
Respecting Partial Privacy of Unstructured Data via Spectrum-Based Encoder

Abstract
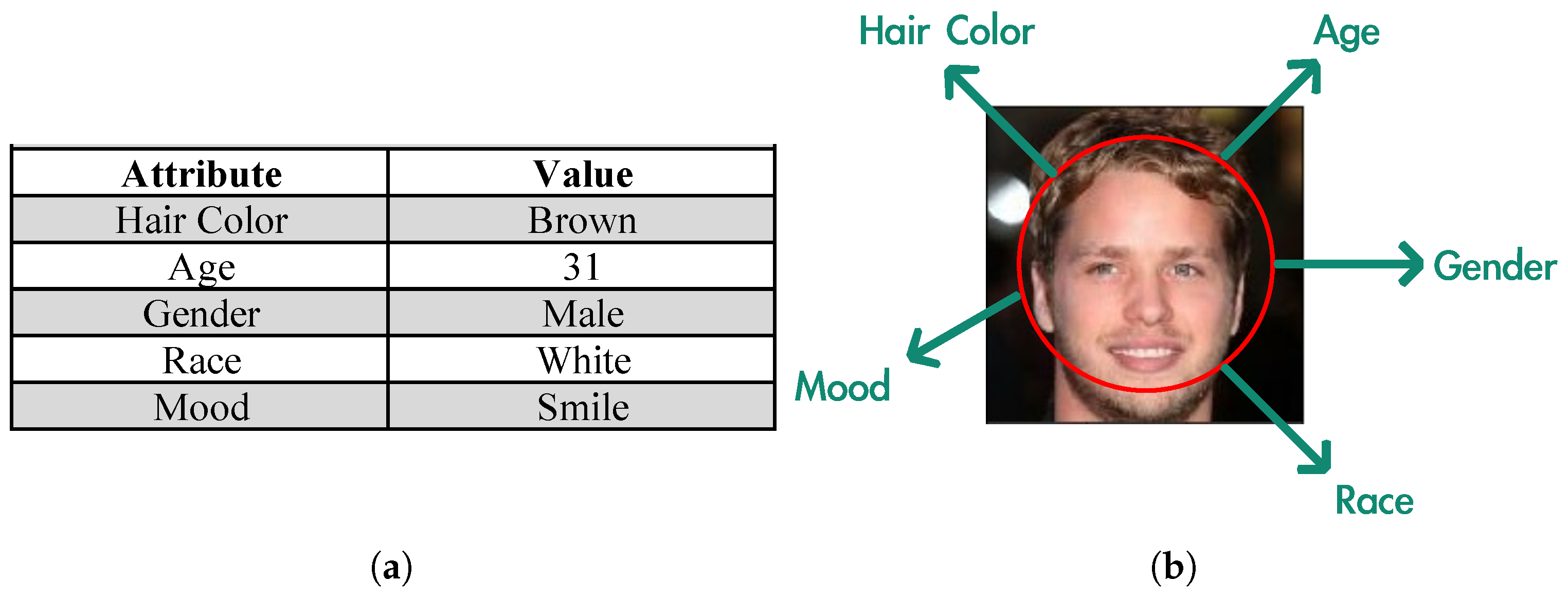
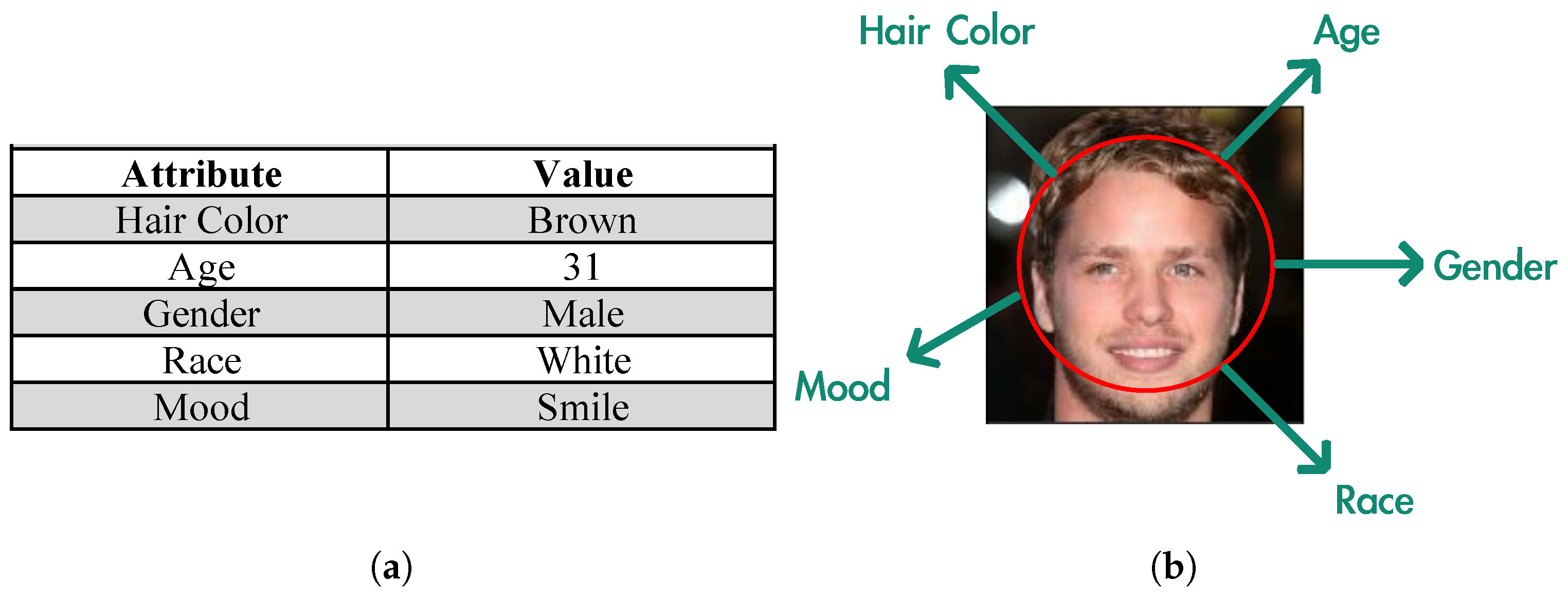
1. Introduction
- We introduce a novel interpretable model called Indicator, which can effectively indicate the critical information required for a specific target task within unstructured data.
- We present a partial privacy-preserving framework that utilizes the designed Indicator to restrict the access of undesired task-independent attacks while preserving the utility of target tasks.
- We fully implement our framework and demonstrate its wide applicability by performing experiments on several standard datasets. The evaluation results show that our framework can achieve sweet trade-offs between privacy and utility, and is resistant to potential attackers.
