
Lightweight Detection Method for X-ray Security Inspection with Occlusion


Abstract
1. Introduction
- (1)
- In order to solve the problem of insufficient feature learning provided by the X-ray image datasets and the lack consideration for the contributions of features from different sources, ASFF architecture modules and a weighted concatenate algorithm were introduced to obtain finer and more comprehensive feature representation.
- (2)
- To increase the attention paid to important information and suppress background noise, the CoordAtt module was embedded into the detection frameworks. The slide loss function was applied to solve the imbalance between simple samples and difficult samples. And we applied the Soft-NMS method to enhance the de-occluded ability of model.
- (3)
- Based on the above algorithms, we proposed the lightweight, high-precision, and de-occluded YOLOv8n and YOLOv8m detection models. The improved YOLOv8n model already has superior detection performance, while the YOLOv8m model has higher accuracy. The comparative experiments results show that our models can achieve state-of-the-art detection accuracies on the PIDray and SIXray datasets.
2. Background
2.1. X-ray Security Inspection
2.2. YOLOv8
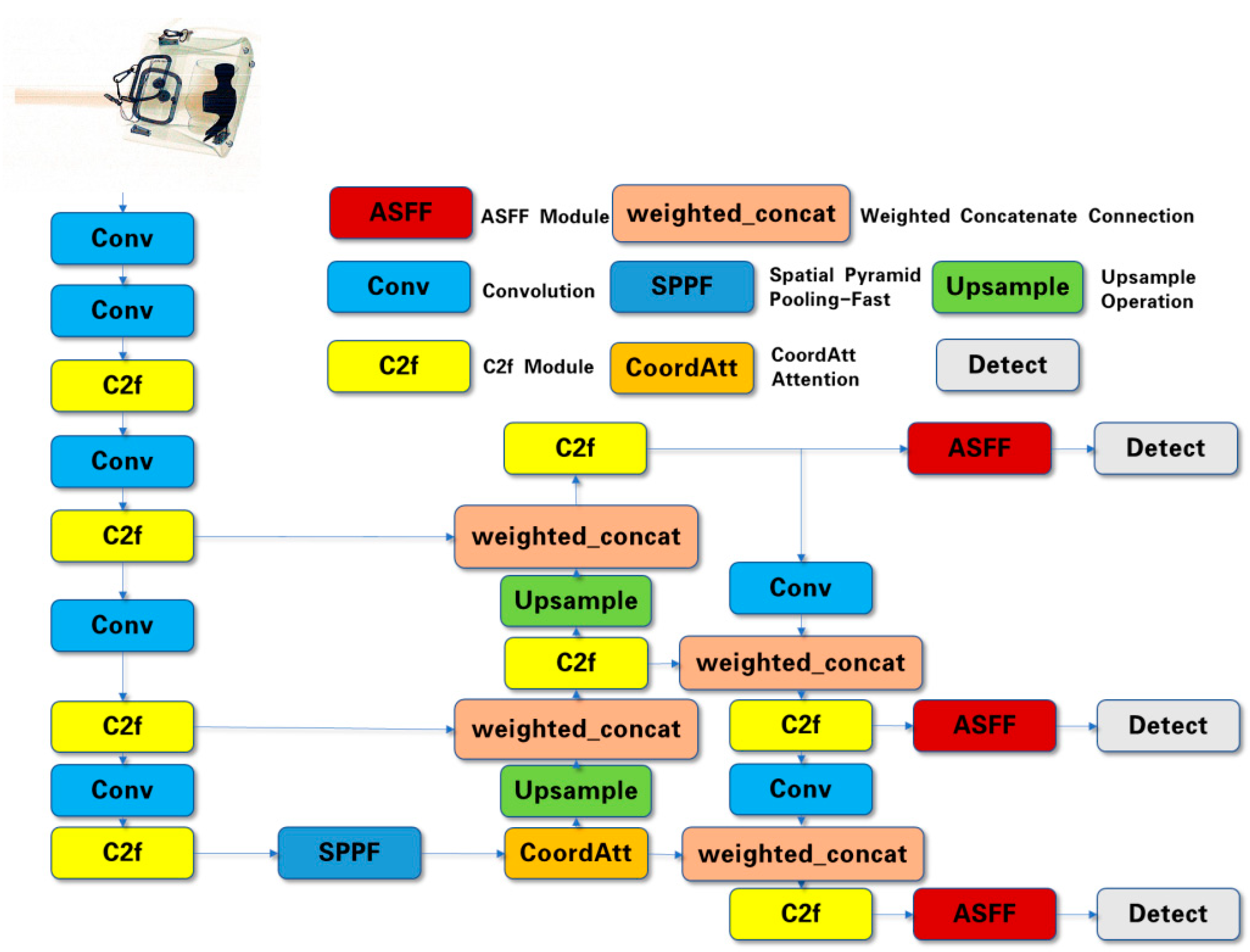
3. Method
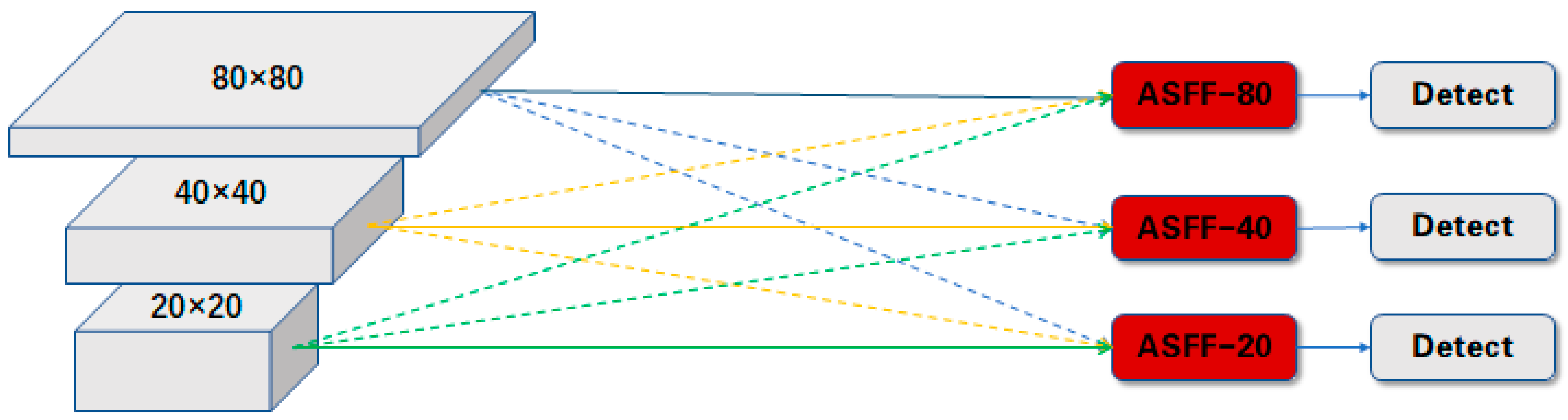
3.1. ASFF
3.2. Attention Mechanism
3.2.1. CBAM
3.2.2. SimAM Attention
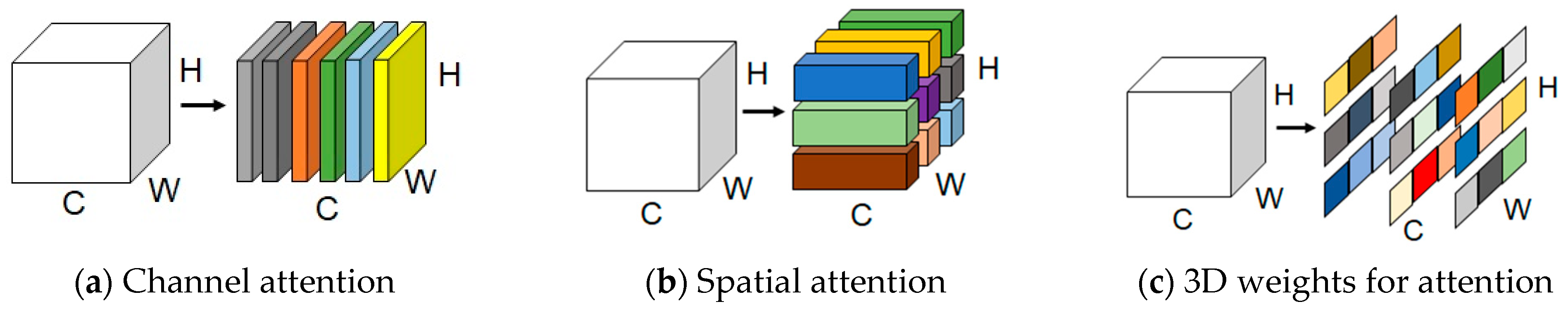
3.2.3. CoordAtt
3.3. Weighted Concatenate
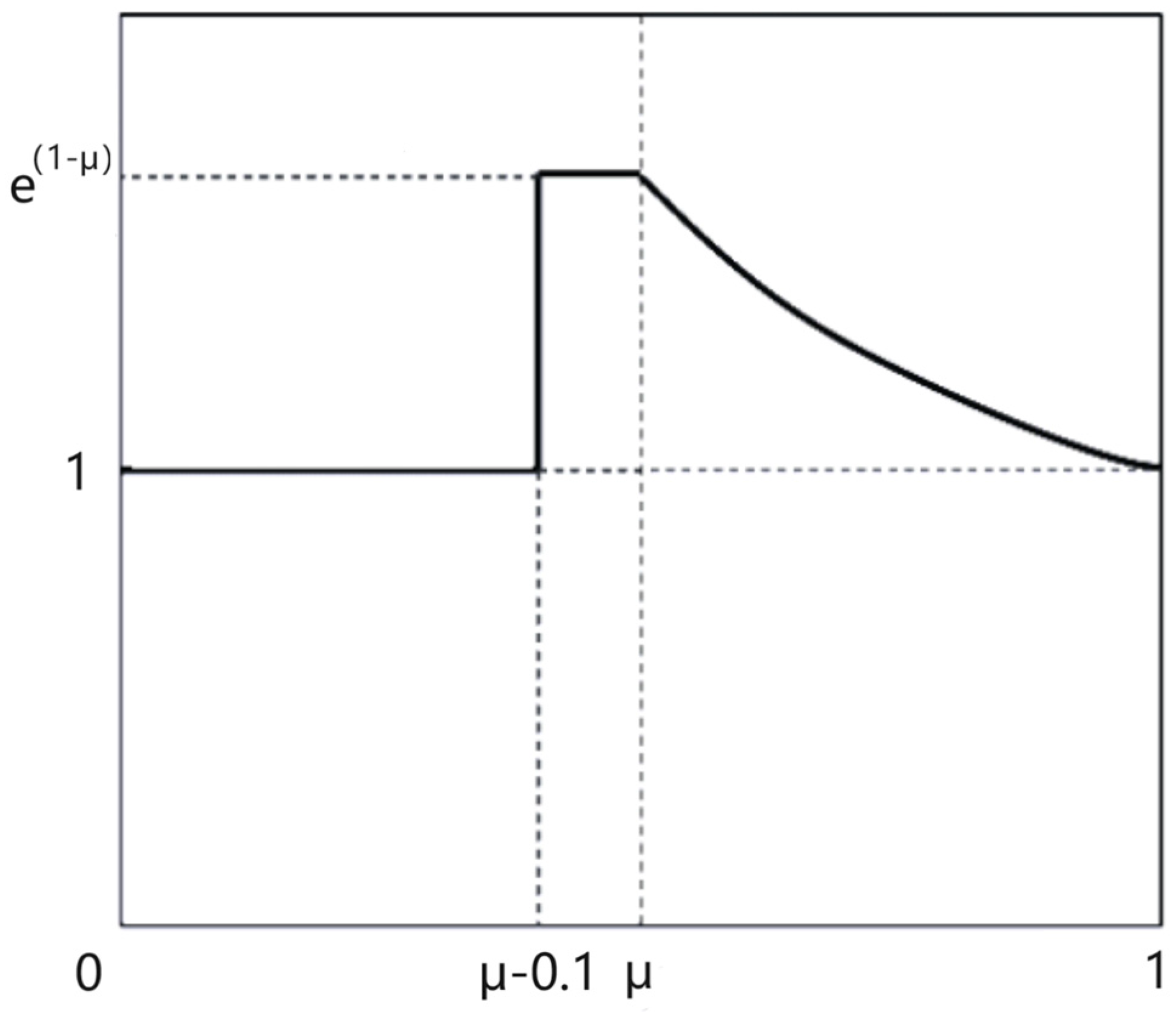
3.4. Slide Loss Function
4. Experiment and Analysis
4.1. Experimental Configuration
4.2. Evaluation Metrics
4.3. Soft-NMS
4.4. Data Augmentation
