


Error Separation Method for Geometric Distribution Error Modeling of Precision Machining Surfaces Based on K-Space Spectrum
 , , ,
, , ,
Abstract
1. Introduction
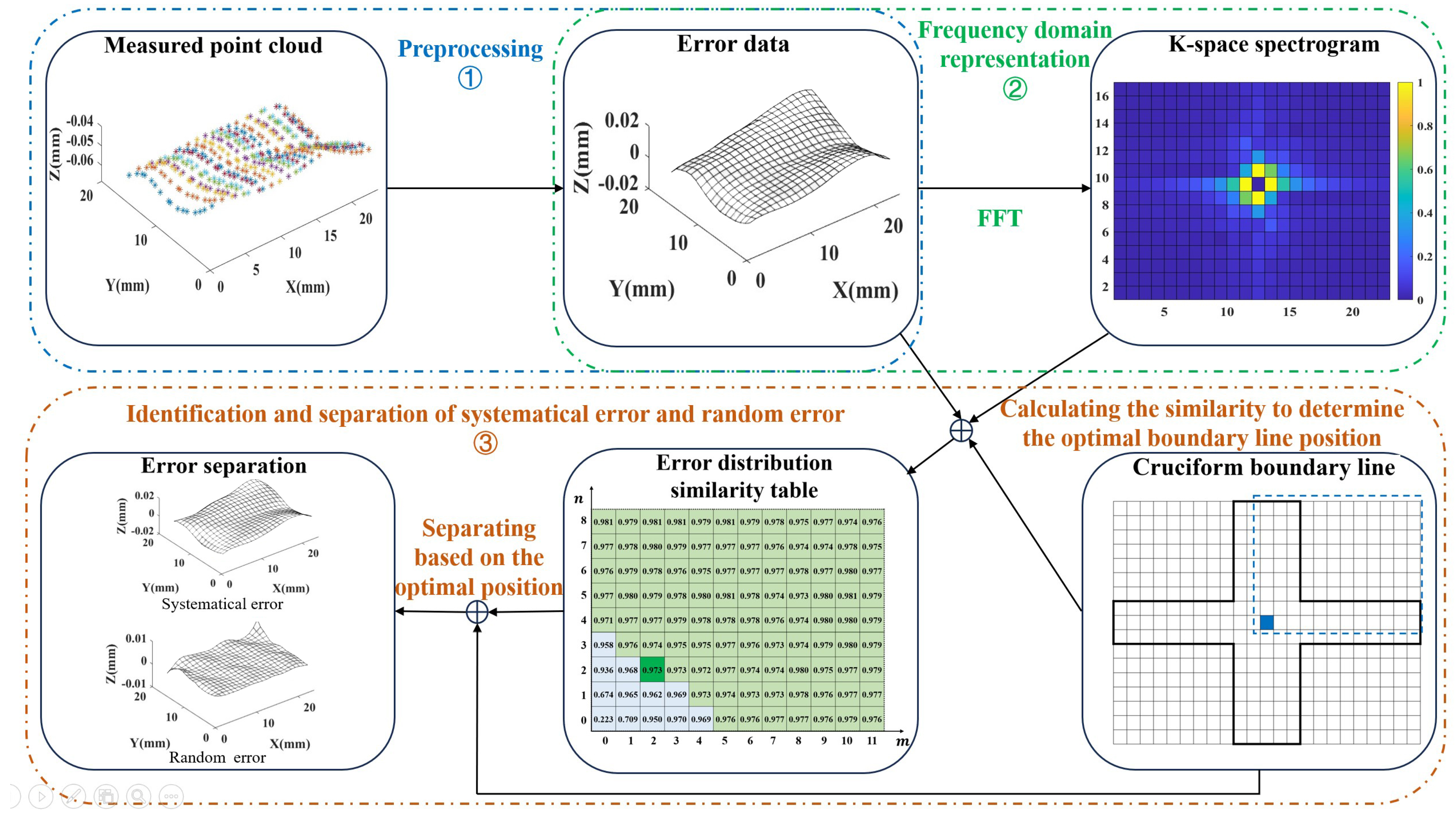
2. The Framework of K-GDES Method
3. Preprocessing and Frequency Domain Representation
3.1. Preprocessing
3.1.1. Compensating for the Error Caused by Measurement
3.1.2. Obtaining Error Data
3.1.3. Constructing Uniformly Distributed Error Data
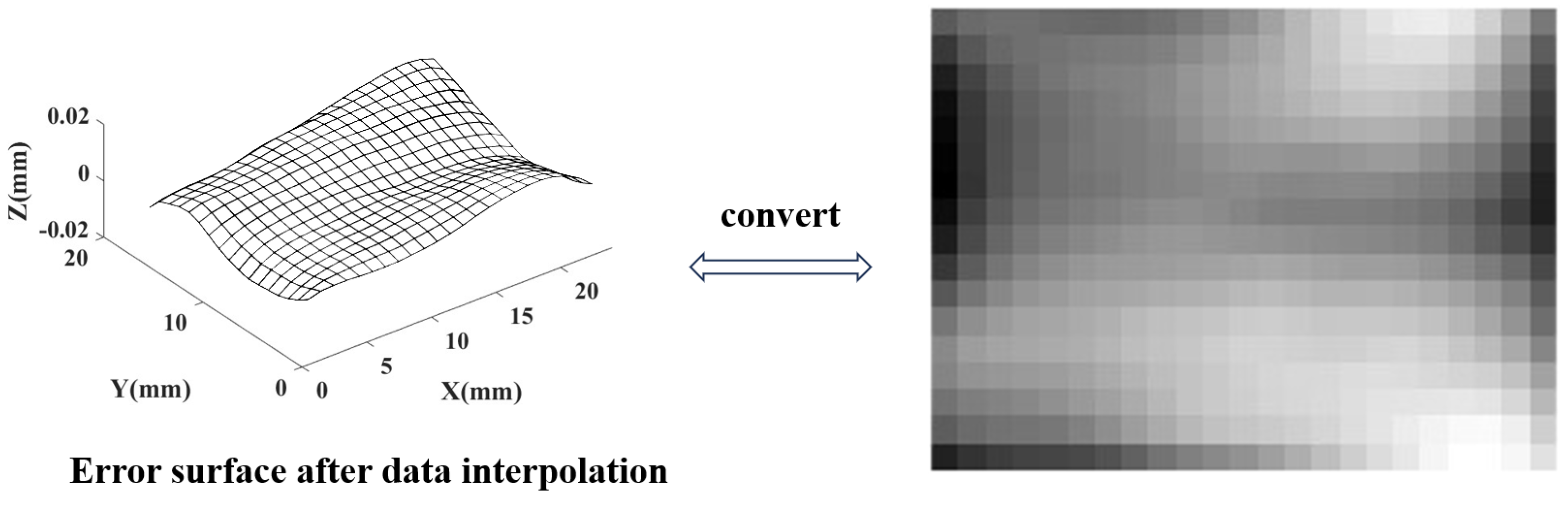
3.2. K-Space Spectrum of GDE
4. Identification and Separation
4.1. Cruciform Boundary Line
4.2. Optimal Cruciform Boundary Position Determine Method