2. Preliminaries and Related Work
2.1. Disentangled Representation Learning
2.2. Data Privacy Protection
2.3. Representation Privacy–Utility Trade-Offs
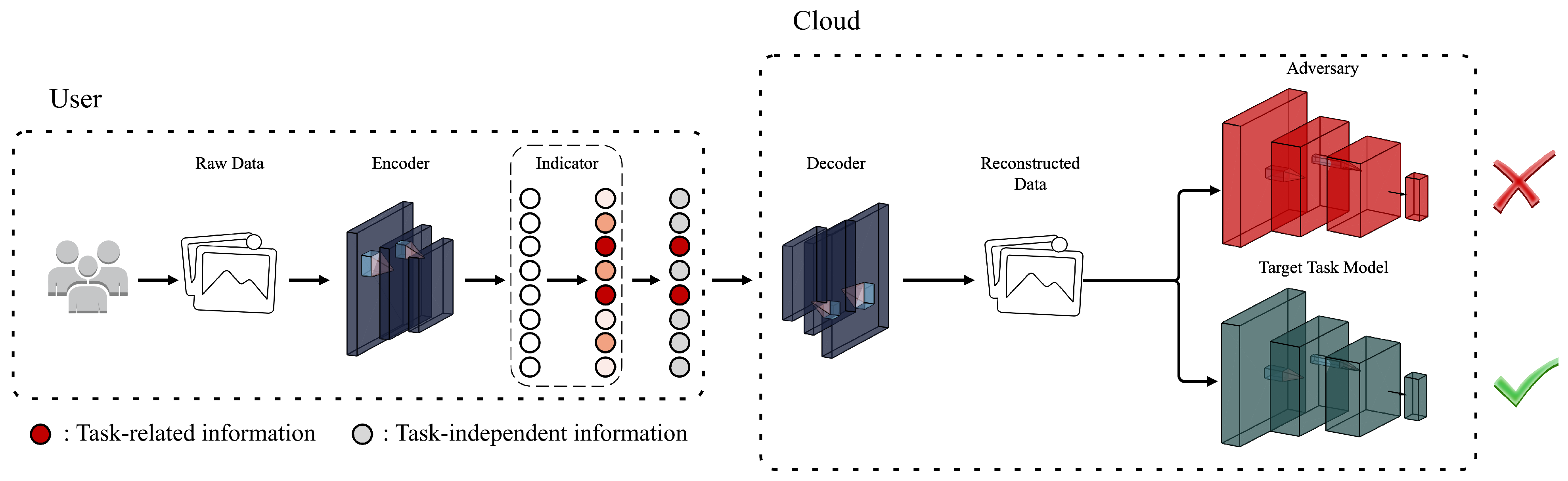
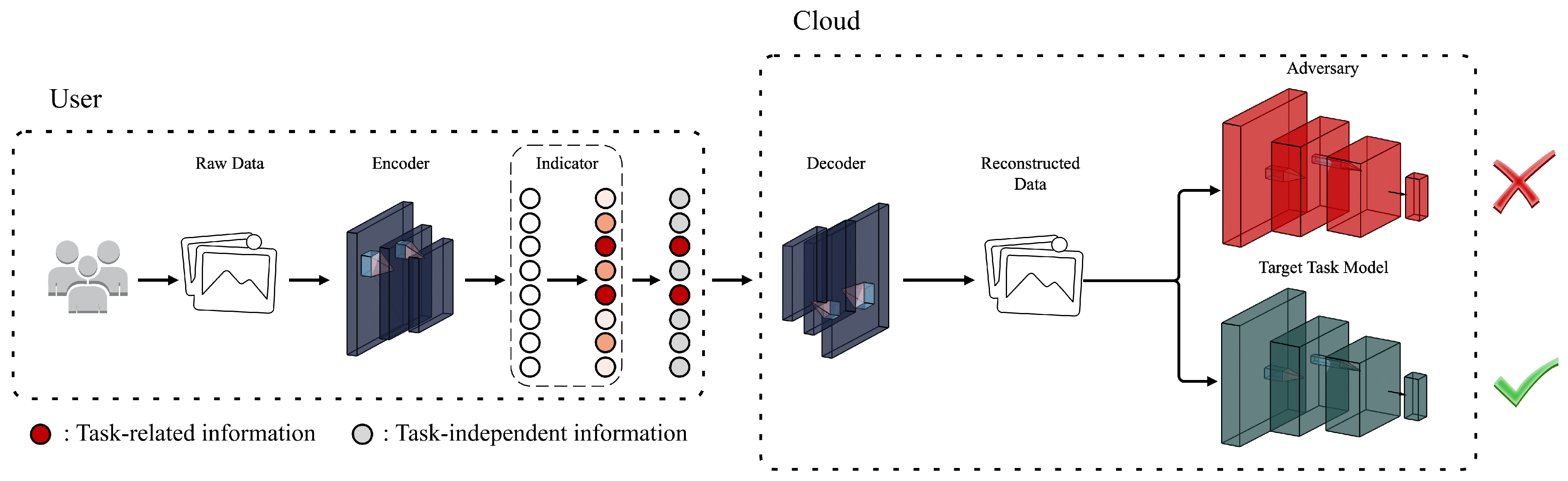
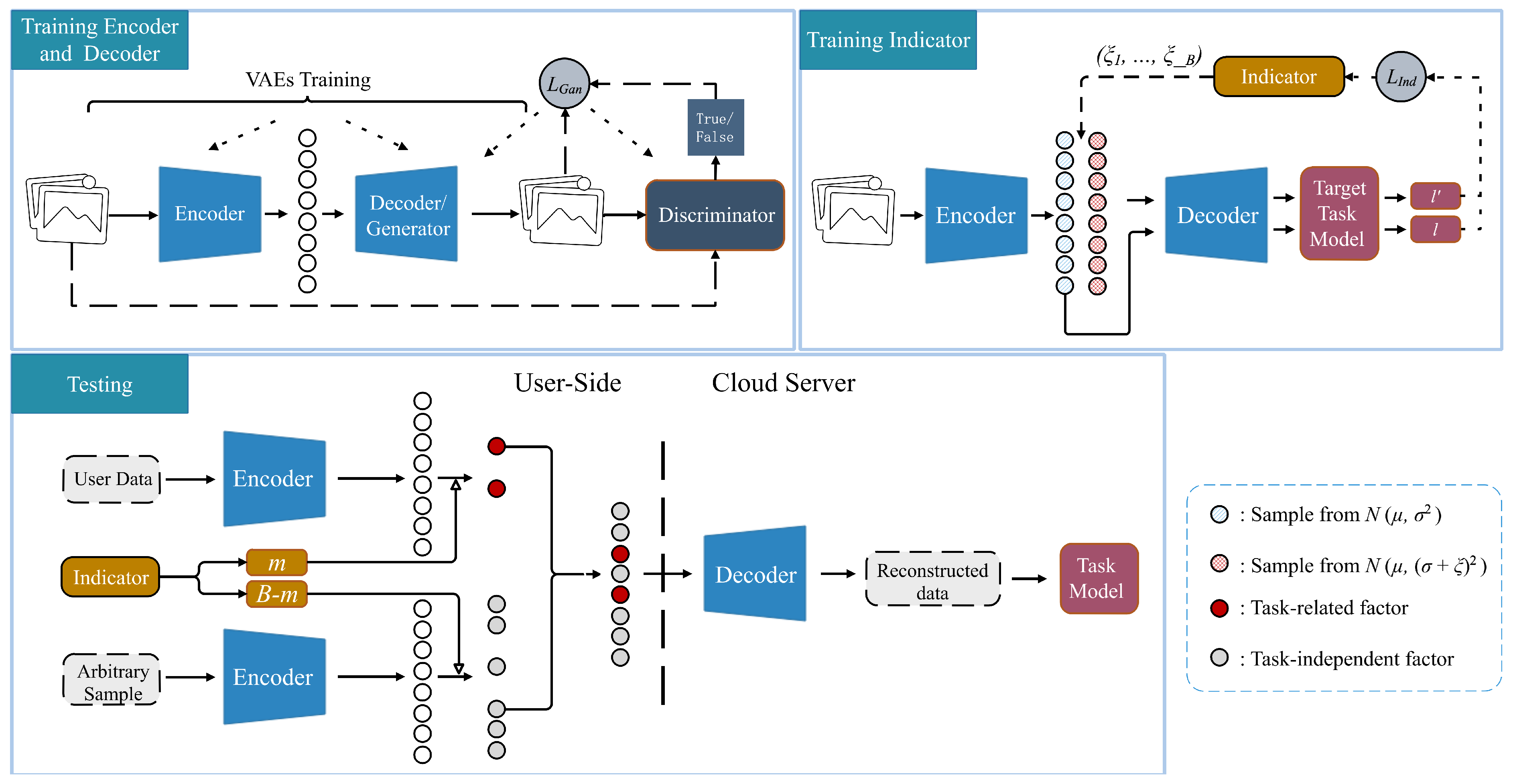
3. Design of Framework
3.1. Overview
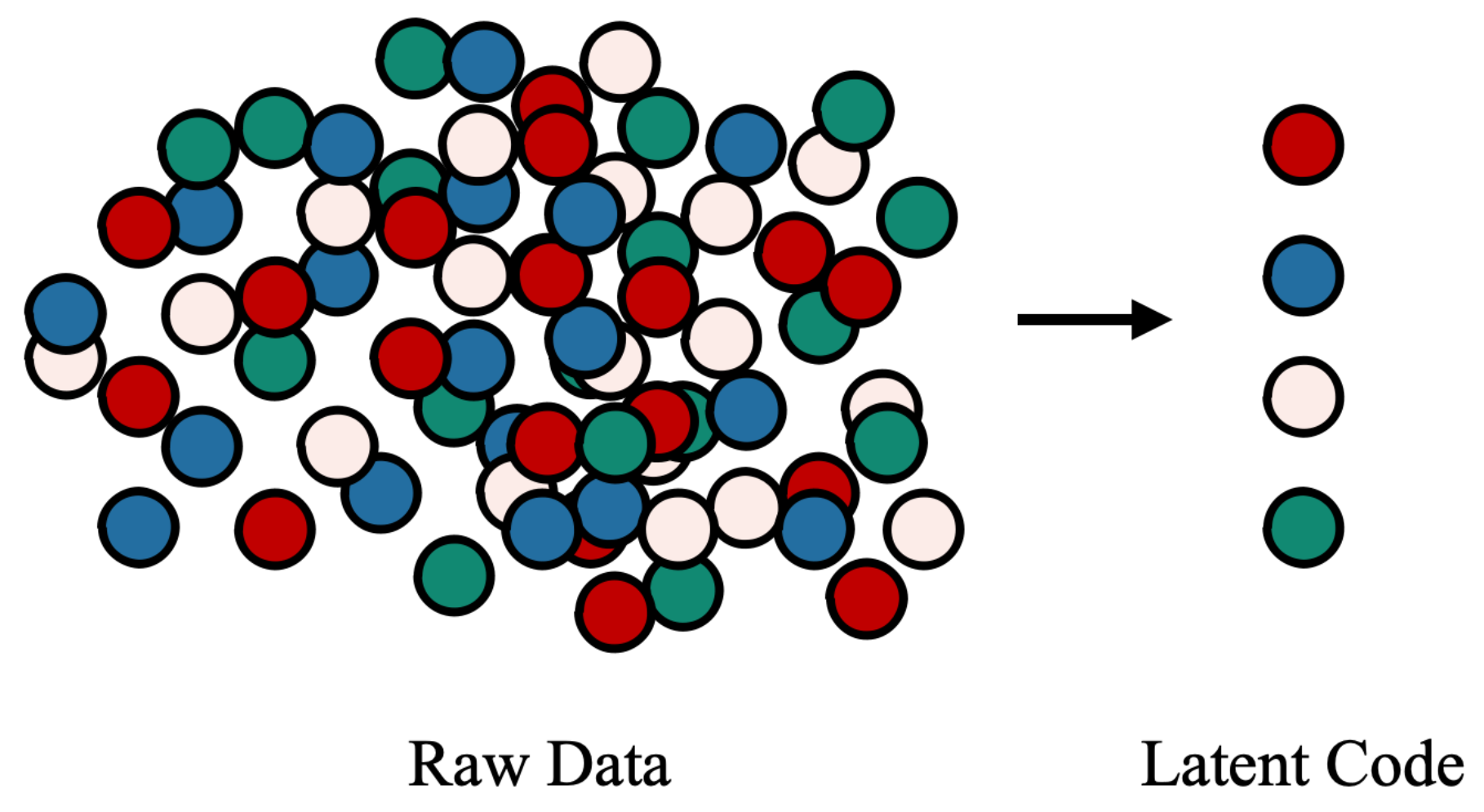
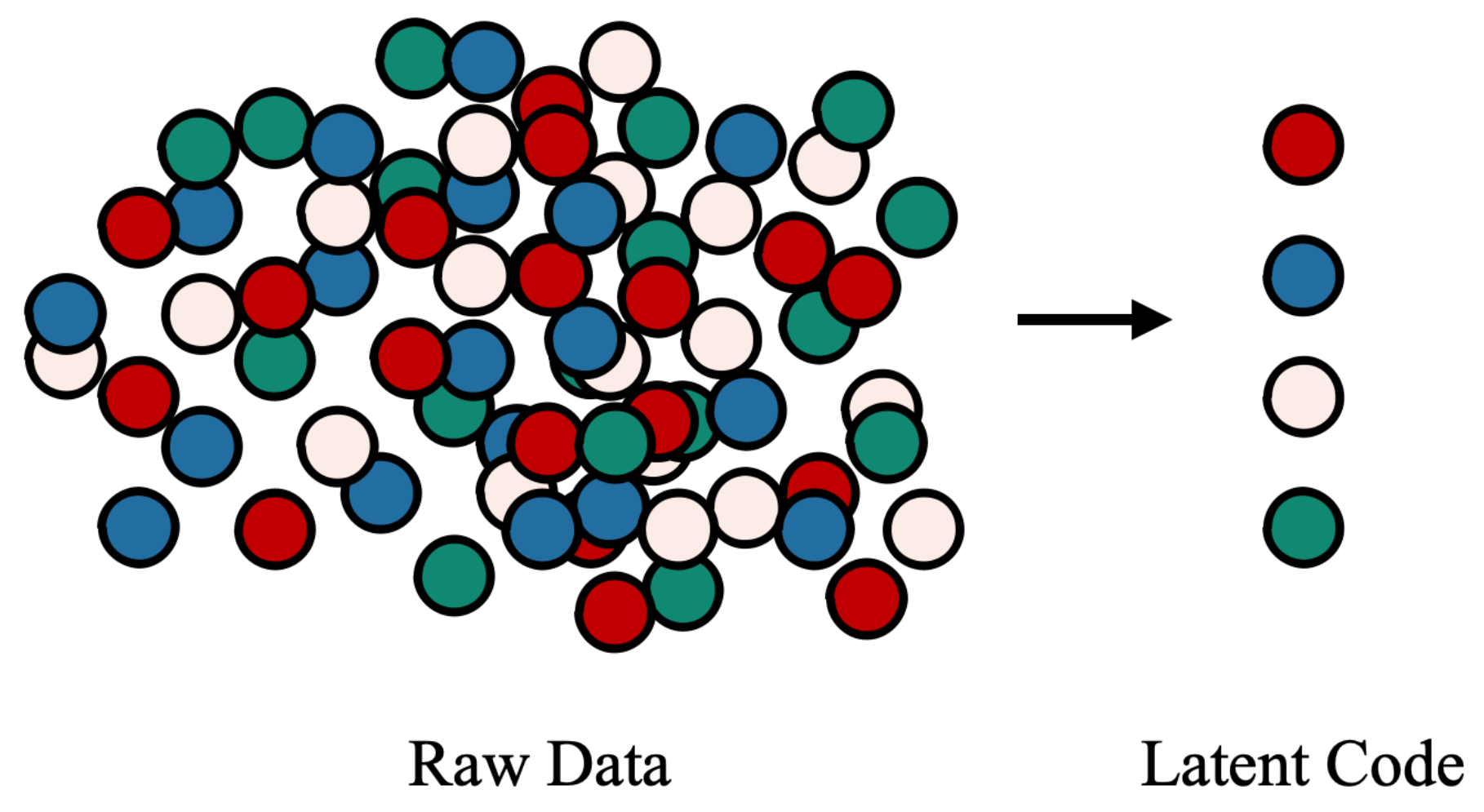
3.2. Unstructured Data Disentanglement
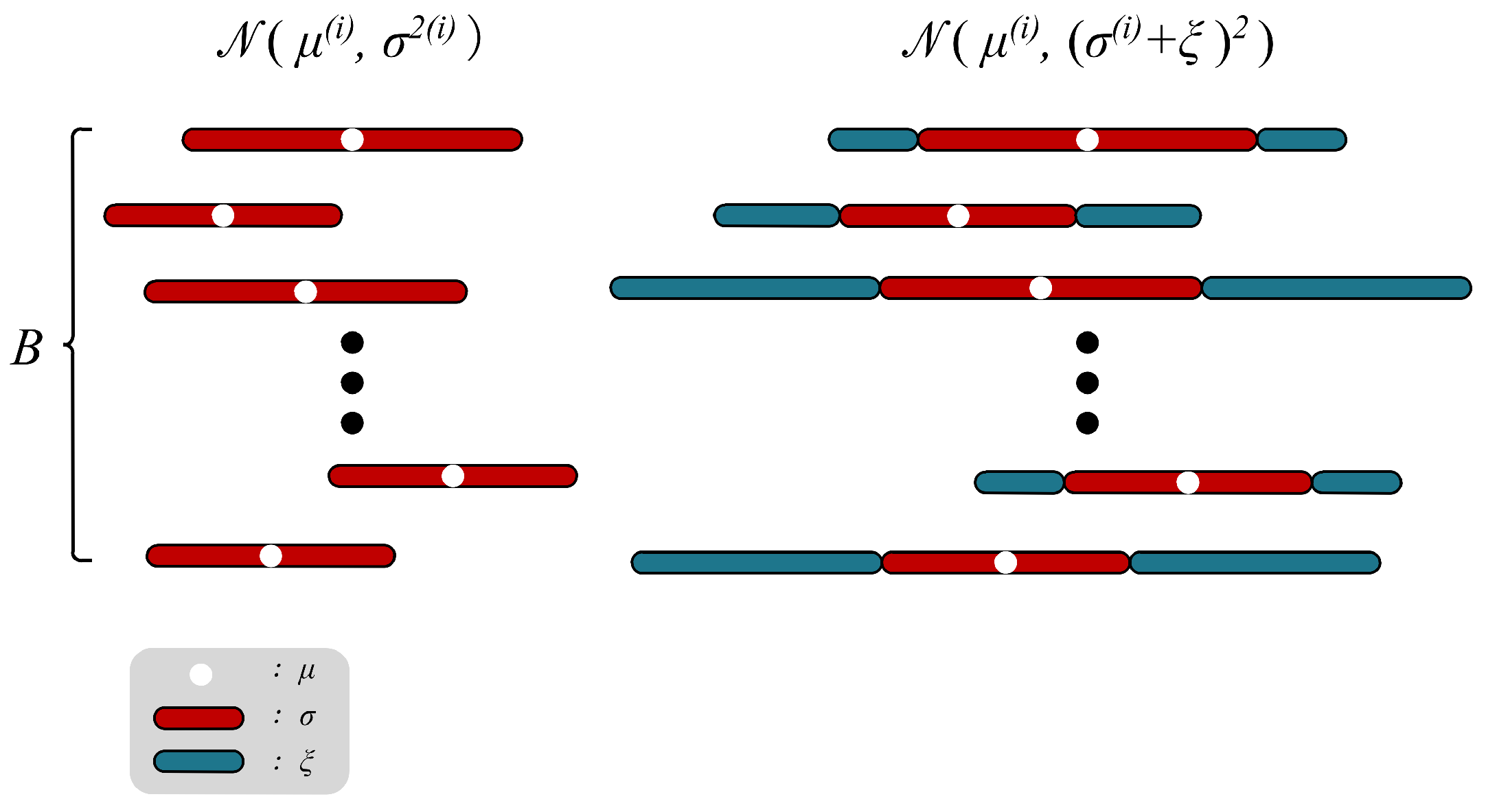
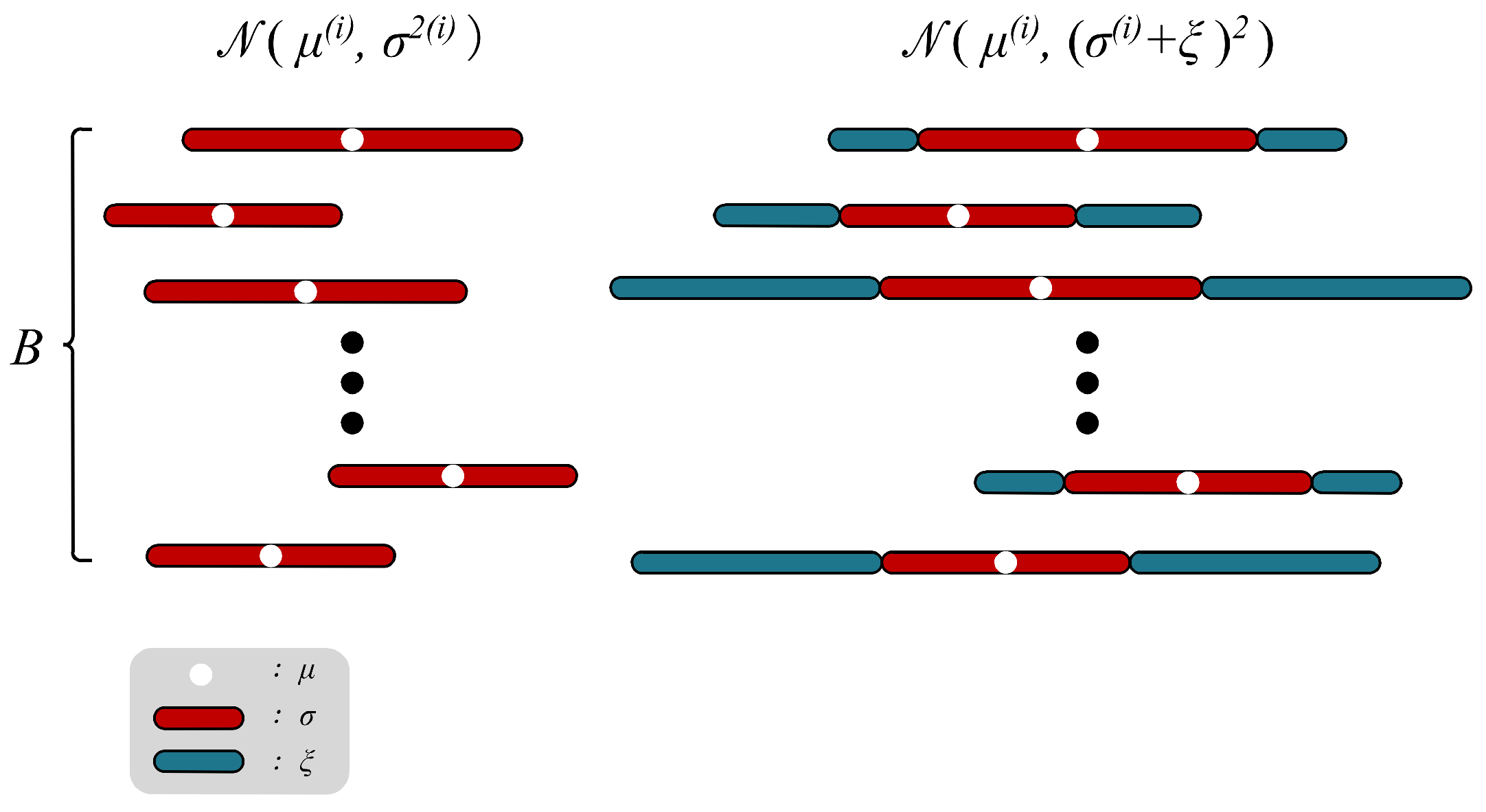
3.3. Representation Oriented Indicator
| Algorithm 1 Indicator Training |
|
3.4. Data Reconstruction
4. Experimental Study
4.1. Indicator Evaluation
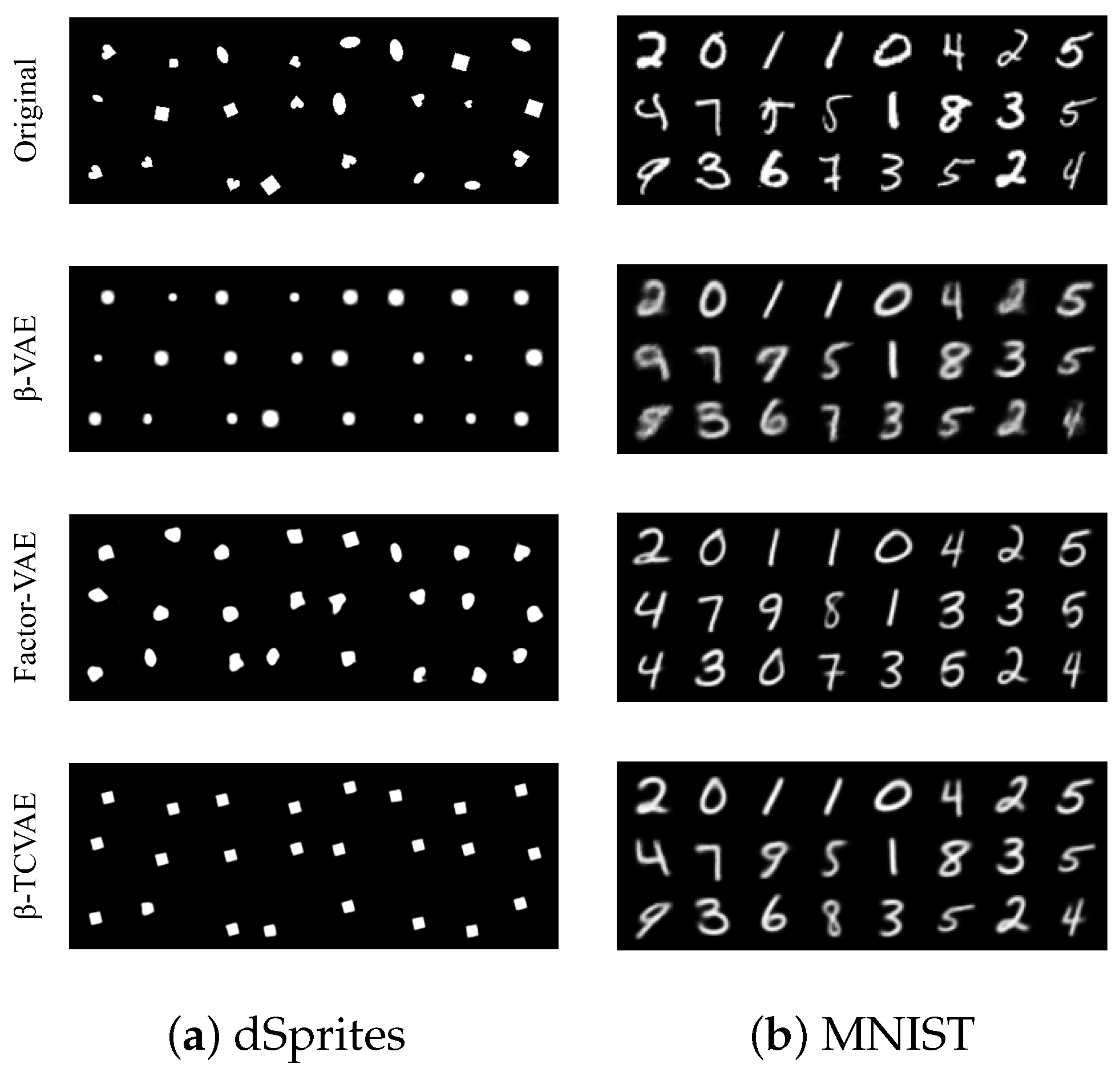
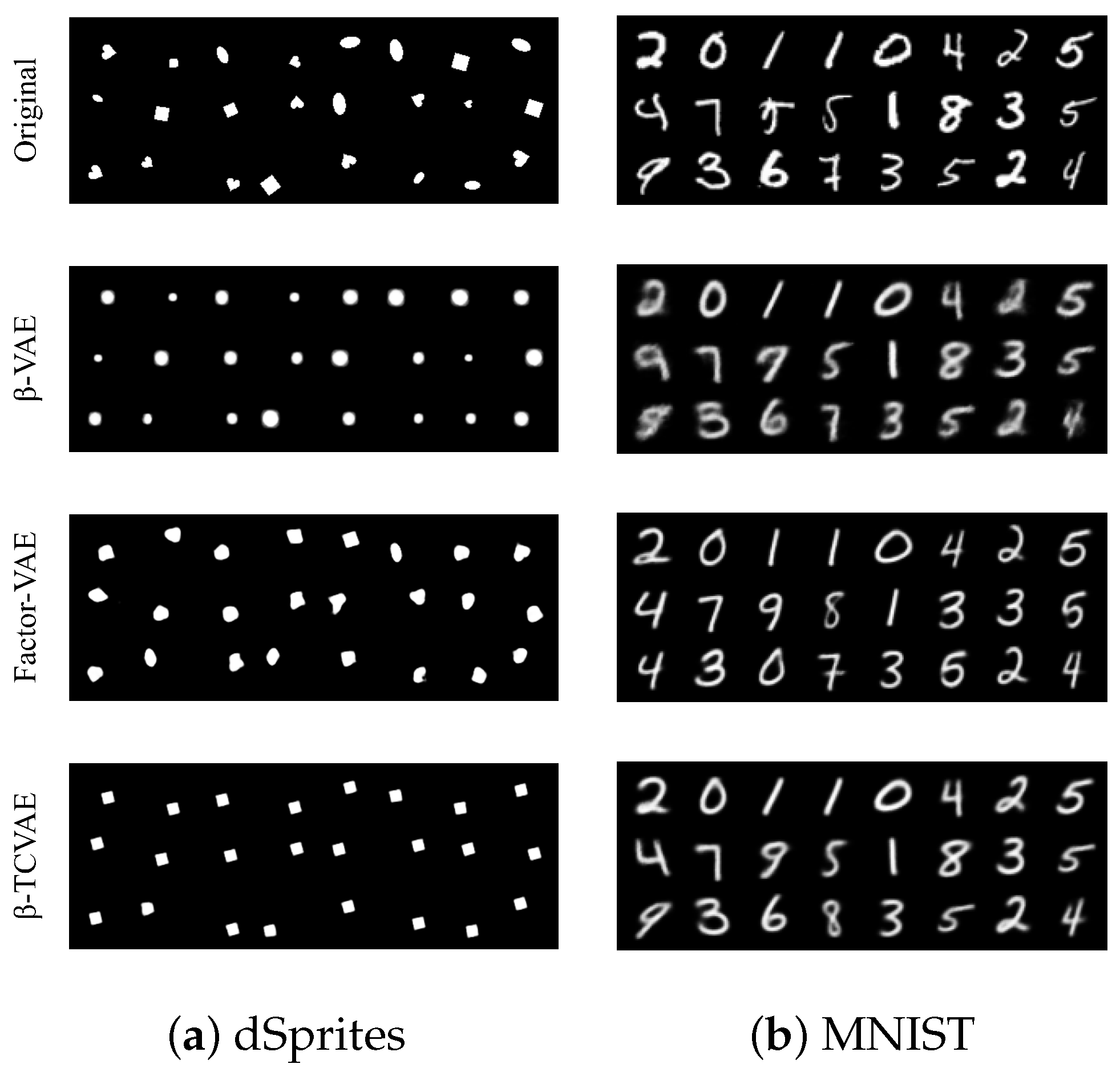
