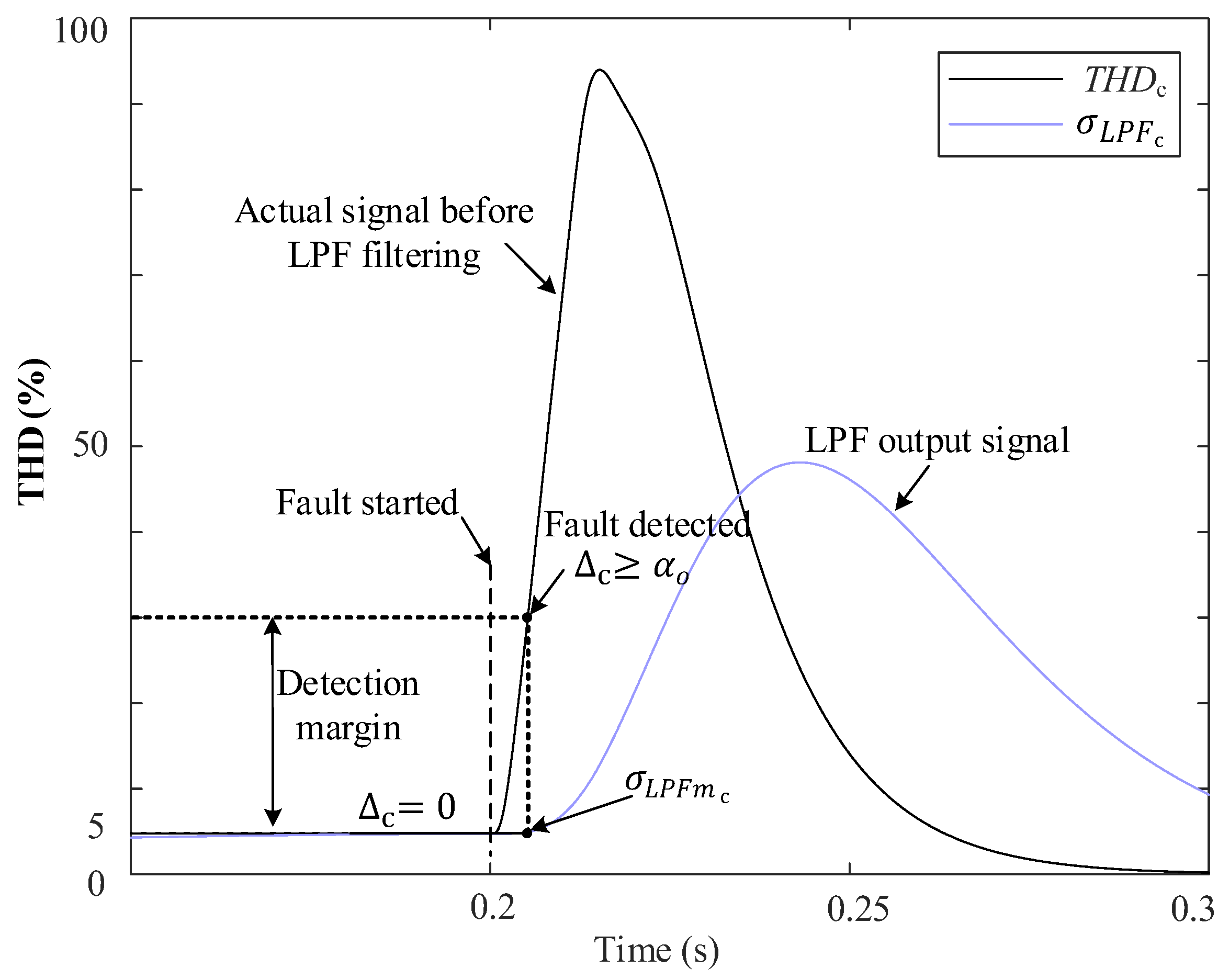
Therefore, to ensure fast and secure fault protection in light of potential communication failures, this paper presents a two-layer protection system for mitigating fault events in the DSs. The first layer uses the THD (
), the estimates of amplitude voltages (
), and the zero-sequence components (
) of the three-phase grid voltages to develop a protection strategy performed using a Finite State Machine (FSM) for the detection and isolation of faults within the grid [
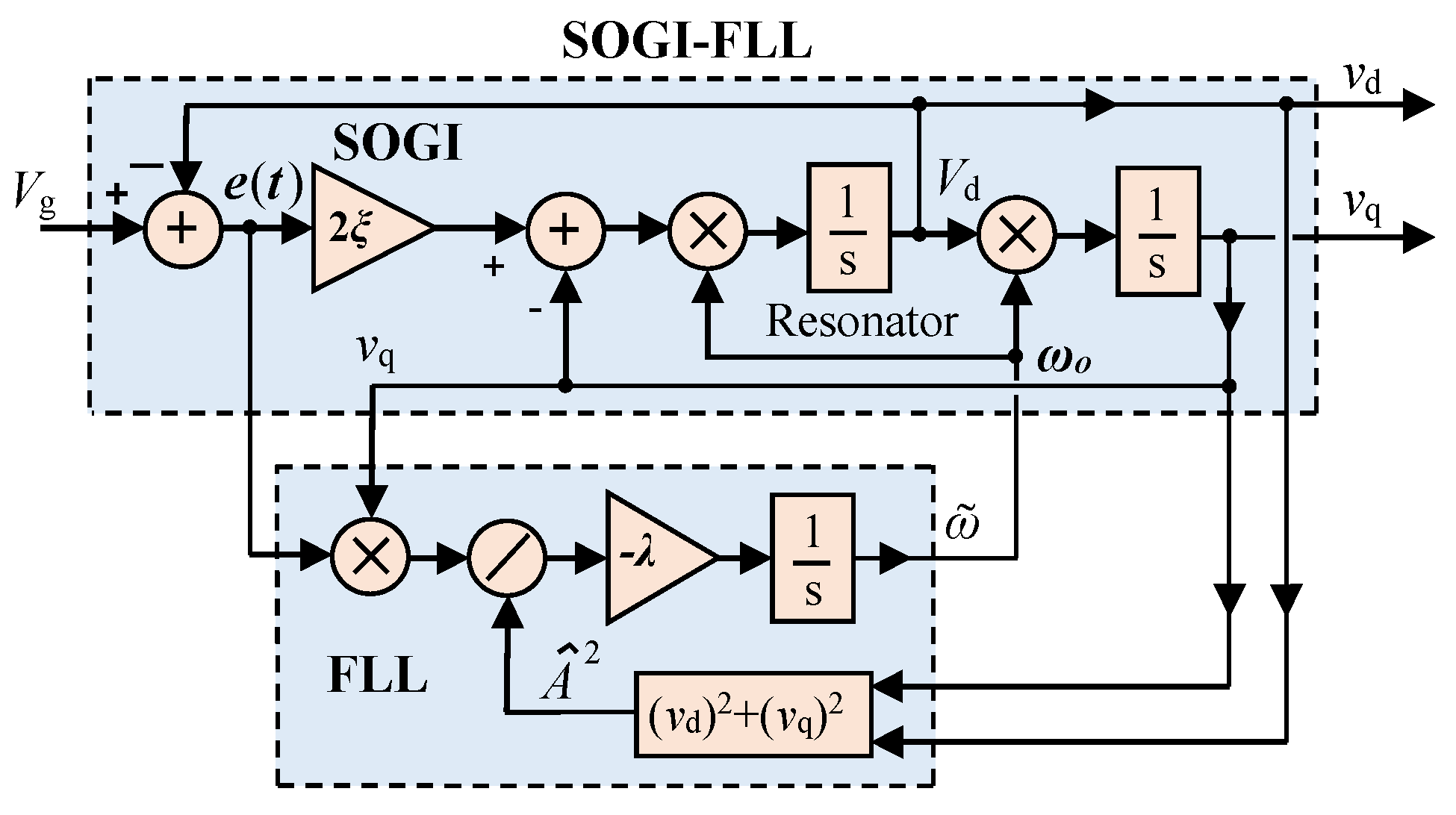
15]. This layer primarily relies on communication protocols for effective coordination. The incorporation of a SOGI expedites the derivation of estimated variables and sequence components, ensuring fast detection with minimal computational overhead.
The second layer uses the behavior of the positive- and negative-sequence components of the grid voltages during fault events to locate and isolate these faults [
28]. This layer operates using the local information of the PDs, avoiding the need for communication channels to transmit trip signals between the PDs. Therefore, to ensure the highest level of security and reliability in case of communication failures, a priority system is proposed between the two protection layers, thereby enhancing system redundancy. It indicates that as soon as a fault is detected, the first layer will automatically be activated and the communication signal will be verified to ensure the availability of the detection decision. In the event of a loss of communication signals, the signals are rechecked to confirm the absence of any transient issues. If the signals are received, the first layer will continue its operation to isolate the fault. In any case, if it is confirmed that communication signals are lost even after rechecking for their availability, the second layer, sequence-based fault protection, will be used as a secondary protection at each PD.
The protection system demonstrated efficient and fast fault protection, particularly in light of potential communication breakdowns. It also operates with a minimal computational load. The system was tested for various fault types, including situations with a high penetration of DG, and both low and high fault resistance. Moreover, it is adaptable for use in grid reconfiguration, providing more stable and redundant protection.
The rest sections are organized as follows:
Section 2 introduces the fault detection algorithm and outlines the THD measurement.
Section 3 provides the secure dual-layered fault protection mechanism. The proposed method undergoes rigorous validation through comprehensive simulations in
Section 4, followed by experimental validation in
Section 5. Finally,
Section 6 concludes the paper findings.
3. Secure Dual-Layered Fault Protection Mechanism
A secure protection is proposed using a dual-layer protection strategy. The first layer consists of a THD-based Finite State Machine (FSM), which works once the fault is detected by the SOGI-THD detection algorithm and using the measured , , and of the PDs of each DL. Each DL has an FSM that will be coordinated with the others in the PDs by means of the communication for secure protection. The second layer is a sequence-based fault location algorithm that will use the sequence-voltage components’ behavior during the fault to isolate it. This algorithm is employed at each PD without the need for communication links; therefore, this level can be used as pack-up protection in the case of poor communication to provide reliable and redundant protection.
