
Automatic Detection and Identification of Defects by Deep Learning Algorithms from Pulsed Thermography Data

 ,
,  ,
,  ,
, 

Abstract
1. Introduction
- A comprehensive and systematic investigation and comparison of three classical deep-learning methods were conducted to analyze the accuracy and efficiency of defect detection using pulsed thermography.
- An innovative instance segmentation method was introduced to predict the irregular shape of each defect instance in thermal images at the pixel level, enabling efficient defect segmentation and identification for each defect type across different specimens.
- Experimental modeling and analysis for the post-processing of inspected data based on deep-learning feature extraction techniques have also been introduced.
- Section 2 outlines the main principles and methods utilized in this research.
- Section 3 provides an introduction to pulsed thermography (PT).
- Section 4 describes the experimental setup, including details on data collection, defective features, and samples.
- Section 6 offers a detailed account of the experimental results and training procedures for each method.
- Section 7 analyzes the results obtained from the experiments.
- Finally, Section 8 concludes the research and highlights future work in this area.
2. Principles
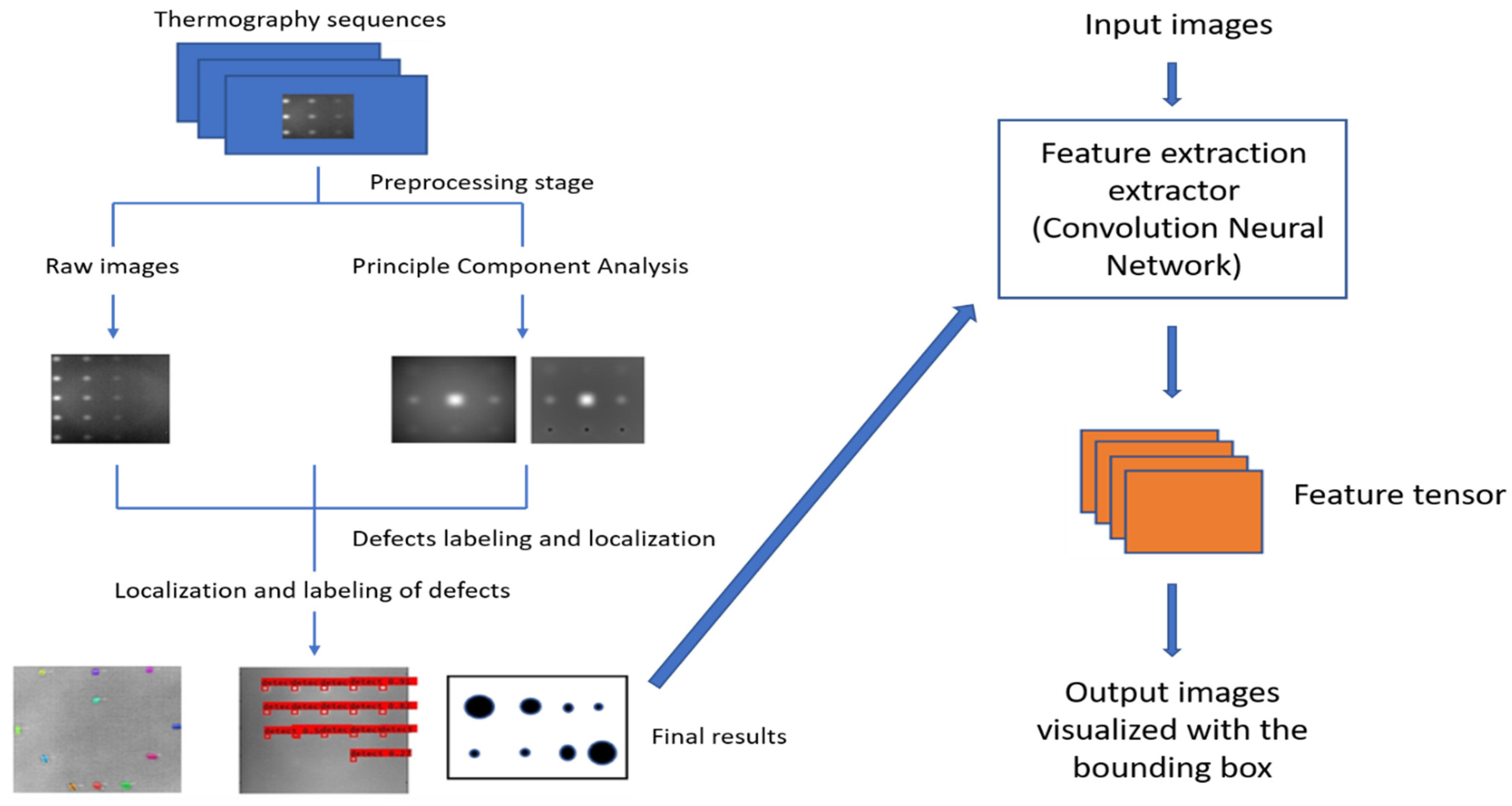
- First, the infrared thermal sequences are acquired by the pulsed thermography (PT) system.
- Secondly, the raw thermal sequences are preprocessed and decomposed by augmentation methods: 1. Principal Component Thermography (PCT), where the sequence decomposes into several orthogonal functions (Empirical Orthogonal Functions: EOF); 2. Flip; 3. Random crop; 4. Shift; 5. Rotation etc.
- In the final step, the defect regions are recognized via deep neural networks, which visualize the defects with the bounding boxes. All defects must be labeled with the locations, then trained with the deep region neural network.
