
Application of Machine Vision Techniques in Low-Cost Devices to Improve Efficiency in Precision Farming

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Related Work
2.1. Depth Estimation
2.2. Object Detection
2.3. Object Detection for Precision Agriculture
2.4. Object Detection with Depth Integration
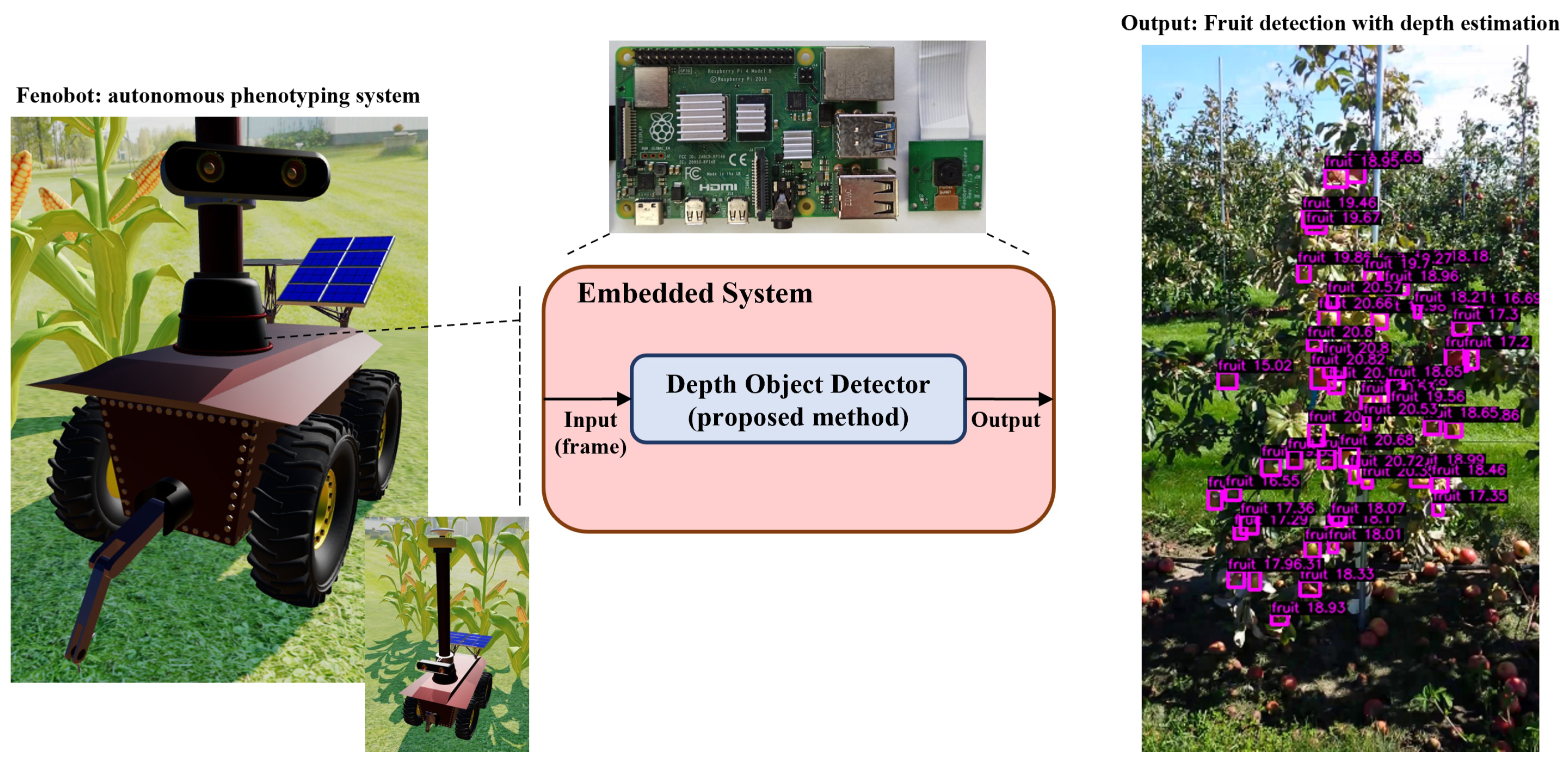
3. Proposed Method
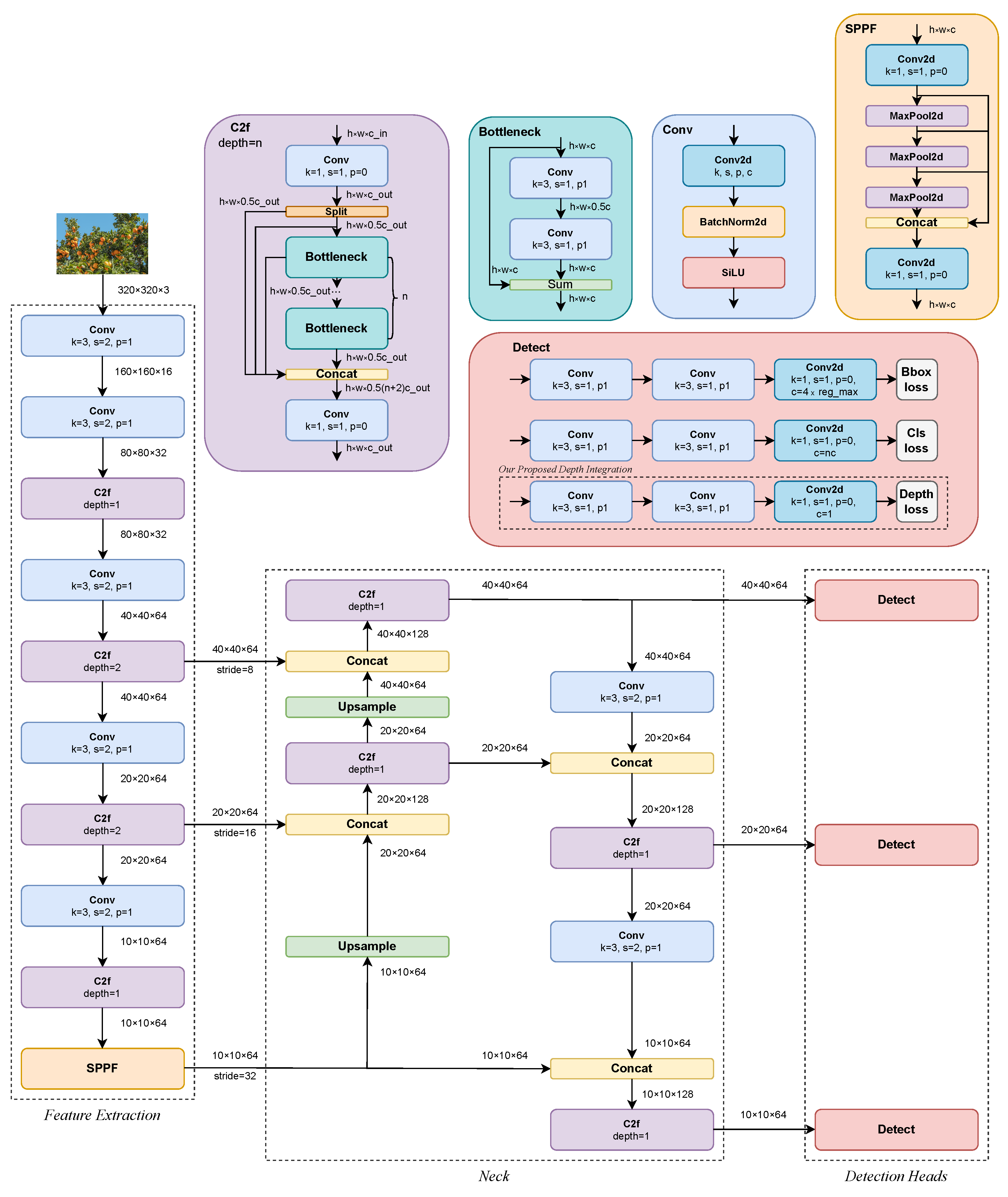
3.1. Architecture
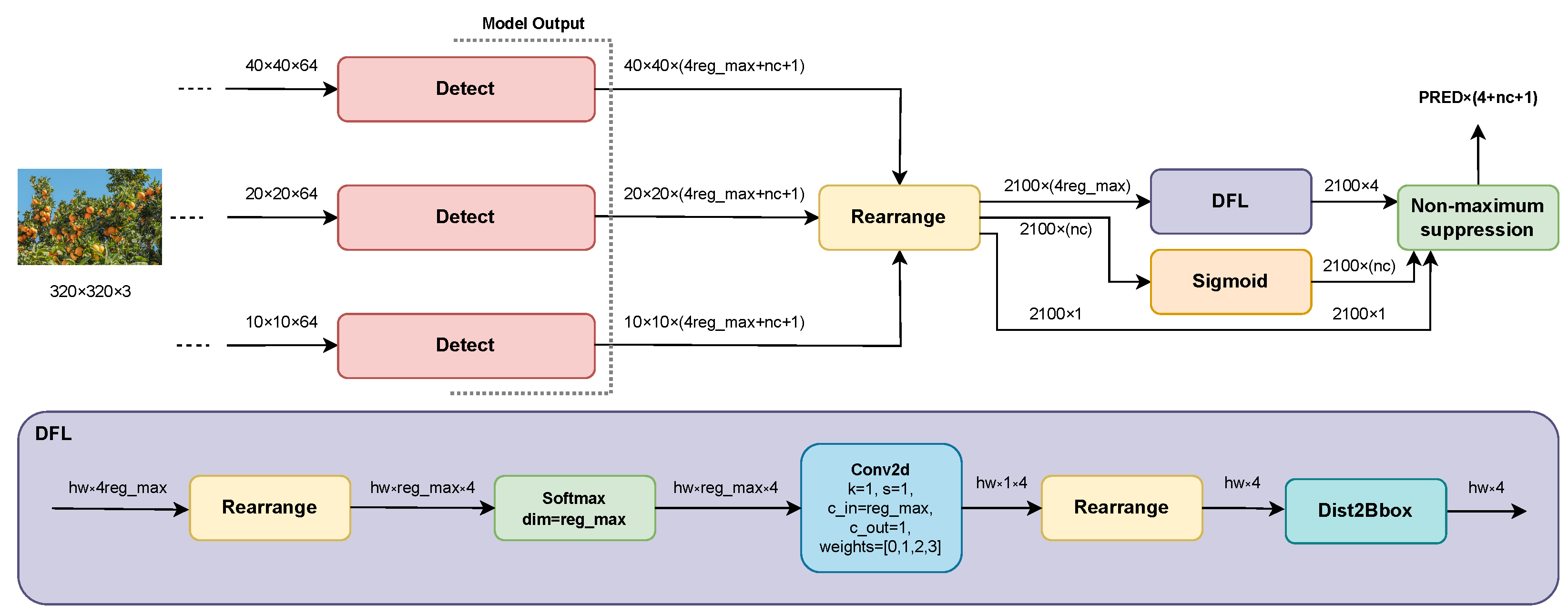
- Bounding box regression: The output is an anchor-free [70] distribution of values for each distance left, right, top, bottom () relative to the center of the prediction cell. After linearly projecting the distributions into four-pixel coordinates in the inference process, the width and height of the bboxes are in the range:given that:The distributional focal loss (DFL) function, proposed by Li et al. [71], introduces the hyperparameter to prevent the boxes from being too large or too small, ensuring the sensitivity of the predictions. For our proposed DOD method, and .
- Classification: The output is logits. For fruit detection, it is only considered one class . In the case of the COCO dataset [33], the number of classes is .
- Depth: The output is one representative depth value as a dimensionless quantity; the closer the object from the foreground, the higher the depth value and vice versa. This quantity is described in detail in Section 3.4.
3.2. Inference Process
3.3. Loss Function
- is the total number of cells containing an object (positive predictions).
- is the indicator function for cells with detected objects.
- is the IoU between predicted and ground-truth bboxes (Equation (8)).
- is a tuple () representing a ground-truth bbox.