3.1. Proposed System
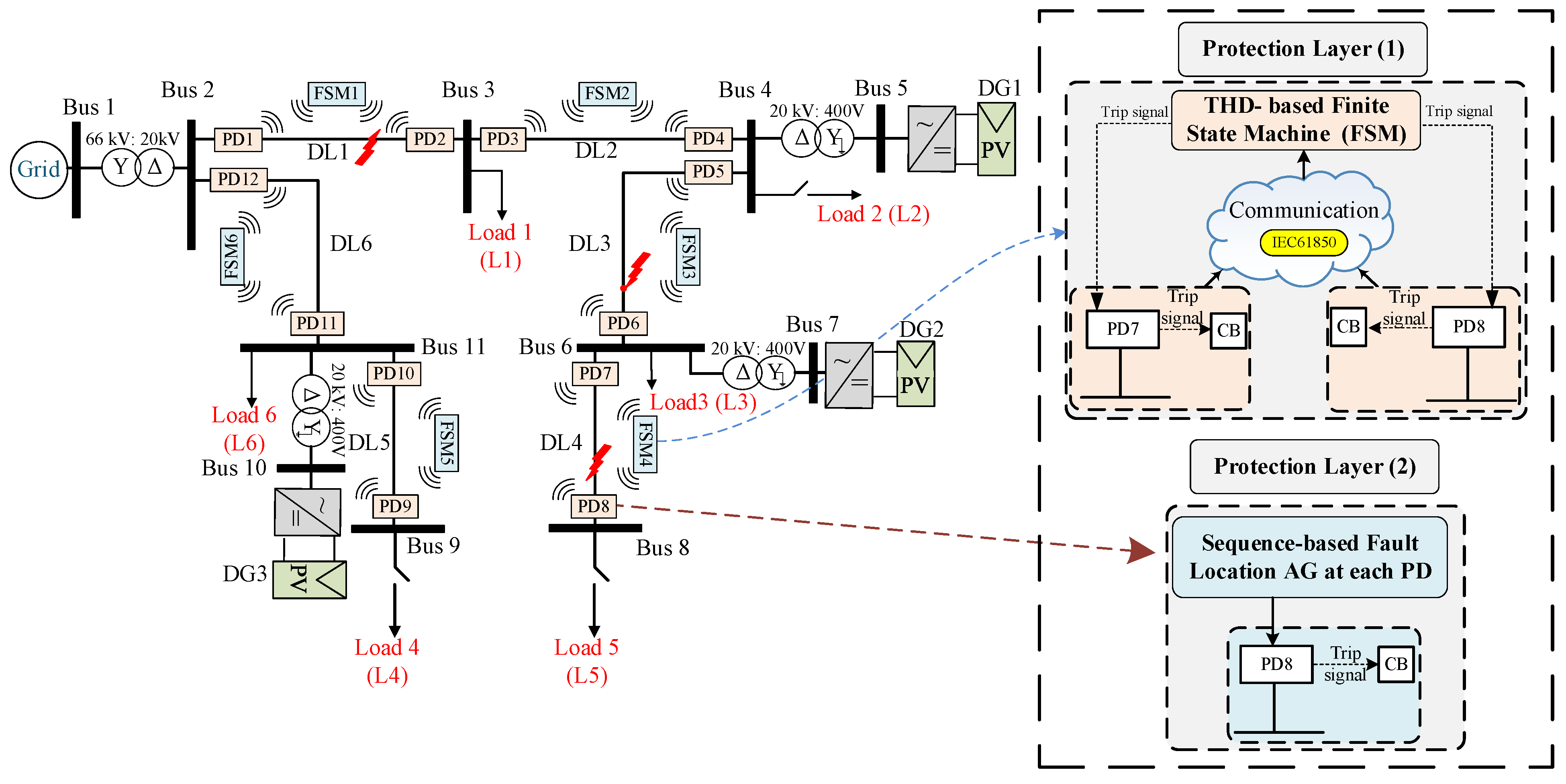
The fault protection methodology presented in this study can be implemented in various DSs. In order to validate the effectiveness of the proposed approach, the IEEE 9-bus standard [
35] radial system with DGs was selected as the test case, as shown in
Figure 7. The system comprises a main grid and multiple DGs connected via various buses. The high-voltage (HV) grid operates at a rated voltage of 66 kV and a power rating of 25 MVA. The HV grid is connected to six distribution lines (DLs), labeled DL1 to DL6, via a step-down transformer. The HV/MV transformer configuration is a star/delta (YNd11). Each DL consists of two PDs positioned on either side of the line and an FSM. Inside each PD, there is a fault detection relay that operates in coordination with the FSM as the primary protection layer to isolate the line during fault events. Communication channels facilitate the exchange of signals between the PDs and the FSM, as well as between the FSMs themselves, to ensure the coordinated tripping of the faulted DLs. Additionally, in case of the communication failure, each PD employs a sequence-based algorithm as a secondary protection layer. Local loads (L1 to L5) are connected at the terminations of each DL. Three DGs, identified as DG1 to DG3, are linked to different buses via an MV/LV transformer. All loads and DGs are connected to the low-voltage side of the system through a delta/star grounded configuration (Dyn11) [
36]. The system parameters, including the voltage ratings, power ratings, transformer configurations, and other relevant details, are provided in
Table 1.
It is important to mention that the integration of DGs into this specific DS configuration creates multiple pathways for delivering electric power to customers. This enhances system reliability and grid efficiency. However, it introduces the possibility of a bidirectional power flow, which adds complexity to the fault protection process. Furthermore, protection techniques often rely on communication-based coordination, potentially creating a vulnerability if communication fails. Hence, new protection strategies are needed to ensure system safety in scenarios with a bidirectional power flow and potential communication failures. Consequently, the proposed approach will undergo a thorough examination and testing under different scenarios. This strategy aims to ensure reliable system operation, providing effective protection regardless of the power flow direction or communication status.
3.2. THD-Based Finite State Machine
In this work, the FSM described in [
15] is utilized as an initial layer of protection, which relies on two distinct communication protocols (see
Figure 7): a Wi-Fi protocol between the PDs and FSM [
37] and the IEC 61850 protocol [
38] between the FSMs themselves for proper coordination and to ensure effective protection.
Figure 8 depicts the conceptual diagram of this protection layer. In
Figure 7, six FSMs are designated for detecting and isolating the faults in various locations of the DS. Each FSM in the system is allocated to a DL with two PDs and comprises six unique states, whose state flow chart diagram is shown in
Figure 9.
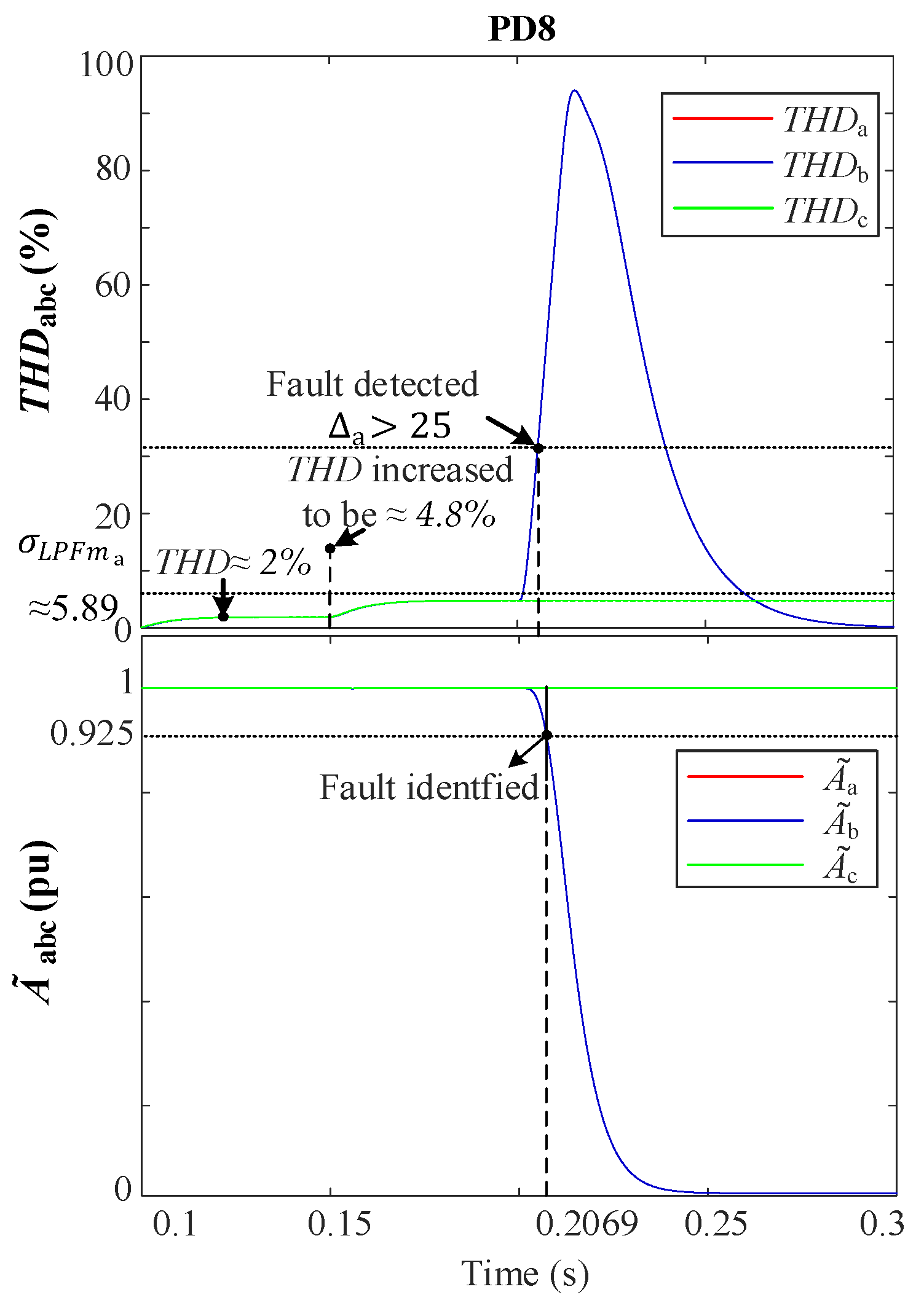
At normal operation, the system functions around the nominal values during state S1 (Normal Operation), which means that the FSM remains in S1 on standby, waiting for any faults to occur. Whenever a fault occurs, the PD closest to the fault is the quickest to detect it. Therefore, upon detection, as explained in
Section 2.2.2, the PD sends a detection message to the FSM, enabling it to initiate its process and transition to state S2 (Fault Detection). It is worth noting that the delay in transmitting a detection message using the Wi-Fi protocol is negligible, taking less than 1 ms [
39].
As a result, the FSM of a faulted DL is the nearest FSM to the fault; therefore, it is always able to detect the fault more rapidly compared to the other FSMs. This fact is used as a kernel for developing a fast and efficient fault isolation approach.
When the FSM of the faulted DL moves into state S2, a timer called
begins running to track the fault duration. Additionally, a new fault signal is dispatched to the remaining FSMs, informing them of the event and enabling them to stop their processes. The transmission delay for this fault message, referred to as
, is estimated to be approximately 10 ms [
38].
Then, when the peak in the THDs eventually disappears, the FSM moves to state S3 (Fault Monitoring), where it systematically monitors the fault with the intention of isolating only permanent faults and avoiding undesirable tripping. It is worth noting that temporary faults are typically resolved within 100 ms without requiring any protective action [
40,
41]. Therefore, during state S3, the timer
keeps running, and once it reaches the maximum limit of 100 ms, the FSM moves to state S4 (Fault Isolation), which is intended for tripping the nearest circuit breaker and isolating the fault.
