
A Multi-Stage Progressive Network with Feature Transmission and Fusion for Marine Snow Removal

Abstract
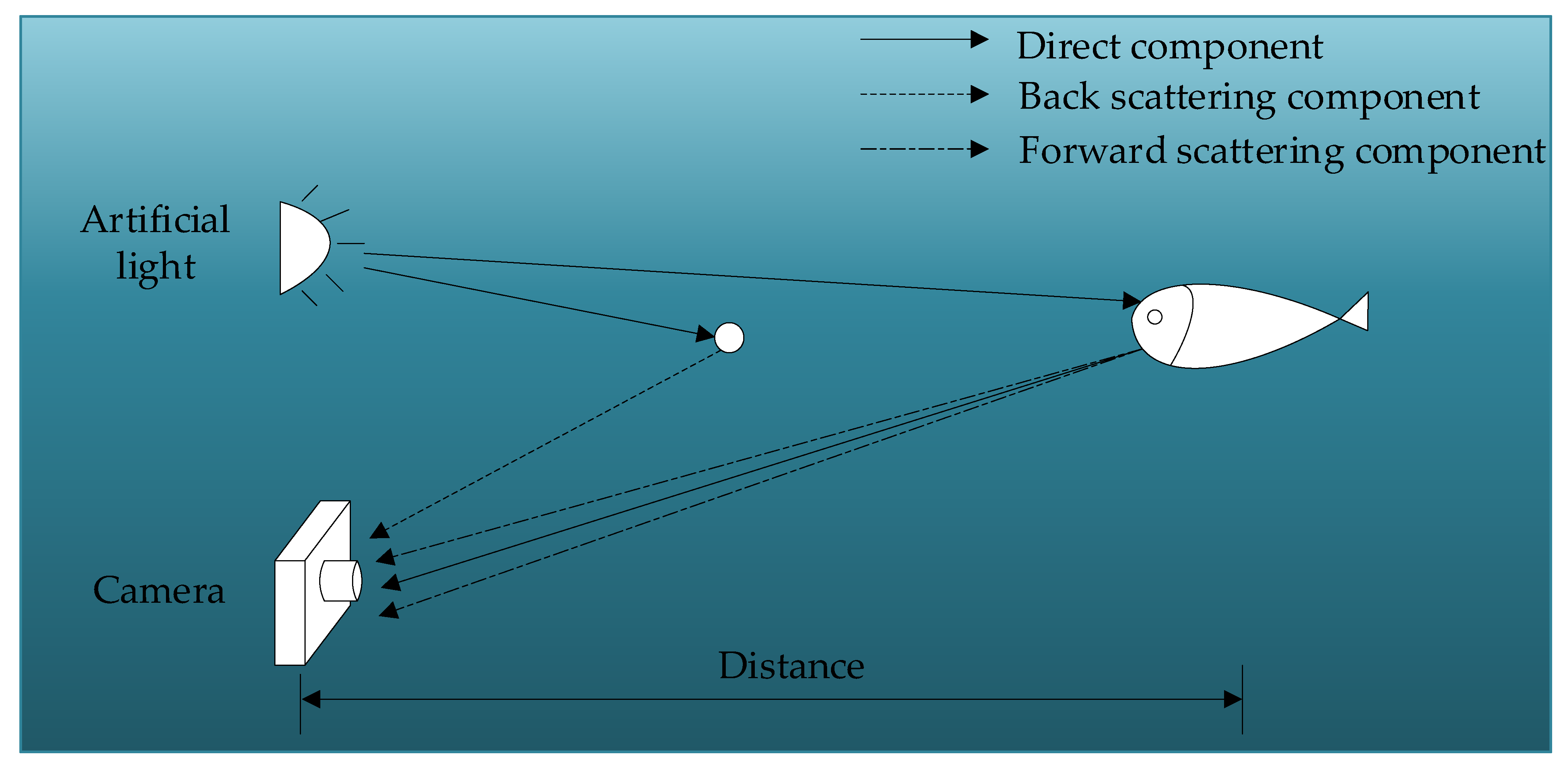
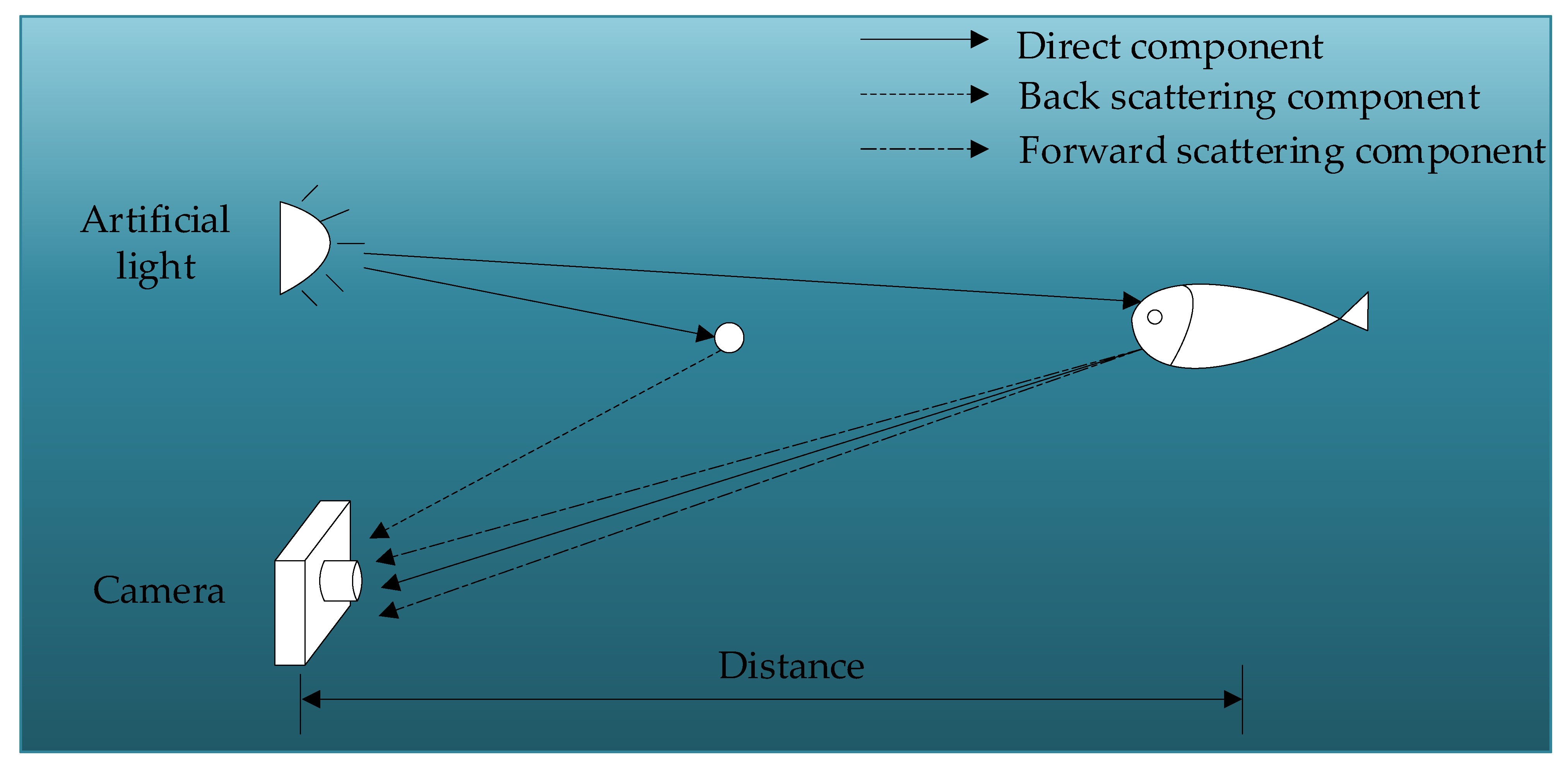
1. Introduction
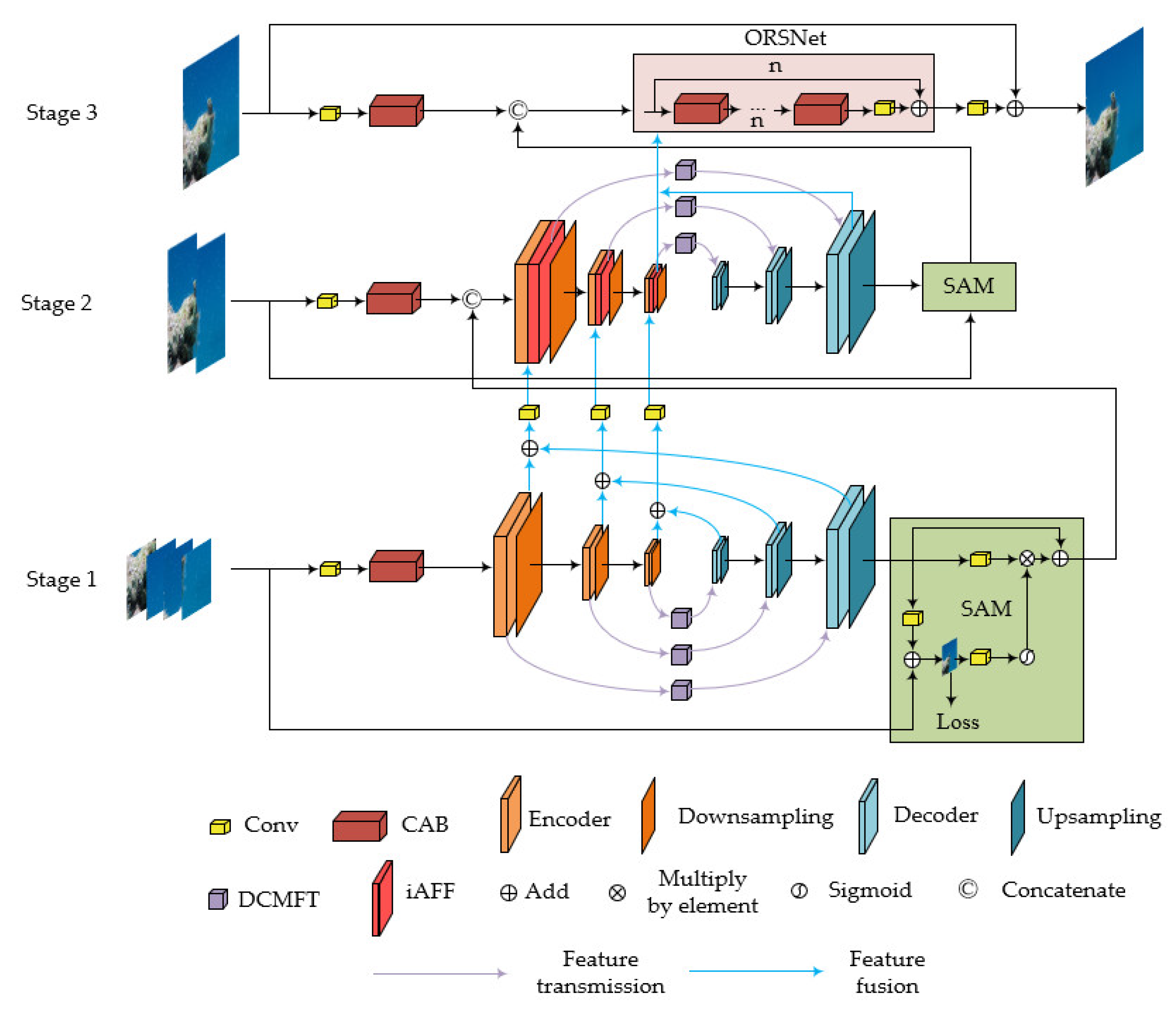
- We incorporate the multi-stage progressive recovery method and a feature fusion module for the marine snow removal task. This strategy not only gradually enhances the extraction of marine snow features but also ensures the full utilization of features at different stages, resulting in favorable outcomes.
