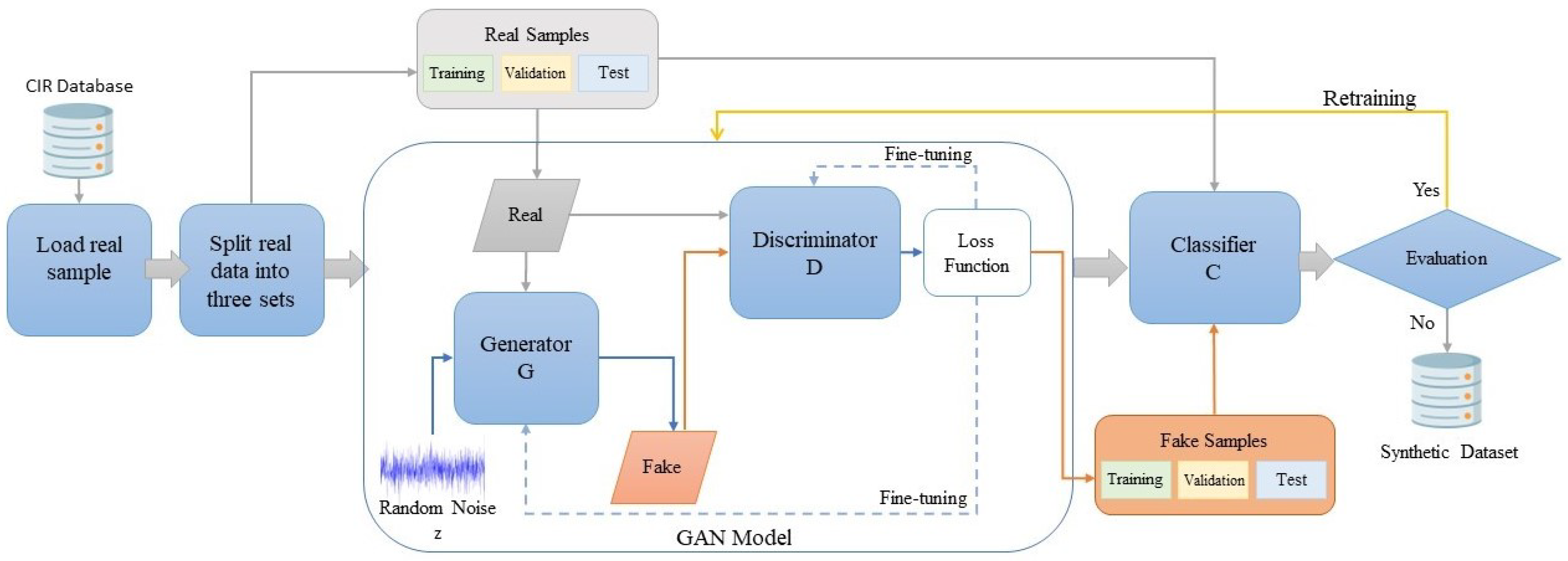
5.1. Training Implementation Details
The proposed models were implemented using Python 3.10.9, Keras library [
38] and TensorFlow [
39]. It is imperative to emphasize that the precise resource prerequisites are contingent upon the desired level of performance. Executing the GAN–WPLA model can incur considerable computational expenses.
Furthermore, the training of the proposed models was conducted on the Aziz supercomputer [
40]. This computational facility comprises 496 computing nodes with approximately 12,000 Intel
® central processing unit cores. Additionally, the supercomputer features two nodes equipped with NVIDIA Tesla K20
® graphical processing units and two nodes outfitted with Intel
® Xeon-Phi accelerators. The collective RAM capacity across the system is 96 GB and the operating system in use is Linux version 3.10.0-1160.el7.x86_64. On the other hand, to achieve minimum acceptable performance, a workstation equipped with an NVIDIA graphics card and a high-performance CPU, such as Intel Core i7, paired with 16 GB of RAM is deemed requisite.
In
Table 4, we provide an overview of the diverse hyperparameters employed in the configuration of the GAN–WPLA model, such as loss function, optimizer, epoch count, learning rate, batch size and dropout rate.
Furthermore, we allocated three datasets from the assembled database for the training, validation and testing of the GAN–WPLA model. The training dataset comprised 70% of the data, the validation dataset encompassed 10% and the test dataset involved 20%. In addition to the data, as mentioned earlier in the allocation, we applied the ’validation_split’ parameter within the Keras.fit() function for the collected dataset. This step was taken to ensure the comprehensive utilization of all collected data during the training and testing phases, thereby preventing overfitting during the training process.
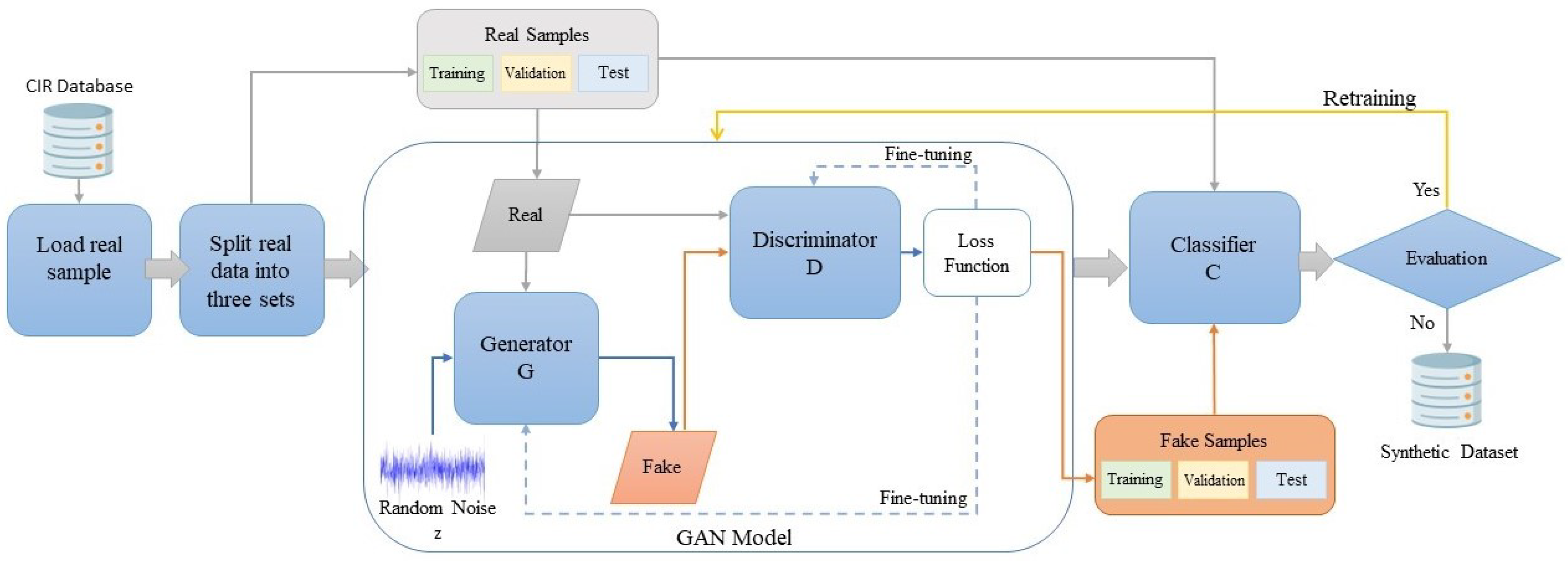
5.2. GAN Model Analysis
The training process of the GAN model was executed sequentially on generator and discriminator networks, with a total dataset consisting of 1300 samples, each with 8188 data points representing a dataset of three industrial wireless nodes. The training started with the generator network, creating a synthetic I/Q vector using random seeds. The combination of real and generated I/Q vectors was used as input data to train the discriminator network. The loss was determined for each network using the outcomes provided by the discriminator. We adopted the Adam optimizer [
41] to optimize the discriminator network parameters, with a learning rate of 0.0002. On the other hand, we applied RMSprop to optimize the generator network. The parameter epoch was set to 50 and the batch size was set to 128.
As previously indicated, GANs face challenges, including nonconvergence issues. Additionally, the case of mode collapse represents another considerable challenge. We applied different DL techniques to refine the training process. Accordingly, in the GAN model training, we monitored loss results and continuously adjusted the parameters to reach the optimal GAN structure, identify issues early and reduce the possibility of collapse. Therefore, the first parameter applied was the choice of MAE as a loss function in the generator. The main objective was to generate data as close to real data as possible. Using MAE encouraged the generator to produce I/Q vectors closer to the real data regarding feature-level similarity. The second parameter activation function, the I/Q vector distribution in the real dataset, was between —1 and 1. Consequently, we considered the tanh activation function to be an effective parameter in our situation, where we wanted the generated fake samples to be centered around zero. To mitigate the vanishing gradient problem, we applied Leaky ReLU to the discriminator.
