1. Introduction
Measuring total losses in electricity distribution, resulting from the difference between energy injected into the distributor’s grid and energy actually supplied to regulated consumers, excluding energy allocated to free consumers, is an inherent challenge throughout the transformation, transport, and distribution process of this vital resource. When these losses reach significant levels, they impose additional demand, ultimately burdening regulated consumers for electricity generation. In general, the long-term marginal cost of generation is substantially higher than investments associated with reducing distribution losses [
1]. Therefore, it is the responsibility of sector stakeholders to minimize these losses in order to optimize system efficiency and, consequently, provide benefits to society.
Non-technical losses (NTLs) in electricity distribution refer to a portion of total losses unrelated to technical factors during energy supply to consumer units. These losses are defined as the energy consumed by clients that are not billed by the utility [
2]. They encompass issues such as theft, measurement inaccuracies, billing process issues, and the absence of metering equipment [
3]. They can be categorized into three main components: commercial losses, related to measurement failures in regular consumer units; losses due to consumption from inaccessible clandestine connections, caused by unauthorized energy consumption without a formal contract, especially in restricted areas; and other technical losses, which are indirectly caused by NTL and are pragmatically considered part of the former [
4,
5].
NTL stemming from theft, fraud, reading errors, measurement inaccuracies, and billing discrepancies, are observed globally, especially in countries with low socioeconomic indicators [
6,
7]. According to a report by ANEEL [
1], in 2020, the total amount of NTL across all Brazilian electric sector concessionaires amounted to BRL 8.4 billion. Several studies have documented the diverse impacts of NTL, with the primary concern being revenue loss, often resulting in utility companies transferring these costs to end consumers through tariffs [
8,
9]. Brazil’s vast expanse poses challenges for field surveillance. The electric distribution company Light serves approximately 4.5 million consumer units (CUs), indicating a high population density concentrated in urban areas, thus presenting a significant opportunity for optimizing field inspection team deployment.
These losses result in significant revenue reductions and adversely impact grid reliability [
8,
10]. NTL can overload transformers, thereby affecting the overall operation of the power system. Additionally, they compromise the quality of electricity supply, leading to issues such as voltage violations, infrastructure damage, blackout risks, and potential threats to public safety [
8,
9,
10,
11,
12,
13]. Consequently, reducing NTLs will also decrease the physical losses within the grid [
14]. Furthermore, the costs associated with on-field inspections to recover these losses must be considered. The low effectiveness of these inspections can further escalate the costs related to NTL. Therefore, it is crucial for utilities to improve their strategies in this area and enhance the success rate of future on-field inspections to effectively recover revenue losses [
2].
With recent technological advancements, modern techniques for detecting buildings and urban areas can lead to results with a high degree of accuracy. Rule-based methods utilize various properties of buildings, such as geometric, spectral, textural, contextual, and vertical characteristics, to identify them in images [
15]. In contrast, image segmentation methods partition the scene into non-overlapping segments and identify buildings as objects of interest. These techniques can achieve satisfactory results with moderate manual input [
16,
17].
Building upon the aforementioned, this study proposes the development of an orbital monitoring system for urban area segmentation in Sentinel-2 satellite images, focusing specifically on regions of Brazil. By analyzing images and geospatial data, we employ computer vision techniques and machine learning algorithms to achieve this objective. The automated delineation of urban areas enables energy companies to prioritize surveillance efforts in regions with a higher risk of theft, thereby optimizing resource allocation and enhancing efficiency in combating energy theft.
The concession area considered in the research exhibits significant economic heterogeneity and encompasses high-risk regions, which complicates the provision, maintenance, and operation of the electricity supply service by operational teams. These regions are designated as areas with severe operating restrictions (ASROs) [
18].
The proposed method has applicability in various fields of study, such as urban planning, deforestation monitoring, and monitoring the growth of urban areas, which is the focus of this work. Therefore, we highlight the following contributions:
An automatic computational method for identifying irregularities in urban areas; and
A method based on public data, capable of directing the efforts of energy companies to combat NTL, by identifying possible irregular areas, including ASROs.
