


An LEO Constellation Early Warning System Decision-Making Method Based on Hierarchical Reinforcement Learning
Abstract
1. Introduction
2. Problem Description
2.1. LEO Constellation Early Warning System
2.1.1. Constellation Configuration
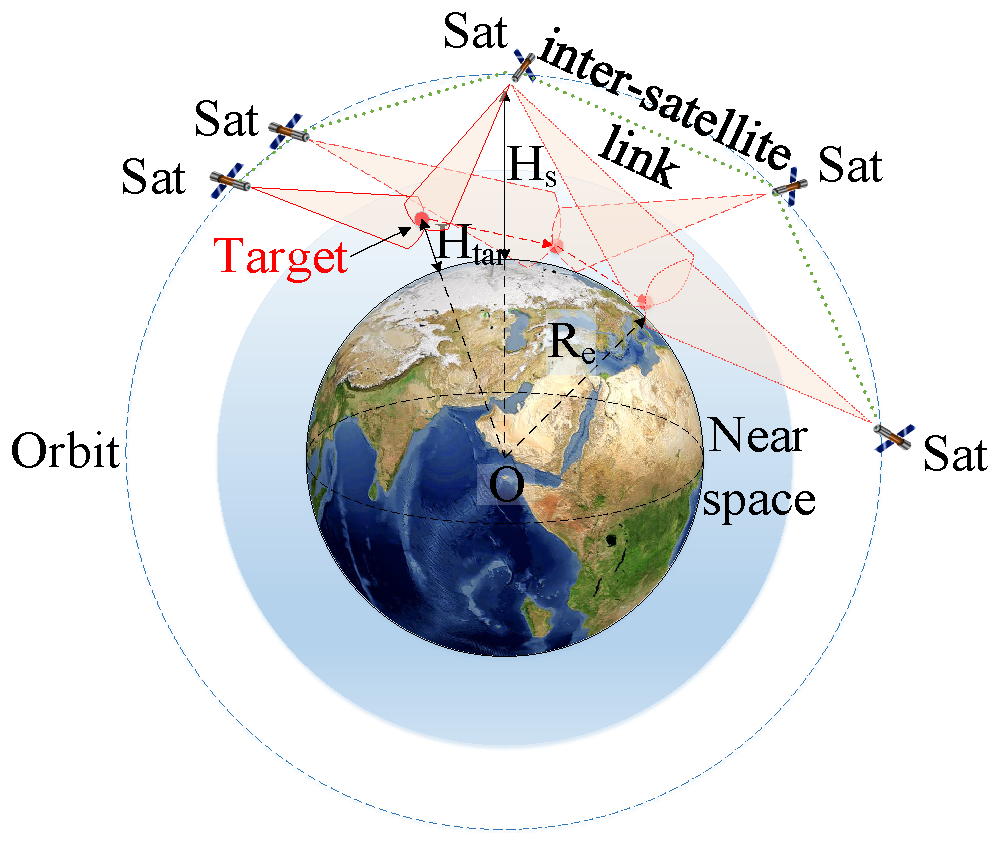
2.1.2. Inter-Satellite Communication Constraints
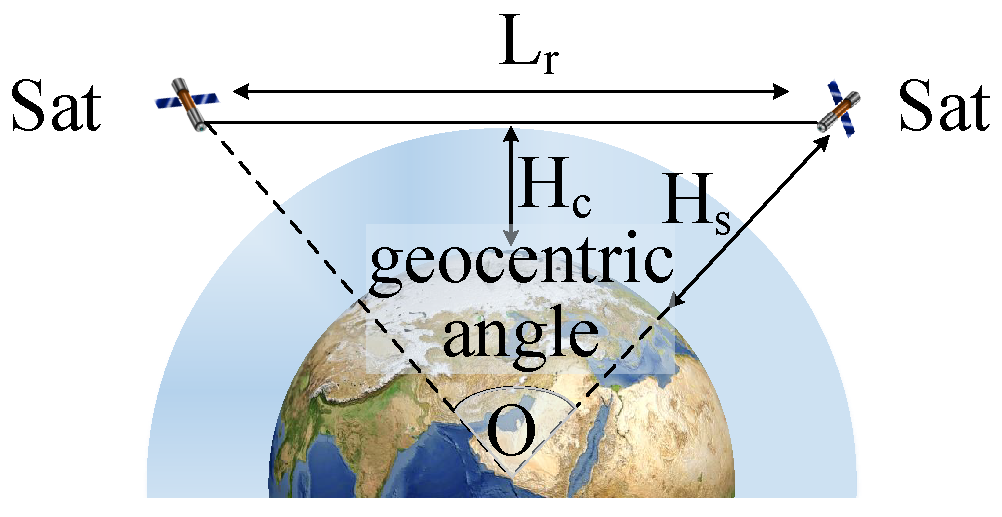
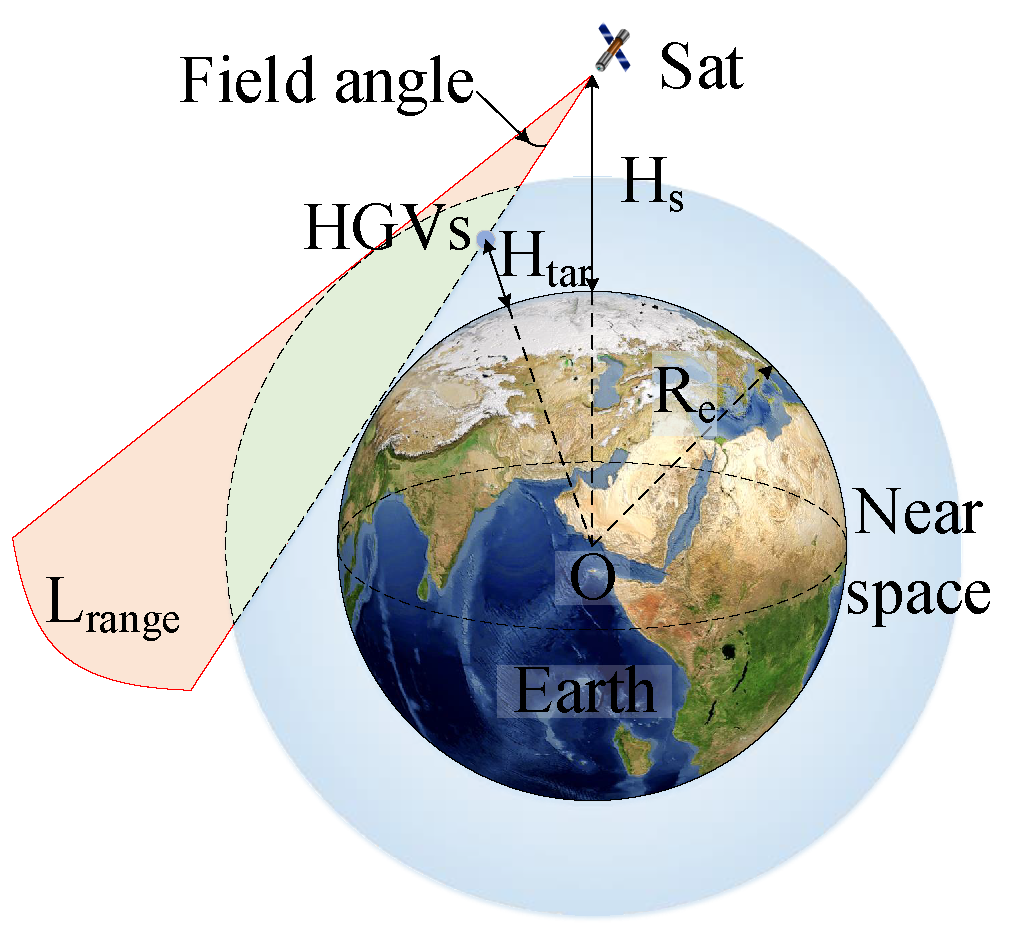
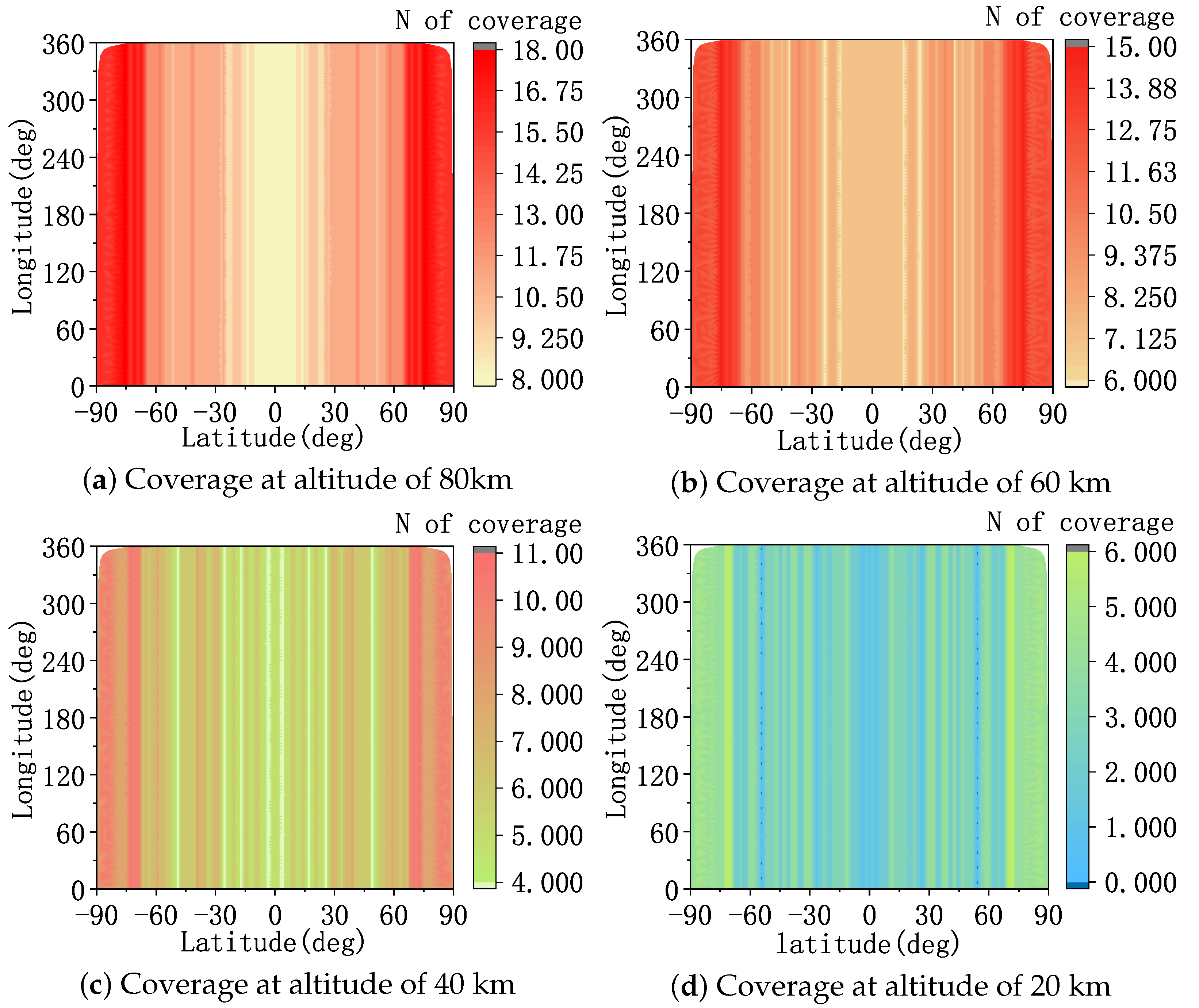
2.1.3. Infrared Sensor Constraint
2.2. LEO Constellation Early Warning System Near-Space Multi-Target Tracking Problem
2.3. Dual Satellite Geometric Positioning
2.4. Constellation Information Sharing Policy
3. Decision-Making Approach Based on Hierarchical Proximal Policy Optimization
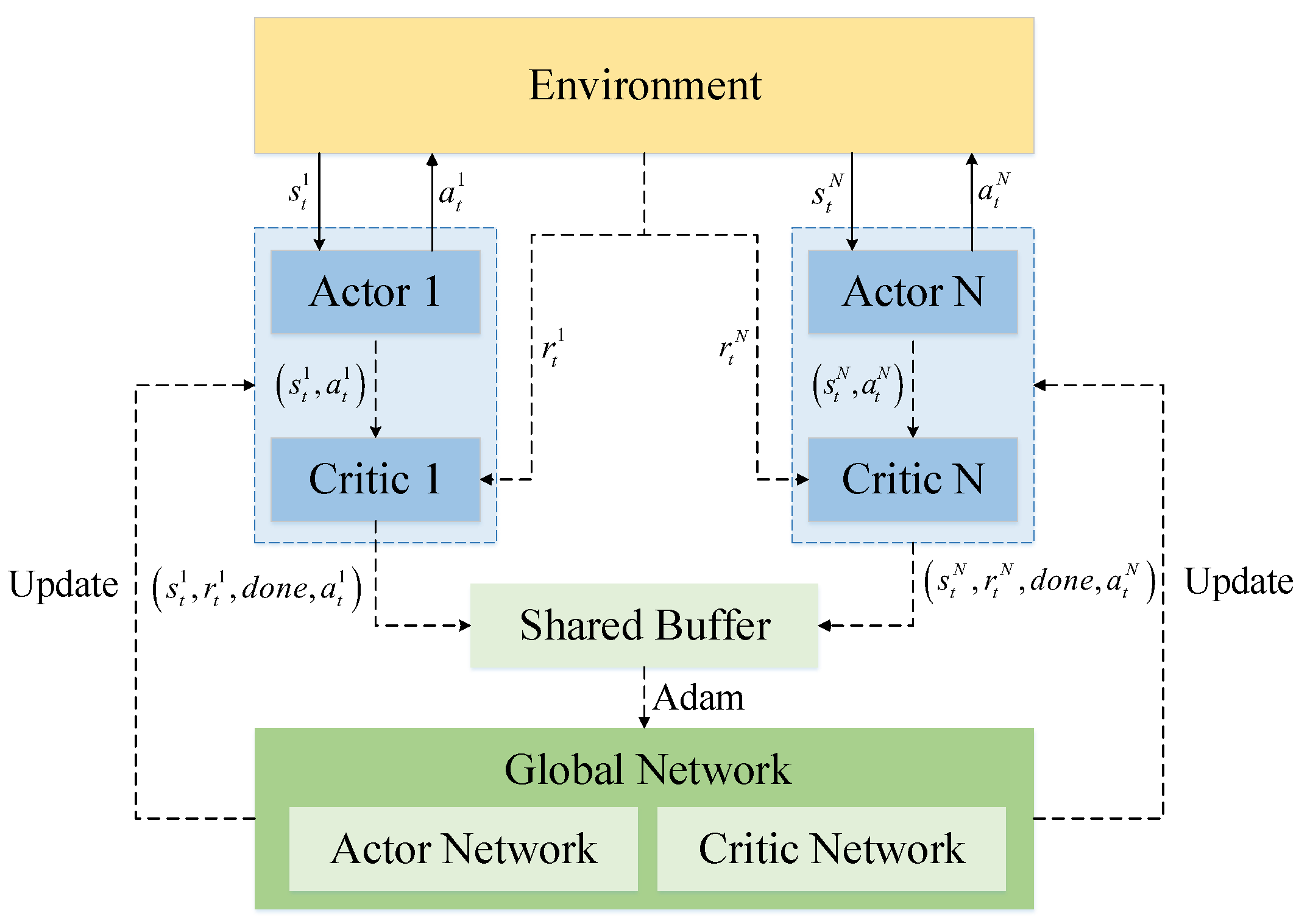
3.1. Multi-Agent Proximal Policy Optimization Algorithm
3.1.1. Environmental State Space
3.1.2. Action Space
3.1.3. Reward Function
3.1.4. Network Update
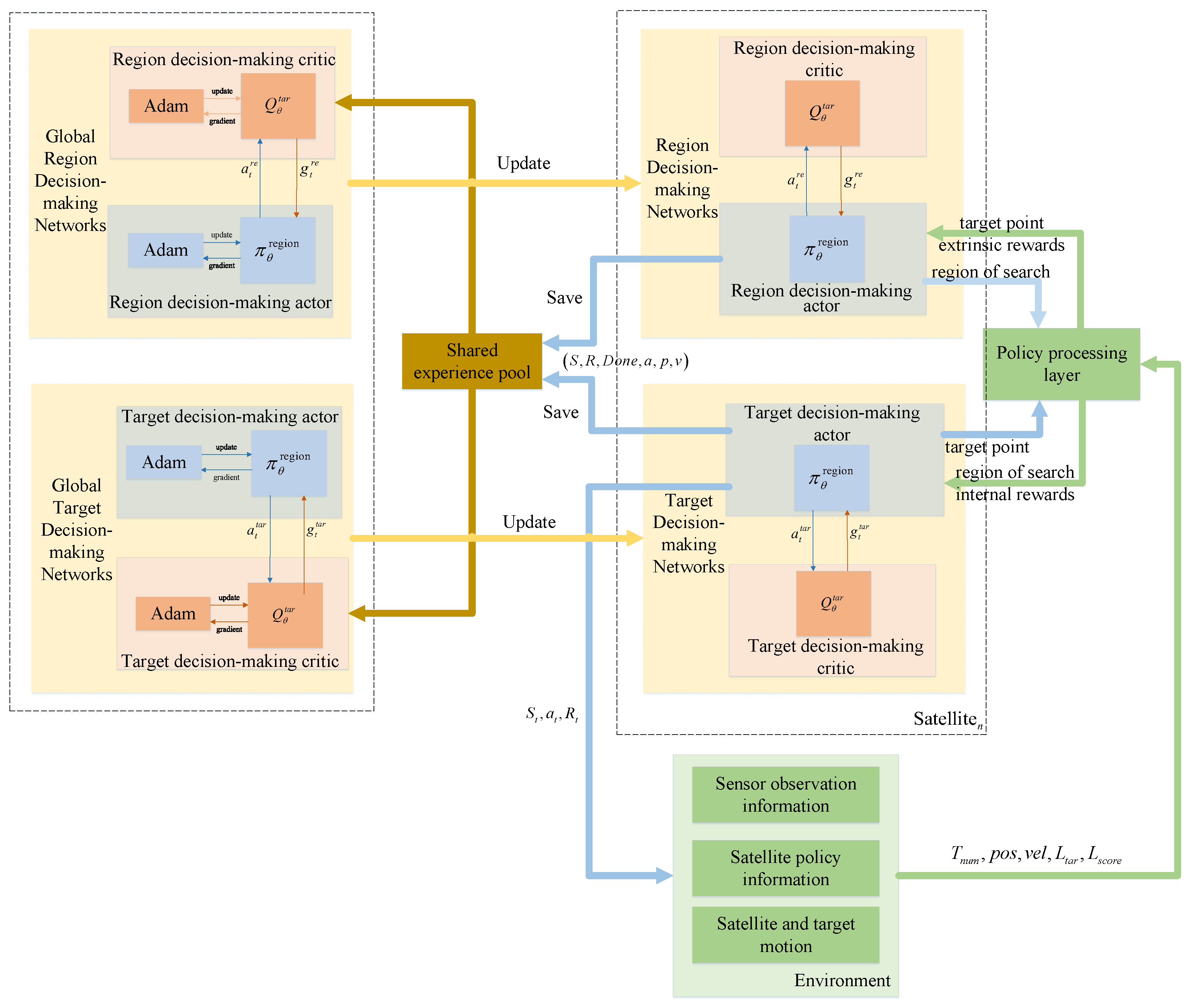
3.2. MAPPO-RHC Algorithm
3.2.1. Hierarchical Decision-Making Network Design
| Algorithm 1: Training and parameter update process of the MAPPO-RHC algorithm |
 |
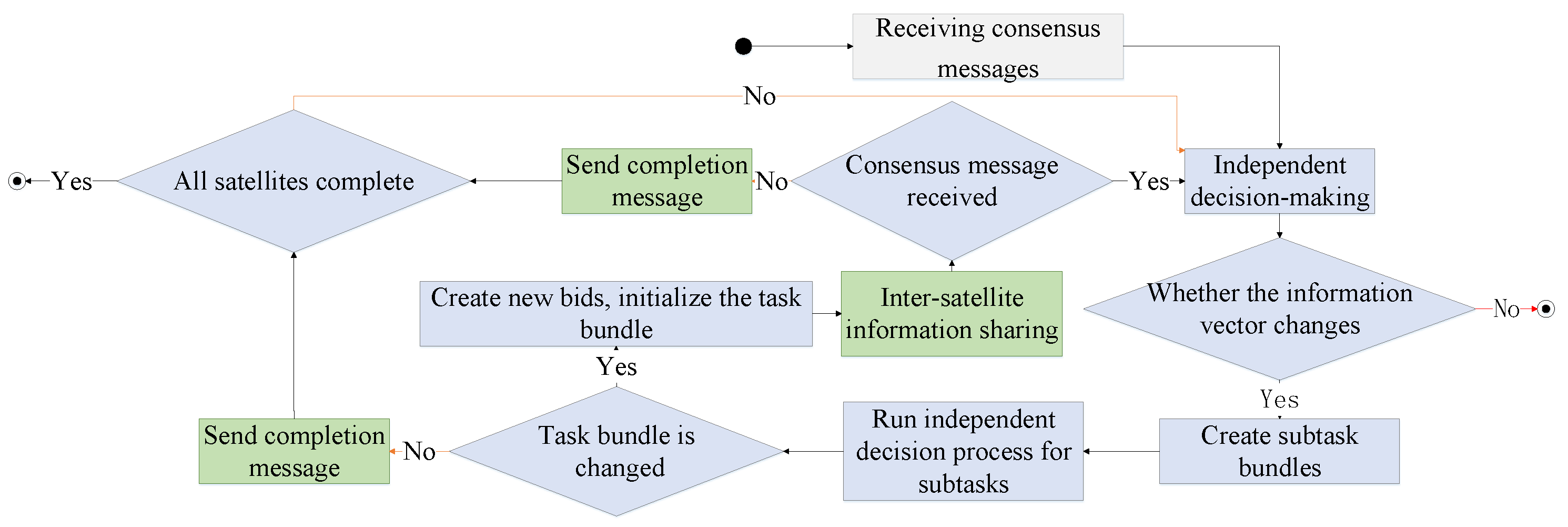
3.2.2. Local Search Algorithm Based on Random Hill Climbing
| Algorithm 2: Single-satellite local search method based on random hill climbing |
Input: : The initial multi-satellite tracking plan is obtained from a hierarchical proximal policy-optimization algorithm. : The maximum number of iterations for the local search. Output: : Final tracking plan  |
4. Simulation and Analysis
4.1. Constellation Parameter Setting
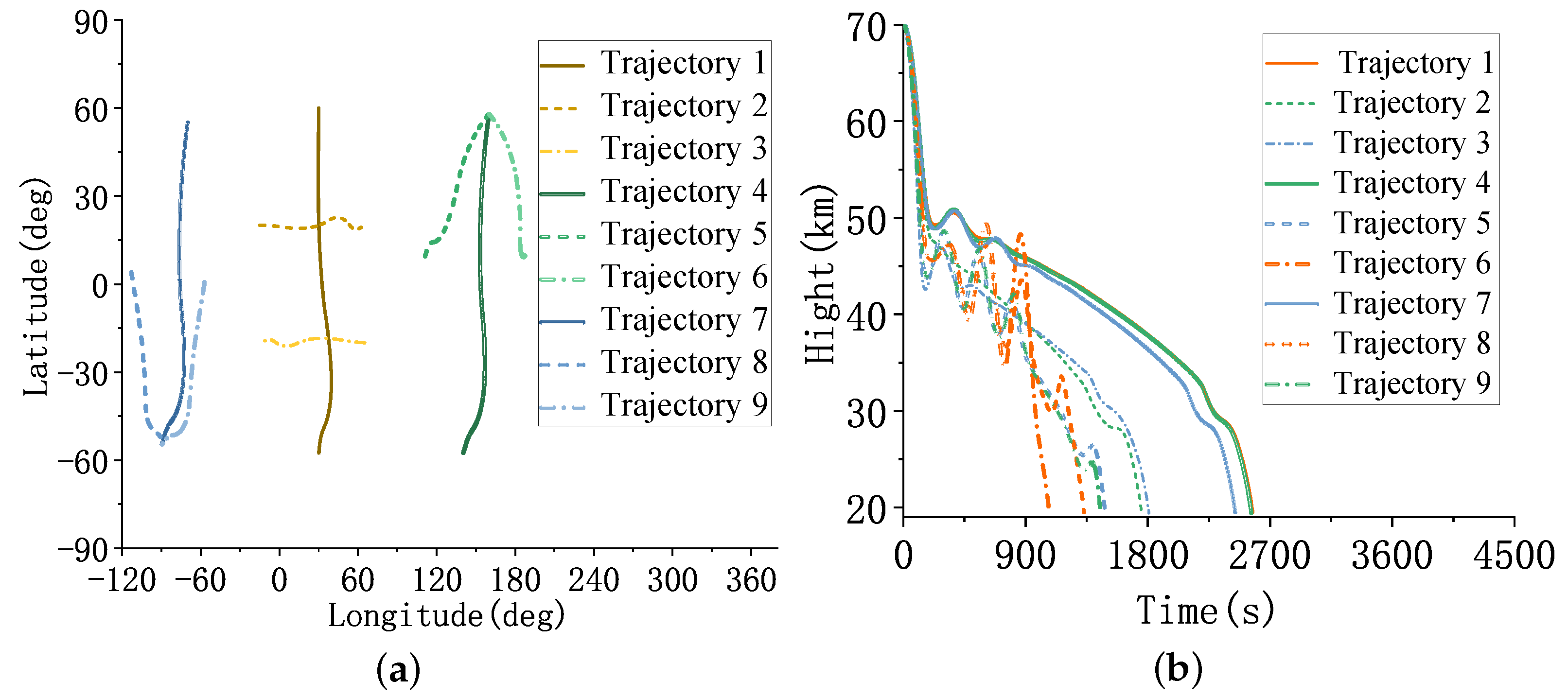
4.2. Generating the Training Set
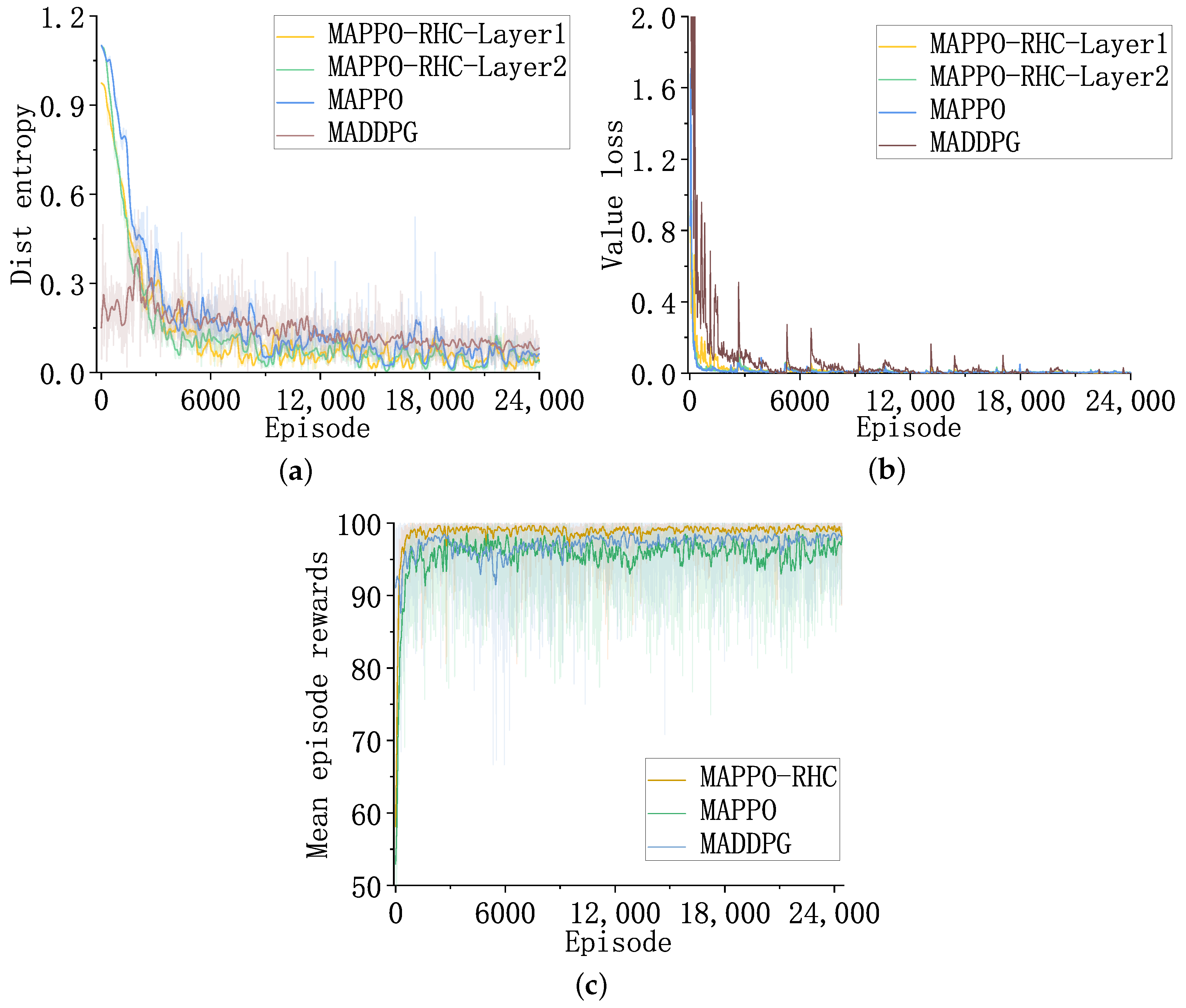
4.3. Training Results
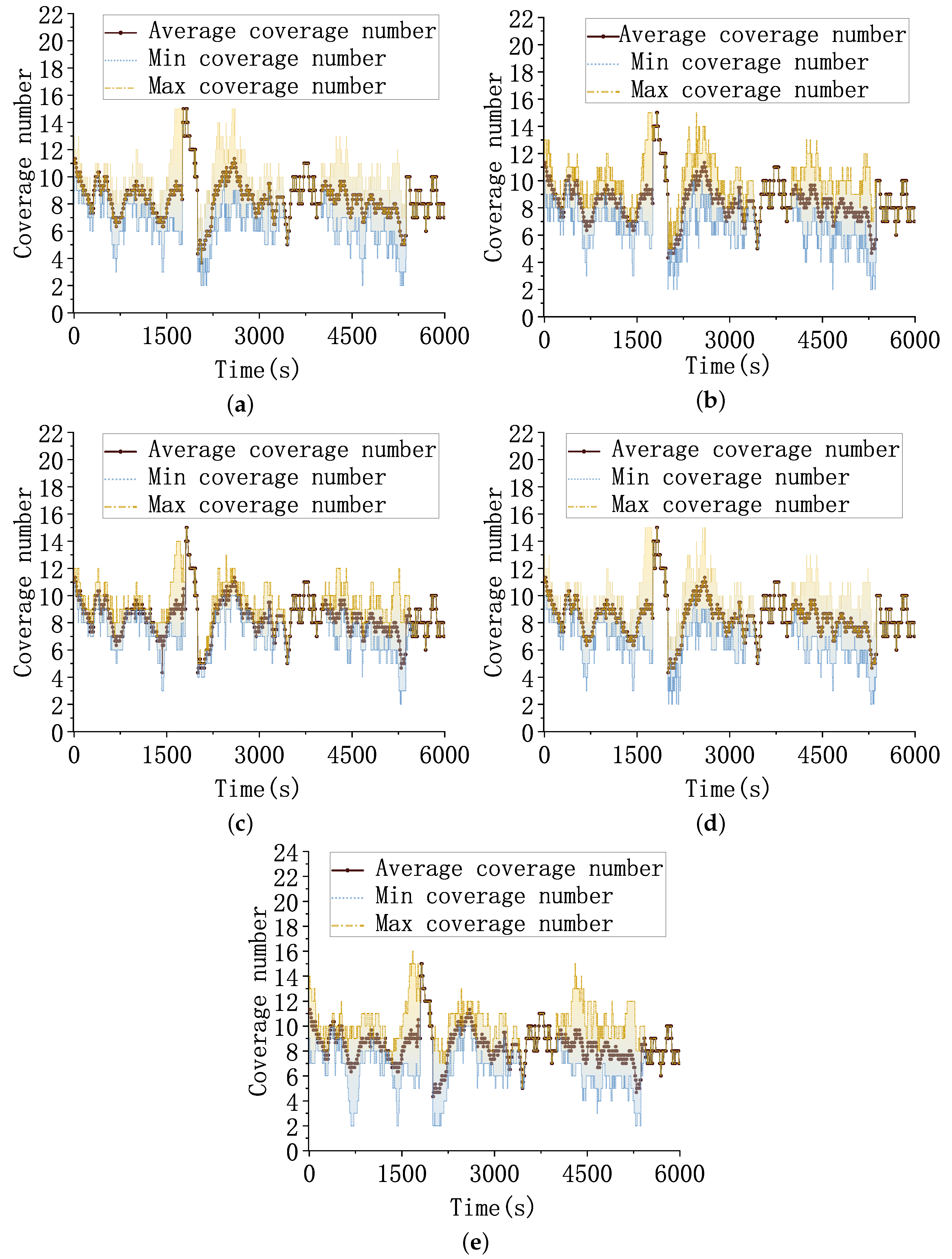
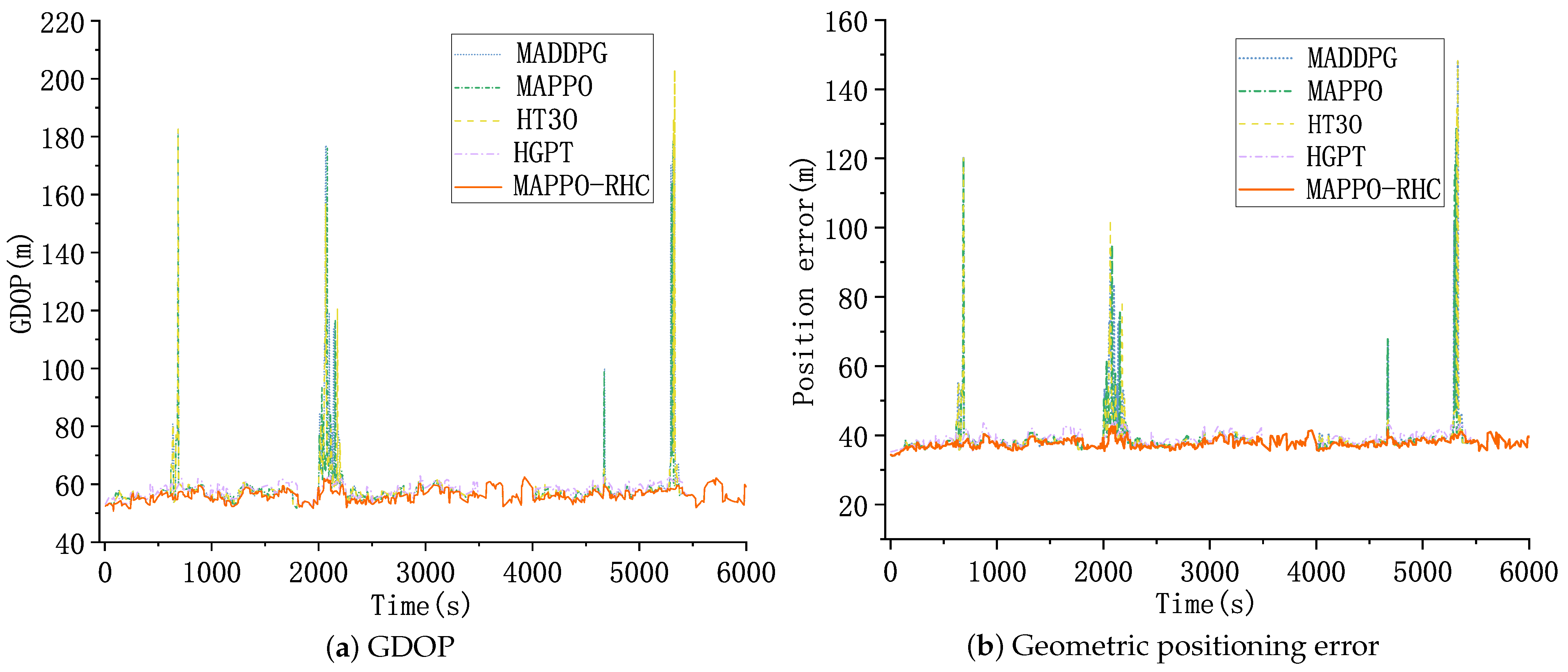
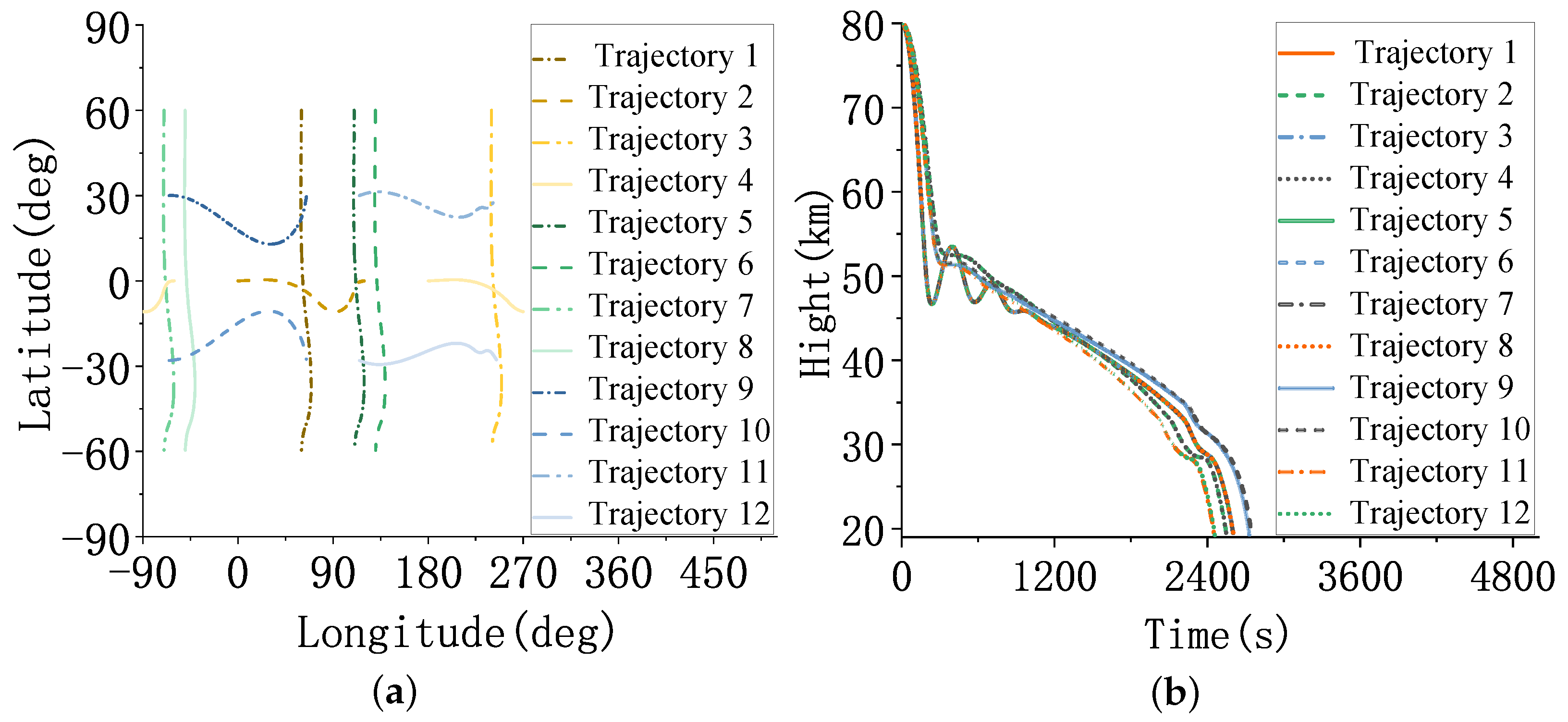