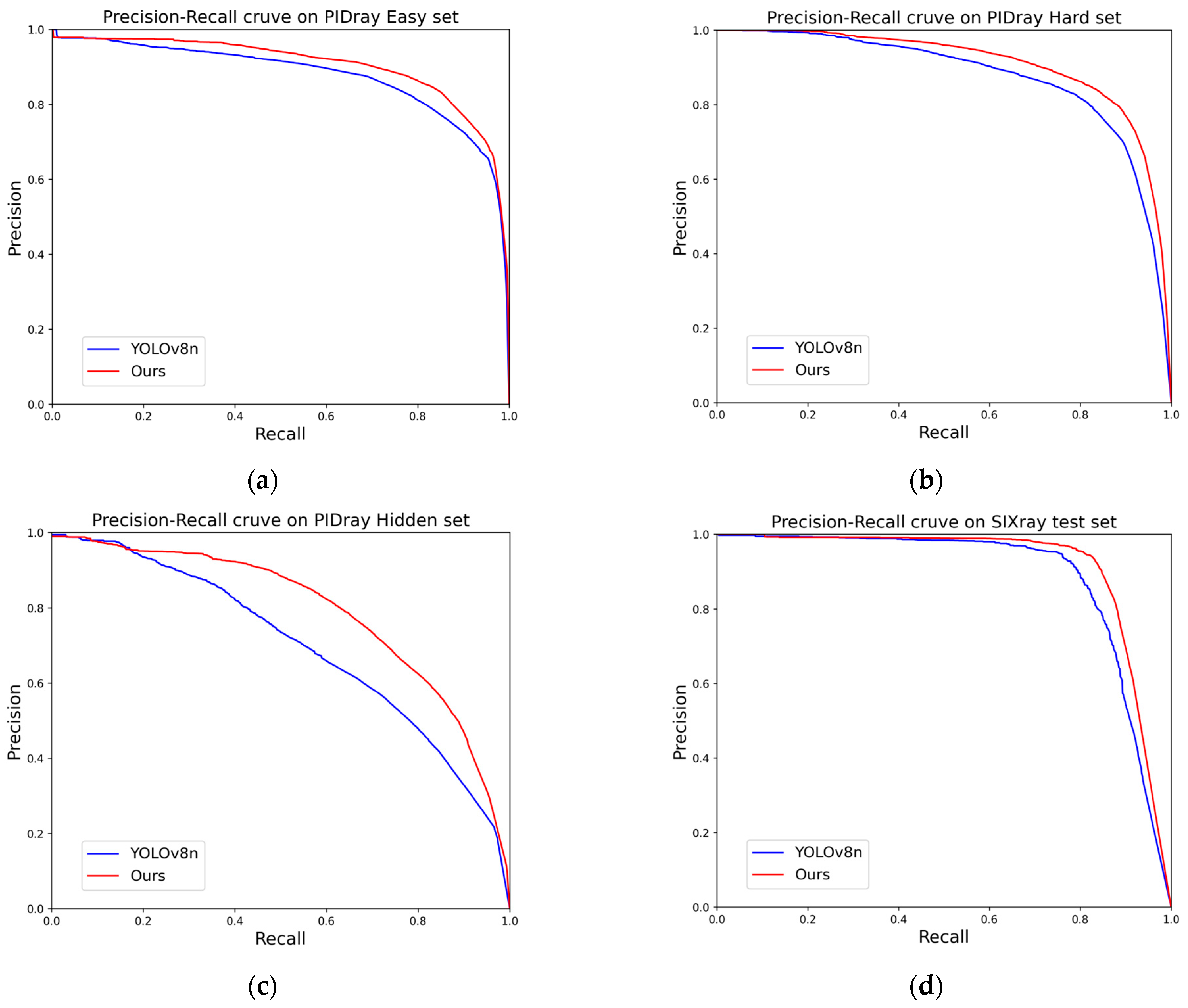
4.5. Results and Evaluation
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | you only look once |
| ASFF | adaptive spatial feature fusion |
| CoordAtt | coordinate attention module |
| NMS | non-maximum suppression |
| mAP | mean average precision |
| EDXRD | energy dispersive X-ray diffraction |
| SVM | support vector machine |
| bAP | base average precision |
| R-CNN | region-convolutional neural network |
| SSD | single shot multibox detector |
| MSA1 | multi-scale attention architecture |
| MSE | multi-scale feature extraction |
| PMMW | passive millimeter wave |
| PANet | path aggregation network |
| MSA2 | multi-scale smoothed atrous |
| MCA | material-aware coordinate attention |
| IoU | intersection over union |
| SD-SIoU | shape decoupled SIoU |
| EFE | edge feature extractor |
| MFE | material feature extractor |
| FPN | feature pyramid network |
| DOAM | de-occlusion attention module |
| ELAN | efficient layer aggregation network |
| SPPF | spatial pyramid pooling -fast |
| PAN-FPN | path aggregation network FPN |
| BCE | binary cross entropy |
| DFL | distribution focal loss |
| CIoU | complete-IoU |
| CBAM | convolutional block attention module |
| CAM | channel attention module |
| SAM | spatial attention module |
| 3D | three-dimensional |
| NWD | normalized Wasserstein distance |
References
- Akcay, S.; Breckon, T. Towards automatic threat detection: A survey of advances of deep learning within X-ray security imaging. Pattern Recognit. 2022, 122, 108245. [Google Scholar] [CrossRef]