- is a bbox predicted by a respective cell.
- is a tuple () representing the central point of a ground-truth bbox.
- is the central point of a bbox predicted by a respective cell.
- is the diagonal distance of the minimum bbox enclosing both a predicted and a ground-truth bbox.
- measures consistency in the aspect ratio between predicted and ground truth bboxes based on their width and height, respectively, (), () (Equation (9)).
- is a positive compensation where the overlap area factor has higher priority for regression, especially for nonoverlapping cases (Equation (10)).
- is the ground-truth label for class c for each individual cell, regardless of whether an object is present.
- is the predicted probability for class c for each individual cell, regardless of whether an object is present (Equation (11)).
- and are tuples () with values closest to the left and right of a ground-truth bbox whose tuple () has been transformed to a relative distance from the center of a positive prediction cell.
- are the probabilities of the predicted distribution by a cell containing an object.
- is the representative value of the relative depth to the background scene of the object in the ground-truth bbox.
- is the representative value of the relative depth to the background scene of the detected object in the prediction cell.
3.4. Depth Integration
| Algorithm 1 Depth extraction. |
|
3.5. Data Augmentation
4. Results
- We primarily benchmarked it against the state-of-the-art YOLOv8 model in a common object detection task using the COCO dataset. This direct comparison, conducted under identical conditions, provided insights into the performance disparities due to having nearly three times fewer parameters.