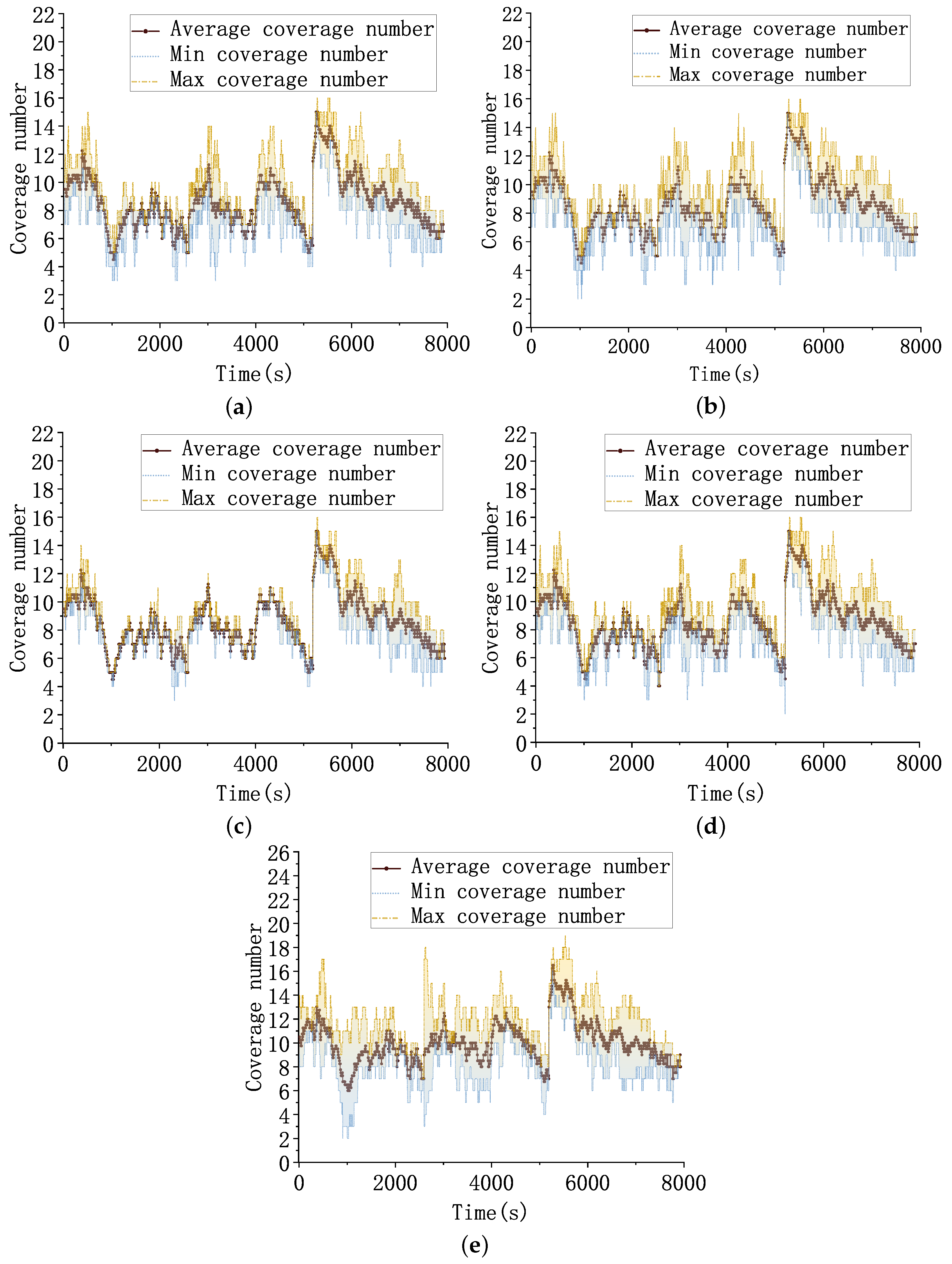
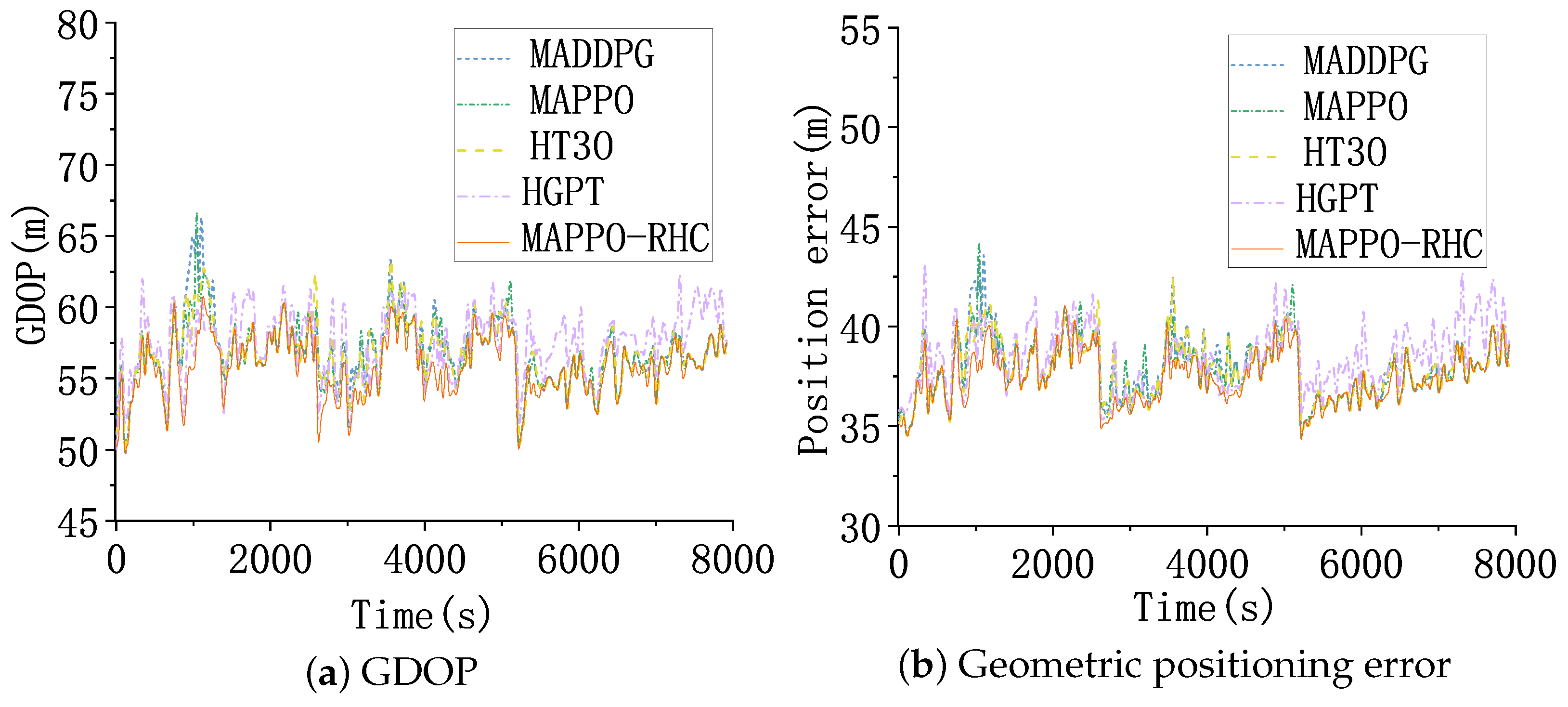
4.4. Test Scenario 1
4.5. Test Scenario 2
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Hyper-Parameter Settings for Networks and Training

{kind=link}
{kind=link}
{kind=link}
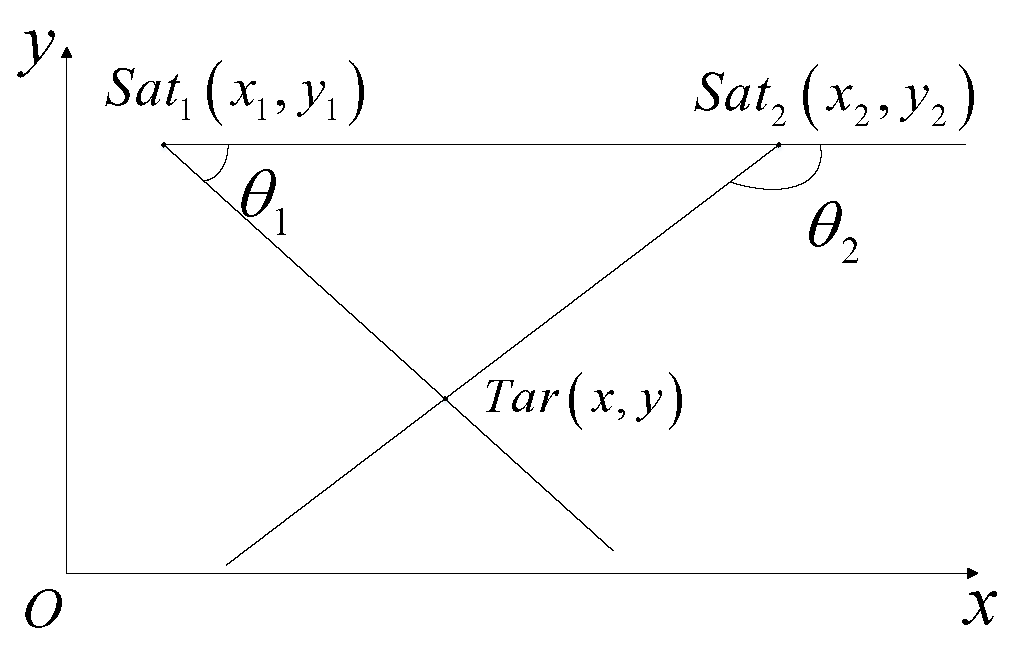{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Episode Length | Hidden Size | Layer N | Gain |
|---|---|---|---|
| 152 | 64 | 3 | 0.1 |
| lr | ppo Epoch | Clip Param | Gamma |
| 15 | 0.2 | 0.99 |
| Episode Length | Hidden Size | Layer N | Learning Start Step |
|---|---|---|---|
| 300 | 64 | 3 | 100 |
| lr | Memory Size | Max Grad Norm | Gamma |
| 0.5 | 0.97 |
Appendix B. The Parameters of HGVs
Appendix B.1. Test Scenario 1
| 1 | 30 | 60 | 70,000 | 7000 | 180 | 30.1 | −57.6 | 19,479 | 2000.4 |
| 1 | −15 | 20 | 70,000 | 6500 | 89 | 64.5 | 19.9 | 19,189 | 2000.4 |
| 1 | 65 | −20 | 70,000 | 6500 | −89 | −14.5 | −19.9 | 19,418 | 2000.5 |
| 1808 | 160 | 58 | 70,000 | 7000 | 190 | 140.3 | −57.6 | 19,445 | 2000.1 |
| 1808 | 160 | 58 | 70,000 | 6500 | 225 | 111.2 | 9.4 | 19,390 | 2000 |
| 3295 | 160 | 58 | 70,000 | 6500 | 135 | 187.6 | 9.7 | 20,760 | 2000.5 |
| 3295 | −70 | 55 | 70,000 | 7000 | 190 | −89.7 | −54.6 | 19,507 | 2000.7 |
| 3295 | −113 | 4 | 70,000 | 6500 | 160 | −89.8 | −54.6 | 19,521 | 2000.1 |
| 4320 | −57 | 0.7 | 70,000 | 6500 | 200 | −89.4 | −54.7 | 19,447 | 1999.8 |
Appendix B.2. Test Scenario 2
| 1 | 60 | 60 | 80,000 | 7000 | 180 | 60.1 | −59.6 | 19,472 | 2000.4 |
| 1 | 0 | 0 | 80,000 | 7000 | 89 | 119.6 | 0 | 19,348 | 1999.9 |
| 1 | 240 | 60 | 80,000 | 7000 | 180 | 240 | −59.6 | 19,472 | 2000.4 |
| 1 | 180 | 0 | 80,000 | 7000 | 89 | −60.4 | 0 | 19,348 | 1999.9 |
| 2549 | 110 | 60 | 80,000 | 7000 | 180 | 110.1 | −59.6 | 19,472 | 2000.4 |
| 2549 | 130 | 60 | 80,000 | 7000 | 180 | 130.1 | −59.6 | 19,472 | 2000.4 |