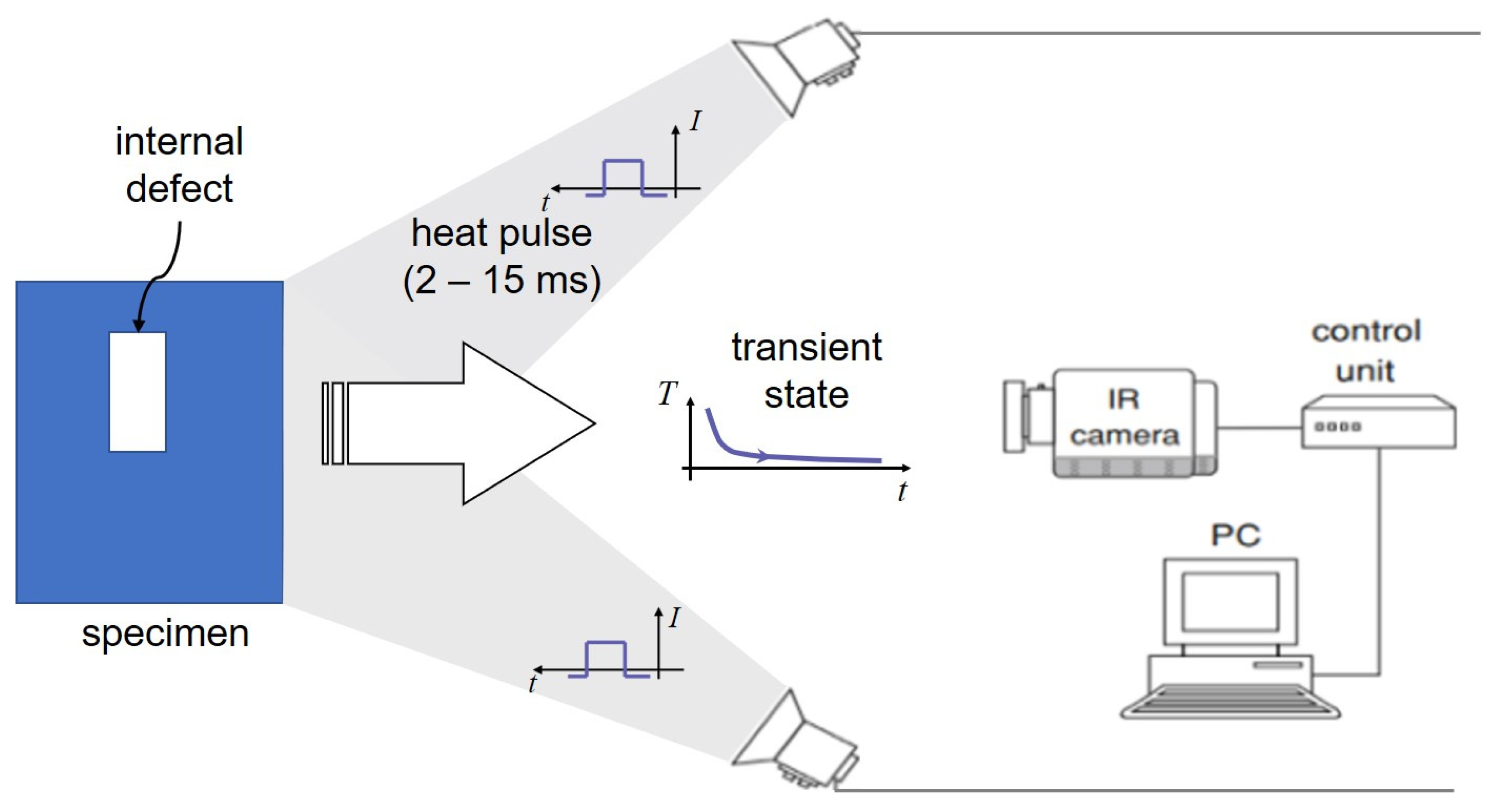
3. Thermography Consideration—Optical Pulsed Thermography
4. Specimens and Experimental Setting Up
4.1. Experiment Setup
4.2. Validation Samples Preparation
- The first sample (a) is from plexiglass material with 25 sub-surface circle defects of different diameter and depth.
- The second sample (b) has eight multiple angle defects that are embedded on the surface of the plexiglass specimen.
- The third sample (c) is from plexiglass material with 25 sub-surface circle defects of same diameter but different depths, increasing from the left to right column (deeper).
- The fourth sample (d) plexiglass has 25 circle and quadrilateral defects of various depths and sizes.
- The fifth sample (e) is a steel sample that has three different diameters of circle defects; the depth being shallower from top to bottom.
- The sixth sample (f) CFRP has 25 triangle defects embedded in the specimen in the form of a folding plane.
- The seventh sample (g) CFRP has 25 triangle defects embedded in the specimen in the form of a flat plane.
- The eighth sample (h) CFRP has 25 triangle defects embedded in the specimen in the form of a curved plane.
4.3. Validation Datasets and Features
4.3.1. Acquisition of the Training Database
4.3.2. Calibration of the Data
4.3.3. Preprocessing and Data Augmentation
5. Methodologies: Defect Detection Methods by Deep Learning Algorithms
5.1. Objective Localization Algorithms
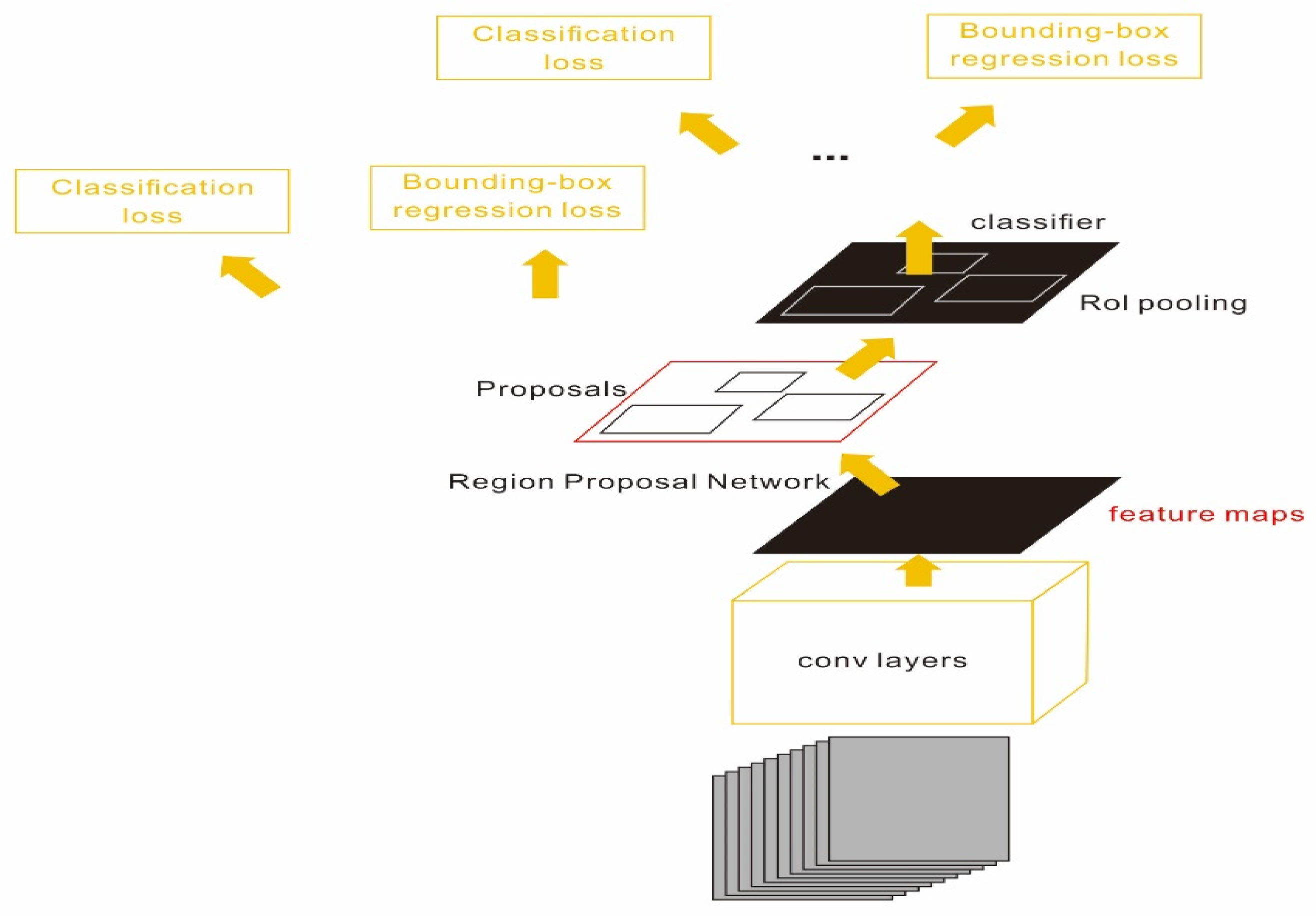
- A fully convolutional network, which included five blocks of basic convolutional layers and a Relu layer with a pooling layer to extract feature from the input images.