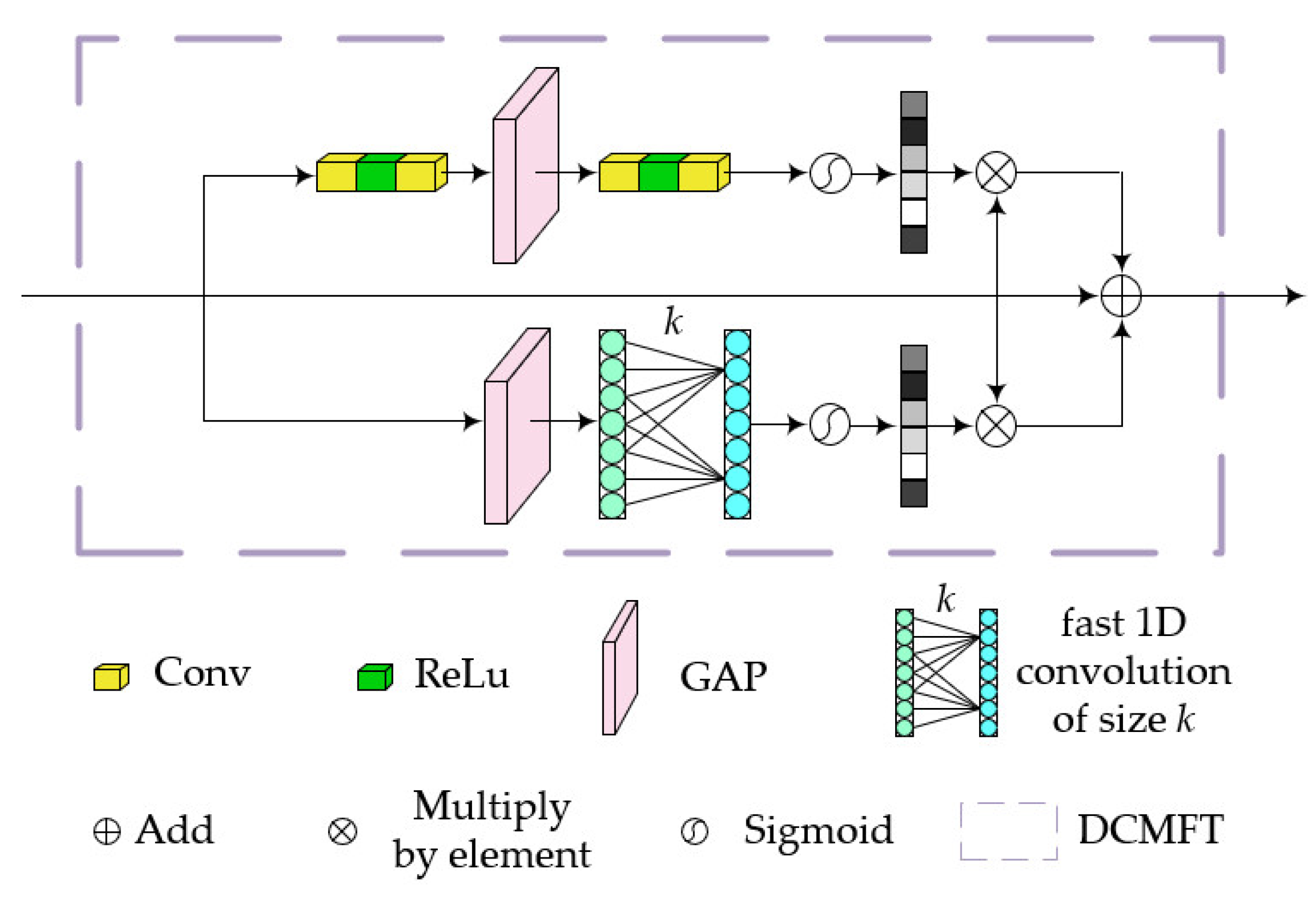
- We propose a novel skip-connection structure, named DCMFT, to ensure comprehensive feature propagation across different scales during the encoding and decoding processes, thus reducing information loss caused by downsampling.
- We also design a new weight multi-scale adaptive loss function to accelerate the convergence speed during the network training process.
2. Related Work
2.1. Traditional Methods
2.2. Deep Learning Methods
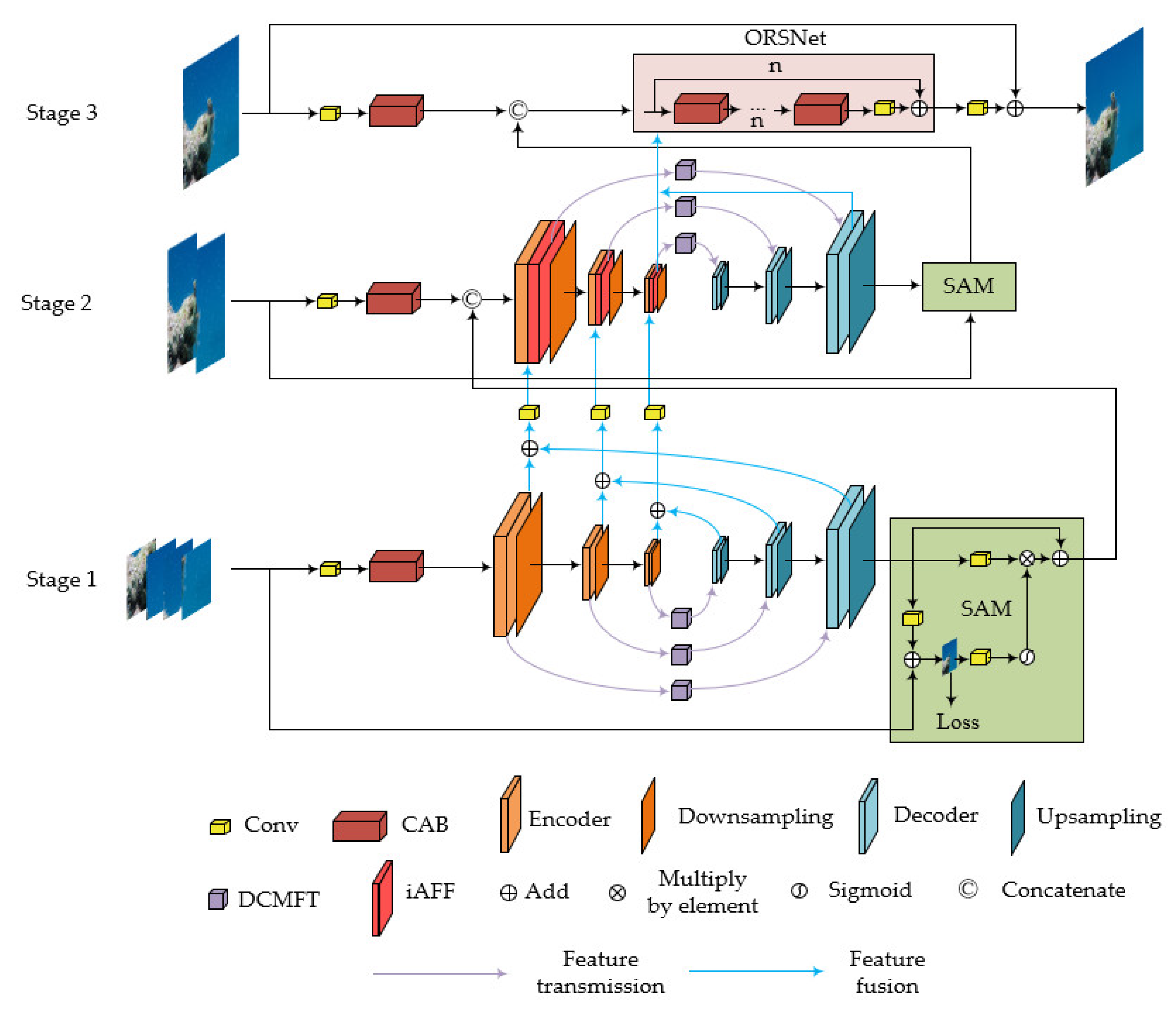
3. Method
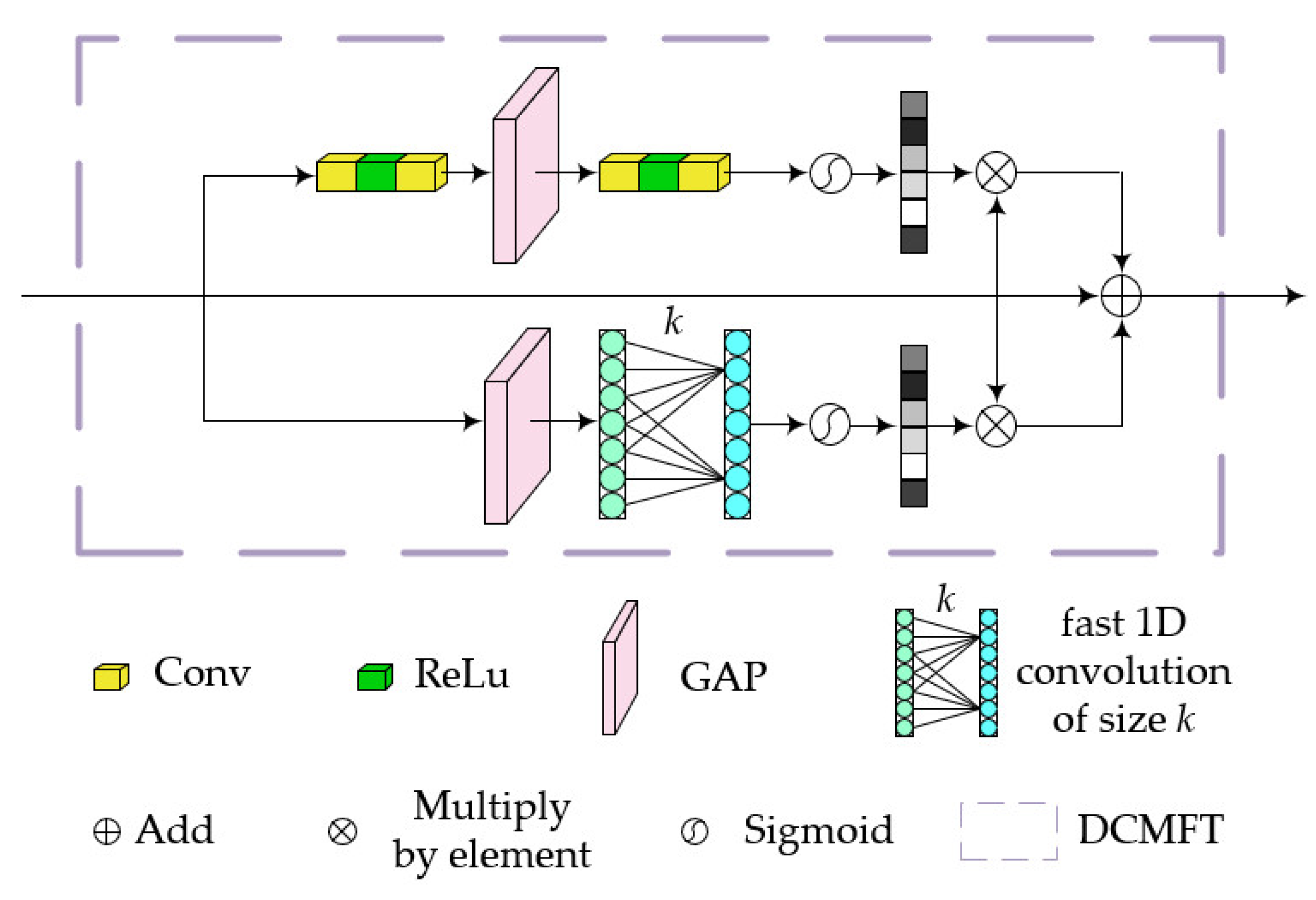
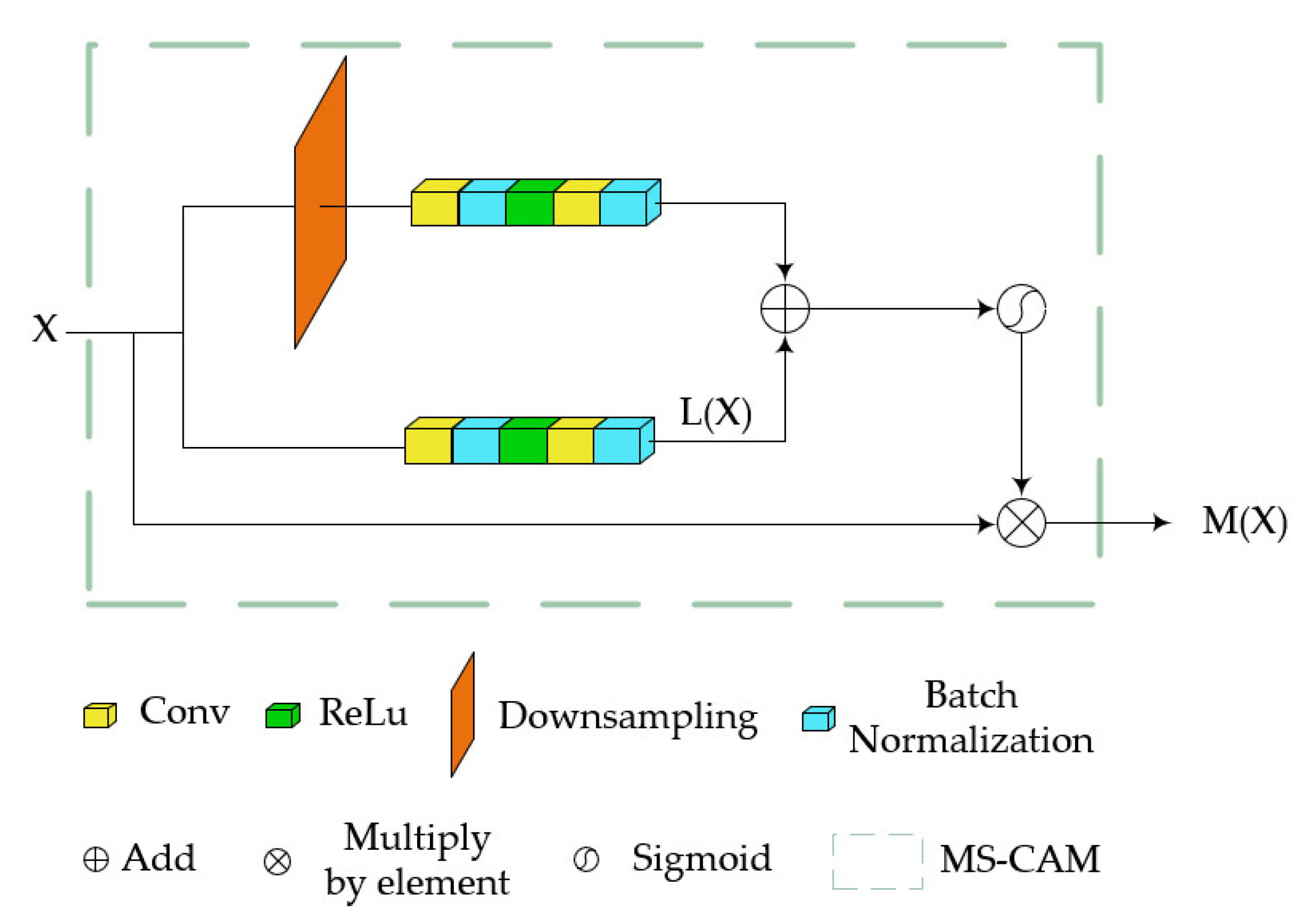
3.1. DCMFT
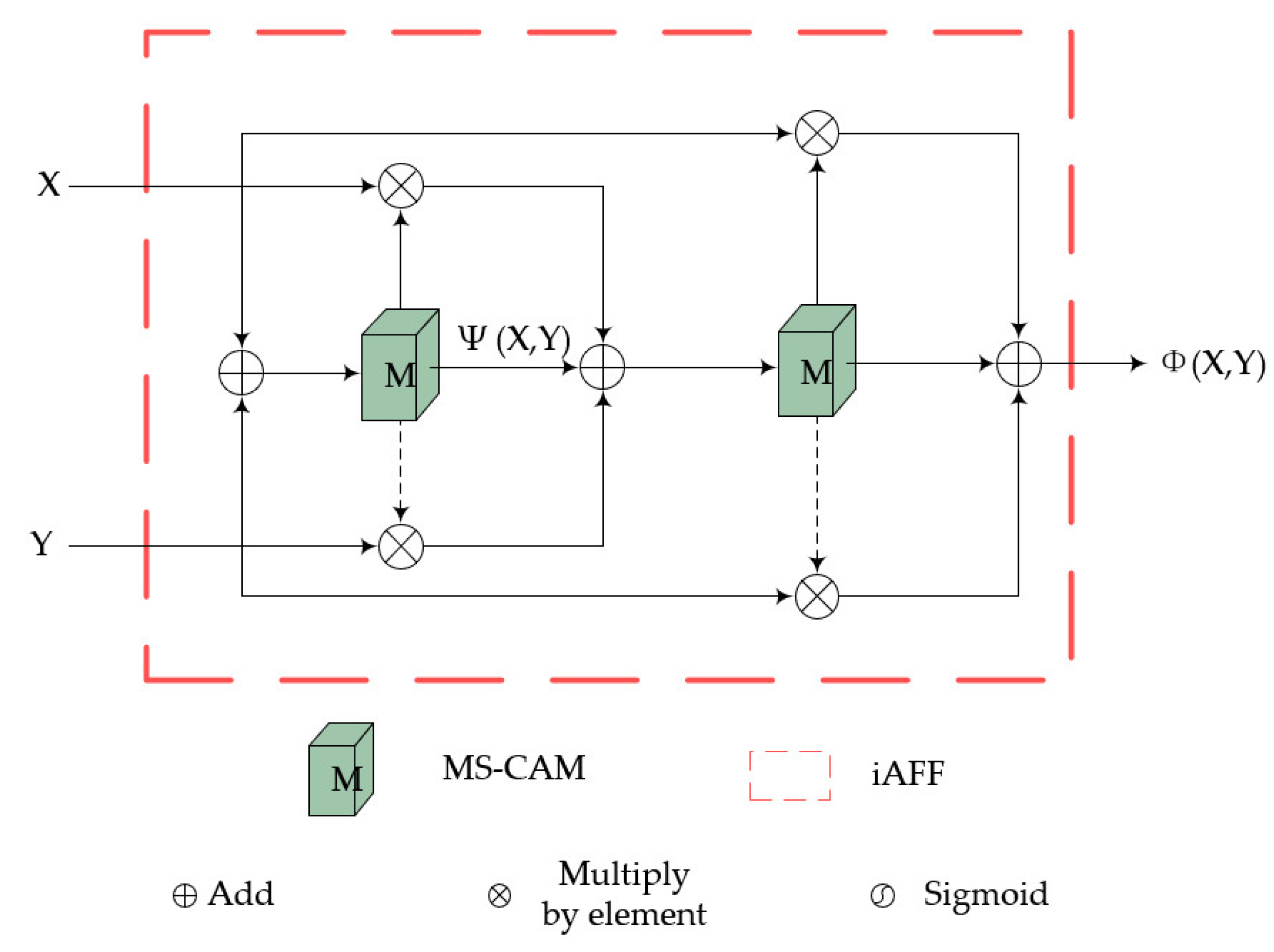
3.2. iAFF
3.3. SAM and ORSNet
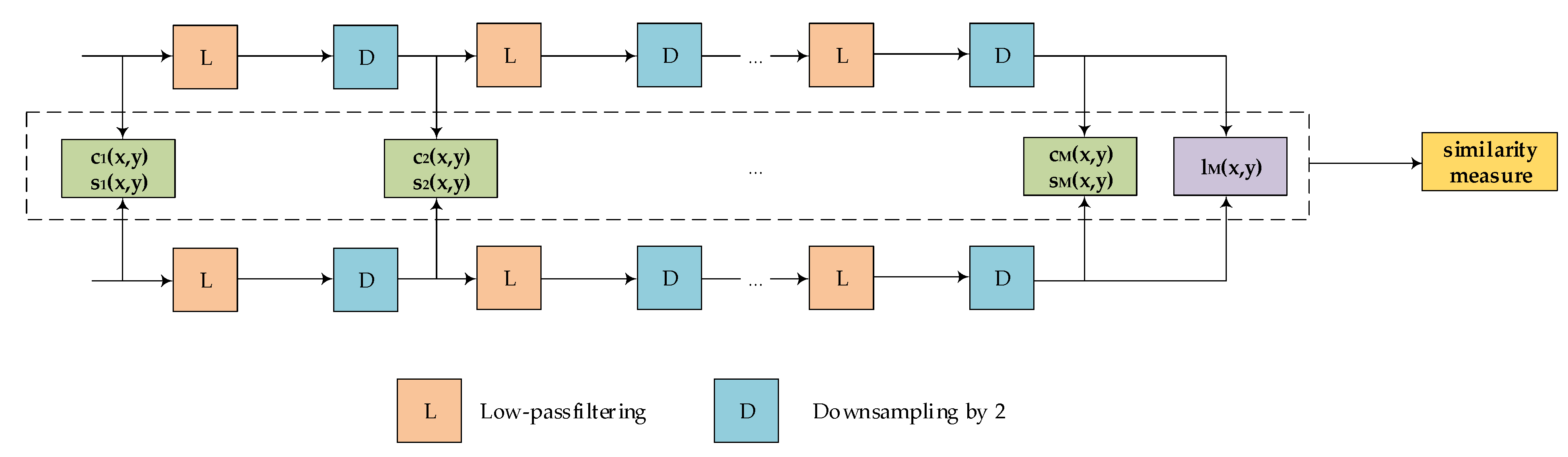
3.4. Loss Function
4. Experiments
4.1. Experiments Configuration
4.2. Dataset
4.3. Parameter Settings
4.4. Comparative Experiments
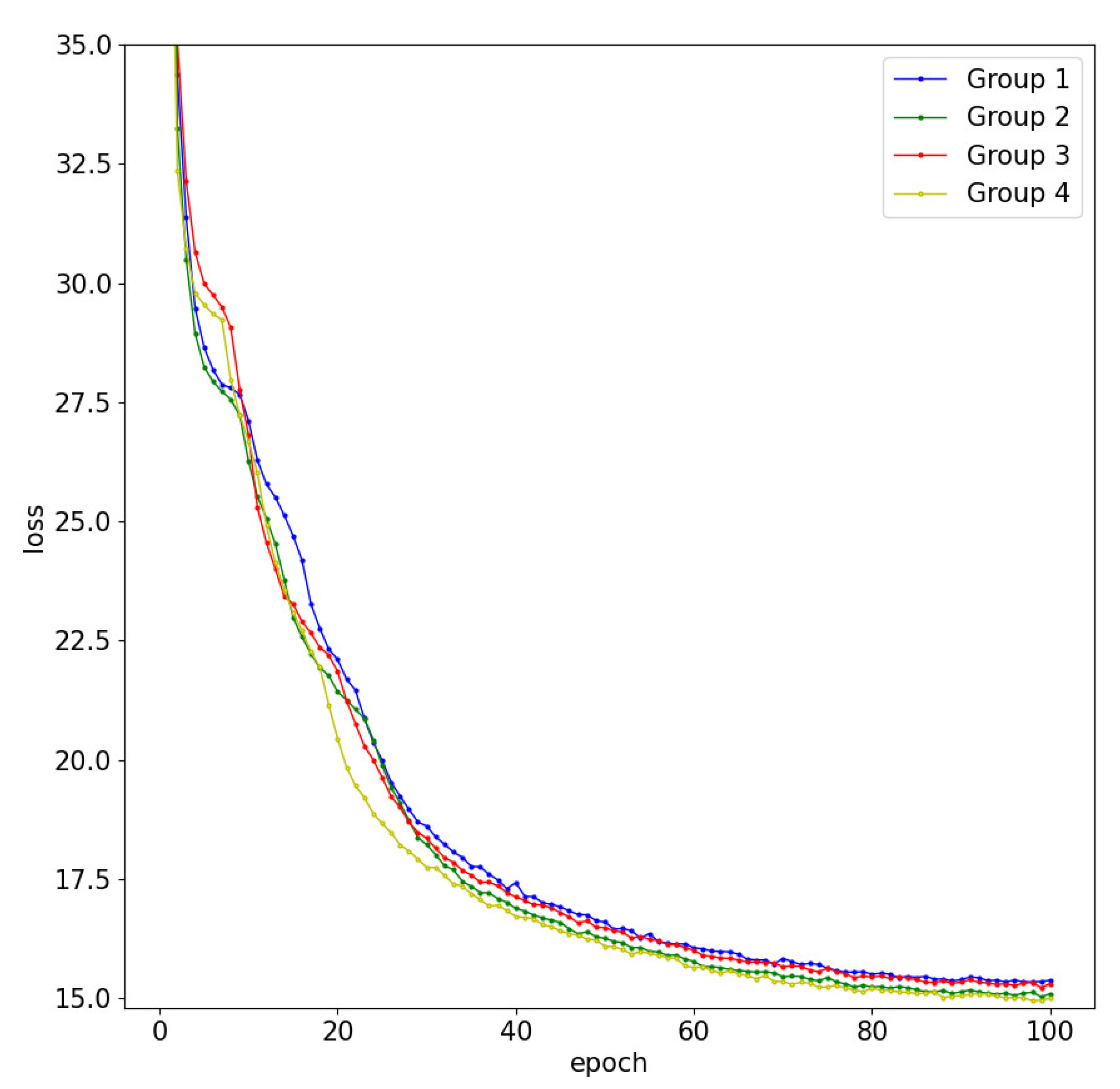
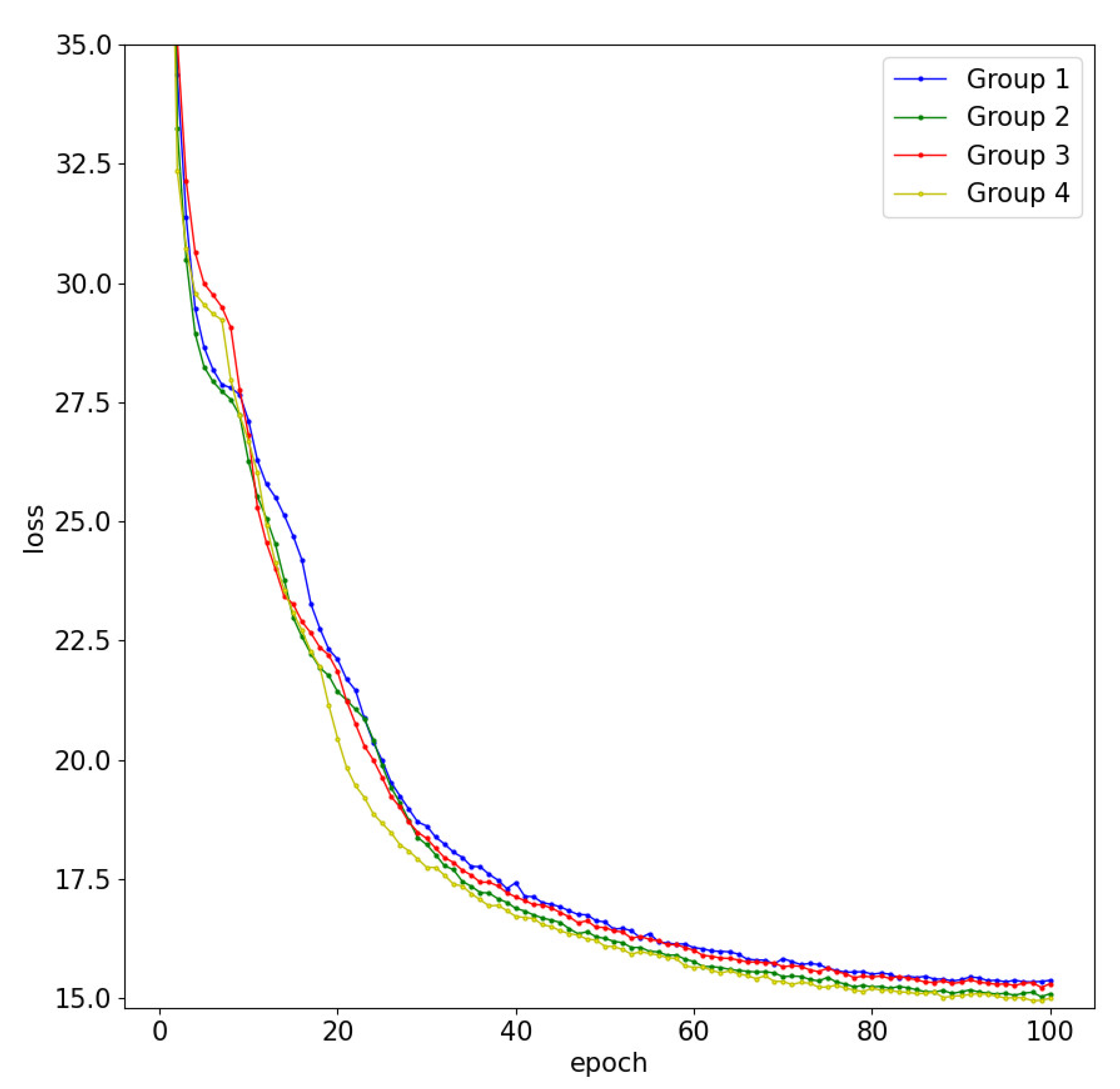
