1. Introduction
Concrete is an extensively used material in building infrastructures, including bridges, buildings, roads, and pavements. Nevertheless, the structural integrity of concrete constructions undergoes a natural degradation process due to several factors. These factors include environmental impacts, excessive loads, and the slow deterioration of components [
1,
2,
3]. The identification of cracks in concrete structures has great significance. These cracks indicate the early stages of degradation, presenting a substantial threat to the durability and stability of the structure [
4]. Cracks function as entry points, facilitating the ingress of water and deleterious chemicals in concrete structures. As a consequence, issues such as corrosion of reinforcing bars (rebar), disintegration, and spalling in the structures arise [
5,
6]. These concerns have the potential to significantly undermine public safety and endanger the structural integrity of the construction project.
Historically, the conventional practice for detecting these fissures has used manual visual examinations [
7]. Nevertheless, this approach is not without its difficulties as it is characterized by a significant investment of time, a large amount of effort, and a strong dependence on the inspector’s competence. Moreover, the practice of human inspections is accompanied by inherent safety hazards [
8]. Therefore, non-invasive methods for assessing the health of concrete structures have been developed and studied in the literature which are becoming increasingly essential in the management of smart facilities [
8]. These systems are based on data-driven artificial intelligence (AI) techniques in which data are usually collected through magnetic shape memory alloys (MSMA), capacitive sensors, embedded piezoelectric (PZT) sensors, and digital cameras [
9,
10,
11]. Automated procedures provide a more economically advantageous, streamlined, and secure substitute for human inspections. The use of machine learning and digital image processing methods for crack detection has been a notable focus of study in this field [
12].
It is effective and robust in detecting cracks in concrete structures through the segmentation of digital images. In this perspective, Bhattacharya et al. proposed an interleaved deep artifacts-aware attention mechanism (iDAAM) to classify images containing structural faults [
13]. The algorithm could extract local discriminant features benefiting the defect identification in the images. In another study, Zhao et al. [
14] proposed a feature pyramid network (crack-FPN) for crack detection, segmentation, and width estimation. First crack detection was performed through You Only Look Once version 5 (YOLOv5) model, and it was later segmented by crack-FPN. Although the proposed algorithm could effectively detect and segment the crack, the proposed methodology had a relatively greater inference time on the test images. Similarly, Zhang et al. [
15] presented a MobileNetv3-based broad learning-based effective concrete surface cracks detection mechanism with high accuracy and improved learning time. In this work, first, features were extracted from the images through MobileNetv3 which were later mapped in a broad learning system to identify cracks. A binary convolutional neural network (CNN) was presented for the identification of cracks in concrete structures [
16]. It integrated regression models such as random forest (RF) and XGBoost and exhibited a high accuracy on a publicly available dataset. However, the accuracy of the model deteriorated when tested with unseen data. In [
17] an optimized Deeplabv3+ BDF network is proposed for concrete crack segmentation. The network is trained using transfer learning, coarse-annotation, and fine-annotation techniques. The developed model could effectively detect cracks in the images.
Although numerous studies have been published on this topic exhibiting satisfactory crack inference performance on images with non-complex backgrounds. Nevertheless, a significant variation in their performance can be observed when tested on images with complex backgrounds, i.e., in the presence of many visual distractions, challenging illumination conditions, and complex backgrounds. Moreover, a lower inference rate is another concern that is associated with the available strategies in the literature. A crack detection model shall be easily adoptable in real-time applications and scalable with lower inference time for test images, ensuring high precision, accuracy, and robustness.
This work presents a novel approach to effectively infer and segment cracks in images with complex backgrounds and distribution patterns with high generalization power. Furthermore, the proposed model is capable of inferring cracks in less time with high precession. The proposed approach introduces an ensemble approach for YOLOv8 models. Using this approach, first, abstract characteristics useful for crack detection are derived from images containing cracks using three YOLOv8 models, i.e., YOLOv8x, YOLOv8m, and YOLOv8s models. Later, the trained models are quantized and combined to create an ensemble of YOLOv8 models in the inference stage. The final prediction of this approach is determined by concatenating the outputs of the trained models. This ensemble approach provides better segmentation results with higher intersection over union (IoU) and confidence threshold values. Moreover, the inference time for the ensemble model on the test images is quite low which makes the proposed model easily adaptable in real-time scenarios with a potential of scalability. The three main contributions of this work are given below.
The main contribution is the improve the crack segmentation capability of the YOLOv8 model from the inferred results.
Furthermore, it demonstrates that the inference process of a YOLOv8 model may be accelerated by quantizing the model, which will be advantageous for the real-time implementation of the suggested model.