- A region proposal network (RPN) connected with the fully convolutional network to obtain the region of interest (RPI).
- A Fast–RCNN detector using the feature region extracted in the (1)–(2) to achieve bounding box regression and SoftMax classification.
5.2. Semantic Defect Segmentation Method
5.3. Instance Defect Segmentation Algorithm
5.4. Regular Infrared Defect Detection Algorithm
6. Experimental Results and Implementation Details
6.1. Training
6.2. Evaluation Metrics
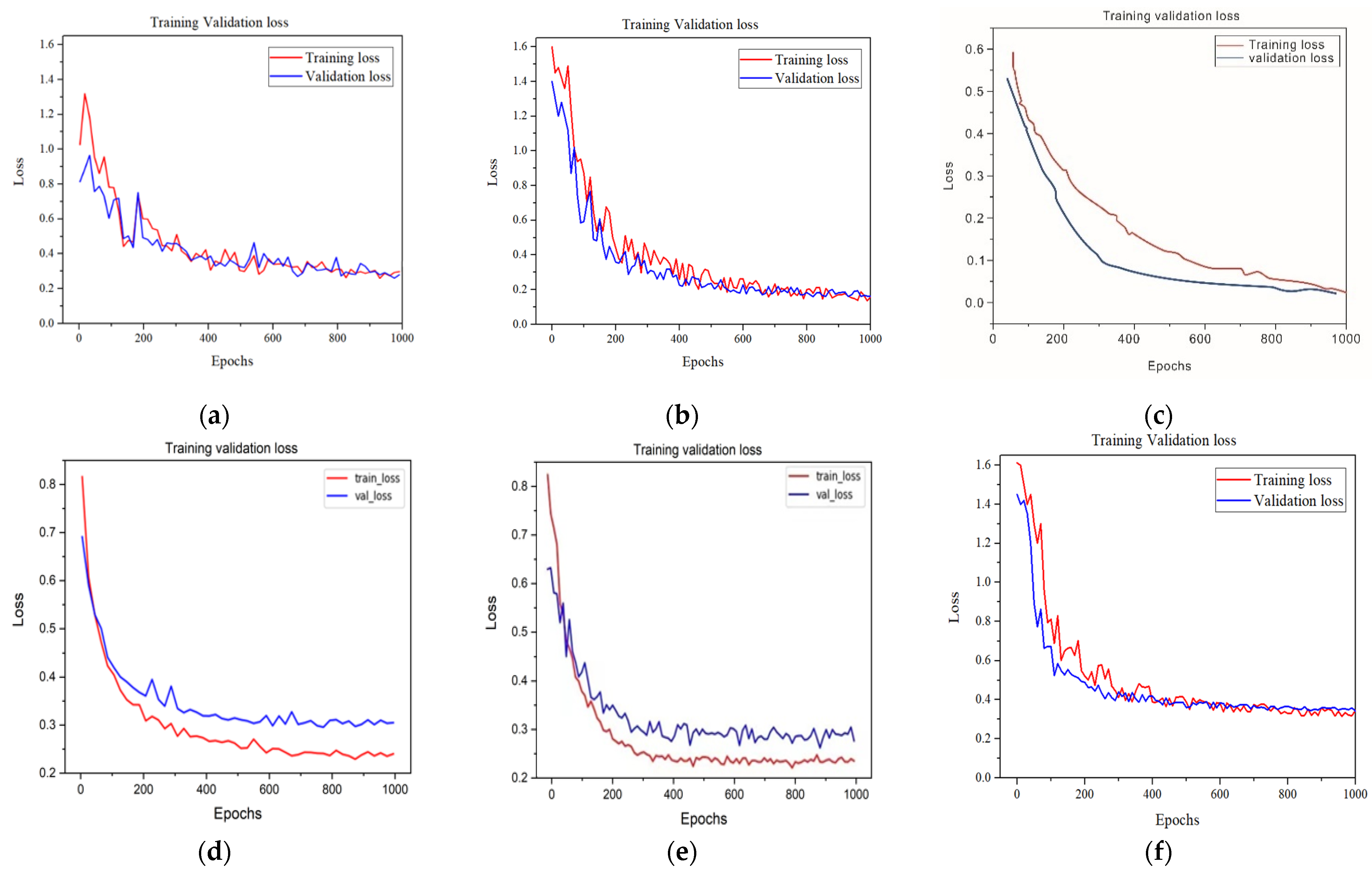
6.3. Learning Curves
6.4. Detection Results
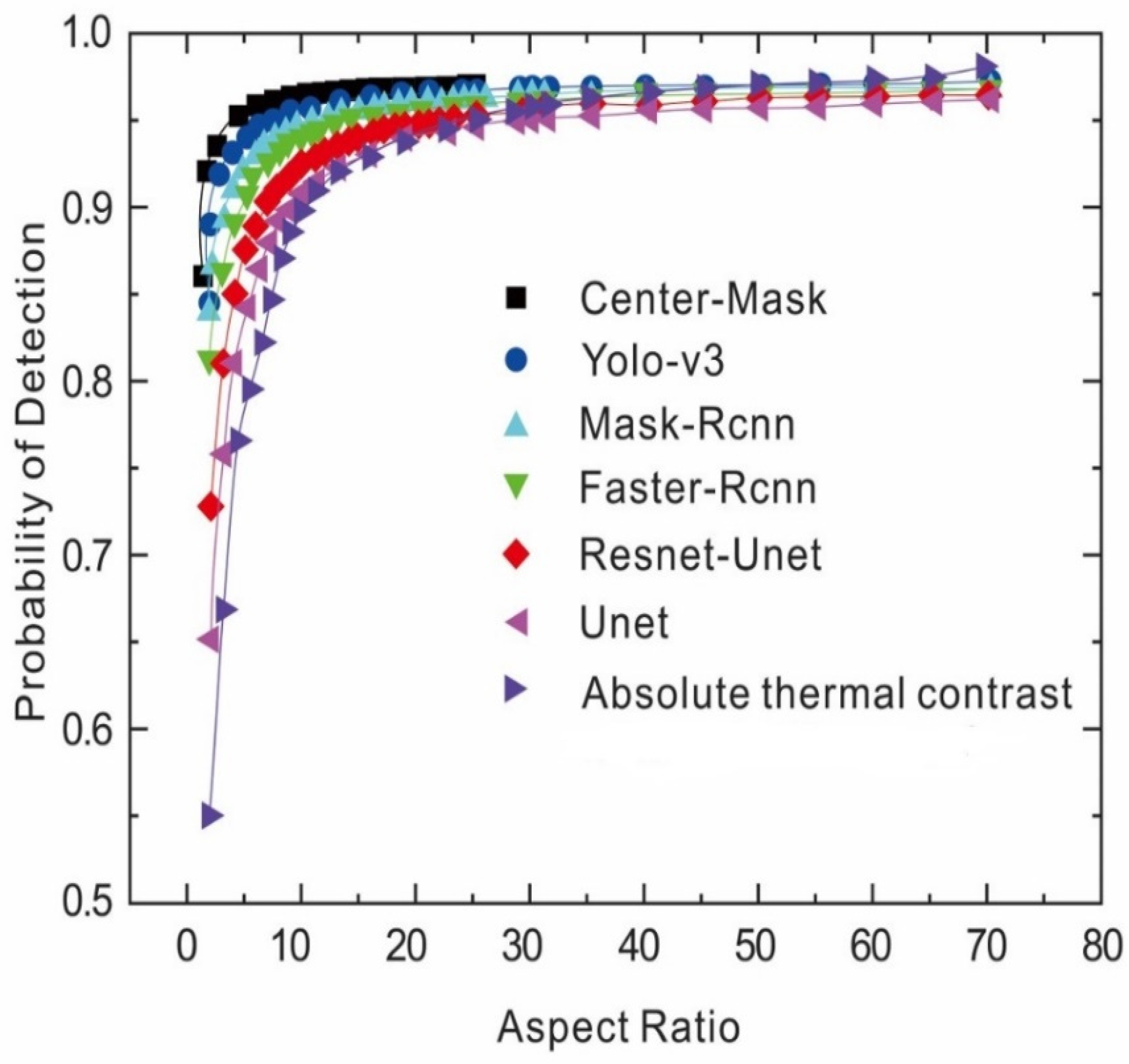
6.5. Reliability Assessment Using Probability of Detection (POD)
6.6. Mean–Average Precision (mAP)
6.7. Running Time Complexity
7. Results Analysis
- To implement a robust detection model, the databases must include enough samples. One way to effectively improve is to increase the size of the dataset by including multiscale images. A database composed of images on different scales (larger or smaller), enables the training to be sensitive to those new dimensions. This would increase the robustness of the deep segmentation algorithms facing larger defects, as well as improve the results on blurry pictures. To help reduce false alarms in the algorithm results and be more convenient for the user, implementing different types of labels is necessary. In the case of this project, each section was labeled with a defect in the spatial segmentation training (Mask–RCNN; U-net; Res–U-net). The proposal is to add different classifications. For example, including the name of the shape of the defect: circle, triangle, or some false positive cases (lighting spots, scratches) would be beneficial. This would allow the algorithm to not detect these shapes as a defect, and, thus, reduce the number of false alarms.
- Another critical point in this experiment to be considered is the marking process. In comparison to other objective detection methods, Mask–RCNN/Center–Mask especially involves a pixel-based marking approach that could mark the defects accurately, as opposed to marking a considerable area around each defect. It can rapidly and easily annotate the object without the bounding boxes restrictions in most cases. In comparison with an instance-segmentation method, U-net and Res–U-net are the auto-encoder format DL models that can be trained based on each pixel level to semantically segment defect pixels from sound pixels. However due to the burden of tackling massive temporal data of thermal frames, U-net and Res–U-net have less time efficiency and high time complexity on the thermal data in comparison to the instance-segmentation model. Therefore, building and creating more diverse and representative training samples is the key point in the future work in this research. There are several ways in which the size of the dataset can be effectively increased. Through data augmentation involving rotation, horizon flipping, and vertical shifts, the deep neural network model could learn the transformations further. By having different scales of larger or smaller training images, the learning procedure will be more sensitive to those new dimensions. This would also enhance the robustness of the algorithm to train for the detection of large defects and improve the results of grayscale images.
