
Learning Autonomous Navigation in Unmapped and Unknown Environments

 ,
,
Abstract
1. Introduction
- We propose an enhanced (DRL) algorithm based on [9], which leverages low-cost, low-precision 2D LiDAR sensors for mapless navigation, enabling robust performance in complex environments without the need for high-precision maps.
- We propose a priority-based excellence experience collection mechanism and a multi-source experience fusion strategy. These strategies allow the agent to efficiently learn optimal policies from prior experiences, significantly reducing the training time required for effective navigation.
- Compared to other algorithms, our method can reach the destination quicker, safer, and more smoothly in unmapped and unknown environments, even when localization is inaccurate. Moreover, the strategies and hyperparameters in the simulation environment can be deployed in the real world without any adjustments.
- Additionally, our algorithm has been open-sourced, and the code repository is available at https://github.com/nfhe/darc_drl_nav (accessed on 28 August 2024).
2. Related Works
3. PEEMEEF-DARC Autonomous Navigation
3.1. DARC Module
3.2. Priority Excellent Experience Date Collection Module
3.3. Multi-Source Experience Fusion Strategy Module
- (1)
- Real-time sorting of the data in the experience pool according to the reward value , and the data with the top reward values are divided into the excellent experience pool. In the process of data selection, samples are prioritized from this excellent experience pool.
- (2)
- In each iteration, the agent generates new data . If the reward value in this data exceeds the set excellent experience pool threshold, it is added to this pool.
- (3)
- For each training session, a total of data sets are chosen. are randomly selected from the excellent experience pool and from the ordinary pool. These are then randomly combined for training.
- (4)
- After training, the agent blends the excellent with the ordinary experience pool. The excellent pool and its reward threshold are reset based on the top in the experience pool.
3.4. Reinforcement Learning Setting Module
- (1)
- State Space and Action Space
- (2)
- Reward Function Design
- (3)
- Network Structure
4. Experiments
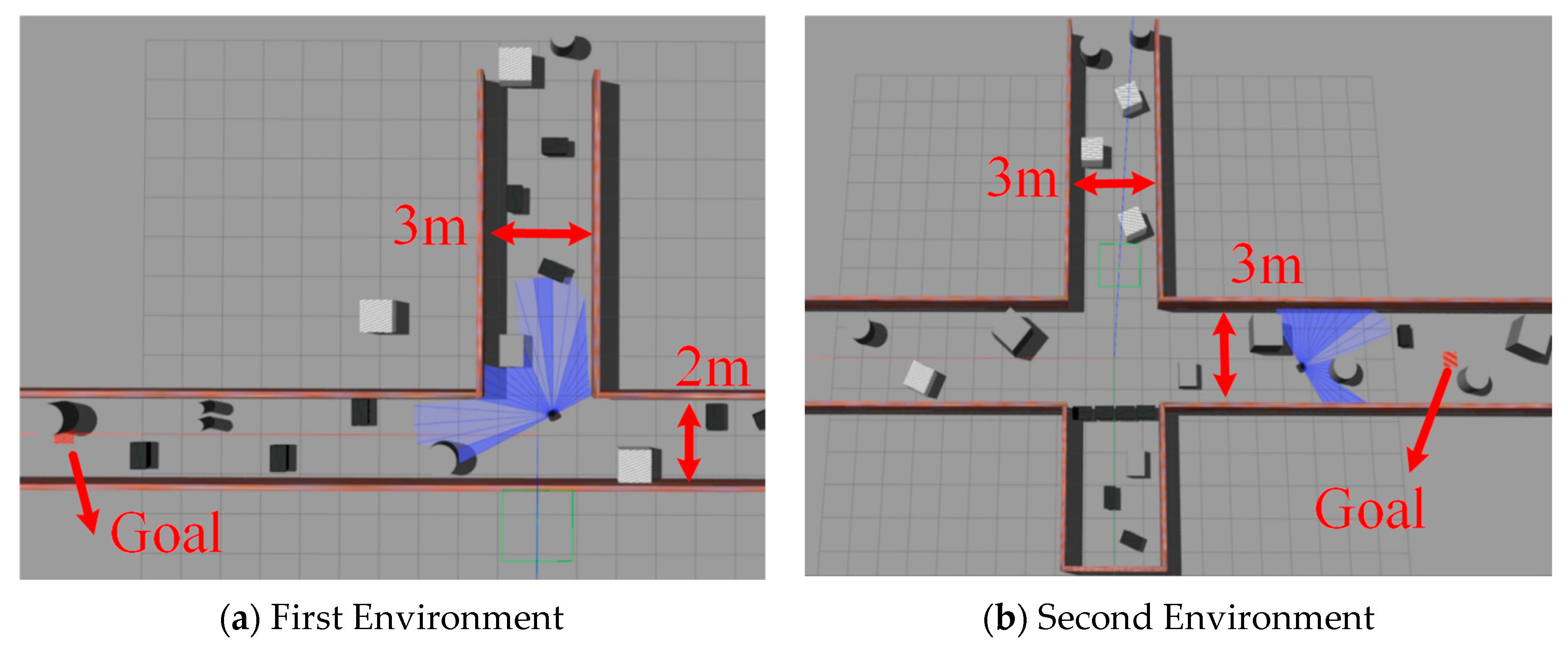
4.1. Environment and Parameter Settings
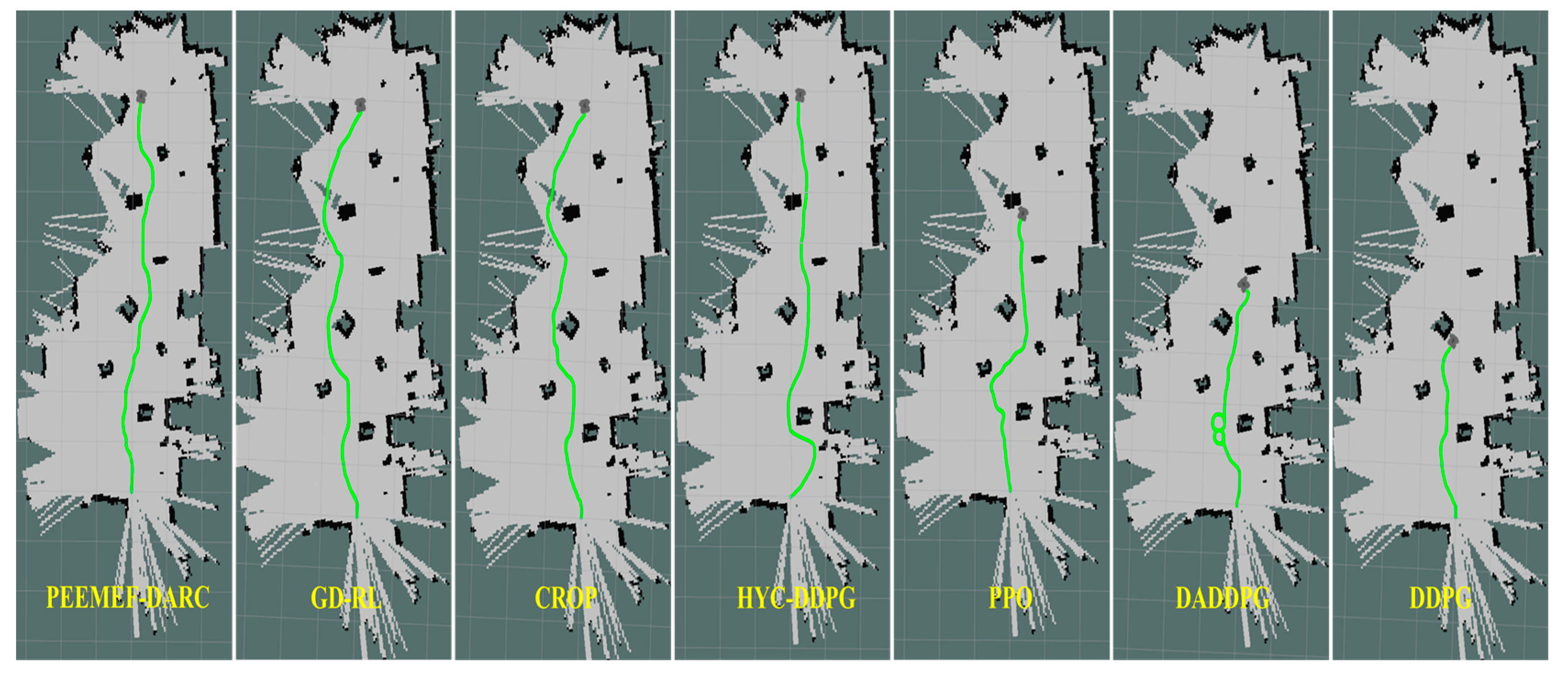
4.2. Comparison of Experimental Results
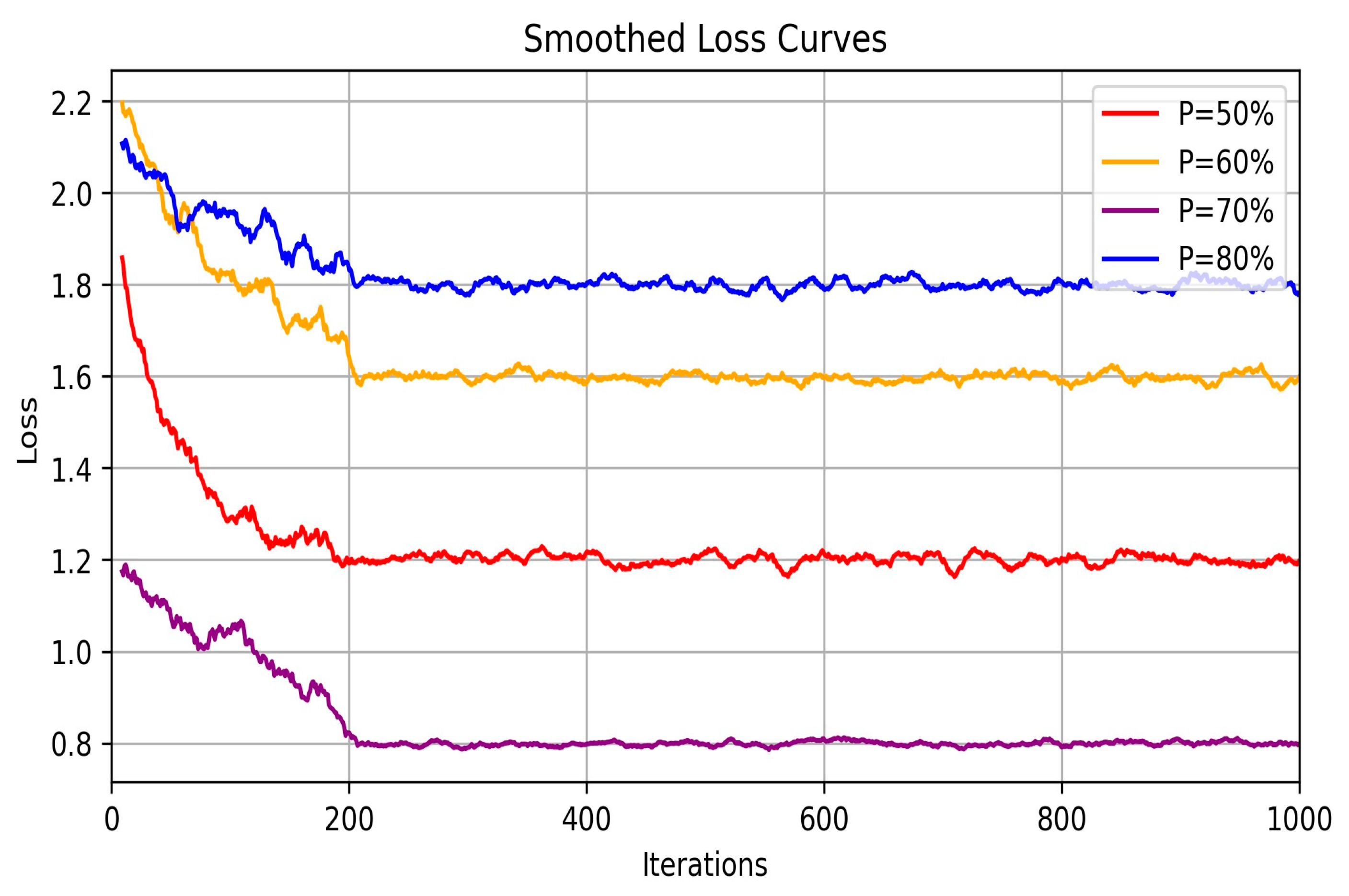
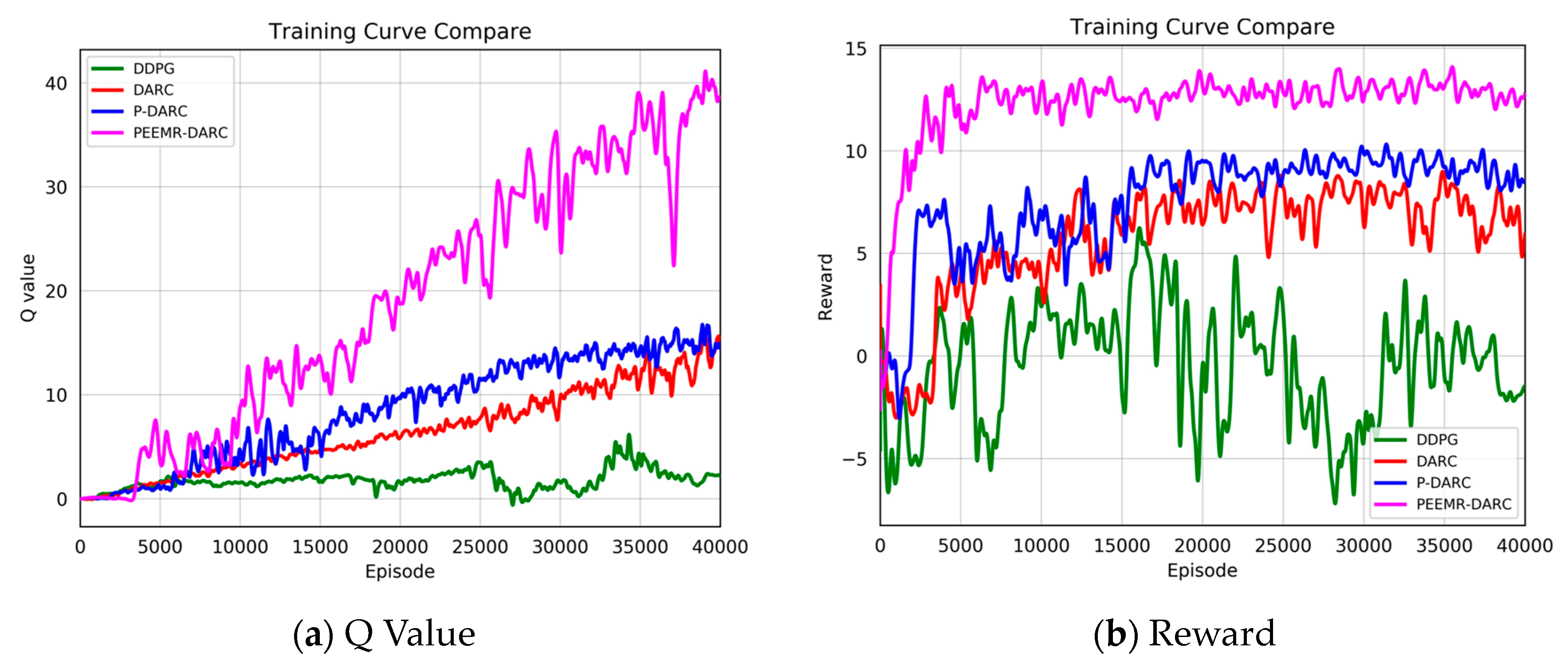
- (1)
- Results of ablation experiment
- (2)
- Simulation Environment Training
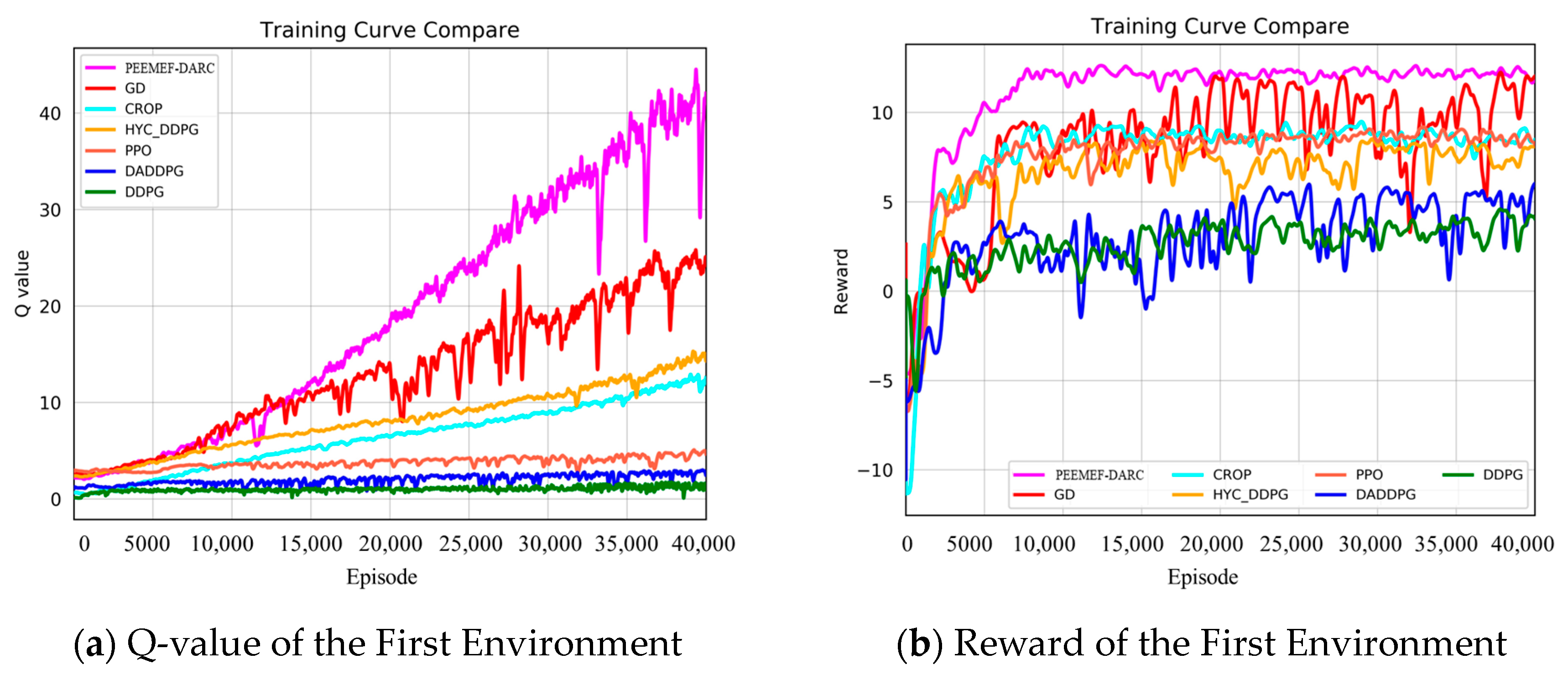
- (3)
- Simulation Environment Results
- (4)