The subsequent structure of this work is outlined as follows: In
Section 1, we contextualize the present study in relation to related works.
Section 2 details the developed methodology, while
Section 3 and
Section 4 present and discuss both quantitative and qualitative results. We conclude the work in
Section 5 with conclusions and suggestions for possible future work. Significantly, the method shows promise, demonstrating efficient performance in new regions and successfully generalizing to unexplored areas. It effectively identifies urban regions and, consequently, images beyond the coverage area of the electric distribution company, indicating potential irregularities.
Related Works
To provide a comprehensive overview of the evolution of methods developed for this purpose, we will present related works to the topic addressed in this research. Land cover classification is commonly addressed as a task of pixel categorization in the remote sensing community [
19].
In the method developed by [
20], the authors employed a hybrid Convolutional Neural Network (CNN) model to classify land cover using Landsat 8 images, achieving an overall accuracy of 92.5%. Similarly, ref. [
21] utilized a U-Net architecture to classify high-resolution remote sensing data, achieving an overall accuracy of 94.6%. In a separate investigation, ref. [
22] utilized a methodology based on Deep Learning (DL) to conduct land cover classification using Sentinel-2 satellite data, resulting in an overall accuracy of 97.8%.
In the study proposed by [
23], a multitask-learning framework for classifying urban land cover was proposed, employing high-resolution images, achieving an overall accuracy of 91.3%. Meanwhile, in the study proposed by [
24], a DL-based method is utilized to detect changes in land cover from multi-temporal Landsat 8 data, achieving an overall accuracy of 96.7%.
Traditional machine learning classifiers such as decision tree (DT), support vector machine (SVM), and random forest (RF) have been employed for land cover classification [
25]. Comparative studies have highlighted the superiority of DL-based approaches over traditional machine learning methods in terms of accuracy [
22,
25], achieving the highest overall accuracy of 97.8% for Sentinel-2 data. These approaches encompass a variety of DL architectures, including CNNs, deep belief networks, and attention-based models.
Land cover analysis is commonly conducted through remote sensing, where data such as satellite images play a central role. This approach enables monitoring changes in land cover, but the accuracy of the results is subject to variables such as the type of sensor used, image resolution, and classification algorithm employed.
The implementation of DL techniques represents a remarkable advancement in the effectiveness and quality of region monitoring, providing highly accurate classifications across various datasets and scenarios. These innovative approaches stand out for their contribution to enhancing environmental monitoring, resource management, and disaster prevention. However, it is important to note that these methods require substantial computational resources and comprehensive training datasets. In this context, to mitigate the challenge of large databases, the present research focuses on investigating the U-Net, exploring various synthetic data augmentation operations and diverse encoders. Thus, optimizing hardware resources with the combination of hyperparameters that results in a robust and versatile method.
Our approach introduces an orbital monitoring system that utilizes Sentinel-2 satellite imagery for the automated segmentation of urban areas, specifically tailored to regions in Brazil. By integrating computer vision techniques and machine learning algorithms, we aim to enhance surveillance capabilities and prioritize resource allocation in areas prone to NTL. This methodology facilitates the identification of irregularities, such as energy theft and unauthorized connections, and also optimizes operational efficiencies for electric distribution companies. Thus, our study aims to contribute to the mitigation of NTL, thereby improving overall grid reliability and reducing financial burdens on regulated consumers.
3. Results
We will provide a detailed presentation of the results obtained through the application of the proposed methodology (
Section 2). All experiments were conducted using hardware with the following specifications: 62 GB RAM, NVIDIA RTX A5000 24 GB, and Intel(R) Xeon(R) Gold 6240R CPU 2.40 GHz
3.1. Definition of the Base Model
To initiate the training of the U-Net, numerous experiments were undertaken to establish the initial configuration and optimize hardware utilization. For model training, we only used the following classes: dense built-up (1), sparse built-up (2), specialized built-up areas (3), specialized but vegetative areas (4), and large-scale networks (5), as they contain the necessary information for the model to specialize in detecting urban areas. These subclasses were combined to form a single class (urban area). It is worth noting that our segmentation network has only two classes: “urban area” and “non-urban area”. Additionally, images from the MultiSenGE dataset were randomly split into 70% for training, 15% for testing, and 15% for validation.