- Mery, D.; Svec, E.; Arias, M.; Riffo, V.; Saavedra, J.M.; Banerjee, S. Modern computer vision techniques for X-ray testing in baggage inspection. IEEE Trans. Syst. Man Cybern. Syst. 2016, 47, 682–692. [Google Scholar] [CrossRef]
- Kundegorski, M.E.; Akcay, S.; Devereux, M.; Mouton, A.; Breckon, T.P. On using feature descriptors as visual words for object detection within X-ray baggage security screening. In Proceedings of the 7th International Conference on Imaging for Crime Detection and Prevention, Madrid, Spain, 23–25 November 2016; pp. 1–6. [Google Scholar]
- Yang, D.; Tian, Y.; Zhang, L. Liquid Contrabands Classification Based on Energy Dispersive X-ray Diffraction and Hybrid Discriminant Analysis. Nucl. Instrum. Methods Phys. Res. Sect. A-Accel. Spectrometers Detect. Assoc. Equip. 2016, 808, 128–134. [Google Scholar]
- Wang, Y.; Zhou, W.H.; Yang, X.M.; Jiang, W.; Wu, W. X-ray image illegal object classification based on computer vision. Chin. J. Liq. Cryst. Disp. 2017, 32, 287–293. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: A Simple and Strong Anchor-Free Object Detector. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 1922–1933. [Google Scholar] [CrossRef]
- Liu, W.; Angueloy, D.; Erhan, D.; Szegedy, D.; Reed, S.; Fu, C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollar, P.; Girsgick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 2961–2969. [Google Scholar]
- Akcay, S.; Kundegorski, M.; Devereux, M.; Breckon, T.P. Transfer learning using convolutional neural networks for object classification within X-ray baggage security imagery. In Proceedings of the 2016 IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 1057–1061. [Google Scholar]