- In addition, the specific training gave results for specific defects in the academic samples. In this work, training only involved using square, circle, and rectangle defects of plexiglass, CFRP, and steel samples. The detection results indicate that similar defects could be detected on other types of training samples. However, the results also show that if the learning model is tested on other defects that the model did not learn on, it would not be an accurate system to rely on. Hence, to use the deep-learning algorithm for training, we should clearly define the type of sample we are working on and enlarge the robustness of the system to learn this type of sample during the neural network training procedure. In addition, due to the time limitation, we simply labeled all the visible defects of each sample in this experiment. However, if we want to extract the feature map completely for each defect area, the positioning of less visible defects in infrared data will be a significant but challenging issue in further research.
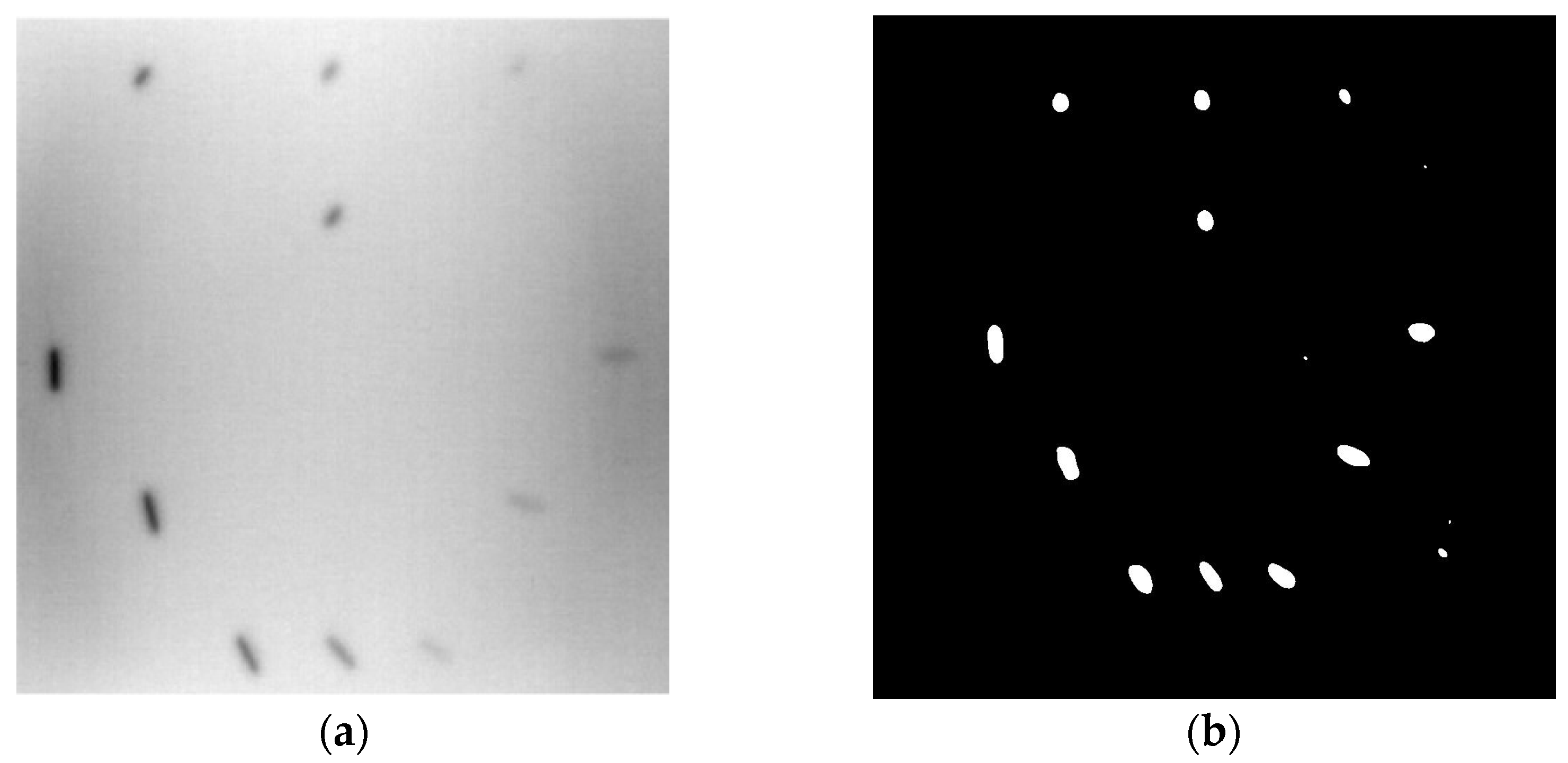
- A specific limitation of the objective localization algorithms is the influence of the labeling process. Although fast and efficient to use, the bounding boxes also led to some restrictions in most cases. As can be seen, when the circle is present in bounding box, this involves a defect that is totally bounded by the box. However, this shows that although the entire defect is contained, the bounding box also extracted the non-defect area, which possibly introduces multiple errors and less accuracy in the results. The proposal is to make a pixel-based labeling to achieve integrity in the image segmentation, which would only label the defects and not a considerable area around each defect. This proposition can be further clarified by segmentation methods. The results presented here lead to a more reliable defects characterization with pulsed thermography (PT).
- A good defect characterization is essential to not replace parts that could yet be used and to not leave critically damaged components without the needed repair. Therefore, these results are important, especially, e.g., in the designing of autonomous diagnosis NDT systems, which can make decisions regarding the integrity of the inspected part by themselves. In this work, three different types of automatic detection, being intelligent techniques, to combine with infrared thermography could improve the detection with industrial applications based on each group of results in the previous section. The critically damaged components could be easier identified and maintained the component that could be used by those algorithms with a high AP rate (81.06%). However, the instance segmentation (e.g., Center–Mask) provided the highest detection rate associated with vivid segmentation results among three different algorithms to provides the better solution of detection capability compared with the conventional thermal inspection method in industries. Therefore, it could be able to apply and contribute to current industrialized infrared inspection and controlling system.