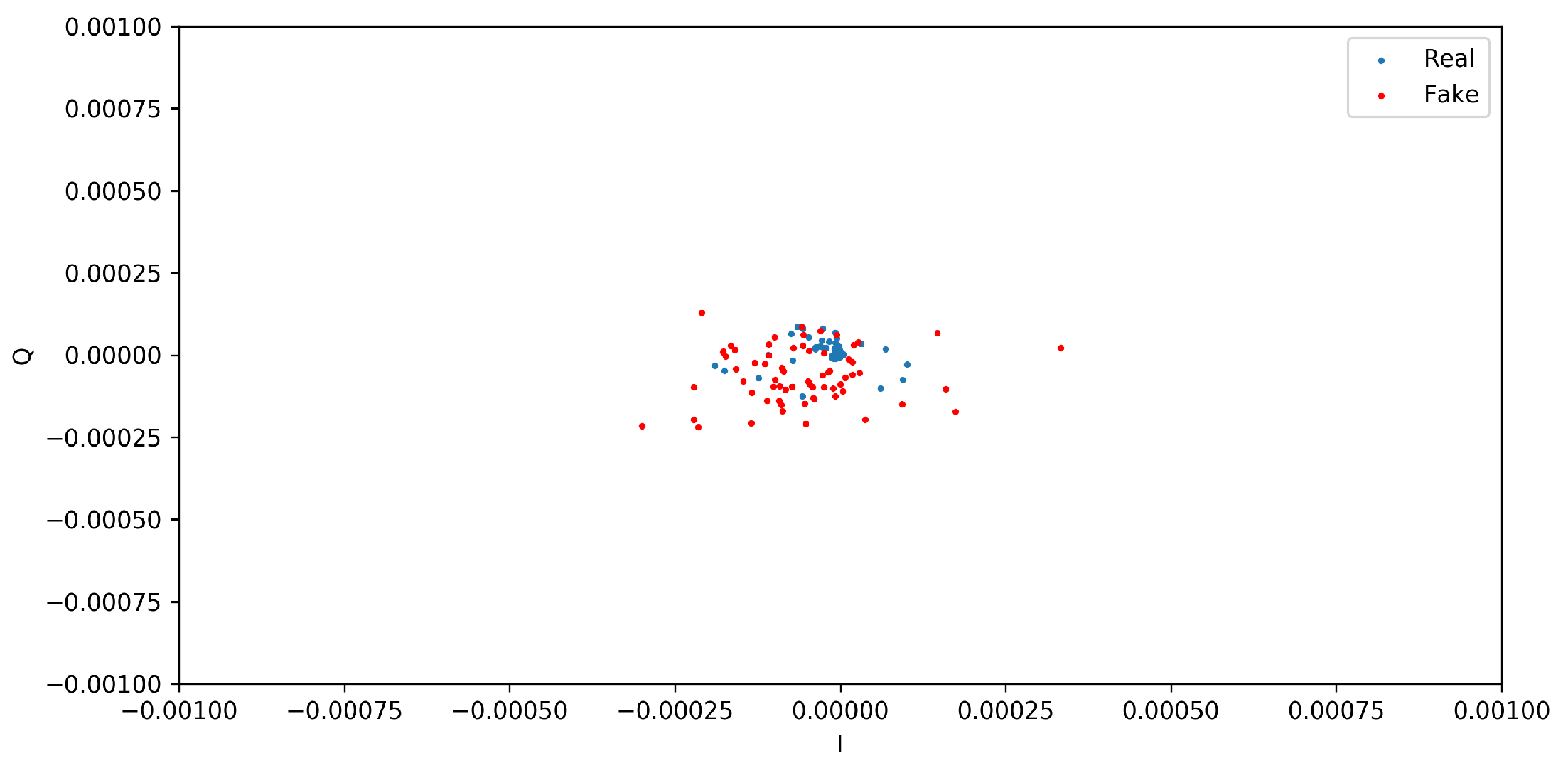
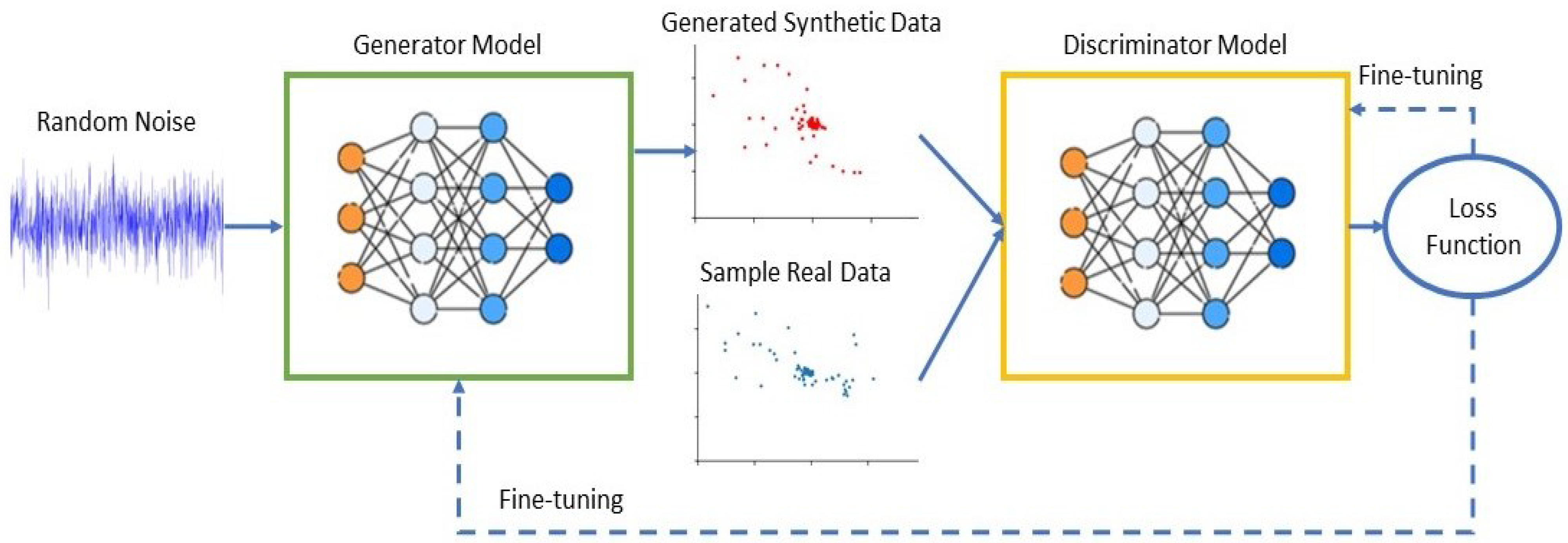
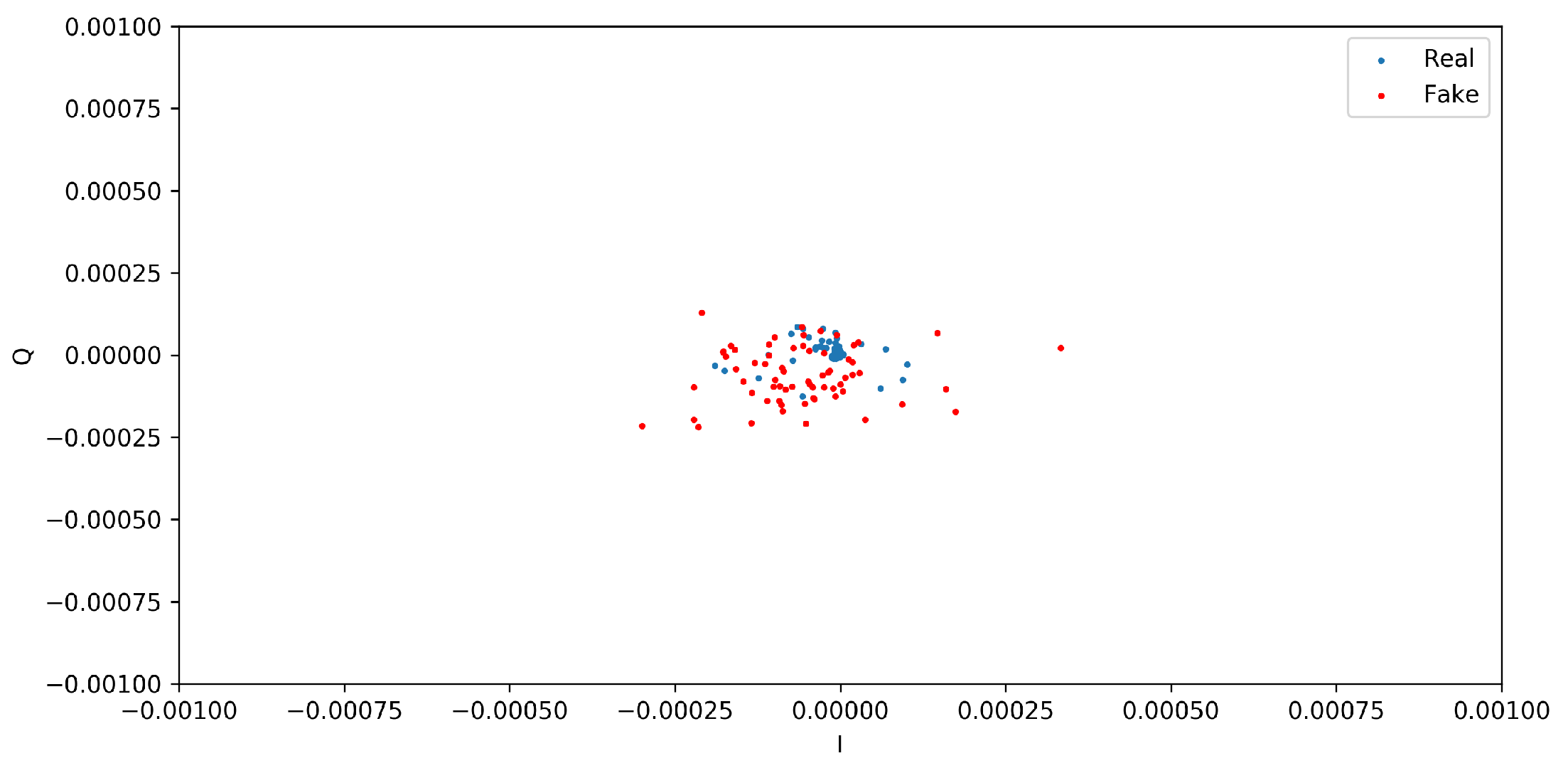
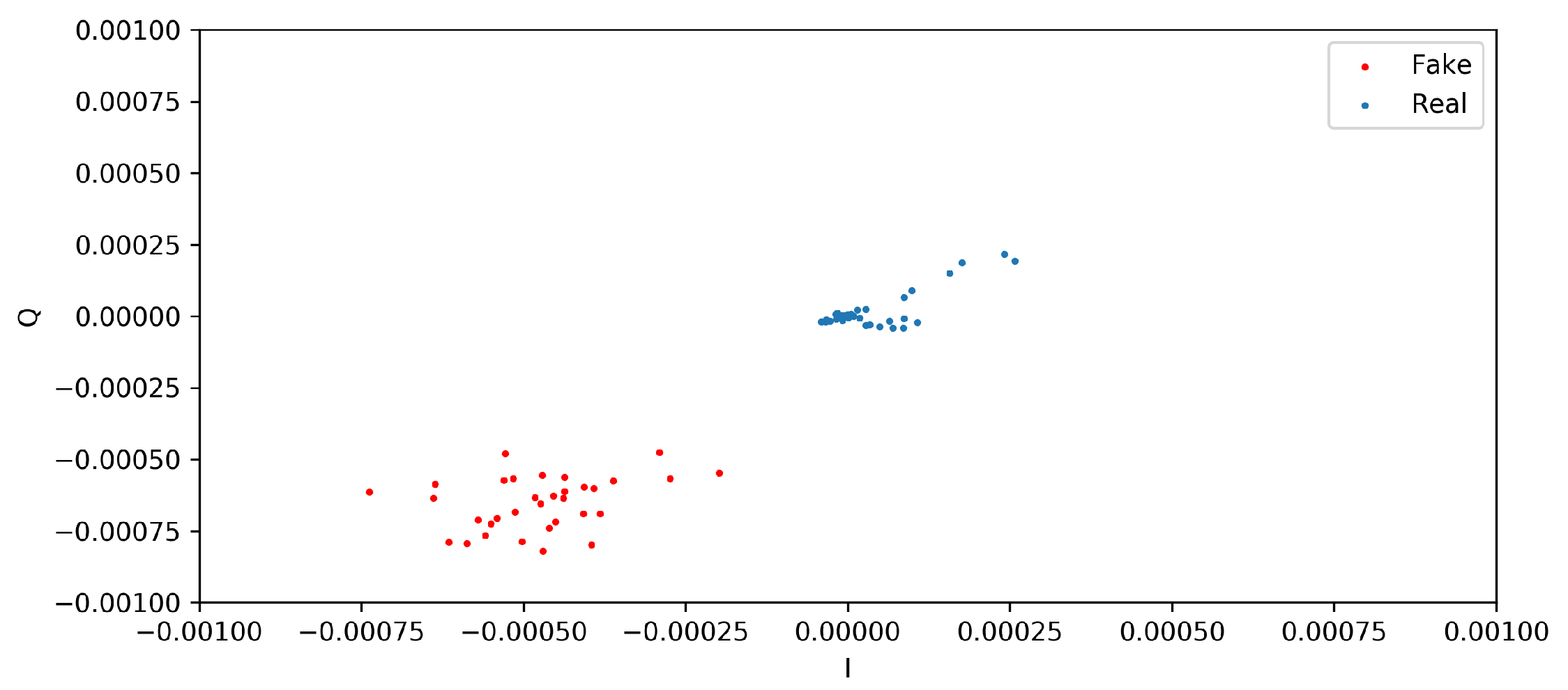
This section presents the two distinct qualitative and quantitative methods used for assessing the quality and similarity of the generated and real I/Q vectors. From the qualitative analysis, the scatter diagrams in
Figure 5 and
Figure 6 show the distributions of I/Q vectors based on the GAN model. Indeed, due to the limited availability of public CIR datasets of wireless nodes, it was necessary to create synthetic CIR samples by employing a GAN in conjunction with existing real samples. Therefore, generating the desired I/Q vector distributions presented a challenging task. The red dots in the figures denote the synthetic I/Q values, while the blue dots denote the real I/Q values. From
Figure 5, we can observe that the two categories of I/Q values show overlapping distributions. Nevertheless, the GAN model sometimes showed instability throughout the training process.
