
Deep Reinforcement Learning-Based Coordinated Beamforming for mmWave Massive MIMO Vehicular Networks



Abstract
1. Introduction
1.1. Related Works
1.2. Contribution
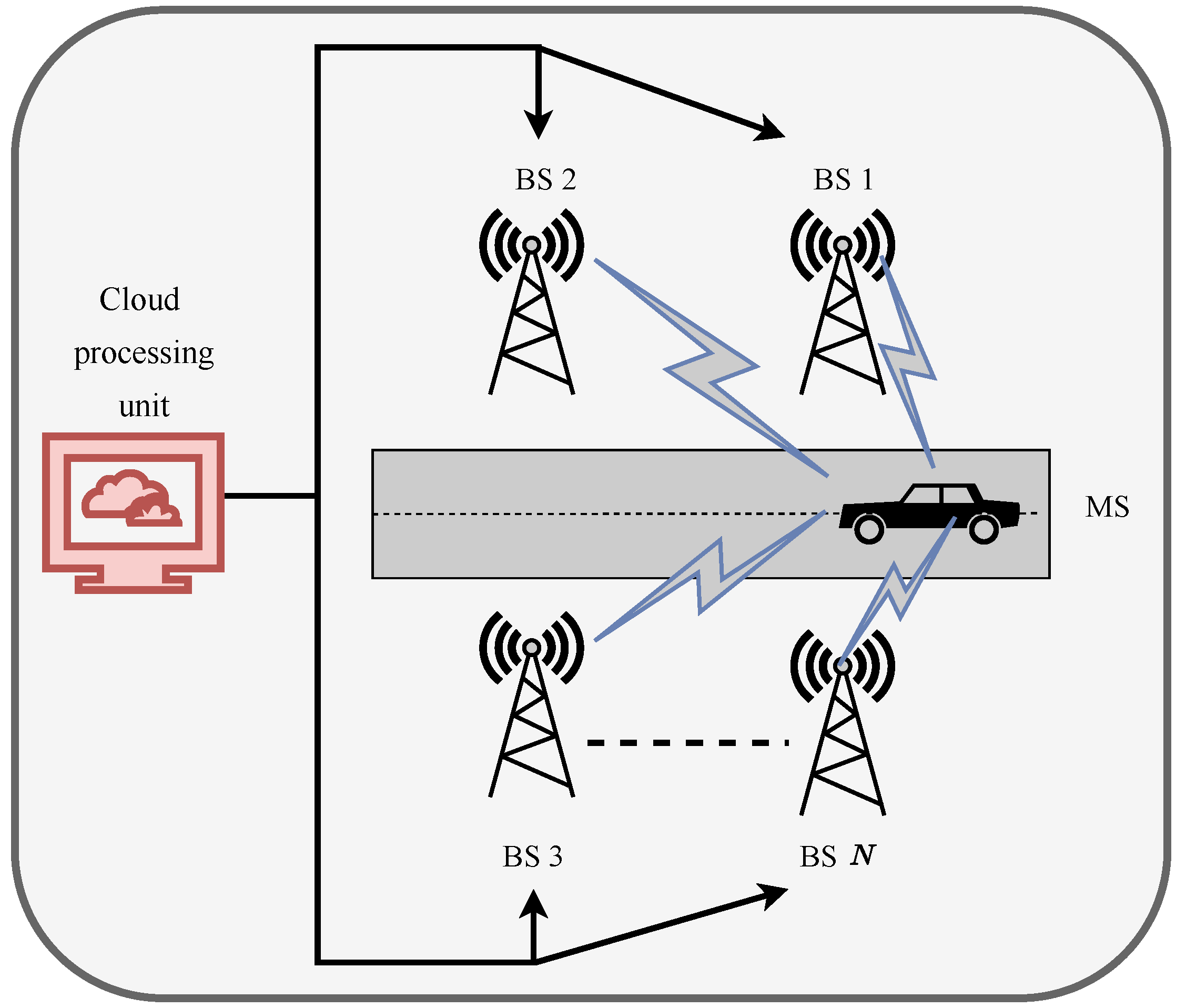
- We develop a simple coordinated beamforming scheme where several BSs employ RF beamforming and are connected to a central cloud processing unit that uses baseband processing, which serves a mobile user at once. To increase the platform’s effective achievable rate, we define a training and design issue for the central baseband processing and for BSs RF beamforming vectors. The trade-off between the beamforming training overhead and the achievable sum rate using the proposed beamforming vectors is taken into account when determining the effective achievable rate for highly mobile mmWave systems.
- For the selected system, we construct a fundamental coordinated beamforming technique that relies on uplink training for creating the RF and baseband beamforming vectors. The BSs choose their RF beamforming vectors from a predetermined codebook as part of this baseline approach. The baseband beamforming is then designed by a central processor to guarantee consistent incorporation by the user. We demonstrate that the standard beamforming technique achieves the best attainable rates in a few unique but crucial situations.
- We introduce a system operation of machine learning modeling of a unique combined DRL and coordinated beamforming solution. In this approach, we incorporate a reverse autoencoder owing to its capability to handle raw data seamlessly so that it can reproduce the input data as closely as possible as a neural network for our DRL model and solve a coordinating beamforming problem. The main concept of the suggested technique is to anticipate the RF beamforming vectors of the coordinating BSs using just beam patterns, i.e., with very little training overhead. The proposed approach also enables minimal coordination overhead harvesting of coordinated beamforming improvements with wide coverage and low latency, making the method a viable solution for highly mobile mmWave applications.