Lastly, it introduces an ensemble technique to combine the inference outcomes of many YOLOv8 models in order to enhance the ultimate segmentation results.
The rest of the paper is structured as follows:
Section 2 offers a detailed examination of the technical background, encompassing a thorough description of the methodologies that underpin the research.
Section 3 presents a thorough elucidation of the adopted methodology. In
Section 4, the description of the dataset used in this study is presented to ensure transparency and capacity to be replicated. In
Section 5 the hyperparameters tuning process for the proposed model is explained.
Section 6 discusses the results, accompanied by a comprehensive analysis, which offers valuable insights into the efficacy of the suggested methodology. The last section, i.e.,
Section 7, summarizes the whole work.
3. Methodology
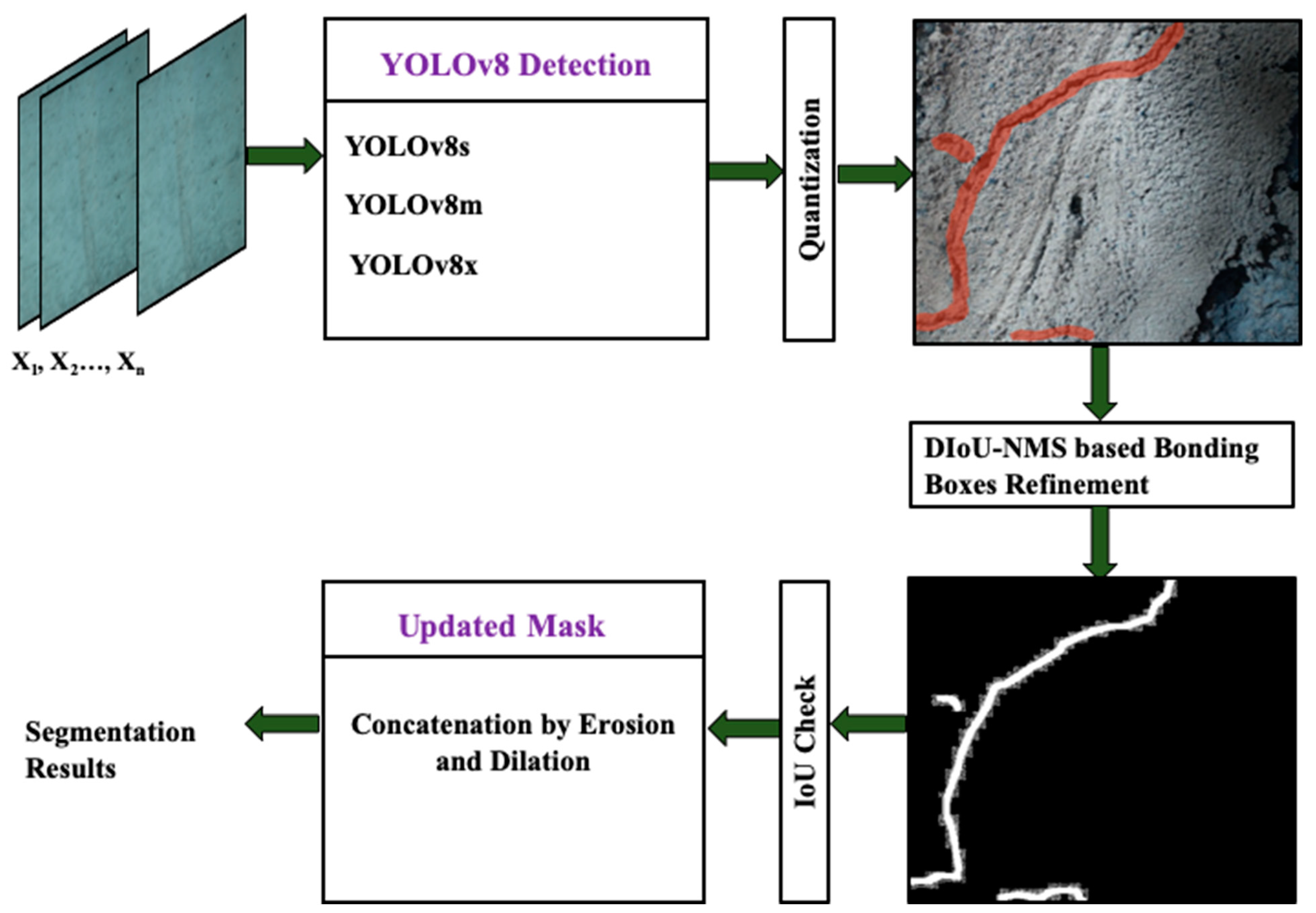
This study presents a robust crack detection and segmentation mechanism by employing an ensemble of quantized YOLOv8 models. The methodology to segment cracks comprises three discrete steps, i.e., training and quantization of the models, inference of cracks, and segmentation of the inferred cracks, as depicted in
Figure 3.
