4.1. Experimental Settings
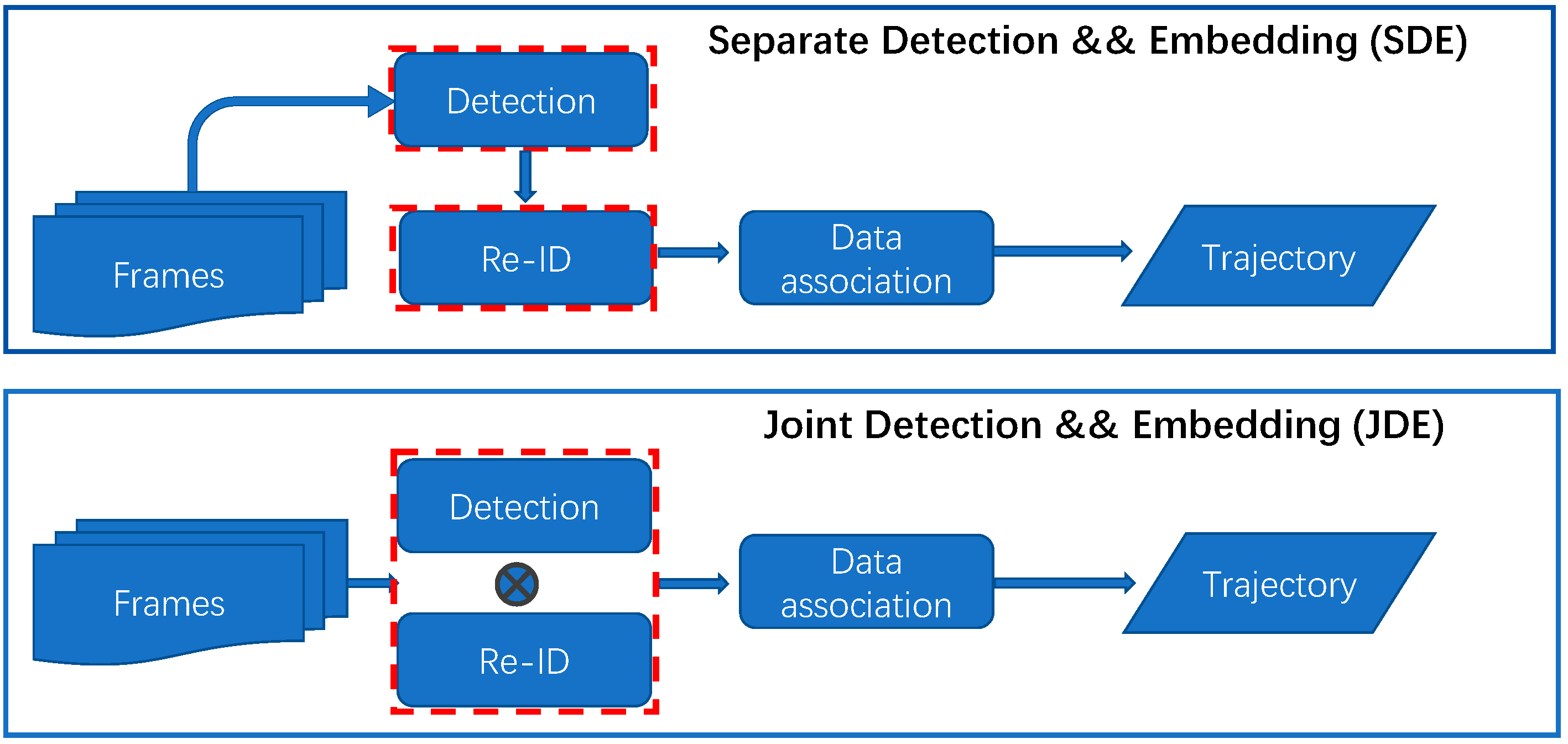
Datasets. The JDE-based CSMOT proposed in this paper consists of three tasks to be learned: object detection, re-ID, and MOT. Therefore, we build a large-scale hybrid dataset for different tasks to jointly train the model following FairMOT. The joint dataset contains rich scenes and a large number of object annotations, which is conducive to improving the generalization and robustness of the MOT algorithm. Regardless of whether or not we add identity annotations during training, we divide the dataset into two categories. The first category includes CrowdHuman (CH) [
27], ETH [
28], and CityPersons (CP) [
29]. We only use the bounding box annotations of these datasets to train the detection branch of our CSMOT. The CH contains many dense pedestrian annotations in crowded scenes, which can significantly improve the tracking ability. The second category includes CalTech (CT) [
30], CUHK-SYSU (CS) [
31], PRW [
32], and MOT17 [
33]. Bounding boxes and identity annotations provided by the category are used to train both the detection and re-ID branches. Specifically, we remove video frames in ETH that overlap with the MOT17 test set for fairness. We present ablation experiments on the validation set of MOT17 and compare the tracking ability with that of other MOT algorithms on the MOT Challenge server. The statistics of the hybrid dataset are shown in
Table 1.
