
Design and Implementation of Dongba Character Font Style Transfer Model Based on AFGAN


Abstract
1. Introduction
2. Related Works
2.1. Image Style Transfer
2.2. Font Style Transfer
2.3. Attention Mechanism
3. Materials and Methods
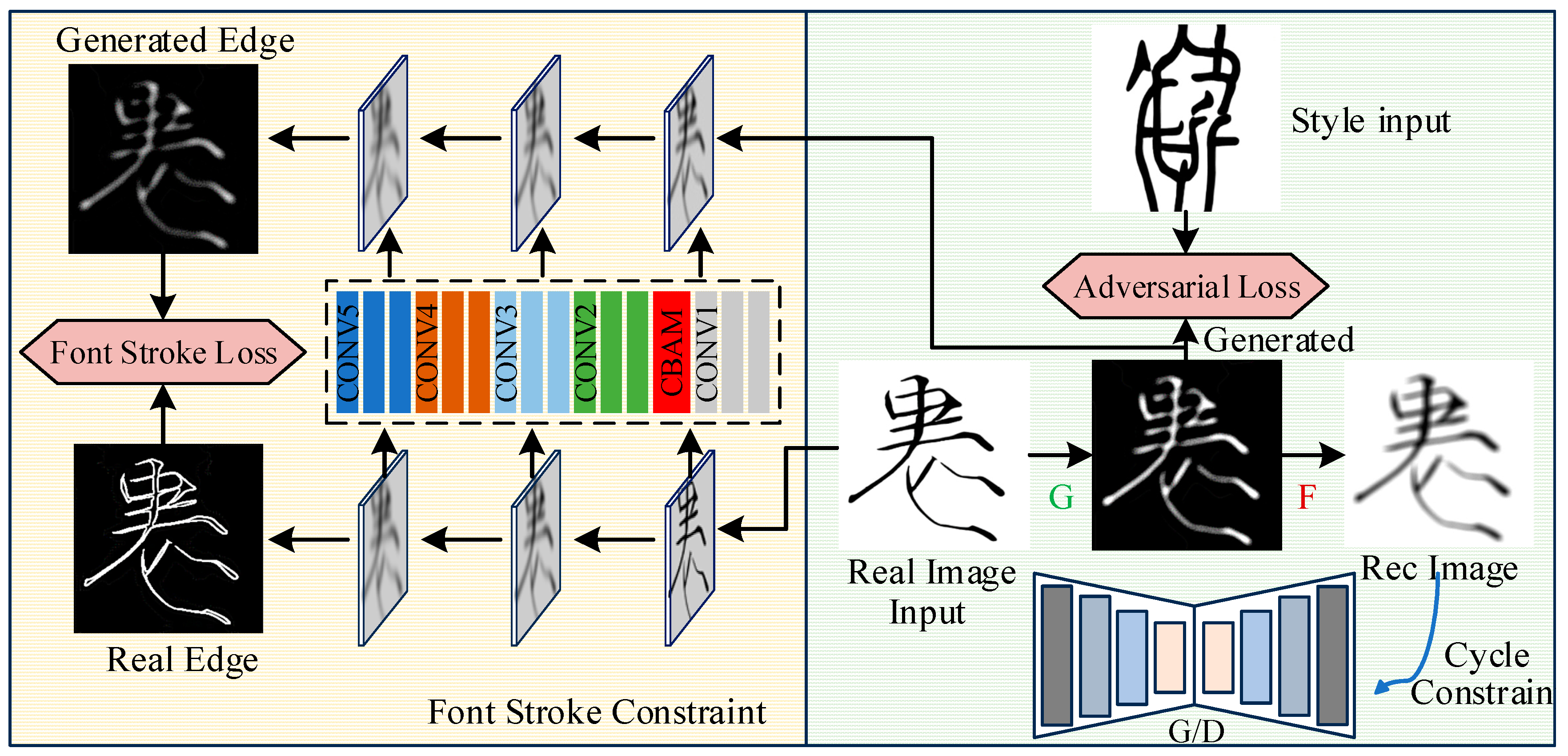
3.1. Structure of AFGAN
3.2. CBAM Mechanism
4. Experiment and Result Analysis
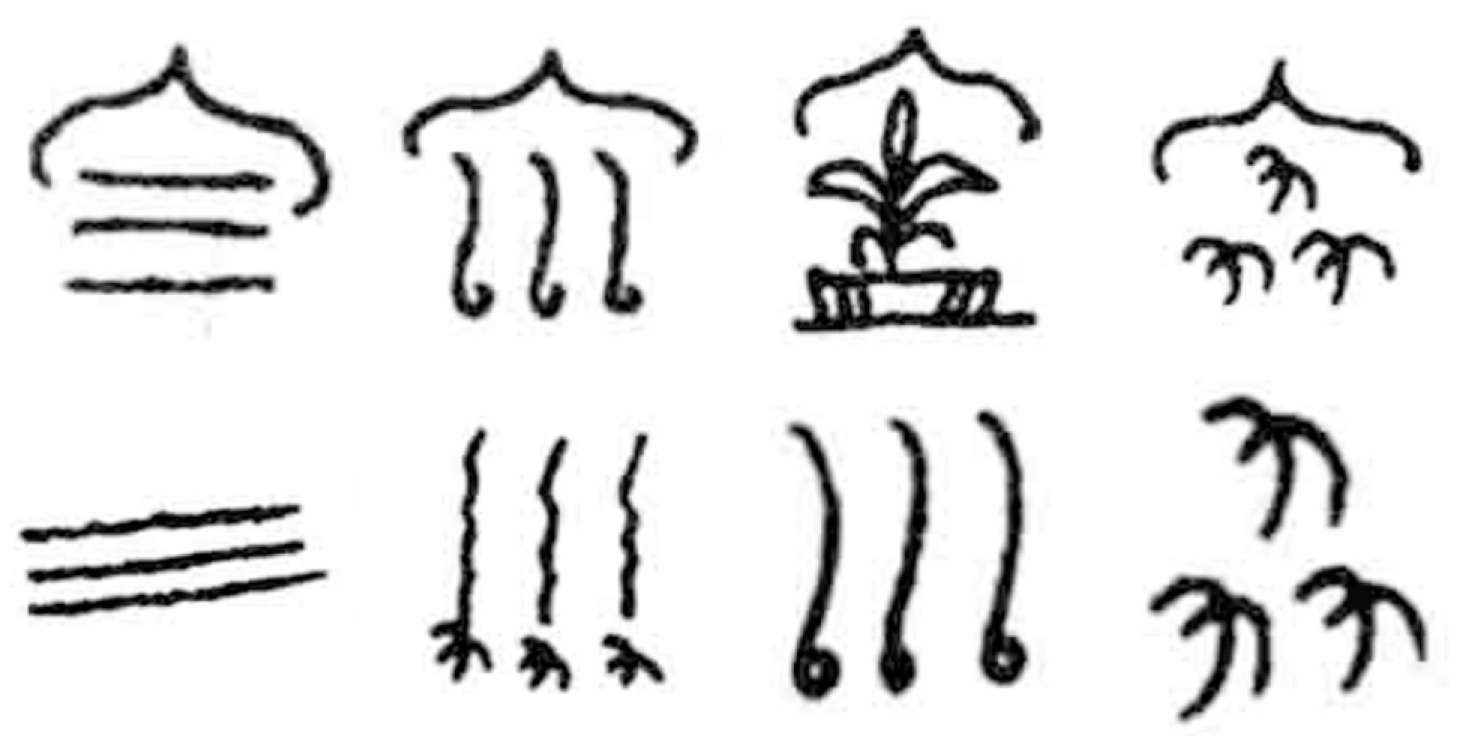
4.1. Experimental Dataset
4.2. Experimental Environment and Parameter Settings
4.3. Result Analysis
4.3.1. Quantitative Analysis
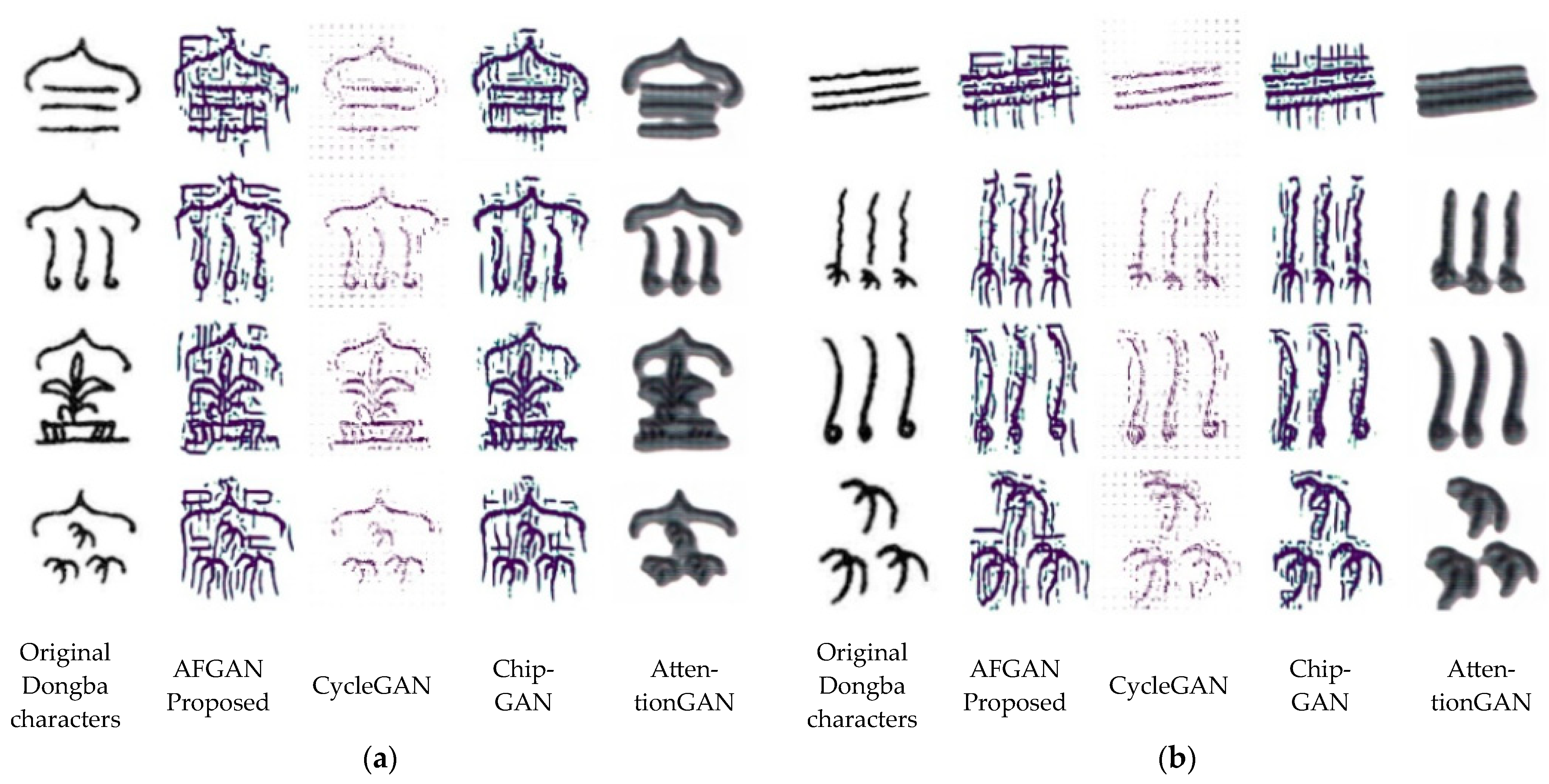
4.3.2. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Luo, Y.; Sun, Y.; Bi, X. Multiple attentional aggregation network for handwritten Dongba character recognition. Expert Syst. Appl. 2023, 213, 118865. [Google Scholar] [CrossRef]
- Zhang, Q.Y.; Huang, S.Y.; Zhou, X.B.; Xi, X.D. Application of Dongba characters in modern furniture design. Packag. Eng. 2020, 41, 213–217. [Google Scholar]
- Zhang, G.; Huang, W.; Chen, R.; Yang, J.; Peng, H. Calligraphic fonts generation based on generative adversarial network. ICIC Express Lett. Part B Appl. 2019, 10, 203–209. [Google Scholar]
- Shen, T.; Zhuang, J.; Wen, W. Research on recognition of Dongba script by a combination of HOG feature extraction and support vector machine. J. Nanjing Univ. (Nat. Sci.) 2020, 56, 870–876. [Google Scholar]
- Dong, J.; Xu, M.; Zhang, X.J.; Gao, Y.Q.; Pan, Y.H. The creation process of Chinese calligraphy and emulation of imagery thinking. IEEE Intell. Syst. 2008, 23, 56–62. [Google Scholar] [CrossRef]
- Dong, J.; Xu, M.; Pan, Y. Statistic model-based simulation on calligraphy creation. Chin. J. Comput. 2008, 23, 56–62. [Google Scholar] [CrossRef]
- Orbay, G.; Kara, L.B. Beautification of design sketches using trainable stroke clustering and curve fitting. IEEE Trans. Vis. Comput. Graph. 2011, 17, 694–708. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Adv. Neural Inf. Process. Syst. 2014, 27, 1–9. [Google Scholar] [CrossRef]