3.1. Training and Quantization
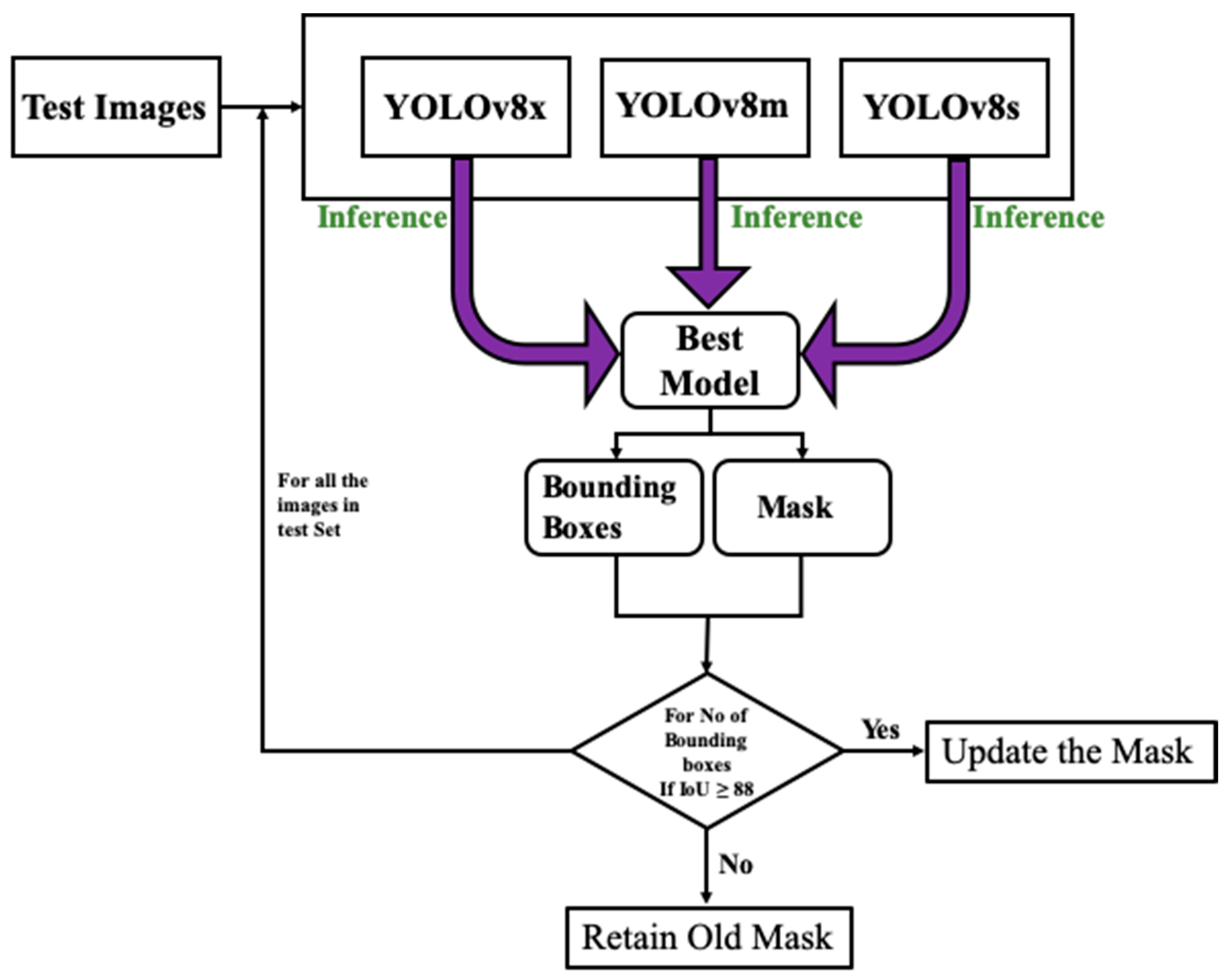
In this work, three YOLOv8 models, including YOLOv8s, YOLOv8m, and YOLOv8x, are utilized to create an ensemble model. The suffixes s, m, and x stand for small, medium, and extra-large sizes of the models. The size of the model represents the number of learnable parameters that each model contains. So, YOLOv8s, YOLOv8m, and YOLOv8x have 11.8, 27.3, and 71.8 million parameters, respectively. First, each model is trained on a distinct image subset. Training with distinct subsets ensures exposure to diverse images of concrete structures with cracks. It also prevents overfitting by enabling each model to learn distinct abstract characteristics. After training, the models are quantized before the inference of cracks on the unseen dataset. The quantization process includes reducing the precision of the weights and activation of the models. It helps the models to utilize less memory, achieve higher inference speed, and reduce latency.