Figure 6 shows that the synthetic samples made by the GAN model were different from the real samples. The model could replicate the association between the synthetic I/Q vectors and the real ones in a broad sense; however, some situations were rejected due to the noncompliance of the synthetic generated I/Q vectors with the expected standards.
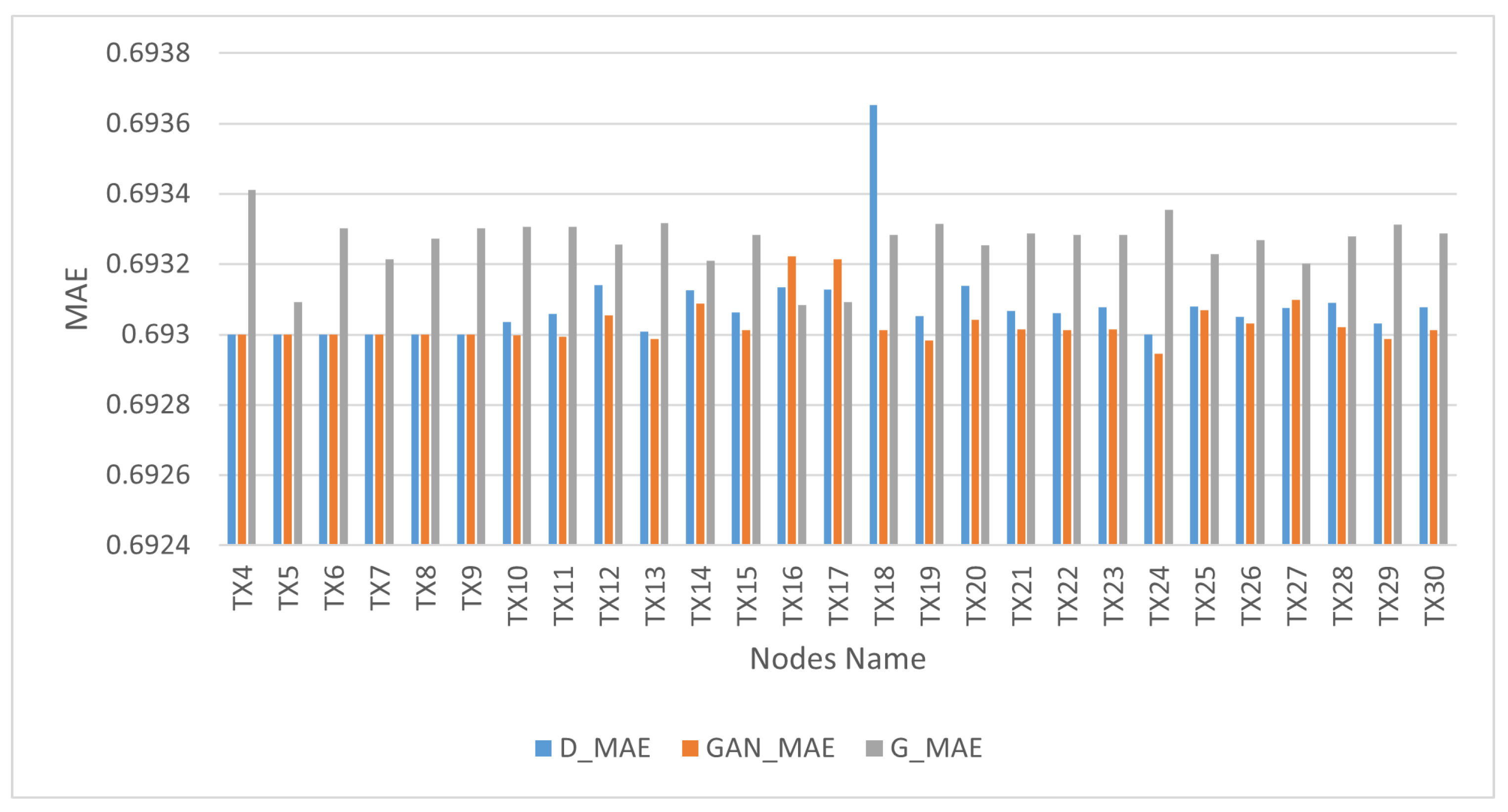
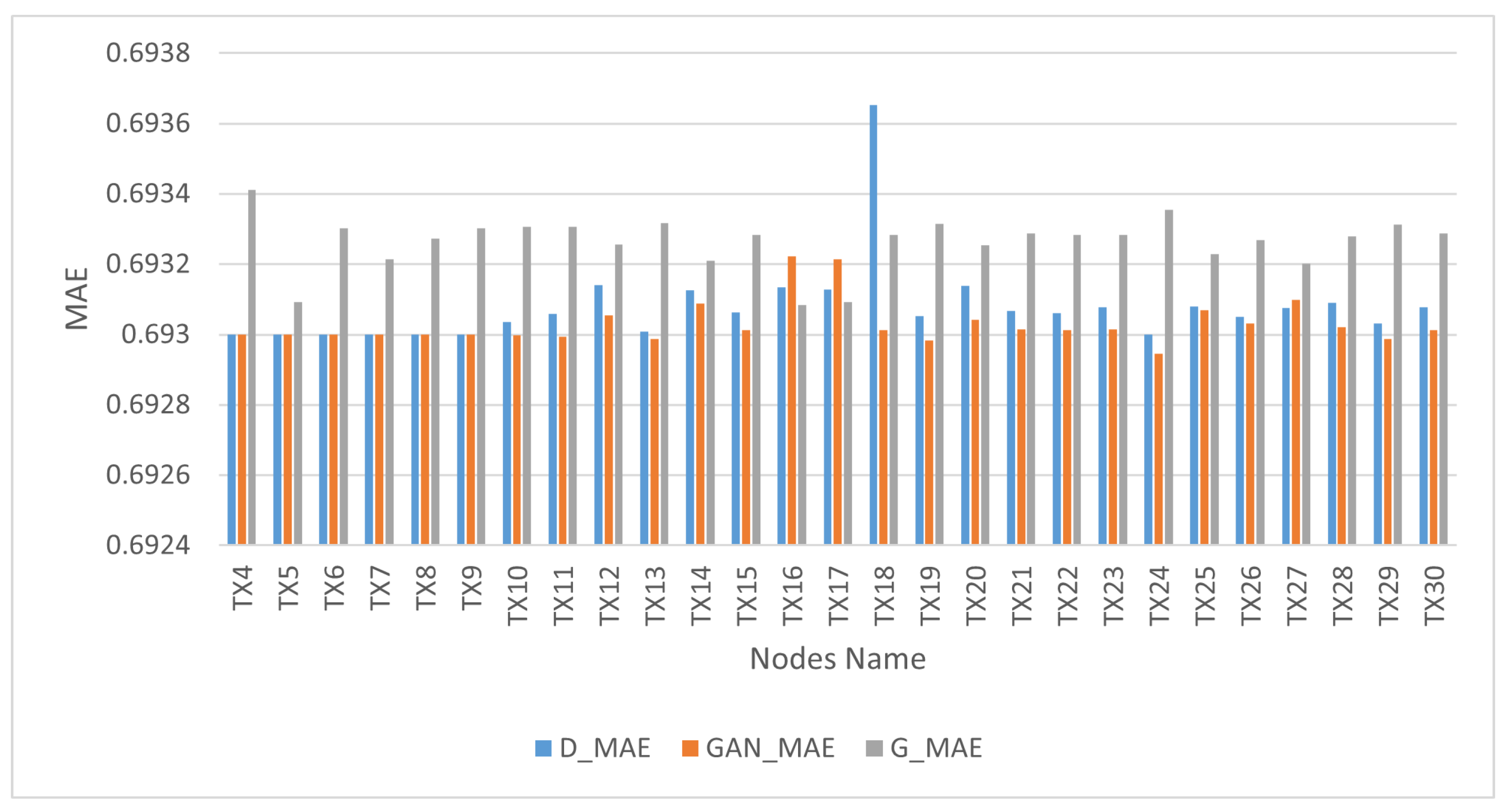
In the context of the quantitative analysis, MAE was utilized as a metric to assess the extent to which the distributions of the synthetic samples served as reliable approximations of the real distributions. We considered the sigmoid cross-entropy loss function when we used MAE in the training process because it can indicate the stability of generated and real data. The bins in
Figure 7 illustrate the performance outcomes of the GAN network, discriminator and generator. The GAN network’s performance is represented by orange bins, the discriminator’s performance by blue bins and the generator’s performance by gray bins. The GAN model demonstrated the ability to reach equilibrium between the generator and discriminator networks, as evidenced by the lowest difference in loss degree throughout training of between 0.0001 and 0.0004.