- Future work includes: (a) Tests that can be performed with the instance segmentation method and other NDT techniques based on images like stereography and holography; (b) The best technique, method instance-segmentation method (Center–Mask), which can still be improved by tuning the network parameters; (c) Since the CNN technique achieves excellent performance, other network architectures must be tested and compared in the future to specify the best intelligent tool for defect measurement with infrared images.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Maldague, X.P.V. Nondestructive Evaluation of Materials by Infrared Thermography; Springer: London, UK, 1993. [Google Scholar]
- Janssens, O.; Van de Walle, R.; Loccufier, M.; Van Hoecke, S. Deep learning for infrared thermal image-based machine health monitoring. IEEE/ASME Trans. Mechatron. 2017, 23, 151–159. [Google Scholar] [CrossRef]
- Ibarra-Castanedo, C.; Maldague, X.P.V. Infrared thermography. In Handbook of Technical Diagnostics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 175–220. [Google Scholar]
- Caliendo, C.; Genovese, G.; Russo, I. Risk Analysis of Road Tunnels: A Computational Fluid Dynamic Model for Assessing the Effects of Natural Ventilation. Appl. Sci. 2020, 11, 32. [Google Scholar] [CrossRef]
- Maldague, X.; Galmiche, F.; Ziadi, A. Advances in pulsed phase thermography. Infrared Phys. Technol. 2002, 43, 175–181. [Google Scholar] [CrossRef]
- Rajic, N. Principal Component Thermography; Defence science and technology organization. Aeronautical and maritime research laboratory: Victoria, ME, Australia, 2002. [Google Scholar]
- Pilla, M.; Klein, M.; Maldague, X.; Salerno, A. New absolute contrast for pulsed thermography. Proc. QIRT 2002, 5, 53–58. [Google Scholar]
- Bison, P.; Cadelano, G.; Grinzato, E. Thermographic Signal Reconstruction with periodic temperature variation applied to moisture classification. Quant. InfraRed Thermogr. J. 2011, 8, 221–238. [Google Scholar] [CrossRef]
- Weng, J.; Zhang, Y.; Hwang, W.S. Candid covariance-free incremental principal component analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1034–1040. [Google Scholar] [CrossRef]
- Lakshmi, A.V.; Gopitilak, V.; Parvez, M.M.; Subhani, S.K.; Ghali, V.S. Artificial neural networks based quantitative evaluation of subsurface anomalies in quadratic frequency modulated thermal wave imaging. InfraRed Phys. Technol. 2019, 97, 108–115. [Google Scholar] [CrossRef]
- Huang, G.B.; Chen, Y.Q.; Babri, H.A. Classification ability of single hidden layer feedforward neural networks. IEEE Trans. Neural Netw. 2000, 11, 799–801. [Google Scholar] [CrossRef]
- Huang, S.; Cai, N.; Pacheco, P.P.; Narrandes, S.; Wang, Y.; Xu, W. Applications of support vector machine (SVM) learning in cancer genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar]
- Erwin, E.; Fachrurrozi, M.; Fiqih, A.; Saputra, B.R.; Algani, R.; Primanita, A. Content based image retrieval for multi-objects fruits recognition using k-means and k-nearest neighbor. In Proceedings of the International Conference on Data and Software Engineering (ICoDSE 2017), Palembang, Indonesia, 1–2 November 2017; pp. 1–6. [Google Scholar]
- Agrawal, S.; Agrawal, J. Survey on anomaly detection using data mining techniques. Procedia Comput. Sci. 2015, 60, 708–713. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, X.; Li, Y.; Wang, H. Deep learning in bioinformatics: Introduction, application, and perspective in the big data era. J. Mol. Cell Biol. 2019, 11, 929–940. [Google Scholar] [CrossRef]
- Aujeszky, T.; Korres, G.; Eid, M. Material classification with laser thermography and machine learning. Quant. InfraRed Thermogr. J. 2019, 16, 181–202. [Google Scholar] [CrossRef]
- Garrido, I.; Lagüela, S.; Fang, Q.; Arias, P. Introduction of the combination of thermal fundamentals and Deep Learning for the automatic thermographic inspection of thermal bridges and water-related problems in infrastructures. Quant. InfraRed Thermogr. J. 2022, 1–25. [Google Scholar] [CrossRef]
- Torres-Galvan, J.C.; Guevara, E.; Kolosovas-Machuca, E.S.; Oceguera-Villanueva, A.; Flores, J.L.; González, F.J. Deep convolutional neural networks for classifying breast cancer using infrared thermography. Quant. InfraRed Thermogr. J. 2022, 19, 283–294. [Google Scholar] [CrossRef]
- Tao, Y.; Hu, C.; Zhang, H.; Osman, A.; Ibarra-Castanedo, C.; Fang, Q.; Sfarra, S.; Dai, X.; Maldague, X.; Duan, Y. Automated Defect Detection in Non-planar Objects Using Deep Learning Algorithms. J. Nondestruct. Eval. 2022, 41, 14. [Google Scholar] [CrossRef]
- Yang, J.; Wang, W.; Lin, G.; Li, Q.; Sun, Y.; Sun, Y. Infrared thermal imaging-based crack detection using deep learning. IEEE Access 2019, 7, 182060–182077. [Google Scholar] [CrossRef]
- Luo, Q.; Gao, B.; Woo, W.L.; Yang, Y. Temporal and spatial deep learning network for infrared thermal defect detection. Ndt. E Int. 2019, 108, 102164. [Google Scholar] [CrossRef]
- Minoglou, K.; Nelms, N.; Ciapponi, A.; Weber, H.; Wittig, S.; Leone, B.; Crouzet, P. Infrared image sensor developments supported by the European Space Agency. Infrared Phys. Technol. 2019, 96, 351–360. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Lee, Y.; Park, J. Centermask: Real-time anchor-free instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13906–13915. [Google Scholar]
