

Multi-Scale Feature Interactive Fusion Network for RGBT Tracking
Abstract
1. Introduction
- We propose a new multi-scale feature interactive fusion network (MSIFNet) to implement robust RGBT tracking. The network can improve the recognition ability of targets of different sizes by fully exploiting multi-scale information, thus improving tracking accuracy and robustness;
- We design a feature selection module that adaptively selects multi-scale features for fusion by the channel-aware mechanism while effectively suppressing noise and redundant information brought by multiple branches;
- We propose a Transformer interactive fusion module to further enhance the aggregated feature and modality-specific features. It improves long-distance feature association and enhances semantic representation by exploring rich contextual information between features;
- We design a global feature fusion module, which adaptively adjusts the global information in spatial and channel dimensions, respectively, to integrate the global information more effectively.
2. Related Work
- (1)
- RGB trackers
- (2)
- RGBT trackers
3. Methods
3.1. Network Architecture
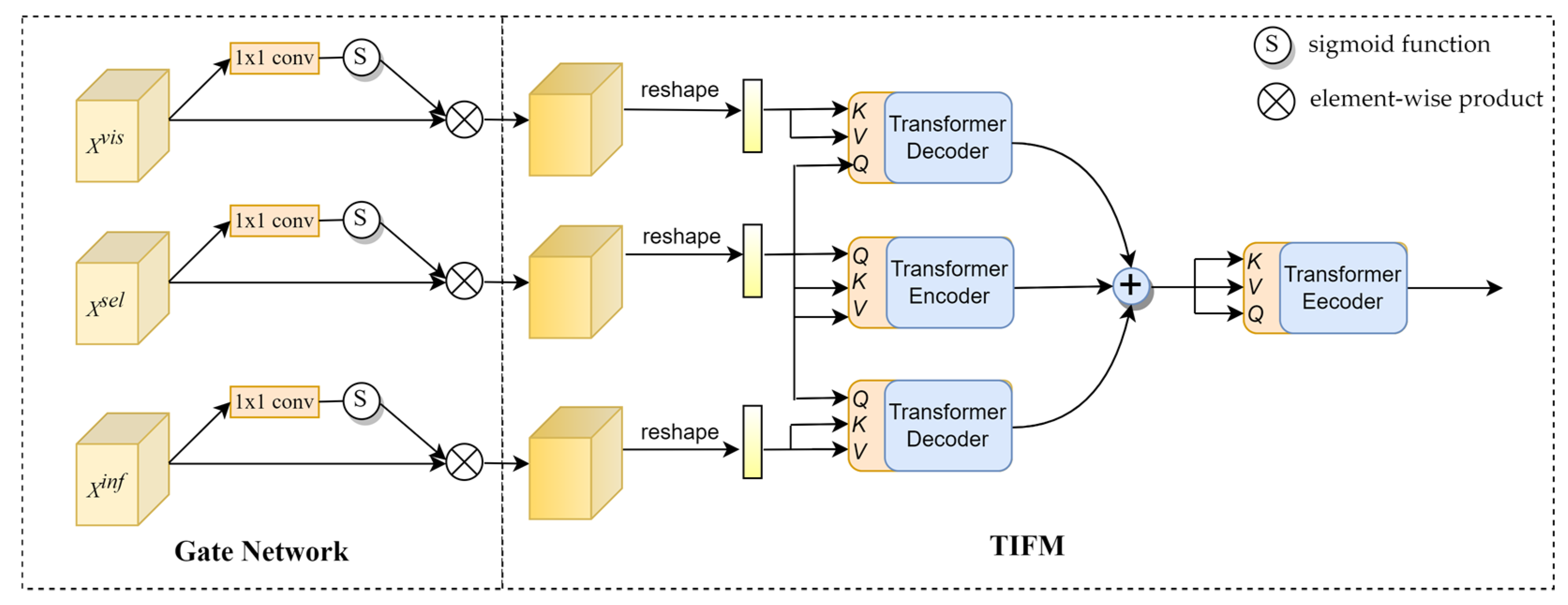
3.2. Feature Selection Module
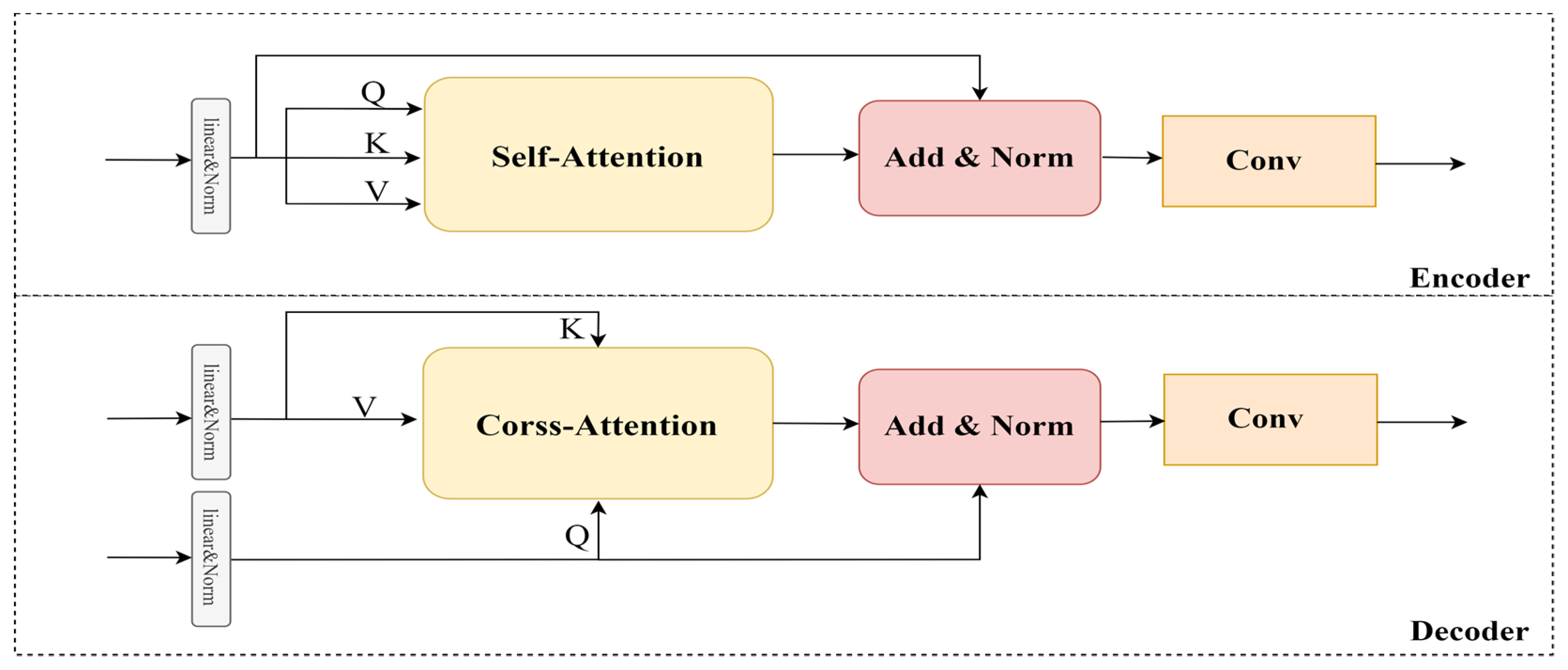
3.3. Transformer Interactive Fusion Module
3.4. Global Feature Fusion Module
4. Experiments
4.1. Implementation Details
4.1.1. Network Training
4.1.2. Online Tracking
4.2. Result Comparisons
4.2.1. Datasets and Evaluation Metrics
- (1)
- GTOT dataset: the GTOT dataset contains 50 pairs of RGBT video sequences collected in different scenarios and conditions, aligned spatially and temporally, totaling about 15K frames. According to the target state, it is divided into 7 challenge attributes to analyze the performance of the tracker under different conditions.