Metrics. In order to make the evaluation results more accurate and objective, we use the general MOT Challenge Benchmark metrics [
32]. The metrics in this paper include false-positive (FP ↓), false-negative (FN ↓), the number of identity switches (IDs ↓), multiple-object tracking accuracy (MOTA ↑), identification F1 score (IDF1 ↑), and higher-order tracking accuracy (HOTA ↑). Here, ↑ means higher is better, and↓ means lower is better. MOTA equally considers FP, FN, and IDs in the trajectory. Since the number of FPs and FNs is much larger than that of IDs, MOTA is more inclined to measure the detection performance. IDF1 focuses on whether the ID of the track remains the same throughout the tracking process. IDF1 is more sensitive to the performance of data association. HOTA is a very recently proposed metric, which computes the geometric mean of detection accuracy and association accuracy.
Implementation Details. The experimental environment is a deep learning server with an Intel Xeon CPU Gold 6130 processor and two RTX 2080 Ti GPUs. We evaluate the tracking performance using a single GPU. For CSMOT, we employ DLA-34 [
10] as the backbone network and initialize the algorithm model by adopting CenterNet [
6] detection model parameters that have been pre-trained on the COCO [
34] dataset. The input image is resized to 1088 × 608. During data preprocessing, we introduce standard data augmentation methods including rotation, scaling, and color jittering. We train our CSMOT with the Adam optimizer for 40 epochs, with an initial learning rate of 10
-4. At the 20th epoch and 35th epoch, the learning rate decreases to 10
-5 and 10
-6, respectively. The model is trained with a batch size of 12. The total training time is about 40 h.
4.2. Ablation Studies
In this section, we present rigorous studies of the four critical factors mentioned in
Section 1, including the encoder–decoder network, re-ID branch loss, feature dimensions, and data association. We train CSMOT on a combination of CrowdHuman and the MOT17 half-training set, if not specified. The remaining half of the MOT17 training set is used for validation. Additionally, we perform a fair comparison with advanced one-shot MOT algorithms and a training data ablation study.