- Sun, J.G. Analysis of pulsed thermography methods for defect depth prediction. J. Heat Transfer. 2006, 128, 329–338. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, H.; Fernandes, H.; Maldague, X. Experimental evaluation of pulsed thermography, lock-in thermography and vibrothermography on foreign object defect (FOD) in CFRP. Sensors 2016, 16, 743. [Google Scholar] [CrossRef]
- Hu, J.; Xu, W.; Gao, B.; Tian, G.Y.; Wang, Y.; Wu, Y.; Yin, Y.; Chen, J. Pattern deep region learning for crack detection in thermography diagnosis system. Metals 2018, 8, 612. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Tokime, R.B.; Elassady, H. Wildland fires detection and segmentation using deep learning. In Proceedings of the Pattern Recognition and Tracking XXIX. International Society for Optics and Photonics, Orlando, FL, USA, 15–19 April 2018 2018; p. 106490B. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Grosse, R. Lecture 15: Exploding and Vanishing Gradients; University of Toronto Computer Science: Toronto, ON, Canada, 2017. [Google Scholar]
- Soomro, T.A.; Afifi, A.J.; Gao, J.; Hellwich, O.; Paul, M.; Zheng, L. Strided U-Net model: Retinal vessels segmentation using dice loss. In Proceedings of the IEEE Digital Image Computing: Techniques and Applications (DICTA), Canberra, ACT, Australia, 10–13 December 2018; pp. 1–8. [Google Scholar]
- Su, L.; Wang, Y.W.; Tian, Y. R-SiamNet: ROI-Align Pooling Baesd Siamese Network for Object Tracking. In Proceedings of the IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), Shenzhen, China, 6–8 August 2020; pp. 19–24. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully convolutional one-stage object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv 2015, arXiv:1512.01274. [Google Scholar]
- Damaskinos, G.; El-Mhamdi, E.M.; Guerraoui, R.; Guirguis, A.; Rouault, S. Aggregathor: Byzantine machine learning via robust gradient aggregation. Proc. Mach. Learn. Syst. 2019, 1, 81–106. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the 30th International Conference on Machine Learning. PMLR, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147. [Google Scholar]
- Wehling, P.; LaBudde, R.A.; Brunelle, S.L.; Nelson, M.T. Probability of detection (POD) as a statistical model for the validation of qualitative methods. J. AOAC Int. 2011, 94, 335–347. [Google Scholar] [CrossRef] [PubMed]
- Robertson, S. A new interpretation of average precision. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Singapore, 20–24 July 2008; pp. 689–690. [Google Scholar]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Type of Materials | Geometrics Specimen | Cross Section | Dimension | Defect Diameters (mm) |
|---|---|---|---|---|---|
| 1 | Plexiglass |  |  | 30 cm × 30 cm | Depth: 5.15 mm, 4.9 mm, 4.65 mm, 4.4 mm, 4.15 mm; Diameter: 9 mm, 18 mm |
| 2 | Plexiglass |  |  | 30 cm × 30 cm | Different angle cracks (0°,15°, 30°, 45° 60°, 75°, 90°); Size: 15 mm × 3 mm; Depth: 3.4 mm; 4.4 mm; 5.15 mm; |
| 3 | Plexiglass |  |  | 30 cm × 30 cm | Depth: 3.4 mm; 4.4 mm; 5.15 mm; Diameter: 10 mm |
| 4 | Plexiglass |  |  | 30 cm × 30 cm | Depth: 0.2, 0.4, 0.6, 0.8, 1.0; Diameter or Size: 3.4, 5.6, 7.9, 11.3, 16.9 D1: 15 mm × 6 mm; D2: 8 mm × 5 mm D3: 5 mm × 4 mm; C1: 14 mm × 6 mm C2: 9 mm × 5 mm; C3: 6 mm × 4 mm B1: 16 mm × 6 mm; B2: 15 mm × 6 mm B3: 8 mm × 4 mm; I1: 18 mm × 6 mm I2: 11 mm × 6 mm; I3: 7 mm × 4 mm |
| 5 | Steel |  |  | 30 cm × 30 cm | Depth: Size: A = 5 mm × 5.0 mm B = 2.5 mm × 10 mm C = 1 mm × 25 mm |
| 6 | CFRP |  |  | 30 cm × 30 cm | Five equivalent diameters (3.4 mm, 5.6 mm, 7.9 mm, 11.3 mm, 16.9 mm) with five different depth of defects (1.0 mm; 0.6 mm; 0.2 mm; 0.4 mm;0.8 mm) The plate has two time folding and at 30 degrees to the horizontal level |
| 7 | CFRP |  |  | 30 cm × 30 cm | Five different lateral size of defects: (3 mm, 5 mm, 7 mm, 10 mm, 15 mm) with five different depth (0.2 mm; 0.4 mm; 0.6 mm; 0.8 mm; 1.0 mm) |
| 8 | CFRP |  |  | 30 cm × 30 cm | Different angle of defects (; ) with different equivalent diameter (3.4 mm, 5.6 mm, 7.9 mm, 11.3 mm, 16.9 mm) and corresponding depth (1.0 mm, ), (0.6 mm, ), (0.2 mm, 0°), (0.4 mm, ), (0.8 mm, ) |
| Deep Learning Model | Training Detailed Information | CPU Time |
|---|---|---|
| U-net | 1. A high-learning momentum (0.99); 2. The weight decay is set as—0.005; 3. A learning rate is 0.005; 4. The number of epochs is 200; 5. The input sequences and the corresponding segmentation images are used to train with U-net with mini-batch gradient descent implantation from Pytorch deep-learning framework. | 2 min 12 s |
| Res–U-net | 1. The Res–U-net in this work was trained based on the MXNET [42] deep-learning library; 2. A batch size of 256 with mammal gradient aggregation [43]; 3. The number of epochs is 300; 4. The weight decay is set as—0.00066; 5. Adam optimizer with initial rate 0.005; 6. A multi-dimension learning momentum [44]; is (0.9,0,09) and the initial learning rate is 0.0005. | 2 min 5 s |
