

Implementation of Engagement Detection for Human–Robot Interaction in Complex Environments



Abstract
1. Introduction
- Four layers of HRI are proposed that organize behaviors between humans and robots and elucidate the significance of action and engagement.
- A robot cognitive system that empowers the robot to identify interactors in complex environments and provide suitable responses is constructed using existing learning-based models and the integration of an improved Hidden Markov Model (HMM).
- This paper also proposes the engagement comfort index and the naturalness index. The engagement comfort index is segmented into four stages of engagement to deduce the suitable moment to initiate a conversation based on head pose and eye movements. The naturalness index detects a user’s feedback, allowing the robot to take appropriate actions.
- To enhance the mobility and functionality of robots, we constructed a novel mobile robot equipped with hands and arms, demonstrating our framework’s efficacy and an authentic HRI sensation in complex environments.
2. Background
2.1. Human–Robot Interaction
- User-centric HRI. The objective of the interaction is to ensure a high-quality user experience by enabling robots to fulfill the desired objectives of humans.
- Robot-centric HRI. The interaction aims to design robots that can perceive, cognize and act effectively with their surroundings.
2.2. Engagement
- Eye gaze. Human beings do not maintain constant eye contact during face-to-face conversations, particularly at the beginning or end of an engagement. Each individual exhibits distinct behaviors while speaking, such as looking downward in contemplation or incorporating gestures.
- Action. Actions involve a human either handing over or receiving an item, which can be seen as maintaining engagement through physical activity. Throughout these processes, the focus is primarily on the object rather than the individual. Consequently, it is imperative to consider actions concurrently during the interaction.