| 2549 | 290 | 60 | 80,000 | 7000 | 180 | −69.9 | −59.6 | 19,472 | 2000.4 |
| 2549 | 310 | 60 | 80,000 | 7000 | 180 | −49.9 | −59.6 | 19,472 | 2000.4 |
| 5150 | −65 | 30 | 80,000 | 7000 | 89 | 64.8 | 29.6 | 19,230 | 2000 |
| 5150 | −65 | −28 | 80,000 | 7000 | 89 | 64.8 | −27.6 | 19,313 | 2000.3 |
| 5150 | 115 | 38 | 80,000 | 7000 | 80 | 244.6 | 29.7 | 19262 | 2000.8 |
| 5150 | 115 | −28 | 80,000 | 7000 | 100 | 244.6 | −27.7 | 19,240 | 2000.7 |
References
- Panda, D.P.; Bandi, K.; Sastry, P.S.; Rambabu, K. Satellite Constellation Design Studies for Missile Early Warning. In Advances in Small Satellite Technologies; Lecture Notes in Mechanical Engineering; Sastry, P.S., Cv, J., Raghavamurthy, D., Rao, S.S., Eds.; Springer: Singapore, 2020; pp. 385–396. [Google Scholar]
- Huang, Z.C.; Zhang, Y.S.; Liu, Y. Research on State Estimation of Hypersonic Glide Vehicle. J. Phys. Conf. Ser. 2018, 1060, 012088. [Google Scholar] [CrossRef]
- Yang, W.; He, L.; Liu, X.; Chen, Y. Onboard coordination and scheduling of multiple autonomous satellites in an uncertain environment. Adv. Space Res. 2021, 68, 4505–4524. [Google Scholar] [CrossRef]
- Zhang, F.; Chen, Y.; Chen, Y. Evolving Constructive Heuristics for Agile Earth Observing Satellite Scheduling Problem with Genetic Programming. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- He, L.; Liang, B.; Li, J.; Sheng, M. Joint Observation and Transmission Scheduling in Agile Satellite Networks. IEEE Trans. Mob. Comput. 2021, 21, 4381–4396. [Google Scholar] [CrossRef]
- Qi, W.; Yang, W.; Xing, L.; Yao, F. Modeling and Solving for Multi-Satellite Cooperative Task Allocation Problem Based on Genetic Programming Method. Mathematics 2022, 10, 3608. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, B.; Shen, C. A multi-objective scheduling method for operational coordination time using improved triangular fuzzy number representation. PLoS ONE 2021, 16, e0252293. [Google Scholar] [CrossRef]