- Lu, E.; Zhao, Z.; Yin, J.; Luo, C.; Tian, Z. Trajectory learning and reproduction for tracked robot based on Bagging-GMM/HSMM. J. Electr. Eng. Technol. 2023, 18, 4441–4453. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- He, B.; Gao, F.; Ma, D.; Shi, B.; Duan, L.Y. ChipGAN: A generative adversarial network for Chinese ink wash painting style transfer. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1172–1180. [Google Scholar]
- Huang, Q.; Li, M.; Agustin, D.; Li, L.; Jha, M. A novel CNN model for classification of Chinese historical calligraphy styles in regular script font. Sensors 2023, 24, 197. [Google Scholar] [CrossRef]
- Lyu, P.; Bai, X.; Yao, C.; Zhu, Z.; Huang, T.; Liu, W. Auto-Encoder Guided GAN for Chinese Calligraphy Synthesis. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; pp. 1095–1100. [Google Scholar]
- Zhu, X.; Lin, M.; Wen, K.; Zhao, H.; Sun, X. Deep deformable artistic font style transfer. Electronics 2023, 12, 1561. [Google Scholar] [CrossRef]
- Chang, B.; Zhang, Q.; Pan, S.; Meng, L. Generating handwritten Chinese characters using CycleGAN. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Lake Tahoe, NV, USA, 12–15 March 2018; IEEE Computer Society Press: Los Alamitos, CA, USA, 2018; pp. 199–207. [Google Scholar]
- Chen, J.; Chen, H.; Xu, X.; Ji, Y.L.; Chen, L.J. Learning to write multi-stylized Chinese characters by generative adversarial networks. J. Univ. Electron. Sci. Technol. China 2019, 48, 674–678. [Google Scholar]
- Sun, D.Y.; Ren, T.Z.; Li, C.X.; Su, H.; Zhu, J. Learning to write stylized Chinese characters by reading a handful of examples. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; Margan Kaufmann: San Francisco, CA, USA, 2018; pp. 920–927. [Google Scholar]
- Yao, W.; Zhao, Z.; Pu, Y.; Xu, D.; Qian, W.; Wu, H. Cuan font generation model of dense adaptive generation adversarial network. J. Comput.-Aided Des. Comput. Graph. 2023, 35, 915–924. [Google Scholar]
