


Decentralized IoT Data Authentication with Signature Aggregation


Abstract
1. Introduction
- Data Integrity: Blockchains’ tamper-proof nature ensures that IoT data remain unaltered throughout their lifecycle, preventing unauthorized modifications or data breaches.
- Device Authentication: A blockchain can serve as a secure repository for device identities, enabling reliable authentication of IoT devices and preventing unauthorized access or data injection from malicious or compromised devices.
- Provenance Tracking: Blockchains’ ability to track data origin and movement provides traceability for IoT data, allowing for the verification of data sources and provenance.
- Our framework prioritizes data privacy by keeping sensitive IoT data confidential. Instead of allowing IoT devices to communicate directly with the blockchain, we handle all data verification through edge aggregator servers. This approach leverages Zero-Knowledge Proofs (ZKPs), enabling us to verify data without exposing the actual information, thus enhancing data privacy even further.
- Impact of different proving systems: Our exploration delves into various proving systems, examining their impact on the efficiency of proving and verification times and the sizes of the proofs required to ensure efficient data authenticity. Within our solution, we observed a shift in the performance bottleneck. It moves from the blockchain network to an off-chain system, which is particularly evident during the proving and verification stages.
- On-chain storage costs: The research also includes an assessment of the financial implications of using public blockchain networks for data storage. This component is vital to maintain a high level of decentralization and trust, providing a clear advantage over private or consortium blockchain networks. Our analysis balances the need for decentralization with the practical aspects of storage costs on public blockchains.
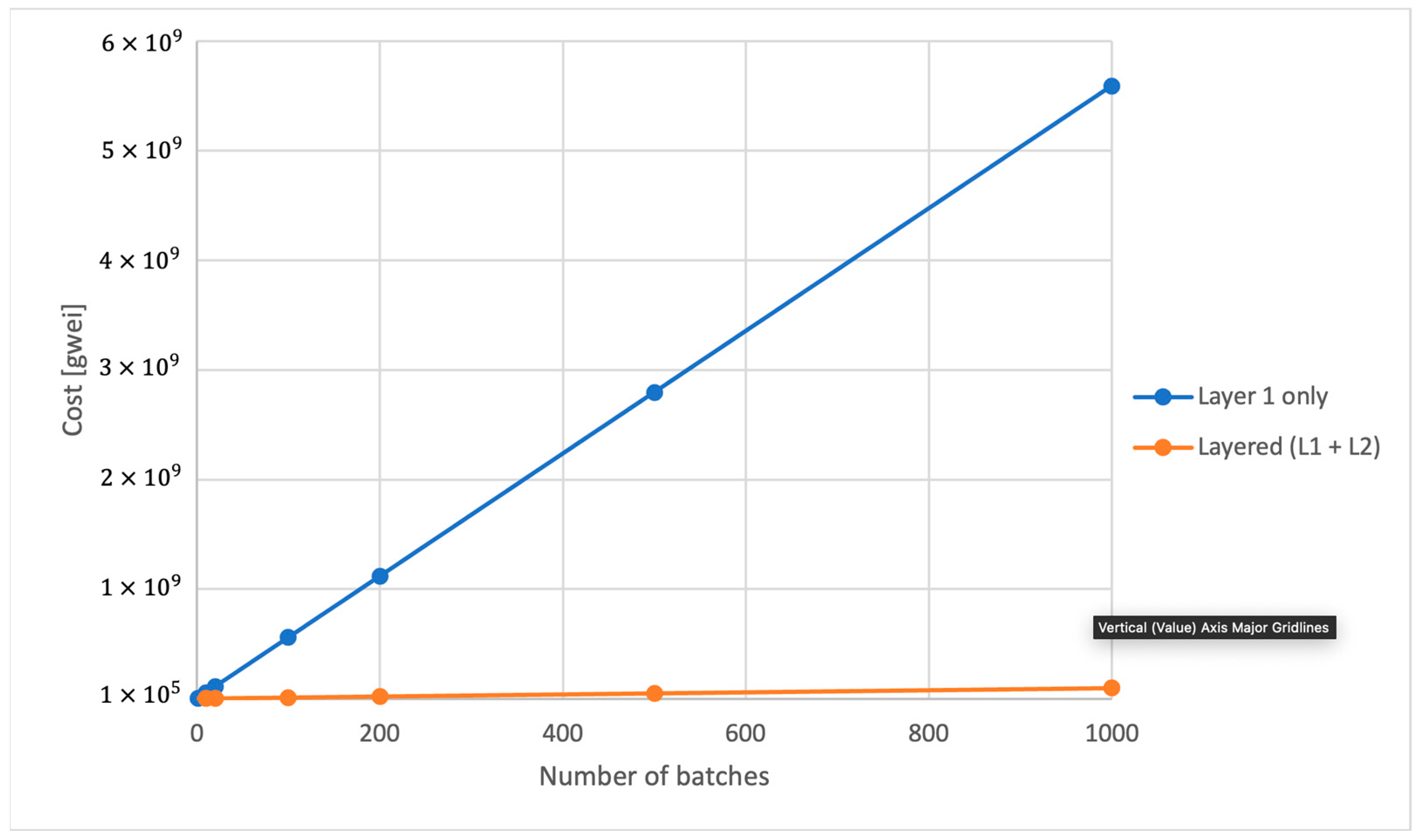
- Development of a novel framework: We introduced a unique framework that integrates edge aggregating servers with Ethereum Layer 2 rollups. This design enhances scalability and security in IoT data authentication, minimizing the need for continuous direct interactions between IoT devices and the blockchain. By recording essential information on L2 rollups, our framework ensures data verifiability and trust, creating an immutable and transparent authentication record.