- Jinming, L.; Yingguo, C.; Rui, W.; Yingwu, C. Complex task planning method of space-aeronautics cooperative observation based on multi-layer interaction. J. Syst. Eng. Electron. 2022, 99, 1–15. [Google Scholar] [CrossRef]
- Jiang, X.; Song, Y.; Xing, L. Dual-Population Artificial Bee Colony Algorithm for Joint Observation Satellite Mission Planning Problem. IEEE Access 2022, 10, 28911–28921. [Google Scholar] [CrossRef]
- Jun, W.; Xiaolu, L.; Lei, H. Real-time online rescheduling for multiple agile satellites with emergent tasks. J. Syst. Eng. Electron. 2021, 32, 1407–1420. [Google Scholar] [CrossRef]
- Zhang, G.; Li, X.; Hu, G.; Zhang, Z.; An, J.; Man, W. Mission Planning Issues of Imaging Satellites: Summary, Discussion, and Prospects. Int. J. Aerosp. Eng. 2021, 2021, 7819105. [Google Scholar] [CrossRef]
- Du, Y.; Wang, T.; Xin, B.; Wang, L.; Chen, Y.; Xing, L. A Data-Driven Parallel Scheduling Approach for Multiple Agile Earth Observation Satellites. IEEE Trans. Evol. Comput. 2020, 24, 679–693. [Google Scholar] [CrossRef]
- Zhou, F.; Wang, Y.; Zheng, W.; Li, Z.; Wen, X. Fast Distributed Multiple-Model Nonlinearity Estimation for Tracking the Non-Cooperative Highly Maneuvering Target. Remote Sens. 2022, 14, 4239. [Google Scholar] [CrossRef]
- Liu, S.; Yang, J. A Satellite Task Planning Algorithm Based on a Symmetric Recurrent Neural Network. Symmetry 2019, 11, 1373. [Google Scholar] [CrossRef]
- Ren, B.; Zhu, Z.; Yang, F.; Wu, T.; Yuan, H. High-altitude satellites range scheduling for urgent request utilizing reinforcement learning. Open Astron. 2022, 31, 268–275. [Google Scholar] [CrossRef]