- Li, J.; Gao, J.; Chen, J.; Wang, Y. Mongolian font style transfer model based on convolutional neural network. J. Inn. Mong. Agric. Univ. (Nat. Sci. Ed.) 2021, 42, 94–99. [Google Scholar]
- Li, C.; Taniguchi, Y.; Lu, M.; Konomi, S.; Nagahara, H. Cross-language font style transfer. Appl. Intell. 2023, 53, 18666–18680. [Google Scholar] [CrossRef]
- Hu, M.F. Research on the generation of handwritten Tangut character samples based on GAN. Master’s Thesis, Ningxia University, Yinchuan, China, 2021. [Google Scholar]
- Zhang, J.; Hou, Y. Image-to-image translation based on improved cycle-consistent generative adversarial network. J. Electron. Inf. Technol. 2020, 42, 1216–1222. [Google Scholar]
- Liu, M.Y.; Tuzel, O. Coupled generative adversarial networks. In Proceedings of the Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 1–29. [Google Scholar]
- Chen, Y.; Lai, Y.K.; Liu, Y.J. CartoonGAN: Generative adversarial networks for photo cartoonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9465–9474. [Google Scholar]
- Chen, J.; Liu, G.; Chen, X. AnimeGAN: A novel lightweight GAN for photo animation. In Proceedings of the 11th International Symposium, ISICA 2019, Guangzhou, China, 16–17 November 2019; pp. 242–256. [Google Scholar]
- Kim, Y.H.; Nam, S.H.; Hong, S.B.; Park, K.R. GRA-GAN: Generative adversarial network for image style transfer of gender, race, and age. Expert Syst. Appl. 2022, 198, 116792. [Google Scholar] [CrossRef]
- Way, D.-L.; Lo, C.-H.; Wei, Y.-H.; Shih, Z.-C. TwinGAN: Twin generative adversarial network for Chinese landscape painting style transfer. IEEE Access 2023, 11, 60844–60852. [Google Scholar] [CrossRef]
