


Explainable Machine Learning for LoRaWAN Link Budget Analysis and Modeling




Abstract
1. Introduction
- (a)
- Critical analysis of the latest AI advancements in the area of propagation modeling.
- (b)
- Comparing the efficiency of AI algorithms for propagation modeling using LoRaWAN practical measurements from multiple transmitters.
- (c)
- Develop an explainable and efficient AI-based model for LoRaWAN propagation estimation.
- (d)
- Using the explainability of AI to provide further insight into deterministic feature engineering and propagation mechanisms of LoRa.
2. AI for Propagation Modeling
- Adaptability: can adapt to different scenarios and technologies such as LPWAN and particularly LoRaWAN, making them suitable for various applications, from urban to rural areas and indoor spaces;
- Accuracy: can outperform empirical models in their accuracy as they learn from real-world data while using environmental information to their advantage;
- Cost and time efficiency: can reduce the time required to generate a propagation estimation.
2.1. Machine Learning for Propagation Modeling
2.2. Deep Learning for Propagation Modeling
2.3. Comparison between DL and ML Approaches
2.3.1. Training and Overfitting
2.3.2. Dataset Origin and Integrity
2.3.3. Reliability and Accuracy
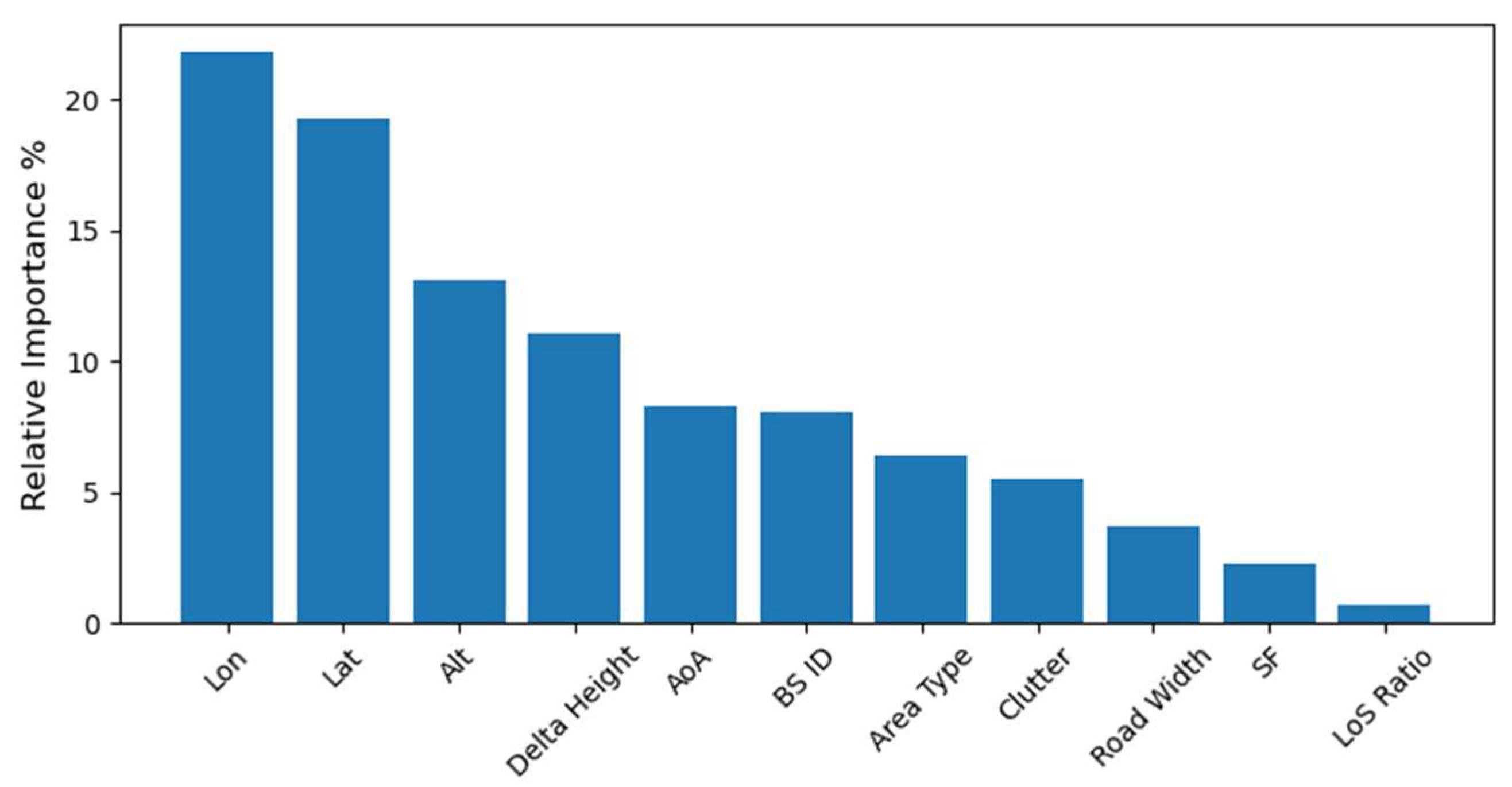
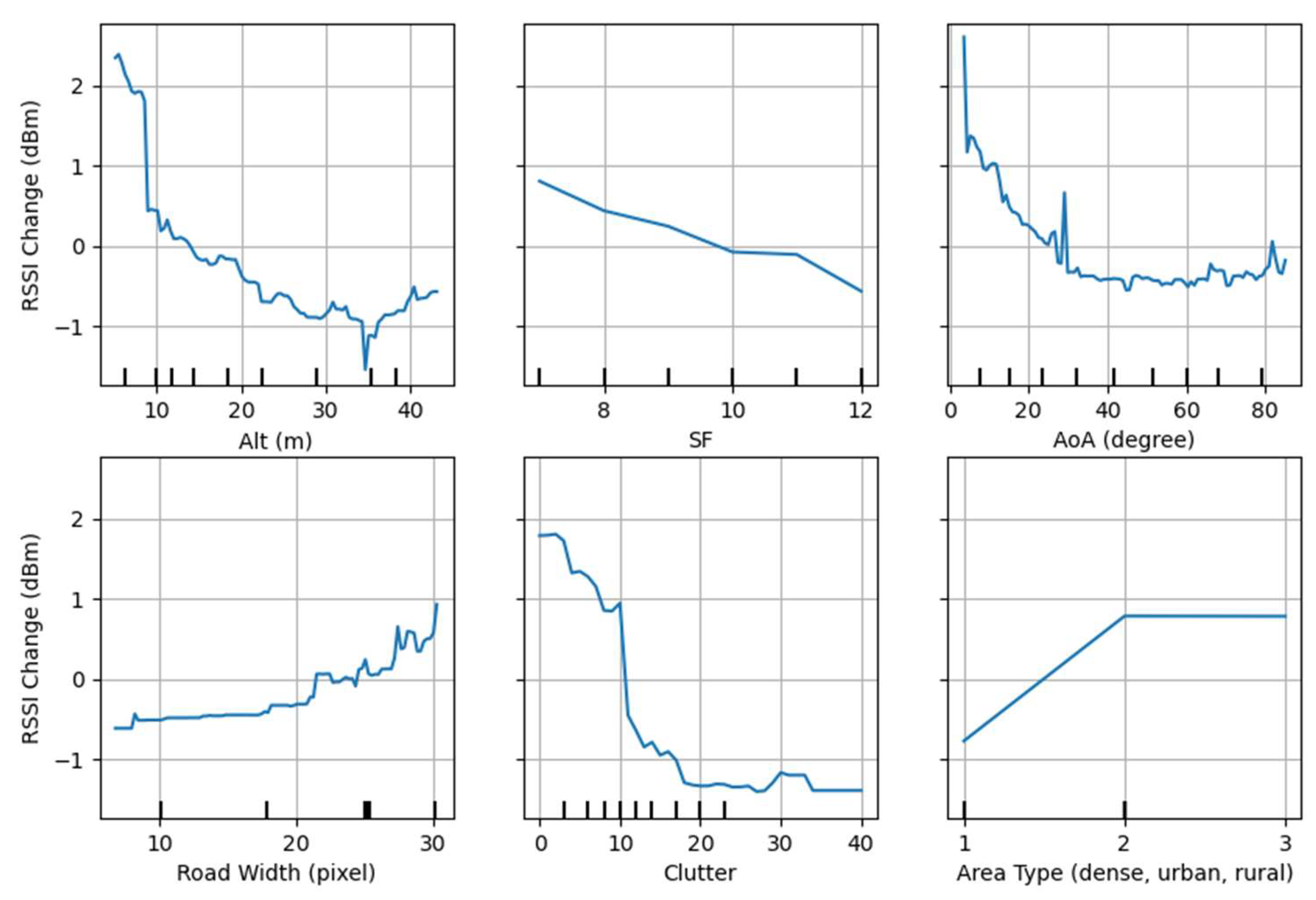
2.3.4. Feature Engineering
3. Implementation and Results
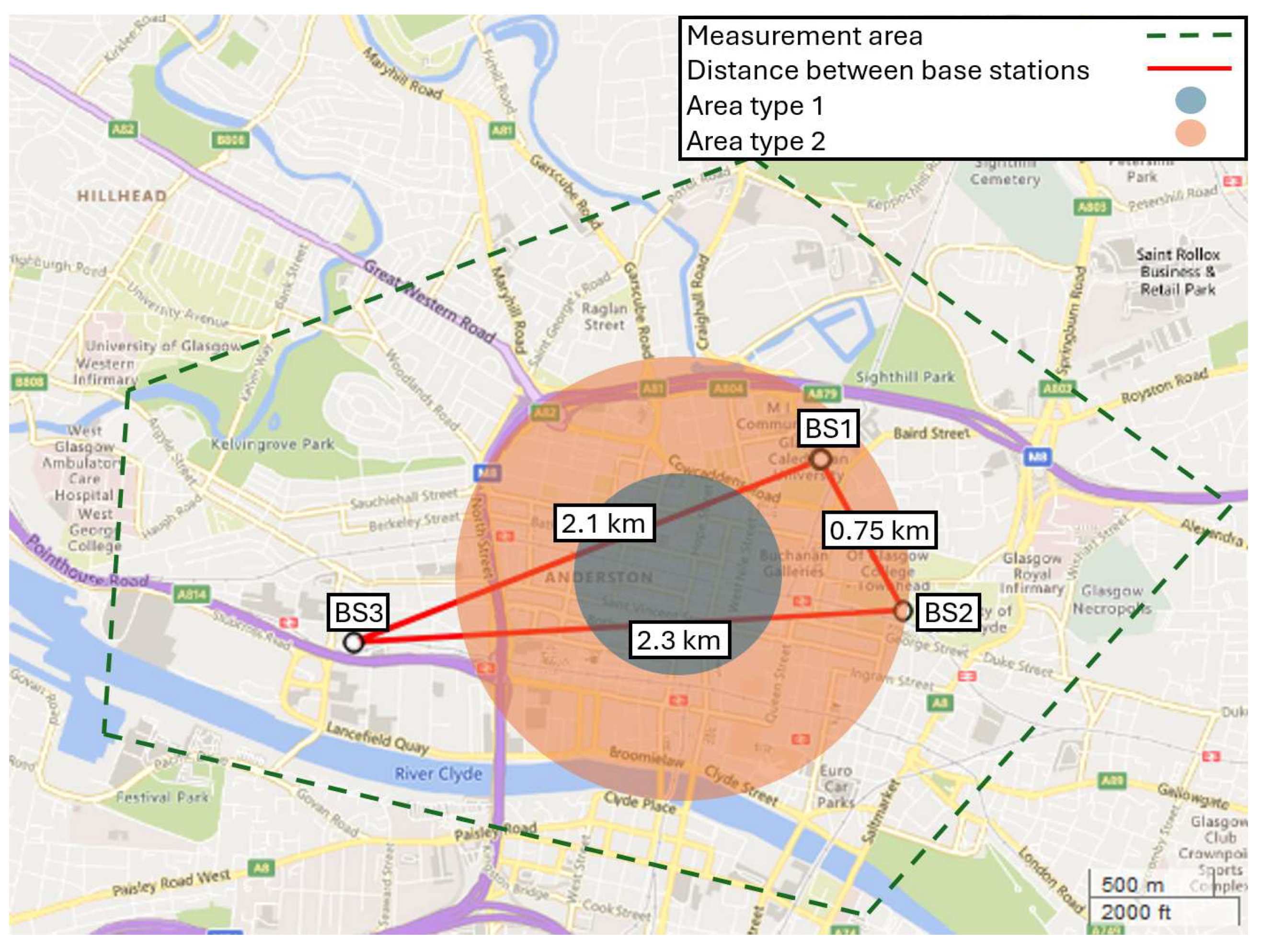
3.1. Dataset and Topographical Features
- SF: LoRa’s spreading factor that varies from 7 to 12;
- Height difference: altitude difference between the transmitter and receiver;
- Lat, Lon, Alt: latitude, longitude, and altitude of the MS, acquired from GPS;
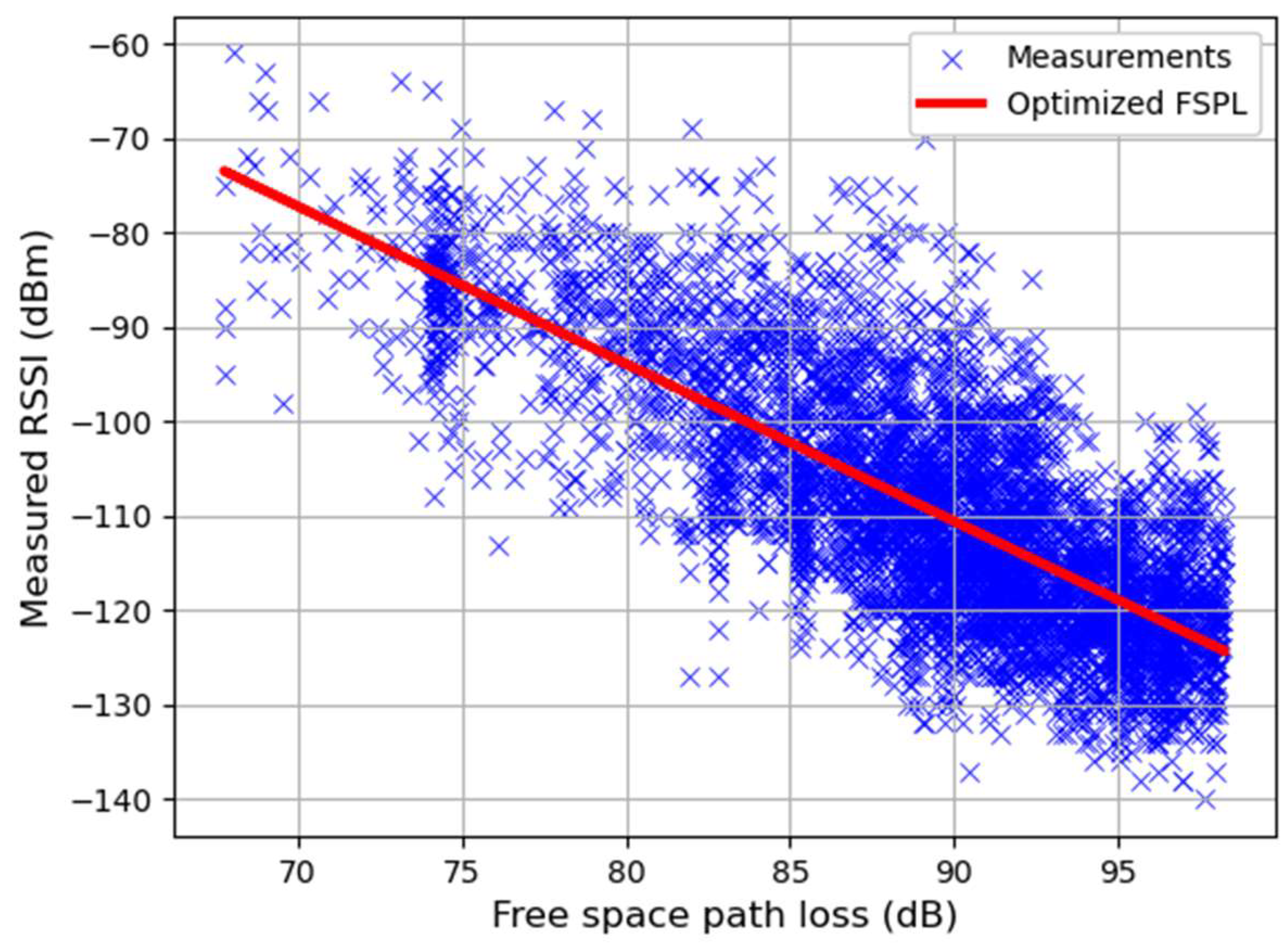
- FSPL: free-space path loss (FSPL) calculated using the distance between the BS and the MS, transmission wavelength m, frequency MHz;
- Clutter: calculated from the number of buildings on the Rx-Tx direct path;
- Road width: relative width of the street;
- AoA: acute angle of the LoS and the road axis;
- LoS ratio: clear the LoS ratio relative to ; this is a non-zero value when part of LoS is over the river;
- BS ID: base station identification BS-ID (BS1, BS2, BS3);
- Area Type: terrain type, (dense-urban = 1, urban = 2, open-urban = 3)
3.2. Model Selection
3.3. Data Analysis and Result
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Statista. IoT Devices Installed Base Worldwide. Available online: https://www.statista.com/statistics/471264/iot-number-of-connected-devices-worldwide (accessed on 27 December 2023).