- (2)
- RGBT234 dataset: it is a large dataset after the RGBT210 [47] dataset, adding 34 video sequences based on RGBT210. It includes 234 pairs of highly aligned RGBT video sequences and 12 challenge attributes for approximately 234K frames. It provides more accurate annotations and considers the challenges posed by various environments.
- (3)
- LasHeR dataset: the LasHeR dataset is a more comprehensive and extensive RGBT dataset containing 1224 pairs of aligned video sequences and 19 attribute annotations. Among them, 245 sequences were selected as the test dataset, and the rest were used for training.
4.2.2. Evaluation of GTOT Dataset
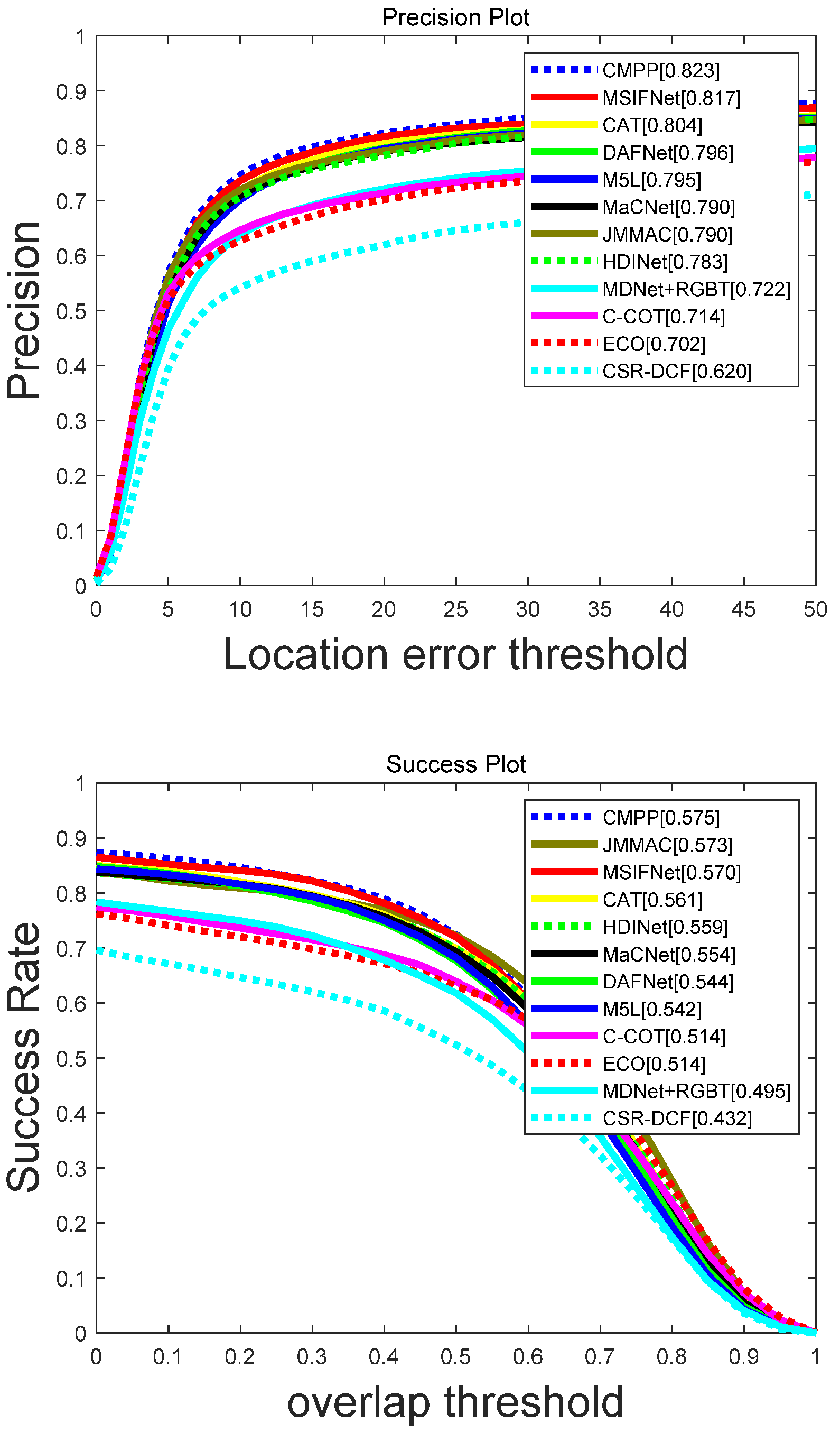
4.2.3. Evaluation on RGBT234 Dataset
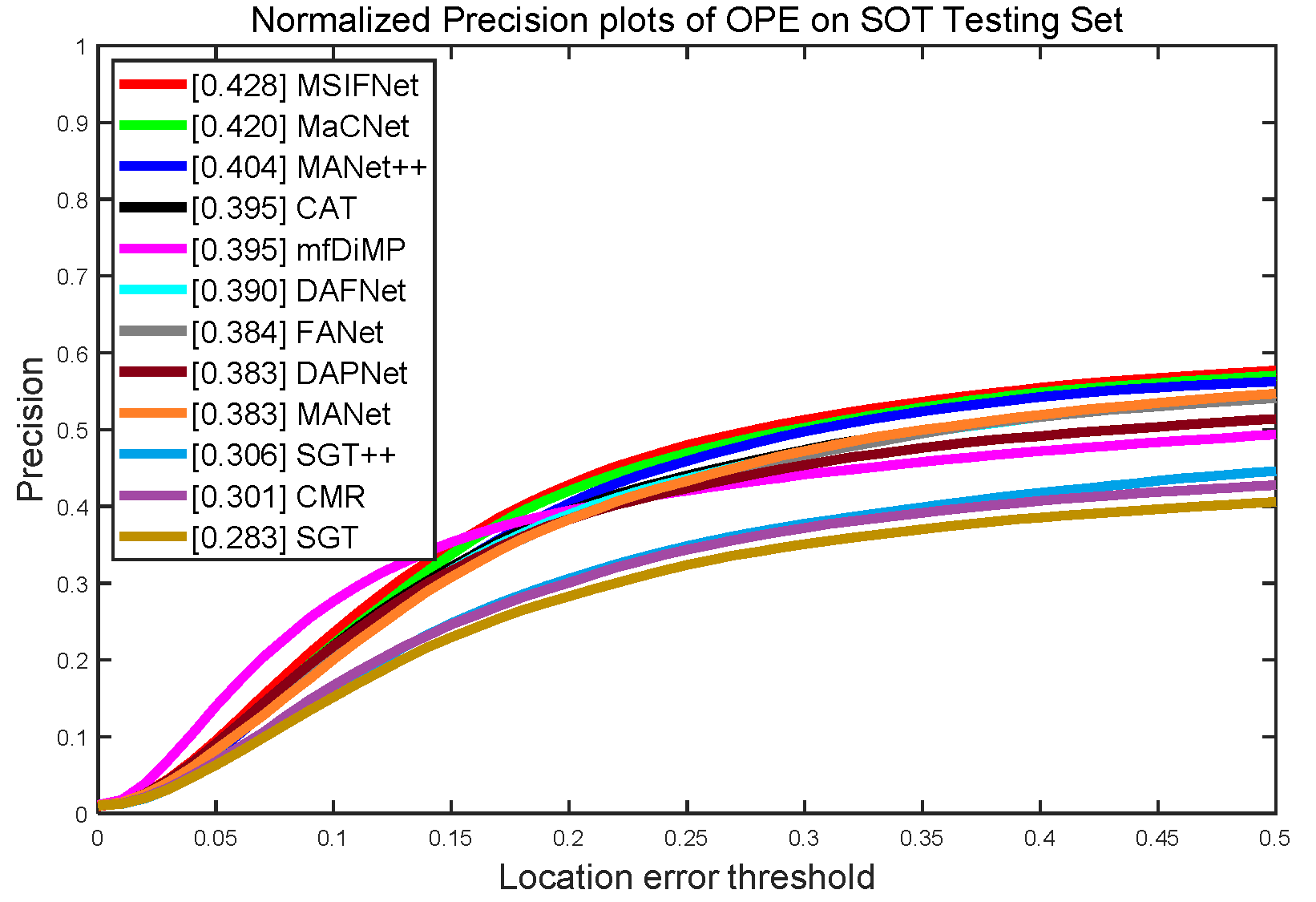
4.2.4. Evaluation of LasHeR Dataset
4.3. Qualitative Analysis
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, Y.; Liu, Z.; Zhang, G. PAC interaction inspection using real-time contact point tracking. IEEE Trans. Instrum. Meas. 2018, 68, 4051–4064. [Google Scholar] [CrossRef]
- Mehmood, K.; Jalil, A.; Ali, A.; Khan, B.; Murad, M.; Khan, W.U.; He, Y. Context-aware and occlusion handling mechanism for online visual object tracking. Electronics 2020, 10, 43. [Google Scholar] [CrossRef]
- Gade, R.; Moeslund, T.B. Thermal cameras and applications: A survey. Mach. Vis. Appl. 2014, 25, 245–262. [Google Scholar] [CrossRef]
- Schnelle, S.R.; Chan, A.L. Enhanced target tracking through infrared-visible image fusion. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; IEEE: New York, NY, USA, 2011; pp. 1–8. [Google Scholar]
- Chan, A.L.; Schnelle, S.R.J.O.E. Fusing concurrent visible and infrared videos for improved tracking performance. Opt. Eng. 2013, 52, 017004. [Google Scholar] [CrossRef]
- Zhang, X.; Ye, P.; Peng, S.; Liu, J.; Xiao, G. DSiamMFT: An RGB-T fusion tracking method via dynamic Siamese networks using multi-layer feature fusion. Signal Process. Image Commun. 2020, 84, 115756. [Google Scholar] [CrossRef]
- Xia, W.; Zhou, D.; Cao, J.; Liu, Y.; Hou, R. CIRNet: An improved RGBT tracking via cross-modality interaction and re-identification. Neurocomputing 2022, 493, 327–339. [Google Scholar] [CrossRef]