- Fang, C.; Liu, J.; Han, P.; Chen, M.; Liao, D. FSVM: A Few-Shot Threat Detection Method for X-ray Security Images. Sensors 2023, 23, 4069. [Google Scholar] [CrossRef]
- Zhang, Y.; Kong, W.; Li, D.; Liu, X. On using XMC RCNN model for contraband detection within X-ray baggage security images. Math. Probl. Eng. 2020, 2020, 1823034. [Google Scholar]
- Zhang, Y.K.; Su, Z.G.; Zhang, H.G.; Yang, J.F. Multi-scale prohibited item detection in X-ray security image. J. Signal Process. 2020, 36, 1096–1106. [Google Scholar]
- Sun, F.; Zhang, X.; Liu, Y.; Jiang, H. Multi-Object Detection in Security Screening Scene Based on Convolutional Neural Network. Sensors 2022, 22, 7836. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Zhang, J.; Chen, X.; Li, D.; Wang, Y.; Zheng, M. AMOD-Net: Attention-based Multi-Scale Object Detection Network for X- Ray Baggage Security Inspection. In Proceedings of the 2021 5th International Conference on Computer Science and Artificial Intelligence, Beijing, China, 4–6 December 2021; pp. 27–32. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, L.; Wen, L.; Liu, X.; Wu, Y. Towards Real-World Prohibited Item Detection: A Large-Scale X-ray Benchmark. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 5392–5401. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, L. Yolo-C: One-stage network for prohibited items detection within X-ray images. Laser Optoelectron. Prog. 2021, 58, 75–84. [Google Scholar]
- Pang, L.; Liu, H.; Chen, Y.; Miao, J. Real-time Concealed Object Detection from Passive Millimeter Wave Images Based on the YOLOv3 Algorithm. Sensors 2020, 20, 1678. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Yuan, W.; Wang, A. X-ray Security Inspection Image Dangerous Goods Detection Algorithm Based on Improved YOLOv4. Electronics 2023, 12, 2644. [Google Scholar] [CrossRef]