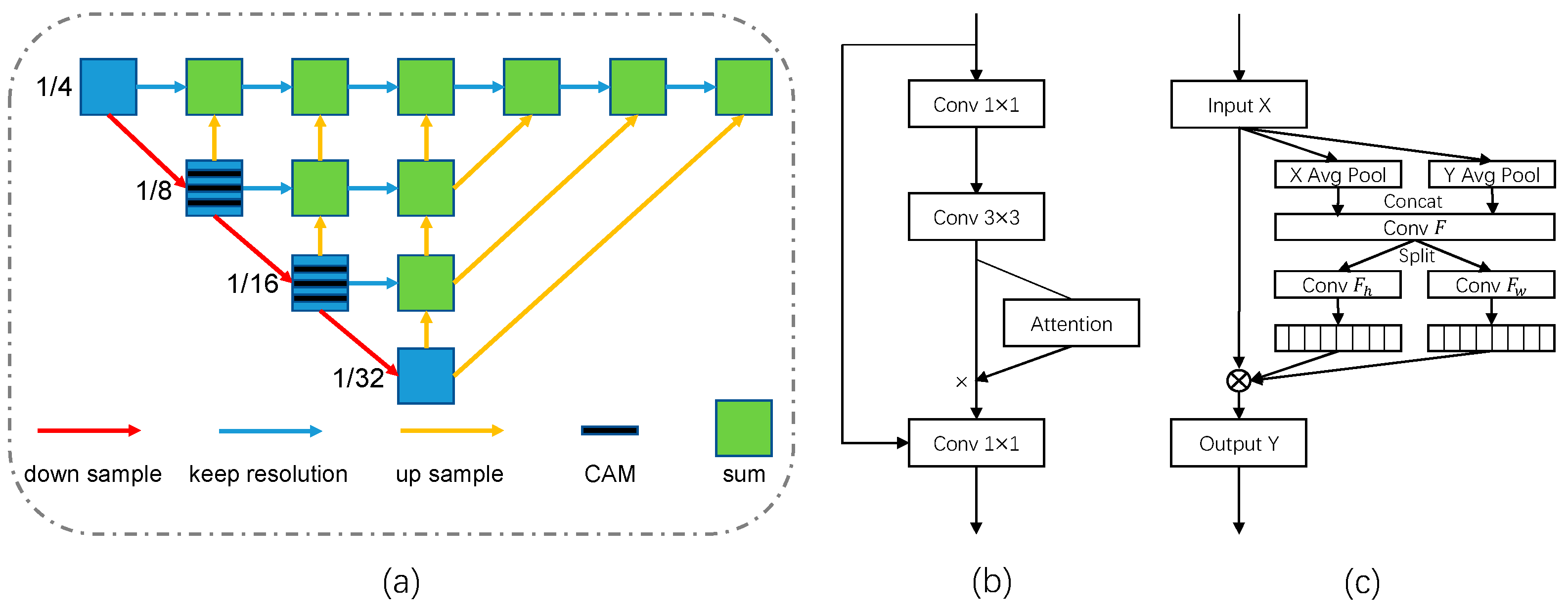
Encoder–Decoder Network. This section presents the tracking performance between the unmodified DLA-34 network and those with CAMs, which are inserted at the head, neck, and backbone locations. The results are shown in
Table 2.
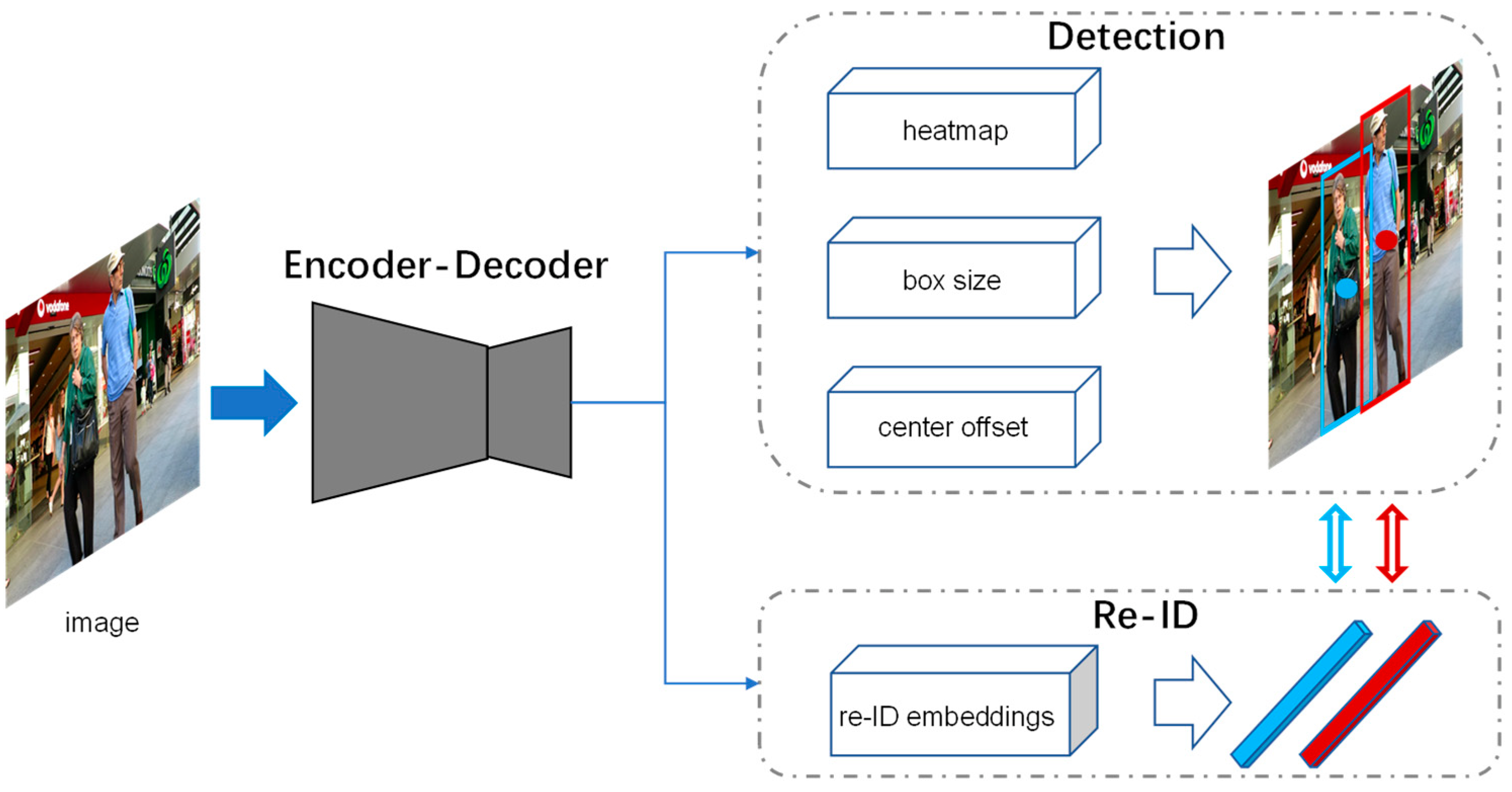
Notably, the head represents the detection and re-ID branch in
Figure 3. The neck and backbone, respectively, represent the “blue” basic blocks and the “green” aggregation blocks in
Figure 4. Our experiments show that CAM is sensitive to location. The tracking performance degrades when the CAMs are inserted into the head and neck locations of the encoder–decoder network. On the one hand, because the resolution of feature maps at the head is too low, the additional spatial masks instead introduce a large proportion of non-pixel information. On the other hand, the number of channels at the neck is large, and the frequent adjustment of the relationship between channels can easily lead to overfitting. When we combine CAMs with the basic blocks in the backbone, which is responsible for feature extraction, it improves the MOTA from 71.2 to 71.9 and the IDF1 from 74.7 to 75.1 and decreases the IDs from 413 to 383. At the same time, it leads to only a small decrease in the inference speed. Therefore, CAMs are more suitable for the middle layers of the encoder–decoder network with a moderate spatial resolution and number of channels. Increasing the weight on the object center improves the tracking accuracy in crowded scenes.
Re-ID Branch Loss. In this section, the tracking performance is presented under the supervision of two loss functions and the proposed angle-center loss. We set the hyperparameter
in Equation (11) to 0.001. The results are shown in
Table 3.
The re-ID subtask in multi-object tracking is a fine-grained classification process. Classifying objects with high similarity necessitates more stringent requirements for the re-ID features. We can see that Normed-Softmax achieves a better performance than Softmax for all metrics, which indicates that optimizing the angle in Equation (8) rather than the inner product can make re-ID features more discriminative. This is fully consistent with the method of using the cosine distance to compute the similarity of re-ID features. In addition, the proposed angle-center loss improves the MOTA of Normed-Softmax from 71.2 to 71.6 and the IDF1 from 74.7 to 75.6 and decreases the IDs from 413 to 365. The numbers of FPs and FNs are also minimized. The cosine distance constraint term based on the angular center can make the intra-class distance more compact. In crowded scenes, high-quality re-ID features can re-associate objects after severe occlusion.
