
A Novel Intelligent Fault Diagnosis Method of Rolling Bearings Based on the ConvNeXt Network with Improved DenseBlock


Abstract
1. Introduction
- In the actual working environment, the operating environment of the bearing is quite complex, and the vibration signal of the bearing will inevitably be polluted by noise, which will lead to fault characteristics that are difficult to identify and make the fault diagnosis work difficult. However, noise pollution has not been considered in most of the existing studies.
- In the actual working environment, it is very difficult to obtain sufficient and effective sample data, but most existing studies have not simulated the situation of insufficient samples.
- The environment in engineering practice is not static, so the diagnostic method needs to have good generalization ability and stability. At present, most studies are limited to the same dataset, and validation on multiple datasets is not considered.
- A continuous wavelet transform is used to fully extract the deep information of the signal and realize the conversion from a one-dimensional signal to a two-dimensional time-frequency image.
- A new two-branch parallel network is constructed that uses a DenseNet branch and a ConvNeXt branch with an improved Denseblock to extract global features and detailed features of images, respectively.
- The Double-Way Fusion Block is introduced to perform channel attention processing on the features extracted from the DenseNet branch and ConvNeXt branch before fusion, so as to complement the information of the two branches and obtain a more comprehensive feature extraction effect.
- The traditional static ReLU function is replaced with the dynamic ReLU activation function, which gives the network a better generalization ability, an enhanced network expression ability, and a better convergence speed.
2. Model Construction
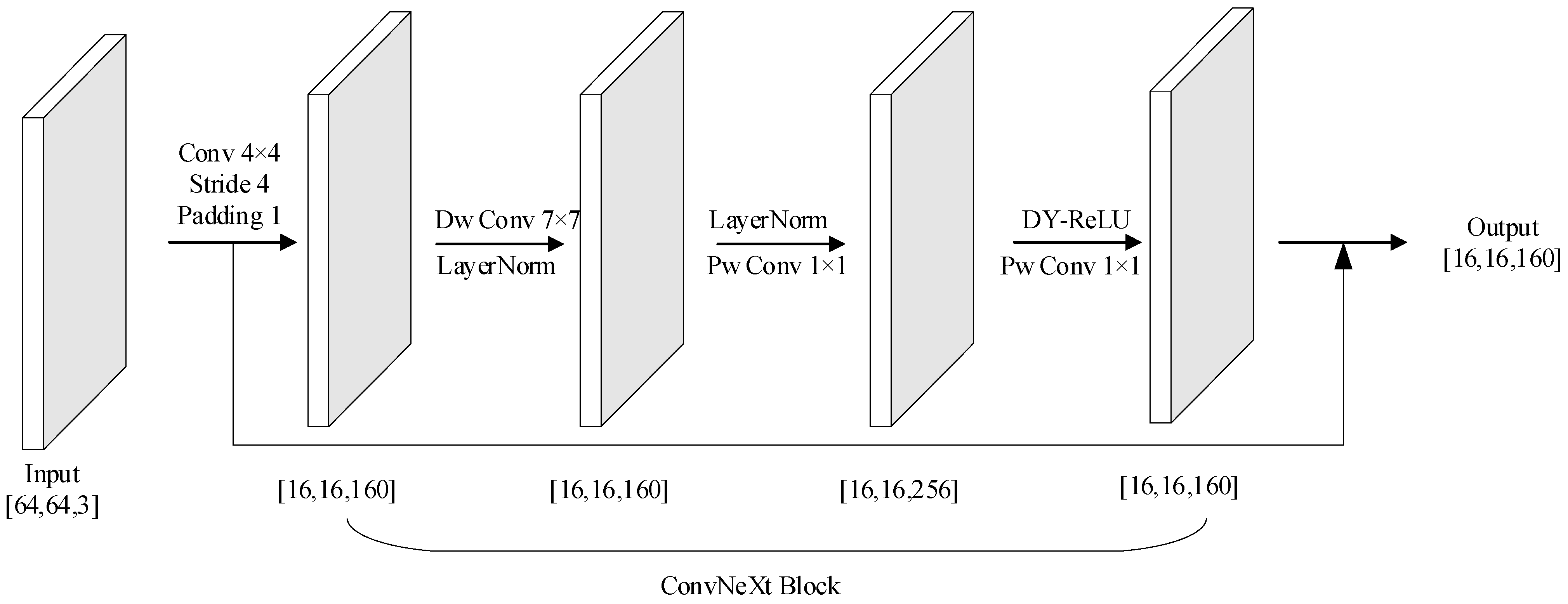
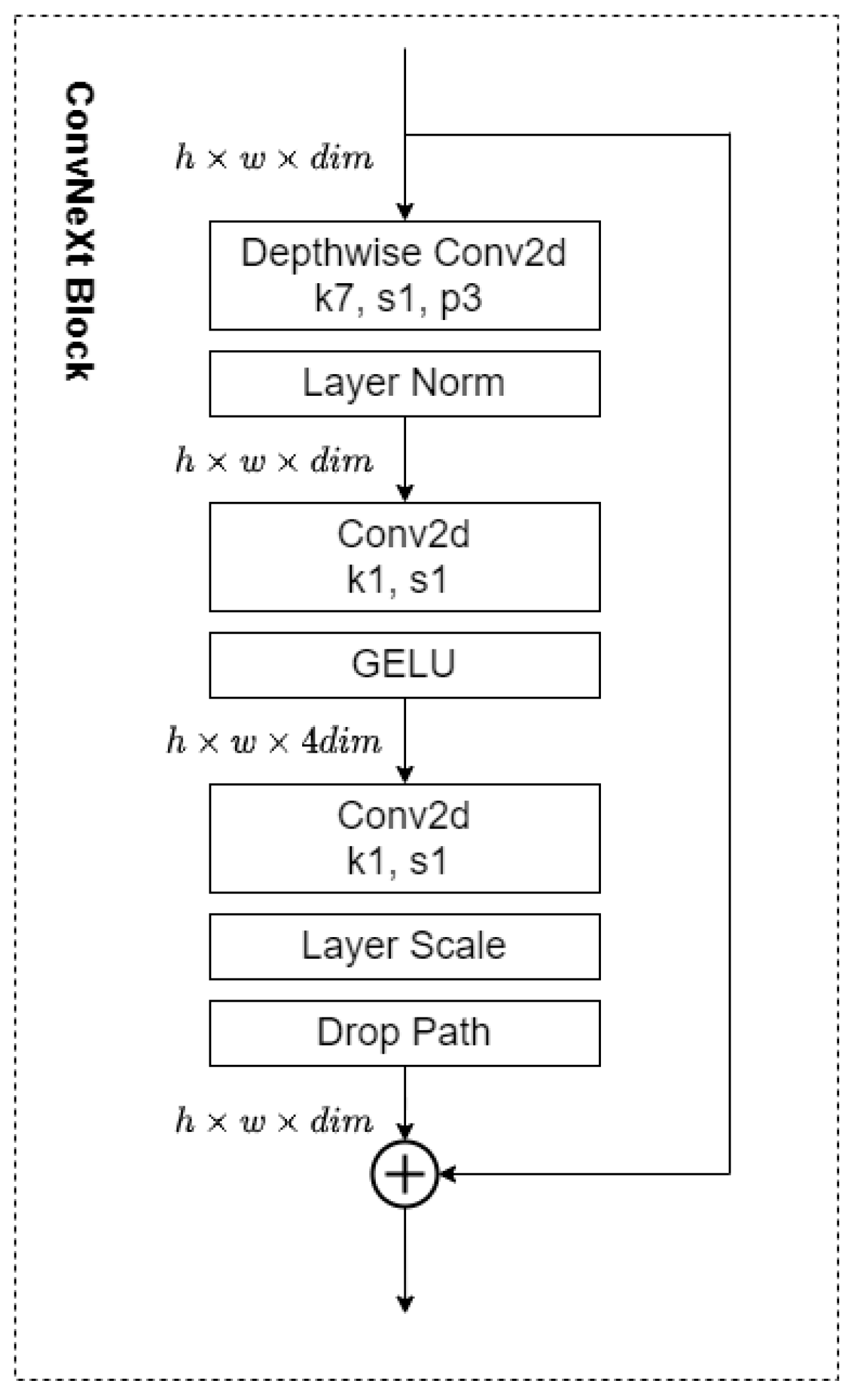
2.1. ConvNeXt Network
2.2. Improved DenseBlock
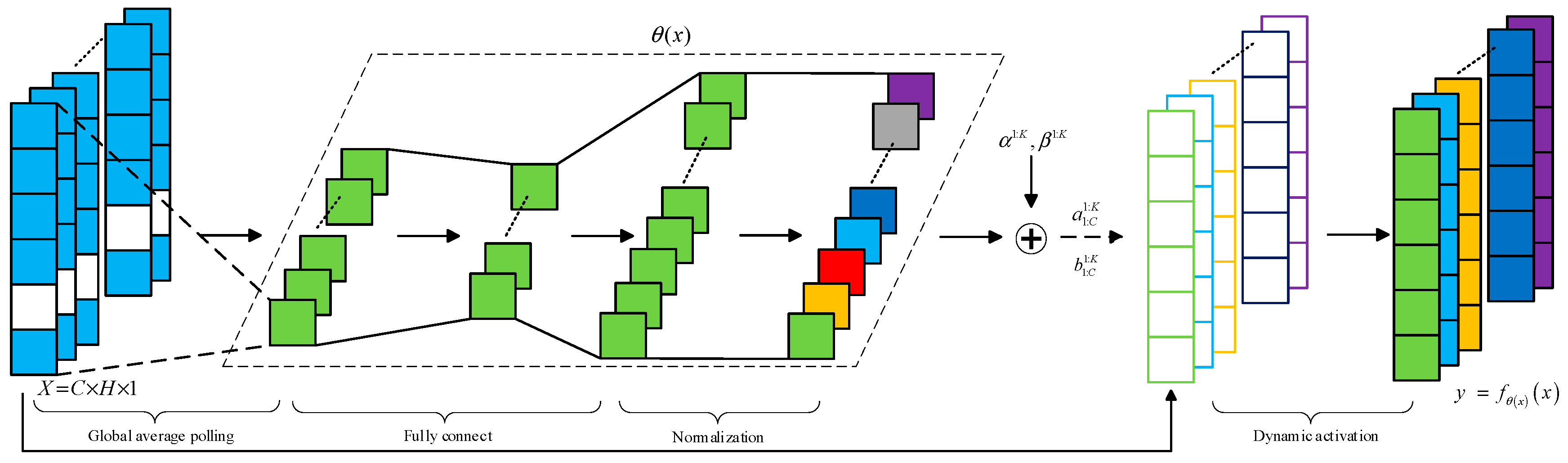
2.3. Dynamic Activation Function
2.4. Continuous Wavelet Transform
2.5. Multi-Feature Fusion Module
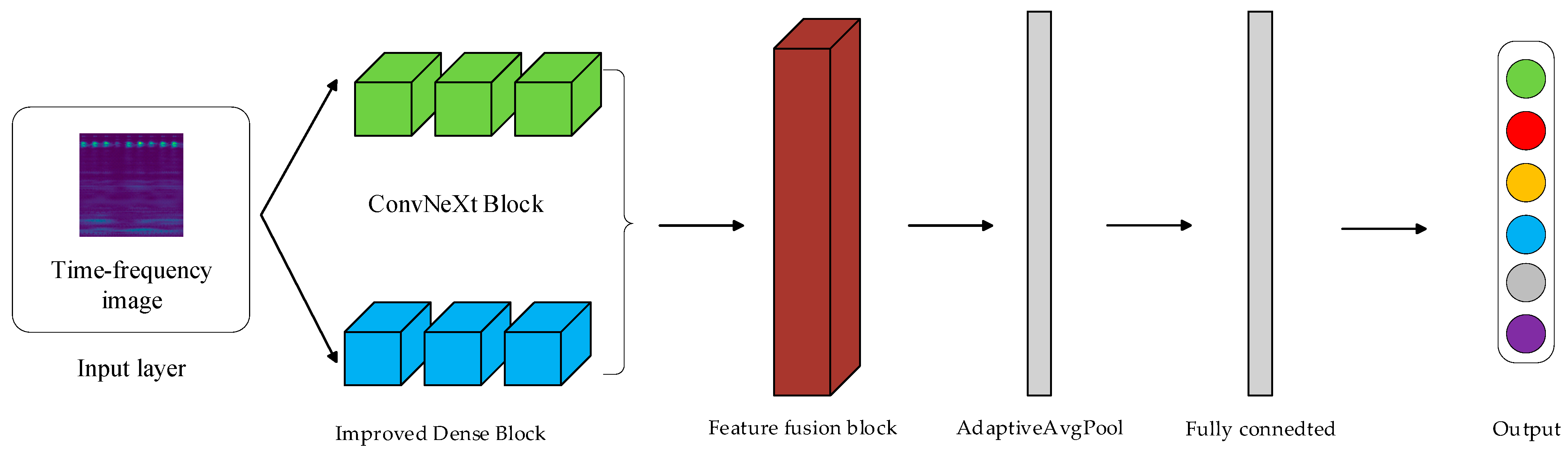
3. Proposed Method
3.1. Fault Diagnosis Process
3.2. Construction of the DCN Model
4. Experiment and Result Analysis