- Chen, H.; Luo, Z.; Peng, S.; Wu, J.; Li, J. HiPGen: An approach for fast generation of multi-satellite observation plans via a hierarchical multi-channel transformer network. Adv. Space Res. 2022, 69, 3103–3116. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, X.; Ma, Z.; Liu, S.; Song, J. An online power allocation algorithm based on deep reinforcement learning in multibeam satellite systems. Int. J. Satell. Commun. Netw. 2020, 38, 450–461. [Google Scholar] [CrossRef]
- He, Y.; Wu, G.; Chen, Y.; Pedrycz, W. A Two-stage Framework and Reinforcement Learning-based Optimization Algorithms for Complex Scheduling Problems. arXiv 2021, arXiv:2103.05847. [Google Scholar]
- Xia, K.; Feng, J.; Yan, C.; Duan, C. BeiDou Short-Message Satellite Resource Allocation Algorithm Based on Deep Reinforcement Learning. Entropy 2021, 23, 932. [Google Scholar] [CrossRef]
- Yin, Y.; Huang, C.; Wu, D.F.; Huang, S.; Ashraf, M.W.A.; Guo, Q.; Zhang, L. Deep Reinforcement Learning-Based Joint Satellite Scheduling and Resource Allocation in Satellite-Terrestrial Integrated Networks. Wirel. Commun. Mob. Comput. 2022, 2022, 1177544. [Google Scholar] [CrossRef]
- Qie, H.; Shi, D.; Shen, T.; Xu, X.; Li, Y.; Wang, L. Joint Optimization of Multi-UAV Target Assignment and Path Planning Based on Multi-Agent Reinforcement Learning. IEEE Access 2019, 7, 146264–146272. [Google Scholar] [CrossRef]
- Bao, X.; Zhang, S.; Zhang, X. An Effective Method for Satellite Mission Scheduling Based on Reinforcement Learning. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 4037–4042. [Google Scholar]
- Dalin, L.; Haijiao, W.; Zhen, Y.; Yanfeng, G.; Shi, S. An Online Distributed Satellite Cooperative Observation Scheduling Algorithm Based on Multiagent Deep Reinforcement Learning. IEEE Geosci. Remote Sens. Lett. 2021, 18, 1901–1905. [Google Scholar] [CrossRef]
- Shen, S.; Shen, G.; Shen, Y.; Liu, D.; Yang, X.; Kong, X. PGA: An Efficient Adaptive Traffic Signal Timing Optimization Scheme Using Actor-Critic Reinforcement Learning Algorithm. KSII Trans. Internet Inf. Syst. 2020, 14, 4268–4289. [Google Scholar]