- Head pose. Head poses serve as an approximation of eye gaze. When the target face is obscured, direct reception of messages from the eyes is not possible; instead, information is inferred from the head pose.
3. Robot Cognitive Architecture
3.1. Engagement Model
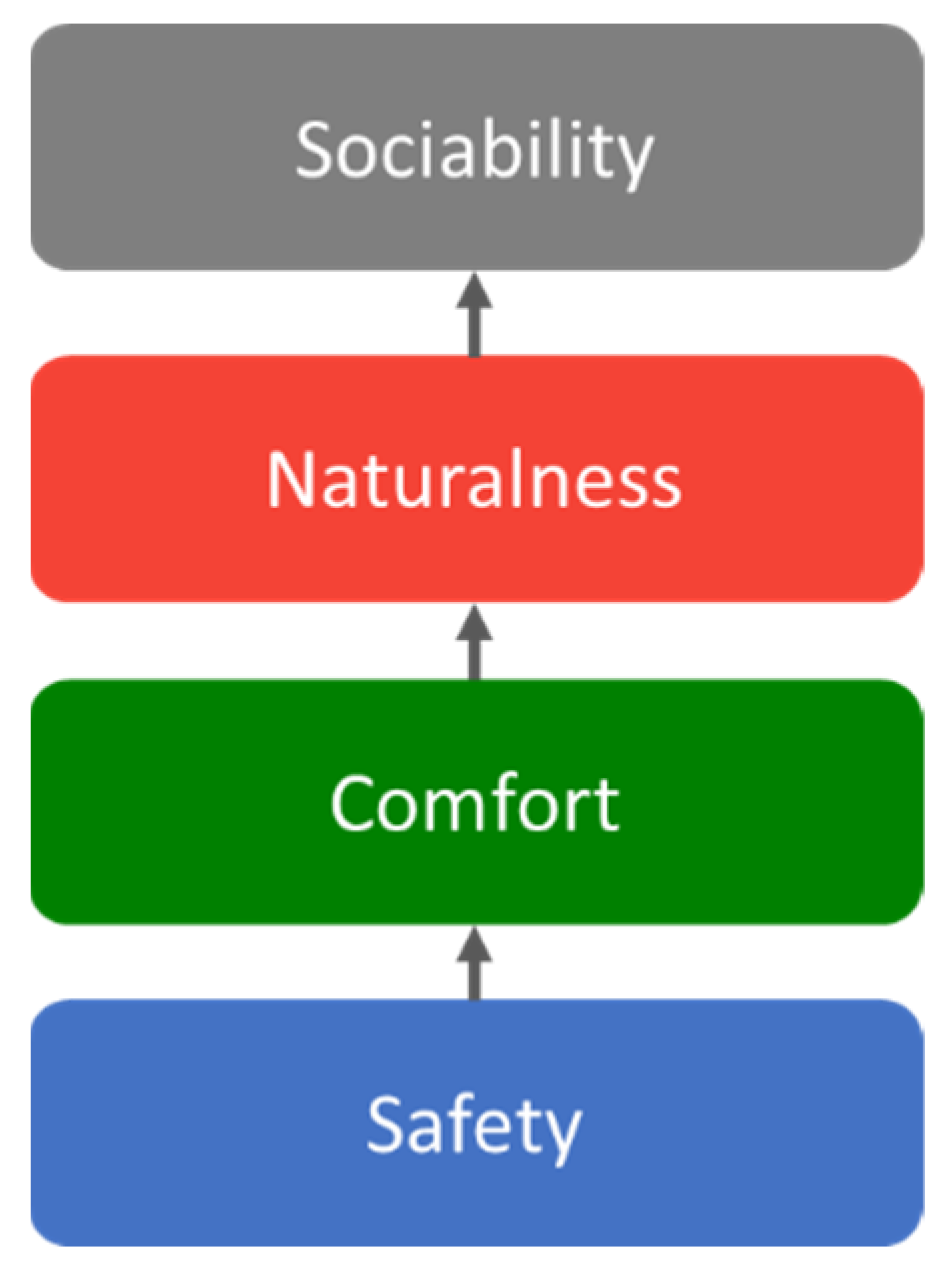
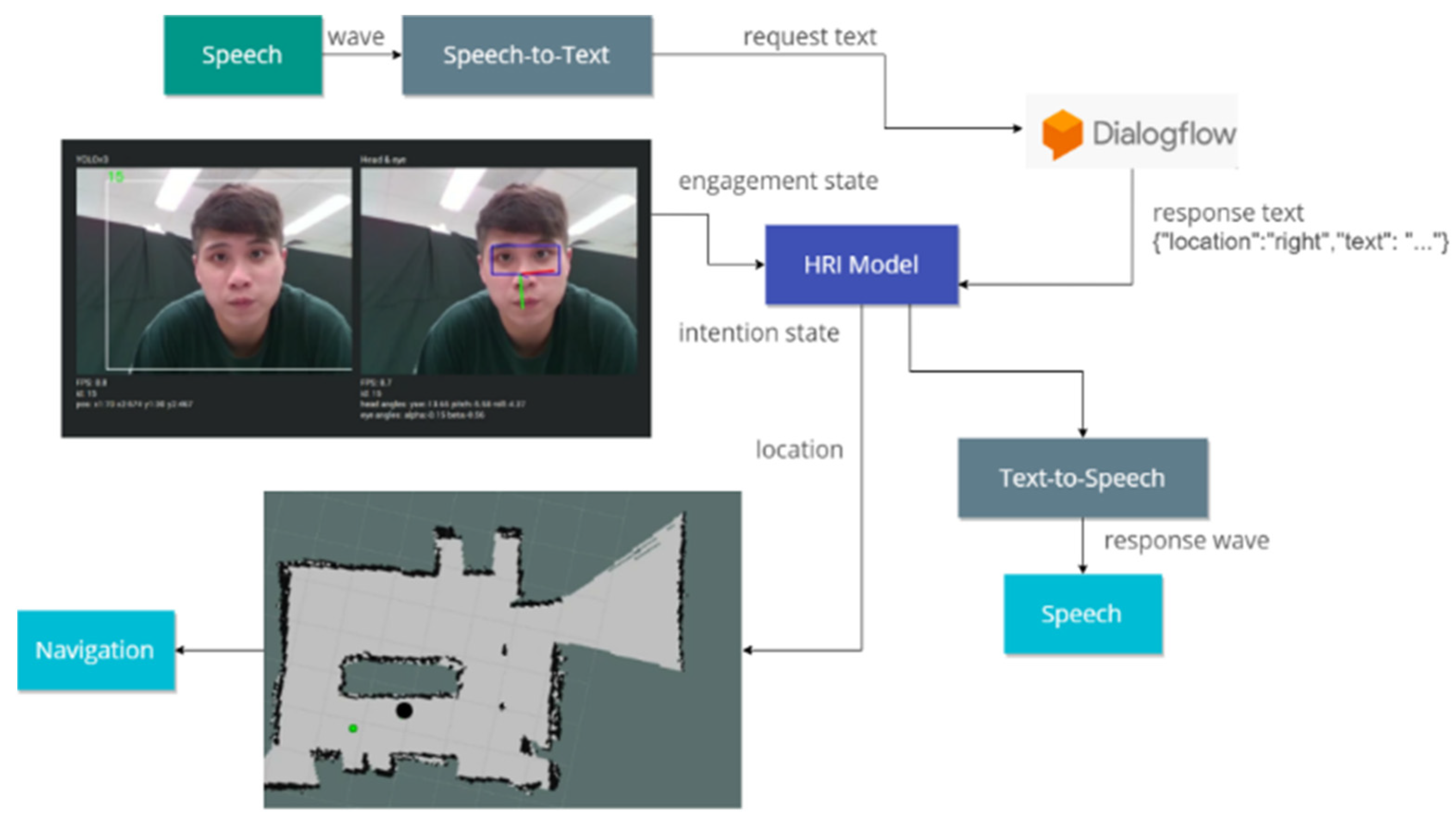
- People detector and face detector for head pose estimation and eye tracking. YOLOv3 is well known for recognizing objects from a complex background with robust performance. The model calculates the images and provides labels with bounding boxes (frame u, frame v, height, width). Before implementing the engagement model, raw images captured by the camera are initially fed into the YOLOv3 multiple people detection system to track each individual by dynamically allocating an identification (ID). Upon determining the location and ID of a person in the image, the face detection algorithm utilizing OpenCV-dlib is employed to extract the facial area. This is significant because YOLOv3 is capable of recognizing individuals even when they are not facing the camera. The face extractor must be integrated to determine whether it captures facial features in the given image. Subsequently, the extracted images are input into two models—head pose estimation and eye tracking—to obtain the angles. For detecting multiple individuals, FairMOT [33] is implemented within our architecture.
- Action recognition. The identification of engagement must be complemented by action, as certain behaviors, such as handshaking, are considered indicative of engagement. Therefore, to facilitate real-time action detection, the SlowFast model was incorporated into our engagement model.
- Engagement HMM. In the engagement HMM, the aforementioned results from each observation are input into the engagement model, which integrates both the sliding window and the moving average techniques. Based on the observations, this model subsequently decodes and predicts the most probable state.