- Lu, A.; Qian, C.; Li, C.; Tang, J.; Wang, L. Duality-gated mutual condition network for RGBT tracking. In IEEE Transactions on Neural Networks and Learning Systems; IEEE: New York, NY, USA, 2022. [Google Scholar]
- He, F.; Chen, M.; Chen, X.; Han, J.; Bai, L. SiamDL: Siamese Dual-Level Fusion Attention Network for RGBT Tracking. SSRN, 2022; submitted. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, X.; Tang, X.; Wu, J.; Fang, J. Response map evaluation for RGBT tracking. Neural Comput. Appl. 2022, 34, 5757–5769. [Google Scholar] [CrossRef]
- Long Li, C.; Lu, A.; Hua Zheng, A.; Tu, Z.; Tang, J. Multi-adapter RGBT trackin. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Li, C.; Liu, L.; Lu, A.; Ji, Q.; Tang, J. Challenge-aware RGBT tracking. In Part XXII 16, Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 222–237. [Google Scholar]
- Zhu, Y.; Li, C.; Luo, B.; Tang, J.; Wang, X. Dense feature aggregation and pruning for RGBT tracking. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 465–472. [Google Scholar]
- Xu, Q.; Mei, Y.; Liu, J.; Li, C. Multimodal cross-layer bilinear pooling for RGBT tracking. IEEE Trans. Multimedia 2021, 24, 567–580. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Lasvegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Danelljan, M.; Hager, G.; Shahbaz Khan, F.; Felsberg, M. Learning spatially regularized correlation filters for visual tracking. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4310–4318. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Part II 14, Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10, 15–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 850–865. [Google Scholar]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High performance visual tracking with siamese region proposal network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8971–8980. [Google Scholar]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 4282–4291. [Google Scholar]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12549–12556. [Google Scholar]
- Chen, Z.; Zhong, B.; Li, G.; Zhang, S.; Ji, R. Siamese box adaptive network for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6668–6677. [Google Scholar]