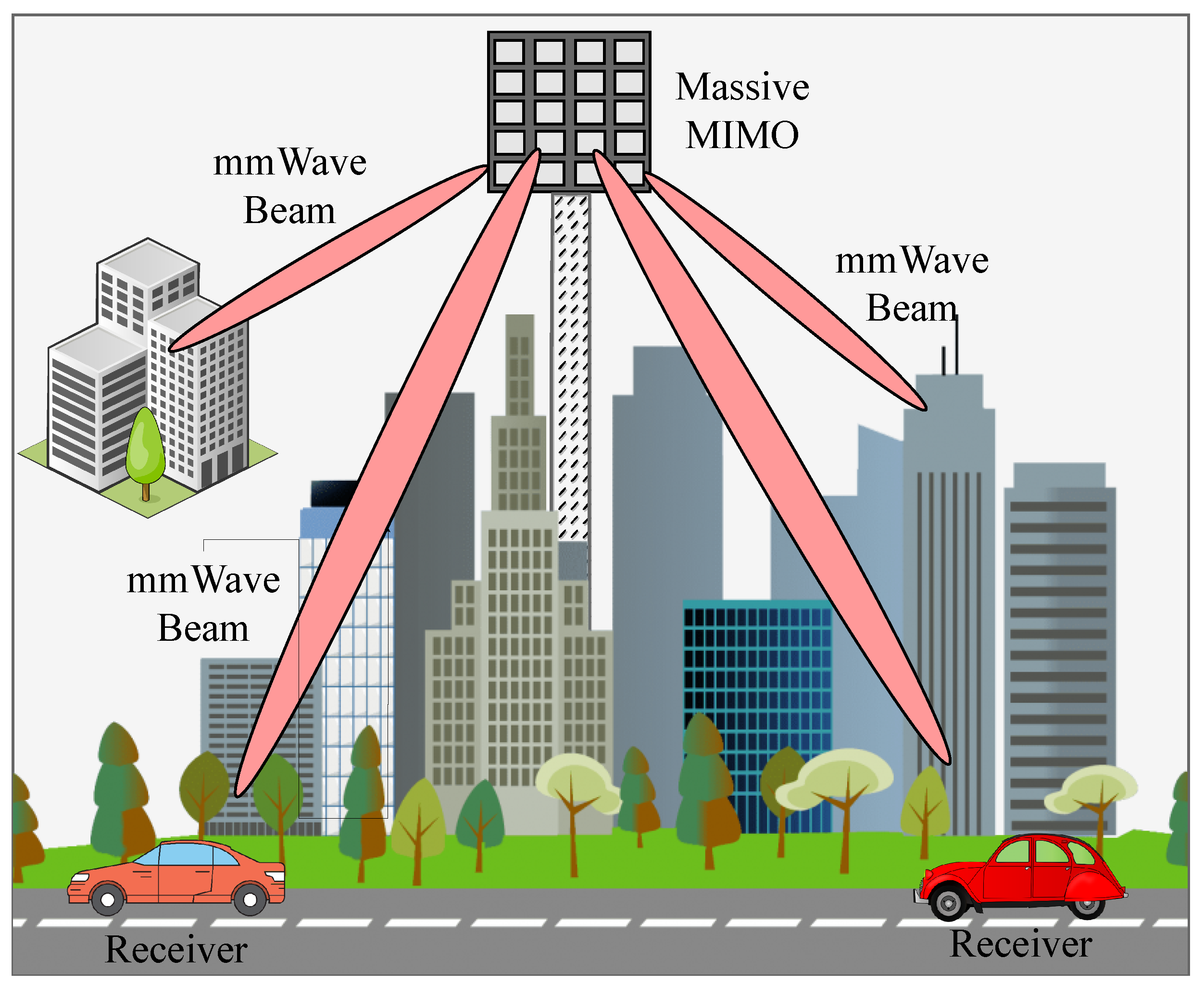
2. System Model
3. Coordinated Beamforming
3.1. Problem Statement
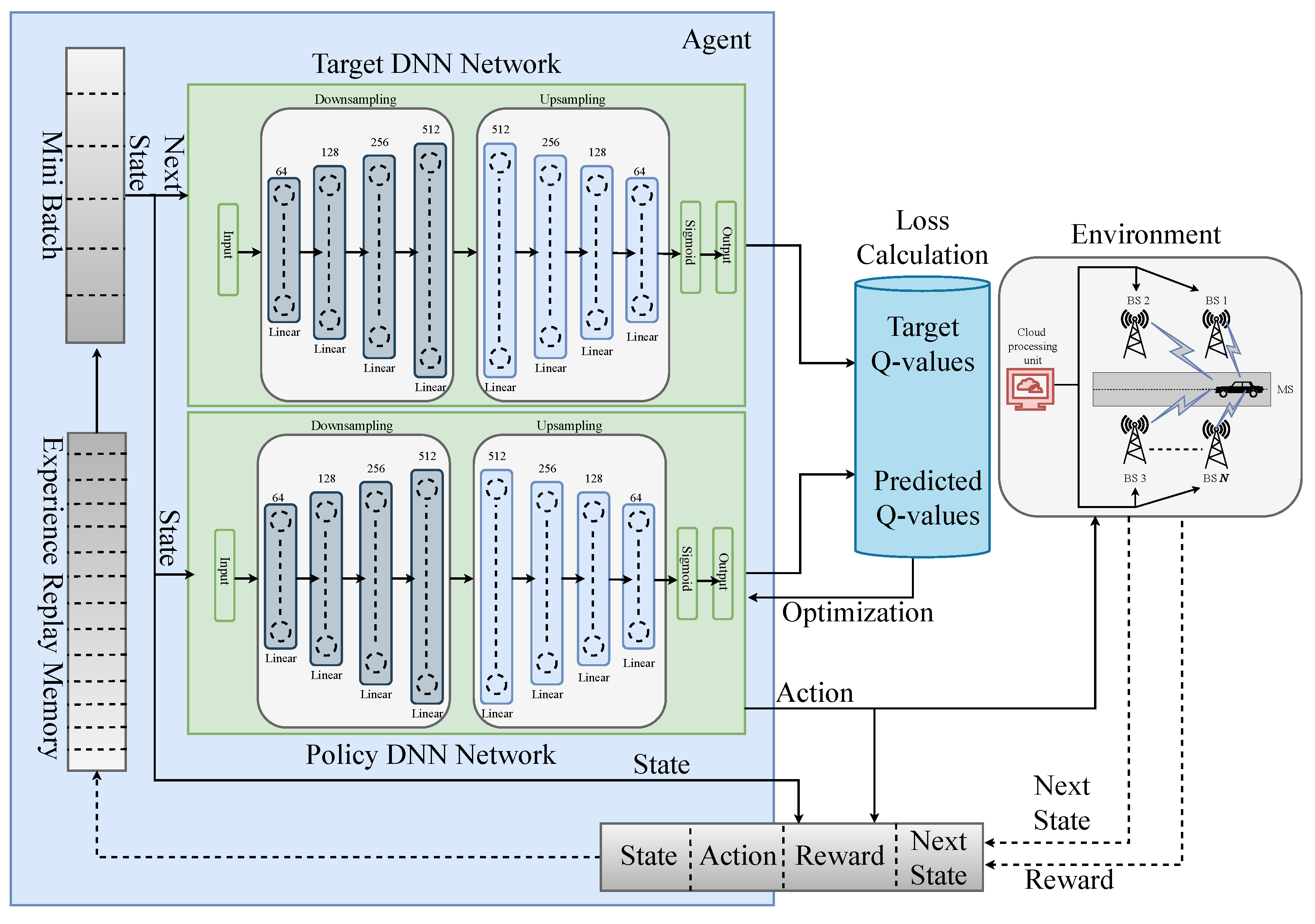
3.2. Drl-Based Coordinated Beamforming Framework
- State: We utilize the channel matrices for all the BSs as the state of our environment. The complex channel matrices are constructed incorporating the bandwidth, user position, noise figure, and noise power. If the environment has Z states each having V number of beams, then, the state space with can be represented as , .
- Action: The goal of the agent is to assign a beam for serving from the action space A. At each episode for a set of S, the agent has to take actions while maintaining one action per V elements from the S. Out of the , the target of the agent is choosing a beam that will maximize the data rate.
- Reward: In our reward function, we first derive the data rate for each channel as follows.For every action the agent takes, we calculate the data rate of the chosen action and feed it as the reward value. Our aim is to acquire the highest possible cumulative reward as it obtains reward for each action, according to
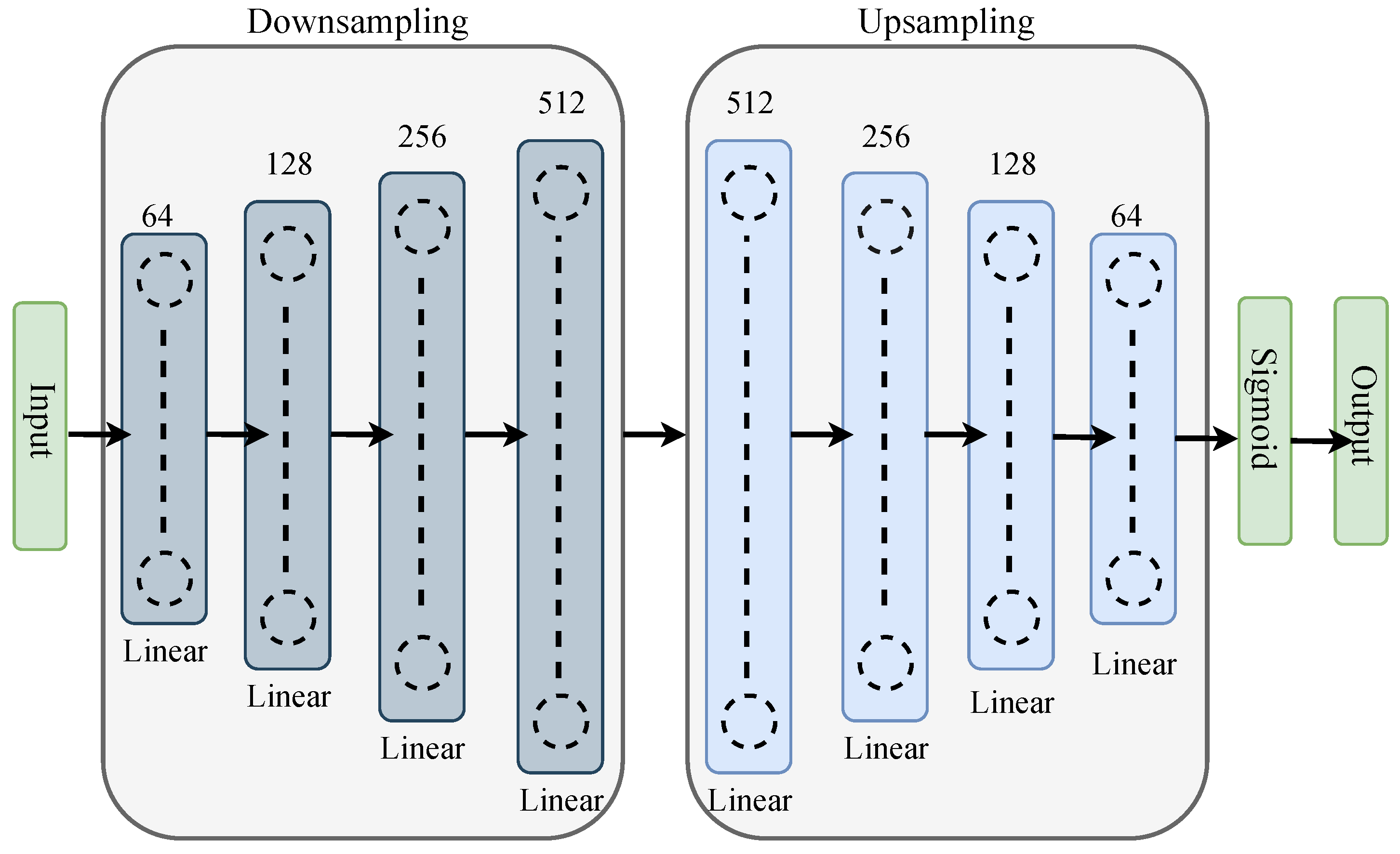
3.3. Reverse Autoencoder
4. Performance Evaluation
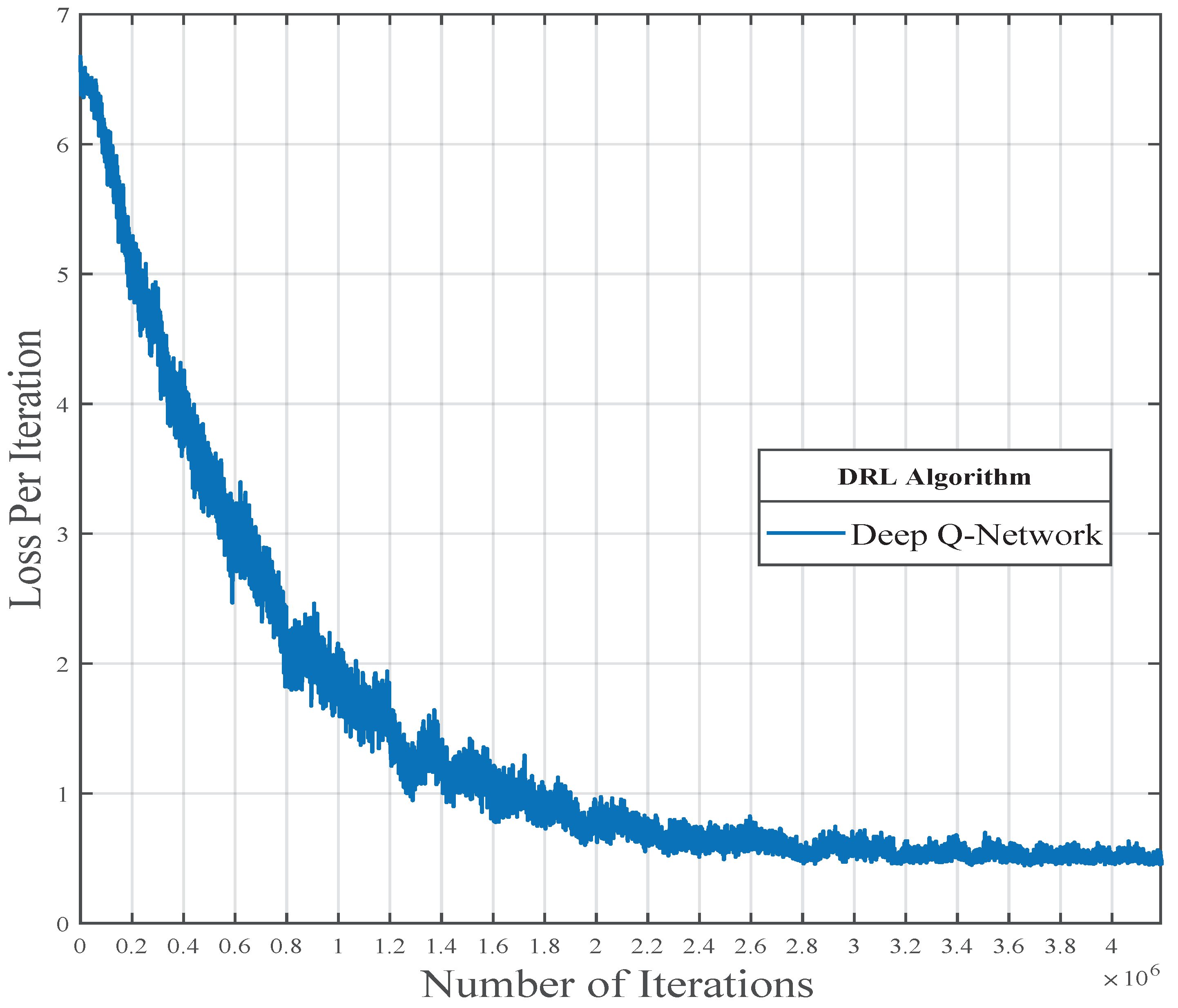
4.1. Training
| Algorithm 1 Proposed deep Q-learning algorithm |
|
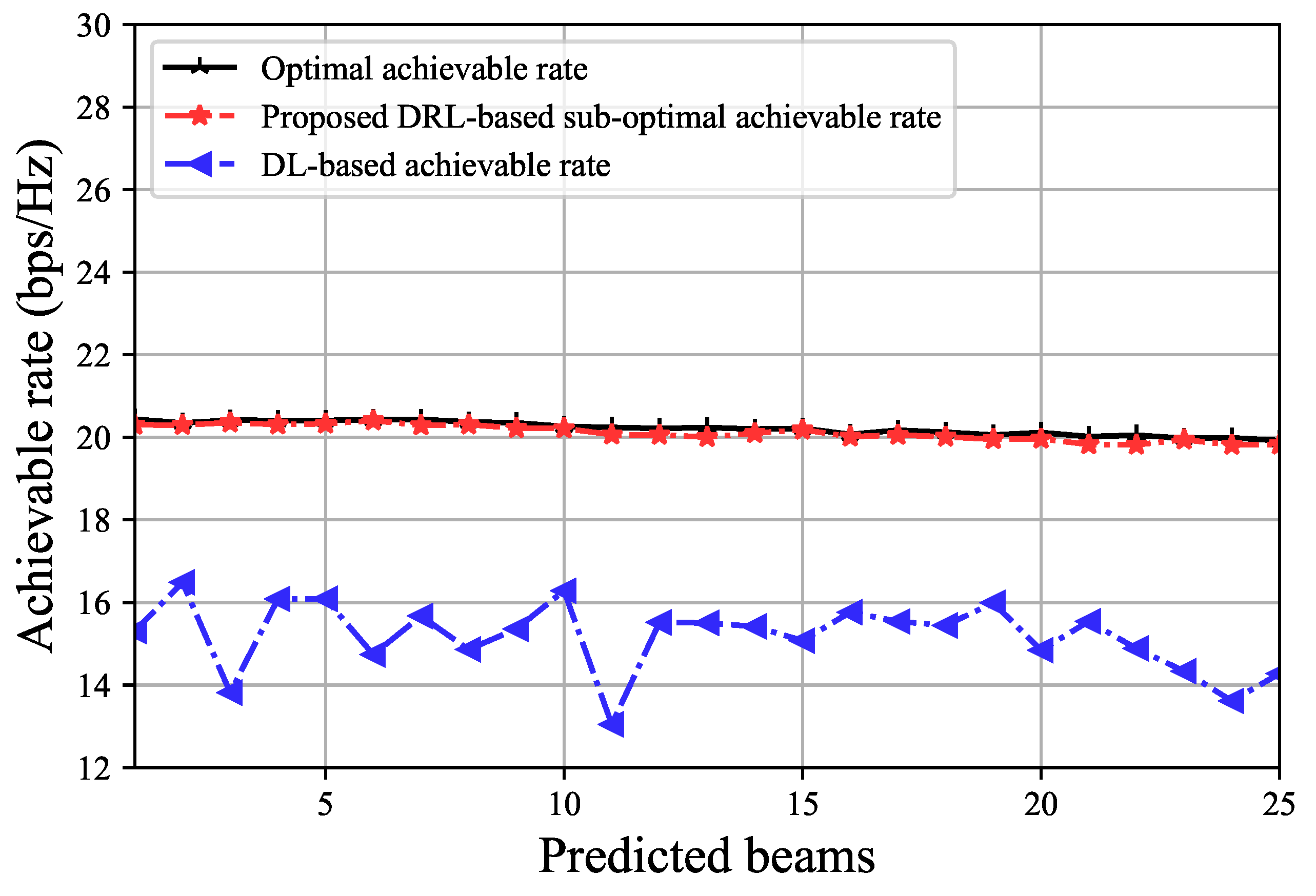
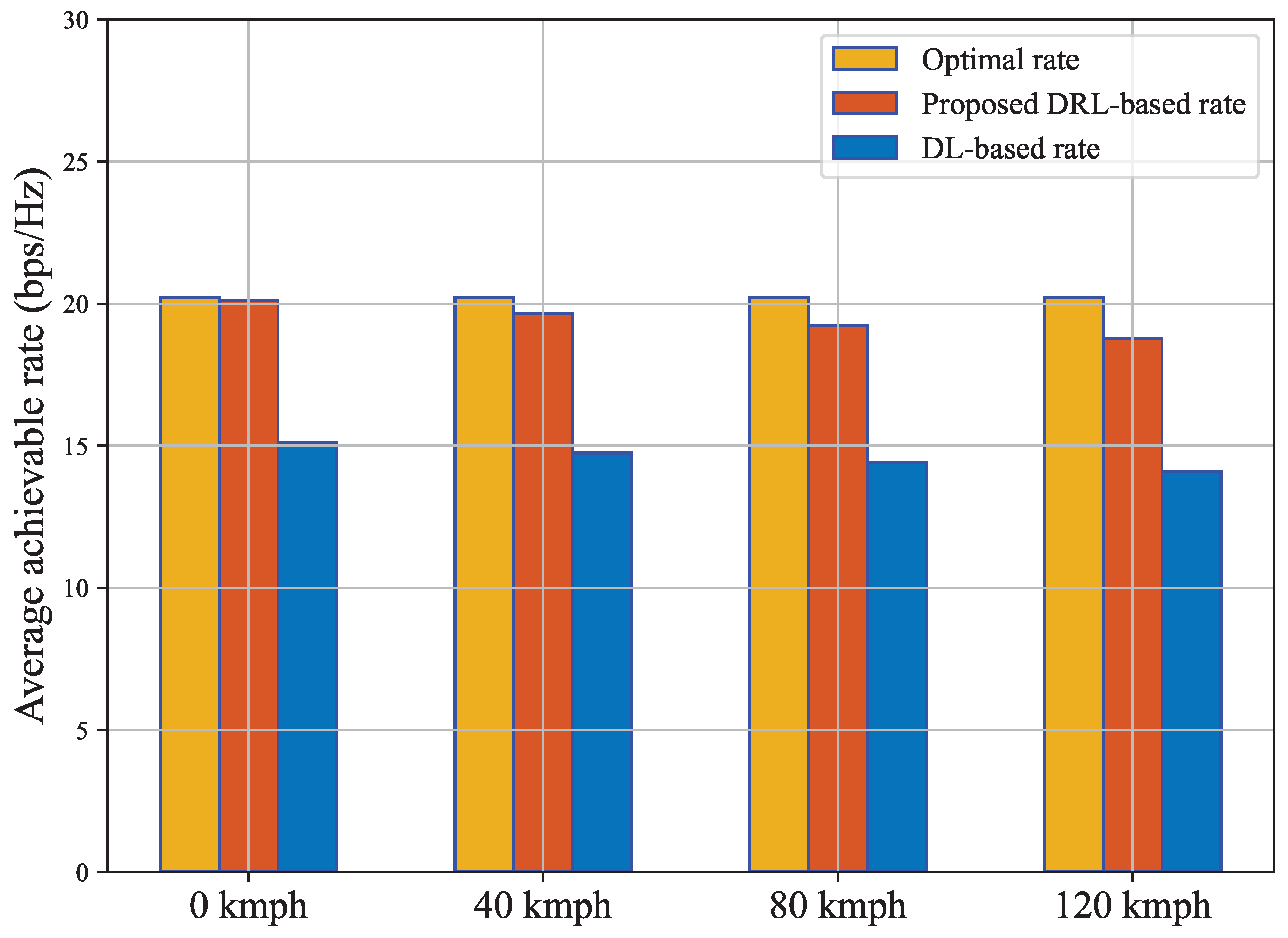
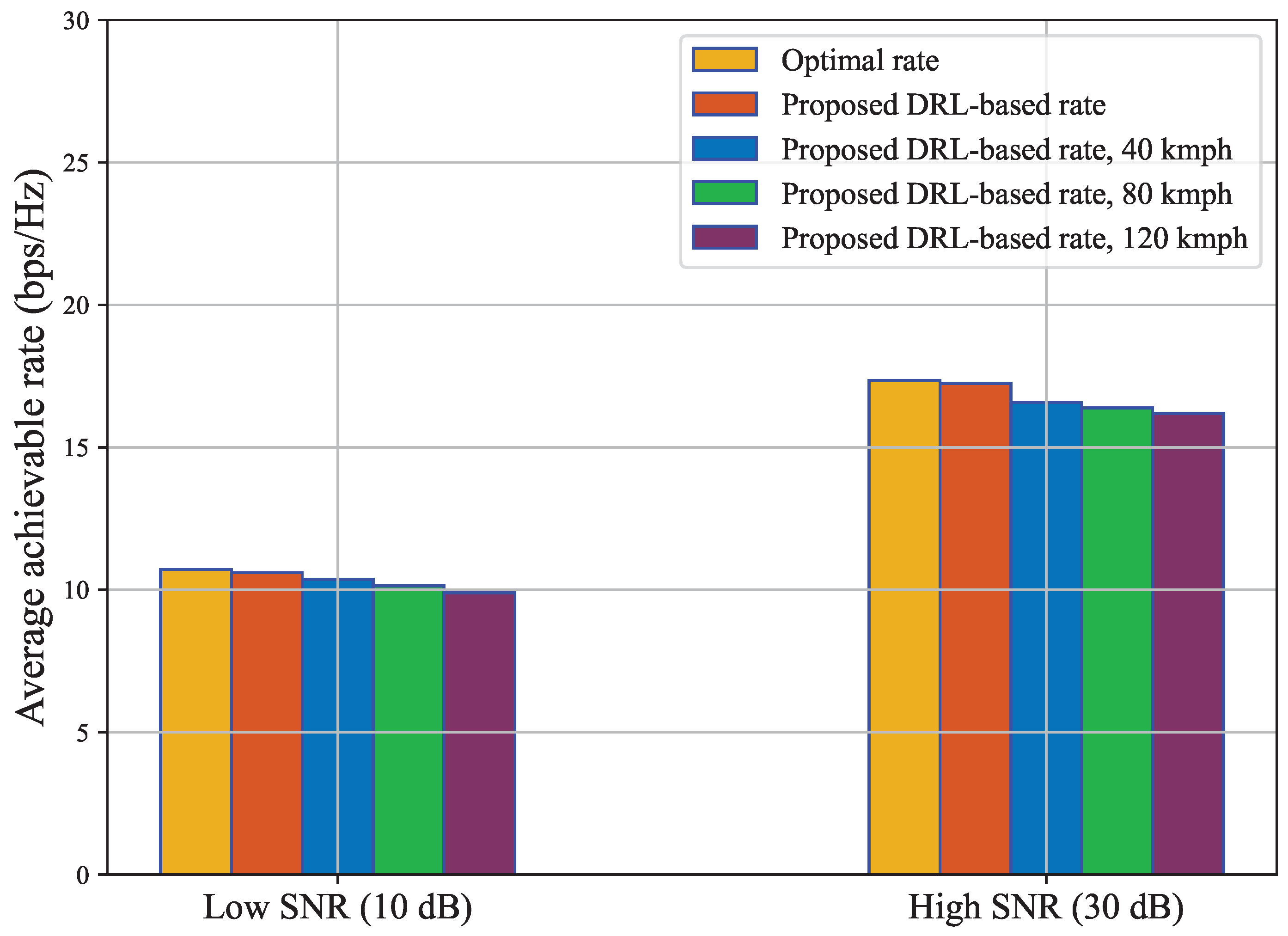
4.2. Performance Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Saghezchi, F.B.; Rodriguez, J.; Mumtaz, S.; Radwan, A.; Lee, W.C.; Ai, B.; Islam, M.T.; Akl, S.; Taha, A.E.M. Drivers for 5G: The ‘pervasive connected world’. In Fundamentals of 5G Mobile Networks; John Wiley & Sons: Hoboken, NJ, USA, 2015; pp. 1–27. [Google Scholar]