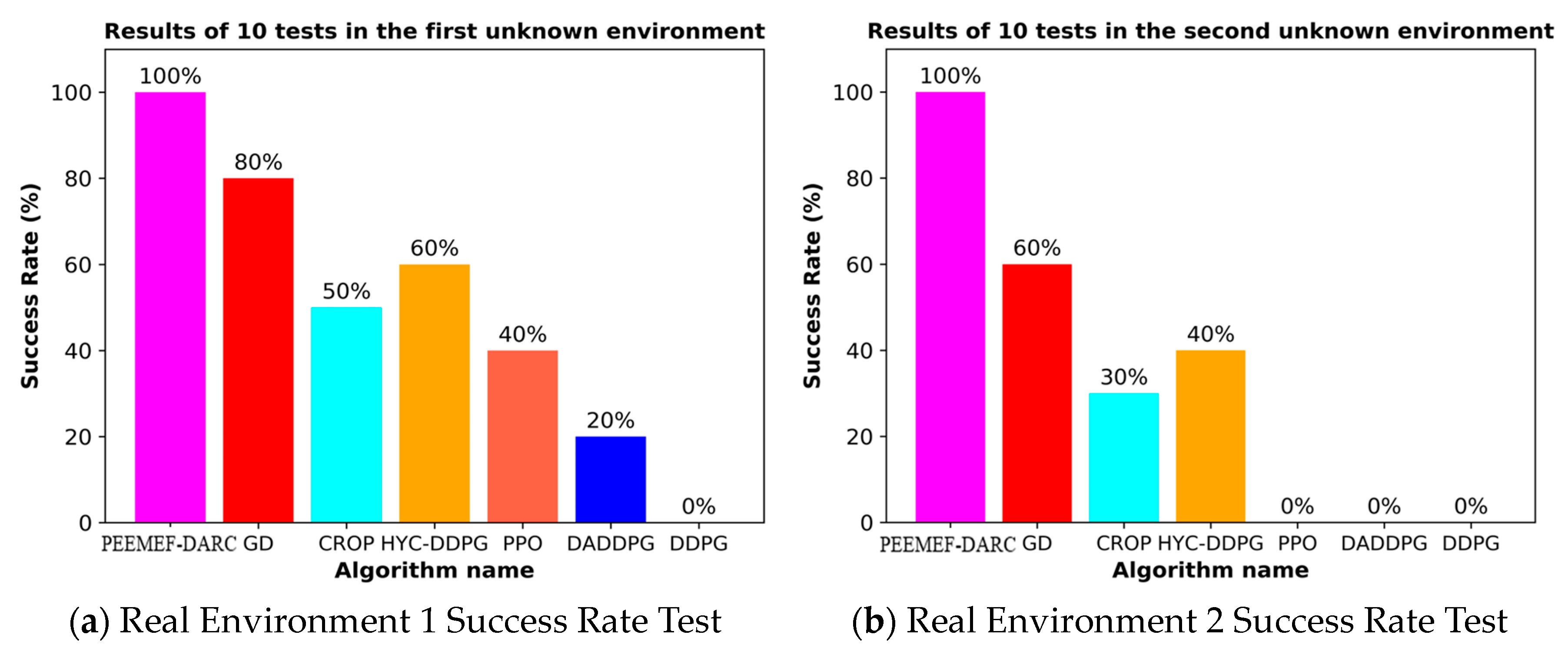
- Real–World Environment Results
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ismail, K.; Liu, R.; Athukorala, A.; Ng BK, K.; Yuen, C.; Tan, U.X. WiFi Similarity-Based Odometry. IEEE Trans. Autom. Sci. Eng. 2023, 21, 3092–3102. [Google Scholar] [CrossRef]
- Zhang, T.; Zhang, H.; Li, Y.; Nakamura, Y.; Zhang, L. Flowfusion: Dynamic dense rgb-d slam based on optical flow. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 7322–7328. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Li, R.; Wang, S.; Gu, D. DeepSLAM: A Robust Monocular SLAM System With Unsupervised Deep Learning. IEEE Trans. Ind. Electron. 2021, 68, 3577–3587. [Google Scholar] [CrossRef]
- Lample, G.; Chaplot, D.S. Playing FPS games with deep reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Monroe, W.; Ritter, A.; Galley, M.; Gao, J.; Jurafsky, D. Deep reinforcement learning for dialogue generation. arXiv 2016, arXiv:1606.01541. [Google Scholar]
- Ismail, J.; Ahmed, A. Improving a sequence-to-sequence nlp model using a reinforcement learning policy algorithm. arXiv 2022, arXiv:2212.14117. [Google Scholar]
- Lyu, J.; Ma, X.; Yan, J.; Li, X. Efficient continuous control with double actors and regularized critics. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 7655–7663. [Google Scholar]