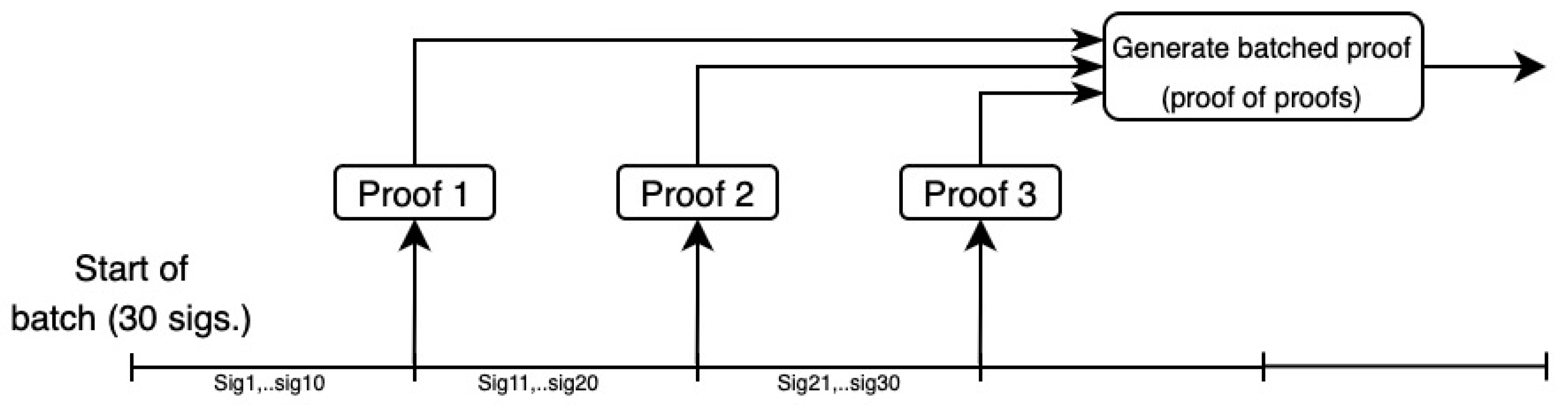
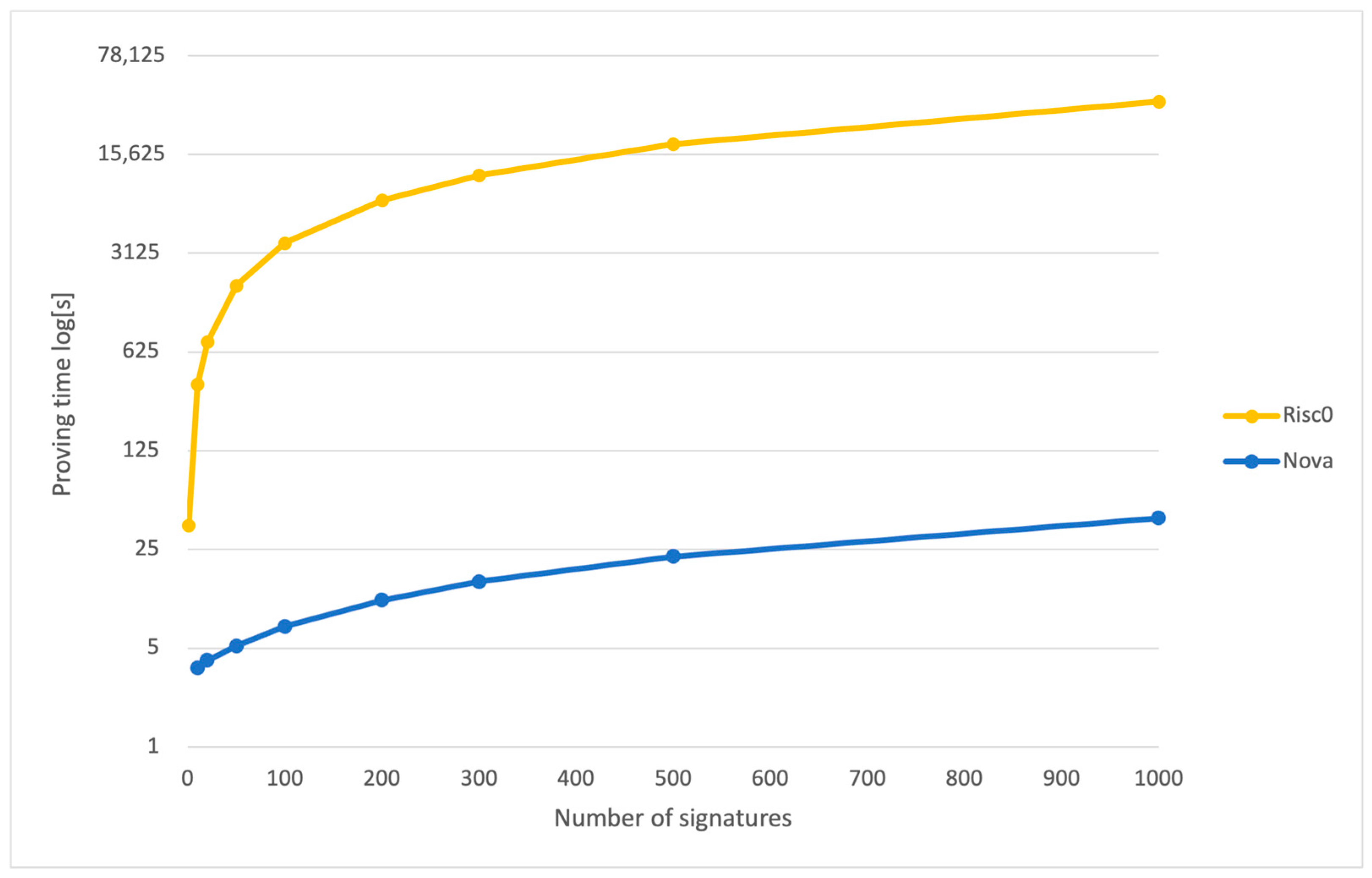
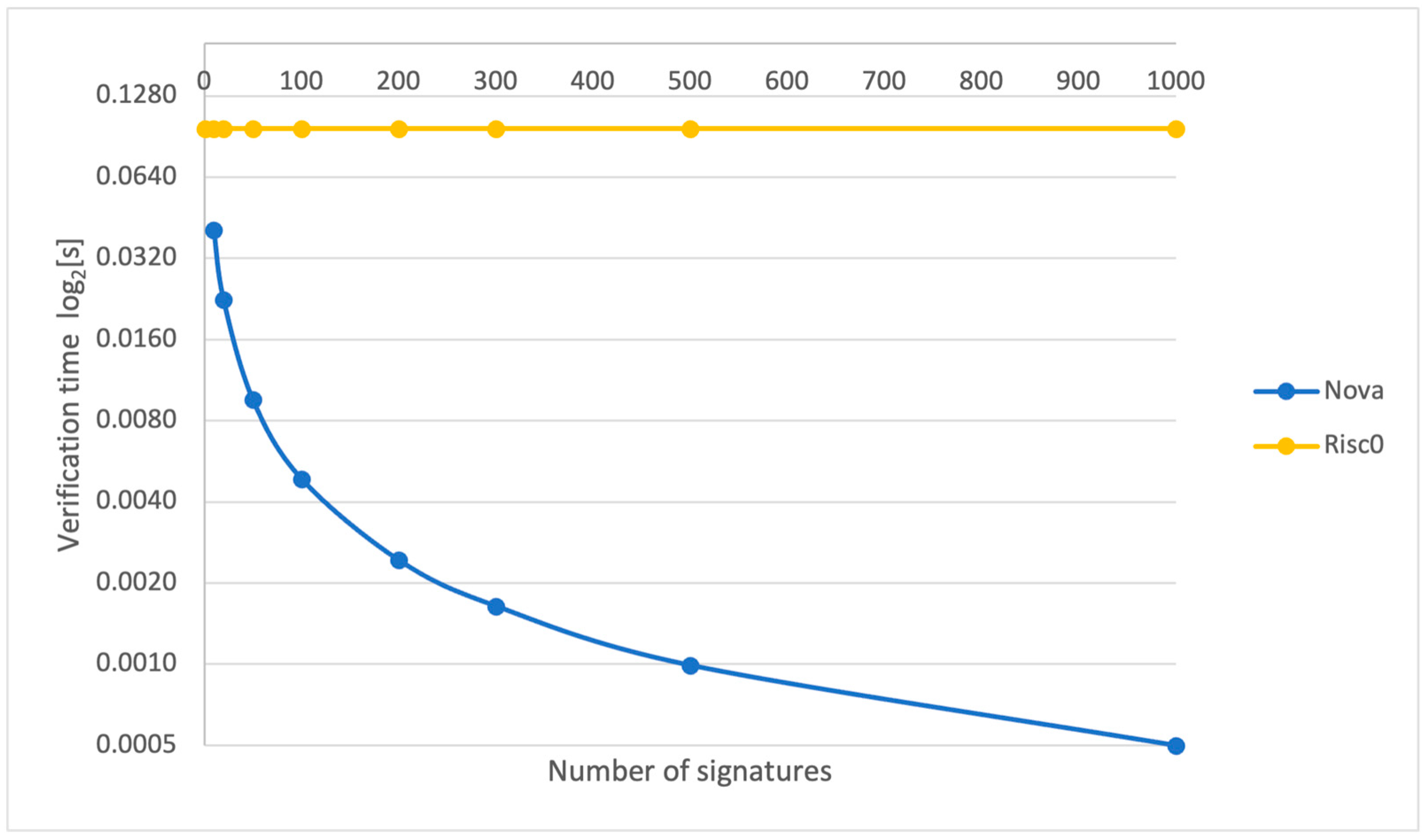
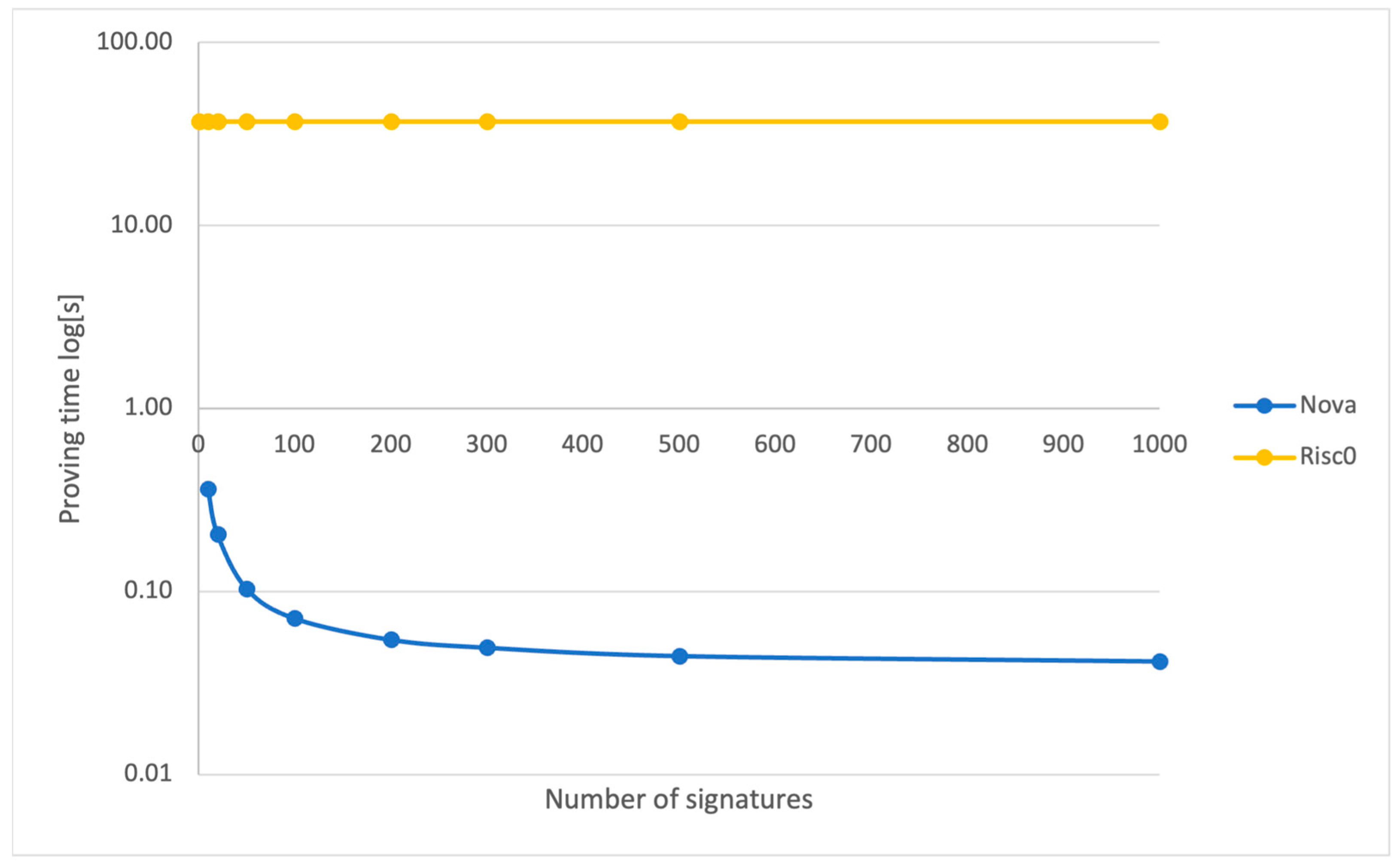
- Analysis of the viability of proving systems for our framework: Our work explored and compared the Nova and Risc0 proving systems, focusing on their efficiency in proof generation and verification times, as well as the proof sizes required for data authenticity. We discovered that employing proof recursion and compression is crucial for achieving superior performance in authentication, surpassing the efficiency of proving a single signature verification, and even outperforming methods like ECDSA batch verification.
- Cost-effective on-chain storage solutions: We assessed the financial implications of using public blockchain networks for data storage. The use of Layer 2 rollups led to significant reductions in on-chain storage costs. Our findings reveal that leveraging rollups atop public blockchains like Ethereum offers low fees while keeping us integrated within the larger, open-source public ecosystem, preventing isolation from the broader market.
2. Literature Review
2.1. Existing Approaches to IoT Data Authentication
- Device authentication (registration and identity management) : Essential for preventing rogue device infiltration and ensuring data originate from verified sources, thereby maintaining IoT ecosystem integrity [7].
- Data integrity: IoT data must remain unchanged during transmission and storage to ensure their reliability [8].
- Data privacy: Protecting the confidentiality of sensitive information collected with IoT devices [9].
Discussion of Cited Studies and Their Implications