3.2. Inference
Following the training process, every model is subsequently tested on unseen images to infer cracks. During inference, non-maximum suppression (NMS) is implemented by applying given thresholds, i.e., IoU and confidence value both set to 0.5. The YOLOv8 model utilizes distance-based intersection over union NMS (DIoU-NMS) to eliminate bounding boxes with low confidence and repetitive findings.
3.3. Segmentation
During the post-inference stage, ensemble predictions are generated by amalgamating outcomes from the three models. Ensemble prediction enhances object detection and segmentation masks to achieve higher levels of accuracy. Refinement entails the evaluation of mask overlap by employing the intersection over union (IoU) concept as illustrated in
Figure 4. The mask and bounding box of the top predictor function as a point of reference for the refinement procedure. If the Intersection over Union between the masks of the top-performing and second-best models exceeds 88% for all bounding boxes, apply morphological operations (namely, erosion and dilation) to update the mask. Otherwise, keep the original mask unchanged. The identical procedure is iterated using the outcomes of the previous model. The refinement method is implemented on every image in the test dataset to achieve the ultimate segmentation outcomes.
By organizing the methodology into three essential stages, our goal is to improve clarity and promote a more comprehensive comprehension of the suggested deep learning technique for crack identification and segmentation.
In Equation (5) AP is the average precision of the category with index value and the number of categories N which in this case is 2.
5. Development and Evaluation of the Model
The training of a neural network is important to ensure that the developed model has updated its parameters according to the task at hand. The initial weights are obtained from three pre-trained YOLOv8 models on the ImageNet dataset. The training data undergoes several transformations such as flipping, rotating, scaling, and other transformations to enhance its diversity. The models are developed using the data configuration discussed in
Section 4, i.e., each model is trained using one of the training subsets and is evaluated on the test subset. Moreover, a batch size of 64 and an Adam optimizer are used to train the network. The performance of a network is mostly subjected to key hyperparameters such as the learning rate and the number of epochs used to train the network.