- Lu, Y. Artificial intelligence: A survey on evolution, models, applications and future trends. J. Manag. Anal. 2019, 6, 1–29. [Google Scholar] [CrossRef]
- Sundaram, J.P.S.; Du, W.; Zhao, Z. A survey on lora networking: Research problems, current solutions, and open issues. IEEE Commun. Surv. Tutor. 2019, 22, 371–388. [Google Scholar] [CrossRef]
- Xia, X.; Chen, Q.; Hou, N.; Zheng, Y.; Li, M. XCopy: Boosting Weak Links for Reliable LoRa Communication. In Proceedings of the ACM MobiCom’23: The 29th Annual International Conference on Mobile Computing and Networking, Madrid, Spain, 2–6 October 2023. [Google Scholar]
- Zhang, H.; Song, Y.; Yang, M.; Jia, Q. Modeling and Optimization of LoRa Networks under Multiple Constraints. Sensors 2023, 23, 7783. [Google Scholar] [CrossRef] [PubMed]
- Tong, S.; Wang, J. Designing, Building, and Characterizing Large-Scale LoRa Networks for Smart City Applications. In Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, Madrid, Spain, 2–6 October 2023. [Google Scholar]
- El Chall, R.; Lahoud, S.; El Helou, M. LoRaWAN network: Radio propagation models and performance evaluation in various environments in Lebanon. IEEE Internet Things J. 2019, 6, 2366–2378. [Google Scholar] [CrossRef]
- Hossain, M.I.; Markendahl, J.I. Comparison of LPWAN technologies: Cost structure and scalability. Wirel. Pers. Commun. 2021, 121, 887–903. [Google Scholar] [CrossRef]
- Bor, M.C.; Roedig, U.; Voigt, T.; Alonso, J.M. Do LoRa low-power wide-area networks scale? In Proceedings of the 19th ACM International Conference on Modeling, Analysis and Simulation of Wireless and Mobile Systems, Marsa, Malta, 13–17 November 2016.