The strategy initially involved defining the basic hyperparameters. In this regard, we attempted to determine the learning rate (LR) and the loss function (LF) that exhibited the best performance in our testing scenario.
Learning rate (LR):
- −
.
- −
.
Loss function (LF):
- −
Dice loss.
- −
Cross-entropy loss with and without weights.
- −
BCE With logit loss.
Due to the large number of possible experiments, a batch size (BS) of 64 was set. Another factor influencing processing time directly is the number of epochs. Therefore, we chose to run 50 epochs per experiment. We determined the optimal number of epochs through prior experimentation. The optimizer used was Adamax, with a scheduler with a weight decay set at 0.001 and a patience of 15 epochs. The bands used were corresponding to red, blue, and green (RGB). Finally, initial augmentations were applied, such as vertical and horizontal flips.
Table 1 presents a summary of the metrics achieved in this testing phase, which aided in defining the hyperparameters for subsequent experiments.
As shown in
Table 1, based on the IoU metric, the best result was achieved for the cross-entropy loss function, with an LR of
.
Figure 7 presents random results obtained for the initial batch of the test set.
As depicted in
Figure 7, several errors are noticeable, highlighting the necessity for improved outcomes. Specifically, while the segmentation network effectively delineates the urban area located closer to the center, it demonstrates limitations in accurately detecting the more peripheral urban regions. This discrepancy suggests a need for refinement in the segmentation model. Initially, we considered all subcategories of “Urban Areas”, encompassing “Dense Built-Up”, “Sparse Built-Up”, “Specialized Built-Up Areas”, “Specialized but Vegetative Areas”, and “Large-Scale Networks”. However, through a thorough examination and numerous tests, we recognized the potential for more promising results by concentrating solely on the categories of “Dense Built-Up”, “Sparse Built-Up”, and “Specialized Built-Up Areas”, which denote significant urban areas. This determination stemmed from empirical observations and previous experiments.
We repeated the experiment using only these three categories, as mentioned in [
28]. Among the top-performing results highlighted in
Table 1, employing the cross-entropy loss function and a learning rate of
exhibited the best performance. This led to improvements in the numerical outcomes, as demonstrated in
Table 2.
Figure 8 presents some visual results for the experiment described.
After defining the best hyperparameters (LR: ; LF: CrossEntropyLoss; using the standard ResNet18 encoder), further experiments were conducted. We detail each of them as follows:
Augmentations using only spatial-level transforms.
- −
Vertical flip (already used).
- −
Horizontal flip (already used).
- −
Random cropping.
Augmentations using only pixel-level transforms.
- −
Blurring.
- −
Channel shuffling.
- −
Random brightness and contrast adjustment.
All augmentation operations combined.
Table 3 presents the results of this set of experiments.
Table 3 reveals that the outcomes from alternative data augmentation approaches did not yield significant positive effects, as evidenced by the absence of improvement in the results. Consequently, we proceeded with training using exclusively spatial augmentation operations. Among the considerations, we emphasize the inadequacy of the chosen augmentation techniques for the specific problem context, the potential introduction of noise or undesired distortions in the images during the augmentation process, or the mismatch between the selected techniques and the problem’s inherent nature. These factors may hinder the augmentation operations from enhancing the model’s generalization capacity, thereby resulting in a lack of improvements in the outcomes.
After presenting the outline earlier, we conducted additional experiments involving various combinations of bands. These experiments were conducted considering the following band variations:
Table 4 presents the results of these band combinations.
Based on the results presented in
Table 4, we note that, up to this point, there have been no significant performance improvements compared to previous experiments. Specifically, the IoU metric considered the most relevant indicator, did not show a significant improvement compared to the best result previously achieved. Given this finding, we have decided to maintain the experimental settings that provided the best performance so far: a learning rate (LR) of
and a loss function (LF) of cross-entropy loss, as illustrated in
Figure 8.