Meanwhile, when the FSM is in S2 or S3, if the fault disappears, as in a temporary fault, the system returns to operate within the normal values. Therefore, the FSM returns to S1 (Normal Operation). In state S4, after fault isolation, the FSM resets to zero and transitions to state S5 (Grid Reconnection), where it waits for the reconnection of the line by the grid operator or maintenance crew to restore the FSM to its normal operating state (S1).
It is worth noting that if a non-faulted FSM is in S1 and a fault signal is received from a faulted FSM, the non-faulted FSM moves to S6 (Holding FSM) to wait for the fault to be resolved or isolated. During this time, a timer named starts counting up, and when it reaches 100 ms, the FSM returns to its normal operating state (S1).
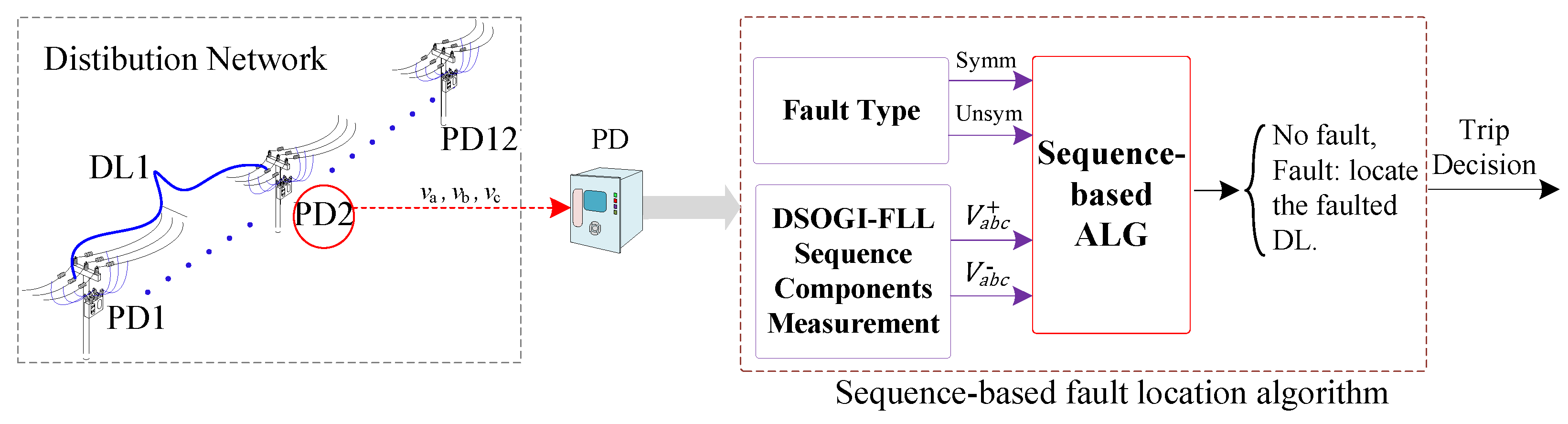
3.3. Sequence-Based Fault Location Algorithm
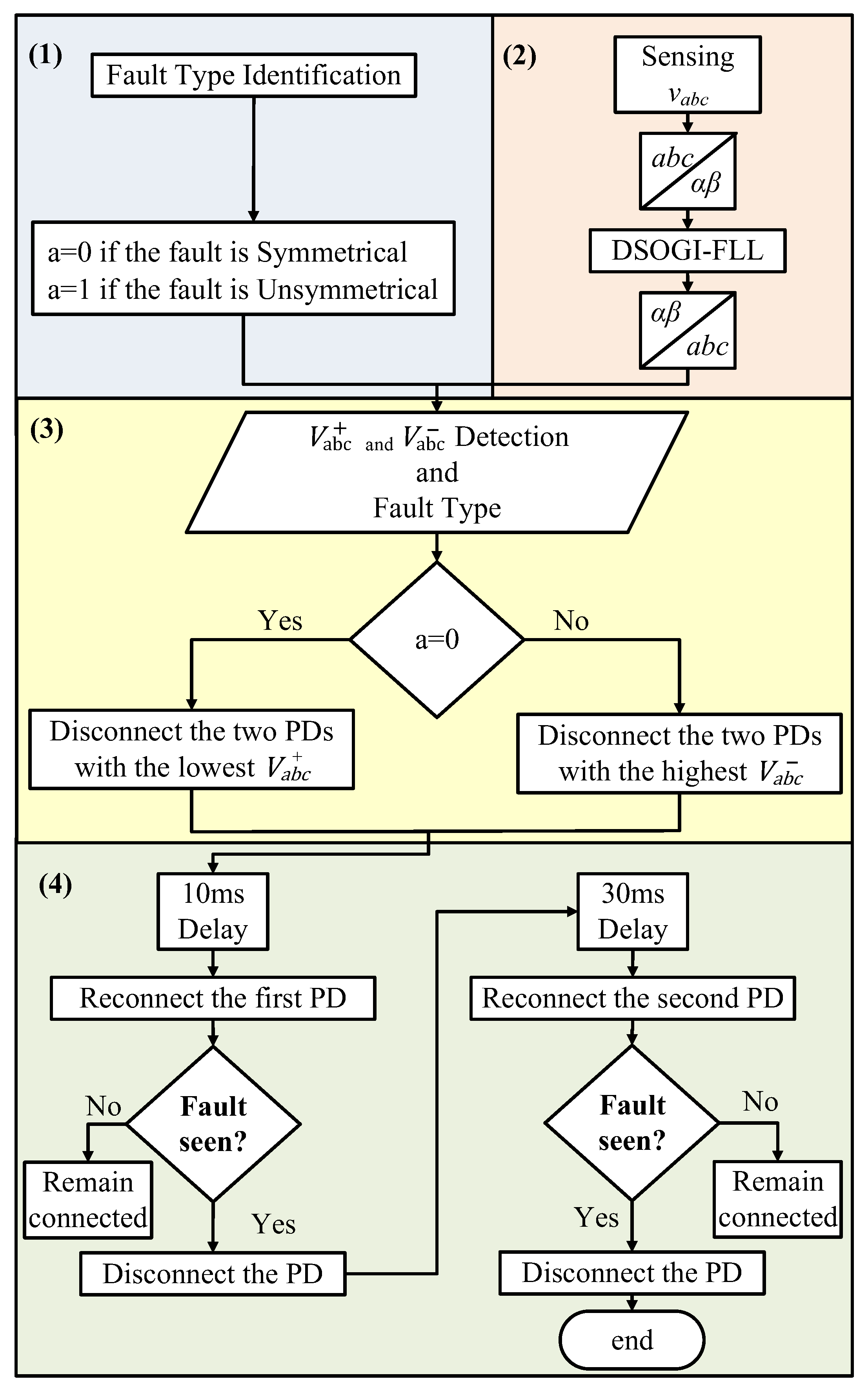
The fault location algorithm is a secondary layer in the system that operates at each PD and employs the voltage sequence components of the PD during fault events [
28,
42] to determine the fault’s location. The algorithm’s kernel is based on the behavior of the sequence components, which depends on the type of fault, whether it is symmetrical or unsymmetrical, and has the advantage of not requiring communication links between PDs. Moreover, this algorithm relies only on local information gathered by each PD to detect the faulted DL.
Figure 10 depicts the conceptual diagram of this protection layer. The algorithm is composed of four stages, which are further elaborated below and depicted in
Figure 11.
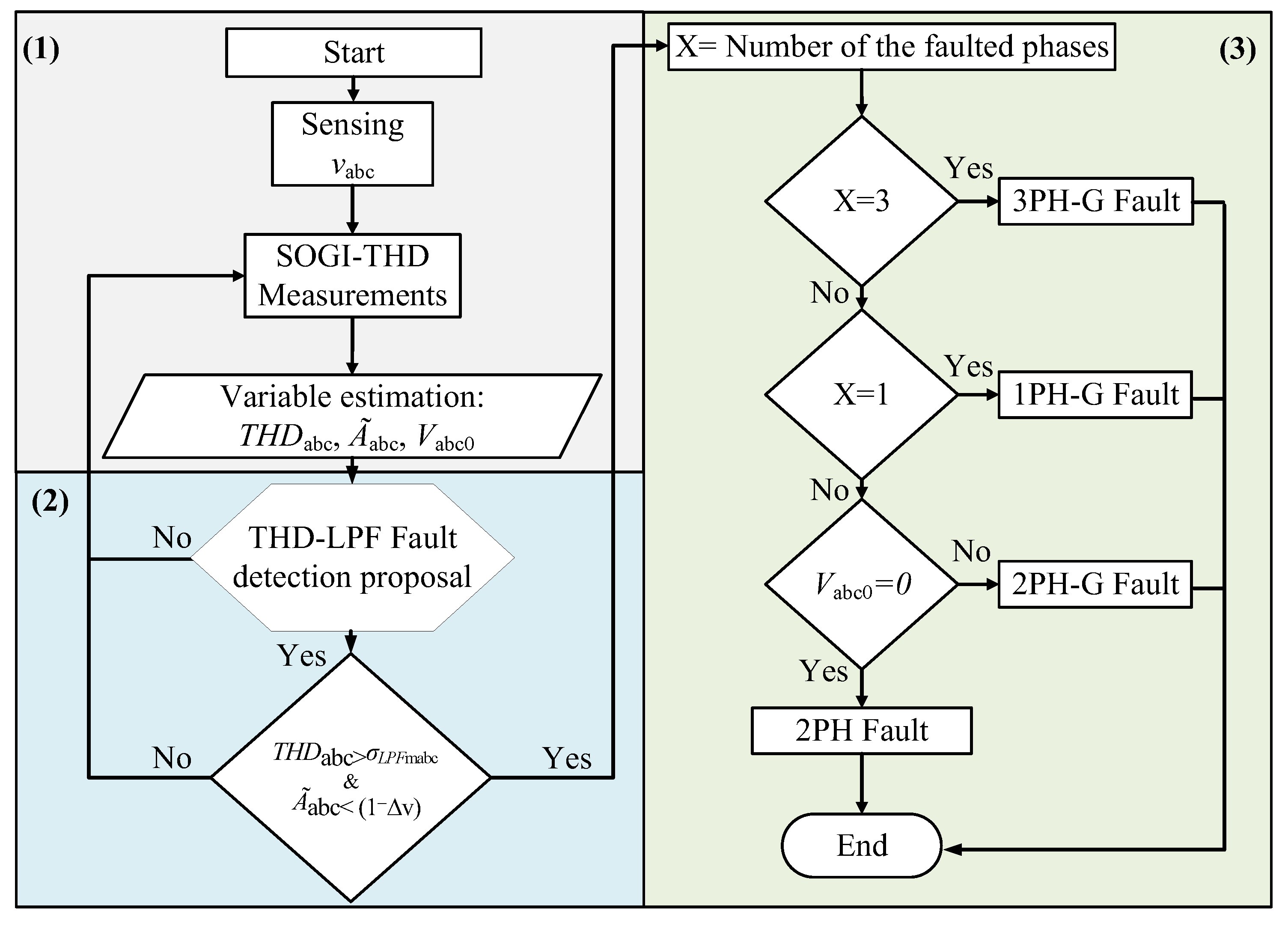
3.3.1. Fault Identification
The fault identification involves identifying the fault type using the procedure illustrated in
Figure 6, where faults are categorized into two primary types: symmetrical faults (3PH-G) and unsymmetrical faults (1PH-G, 2PH-G, and 2PH).