- Tani, J. Model-based learning for mobile robot navigation from the dynamical systems perspective. IEEE Trans. Syst. Man Cybern. Part B (Cybern.) 1996, 26, 421–436. [Google Scholar] [CrossRef] [PubMed]
- Zhu, A.; Yang, S.X. Neurofuzzy-based approach to mobile robot navigation in unknown environments. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2007, 37, 610–621. [Google Scholar] [CrossRef]
- Liu, B.; Xiao, X.; Stone, P. A lifelong learning approach to mobile robot navigation. IEEE Robot. Autom. Lett. 2021, 6, 1090–1096. [Google Scholar] [CrossRef]
- Liu, Z.; Zhai, Y.; Li, J.; Wang, G.; Miao, Y.; Wang, H. Graph Relational Reinforcement Learning for Mobile Robot Navigation in Large-Scale Crowded Environments. IEEE Trans. Intell. Transp. Syst. 2023, 24, 8776–8787. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real-time loop closure in 2D LIDAR SLAM. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; IEEE: New York, NY, USA, 2016; pp. 1271–1278. [Google Scholar]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 4758–4765. [Google Scholar]
- Kim, G.; Kim, A. LT-mapper: A modular framework for lidar-based lifelong mapping. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 7995–8002. [Google Scholar]
- Wang, J.; Rünz, M.; Agapito, L. DSP-SLAM: Object oriented SLAM with deep shape priors. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; IEEE: New York, NY, USA, 2021; pp. 1362–1371. [Google Scholar]