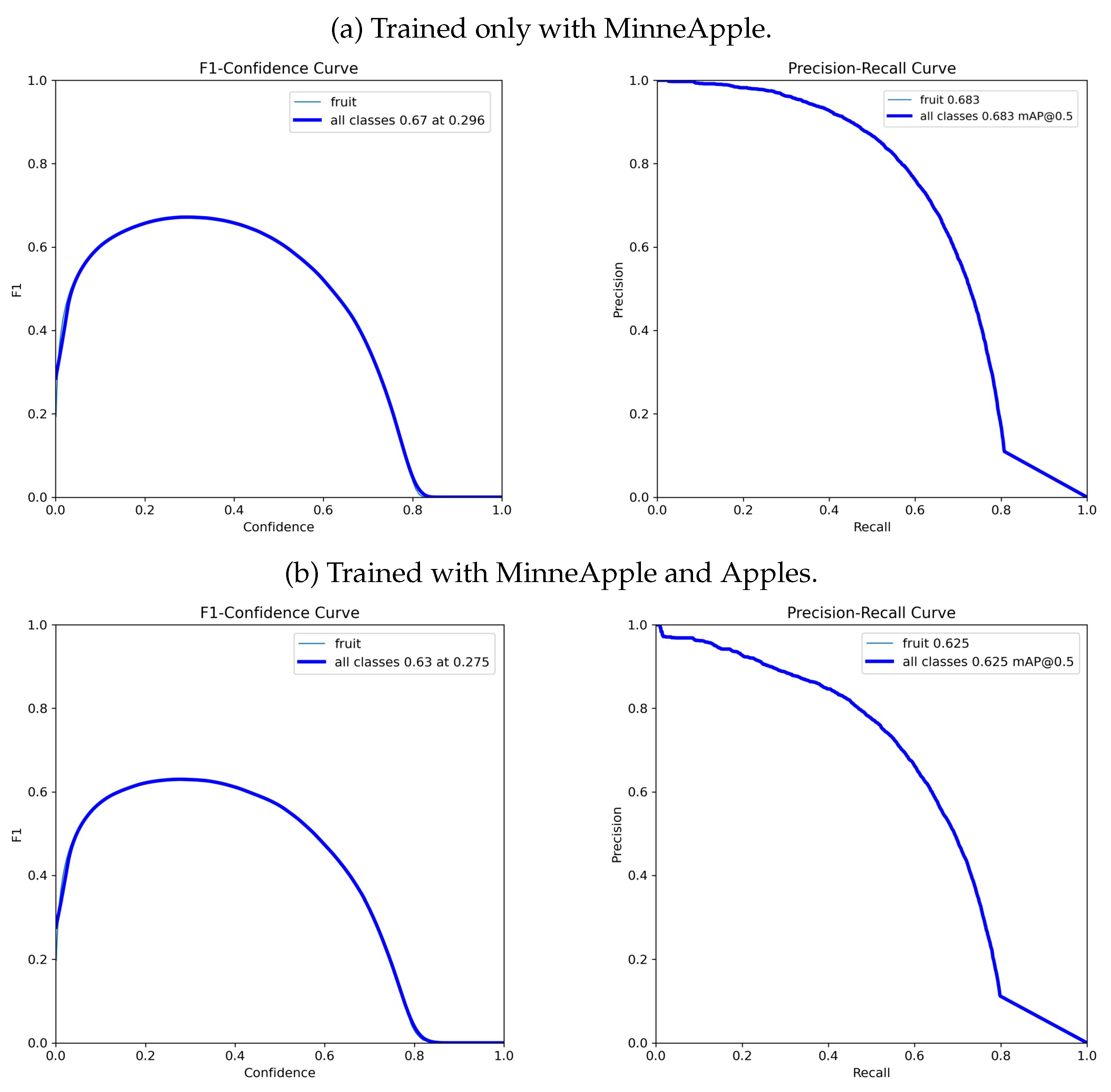
- DOD trained only with MinneApple presented a generalization deficit for relatively large or medium-sized fruits. Therefore, we added some training samples from the Apples dataset [76] and compare the performance disparities on MinneApple.
- Afterwards, we used MinneApple again to benchmark DOD’s performance with a better generalization on the embedded system, a Raspberry Pi 4 board [77,78], using a 32-bit floating-point precision and a quantized 8-bit signed-integer precision. The quantization process aimed to balance model accuracy and reduced storage for computational requirements, making it suitable for deployment on microcontrollers or embedded systems with limited resources.
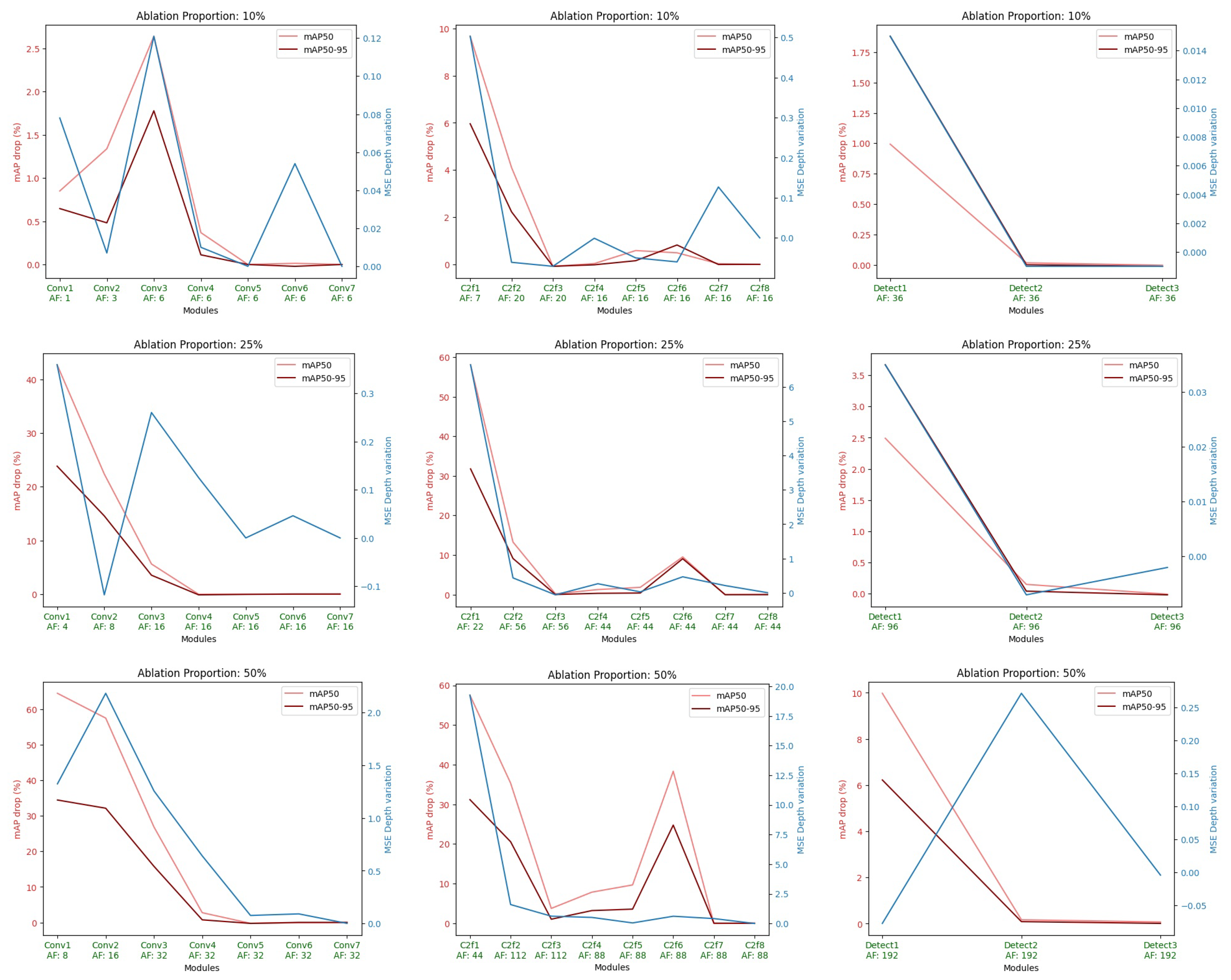
- Finally, an ablation study was performed to analyze the behavior of the different main components of the DOD architecture.