- Miao, C.; Xie, L.; Wan, F.; Su, C.; Liu, H.; Jiao, J.; Ye, Q. SIXray: A large-scale security inspection X-ray benchmark for prohibited item discovery in overlapping images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2114–2123. [Google Scholar] [CrossRef]
- Song, B.; Li, R.; Pan, X.; Liu, X.; Xu, Y. Improved YOLOv5 Detection Algorithm of Contraband in X-ray Security Inspection Image. In Proceedings of the 2022 5th International Conference on Pattern Recognition and Artificial Intelligence, Chengdu, China, 19–21 August 2022; pp. 169–174. [Google Scholar] [CrossRef]
- Xiang, N.; Gong, Z.; Xu, Y.; Xiong, L. Material-Aware Path Aggregation Network and Shape Decoupled SIoU for X-ray Contraband Detection. Electronics 2023, 12, 1179. [Google Scholar] [CrossRef]
- Wei, Y.; Tao, R.; Wu, Z.; Ma, Y.; Zhang, L.; Liu, X. Occluded prohibited items detection: An X-ray security inspection benchmark and de-occlusion attention module. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 138–146. [Google Scholar] [CrossRef]
- Cheng, L.; Chao, J. X-ray image rotating object detection based on improved YOLOv7. J. Graph. 2023, 44, 324. [Google Scholar]
- Jing, B.; Duan, P.; Chen, L.; Du, Y. EM-YOLO: An X-ray Prohibited-Item-Detection Method Based on Edge and Material Information Fusion. Sensors 2023, 23, 8555. [Google Scholar] [CrossRef] [PubMed]