3.3.2. Sequence Components Detection
At this stage, a dual-SOGI (DSOGI) structure [
30] is used to extract the sequence components of the three-phase voltage. This operation is carried out individually for the
and
omponents subsequent to the application of a waveform transformation. The resulting sequence components within the
frames are defined in Equations (14) and (15), where
and
denote the positive sequences within the
frames, while
and
represent the corresponding negative sequences.
The derivation of the positive and negative sequence components of the three-phase voltage is done by the means of the following equations based on Lyon’s methods [
43,
44]:
Here, the parameter
denotes the Fortescue phase-shifting operator. The grid voltage undergoes a conversion from the
to the
frames, a process executed through the application of the
Clarke transformation, as in Equation (18).
In light of this, Equations (19) and (20) are used for the computation of the positive and negative-sequence voltage components in the
frames. This equation uses a
-lagging phase-shifting operator in the time domain, resulting in an in-quadrature depiction of the input waveforms.
In
Figure 12, the DSOGI-FLL block diagram is depicted, showcasing its functionality for obtaining the positive- and negative-sequence components of a three-phase voltage at a frequency of
. This configuration incorporates two SOGIs operating on the
frame to yield input signals for the sequence voltages calculation block. Within this block, the transformations in Equations (19) and (20) are applied with precision to compute the positive- and negative-sequence components.
3.3.3. PDs’ Initial Disconnection
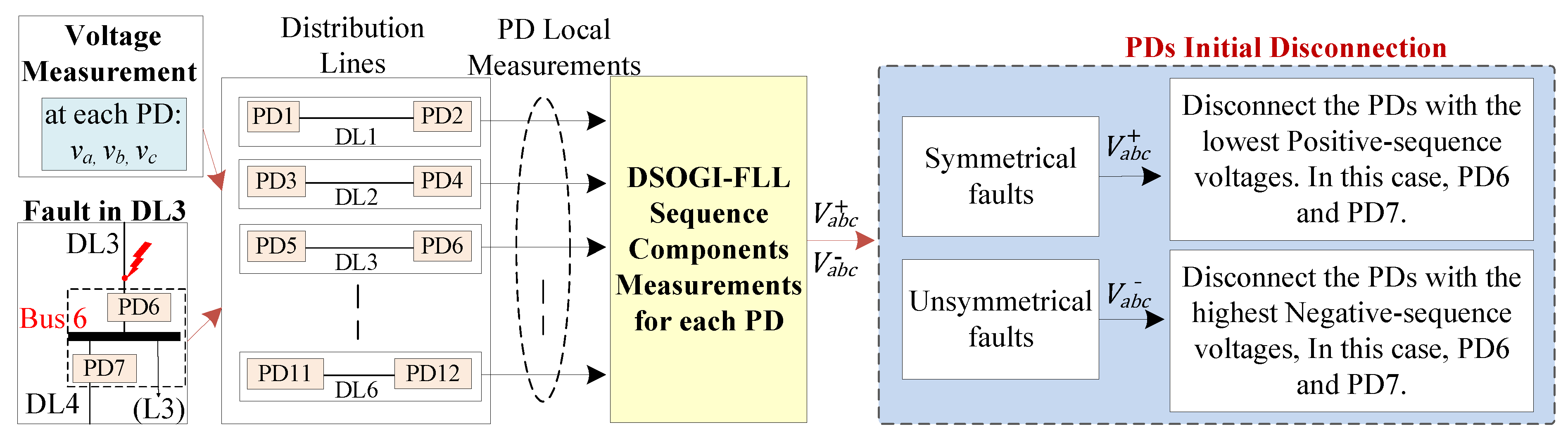
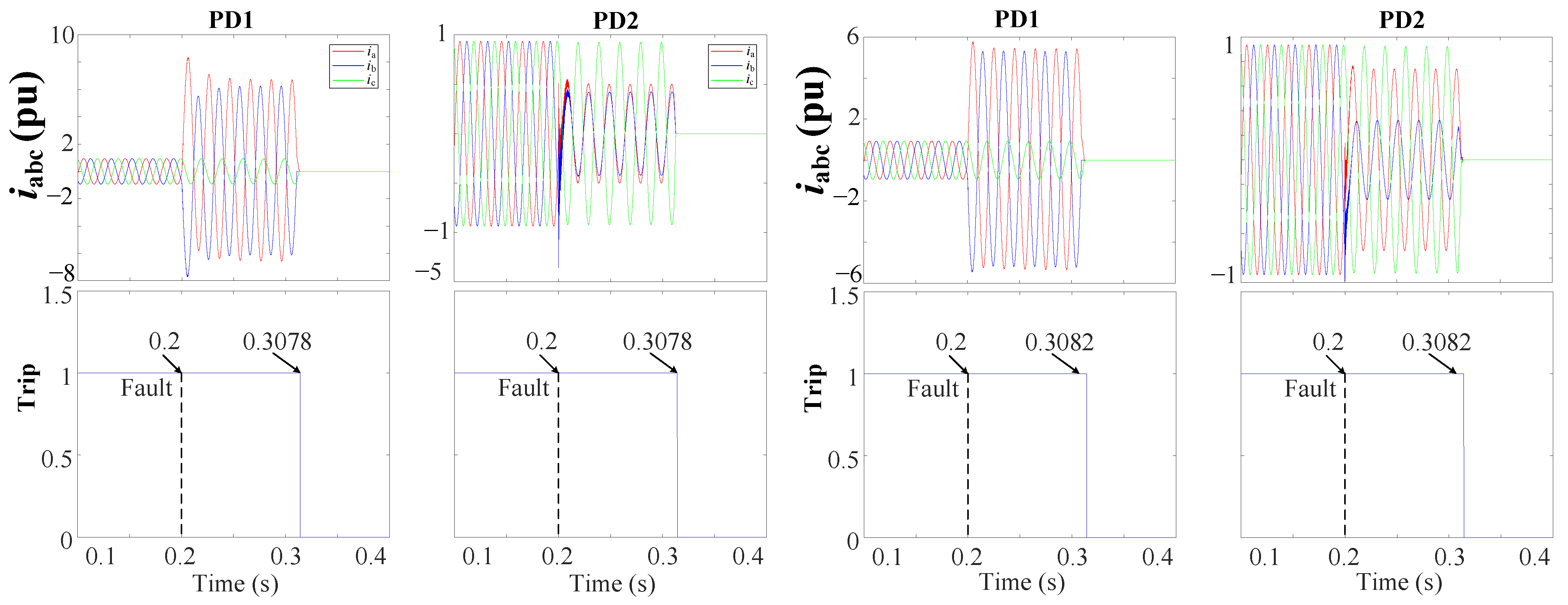
The behavior of the sequence voltages is dependent on the type of fault detected, which is the kernel of this algorithm for the secure location of the faulted DL. For instance, in the case of symmetrical faults, i.e., a 3PH-G fault at the end of DL3, see
Figure 7, the faulted DL can be located by monitoring the Positive-Sequence Voltage (PSV) during the fault. The simulations showed that during the fault, the PSV at PD6 of DL3, which is the nearest to the fault, will be lower than that of the other unfaulted DLs [
28,
42]. As a result, PD6 with the lowest PSV value will be disconnected to isolate the faulted DL more quickly than the other PDs.
In the case of unsymmetrical faults, i.e., a 1PH-G fault at the end of DL1, see
Figure 7. The location of the faulted DL can be determined by examining the Negative-Sequence Voltage (NSV) behavior. Specifically, the NSV at PD2 of DL1 will be higher than that of any other PDs. Thus, in this scenario, PD2 that detects the fault with the highest negative-sequence value will trip first, before the other PDs.
It is crucial to emphasize that two PDs located on opposite sides of each bus are connected, i.e., “bus 6 is connected to both PD6 and PD7”, see
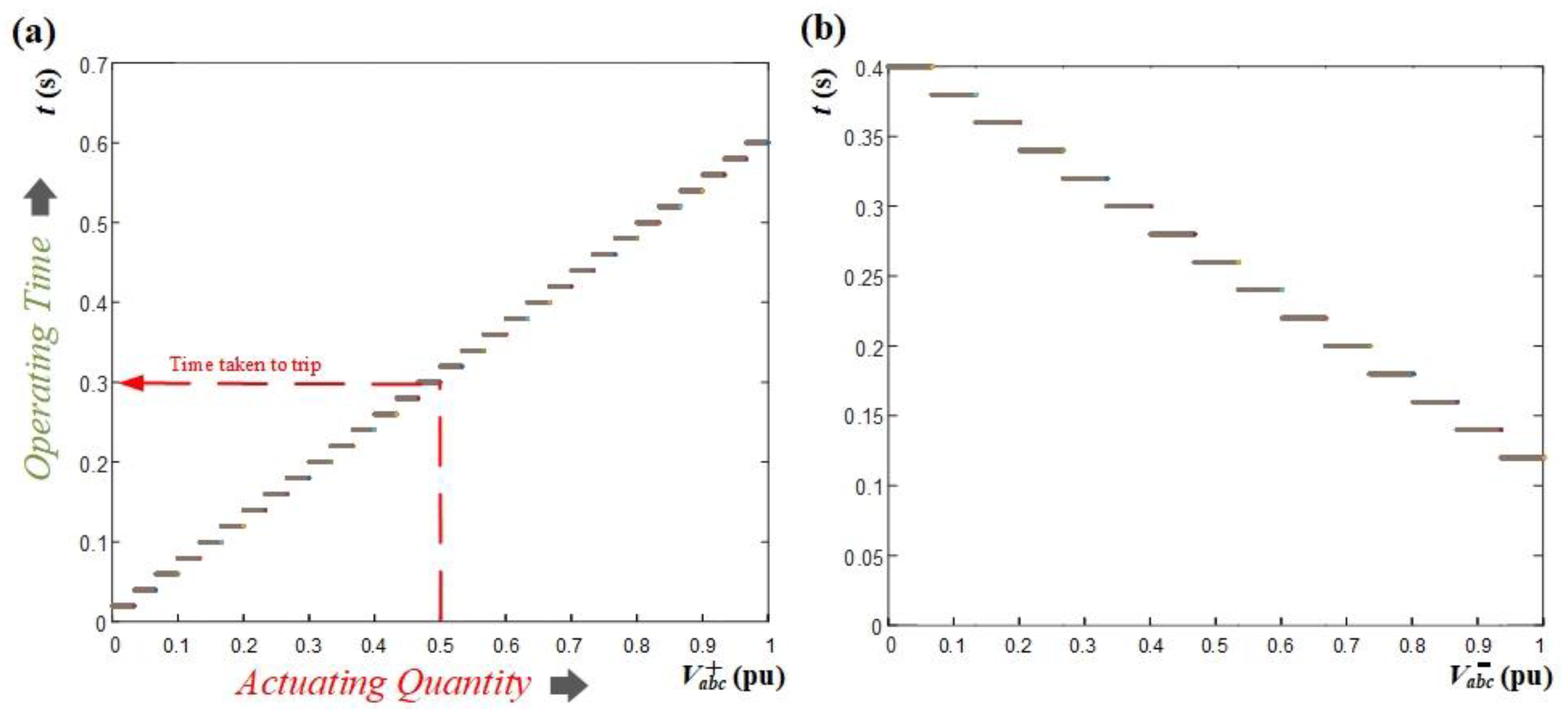
Figure 7. This implies that at each bus, two points with identical voltages are acquired, resulting in matching sequence voltages. Consequently, if a fault happens, both PDs will be disconnected simultaneously as an initial protection measure. Therefore, the disconnection of the aforementioned PDs conforms to the definite time-voltage characteristic curves, as illustrated in
Figure 13, and is predicated upon the type of fault.