- (1)
- ResNet: ResNet was proposed in 2015 by He et al. [40]. ResNet greatly improves the solution to the degradation problem of deep networks with its residual connectivity property while significantly reducing the number of parameters.
- (2)
- CN: CapsNet (CN) was proposed by Sabour et al. [41] in 2017. As the information of features in CN is in the form of vectors, the network is able to retain the relative positional relationships between the input object parts, i.e., the network has a built-in understanding of 3D space. Compared to traditional CNNs, CN requires only a small amount of data to achieve good learning results.
- (3)
- Inception: This network was proposed by Szegedy et al. [42] in 2015. The core structure of Inception is the Inception layer, and the data input to this layer will be passed in parallel to multiple convolutional and pooling operations, which eventually merge their outputs.
- (4)
- TST: TST is based on the architecture proposed by A. Vaswan et al. [43] in 2017, improving its attention module to accommodate time series data. The method is designed to better capture temporal dependencies in a time series using the Transformer self-attention mechanism and positional coding and has become a popular method in the field of time series analysis.
- (5)
- ConvNeXt: ConvNeXt was proposed by Liu, Z. et al. [31] in 2022. ConvNext incorporates the successful designs of ResNet and Swin Transformer to achieve smoother network gradients, which leads to faster convergence and further increases the performance of the network.
- (6)
- FCN: This network was proposed by Jiang, G.J. et al. [25] in 2024, and it combines a capsule neural network (CN) with a fast routing algorithm with an improved DenseBlock, which effectively mitigates the problems of long training time and high requirement of training equipment for capsule networks.
- (7)
- ADAC-CN: The network was proposed by Jiang, G.J. et al. [26] in 2024. It combines the convolutional layer and pooling layer into one layer, enabling the network to extract deeper features while reducing the parameter number. In addition, they introduced dynamic ReLU into the ADAC-CN, which further improves the efficiency of the feature extraction and achieves a higher accuracy in the cross-domain diagnostics of bearings.