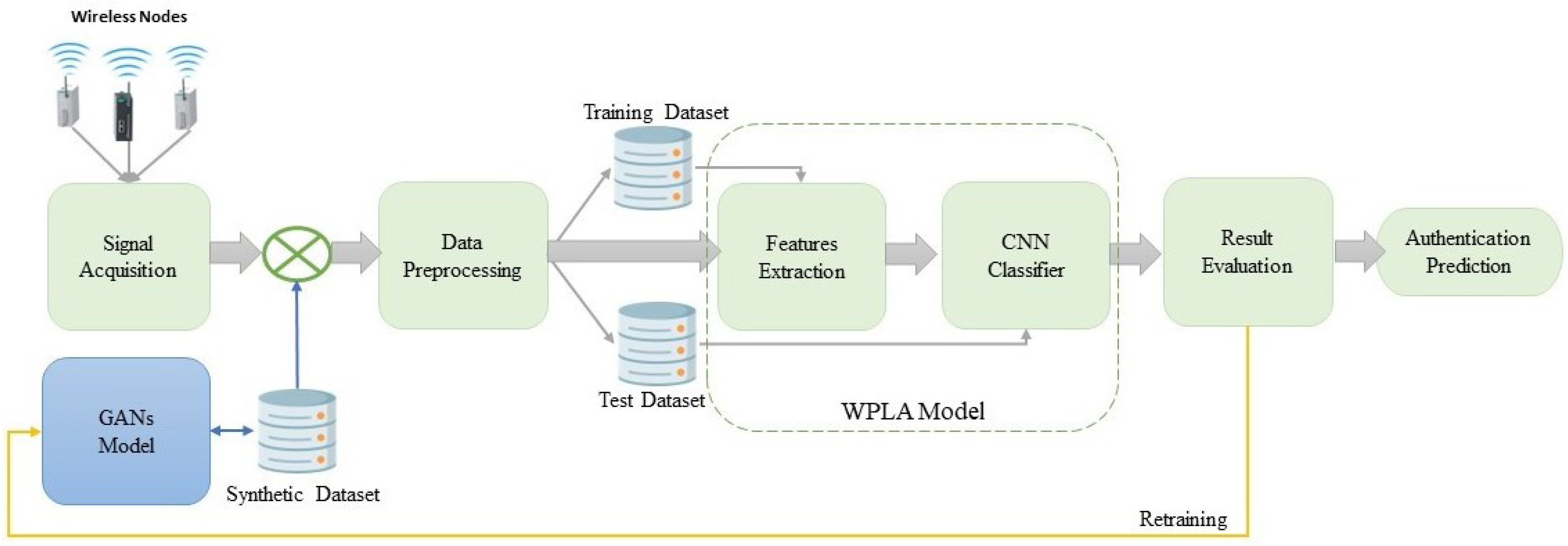
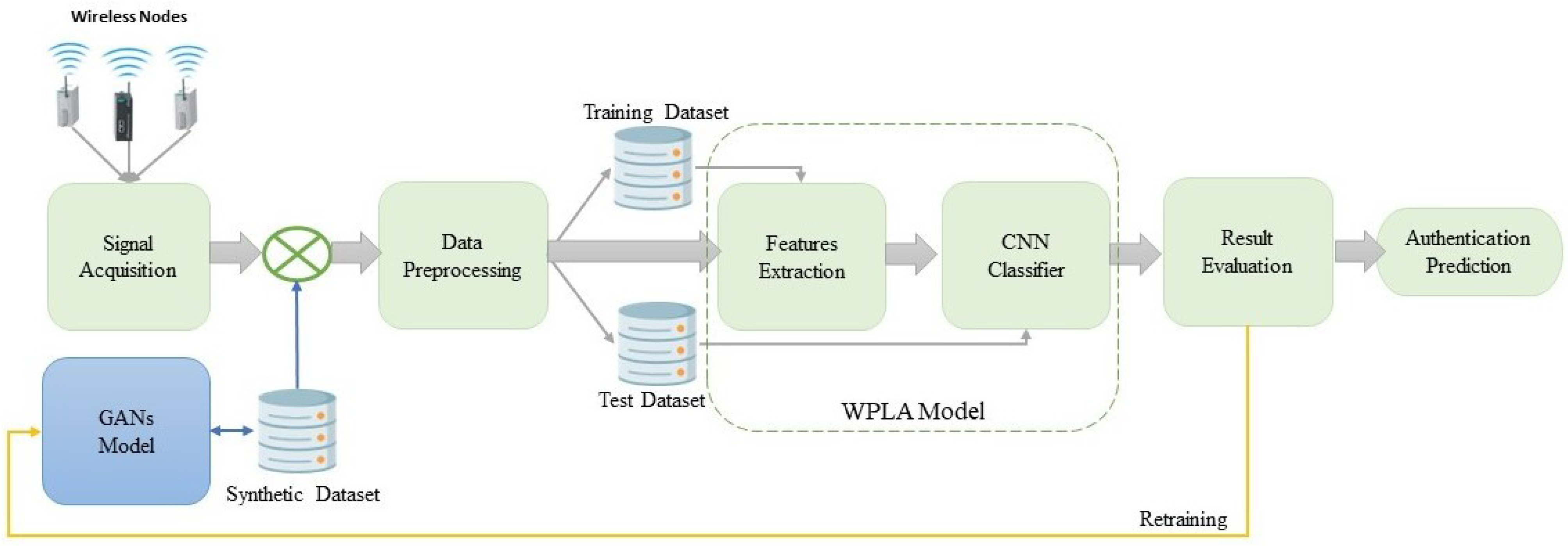
5.3. GAN–WPLA Model Analysis
The analysis of the GAN–WPLA model’s performance was based on validating the satisfied CNN architecture classification of wireless nodes. To train the proposed model, we used datasets generated from the GAN model, which consisted of 18,850 samples, each with 8188 data points. We then divided it into two sets: the training set, which contained 15,080 (80%) samples, and the test set, which contained 3770 (20%) samples. During the experiments, we divided the training set into training and validation batches at a ratio of 7:1. In addition, we optimized the model parameters by adopting the Adam optimizer, with a learning rate of 0.001. The parameter training epoch was set to 100 and the batch size was set to 15,000. Category cross-entropy was adopted as the loss function to validate the model’s performance. In