- Yan, H.; Zhang, H.; Shi, J.; Ma, J.; Xu, X.; Yan, H.; Zhang, H.; Shi, J.; Ma, J.; Xu, X. Inspiration transfer for intelligent design: A generative adversarial network with fashion attributes disentanglement. IEEE Trans. Consum. Electron. 2023, 69, 1152–1163. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Yu, D.; Fu, J.; Mei, T.; Rui, Y. Multi-level attention networks for visual question answering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4709–4717. [Google Scholar]
- Chen, X.; Xu, C.; Yang, X.; Tao, D. Attention-GAN for object transfiguration in wild images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 164–180. [Google Scholar]
- Yang, C.; Kim, T.; Wang, R.; Peng, H.; Kuo, C.-C.J. Show, attend, and translate: Unsupervised image translation with self-regularization and attention. IEEE Trans. Image Process. 2019, 28, 4845–4856. [Google Scholar] [CrossRef]
- Huo, X.; Jiang, B.; Hu, H.; Zhou, X.; Zhang, B. OSAGGAN: One-shot unsupervised image-to-image translation using attention-guided generative adversarial networks. Int. J. Mach. Learn. Cybern. 2023, 14, 3471–3482. [Google Scholar] [CrossRef]
- Tang, H.; Liu, H.; Xu, D.; Torr, P.H.S.; Sebe, N. AttentionGAN: Unpaired image-to-image translation using attention-guided generative adversarial networks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 1972–1987. [Google Scholar] [CrossRef] [PubMed]
- Yadav, N.K.; Singh, S.K.; Dubey, S.R. TVA-GAN: Attention guided generative adversarial network for thermal to visible image transformations. Neural Comput. Appl. 2023, 35, 19729–19749. [Google Scholar] [CrossRef]
- Zheng, X.; Yang, X.; Zhao, Q.; Zhang, H.; He, X.; Zhang, J.; Zhang, X. CFA-GAN: Cross fusion attention and frequency loss for image style transfer. Displays 2024, 81, 102588. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 1–17. [Google Scholar]
- Zhang, F.; Zhao, H.; Li, Y.; Wu, Y.; Sun, X. CBA-GAN: Cartoonization style transformation based on the convolutional attention module. Comput. Electr. Eng. 2023, 106, 108575. [Google Scholar] [CrossRef]
- Zhao, J.X. Translations of Everyday Words for Pictographs of Dongba Religion (Revised Edition); Yunnan People’s Publishing House: Kunming, China, 2011. [Google Scholar]