| YOLO-V3 | 1. Momentum was implemented as optimizer during the training; 2. The learning momentum was 0.9; 3. The learning rate was set as 0.001; 4. The backbone is adapted Darknet51; 5. The weight decay was 0.0005; 6. The maximum batch size of iteration was 50,200. | 45 s |
| Faster–RCNN | Batch size 256; Overlap threshold for ROI 0.5; Learning rate 0.001; Momentum for SGD 0.9; Weight decay for regularization 0.0001 | 1 min 55 s |
| Mask–RCNN | 1. Network training using Resnet50 as backbone; 2. The mini mask size is 28 × 28; 3. The weight decay is set as—0.0001; 4. The loss weight is equal for each class and mask ( RPN class, RPN bounding box, MRCNN class, MRCNN bounding box and MRCNN mask); 5. The learning momentum is 0.9 and learning rate is 0.0003; 6. Training of the first 20 epochs of network heads was followed by the training of all network layers for 80 epochs, the model weight. | 1 min 45 s |
| Center–Mask | Stochastic Gradient Descent (SGD) for 90K iterations (200 epoch) with a mini batch of two images and initial learning rate of 0.01; a weight decay of 0.9 and a momentum of 0.01, respectively. All backbone models are initialized by ImageNet pre-trained weights. | 1 min 10 s |
| Res–U-Net | U-Net | Faster–RCNN | Yolo-v3 | |
|---|---|---|---|---|
| (a) |  |  |  |  |
| (b) |  |  |  |  |
| (c) |  |  |  |  |
| (d) |  |  |  |  |
| (e) |  |  |  |  |
| (f) |  |  |  |  |
| (g) |  |  |  |  |
| (h) |  |  |  |  |
| Raw | ATC | Mask–RCNN | Center–Mask | |
|---|---|---|---|---|
| (a) |  |  |  |  |
| (b) |  |  |  |  |
| (c) |  |  |  |  |
| (d) |  |  |  |  |
| (e) |  |  |  |  |
| (f) |  |  |  |  |
| (g) |  |  |  |  |
| (h) |  |  |  |  |
| Methods | POD of Different Samples | |||||||
|---|---|---|---|---|---|---|---|---|
| Sample (a) | Sample (b) | Sample (c) | Sample (d) | Sample (e) | Sample (f) | Sample (g) | Sample (h) | |
| Mask–RCNN | 1 | 0.91 | 0.87 | 0.84 | 0.80 | 0.91 | 0.89 | 0.87 |
| Center–Mask | 1 | 0.94 | 0.92 | 0.94 | 0.82 | 0.91 | 0.92 | 0.95 |
| U-net | 0.81 | 0.84 | 0.85 | 0.81 | 0.75 | 0.80 | 0.63 | 0.76 |
| Res–U-net | 0.89 | 0.87 | 0.83 | 0.83 | 0.79 | 0.85 | 0.79 | 0.85 |
| Faster–RCNN | 0.90 | 0.88 | 0.84 | 0.83 | 0.80 | 0.85 | 0.90 | 0.86 |
| YOLO-V3 | 1 | 0.92 | 0.91 | 0.90 | 0.82 | 0.82 | 0.94 | 0.89 |
| Absolute thermal contrast with global threshold | 0.65 | 0.71 | 0.73 | 0.78 | 0.61 | 0.73 | 0.57 | 0.65 |
| Samples | Evaluations | Methods | ||||||
|---|---|---|---|---|---|---|---|---|
| Mask–RCNN | U-Net | Res–U-net | Faster–RCNN | Yolo-v3 | Center–Mask | ATC | ||
| A | Precision | 0.46 | 0.45 | 0.45 | 0.47 | 0.40 | 0.45 | 0.30 |
| Recall | 1 | 0.81 | 0.89 | 0.90 | 1 | 1 | 0.75 | |
| F-scores | 80% | 70% | 74% | 76% | 76% | 80% | 57.6% | |
| B | Precision | 0.41 | 0.50 | 0.46 | 0.43 | 0.52 | 0.55 | 0.25 |
| Recall | 0.91 | 0.84 | 0.87 | 0.88 | 0.92 | 0.94 | 0.69 | |
| F-scores | 73.2% | 74% | 73.8% | 72% | 80% | 82% | 51% | |
| C | Precision | 0.45 | 0.44 | 0.47 | 0.49 | 0.57 | 0.59 | 0.28 |
| Recall | 0.87 | 0.85 | 0.83 | 0.84 | 0.91 | 0.92 | 0.63 | |
| F-scores | 83% | 72% | 71.9% | 73% | 81% | 82% | 50% | |
| D | Precision | 0.46 | 0.47 | 0.49 | 0.40 | 0.59 | 0.60 | 0.22 |
| Recall | 0.84 | 0.81 | 0.83 | 0.83 | 0.90 | 0.94 | 0.78 | |
| F-sccores | 73.3% | 71.6% | 72.8% | 72% | 81.4% | 84.4% | 52% | |
| E | Precision | 0.41 | 0.40 | 0.50 | 0.52 | 0.60 | 0.66 | 0.38 |
| Recall | 0.80 | 0.75 | 0.79 | 0.80 | 0.82 | 0.82 | 0.66 | |
| F-scores | 67.2% | 64% | 70% | 72% | 76% | 78% | 57% | |
| F | Precision | 0.42 | 0.35 | 0.46 | 0.41 | 0.64 | 0.67 | 0.38 |
| Recall | 0.91 | 0.80 | 0.85 | 0.85 | 0.82 | 0.91 | 0.61 | |
| F-scores | 73.7% | 57.2% | 74.9% | 70% | 78% | 85% | 54% | |
| G | Precision | 0.49 | 0.42 | 0.60 | 0.41 | 0.65 | 0.61 | 0.46 |
| Recall | 0.89 | 0.63 | 0.79 | 0.90 | 0.94 | 0.92 | 0.69 | |
| F-scores | 76.5% | 57.2% | 74.9% | 73% | 87% | 83% | 62% | |
| H | Precision | 0.42 | 0.59 | 0.55 | 0.42 | 0.54 | 0.64 | 0.31 |
| Recall | 0.87 | 0.76 | 0.85 | 0.89 | 0.89 | 0.95 | 0.75 | |
| F-scores | 71.64% | 71.8% | 77% | 73% | 79% | 86% | 58% | |
| Average | F-scores | 74.8% | 67.25% | 70.66% | 72.62% | 79.8% | 82.55% | 55.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Q.; Ibarra-Castanedo, C.; Garrido, I.; Duan, Y.; Maldague, X. Automatic Detection and Identification of Defects by Deep Learning Algorithms from Pulsed Thermography Data. Sensors 2023, 23, 4444. https://doi.org/10.3390/s23094444
Fang Q, Ibarra-Castanedo C, Garrido I, Duan Y, Maldague X. Automatic Detection and Identification of Defects by Deep Learning Algorithms from Pulsed Thermography Data. Sensors. 2023; 23(9):4444. https://doi.org/10.3390/s23094444
Chicago/Turabian StyleFang, Qiang, Clemente Ibarra-Castanedo, Iván Garrido, Yuxia Duan, and Xavier Maldague. 2023. "Automatic Detection and Identification of Defects by Deep Learning Algorithms from Pulsed Thermography Data" Sensors 23, no. 9: 4444. https://doi.org/10.3390/s23094444
APA StyleFang, Q., Ibarra-Castanedo, C., Garrido, I., Duan, Y., & Maldague, X. (2023). Automatic Detection and Identification of Defects by Deep Learning Algorithms from Pulsed Thermography Data. Sensors, 23(9), 4444. https://doi.org/10.3390/s23094444