- Limited Post-Storage Verification: Some studies focus primarily on post-storage data integrity, overlooking the critical aspect of data-origin authentication.
- Over-Reliance on Edge Servers: Certain methods depend heavily on edge servers for data authentication without a clear mechanism to verify the correctness of the work carried out, raising potential security vulnerabilities.
- Permissioned Blockchain Limitations: Some frameworks utilize permissioned blockchains, which compromise the ideal of full decentralization. Additionally, when public blockchains are used, they often rely on expensive platforms without employing scaling solutions.
- Impractical Blockchain Interaction for IoT Devices: Other solutions require direct blockchain interactions using IoT devices, leading to high computational and financial costs.
- Practicality Concerns in Key Management: There are systems proposing new key management schemes that may not be practical for diverse IoT contexts. The challenge lies in adopting these new schemes as opposed to using widely used ones.
- Computational Overhead from Cryptosystems: Certain solutions, while enhancing privacy, add a significant computational workload, rendering them unsuitable for resource-constrained IoT devices.
2.2. Layered Blockchain Structure
Layer 2 Scaling Solutions
2.3. Proving Systems
- Zero-Knowledge Proofs (ZKPs): A specialized form of validity proof, ZKPs enable a party to prove the truth of a statement to another party without revealing any additional information beyond the fact that the statement is true. This characteristic is particularly important for preserving privacy in various applications [26].