In order to find out the optimal hyperparameter setting, initially, YOLOv8s is trained using learning rates of 0.01, 0.001, and 0.0001, and 50, 100, 150, 200, and 300 epochs. Afterward, all three models are trained using the optimal configuration for hyperparameters explored earlier.
5.1. Hyper Parameters Tuning
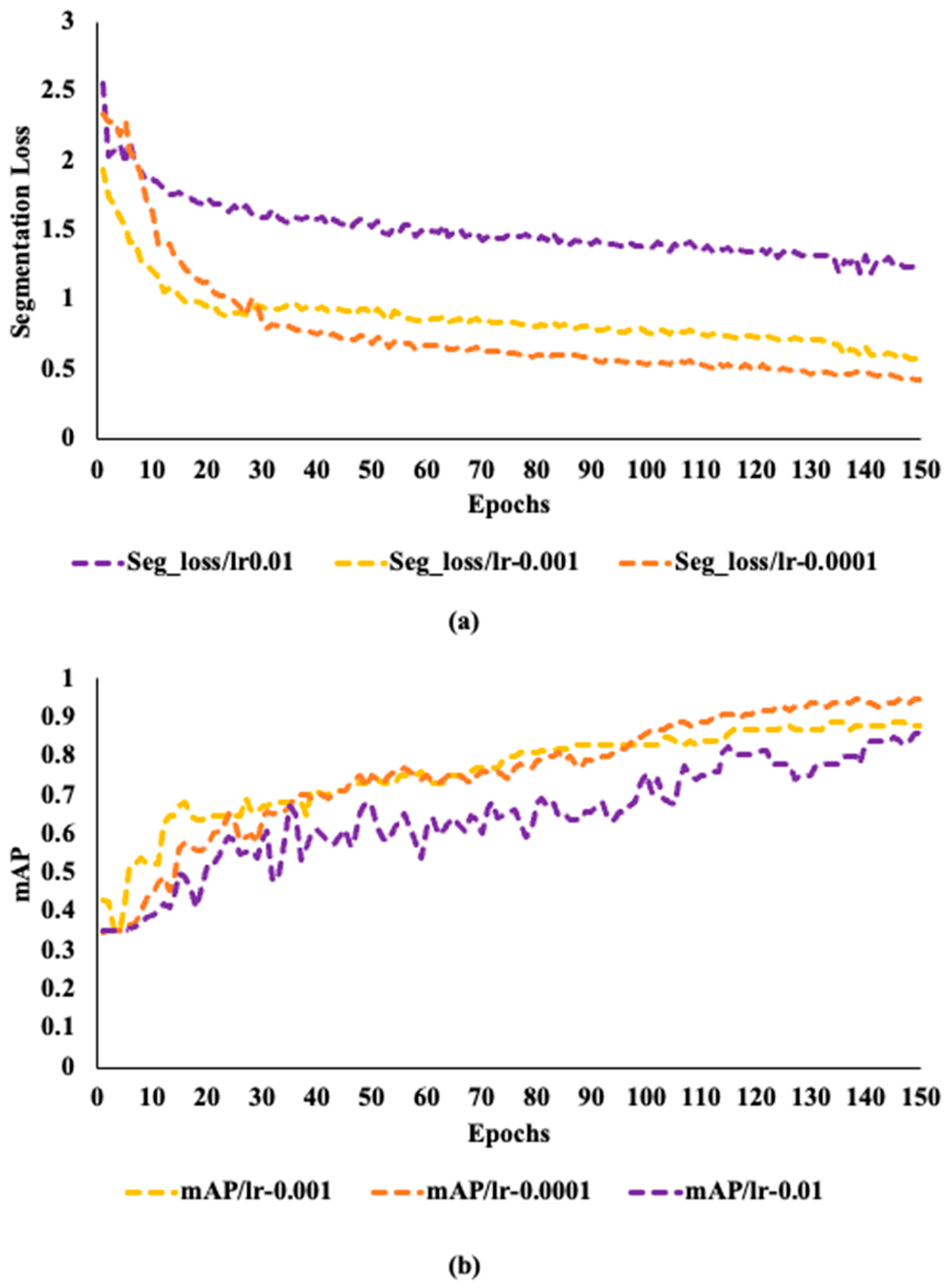
Figure 5 shows how segmentation loss and mAP for the three models vary over the epochs when training at various fixed learning rates.
Figure 5a shows that throughout training, the segmentation loss first drops off quickly before steadily stabilizing as the number of epochs rises. On the contrary, mAP has a different behavior as depicted in
Figure 5b. Better training performance is ensured when the learning rate is 0.0001 than the other two learning rates, as the mAP rises gradually with few changes to a value of 0.91.
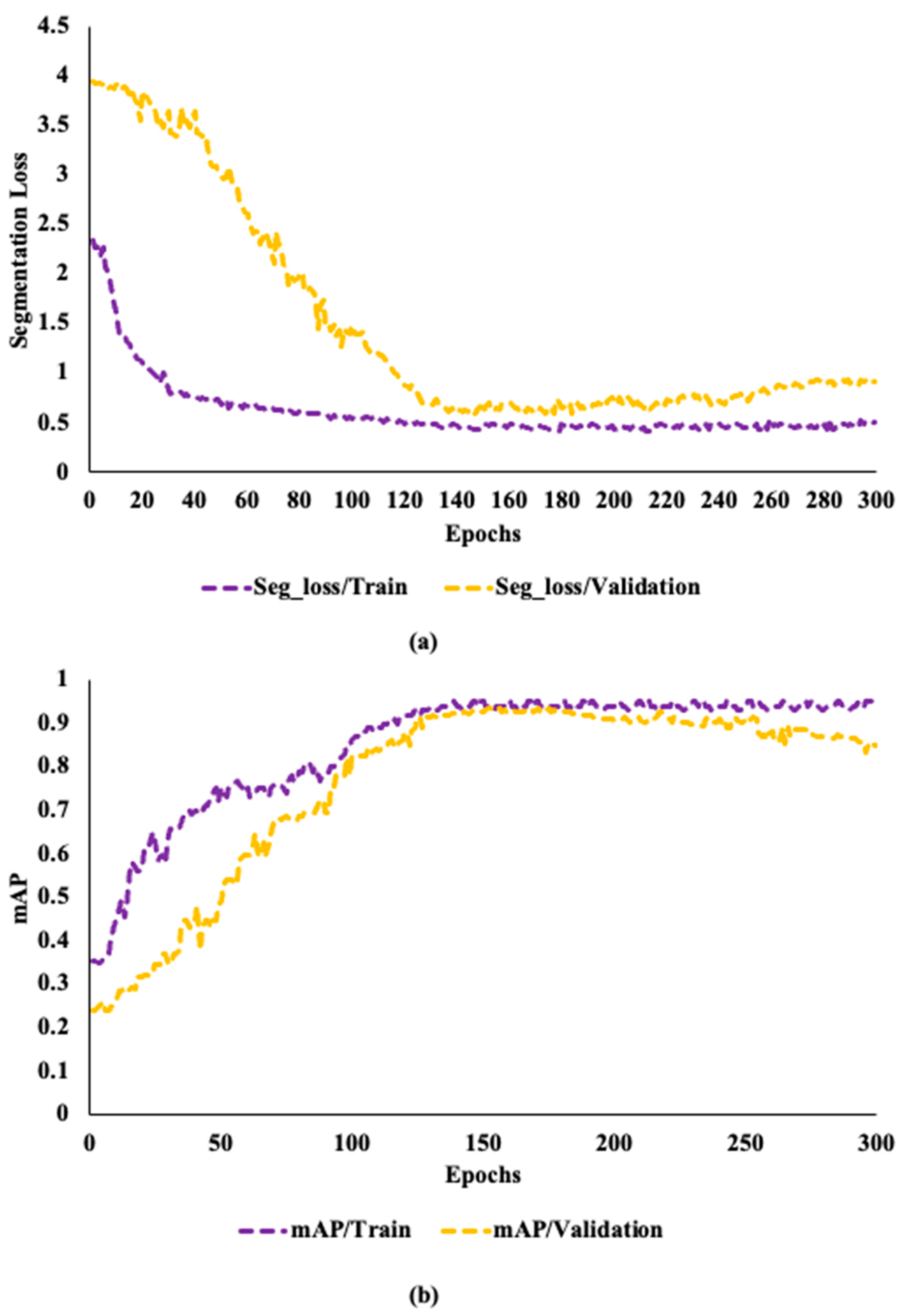
To determine the overfitting, the model was trained with 50, 100, 150, 200, and 300 epochs. The changes in segmentation loss and mAP for the network trained on the dataset with a learning rate of 0.0001 reach a limit after 150 epochs. The network in training and validation sets retains a good learning efficiency for the first 150 epochs. Even while the segmentation loss and mAP demonstrate improvement after 150 epochs, this performance could point to overfitting. Due to the parameters showing a steadily reduced network learning on the validation set.
Figure 6a,b shows that over the next 150 epochs, segmentation loss only drops by 0.004 and mAP only grows by 0.005. Due to high efficiency, this study employs 150 epochs for training all the YOLOv8 models at a learning rate of 0.0001, and grayscale images.
5.2. Performance Evaluation Matrices
The precision, recall, mAP0.5, and inference speed are used as evaluation matrices to assess the object detection performance of the proposed ensemble Yolov8 model. The mathematical formulation to calculate the precession of a model is given below.
Moreover, the ratio of accurately predicted true positive samples by the model to the number of actual true positive samples is known as recall. The mathematical expression for the recall calculation is as follows.
Furthermore, Equation (5) illustrates the formula for calculating mean average precision (
), which is the outcome of a weighted average of the average precision values of all sample categories. This metric is used to assess the detection ability of the model across all categories.
6. Result Analysis