These curves demonstrate the correlation between the positive- and negative-sequence voltages and the corresponding time taken by each PD to activate. The design of these curves ensures that the PD transmits a trip signal in accordance with the measured sequence voltage value. These curves are specifically formulated to comply with IEEE time standards [
45,
46] and are compatible with various electrical networks. The characteristic curves have undergone a meticulous design process and have been refined through numerous fault simulations preformed at different locations within the system. The curves have been continuously updated to ensure their applicability for all possible fault cases at different locations in the system. However, the DLs are considered relatively short with low impedance, resulting in only slight voltage differences between both ends of the line. Therefore, to ensure effective coordination, the curves have been crafted to be highly sensitive to even small changes in sequence voltages. For example, in the case of the positive-sequence voltage curve, the trip time is precisely adjusted by 0.02 s when the positive-sequence voltage changes by 0.0333 pu. Similarly, for the negative-sequence voltage curve, the time is adjusted by 0.02 s with a change of 0.0667 pu in the negative-sequence voltage. These specific values have been thoughtfully selected based on the system sequence voltages obtained from extensive fault simulations conducted at various system locations to prevent any potential miscoordination issues. Furthermore, as both ends of the distribution line need to be disconnected during a fault, the proposed fault location algorithm can effectively operate using the concept of PD reconnection, ensuring a reliable and robust protective system.
Figure 13a depicts the time curve for the PSV magnitude. This curve is employed in scenarios of symmetrical faults, wherein the lowest PSV triggers the fastest trip. In contrast,
Figure 13b illustrates the time curve for the NSV magnitude. This curve is used in the case of unsymmetrical faults, where the highest NSV is the first to trigger the trip. The conceptual block diagram of the PD’s first disconnection stage in case of a fault at DL3 is given in
Figure 14.
3.3.4. PDs’ Re-Energization
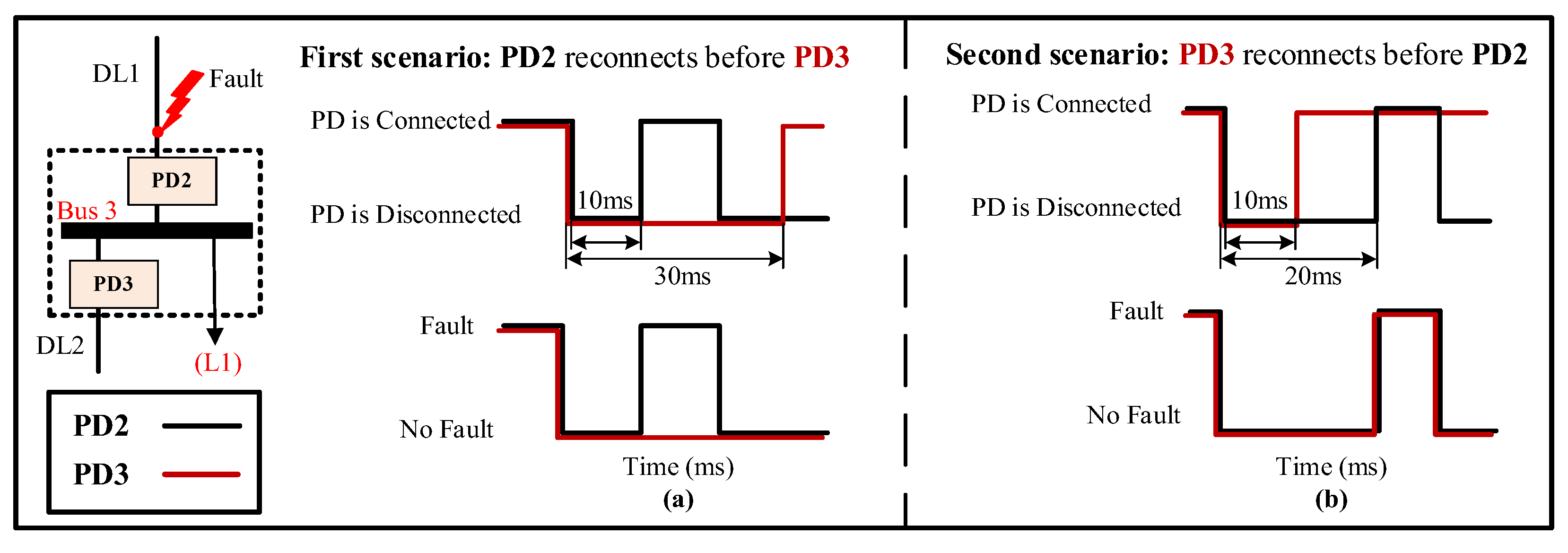
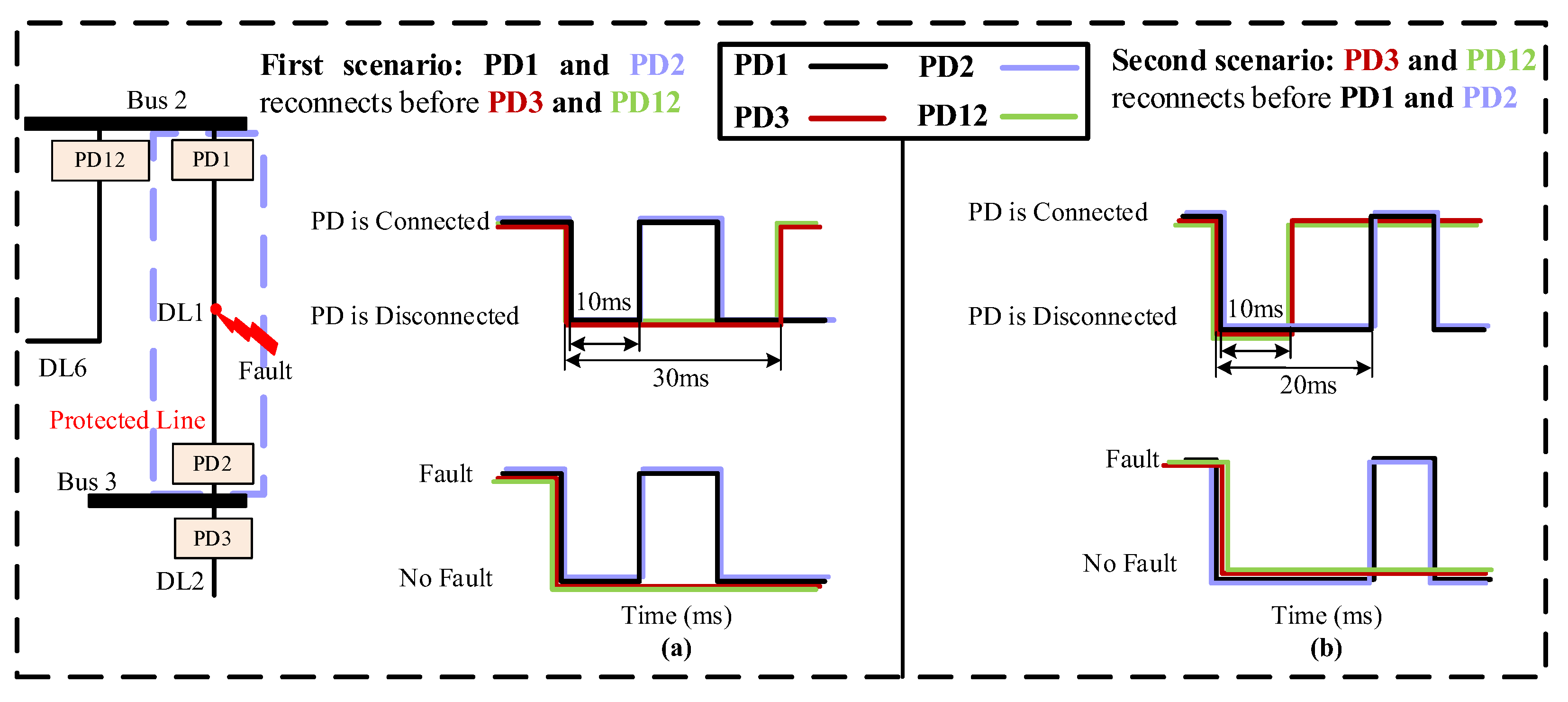
As previously mentioned, as a first protection action, the PDs located on both sides of the bus connected to a faulted DL will be disconnected. However, it is only necessary to disconnect the PD on the faulty side, while the other PD, on the unfaulty side, should remain connected. To address this issue, the algorithm has been developed to sequentially reconnect each PD with a specific delay and check for fault existence. As a result, the PD that continues to detect the fault will be permanently disconnected, while the other will remain connected. There are two possible situations for reconnecting the PDs at the faulted DL, depending on the location of the fault.
- (1)
The fault at any end of the DL
In this case, two scenarios for the reconnection of the PDs at the faulted DL are possible. For instance, if there is a fault in DL1, both PD2 and PD3, which are connected to bus 3, will trip simultaneously. Following this, the reconnection scenarios will be implemented. The first scenario involves the faster reconnection of PD2 compared to PD3, while the second scenario involves the faster reconnection of PD3 compared to PD2.
Figure 15 provides an illustration of these two scenarios.
The first one,
Figure 15a, involves the reconnection of PD2 first, after a specified delay, which can range from a few milliseconds to several seconds [
47]. In this work, the delay is set to 10 ms [
48]. As a result, PD2 will detect the fault once again and be permanently disconnected. On the other hand, PD3 will be reconnected after a longer delay of 30 ms [
48] to ensure complete fault isolation on the first side of DL1. As a result, PD3 will remain connected since it does not detect the fault.
The second one,
Figure 15b, involves the reconnection of PD3 first, after a delay of 10 ms. Given that the fault occurred at DL1 and PD2 remains disconnected, PD3 does not detect the fault and thus remains connected. Following this, PD2 is reconnected after a delay of 20 ms [
48]. Nonetheless, due to the persisting presence of the fault, PD2 identifies the fault once again, resulting in its permanent disconnection.