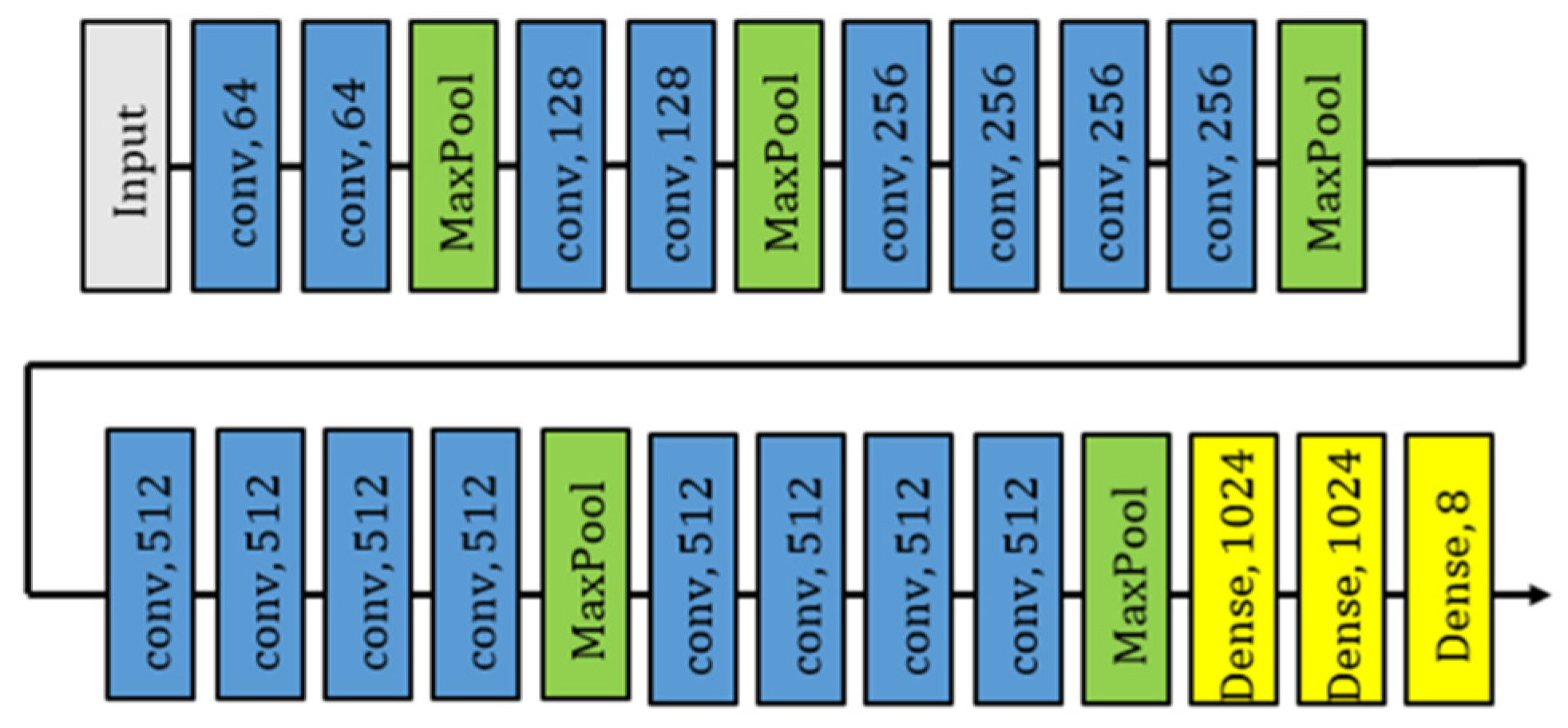
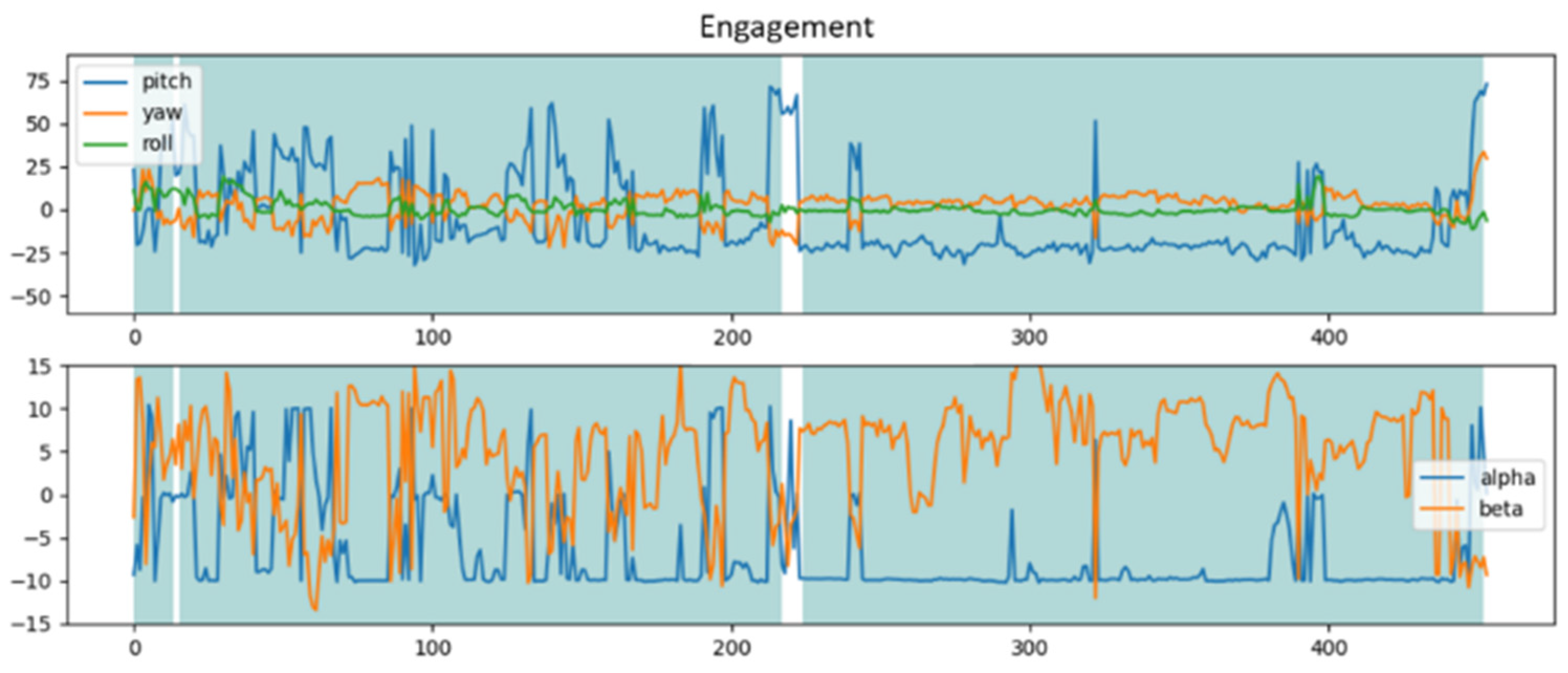
3.1.1. FSA-Net in Head Pose Estimation
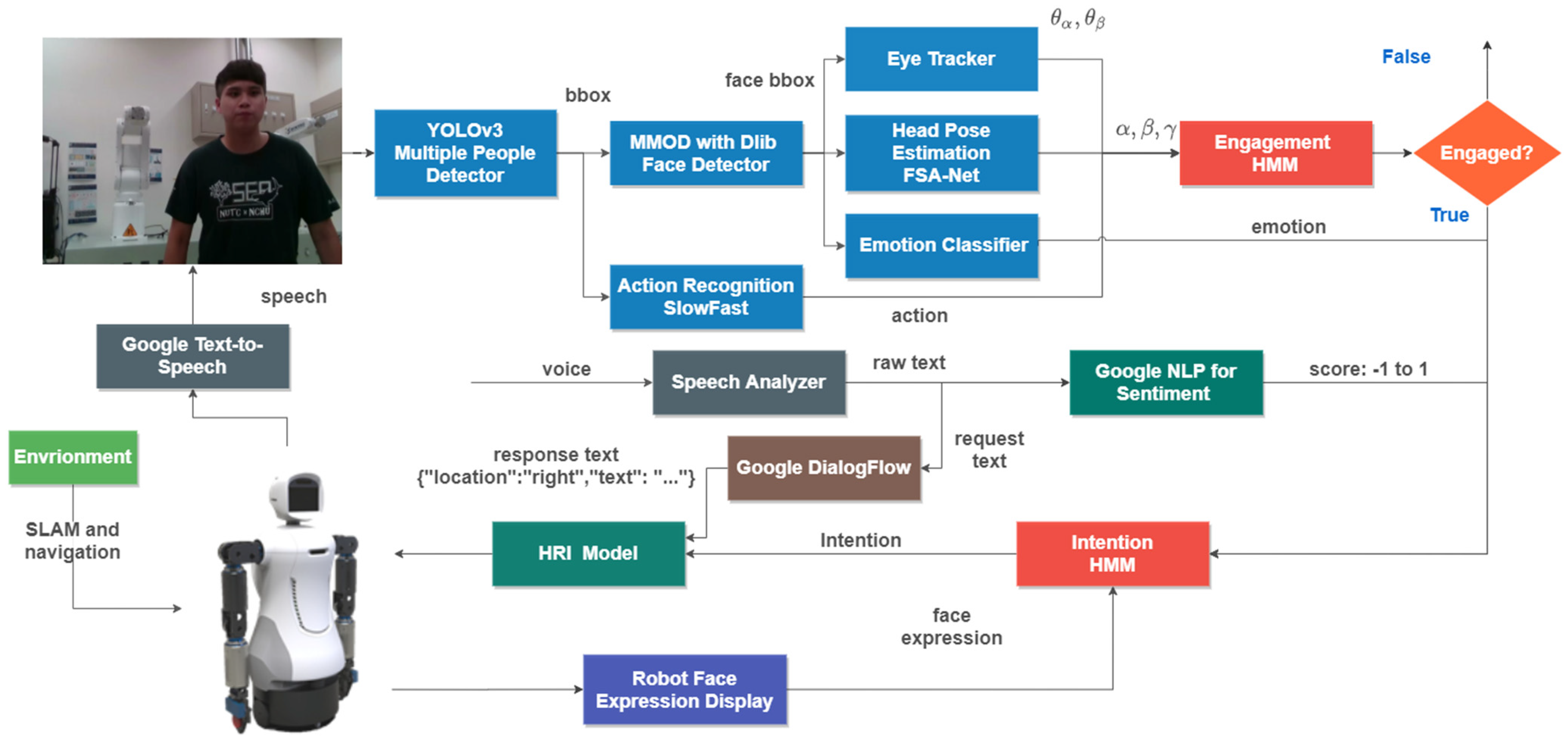
3.1.2. CNN-Based Eye Tracker
3.1.3. Action Recognition in Engagement
3.1.4. Engagement HMM
| Algorithm 1. Engagement HMM for Multiple People |
| Input: Result: new people list with new state struct : end struct
|
3.2. Intention Model
3.2.1. Emotion Classifier
3.2.2. Speech Analyzer and Google NLP Sentiment
3.2.3. Intention HMM
3.3. Human–Robot Interaction Model
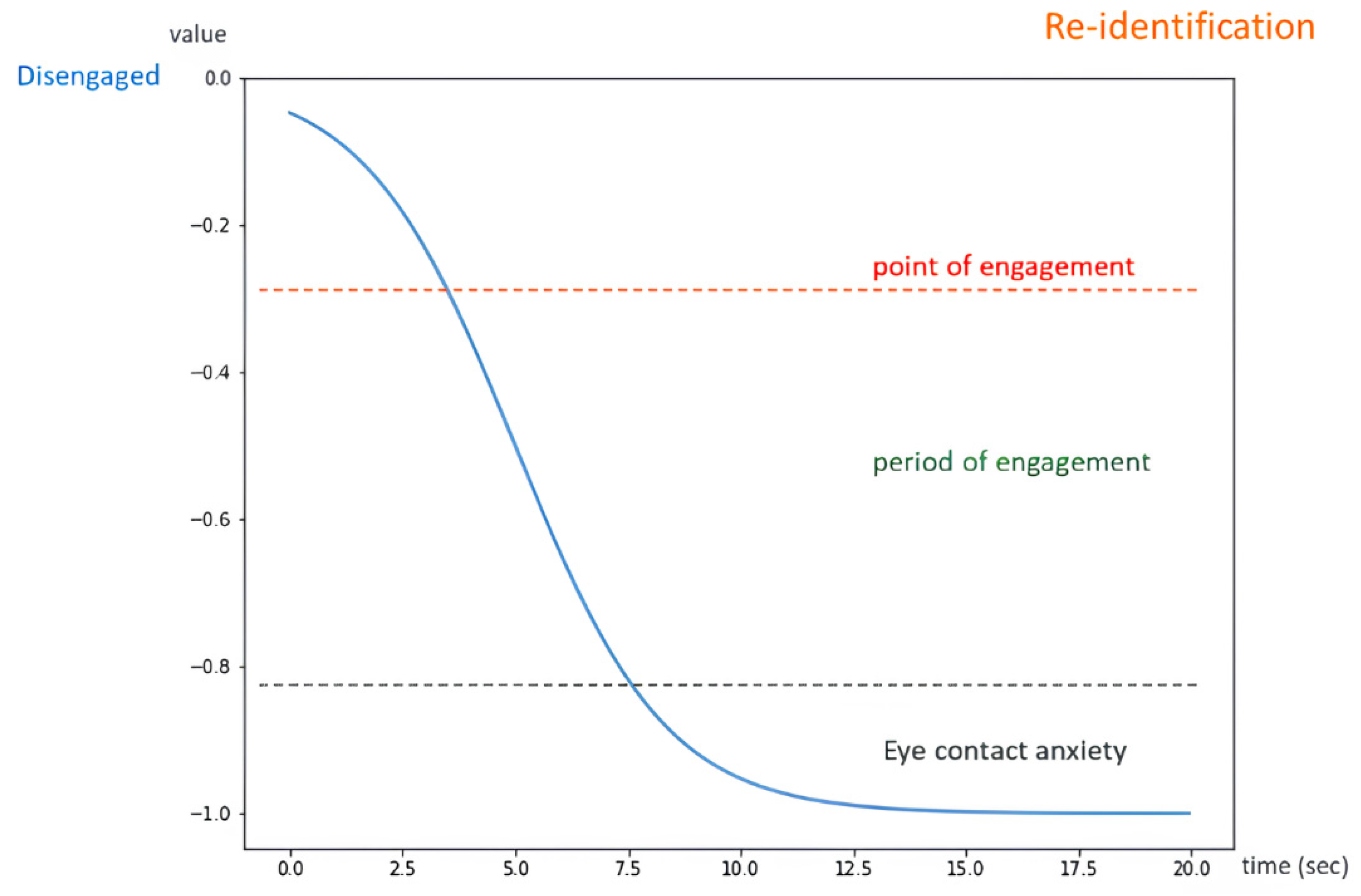
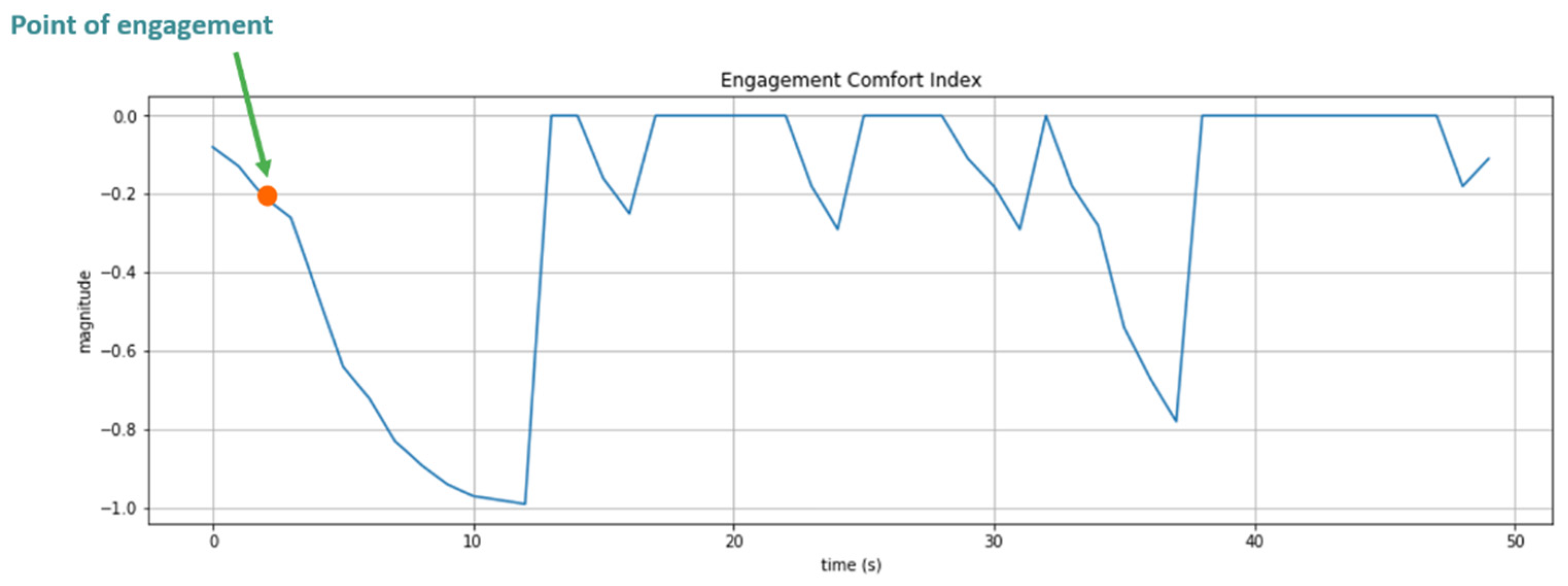
3.3.1. Engagement Comfort Index
3.3.2. Naturalness Index
4. Implementation
4.1. Scenario
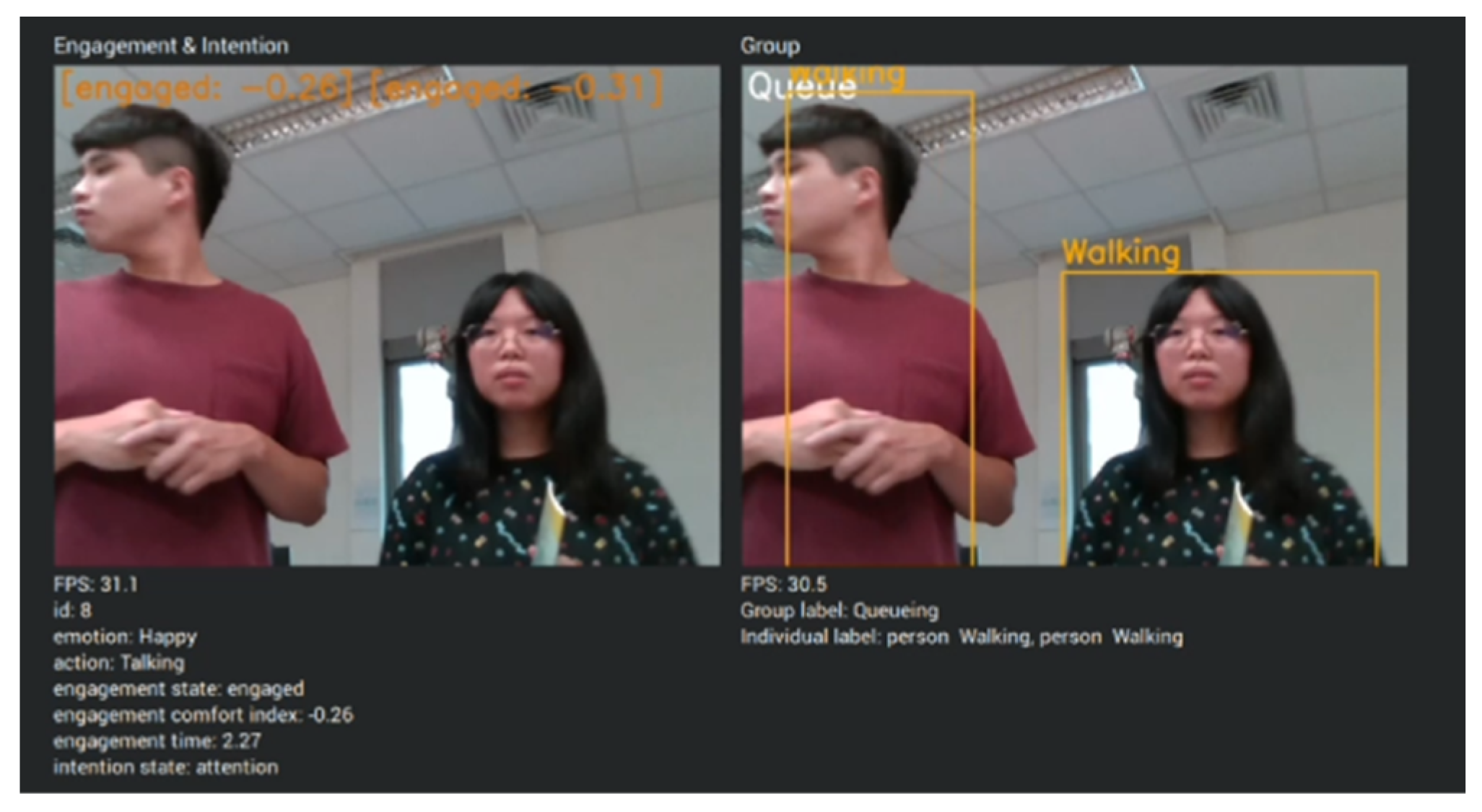
- Engagement and intention detection. To identify people in need of help in a complex environment, engagement and intention detection must be used in the system.
- Navigation and SLAM. The robot must know the overall environment and the location of obstacles in order to guide or lead guests.
- HRI design. To make sure the interaction is safe and smooth, HRI must be considered. For example, the walking speed of the robot must change dynamically depending on the environment or obstacles.
4.2. Engagement Model
4.3. Engagement Model Benchmark
| L’F’A’ | L’F’A | L’FA’ | L’FA | LF’A’ | LF’A | LFA’ | LFA | |||
| Disengagement | 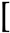 | 0.6 | 0.1 | 0.1 | 0 | 0.1 | 0.05 | 0.05 | 0 |  |
| Engagement | 0.0 | 0.05 | 0.1 | 0.1 | 0.05 | 0.1 | 0.3 | 0.3 |
| Engagement | ||||
| Disengagement | | | ||
| Engagement |
4.4. System Integration
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fraboni, F.; Brendel, H.; Pietrantonib, L.; Vidoni, R.; Dallasega, P.; Gualtieri, L. Updating Design Guidelines for Cognitive Ergonomics in Human-Centred Collaborative Robotics Applications: An Expert Survey. Appl. Ergon. 2024, 117, 104246. [Google Scholar]
- Moriuchi, E.; Murdy, S. The Role of Robots in the Service Industry: Factors Affecting Human-Robot Interactions. Int. J. Hosp. Manag. 2024, 118, 103682. [Google Scholar] [CrossRef]