The remaining experiments continue using the U-Net with different encoders (ResNet, EfficientNet, and Mix-vision-transform). In
Table 5, we present the corresponding values.
Finally, after analyzing the experiments detailed in
Table 5, where we evaluated the performance of the U-Net combined with various encoders, we chose to select the combination that yielded the best results for each one, bearing in mind that the ResNet18 encoder has already been tested in the initial experiments, as it is the default encoder:
- -
ResNet18
- -
ResNet34
- -
Mix-vision-transform-b3
Statistical Tests
To validate the choice of model hyperparameters, we opted to perform two statistical tests. First, a one-way ANOVA [
37] (
Table 6) to compare the different loss functions, i.e., Dice, CE, BCE, and CE wgt for a fixed LR of
. This test will determine if there are significant differences in performance metrics (Acc, F1, IoU, and ) between the loss functions. Next, we performed an independent samples
t-test [
38] (
Table 7) to compare learning rates of
and
, using the CE loss function, to verify if a specific learning rate provides better performance. We chose to perform these two tests because they are fundamental choices that were used throughout the methodology and were established at the beginning of the experiment.
The results presented in
Table 6 show significant differences in the performance metrics Acc, F1, IoU, precision, and recall among the different loss functions when the learning rate is fixed at
. To account for multiple comparisons, the Bonferroni correction [
39] was applied. All adjusted
p-values remain below the standard significance level of 0.05, confirming the statistical significance of these differences.
The
t-test results (
Table 7) indicate significant differences in the performance metrics Acc, F1, IoU, precision, and recall between the two learning rates of
and
, using the CE loss function. For Acc, precision, and recall, the
p-values are lower than the standard significance level of 0.05, indicating that the differences are statistically significant, with a learning rate of
showing superior performance. For F1 and IoU, the
p-values are slightly higher than 0.05, suggesting that the differences are nearly significant, still indicating a trend of better performance for the
learning rate.
In conclusion, both tests affirm the superior performance of using the CE loss function with LR of across a range of evaluation metrics.
3.2. Results of the U-Net Applied to the Rio de Janeiro Region
After defining the necessary hyperparameters for model construction, we evaluated them in the ROI defined in
Section 2.1.1 (
Figure 2), namely, for the Rio de Janeiro region. Specifically, a subset of images corresponding to 2232 images from 22 July 2023, was chosen due to the absence of cloud cover in the ROI.
Table 8 presents the results of the different combinations of encoders considered.
When applying the U-Net trained on the MultiSenGE dataset to the region of Rio de Janeiro, we observe promising results, with IoU scores exceeding 88% for the test image set. It is noteworthy that the U-Net was originally trained using data from France (MultiSenGE) and has now been applied to a different geographical area (Rio de Janeiro, Brazil). This scenario facilitates the evaluation of the model’s generalization capacity across diverse geographic contexts.
In
Figure 9, we display the outcome of the network for the ROI. As can be seen, the numbers presented in
Table 8 corroborate the qualitative outcome of the proposed methodology.
3.3. Results of Urban Area Segmentation versus BDGD
In this section, we investigate the relationship between urban area segmentation data and coverage information provided by the electric distribution company in the BDGD repository. Initially, we present the coverage area of the electric distribution company based on BDGD data for the ROI with a 100 m buffer.