- Chen, T.; Matinmikko, M.; Chen, X.; Zhou, X.; Ahokangas, P. Software defined mobile networks: Concept, survey, and research directions. IEEE Commun. Mag. 2015, 53, 126–133. [Google Scholar] [CrossRef]
- Boccardi, F.; Heath, R.W.; Lozano, A.; Marzetta, T.L.; Popovski, P. Five disruptive technology directions for 5G. IEEE Commun. Mag. 2014, 52, 74–80. [Google Scholar] [CrossRef]
- Busari, S.A.; Huq, K.M.S.; Mumtaz, S.; Dai, L.; Rodriguez, J. Millimeter-Wave Massive MIMO Communication for Future Wireless Systems: A Survey. IEEE Commun. Surv. Tutorials 2018, 20, 836–869. [Google Scholar] [CrossRef]
- Li, Q.; Niu, H.; Papathanassiou, A.T.; Wu, G. 5G Network Capacity: Key Elements and Technologies. IEEE Veh. Technol. Mag. 2014, 9, 71–78. [Google Scholar] [CrossRef]
- Larsson, E.G.; Edfors, O.; Tufvesson, F.; Marzetta, T.L. Massive MIMO for next generation wireless systems. IEEE Commun. Mag. 2014, 52, 186–195. [Google Scholar] [CrossRef]
- Ghosh, A.; Thomas, T.A.; Cudak, M.C.; Ratasuk, R.; Moorut, P.; Vook, F.W.; Rappaport, T.S.; MacCartney, G.R.; Sun, S.; Nie, S. Millimeter-Wave Enhanced Local Area Systems: A High-Data-Rate Approach for Future Wireless Networks. IEEE J. Sel. Areas Commun. 2014, 32, 1152–1163. [Google Scholar] [CrossRef]
- Rusek, F.; Persson, D.; Lau, B.K.; Larsson, E.G.; Marzetta, T.L.; Edfors, O.; Tufvesson, F. Scaling Up MIMO: Opportunities and Challenges with Very Large Arrays. IEEE Signal Process. Mag. 2013, 30, 40–60. [Google Scholar] [CrossRef]
- Hoydis, J.; ten Brink, S.; Debbah, M. Massive MIMO in the UL/DL of Cellular Networks: How Many Antennas Do We Need? IEEE J. Sel. Areas Commun. 2013, 31, 160–171. [Google Scholar] [CrossRef]
