1. Introduction
Video instance segmentation (VIS) involves identifying and delineating individual objects in a video sequence, while distinguishing between different instances of the same object category. This task combines three main components: object detection: identifying and localizing objects within each video frame; object tracking: keeping track of the same objects as they move across frames, maintaining their identities; and instance segmentation: providing a pixel-level mask for each object instance.
Video instance segmentation plays a key role across diverse applications, such as autonomous driving, surveillance, robotics, and video analysis. By identifying and tracking individual instances of objects, this technique is instrumental in enabling systems to comprehend the details of object movements and interactions within a temporal context in a given video stream. Its applications extend beyond visual comprehension, providing insights into the spatial and temporal relationships among objects. In autonomous driving scenarios, for instance, video instance segmentation is indispensable for real-time decision making, ensuring the safe navigation of vehicles through complex environments. In surveillance and robotics, this technology facilitates the precise monitoring and manipulation of objects, improving the efficiency and accuracy of these systems. Furthermore, in video analysis, the capability to discern and isolate specific instances greatly contributes to extracting meaningful information and patterns from large datasets. As technological advancements continue, the importance of video instance segmentation becomes increasingly apparent, changing the way we perceive and interact with visual data across various domains.
Cutting-edge VIS models currently rely on comprehensive video annotations from VIS datasets [
1,
2] to face this demanding challenge. However, video annotation is expensive, especially when creating precise object masks. In addition, there are instances where it becomes difficult to precisely delineate the boundaries of objects due to occlusion [
3] or blurring. Even the less precise polygon-based mask annotations are significantly more time-consuming than annotating videos with bounding boxes [
4,
5] or scribbles. This issue is particularly critical for recent transformer-based VIS models [
6,
7,
8], as they have a high demand for training data.
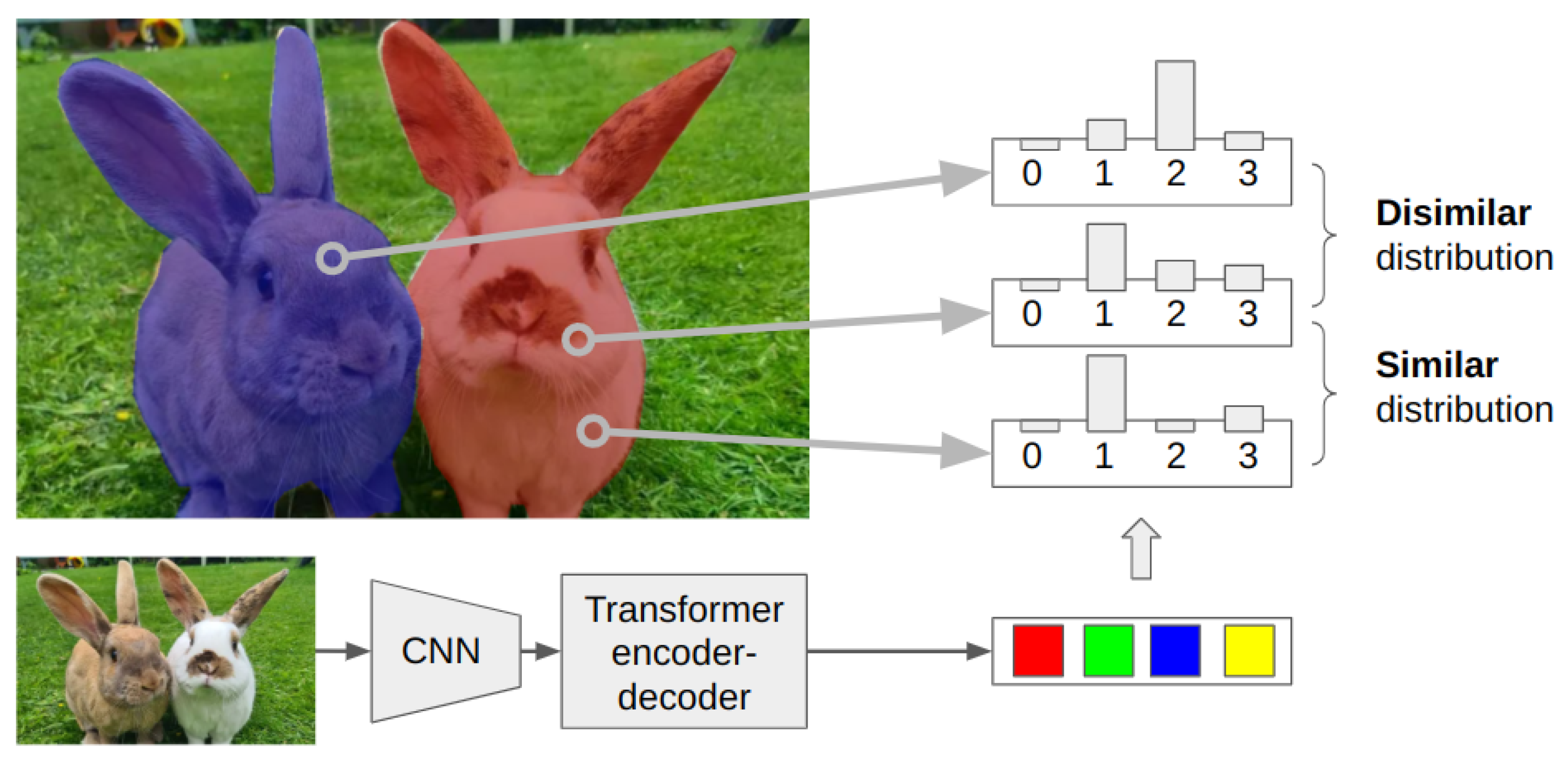
Our objective in this paper is to develop a competitive video instance segmentation model using lightweight annotations. We found that scribbles—free-hand curvy lines drawn across the characteristic parts of the instance—are not only an effective way to provide partial mask information, but also sufficient to achieve competitive performance on VIS benchmarks.
We combine the Mask2Former [
7,
9] model (to achieve high VIS performance) with similarity-based constraint loss (to enable the semisupervised nature of clustering-based methods). For an illustration of clustering-based methods, see
Figure 1.