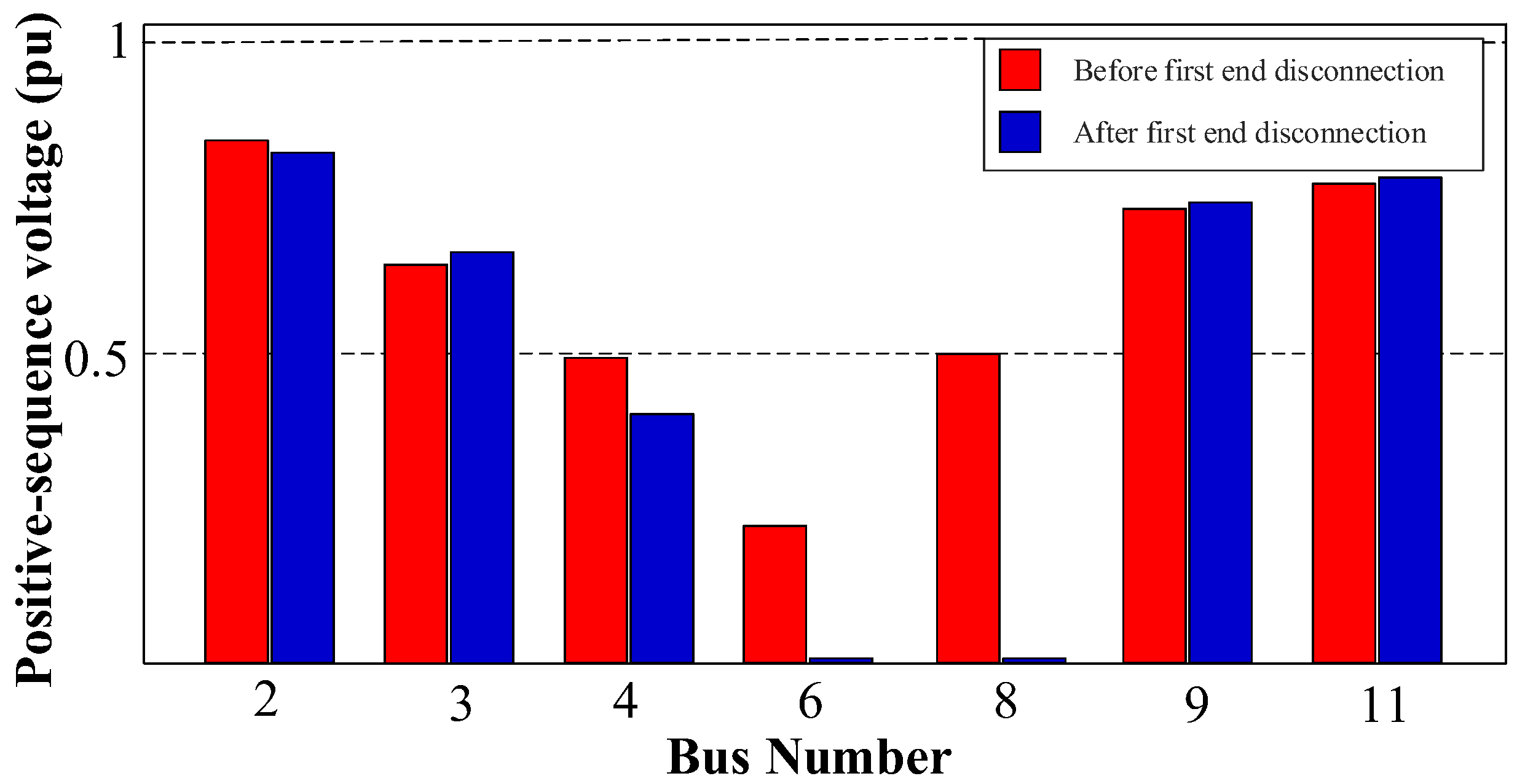
Additionally, to achieve complete fault isolation at DL1, it is essential to disconnect the second end of the line as well, see in
Figure 7. Therefore, after disconnecting the first end of DL1 and re-measuring the sequence voltages of the grid, it is observed that the second end of DL1 displays the lowest PSVs during symmetrical faults and the highest negative-sequence voltages during unsymmetrical faults, which aligns with the algorithm’s core principles. Thus, the same technique employed for the first end is used at the second end to ensure reliable protection. Note that a comprehensive discussion of these findings is given in the results section.
- (2)
The fault at the middle of the DL
If a fault occurs in the middle of the DL, as depicted in
Figure 16, the four PDs connected to the two buses at the ends of the faulted DL will share the same sequence voltages. In this case, the reconnection technique will be employed at both ends of the DL. For instance, when a fault happens in the middle of DL1, then PD1, PD2, PD3, and PD12 will be disconnected simultaneously due to their identical sequence voltages. Following this, two reconnection scenarios will be implemented.
The first one,
Figure 16a, involves the faster reconnection of PD1 and PD2 compared to PD3 and PD12. Therefore, PD1 and PD2 are reconnected first, after a specified delay of 10 ms. As a result, PD1 and PD2 will detect the fault once again and be permanently disconnected. On the other hand, PD3 and PD12 will be reconnected after a longer delay of 30 ms to ensure the complete isolation of DL1. As a result, PD3 and PD12 will remain connected since they do not detect the fault.
The second one,
Figure 16b, involves the faster reconnection of PD3 and PD12 compared to PD1 and PD2. Therefore, PD3 and PD12 are connected first, after a delay of 10 ms. Given that the fault occurred at DL1 and PD1 and PD2 remain disconnected, PD3 and PD12 do not detect the fault and thus remain connected. Following this, PD1 and PD2 are reconnected after a delay of 20 ms. Nonetheless, due to the persisting presence of the fault, PD1 and PD2 identify the fault once again, resulting in its permanent disconnection.
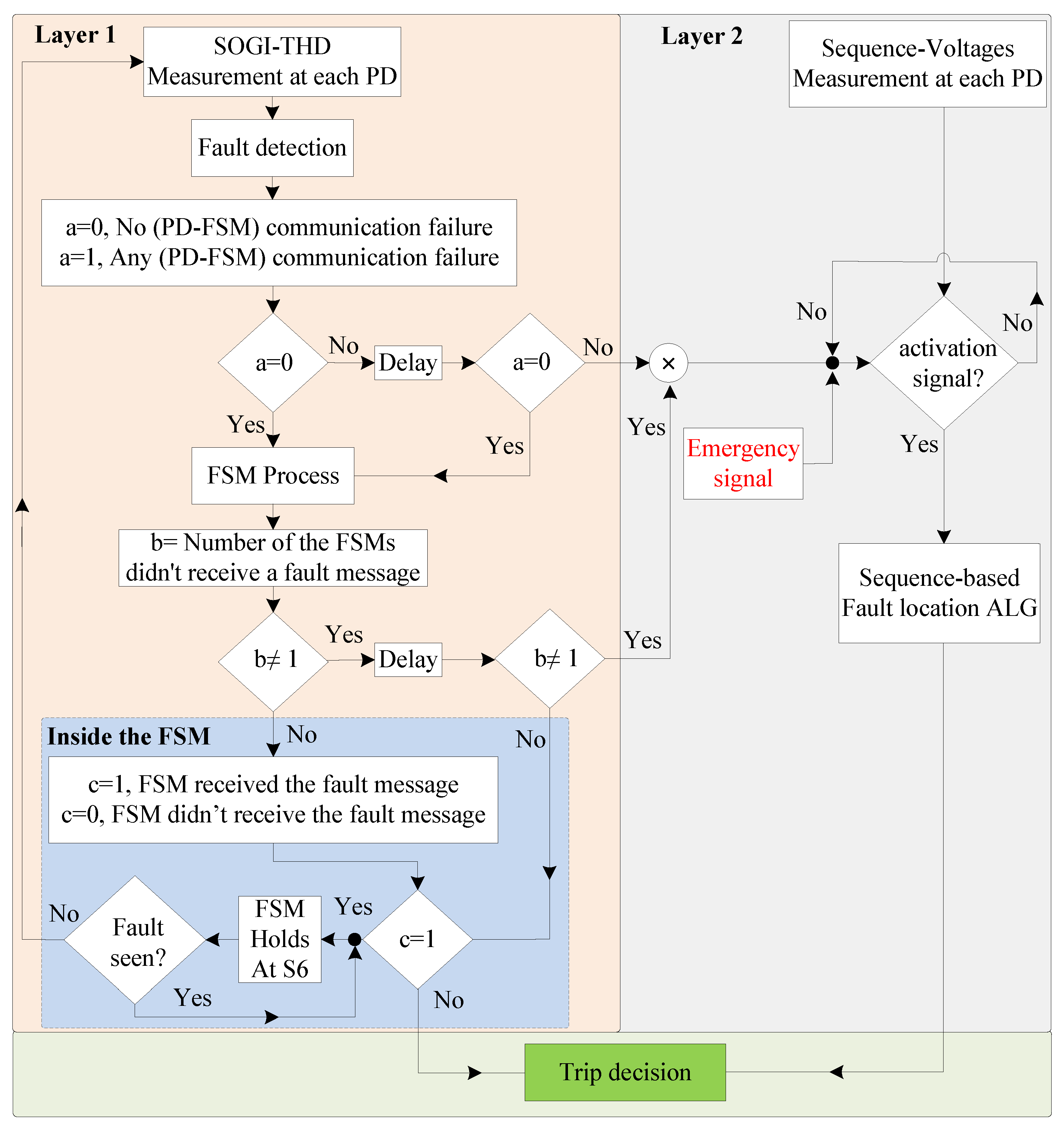
3.4. Priority System
To ensure the highest level of security and reliability in case of communication failures, a priority system is proposed between the two protection levels, thereby enhancing system redundancy.
The flow chart of the two-layered priority system is illustrated in
Figure 17, which is critical for maintaining the system’s integrity. It indicates that as soon as a fault is detected at the PD using the SOGI-THD, a detection message is immediately transmitted to the FSM via Wi-Fi communication links. Thus, before the FSM is initiated, the communication signal is verified to ensure the availability of the detection decision. This verification involves checking if the message received at the FSM receiver is (1), indicating a successful communication, or (0), signifying message loss. In case of the failure of the PDs at a faulted DL (resulting in the loss of communication signals), a delay of 20 ms [
48] is introduced, and then the signals are rechecked to confirm the absence of any transient issue. If the signals are received, the FSM begins its operation, as explained in
Figure 9.