- Zhang, H.; Liu, X.; Long, K.; Poor, H.V. Primal Dual PPO Learning Resource Allocation in Indoor IRS-Aided Networks. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Li, X.; Chen, J.; Cai, X.; Cui, N. Satellite Online Scheduling Algorithm Based on Proximal Policy. In Artificial Intelligence in China; Series Title: Lecture Notes in Electrical, Engineering; Liang, Q., Wang, W., Mu, J., Liu, X., Na, Z., Eds.; Springer: Singapore, 2022; Volume 854, pp. 100–108. [Google Scholar]
- Wei, L.; Chen, Y.; Chen, M.; Chen, Y. Deep reinforcement learning and parameter transfer based approach for the multi-objective agile earth observation satellite scheduling problem. Appl. Soft Comput. 2021, 110, 107607. [Google Scholar] [CrossRef]
- Huang, Y.; Mu, Z.; Wu, S.; Cui, B.; Duan, Y. Revising the Observation Satellite Scheduling Problem Based on Deep Reinforcement Learning. Remote Sens. 2021, 13, 2377. [Google Scholar] [CrossRef]
- Kopacz, J.; Roney, J.; Herschitz, R. Deep replacement: Reinforcement learning based constellation management and autonomous replacement. Eng. Appl. Artif. Intell. 2021, 104, 104316. [Google Scholar] [CrossRef]
- Ren, T.; Niu, J.; Dai, B.; Liu, X.; Hu, Z.; Xu, M.; Guizani, M. Enabling Efficient Scheduling in Large-Scale UAV-Assisted Mobile-Edge Computing via Hierarchical Reinforcement Learning. IEEE Internet Things J. 2022, 9, 7095–7109. [Google Scholar] [CrossRef]
- Ren, L.; Ning, X.; Li, J. Hierarchical Reinforcement-Learning for Real-Time Scheduling of Agile Satellites. IEEE Access 2020, 8, 220523–220532. [Google Scholar] [CrossRef]
- Zhao, X.; Wang, Z.; Zheng, G. Two-Phase Neural Combinatorial Optimization with Reinforcement Learning for Agile Satellite Scheduling. J. Aerosp. Inf. Syst. 2020, 17, 346–357. [Google Scholar] [CrossRef]