- Guo, D.; Wang, J.; Cui, Y.; Wang, Z.; Chen, S. SiamCAR: Siamese fully convolutional classification and regression for visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 6269–6277. [Google Scholar]
- Danelljan, M.; Bhat, G.; Khan, F.S.; Felsberg, M. Atom: Accurate tracking by overlap maximization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4660–4669. [Google Scholar]
- Wang, N.; Zhou, W.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1571–1580. [Google Scholar]
- Mayer, C.; Danelljan, M.; Bhat, G.; Paul, M.; Paudel, D.P.; Yu, F.; Van Gool, L. Transforming model prediction for tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8731–8740. [Google Scholar]
- Wu, Y.; Blasch, E.; Chen, G.; Bai, L.; Ling, H. Multiple source data fusion via sparse representation for robust visual tracking. In Proceedings of the 14th International Conference on Information Fusion, Chicago, IL, USA, 5–8 July 2011; IEEE: New York, NY, USA, 2011; pp. 1–8. [Google Scholar]
- Li, L.; Li, C.; Tu, Z.; Tang, J. A fusion approach to grayscale-thermal tracking with cross-modal sparse representation. In Proceedings of the Image and Graphics Technologies and Applications: 13th Conference on Image and Graphics Technologies and Applications, IGTA 2018, Beijing, China, 8–10 April 2018; Revised Selected Papers 13; Springer: Berlin/Heidelberg, Germany, 2018; pp. 494–505. [Google Scholar]
- Lan, X.; Ye, M.; Zhang, S.; Zhou, H.; Yuen, P.C. Modality-correlation-aware sparse representation for RGB-infrared object tracking. Pattern Recognit. Lett. 2020, 130, 12–20. [Google Scholar] [CrossRef]
- Li, C.; Zhu, C.; Huang, Y.; Tang, J.; Wang, L. Cross-modal ranking with soft consistency and noisy labels for robust RGB-T tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 808–823. [Google Scholar]
- Shen, L.; Wang, X.; Liu, L.; Hou, B.; Jian, Y.; Tang, J.; Luo, B. RGBT tracking based on cooperative low-rank graph model. Neurocomputing 2022, 492, 370–381. [Google Scholar] [CrossRef]
- Xu, N.; Xiao, G.; Zhang, X.; Bavirisetti, D.P. Relative object tracking algorithm based on convolutional neural network for visible and infrared video sequences. In Proceedings of the 4th International Conference on Virtual Reality, Hong Kong, China, 24–26 February 2018; pp. 44–49. [Google Scholar]