To our knowledge, our Cluster2Former model is the first VIS method trained in partial masking that achieves high-quality segmentation results (for a survey of recent VIS models, see [
10]). The main contributions of this paper are summarized as follows:
We propose a VIS model, which is trained by scribbles drawn on the training video frames. Our model achieves competitive performance despite using only 0.5% of the pixel count of the full training masks as annotation.
The above result is achieved by modifying the learning objective only, leaving the architecture of the transformer (in this work, Mask2Former) intact. This not only eliminates costly architecture-specific hyperparameter optimization, but also enables the application of the same loss function modification to future, more advanced VIS architectures.
We demonstrate that the pairwise approach for training, based on feature vectors obtained by transformers, provides an efficient solution to video instance segmentation.
2. Related Works
With the development of the DETR model [
11], a paradigm shift took place in the field of image instance detector development. Beforehand, a technical change implemented to improve performance typically complicated the algorithm to such a degree that further incremental enhancements became increasingly difficult. Starting with DETR, it has been important to maintain the simple and transparent end-to-end scheme, replacing proxy-based approaches. This has enabled developments such as the Mask2Former model [
9] for still images, which, due to its simplicity, reaches a state-of-the-art level in solving several different tasks, such as semantic segmentation, instance segmentation, and panoptic segmentation. With a minor change, Mask2Former became capable of handling video instance segmentation, beating the competition at the time of its introduction [
7].
Clustering-based approaches like [
12,
13] have already shown that they can achieve state-of-the-art performance in proposal-free instance segmentation. They utilized one important property of instance labeling: the pairwise relationship between pixels as the supervision to formulate the learning objective. That leads to a semisupervised clustering problem, which we also employ. This approach beats the conventional two-stage method (feature embedding with k-means) by a significant margin [
12].
In a related work, pairwise constraints and subset allocation have been employed to redefine similarity-based constraints and accurately utilize strong-supervised information [
14]. The efficacy of pixelwise clustering techniques has been demonstrated in challenging video instance segmentation tasks, such as tracking identical objects, utilizing pairwise clustering methods [
15].
CMT-DeepLab [
16] has a targeted segmentation as a pixel clustering problem. It considers the object queries as cluster centers, and is responsible for grouping pixels for segmentation. That way, it improved the performance of the existing approaches, and achieved a state-of-the-art result on COCO test-dev. Although it achieved a remarkable result, the price of this was the complexity of the architecture, which limits its applicability in various research areas.