- Marzetta, T.L. Noncooperative Cellular Wireless with Unlimited Numbers of Base Station Antennas. IEEE Trans. Wirel. Commun. 2010, 9, 3590–3600. [Google Scholar] [CrossRef]
- Choi, J.; Va, V.; Gonzalez-Prelcic, N.; Daniels, R.; Bhat, C.R.; Heath, R.W. Millimeter-Wave Vehicular Communication to Support Massive Automotive Sensing. IEEE Commun. Mag. 2016, 54, 160–167. [Google Scholar] [CrossRef]
- Tarafder, P.; Choi, W. MAC Protocols for mmWave Communication: A Comparative Survey. Sensors 2022, 22, 3853. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Dai, L.; Chen, Z.; Wang, Z.; Zhang, Z. Near-Optimal Beam Selection for Beamspace MmWave Massive MIMO Systems. IEEE Commun. Lett. 2016, 20, 1054–1057. [Google Scholar] [CrossRef]
- Pal, R.; Srinivas, K.V.; Chaitanya, A.K. A Beam Selection Algorithm for Millimeter-Wave Multi-User MIMO Systems. IEEE Commun. Lett. 2018, 22, 852–855. [Google Scholar] [CrossRef]
- Alkhateeb, A.; Alex, S.; Varkey, P.; Li, Y.; Qu, Q.; Tujkovic, D. Deep Learning Coordinated Beamforming for Highly-Mobile Millimeter Wave Systems. IEEE Access 2018, 6, 37328–37348. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, B.; Wang, H.; Zhang, T.; Qian, Y. Deep Learning-based Coordinated Beamforming for Massive MIMO-Enabled Heterogeneous Networks. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Tao, J.; Wang, Q.; Luo, S.; Chen, J. Constrained Deep Neural Network Based Hybrid Beamforming for Millimeter Wave Massive MIMO Systems. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar] [CrossRef]
- MacCartney, G.R.; Rappaport, T.S.; Ghosh, A. Base Station Diversity Propagation Measurements at 73 GHz Millimeter-Wave for 5G Coordinated Multipoint (CoMP) Analysis. In Proceedings of the 2017 IEEE Globecom Workshops (GC Wkshps), Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Maamari, D.; Devroye, N.; Tuninetti, D. Coverage in mmWave Cellular Networks with Base Station Co-Operation. IEEE Trans. Wirel. Commun. 2016, 15, 2981–2994. [Google Scholar] [CrossRef]