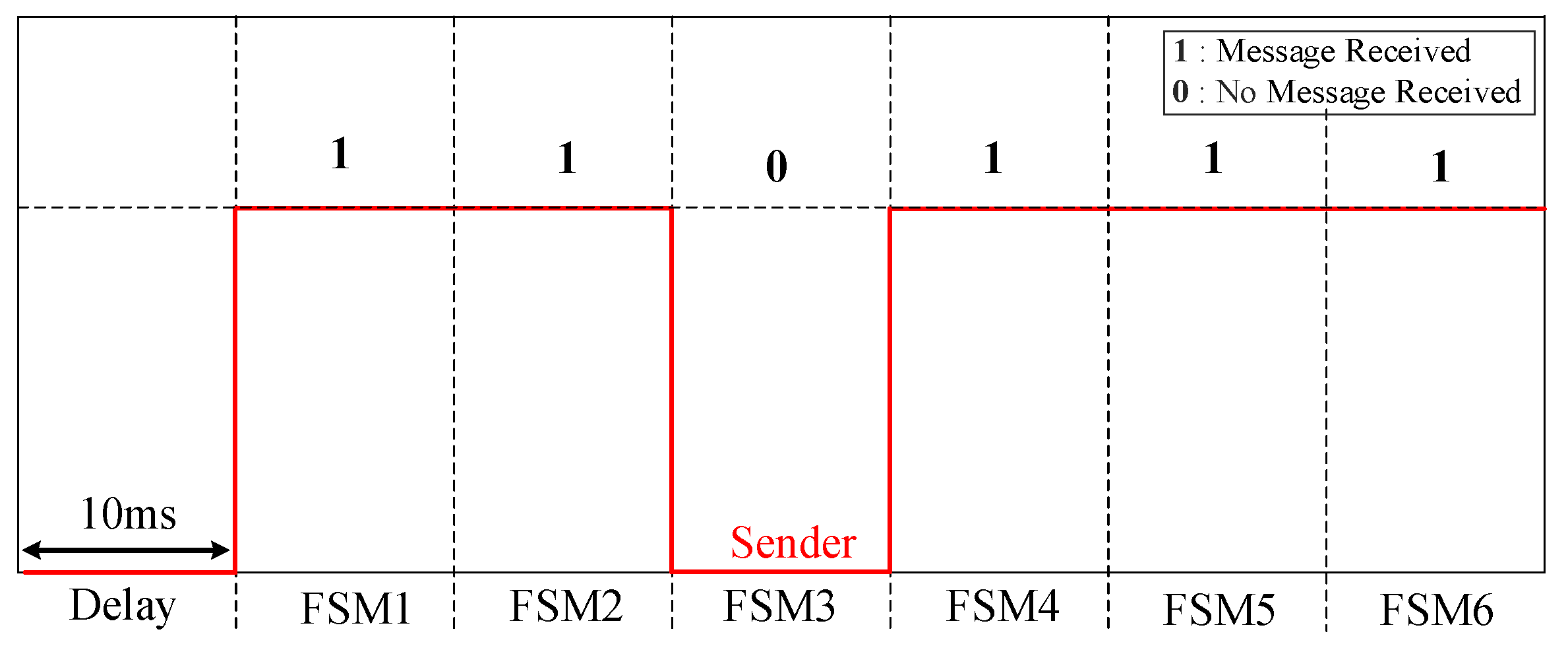
As stated earlier, the FSM of the faulted DL is the quickest to detect the fault and sends a fault signal to the other FSMs via communication links for coordinated protection. Therefore, to prevent false tripping, this signal is verified at all FSMs. With six FSMs in total, each corresponding to a DL, under normal conditions, five FSMs should receive the communication message (indicated by a signal of 1 at each receiver), while the remaining FSM, responsible for transmitting the messages to the others, registers a signal of 0 at its receiver. Now, following
Figure 17, if only one FSM does not receive the message, it indicates that there is no communication failure, which is expected to be the FSM of the faulted DL sending the message to the other FSMs. However, if there is a communication failure (i.e., at least one signal is lost), another 30 ms delay is introduced [
48], and then the signals are rechecked to confirm the failure.
Nevertheless, if the fault message is received, each FSM will independently check whether it has received the message. If so, the FSM will move to S6 (FSM Holding) to stop its operation, indicating that it is not faulted. Otherwise, it will continue its operation and make a trip decision (Layer 1). Once on hold at S6, the FSM will continuously monitor for fault clearance before returning to normal operation.
In any case, if it is confirmed that communication signals are lost even after rechecking for their availability, the sequence-based fault location algorithm (see
Figure 11) will be used as a secondary protection at each PD. This second layer of protection can be activated using two signals, namely the Activation signal and the Emergency signal. The system automatically generates an activation signal for the second layer at each PD if the signals in the first layer cannot be received due to either communication problems or vulnerability. Additionally, the emergency signal can manually activate the second layer of protection at each PD through an external signal.
5. Experimental Verification
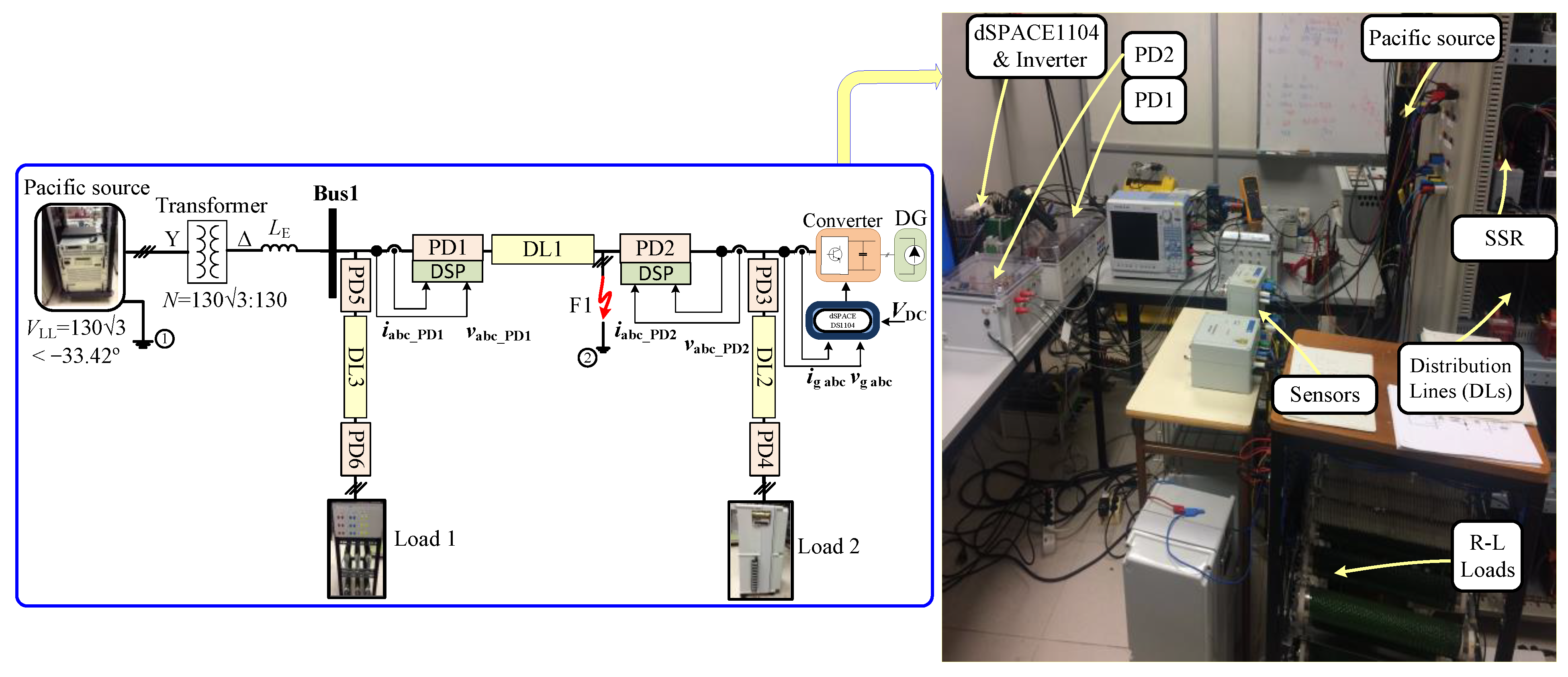
To experimentally validate the proposed algorithm, an equivalent model was constructed in the laboratory to replicate the identical response and dynamic behavior observed in the analyzed grid. This study focused on a radial grid network configuration integrated with DGs. The practical implementation of the proposed algorithm involved the utilization of a numerical relay, based on DSP, to process measurement data acquired from sensors. The relay then executed the algorithms, ultimately providing appropriate decisions in the form of trip signals. The Solid State Relay (SSR) functioned as a PD within the examined radial grid.
Figure 35 depicts the detailed equipment setup of the laboratory-implemented grid, while
Table 3 outlines the parameters of the devices employed in the experimental setup.
Figure 35 offers an overview of the laboratory setup emulating the radial grid. It incorporates three lines (DL1, DL2, and DL3) to represent the examined grid. The adjustments include doubling the equivalent value of DL2 and tripling that of DL3 in comparison to DL1. Additionally, points 1 and 2 are connected to the common ground point, which corresponds to the ground of the Smart Source. The load was arranged in an isolated star configuration. To accurately replicate the impedance characteristics of the main grid, an inductor was introduced before bus 1, as illustrated in
Figure 35.
The aim is to replicate identical voltages, currents, and impedances in per unit (pu) within the laboratory system, ensuring precise conformity with the actual operational dynamics. In the real DS grid, the designated base values are
VBase = 20 kV,
SBase = 25 MVA, and
IBase = 721.69 A, detailed in
Table 4. These specific base values are intentionally chosen to establish per unit equivalency in the voltage and current during the steady-state conditions of a radial grid. The strategic choice of laboratory base values is designed to facilitate experimentation with reduced voltages and currents while maintaining per unit results consistent with those observed in the authentic grid.