4.1. Case 1
4.1.1. Datasets and Data Preprocessing
4.1.2. Experimental Results and Analysis
- (1)
- Fault Diagnosis in a Simulated Noise Environment
- (2)
- Fault diagnosis in case of insufficient simulation samples
4.2. Case 2
4.2.1. Datasets and Data Preprocessing
4.2.2. Experimental Results and Analysis
4.3. Ablation Experiment
4.3.1. Activation Function
4.3.2. DenseBlock
4.3.3. Hyperparameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiang, G.J.; Yang, J.S.; Cheng, T.C.; Sun, H.H. Remaining useful life prediction of rolling bearings based on Bayesian neural network and uncertainty quantification. Qual. Reliab. Eng. Int. 2023, 39, 1756–1774. [Google Scholar] [CrossRef]
- Li, H.; Soaresc, G. Assessment of failure rates and reliability of floating offshore wind turbines. Reliab. Eng. Syst. Saf. 2022, 228, 108777. [Google Scholar] [CrossRef]
- Guoj, Y.; Wang, J.; Wang, Z.Y.; Gong, Y.; Qi, J.; Wang, G.; Tang, C. A CNN-BiLSTM-Bootstrap integrated method for remaining useful life prediction of rolling bearings. Qual. Reliab. Eng. Int. 2023, 39, 1796–1813. [Google Scholar]
- Liu, D.D.; Cui, L.L.; Chengw, D. Flexible Generalized Demodulation for Intelligent Bearing Fault Diagnosis Under Nonstationary Conditions. IEEE Trans. Ind. Inform. 2023, 19, 2717–2728. [Google Scholar] [CrossRef]
- Jial, S.; Chowt, W.S.; Yuany, X. GTFE-Net: A Gramian Time Frequency Enhancement CNN for bearing fault diagnosis. Eng. Appl. Artif. Intel. 2023, 119, 105794. [Google Scholar]
- Han, T.; Xie, W.Z.; Pei, Z.Y. Semi-supervised adversarial discriminative learning approach for intelligent fault diagnosis of wind turbine. Inform. Sci. 2023, 648, 119496. [Google Scholar] [CrossRef]
- Wang, H.; Wang, J.W.; Zhao, Y.K.; Liu, Q.; Liu, M.; Shen, W. Few-Shot Learning for Fault Diagnosis With a Dual Graph Neural Network. IEEE Trans. Ind. Inform. 2023, 19, 1559–1568. [Google Scholar] [CrossRef]
- Li, C.J.; Li, S.B.; Wang, H.; Gu, F.; Ball, A.D. Attention-based deep meta-transfer learning for few-shot fine-grained fault diagnosis. Knowl.-Based Syst. 2023, 264, 110345. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, Z.W.; Chen, Y.P.; Jin, Y.; Bai, G. Selective kernel convolution deep residual network based on channel-spatial attention mechanism and feature fusion for mechanical fault diagnosis. ISA Trans. 2023, 133, 369–383. [Google Scholar] [CrossRef]
- Lv, Z.H.; Guo, J.K.; Lv, H.B. Safety Poka Yoke in Zero-Defect Manufacturing Based on Digital Twins. IEEE Trans. Ind. Inform. 2023, 19, 1176–1184. [Google Scholar] [CrossRef]
- Zhou, K.; Diehl, E.; Tang, J. Deep convolutional generative adversarial network with semi-supervised learning enabled physics elucidation for extended gear fault diagnosis under data limitations. Mech. Syst. Signal Process. 2023, 185, 109772. [Google Scholar] [CrossRef]
- Yang, B.; Lei, Y.G.; Li, X.; Roberts, C. Deep Targeted Transfer Learning Along Designable Adaptation Trajectory for Fault Diagnosis Across Different Machines. IEEE Trans. Ind. Electron. 2023, 70, 9463–9473. [Google Scholar] [CrossRef]