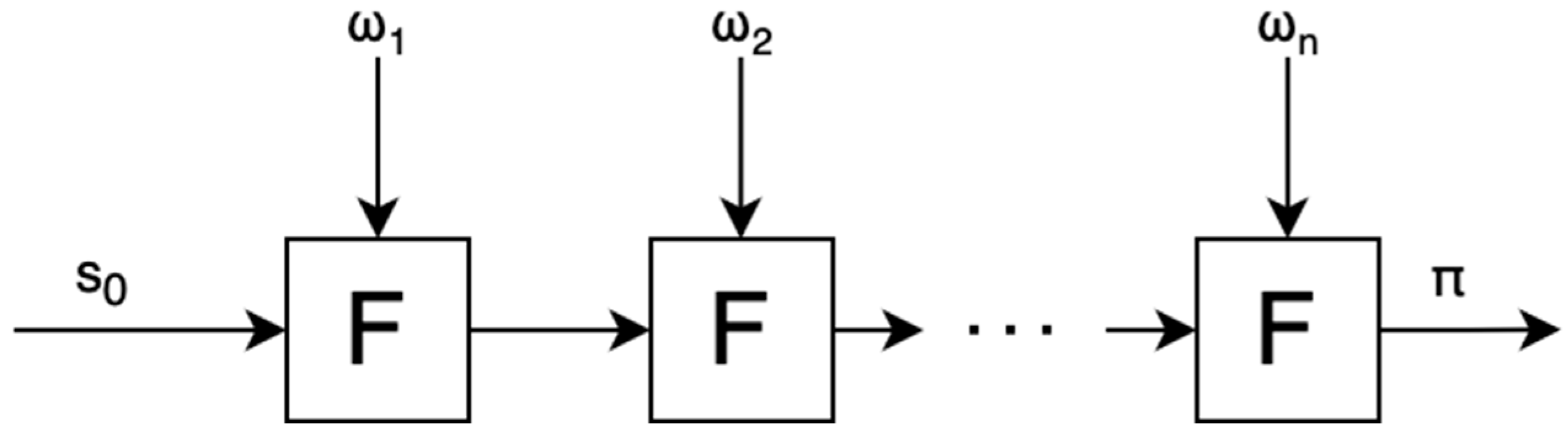
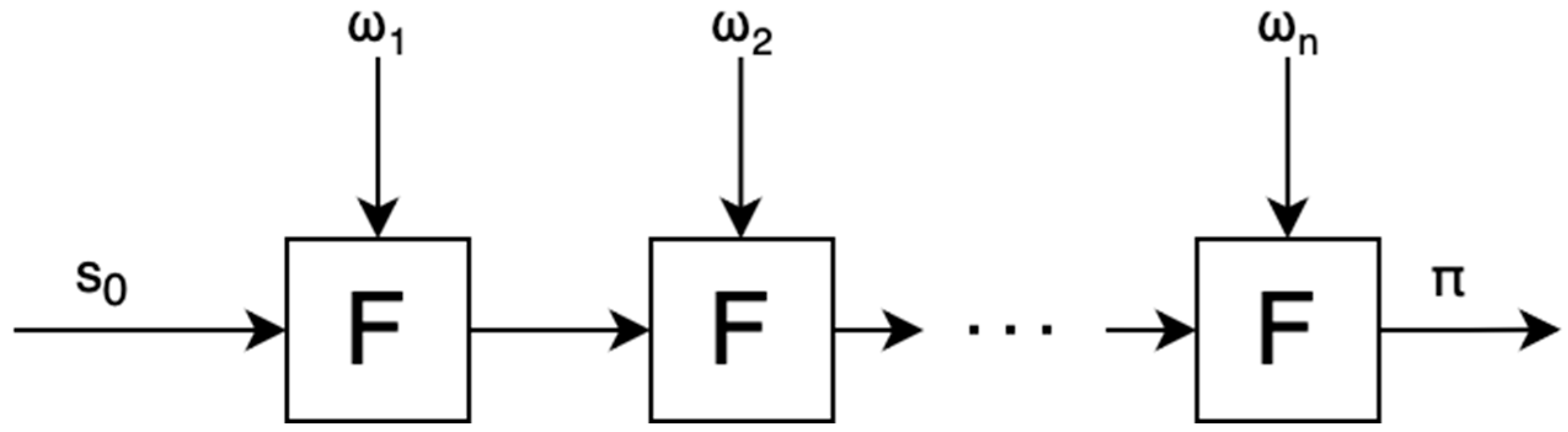
2.3.1. Snark Composition, Aggregation, and Recursion
2.3.2. Signature Aggregation
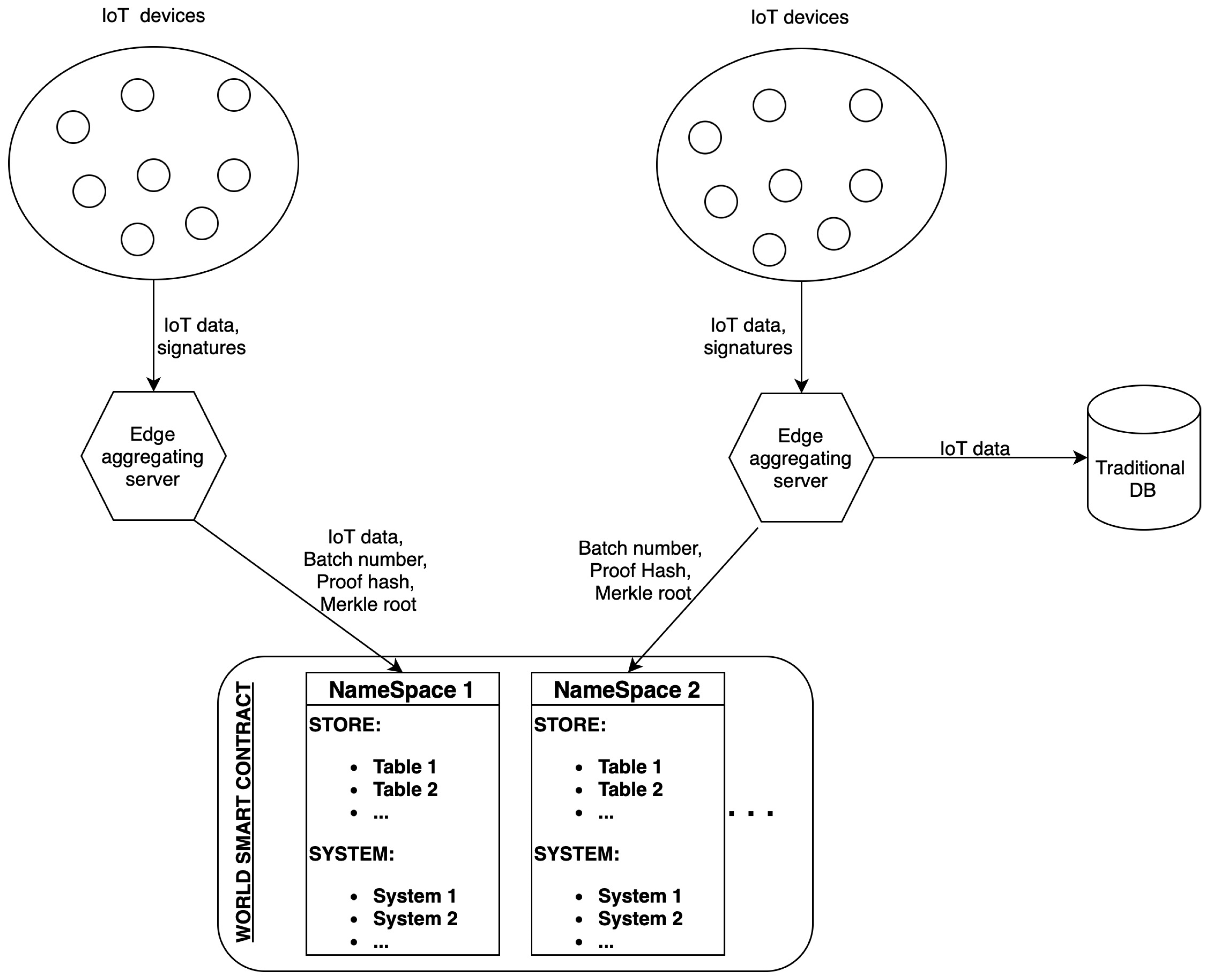
3. Framework Design
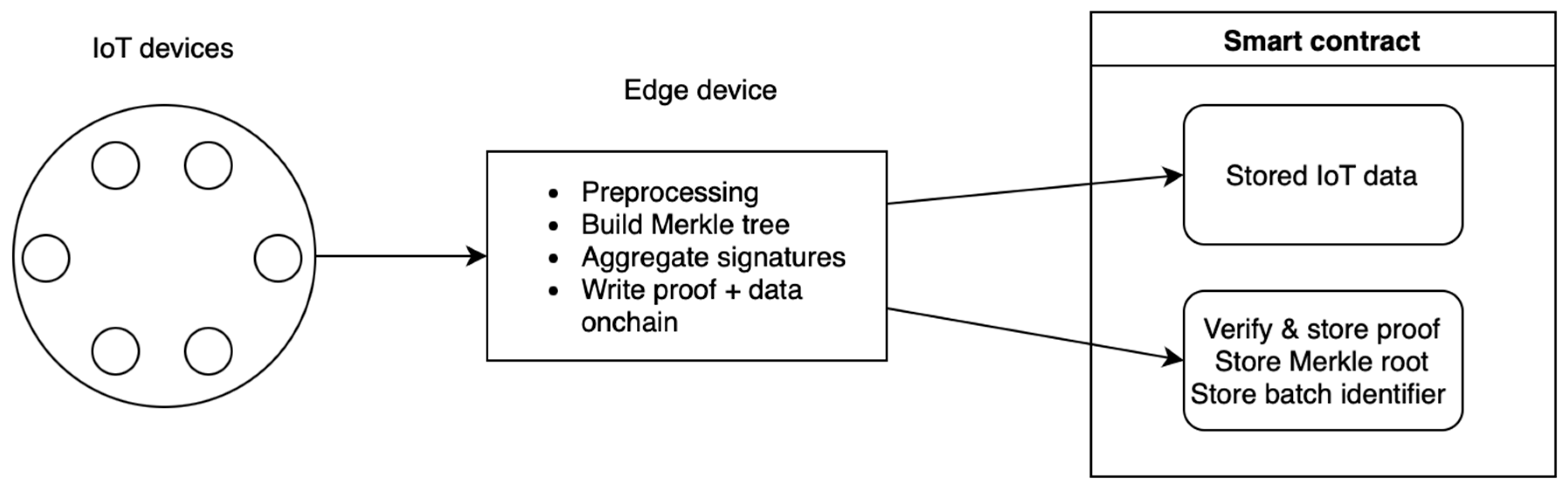
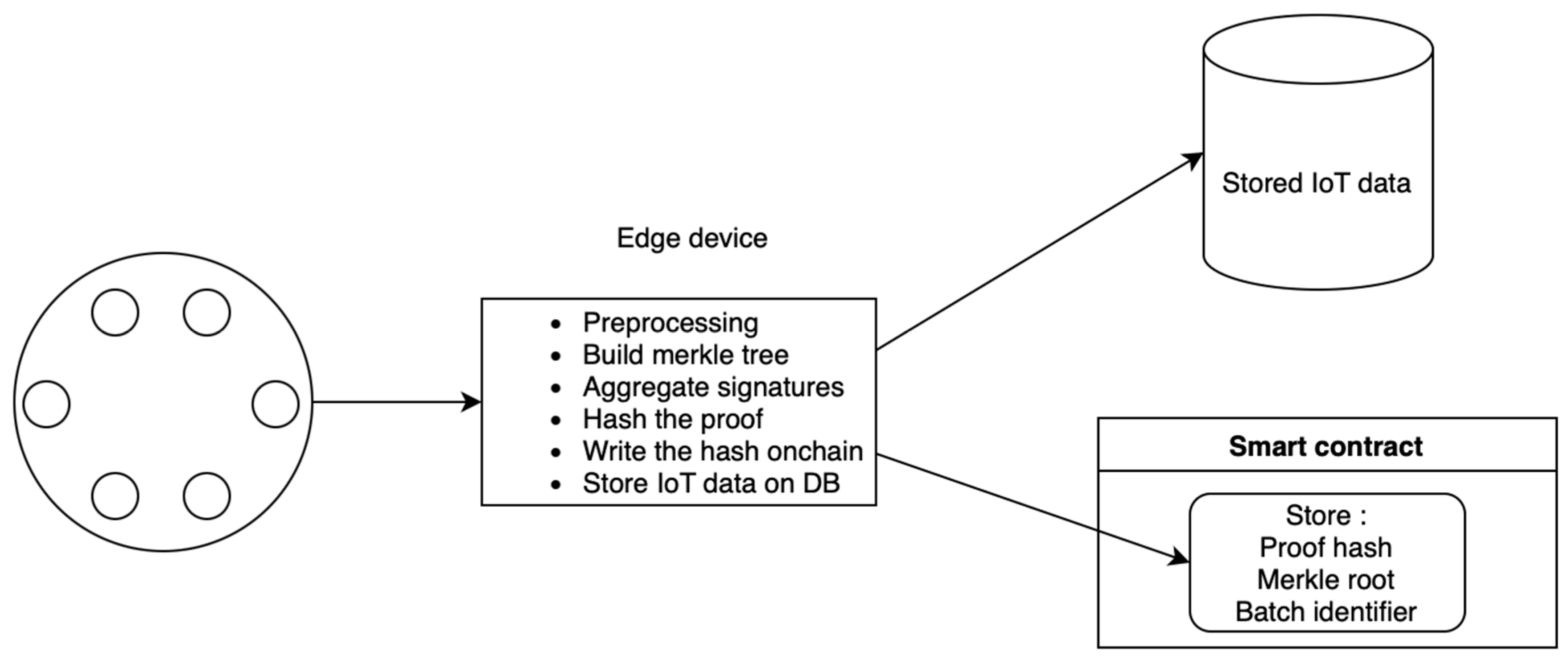
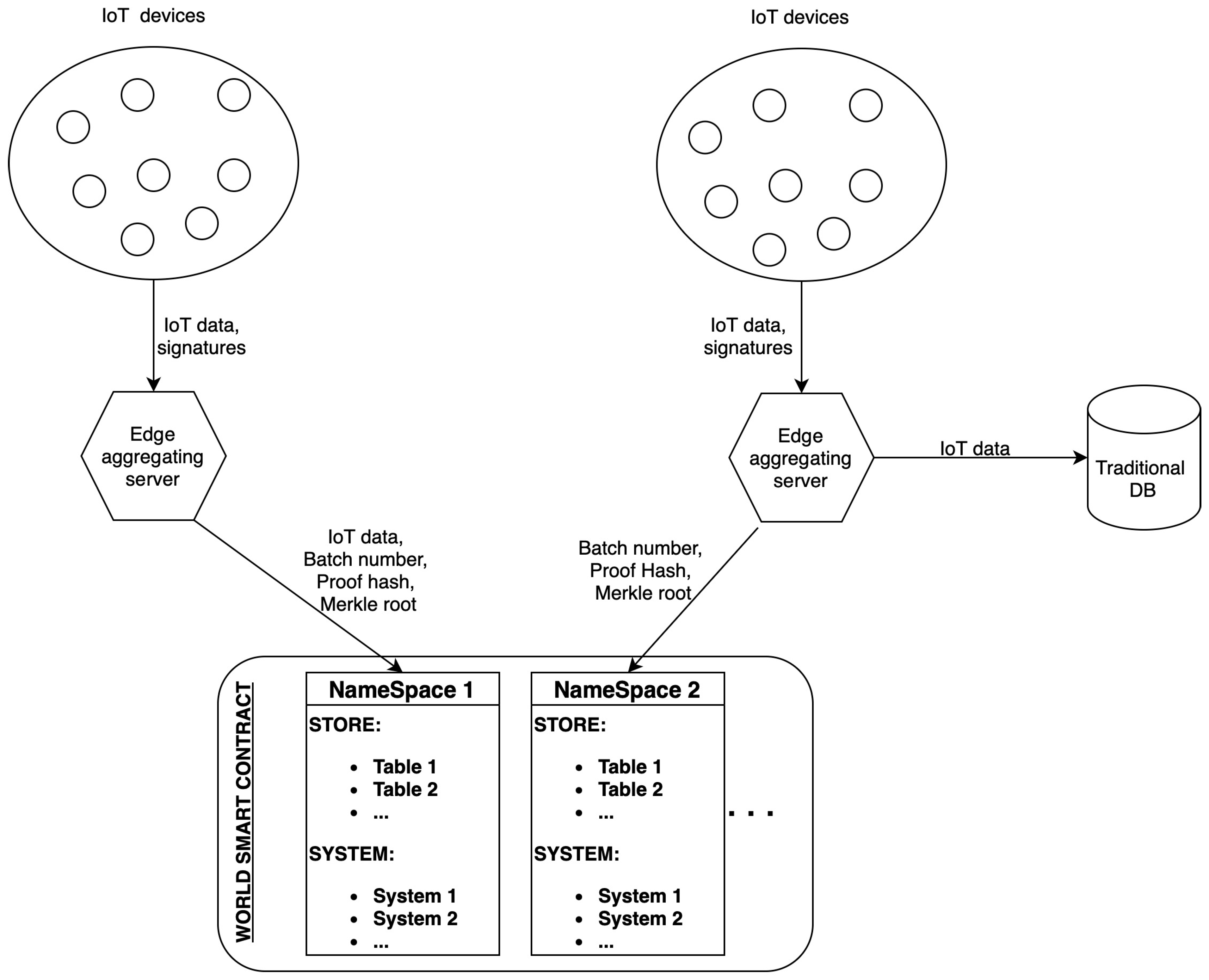
- Off-chain components include IoT devices and edge aggregating servers. The aggregators serve as the first point of data aggregation and authentication, collecting and validating data from IoT devices, thus preparing it for on-chain integration. This process significantly reduces the computational load on individual IoT devices and decreases the need for direct blockchain interaction.