The algorithms are executed using a DSP TMS320F28335. Additionally, ControlDesk and dSPACETM DS1104 are utilized for implementing the inverter control. Both the algorithms and inverter control are programmed using Matlab
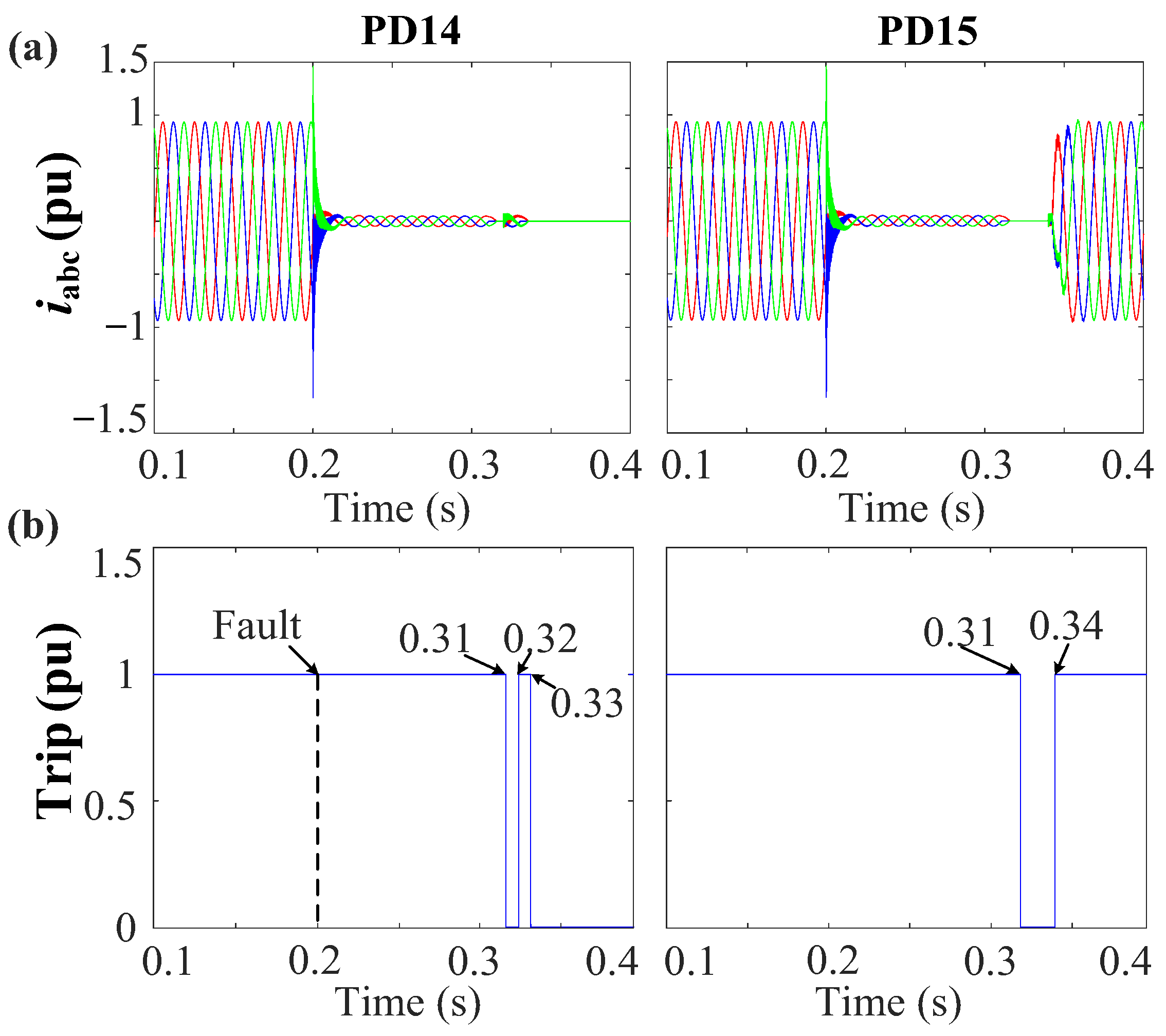
TM software 2023.a. Various symmetrical and unsymmetrical faults underwent rigorous testing to assess the efficacy of the protection system. In this phase, validation was prompted by a communication anomaly, leading to the activation of the second layer (sequence-based). This evaluation specifically targeted a single-phase fault occurrence at 0.5 s, specifically in the F1 fault location, illustrated in
Figure 35.
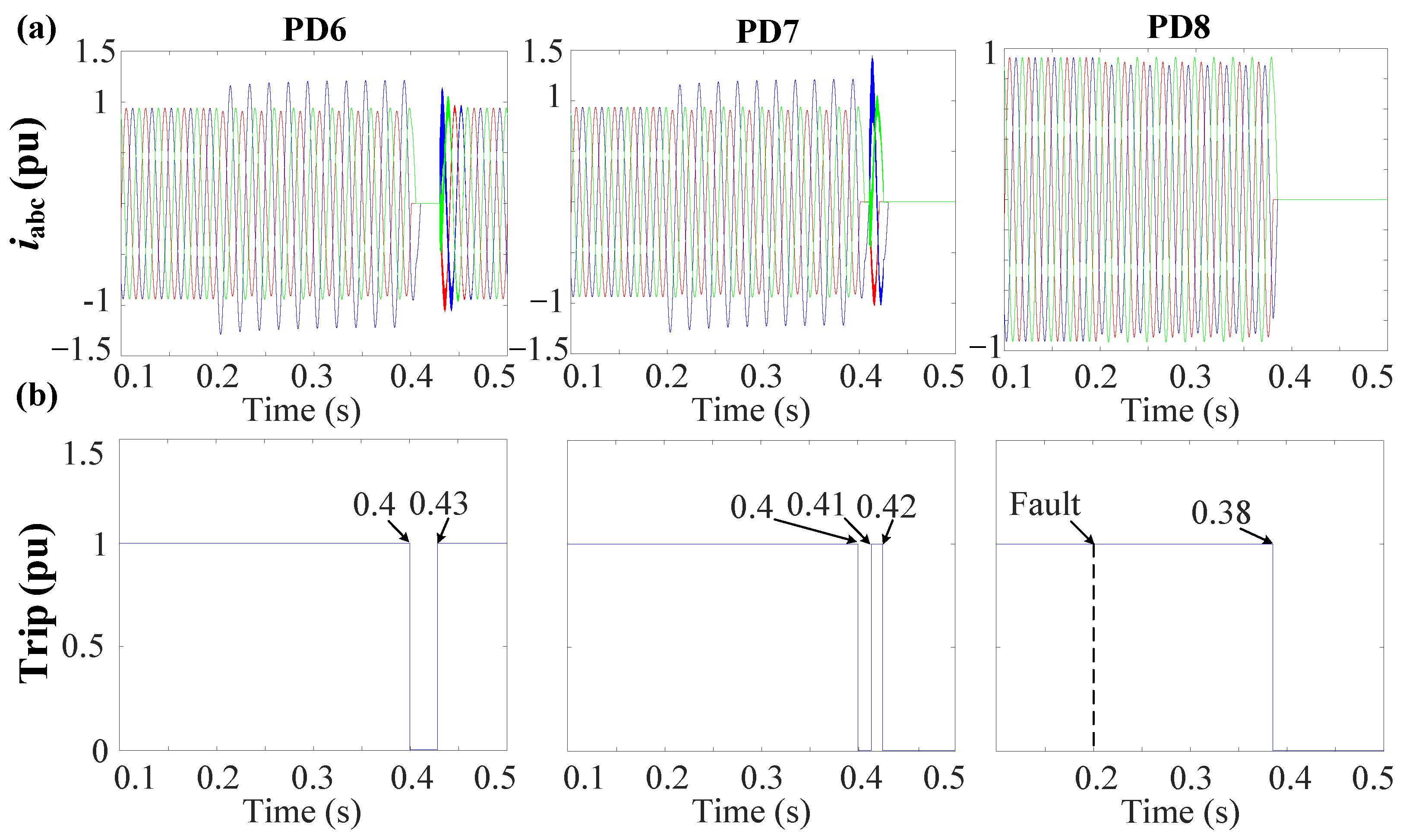
In
Figure 36, the first layer is activated automatically, detecting the fault in 7.5 ms. Due to communication issues, a given delay is introduced for checking and confirming the failure. Subsequently, Layer 2 is engaged to isolate the fault.
Following this, the sequence components are measured, and the sequence-based fault location layer is employed to precisely locate and isolate the fault, using the behavior of the NSV due to the fault’s unsymmetrical nature. The NSV profile of the system during the fault depicts that the bus situated at the terminal of the faulted line (DL1) and connected to PD2 and PD3 exhibits the highest NSV value of 0.82 pu. With reference to the definite time–voltage curve outlined in
Figure 13b and employing a procedure akin to that in
Figure 11, it can be observed that PD8 necessitates approximately
0.15 s from the time of fault occurrence to initiate the tripping signal.
Figure 37 illustrates the simulation and the experimental behavior of the grid voltages,
, grid currents,
, and the corresponding tripping signals during the occurrence of the 1PH-G fault, respectively. As seen in
Figure 37, both PD2 initiates tripping simultaneously at 0.65 s.
Following this, both PD2 and PD3 implement the reconnection algorithm. Following the first scenario, PD3 successfully restores the connection after a 10 ms delay at 0.66 s. However, given the radial system configuration and PD2’s ongoing disconnection, it will remain unaffected by the fault. In contrast, PD2 requires 30 ms to re-establish connection at 0.7 s, and promptly trips again as the fault is not cleared. To isolate the fault at DL1, the same procedure is replicated at the second end of the line, specifically for PD1 and PD5. The agreement observed between the experimental and simulated outcomes, as seen in
Figure 37, provides validation for the efficiency of the proposed methodology. It is essential to emphasize that the SSR behaves differently than the ideal breaker. In
Figure 37, the substantial overcurrent in the experimental
currents of PD2 and PD3 deviates from the simulated results. This discrepancy is primarily attributed to the SSRs, which open instantly, generating sparks and leading to a significant increase in current, nearly doubling the expected levels.
6. Conclusions
This paper introduces a dual-layer protection system designed to mitigate fault events within DSs, providing rapid and reliable fault protection even in the event of potential communication failures. The first layer incorporates the THD, the estimated amplitude voltages, and the zero-sequence grid voltage components to formulate a protection strategy. This strategy is implemented through an FSM for the purpose of fault detection and isolation within the grid. The effectiveness of this layer is contingent on robust communication protocols for effective coordination.
The second layer of the protection system capitalizes on the distinctive behavior of PSV and NSV during fault events, enabling precise fault localization and isolation. This layer operates autonomously, utilizing localized data from PDs without relying on communication channels to transmit trip signals. The SOGI-FLL is used for the derivation of the estimated variables and sequence components, ensuring fast detection with minimal computational overhead.
A priority system is defined to manage the interactions between the two protection layers, offering an effective solution in cases of communication disruption. This prioritization ensures the highest level of security and reliability, thereby enhancing system redundancy. Specifically, upon detecting a fault, the first layer is automatically activated, and the communication signal is checked to verify the availability of the detection decision. In the event of a loss of communication signals, a secondary verification is performed to definitively rule out any transient issues. If the signals are received, the first layer continues its operation to isolate the fault. However, in cases where it is confirmed that communication signals are permanently lost even after re-evaluation, the second layer serves as a secondary protection at each PD to isolate the fault.
The system was tested for various fault types, including situations with a high penetration of DG and both low and high fault resistances. Across all test cases, the simulation and experimental results validate the efficacy of the protection system, demonstrating its prompt and reliable response to faults, even in the presence of potential communication disruptions. The fault detection times consistently fell within the range of 6 to 8.5 ms. Furthermore, the system works with minimal computational overhead and is adaptable to grid reconfiguration, which not only enhances stability, but also fortifies redundancy in the system.
In subsequent studies, we envisage delving into the impact of high-voltage grid codes on our protection scheme, specifically assessing their adaptability and efficacy under varying transformer configurations. This exploration aims to enhance the comprehensiveness of our findings and contribute valuable insights to the field of power system protection. We recognize the importance of extending our research to encompass a broader range of grid scenarios, and future studies will be dedicated to addressing this aspect to ensure a more comprehensive understanding of the protection system’s performance across diverse grid environments.
Moreover, another future research endeavor can address critical gaps identified in this study. Firstly, an exploration of the frequency and economic impact of communication loss between protective devices in modern distribution grids will be undertaken, shedding light on the practical implications and potential economic consequences of such disruptions. Additionally, experimental validation will be extended beyond laboratory emulations to encompass real-world distribution networks with DERs. This expansion aims to assess the effectiveness of the proposed solution in practical deployment scenarios, specifically in modern dispatch centers of Distribution System Operators (DSOs) and SCADA systems. This multifaceted approach will enhance the robustness and applicability of the proposed solution in addressing protection challenges in real-world distribution environments.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}