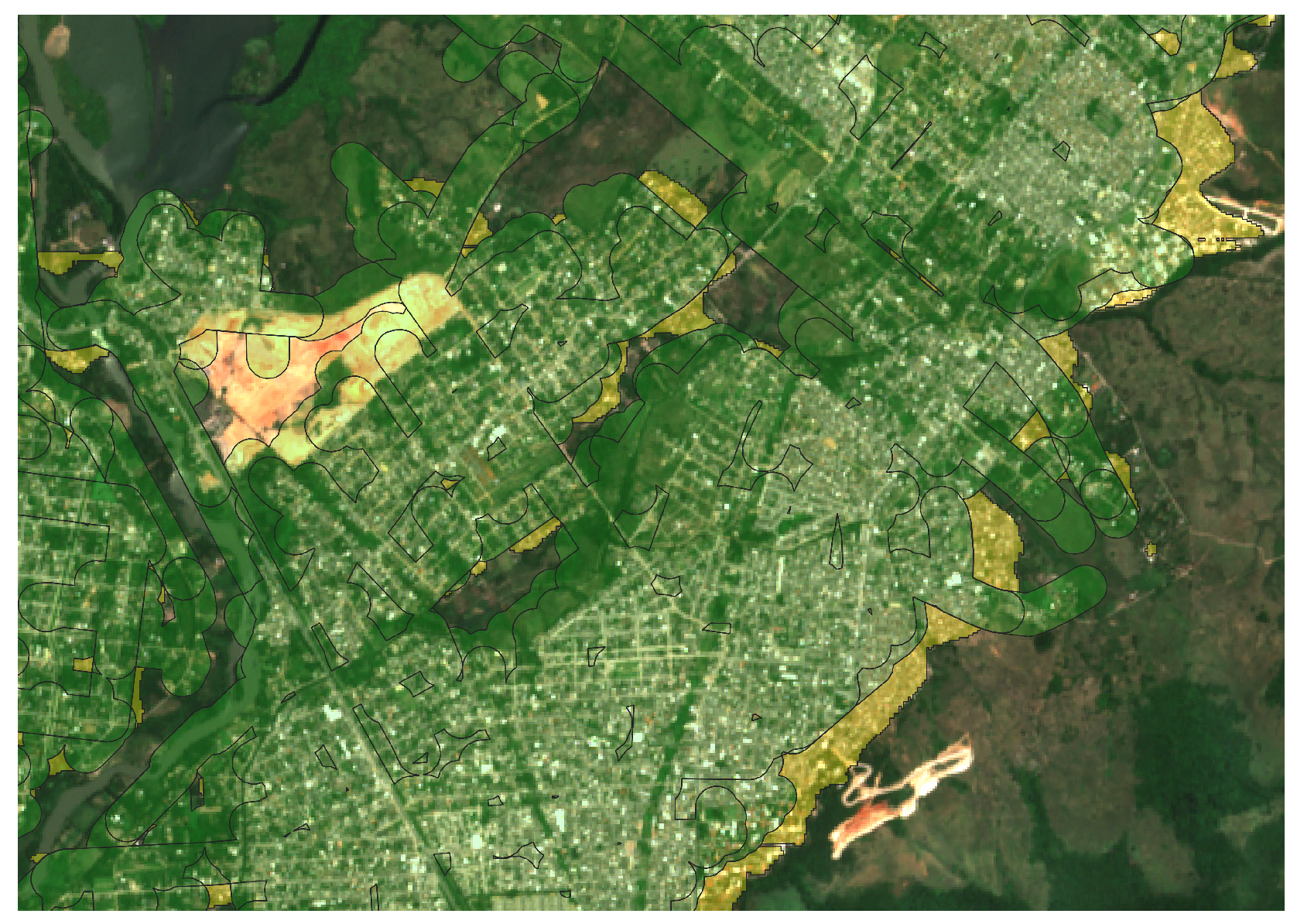
In
Figure 10, it is possible to observe the area segmented by the model proposed in the methodology advocated here (in red), compared to the coverage area of the electric distribution company (in yellow).
To identify probable invasion areas, we conducted a subtraction between the region formed by the union of the medium and low voltage network coverages and the result of the proposed methodology. This procedure reveals the ‘excess’ area that requires further investigation by the electric distribution company. In
Figure 11, we can see the result for the entire region of interest.
As seen in
Figure 11, many red areas lie outside the coverage area provided by the electric distribution company; these regions are what our methodology characterizes as potential invasion areas.