- Yan, Y.; Li, J. Anchor-free person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Liu, S.T.; Huang, D.; Wang, Y.H. Receptive field block net for accurate and fast object detection. In Proceedings of the 15th European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Yang, L.; Zhang, R.Y.; Li, L.; Xie, X. SimAM: A simple, parameter-free attention module for convolutional neural networks. In Proceedings of the 38th International Conference on Machine Learning, Online, 18–24 July 2021; pp. 11863–11874. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. YOLO-FaceV2: A Scale and Occlusion Aware Face Detector. arXiv 2022, arXiv:2208.02019. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS--improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Ghiasi, G.; Cui, Y.; Srinivas, A.; Qian, R.; Lin, T.Y.; Cubuk, E.D.; Le, Q.V.; Zoph, B. Simple copy-paste is a strong data augmentation method for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2918–2928. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable feature. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Ma, C.; Zhuo, L.; Li, J.; Zhang, Y.; Zhang, J. Occluded prohibited object detection in X-ray images with global Context-aware Multi-Scale feature Aggregation. Neurocomputing 2022, 519, 1–16. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
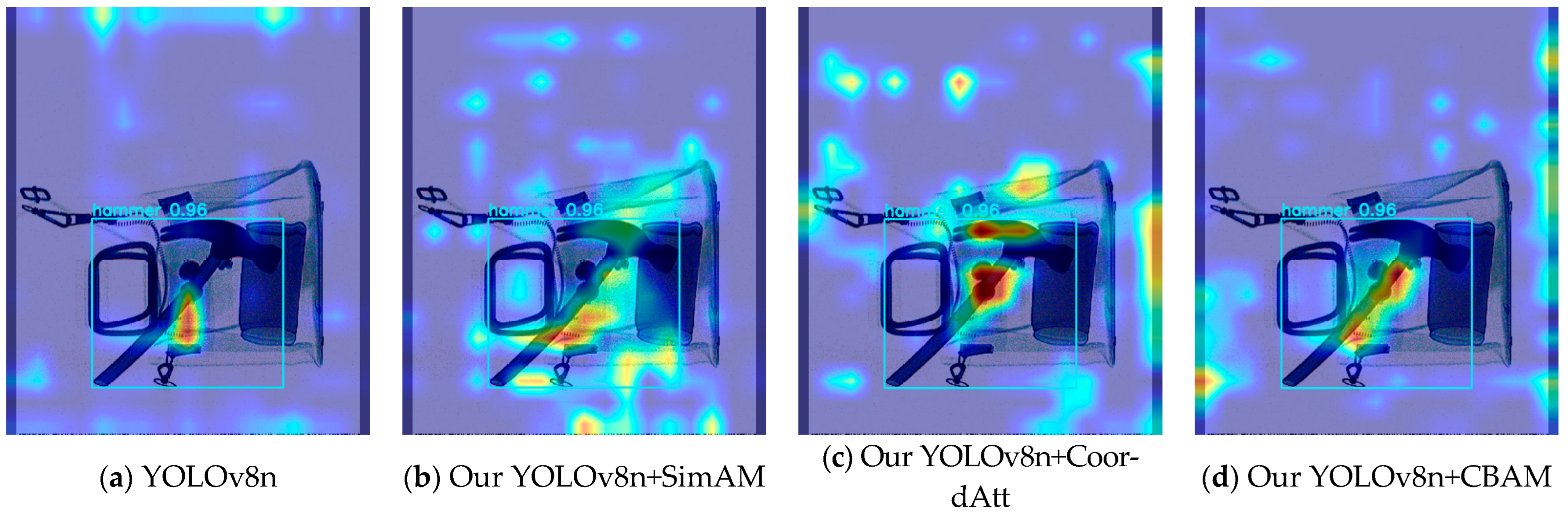
| YOLOv8n | 87.5 | 87.4 | 69.8 |
| our YOLOv8n+SimAM | 89.6 | 90.0 | 79.6 |
| our YOLOv8n+CoordAtt | 90.2 | 90.5 | 79.1 |
| our YOLOv8n+CBAM | 89.8 | 89.9 | 78.8 |
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Data Augmentation | Soft-NMS | ASFF + Weighted Concatenate | CoordAtt Attention | Slide Function | Easy | Hard | Hidden | Easy | Hard | Hidden |
| 87.5 | 87.4 | 69.8 | 77.8 | 73.2 | 52.1 | |||||
| √ | 88.3 | 89.9 | 74.1 | 79.0 | 77.0 | 61.4 | ||||