- CPU AMD Ryzen 7 5800H 3.20 GHz.
- GPU NVIDIA GeForce RTX 3070 Laptop GPU.
- CPU ARM Cortex-A72 1.5 GHz 64-bits Broadcom SoC BCM2711 on Raspberry Pi 4.
- NVIDIA driver version: 520.61.05.
- CUDA version: 11.8.89.
- PyTorch version: 2.0.1+cu117.
- Torchvision version: 0.15.2+cu117.
- OpenCV version: 4.7.0.
- Albumentation version: 1.3.0.
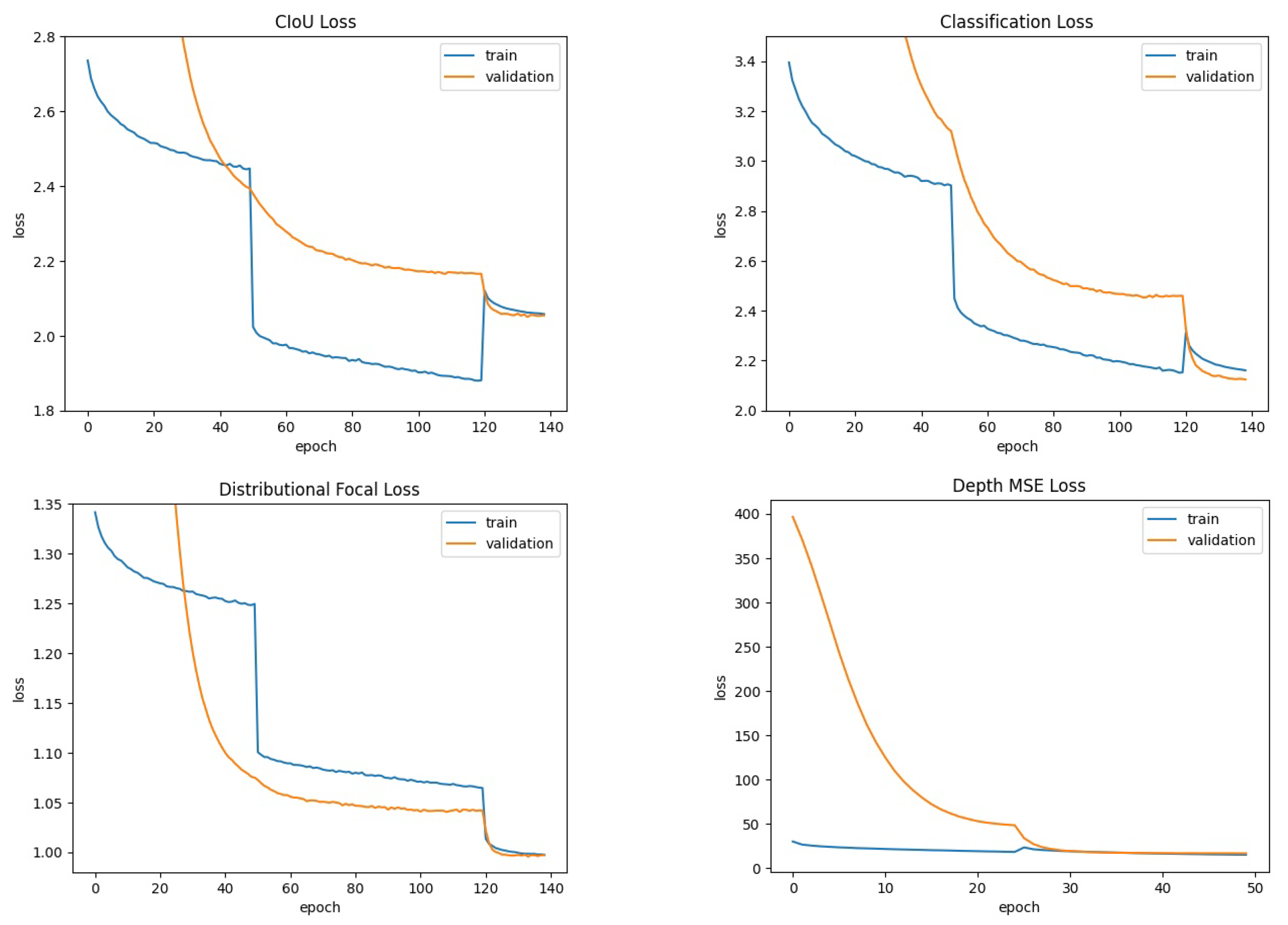
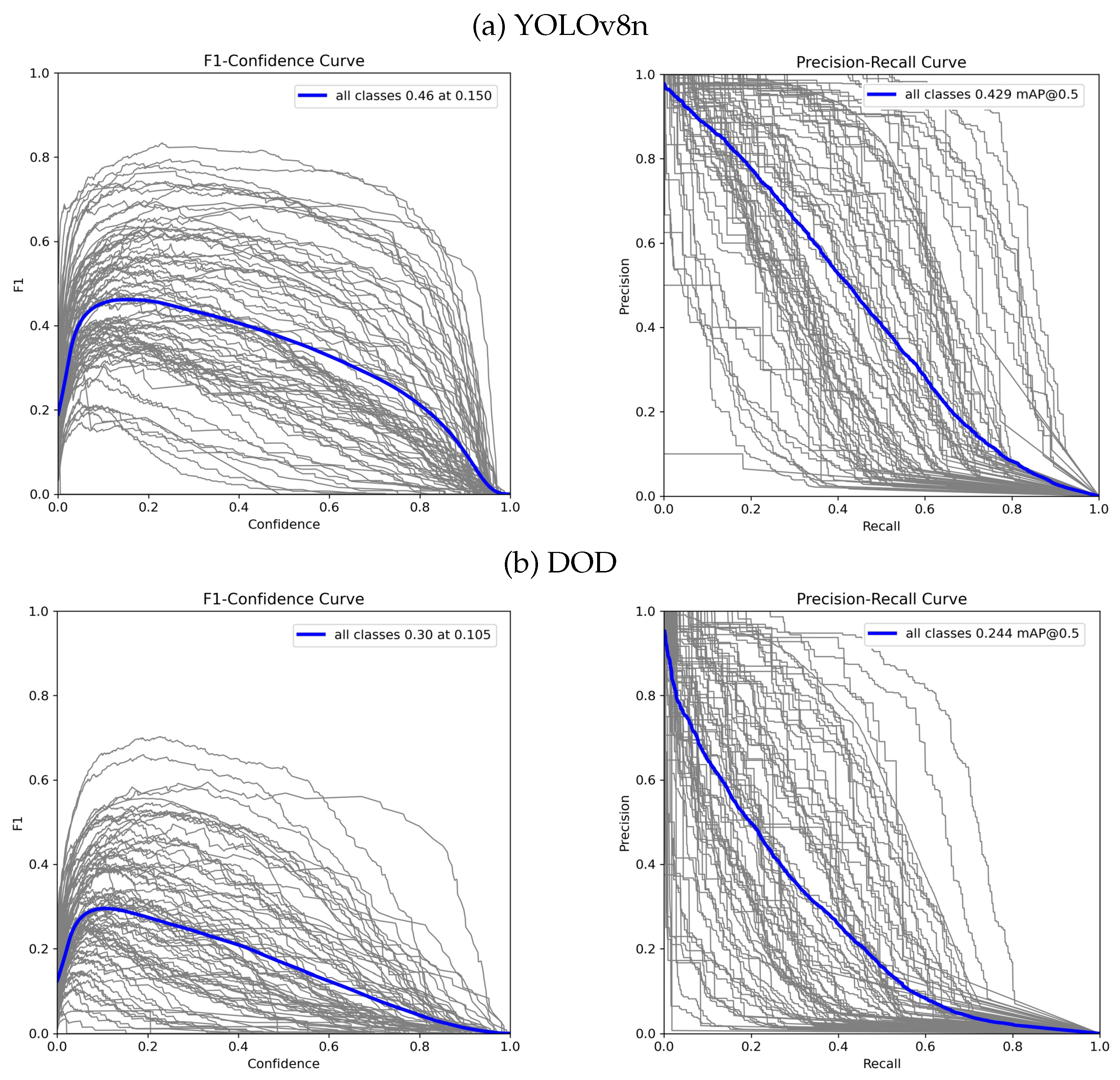
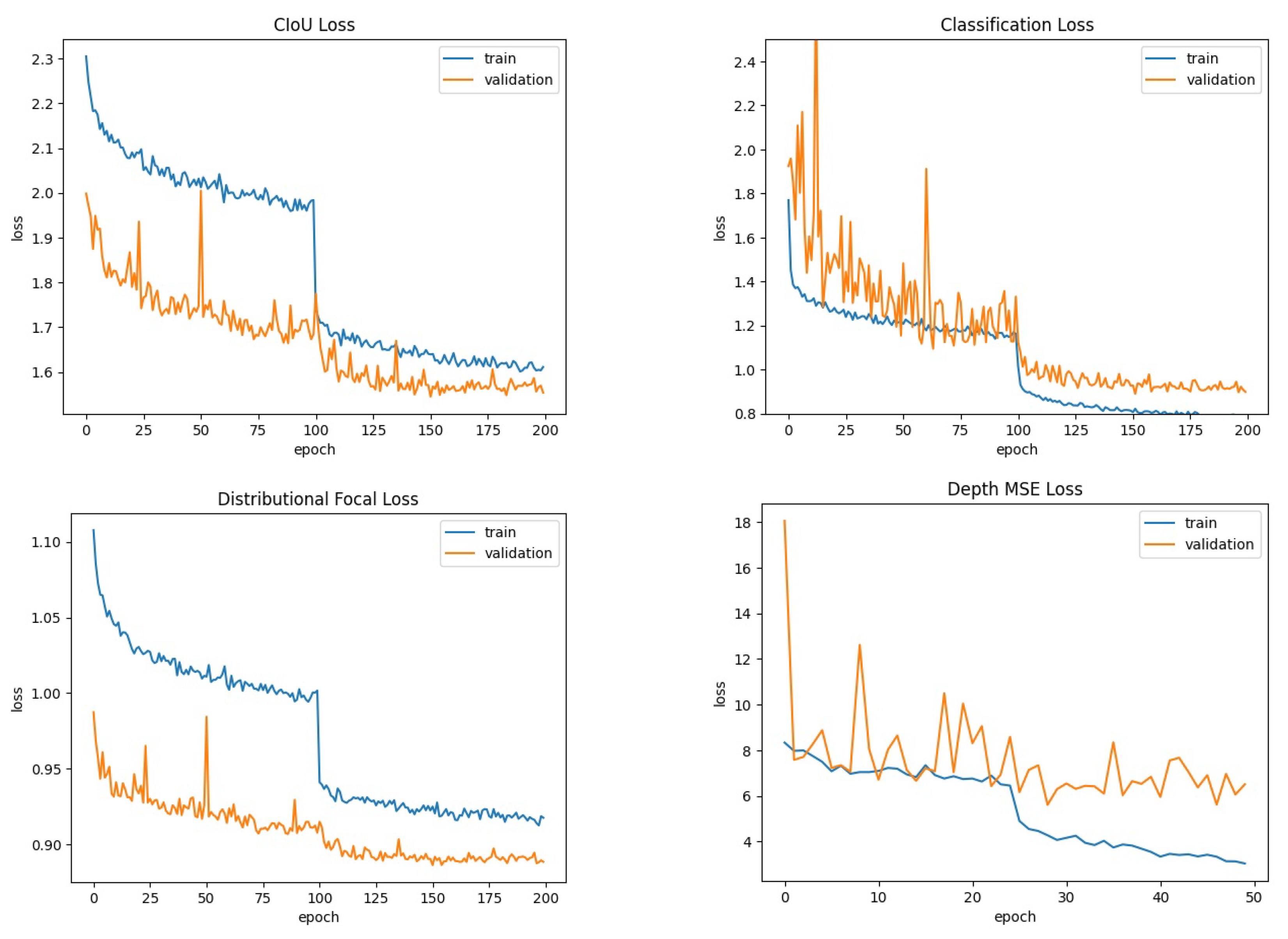
4.1. Common Objects Detection: COCO
- Three warm-up epochs with a linear learning rate schedule from 0.0001 to 0.001.
- A cosine annealing factor from 0.001 to 0.0001.
- For object detection: 140 training epochs. MixUp: first 50 epochs. Mosaic: first 120 epochs.
- For depth estimation: 50 training epochs. MixUp: none. Mosaic: first 25 epochs.
4.2. Fruit Detection: MinneApple
- Three warm-up epochs with a linear learning rate schedule from 0.0001 to 0.001.
- A cosine annealing factor from 0.001 to 0.0001.
- For object detection: 200 training epochs. MixUp: first 100 epochs. Mosaic: not applied.
- For depth estimation: 50 training epochs. MixUp: none. Mosaic: first 25 epochs.
4.2.1. Improving Generalization
4.2.2. Quantization
- Initialize the DOD with the weights of the best-trained version.
- Create a quantizable version of the DOD by specifying the operations to be quantized using Pytorch’s Quant/DeQuant placement methods [82]. The library only supports quantizing the following operations: 2D convolution, batch normalization, linear layer, and rectified linear unit (ReLU) activation. The architecture proposed in this work (see Figure 2) uses the sigmoid linear unit (SiLU) activation function for its superior performance in the state of the art compared to ReLU. Therefore, the only quantizable operations in the proposed model are 2D convolutions and their batch normalization.