- On-chain components feature a layered blockchain structure and smart contracts built atop each L2 network. Ethereum is the foundational Layer 1 (L1), ensuring secure and reliable operations, while Layer 2 networks, such as Optimism Rollups, provide scalability and efficiency. Smart contracts facilitate IoT and edge-server registration and data storage.
3.1. Off-Chain
3.1.1. IoT Devices
- Initial on-chain registration (only once);
- Data authentication via digital signatures.
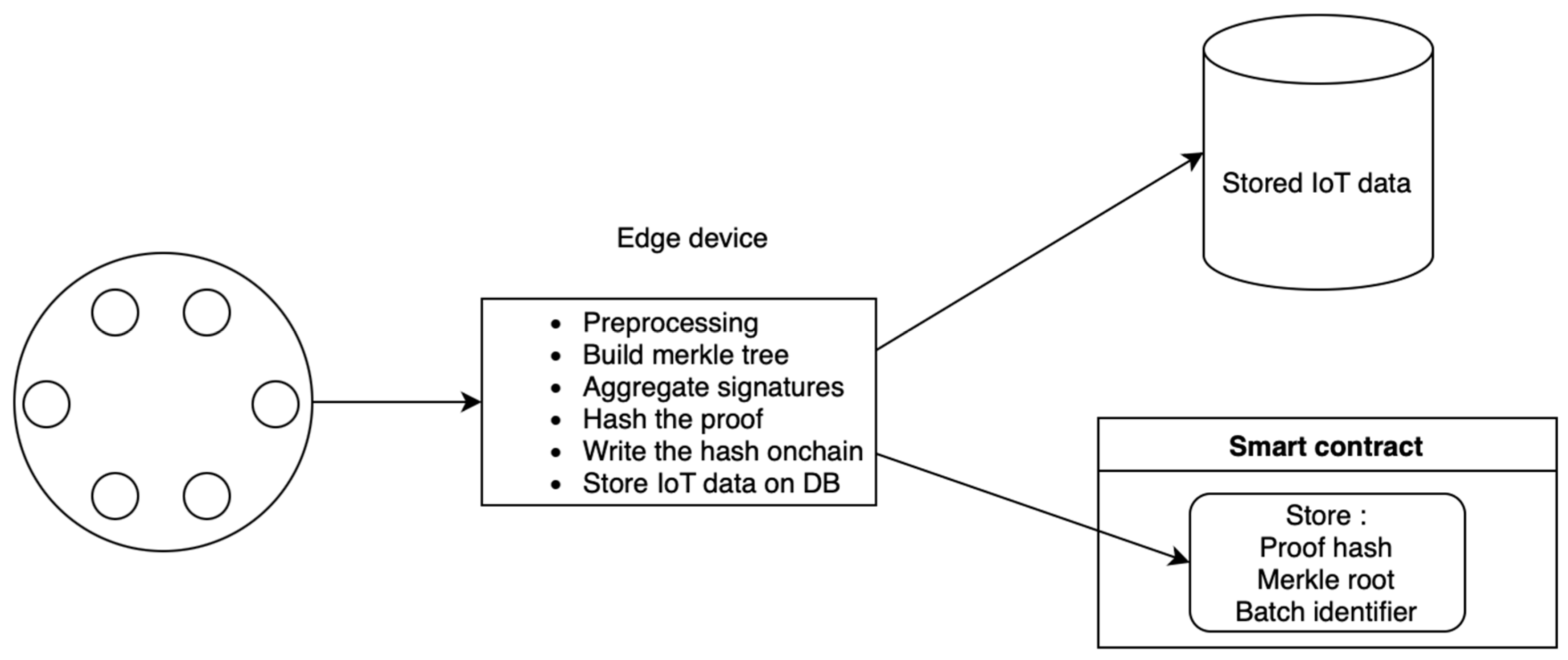
3.1.2. Edge Aggregating Servers
- Initial on-chain registration (only once).
- Signature pre-processing (conform with efficient ECDSA).
- Building a Merkle tree for each batch (includes public keys, signatures, messages, and batch identifiers) ensures all relevant data are accounted for in a verifiable structure.
- The edge aggregator signs the Merkle root along with the batch number and uses this as the public input to the prover. This ties the proof generation directly to the specific dataset represented by the Merkle tree.
- Writing each batch’s Merkle root, proof hash, and batch identifier on-chain. It enhances transparency and provides an immutable record that can be independently verified.
Aggregating Signatures
Data Storage
3.2. Proving System Implementation
3.3. On-Chain
3.3.1. Layer 2 Rollups
3.3.2. Smart Contract
4. Results
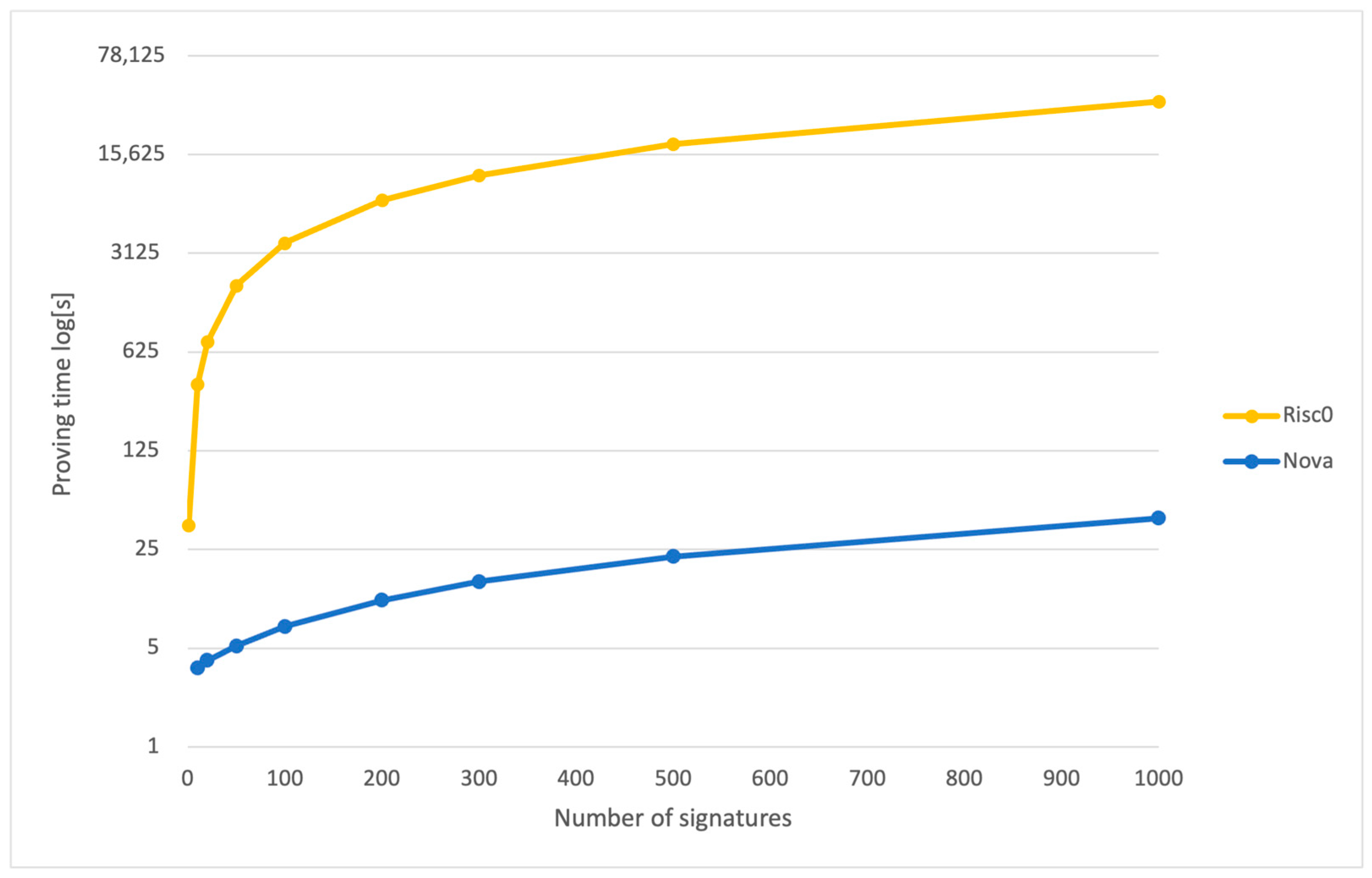
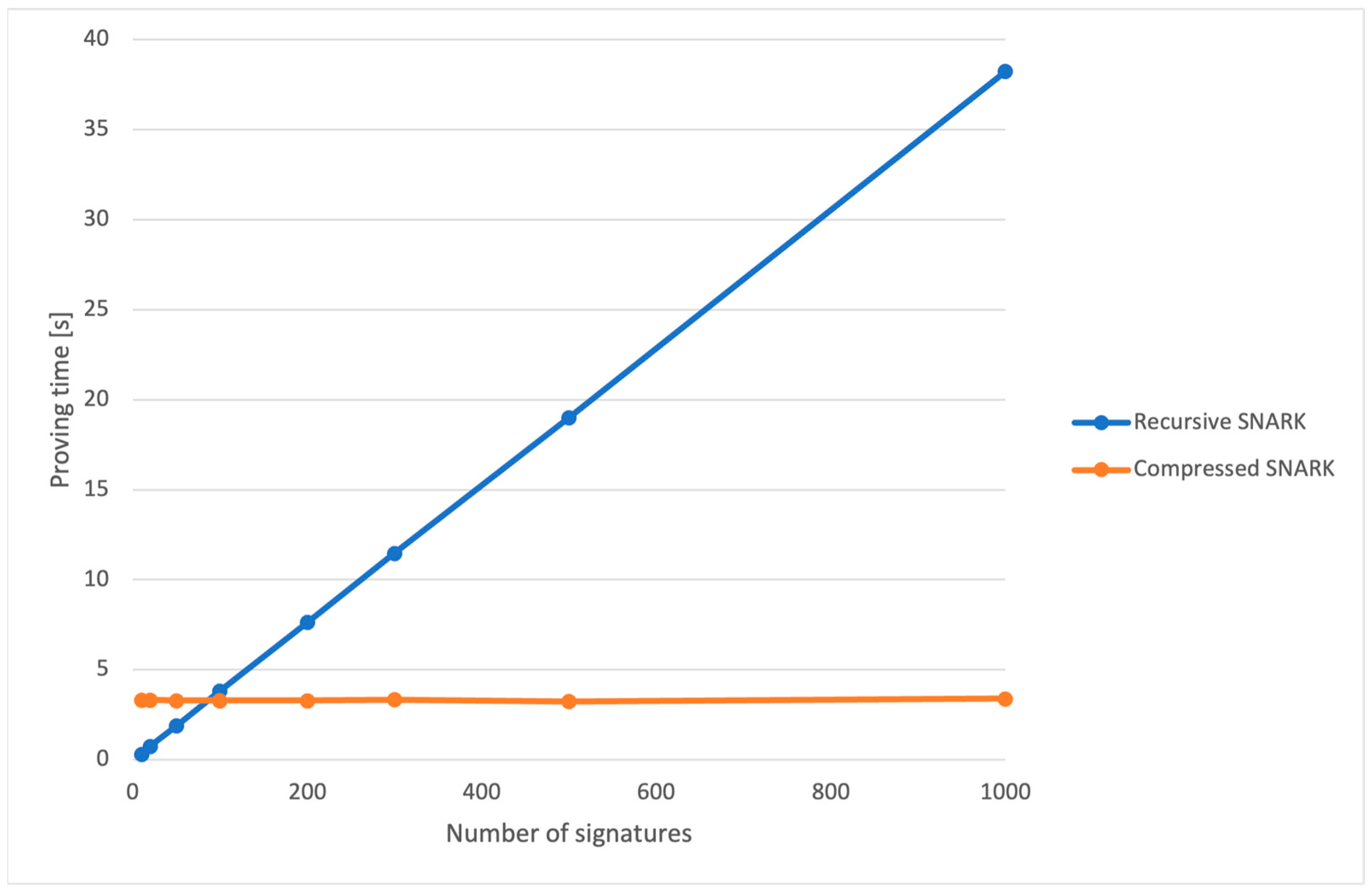
4.1. Proving Times and Proof Sizes
4.2. On-Chain Storing Costs
5. Discussion
5.1. Off-Chain Results
5.2. On-Chain Results
5.3. Security Discussion
- 1.
- Modifying the Prover.
- Modify the prover to take public keys as inputs and signatures and messages as private inputs. This could provide a more direct link between the data sources (IoT devices) and the proof.
- Modify the prover to construct the Merkle tree as part of the proof generation process. This would tightly couple the data verification with the proof itself, providing strong assurance that the same data are used in both the Merkle tree and the proof, without the need to disclose any data for each batch.
- 2.
- Proving that the process of building a Merkle tree used the same data as the process of aggregating signatures. This could be completed by utilizing yet another proving system or for example, Intel’s trusted execution environment (SGX).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Panchal, A.C.; Khadse, V.M.; Mahalle, P.N. Security Issues in IIoT: A Comprehensive Survey of Attacks on IIoT and Its Countermeasures. In Proceedings of the 2018 IEEE Global Conference on Wireless Computing and Networking (GCWCN), Lonavala, India, 23–24 November 2018; pp. 124–130. [Google Scholar]
- Passlick, J.; Dreyer, S.; Olivotti, D.; Grützner, L.; Eilers, D.; Breitner, M.H. Predictive Maintenance as an Internet of Things Enabled Business Model: A Taxonomy. Electron. Mark. 2021, 31, 67–87. [Google Scholar] [CrossRef]
- Al-Ali, A.R.; Zualkernan, I.A.; Rashid, M.; Gupta, R.; Alikarar, M. A Smart Home Energy Management System Using IoT and Big Data Analytics Approach. IEEE Trans. Consum. Electron. 2017, 63, 426–434. [Google Scholar] [CrossRef]
- Kumar, S.; Tiwari, P.; Zymbler, M. Internet of Things Is a Revolutionary Approach for Future Technology Enhancement: A Review. J. Big Data 2019, 6, 111. [Google Scholar] [CrossRef]
- Adi, E.; Anwar, A.; Baig, Z.; Zeadally, S. Machine Learning and Data Analytics for the IoT. Neural Comput. Appl. 2020, 32, 16205–16233. [Google Scholar] [CrossRef]
- Hafid, A.; Hafid, A.S.; Samih, M. Scaling Blockchains: A Comprehensive Survey. IEEE Access 2020, 8, 125244–125262. [Google Scholar] [CrossRef]