- Yan, X.A.; She, D.M.; Xu, Y.D. Deep order-wavelet convolutional variational autoencoder for fault identification of rolling bearing under fluctuating speed conditions. Expert Syst. Appl. 2023, 216, 119479. [Google Scholar] [CrossRef]
- Deng, Y.F.; Lv, J.; Huang, D.L.; Du, S. Combining the theoretical bound and deep adversarial network for machinery open-set diagnosis transfer. Neurocomputing 2023, 548, 126391. [Google Scholar] [CrossRef]
- Ruan, D.W.; Wang, J.; Yan, J.P.; Gühmann, C. CNN parameter design based on fault signal analysis and its application in bearing fault diagnosis. Adv. Eng. Inform. 2023, 55, 101877. [Google Scholar] [CrossRef]
- Wei, Z.X.; He, D.Q.; Jin, Z.Z.; Liu, B.; Shan, S.; Chen, Y.; Miao, J. Density-Based Affinity Propagation Tensor Clustering for Intelligent Fault Diagnosis of Train Bogie Bearing. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6053–6064. [Google Scholar] [CrossRef]
- Zhao, X.L.; Yao, J.Y.; Deng, W.X.; Ding, P.; Zhuang, J.; Liu, Z. Multiscale Deep Graph Convolutional Networks for Intelligent Fault Diagnosis of Rotor-Bearing System Under Fluctuating Working Conditions. IEEE Trans. Ind. Inform. 2023, 19, 166–176. [Google Scholar] [CrossRef]
- Xiao, Y.M.; Shao, H.D.; Feng, M.J.; Han, T.; Wan, J.; Liu, B. Towards trustworthy rotating machinery fault diagnosis via attention uncertainty in transformer. J. Manuf. Syst. 2023, 70, 186–201. [Google Scholar] [CrossRef]
- Zhang, J.S.; Zhang, K.; An, Y.Y.; Luo, H.; Yin, S. An Integrated Multitasking Intelligent Bearing Fault Diagnosis Scheme Based on Representation Learning Under Imbalanced Sample Condition. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 6242–6291. [Google Scholar] [CrossRef]
- Chen, B.Y.; Zhang, W.H.; Gu, J.X.; Song, D.; Cheng, Y.; Zhou, Z.; Gu, F.; Ball, A.D. Product envelope spectrum optimization-gram: An enhanced envelope analysis for rolling bearing fault diagnosis. Mech. Syst. Signal Process. 2023, 193, 110270. [Google Scholar] [CrossRef]
- Lin, J.; Shao, H.D.; Zhou, X.D.; Cai, B.; Liu, B. Generalized MAML for few-shot cross-domain fault diagnosis of bearing driven by heterogeneous signals. Expert Syst. Appl. 2023, 230, 120696. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Li, Y.H.; Wang, Y.P.; Zhao, X.; Chen, Z. A deep reinforcement learning-based intelligent fault diagnosis framework for rolling bearings under imbalanced datasets. Control Eng. Pract. 2024, 145, 105845. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Qin, N.; Huang, D.Q.; Yang, A.; Jia, X.; Du, J. Generalized Zero-Shot Approach Leveraging Attribute Space for High-Speed Train Bogie. IEEE Trans. Instrum. Meas. 2024, 73, 3512412. [Google Scholar] [CrossRef]
- Jiang, G.J.; Li, D.Z.; Li, Q.; Sun, H.H. A novel intelligent fault diagnosis method of rolling bearings based on capsule network with Fast Routing algorithm. Qual. Reliab. Eng. Int. 2024, 40, 2235–2255. [Google Scholar] [CrossRef]