- Gupta, A.K.; Andrews, J.G.; Heath, R.W. Macrodiversity in cellular networks with random blockages. IEEE Trans. Wirel. Commun. 2017, 17, 996–1010. [Google Scholar] [CrossRef]
- Wang, J.; Lan, Z.; Woo Pyo, C.; Baykas, T.; Sean Sum, C.; Rahman, M.; Gao, J.; Funada, R.; Kojima, F.; Harada, H.; et al. Beam codebook based beamforming protocol for multi-Gbps millimeter-wave WPAN systems. IEEE J. Sel. Areas Commun. 2009, 27, 1390–1399. [Google Scholar] [CrossRef]
- Niu, H.; Lin, Z.; Chu, Z.; Zhu, Z.; Xiao, P.; Nguyen, H.X.; Lee, I.; Al-Dhahir, N. Joint beamforming design for secure RIS-assisted IoT networks. IEEE Internet Things J. 2022, 10, 1628–1641. [Google Scholar] [CrossRef]
- Lin, Z.; Niu, H.; An, K.; Wang, Y.; Zheng, G.; Chatzinotas, S.; Hu, Y. Refracting RIS-aided hybrid satellite-terrestrial relay networks: Joint beamforming design and optimization. IEEE Trans. Aerosp. Electron. Syst. 2022, 58, 3717–3724. [Google Scholar] [CrossRef]
- Lin, Z.; Lin, M.; Wang, J.B.; De Cola, T.; Wang, J. Joint beamforming and power allocation for satellite-terrestrial integrated networks with non-orthogonal multiple access. IEEE J. Sel. Top. Signal Process. 2019, 13, 657–670. [Google Scholar] [CrossRef]
- Lin, Z.; An, K.; Niu, H.; Hu, Y.; Chatzinotas, S.; Zheng, G.; Wang, J. SLNR-based secure energy efficient beamforming in multibeam satellite systems. IEEE Trans. Aerosp. Electron. Syst. 2022. [Google Scholar] [CrossRef]