| √ | √ | 89.0 | 90.1 | 78.3 | 80.4 | 78.9 | 66.2 | |||
| √ | √ | √ | 88.6 | 90.3 | 78.3 | 80.6 | 79.2 | 66.3 | ||
| √ | √ | √ | √ | 88.2 | 90.1 | 78.9 | 80.0 | 79.5 | 67.1 | |
| √ | √ | √ | √ | 88.7 | 89.9 | 79.1 | 80.4 | 79.5 | 67.6 | |
| √ | √ | √ | √ | 88.3 | 90.2 | 78.0 | 80.1 | 79.7 | 66.6 | |
| √ | √ | √ | √ | √ | 90.2 | 90.5 | 79.1 | 81.8 | 80.5 | 67.9 |
| Method | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Data Augmentation | Soft-NMS | ASFF + Weighted Concatenate | CoordAtt Attention | Slide Function | All | Knife | Gun | Wrench | Pliers | Scissors |
| 89.0 | 85.7 | 91.2 | 84.3 | 91.6 | 92.1 | |||||
| √ | 89.8 | 89.2 | 92.3 | 84.4 | 91.4 | 91.7 | ||||
| √ | √ | 89.6 | 89.9 | 92.0 | 84.7 | 90.5 | 91.8 | |||
| √ | √ | √ | 89.9 | 88.2 | 92.2 | 85.7 | 91.3 | 92.2 | ||
| √ | √ | √ | √ | 89.7 | 89.0 | 92.6 | 84.2 | 90.7 | 91.9 | |
| √ | √ | √ | √ | 90.8 | 89.8 | 92.7 | 87.3 | 92.3 | 91.8 | |
| √ | √ | √ | √ | 90.5 | 89.7 | 92.9 | 85.7 | 91.6 | 92.5 | |
| √ | √ | √ | √ | 91.1 | 88.8 | 92.1 | 86.9 | 93.2 | 94.3 | |
| √ | √ | √ | √ | √ | 91.4 | 89.8 | 92.8 | 87.4 | 92.2 | 95.0 |
| Model | Year | Easy | Hard | Hidden | Params/M |
|---|---|---|---|---|---|
| AMOD-Net [15] | 2021 | 86.7 | 88.3 | 66.9 | - |
| SDANet [16] | 2021 | 71.2 | 64.2 | 49.5 | - |
| YOLOv5s | 2020 | 85.2 | 86.9 | 61.5 | 7.04 |
| Song et al. [21] | 2022 | 88.2 | 89.2 | 70.5 | 5.67 |
| YOLOv7-tiny | 2022 | 63.4 | 57.3 | 53.2 | 6.04 |
| Cheng et al. [24] | 2023 | 84.5 | 65.4 | 49.2 | 112.6 |
| YOLOv8n | 2023 | 87.5 | 87.4 | 69.8 | 3.008 |
| YOLOV8n+ours | 2023 | 90.2 | 90.5 | 79.1 | 3.014 |
| YOLOv8m | 2023 | 90.3 | 90.8 | 73.5 | 25.857 |