To build a robust framework for crack detection, this study employs deep learning techniques, consisting of an ensemble of the YOLOv8 models, i.e., YOLOv8x, YOLOv8m, and YOLOv8s. The overall methodology consists of three phases, (1) the training and quantization of the three models, (2) the inference of the cracks in the test images, and (3) the extraction of the masks for cracks from the inferred results through the segmentation process. The criteria to present the final segmented results is to concatenate the masks of the three models based on the calculation of IoU among the masks of the three masks models. The results presented here are generated on a Tesla T4 GPU with 16 GB of random access memory (RAM). In
Table 2, the precision, recall, and mAP for the three models during the training and validation phases are presented. It can be observed that during the training phase, the YOLOv8x has the highest precision, recall, and mAP, i.e., 93.13%, 91%, and 90.13%, respectively. The second-best performance is of the YOLOv8m with 92.20%, 90.68%, and 89.90%, precision, recall, and mAP values, respectively. The least precision, recall, and mAP values can be observed for the YOLOv8s model with 90.69%, 89.53%, and 88.24%, respectively. A similar trend is observed in the case of the validation phase of the models. The maximum values for precision and recall matrices are observed for the YOLOv8x model followed by YOLOv8m, and YOLOv8s. The convergence of all the models towards optimal values in both the training and validation phases indicates that the models are ready to be evaluated on the unseen data and make the inference about the cracks.
The models are evaluated on the test dataset containing 1578 images as discussed in
Section 4. In
Figure 7, the original images and the inference results from the three models are given in
Figure 7a–d. It is evident from the inferred results that all the models could infer cracks in the test images. However, the inference results of the three models cover the crack area with varying confidence levels. It can be YOLOv8x accurately identifying cracks as evident in
Figure 7b. Similarly, in
Figure 7c it is noticeable that the YOLOv8m model identification result is better than the rest of the two models, and in
Figure 7d the superiority of the YOLOv8s is evident. It is noteworthy that the inference performance of the models is not the same for all the images. It can be assumed that the three models have acquired different knowledge from the datasets during the training phase. Therefore, the behavior of the three models differs during the inference phase. Due to this reason, an ensemble segmentation approach based on the result of the three YOLOv8 models is adopted to refine the final segmentation results.