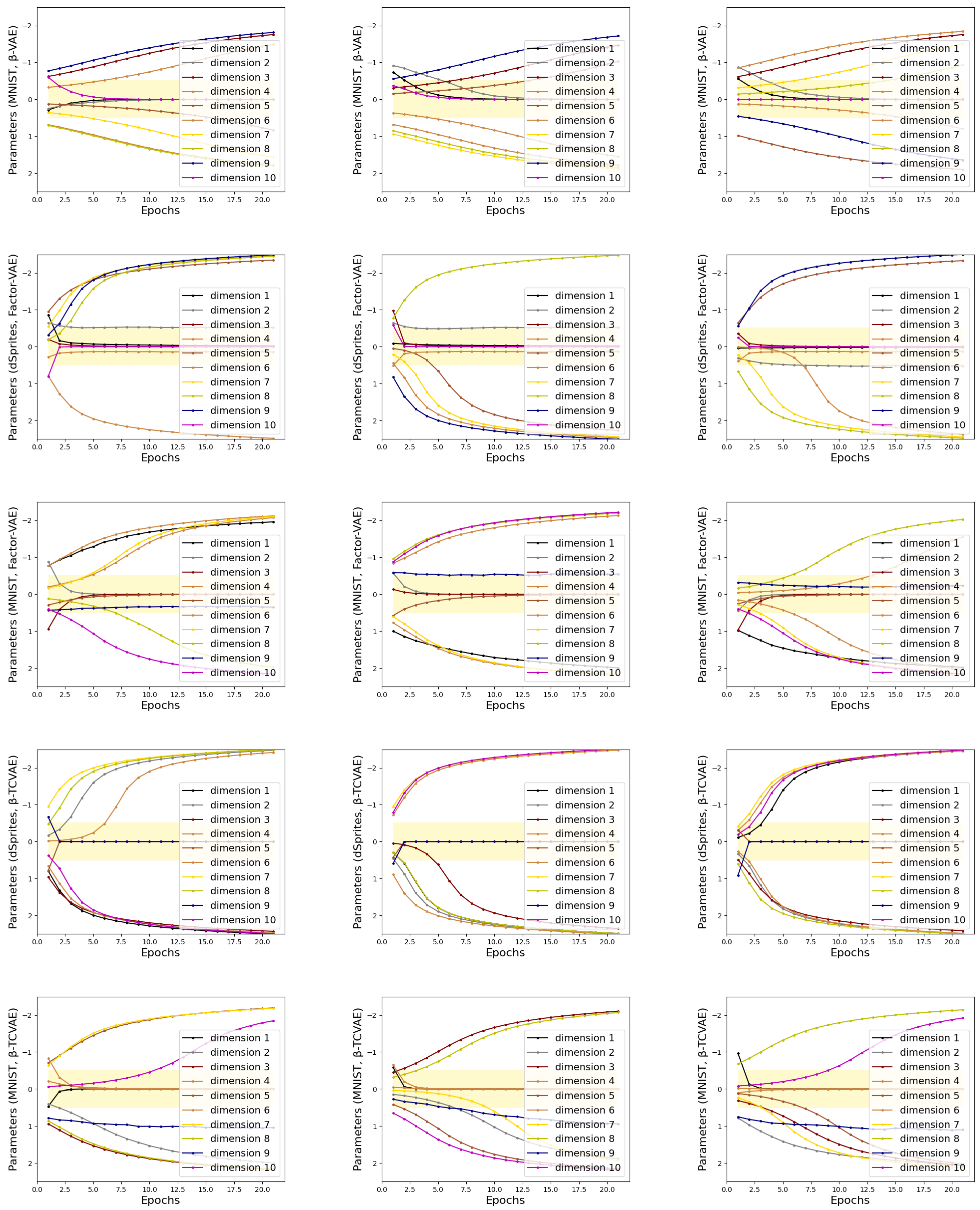
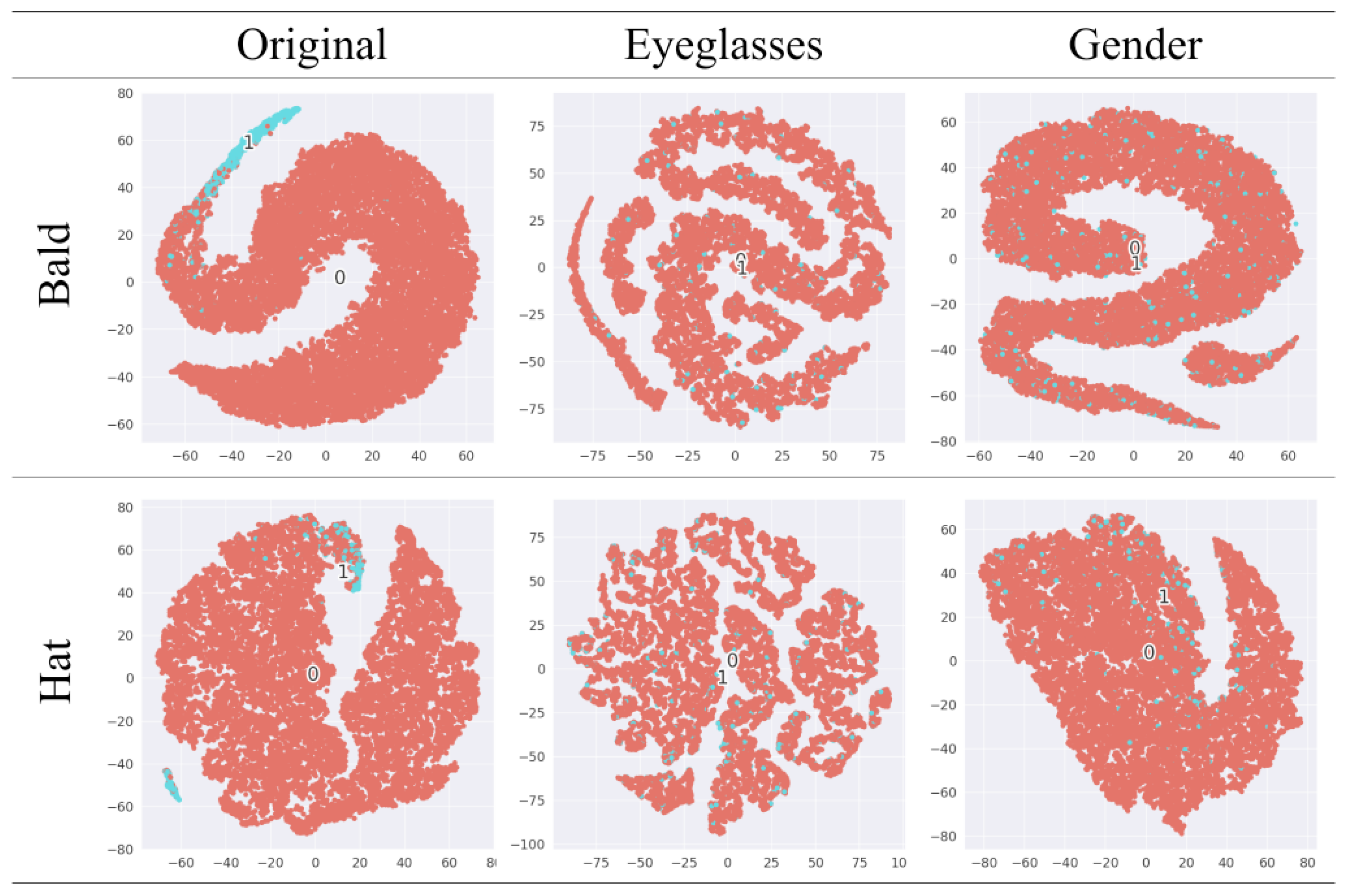
4.1.1. Versatility
4.1.2. Reliability
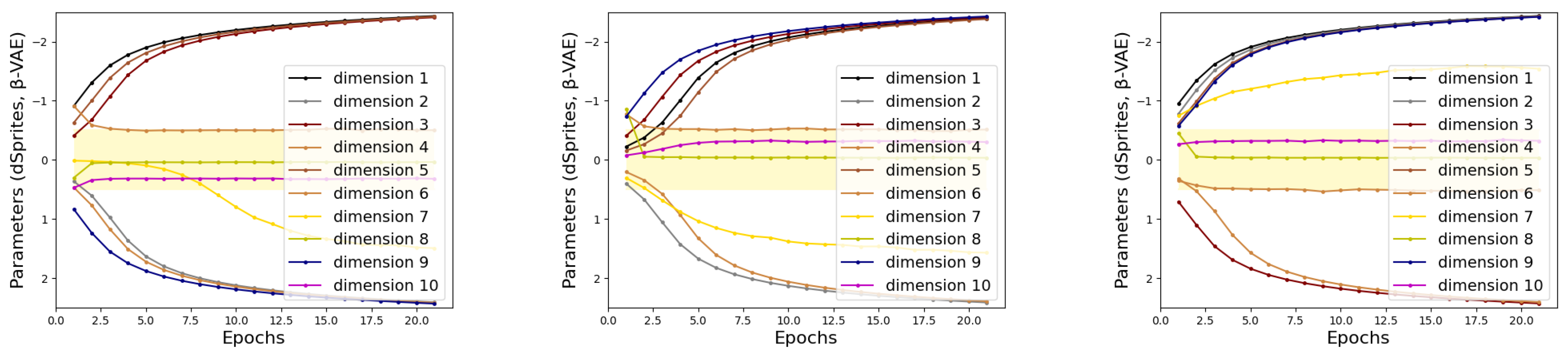
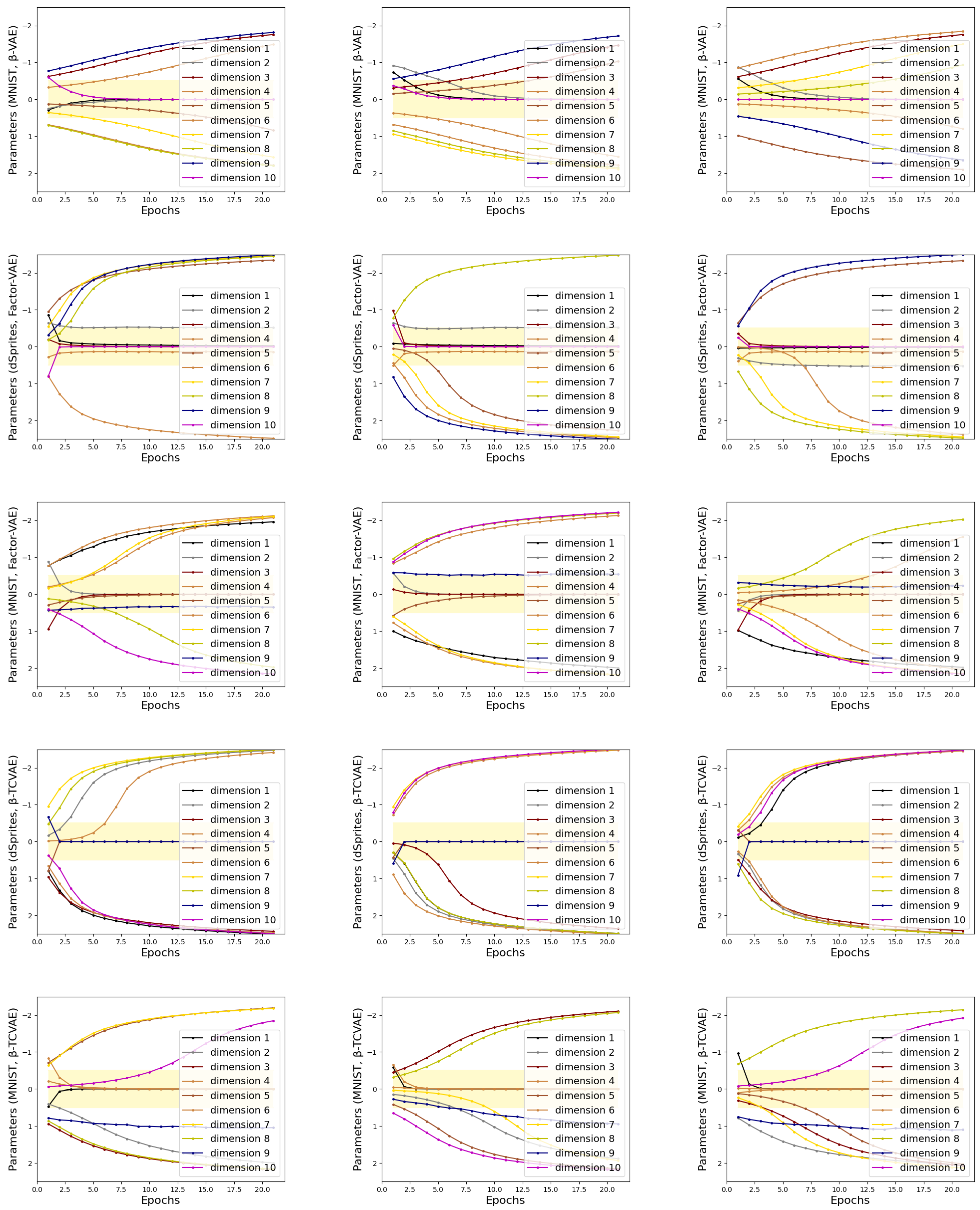
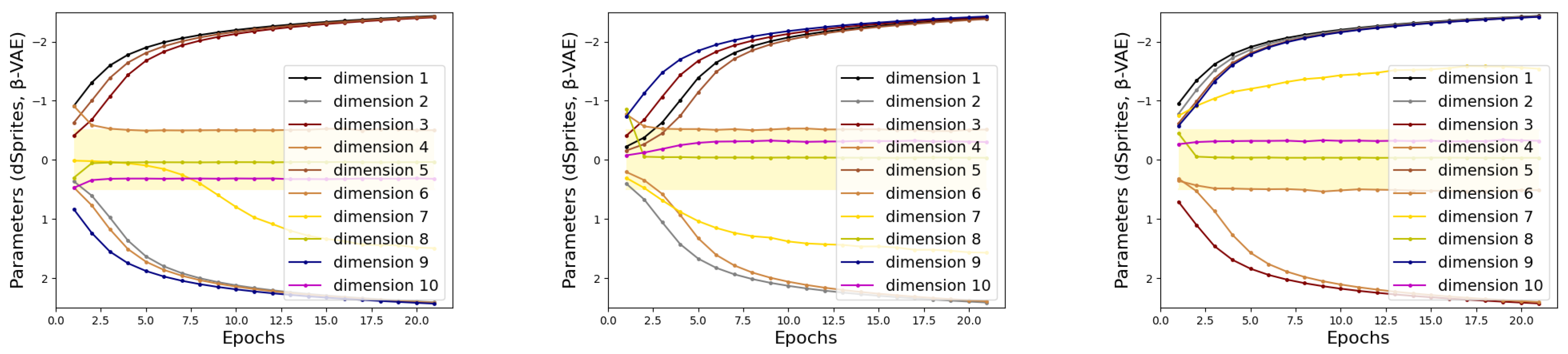
4.1.3. Stability
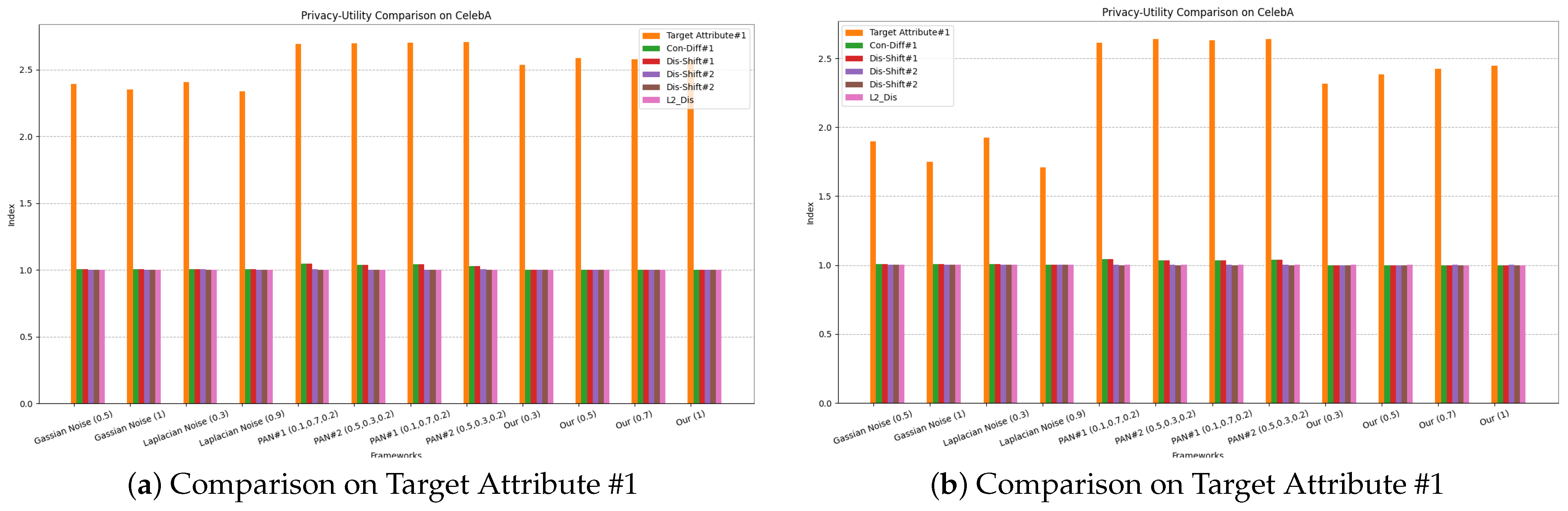
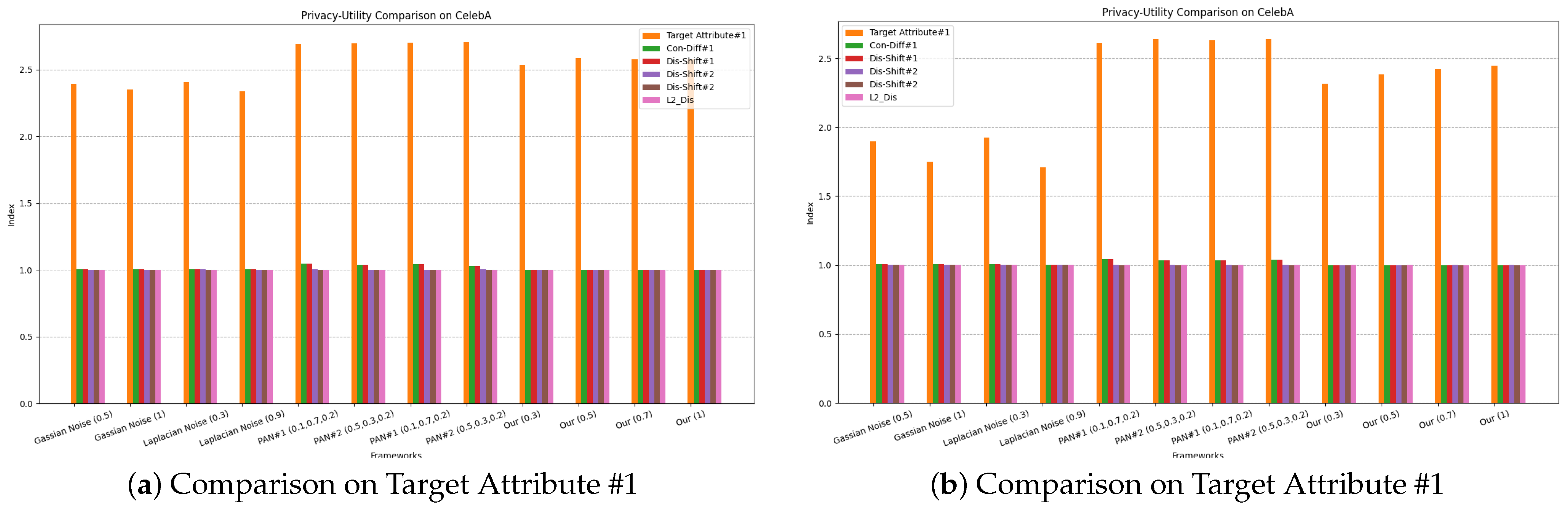
4.2. Privacy–Utility Trade-Offs Evaluation and Comparison
4.2.1. Setup
4.2.2. Baselines
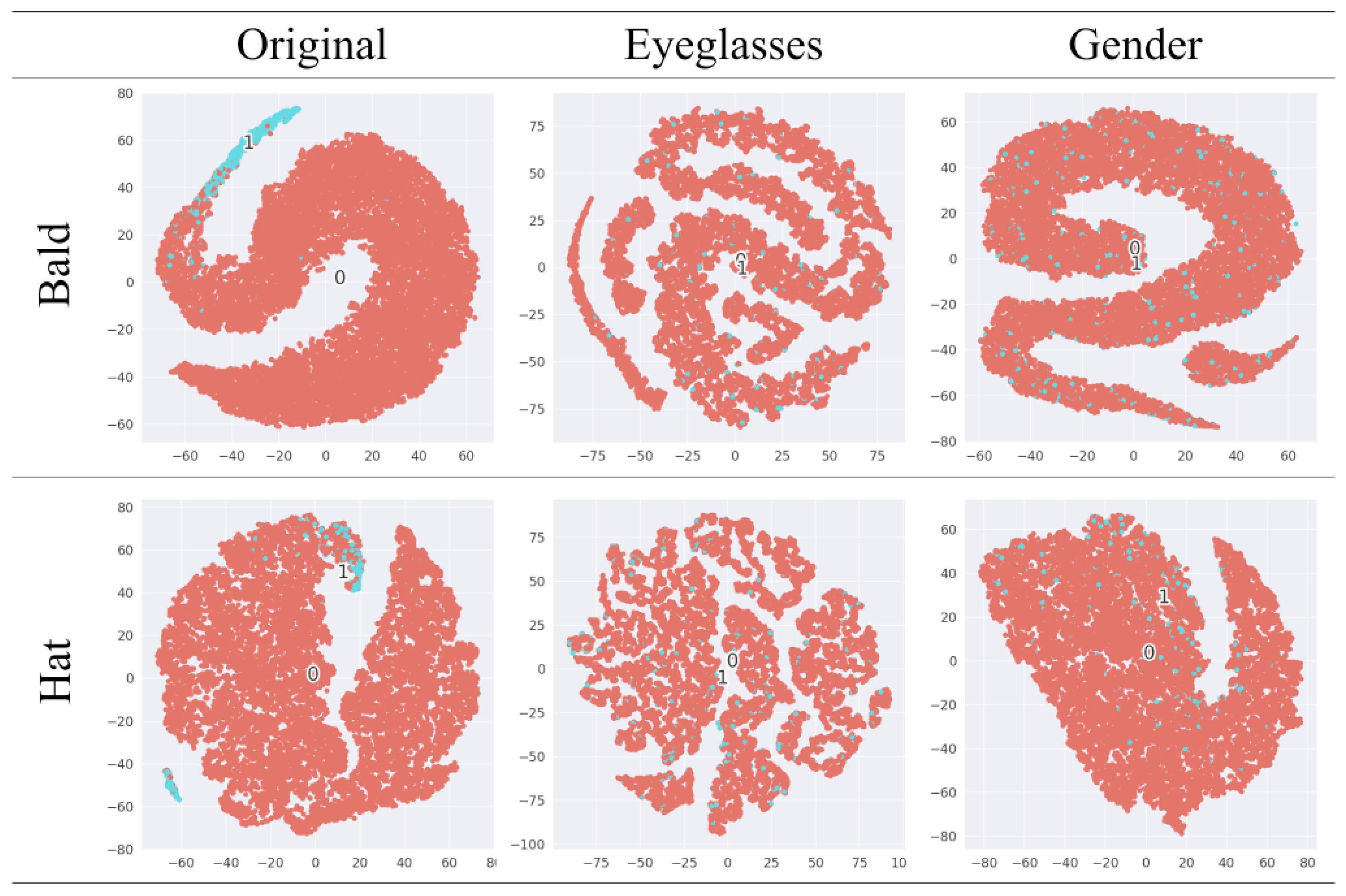
4.2.3. Evaluation and Comparison
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Long and Short Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. Available online: http://arxiv.org/abs/2010.11929 (accessed on 6 December 2023).