Re-ID Feature Dimensions. Previous two-step MOT algorithms usually learn 512-dimensional re-ID features. High-dimensional features are effective for algorithms that use an independent network to extract re-ID features. Our experiments show that one-shot algorithms based on the joint detection and re-ID paradigm are better adapted to lower-dimensional features. The subtasks in multitask learning are coupled with each other, and the feature dimension plays an important role in balanced learning. We evaluate two choices for the re-ID feature dimensions of JDE, FairMOT, and CSMOT in
Table 4.
For JDE, the 64-dimensional feature performs better than the 512-dimensional feature for all metrics. For FairMOT and CSMOT, the performance of the two algorithms is similar. We can see that 512 achieves higher IDF1 scores, which indicates that the high-dimensional re-ID features have stronger discriminability. However, 64 performs better on the MOTA and ID metrics. Lower feature dimensions can reduce the constraints on the detection branch, and more accurate detections further ensure the continuity of the trajectory. For one-shot MOT algorithms, the re-ID features can be adaptively adjusted to low dimensions to balance the two subtasks of detection and re-ID.
Data Association Methods. This section evaluates two ingredients, the bounding box IoU and re-ID features, in different data association methods including MOTDT [
35] and ByteTrack. MOTDT integrates motion-guided box propagation results and detection results to associate unreliable detection results with tracklets. The results are shown in
Table 5.
Box IoU and re-ID features are used to compute the similarity between detections and tracks. We can see that relying solely on box IoU leads to a poor tracking performance for both methods. IoU cannot cope with re-identification after severe occlusion between objects. This is particularly true for crowded scenes. Adding re-ID features significantly increases IDF1 and decreases the number of ID switches, which also improves MOTA. Accordingly, the importance of high-quality re-ID features for tracking is also confirmed. ByteTrack improves the MOTA of MOTDT from 71.8 to 72.6 and the IDF1 from 75.6 to 76.1 and decreases IDs from 348 to 289. By making full use of low-score detections to associate trajectories, it can improve tracking accuracy and reduce the rate of fragmented trajectories.
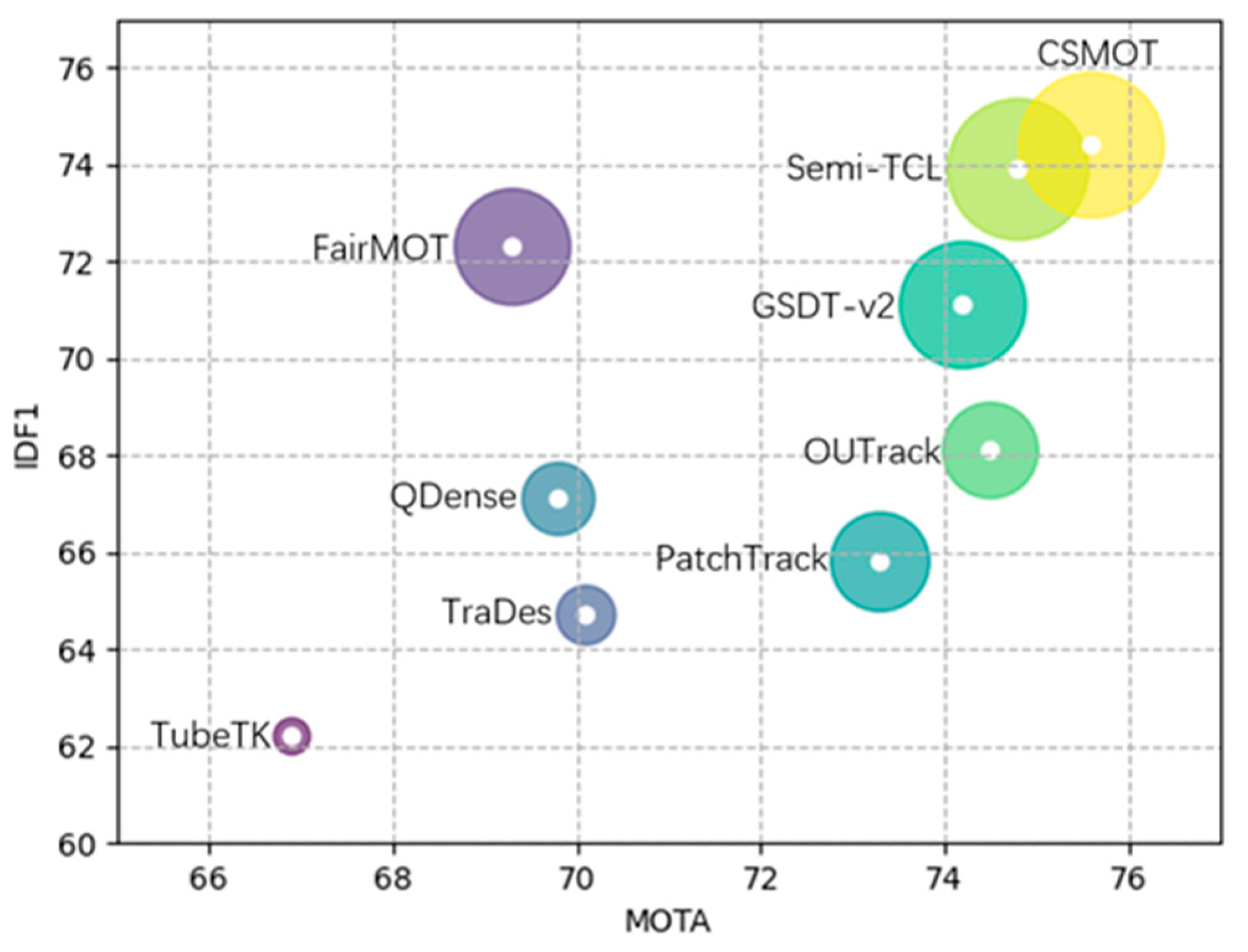