- Abiodun Odesanmi, G.; Wang, Q.; Mai, J. Skill Learning Framework for Human–Robot Interaction and Manipulation Tasks. Robot. Comput.-Integr. Manuf. 2023, 79, 102444. [Google Scholar] [CrossRef]
- Li, C.; Zheng, P.; Yin, Y.; Pang, Y.M.; Huo, S. An AR-assisted Deep Reinforcement Learning-based approach towards mutual-cognitive safe human-robot interaction. Robot. Comput.-Integr. Manuf. 2023, 80, 102471. [Google Scholar] [CrossRef]
- Li, S.; Zheng, P.; Liu, S.; Wang, Z.; Wang, X.V.; Zheng, L.; Wang, L. Proactive Human-Robot Collaboration: Mutual-Cognitive, Predictable, and Self-Organising Perspectives. Robot. Comput.-Integr. Manuf. 2023, 81, 102510. [Google Scholar] [CrossRef]
- Liu, A.; Chen, T.; Zhu, H.; Fu, M.; Xu, J. Fuzzy Variable Impedance-Based Adaptive Neural Network Control in Physical Human–Robot Interaction. Proc. IMechE Part I J. Syst. Control Eng. 2023, 237, 220–230. [Google Scholar] [CrossRef]
- Liu, S.; Wang, L.; Gao, R.X. Cognitive neuroscience and robotics: Advancements and future research directions. Robot. Comput.-Integr. Manuf. 2024, 85, 102610. [Google Scholar] [CrossRef]
- Maroto-Gómez, M.; Marqués-Villaroya, S.; Castillo, J.C.; Castro-González, Á.; Malfaz, M. Active Learning Based on Computer Vision and Human–Robot Interaction for User Profiling and Behavior Personalization of an Autonomous Social Robot. Eng. Appl. Artif. Intell. 2023, 117, 105631. [Google Scholar] [CrossRef]
- Li, X.; Li, T.; Li, S.; Tian, B.; Ju, J.; Liu, T.; Liu, H. Learning Fusion Feature Representation for Garbage Image Classification Model in Human-Robot Interaction. Infrared Phys. Technol. 2023, 128, 104457. [Google Scholar] [CrossRef]
- Urakami, J.; Seaborn, K. Nonverbal Cues in Human–Robot Interaction: A Communication Studies Perspective. ACM Trans. Hum.-Robot Interact. 2023, 12, 22. [Google Scholar] [CrossRef]
- Panagou, S.; Neumann, W.P.; Fruggiero, F. A scoping review of human robot interaction research towards Industry 5.0 human-centric workplaces. Int. J. Prod. Res. 2023, 62, 974–990. [Google Scholar] [CrossRef]
- Apraiz, A.; Lasa, G.; Mazmela, M. Evaluation of User Experience in Human–Robot Interaction: A Systematic Literature Review. Int. J. Soc. Robot. 2023, 15, 187–210. [Google Scholar] [CrossRef]