- Li, A.; Guo, J.; Yang, H.; Salim, F.D.; Chen, Y. DeepObfuscator: Obfuscating Intermediate Representations with Privacy-Preserving Adversarial Learning on Smartphones. In Proceedings of the IoTDI’21: International Conference on Internet-of-Things Design and Implementation, Charlottesville, VA, USA, 18–21 May 2021; ACM: New York, NY, USA, 2021; pp. 28–39. [Google Scholar] [CrossRef]
- Ribeiro, M.; Grolinger, K.; Capretz, M.A. MLaaS: Machine Learning as a Service. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 896–902. [Google Scholar] [CrossRef]
- Achille, A.; Soatto, S. Emergence of Invariance and Disentanglement in Deep Representations. J. Mach. Learn. Res. 2018, 19, 1947–1980. [Google Scholar]
- Google. Google Now Launcher. 2018. Available online: https://en.wikipedia.org/wiki/Google_Now (accessed on 6 December 2023).
- Google. Data Preparation. 2018. Available online: https://cloud.google.com/ml-engine/docs/tensorflow/data-prep (accessed on 6 December 2023).
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model Inversion Attacks That Exploit Confidence Information and Basic Countermeasures. In Proceedings of the CCS’15, 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar] [CrossRef]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar] [CrossRef]
- Hidano, S.; Murakami, T.; Katsumata, S.; Kiyomoto, S.; Hanaoka, G. Model Inversion Attacks for Prediction Systems: Without Knowledge of Non-Sensitive Attributes. In Proceedings of the 2017 15th Annual Conference on Privacy, Security and Trust (PST), Calgary, AB, Canada, 28–30 August 2017; pp. 115–11509. [Google Scholar] [CrossRef]