- Gao, Y.; Li, C.; Zhu, Y.; Tang, J.; He, T.; Wang, F. Deep adaptive fusion network for high performance RGBT tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019. [Google Scholar]
- Wang, C.; Xu, C.; Cui, Z.; Zhou, L.; Zhang, T.; Zhang, X.; Yang, J. Cross-modal pattern-propagation for RGB-T tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7064–7073. [Google Scholar]
- Zhang, P.; Wang, D.; Lu, H.; Yang, X. Learning adaptive attribute-driven representation for real-time RGB-T tracking. Int. J. Comput. Vis. 2021, 129, 2714–2729. [Google Scholar] [CrossRef]
- Xiao, Y.; Yang, M.; Li, C.; Liu, L.; Tang, J. Attribute-based progressive fusion network for rgbt tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2022; pp. 2831–2838. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 510–519. [Google Scholar]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. In Proceedings of the British Machine Vision Conference 2014, Nottinghamshire, UK, 1–5 September 2014. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8126–8135. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Li, C.; Cheng, H.; Hu, S.; Liu, X.; Tang, J.; Lin, L. Learning collaborative sparse representation for grayscale-thermal tracking. IEEE Trans. Image Process. 2016, 25, 5743–5756. [Google Scholar] [CrossRef]
- Li, C.; Liang, X.; Lu, Y.; Zhao, N.; Tang, J. RGB-T object tracking: Benchmark and baseline. Pattern Recognit. 2019, 96, 106977. [Google Scholar] [CrossRef]
- Li, C.; Xue, W.; Jia, Y.; Qu, Z.; Luo, B.; Tang, J.; Sun, D. LasHeR: A large-scale high-diversity benchmark for RGBT tracking. IEEE Trans. Image Process. 2021, 31, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Nam, H.; Han, B. Learning multi-domain convolutional neural networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4293–4302. [Google Scholar]
- Li, C.; Zhao, N.; Lu, Y.; Zhu, C.; Tang, J. Weighted sparse representation regularized graph learning for RGB-T object tracking. In Proceedings of the 25th ACM International Conference on Multimedia, New York, NY, USA, 23–27 October 2017; pp. 1856–1864. [Google Scholar]