- Va, V.; Choi, J.; Shimizu, T.; Bansal, G.; Heath, R.W. Inverse Multipath Fingerprinting for Millimeter Wave V2I Beam Alignment. IEEE Trans. Veh. Technol. 2018, 67, 4042–4058. [Google Scholar] [CrossRef]
- Cao, D.; Zheng, B.; Ji, B.; Lei, Z.; Feng, C. A robust distance-based relay selection for message dissemination in vehicular network. Wirel. Netw. 2020, 26, 1755–1771. [Google Scholar] [CrossRef]
- Zhou, X.; Zhang, X.; Chen, C.; Niu, Y.; Han, Z.; Wang, H.; Sun, C.; Ai, B.; Wang, N. Deep Reinforcement Learning Coordinated Receiver Beamforming for Millimeter-Wave Train-Ground Communications. IEEE Trans. Veh. Technol. 2022, 71, 5156–5171. [Google Scholar] [CrossRef]
- Heath, R.W.; González-Prelcic, N.; Rangan, S.; Roh, W.; Sayeed, A.M. An Overview of Signal Processing Techniques for Millimeter Wave MIMO Systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 436–453. [Google Scholar] [CrossRef]
- Rappaport, T.S.; Sun, S.; Mayzus, R.; Zhao, H.; Azar, Y.; Wang, K.; Wong, G.N.; Schulz, J.K.; Samimi, M.; Gutierrez, F. Millimeter Wave Mobile Communications for 5G Cellular: It Will Work! IEEE Access 2013, 1, 335–349. [Google Scholar] [CrossRef]
- Akdeniz, M.R.; Liu, Y.; Samimi, M.K.; Sun, S.; Rangan, S.; Rappaport, T.S.; Erkip, E. Millimeter Wave Channel Modeling and Cellular Capacity Evaluation. IEEE J. Sel. Areas Commun. 2014, 32, 1164–1179. [Google Scholar] [CrossRef]
- Samimi, M.K.; Rappaport, T.S. Ultra-wideband statistical channel model for non line of sight millimeter-wave urban channels. In Proceedings of the 2014 IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014; pp. 3483–3489. [Google Scholar] [CrossRef]
- Schniter, P.; Sayeed, A. Channel estimation and precoder design for millimeter-wave communications: The sparse way. In Proceedings of the 2014 48th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 2–5 November 2014; pp. 273–277. [Google Scholar] [CrossRef]