- Copy the weights of all operations from the DOD in 32-bit floating-point precision to the quantizable model.
- Calibrate the quantized model using a small number of inference steps on the validation dataset. This is performed to identify the operating ranges of quantized operations and assign the most optimal variable type for storing each weight and operation.
4.3. Ablation Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jahan, N.; Akilan, T.; Phalke, A.R. Machine Learning for Global Food Security: A Concise Overview. In Proceedings of the 2022 IEEE International Humanitarian Technology Conference (IHTC), Ottawa, ON, Canada, 2–4 December 2022; pp. 63–68. [Google Scholar] [CrossRef]
- Kiruthiga, C.; Dharmarajan, K. Machine Learning in Soil Borne Diseases, Soil Data Analysis & Crop Yielding: A Review. In Proceedings of the 2023 International Conference on Intelligent and Innovative Technologies in Computing, Electrical and Electronics (IITCEE), Bengaluru, India, 27–28 January 2023; pp. 702–706. [Google Scholar] [CrossRef]
- Kolhe, P.; Kalbande, K.; Deshmukh, A. Internet of Thing and Machine Learning Approach for Agricultural Application: A Review. In Proceedings of the 2022 10th International Conference on Emerging Trends in Engineering and Technology—Signal and Information Processing (ICETET-SIP-22), Nagpur, India, 29–30 April 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Basharat, A.; Mohamad, M.M.B. Security Challenges and Solutions for Internet of Things based Smart Agriculture: A Review. In Proceedings of the 2022 4th International Conference on Smart Sensors and Application (ICSSA), Kuala Lumpur, Malaysia, 26–28 July 2022; pp. 102–107. [Google Scholar] [CrossRef]
- Ranganathan, V.; Kumar, P.; Kaur, U.; Li, S.H.; Chakraborty, T.; Chandra, R. Re-Inventing the Food Supply Chain with IoT: A Data-Driven Solution to Reduce Food Loss. IEEE Internet Things Mag. 2022, 5, 41–47. [Google Scholar] [CrossRef]
- Bini, D.; Pamela, D.; Prince, S. Machine Vision and Machine Learning for Intelligent Agrobots: A review. In Proceedings of the 2020 5th International Conference on Devices, Circuits and Systems (ICDCS), Coimbatore, India, 5–6 March 2020; pp. 12–16. [Google Scholar] [CrossRef]
- Shahrooz, M.; Talaeizadeh, A.; Alasty, A. Agricultural Spraying Drones: Advantages and Disadvantages. In Proceedings of the 2020 Virtual Symposium in Plant Omics Sciences (OMICAS), Colombia, India, 23–27 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sharma, M.; Hema, N. Comparison of Agricultural Drones and Challenges in Implementation: A Review. In Proceedings of the 2021 7th International Conference on Signal Processing and Communication (ICSC), Noida, India, 25–27 November 2021; pp. 26–30. [Google Scholar] [CrossRef]
- Zhang, X.; Cao, Z.; Dong, W. Overview of Edge Computing in the Agricultural Internet of Things: Key Technologies, Applications, Challenges. IEEE Access 2020, 8, 141748–141761. [Google Scholar] [CrossRef]
- United Nations Department of Economic and Social Affairs, Population Division. World Population Prospects 2022: Summary of Results; Technical Report; Population Division, Department of Economic and Social Affairs, United Nations: New York, NY, USA, 2022; Available online: https://www.un.org/development/desa/pd/sites/www.un.org.development.desa.pd/files/undesa_pd_2022_wpp_key-messages.pdf (accessed on 21 January 2024).
- Briones-Vozmediano, E.; González-González, A. Explotación y precariedad sociolaboral, la realidad de las personas migrantes trabajadoras en agricultura en España. Arch. Prevención Riesgos Laborales 2022, 25, 18–24. [Google Scholar] [CrossRef] [PubMed]
- FAO. “Digital Action” @ WSIS Forum 2023: FAO Takes Stock of Agrifood Systems Transformation for SDGs. 2023. Available online: https://www.fao.org/e-agriculture/news/digital-action%E2%80%9D-wsis-forum-2023-fao-takes-stock-agrifood-systems-transformation-sdgs (accessed on 21 January 2024).
- Nanda, A.; Swain, K.K.; Reddy, K.S.; Agarwal, R. sTransporter: An Autonomous Robotics System for Collecting Fresh Fruit Crates for the betterment of the Post Harvest Handling Process. In Proceedings of the 2020 6th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 6–7 March 2020; pp. 577–582. [Google Scholar] [CrossRef]
- Arikapudi, R.; Vougioukas, S.G. Robotic Tree-Fruit Harvesting with Telescoping Arms: A Study of Linear Fruit Reachability Under Geometric Constraints. IEEE Access 2021, 9, 17114–17126. [Google Scholar] [CrossRef]
- Elfferich, J.F.; Dodou, D.; Santina, C.D. Soft Robotic Grippers for Crop Handling or Harvesting: A Review. IEEE Access 2022, 10, 75428–75443. [Google Scholar] [CrossRef]
- Qiu, A.; Young, C.; Gunderman, A.L.; Azizkhani, M.; Chen, Y.; Hu, A.P. Tendon-Driven Soft Robotic Gripper with Integrated Ripeness Sensing for Blackberry Harvesting. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 11831–11837. [Google Scholar] [CrossRef]
- Mail, M.F.; Maja, J.M.; Marshall, M.; Cutulle, M.; Miller, G.; Barnes, E. Agricultural Harvesting Robot Concept Design and System Components: A Review. AgriEngineering 2023, 5, 777–800. [Google Scholar] [CrossRef]
- Droukas, L.; Doulgeri, Z.; Tsakiridis, N.L.; Triantafyllou, D.; Kleitsiotis, I.; Mariolis, I.; Giakoumis, D.; Tzovaras, D.; Kateris, D.; Bochtis, D. A Survey of Robotic Harvesting Systems and Enabling Technologies. J. Intell. Robot. Syst. 2023, 107, 21. [Google Scholar] [CrossRef]
- Dai, Q.; Cheng, X.; Qiao, Y.; Zhang, Y. Agricultural Pest Super-Resolution and Identification with Attention Enhanced Residual and Dense Fusion Generative and Adversarial Network. IEEE Access 2020, 8, 81943–81959. [Google Scholar] [CrossRef]
- Yamamoto, K.; Togami, T.; Yamaguchi, N. Super-Resolution of Plant Disease Images for the Acceleration of Image-based Phenotyping and Vigor Diagnosis in Agriculture. Sensors 2017, 17, 2557. [Google Scholar] [CrossRef]
- Liu, J.; Yu, S.; Liu, X.; Lu, G.; Xin, Z.; Yuan, J. Super-Resolution Semantic Segmentation of Droplet Deposition Image for Low-Cost Spraying Measurement. Agriculture 2024, 14, 106. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Zhang, R. Fruit Detection and Recognition Based on Deep Learning for Automatic Harvesting: An Overview and Review. Agronomy 2023, 13, 1625. [Google Scholar] [CrossRef]
- Kang, H.; Zhou, H.; Chen, C. Visual Perception and Modeling for Autonomous Apple Harvesting. IEEE Access 2020, 8, 62151–62163. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, H.; Lee, E.; Kwon, H.; Bhattacharyya, S. Exploiting Simplified Depth Estimation for Stereo-based 2D Object Detection. In Proceedings of the 2022 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 11–13 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Mirbod, O.; Choi, D.; Heinemann, P.H.; Marini, R.P.; He, L. On-tree apple fruit size estimation using stereo vision with deep learning-based occlusion handling. Biosyst. Eng. 2023, 226, 27–42. [Google Scholar] [CrossRef]