Clustering, in particular incorporating clustering features into the learning process, has been shown to improve image segmentation with class imbalanced datasets [
17]. The precision of the segmentation at critical edges can be enhanced by using a supervised edge attention module [
18].
We aim to keep the idea of the cluster-based approach and provide a much simpler solution, which can then be further successfully developed to target other areas, like video instance segmentation and multiview problems.
Video instance segmentation (VIS) stands as a significant domain within computer vision, tasked with the challenging goal of simultaneously detecting, tracking, and segmenting objects in video sequences. Unlike conventional image-based tasks, VIS operates in the dynamic realm of videos, necessitating the ability to identify objects across multiple frames and provide precise pixel-level segmentation masks for each object instance. To gain a better understanding of this field, it is important to categorize the existing methods as two-stage approaches and one-stage approaches. The two-stage approaches [
1,
19,
20] first tackle object detection in each frame, and then proceed to perform instance segmentation. It is akin to the well-established two-stage architecture seen in image-based tasks and includes well-known models like faster R-CNN [
21] and mask R-CNN [
22]. One-stage methods, on the contrary, integrate object detection and instance segmentation into a single process. Although they are more computationally efficient, they may sacrifice accuracy. YOLACT [
23] and BlendMask [
24] are examples of one-stage approaches.
Track-then-segment approaches [
25,
26] initially focus on object tracking across video frames, and subsequently apply instance segmentation. They rely on specialized tracking algorithms to establish object identities across frames before segmentation. Recent advances in deep learning have led to end-to-end deep learning models [
27] that directly address video instance segmentation, often using temporal information to enhance results. Online and real-time methods [
28,
29,
30,
31] are tailored for applications like autonomous vehicles and robotics; these methods are optimized for real-time or online video processing, emphasizing low-latency inference. Multiobject tracking and segmentation [
32,
33,
34,
35,
36,
37] aim to track and segment multiple objects simultaneously to address complex scenarios involving multiple interacting or overlapping objects.
Temporal consistency models [
6,
16,
27,
28,
31,
38,
39] tackle object tracking and segmentation challenges by leveraging temporal relationships between frames in videos. Attention-based models, which use attention mechanisms to focus on relevant frame details at different time steps, excel in capturing object motion, occlusion, and appearance changes over time. This makes attention a crucial component for maintaining consistency in video instance segmentation. Most of these models use full pixel-level mask annotation of the objects to be segmented. In contrast, our approach only uses a fraction of this during training. CMT [
16] is a transformer-based segmentation framework that transforms traditional transformer architectures for segmentation and detection to utilize object queries as cluster centers, which play a pivotal role in pixel grouping for segmentation. The clustering process involves two alternating steps: initially assigning pixels to clusters based on feature similarity and subsequently updating cluster centers and pixel features. Cluster2Former follows similar principles, but only with the application of the training objective, without changing the architecture.
Given the expense and complexity of annotating videos, semisupervised and weakly supervised methods aim to reduce annotation requirements by using fewer annotated frames or less detailed annotations (such as bounding boxes) for training. In the early stages of VIS, there were explorations of using videos for segmentation tasks that involve weak, semisupervised, or unsupervised methods, with a focus on motion or temporal consistency. However, many of these earlier methods did not specifically tackle object coherence and relied on optical flow for frame-to-frame matching. An approach to unsupervised feature learning leverages low-level motion-based grouping cues [
40], resulting in an effective visual representation trained using unsupervised motion-based segmentation on videos. Ref. [
41] predicts segmentation masks of multiple instances by learning instance tracking networks using labeled images and unlabeled video sequences. MinVIS [
42] achieves VIS performance without specialized video architectures by training an image-based instance segmentation model and treating video frames as independent images, thanks to its query-based approach for temporal consistency and memory-efficient inference online. MaskFreeVIS [
5] achieves competitive VIS performance using only bounding-box annotations. The approach leverages temporal mask consistency through the temporal KNN-patch loss without any labeled masks, significantly reducing annotation costs. That method outperforms the optical flow-based baselines, using bounding box annotation. While boundary boxes require even less information than the scribble method we employ, it can be misleading in scenarios of significant occlusion, making uncertain which object it encompasses. Additionally, for objects with ambiguous boundaries, obtaining precise human annotation becomes challenging.