- Hosseinzadeh, S.; Ramzan, N.; Yousefi, M.; Curtis, K.; Larijani, H. Impact of spreading factor on LoRaWAN propagation in a metropolitan environment. In Proceedings of the 2020 International Conference on UK-China Emerging Technologies (UCET), Glasgow, UK, 20–21 August 2020. [Google Scholar]
- Farhad, A.; Pyun, J.-Y. LoRaWAN Meets ML: A Survey on Enhancing Performance with Machine Learning. Sensors 2023, 23, 6851. [Google Scholar] [CrossRef] [PubMed]
- Gava, M.A.; Rocha, H.R.O.; Faber, M.J.; Segatto, M.E.V.; Wörtche, H.; Silva, J.A.L. Optimizing Resources and Increasing the Coverage of Internet-of-Things (IoT) Networks: An Approach Based on LoRaWAN. Sensors 2023, 23, 1239. [Google Scholar] [CrossRef]
- Gregora, L.; Vojtech, L.; Neruda, M. Indoor signal propagation of LoRa technology. In Proceedings of the 2016 17th International Conference on Mechatronics-Mechatronika (ME), Prague, Czech Republic, 7–9 December 2016. [Google Scholar]
- Haxhibeqiri, J.; Karaagac, A.; Van den Abeele, F.; Joseph, W.; Moerman, I.; Hoebeke, J. LoRa indoor coverage and performance in an industrial environment: Case study. In Proceedings of the 2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Limassol, Cyprus, 12–15 September 2017. [Google Scholar]
- Bertoldo, S.; Paredes, M.; Carosso, L.; Allegretti, M.; Savi, P. Empirical indoor propagation models for LoRa radio link in an office environment. In Proceedings of the 2019 13th European Conference on Antennas and Propagation (EuCAP), Krakow, Poland, 31 March–5 April 2019. [Google Scholar]
- Hosseinzadeh, S.; Larijani, H.; Curtis, K. An enhanced modified multi wall propagation model. In Proceedings of the 2017 Global Internet of Things Summit (GIoTS), Geneva, Switzerland, 6–9 June 2017. [Google Scholar]
- Harinda, E.; Hosseinzadeh, S.; Larijani, H.; Gibson, R.M. Comparative performance analysis of empirical propagation models for lorawan 868mhz in an urban scenario. In Proceedings of the 2019 IEEE 5th World Forum on Internet of Things (WF-IoT), Limerick, Ireland, 15–18 April 2019. [Google Scholar]
- Petajajarvi, J.; Mikhaylov, K.; Roivainen, A.; Hanninen, T.; Pettissalo, M. On the coverage of LPWANs: Range evaluation and channel attenuation model for LoRa technology. In Proceedings of the 2015 14th International Conference on Its Telecommunications (ITST), Copenhagen, Denmark, 2–4 December 2015. [Google Scholar]
- Anusha, V.S.; Nithya, G.K.; Rao, S.N. A comprehensive survey of electromagnetic propagation models. In Proceedings of the 2017 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 6–8 April 2017. [Google Scholar]
- Wong, L.J.; Michaels, A.J. Transfer learning for radio frequency machine learning: A taxonomy and survey. Sensors 2022, 22, 1416. [Google Scholar] [CrossRef]
- Huang, C.; He, R.; Ai, B.; Molisch, A.F.; Lau, B.K.; Haneda, K.; Liu, B.; Wang, C.X.; Yang, M.; Oestges, C.; et al. Artificial intelligence enabled radio propagation for communications—Part II: Scenario identification and channel modeling. IEEE Trans. Antennas Propag. 2022, 70, 3955–3969. [Google Scholar] [CrossRef]
- Chiroma, H.; Nickolas, P.; Faruk, N.; Alozie, E.; Olayinka, I.F.Y.; Adewole, K.S.; Abdulkarim, A.; Oloyede, A.A.; Sowande, O.A.; Garba, S.; et al. Large scale survey for radio propagation in developing machine learning model for path losses in communication systems. Sci. Afr. 2023, 19, e01550. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Zhou, H.; Wang, F.; Yang, C. Application of artificial neural networks to the prediction of field strength in indoor environment for wireless LAN. In Proceedings of the 2005 International Conference on Wireless Communications, Networking and Mobile Computing, Wuhan, China, 26 September 2005. [Google Scholar]
- Ozdemir, A.R.; Alkan, M.; Kabak, M.; Gulsen, M.; Sazli, M.H. The prediction of propagation loss of FM radio station using artificial neural network. J. Electromagn. Anal. Appl. 2014, 6, 358. [Google Scholar] [CrossRef]