4.5. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bonin-Font, F.; Oliver, G.; Wirth, S.; Massot, M.; Negre, P.L.; Beltran, J.-P. Visual sensing for autonomous underwater exploration and intervention tasks. Ocean. Eng. 2015, 93, 25–44. [Google Scholar] [CrossRef]
- Li, C.-Y.; Guo, J.-C.; Cong, R.-M.; Pang, Y.-W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.-T.; Cosman, P.C. Underwater image restoration based on image blurriness and light absorption. IEEE Trans. Image Process. 2017, 26, 1579–1594. [Google Scholar] [CrossRef] [PubMed]
- Schechner, Y.Y.; Karpel, N. Clear underwater vision. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2004. CVPR 2004, Washington, DC, USA, 27 June–2 July 2004; p. I. [Google Scholar]
- Boffety, M.; Galland, F. Phenomenological marine snow model for optical underwater image simulation: Applications to color restoration. In Proceedings of the 2012 Oceans-Yeosu, Yeosu, Korea, 21–24 May 2012; pp. 1–6. [Google Scholar]
- Zhou, J.; Liu, Z.; Zhang, W.; Zhang, D.; Zhang, W. Underwater image restoration based on secondary guided transmission map. Multimed. Tools Appl. 2021, 80, 7771–7788. [Google Scholar] [CrossRef]
- Arnold-Bos, A.; Malkasse, J.-P.; Kervern, G. Towards a model-free denoising of underwater optical images. In Proceedings of the Europe Oceans 2005, Brest, France, 20–23 June 2005; pp. 527–532. [Google Scholar]
- Banerjee, S.; Sanyal, G.; Ghosh, S.; Ray, R.; Shome, S.N. Elimination of marine snow effect from underwater image-an adaptive probabilistic approach. In Proceedings of the 2014 IEEE Students’ Conference on Electrical, Electronics and Computer Science, Bhopal, India, 1–2 March 2014; pp. 1–4. [Google Scholar]
- Cyganek, B.; Gongola, K. Real-time marine snow noise removal from underwater video sequences. J. Electron. Imaging 2018, 27, 043002. [Google Scholar] [CrossRef]
- Farhadifard, F.; Radolko, M.; Freiherr von Lukas, U. Marine Snow Detection and Removal: Underwater Image Restoration Using Background Modeling; UNION Agency: Charlotte, NC, USA, 2017. [Google Scholar]