- Jiang, G.J.; Li, D.Z.; Li, Y.F.; Zhao, Q.; Luan, Y.; Duan, Z. A novel fault diagnosis framework of rolling bearings based on adaptive dynamic activation convolutional capsule network. Meas. Sci. Technol. 2024, 35, 045119. [Google Scholar] [CrossRef]
- Wang, C.D.; Yang, J.L.; Zhang, B.Q. A fault diagnosis method using improved prototypical network and weighting similarity-Manhattan distance with insufficient noisy data. Measurement 2024, 226, 114171. [Google Scholar] [CrossRef]
- Yang, J.L.; Wang, C.D.; Wei, C.A. A novel Brownian correlation metric prototypical network for rotating machinery fault diagnosis with few and zero shot learners. Adv. Eng. Inform. 2022, 54, 101815. [Google Scholar] [CrossRef]
- Xu, Z.B.; Tang, X.Y.; Wang, Z.G. A Multi-Information Fusion ViT Model and Its Application to the Fault Diagnosis of Bearing with Small Data Samples. Machines 2023, 11, 277. [Google Scholar] [CrossRef]
- Peng, C.; Zhang, S.T.; Li, C.Y. A Rolling Bearing Fault Diagnosis Based on Conditional Depth Convolution Countermeasure Generation Networks under Small Samples. Sensors 2022, 22, 5658. [Google Scholar] [CrossRef]
- Liu, Z.; Mao, H.Z.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. A ConvNet for the 2020s. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11966–11976. [Google Scholar]
- Yang, S.W.; Xiang, Y.X.; Long, Z.; Ma, X.; Ding, Q.; Jia, J. Fault Diagnosis of Harmonic Drives Based on an SDP-ConvNeXt Joint Methodology. IEEE Trans. Instrum. Meas. 2023, 72, 3519608. [Google Scholar] [CrossRef]
- Zhang, C.; Qin, F.F.; Zhao, W.T.; Li, J.; Liu, T. Research on Rolling Bearing Fault Diagnosis Based on Digital Twin Data and Improved ConvNext. Sensors 2023, 23, 5334. [Google Scholar] [CrossRef] [PubMed]
- Zeng, R.; Song, Y. A Fast Routing Capsule Network With Improved Dense Blocks. IEEE Trans. Ind. Inform. 2022, 18, 4383–4392. [Google Scholar] [CrossRef]
- Chen, Y.; Dai, X.; Liu, M.; Chen, D.; Yuan, L.; Liu, Z. Dynamic ReLU. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIX; Springer: Glasgow, UK, 2020; pp. 351–367. [Google Scholar]
- Rioul, O.; Vetterli, M. Wavelets and signal processing. IEEE Signal Process. Mag. 1991, 8, 14–38. [Google Scholar] [CrossRef]
- Ke, L.; Yukai, L. Lightweight single-image super-resolution network based on dual paths. arXiv 2024, arXiv:2409.06590. [Google Scholar]
- Smith, W.A.; Randall, R.B. Rolling element bearing diagnostics using the Case Western Reserve University data: A benchmark study. Mech. Syst. Signal Process. 2015, 64, 100–131. [Google Scholar] [CrossRef]
- Hou, L.; Yi, H.; Yuhong, J.; Gui, M.; Sui, L.; Zhang, J.; Chen, Y. Inter-shaft Bearing Fault Diagnosis Based on Aero-engine System: A Benchmarking Dataset Study. J. Dyn. Monit. Diagn. 2023, 2, 228–242. [Google Scholar] [CrossRef]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.Q.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (Cvpr), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Condition | Speed | Load(HP) |
|---|---|---|
| 1 | 1797 | 0 |
| 2 | 1772 | 1 |