- Hosseinzadeh, S.; Almoathen, M.; Larijani, H.; Curtis, K. A neural network propagation model for LoRaWAN and critical analysis with real-world measurements. Big Data Cogn. Comput. 2017, 1, 7. [Google Scholar] [CrossRef]
- Hosseinzadeh, S.; Larijani, H.; Curtis, K.; Wixted, A. An adaptive neuro-fuzzy propagation model for LoRaWAN. Appl. Syst. Innov. 2019, 2, 10. [Google Scholar] [CrossRef]
- Van Nguyen, T.; Jeong, Y.; Shin, H.; Win, M.Z. Machine learning for wideband localization. IEEE J. Sel. Areas Commun. 2015, 33, 1357–1380. [Google Scholar] [CrossRef]
- Zhang, X.; Shu, X.; Zhang, B.; Ren, J.; Zhou, L.; Chen, X. Cellular network radio propagation modeling with deep convolutional neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020. [Google Scholar]
- Yun, S.Z.; Iskander, M.F. Ray tracing for radio propagation modeling: Principles and applications. IEEE Access 2015, 3, 1089–1100. [Google Scholar] [CrossRef]
- Levie, R.; Yapar, Ç.; Kutyniok, G.; Caire, G. RadioUNet: Fast radio map estimation with convolutional neural networks. IEEE Trans. Wirel. Commun. 2021, 20, 4001–4015. [Google Scholar] [CrossRef]
- Sotiroudis, S.P.; Goudos, S.K.; Siakavara, K. Deep learning for radio propagation: Using image-driven regression to estimate path loss in urban areas. ICT Express 2020, 6, 160–165. [Google Scholar] [CrossRef]
- Imai, T.; Kitao, K.; Inomata, M. Radio propagation prediction model using convolutional neural networks by deep learning. In Proceedings of the 2019 13th European Conference on Antennas and Propagation (EuCAP), Krakow, Poland, 31 March–5 April 2019. [Google Scholar]
- Masood, U.; Farooq, H.; Imran, A. A machine learning based 3D propagation model for intelligent future cellular networks. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Liu, L.; Yao, Y.; Cao, Z.; Zhang, M. Deeplora: Learning accurate path loss model for long distance links in LPWAN. In Proceedings of the INFOCOM, Vancouver, BC, Canada, 10–13 May 2021. [Google Scholar]
- Semtech. Product Details SX1272. Available online: https://www.semtech.com/products/wireless-rf/lora-connect/sx1272 (accessed on 27 December 2023).
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable ai: A review of machine learning interpretability methods. Entropy 2020, 23, 18. [Google Scholar] [CrossRef] [PubMed]
- Ritter, A.; Muñoz-Carpena, R. Performance evaluation of hydrological models: Statistical significance for reducing subjectivity in goodness-of-fit assessments. J. Hydrol. 2013, 480, 33–45. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A brief survey on history, research areas, approaches and challenges. In Proceedings of the Natural Language Processing and Chinese Computing: 8th CCF International Conference, NLPCC 2019, Proceedings, Part II 8, Dunhuang, China, 9–14 October 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE | NSC | |
|---|---|---|---|
| Parametric regression | Optimized FSPL | 9.01 | 0.25 |
| LR | 8.01 | 0.37 | |
| PR | 6.65 | 0.67 | |
| Advanced nonlinear | MLP | 6.85 | 0.62 |
| ANFIS | 7.16 | 0.57 | |
| Kernel based | SVM | 7.03 | 0.58 |
| RVM | 7.19 | 0.57 | |
| Instance based | KNN | 6.7 | 0.63 |
| Tree based | DT | 6.54 | 0.71 |
| Ensemble of trees | RF | 5.7 | 0.77 |
| GR | 5.53 | 0.78 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hosseinzadeh, S.; Ashawa, M.; Owoh, N.; Larijani, H.; Curtis, K. Explainable Machine Learning for LoRaWAN Link Budget Analysis and Modeling. Sensors 2024, 24, 860. https://doi.org/10.3390/s24030860
Hosseinzadeh S, Ashawa M, Owoh N, Larijani H, Curtis K. Explainable Machine Learning for LoRaWAN Link Budget Analysis and Modeling. Sensors. 2024; 24(3):860. https://doi.org/10.3390/s24030860
Chicago/Turabian StyleHosseinzadeh, Salaheddin, Moses Ashawa, Nsikak Owoh, Hadi Larijani, and Krystyna Curtis. 2024. "Explainable Machine Learning for LoRaWAN Link Budget Analysis and Modeling" Sensors 24, no. 3: 860. https://doi.org/10.3390/s24030860
APA StyleHosseinzadeh, S., Ashawa, M., Owoh, N., Larijani, H., & Curtis, K. (2024). Explainable Machine Learning for LoRaWAN Link Budget Analysis and Modeling. Sensors, 24(3), 860. https://doi.org/10.3390/s24030860