4. Results
In this section, we present details about the datasets used, the implementation, and the experimental results. We provide detailed ablation studies in addition to standard benchmark results to illustrate the effectiveness of individual parameter settings and their combinations.
4.1. Datasets
We conducted our experiments using the datasets YouTube-VIS 2019 and 2021. The YouTube-VIS 2019 dataset consists of 2883 videos with annotations for 131,000 object instances spanning 40 categories. To address more intricate scenarios, the 2021 version of YouTube-VIS introduces an additional 794 training videos and 129 validation videos, featuring tracklets with intricate motion trajectories.
We made a scribbled version of both datasets. With the DAVIS Interactive Robot [
43,
44]—which generates realistic scribbles that simulate human interaction—we modified the annotations for the training process. Instead of the original ground truth masks, which cover the whole objects, we used the scribble annotations.
4.2. Implementation Details
As mentioned in the
Section 3, we adapt Mask2Former [
7] (especially sampling and training loss), but keep the architecture unchanged. Unless otherwise specified, all other training schedules and settings are kept the same as in the original model. To generate the pixel pairs for the similarity-based constraint loss, 300 pixels are sampled randomly from each frame foreground scribble, distributed evenly between the instances on that frame, as well as 300 pixels from the background scribbles. The choice of framewise sample count (as opposed to instancewise sample count as in [
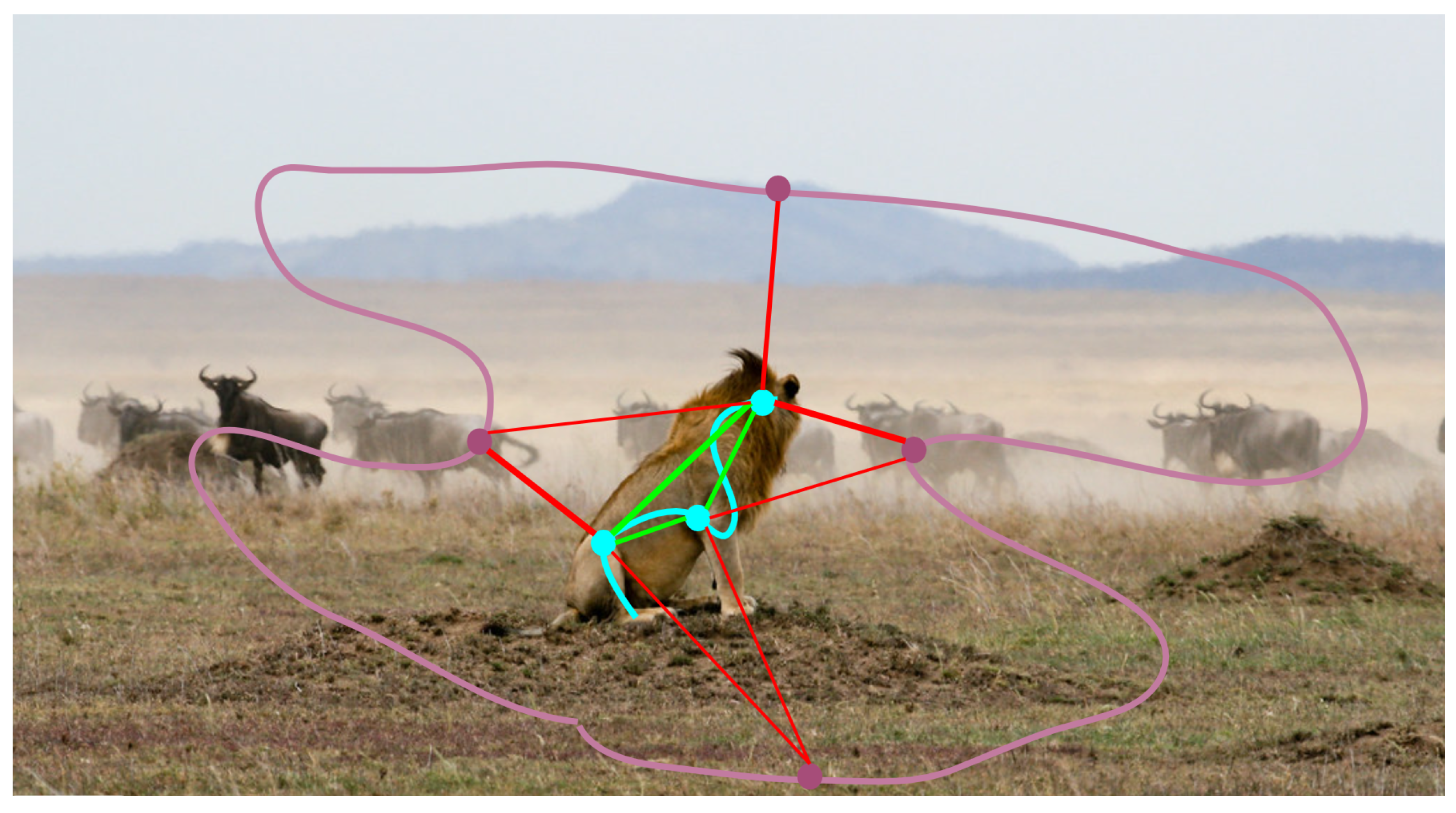
13]) enables good memory control. In case either the foreground or the background scribbles contain less than 300 possible pixels for sampling, e.g., due to cropping, the sample count is reduced for both to keep the balance. We make two disjoint sets of pixel-pair connections: in-frame and interframe connections. The in-frame connections contain a pixel pair, where the two pixels come from the same frame, while the interframe connections contain pixel pairs, where the two pixels come from different frames. When only a single frame is considered, there are no interframe connections set. For in-frame connections, we connect each pixel from the instances with all other pixels from the instances (they can be positive or negative pairs, depending on whether the pixels are from the same instance) and with the background pixels (these are all negative pairs). In the case of interframe connections for each frame pair, we connect each instance pixel from one frame with all other instance pixels from the other frame (they can be positive or negative pairs; see
Figure 5). Additionally, we connect the background pixels for each of the two frames with all instance pixels from the other frame (negative pairs). We do not use pixel-pair sparsification—we do not drop out any connection. We set the prefactor of the similarity-based constraint loss to