- Usman, M.; Ling, Q. Point-pixel fusion for object detection and depth estimation. In Proceedings of the 2022 41st Chinese Control Conference (CCC), Heifei, China, 25–27 July 2022; pp. 5458–5462. [Google Scholar] [CrossRef]
- Wang, H.M.; Lin, H.Y.; Chang, C.C. Object Detection and Depth Estimation Approach Based on Deep Convolutional Neural Networks. Sensors 2021, 21, 4755. [Google Scholar] [CrossRef]
- Fan, C.; Yin, Z.; Huang, X.; Li, M.; Wang, X.; Li, H. Faster 3D Reconstruction by Fusing 2D Object Detection and Self-Supervised Monocular Depth Estimation. In Proceedings of the 2022 11th International Conference of Information and Communication Technology (ICTech)), Wuhan, China, 4–6 February 2022; pp. 492–497. [Google Scholar] [CrossRef]
- Coll-Ribes, G.; Torres-Rodríguez, I.J.; Grau, A.; Guerra, E.; Sanfeliu, A. Accurate detection and depth estimation of table grapes and peduncles for robot harvesting, combining monocular depth estimation and CNN methods. Comput. Electron. Agric. 2023, 215, 108362. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8. 2023. Available online: https://docs.ultralytics.com (accessed on 21 January 2024).
- Ranftl, R.; Bochkovskiy, A.; Koltun, V. Vision Transformers for Dense Prediction. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Ranftl, R.; Lasinger, K.; Hafner, D.; Schindler, K.; Koltun, V. Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-Shot Cross-Dataset Transfer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1623–1637. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Häni, N.; Roy, P.; Isler, V. MinneApple: A Benchmark Dataset for Apple Detection and Segmentation. IEEE Robot. Autom. Lett. 2020, 5, 852–858. [Google Scholar] [CrossRef]
- Scharstein, D.; Szeliski, R.; Zabih, R. A taxonomy and evaluation of dense two-frame stereo correspondence algorithms. In Proceedings of the IEEE Workshop on Stereo and Multi-Baseline Vision (SMBV 2001), Kauai, HI, USA, 9–10 December 2001; pp. 131–140. [Google Scholar] [CrossRef]
- Szeliski, R. Computer Vision —Algorithms and Applications, 2nd ed.; Texts in Computer Science; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar] [CrossRef]
- Bazrafkan, S.; Javidnia, H.; Lemley, J.; Corcoran, P. Semiparallel deep neural network hybrid architecture: First application on depth from monocular camera. J. Electron. Imaging 2018, 27, 043041. [Google Scholar] [CrossRef]
- Kuznietsov, Y.; Stückler, J.; Leibe, B. Semi-Supervised Deep Learning for Monocular Depth Map Prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2215–2223. [Google Scholar] [CrossRef]
- Masoumian, A.; Rashwan, H.A.; Cristiano, J.; Asif, M.S.; Puig, D. Monocular Depth Estimation Using Deep Learning: A Review. Sensors 2022, 22, 5353. [Google Scholar] [CrossRef]
- Park, C.; Kim, H.; Kim, M.; Sung, J.; Paik, J. Monocular 3D Object Detection of Moving Objects Using Random Sampling and Deep Layer Aggregation. In Proceedings of the 2023 IEEE International Conference on Consumer Electronics (ICCE), Berlin, Germany, 2–5 September 2023; pp. 1–2. [Google Scholar] [CrossRef]
- Wang, H.M.; Lin, H.Y. A Real-Time Forward Collision Warning Technique Incorporating Detection and Depth Estimation Networks. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 1966–1971. [Google Scholar] [CrossRef]
- Kato, H.; Nagata, F.; Murakami, Y.; Koya, K. Partial Depth Estimation with Single Image Using YOLO and CNN for Robot Arm Control. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–9 August 2022; pp. 1727–1731. [Google Scholar] [CrossRef]
- Pogaru, S.; Bose, A.; Elliott, D.; O’Keefe, J. Multiple Object Association Incorporating Object Tracking, Depth, and Velocity Analysis on 2D Videos. In Proceedings of the SoutheastCon 2021, Atlanta, GA, USA, 10–13 March 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Xu, C.; Huang, B.; Elson, D.S. Self-Supervised Monocular Depth Estimation with 3-D Displacement Module for Laparoscopic Images. IEEE Trans. Med. Robot. Bionics 2022, 4, 331–334. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.; Wang, Y.; Hou, F.; Yuan, J.; Tian, J.; Zhang, Y.; Shi, Z.; Fan, J.; He, Z. A Survey of Visual Transformers. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–21. [Google Scholar] [CrossRef]
- Zhao, W.; Rao, Y.; Liu, Z.; Liu, B.; Zhou, J.; Lu, J. Unleashing Text-to-Image Diffusion Models for Visual Perception. arXiv 2023, arXiv:2303.02153. [Google Scholar]
- Peluso, V.; Cipolletta, A.; Calimera, A.; Poggi, M.; Tosi, F.; Aleotti, F.; Mattoccia, S. Monocular Depth Perception on Microcontrollers for Edge Applications. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1524–1536. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A Comprehensive Review of YOLO: From YOLOv1 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar]
- Zhang, C.; Zhang, C.; Li, C.; Qiao, Y.; Zheng, S.; Dam, S.K.; Zhang, M.; Kim, J.U.; Kim, S.T.; Choi, J.; et al. One Small Step for Generative AI, One Giant Leap for AGI: A Complete Survey on ChatGPT in AIGC Era. arXiv 2023, arXiv:2304.06488. [Google Scholar]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Zhang, C.; Han, D.; Qiao, Y.; Kim, J.U.; Bae, S.H.; Lee, S.; Hong, C.S. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications. arXiv 2023, arXiv:2306.14289. [Google Scholar]
- Häni, N.; Roy, P.; Isler, V. A comparative study of fruit detection and counting methods for yield mapping in apple orchards. J. Field Robot. 2019, 37, 263–282. [Google Scholar] [CrossRef]
- Häni, N.; Roy, P.; Isler, V. Apple Counting using Convolutional Neural Networks. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 2559–2565. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Xiang, A.J.; Huddin, A.B.; Ibrahim, M.F.; Hashim, F.H. An Oil Palm Loose Fruits Image Detection System using Faster R -CNN and Jetson TX2. In Proceedings of the 2021 International Conference on Electrical Engineering and Informatics (ICEEI), Kuala Terengganu, Malaysia, 12–13 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Nagaraju, Y.; Venkatesh; Venugopal, K.R. A Fruit Detection Method for Vague Environment High-Density Fruit Orchards. In Proceedings of the 2022 IEEE 3rd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 7–9 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Jocher, G.; Stoken, A.; Chaurasia, A.; Borovec, J.; NanoCode012; Xie, T.; Kwon, Y.; Michael, K.; Changyu, L.; Fang, J.; et al. ultralytics/yolov5: v6.0—YOLOv5n ’Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support. 2021. Available online: https://doi.org/10.5281/zenodo.5563715 (accessed on 21 January 2024).