- Farhadifard, F.; Radolko, M.; von Lukas, U.F. Single Image Marine Snow Removal based on a Supervised Median Filtering Scheme. In Proceedings of the VISIGRAPP (4: VISAPP), Porto, Portugal, 27 February–1 March 2017; pp. 280–287. [Google Scholar]
- Koziarski, M.; Cyganek, B. Marine snow removal using a fully convolutional 3d neural network combined with an adaptive median filter. In Proceedings of the Pattern Recognition and Information Forensics: ICPR 2018 International Workshops, CVAUI, IWCF, and MIPPSNA, Revised Selected Papers 24, Beijing, China, 20–24 August 2018; pp. 16–25. [Google Scholar]
- Liu, H.; Chau, L.-P. Deepsea video descattering. Multimed. Tools Appl. 2019, 78, 28919–28929. [Google Scholar] [CrossRef]
- Guo, D.; Huang, Y.; Han, T.; Zheng, H.; Gu, Z.; Zheng, B. Marine snow removal. In Proceedings of the OCEANS 2022-Chennai, Chennai, India, 21–24 February 2022; pp. 1–7. [Google Scholar]
- Wang, Y.; Yu, X.; An, D.; Wei, Y. Underwater image enhancement and marine snow removal for fishery based on integrated dual-channel neural network. Comput. Electron. Agric. 2021, 186, 106182. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.-H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Zhang, W.; Zhou, L.; Zhuang, P.; Li, G.; Pan, X.; Zhao, W.; Li, C. Underwater image enhancement via weighted wavelet visual perception fusion. IEEE Trans. Circuits Syst. Video Technol. 2023. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.-H.; Li, G.; Kwong, S.; Li, C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef] [PubMed]
- Hwang, H.; Haddad, R.A. Adaptive median filters: New algorithms and results. IEEE Trans. Image Process. 1995, 4, 499–502. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual dense network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2472–2481. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.-Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000452649400067 (accessed on 29 December 2023).