3.4. Case Studies
To facilitate the understanding of the results and investigate potential areas suggestive of invasion, we conducted detailed case studies. In these case studies, a buffer zone of 100 m around the transmission and distribution lines was selected to represent the potentially covered area. There are clandestine connections within the buffer zone with a distance of less than 100 m to the power grid. Therefore, this method is more suitable for critical regions such as Rio de Janeiro. This choice ensures that only areas considerably distant from the coverage area are identified as potential invasion zones. Given their distance from the coverage area, these regions are more suspicious of being potential invasion areas. However, it is important to highlight that the chosen buffer value directly impacts the number of regions suggestive of irregularities. The smaller the buffer, the greater the number of identified regions. Therefore, this parameter can be adjusted according to the needs and characteristics of the location (areas with higher or lower urban concentration) of the analysis to be conducted.
In
Figure 12, we present an example of areas suggestive of invasion. The central point (approximate) is located at −22.845202, −43.531593, and the average area is 496,922.767
or
.
It is important to highlight that only the larger region (bounded by dashed lines) was considered for area calculation, but as can be seen, other regions also exhibit similar characteristics and require further analysis by the electric distribution company.
Continuing with the case studies, we now delve into the situation illustrated in
Figure 13. Upon analyzing the example, it becomes evident that the region in question exhibits highly suggestive characteristics of invasion, as its growth extends toward the peripheral area.
Lastly,
Figure 14 illustrates several areas exhibiting behavior suggestive of invasion.
5. Conclusions
The proposed method demonstrated promising results in urban area detection, both in the training and test datasets. The effectiveness was evidenced by quantitative results, with IoU scores exceeding 88% in the task of urban area segmentation, and by qualitative results from the presented case studies.
The cloud removal strategy using masks available in the SCL allowed for a more thorough analysis, facilitating a more precise and reliable assessment of urban areas. This approach ensured more consistent and informative results.
In the context of constructing the test dataset, the use of masks available in OpenStreetMap as a form of pre-annotation proved to be significant. This allowed for the demarcation of areas independent of location, although some corrections are necessary due to the collaborative nature of the annotations in OpenStreetMap.
Apart from the promising segmentation results, the method proved to be generic, allowing training in one region of the world and successful application in another without the need for retraining. This generalization potential was confirmed through predictions in the Rio de Janeiro region.
The integration of different encoders in the U-Net approach, especially the use of a Vision Transformer-based encoder, enhanced precision in pixel classification during semantic segmentation, thanks to its ability to divide images into small “patches”.
The strategy employed for constructing the coverage area with BDGD data was crucial, covering different electric distribution companies and allowing the analysis of various regions in Brazil. The results obtained outside the coverage area of the electric distribution companies demonstrated that the method efficiently identifies regions with limited urban information, indicating possible irregularities. The case studies suggest that the identified areas are indeed invasion areas, which can have significant implications for the assessment and management of geographic risks.
Finally, the integration of this knowledge can increase the reliability and safety of energy infrastructure, contributing to the effective management of geological risks. Accurate identification of urban areas and irregularities is essential for land use planning and to ensure that energy distribution networks are resilient and adaptable to future challenges.
For future research aimed at enhancement, we propose:
Model refinement to mitigate false positives, by considering specific characteristics of airports, military areas, and public spaces.
Exploration of advanced image processing techniques to improve segmentation accuracy, particularly in challenging areas.
Investigation of alternative indicators or data sources to complement the identification of areas susceptible to invasions or NTL. This could include analyzing factors such as energy consumption patterns, payment behavior, historical outage data, population density, economic activity, community reports, and the urban growth rate of the region.
Assessment of the urban growth rate using the proposed methodology applied to past years’ data, providing insights into the expansion of urban areas and potential correlations with irregularities in energy consumption or distribution.
Utilization of machine learning techniques to predict NTL hotspots, enhancing the precision of identifying high-risk areas.
Integration of additional datasets to improve the understanding of urban energy consumption patterns, potentially including socio-economic data, climate data, and detailed infrastructure maps.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}