| 3 | 1750 | 2 |
| 4 | 1730 | 3 |
| Degree of Damage (inches) | 0.007 | 0.007 | 0.007 | 0.014 | 0.014 | 0.014 | 0.021 | 0.021 | 0.021 | 0 |
| Failure position | Ball fault | Inner ring fault | Outer ring fault | Ball fault | Inner ring fault | Outer ring fault | Ball fault | Inner ring fault | Outer ring fault | Normal state |
| Label | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| LP Speed (r/min) | HP Speed (r/min) | Speed Ratio | LP Speed (r/min) | HP Speed (r/min) | Speed Ratio |
|---|---|---|---|---|---|
| 1000 | 1200 | 1.2 | 4400 | 5280 | 1.2 |
| 1500 | 1800 | 1.2 | 4500 | 5400 | 1.2 |
| 2000 | 2400 | 1.2 | 4600 | 5520 | 1.2 |
| 2500 | 3000 | 1.2 | 4700 | 5640 | 1.2 |
| 3000 | 3600 | 1.2 | 4800 | 5760 | 1.2 |
| 3500 | 4200 | 1.2 | 4900 | 5880 | 1.2 |
| 3600 | 4320 | 1.2 | 5000 | 6000 | 1.2 |
| 3700 | 4440 | 1.2 | 3000 | 3600 | 1.2 |
| 3800 | 4560 | 1.2 | 3000 | 3900 | 1.3 |
| 3900 | 4680 | 1.2 | 3000 | 4200 | 1.4 |
| 4000 | 4800 | 1.2 | 3000 | 4500 | 1.5 |
| 4100 | 4920 | 1.2 | 3000 | 4800 | 1.6 |
| 4200 | 5040 | 1.2 | 3000 | 5100 | 1.7 |
| 4300 | 5160 | 1.2 | 3000 | 5400 | 1.8 |
| Label | Failure Position | Depth_length of Damage (mm) | Speed Ratio |
|---|---|---|---|
| 0 | Normal | 0_0 | 1.2 |
| 1 | Inner ring | 0.5_0.5 | 1.2 |
| 2 | Inner ring | 0.5_1.0 | 1.2 |
| 3 | Outer ring | 0.5_0.5 | 1.2 |
| Methods | Parameter Number | Accuracy | Total Time | 10 Epoch Accuracy |
|---|---|---|---|---|
| DCN-DY-ReLU | 1.854 M | 100% | 247.52 s | 97.2% |
| DCN-ReLU | 1.756 M | 98.6% | 230.68 s | 95.57% |
| DCN-GELU | 1.757 M | 99.1% | 233.52 s | 95.64% |
| DenseBlock | Accuracy | Total Time |
|---|---|---|
| Improved | 100% | 270.13 s |
| Traditional | 98.67% | 265.42 s |
| C\D | 2 × 2 | 3 × 3 | 5 × 5 |
|---|---|---|---|
| 3 × 3 | 271.29 s | 267.94 s | 256.29 s |
| 7 × 7 | 249.83 s | 247.55 s | 242.13 s |
| 10 × 10 | 259.94 s | 260.65 s | 266.52 s |
| C\D | 2 × 2 | 3 × 3 | 5 × 5 |
|---|---|---|---|
| 3 × 3 | 90.5% | 94.6% | 93.7% |
| 7 × 7 | 93.4% | 96.8% | 96% |
| 10 × 10 | 92.7% | 95.5% | 94.5% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, J.; Nie, X.; Wu, C.; Zheng, N. A Novel Intelligent Fault Diagnosis Method of Rolling Bearings Based on the ConvNeXt Network with Improved DenseBlock. Sensors 2024, 24, 7909. https://doi.org/10.3390/s24247909
Song J, Nie X, Wu C, Zheng N. A Novel Intelligent Fault Diagnosis Method of Rolling Bearings Based on the ConvNeXt Network with Improved DenseBlock. Sensors. 2024; 24(24):7909. https://doi.org/10.3390/s24247909
Chicago/Turabian StyleSong, Jiahao, Xiaobo Nie, Chuang Wu, and Naiwei Zheng. 2024. "A Novel Intelligent Fault Diagnosis Method of Rolling Bearings Based on the ConvNeXt Network with Improved DenseBlock" Sensors 24, no. 24: 7909. https://doi.org/10.3390/s24247909
APA StyleSong, J., Nie, X., Wu, C., & Zheng, N. (2024). A Novel Intelligent Fault Diagnosis Method of Rolling Bearings Based on the ConvNeXt Network with Improved DenseBlock. Sensors, 24(24), 7909. https://doi.org/10.3390/s24247909