- Ding, I.-J.; Su, J.-L. Designs of Human–Robot Interaction Using Depth Sensor-Based Hand Gesture Communication for Smart Material-Handling Robot Operations. Proc. IMechE Part B J. Eng. Manuf. 2023, 237, 392–413. [Google Scholar] [CrossRef]
- Gervasi, R.; Barravecchia, F.; Mastrogiacomo, L.; Franceschini, F. Applications of affective computing in human-robot interaction: State-of-art and challenges for manufacturing. J. Eng. Manuf. 2022, 237, 815–832. [Google Scholar] [CrossRef]
- Vinanzi, S.; Cangelosi, A. CASPER: Cognitive Architecture for Social Perception and Engagement in Robots. Int. J. Soc. Robot. 2024. [Google Scholar] [CrossRef]
- Dahiyaa, A.; Aroyoa, A.M.; Dautenhahn, K.; Smitha, S.L. A survey of multi-agent Human–Robot Interaction systems. Robot. Auton. Syst. 2023, 161, 104335. [Google Scholar] [CrossRef]
- Frijns, H.A.; Schürer, O.; Koeszegi, S.T. Communication Models in Human–Robot Interaction: An Asymmetric MODel of ALterity in Human–Robot Interaction (AMODAL-HRI). Int. J. Soc. Robot. 2023, 15, 473–500. [Google Scholar] [CrossRef]
- Ruiz-Equihua, D.; Romero, J.; Loureiro, S.M.C.; Ali, M. Human–robot interactions in the restaurant setting: The role of social cognition, psychological ownership and anthropomorphism. Int. J. Contemp. Hosp. Manag. 2022, 35, 1966–1985. [Google Scholar] [CrossRef]
- Peller-Konrad, F.; Kartmann, R.; Dreher, C.R.G.; Meixner, A.; Reister, F.; Grotz, M.; Asfour, T. A memory system of a robot cognitive architecture and its implementation in ArmarX. Robot. Auton. Syst. 2023, 164, 104415. [Google Scholar] [CrossRef]
- Taniguchi, T.; Murata, S.; Suzuki, M.; Ognibene, D.; Lanillos, P.; Ugur, E.; Jamone, L.; Nakamura, T.; Ciria, A.; Lara, B.; et al. World models and predictive coding for cognitive and developmental robotics: Frontiers and challenges. Adv. Robot. 2023, 37, 780–806. [Google Scholar] [CrossRef]
- Nocentini, O.; Fiorini, L.; Acerbi, G.; Sorrentino, A.; Mancioppi, G.; Cavallo, F. A Survey of Behavioral Models for Social Robots. Robotics 2019, 8, 8030054. [Google Scholar] [CrossRef]