- Shen, M.; Liu, H.; Zhu, L.; Xu, K.; Yu, H.; Du, X.; Guizani, M. Blockchain-Assisted Secure Device Authentication for Cross-Domain Industrial IoT. IEEE J. Sel. Areas Commun. 2020, 38, 942–954. [Google Scholar] [CrossRef]
- Liu, B.; Yu, X.L.; Chen, S.; Xu, X.; Zhu, L. Blockchain Based Data Integrity Service Framework for IoT Data. In Proceedings of the 2017 IEEE International Conference on Web Services (ICWS), Honolulu, HI, USA, 25–30 June 2017; pp. 468–475. [Google Scholar]
- Zhou, J.; Cao, Z.; Dong, X.; Vasilakos, A.V. Security and Privacy for Cloud-Based IoT: Challenges. IEEE Commun. Mag. 2017, 55, 26–33. [Google Scholar] [CrossRef]
- Barki, A.; Bouabdallah, A.; Gharout, S.; Traoré, J. M2M Security: Challenges and Solutions. IEEE Commun. Surv. Tutor. 2016, 18, 1241–1254. [Google Scholar] [CrossRef]
- Ammar, M.; Russello, G.; Crispo, B. Internet of Things: A Survey on the Security of IoT Frameworks. J. Inf. Secur. Appl. 2018, 38, 8–27. [Google Scholar] [CrossRef]
- Guo, S.; Hu, X.; Guo, S.; Qiu, X.; Qi, F. Blockchain Meets Edge Computing: A Distributed and Trusted Authentication System. IEEE Trans Ind. Inf. 2020, 16, 1972–1983. [Google Scholar] [CrossRef]
- Xu, L.; Chen, L.; Gao, Z.; Fan, X.; Suh, T.; Shi, W. DIoTA: Decentralized-Ledger-Based Framework for Data Authenticity Protection in IoT Systems. IEEE Netw. 2020, 34, 38–46. [Google Scholar] [CrossRef]
- Thantharate, P.; Thantharate, A. ZeroTrustBlock: Enhancing Security, Privacy, and Interoperability of Sensitive Data through ZeroTrust Permissioned Blockchain. Big Data Cogn. Comput. 2023, 7, 165. [Google Scholar] [CrossRef]
- Lee, C.H.; Kim, K.-H. Implementation of IoT System Using Block Chain with Authentication and Data Protection. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018; pp. 936–940. [Google Scholar]
- Xu, R.; Zhou, Y.; Yang, Q.; Yang, K.; Han, Y.; Yang, B.; Xia, Z. An Efficient and Secure Certificateless Aggregate Signature Scheme. J. Syst. Archit. 2024, 147, 103030. [Google Scholar] [CrossRef]
- Fathima, N.; Banu, R.; Ahammed, G.F.A. Integrated Signing Procedure Based Data Transfer Security and Authentication Framework for Internet of Things Applications. Wirel. Pers. Commun. 2023, 130, 401–420. [Google Scholar] [CrossRef]
- Shang, S.; Li, X.; Gu, K.; Li, L.; Zhang, X.; Pandi, V. A Robust Privacy-Preserving Data Aggregation Scheme for Edge-Supported IIoT. IEEE Trans. Ind. Inf. 2023, 1–12. [Google Scholar] [CrossRef]
- Kittur, A.S.; Pais, A.R. A New Batch Verification Scheme for ECDSA*signatures. Sādhanā 2019, 44, 157. [Google Scholar] [CrossRef]
- Scaling. Available online: https://ethereum.org/en/developers/docs/scaling/ (accessed on 22 November 2023).
- Polge, J.; Robert, J.; Le Traon, Y. Permissioned Blockchain Frameworks in the Industry: A Comparison. ICT Express 2021, 7, 229–233. [Google Scholar] [CrossRef]
- Thibault, L.T.; Sarry, T.; Hafid, A.S. Blockchain Scaling Using Rollups: A Comprehensive Survey. IEEE Access 2022, 10, 93039–93054. [Google Scholar] [CrossRef]
- Burgos, J.B.; Pustišek, M. Tackling Trust and Scalability of the Blockchain-Based Shared Manufacturing Concept. In Proceedings of the 2023 17th International Conference on Telecommunications (ConTEL), Graz, Austria, 11–13 July 2023; pp. 1–7. [Google Scholar]
- Optimistic Rollups. Available online: https://ethereum.org/en/developers/docs/scaling/optimistic-rollups/ (accessed on 29 December 2023).
- Zero-Knowledge Rollups. Available online: https://ethereum.org/en/developers/docs/scaling/zk-rollups/ (accessed on 29 December 2023).
- Thaler, J. Proofs, Arguments, and Zero-Knowledge; Now Foundation and Trends: Boston, MA, USA, 2023. [Google Scholar]