(keeping
) and the minimum weight to
. In case of inference, after applying a softmax for the mask logits along the queries dimension, we produce the predictions by thresholding the given values with 0.1. In this way, a point makes a prediction mask if its value is bigger than 0.1. We call this hyperparameter the inference threshold.
Originally, Mask2Former [
7]-based models are trained with a batch size of 16 and a learning rate of
. We adapted these to our hardware resources, which were initially two NVIDIA RTX TITAN GPUs, followed by NVIDIA A100 GPUs. If we do not specify it otherwise, we use a batch size of 4 with a learning rate of
. We also increased the number of iterations to 24k (32k) and the steps for the learning rate decay to 16k (22k) for the YouTube-VIS 2019 (2021) val datasets to allow the model to see the same number of inputs as with the original configuration. As the architecture is unchanged, the computational requirements for prediction (inference) are identical to those of Mask2Former.
4.3. Experiments
Our first results, shown in
Table 1, demonstrates the power of our method. We compare the standard YouTube-VIS average precision and average recall benchmarks [
1] for different model configurations on the YouTube-VIS 2019 val dataset. The integration of similarity-based constraint loss with Mask2Former’s segmentation losses (first row) showed no change in performance. When training with our Cluster2Former schedule (few sampled pixels only, randomly selected from the full mask; third row), a slight decay is observed, which we attribute to the information reduction of sampled pixels vs. full mask use (note that Mask2Former also samples pixels, but 12,544 of them with the default configurations). Our main point is the fourth row: when the sampling of Cluster2Former is performed from pixels with a scribble curve, only a slight reduction in performance is observed, while the training involves typically 100 times less pixels.
The same experiment has been performed on the more challenging YouTube-VIS 2021 val dataset as well; see
Table 2. It is remarkable that simply adding similarity-based constraint loss (second row) outperforms the original Mask2Former model without altering resource requirements. We stress that if, unlike the rest of this paper, the objective is to use full annotation masks to achieve best segmentation performance, then the best strategy is to take the linear combination of Mask2Former’s original mask losses with the similarity-based constraint loss. This dataset is more difficult than the 2019 version, which is reflected in the benchmark figures for model configurations using only the pairwise-sampling-based loss. We offer a possible explanation in
Section 5.
Next, we compare our system with a few (original) state-of-the art models for the two datasets; the results are presented in
Table 3 and
Table 4. Similar conclusions can be drawn as above.