- Yue, J.; Wen, W.; Han, J.; Hsu, L.T. LiDAR data enrichment using deep learning based on high-resolution image: An approach to achieve high-performance LiDAR SLAM using Low-cost LiDAR. arXiv 2020, arXiv:2008.03694. [Google Scholar]
- Taketomi, T.; Uchiyama, H.; Ikeda, S. Visual SLAM algorithms: A survey from 2010 to 2016. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 1–11. [Google Scholar] [CrossRef]
- Henein, M.; Zhang, J.; Mahony, R.; Ila, V. Dynamic SLAM: The need for speed. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 2123–2129. [Google Scholar]
- Helmberger, M.; Morin, K.; Berner, B.; Kumar, N.; Cioffi, G.; Scaramuzza, D. The hilti slam challenge dataset. IEEE Robot. Autom. Lett. 2022, 7, 7518–7525. [Google Scholar] [CrossRef]
- Bektaş, K.; Bozma, H.I. Apf-rl: Safe mapless navigation in unknown environments. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 7299–7305. [Google Scholar]
- Surmann, H.; Jestel, C.; Marchel, R.; Musberg, F.; Elhadj, H.; Ardani, M. Deep reinforcement learning for real autonomous mobile robot navigation in indoor environments. arXiv 2020, arXiv:2005.13857. [Google Scholar]
- Cimurs, R.; Suh, I.H.; Lee, J.H. Goal-driven autonomous exploration through deep reinforcement learning. IEEE Robot. Autom. Lett. 2021, 7, 730–737. [Google Scholar] [CrossRef]