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Park, T.; Efros, A.A.; Zhang, R.; Zhu, J.-Y. Contrastive learning for unpaired image-to-image translation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings, Part IX 16, Glasgow, UK, 23–28 August 2020; pp. 319–345. [Google Scholar]
- Zhu, J.-Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward multimodal image-to-image translation. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000452649400045 (accessed on 29 December 2023).
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 3560–3569. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Proceedings, Part III 18, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Charbonnier, P.; Blanc-Feraud, L.; Aubert, G.; Barlaud, M. Two deterministic half-quadratic regularization algorithms for computed imaging. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994; pp. 168–172. [Google Scholar]
- Charrier, C.; Knoblauch, K.; Maloney, L.T.; Bovik, A.C. Calibrating MS-SSIM for compression distortions using MLDS. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; pp. 3317–3320. [Google Scholar]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Sato, Y.; Ueda, T.; Tanaka, Y. Marine snow removal benchmarking dataset. arXiv 2021, arXiv:2103.14249. [Google Scholar]
- Islam, M.J.; Luo, P.; Sattar, J. Simultaneous enhancement and super-resolution of underwater imagery for improved visual perception. arXiv 2020, arXiv:2002.01155. [Google Scholar]
- Li, C.; Guo, C.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An underwater image enhancement benchmark dataset and beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Li, C.; Anwar, S.; Porikli, F. Underwater Scene Prior Inspired Deep Underwater Image and Video Enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef] [PubMed]
- Wallach, D.; Goffinet, B. Mean squared error of prediction as a criterion for evaluating and comparing system models. Ecol. Model. 1989, 44, 299–306. [Google Scholar] [CrossRef]
- Zou, Z.; Lei, S.; Shi, T.; Shi, Z.; Ye, J. Deep adversarial decomposition: A unified framework for separating superimposed images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12806–12816. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hardware | Software | ||
|---|---|---|---|
| Divices | Model/Size | Tool Stack | Version |
| CPU | 64 Intel(R) Xeon(R) Gold 6346 | OS | Ubuntu 18.04 |
| RAM | 256 GB | Python | 3.9 |
| GPU | Nvidia GTX3090 | CUDA | 11.4 |
| \ | \ | Pytorch | 1.12 |
| Method | PSNR (dB) | SSIM | MSE | Speed (FPS) | Model Size (MB) |
|---|---|---|---|---|---|
| CycleGAN [23] | 25.3431 | 0.8382 | 348.3727 | 7.26 | 43.42 |
| pix2pix [24] | 30.9850 | 0.8846 | 68.8730 | 16.58 | 207.64 |
| BicycleGAN [26] | 30.4210 | 0.8653 | 159.4803 | 7.10 | 209.04 |
| CUT [25] | 26.2229 | 0.8440 | 287.0160 | 14.25 | 43.46 |
| MPRNet [16] | 38.5108 | 0.9747 | 14.2182 | 10.91 | 41.97 |
| DAD [40] | 34.2794 | 0.9257 | 41.4867 | 2.26 | 813.70 |
| Ours | 38.9251 | 0.9761 | 13.4415 | 10.44 | 45.23 |
| Group | Module | Stage | PSNR (dB) | SSIM | MSE | |||
|---|---|---|---|---|---|---|---|---|
| Baseline | iAFF | MS_SSIM | DCMFT | |||||
| 1 | √ | \ | \ | \ | 1 | 35.1214 | 0.9581 | 26.3924 |
| \ | \ | \ | 2 | 36.2208 | 0.9654 | 21.5644 | ||
| \ | \ | \ | 3 | 38.5108 | 0.9747 | 14.2182 | ||
| 2 | √ | \ | \ | 1 | 35.3099 | 0.9600 | 25.6271 | |
| √ | \ | \ | 2 | 36.6715 | 0.9676 | 19.5356 | ||
| \ | \ | \ | 3 | 38.6133 | 0.9753 | 14.1122 | ||
| 3 | √ | √ | \ | 1 | 35.4822 | 0.9607 | 24.7388 | |
| √ | √ | \ | 2 | 36.7619 | 0.9678 | 19.1418 | ||
| \ | √ | \ | 3 | 38.7733 | 0.9756 | 13.8419 | ||
| 4 | √ | √ | √ | 1 | 35.7354 | 0.9621 | 23.6104 | |
| √ | √ | √ | 2 | 37.2048 | 0.9690 | 17.7378 | ||
| \ | √ | \ | 3 | 38.9251 | 0.9761 | 13.4415 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Liao, Y.; He, B. A Multi-Stage Progressive Network with Feature Transmission and Fusion for Marine Snow Removal. Sensors 2024, 24, 356. https://doi.org/10.3390/s24020356
Liu L, Liao Y, He B. A Multi-Stage Progressive Network with Feature Transmission and Fusion for Marine Snow Removal. Sensors. 2024; 24(2):356. https://doi.org/10.3390/s24020356
Chicago/Turabian StyleLiu, Lixin, Yuyang Liao, and Bo He. 2024. "A Multi-Stage Progressive Network with Feature Transmission and Fusion for Marine Snow Removal" Sensors 24, no. 2: 356. https://doi.org/10.3390/s24020356
APA StyleLiu, L., Liao, Y., & He, B. (2024). A Multi-Stage Progressive Network with Feature Transmission and Fusion for Marine Snow Removal. Sensors, 24(2), 356. https://doi.org/10.3390/s24020356