4.4. Ablation Experiments
In the context of our ablation study within the YouTube-VIS 2019 validation set and using the ResNet-50 backbone, we meticulously dissect Cluster2Former. As our baseline VIS method, we employ Mask2Former [
7], fully integrating it into our approach, the only modification being the replacement of mask losses with our custom losses. We analyze the distinct components of the pixel-pair selection strategies with a focus on the following aspects (see
Table 5):
(1) Investigation of the interaction among background pixels. This exploration stems from the hypothesis that allowing our model the freedom to distinguish background elements into multiple clusters could potentially enhance performance.
(2) Examination of pixel relations within instances based on their spatial proximity. By emphasizing distant positive pairs and nearby negative pairs, we aim to facilitate the connection of occluded regions while effectively separating different instances in close contact.
(3) Evaluation of pixel relationships across instances in successive frames, elucidating the impact of temporal relations on tracking. This involves the classification of consecutive pixels belonging to the same instance into a shared cluster.
Furthermore, we extend our analysis to consider scenarios where more than two frames are interconnected in this manner, offering a perspective on the temporal aspect. In this experiment, a varying number of frames (“tube length”) are selected randomly from a 20-frame video sequence; benchmark results are shown in
Table 6. As expected, discarding temporal links (tube length 1) deteriorates performance. However, it is interesting to see that the best results are obtained for tube length 2; for a longer tube length, the temporal connections might have been diluted.
5. Discussion
In the previous sections, we presented our Cluster2Former model designed to tackle VIS and showed that competitive results can be obtained despite using lightweight, scribble annotation.
Annotation based on scribbles has several benefits compared with both full pixel-level masks and another popular lightweight masks: the bounding boxes. When compared full masks, they have a number of advantages: (1) Scribbles require significantly less annotator time and training. Full mask annotation can be extremely time-consuming and costly, while scribbles are quicker and easier for annotators. Scribbles are more forgiving to annotator errors and require less skills to provide good-quality annotations. (2) Scribbles are less prone to ambiguity: in challenging scenarios with blurred images or a strong object overlap, determining precise object boundaries for full masks can be ambiguous. Scribbles, on the other hand, provide a clear indication of object locations without the need for exact boundary delineation. (3) Scribbles are computationally efficient: training VIS models with scribbles typically requires less computational resources than full mask-based training, making it a more feasible option for resource-limited scenarios.
It has been shown by MaskFreeVIS [
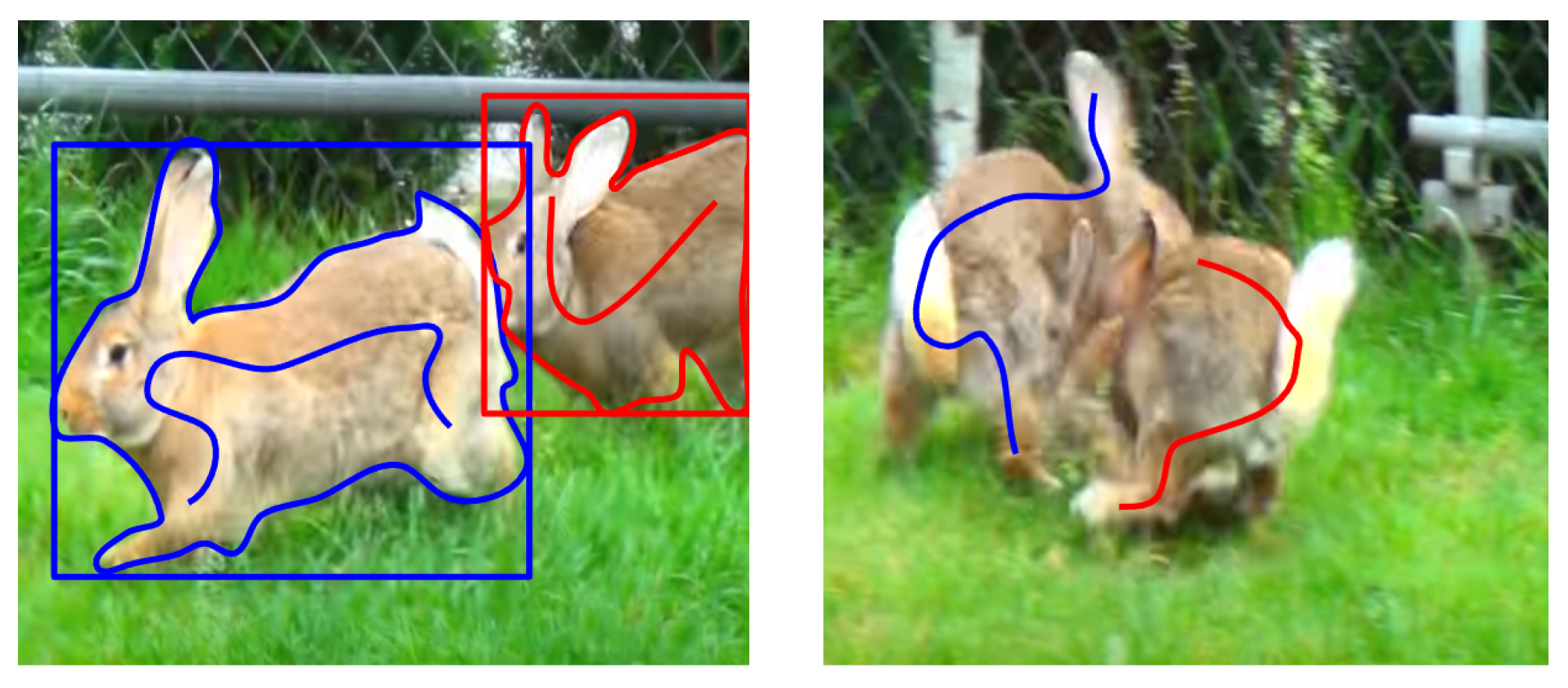