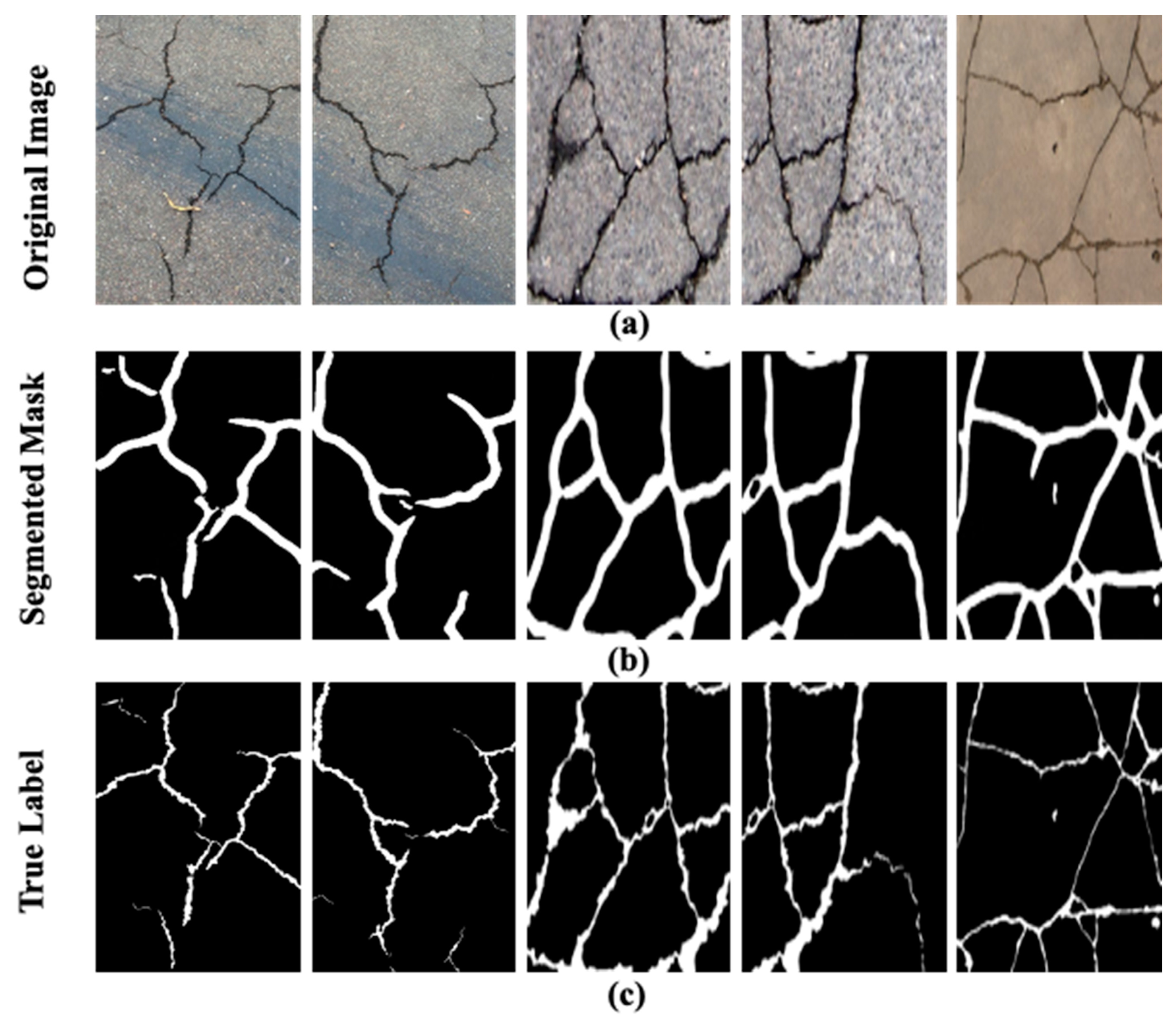
In
Figure 8, a few of the original images in the test dataset, the segmentation masks generated through various models as the true labels are presented. The original images given in
Figure 8a contain complex backgrounds and varying illumination conditions which makes the segmentation task more challenging. It is apparent in
Figure 8d, that the segmentation masks generated through the proposed approach depict a close resemblance to that of the true label for the given images shown in
Figure 8e. Moreover, the segmentation results of the proposed model are compared with a few state-of-the-art crack models, i.e., deep U shaped Network (U-NET) and U-NET++ used for crack detection as shown in
Figure 8c,d. The segmentation performance of the UNET and U-NET++ in the presence of a challenging background and illumination deteriorates as evident in the pictures. Based on the segmentation results presented in
Figure 8, the superiority of the proposed ensemble approach to segment the cracks is justified.