- Va, V.; Choi, J.; Heath, R.W. The Impact of Beamwidth on Temporal Channel Variation in Vehicular Channels and Its Implications. IEEE Trans. Veh. Technol. 2017, 66, 5014–5029. [Google Scholar] [CrossRef]
- Sana, M.; De Domenico, A.; Yu, W.; Lostanlen, Y.; Calvanese Strinati, E. Multi-Agent Reinforcement Learning for Adaptive User Association in Dynamic mmWave Networks. IEEE Trans. Wirel. Commun. 2020, 19, 6520–6534. [Google Scholar] [CrossRef]
- McClelland, J.L.; Rumelhart, D.E.; PDP Research Group. Volume 2: Explorations in the Microstructure of Cognition: Psychological and Biological Models. In Parallel Distributed Processing; MIT Press: Cambridge, MA, USA, 1987; Volume 2. [Google Scholar]
- Bank, D.; Koenigstein, N.; Giryes, R. Autoencoders. arXiv 2020, arXiv:2003.05991. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Ling, C.; Cao, G.; Cao, W.; Wang, H.; Ren, H. IAE-ClusterGAN: A new Inverse autoencoder for Generative Adversarial Attention Clustering network. Neurocomputing 2021, 465, 406–416. [Google Scholar] [CrossRef]
- Alkhateeb, A. DeepMIMO: A Generic Deep Learning Dataset for Millimeter Wave and Massive MIMO Applications. In Proceedings of the Information Theory and Applications Workshop (ITA), San Diego, CA, USA, 10–15 February 2019; pp. 1–8. [Google Scholar]
- Remcom. Wireless InSite. Available online: http://www.remcom.com/wireless-insite (accessed on 1 October 2022).
- Rezwan, S.; Choi, W. Priority-based joint resource allocation with deep q-learning for heterogeneous NOMA systems. IEEE Access 2021, 9, 41468–41481. [Google Scholar] [CrossRef]
- Sutton, R.S.; McAllester, D.; Singh, S.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 12, 1057–1063. [Google Scholar]