- Goldreich, O.; Micali, S.; Wigderson, A. Proofs That Yield Nothing but Their Validity and a Methodology of Cryptographic Protocol Design. In Providing Sound Foundations for Cryptography: On the Work of Shafi Goldwasser and Silvio Micali; Association for Computing Machinery: New York, NY, USA, 2019; pp. 285–306. ISBN 9781450372664. [Google Scholar]
- Petkus, M. Why and How Zk-Snark Works. arXiv 2019, arXiv:1906.07221. [Google Scholar]
- Kothapalli, A.; Setty, S.; Tzialla, I. Nova: Recursive Zero-Knowledge Arguments from Folding Schemes. In Lecture Notes in Computer Science, Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 15–18 August 2022; Springer: Cham, Switzerland, 2022; pp. 359–388. [Google Scholar]
- Nguyen, W.; Boneh, D.; Setty, S. Revisiting the Nova Proof System on a Cycle of Curves. Cryptol. Eprint Arch. 2023, 2023, 969. [Google Scholar]
- Boneh, D.; Gentry, C.; Lynn, B.; Shacham, H. A Survey of Two Signature Aggregation Techniques. 2003. Available online: https://networkdls.com/Articles/crypto6n2.pdf#page=2 (accessed on 2 December 2023).
- Personae Labs Efficient ECDSA & the Case for Client-Side Proving. Available online: https://personaelabs.org/posts/efficient-ecdsa-1/#precomputing-point-multiples (accessed on 5 December 2023).
- Mud Introduction. Available online: https://mud.dev/introduction (accessed on 17 January 2024).
- Buterin, V. Exit Games for EVM Validiums: The Return of Plasma. Available online: https://vitalik.eth.limo/general/2023/11/14/neoplasma.html (accessed on 23 November 2023).
- Volition on Starknet: Your Data, Your Choice. Available online: https://www.starknet.io/en/posts/developers/volition-on-starknet-your-data-your-choice (accessed on 25 November 2023).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device Registration | Aggregator Data Entry (Batch Info) |
|---|---|
| keySchema: { owner: “address”, }, valueSchema: { isIotDevice: “bool”, }, | keySchema: { owner: “address”, }, valueSchema: { batchNumber: “uint32”, proofHash: “string”, merkleRoot: “string”, }, |
| Layer 1 | Layer 2 | |||
|---|---|---|---|---|
| Base Price [gwei/gas] | Priority Price [gwei/gas] | Base Price [gwei/gas] | Priority Price [gwei/gas] | ETH Price [USD/ETH] |
| 28 | 0.1 | 0.00345 | 0.02 | 2150 |
| Layer 1 Only | Layered (L1 + L2) | ||
|---|---|---|---|
| Gas Used | Gas Used L1 | Gas Used L2 | |
| Registration | 74,653 | 2188 | 74,653 |
| Cost in gwei and USD | |||
| Cost [gwei] | 2,097,749.3 | 41,904.576 | 1750.612 |
| Cost [USD] | 4.51 | 0.090 | 0.003 |
| Cost total [USD] | 4.51 | 0.093 | |
| Layer 1 Only | Layered (L1 + L2) | ||
|---|---|---|---|
| Gas Used | Gas Used L1 | Gas Used L2 | |
| Writing data | 198,979 | 4820 | 198,979 |
| Cost in gwei and USD | |||
| Cost [gwei] | 5,591,309.9 | 92,312.64 | 4666.057 |
| Cost [USD] | 12.02 | 0.198 | 0.010 |
| Cost total [USD] | 12.02 | 0.208 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bojič Burgos, J.; Pustišek, M. Decentralized IoT Data Authentication with Signature Aggregation. Sensors 2024, 24, 1037. https://doi.org/10.3390/s24031037
Bojič Burgos J, Pustišek M. Decentralized IoT Data Authentication with Signature Aggregation. Sensors. 2024; 24(3):1037. https://doi.org/10.3390/s24031037
Chicago/Turabian StyleBojič Burgos, Jay, and Matevž Pustišek. 2024. "Decentralized IoT Data Authentication with Signature Aggregation" Sensors 24, no. 3: 1037. https://doi.org/10.3390/s24031037
APA StyleBojič Burgos, J., & Pustišek, M. (2024). Decentralized IoT Data Authentication with Signature Aggregation. Sensors, 24(3), 1037. https://doi.org/10.3390/s24031037