- Sonntag, D. Persuasive Ai Technologies for Healthcare Systems. In Proceedings of the AAAI Fall Symposium Series 2016, Arlington, VA, USA, 17–19 November 2016. [Google Scholar]
- Cavallo, F.; Semeraro, F.; Fiorini, L.; Magyar, G.; Sinčák, P.; Dario, P. Emotion Modelling for Social Robotics Applications: A Review. J. Bionic Eng. 2018, 15, 185–203. [Google Scholar] [CrossRef]
- Kim, S.; Yu, Z.; Lee, M. Understanding Human Intention by Connecting Perception and Action Learning in Artificial Agents. Neural Netw. 2017, 92, 29–38. [Google Scholar] [CrossRef] [PubMed]
- Walters, M.L. The Design Space for Robot Appearance and Behaviour for Social Robot Companions. Ph.D. Thesis, University of Hertfordshire, Hatfield, UK, 2008. [Google Scholar]
- Kruse, T.; Pandey, A.K.; Alami, R.; Kirsch, A. Human-Aware Robot Navigation: A Survey. Robot. Auton. Syst. 2013, 61, 1726–1743. [Google Scholar] [CrossRef]
- Kim, M.; Oh, K.; Choi, J.; Jung, J.; Kim, Y. User-Centered Hri: Hri Research Methodology for Designers. In Mixed Reality and Human-Robot Interaction; Springer: Berlin/Heidelberg, Germany, 2011; pp. 13–33. [Google Scholar]
- Brockmyer, J.H.; Fox, C.M.; Curtiss, K.A.; McBroom, E.; Burkhart, K.M.; Pidruzny, J.N. The Development of the Game Engagement Questionnaire: A Measure of Engagement in Video Game-Playing. J. Exp. Soc. Psychol. 2009, 45, 624–634. [Google Scholar] [CrossRef]
- Monkaresi, H.; Bosch, N.; Calvo, R.A.; D’Mello, S.K. Automated Detection of Engagement Using Video-Based Estimation of Facial Expressions and Heart Rate. IEEE Trans. Affect. Comput. 2016, 8, 15–28. [Google Scholar] [CrossRef]
- Doherty, K.; Doherty, G. Engagement in Hci: Conception, Theory and Measurement. ACM Comput. Surv. CSUR 2018, 51, 1–39. [Google Scholar] [CrossRef]
- Youssef, A.B.; Clavel, C.; Essid, S. Early Detection of User Engagement Breakdown in Spontaneous Human-Humanoid Interaction. IEEE Trans. Affect. Comput. 2019, 12, 776–787. [Google Scholar] [CrossRef]