- Zhang, S.; Sutton, R.S. A deeper look at experience replay. arXiv 2017, arXiv:1712.01275. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- SmoothL1Loss—PyTorch 1.13 Documentation. Available online: https://pytorch.org/docs/stable/generated/torch.nn.SmoothL1Loss.html (accessed on 1 October 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Scenario | O1_60 |
| Active BS | 3,4,5,6 |
| Receivers | R1000–R1300 |
| Frequency band | 60 GHz |
| Bandwidth | 500 MHz |
| Number of OFDM subcarriers | 1024 |
| Subcarrier limit | 64 |
| Number of paths | 5 |
| BS antenna shape | |
| Receiver antenna shape |
| Parameters | Values |
|---|---|
| Beams per BS distribution | 16 |
| Total beams | 64 |
| Transmit power | 30 dBm |
| Learning rate (LR) | 0.0005 |
| Discount factor () | 0.999 |
| Epsilon () | [1, 0.1, 0.001] |
| Batch size | 96 |
| Number of episodes | 250 |
| Data instances | 200 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tarafder, P.; Choi, W. Deep Reinforcement Learning-Based Coordinated Beamforming for mmWave Massive MIMO Vehicular Networks. Sensors 2023, 23, 2772. https://doi.org/10.3390/s23052772
Tarafder P, Choi W. Deep Reinforcement Learning-Based Coordinated Beamforming for mmWave Massive MIMO Vehicular Networks. Sensors. 2023; 23(5):2772. https://doi.org/10.3390/s23052772
Chicago/Turabian StyleTarafder, Pulok, and Wooyeol Choi. 2023. "Deep Reinforcement Learning-Based Coordinated Beamforming for mmWave Massive MIMO Vehicular Networks" Sensors 23, no. 5: 2772. https://doi.org/10.3390/s23052772
APA StyleTarafder, P., & Choi, W. (2023). Deep Reinforcement Learning-Based Coordinated Beamforming for mmWave Massive MIMO Vehicular Networks. Sensors, 23(5), 2772. https://doi.org/10.3390/s23052772