Figure 8 and
Figure 9, the training graphics of the proposed model are presented.
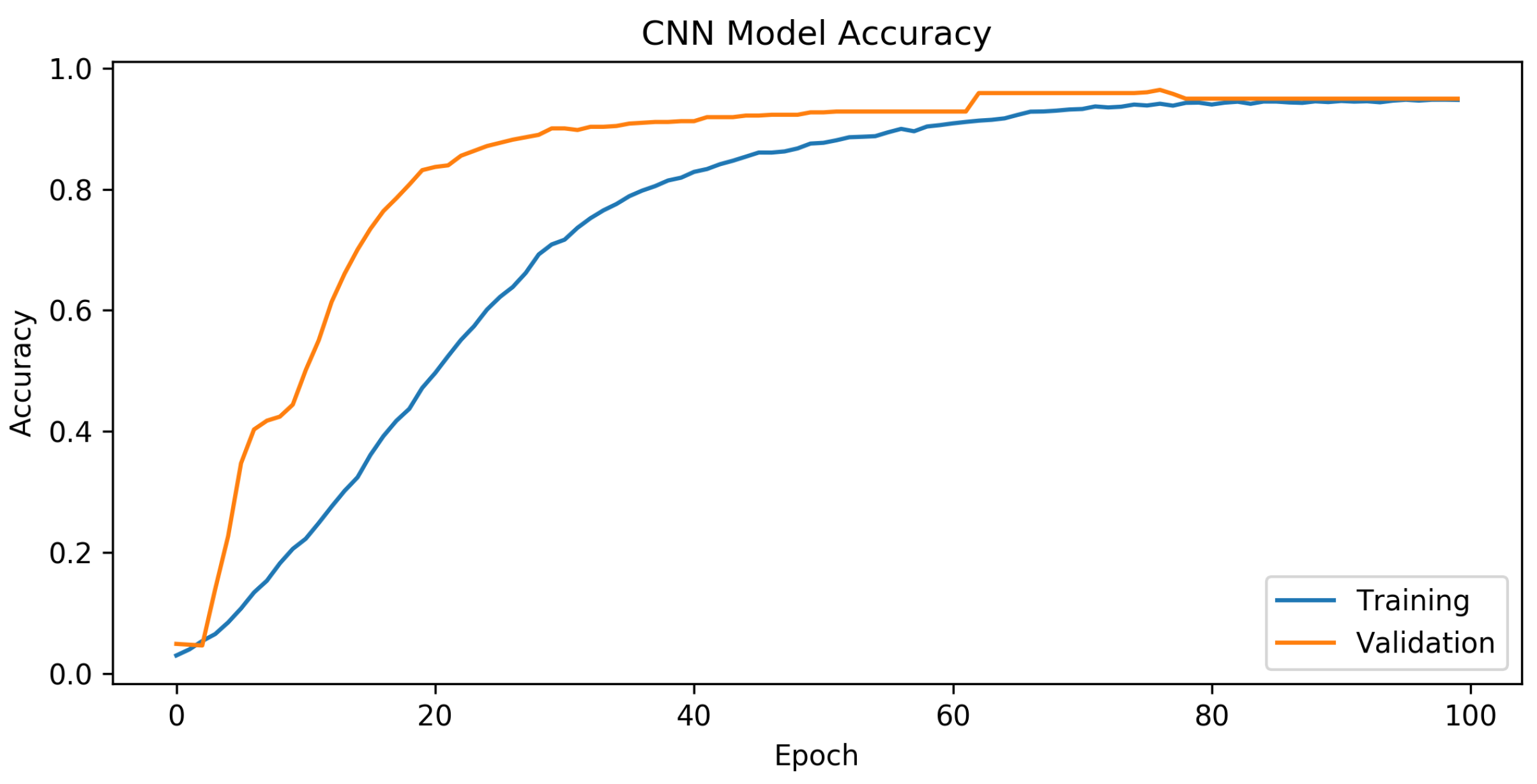
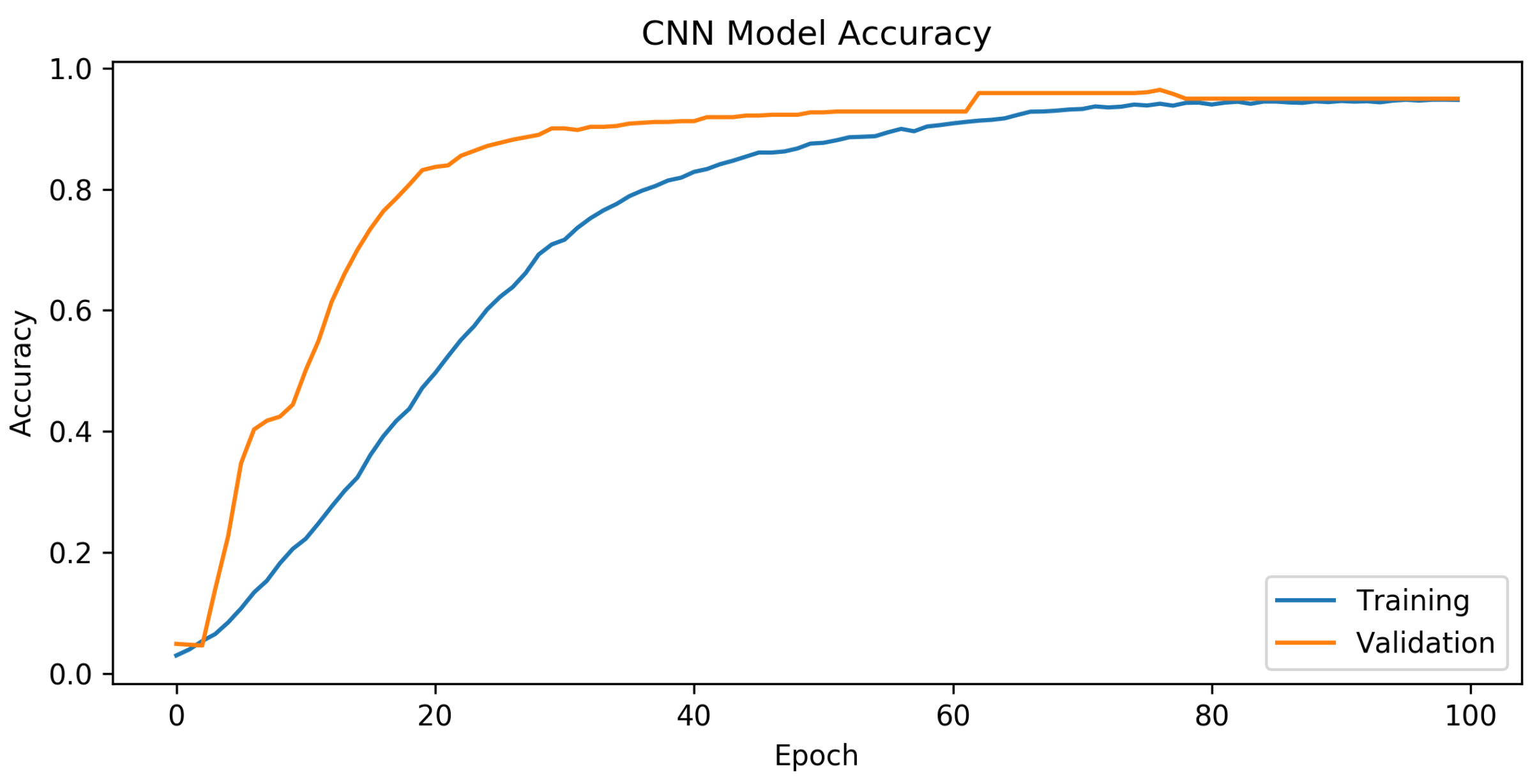
According to the results presented in
Figure 8, the CNN design showed exceptional performance. The mean training accuracy rate obtained was 73.3%, with the highest recorded rate reaching 94.8% across the epoch range running from 1 to 100. Based on the findings in
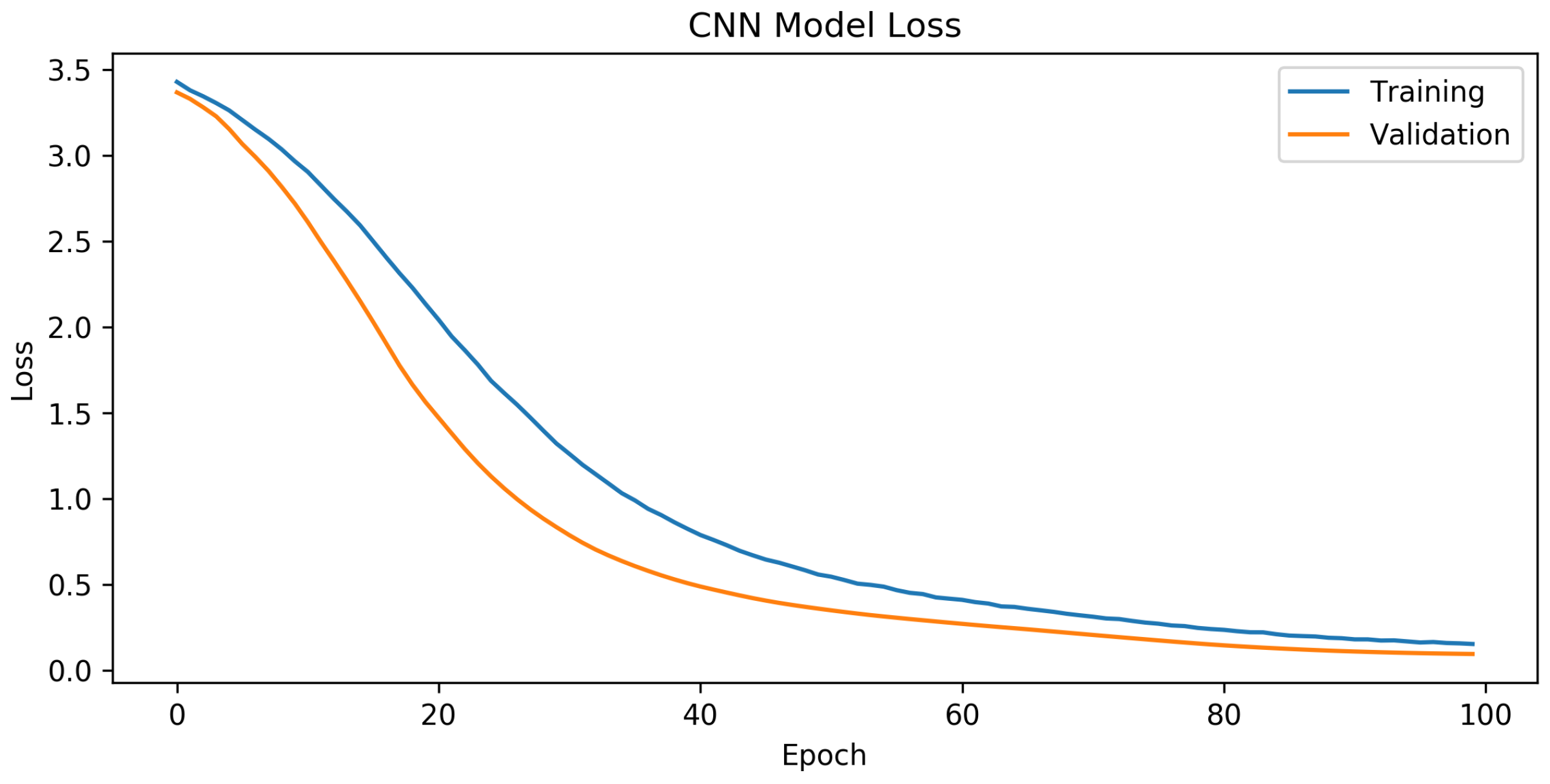
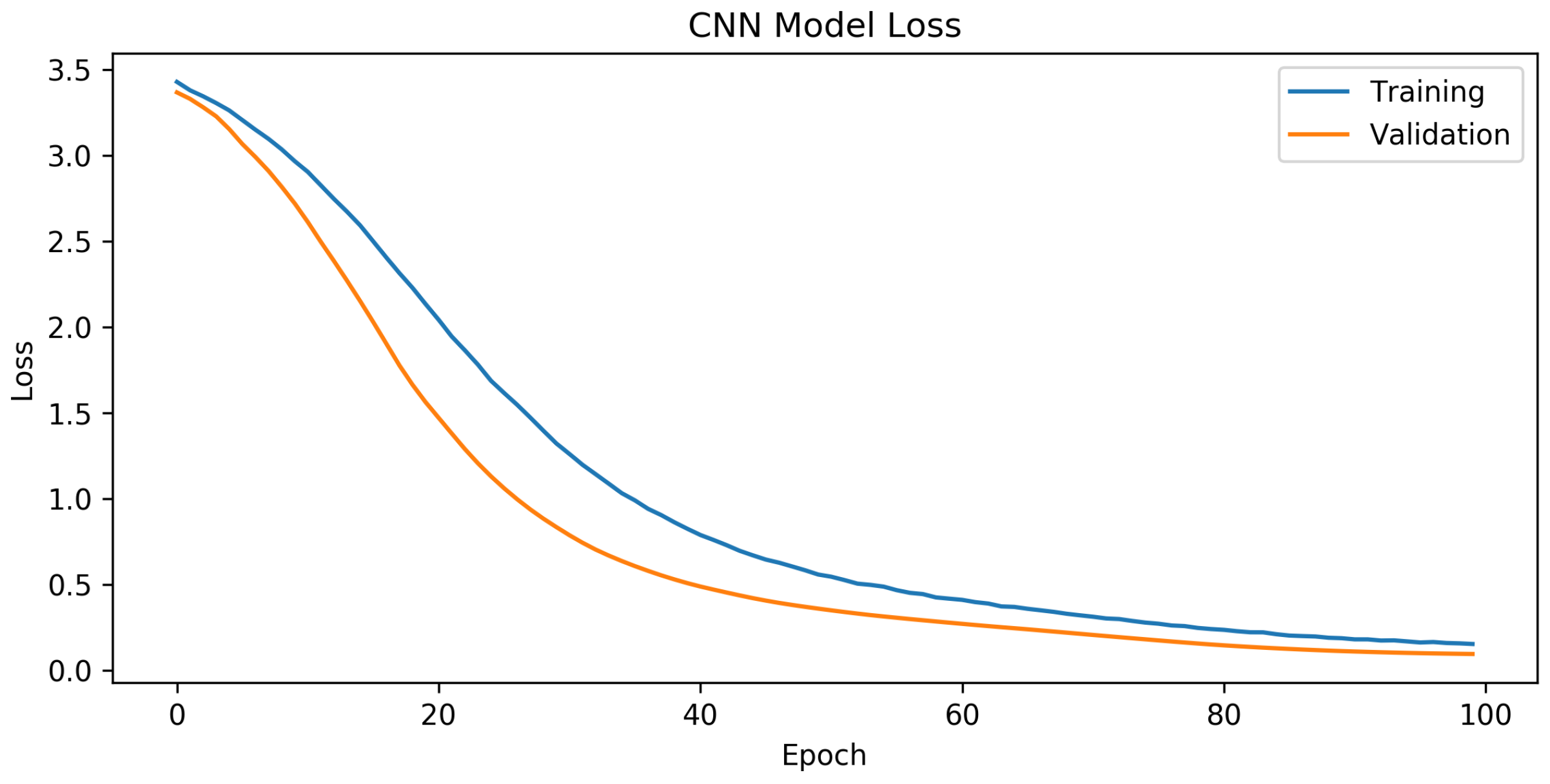
Figure 9, it can be concluded that in the last part of the graph, there is a noticeable convergence of the training and validation losses, indicating the successful training of the CNN network. The model demonstrated a satisfactory configuration, as there was no evidence of either overfitting or underfitting.