- Osia, S.A.; Shahin Shamsabadi, A.; Sajadmanesh, S.; Taheri, A.; Katevas, K.; Rabiee, H.R.; Lane, N.D.; Haddadi, H. A Hybrid Deep Learning Architecture for Privacy-Preserving Mobile Analytics. IEEE Internet Things J. 2020, 7, 4505–4518. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; Volume 27. [Google Scholar]
- Liu, S.; Du, J.; Shrivastava, A.; Zhong, L. Privacy Adversarial Network: Representation Learning for Mobile Data Privacy. Proc. Acm Interact. Mobile, Wearable Ubiquitous Technol. 2019, 3, 144. [Google Scholar] [CrossRef]
- Li, A.; Duan, Y.; Yang, H.; Chen, Y.; Yang, J. TIPRDC: Task-Independent Privacy-Respecting Data Crowdsourcing Framework for Deep Learning with Anonymized Intermediate Representations. In Proceedings of the KDD’20, 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 824–832. [Google Scholar] [CrossRef]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar] [CrossRef]
- Chattopadhay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V.N. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 839–847. [Google Scholar] [CrossRef]
- Zhang, Q.; Rao, L.; Yang, Y. Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks. arXiv 2021, arXiv:2103.13859. Available online: http://arxiv.org/abs/2103.13859 (accessed on 6 December 2023).
- Zhang, Q.; Wang, X.; Wu, Y.N.; Zhou, H.; Zhu, S.C. Interpretable CNNs for Object Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3416–3431. [Google Scholar] [CrossRef] [PubMed]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017; Conference Track Proceedings. Available online: http://OpenReview.net (accessed on 6 December 2023).