- Herath, S.; Harandi, M.; Porikli, F. Going Deeper into Action Recognition: A Survey. Image Vis. Comput. 2017, 60, 4–21. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Wang, X.; Zeng, W.; Liu, W. FairMOT: On the Fairness of Detection and Re-identification in Multiple Object Tracking. Int. J. Comput. Vis. 2021, 129, 3069–3087. [Google Scholar] [CrossRef]
- Parsons, J.; Taylor, L. Improving Student Engagement. Curr. Issues Educ. 2011, 14, 1–32. [Google Scholar]
- Yu, L.; Long, X.; Tong, C. Single Image Super-Resolution Based on Improved WGAN. In Proceedings of the 2018 International Conference on Advanced Control, Automation and Artificial Intelligence (ACAAI 2018) 2018, Shenzhen, China, 21–22 January 2018; pp. 101–104. [Google Scholar]
- West, R.L.; Nagy, G. Using GOMS for Modeling Routine Tasks Within Complex Sociotechnical Systems: Connecting Macrocognitive Models to Microcognition. J. Cogn. Eng. Decis. Mak. 2007, 1, 186–211. [Google Scholar] [CrossRef]
- Laird, J.E.; Kinkade, K.R.; Mohan, S.; Xu, J.Z. Cognitive Robotics Using the Soar Cognitive Architecture. In Proceedings of the Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, Ontario, Canada, 22–26 July 2012; pp. 46–54. [Google Scholar]
- Popoola, O.P.; Wang, K. Video-Based Abnormal Human Behavior Recognition—A Review. IEEE Trans. Syst. Man Cybern. —Part C Appl. Rev. 2012, 42, 865–878. [Google Scholar] [CrossRef]
- Luo, L.; Zhou, S.; Cai, W.; Low, M.Y.H.; Tian, F.; Wang, Y.; Xiao, X.; Chen, D. Agent-based human behavior modeling for crowd simulation. Comput. Animat. Virtual Worlds 2008, 19, 271–281. [Google Scholar] [CrossRef]
- Sun, R. Cognition and Multi-Agent Interaction: From Cognitive Modeling to Social Simulation; Cambridge University Press: Cambridge, UK, 2006; pp. 29–31. [Google Scholar]
- Kieras, D.E.; Meyer, D.E.; Mueller, S.; Seymour, T. Insights into Working Memory from the Perspective of the EPIC Architecture for Modeling Skilled Perceptual-Motor and Cognitive Human Performance; EPIC Report; University of Michigan: Ann Arbor, MI, USA, 1998; p. 10. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Interaction Behavior |
|---|---|
| 2 | answering questions |
| 3 | applauding |
| 397 | yawning |
| 257 | pumping gas |
| 279 | rock scissors paper |