Next, we present a comparison of the accuracy rate, loss, precision and recall of the proposed model after including different numbers of samples generated by the GAN model. To evaluate the robustness of the classification, Gaussian white noise was added to the generated data. This noise replicates the channel estimation error that develops throughout the channel estimation procedure.
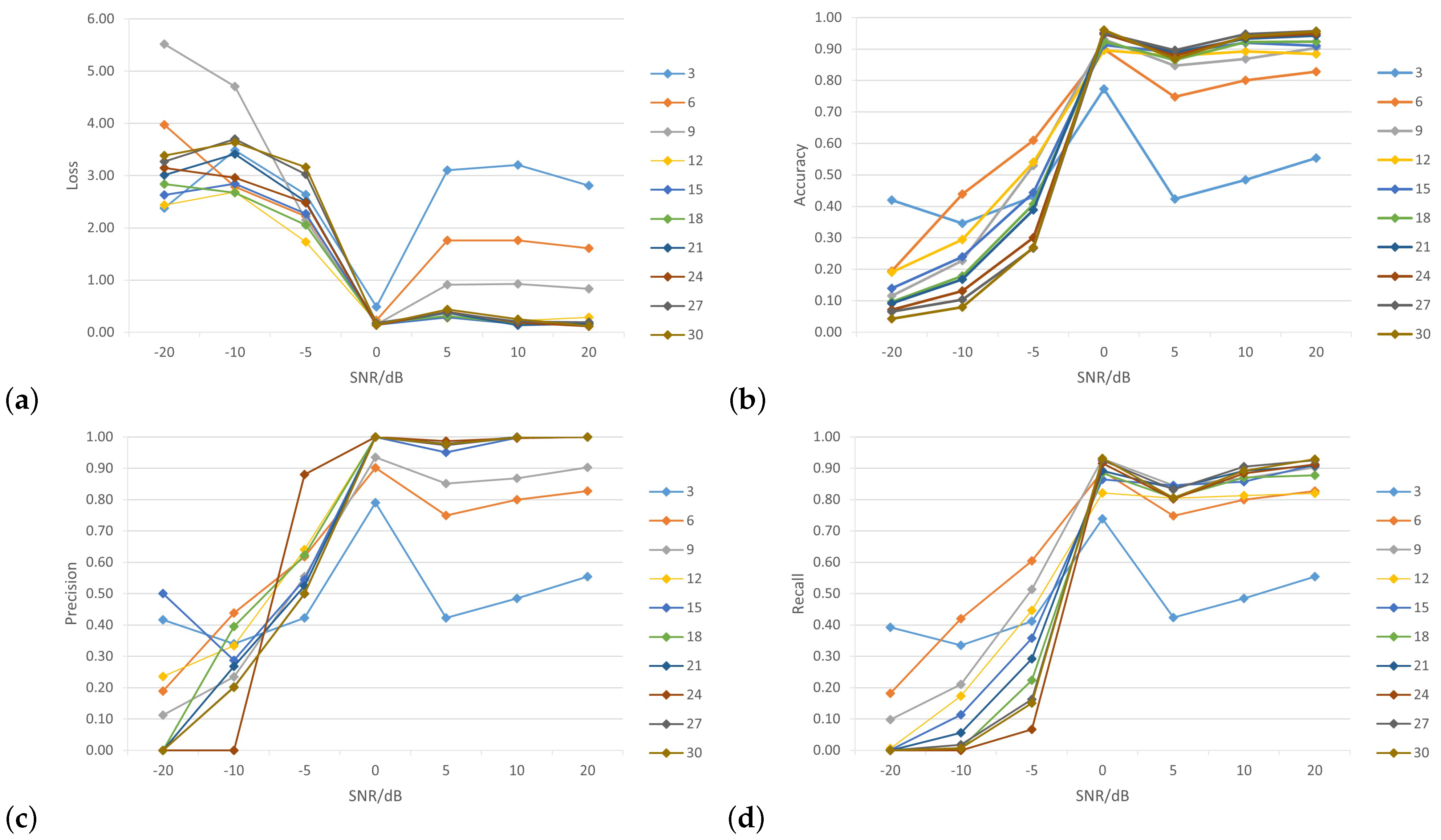
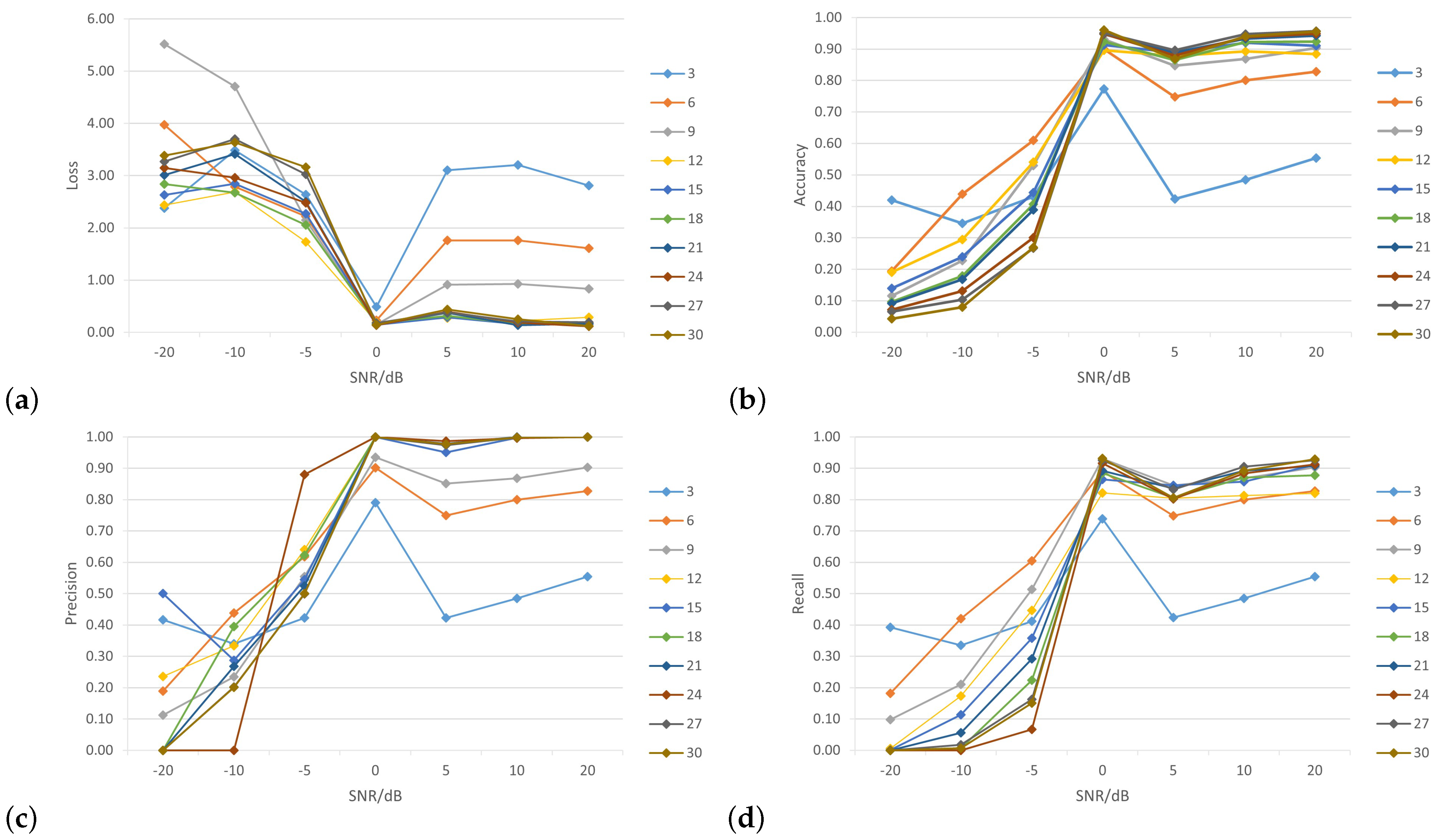
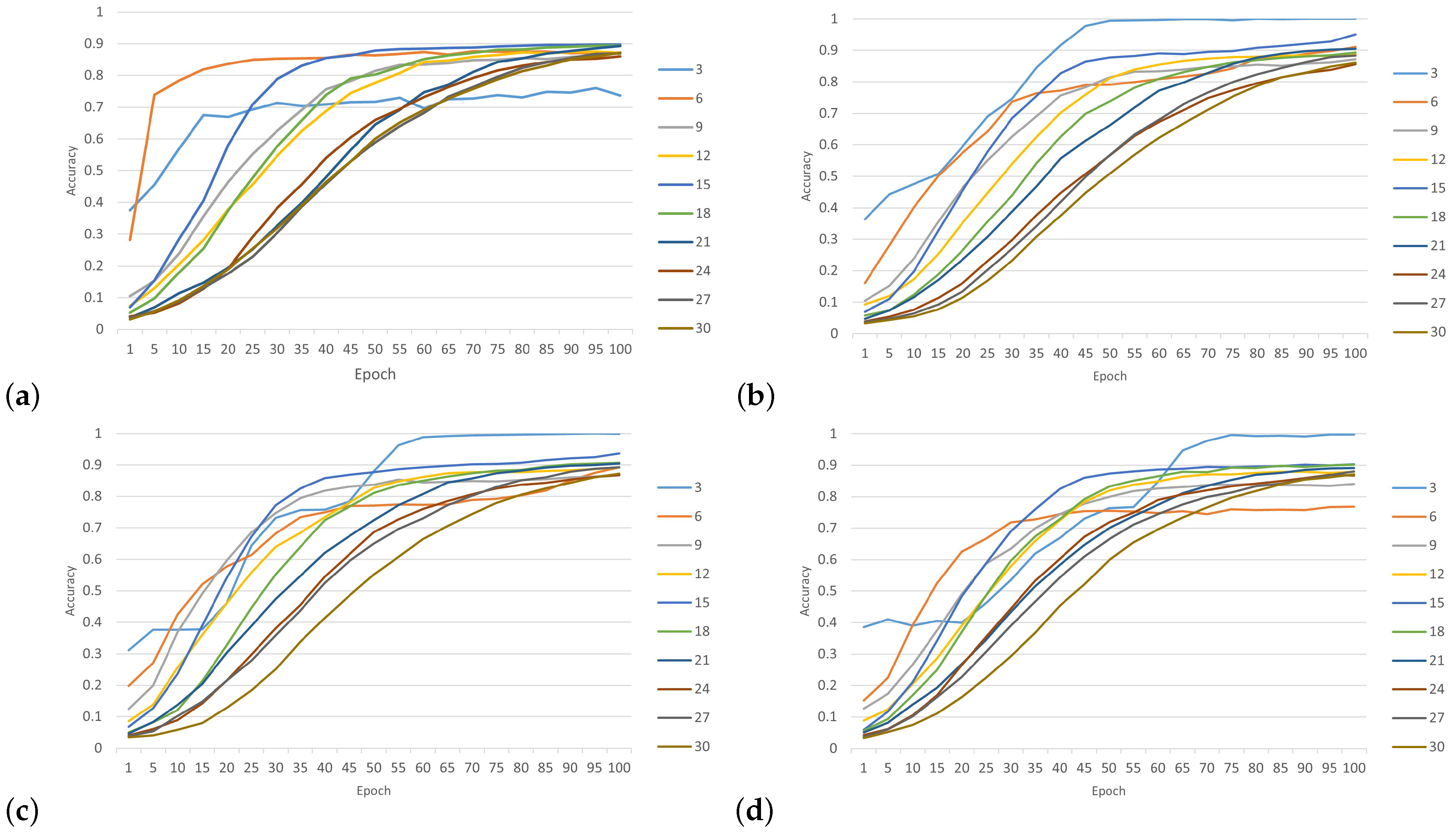
Figure 10 shows the impacts of different wireless nodes to SNR levels (0 dB, —5 dB, —10 dB, —20 dB, 5 dB, 10 dB and 20 dB) on the performance of the WPLA model.
In
Figure 10a, the horizontal axis represents the number of SNR levels while the vertical axis represents the value of the loss function. As SNR levels increased, the value of the loss function decreased. Additionally, the loss function value decreased more as the number of nodes increased, although it is noticeable that the loss function value was still high with fewer nodes (such as 3, 6 and 9).
Figure 10b shows the relationship between the overall classification accuracy and SNR for varying numbers of wireless nodes, where the CNN was trained using the training-generated dataset to assess the effectiveness of our proposed model. In general, the accuracy of classification demonstrated an upward trend with an increase in SNR. When the SNR levels increased from 20 dB to 0 dB, there was a significant increase in classification accuracy. The initial findings indicated that at SNR levels of 0 dB and 20 dB, the average test accuracy surpassed 95% while the precision rate reached 100%. Therefore, the proposed model can achieve both accuracy and precision. When the SNR was less than 10 dB, the energy of the noise was significantly greater than the energy of the signal. In this scenario, the extraction of CIRs from background noise is a significant challenge for all existing techniques. The model lacked classification capability, resulting in an average classification accuracy of approximately 14%. Furthermore, the precision and recall results of the classification are shown in