- Kim, H.; Mnih, A. Disentangling by Factorising. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Dy, J.G., Krause, A., Eds.; Proceedings of Machine Learning Research: Breckenridge, CO, USA, 2018; Volume 80, pp. 2654–2663. [Google Scholar]
- Chen, T.Q.; Li, X.; Grosse, R.B.; Duvenaud, D. Isolating Sources of Disentanglement in Variational Autoencoders. In Advances in Neural Information Processing Systems 31, Proceedings of theAnnual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Neural Information Processing Systems: La Jolla, CA, USA, 2018; pp. 2615–2625. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Advances in Neural Information Processing Systems 29, Proceedings of theAnnual Conference on Neural Information Processing Systems 2016, Barcelona, Spain, 5–10 December 2016; Lee, D.D., Sugiyama, M., von Luxburg, U., Guyon, I., Garnett, R., Eds.; Neural Information Processing Systems: La Jolla, CA, USA, 2016; pp. 2172–2180. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1x1 Convolutions. In Advances in Neural Information Processing Systems 31, Proceedings of the Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada 3–8 December 2018; Bengio, S., Wallach, H.M., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Neural Information Processing Systems: La Jolla, CA, USA, 2018; pp. 10236–10245. [Google Scholar]
- Sweeney, L. k-Anonymity: A Model for Protecting Privacy. Int. J. Uncertain. Fuzziness Knowl. Based Syst. 2002, 10, 557–570. [Google Scholar] [CrossRef]
- Machanavajjhala, A.; Gehrke, J.; Kifer, D.; Venkitasubramaniam, M. L-diversity: Privacy beyond k-anonymity. In Proceedings of the 22nd International Conference on Data Engineering (ICDE’06), Atlanta, GA, USA, 3–7 April 2006; p. 24. [Google Scholar] [CrossRef]
- Li, N.; Li, T.; Venkatasubramanian, S. t-Closeness: Privacy Beyond k-Anonymity and l-Diversity. In Proceedings of the 2007 IEEE 23rd International Conference on Data Engineering, Atlanta, GA, USA, 3–7 April 2006; pp. 106–115. [Google Scholar] [CrossRef]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2014, 9, 211–407. [Google Scholar] [CrossRef]
- Mironov, I. Rényi Differential Privacy. In Proceedings of the 2017 IEEE 30th Computer Security Foundations Symposium (CSF), Santa Barbara, CA, USA, 21–25 August 2017; pp. 263–275. [Google Scholar] [CrossRef]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the CCS’16, 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar] [CrossRef]
- Papernot, N.; Song, S.; Mironov, I.; Raghunathan, A.; Talwar, K.; Erlingsson, Ú. Scalable Private Learning with PATE. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018; Conference Track Proceedings. Available online: http://OpenReview.net (accessed on 6 December 2023).
- Oh, S.J.; Benenson, R.; Fritz, M.; Schiele, B. Faceless Person Recognition: Privacy Implications in Social Media. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 19–35. [Google Scholar]
- Dowlin, N.; Gilad-Bachrach, R.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. CryptoNets: Applying Neural Networks to Encrypted Data with High Throughput and Accuracy. In Proceedings of the ICML’16 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 201–210. Available online: http://JMLR.org (accessed on 6 December 2023).
- Li, J.; Kuang, X.; Lin, S.; Ma, X.; Tang, Y. Privacy preservation for machine learning training and classification based on homomorphic encryption schemes. Inf. Sci. 2020, 526, 166–179. [Google Scholar] [CrossRef]
- Riazi, M.S.; Weinert, C.; Tkachenko, O.; Songhori, E.M.; Schneider, T.; Koushanfar, F. Chameleon: A Hybrid Secure Computation Framework for Machine Learning Applications. In Proceedings of the ASIACCS’18, 2018 on Asia Conference on Computer and Communications Security, Incheon, Republic of Korea, 4 June 2018; pp. 707–721. [Google Scholar] [CrossRef]
- Liu, J.; Juuti, M.; Lu, Y.; Asokan, N. Oblivious Neural Network Predictions via MiniONN Transformations. In Proceedings of the CCS’17, Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 619–631. [Google Scholar] [CrossRef]
- Mohassel, P.; Zhang, Y. SecureML: A System for Scalable Privacy-Preserving Machine Learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, B.; Kuang, Z.; Lin, D.; Fan, J. iPrivacy: Image Privacy Protection by Identifying Sensitive Objects via Deep Multi-Task Learning. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1005–1016. [Google Scholar] [CrossRef]
- Malekzadeh, M.; Clegg, R.G.; Haddadi, H. Replacement AutoEncoder: A Privacy-Preserving Algorithm for Sensory Data Analysis. In Proceedings of the 2018 IEEE/ACM Third International Conference on Internet-of-Things Design and Implementation (IoTDI), Orlando, FL, USA, 17–20 April 2018; pp. 165–176. [Google Scholar] [CrossRef]
- Aloufi, R.; Haddadi, H.; Boyle, D. Privacy-Preserving Voice Analysis via Disentangled Representations. In Proceedings of the CCSW’20, 2020 ACM SIGSAC Conference on Cloud Computing Security Workshop, Virtual, 9 November 2020; pp. 1–14. [Google Scholar] [CrossRef]
- van den Oord, A.; Vinyals, O.; kavukcuoglu, K. Neural Discrete Representation Learning. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Kalchbrenner, N.; Elsen, E.; Simonyan, K.; Noury, S.; Casagrande, N.; Lockhart, E.; Stimberg, F.; van den Oord, A.; Dieleman, S.; Kavukcuoglu, K. Efficient Neural Audio Synthesis. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Dy, J.G., Krause, A., Eds.; Proceedings of Machine Learning Research: Breckenridge, CO, USA, 2018; Volume 80, pp. 2415–2424. [Google Scholar]
- Gong, M.; Liu, J.; Li, H.; Xie, Y.; Tang, Z. Disentangled Representation Learning for Multiple Attributes Preserving Face Deidentification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 33, 244–256. [Google Scholar] [CrossRef]
- Wu, H.; Tian, X.; Li, M.; Liu, Y.; Ananthanarayanan, G.; Xu, F.; Zhong, S. PECAM: Privacy-Enhanced Video Streaming and Analytics via Securely Reversible Transformation. In Proceedings of the MobiCom’21, 27th Annual International Conference on Mobile Computing and Networking, New Orleans, Louisiana, 25–29 October 2021; pp. 229–241. [Google Scholar] [CrossRef]
- Jia, J.; Gong, N.Z. Attriguard: A Practical Defense against Attribute Inference Attacks via Adversarial Machine Learning. In Proceedings of the SEC’18, 27th USENIX Conference on Security Symposium, Baltimore, MD, USA, 15–17 August 2018; pp. 513–529. [Google Scholar]
- Wu, Z.; Wang, Z.; Wang, Z.; Jin, H. Towards Privacy-Preserving Visual Recognition via Adversarial Training: A Pilot Study. In Computer Vision—ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; pp. 627–645. [Google Scholar]
- Larsen, A.B.L.; Sønderby, S.K.; Larochelle, H.; Winther, O. Autoencoding beyond Pixels Using a Learned Similarity Metric. In Proceedings of the ICML’16, 33rd International Conference on International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; Volume 48, pp. 1558–1566. [Google Scholar]
- Matthey, L.; Higgins, I.; Hassabis, D.; Lerchner, A. dSprites: Disentanglement Testing Sprites Dataset. 2017. Available online: https://github.com/deepmind/dsprites-dataset/ (accessed on 6 December 2023).
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R. A Hybrid Approach to Privacy-Preserving Federated Learning. In Proceedings of the AISec’19, 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 1–2. [Google Scholar]
- van der Maaten, L.; Hinton, G. Viualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Target Attribute #1 | Privacy Attribute #1 | Privacy Attribute #2 | L2-DIS | ||
|---|---|---|---|---|---|---|
| Dis-Shift | Con-Diff | Dis-Shift | Con-Diff | |||
| Gaussian noise | 87.3% | |||||
| Gaussian noise | ||||||
| Laplacian noise () | ||||||
| Laplacian noise () | ||||||
| PAN (#1, ) | ||||||
| PAN (#1, ) | ||||||
| PAN (#2, ) | ||||||
| PAN (#2, ) | ||||||
| Our framework | ||||||
| Our framework | ||||||
| Our framework | ||||||
| Our framework | ||||||
| Methods | Target Attribute #2 | Privacy Attribute #1 | Privacy Attribute #2 | L2-DIS | ||
| Dis-Shift | Con-Diff | Dis-Shift | Con-Diff | |||
| Gaussian noise | ||||||
| Gaussian noise | ||||||
| Laplacian noise () | ||||||
| Laplacian noise () | ||||||
| PAN (#1, ) | ||||||
| PAN (#1, ) | ||||||
| PAN (#2, ) | ||||||
| PAN (#2, ) | ||||||
| Our framework | ||||||
| Our framework | ||||||
| Our framework | ||||||
| Our framework | ||||||
| Methods | Dis-Shift (Original Attacker) | Dis-Shift (Potential Attacker) |
|---|---|---|
| Gaussian noise | ||
| Gaussian noise | ||
| Laplacian noise | ||
| Laplacian noise | ||
| PAN | ||
| PAN | ||
| Our framework | ||
| Our framework |
| Method | Target Attribute #1 | Privacy Attribute #1 | Privacy Attribute #2 |
|---|---|---|---|
| Our framework | |||
| Our framework | |||
| Our framework | |||
| Our framework | |||
| Method | Target Attribute #1 | Privacy Attribute #1 | Privacy Attribute #2 |
| Our framework | |||
| Our framework | |||
| Our framework | |||
| Our framework |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, Q.; Li, H. Respecting Partial Privacy of Unstructured Data via Spectrum-Based Encoder. Sensors 2024, 24, 1015. https://doi.org/10.3390/s24031015
Luo Q, Li H. Respecting Partial Privacy of Unstructured Data via Spectrum-Based Encoder. Sensors. 2024; 24(3):1015. https://doi.org/10.3390/s24031015
Chicago/Turabian StyleLuo, Qingcai, and Hui Li. 2024. "Respecting Partial Privacy of Unstructured Data via Spectrum-Based Encoder" Sensors 24, no. 3: 1015. https://doi.org/10.3390/s24031015
APA StyleLuo, Q., & Li, H. (2024). Respecting Partial Privacy of Unstructured Data via Spectrum-Based Encoder. Sensors, 24(3), 1015. https://doi.org/10.3390/s24031015