- Muller, M.; Bibi, A.; Giancola, S.; Alsubaihi, S.; Ghanem, B. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 300–317. [Google Scholar]
- Tu, Z.; Lin, C.; Zhao, W.; Li, C.; Tang, J. M 5 l: Multi-modal multi-margin metric learning for RGBT tracking. IEEE Trans. Image Process. 2021, 31, 85–98. [Google Scholar] [CrossRef]
- Mei, J.; Zhou, D.; Cao, J.; Nie, R.; Guo, Y. Hdinet: Hierarchical dual-sensor interaction network for rgbt tracking. IEEE Sens. J. 2021, 21, 16915–16926. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, L.; Zhuo, L.; Zhang, J. Object tracking in RGB-T videos using modal-aware attention network and competitive learning. Sensors 2020, 20, 393. [Google Scholar] [CrossRef]
- Danelljan, M.; Bhat, G.; Shahbaz Khan, F.; Felsberg, M. Eco: Efficient convolution operators for tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6638–6646. [Google Scholar]
- Jung, I.; Son, J.; Baek, M.; Han, B. Real-time mdnet. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 83–98. [Google Scholar]
- Zhang, P.; Zhao, J.; Bo, C.; Wang, D.; Lu, H.; Yang, X. Jointly modeling motion and appearance cues for robust RGB-T tracking. IEEE Trans. Image Process. 2021, 30, 3335–3347. [Google Scholar] [CrossRef] [PubMed]
- Lu, A.; Li, C.; Yan, Y.; Tang, J.; Luo, B. RGBT tracking via multi-adapter network with hierarchical divergence loss. IEEE Trans. Image Process. 2021, 30, 5613–5625. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SGT | MDNet + RGBT | MANet | CAT | APFNet | MSIFNet | |
|---|---|---|---|---|---|---|
| OCC | 81.0/56.7 | 82.9/64.1 | 88.2/69.6 | 89.9/69.2 | 90.3/71.3 | 90.9/72.2 |
| LSV | 84.2/54.7 | 77.0/57.3 | 86.9/70.6 | 85.0/67.9 | 87.7/71.2 | 88.0/72.0 |
| FM | 79.9/55.9 | 80.5/59.8 | 87.9/69.4 | 83.9/65.4 | 86.5/68.4 | 88.2/70.2 |
| LI | 88.4/65.1 | 79.5/64.3 | 91.4/73.6 | 89.2/72.3 | 91.4/74.8 | 91.2/74.5 |
| TC | 84.8/61.5 | 79.5/60.9 | 88.9/70.2 | 89.9/71.0 | 90.4/71.6 | 91.4/72.9 |
| SO | 91.7/61.8 | 87.0/66.2 | 93.2/70.0 | 94.7/69.9 | 94.3/71.3 | 95.9/72.3 |
| DEF | 91.9/73.3 | 81.6/68.8 | 92.3/75.2 | 92.5/75.5 | 94.6/78.0 | 92.8/77.5 |
| ALL | 85.1/62.8 | 80.0/63.7 | 89.4/72.4 | 88.9/71.7 | 90.5/73.7 | 90.4/74.1 |
| MDNet + RGBT | DAFNet | M5L | CAT | HDINet | MSIFNet | |