6.1. Checking the Generalization Performance
To check the generalization performance, the proposed model is further evaluated on the pavement cracks [
29] and deepcrack datasets [
30]. The pavement cracks dataset contains images of a 386 m long road taken with a 12-megapixel camera, an 83-degree field of view, and 1920 × 1080 resolution. Similarly, the deepcrack dataset contains 537 images of concrete structures with 544 × 384 resolution. It is challenging to perform the crack detection and segmentation of the drone images as it contains extra information in the scene such as greenery, trees, and edges of the road. The presence of the extra information adds complexity to the ground region. Moreover, the irregular pattern of cracks (diagonal and crazing) in various scenes and scales as given in deepcrack dataset also makes the segmentation a challenging task. The qualitative results of the proposed model on the pavement cracks and deepcrack datasets segmentation are shown in
Figure 9a–c and
Figure 10a–c, respectively. It can be perceived from the segmentation results in
Figure 9b while using the pavement cracks dataset that the proposed ensemble YOLOv8 could infer the cracks in these complex images with high quality. However, during segmentation, it also included outliers such as edges of the road as cracks, as the extra information present in the images adds complexity to the segmentation process. Nevertheless, overall segmentation results presented in the figure closely resemble the true labels given in
Figure 9c. It is evident from the segmentation results given in
Figure 10b that the proposed model could also segment cracks with complex skeleton and distribution patterns. These segmented masks are similar to the true labels given in
Figure 10c validating the efficacy of the proposed model. These results justify that the proposed model has high generalization power as it could infer cracks in the images with different resolutions and more complex backgrounds.
To further consolidate the analysis a comprehensive analysis in terms of precision, recall, and F1 score for the proposed model in contrast to existing state-of-the-art techniques is given in
Table 3. These metrics are essential for evaluating the performance of the model. The results are generated by utilizing three distinct datasets, i.e., the heterogeneous dataset [
28], the pavement cracks dataset [
29], and the deepcrack dataset [
30].
In the case of the heterogeneous dataset, the proposed model consistently demonstrated superior performance in comparison to the U-NET and U-NET++ models across all the assessment metrics. There is an enhancement of at least 3.88%, 3.68%, and 3.78% in precision, recall, and F1 score for the proposed model. It is noteworthy that the proposed model is capable of yielding results with high precision in comparatively less inference time, i.e., 2 milliseconds less time per image. The inference time is a critical factor, particularly in situations that necessitate quick decision-making or processing large volumes of images in realtime.
In the case of the pavement cracks and deepcrack dataset, the superiority of the proposed model is once again evident. It has the highest values for precision, recall, and F1 score as well as high inference speed. The results of the proposed model are at least 5.36%, more precise than the other two networks on both datasets. Similarly, at least 6.82% and 6.11% improvement can be observed for recall and F1 score, respectively. The inference results are at least 2 milliseconds faster on both datasets. The fact that the suggested model consistently outperforms the comparison models highlights its ability to effectively infer cracks in different datasets, confirming its generalization ability.
6.2. Ablation Analysis
In this section, we evaluated the performance impact of the different modules of the suggested strategy by an ablation analysis. To assess the relevant changes in performance metrics, we specifically examined quantization and ensemble prediction modules and removed them one at a time with the dataset containing heterogeneous images [
30]. The complete description of the ablation analysis is presented in
Table 4.
Following the comprehensive ablation study, it is evident that the IoU threshold for the three models significantly diminishes in the absence of the ensemble module. The deterioration occurs because the inference of each model on the test image varies. This variation is based on the specific set of abstract features acquired by each model during the training phase. Furthermore, the inference time of individual models on a single image is shorter compared to the ensemble model. In general, the inclusion of the ensemble YOLOv8 model has resulted in a significant enhancement in segmentation performance, as seen by a 3% rise. This improvement emphasizes the extent to which one model in the ensemble enhances the others, leading to a segmentation that is more dependable and precise.
Moreover, an analysis was conducted to assess the impact of quantization on the segmentation performance of the model. Curiously, the data shows that quantization does not have a direct impact on segmentation performance. Conversely, it has a substantial role in a 7% decrease in computational expenses, as evidenced by the table.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}