| YOLOv8m+ours | 2023 | 92.9 | 92.7 | 82.9 | 25.824 |
| Model | Year | All | Knife | Gun | Wrench | Pliers | Scissors | Params/M |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 2020 | 90.0 | 85.2 | 92.0 | 87.5 | 91.8 | 93.4 | 7.024 |
| YOLOv7-tiny | 2022 | 82.6 | 70.2 | 89.6 | 78.9 | 87.3 | 87.1 | 6.018 |
| POD-F-R [38] | 2022 | 86.1 | 92.5 | 88.9 | 83.8 | 87.6 | 87.7 | 118.32 |
| POD-F-X [38] | 2022 | 86.9 | 82.6 | 90.0 | 84.1 | 88.2 | 89.6 | 119.67 |
| POD-Y [38] | 2022 | 90.4 | 87.9 | 92.6 | 87.6 | 92.1 | 91.8 | 47.19 |
| YOLOv8n | 2023 | 89.0 | 85.7 | 91.2 | 84.3 | 91.6 | 92.1 | 3.007 |
| YOLOV8n+ours | 2023 | 91.4 | 89.8 | 92.8 | 87.4 | 92.2 | 95.0 | 3.013 |
| YOLOv8m | 2023 | 91.5 | 88.8 | 92.5 | 88.2 | 94.6 | 93.5 | 25.843 |
| YOLOv8m+ours | 2023 | 93.3 | 90.8 | 94.3 | 91.6 | 94.2 | 95.4 | 25.821 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Wang, X.; Shi, Y.; Qi, H.; Jia, M.; Wang, W. Lightweight Detection Method for X-ray Security Inspection with Occlusion. Sensors 2024, 24, 1002. https://doi.org/10.3390/s24031002
Wang Z, Wang X, Shi Y, Qi H, Jia M, Wang W. Lightweight Detection Method for X-ray Security Inspection with Occlusion. Sensors. 2024; 24(3):1002. https://doi.org/10.3390/s24031002
Chicago/Turabian StyleWang, Zanshi, Xiaohua Wang, Yueting Shi, Hang Qi, Minli Jia, and Weijiang Wang. 2024. "Lightweight Detection Method for X-ray Security Inspection with Occlusion" Sensors 24, no. 3: 1002. https://doi.org/10.3390/s24031002
APA StyleWang, Z., Wang, X., Shi, Y., Qi, H., Jia, M., & Wang, W. (2024). Lightweight Detection Method for X-ray Security Inspection with Occlusion. Sensors, 24(3), 1002. https://doi.org/10.3390/s24031002