- Yue, L.; Yang, R.; Zuo, J.; Zhang, Y.; Li, Q.; Zhang, Y. Unmanned Aerial Vehicle Swarm Cooperative Decision-Making for SEAD Mission: A Hierarchical Multiagent Reinforcement Learning Approach. IEEE Access 2022, 10, 92177–92191. [Google Scholar] [CrossRef]
- Guo, D.; Tang, L.; Zhang, X.; Liang, Y.C. Joint Optimization of Handover Control and Power Allocation Based on Multi-Agent Deep Reinforcement Learning. IEEE Trans. Veh. Technol. 2020, 69, 13124–13138. [Google Scholar] [CrossRef]
- Peng, G.; Song, G.; He, Y.; Yu, J.; Xiang, S.; Xing, L.; Vansteenwegen, P. Solving the Agile Earth Observation Satellite Scheduling Problem With Time-Dependent Transition Times. IEEE Trans. Syst. Man Cybern. Syst. 2022, 52, 1614–1625. [Google Scholar] [CrossRef]
- Liu, J.; Luo, Q.; Lou, J.; Li, Y. An Adaptive Infrared Tracking Method for Spacebased Surveillance to a Hypersonic Cruise Vehicle. In Proceedings of the 2020 Chinese Automation Congress (CAC), Shanghai, China, 6–8 November 2020; pp. 249–254. [Google Scholar]
- Bing, H.; Hongru, L.; Guoming, L.; Zhijun, P.; Tao, J. Simulation modeling and detection performance analysis of space-based infrared early warning system. In Proceedings of the 2022 IEEE fifth International Conference on Information Systems and Computer Aided Education (ICISCAE), Dalian, China, 23–25 September 2022; pp. 969–977. [Google Scholar]
- Shi, A.H.; Shi, W.B.; Zhang, Z.G.; Liao, H.H.; Liu, S. Analysis of Infrared Satellite’s Detectability for Common Hypersonic Glide Body. INFRARED 2021, 42, 1–8. [Google Scholar]
- Zhang, Z.; Gao, C. Infrared measurement and composite tracking algorithm for air-breathing hypersonic vehicles. J. Electron. Imaging 2018, 27, 1. [Google Scholar] [CrossRef]