Figure 10c,d. It is clear from the figures that as the number of nodes and SNR levels increased, the model showed excellent performance, with a precision rate of 100% and a recall rate of 93%.
The proposed model was tested with 30 wireless nodes at four SNR levels (0 dB, 5 dB, 10 dB and 20 dB).
Figure 11 shows the performance training of the CNN network. As the SNR increased, the extraction of the CIRs became more feasible, leading to a continuous improvement in training accuracy. When the SNR was 0 dB, the power of the noise was equivalent to the power of the signal. This scenario could be interpreted as occurring within highly noisy environments. In the context of simulated environments, it is unlikely that classification accuracy would experience a substantial decrease. The impact of environmental noise on discrimination was significant. When the model classified three nodes, we can see that when SNR was 0 dB, the accuracy rate was 76% and began to increase significantly until reaching 100% with SNR levels of 5 dB, 10 dB and 20 dB. On the other hand, when the model classified more nodes, we can see that the accuracy rate slightly improved in SNR environments of 5 dB, 10 dB and 20 dB. However, both SNR levels of 5 dB and 10 dB showed better classification performance. In addition, we found that when the model classified 15 nodes, the accuracy rate was 95% for SNR levels of under 5 dB, but when the number of nodes was greater than 15 in the SNR environment of 20 dB, the accuracy rate of classification increased relatively. Overall, the proposed model demonstrated a higher level of accuracy in identifying the source nodes of received CIR signals.