- Marchesini, E.; Farinelli, A. Enhancing deep reinforcement learning approaches for multi-robot navigation via single-robot evolutionary policy search. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5525–5531. [Google Scholar]
- Lodel, M.; Brito, B.; Serra-Gómez, A.; Ferranti, L.; Babuška, R.; Alonso-Mora, J. Where to look next: Learning viewpoint recommendations for informative trajectory planning. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 4466–4472. [Google Scholar]
- Lee, K.; Kim, S.; Choi, J. Adaptive and Explainable Deployment of Navigation Skills via Hierarchical Deep Reinforcement Learning. arXiv 2023, arXiv:2305.19746. [Google Scholar]
- Dawood, M.; Dengler, N.; de Heuvel, J.; Bennewitz, M. Handling Sparse Rewards in Reinforcement Learning Using Model Predictive Control. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: New York, NY, USA, 2023; pp. 879–885. [Google Scholar]
- Cui, Y.; Lin, L.; Huang, X.; Zhang, D.; Wang, Y.; Jing, W.; Chen, J.; Xiong, R.; Wang, Y. Learning Observation-Based Certifiable Safe Policy for Decentralized Multi-Robot Navigation. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 5518–5524. [Google Scholar]
- Shen, Y.; Li, W.; Lin, M.C. Inverse reinforcement learning with hybrid-weight trust-region optimization and curriculum learning for autonomous maneuvering. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: New York, NY, USA, 2022; pp. 7421–7428. [Google Scholar]
- Xiong, Z.; Eappen, J.; Qureshi, A.H.; Jagannathan, S. Model-free neural lyapunov control for safe robot navigation. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; IEEE: New York, NY, USA, 2022; pp. 5572–5579. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Marchesini, E.; Farinelli, A. Discrete deep reinforcement learning for mapless navigation. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 10688–10694. [Google Scholar]
- Niu, H.; Ji, Z.; Arvin, F.; Lennox, B.; Yin, H.; Carrasco, J. Accelerated sim-to-real deep reinforcement learning: Learning collision avoidance from human player. In Proceedings of the 2021 IEEE/SICE International Symposium on System Integration (SII), Iwaki, Fukushima, Japan, 11–14 January 2021; IEEE: New York, NY, USA, 2021; pp. 144–149. [Google Scholar]
- Marzari, L.; Marchesini, E.; Farinelli, A. Online Safety Property Collection and Refinement for Safe Deep Reinforcement Learning in Mapless Navigation. arXiv 2023, arXiv:2302.06695. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | PEEMEF-DARC | GD | CROP | HYC-DDPG | PPO | DADDPG | DDPG |
|---|---|---|---|---|---|---|---|