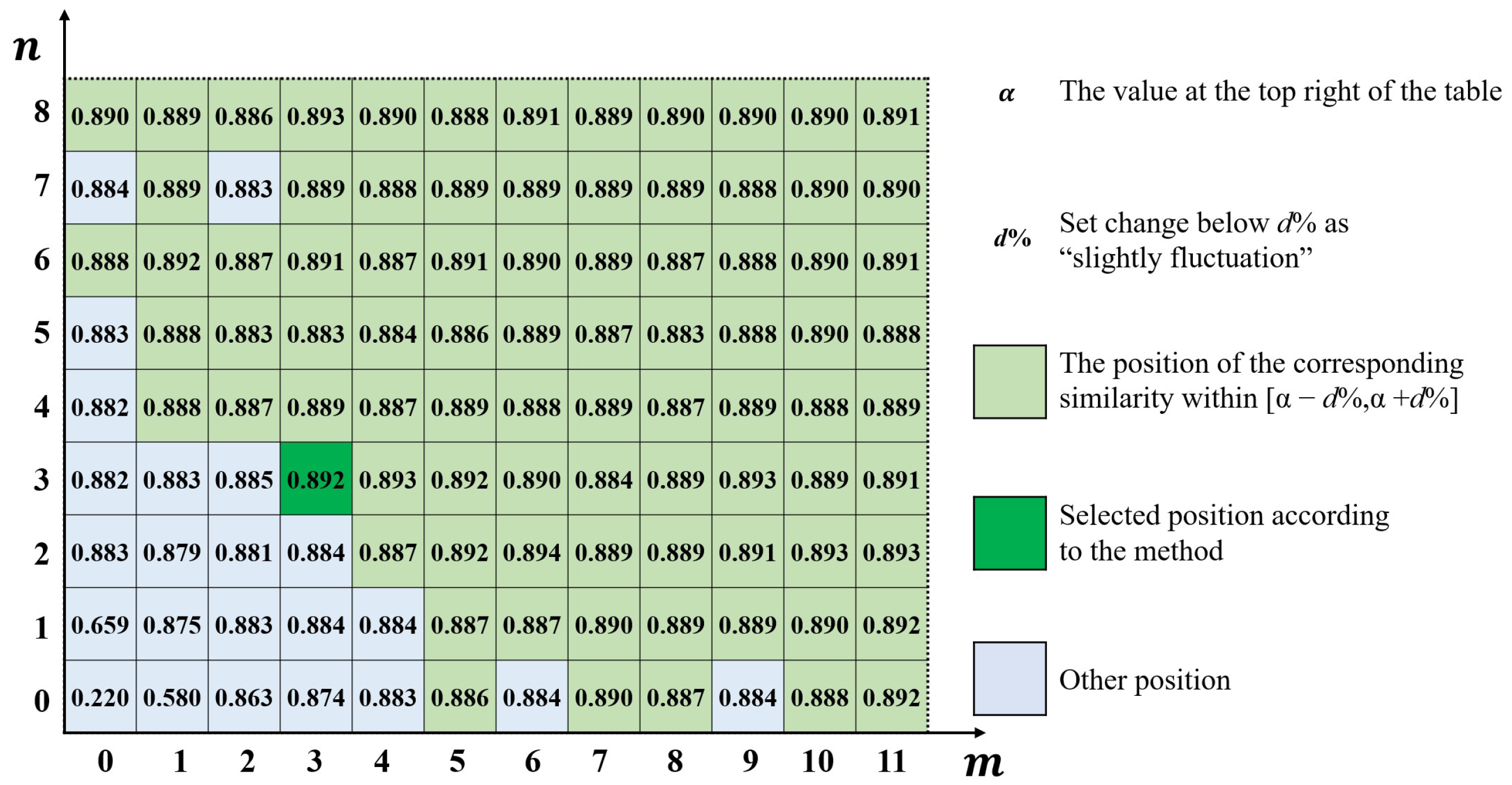
4.2.1. Representation Method of Cruciform Boundary Position
4.2.2. Calculation Method of Error Distribution Similarity
4.2.3. Error Distribution Similarity Table
4.2.4. Determine the Optimal Boundary Position
4.3. Results of K-GDES and Modeling
5. Experimental Verification and Method Analysis
5.1. Experimental Condition
5.2. Examples of K-GDES Application
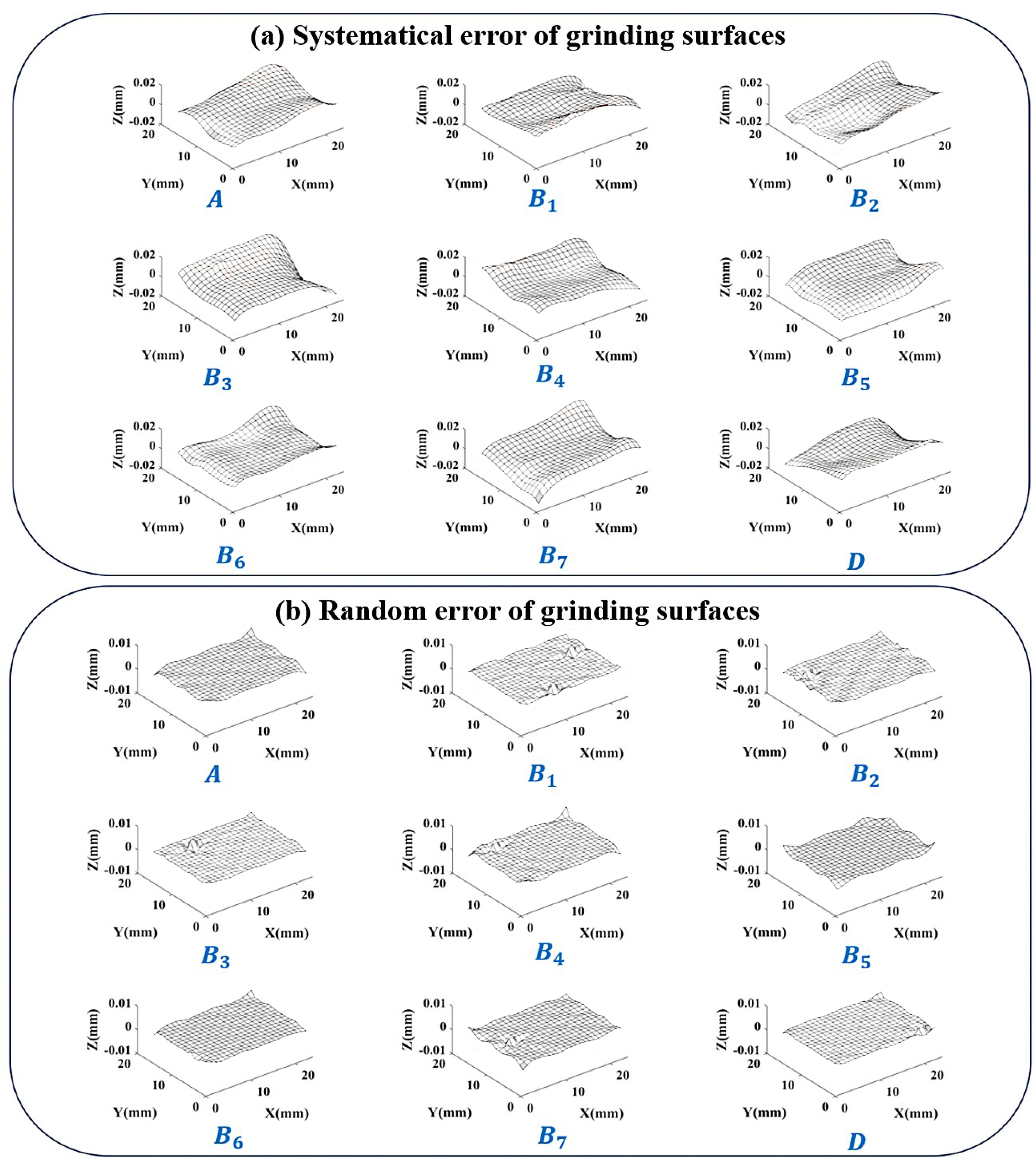
5.2.1. Verification Based on Grinding Surfaces
- The error distribution similarity between the systematical error surface and the original error surfaceShows the similarity between the surface composed of systematical error and the surface containing all error. The average value of between the 8 error surfaces involved in the calculation and their respective systematical error surfaces is . And the of validation surface D is . A high degree of similarity indicates that the error component of the control surface shape has been successfully segmented into systematical error parts.
- The proportion of systematical error amplitude to the total error amplitudeThis indicator represents the proportional relationship between the separated systematical error and random error. Calculate the proportion of systematical error in the K-space amplitude spectrum of the error surface to the total error amplitude. The average of the 8 error surfaces participating in the calculation is . And the of validation surface D is . In this group of grinding surfaces, due to the low random error components, the value is relatively high.
- Random error peak to peak valueThe D-value between the highest and lowest points of the Z coordinate in the separated random error. The average value of the 8 error surfaces in the calculation is 4.6 m, and the of validation surface D is 2.9 m. The magnitude of random error is in the micrometer range.