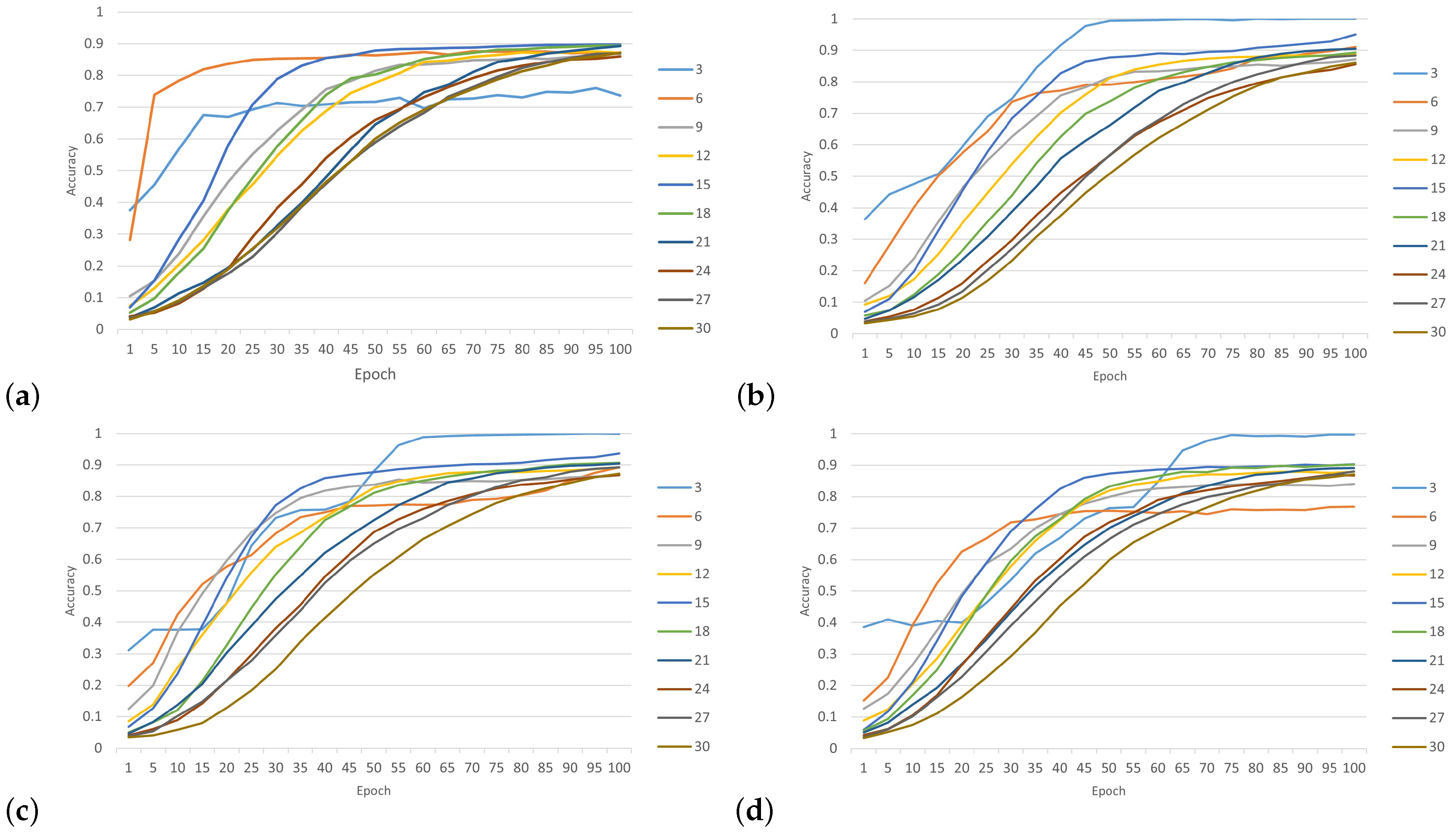
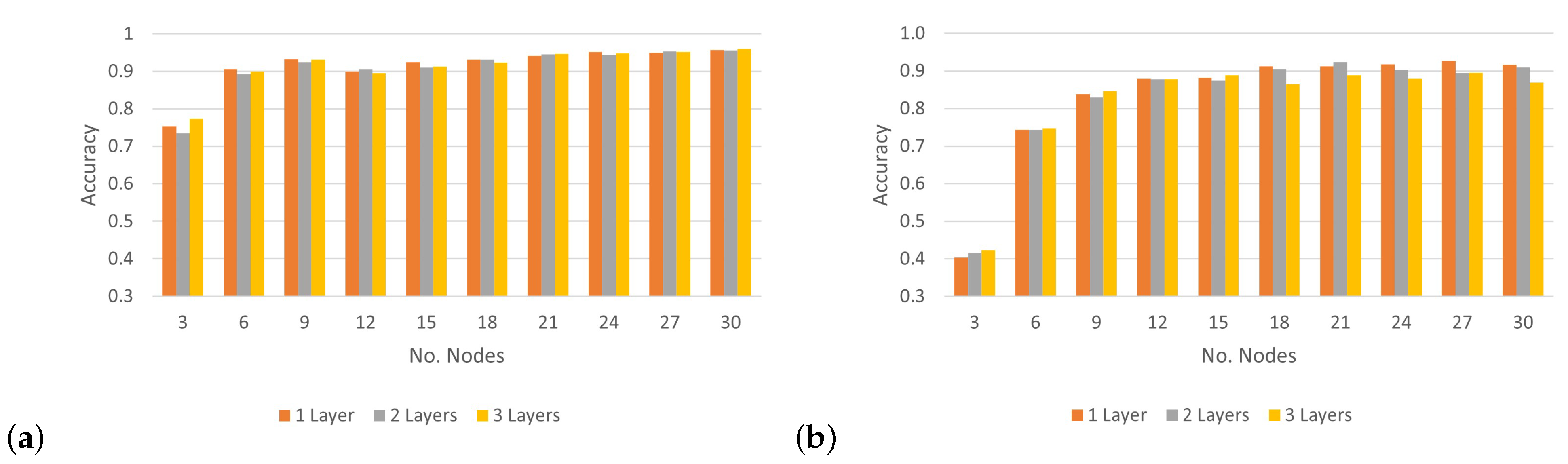
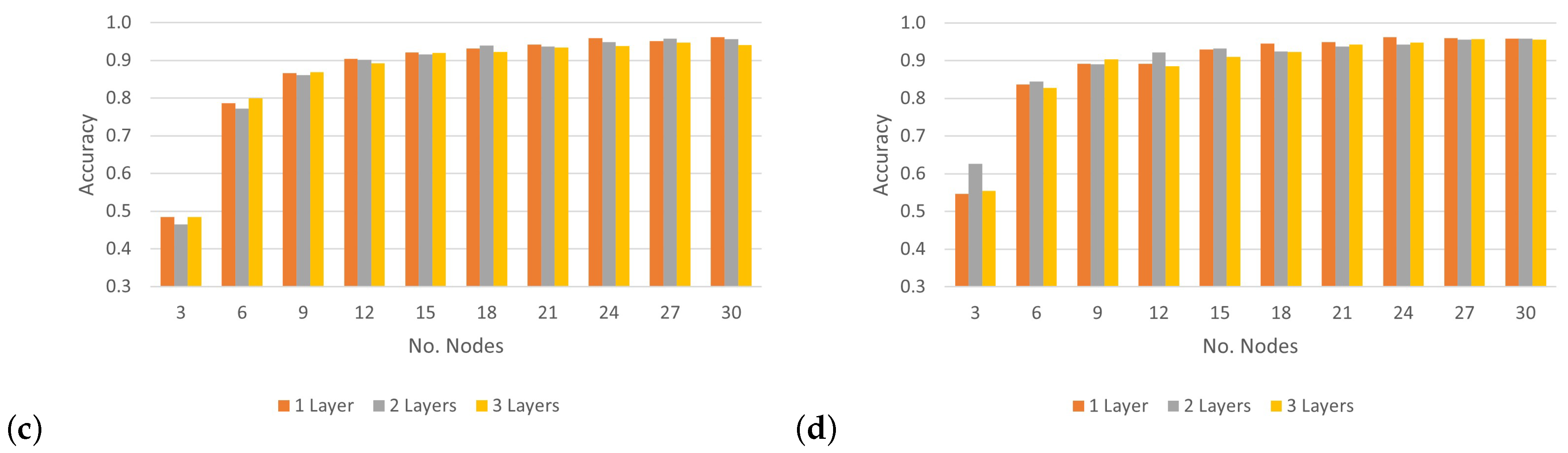
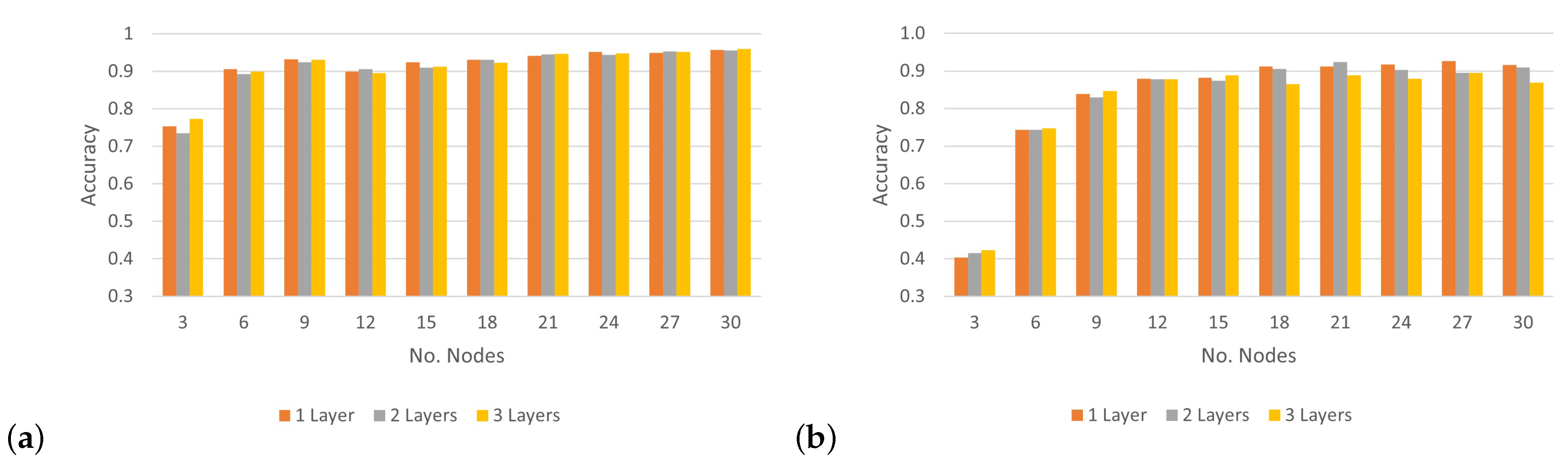
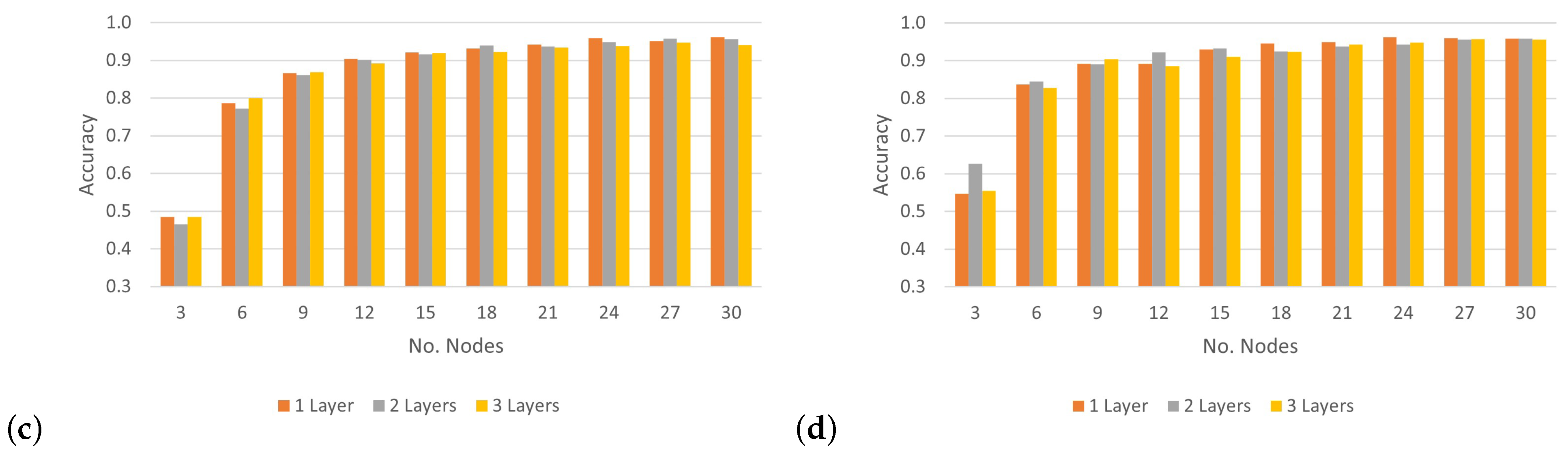
To analyze the impact of applying various numbers of hidden layers on the CNN’s accuracy rate and determine the optimal layers for classifying 30 wireless nodes,
Figure 12 shows the results of the accuracy rate of the proposed model, which uses three convolutional layers at different SNR levels. Based on the results in
Figure 12a, under the condition of an SNR level of 0 dB, the CNN architecture could achieve more than 90% accuracy when classifying 15 nodes or more by applying different numbers of convolutional layers. Furthermore, when the model tried to classify three nodes, we can see the best accuracy was recorded under an SNR of 0 dB. However, in the case of an SNR of 5 dB, the performance of the model with a different number of convolutional layers recorded a low classification accuracy, with an average rate of 81.8%. Following the model, performance with SNRs of 10 dB and 20 dB was similar and considered better than that with an SNR of 5 dB, with an average rate of more than 87%. As a result, there were no significant differences in the performance of the CNN architecture when increasing the number of layers. However, notable differences were apparent when the number of nodes was relatively small. Based on these experiments, the best number of convolutional layers for the CNN architecture was one layer with a suitable number of output filters, which further improved accuracy without increasing computation.
In summary, experimental validation showed that the GAN–WPLA model worked well to strengthen the WPLA model in relation to complex and changing channel information.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}