| Environment-1 | 12.32 | 13.02 | 12.68 | 13.59 | 12.86 | 14.65 | - |
| Environment-2 | 13.56 | 13.95 | 14.14 | 14.87 | - | - | - |
| Environment-3 | 12.93 | 13.35 | 13.31 | 14.05 | 13.50 | 15.38 | - |
| Environment-4 | 13.24 | 14.05 | 14.01 | 15.11 | - | - | - |
| Environment | PEEMEF-DARC | GD | CROP | HYC-DDPG | PPO | DADDPG | DDPG |
|---|---|---|---|---|---|---|---|
| Environment-1 | 8.54 | 9.02 | 8.86 | 9.25 | 8.95 | 9.85 | - |
| Environment-2 | 15.68 | 15.89 | 16.62 | 16.54 | - | - | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, N.; Yang, Z.; Bu, C.; Fan, X.; Wu, J.; Sui, Y.; Que, W. Learning Autonomous Navigation in Unmapped and Unknown Environments. Sensors 2024, 24, 5925. https://doi.org/10.3390/s24185925
He N, Yang Z, Bu C, Fan X, Wu J, Sui Y, Que W. Learning Autonomous Navigation in Unmapped and Unknown Environments. Sensors. 2024; 24(18):5925. https://doi.org/10.3390/s24185925
Chicago/Turabian StyleHe, Naifeng, Zhong Yang, Chunguang Bu, Xiaoliang Fan, Jiying Wu, Yaoyu Sui, and Wenqiang Que. 2024. "Learning Autonomous Navigation in Unmapped and Unknown Environments" Sensors 24, no. 18: 5925. https://doi.org/10.3390/s24185925
APA StyleHe, N., Yang, Z., Bu, C., Fan, X., Wu, J., Sui, Y., & Que, W. (2024). Learning Autonomous Navigation in Unmapped and Unknown Environments. Sensors, 24(18), 5925. https://doi.org/10.3390/s24185925