Comparison of Advanced One-Shot MOT Algorithms. Advanced works based on joint detection and embedding include JDE, TrackRCNN, and FairMOT. For fairness, we use the same training data to compare all of these methods, as described in the relevant papers. The test set is derived from six videos of 2DMOT15. JDE, FairMOT, and CSMOT all use the large-scale dataset described in Datasets. Since TrackRCNN requires segmentation labels for training, only four videos with segmentation labels from MOT17 were used as the training set. The results are shown in
Table 6.
When the training set is the large-scale HYBRID, we achieve a significant improvement in the performance of CSMOT compared to that of JDE. The IDF1 score increases from 66.7 to 80.5, and the number of ID switches decreases from 218 to 51. This is because the anchor-free method can better solve the problem of the ambiguous expression of anchor boxes in the MOT task. Without loading pre-trained weights, CSMOT has an advantage over FairMOT in the IDF1 and IDs metrics, which proves its better performance in maintaining trajectory continuity. When the training set is the small-scale MOT17Seg, CSMOT has an overwhelming advantage over TrackRCNN and FairMOT. CSMOT achieves a much higher IDF1 score (75.9 vs. 49.4, 64.0), a higher MOTA (72.9 vs. 69.2, 70.2), and fewer ID switches (69 vs. 294, 96). This proves that the proposed CSMOT has stronger generalization and robustness on the small-scale dataset.
Comparison of Different Training data. We evaluated the performance of CSMOT using different combinations of training data, and the results are shown in
Table 7.
When only the first half of MOT17 is used for training, a MOTA of 67.6 and an IDF1 of 69.9 are achieved. This already constitutes an outperformance of most MOT algorithms, which shows the superiority of our CSMOT. When further adding CrowdHuman, the MOTA and IDF1 metrics improve significantly. On the one hand, CrowdHuman boosts the detection branch, enabling it to recognize occluded objects. On the other hand, more accurate detection boxes can improve the performance of data association. In addition, when we add large-scale training datasets, MOTA and IDF1 achieved improvements of only 0.1 and 0.7, respectively, because the network model has already achieved good fitting under the training of the CrowdHuman and MOT17 datasets. The experimental results prove that CSMOT is not data-hungry, which is an advantage in many applications.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}