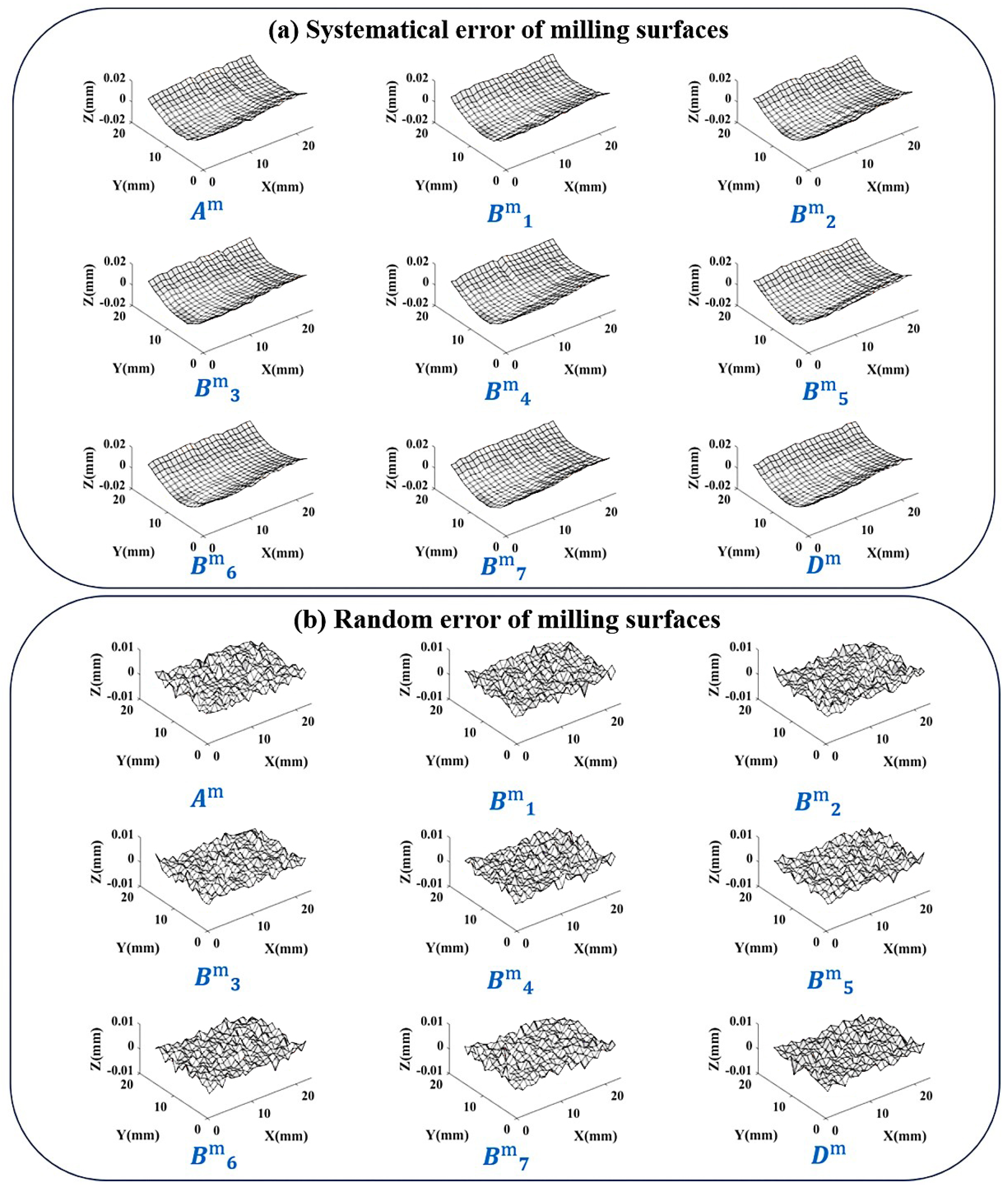
5.2.2. Verification Based on Milling Surfaces
- The error distribution similarity between the systematical error surface and the original error surfaceThe average value of between the 8 error surfaces involved in the calculation and their respective systematical error surfaces is . And the of validation surface is . A high degree of similarity indicates that the error component of the control surface shape has been successfully segmented into systematical error parts.
- The proportion of systematical error amplitude to the total error amplitudeThe average of the 8 error surfaces participating in the calculation is . And the of validation surface is . Compared to grinding surfaces, the random error amount in milling surfaces significantly increases, so the proportion of systematical error decreases, which is consistent with the actual situation.
- Random error peak to peak valueThe average value of the 8 error surfaces in the calculation is 7.8 m, and the of validation surface is 7.2 m. The random error peak-to-peak values of milling surfaces are higher than those of grinding surfaces because the milling accuracy is lower than that of grinding, which is consistent with the actual situation.
5.3. Stability Analysis of K-GDES
6. Discussion
- Unified error separation of a batch of machining surfaces is achieved under the same processing method;
- Can still be used normally under low data density;
- When there is a certain periodic pattern in the machining features, the ability to preserve the machining features is excellent;
- Due to the fact that the method is based on frequency, it can still be used normally when the amplitude of high-frequency random error is high.