- Zhang, H.L.; Zhou, L.; Zuo, W.B.; Fan, Q.; Tan, X.J. Study on infrared radiation feature of near space hypersonic missile. Laser Infrared 2015, 45, 41–44. [Google Scholar]















| True | 40 | 60 | 40 | 60 | |
| False | 10 | 20 | 20 | 0 | |
| (s) | |||||
|---|---|---|---|---|---|
| Maximum | 0.0041 | 0.0068 | 0.0031 | 0.0030 | 0.019 |
| Average | 0.0028 | 0.0038 | 0.0012 | 0.0010 | 0.017 |
| Minimum | 0.0019 | 0.0028 | 0.0005 | 0.005 | 0.015 |
| Maximum | 0.017 | 0.0091 | 0.0068 | 0.7564 | 0.0014 |
| Average | 0.015 | 0.0073 | 0.0048 | 0.2639 | 0.0002 |
| Minimum | 0.014 | 0.0047 | 0.0027 | 0.2508 | 0 |
| (s) | |||||
|---|---|---|---|---|---|
| Maximum | 0.0063 | 0.0077 | 0.0042 | 0.0048 | 0.022 |
| Average | 0.0041 | 0.0043 | 0.0015 | 0.0020 | 0.013 |
| Minimum | 0.0029 | 0.0029 | 0.0006 | 0.0010 | 0.007 |
| Maximum | 0.019 | 0.022 | 0.015 | 0.2274 | 0.0048 |
| Average | 0.011 | 0.013 | 0.007 | 0.1633 | 0.0005 |
| Minimum | 0.006 | 0.008 | 0.003 | 0.1581 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.; Wei, C.; Sun, S.; You, B.; Zhao, Y. An LEO Constellation Early Warning System Decision-Making Method Based on Hierarchical Reinforcement Learning. Sensors 2023, 23, 2225. https://doi.org/10.3390/s23042225
Cheng Y, Wei C, Sun S, You B, Zhao Y. An LEO Constellation Early Warning System Decision-Making Method Based on Hierarchical Reinforcement Learning. Sensors. 2023; 23(4):2225. https://doi.org/10.3390/s23042225
Chicago/Turabian StyleCheng, Yu, Cheng Wei, Shengxin Sun, Bindi You, and Yang Zhao. 2023. "An LEO Constellation Early Warning System Decision-Making Method Based on Hierarchical Reinforcement Learning" Sensors 23, no. 4: 2225. https://doi.org/10.3390/s23042225
APA StyleCheng, Y., Wei, C., Sun, S., You, B., & Zhao, Y. (2023). An LEO Constellation Early Warning System Decision-Making Method Based on Hierarchical Reinforcement Learning. Sensors, 23(4), 2225. https://doi.org/10.3390/s23042225