5] that the performance of state-of-the-art traditional VIS algorithms can be approached by using another light annotation: bounding boxes. Still, scribbles offer a number of advantages over bounding boxes as well: (1) Better object separation and reduced ambiguity. Scribbles provide a more effective means of separating objects, especially when they overlap or intersect. The ambiguity of object reference for nearly coinciding bounding boxes is dissolved by applying scribbles in clearly identifiable parts of the image. See
Figure 6 for illustration.
(2) Enhanced object location and adaptability to object shape. Scribbles offer finer-grained localization information. Unlike bounding boxes, which encompass a fixed rectangular area, scribbles can guide the model to better capture the object contour, especially complex shapes. (3) Reduced annotation effort. Although both methods are partial annotations, scribbles typically require less annotator time than meticulously aligning bounding boxes to object edges, making the annotation process more efficient.
We show that Cluster2Former can successfully address challenging VIS situations.
Figure 7 demonstrates that disjoint parts of an occluded object are combined to make a proper instance. In
Figure 8, we show that the edges separating neighboring instances are correctly delineated despite the fact that scribbles provide only an approximation to the full shape.
Figure 9 demonstrates that Cluster2Former successfully copes with situations of multiple occlusions. The two objects (turtle and human) are correctly segmented despite the fact that the pixels of the human are split into a number of disjoint regions.
Limitations: since the scribbles we use in the experiments (generated by DAVIS Interactive, similar to skeletons) sample pixels typically from the inner parts of the objects, pixels near the edges are less represented; consequently, the segmentation quality near the edges might suffer. See
Figure 10 for illustration. On the one hand, this is not necessarily a serious impediment, for example, for applications where tracking of similar instances is the ultimate task. On the other hand, there are solutions to overcome this issue, including using scribbles that approach object edges at places or strengthening the segmentation near the edges, for example, using supervised edge attention [
18].
Based on the above arguments, we believe that Cluster2Former can be one of the best overall VIS methods in a number of practical situations when training is limited by annotation resources. Even though, for a fixed-size training dataset, our model is slightly weaker than full mask methods, using a fixed amount of annotator time, much larger training sets can be prepared with scribbles than full masks, resulting in a better overall performance. As an outlook, one of the applications we have in mind is tracking almost-identical-looking individuals (“instances”) of animals, where maintaining the identity of individuals through frames is much more important than segmentation quality. Additionally, we work on an extension of our model, which is capable of handling a mixture of scribbles and full masks. Full or nearly full masks, which are easy for the annotator, enable maintaining the full VIS benchmark of the underlying architecture, but can fall back to scribbles where a full mask is costly or impossible due to blur, still enabling suitable precision for tracking.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}