- The effectiveness of K-GDES under high data density has not been verified and compared with other methods;
- A batch of machining surfaces is required, so it is not applicable to a single surface;
- When the magnitude of the random error is much lower than systematical error, K-GDES does not have a significant advantage over smoothing methods such as the Gaussian filter method;
- Difficult to handle low-frequency random errors that may exist in measurement data.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GDE | Geometric Eistribution Error |
| K-GDES | An error separation method for GDE based on K-space spectrum |
References
- Shang, K.; Wu, T.; Jin, X.; Zhang, Z.; Li, C.; Liu, R.; Wang, M.; Dai, W.; Liu, J. Coaxiality prediction for aeroengines precision assembly based on geometric distribution error model and point cloud deep learning. J. Manuf. Syst. 2023, 71, 681–694. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, Z.; Jin, X.; Zhang, Q. A novel modelling method of geometric errors for precision assembly. Int. J. Adv. Manuf. Technol. 2018, 94, 1139–1160. [Google Scholar] [CrossRef]
- Qimuge, S.; Zhang, Z.; Xiong, J.; Chen, X.; Zhu, D.; Wu, W.; Jin, X.; Shang, K. An accuracy and performance-oriented accurate digital twin modeling method for precision microstructures. J. Intell. Manuf. 2023, 35, 2887–2911. [Google Scholar]
- Chen, X.; Jin, X.; Shang, K.; Zhang, Z. Entropy-Based Method to Evaluate Contact-Pressure Distribution for Assembly-Accuracy Stability Prediction. Entropy 2019, 21, 322. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Jin, X.; Liu, Z.; Zhang, Z.; Yan, F.; Zhang, Z.; Ledoux, Y. A new approach of surfaces registration considering form errors for precise assembly. Assem. Autom. 2020, 40, 789–800. [Google Scholar] [CrossRef]
- Wang, Z.; Zhang, Z.; Chen, X.; Jin, X. An Optimization Method of Precision Assembly Process Based on the Relative Entropy Evaluation of the Stress Distribution. Entropy 2020, 22, 137. [Google Scholar] [CrossRef] [PubMed]
- Pawlus, P.; Reizer, R.; Wieczorowski, M.; Krolczyk, G. Study of surface texture measurement errors. Measurement 2023, 210, 112568. [Google Scholar] [CrossRef]
- Sun, L.; Ren, J.; Xu, X. A data-driven machining errors recovery method for complex surfaces with limited measurement points. Measurement 2021, 181, 109661. [Google Scholar] [CrossRef]
- Li, Y.; Xie, G.; Meng, F.; Zhang, D. Using the Point Cloud Data to Reconstructing CAD Model by 3D Geometric Modeling Method in Reverse Engineering. In Proceedings of the International Conference on Manufacturing Engineering and Intelligent Materials, Guangzhou, China, 25–26 February 2017. [Google Scholar]
- Khameneifar, F.; Feng, H.Y. Establishing a balanced neighborhood of discrete points for local quadric surface fitting. Comput. Aided Des. 2017, 84, 25–38. [Google Scholar] [CrossRef]
- Zeng, F.; Liang, L.I. Research on Point Cloud Filtering based on Lagrange Operator and Surface Fitting. Laser J. 2016, 37, 75–78. [Google Scholar]
- Deng, C.; Lin, H. Progressive and iterative approximation for least squares B-spline curve and surface fitting. Comput. Aided Des. 2014, 47, 32–44. [Google Scholar] [CrossRef]
- Wu, N.; Liu, C. Randomized progressive iterative approximation for B-spline curve and surface fittings. arXiv 2022, arXiv:2212.06398. [Google Scholar] [CrossRef]
- Martínez-Otzeta, J.M.; Rodríguez-Moreno, I.; Mendialdua, I.; Sierra, B. RANSAC for Robotic Applications: A Survey. Sensors 2022, 23, 327. [Google Scholar] [CrossRef]
- Buades, A.; Coll, B.; Morel, J.M. A non-local algorithm for image denoising. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 2, pp. 60–65. [Google Scholar]
- Nercessian, S.; Panetta, K.A.; Agaian, S.S. A multi-scale non-local means algorithm for image de-noising. Proc. SPIE Int. Soc. Opt. Eng. 2015, 8406, 16. [Google Scholar]