| 304 | singing |
| 319 | sneezing |
| 320 | sniffing |
| 331 | sticking tongue out |
| 344 | swinging on something |
| Index | Meaning |
|---|---|
| Positive | The person is positive to interact with you and willing to share. |
| Neutral | The person is neutral. |
| Negative | The person has no desire to interact with you and potentially needs help. |
| State | Engagement | Emotion | Sentiment |
|---|---|---|---|
| Unawareness | Disengagement | ||
| Openness | Engagement | ||
| Attention | Engagement | Neutral | Positive Neutral |
| Reflection | Engagement | Disgust Neutral | Neutral |
| Addressing | Engagement (head pose) | Happy Angry Neutral | Neutral |
| Empathy | Engagement | Sad Neutral | Negative |
| Appealing | Engagement | Disgust Sad Angry Fear | Negative |
| Index | ) |
|---|---|
| Positive | Happy (0.9) |
| Neutral | Neutral (−0.1), Surprise (0.3) |
| Negative | Disgust (−0.9), Angry (−0.9), Fear (−0.8), Sad (−0.9) |
| Interactions | Interaction Time | F1 Score (%) |
|---|---|---|
| S1 | 20 | 98.5 |
| S2 | 24 | 92.2 |
| S3 | 10 | 84.6 |
| S4 | 8 | 92.5 |
| S5 | unrecognized | 0 |
| S6 | 36 | 54.4 |
| S7 | 17 | 91.2 |
| S8 | 34 | 72.7 |
| S9 | 18 | 86.6 |
| S10 | 28 | 84.6 |
| Average | 21.7 | 75.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, S.-R.; Lo, J.-H.; Hong, Y.-T.; Huang, H.-P. Implementation of Engagement Detection for Human–Robot Interaction in Complex Environments. Sensors 2024, 24, 3311. https://doi.org/10.3390/s24113311
Lu S-R, Lo J-H, Hong Y-T, Huang H-P. Implementation of Engagement Detection for Human–Robot Interaction in Complex Environments. Sensors. 2024; 24(11):3311. https://doi.org/10.3390/s24113311
Chicago/Turabian StyleLu, Sin-Ru, Jia-Hsun Lo, Yi-Tian Hong, and Han-Pang Huang. 2024. "Implementation of Engagement Detection for Human–Robot Interaction in Complex Environments" Sensors 24, no. 11: 3311. https://doi.org/10.3390/s24113311
APA StyleLu, S.-R., Lo, J.-H., Hong, Y.-T., & Huang, H.-P. (2024). Implementation of Engagement Detection for Human–Robot Interaction in Complex Environments. Sensors, 24(11), 3311. https://doi.org/10.3390/s24113311