- Li, Z.; Qi, Y. An improved CycleGAN image style transfer algorithm. J. Beijing Inst. Graph. Commun. 2023, 31, 1–6. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software/Hardware | Version/Model |
|---|---|
| CPU | Intel Core i5-12500H (Santa Clara, CA, USA) |
| RAM | 16 G |
| GPU | Nvidia RTX3050 (Santa Clara, CA, USA) |
| Python | 3.7 |
| Pytorch-GPU | 1.7 |
| CUDA | 8.0 |
| CUDNN | 6.0 |
| Indicators | SSIM | MSE | PSNR | |
|---|---|---|---|---|
| Methods | ||||
| CycleGAN [10] | 0.256 ± 0.012 | 303.256 ± 7.35 | 22.875 ± 1.13 | |
| ChipGAN [11] | 0.389 ± 0.029 | 220.185 ± 6.09 | 25.032 ± 1.71 | |
| AttentionGAN [34] | 0.278 ± 0.098 | 414.256 ± 9.82 | 23.863 ± 2.95 | |
| Proposed AFGAN | 0.492 ± 0.011 | 210.663 ± 7.33 | 27.921 ± 1.77 | |
| Indicators | SSIM | MSE | PSNR | |
|---|---|---|---|---|
| Methods | ||||
| CycleGAN [10] | 0.262 ± 0.019 | 300.254 ± 8.19 | 22.081 ± 1.39 | |
| ChipGAN [11] | 0.385 ± 0.083 | 221.952 ± 7.83 | 24.653 ± 1.87 | |
| AttentionGAN [34] | 0.271 ± 0.035 | 418.235 ± 9.97 | 23.901 ± 3.62 | |
| Proposed AFGAN | 0.446 ± 0.026 | 210.632 ± 8.05 | 27.332 ± 1.99 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bao, C.; Li, Y.; Lu, E. Design and Implementation of Dongba Character Font Style Transfer Model Based on AFGAN. Sensors 2024, 24, 3424. https://doi.org/10.3390/s24113424
Bao C, Li Y, Lu E. Design and Implementation of Dongba Character Font Style Transfer Model Based on AFGAN. Sensors. 2024; 24(11):3424. https://doi.org/10.3390/s24113424
Chicago/Turabian StyleBao, Congwang, Yuan Li, and En Lu. 2024. "Design and Implementation of Dongba Character Font Style Transfer Model Based on AFGAN" Sensors 24, no. 11: 3424. https://doi.org/10.3390/s24113424
APA StyleBao, C., Li, Y., & Lu, E. (2024). Design and Implementation of Dongba Character Font Style Transfer Model Based on AFGAN. Sensors, 24(11), 3424. https://doi.org/10.3390/s24113424