- Thangaraj, V.; Subudhi, B.N.; Sankaralingam, E. Empirical mode decomposition and adaptive bilateral filter approach for impulse noise removal. Expert Syst. Appl. 2019, 121, 18–27. [Google Scholar]
- Lian, Z.; Gu, Y.; You, K.; Xie, X.; Qiu, G. An adaptive multi-scale point cloud filtering method for feature information retention. Opt. Lasers Eng. 2024, 177, 108144. [Google Scholar] [CrossRef]
- Fu, S.; Muralikrishnan, B.; Raja, J. Engineering Surface Analysis With Different Wavelet Bases. J. Manuf. Sci. Eng. 2003, 125, 844–852. [Google Scholar] [CrossRef]
- Shao, Y.; Du, S.; Tang, H. An extended bi-dimensional empirical wavelet transform based filtering approach for engineering surface separation using high definition metrology. Measurement 2021, 178, 109259. [Google Scholar] [CrossRef]
- An, Q.; Chen, X.; Wang, H.; Yang, H.; Yang, Y.; Huang, W.; Wang, L. Segmentation of Concrete Cracks by Using Fractal Dimension and UHK-Net. Fractal Fract. 2022, 6, 95. [Google Scholar] [CrossRef]
- Qian, Y.; Huang, Z.; Fang, H.; Zuo, Z. WGLFNets: Wavelet-based global–local filtering networks for image denoising with structure preservation. Optik 2022, 261, 169089. [Google Scholar] [CrossRef]
- Zhou, J.; Jin, W.; Wang, M.; Liu, X.; Li, Z.; Liu, Z. Improvement of Normal Estimation for PointClouds via Simplifying Surface Fitting. arXiv 2021, arXiv:2104.10369. [Google Scholar]
- Swornowski, P.J. A new concept of continuous measurement and error correction in Coordinate Measuring Technique using a PC. Measurement 2014, 50, 99–105. [Google Scholar] [CrossRef]
- Ito, S.; Tsutsumi, D.; Kamiya, K.; Matsumoto, K.; Kawasegi, N. Measurement of form error of a probe tip ball for coordinate measuring machine (CMM) using a rotating reference sphere. Precis. Eng. 2020, 61, 41–47. [Google Scholar] [CrossRef]
- Kidangan, R.T.; Unnikrishnakurup, S.; Krishnamurthy, C.V.; Balasubramaniam, K. Uncovering the hidden structure: A study on the feasibility of induction thermography for fiber orientation analysis in CFRP composites using 2D-FFT. Compos. Part Eng. 2024, 269, 111107. [Google Scholar] [CrossRef]
- Zhao, C.; Lv, J.; Du, S. Geometrical deviation modeling and monitoring of 3D surface based on multi-output Gaussian process. Measurement 2022, 199, 111569. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2.9 m | 2.5 m |
| Method Category | ||
|---|---|---|
| K-GDES | 7.1 m | |
| Gaussian = 0.5 | 3.3 m | |
| Gaussian = 0.7 | 7.2 m | |
| Low pass filter | 7.9 m | |
| Wavelet filter | 8.3 m | |
| Wiener2 | 11.1 m | |
| Bilateral filter | 4.0 m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, Z.; Xiong, J.; Zhang, Z.; Su, T.; Zhang, M.; Saren, Q.; Chen, X. Error Separation Method for Geometric Distribution Error Modeling of Precision Machining Surfaces Based on K-Space Spectrum. Sensors 2024, 24, 8067. https://doi.org/10.3390/s24248067
Sheng Z, Xiong J, Zhang Z, Su T, Zhang M, Saren Q, Chen X. Error Separation Method for Geometric Distribution Error Modeling of Precision Machining Surfaces Based on K-Space Spectrum. Sensors. 2024; 24(24):8067. https://doi.org/10.3390/s24248067
Chicago/Turabian StyleSheng, Zhichao, Jian Xiong, Zhijing Zhang, Taiyu Su, Min Zhang, Qimuge Saren, and Xiao Chen. 2024. "Error Separation Method for Geometric Distribution Error Modeling of Precision Machining Surfaces Based on K-Space Spectrum" Sensors 24, no. 24: 8067. https://doi.org/10.3390/s24248067
APA StyleSheng, Z., Xiong, J., Zhang, Z., Su, T., Zhang, M., Saren, Q., & Chen, X. (2024). Error Separation Method for Geometric Distribution Error Modeling of Precision Machining Surfaces Based on K-Space Spectrum. Sensors, 24(24), 8067. https://doi.org/10.3390/s24248067