|---|---|---|---|---|---|---|
| NO | 86.2/61.1 | 90.0/63.6 | 93.1/64.6 | 93.2/66.8 | 88.4/65.1 | 92.6/66.0 |
| PO | 76.1/51.8 | 85.9/58.8 | 86.3/58.9 | 85.1/59.3 | 84.9/60.4 | 84.7/59.5 |
| HO | 61.9/42.1 | 68.6/45.9 | 66.5/45.0 | 70.0/48.0 | 67.1/47.3 | 73.8/50.5 |
| LI | 67.0/45.5 | 81.2/54.2 | 82.1/54.7 | 81.0/54.7 | 77.7/53.2 | 83.2/55.7 |
| LR | 75.9/51.5 | 81.8/53.8 | 82.3/53.5 | 82.0/53.9 | 80.1/54.5 | 85.1/56.5 |
| TC | 75.6/51.7 | 81.1/58.3 | 82.1/56.4 | 80.3/57.7 | 77.2/57.5 | 84.4/59.0 |
| DEF | 66.8/47.3 | 74.1/51.6 | 73.6/51.1 | 76.2/54.1 | 76.2/56.5 | 74.7/53.5 |
| FM | 58.6/36.3 | 74.0/46.5 | 72.8/46.5 | 73.1/47.0 | 71.7/47.5 | 74.7/47.5 |
| SV | 73.5/50.5 | 79.1/54.4 | 79.6/54.2 | 79.7/56.6 | 77.5/55.8 | 82.0/57.6 |
| MB | 65.4/46.3 | 70.8/50.0 | 73.8/52.8 | 68.3/49.0 | 70.8/52.6 | 75.8/54.4 |
| CM | 64.0/45.4 | 72.3/50.6 | 75.2/52.9 | 75.2/52.7 | 69.7/51.4 | 77.3/54.9 |
| BC | 64.4/43.2 | 79.1/49.3 | 75.0/47.7 | 81.1/51.9 | 71.1/47.8 | 80.5/52.3 |
| ALL | 72.2/49.5 | 79.6/54.4 | 79.5/54.2 | 80.4/56.1 | 78.3/55.9 | 81.7/57.0 |
| MSIFNet-FSM | MSIFNet-TIFM | MSIFNet-GFM | MSIFNet-Gate | MSIFNet | ||
|---|---|---|---|---|---|---|
| RGBT234 | PR | 0.799 | 0.806 | 0.813 | 0.811 | 0.817 |
| SR | 0.557 | 0.561 | 0.564 | 0.565 | 0.570 |
| MSIFNet-L1 | MSIFNet-L2 | MSIFNet-L3 | MSIFNet | ||
|---|---|---|---|---|---|
| RGBT234 | PR | 0.801 | 0.806 | 0.814 | 0.817 |
| SR | 0.563 | 0.563 | 0.568 | 0.570 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiao, X.; Xiong, X.; Meng, F.; Chen, Z. Multi-Scale Feature Interactive Fusion Network for RGBT Tracking. Sensors 2023, 23, 3410. https://doi.org/10.3390/s23073410
Xiao X, Xiong X, Meng F, Chen Z. Multi-Scale Feature Interactive Fusion Network for RGBT Tracking. Sensors. 2023; 23(7):3410. https://doi.org/10.3390/s23073410
Chicago/Turabian StyleXiao, Xianbing, Xingzhong Xiong, Fanqin Meng, and Zhen Chen. 2023. "Multi-Scale Feature Interactive Fusion Network for RGBT Tracking" Sensors 23, no. 7: 3410. https://doi.org/10.3390/s23073410
APA StyleXiao, X., Xiong, X., Meng, F., & Chen, Z. (2023). Multi-Scale Feature Interactive Fusion Network for RGBT Tracking. Sensors, 23(7), 3410. https://doi.org/10.3390/s23073410