- Wu, Z.; Sun, X.; Jiang, H.; Mao, W.; Li, R.; Andriyanov, N.; Soloviev, V.; Fu, L. NDMFCS: An automatic fruit counting system in modern apple orchard using abatement of abnormal fruit detection. Comput. Electron. Agric. 2023, 211, 108036. [Google Scholar] [CrossRef]
- Ning, M.; Lu, Y.; Hou, W.; Matskin, M. YOLOv4-object: An Efficient Model and Method for Object Discovery. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain,, 12–16 July 2021; pp. 31–36. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets Robotics: The KITTI Dataset. Int. J. Robot. Res. (IJRR) 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. In Proceedings of the Computer Vision – ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Cham, Switzerland, 2014; pp. 346–361. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing Network Design Strategies Through Gradient Path Analysis. arXiv 2022, arXiv:2211.04800. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, ICML’15, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-Weighted Linear Units for Neural Network Function Approximation in Reinforcement Learning. arXiv 2017, arXiv:1702.03118. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the Difficulty of Training Recurrent Neural Networks. In Proceedings of the 30th International Conference on International Conference on Machine Learning, ICML’13, Atlanta, GE, USA, 16–21 June 2013; Volume 28, pp. III-1310–III-1318. [Google Scholar]
- Wang, C.Y.; Mark Liao, H.Y.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar] [CrossRef]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Li, X.; Lv, C.; Wang, W.; Li, G.; Yang, L.; Yang, J. Generalized Focal Loss: Towards Efficient Representation Learning for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3139–3153. [Google Scholar] [CrossRef]
- Feng, C.; Zhong, Y.; Gao, Y.; Scott, M.R.; Huang, W. TOOD: Task-Aligned One-Stage Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 3490–3499. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12993–13000. [Google Scholar] [CrossRef]
- Zhang, H.; Cissé, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Ciaglia, F.; Zuppichini, F.S.; Guerrie, P.; McQuade, M.; Solawetz, J. Roboflow 100: A Rich, Multi-Domain Object Detection Benchmark. arXiv 2022, arXiv:2211.13523, arXiv:2211.13523. [Google Scholar]
- Raspberry Pi Foundation. Raspberry Pi. 2023. Available online: https://www.raspberrypi.org/ (accessed on 21 August 2023).
- Gay, W. Raspberry Pi Hardware Reference, 1st ed.; Apress: New York City, NY, USA, 2014. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Reddi, S.J.; Kale, S.; Kumar, S. On the Convergence of Adam and Beyond. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS-W, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dukhan, M.; Wu, Y.; Lu, H.; Maher, B. QNNPACK: Quantized Neural Network PACKage. 2019. Available online: https://github.com/pytorch/QNNPACK (accessed on 22 August 2023).
- Ahn, H.; Chen, T.; Alnaasan, N.; Shafi, A.; Abduljabbar, M.; Subramoni, H.; Panda, D. Performance Characterization of using Quantization for DNN Inference on Edge Devices: Extended Version. In Proceedings of the IEEE ICFEC 2023, Bengaluru, India, 30–31 January 2023. [Google Scholar]
- Meyes, R.; Lu, M.; de Puiseau, C.W.; Meisen, T. Ablation Studies in Artificial Neural Networks. arXiv 2019, arXiv:1901.0864. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P (%) | R (%) | mAP 50 (%) | mAP 50–95 (%) | MSE Depth | Vel. CPU * (fps) | Vel. GPU * (fps) | Parameters (M) | Size (MB) |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv8n | 59.3 | 39.7 | 42.8 | 29.3 | - | 47.3 | 83.8 | 3.15 | 6.23 |
| DOD | 41.3 | 25.9 | 24.3 | 12.3 | 59.3 | 57.1 | 84.7 | 1.06 | 4.24 |
| Model | P (%) | R (%) | mAP 50 (%) | mAP 50–95 (%) | MSE Depth | Parameters (M) |
|---|---|---|---|---|---|---|
| DOD * | 73.7 | 60.8 | 68.5 | 35.7 | 9.4 | 1.1 |
| DOD ** | 68.6 | 58.1 | 62.4 | 31.9 | 8.5 | 1.1 |
| TF-RCNN | - | - | 63.9 | 34.1 | - | ≈41 |
| F-RCNN | - | - | 77.5 | 43.8 | - | ≈41 |
| M-RCNN | - | - | 76.3 | 43.4 | - | ≈63 |
| Model | P (%) | R (%) | mAP 50 (%) | mAP 50–95 (%) | MSE Depth | Vel. AMD * (fps) | Vel. ARM ** (fps) | Parameters (M) | Size (MB) |
|---|---|---|---|---|---|---|---|---|---|
| DOD (fp32) | 68.6 | 58.1 | 62.4 | 31.9 | 8.5 | 27.2 | 2.14 | 1.04 | 4.18 |
| DOD (int8) | 67.2 | 57.8 | 61.4 | 30.4 | 9.3 | 33.6 | 2.34 | 1.04 | 1.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaramillo-Hernández, J.F.; Julian, V.; Marco-Detchart, C.; Rincón, J.A. Application of Machine Vision Techniques in Low-Cost Devices to Improve Efficiency in Precision Farming. Sensors 2024, 24, 937. https://doi.org/10.3390/s24030937
Jaramillo-Hernández JF, Julian V, Marco-Detchart C, Rincón JA. Application of Machine Vision Techniques in Low-Cost Devices to Improve Efficiency in Precision Farming. Sensors. 2024; 24(3):937. https://doi.org/10.3390/s24030937
Chicago/Turabian StyleJaramillo-Hernández, Juan Felipe, Vicente Julian, Cedric Marco-Detchart, and Jaime Andrés Rincón. 2024. "Application of Machine Vision Techniques in Low-Cost Devices to Improve Efficiency in Precision Farming" Sensors 24, no. 3: 937. https://doi.org/10.3390/s24030937
APA StyleJaramillo-Hernández, J. F., Julian, V., Marco-Detchart, C., & Rincón, J. A. (2024). Application of Machine Vision Techniques in Low-Cost Devices to Improve Efficiency in Precision Farming. Sensors, 24(3), 937. https://doi.org/10.3390/s24030937